

Abstract
As an individual moves through its life cycle, it passes through a series of states (age classes, size classes, reproductive states, spatial locations, health statuses, etc.) before its eventual death. The occupancy time in a state is the time spent in that state over the individual’s life. Depending on the life cycle description, the occupancy times describe different demographic variables, for example, lifetime breeding success, lifetime habitat utilisation, or healthy longevity.
Models based on absorbing Markov chains provide a powerful framework for the analysis of occupancy times. Current theory, however, can completely analyse only the occupancy of single states, although the occupancy time in a set of states is often desired. For example, a range of sizes in a size-classified model, an age class in an agestage model, and a group of locations in a spatial stage model are all sets of states.
We present a new mathematical approach to absorbing Markov chains that extends the analysis of life histories by providing a comprehensive theory for the occupancy of arbitrary sets of states, and for other demographic variables related to these sets (e.g., reaching time, return time). We apply this approach to a matrix population model of the Southern Fulmar (Fulmarus glacialoides). The analysis of this model provides interesting insight into the lifetime number of breeding attempts of this species.
Our new approach to absorbing Markov chains, and its implementation in matrix oriented software, makes the analysis of occupancy times more accessible to population ecologists, and directly applicable to any matrix population models.
Keywords: Matrix population models, Absorbing Markov chains, Multistage models, Demography, Occupancy time, Longevity, Southern fulmar
1. Introduction
The life of an individual is a sequence of events. Birth and death are events common to every individual, but the sequence between birth and death – unique to each individual – consists of a potentially endless list of random events (e.g., surviving, developing, mating, reproducing, growing, dispersing, moving among social or occupational classes, or changing health status). Each event corresponds to a change in the state of the individual, resulting in a stochastic pathway that ends eventually in death. A central role in the analysis of these pathways is played by the concepts of occupancy time (the time spent in, or the number of visits to, a state over the individual’s lifetime). Occupancy is a property of the stochastic pathway of an individual, and occupancy times define the time spent in each of the possible states during the lifetime. In particular, the longevity of an individual is measured by the sum of all these occupancy times. The interpretation of occupancy times depends on the identity of the transient states and the nature of the absorption. Thus, when the states are health status, occupancy time represents years of life while healthy, not healthy, disabled, etc. When the states are spatial locations, occupancy time represents time spent in different places. When the states are marital status, occupancy times measure the part of the lifetime spent single, married, divorced, remarried, etc. When the states are employment status, or breeding activities, or any other interesting categorisation of individuals, the interpretation follows the same lines. As for absorption, it may be death, in which case occupancy time is a “lifetime” measure in the literal sense. But absorption can be defined as the first entrance to some state or set of states (e.g., occurrence of first breeding, or graduation, or metamorphosis, or hospitalisation, etc.).
Because the pathways are stochastic, occupancy time is a random variable. It is often described by its mean (e.g., life expectancy, expected lifetime reproduction). However, some individuals will live longer and some shorter, than the mean; some will mature later and some earlier than the mean. To characterise this variation, the probability distribution of occupancy time, or at least its moments, must be considered.
Models based on absorbing Markov chains provide a powerful framework for the analysis of occupancy times. An absorbing Markov chain describes the fate of an individual – under the assumption that the future of the individual, given its present, is independent of its past – evolving in a set of states and being eventually absorbed by the death state. The states may refer to developmental states, physiological measures, behaviourtypes, locations, and so on. The set of transition rates between these states – described by a transition matrix – defined an absorbing Markov chain. As a population projection matrix describes the fate of a population, the transition matrix describes the fate of individuals in a population, and often is one component of a population projection matrix. The mathematical theory of absorbing Markov chain provides formulae for basic descriptive quantities of the absorbing Markov chain, based on its fundamental matrix (see e.g. Iosifescu (1980) and Kemeny and Snell (1961) for a mathematical perspective, and Caswell (2001) for a demographical perspective). Applied to demographic models, this theory provides simple and direct formulae for the probability distribution, the mean, variance, and all moments of longevity, the distribution of age or stage at death, the survivorship and mortality functions, causes of death, and a variety of measures of life disparity (e.g., [11], [9], [1], [2], [3], [26], [12], [28]). Powerful sensitivity analyses are available for all these quantities [2], [3], [5], [6].
Current theory, however, can completely analyseonly the occupancy time of single states and the occupancy time of the whole state space. Our goal is to extend the analysis of life histories by providing a comprehensive theory for the occupancy of arbitrary sets of states. One type of set is a collection of states deemed biologically relevant for some purpose; we call these super-states. For example, a model based on reproductive behaviour might include states describing many details of the success, failure, timing, and number of offspring produced by breeding, but one might want to investigate the super-states created by aggregating these into “successful breeding” and “non-successful breeding” sets. A spatial model might describe habitats along an altitudinal gradient, and one might want to aggregate in order to compare the occupancy of low altitude and high altitude sites. A medical demography study might distinguish a variety of health conditions and treatments, but one might want to compare the occupancy of all states requiring hospitalisation and those not requiring hospitalisation. The utility of super-states will increase as more matrix models are created from the growth and survival kernels of integral projection models (e.g., Ellner et al., 2016). These matrices typically contain hundreds of size classes, no one of which is of particular interest, but sets of which (e.g., all trees large enough to reach the forest canopy) are of great interest.
A second type of sets of states arises in the context of multistate (or megamatrix) or hyperstate models (e.g., [19], [16], [18], [27], [20]) in which individuals are classified by two or more criteria (age and stage, stage and location, etc.). One may want to analyse the occupancy of sets of states defined by integrating over one of these criteria; we call these marginal sets. For example, in a stagesize-classified model, the marginal set associated with the juvenile stage is the set containing the juvenile stage, integrated over all possible sizes.
The extension of occupancy time calculations to sets of states may seem trivial because the occupancy time in a set is the sum of the occupancy times in each state belonging to this set. Therefore, the mean occupancy time in a set is the sum of the means of the occupancy times in each state. However, this observation does not hold for the variance, for any higher moments, or for the probability distribution, because occupancy times in single states are not independent from each other. There are few analyses of the occupancy time in set of states, but they only focus on specific aspects of it. For example, Steiner and Tuljapurkar (2012) provide formulae for the mean and variance of the reproductive output using the joint generating function of the single state occupancy times. The reproductive output of an individual is closely related to the occupancy time in the set of reproductive states (both are equal when fertility rates are ones in each reproductive state). Caswell (2011a) provides similar formulae using the theory of Markov chain with reward. The same theory is used by Caswell and Kluge (2015) to calculate the moments of lifetime accumulation of economic variables, which are also closely related to occupancy times. However, these studies do not provide the probability distribution of occupancy time in a set of states. In the mathematical literature, Sericola (2000) provides an iterative formula for the probability distribution of the partial (i.e. up to a fixed time) occupancy time in a set of states, but does not provide a closed formula for the total occupancy time. Here, we present a comprehensive approach to calculate the any moment and the probability distribution of the occupancy time in arbitrary sets of states. Our approach relies on the construction of a sub Markov chain, which describes the original Markov chain viewed through a filter that allows one to see only the states in the set of interest. As a consequence, all the statistics of the occupancy time in the set of interest may be calculated with the existing theory of absorbing Markov chain (Iosifescu, 1980), applied to the sub Markov chain.
The construction and the analysis of the sub chain extends the classical theory of absorbing Markov chain by providing not only several measures related to the occupancy of sets of states but also forms a basis for further calculations of measures related to sets of states, including
-
The set occupancy time. Depending on the life cycle description, set occupancy times describe different demographic variables (e.g., lifetime breeding attempts in a model of reproductive behaviour, or lifetime habitat utilisation in a spatial model). We provide for the probability distribution, mean, and variance of the occupancy times.
-
The correlation between the occupancy times in two different sets. This is an indicator of how the two sets are connected in the life cycle. As a particular case, we provide, for the first time, a formula for the correlation between the occupancy time in a state and the longevity of an individual. Depending on the life cycle description, this formula gives the correlation between different demographic variables and longevity (e.g., lifetime breeding attempts and longevity, lifetime reproduction and longevity, time to maturation and longevity).
-
Properties of winners and losers. Relative to a particular target set, a winner is an individual that enters the set at least once in its life, and a loser is an individual that never enters the set. In a model classifying individuals by their developmental state, the winners might represent those individuals that successfully mature, and the losers those that do not. We provide the probability of becoming a winner, the distribution, mean, and variance of the time required for a winner to reach the set, and the longevity of a loser. After its first success, a winner may leave the set and never return, or it may return at some future time. We obtain the probability that a winner returns, and for those that do return, the probability distribution, mean, and variance of the return time.
Table 1 lists the demographic results to be presented and the equations in which they are derived. All the results are obtained directly from a single matrix, describing the transition probabilities among transient states. This matrix is obtainable from most population projection matrices (Caswell, 2001). Despite the large number of matrices and sometimes complicated expressions that appear in our derivations, our results are easily computed in matrix-oriented software. In the Supplementary Material, we provide the Matlab code for calculating all of the demographic results listed in Table 1.
Notation
Matrices are denoted by upper-case bold symbols, vectors by lower-case bold symbols. Vectors are column vectors by default. When a matrix has a subscript (e.g., ), we note its entries with a superscript, . The vector is the vector of ones, and the vector is the vector of zeros. The matrix is the identity matrix of size . The transpose of is . The diagonal matrix with the vector on its diagonal is . The Hadamard product (component by component) of and is . Any random variable is defined on a probability space with probability , its expectation is denoted by and its variance is denoted by . The th moment, , of a random vector is denoted by .
Table 1.
Results of the set analysis in a Markov chain demographic model.
| Output | Expression | Equation |
|---|---|---|
| Occupancy time in | ||
| Mean and variance | (20), (24), (25), (26) | |
| Moments | (23)–(25) | |
| Distribution | (28)–(29) | |
| Reaching the set | ||
| Probability to reach | (39) | |
| Time to reach: | (41) | |
| Mean and variance | (43)–(44) | |
| Moments | (42) | |
| Distribution | (45) | |
| Returning to the set | ||
| Probability to return | (47) | |
| Time to return: | (48) | |
| Mean and variance | (53)–(54) | |
| Moments | (97), in the appendix | |
| Distribution | (51)–(52) | |
| Correlation between the occupancy times in two sets | ||
| Correlation | (86)–(36) | |
| Correlation between the occupancy time in and the longevity | ||
| Correlation | (38) | |
2. Absorbing Markov chains as demographic models
An absorbing Markov chain describes the fate of a particle – under the assumption that the future of the particle, given its present, is independent of its past – evolving in a set of states and being eventually absorbed by an absorbing state. In a demographic model, the absorbing Markov chain describes the fate of an individual evolving through a set of states and being absorbed by the state representing its death. The absorbing Markov chain is determined by two key elements: the living states of the individuals, and the transition probabilities between those states, which depend on the entire set of vital rates.
Formally, we consider the finite set of living states , and the inevitable state , representing death. The living states and the death state are called respectively the transient states and absorbing state of the Markov chain. The state space of the Markov chain is their union,
| (1) |
An absorbing Markov chain is uniquely defined by the one-step transition probabilities and an initial probability distribution. The transition probabilities are described by the matrix of size . For each , the entry of is the probability that an individual in state moves to state . Therefore, the columns of sum to one (i.e. is a stochastic matrix). Note that in the mathematical literature, the transition matrix is given by the transpose of ; however, our notation is widely used in the demographical literature. The matrix can be decomposed in four blocks:
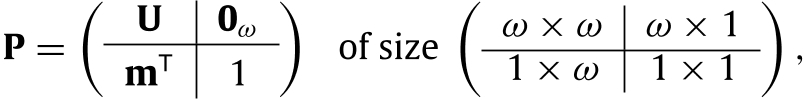 |
(2) |
where the matrix of size is the transient transition matrix, which describes the transition probabilities between the transient states, and the column vector of size contains the probabilities of death from each transient state.
Since the column sums of are equal to one, the column sums of matrix are less than one (strictly less than one if the death probabilities are assumed to be non zero). Moreover, since there is a single absorbing state, the vector is in fact a function of the matrix ,
| (3) |
As a consequence, the matrix is function of the transient transition matrix , which is the only variable of the model.
An absorbing Markov chain from a population projection matrix
A population projection matrix can often be decomposed in two parts: one is the matrix that describes the transitions of living individuals and the other is a matrix that describes the rates of production of new individuals (see e.g. Caswell (2001)). Therefore, the population projection matrices contain an absorbing Markov chain, which is defined by the transient transition matrix .
Target states
The focus of this paper is the occupancy time in a set of living states, which we call the target set. To fix the idea, we define a target set composed of transient states, and we re-number the states so that the target states are the last elements of , i.e.
where . According to this renumbering of the states, we re-arrange the entries of the matrix . This results in a new matrix and a new vector . To avoid overloaded notation, we shall retain the symbols and . It will be clear from the context which arrangement is being used.
Iosifescu (1980) derives formulae for the moments of the occupancy time of the Markov chain in a single target state (see also Caswell (2009)). The key element for those calculations is the fundamental matrix
| (4) |
The -th entry of the matrix is the mean occupancy time in the state for an individual starting in state . Any higher moment of the occupancy time is derived from the fundamental matrix. In particular, the variances are given by the matrix,
| (5) |
The mean occupancy time in the target set is the sum of the mean occupancy times in each target state. Hence, the mean is directly deduced from the fundamental matrix by summing the corresponding entries. However, this technique breaks down when calculating the variance of the occupancy time. Indeed, the variance of a sum of random variables is not the sum of the variance of each variable (unless the variables are independent). This complication motivates the need of the new technique presented in the next Section. This technique provides not only a straightforward formula for the variance, but also an entire set of new formulae for diverse measures of life history traits, as listed in Table 1.
Example
The model and the results are illustrated throughout the paper with a model for the Southern Fulmar (Fulmarus glacialoides) derives by Jenouvrier et al. (2015). The life cycle graph shown in Fig. 1 is broken into four stages, which are defined at the end of the breeding season: pre-breeders, who have yet to breed for the first time; this include fledged chicks from the previous season; non-breeders, who have bred at least once before, but not in the current season; successful breeders, who have successfully raised a chick during the current season, and failed breeders, who have not successfully raised a chick during the current season because they failed to either hatch an egg or raise a chick. Hence, the set of transient states is and the individual state space is . We define two target sets: ( and ) and ( and ). The former represents the super-state adult, that is an individual in is characterised by having bred at least once. The latter represents the super-state breeding; an individual in is currently attempting to breed regardless of its success.
Fig. 1.

Life cycle graph of Southern Fulmar. State is the pre-breeder state. State is the non-breeder state. State is the successful breeder state. State is the failed breeder state. State is the death state. To lighten the graph we omit the transitions to the death state.
Outcome of a Markov chain model
An outcome of a demographic Markov chain model is function of the initial state of an individual, and its pathway through the life cycle. For example, the number of breeding attempt of a newborn Southern Fulmar is the result of its entire pathway — from birth to death. Here, the initial state is pre-breeder because any newborn is in this state. The number of breeding attempt of an adult is a result of its pathway, but only from its first passage in the super-state adult to death. Here, the initial state is successful breeder (or failed breeder) because an individual matures when it reaches one of these two states. For this reason, any result listed in Table 1 is a vector and each entry corresponds to a specific initial condition. For example, the occupancy time in is given by the vector
| (6) |
where is the occupancy time in the set for an individual that is initially in state .
3. Constructing the induced Markov chains
To derive our results, we construct three new Markov chains associated with the set of target states . These chains are created from the original Markov chain and the target set .
-
The killed Markov chain, with transition matrix . This Markov chain is a copy of the original Markov chain that is stopped as soon as it enters in the target set. If the individual never enters the target set, then the pathway of the killed Markov chain is equivalent to the pathway of the initial Markov chain. See Section 3.1 for a formal definition.
-
The conditional Markov chain, with transition matrix . This Markov chain concerns only individuals that successfully reach the target set. It describes their pathway from their initial state to their first entrance to the target set. In other words, it describes these pathways of the killed Markov chain that do reach a target state. See Section 3.2 for a formal definition.
-
The sub-Markov chain, with transition matrix . This Markov chain is a copy of the original Markov chain viewed through a filter that allows one to see only the target set. The pathways of the sub-Markov chain corresponds to the pathways of the original Markov chain observed through this filter. See Section 3.3 for a formal definition.
To each pathway of the original Markov chain there corresponds a pathway in each induced Markov chain. Fig. 2 shows three pathways through the life cycle of the Southern Fulmar, and, below each of them, the corresponding pathways of the induced Markov chains, associated with the target set , consisting of the breeding states.
Fig. 2.

The first row of each block is a realisation of the original Markov chain describing the Southern Fulmar life cycle. Under them are the corresponding realisations of the induced Markov chains associated with the target states : the killed Markov chain in brown, the conditional Markov chain in green, and the sub-Markov chain in blue. The realisations of the sub chain may have longer jumps because it describes the pathways of the original chain only in the target set. In the second block, the conditional chain has no realisation because the original chain does not enter any target state. (For interpretation of the references to colour in this figure legend, the reader is referred to the web version of this article.)
We now explain in detail how to construct the matrices , , and from the matrix ; we illustrate this construction with the Southern Fulmar example. After the rearrangement of the matrix according to the numbering of the states (see Section 2), the transition matrix can be split in four block matrices, which contain the transition probabilities from to , from to , from to , and from to , respectively. These block matrices are denoted by , , , and , and appear within as Eq. (7) given in (Box I).
Box I.
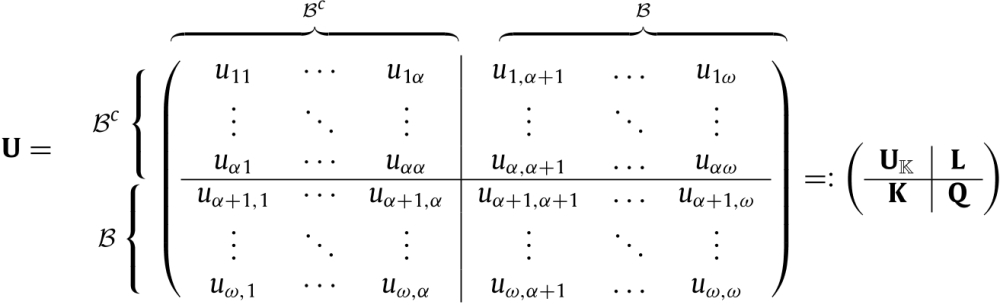 |
(7) |
These four matrices are essential to the construction of the killed, the conditional, and the sub Markov chains. All the other matrices used for this construction and for the derivation of the results are tabulated for easy reference in Table 2.
Table 2.
Matrices used the construction and in the analysis of the Markov chain demographic model. and denote the number of living states in the life cycle and the number of states in the set , respectively, and .
| Notation | Expression | Size | Description |
|---|---|---|---|
| Matrices describing demographic model | |||
| Transition probabilities | |||
| Living states transition probabilities | |||
| Mortality probabilities | |||
| Fundamental matrix | |||
| Decomposition of | |||
| Eq. (7) | -to- transitions | ||
| Eq. (7) | -to- transitions | ||
| Eq. (7) | -to- transitions | ||
| Eq. (7) | -to- transitions | ||
| Matrices describing the killed MC | |||
| Transition probabilities | |||
| Transient state transition probabilities | |||
| Eq. (9) | Absorbing transition probabilities | ||
| Fundamental matrix | |||
| Matrices describing the conditional MC | |||
| Transition probabilities | |||
| Transient state transition probabilities | |||
| Absorbing transition probabilities | |||
| Fundamental matrix | |||
| Matrices describing the sub MC | |||
| Transition probabilities | |||
| Transient state transition probabilities | |||
| Mortality probabilities | |||
| Fundamental matrix | |||
| Other | |||
| Reaching a state in probabilities | |||
| Reaching probabilities | |||
| Transition probabilities given individual returns in | |||
| to transitions | |||
| to transitions | |||
3.1. The killed Markov chain
The transition matrix describes a copy of the original Markov chain that is stopped as soon as it enters . In this chain, the states in and the death state are now absorbing, and the new transient set is . The state space of the killed Markov chain is , and its transition probability matrix is
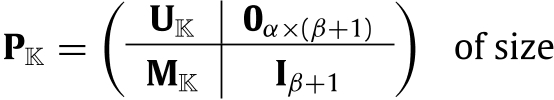 |
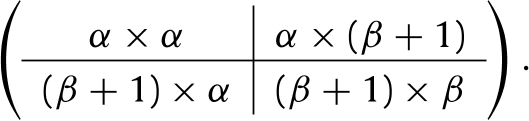 |
(8) |
The entry is the transition probability from non-target state to non-target state . The entry is the transition probability from state to target state , for , and to the death state, for . The matrix is extracted from the original transition matrix , as in Eq. (7). The matrix is composed of two blocks:
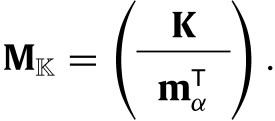 |
(9) |
The matrix describes the transitions from the non target states to the target states; it is directly extracted from the original transition matrix , as in Eq. (7). The vector describes the transitions from the non target states to the death states; it is extracted from the original vector describing the probabilities of death (Eq. (2)),
| (10) |
Example
Fig. 3 shows the graphs of the killed Markov chains associated with the target states and , respectively.
Fig. 3.

Graphs of the killed Markov chain associated with the sets (a), and (b), respectively. The grey circles are the target states, which are absorbing states for the killed Markov chain. The dashed arrows are the transitions into the absorbing states. To lighten the graph we omit the transitions to the death state.
3.1.1. Absorption probabilities
In order to define the conditional Markov chain, we need to calculate, for each target state and non-target state , the probability that an individual starting in passes through before eventual death. For , and , let denote the probability that the killed chain initially in state (non target state) is absorbed into the target state . Following Theorem 3.3 in Iosifescu (1980), those probabilities are described by the matrix
| (11) |
where is the fundamental matrix associated with the killed Markov chain. Note that the matrix is a sub-matrix of the matrix , which describes the entire distribution of fates for any starting non-target state, i.e. the probabilities that the killed Markov chain is stopped in any of the target states or in the death state. Therefore the columns of sum to one.
The probabilities of absorption in the set – regardless of the specific state in which the chain is absorbed – are given by the vector which satisfies the equation
| (12) |
The th entry of is the probability that the killed Markov chain, initially in state , is absorbed in a target state.
By definition of the killed Markov chain, is the probability that the first target state, visited by an individual initially in state , is . Similarly, is the probability that an individual initially in state reaches a target state. In the Southern Fulmar example with target set , the entry is the probability that the first breeding attempt of a newborn is successful, and is the probability that a newborn attempts breeding.
3.2. The conditional Markov chain
The transition matrix describes the transition probabilities of the killed Markov chain, conditional on absorption in the target set. Therefore, the absorbing states are and the new transient set is . The state space of the conditional Markov chain is , and its transition probability matrix is
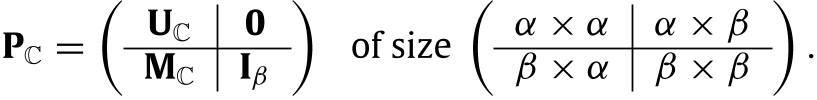 |
(13) |
Note that the death state does not belong to the state space of the conditional Markov chain because all its trajectories are absorbed by the target set before death is reached. The entry is the conditional probability of the transition form state to state given that the individual will eventually enter in the set . The entry is the conditional transition probability from the state to the target state , given that the individual will eventually enter in the set . The columns of sum to . The block matrices and are given by
| (14) |
where
| (15) |
is a diagonal matrix with, on the diagonal, the probabilities of absorption in the target states, (defined in Eq. (11)).
In Appendix A.2, we provide a formal proof that the matrix , defined by Eqs. (13), (14), describes the Markov chain whose trajectories are precisely those of the killed Markov chain that do not encounter death before entering the target set. This proof is deeply inspired by the proof, written by Iosifescu (1980) (Section 3.2.9), in the special case where the target set is a single state.
Example
Fig. 4 shows the graphs of the conditional Markov chains associated with the target states and , respectively.
Fig. 4.

Graphs of the conditional chain associated with the sets (a), and (b), respectively. The grey circles are the target states. The dashed arrows are the transitions into the absorbing states.
3.3. The sub-Markov chain
The transition matrix contains, for each pair of target states and , the probabilities that an individual currently in state returns to the target set in state or dies before returning to the target set. Note that the return may take more than one time step. The transient state space is , and is the only absorbing state. The state space of the sub-Markov chain is . The transition probability matrix is
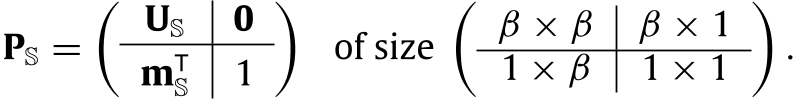 |
(16) |
The entry is the probability that an individual starting in state reaches the state without passing through any other state in . The entry is the probability that an individual starting in state dies before it reaches a state in . Since the columns of the matrix sum to one,
| (17) |
and the only variable is the matrix . In Appendix A.1, we derive the matrix from the matrix ,
| (18) |
The matrix (defined in Eq. (7)) contains the probabilities that an individual starting in a target state makes a one-step transition to a target state. The product describes the probabilities that the individual first leaves, and then re-enters, the target set. The matrix is defined in Eq. (7), and the matrix is defined in Eq. (11).
Note that one time-step for the sub-Markov chain corresponds to a random number of time-steps for the initial Markov chain. However, the number of passages in a specific state in starting in is equivalent for both chains (see Section 4 for more details).
Example
Fig. 5 shows the graphs of the conditional Markov chains associated with the target states and , respectively.
Fig. 5.

Graphs of the sub-Markov chain associated with the sets (a), and (b), respectively. The dashed arrows are the transitions into the absorbing states. The dashed circles are the target states. To lighten the graph we omit the transitions to the death state.
4. Occupancy time in the target states
The occupancy time in the target states is the time spent in the target states over the individual’s life. Because the pathways taken by individuals through their life is stochastic, the occupancy time is a random variable; each of its realisation is associated with the realised pathway of an individual. In this section, we calculate the distribution of the occupancy time in and we provide formulae for its mean and variance, and for any of its higher moments.
Let denote the occupancy time in the set for an individual initially in state . The occupancy times are grouped into two vectors, and , depending on the initial state being in or out of the set , and both of the vectors are concatenated in the vector ,
| (19) |
Let , , and denote the th moment of the random vectors , , and , respectively.
Moments of the occupancy time
First, we consider an individual initially in a state within the target set . To calculate its occupancy time in , we follow its pathway, and count the number of visits to target states. The parts of the pathway between two target-state visits are irrelevant for this count. Hence, it is sufficient to follow the pathway of the sub-Markov chain, and count its number of visits to . That is the number of steps in which the sub-Markov chain is in one of its transient states. Iosifescu (1980) (Theorem 3.2) provides a recursion formula for the moments of this number, which translates here into a formula for the moments of the occupancy time in the target set for an individual initially in a target state:
| (20) |
| (21) |
| (22) |
| (23) |
where is the fundamental matrix associated with the sub Markov chain.
From Eqs. (20), (21), we obtain a formula for the variance of the occupancy time in for an individual initially in a state within the target set ,
| (24) |
Second, we consider an individual initially in a non-target state. Since the sub-Markov chain is not defined outside the target states, we cannot directly apply the technique used above. However, we know that, either the individual never enters , in which case its occupancy time is zero, or it reaches some target state . In the latter case, the probabilistic fate of the individual after it reaches is equivalent to the fate of an individual that starts in the target state ; this is the strong Markov property (see e.g., Meyn and Tweedie (2009)). Thus, the conditional mean occupancy time, given the first-reached target state , is the mean occupancy time of an individual initially in . The unconditional mean occupancy time is the average, over the target states, of the means of the occupancy time of an individual initially in a target state, weighted by the probabilities to reach first these target states. This holds for all moments, and is translated in matrix notation into
| (25) |
where the matrix contains the probabilities of reaching the target states (defined in Eq. (11)), and the vector is given by Eq. (23). In Appendix A.3, we provide a formal proof of Eq. (25).
From Eq. (25), we obtain a formula for the variance of the occupancy time in for an individual initially in a non-target state,
| (26) |
and
| (27) |
Distribution of the occupancy time
First, we calculate the distribution of the occupancy time in for an individual initially in a state within the target set. Similarly to the moment calculations, this distribution is equivalent to the distribution of the number of steps in which the sub-Markov chain is in one of its transient states. Following Iosifescu (1980) (p. 104), we obtain
| (28) |
Second, we calculate the distribution of the occupancy time in for an individual initially in a non-target state. Similarly to the moment calculations, we use the strong Markov property to deduce this distribution from the distribution of the occupancy time in for an individual initially in a state within the target set, given in Eq. (28). The probability that the occupancy time is zero, however, requires a special attention. This probability is equal to the probability that the individual dies before it enters any target state; that is one minus the absorbing probability (see Eq. (12)). Hence, the distribution of the occupancy time in for an individual initially in a non-target state is
| (29) |
5. Correlation between the occupancy times in two sets
Consider two subsets and , of the transient set . In this section we calculate the correlation between the occupancy time in and the occupancy time in . A positive (resp. negative) correlation means that both of the occupancy times tend to have the same (resp. opposite) “behaviour”, i.e. when one is greater than its mean, the other tends to be greater (resp. smaller) than its mean and vice versa when it is smaller. The correlation between and is defined as follows
| (30) |
where the covariance between and is
| (31) |
The denominator in the right hand side of Eq. (30) is directly calculated with the formulae (24), (26) applied successively to and . To calculate the numerator let us split the set into three pairwise disjoint sets (possibly empty): the states in that are not in :
| (32) |
the states in that are not in :
| (33) |
and the states that are in and in
| (34) |
Then we have
| (35) |
| (36) |
The covariances in the right hand side of Eq. (36) are calculated with formula (86) applied to the appropriate sets. The variance is calculated with formulae (24) and (26) applied to the set .
If the sets and are disjoint, Eq. (36) boils down to
| (37) |
(see Appendix A.4 for details). The variances , , and are calculated with the formulae (24), (26) applied to the sets , , and , respectively.
5.1. Correlation between occupancy time and longevity
In the particular case when the set is the entire transient set, and is another target set, the calculations above provide a formula for the correlation between occupancy time in and the longevity.
Let denote the longevity for an individual initially in state . The longevity is the sum of the time spent in all the transient states before death, that is the occupancy time in the entire transient set (see Caswell (2001)). Therefore the correlation between the occupancy time in the target states and the longevity of an individual can be calculated with the formula (30) applied to and . In this particular case, the calculations above boil down to
| (38) |
6. Behaviour of winners and losers
For want a better term, we call the individuals that eventually reach the target states winners. Individuals that never reach the target states are called losers (the terminology implies nothing about the desirability of the states). In the Southern Fulmar example with target set , the winners are individuals that eventually breed, successfully or not, and the losers are individuals that never breed. Two demographic variables are related to the behaviour of the winners: the time required to reach the target set, and the time to return to the target set. In the Southern Fulmar example with target set , these variables translate into the time to maturation, and the time interval between two breeding attempts. In this Section, we calculate the probability that an individual eventually becomes a winner, and the conditional probability distribution of the time to reach the target set, given that the individual eventually does so. We also provide formulae for the variance and any moments of this distribution. Then, we calculate the probability that a winner returns to the target set, after its first visit. Finally, we calculate the conditional probability distribution of the time to return to the target set, given that the individual eventually returns. We also provide formulae for the variance and any moments of this distribution.
6.1. Probability of reaching the target states
The probability that an individual eventually reaches the target set is the probability that the killed Markov chain is absorbed into a target state (see Section 3.1.1). Therefore the probabilities of being a winner, given the current state, are given by the entries of the vector ,
| (39) |
| (40) |
6.2. Time to reach the target states
Let denote the random time required to reach the target set by a winner initially in the non target state , and
| (41) |
The time required by a winner to reach the target set is the occupancy time of the conditional Markov chain in its entire transient set. Indeed, by definition, the conditional Markov chain describes the transitions of winners before they enter the target set. Theorem 3.2 in Iosifescu (1980), applied to the conditional Markov chain, provides a recursion formula for the moments of the occupancy time, which translates here into a formula for the moments of the time required to reach the target states,
| (42) |
where is the fundamental matrix associated with the conditional Markov chain. In particular, Eq. (42) yields the mean and variance of ,
| (43) |
| (44) |
Following Iosifescu (1980) (see p. 104), we also obtain a formula for the distribution of
| (45) |
6.3. Return to the target states
A winner will eventually enter the target set but its life may not end there. It may leave one time-step after its first entrance and never return, it may leave but return eventually, it may stay and leave later, or it may stay forever. An individual returns to the target set if it is in one of the target states at some time, and it visits a target state at a later time, but without passing through any target state in-between.
6.3.1. Return probabilities
The entries of the sub-Markov chain describe the probabilities for an individual to go – in possibly more than one time-step – from one target state to another, without passing through other target states in-between. Hence, the entry (Eq. (18)) is the probability that an individual in target state returns to in target state ,
| (46) |
The probabilities of returning to regardless in which state are given by the vector
| (47) |
6.3.2. Return time
The return time to the target set is the time between two visits to this set. For a demographic Markov chain, it is the time interval between two instances of the demographic events described by the target set, e.g., the number of years between two breeding attempts. This time interval can be as small as if the individual breeds the next year, but it can be infinite if the individual dies before breeding again. To avoid the later scenario, we calculate the conditional probability distribution of the return time, given that the individual does eventually return to . Caswell (2006) provides formulae for the distribution and the moments of the interval between demographic events that are described by a single target state. By using a different method, we generalise this result to events described by several target states.
Let denote the return time for an individual initially in target state , and
| (48) |
To calculate the probability distribution of , we need to calculate the one-time-step transition probabilities from target states to target states, and from target states to non-target states, conditional on eventual return to the target set.
Let , of size , denote the matrix which contains the conditional probabilities that an individual initially in a target state moves to a target state in one step, given that it eventually returns to the target set. By definition of conditional probabilities, we have
| (49) |
where diagonal of contains the return probabilities, as defined in Eq. (47), and contains the unconditional probabilities that an individual initially in a target state moves to a target state, as defined in Eq. (7). Eq. (49) is derived in detail in Appendix A.5.
Let of size denote the matrix which contains the conditional probabilities that an individual initially in a target state moves to a non-target state, given that it eventually returns to the target set. Similar to the calculation of the transition probabilities of the conditional Markov chain (Section 3.2), the calculation of follows from the definition of conditional probabilities and the Markov properties of the original chain,
| (50) |
where and , respectively, contain on their diagonal the probabilities of return to, and the probabilities of absorption in, the target states, as defined in Eqs. (11), (47). The matrix contains the unconditional probabilities that an individual initially in a target state moves to a non-target state, as defined in Eq. (7). Eq. (50) is derived in detail in Appendix A.5.
The probability distribution of is derived from the matrices , , and the transition matrix of the conditional Markov chain. The return time of an individual initially in the target set is equal to one if its first transition is into the target set. The probabilities of those transitions are obtained by summing the columns of matrix , i.e.
| (51) |
To calculate the probabilities that the return time is , with , we use the Markov property. An individual with a return time equal to has first moved to a non-target state, and from there it has reached the target set in steps. Hence, the probability that the return time is equal to is the sum, over all non-target states, of the product of the probability that an individual moves to a non-target state and the probability that an individual reaches the target set from this non-target state, in steps. Hence,
| (52) |
The probabilities that an individual initially in a target state moves to a non-target set are given by the column-sums of the matrix . The bracketed term is the probability of reaching the target set in steps, as given in Eq. (45).
In Appendix A.5, we also derive a formula for the moments of . In particular, this formula yields the mean and variance of ,
| (53) |
| (54) |
7. Example: the Southern Fulmar
The Southern Fulmar is an ice-dependent seabird. This species breeds along the coast of Antarctica and outlying islands, and its individuals forage near the ice edge. Because of its breeding and foraging habitat, the vital rates of the Southern Fulmar are, to some extent, dependent on the sea ice condition. Using the life cycle illustrated in Fig. 1, Jenouvrier et al. (2015) estimated matrix population models for three ice conditions: favourable, ordinary, and unfavourable. From these models, we derive three transient state transition matrices, , and , describing transitions and survival in a favourable, ordinary, and unfavourable ice conditions, respectively. These matrices are provided in the Supplementary Material.
We choose to focus on the super-state “breeding attempt”; that is, the target states . This set plays an important role in the developmental description of an individual. The pre-breeder state describes juvenile individuals, the non-breeder state describes adult individuals that are skipping reproduction, and captures the actively reproducing individuals. In this section, we first show the construction of the killed Markov chain, the conditional Markov chain, and the sub Markov chain for . Then, we illustrate the calculations listed in Table 1, describe their biological meaning for the target set , and compare them between the three ice conditions. In the Supplementary Material, we provide the matlab code for calculating all the measures presented here. Due to space constraints, we only show matrices associated with the ordinary ice conditions.
Original Markov chain
The transition probabilities between the transient states of the original Markov chain are extracted from Jenouvrier et al. (2015),
| (55) |
The death probability vector is deduced from ,
| (56) |
Constructing the killed Markov chain
The killed chain is the original chain that is stopped as soon as it enters . The transient states of the killed chain are , and the absorbing states are . Fig. 3 (a) shows the graph of the killed Markov chain. The variables required to describe the transition matrix (Eq. (8)) are the matrices and (both extracted from as shown in Eq. (7)), and the vector containing the death probabilities from the non-target states (as defined in Eq. (9)):
| (57) |
Constructing the conditional Markov chain
The conditional Markov chain is the killed chain, conditional on eventual absorption in the target states. The transient states of the conditional chain are , and the absorbing state are . Fig. 4 (a) shows the graph of the conditional Markov chain. The variables required to construct the transition matrix Eq. (8) are the matrices and , both defined in Eq. (14),
| (58) |
Constructing the sub Markov chain
The sub Markov chain is the original chain observed through a filter that makes visible only the target states and the death state. The transient states of the sub chain are the target states , and the absorbing state is . Fig. 5 (a) shows the graph of the sub-Markov chain. The variables required to construct the transition matrix (Eq. (16)) are the matrix (defined in Eq. (18)), and the vector (defined in Eq. (17),
| (59) |
Now, we illustrate the calculations listed in Table 1 for each ice condition.
Occupancy time in .
The occupancy time in the set is the lifetime number of breeding attempts. Fig. 6 illustrates the mean and coefficient of variation of the lifetime number of breeding attempts (i.e. occupancy time in ), calculated with formulae (20), (24), (25), and (26), applied to .
Fig. 6.

Mean (a) and coefficient of variation (b) of the occupancy time in the set for an individual initially in the states pre-breeder (PB), successful breeder (SB), failed breeder (FB), and non breeder (NB).
The mean number of breeding attempt is extremely low under unfavourable ice conditions (Fig. 6). This is a consequence of the long time to maturation under unfavourable ice conditions. In fact, the probability of maturation in unfavourable conditions is only 0.0544. Thus, less than 1/20th of the newborns mature; 19/20 never attempt breeding. However, those that do mature have a relatively large number of breeding attempts (see Fig. 6 (a), initial states successful breeder and failed breeder). This large difference between the mean number of breeding attempt of newborns and adults explains partially the large standard deviation of the number of breeding attempts of newborns, which is almost six times the mean, as shown in Fig. 6 (b). In contrast, under favourable conditions, half of the newborns will reach maturity, which brings the mean number of breeding attempt for newborns closer to the mean number of breeding attempt for adults. As a consequence, the standard deviation of the number of breeding attempts is less than twice its mean.
Fig. 7 illustrates the probability distribution of the lifetime number of breeding attempt for adults under each ice condition, calculated by applying Eq. (28) to the set . These distributions are approximately geometric, with parameter , where is the average probability of returning to (see Eq. (47)), which ranges from 0.9272 (favourable conditions) to 0.6951 (unfavourable conditions). The mean and coefficient of variation of this distribution are and , respectively. This explains why the relative decrease of the mean number of breeding events after maturation between favourable ice conditions and unfavourable conditions is approximately 0.7, but the relative decrease of the coefficient of variation is only 0.1, as shown in Fig. 7.
Fig. 7.

Distributions of the occupancy time in the set for an individual starting in the state successful breeder under favourable condition (left), ordinary condition (centre), and unfavourable condition (right).
Correlation between occupancy time and longevity.
The correlation between the longevity of an individual and its number of breeding attempts provides information on how longevity affects the total number of breeding attempts. Using formula (38), we find a positive correlation (Fig. 8) for each ice condition. Indeed, we expect that on average a particularly large longevity results in a particularly large number of breeding attempt and vice versa. Because newborn individual cannot breed before maturity, the correlation between longevity and breeding attempts for newborn is smaller than the correlation for adults. Under favourable ice conditions, individuals spend most of their lives in , and the correlation approaches .
Fig. 8.

Correlation between occupancy time in and the expected longevity for an individual initially in the states pre-breeder (PB), successful breeder (SB), failed breeder (FB), and non breeder (NB).
Time required to reach .
The target states in describe active reproduction, and the time to reach is the time to maturation. Fig. 9 illustrates the mean and coefficient of variation of this time, calculated with formulae (43), (44) applied to . The average maturation time under unfavourable ice conditions among individuals that do successfully mature is twice as large as that under favourable ice conditions.
Fig. 9.

Mean (a) and coefficient of variation (b) of the time to reach the set for individual initially in the states pre-breeder (PB), and non breeder (NB).
Time required to return to .
This time corresponds to the time between two breeding attempts, which is a measure of inter-birth interval and an indicator of the individual’s reproduction consistency. This time is for individuals that never skip reproduction, and is infinite for individuals that reproduce only once. In terms of the Markov chain, this time is the return time to the set . The mean return time increases as the ice condition becomes less favourable (Fig. 10). Unlike for the maturation time, the coefficient of variation of the time between breeding increases significantly as well. One reason is that non-breeding individuals have a smaller probability of attempting breeding the following year under unfavourable ice conditions () than under favourable ice conditions (). This results in more variation in the distribution of the time required to attempt breeding after a non breeding season under unfavourable ice conditions than under favourable ice conditions, as shown in Figures S1 and S2 provided in the Supplementary Material.
Fig. 10.

Mean (a) and coefficient of variation (b) of the time to return to the set for an individual initially in the states successful breeder (SB), and failed breeder (FB).
8. Discussion
From birth to death, an individual goes through a sequence of random events (e.g., surviving, developing, mating, reproducing, growing, dispersing, moving among social or occupational classes, or changing health status). This results in a stochastic pathway through the individual state space. Many important life history traits are direct functions of these pathways (e.g., longevity, reproductive output, age at maturity) and are often related to the concept of occupancy time in a state. Absorbing Markov chains are a powerful model framework to analyse these stochastic pathways, but current theory can only calculate the occupancy times in a single state. However, often the occupancy time in a set of states is desired. For example, a size range in a size-classified model, an age class in a agestage model, or a set of locations in a spatial model are all sets of states. We have presented a new mathematical approach to absorbing Markov chains that generalises the occupancy calculations to sets of states and enlarges the list of demographic measures that can be calculated from a demographic model.
For any number of target states, we provide formulae to calculate any moments (e.g., mean and variance) and the probability distribution of
-
the occupancy time in a target set
-
the time required to reach a target set
-
the time required to return to a target set.
Last but not least, we provide a formula to calculate the correlation between the occupancy times in two different sets. These formulae are straightforward to calculate in matrix oriented software.
In demographic models based on absorbing Markov chains, any life history trait that is a function of the individual’s pathway is stochastic. The calculation of the resulting distribution of this trait among individuals is complicated, and is often approximated by its mean and, sometime, its variance. While the current theory can calculate any moment of the occupancy time in a single state, our generalisation to the set occupancy time provides also a formula for its probability distribution.
As the questions in population ecology become more sophisticated and data become more detailed, the use of multistate and hyperstate matrix models will become increasingly important (Roth and Caswell, 2016). For these models, it is often useful to consider marginal sets. For example, in a agestage-structured model, the marginal set age describes individuals in age class independently of their stage. Similarly, an increasingly number of studies use integral projection models (Ellner et al., 2016) which are approximated – and then analysed – by matrix projection models with highly detailed i-state space (e.g., large number of size classes). For these models, the occupancy in a single state is often of no interest, while the occupancy in a set of state can be biological important (e.g., range of ages or sizes corresponding to a specific developmental stages). Our work generalises the occupancy calculations for these two highly powerful family of models.
In human demography, multistate models often combine age classes with health or social categories. Studies may focus on the expected occupancy times (e.g., Siegel (2012) and Clark et al. (2016)), but very little use is made of the Markov chain framework presented here. Applying our results to such human demographic models would significantly improve the calculations of the occupancy by providing the variance and its probability distribution.
The only data required for our calculations are the transition probabilities between the states that describe the individuals. These probabilities can be obtained from most population projection matrices. The availability of projection matrix data has been improved by the databases COMPADRE for plant and COMADRE for animals [21], [22]. Hence, our approach to absorbing Markov chain makes the analysis of occupancy times accessible for a wide range of existing projection matrix models.
The power of our results is to provide easy-to-use formulae to calculate demographic measures that seem, a priori, to be complicated. All the indices listed in Table 1 can be calculated with matrix expressions, which are very easy to implement in matrix oriented softwares. In the Supplementary Material, we provide the matlab code that calculates the results listed in Table 1 from a given transition matrix and a set of transient states . We also provide the matlab code for calculating the results of the Southern Fulmar example presented in Section 7.
In ecology and in human demography, discrete time models are widely used for their simplicity in their formulation and for their fit with data observed at specific times. However, the underlying processes of these dynamics are certainly continuous in time. Hence, extending the occupancy calculations to continuous time Markov chains would significantly enlarge the range of applications.
Acknowledgements
This research was supported by Advanced Grant 322989 from the European Research Commission and National Science Foundation (NSF) Grant DEB-1257545. The authors thank the anonymous referee for useful comments on an earlier draft of this paper.
Footnotes
Supplementary material related to this article can be found online at https://doi.org/10.1016/j.tpb.2017.12.007.
Appendix A.
To derive our formulae, we need to define formally the stochastic process described by the transition matrices and . The Markov chain associated with the transition matrix describes a stochastic process taking values in the i-state space and satisfying the Markov property
| (60) |
for any . Likewise, the killed Markov chain, the conditional Markov chain, and the sub-Markov chain describe the stochastic processes , which satisfy the Markov property, respectively.
A.1. Derivation of the matrix and the vector
Let be two target states. The entry is the probability that an individual initially in target state to reach the state without passing by any other states in . Define the stopping time . The time is the random time – possibly infinite – at which the individual will enter the set . In particular, is the state through which the individual enters for its first time in . Then we can rewrite as
| (61) |
By definition of the absorbing probabilities (Eq. (11)), for a non target state , we have
| (62) |
Using the Chapman–Kolmogorov equation (see e.g., Meyn and Tweedie (2009)), we obtain
| (63) |
In matrix notation, equation (63) is equivalent to Eq. (18), i.e.
| (64) |
where the matrices and are extracted from the matrix , as in Eq. (7).
A.2. Proof that is a Markov chain
Iosifescu (1980) (section 3.2.9) proves that an absorbing Markov chain, with respect to the conditional probability that it is absorbed by a specific state, is still an absorbing Markov chain. Here, we generalise this statement to the condition that the chain is absorbed in a specific set of states.
Let us define the event , i.e. the killed chain is absorbed in the target set. We consider the stochastic process , living on the space , defined by
| (65) |
for any measurable set . To ease the notation, we write .
By definition, the process corresponds to the killed Markov chain, where trajectories encountering death before target states are set aside. We first prove that is a Markov chain and then we show that its transition probabilities are describe by the matrix defined in Section 3.2. As a consequence, this proves that the conditional Markov chain is indeed a Markov chain and that it corresponds to the killed Markov chain, where trajectories encountering death before target states are set aside.
To prove that is a Markov chain, we only need to show that it satisfies the Markov property, i.e.
| (66) |
for .
Fix , and define the event , for .
From the definitions of conditional probabilities and the process , we have
| (67) |
If , then
for any . The second equality is a consequence of the Markov property of the killed Markov chain, and the third equality follows from the definition of the absorbing probability vector (see Eq. (12)).
Similarly,
| (68) |
| (69) |
| (70) |
| (71) |
| (72) |
where equals if and otherwise.
If , then , for , and
| (73) |
| (74) |
| (75) |
Eqs. (72), (75) imply that the ratio on the right hand side of Eq. (67) does not depend on , for . In particular,
| (76) |
| (77) |
This prove that satisfies the Markov property.
The transition probabilities of the Markov chain follow from the equations above. For and ,
| (78) |
with the convention that for . And we have for ,
| (79) |
It follows form Eqs. (78), (79) that the transition probabilities of the Markov chain are given by the matrix defined in Section 3.2, i.e.
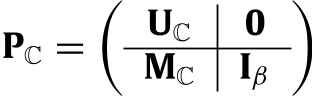 |
(80) |
where
| (81) |
where is a diagonal matrix with, on the diagonal, the probabilities of absorption in the target states.
A.3. Moments of occupancy times
To calculate the moments of the occupancy time for individuals initially outside the target set , we use the strong Markov property. If the individual never enters in , then its occupancy time is zero. If it does enter in , say through the state , then the law of its occupancy time is equal to the law of the occupancy time for an individual starting in the state . To fix the idea, consider the state . Then
| (82) |
where is the probability that the killed Markov chain, starting in state , is absorbed by the state , as in Section 3.1.1. In matrix notation, Eq. (82) is equivalent to
| (83) |
A.4. Covariance between the occupancy times in two disjoint sets
Here, we calculate the covariance between the occupancy time in two disjoint subsets and , of the transient set . As stated in the main text, the covariance between and is
| (84) |
We rewrite the covariance between and in terms of their variances and the variance of their sum,
| (85) |
Since the sets and are disjoint, the occupancy time in the union is the sum of the occupancy times in each of the subsets. Thus,
| (86) |
The variances , , and are calculated with the formulae (24), (26) applied to the sets , , and , respectively.
A.5. One-step transition probabilities from given return
Let be the conditional probability that an individual in target state moves to the target state , in one time-step, given that it eventually returns to the target set. Then,
| (87) |
where describes the return probabilities, as defined in Eq. (47). Thus,
| (88) |
where and the matrix is extracted from the matrix , as in Eq. (7). Let be the conditional probability that an individual in target state moves to the non-target state , in one time-step, given that it eventually returns to the target set. Then
| (89) |
where the vector describes the probabilities of absorption in the target states, as defined in Eq. (11). Thus,
| (90) |
where , , and the matrix is extracted form the matrix , as in Eq. (7).
Now, we derive the moments of , conditional on the individual returning to the target set. Let be a target state. Then
| (91) |
| (92) |
| (93) |
| (94) |
| (95) |
| (96) |
Hence, in matrix notation,
| (97) |
Appendix B. Supplementary data
The following is the Supplementary material related to this article.
Figures S1 and S2. S1 shows the distribution of the time required to return to the set target set Bb for an individual initially in the state successful breeder, under each environmental conditions. S2 shows the distribution of the time required to reach the set Bb for an individual initially in the state non breeder, under each environmental conditions.
This file contains the MATLAB codes to carry out the calculations presented in this paper for any transition matrix and any target set. This file contains also the transition matrices used in the Example.
References
- 1.Caswell H. second ed. Sinauer Associates; Sunderland, MA: 2001. Matrix Population Models: Construction, Analysis, and Interpretation. [Google Scholar]
- 2.Caswell H. MAM2006: Markov Anniversary Meeting. Boson Books; Raleigh, North Carolina: 2006. Applications of markov chains in demography; pp. 319–334. [Google Scholar]
- 3.Caswell H. Stage, age and individual stochasticity in demography. Oikos. 2009;118(12):1763–1782. [Google Scholar]
- 4.Caswell H. Beyond : Demographic models for variability of lifetime reproductive output. PloS ONE. 2011;6(6):e20809. doi: 10.1371/journal.pone.0020809. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Caswell H. Perturbation analysis of continuous-time absorbing Markov chains. Numer. Linear Algebra Appl. 2011;18(6):901–917. [Google Scholar]
- 6.Caswell H. Sensitivity analysis of discrete Markov chains via matrix calculus. Linear Algebra Appl. 2013;438(4):1727–1745. [Google Scholar]
- 7.Caswell H., Kluge F.A. Demography and the statistics of lifetime economic transfers under individual stochasticity. Demographic Res. 2015;32:563–588. [Google Scholar]
- 8.Clark D.E., Ostrander K.R., Cushing B.M. A multistate model predicting mortality, length of stay, and readmission for surgical patients. Health Serv. Res. 2016;51(3):1074–1094. doi: 10.1111/1475-6773.12400. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Cochran M.E., Ellner S.P. Simple methods for calculating age-based life history parameters for stage-structured populations. Ecol. Monograph. 1992;62(3):345–364. [Google Scholar]
- 10.Ellner S.P., Childs D.Z., Rees M. Springer; 2016. Data-Driven Modelling of Structured Populations: A Practical Guide to the Integral Projection Model. [Google Scholar]
- 11.Feichtinger G. Lecture Notes in Economics and Mathematical Systems. Springer-Verlag; Berlin: 1971. Stochastische modelle demographischer prozesse. [Google Scholar]
- 12.Horvitz C.C., Tuljapurkar S. Stage dynamics, period survival, and mortality plateaus. Amer. Naturalist. 2008;172(2):203–215. doi: 10.1086/589453. [DOI] [PubMed] [Google Scholar]
- 13.Iosifescu M. Wiley; New York, New York: 1980. Finite Markov Processes and Their Applications. [Google Scholar]
- 14.Jenouvrier S., Pron C., Weimerskirch H. Extreme climate events and individual heterogeneity shape life-history traits and population dynamics. Ecol. Monograph. 2015;85(4):605–624. [Google Scholar]
- 15.Kemeny J.G., Snell J.L. Finite continuous time Markov chains. Theory Probab. Appl. 1961;6(1):101–105. [Google Scholar]
- 16.Lebreton J.-D. Demographic models for subdivided populations: the renewal equation approach. Theoret. Popul. Biol. 1996;49(3):291–313. doi: 10.1006/tpbi.1996.0015. [DOI] [PubMed] [Google Scholar]
- 17.Meyn S.P., Tweedie R.L. Cambridge Univ. Press; 2009. Markov Chains and Stochastic Stability. [Google Scholar]
- 18.Pascarella J.B., Horvitz C.C. Hurricane disturbance and the population dynamics of a tropical understory shrub: Megamatrix elasticity analysis. Ecology. 1998;79(2):547–563. [Google Scholar]
- 19.Rogers A. Wiley; New York, New York: 1975. Introduction to Multiregional Mathematical Demography. [Google Scholar]
- 20.Roth G., Caswell H. Hyperstate matrix models: extending demographic state spaces to higher dimensions. Methods Ecol. Evol. 2016;7(12):1438–1450. [Google Scholar]
- 21.Salguero-Gómez R., Jones O.R., Archer C.R., Bein C., Buhr H., Farack C., Gottschalk F.and Hartmann, A., Henning A., Hoppe G.and Romer, G., Ruoff T., Sommer V., Wille J., Voigt J., Zeh S., Vieregg D., Buckley Yvonne M, Che-Castaldo J., Hodgson D., Scheuerlein A., Caswell H.and Vaupel, J.W. COMADRE: a global data base of animal demography. J. Anim. Ecol. 2016;85(2):371–384. doi: 10.1111/1365-2656.12482. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Salguero-Gómez R., Jones O.R., Archer C.R., Buckley Y.M., Che-Castaldo J., Caswell H., Hodgson D., Scheuerlein A., Conde D.A., Brinks E. The compadre plant matrix database: an open online repository for plant demography. J. Ecol. 2015;103(1):202–218. [Google Scholar]
- 23.Sericola B. Occupation times in Markov processes. Comm. Statist. Stochastic Models. 2000;16(5):479–510. [Google Scholar]
- 24.Siegel J.S. The Demography and Epidemiology of Human Health and Aging. Springer; New York: 2012. The life table; pp. 135–216. [Google Scholar]
- 25.Steiner U.K., Tuljapurkar S. Neutral theory for life histories and individual variability in fitness components. Proc. Natl. Acad. Sci. 2012;109(12):4684–4689. doi: 10.1073/pnas.1018096109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Tuljapurkar S., Horvitz C.C. From stage to age in variable environments: life expectancy and survivorship. Ecology. 2006;87(6):1497–1509. doi: 10.1890/0012-9658(2006)87[1497:fstaiv]2.0.co;2. [DOI] [PubMed] [Google Scholar]
- 27.Tuljapurkar S., Horvitz C.C., Pascarella J.B. The many growth rates and elasticities of populations in random environments. Amer. Naturalist. 2003;162(4):489–502. doi: 10.1086/378648. [DOI] [PubMed] [Google Scholar]
- 28.Van Raalte A.A., Caswell H. Perturbation analysis of indices of lifespan variability. Demography. 2013;50(5):1615–1640. doi: 10.1007/s13524-013-0223-3. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Figures S1 and S2. S1 shows the distribution of the time required to return to the set target set Bb for an individual initially in the state successful breeder, under each environmental conditions. S2 shows the distribution of the time required to reach the set Bb for an individual initially in the state non breeder, under each environmental conditions.
This file contains the MATLAB codes to carry out the calculations presented in this paper for any transition matrix and any target set. This file contains also the transition matrices used in the Example.