

Abstract
It is well established that Parkinson’s disease leads to impaired learning from reward and enhanced learning from punishment. The administration of dopaminergic medications reverses this learning pattern. However, few studies have investigated the neural underpinnings of these cognitive processes. In this study, using fMRI, we tested a group of Parkinson’s disease patients on and off dopaminergic medications and matched healthy subjects. All subjects completed an fMRI cognitive task that dissociates feedback learning from reward versus punishment. The administration of dopaminergic medications attenuated BOLD responses to punishment in the bilateral putamen, in bilateral dorsolateral prefrontal cortex and the left premotor cortex. Further, the administration of dopaminergic medications resulted in a higher ratio of BOLD activity between reward and punishment trials in these brain areas. BOLD activity in these brain areas was significantly correlated with learning from punishment, but not from reward trials. Furthermore, the administration of dopaminergic medications altered BOLD activity in the right insula and ventromedial prefrontal cortex when Parkinson’s disease patients were anticipating feedback. These findings are in agreement with a large body of literature indicating that Parkinson’s disease is associated with enhanced learning from punishment. However, it was surprising that dopaminergic medications modulated punishment learning as opposed to reward learning, although reward learning has been directly linked to dopaminergic function. We argue that these results might be attributed to both a change in the balance between direct and indirect pathway activation in the basal ganglia as well as the differential activity of D1 versus D2 dopamine receptors.
Keywords: dopamine, fMRI, reward, punishment, Parkinson’s disease
Introduction
Converging evidence suggests that Parkinson’s disease impairs sensitivity to rewards and enhances learning based on punishment feedback, while antiparkinsonian dopaminergic agents reverse this learning pattern (Bodi et al., 2009; Frank et al., 2004). This is thought to stem from the imbalance between direct and indirect basal ganglia pathways in Parkinson’s disease, which is reversed by dopaminergic medications. Various studies have suggested a functional segregation between the direct and indirect pathways in the striatum, implicating the direct pathway in reward processing and the indirect pathway in punishment learning (Frank et al., 2004; Bromberg-Martin et al., 2010; Lobo et al., 2010; Hikida et al., 2010; Ferguson et al., 2011; Kravitz et al., 2012). The direct and indirect pathways reflect a dual organization of the coritco-striato-thalamo-cortico loops, with distinct connectivity patterns and physiological properties of the striatum and basal ganglia. Dopamine stimulates the direct pathway through D1 receptors which initiates a (“Go”) signal, while it inhibits indirect pathways via D2 receptors which results in a (“NoGo”) signal. Therefore, the lack of dopamine, as in Parkinson’s disease, may increase indirect pathway activity relative to direct pathway processing, leading to the observed imbalance in punishment based and reward based learning. Conversely, too much dopamine might cause an overly activated direct pathway resulting in higher sensitivity to reward as compared to punishment (Hikida et al., 2010).
To date, the neural underpinnings of the effects of Parkinson’s disease versus those of dopaminergic medications on learning have not been sufficiently studied using neuroimaging. Electrophysiological studies suggest that dopamine neuronal firing increases in response to unexpected reward and dips after the omission of reward (Bromberg-Martin et al., 2010; Schultz et al., 1997). Further, dopaminergic neurons code for motivational salience during both reward and punishment (Barr et al., 2009; Bromberg-Martin et al., 2010; Fadok et al., 2009). Previous studies in healthy volunteers have reported striatal activation during learning from both reward and punishment feedback (Garrison et al., 2013). However, it was unclear how striatal activity during reward and punishment feedback is related to dopaminergic modulation.
In this study, we aimed to investigate the relationship between neural activation during learning from reward and punishment in Parkinson’s disease patients before and during treatment with dopaminergic medications. We utilized a computer-based cognitive task, developed by Gluck and colleagues at Rutgers University-Newark, and similar to that used by Bodi et al. (2009), to dissociate learning from reward and punishment. Our main hypothesis was that the dopamine-depleted striatum in medication-withdrawn Parkinson’s disease patients will have increased activation in response to punishment than to reward, while the administration of dopaminergic medication would reverse this relationship: neural responses would be higher with reward than punishment.
Methods
Participants
We tested 11 patients with Parkinson’s disease (4 female, age: 63.1 ± 10.3, age range: 45-75) and 11 healthy volunteers (age: 57.6 ± 8.5, age range: 43-72; no significant age difference between groups: t=1.37, df=20, p=0.19). All Parkinson’s disease patients were tested under two conditions; a dopamine OFF and ON condition, in a within-subject design. Of the 11 Parkinson’s disease patients, six were on levodopa only, while the other five patients were on a combination of levodopa and dopamine agonist (pramipexole). The average dosage of levodopa and pramipexole were 542 ± 172 mg and 2.8 mg ± 0.7 respectively (altogether Levodopa Equivalent Dose: 822 ± 242 mg). As expected, treated patients (ON) had better UPDRS scores. For the OFF state, participating Parkinson’s disease patients were withdrawn from their medications (levodopa or pramipexole or both respectively) for a minimum of 18 hours before testing. Patients experienced severe worsening in their symptoms on OFF days reflected in their UPDRS (OFF UPDRS: 18.6 ± 7.2; ON UPDRS: 10.8 ± 6.1, paired-samples t-test p<0.001). The average disease duration was 5.5 ± 2.8 years, and average H&Y was 1.9 ± 0.6.
All participants gave written informed consent that was previously approved by the IRB of Feinstein Institute for Medical Research, Manhasset, NY. Participants were recruited from the Long Island Jewish Health System, NY.
Experimental task
We used a computer-based cognitive task that dissociates learning from reward and punishment. The task which was developed by Gluck and colleagues at Rutgers University – Newark was previously used in fMRI (Mattfeld et al., 2011) and cognitive studies of Parkinson’s disease patients (Bodi et al., 2009). We modified the cover story to simulate real life experiences. Further, we increased the duration of stimulus presentation. In each trial, participants were presented with a casino roulette wheel (with a different background image) and were instructed that these roulette wheels were either biased to the red or the black side of the screen as shown in Figure 1. When the roulette wheel appeared on the screen, subjects were asked to put their tokens on red or black by pressing MRI compatible buttons with their thumb or index finger, respectively. Subjects were told that based on where the roulette ball landed, they would win money, lose money or get an empty box. The task did not include any further details about the biases of the four different roulette wheels. Therefore, subjects were required to learn the associations by trial-and-error. Each participant started the experiment with 500 tokens. Subjects were instructed to earn as many tokens as possible.
Figure 1.
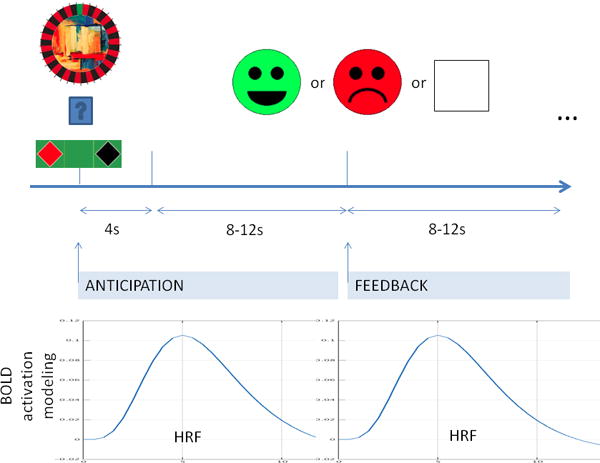
Illustration of the reward and punishment learning task. First, there is the presentation of the cue. The participant has 4 seconds to choose either red or black. Feedback is shown after 8-12 seconds (randomized) of waiting period. Similarly, feedback is followed by 8-12 seconds long period. These longer periods prevent HRFs (hemodynamic response function) to interfere across trials and provide a framework to model anticipation and feedback separately. (For more detail see text.)
Each trial began with the presentation of one of four roulette wheels with their respective background images and a casino table with instructions to place bets. The roulette wheel (cue) was presented for a fixed period of 3 seconds and was followed by a fixation cross for 8-10 seconds. Feedback was then presented for 3 seconds followed by a fixation cross for 10-12 seconds. Thus, an average trial was 26 seconds long. Feedback was either a reward with a smiley face indicating winning 25 tokens, a punishment with a sad face indicating losing 25 tokens, or an empty box indicating a neutral outcome (no feedback).
Two of the roulette wheels were biased toward red, and the other two were biased toward black. Two roulette wheels (one red-biased and one black-biased) were pre-assigned to result in reward if answered optimally and no feedback if answered non-optimally, while the other two give punishment if answered non-optimally and no feedback if answered optimally. In reward trials, when participants selected an optimal choice, they received reward feedback with 80% probability. They received no feedback for the remaining 20% of the trials when they selected the optimal choice. However, if the participant selected a nonoptimal choice, they would receive reward feedback with 20% probability, but no feedback for the remaining 80% of the trials. Similarly, on the punishment trials, when participants selected the optimal choice, they received no feedback 80% of trials and punishment in the remaining 20% of trials and vice versa.
All participants completed four scanning runs per session except one Parkinson’s disease subject who had only two runs in the OFF condition. The order of stimulus presentation was randomly determined. A run consisted of 20 trials, with each run lasting 8 minutes and 40 seconds. We calculated optimal responses and reaction time in each run for both reward and punishment. We also measured learning scores, which was the difference between the average of the optimal responses in the 3rd and 4th runs from the average optimal responses in the 1st run. Using the same approach, we also calculated reaction time for reward and punishment trials.
MRI acquisition
MRI scans were conducted at the North Shore University Hospital on a single 3T scanner (GE Signa HDx; General Electric, Milwaukee, Wisconsin). For image registration, we acquired anatomical scans in the coronal plane using an inversion-recovery prepared 3D fast spoiled gradient (IR-FSPGR) sequence (TR = 7.5 ms, TE = 3 ms, TI = 650 ms matrix = 256×256, FOV = 240 mm) producing 216 contiguous images (slice thickness = 1mm) through the whole brain. All scans were reviewed by a radiologist and a member of the research team. Any scan with significant artifacts was repeated. We also acquired functional scans comprising of 264 echo-planner imaging (EPI) volumes per run with the following parameters: TR = 2000 ms, TE = 30 ms, matrix = 64*64, FOV = 240 mm, slice thickness = 3 mm, 40 continuous axial oblique slices (one voxel = 3.75×3.75×3 mm). During data acquisition, the behavioral task was presented on an MR compatible screen.
Image processing and statistical analysis
We used FSL (http://www.fmrib.ox.ac.uk) FEAT for preprocessing and for the statistical analysis of our images. First level analysis consisted of standard preprocessing, modeling and the calculation of the transformation matrix of the registration. Standard preprocessing and modeling included removal of the first four “dummy” scans, motion correction and spatial smoothing (6-mm FWHM Gaussian kernel) followed by GLM estimation of parameters associated with the design matrix variables. We modeled the hemodynamic response functions (HRFs) in two different ways. First, we modeled the HRF associated with the feedback types (reward, punishment, and no feedback). Second, we analyzed our data in the anticipation phase, modeling our HRF locked to the different type of cues (reward or punishment). In both type of analysis (feedback or anticipation) a custom boxcar function associated with the 3s presentation of feedback and cue was convoluted with standard HRF. In addition to these variables, we added to the GLM the first time derivative of these variables and the six movement parameters to regress out large effects of movement. Further, standard registration and normalization to MNI152 space were also carried out, and registration matrices were calculated for the second level analysis. During the first level analysis, we also contrasted punishment versus reward in both feedback and anticipation. This was followed by a group level analysis – multi-way ANOVA, with factors of feedback type (reward or punishment), medication condition (ON, OFF), repetitions (four runs). Post-hoc calculations were carried out with Featquery and lab-based R scripts. All the reported results were cluster corrected for the whole brain with p<0.05 (with standard FSL z=2.3 initial threshold). No mask was used at any point during the analysis.
Results
Behavioral results
Parkinson’s disease patients were unable to learn to categorize the roulette wheels correctly. Learning curves did not increase significantly in any of the treatment conditions (F1,164=0.3, p=0.56) with the average correct response of 61.5 ± 25.3% and 51.8 ± 23.9% across trial types for OFF and ON conditions respectively. Learning score did not show differences between reward and punishment trials in any of the treatment conditions (condition: F1,38=1.68, p=0.2; trial type: F1,38=1.76, p=0.19, interaction: F1,38=0.13, p=0.72). However, Parkinson’s disease patients’ reaction time suggested that they learned whether a roulette wheel represents a reward or a punishment cue. Patients responded to reward cues progressively faster during the course of the runs, in both ON and OFF condition (average reaction time changes: reward-OFF and ON: −370 ms and −302 ms, punishment OFF and ON: 53 ms and 54 ms respectively, repeated ANOVA, condition: F1,38=0.06, p=0.81; trial type: F1,38=6.3, p=0.02, interaction: F1,38=0.05, p=0.82; Figure 2). This significant difference indicates that Parkinson’s disease patients differentiated trials based on their associated feedback. The lack of difference in reaction times in general (1914 ± 487 ms and 1911 ± 466 ms OFF and ON respectively) between treatment conditions suggests that our behavioral and neuroimaging results are not merely the result of Parkinson’s disease motor symptoms and dopaminergic medications.
Figure 2.
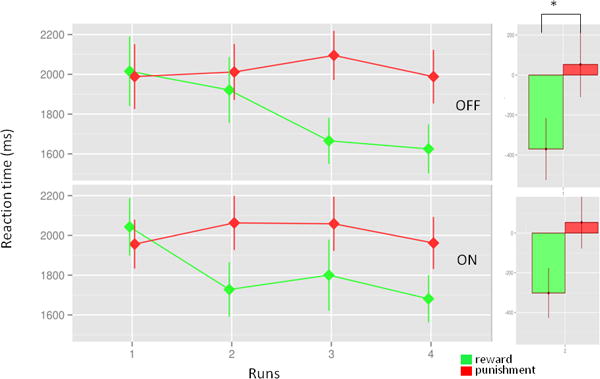
Reaction time change. The figure illustrates that the reaction times decrease selectively in reward cue related trials. The chart indicates that participant learned to distinguish between the cues (reward or punishment). There was no difference across treatment conditions.
Age-matched healthy volunteers showed very similar results: 61.5 ± 25.4% correct response across both trial types. Healthy controls showed moderate improvement in learning scores only in punishment, but not reward, trials across runs (8.1 % (t=1.56, df=10, p=0.15) and 12.3 % (t=2.46, df=10, p=0.03) in reward and punishment trials respectively). Reaction times were similar to those of the Parkinson’s disease cohort (RT=1515 ± 359 ms) and became progressively faster for reward trials as compared to punishment trials (reward: −204 ms, punishment: +1 ms; F1,19=6.19, p=0.02, Figure S1, Supplementary Digital Content).
Feedback related BOLD activations
Feedback, in general, strongly activated the dorsal attention network, the salience network and the occipital areas across trial types (Figure S2, regions listed in Table S1, cluster corrected p<0.05, Supplementary Digital Content). There was no deactivation at this same level of significance of the main effect.
When we compared the effect of medication status without differentiating trial types, no effect was detected. While BOLD activity was not modulated by medication status in reward trials, we found that medication status significantly attenuated response to punishment trials (OFF>ON) in several brain regions (L and R DLPFC, L and R putamen and L premotor cortex; cluster corrected p<0.05, Table 1). When we explicitly tested whole brain voxel level interaction between feedback type (reward versus punishment) and medication status (OFF versus ON) the same brain regions remained significantly engaged (Figure 3A, cluster corrected p<0.05).
Table 1.
Regions modulated by dopamine administration
| Regions | x | y | z | peak z |
|---|---|---|---|---|
| Feedback modulated by dopamine | ||||
| Premotor Cortex, BA 6 L | −32 | −2 | 52 | 3.7 |
| Putamen R | 20 | 4 | 14 | 3.4 |
| Putamen L | −22 | 12 | 4 | 3.4 |
| DLPFC R | 50 | 43 | 21 | 3.4 |
| DLPFC L | −43 | 43 | 22 | 3.2 |
| Anticipation modulated by dopamine | ||||
| vmPFC, BA 11m and 14r | 4 | 39 | −18 | 4.8 |
| Insula R | 38 | 20 | 2 | 3.9 |
x,y,z: MNI coordinates; peak coordinates reported z>2.3 and cluster corrected p<0.05
DLPFC: Dorso-lateral Prefrontal Cortex, vmPFC: Ventro-medial Prefrontal Cortex
Figure 3.
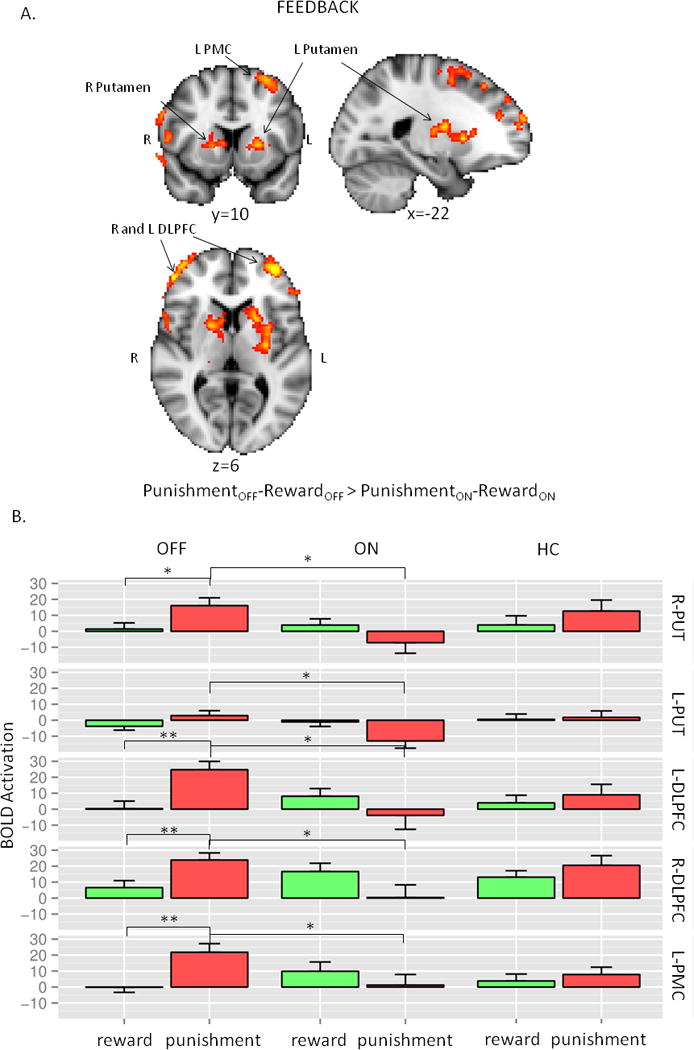
A. Neuroimaging results: interaction between trial types and treatment condition. B. Post hoc presentation of the significant regions of the interaction analysis in Figure 3A. The first two columns are OFF and ON conditions in Parkinson’s disease, while the last column represents HC. Each row represents the average values of the respective regions (R-PUT and L-PUT: right and left putamen, R-DLPFC and L-DLPFC: right and left dorso-lateral prefrontal cortex, L-PMC: left premotor cortex) from the primary analysis. The most significant differences were found between OFF and ON in the punishment trials. For more details see text.
Post hoc analysis of these regions revealed the same pattern across all the regions (condition: F1,792=11.5, p<0.001, feedback: F1,792=1.1, p=0.3, region: F1,792=1.9, p=0.17, feedback-condition interaction: F1,792 = 39.0, p<0.001): significantly higher BOLD signal during punishment trials than in the reward trials in the OFF condition. Activation during punishment trials significantly decreased in ON condition (Figure 3B). Side by side comparison of the activations of the healthy controls and Parkinson’s disease patients in different treatment conditions indicated that activation patterns in healthy controls looked similar to OFF conditions in all regions (Figure S3, Supplementary Digital Content, Figure 3B).
By correlating BOLD responses with behavioral results, we found that the average difference in activation between punishment and reward trials correlated with learning scores. This was true for all five regions that were activated (L and R DLPFC, L and R putamen and L premotor cortex). The higher the BOLD activity in these brain regions during punishment trials in reference to reward trials the better the individual learned to categorize punishment cues. Post-hoc analyses showed that activity in these brain regions showed no connection to learning to categorize reward cues (General Linear Model: punishment-reward BOLD signal: F1,60= 15.8, p<0.001, feedback type: F1,60=9.6, p=0.003; medication: F1,60=3.3, p=0.08, and region: F4,60=0.16, p=0.96.(Figure 4, only first two areas showed here, for all the values see Table S2).
Figure 4.
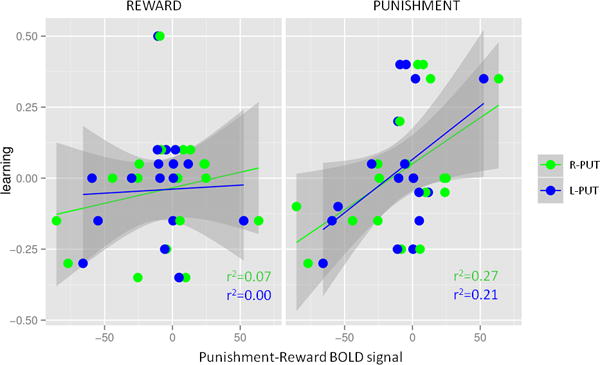
Neuroimaging findings correlated with learning. Average activation differences during the feedback period between punishment and reward trials predicted learning from punishment, but not from reward. R-PUT: right putamen, L-PUT: left putamen.
Anticipation: cue-related BOLD activity
The main effect of anticipation (Figure S4, regions listed in Table S1, Supplementary Digital Content) involved similar areas as the main effect of feedback (Figure S2, Supplementary Digital Content). The dorsal attention network, the salience network, and the occipital areas were similarly activated across trial types and medication conditions after the presentation of cues. BOLD activity in the anticipation phase was more robust than it was after feedback, as it is apparent from comparing Figure S2 and S4 (Supplementary Digital Content) on the same scale. Anticipation, unlike feedback, elicited significant “negative activation” in the vmPFC (Area 11m and 14r, Mackey and Petrides, 2014) and the parieto-temporal juncture (Figure S4, Supplementary Digital Content). While the interpretation of the negative peaks is often problematic, these regions likely represent true deactivations given the spatial overlap with the default mode network. Voxel wised paired t-test between OFF and ON condition revealed that vmPFC/gyrus rectus had significantly lower BOLD activity during the ON condition in both cue types (Figure 5A, Table 1). Moreover, the right anterior insula was significantly activated in the ON condition (Figures 5A and 5B, Table 1). There was no interaction between medication condition and cue types. Anticipatory activity did not correlate with the behavioral findings. In the right insula, the BOLD activation during OFF condition showed closer resemblance with healthy controls (Figure S5, Supplementary Digital Content. Figure 5B). This was similar what we reported above regarding the brain regions activated by feedback. However, the pattern in the vmPFC/gyrus rectus was similar between healthy subjects and ON condition (Figure S5, Supplementary Digital Content, Figure 5B).
Figure 5.
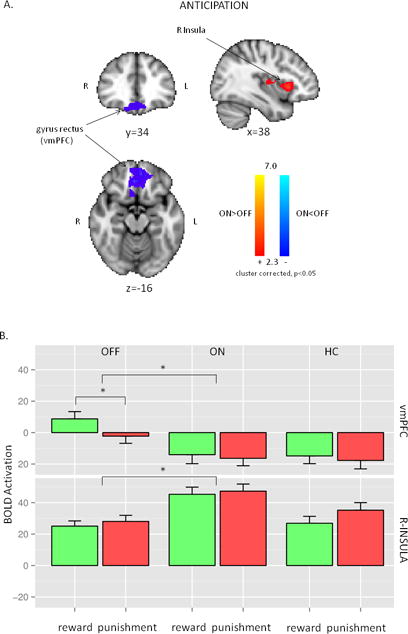
A. Neuroimaging results: the main effect of treatment condition during the anticipation of the feedback. R-Insula had increased activation during ON condition, while left vmPFC (ventro-medial prefrontal cortex) had lower activation during ON condition. B. Post-hoc presentation of the significant regions of the treatment condition analysis in Figure 5A. The first two columns are OFF and ON conditions in Parkinson’s disease, while the last column represents HC. Each row represents the average values of the respective regions (vmPFC: ventro-medial prefrontal cortex, R-INSULA: right insula) from the primary analysis. The most significant differences were found between OFF and ON conditions. For more details see text.
Discussion
This study demonstrated that the administration of dopaminergic medications to Parkinson’s disease patients was associated with modulation of the neural response to both feedback and anticipation. First, dopaminergic medications attenuated the neural response to punishment feedback in the left and right putamen, the left and right dlPFC and the left premotor cortex. The same regions exhibited a higher ratio of activity between reward and punishment during the ON condition as compared to the OFF condition. Neural activity correlated with the behavioral output in punishment trials only, implicating the role of these regions in processing punishment feedback. Second, we detected enhanced right insula activation and attenuated vmPFC/gyrus rectus activation during the anticipation phase in the ON-medication condition. This effect was similar for both reward and punishment trials.
These data are consistent with previous behavioral studies that found opposite patterns of sensitivity to reward and punishment between dopamine depleted (OFF) and dopamine supplemented (ON) conditions in Parkinson’s disease (Bodi et al., 2009; Frank et al., 2004). In agreement with these previous results, we have found higher BOLD activity in response to punishment as compared to reward during the OFF condition. Conversely, during the ON condition, punishment related BOLD activity was significantly decreased, while reward related activity remained unaffected, such that the ratio of activity between reward and punishment was higher during the ON condition as compared to the OFF condition. Our analysis revealed that this pattern of BOLD activity was not only limited to the dorsal striatum but was also observed in the dlPFC bilaterally and in the left premotor cortex. These findings indicate that the observed BOLD activity reflects modulation along the fronto-striatal circuits, not only within the striatum. The feedback-related pattern of BOLD activity correlated strongly among the observed regions (putamen, DLPFC, and premotor area) indicating that these regions operate within the same neural network to execute this behavior. These observations are also congruent with the proposed model of functional segregation between direct and indirect pathways within the basal ganglia, attributing changes in BOLD activity during the ON vs. OFF conditions to differential engagement of the indirect pathway (Frank et al., 2004; Bromberg-Martin et al., 2010; Lobo et al., 2010; Hikida et al., 2010; Ferguson et al., 2011; Kravitz et al., 2012). An alternative explanation is offered by Keeler et al. who argue that these cognitive differences can be explained by the activation of D1 versus D2 receptors in the direct and indirect pathways, respectively, where the direct pathway codes for habitual responses, while indirect pathway codes for goal directed behavior (Keeler et al., 2014). This theory predicts that shortening of reaction time is an indicator that task is becoming more habitual, thus mediated by higher D1 receptor activation. In our behavioral results, reaction times became shorter only during reward related trials, during both OFF and ON conditions, indicating that both of these theories are potentially consistent with our results. Most critically, according to both theories, our data suggest that the administration of dopaminergic medications interfered mainly with the indirect D2 pathway, not with the direct D1 pathway. These results are surprising since levodopa is thought to change phasic dopamine signaling and enhance activity in the direct D1 pathway. D2 receptors, on the other hand, are thought to be driven by tonic dopamine levels (Moustafa et al., 2013). Prior computational modeling of phasic and tonic characteristics of dopamine release in the dorsal striatum have suggested, however, that the relationship between D1 and D2 receptor pathways is much more complex than initially thought (Dreyer et al., 2010), and D2 receptor postsynaptic signaling can be significantly activated through phasic dopamine modulation.
Inferring a dopamine-related mechanism based BOLD signals can be problematic since BOLD responses are not a direct measure of dopamine activation. Recent evidence, however, suggests that dopamine release can increase BOLD activity in the dorsal striatum in a dose dependent manner (Ferenczi et al., 2016). Our healthy control data provides additional insights into the interpretation of the BOLD signal by establishing a baseline for acquired BOLD signal from Parkinson’s disease patients. The decaying nature of dopamine signals during cognitive tasks can be explained by phasic dopamine prediction error signaling in response to unexpected feedback in the first runs. This suggests that feedback related BOLD activity during the first half of the session (run 1 and 2) might be attributed to variations in dopaminergic signaling (Figure S4, Supplementary Digital Content). The decrease in BOLD activity in response to reward versus punishment feedback further strengthen the case that the measured BOLD signals are related to reward prediction error (Schultz et al., 1997). Because of the nature of our task, reward trials elicited high reward prediction error initially. As subjects learned that a cue was rewarding (manifested in decreasing reaction time), reward prediction error decreased. On the other hand, irrespective of the subject’s knowledge of the punishment related cues, it always elicited high punishment prediction error during punishment trials indicating that processing of punishment feedback is not a mirror image of reward feedback, but could have different neural underpinnings (Hikida et al., 2010; Kravitz et al., 2012). However, it is important to note that while punishment prediction error signaling can decrease dopaminergic activation, it can manifest as higher BOLD activity due to active disinhibition of the indirect pathway.
In contrast to the feedback-related BOLD signals, the anticipation BOLD signals can be explained by dopaminergic signaling associated with the salience of stimuli given the lack of change in these signals over time (Figure S6, Supplementary Digital Content). Further, the anticipatory BOLD signals were mainly observed in salience-related brain regions (Seeley et al., 2007). It is well established that salient stimuli elicit BOLD activity in the anterior insula as a part of the salience network, while the vmPFC tends to deactivate as a part of default mode network. According to this model, administration of dopaminergic medications made participants more sensitive to external stimuli. We acknowledge, however, that our task was not designed to dissociate motivational salience and motivational value related BOLD activations (Bromberg-Martin et al., 2010). Hence, the BOLD signals could be driven by both salience and value.
In contrast to other studies by Gluck and colleagues using variations on this task, patients in our study were unable to learn the optimal cue-outcome associations. This was likely due to the current task design where cue and feedback were separated by 8-12 seconds, in contrast to previous studies where feedback was directly displayed after the subject selected a choice (Bodi et al., 2009; Mattfeld et al., 2011). The longer inter-stimuli interval was chosen to make a clearer distinction between feedback and anticipation related BOLD signals. However, this design made processing cue-feedback associations much more difficult. Also, because of the increased inter-stimuli intervals, we could only deliver half as many trials as in the previous studies. Although subjects did not learn the optimal associations, the trial type (reward or punishment) was increasingly identified across the runs as implicated by the decreasing reaction time after reward-only associated cues. Thus, these reaction time changes verify that patients were learning and performing reinforcement learning.
Another likely consequence of the current task design was that while a strong interaction between dopaminergic medication and the neural response to punishment was evident, the effect on reward learning was unclear. Furthermore, since the anticipation phase (part of the current design) did not distinguish between reward and punishment related BOLD signals, future work might benefit from examining the neural correlates of motivational bias with the original task design (Bodi et al., 2009). Using high resolution fMRI, Mattfeld et al. (2011) found that in healthy young participants, unique subregions of the striatum—separated along both a dorsal/ventral and anterior/posterior axis— differentially participate in the learning of associations through reward and punishment. This double dissociation within the striatum can help differentiate between learning from reward versus punishment and how variability in dopaminergic signaling individually modulates them.
Understanding the role of dopamine in reward and punishment processing could provide valuable insight into the understanding of impulse control disorders, amotivational syndromes, and major depressive disorder. In impulse control disorders, patients underestimate risks and overestimate potential rewards possibly due to the imbalance in learning from rewarding and punishing stimuli (de Ruiter et al., 2008). In sharp contrast, depressed patients are thought to be overly sensitive to punishment as compared to reward (Eshel and Roiser, 2010; Herzallah et al., 2013; Must et al., 2006).
In sum, we demonstrated the modulation of the neural encoding of feedbacks across trial types (reward or punishment) and treatment condition (OFF and ON) involving the fronto-striatal circuitry (DLPFC, premotor and putamen). These results indicate that during the ON condition there is a relative hypersensitivity toward rewards, which reverses during the OFF condition. This flip has the potential to make patients vulnerable to cognitive distortions, which could be the underlying neural mechanism through which dopamine depleted, and dopamine enhanced conditions can lead to behavioral manifestations such as clinical depression and compulsive gambling.
Supplementary Material
Abbreviations
- BOLD
Blood oxygen level dependent
- DLPFC
dorsolateral prefrontal cortex
- UPDRS
Unified Parkinson’s Disease Rating Scale
References
- Barr GA, Moriceau S, Shionoya K, Muzny K, Gao P, Wang S, Sullivan RM. Transitions in infant learning are modulated by dopamine in the amygdala. Nat Neurosci. 2009;12:1367–1369. doi: 10.1038/nn.2403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bodi N, Keri S, Nagy H, Moustafa A, Myers CE, Daw N, Dibo G, Takats A, Bereczki D, Gluck MA. Reward-learning and the novelty-seeking personality: a between- and within-subjects study of the effects of dopamine agonists on young Parkinson’s patients. Brain. 2009;132:2385–2395. doi: 10.1093/brain/awp094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bromberg-Martin ES, Matsumoto M, Hikosaka O. Dopamine in Motivational Control: Rewarding, Aversive, and Alerting. Neuron. 2010;68:815–834. doi: 10.1016/j.neuron.2010.11.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Ruiter MB, Veltman DJ, Goudriaan AE, Oosterlaan J, Sjoerds Z, van den Brink W. Response Perseveration and Ventral Prefrontal Sensitivity to Reward and Punishment in Male Problem Gamblers and Smokers. Neuropsychopharmacology. 2008;34:1027–1038. doi: 10.1038/npp.2008.175. [DOI] [PubMed] [Google Scholar]
- Dreyer JK, Herrik KF, Berg RW, Hounsgaard JD. Influence of Phasic and Tonic Dopamine Release on Receptor Activation. J Neurosci. 2010;30:14273–14283. doi: 10.1523/JNEUROSCI.1894-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eshel N, Roiser JP. Reward and Punishment Processing in Depression. Biological Psychiatry, Vascular Function in Depression in Older Adults. 2010;68:118–124. doi: 10.1016/j.biopsych.2010.01.027. [DOI] [PubMed] [Google Scholar]
- Fadok JP, Dickerson TMK, Palmiter RD. Dopamine Is Necessary for Cue-Dependent Fear Conditioning. J Neurosci. 2009;29:11089–11097. doi: 10.1523/JNEUROSCI.1616-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferenczi EA, Zalocusky KA, Liston C, Grosenick L, Warden MR, Amatya D, Katovich K, Mehta H, Patenaude B, Ramakrishnan C, et al. Prefrontal cortical regulation of brainwide circuit dynamics and reward-related behavior. Science. 2016;351:aac9698. doi: 10.1126/science.aac9698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferguson SM, Eskenazi D, Ishikawa M, Wanat MJ, Phillips PEM, Dong Y, Roth BL, Neumaier JF. Transient neuronal inhibition reveals opposing roles of indirect and direct pathways in sensitization. Nat Neurosci. 2011;14:22–24. doi: 10.1038/nn.2703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frank MJ, Seeberger LC, O’Reilly RC. By Carrot or by Stick: Cognitive Reinforcement Learning in Parkinsonism. Science. 2004;306:1940–1943. doi: 10.1126/science.1102941. [DOI] [PubMed] [Google Scholar]
- Garrison J, Erdeniz B, Done J. Prediction error in reinforcement learning: A meta-analysis of neuroimaging studies. Neuroscience & Biobehavioral Reviews. 2013;37:1297–1310. doi: 10.1016/j.neubiorev.2013.03.023. [DOI] [PubMed] [Google Scholar]
- Herzallah MM, Moustafa AA, Natsheh JY, Abdellatif SM, Taha MB, Tayem YI, Sehwail MA, Amleh I, Petrides G, Myers CE, Gluck MA. Learning from negative feedback in patients with major depressive disorder is attenuated by SSRI antidepressants. Front Integr Neurosci. 2013;7:67. doi: 10.3389/fnint.2013.00067. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hikida T, Kimura K, Wada N, Funabiki K, Nakanishi S. Distinct roles of synaptic transmission in direct and indirect striatal pathways to reward and aversive behavior. Neuron. 2010;66:896–907. doi: 10.1016/j.neuron.2010.05.011. [DOI] [PubMed] [Google Scholar]
- Keeler JF, Pretsell DO, Robbins TW. Functional implications of dopamine D1 vs. D2 receptors: A “prepare and select” model of the striatal direct vs indirect pathways Neuroscience. The Ventral Tegmentum and Dopamine: A New Wave of Diversity. 2014;282:156–175. doi: 10.1016/j.neuroscience.2014.07.021. [DOI] [PubMed] [Google Scholar]
- Kravitz AV, Tye LD, Kreitzer AC. Distinct roles for direct and indirect pathway striatal neurons in reinforcement. Nat Neurosci. 2012;15:816–818. doi: 10.1038/nn.3100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lobo MK, Covington HE, Chaudhury D, Friedman AK, Sun H, Damez-Werno D, Dietz DM, Zaman S, Koo JW, Kennedy PJ, Mouzon E, Mogri M, Neve RL, Deisseroth K, Han MH, Nestler EJ. Cell Type–Specific Loss of BDNF Signaling Mimics Optogenetic Control of Cocaine Reward. Science. 2010;330:385–390. doi: 10.1126/science.1188472. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mackey S, Petrides M. Architecture and morphology of the human ventromedial prefrontal cortex. Eur J Neurosci. 2014;40:2777–2796. doi: 10.1111/ejn.12654. [DOI] [PubMed] [Google Scholar]
- Mattfeld AT, Gluck MA, Stark CEL. Functional specialization within the striatum along both the dorsal/ventral and anterior/posterior axes during associative learning via reward and punishment. Learn Mem. 2011;18:703–711. doi: 10.1101/lm.022889.111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moustafa AA, Herzallah MM, Gluck MA. Dissociating the cognitive effects of levodopa versus dopamine agonists in a neurocomputational model of learning in Parkinson’s disease. Neurodegener Dis. 2013;11:102–111. doi: 10.1159/000341999. [DOI] [PubMed] [Google Scholar]
- Must A, Szabó Z, Bódi N, Szász A, Janka Z, Kéri S. Sensitivity to reward and punishment and the prefrontal cortex in major depression. Journal of Affective Disorders. 2006;90:209–215. doi: 10.1016/j.jad.2005.12.005. [DOI] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A Neural Substrate of Prediction and Reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Seeley WW, Menon V, Schatzberg AF, Keller J, Glover GH, Kenna H, Reiss AL, Greicius MD. Dissociable Intrinsic Connectivity Networks for Salience Processing and Executive Control. J Neurosci. 2007;27:2349–2356. doi: 10.1523/JNEUROSCI.5587-06.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.