

SUMMARY
In clinical practice, an informative and practically useful treatment rule should be simple and transparent. However, because simple rules are likely to be far from optimal, effective methods to construct such rules must guarantee performance, in terms of yielding the best clinical outcome (highest reward) among the class of simple rules under consideration. Furthermore, it is important to evaluate the benefit of the derived rules on the whole sample and in pre-specified subgroups (e.g., vulnerable patients). To achieve both goals, we propose a robust machine learning method to estimate a linear treatment rule that is guaranteed to achieve optimal reward among the class of all linear rules. We then develop a diagnostic measure and inference procedure to evaluate the benefit of the obtained rule and compare it with the rules estimated by other methods. We provide theoretical justification for the proposed method and its inference procedure, and we demonstrate via simulations its superior performance when compared to existing methods. Lastly, we apply the method to the Sequenced Treatment Alternatives to Relieve Depression (STAR*D) trial on major depressive disorder and show that the estimated optimal linear rule provides a large benefit for mildly depressed and severely depressed patients but manifests a lack-of-fit for moderately depressed patients.
Keywords: Dynamic Treatment Regime, Machine Learning, Qualitative Interaction, Robust Loss Function, Treatment Response Heterogeneity
1. Introduction
Heterogeneity in patient response to treatment is a long-recognized challenge in the clinical community. For example, in adults affected by major depression, only around 30% of patients achieve remission with a single acute phase of treatment (Trivedi et al., 2006; Rush et al., 2004); the remaining 70% of patients require augmentation of the current treatment or a switch to a new treatment. Thus, a universal strategy that treats all patients by the same treatment is inadequate, and individualized treatment strategies are required to improve response in individual patients. In this regard, rapid advances in technologies for collecting patient-level data have made it possible to tailor treatments to individual patients based on specific characteristics, thereby enabling the new paradigm of personalized medicine.
Statistical methods have been proposed to estimate optimal individualized treatment rules (ITR) (Lavori and Dawson, 2004) using predictive and prescriptive clinical variables that manifest quantitative and qualitative treatment interactions, respectively (Carini et al., 2014; Gunter et al., 2011). Q-learning (Watkins, 1989; Qian and Murphy, 2011) and A-learning (Murphy, 2003; Blatt et al., 2004) are proposed to identify an optimal ITR. Q-learning estimates an ITR by directly modelling the Q-function. A-learning only requires posited models for contrast functions and uses a doubly robust estimating equation to estimate the contrast functions. This makes A-learning more robust to model misspecification than Q-learning and provides a consistent estimation of an ITR (Schulte et al., 2014). Other proposed approaches include semiparametric methods and machine learning methods (Zhang et al., 2012; Foster et al., 2011; Zhao et al., 2012; Chakraborty and Moodie, 2013). For example, the virtual twins approach (Foster et al., 2011) uses tree-based estimators to identify subgroups of patients who show larger than expected treatment effects. Zhang et al. (2012, 2013) estimated the optimal ITR by directly maximizing the value function over a specified parametric class of treatment rules through augmented inverse probability weighting. In contrast, Zhao et al. (2012) proposed outcome weighted learning (O-learning), which utilizes weighted support vector machine to maximize the value function. More recently, Huang and Fong (2014) proposed a robust machine learning method to select the ITR that minimizes a total burden score. Interactive Q-learning (Laber et al., 2014) models two ordinary mean-variance functions instead of modeling the predicted future optimal outcomes. Fan et al. (2016) proposed a concordance function for prescribing treatment, where a patient is more likely to be assigned to a treatment than another patient if s/he has a greater benefit than the other patient.
In clinical practice, simple treatment rules such as linear rules, are preferred due to their transparency and convenience for interpretation. However, when only linear rules are in consideration, many existing methods including semiparametric models and some machine learning methods may not yield a rule with optimal performance, because they focus on optimization of a surrogate objective function of treatment benefit. Using surrogate objective functions may only guarantee the optimality when there is no restriction on the functional form of the treatment rules. For example, with O-learning, the objective function is a weighted hinge-loss, which yields the optimal rule among nonparametric rules, but may not be optimal when the candidate rules are restricted to the linear form. Therefore, learning algorithms are desired to derive a treatment rule with guaranteed performance when constraints are placed on the class of candidate rules.
An additional consideration is the need to evaluate, through diagnostics, any approach for rule estimation. However, less emphasis has been placed on the evaluation of the estimated ITR in the context of personalized medicine. Residual plots were used to evaluate model fit for G-estimation (Rich et al., 2010) and Q-learning (Ertefaie et al., 2016). In the recent work by Wallace et al. (2016), a dynamic treatment regime (DTR) is estimated by G-estimation and double robustness is exploited for model diagnosis. How to evaluate the optimality of an ITR in general remains an open research question.
The purpose of this paper is two-fold: we first develop a general approach to identify a linear ITR with guaranteed performance; we then propose a diagnostic method to evaluate performance of any derived ITR including the proposed one. Our two-stage approach separates the estimation of the ITR from its evaluation and the sample used in each stage. Specifically, in the first stage, we propose ramp-loss-based (McAllester and Keshet, 2011; Huang and Fong, 2014) learning for the estimation and we show that this approach guarantees the derived linear ITR to be asymptotically optimal within the class of all linear rules. We refer our method as Asymptotically Best Linear O-learning, ABLO. For the second stage, in practice, it is infeasible to expect that an ITR that benefits each individual can be identified due to the unknown treatment mechanism and the likely omission of some prescriptive variables. Thus, we propose a practical solution to calibrate the average ITR effect in the population given the observed variables, or in pre-specified important subgroups (e.g., patients in most severe state). Specifically, to obtain an ITR evaluation criterion, we define the benefit of a candidate ITR as the average difference in the value function between those who follow the ITR and those who do not. We then use the ITR benefit as a diagnostic measure to evaluate its optimality. Our method exploits the fact that if an ITR is truly optimal for all individuals, then for any given patient subgroup, the average outcome for patients who are treated according to the ITR should be greater than for those who are not treated according to the ITR. On the contrary, if the average outcome of the ITR is worse for some patients who follow the ITR than for those who do not, then the ITR is not optimal on this subgroup.
Compared to the existing literature, two main contributions of this work are to propose a benefit function to calibrate an ITR, and a diagnostic procedure to evaluate optimality of a derived ITR, while most of the existing work focuses on the estimation of ITR/DTR. A third contribution is to prove asymptotic properties of ITR estimated under the ramp loss (Huang and Fong, 2014). Asymptotic results in the existing literature (e.g., Zhao et al., 2012) are obtained for the hinge loss. Due to these theoretical results, we can provide valid statistical inference procedure for testing optimality of an ITR using asymptotic normality.
In the remainder of this paper, we show that ABLO consistently estimates the ITR benefit for a class of candidate rules regardless of two potential pitfalls: 1) the consistency of benefit estimator is maintained even though the functional form of the rule is misspecified; 2) the rule does not include all prescriptive/tailoring variables and thus the true global optimal rule is not in the specified class. We further derive the asymptotic distribution for the proposed diagnostic measure. We conduct simulation studies to demonstrate finite sample performance and show advantages over existing machine learning methods. Lastly, we apply the method to the Sequenced Treatment Alternatives to Relieve Depression (STAR*D) trial on major depressive disorder (MDD), where substantial treatment response heterogeneity has been documented (Trivedi et al., 2006; Huynh and McIntyre, 2008). Our analyses estimate an optimal linear ITR, and we demonstrate a large benefit in mildly depressed and severely depressed patients but a lack-of-fit among moderately depressed patients.
2. Methodology
Let R denote a continuous variable measuring clinical response after treatment (e.g., reduction of depressive symptoms). Without loss of generality, assume a large value of R is desirable. Let X denote a vector of subject-specific baseline feature variables, and let A = 1 or A = −1 denote two alternative treatments being compared. Assume that we observe (Ai, Xi, Ri) for the ith subject in a two-arm randomized trial with randomization probability P(Ai = a|Xi = x) = π(a|x), for i = 1, …, n.
An ITR, denoted as , is a binary decision function that maps X into the treatment domain A = {−1, 1}. Let denote the distribution of (A, X, R) in which is used to assign treatments. The value function of satisfies
| (1) |
In most applications, is determined by the sign of a function, f(X), which is referred to as the ITR decision function. That is, . In general settings, can take any form, either a parametric function or a non-parametric function. To quantify the benefit of an ITR, a measure related to the value function is a natural choice. The mean difference is widely used to compare the average effect of two treatments. Analogously, we define the benefit function corresponding to an ITR as the difference in the value function between two complementary strategies: one that assigns treatments according to and the other assigns according to the complementary rule for any given feature variables X. That is, the benefit function for is
| (2) |
2.1 Estimating Optimal Linear Treatment Rule
To obtain a practically useful and transparent ITR, we consider a class of linear ITR decision functions, denoted by , and estimate the optimal linear function , that maximizes the value function (1) among this class. To this end, following the original idea of Liu et al. (2014), we note that maximizing is equivalent to minimizing a residual-weighted misclassification error given as
where r(X) is any function of X, taken as an approximation to the conditional mean of R given X. Thus, we aim to minimize the empirical version of the above quantity, given as
for , where , Zi = sign(Wi), and is obtained from a working model by regressing Ri on Xi (Liu et al., 2014).
The above optimization with zero-one loss is a non-deterministic polynomial-time hard (NP-hard) problem (Natarajan, 1995). To avoid this computational challenge, the zero-one loss was replaced by some convex surrogate loss in existing methods, for instance, the squared loss or hinge loss. Let f∗ denote the global optimal decision function corresponding to the optimal treatment rule among any decision functions. That is, f∗(X) = E(R|A = 1, X) − E(R|A = −1, X). When consists of linear decision functions that are far from the global optimal rule such that , estimating optimal linear rule by minimizing the surrogate loss (e.g., hinge loss or squared loss) no longer guarantees that the induced value or benefit is maximized among the linear class.
In order to obtain the best linear ITR with guaranteed performance, we propose to use an authentic approximation loss that will converge to zero-one loss, referred to as the ramp loss (McAllester and Keshet, 2011; Huang and Fong, 2014), for value maximization. The ramp loss, as plotted in Figure A.1 in the Supplementary Material, has been used in the machine learning literature to provide a tight bound on the misclassification rate (McAllester and Keshet, 2011; Collobert et al., 2006). Mathematically, this function can be expressed as
| (3) |
where s is a tuning parameter to be chosen in a data-adaptive fashion. Clearly, when s converges to zero, the ramp loss function converges to the zero-one loss; thus, we expect that the estimated rule from this loss function should approximately maximize the value function among class .
Specifically, with the ramp loss (3), we propose to estimate the optimal linear ITR decision function, , by minimizing the penalized weighted sum of ramp loss of a linear decision function f(X) = β0 + XT β,
| (4) |
where C is the cost parameter. Because the ramp loss is not convex, we solve the optimization by the difference of convex functions algorithm (DCA) (An et al., 1996). First, we express hs(u) as the difference of two convex functions, , where function (x)+ denotes the positive part of x. Let ηi denote ZiAif(Xi). With the DCA, starting from an initial value for η, the minimization in (4) can be carried out iteratively, and denote the solution as
| (5) |
where , and . The iteration stops when the change in the objective function is less than a pre-specified threshold. Detailed steps in estimating β are provided in Section A1 of the Supplementary Materials.
We denote the optimal linear decision function obtained by the above procedure as and denote the optimal ITR as . In the Supplementary Materials (Section A2), we show that converges to the true best linear rule, , asymptotically, at a slower rate than the usual root-n rate. We refer the proposed estimation procedure as Asymptotically Best Linear O-learning, ABLO. We also prove the asymptotic normality of and the estimated benefit function, which provides justification of the inference procedures proposed in the next two sections.
2.2 Performance Diagnostics for the Estimated ITR
ABLO guarantees that the optimal value among the class is achieved asymptotically. Nevertheless, the optimal linear rule may still be far from the global optimal, f∗, such that for some important subgroups, may be non-optimal or even worse than the complementary treatment rule. Therefore, an empirical measure must be constructed to evaluate the performance of an estimated ITR.
To develop a practically feasible diagnostic method for any estimated ITR, given by we note that if is truly optimal among any decision functions in , i.e., has the same sign as f∗(X), then for any subgroup defined by for a given set in the domain of X, the value function for those subjects whose treatments are the same as . should always be larger than or equal to the value function for those subjects with the same , but whose treatments are opposite to . This is because
It then follows that the group-average benefit for , defined as
should be non-negative. On the other hand, if holds for any subset , then the above derivation also indicates that must have the same sign as f∗(X), i.e., is the optimal treatment rule for subjects in .
These observations suggest a diagnostic measure for any subgroup . Specifically, we propose an empirical ITR diagnostic measure as
Because approximates the measure is expected to be positive with a high probability if is close to the global true optimal. Furthermore, the evidence that is positive for a rich class of subsets will support the approximate optimality of in the class. However, because it is infeasible to exhaust all subgroups, we suggest a class of pre-specified subgroups and calculate the corresponding . An aggregated diagnostic measure is . A positive value of implies approximate optimality of when m is large enough. In practice, we consider to be pre-specified groups or the sets determined by the tertiles of each component of X, for example, the jth component of X below its first tertile, between the first and the second tertiles, or above the second tertile. Moreover, using the proposed diagnostic measure, by examining the subsets (or tertiles defined by variables) with negative or close to zero values of , we can identify subgroups or components of X for which the estimated rule may not be sufficiently optimal. Thus, we can further improve the rule estimation in this subgroup to obtain an improved ITR.
If the same data are used for estimating the optimal ITR and performing diagnostics, the latter may not be an honest measure of performance (Athey and Imbens, 2016). Thus, we suggest the following sample-splitting scheme. Divide the data into K folds, and denote as the optimal ITR obtained using data without the kth-fold. Next, each is calibrated on the kth-fold data using the diagnostic measure and then averaged. Let nk denote the sample size of the kth-fold, and let Ik index subjects in this fold. The honest diagnostic measure for subgroup is estimated by , where
We will implement this scheme in subsequent analysis.
2.3 Inference Using the Diagnostic Measure
The proposed diagnostic measure, , can be used to compare different ITRs and non-personalized rules, make comparisons within certain subgroups, and assess heterogeneity of ITR benefit (HTB) across subgroups. Hypotheses of interest may include:
Test significance of the optimal linear rule compared to the non-personalized rule in the overall sample, i.e., , v.s. , where δ0 is the average treatment effect of a non-personalized rule (difference in the mean response between treatment groups). For this purpose, we can construct the test statistic based on , where is obtained from any method, and is the whole population. We reject the null hypothesis at a significance level of α if the (1−α)-confidence interval with ∞ as the upper bound for does not contain 0.
Test significance of the optimal linear rule compared to the non-personalized rule in a subgroup k, i.e., v.s., where δ0k is the average treatment effect in the subgroup. The same test statistic as the previous one can be used but with .
Test the HTB across subgroups , i.e., . We propose the HTB test statistic , where . It can be shown that T asymptotically follows under H0, so we reject H0 when T is larger than the (1 − α)-quantile of .
Test the non-optimality of the best linear rule in a subgroup by evaluating v.s. . For this purpose, we can directly use and reject the null hypothesis if the confidence interval with lower bound of −∞ does not contain zero.
The asymptotic properties of and are required to perform inference above. Based on the theoretical properties (asymptotic normality) given in the Supplementary Materials (Section A2), we propose a bootstrap method to compute confidence interval for the diagnostic measure. We denote the bth bootstrap sample as , where i = 1, 2, ⋯, n, and re-estimate residuals as in (5). Next, we re-fit treatment rule and obtain . The 95% confidence interval for is constructed from the empirical quantiles of .
3. Simulation Studies
3.1 Simulation Design
For all simulation scenarios, we first generated four latent subgroups of subjects based on 10 feature variables X = (X1, ⋯, X10) informative of optimal treatment choice from a pattern mixture model. Treatment A = 1 has a greater average effect for subjects in subgroups 1 and 2, and the alternative treatment −1 has a greater average effect in subgroups 3 and 4. Within each subgroup, X were independently simulated from a normal distribution with different means and standard deviation of one. Two settings were considered. In Setting 1, the means of the feature variables for subjects in the four subgroups were (1, 0.5, −1, −0.5), respectively. In Setting 2, the means were (1, 0.3, −1, −0.3). Five noise variables U = (U1, ⋯, U5) not contributing to R were independently generated from the standard normal distribution and included in the analyses in order to assess the robustness of each method in the presence of noise features. The treatments for each subject were randomly assigned to 1 or −1 with equal probability, and the number of subjects in each subgroup was equal.
Three additional feature variables W, V, and S were generated to be directly associated with the clinical outcome R. Here, W is an observed prescriptive variable informative of the optimal treatment, V is a prognostic variable predictive of the outcome but not the optimal treatment, and S is an unobserved prescriptive variable not available in the analysis. The clinical outcome for subjects in the kth subgroup was generated by
where e ∼ N(0, 0.25), V, W, and S are i.i.d. and follow the standard normal distribution, , and β =2α within each group k, there is a qualitative interaction between treatment and W. Additional visualization of the simulation setting is provided in the Supplementary Materials (Figure A.2).
The benefit function of the theoretical global optimal ITR decision function, denoted as f∗, was computed numerically by simulating the clinical outcome R under treatment 1 or −1, using all observed feature variables (i.e., X, W, and V), and taking the average difference of R under the true optimal and non-optimal treatments using a large independent test set of N = 100, 000. In practice, this global optimum may not be attained by a linear rule due to the unknown and potentially nonlinear true optimal treatment rule. The theoretical optimal linear rule was computed numerically using the observed variables and maximizing the value function in the class of all linear rules under each simulation model (details in the Supplementary Materials; Section A3). The benefit of was then computed with a large independent test set of N = 50, 000.
For each simulated data set, predictive modeling (PM), Q-learning, O-learning, and ABLO were applied to estimate the optimal ITR. For PM, we considered a random forest-based prediction related to the virtual twins approach of Foster et al. (2011). PM first applies random forest on R, including all observed feature variables Z = (X, U, W, V) and treatment assignments. It next predicts the outcome for the ith subject given (Zi, Ai = 1) and (Zi, Ai = −1), denoted as and , respectively. The optimal treatment for the subject is . Q-learning was implemented by a linear regression including all the observed feature variables, treatment assignments, and their interactions. Benefit of the estimated optimal ITR under each method and was computed by in Section 2.2.
In the simulations, observed feature variables Z were used in all methods, while the unobserved prescriptive variable S and latent subgroup membership were not included. Linear kernel was used for O-learning and ABLO. Five-fold cross validation was used to select the tuning parameters C and s. For each method, the optimal treatment selection accuracy and ITR benefit were estimated using two-fold cross validation with equal size of training and testing sets. The training set was used to estimate the ITR and the testing set was used to estimate the ITR benefit and accuracy. Bootstrap was used to estimate the confidence interval of the ITR benefit under the estimated rule. Coverage probabilities were reported to evaluate the performance of the inference procedure. To evaluate performance on subgroups, we partitioned W, V, X1, and U1 into three groups based on values in the intervals (−∞, −0.5), [−0.5, 0.5], or (0.5, ∞). We calculated the HTB test for the candidate variables and tested the difference between the estimated rules and the overall non-personalized rules.
3.2 Simulation Results
Results from 500 replicates are summarized in Table 1, 2, 3, Figure 1 and 2. For both simulation settings, ABLO with linear kernel has the largest optimal treatment selection accuracy regardless of the sample size, and it is also close to the maximal accuracy rate based on the theoretical best linear rule. In addition, ABLO estimates the ITR benefit closest to the true global maximal value of 0.678 on the overall sample, and it is almost identical to the benefit estimated by the theoretical best linear rule when the sample size is large (= 800 training, 800 testing). PM, Q-learning, and O-learning all underestimate the ITR benefit, especially when the sample size is smaller (N = 400 training, 400 testing), and thus they do not attain the maximal value of the theoretical optimal linear rule. Based on the empirical standard deviation, we also observe that ABLO is more robust than all other methods. For all methods, as the sample size increases, the treatment selection accuracy increases and the estimated mean benefit is closer to the true optimal value. Furthermore, the estimated ITR benefit increases as the accuracy rate increases. The coverage probability of the overall benefit of the best linear rule is close to the nominal level of 95% using ABLO, but less than 95% using other methods. The coverages are not nominal for O-learning, Q-learning, and PM, since their benefit estimates are biased when the candidate rules are misspecified (e.g., true optimal rule is not linear). This is because they use a surrogate loss function that does not guarantee convergence to the indicator function in the benefit function .
Table 1.
Simulation results: mean and standard deviation of the accuracy rate, mean ITR benefit, and coverage probability for estimation of the benefit of the optimal ITR. PM: predictive modeling by random forest; Q-learning: Q-learning with linear regression; O-learning: improved single stage O-learning (Liu et al., 2014); ABLO: asymptotically best linear O-learning.
| Setting 1. Four region means = (1, 0.5, −1, −0.5). | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||
| Overall Benefit | W < −0.5 | W ∈ [−0.5, 0.5] | W > 0.5 | ||||||||||
|
| |||||||||||||
| Accuracy rate | Mean (sd) | Coverage | Mean (sd) | Coverage | Mean (sd) | Coverage | Mean (sd) | Coverage | |||||
| N = 800 | |||||||||||||
| PM | 0.71 (0.04) | 0.37 (0.17) | 0.69 | 0.08 (0.23) | 0.97 | 0.36 (0.23) | 0.82 | 0.67 (0.30) | 0.72 | ||||
| Q-learning | 0.76 (0.03) | 0.45 (0.17) | 0.80 | 0.17 (0.22) | 0.97 | 0.46 (0.23) | 0.89 | 0.73 (0.29) | 0.78 | ||||
| O-learning | 0.77 (0.05) | 0.46 (0.18) | 0.82 | 0.17 (0.24) | 0.97 | 0.46 (0.24) | 0.89 | 0.76 (0.30) | 0.80 | ||||
| ABLO | 0.83 (0.04) | 0.65 (0.14) | 0.94 | 0.30 (0.23) | 0.92 | 0.64 (0.20) | 0.96 | 1.01 (0.24) | 0.93 | ||||
|
| |||||||||||||
| N = 1600 | |||||||||||||
| PM | 0.75 (0.03) | 0.44 (0.12) | 0.64 | 0.11 (0.17) | 0.96 | 0.43 (0.17) | 0.80 | 0.79 (0.20) | 0.71 | ||||
| Q-learning | 0.81 (0.02) | 0.52 (0.11) | 0.86 | 0.18 (0.16) | 0.97 | 0.53 (0.15) | 0.92 | 0.86 (0.19) | 0.82 | ||||
| O-learning | 0.84 (0.02) | 0.57 (0.11) | 0.93 | 0.19 (0.15) | 0.97 | 0.57 (0.16) | 0.95 | 0.94 (0.19) | 0.90 | ||||
| ABLO | 0.86 (0.02) | 0.63 (0.09) | 0.96 | 0.22 (0.15) | 0.97 | 0.63 (0.15) | 0.95 | 1.04 (0.17) | 0.94 | ||||
|
| |||||||||||||
| Best linear rule† | 0.890 |
|
|
|
|
||||||||
| Setting 2. Four region means = (1, 0.3, −1, −0.3). | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||
| Overall Benefit | W < −0.5 | W ∈ [−0.5, 0.5] | W > 0.5 | ||||||||||
|
| |||||||||||||
| Accuracy rate | Mean (sd) | Coverage | Mean (sd) | Coverage | Mean (sd) | Coverage | Mean (sd) | Coverage | |||||
| N = 800 | |||||||||||||
| PM | 0.68 (0.04) | 0.34 (0.17) | 0.67 | 0.10 (0.24) | 0.95 | 0.34 (0.24) | 0.83 | 0.59 (0.30) | 0.71 | ||||
| Q-learning | 0.74 (0.03) | 0.43 (0.16) | 0.85 | 0.16 (0.23) | 0.97 | 0.44 (0.22) | 0.92 | 0.70 (0.28) | 0.82 | ||||
| O-learning | 0.73 (0.04) | 0.42 (0.17) | 0.84 | 0.16 (0.21) | 0.98 | 0.43 (0.24) | 0.90 | 0.68 (0.29) | 0.79 | ||||
| ABLO | 0.78 (0.03) | 0.62 (0.13) | 0.95 | 0.30 (0.21) | 0.96 | 0.62 (0.21) | 0.96 | 0.94 (0.25) | 0.92 | ||||
|
| |||||||||||||
| N = 1600 | |||||||||||||
| PM | 0.72 (0.03) | 0.42 (0.12) | 0.69 | 0.12 (0.17) | 0.95 | 0.42 (0.17) | 0.84 | 0.72 (0.20) | 0.73 | ||||
| Q-learning | 0.78 (0.02) | 0.51 (0.11) | 0.89 | 0.19 (0.16) | 0.96 | 0.52 (0.15) | 0.94 | 0.81 (0.18) | 0.85 | ||||
| O-learning | 0.79 (0.02) | 0.52 (0.11) | 0.91 | 0.19 (0.16) | 0.95 | 0.53 (0.16) | 0.93 | 0.85 (0.19) | 0.89 | ||||
| ABLO | 0.82 (0.02) | 0.61 (0.10) | 0.94 | 0.25 (0.16) | 0.94 | 0.61 (0.15) | 0.95 | 0.96 (0.17) | 0.95 | ||||
|
| |||||||||||||
| Best linear rule† | 0.850 |
|
|
|
|
||||||||
|
| |||||||||||||
| Best global rule† |
|
|
|
|
|||||||||
The theoretical best linear rule for both settings is sign(Xs), where Xs = X1 + X2 + ⋯ + X10.
The true value of the best linear rule and best global rule is computed from a large independent test data set.
Table 2.
Simulation results: probability of rejecting the null hypothesis that the treatment benefit across subgroups is equivalent by the HTB test.
| Setting 1. Four region means = (1, 0.5, −1, −0.5). | ||||
|---|---|---|---|---|
|
| ||||
| W | X1 | V | U1 | |
| N = 800 | ||||
| PM | 0.16 | 0.05 | 0.03 | 0.02 |
| Q-learning | 0.18 | 0.06 | 0.03 | 0.03 |
| O-learning | 0.21 | 0.05 | 0.03 | 0.03 |
| ABLO | 0.42 | 0.07 | 0.05 | 0.06 |
|
| ||||
| N = 1600 | ||||
| PM | 0.52 | 0.05 | 0.05 | 0.02 |
| Q-learning | 0.61 | 0.05 | 0.04 | 0.02 |
| O-learning | 0.71 | 0.04 | 0.04 | 0.02 |
| ABLO | 0.84 | 0.05 | 0.05 | 0.03 |
|
| ||||
| Setting 2. Four region means = (1, 0.3, −1, −0.3). | ||||
|
| ||||
| N = 800 | ||||
| PM | 0.12 | 0.03 | 0.02 | 0.02 |
| Q-learning | 0.17 | 0.04 | 0.03 | 0.04 |
| O-learning | 0.15 | 0.03 | 0.03 | 0.03 |
| ABLO | 0.34 | 0.06 | 0.04 | 0.05 |
|
| ||||
| N = 1600 | ||||
| PM | 0.42 | 0.06 | 0.04 | 0.03 |
| Q-learning | 0.56 | 0.07 | 0.04 | 0.03 |
| O-learning | 0.57 | 0.07 | 0.03 | 0.03 |
| ABLO | 0.74 | 0.10 | 0.04 | 0.05 |
W has strong signal; X1 has weak signal; V and U1 have no signal.
Table 3.
Simulation results: Comparison of the ITR to the non-personalized universal rule. The proportion of rejecting the null that the ITR has the same benefit as the universal rule∗ are reported for the overall sample and by subgroups.
| Setting 1. Four region means = (1, 0.5, −1, −0.5). | ||||
|---|---|---|---|---|
|
| ||||
| Overall | W < −0.5 | W ∈ [−0.5, 0.5] | W > 0.5 | |
| N = 800 | ||||
| PM | 0.22 | 0 | 0.09 | 0.33 |
| Q-learning | 0.37 | 0.02 | 0.20 | 0.40 |
| O-learning | 0.39 | 0.02 | 0.20 | 0.43 |
| ABLO | 0.86 | 0.07 | 0.47 | 0.78 |
|
| ||||
| N = 1600 | ||||
| PM | 0.76 | 0.02 | 0.38 | 0.83 |
| Q-learning | 0.92 | 0.05 | 0.59 | 0.90 |
| O-learning | 0.95 | 0.06 | 0.67 | 0.94 |
| ABLO | 0.99 | 0.08 | 0.79 | 0.98 |
|
| ||||
| Setting 2. Four region means = (1, 0.3, −1, −0.3). | ||||
|
| ||||
| N = 800 | ||||
| PM | 0.18 | 0.01 | 0.07 | 0.27 |
| Q-learning | 0.35 | 0.03 | 0.17 | 0.37 |
| O-learning | 0.31 | 0.03 | 0.17 | 0.35 |
| ABLO | 0.82 | 0.07 | 0.43 | 0.74 |
|
| ||||
| N = 1600 | ||||
| PM | 0.72 | 0.03 | 0.38 | 0.75 |
| Q-learning | 0.88 | 0.05 | 0.57 | 0.86 |
| O-learning | 0.90 | 0.07 | 0.59 | 0.86 |
| ABLO | 0.99 | 0.12 | 0.77 | 0.97 |
For Setting 1, the mean difference (sd) of the universal rule is 0.09(0.08) for N = 800 and 0.07(0.05) for N = 1600.
For Setting 2, the mean difference (sd) of the universal rule is 0.11(0.08) for N = 800 and 0.08(0.05) for N = 1600.
Figure 1.
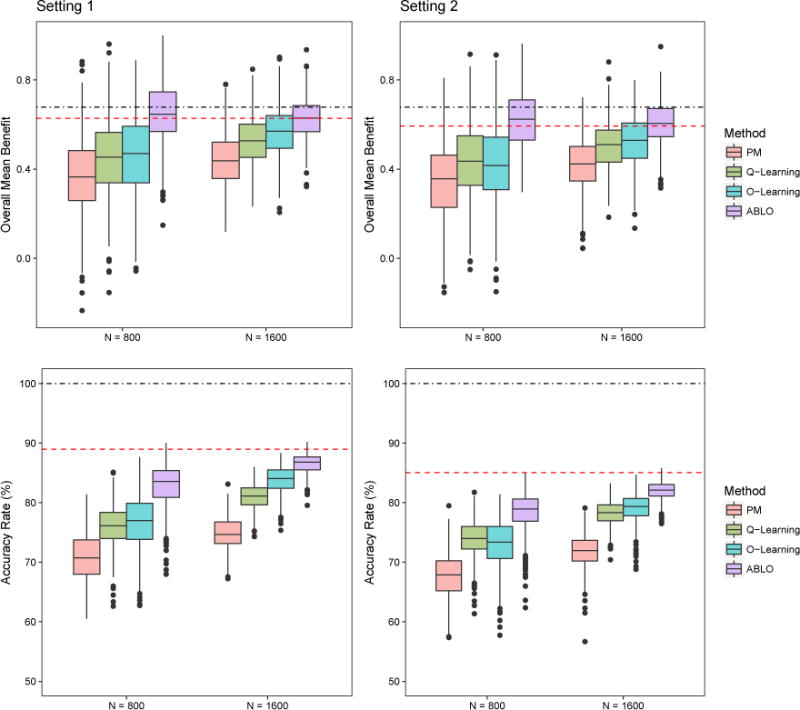
Simulation results: Overall ITR benefit and optimal treatment accuracy rates for the four methods. Dotted-dashed lines represent the benefit (top panels) and accuracy (bottom panels) under the theoretical global optimal treatment rule f∗. Dashed lines represent the benefit and accuracy under the theoretical optimal linear rule . The methods being compared are (from left to right): PM: predictive modeling by random forest; Q-learning: Q-learning with linear regression; O-learning: improved single stage O-learning (Liu et al., 2014); ABLO: asymptotically best linear O-learning. This figure appears in color in the electronic version of this article.
Figure 2.
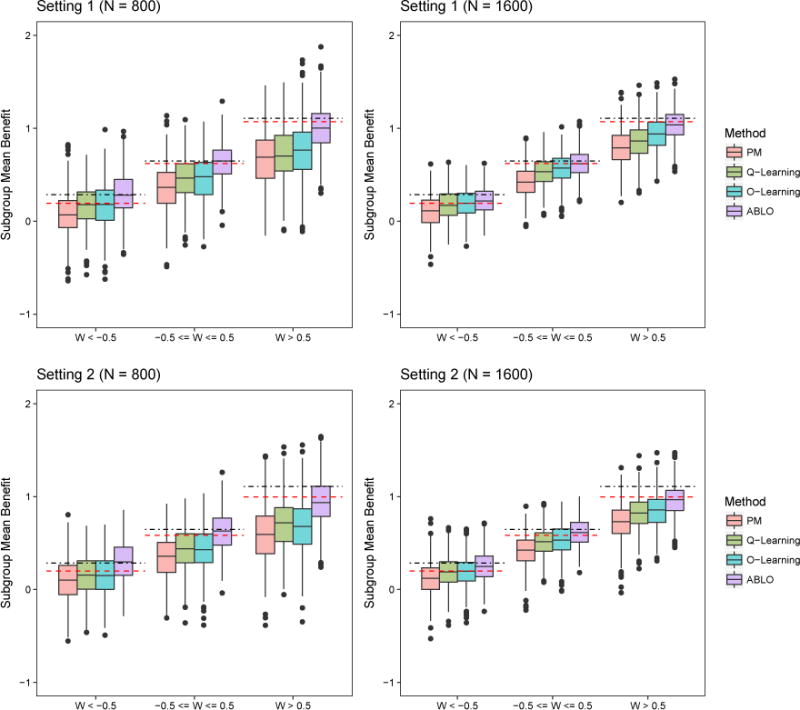
Simulation results: Subgroup ITR benefit for the four methods. Dotted-dashed lines represent the benefit under the theoretical global optimal treatment f∗. Dashed lines represent the benefit under the theoretical optimal linear rule . The methods being compared are (from left to right): PM: predictive modeling by random forest; Q-learning: Q-learning with linear regression; O-learning: improved single stage O-learning (Liu et al., 2014); ABLO: asymptotically best linear O-learning. This figure appears in color in the electronic version of this article.
The performance of estimation of the subgroup ITR benefit shows similar results, whereby ABLO outperforms O-learning, Q-learning, and PM in both settings, especially when W ∈ [−0.5, 0.5], and W > 0.5. Table 2 reports the probability of rejecting , k= 1 or 2, using the HTB test with a null distribution of . The rejection rates of the HTB tests of V and U1 that do not have a difference in ITR benefit across subgroups correspond to the type I error rate. The type I error rates of ABLO are close to 5%, but conservative for the other three methods. To examine the power, we test the effect of W on the benefit across subgroups defined by discretizing W at −0.5 and 0.5. The power of ABLO is much greater than the other three methods especially when the sample size is small. The other three methods underestimate the benefit function, and thus the HTB test is conservative and less powerful.
Lastly, we test the difference in the benefit between the ITRs and the non-personalized rule in the overall sample and the subgroups. Table 3 shows that with a sample size of 800, ABLO is the only method that provides a significantly better benefit than the non-personalized rule with a large power (> 80%). When the sample size is large (N = 1600), ABLO, Q-learning, and O-learning have a power of ⩾ 88%. As for the subgroups, the ITR estimated by ABLO is more likely to outperform the non-personalized rule on the subgroups showing a larger true benefit (i.e., when W > 0.5).
Additional simulation results varying the strength of the prescriptive feature variable W are described in the Supplementary Materials (Section A4).
4. Application to the STAR*D Study
STAR*D (Rush et al., 2004) was conducted as a multi-site, multi-level, randomized controlled trial designed to compare different treatment regimes for major depressive disorder when patients fail to respond to the initial treatment of Citalopram (CIT) within 8 weeks. The primary outcome, Quick Inventory of Depressive Symptomatology (QIDS) score (ranging from 0 to 27), was measured to assess the severity of depression. A lower QIDS score indicates less symptoms and thus reflects a better outcome. Participants with a total QIDS score under 5 were considered to experience a clinically meaningful response to the assigned treatment and were therefore remitted from future treatments.
The trial had four levels of treatments (e.g., see Figure 2.3 in Chakraborty and Moodie (2013)); we focused on the first two levels. At the first level, all participants were treated with CIT for a minimum of 8 weeks. Participants who had clinically meaningful response were excluded from level-2 treatment. At level-2, participants without remission with level-1 treatment were randomized to level-2 treatment based on their preference to switch or augment their level-1 treatment. Patients who preferred to switch treatment were randomized with equal probability to bupropion (BUP), cognitive therapy (CT), sertraline (SER), or venlafaxine (VEN). Those who preferred augmentation were randomly assigned to CIT+BUP, CIT+buspirone (BUS), or CIT+CT. If a patient had no preference, s/he was randomized to any of the above treatments.
The clinical outcome (reward) is the QIDS score at the end of level-2 treatment. There were 788 participants with complete feature variable information included in our analysis. We compared two categories of treatments: 1) treatment with selective serotonin reputake inhibitors (SSRIs, alone or in combination): CIT+BUS, CIT+BUP, CIT+CT, and SER; and 2) treatment with one or more non-SSRIs: CT, BUP, and VEN. Feature variables used to estimate the optimal ITR included the QIDS scores measured at the start of level-2 treatment (level 2 baseline), the change in the QIDS score over the level-1 treatment phase, patient preference regarding level-2 treatment, and demographic variables (gender, age, race), and family history of depression. As the randomization to treatment was based on patient preference, we estimated π(Ai|Xi) using empirical proportions based on preferring switching or no preference, because patients who preferred augmentation were all treated with an SSRI and were excluded from the analysis.
We applied four methods to estimate the optimal ITR for patients with MDD who did not achieve remission with 8 weeks of treatment with CIT. For all methods, we randomly split the sample into a training and testing set with a 1:1 ratio and repeated the procedure 500 times. The value function and ITR benefits were evaluated on the testing set. PM, Q-learning, O-learning, and ABLO are compared in Figure 3. The non-personalized rules yield a QIDS score of 10.16 for SSRI and 9.60 for non-SSRI, with a difference of 0.56. The ITR estimated by ABLO yields a QIDS score of 9.32 (sd = 0.23), which is smaller than PM (9.69, sd = 0.38), Q-learning (9.50, sd=0.35), and O-leaning (9.55, sd = 0.41). The overall ITR benefit estimated by ABLO (1.11, sd = 0.46) is much larger than PM (0.38, sd = 0.76), Q-learning (0.77, sd = 0.70), and O-leaning (0.66, sd = 0.82). The ITR benefit based on ABLO is also larger than the non-personalized rule (1.11 versus 0.56). The final ITR estimated by ABLO is reported in Supplementary Materials (Section A5).
Figure 3.
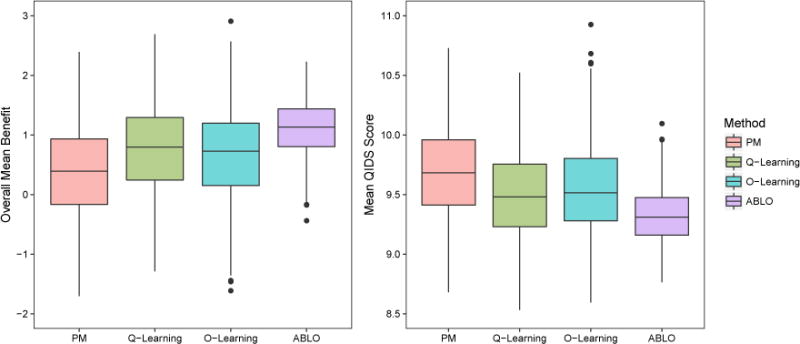
STAR*D analysis results: Distribution of the estimated ITR benefit (the higher the better) and QIDS score (the lower the better) at the end of level-2 treatment for the four methods (based on 500 cross-validation runs). The methods being compared are (from left to right): PM: predictive modeling by random forest; Q-learning: Q-learning with linear regression; O-learning: improved single stage O-learning (Liu et al., 2014); ABLO: asymptotically best linear O-learning. This figure appears in color in the electronic version of this article.
Clinical literature suggests that the baseline MDD severity may be a moderator for treatment response (Bower et al., 2013). In addition, baseline MDD severity is highly associated with suicidality; thus, patients with severe baseline MDD (QIDS ⩾ 16) represent an important subgroup. We partitioned patients into mild (QIDS ≤ 10), moderate (QIDS ∈ [11, 15]), and severe (QIDS ⩾ 16) MDD subgroups. Using ABLO and the HTB test, baseline QIDS score was found to be significantly associated with ITR benefit: two subgroups show a large positive ITR benefit (2.22 for the mild group and 2.02 for the severe group), whereas the moderate subgroup shows no benefit (ITR benefit = −0.18). This result indicates that patients with mild or severe baseline depressive symptoms (high or low QIDS score) might benefit from following the estimated linear ITR. For patients who are moderately depressed (QIDS ∈ [11, 15]), the linear ITR estimated from the overall sample does not adequately fit the data and does not outperform a non-personalized rule. Thus, we re-fit a linear rule using ABLO for the moderate subgroup only. The re-estimated ITR yields a lower average QIDS score of 8.93 (sd = 0.35), with a much improved subgroup ITR benefit of 0.60 (sd = 0.70). This analysis demonstrates the advantage of the ITR benefit diagnostic measure, the HTB test, and the value of re-fitting the ITR on subgroups showing a lack-of-fit.
5. Discussion
In this work, we propose a diagnostic measure (benefit function) to compare candidate ITRs, a machine learning method (ABLO) to estimate the optimal linear ITR, and several tests for goodness-of-fit. In practice, often not all predictive and prescriptive variables that influence heterogeneous responses to treatment are known and collected. Thus, it is unrealistic to expect that an ITR that benefits each and every individual can be identified. Our practical solution proposes to evaluate the average ITR effect over the entire population and on vulnerable or important subgroups. Although we focus on linear decision functions here, it is straightforward to extend ABLO to other simple decision functions such as polynomial rules by choosing other kernel functions (i.e., polynomial kernel). ABLO can also be applied to observational studies using propensity scores to replace π(A|X) under the assumption that the propensity score model is correctly specified. We prove the asymptotic properties of ABLO and identify a condition to avoid the non-regularity issue (in Supplementary Material Section A2). In practice, when such issue is of concern, adaptive inference (Laber and Murphy, 2011) can be used to construct confidence intervals.
ABLO can consistently estimate the ITR benefit function regardless of misspecification of the rule by drawing a connection with the robust machine learning approach for approximating the zero-one loss. We provide an objective diagnostic measure for assessing optimization. In our method, prescriptive variables mostly contribute to the estimation of the optimal treatment rule while predictive variables mostly contribute to the development of the diagnostic measure and assessment of the benefit of the optimal rule. Future work will consider methods to distinguish these two sets of variables, which potentially overlap.
ABLO is slower than O-learning because it involves iterations of quadratic programming when applying the DCA. In addition, certain simulations show that the algorithm can be slightly sensitive to the initial values in extreme cases (examples provided in Figure A.5 in the Supplementary Materials). However, our numeric results show that O-learning estimators serve as adequate initial values leading to fast convergence of the DCA. Another limitation is that the current methods only apply to single-stage trials. ABLO can be extended to multiple stage setting following a similar backward multi-stage O-learning in Zhao et al. (2015). The objective function in multi-stage O-learning will be replaced by the ramp loss and the benefit function will be extended with some attention to subjects whose observed treatment sequences are partially consistent with the predicted optimal treatment sequences.
Supplementary Material
Acknowledgments
We thank the editor, the AE, and the referees for their help in improving this paper. This research is sponsored by the U.S. NIH grants NS073671 and NS082062.
Footnotes
This paper has been submitted for consideration for publication in Biometrics
Supplementary Materials
Appendices and all tables and figures referenced in Sections 2, 3, 4 and 5 are available at the Wiley Online Biometrics website. Matlab code implementing the new ABLO method is available with this paper at the Biometrics website on Wiley Online Library.
References
- An LTH, Tao PD, Muu LD. Numerical solution for optimization over the efficient set by D.C. optimization algorithms. Operations Research Letters. 1996;19:117–128. [Google Scholar]
- Athey S, Imbens G. Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences. 2016;113:7353–7360. doi: 10.1073/pnas.1510489113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blatt D, Murphy S, Zhu J. A-learning for approximate planning. The Methodology Center, Pennsylvania State University, State College; 2004. (Technical Report 04-63). [Google Scholar]
- Bower P, Kontopantelis E, Sutton A, Kendrick T, Richards DA, Gilbody S, et al. Influence of initial severity of depression on effectiveness of low intensity interventions: meta-analysis of individual patient data. BMJ. 2013;346:f540. doi: 10.1136/bmj.f540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carini C, Menon SM, Chang M. Clinical and Statistical Considerations in Personalized Medicine. CRC Press; 2014. [Google Scholar]
- Chakraborty B, Moodie E. Statistical methods for dynamic treatment regimes. Springer; 2013. [Google Scholar]
- Collobert R, Sinz F, Weston J, Bottou L. Trading convexity for scalability; Proceedings of the 23rd international conference on Machine learning; 2006. pp. 201–208. [Google Scholar]
- Ertefaie A, Shortreed S, Chakraborty B. Q-learning residual analysis: application to the effectiveness of sequences of antipsychotic medications for patients with schizophrenia. Statistics in medicine. 2016;35:2221–2234. doi: 10.1002/sim.6859. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan C, Lu W, Song R, Zhou Y. Concordance-assisted learning for estimating optimal individualized treatment regimes. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2016 doi: 10.1111/rssb.12216. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Foster JC, Taylor JM, Ruberg SJ. Subgroup identification from randomized clinical trial data. Statistics in medicine. 2011;30:2867–2880. doi: 10.1002/sim.4322. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gunter L, Zhu J, Murphy S. Variable selection for qualitative interactions. Statistical methodology. 2011;8:42–55. doi: 10.1016/j.stamet.2009.05.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang Y, Fong Y. Identifying optimal biomarker combinations for treatment selection via a robust kernel method. Biometrics. 2014;70:891–901. doi: 10.1111/biom.12204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huynh NN, McIntyre RS. What are the implications of the STAR* D trial for primary care? a review and synthesis. Primary care companion to the Journal of clinical psychiatry. 2008;10:91–96. doi: 10.4088/pcc.v10n0201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laber EB, Linn KA, Stefanski LA. Interactive model building for q-learning. Biometrika. 2014;101:831–847. doi: 10.1093/biomet/asu043. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laber EB, Murphy SA. Adaptive confidence intervals for the test error in classification. Journal of the American Statistical Association. 2011;106:904–913. doi: 10.1198/jasa.2010.tm10053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lavori PW, Dawson R. Dynamic treatment regimes: practical design considerations. Clinical trials. 2004;1:9–20. doi: 10.1191/1740774s04cn002oa. [DOI] [PubMed] [Google Scholar]
- Liu Y, Wang Y, Kosorok M, Zhao Y, Zeng D. Robust hybrid learning for estimating personalized dynamic treatment regimens. 2014 arXiv preprint arXiv:1611.02314. [Google Scholar]
- McAllester DA, Keshet J. Generalization bounds and consistency for latent structural probit and ramp loss; Neural Information Processing Systems; 2011. pp. 2205–2212. [Google Scholar]
- Murphy SA. Optimal dynamic treatment regimes. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2003;65:331–355. [Google Scholar]
- Natarajan BK. Sparse approximate solutions to linear systems. SIAM journal on computing. 1995;24:227–234. [Google Scholar]
- Qian M, Murphy SA. Performance guarantees for individualized treatment rules. Annals of statistics. 2011;39:1180–1210. doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rich B, Moodie EE, Stephens DA, Platt RW. Model checking with residuals for g-estimation of optimal dynamic treatment regimes. The international journal of biostatistics. 2010;6 doi: 10.2202/1557-4679.1210. Article 12. [DOI] [PubMed] [Google Scholar]
- Rush AJ, Fava M, Wisniewski SR, Lavori PW, Trivedi MH, Sackeim HA, et al. Sequenced treatment alternatives to relieve depression (STAR*D): rationale and design. Controlled clinical trials. 2004;25:119–142. doi: 10.1016/s0197-2456(03)00112-0. [DOI] [PubMed] [Google Scholar]
- Schulte PJ, Tsiatis AA, Laber EB, Davidian M. Q-and a-learning methods for estimating optimal dynamic treatment regimes. Statistical science: a review journal of the Institute of Mathematical Statistics. 2014;29:640–661. doi: 10.1214/13-STS450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trivedi MH, Rush AJ, Wisniewski SR, Nierenberg AA, Warden D, Ritz L, et al. Evaluation of outcomes with citalopram for depression using measurement-based care in STAR*D: implications for clinical practice. American journal of Psychiatry. 2006;163:28–40. doi: 10.1176/appi.ajp.163.1.28. [DOI] [PubMed] [Google Scholar]
- Wallace MP, Moodie EE, Stephens DA. Model assessment in dynamic treatment regimen estimation via double robustness. Biometrics. 2016;72:855–864. doi: 10.1111/biom.12468. [DOI] [PubMed] [Google Scholar]
- Watkins CJCH. PhD thesis. University of Cambridge England; 1989. Learning from delayed rewards. [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012;68:1010–1018. doi: 10.1111/j.1541-0420.2012.01763.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, Davidian M. Robust estimation of optimal dynamic treatment regimes for sequential treatment decisions. Biometrika. 2013;100:681–694. doi: 10.1093/biomet/ast014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Zeng D, Rush AJ, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. Journal of the American Statistical Association. 2012;107:1106–1118. doi: 10.1080/01621459.2012.695674. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao YQ, Zeng D, Laber EB, Kosorok MR. New statistical learning methods for estimating optimal dynamic treatment regimes. Journal of the American Statistical Association. 2015;110:583–598. doi: 10.1080/01621459.2014.937488. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.