

Abstract
Monkeys and other animals appear to share with humans two risk attitudes predicted by prospect theory: an inverse-S-shaped probability-weighting (PW) function and a steeper utility curve for losses than for gains. These findings suggest that such preferences are stable traits with common neural substrates. We hypothesized instead that animals tailor their preferences to subtle changes in task contexts, making risk attitudes flexible. Previous studies used a limited number of outcomes, trial types, and contexts. To gain a broader perspective, we examined two large datasets of male macaques' risky choices: one from a task with real (juice) gains and another from a token task with gains and losses. In contrast to previous findings, monkeys were risk seeking for both gains and losses (i.e., lacked a reflection effect) and showed steeper gain than loss curves (loss seeking). Utility curves for gains were substantially different in the two tasks. Monkeys showed nearly linear PWs in one task and S-shaped ones in the other; neither task produced a consistent inverse-S-shaped curve. To account for these observations, we developed and tested various computational models of the processes involved in the construction of reward value. We found that adaptive differential weighting of prospective gamble outcomes could partially account for the observed differences in the utility functions across the two experiments and thus provide a plausible mechanism underlying flexible risk attitudes. Together, our results support the idea that risky choices are constructed flexibly at the time of elicitation and place important constraints on neural models of economic choice.
SIGNIFICANCE STATEMENT We respond in reliable ways to risk, but are our risk preferences stable traits or ephemeral states? Using various computational models, we examined two large datasets of macaque risky choices in two different tasks. We observed several deviations from “classic” risk preferences seen in humans and monkeys: no reflection effect, loss seeking as opposed to loss aversion, and linear and S-shaped, as opposed to inverse-S-shaped, probability distortion. These results challenge the idea that our risk attitudes are evolved traits shared with the last common ancestor of macaques and humans, suggesting instead that behavioral flexibility is the hallmark of risky choice in primates. We show how this flexibility can emerge partly as a result of interactions between attentional and reward systems.
Keywords: cognitive flexibility, loss seeking, probability distortion, reflection effect, risk
Introduction
Humans and other animals live in a complex world in which uncertainty is often unavoidable (Kacelnik and Bateson, 1997; Platt and Huettel, 2008; Pearson et al., 2014). Understanding the strategies used to deal with risk, which we call risk attitudes, and underlying neural mechanisms is an important quest for behavioral economics, comparative psychology, foraging theory, and neuroscience (Kahneman and Tversky, 2000; McCoy and Platt, 2005; Trepel et al., 2005; O'Neill and Schultz, 2010; So and Stuphorn, 2010; Paglieri et al., 2014). When a strategy for dealing with risk is beneficial, it is liable to become selected for and canalized; that is, it becomes seen robustly across contexts and developmental trajectories. Consistent preferences across many or all members of a species have often been used to suggest that those preferences are innate and rely on similar neural substrates (Stevens et al., 2005; Heilbronner et al., 2008; De Petrillo et al., 2015; Mendelson et al., 2016; Heilbronner, 2017).
The rhesus macaque is a particularly important model organism in neuroeconomics. Macaques share many economic biases and preferences with humans, including attitudes toward counterfactual outcomes, the hot handeffect, a peak end bias, framing, cognitive dissonance, and the description-experience gap (Egan et al., 2007; Hayden et al., 2009; Abe and Lee, 2011; Lakshminarayanan et al., 2011; Beran et al., 2014; Blanchard et al., 2014a,b; Blanchard and Hayden, 2015; Heilbronner and Hayden, 2016). Some recent research suggests that macaques and other nonhuman primates share core risk attitudes as characterized by prospect theory (Kahneman and Tversky, 1979). Most notably, these include loss aversion (overweighting of possible losses compared with gains; Chen et al., 2006), the reflection effect (simultaneous risk aversion with gains and risk seeking with losses; Lakshminarayanan et al., 2011), and an inverse-S-shaped probability-weighting (PW) function (overweighting and underweighting of small and large probabilities, respectively; Stauffer et al., 2015). However, whereas humans are reliably risk averse in many contexts, macaques are generally risk seeking (Heilbronner and Hayden, 2013; but see Yamada et al., 2013). The consistency of these results across studies and, with the exception of risk seeking, across species, have been used to suggest that such preferences are stable traits with common neural substrates and to motivate the use of nonhuman primates for studying choice under risk and uncertainty (Heilbronner, 2017).
Whereas risk attitudes are important, cognitive flexibility is also important for any organism that will encounter dynamic environments (Diamond, 2013). Flexible cognition that allows for rapid adjustment of risky choice strategy to even subtle changes in the environment should be selected for as well. Cognitive flexibility is not necessarily inconsistent with evolved risk attitudes, but primates' remarkable flexibility raises the possibility that ostensibly shared risk attitudes may be task dependent. Specifically, if preferences are task dependent, then comparing two species' attitudes in the same task or one species' attitudes across two tasks may produce similar preferences because the computational demands of the task or tasks are similar (e.g., range of reward probabilities). For this reason, testing risk attitudes across multiple contexts can be informative.
To obtain a broader view on the flexibility of risk attitudes, we examined two large datasets supplemented with new data: one from a juice-based gambling task in which monkeys chose between two win/nothing gambles on each trial (Strait et al., 2014, 2015) and one from a token-based gambling task in which monkeys selected between two mixed (win/loss) gambles (Strait et al., 2016; Azab and Hayden, 2017, 2018). Our aim was to examine monkeys' behavior in light of extant findings and predictions made under prospect theory. By fitting choice behavior with various models using cross-validation, we found that monkeys were risk seeking in both tasks, although their utility curves for gains had different convex shapes. Monkeys were loss seeking in the token-gambling task and exhibited a convex utility curve for losses shallower than the one for gains. Finally, the PW function was S-shaped (the inverse of the previously reported shape) in the juice-gambling task and almost linear in the token-gambling task.
Materials and Methods
Overview of the experimental procedures.
Behavioral data were collected in two separate experiments in which monkeys selected between two gambles offering juice or tokens. In each trial of the juice-gambling experiment, monkeys selected one of two options, each offering a simple gamble for juice or water (Strait et al., 2014, 2015). Options were represented by a rectangular bar and offered either a gamble or a safe bet (100% probability) for liquid reward. Gamble offers were represented by a bar that was divided into two portions corresponding to the two possible outcomes: no reward or a medium or large reward (Fig. 1a).
Figure 1.

Experimental procedure. a, Timeline of the juice-gambling task. In each trial, two options were presented, each offering a gamble for juice reward. Gambles were represented by a rectangle, some portion of which was red, blue, or green, signifying no reward, medium, or large reward, respectively. The area of the colored portion indicates the probability that choosing that offer would yield the corresponding reward. We also used a safe offer that was entirely gray and always carried a 100% probability of a small reward. b, Timeline of the token-gambling task with gains and losses. In each trial, two options were presented, each offering a gamble for tokens. The size of each colored portion within each offer indicated the probability that choosing that offer would yield the corresponding outcome. A small reward was administered for each completed trial. When at least six tokens were earned, a large “jackpot” reward was administered and the earned token count was reset to 0. The inset shows the colors associated with different tokens and combinations used.
In each trial of the token-gambling experiment, monkeys selected between two options, each offering a mixed gamble for tokens (Strait et al., 2016; Azab and Hayden, 2017, 2018). Visual display of gambles was similar to the juice-gambling task except that six colors were used corresponding to six possible reward magnitudes in terms of tokens (three gains, two losses, and zero; Fig. 1b). In addition, the probabilities of reward outcome were limited to five values (0.1, 0.3, 0.5, 0.7, and 0.9). Each gamble included at least one positive or zero outcome, ensuring that every gamble carried the possibility of a win. This decreased the number of trivial choices presented to subjects and maintained motivation. Monkeys were trained to collect six tokens to receive a large (300 μL) liquid reward (see “Token-gambling task” below for more details). Therefore, each token corresponded to 50 μL of reward juice.
In total, three male monkeys (subject B, C, and J) performed 108,272 and 66,500 trials in the juice and token-gambling tasks, respectively. Monkeys B and J participated in both experiments. Monkeys B, C, and J performed 70,700, 24,700, and 12,872 trials in the juice-gambling task, respectively. Monkeys B and J performed 28,700 and 37,800 trials in the token-gambling task, respectively. Subjects were initially trained on a two-option task (Strait et al., 2014) and were later also trained on a task that involved single-option accept–reject gambles (Blanchard et al., 2015). Although subjects were not tested with novel colors in this study, we have tested extensively macaques' abilities to learn new associations quickly. This approach to training risk tasks was explained in detail previously (Hayden et al., 2010).
Proportional gambling tasks have been used in many studies since 2010 (O'Neill and Schultz, 2010; So and Stuphorn, 2012; Yamada et al., 2013; Strait et al., 2014; Chen and Stuphorn, 2015). There is plentiful evidence that monkeys readily understand and correctly interpret such displays with no special training requirements. The Hayden laboratory has been developing methods for training macaques to perform such tasks for over a decade and we have developed several checks and training strategies to make sure that they understand the task. Subjects were trained in two stages. Our subjects were first trained extensively (for 2 or more years) on a simple gambling task with multiple possible juice (i.e., nontoken) reward amounts. In this stage, they were tested on multiple variations of the gambling task and performance was validated through multiple control tests (Hayden et al., 2010). Performance was consistent (including two consistent biases, risk seeking, and win-stay-lose-shift) across single option (Blanchard et al., 2015) and two option (Strait et al., 2014) versions of the task. The token element of the task was new to us, although it has been used in studies previously (Seo and Lee, 2009; Seo et al., 2014). Behavior in the token version of the task was overall quite similar to that in the juice version, indicating that the monkeys readily learned to treat secondary rewards as reinforcing. However, the strongest evidence for the monkeys' understanding of the task comes from their consistent preferences for higher probabilities of large rewards and smaller probabilities of small rewards.
Juice-gambling task.
Two offers were presented on each trial. Each offer was represented by a rectangle 300 pixels tall and 80 pixels wide (11.35° of visual angle tall and 4.08° of visual angle wide). Options offered either a gamble or a safe (100% probability) bet for liquid reward. Gamble offers were defined by two parameters, reward size and probability. Each gamble rectangle was divided into two portions: one red and the other either blue or green. The size of the green or blue portions signified the probability of winning a medium (mean 165 μL) or large reward (mean 240 μL), respectively. These probabilities were drawn from a uniform distribution between 0% and 100%. The rest of the bar was colored red; the size of the red portion indicated the probability of no reward. The safe offer was entirely gray and always carried a 100% probability of a small reward (125 μL).
On each trial, one offer appeared on the left side of the screen and the other appeared on the right. Offers were separated from the fixation point by 550 pixels (4.5° of visual angle). The side of the first and second offer (left and right) was randomized by trial. Each offer appeared for 400 ms and was followed by a 600 ms blank period. Monkeys were free to fixate upon the offers when they appeared (and in our casual observations almost always did so). After the offers were presented separately, a central fixation spot appeared and the monkey fixated on it for 100 ms. After this, both offers appeared simultaneously and the animal indicated its choice by shifting gaze to its preferred offer and maintaining fixation on it for 200 ms. Failure to maintain gaze for 200 ms did not lead to the end of the trial, but instead returned the monkey to a choice state; therefore, monkeys were free to change their mind if they did so within 200 ms (although in our observations they seldom did so). After a successful 200 ms fixation, the gamble was immediately resolved and reward delivered. Trials that took >7 s were considered inattentive trials and were not included in analysis (this removed <1% of trials). Outcomes that yielded rewards were accompanied by a visual cue: a white circle in the center of the chosen offer. All trials were followed by an 800 ms intertrial interval (ITI) with a blank screen.
Token-gambling task.
Monkeys performed a mixed (two option) gambling task. The task was similar to one we have used previously (Strait et al., 2014, 2015), albeit with two major differences: first, monkeys gambled for virtual tokens rather than liquid rewards and, second, outcomes could be losses as well as wins.
Two offers were presented on each trial. Each offer was represented by a rectangle 300 pixels tall and 80 pixels wide (11.35° of visual angle tall and 4.08° of visual angle wide). Twenty percent of options were safe (100% probability of either 0 or 1 token), whereas the remaining 80% were gambles. Safe offers were entirely red (0 tokens) or blue (1 token). The size of each portion indicated the probability of the respective reward. Each gamble rectangle was divided horizontally into a top and bottom portion, each colored according to the token reward offered. Gamble offers were thus defined by three parameters: two possible token outcomes and probability of the top outcome (the probability of the bottom was strictly determined by the probability of the top). The probability of the outcome was selected from the following values: 0.1, 0.3, 0.5, 0.7, or 0.9. The token values of the two possible outcomes were selected at random from the values −2 (black stripe), −1 (gray stripe), 0 (red), 1 (blue), 2 (green), or 3 (purple). The combinations used are shown in the inset of Figure 1b. Only red (0 token) and blue (1 token) were used as safe offers. Each gamble included at least one positive or zero outcome, ensuring that every gamble carried the possibility of a win. This decreased the number of trivial choices presented to subjects and maintained motivation.
Six initially unfilled circles arranged horizontally at the bottom of the screen indicated the number of tokens to be collected before the subject obtained a liquid reward. These circles were filled appropriately at the end of each trial according to the outcome of that trial. When six or more tokens were collected, the tokens were covered with a solid rectangle while a liquid reward was delivered. Tokens beyond six did not carry over, nor could the number of tokens fall below zero.
On each trial, one offer appeared on the left side of the screen and the other appeared on the right. Offers were separated from the fixation point by 550 pixels (4.5° of visual angle). The side of the first offer (left and right) was randomized by trial. Each offer appeared for 600 ms and was followed by a 150 ms blank period. Monkeys were free to fixate upon the offers when they appeared (and in our observations almost always did so). After the offers were presented separately, a central fixation spot appeared and the monkey fixated on it for 100 ms. After this, both offers appeared simultaneously and the animal indicated its choice by shifting gaze to its preferred offer and maintaining fixation for 200 ms. Failure to maintain gaze for 200 ms did not lead to the end of the trial, but instead returned the monkey to a choice state; therefore, monkeys were free to change their mind if they did so within 200 ms (although in our observations they seldom did so). A successful 200 ms fixation was followed by a 750 ms delay, after which the gamble was resolved and a small “motivation” reward (100 μL) was delivered, regardless of the outcome of the gamble, to sustain motivation. This small reward was delivered within a 300 ms window. If six tokens were collected, a delay of 500 ms was followed by a large liquid reward (300 μL) within a 300 ms window, followed by a random ITI between 500 and 1500 ms. If six tokens were not collected, subjects proceeded immediately to the ITI.
Surgical procedures, eye tracking, and reward delivery.
All procedures were approved by the University Committee on Animal Resources at the University of Rochester or by the Institutional Animal Care and Use Committee at the University of Minnesota and were designed and conducted in compliance with the Public Health Service's Guide for the Care and Use of Animals. Three male rhesus macaques (Macaca mulatta) served as subjects. A small prosthesis for holding the head was used. A Cilux recording chamber (Crist Instruments) was placed over the prefrontal cortex. Animals were habituated to laboratory conditions and then trained to perform oculomotor tasks for liquid reward. Animals received appropriate analgesics and antibiotics after all procedures. Throughout both behavioral and physiological recording sessions, the chamber was kept sterile with regular antibiotic washes and sealed with sterile caps. All recordings were performed during the animals' light cycle between 8:00 A.M. and 5:00 P.M.
Eye position was sampled at 1000 Hz by an infrared eye-monitoring camera system (SR Research). Stimuli were controlled by a computer running MATLAB (The MathWorks) with Psychtoolbox (Brainard, 1997) and Eyelink Toolbox (Cornelissen et al., 2002). Visual stimuli were colored rectangles on a computer monitor placed 57 cm from the animal and centered on its eyes (Fig. 1a,b). A standard solenoid valve controlled the duration of juice delivery. The relationship between solenoid open time and juice volume was established and confirmed before, during, and after recording.
Overview of computational models.
We first used four base models, expected value (EV), EV + probability weighting (PW), expected utility (EU), and subjective utility (SU), for the estimation of subjective value. In all of these models, the subjective value of each gamble (e.g., the gamble on the left) was computed as follows:
where SVL is the subjective value of the left gamble; ML and pL are the magnitude (in microliters) and probability associated with the left gamble's larger magnitude outcome; mL is the magnitude of the other left gamble outcome (ML > mL), which is equal to zero in the juice-gambling task; u(m) is the utility function; and w(p) is the PW function. The four models differed in the form of their utility and PW functions. The EV model included linear utility and PW functions. The EU model included only a nonlinear utility function, whereas the EV+PW included only a nonlinear PW function. Finally, the SU included both nonlinear utility and PW functions (see “Base models” section below for more details).
The estimated subjective values of the two options presented in each trial were then used to compute the probability of selecting between the two options based on a logistic function as follows:
 |
where PL is the probability of choosing the left option, biasL measures a response bias toward the left option to capture any location bias, biasO measures a response bias toward the first offer (FO) that appeared on the screen (order bias) and was only significant in the token-gambling task, FOL(FOR) is 1 if the first offer appeared on the left (right) side, and σ is a parameter that measures the level of stochasticity in decision processes.
We also extended our base models to include two types of differential weighting (DW) mechanisms (see “Models with DW mechanism” section below for more details). First, we considered alternative “within-option” DW mechanisms by which the gamble outcome with a larger reward magnitude, reward probability, or EV could influence the overall value more than the alternative outcome. This was done to investigate how magnitudes and probabilities of the two possible gamble outcomes can influence the weight of each gamble outcome on the overall gamble value. These models were only used for the token-gambling task because gambles in the juice-gambling task only had one nonzero outcome. Second, we considered the possibility that, when comparing two gambles, the value of the better outcome of each gamble (in terms of magnitude, probability, or EV) could influence their overall value relative to the other gamble (“cross-option” DW). This was done to investigate how nonzero (or the better) outcomes of the gambles on each trial modulate the value of these gamble in the juice-gambling (respectively, token-gambling) task.
Base models.
In the EV model, actual probabilities and a linear utility function were used to estimate the subjective value of each gamble. However, this model also includes different slopes for gains and losses as follows:
 |
where βG and βL are slopes for the gain and loss domains, respectively. We normalized the juice reward magnitude by 100 μL to limit utility to small numbers.
In the EU model, we considered a nonlinear utility function and a loss aversion coefficient as follows:
 |
where u(m) is the SU, λ is the loss aversion coefficient, and ρG and ρL are the exponents of the power law function and determine risk aversion for the gain and loss domains, respectively; ρ > 1 indicates risk seeking, ρ < 1 indicates risk aversion, and ρ = 1 indicates risk neutrality.
In the EV+PW model, we considered a linear utility function and nonlinear PW function. The PW was computed using a one-parameter Prelec function as follows:
where w(p) is the PW and γ is a parameter that determines probability distortion.
Finally, in the SU model, we used both nonlinear utility and nonlinear PW functions to estimate the subjective value of each gamble.
Models with DW mechanisms.
We extended our base models to include two types of DW mechanisms. First, we considered alternative DW mechanisms by which the gamble outcome with a larger reward magnitude, reward probability, or EV could influence the overall value more than the alternative outcome (“within-option” DW; Fig. 2a–c). Second, we considered the possibility that, when comparing two gambles, the value of the better outcome of each gamble (in terms of magnitude, probability, or EV) could influence their overall value relative to the other gamble (“cross-option” DW; Fig. 2d–i).
Figure 2.

Alternative models for DW. a–c, Alternative DW between the two outcomes of each gamble (within-option) in the token-gambling task with two nonzero reward outcomes. a–c show three mechanisms for how magnitudes and probabilities of the two possible gamble outcomes can influence the weight of each gamble outcome on the overall gamble value: DW by magnitude (a); DW by probability (b); and DW by EV (c). In all panels, ML and pL indicate the magnitude and probability associated with the left gamble's larger magnitude outcome, respectively, and mL is the magnitude of the other left gamble outcome (the probability of this outcome is 1 − pL). The same convention is used for the right gamble. The blue box shows the outcome that is assigned with a larger weight based on a given mechanism. The DW factors determine the strength of DW according to the reward magnitude (DWm), reward probability (DWp), and EV (DWEV) of the two outcomes. d–f, Alternative DW between better outcomes of the two alternative gambles (cross-option) in the token-gambling task with two nonzero reward outcomes. d–f show three mechanisms for how magnitudes and probabilities of the better outcome of the two alternative gambles can modulate their values: cross-option DW by magnitude (d), cross-option DW by probability (e), and cross-option DW by EV (f). The blue box shows the gamble that is assigned with a larger weight based on a given mechanism. The DW factors determine the strength of DW according to the reward magnitude (d), the reward probability (e), and EV of the two gambles (f). g–i, Alternative cross-option DW between nonzero outcomes of the two alternative gambles in the juice-gambling task. g–i show three mechanisms for how magnitudes and probabilities of the nonzero outcome of the two alternative gambles can modulate their values. Importantly, as shown in Figure 2-1 and Figure 2-2, our fitting method is able to identify correctly the model used to generate a given set of data and thus can distinguish between the alternative models.
We constructed three within-option DW models (DW by magnitude, DW by probability, and DW by EV; Fig. 2a–c) to investigate how magnitudes and probabilities of the two possible gamble outcomes can influence the weight of each gamble outcome on the overall gamble value. These models were only used for the token-gambling task because gambles in the juice-gambling task only had one nonzero outcome.
In the model with within-option DW by magnitude, the subjective value of each gamble (say for the left gamble) was computed as follows:
 |
where DWm determines the strength of DW by magnitudes; ML and pL are the magnitude and probability associated with the left gamble's larger magnitude outcome, respectively; and mL is the magnitude of the other left gamble outcome (ML > mL).
In the model with within-option DW by probability, the subjective value was computed as follows:
 |
where DWp determines the strength of DW by probability and mL (mL′) is the magnitude associated with the left gamble's larger (respectively, smaller) probability outcome (PL > 0.5).
Finally, in the model with within-option DW by EV, the subjective value was computed as follows:
 |
where DWEV determines the strength of DW by EV, mL and pL are the magnitude and probability associated with the left gamble's outcome with a larger EV, respectively, and mL′ is the magnitude associated with the left gamble's outcome with a smaller EV, as follows: pL * mL > (1 − pL) * mL′.
We also constructed three cross-option DW models (cross-option DW by magnitude, cross-option DW by probability, and cross-option DW by EV) to investigate how nonzero (or the better) outcomes of the gambles on each trial modulate the value of these gamble in the juice-gambling (respectively, token-gambling) task.
In all of the models with cross-option DW, the probability of selecting between the gambles was computed as follows (if the left gamble was assigned with the larger weight):
where DW determines the strength of DW between the two nonzero or better outcomes of the two alternative gambles based on one of the three alternative mechanisms: DW by magnitude; DW by probability; and DW by EV (Fig. 2d–i).
In the models with cross-option DW by magnitude (Fig. 2g), DW was multiplied by the value of the gamble with a larger magnitude outcome; for example, the left gamble, if ML > MR, where Mi denotes the larger magnitude outcome of each gamble. In the models with cross-option DW by probability (Fig. 2h), DW was multiplied by the value of the gamble with a larger probability outcome for which the magnitude was nonzero; for example, the left gamble, if PL > PR, where Pi denotes the larger probability outcome of each gamble. Finally, in the models with cross-option DW by EV (Fig. 2i), DW was multiplied by the value of the gamble with a larger EV outcome; for example, the left gamble, if mL * (1 − pL) > MR * pR, when mL * (1 − pL) and MR * pR are the EV of the larger EV outcomes of the two gambles.
Fitting procedure and data analyses.
To determine how monkeys constructed subjective value for risky options, we used various models to fit choice behavior during each gambling task; the best model revealed the most plausible mechanism for the construction of subjective value for a given monkey/task. Models were fitted to experimental data by minimizing the negative log likelihood of the predicted choice probability given different model parameters using the fminsearch function in MATLAB (The MathWorks). There are two main issues when comparing the goodness-of-fit between models with different number of parameters: more complex models could explain data better by virtue of having a greater number of parameters and models with more parameters could overfit the data such that the fitting is not generalizable to similar datasets. For these reasons, we fit choice behavior with different models based on a fivefold cross-validation method using parameters estimated from 80% of the data for a given monkey/task to predict choices on the remaining 20%. Importantly, cross-validation automatically deals with different numbers of model parameters because redundant parameters result in overfitting and thus do not add any explanatory power. Moreover, it has been shown that, in many cases, the cross-validation method provides an approximation to the Akaike information criterion (AIC), whereas the AIC does not address the overfitting issue. The cross-validation was done 50 times separately for data from each monkey in a given task.
In addition, we also fit choice behavior from each session of the experiment individually to capture the diversity of risk attitudes on different days of the experiment. For this analysis, we used the interquartile range rule to remove outlier sessions in terms of the estimated parameters. More specifically, we only included sessions that did not yield an outlier for any of the fitting parameters. This was done to ensure a reliable estimate for all the parameters in a given session. In the juice-gambling task, the exclusion criterion resulted in removal of 2% and 11% of sessions from the lower and upper outlier bounds, respectively. In the token-gambling task, this exclusion criterion resulted in removal of 4% and 12% of sessions from the lower and upper outlier bounds, respectively. Importantly, we obtained qualitatively similar results for session-by-session analyses even with the inclusion of outlier sessions.
To test whether our fitting procedure is able to distinguish between alternative models and identify the correct model and to estimate model parameters accurately, we simulated the aforementioned 16 models over a range of parameters estimated from monkeys' choice behavior in the two experiments. More specifically, we generated choice data for the juice-gambling task using the exponent of the utility function (ρ) ranging from 1 to 4, the probability distortion parameter (γ) ranging from 0.8 to 2, the differential-weighting factor (DW) ranging from 0.55 to 0.65, and the stochasticity in choice (σ) ranging from 0.5 to 10. In the token-gambling task, we generated choice data by adopting the following range for model parameters: [1, 2] for the exponent of the utility function between (ρ), [0.4, 1.2] for the loss aversion coefficient (λ), [0.8, 1.2] for the probability distortion parameter (γ), [0.55, 0.65] for the DW factor (DW), and [0.4, 1] for stochasticity in choice (σ). We then fit the simulated data with all the models to compute the goodness-of-fit (in terms of AIC) and to estimate model parameters. Because model parameters could take on very different values, we computed the error in estimation of model parameters using the relative value of each estimated parameter to its actual value. The average goodness-of-fit and estimation error were calculated by averaging the corresponding values over all fits based on all sets of parameters. Moreover, to account for the overall difficulty of fitting data generated with certain models, we rescaled AIC values across all models used to fit a given set of simulated data. This rescaling was done by first subtracting the minimum AIC value obtained by fitting a given set of data and then dividing the outcome by the difference between the maximum and minimum values of AIC for that set of data.
To test correlation between model parameters, we used two methods: the Hessian matrix and session-by-session values of fitting parameters. In the first method, we estimated correlations between model parameters numerically using the Hessian matrix for the base SU model and the SU model with DW at parameter values for which we obtained of best fit. The relationship between the matrix of correlation between model parameters and the Hessian matrix builds on the theorem that because the maximum likelihood estimator is asymptotically normal, the distribution of the maximum likelihood estimator (θ̂n) can be approximated by a multivariate normal distribution with a certain mean (θ0) and a covariance matrix , where n is the number of model parameters. This covariance matrix can be estimated by − E[∇ θθln(fX(X; θ0))]−1, where ∇ θθln(fX(X; θ0)) is the matrix of the second-order partial derivatives of the log-likelihood function or the Hessian matrix. As a result, the matrix of correlation between model parameters can be calculated from the inverse of the Hessian matrix. To estimate the Hessian matrix, we first computed the derivatives of the log likelihood with respect to model parameters to form the Jacobian matrix. Next, we calculated the derivative of the Jacobian matrix to compute the Hessian matrix of the cost function for fitting.
In the second method, we calculated the correlation between model parameters directly based on the estimated parameters across all sessions using the base SU model and the SU model with DW. Using session-by-session fitting parameters, we also calculated the correlation between model parameters of both models. The two methods for calculating correlation between model parameters yielded compatible results (see Results).
We also examined the likelihood surface of the model to calculate the error associated with the estimated parameters. We calculated variability in the estimate of negative log-likelihood function by computing the SD of this function, std(−LL), at the global minimum across many instances of cross-validation. We then calculated the order of magnitude (scale) of the error associated with estimated parameters using the eigenvector associated with the smallest eigenvalue of the Hessian matrix (as a measure of the direction with the minimum slope of log-likelihood surface) as follows:
 |
where λmin is the smallest eigenvalue and Vλmin is the corresponding eigenvector.
Finally, to quantify changes in the sensitivity to reward information as a function of the number of collected tokens (see Fig. 5), we fit the psychometric function using a sigmoid function and estimates indifference point (μ) and stochasticity in choice (σ) as follows:
 |
where p(left) is the probability of choosing the option on left and EVL and EVR are the EV of the left and right options, respectively.
Figure 5.

Monkeys' sensitivity to reward information increased with more collected tokens at the beginning of each trial. a, b, Each plot shows the probability of choosing the left gamble as a function of the difference in EVs of two gambles in a given trial separately for different numbers of collected tokens at the beginning of each trial (shown with different colors) and for individual monkeys. The inset plots the estimated indifference point (μ) and stochasticity in choice (σ) as a function of different numbers of collected tokens (Eq. 11). One and two stars indicate that the slope of regression line is significantly different from zero at p < 0.05 and p < 0.01, respectively (two-sided t test). The stochasticity in choice decreased with more collected tokens in both monkeys.
Statistical analysis.
MATLAB (The MathWorks) was used for all statistical analysis. Statistical comparisons of extracted model parameters within experiments were done using two-sided sign test. Statistical comparisons of extracted model parameters between experiments were done using the two-sided rank-sum test. Results were considered significant at p < 0.05. The reported effect sizes are Cohen's d values. All extracted model parameters are expressed as median ± interquartile range (IQR). The statistics for changes in the sensitivity of psychometric function as a function of number of collected tokens were obtained using linear regression.
Results
We used various computational models to analyze monkeys' choice behavior from two separate experiments in which subjects chose between two (gambles or safe) options offering either juice (juice-gambling task) or token (token-gambling task) rewards (Fig. 1). The juice-gambling task involved options with the possibility of one of three reward sizes or no reward, whereas options in the token-gambling task involved a mix of gain, loss, or no reward possibilities (see Materials and Methods).
Fitting procedure is able to identify the model used for simulating data correctly. (a) Plot shows the goodness-of-fit (in terms of the average AIC over a set parameters) for fitting choice data generated with a given model and fit with the same or different models (total 16 models) for the juice-gambling task. The models used to generate and fit data are indicated on the x- and y-axis, respectively. (b) The same as in (a), but the AIC values for data generated with a given model (each column) are rescaled by first subtracting the minimum AIC value obtained by fitting a given set of data and then dividing the outcome by the difference between the maximum and minimum values of AIC for that set of data. As a result, rescaled AIC values for each set of simulated data fall between 0 and 1. (c-d) The same as in (a-b) but for the token-gambling task. Overall, the same model used to generate a given set of data provided the best overall fit. Download Figure 2-1, TIF file (1.6MB, tif)
Fitting procedure is able to estimate model parameters accurately and with relatively small error. (a) Plotted is the average relative estimation error (i.e. the difference between the estimated and actual parameter values divided by the actual value) in fitting choice data generated with a given model and fit with the same or different models (total 16 models) for the juice-gambling task. The fit using the same model used to generate a given set of data provided unbiased estimates of model parameters. (b) Plotted is average of the absolute value of relative estimation error (as a more robust measure of variance in estimation error) in fitting choice data generated with a given model and fit with the same or different models. The variance in estimated parameters was the minimum for fit using the same model used to generate a given set of data. (c-d) The same as in (a-b) but for the token-gambling task. Download Figure 2-2, TIF file (1.5MB, tif)
Monkeys exhibit risk seeking and loss seeking
We first investigated whether the animals integrated information about reward magnitude and probability appropriately to select between gambles. To do so, we computed the probability of choosing the left gamble as a function of the difference between the EVs (i.e., reward probability times magnitude) of the left and right gambles (Fig. 3c,d). This analysis showed that all monkeys consistently selected the gamble with higher EV (81%, 84%, and 85% for monkeys B, C, and J in the juice-gambling task, respectively, and 79% and 74% for monkeys B and J in the token-gambling task, respectively; binomial test, p = 10−32). Moreover, psychometric functions plotted in Figure 3, c and d, provide strong evidence that all monkeys considered both length (probability) and color (magnitude) of gambles for making decisions.
Figure 3.

Standard and nonstandard evaluation of reward magnitude and probability according to prospect theory and the overall sensitivity of monkeys' choice behavior to the difference in EVs of gambles on each trial. a, Utility function quantifying the relationship between reward magnitude and SU. Plotted in blue is a hypothetical, standard utility function based on prospect theory with concave and convex curves for gains and losses, respectively. In contrast, the red curve shows a utility function that is convex for gains and losses, resulting in risk-seeking behavior for both gains and losses and thus violating the reflection effect. Parameters ρG and ρL are the exponents of the power law used to generate the utility curves for gain and loss domains, respectively. b, PW function quantifying the transformation of actual reward probability for making decisions. Plotted are several possible shapes of PW. Prospect theory predicts inverse-S-shaped weighting functions (blue curves). Parameter γ determines the curvature of the function. c, Psychometric functions in two monkeys during the juice-gambling task. Probability of choosing the left target is plotted as a function of the difference in EVs of two gambles in a given trial. The inset plots the probability (mean ± SEM) of choosing a sure option against a gamble with an equal EV (n = 32 trials) and the probability of choosing the less risky option in pairs of gambles with equal EVs (n = 717 trials). d, Same as c, but for the token-gambling task. The top inset plots the probability of choosing the sure option of one token against a gamble with an equal EV (n = 69 trials) and the probability of choosing the less risky option in pairs of gambles with equal EVs (n = 271 trials). The bottom inset plots the probability of choosing the sure option with no reward over a 50/50 gamble of winning and losing one (n = 55 trials) or two tokens (n = 62 trials).
To measure overall preference for risk and loss, we next examined choices between pairs of a safe option and a risky gamble with equal EV or between pairs of risky gambles with equal EVs. We found that, in both experiments, monkeys consistently selected the offer with the smaller reward probability and larger reward magnitude (i.e., the more risky option) over the one with the larger reward probability and smaller reward magnitude, indicating significant risk-seeking behavior (Fig. 3c,d, insets). Moreover, in the token-gambling task with gains and losses, monkeys consistently selected the 50/50 gambles with equal amounts of gains and losses over the sure option that did not deliver reward. This indicates that monkeys preferred to accept, rather than reject, gambles with loss and zero EV, signifying loss-seeking behavior (Fig. 3d, inset).
To better demonstrate that monkeys understood the task and incorporated information about both reward probability and magnitude, we calculated choice probability separately for each set of gambles with similar reward magnitudes as a function of the probability of reward for the larger magnitude outcomes of the two gambles or the only gamble when the competing choice option was a safe one (Fig. 4). This analysis showed that the probability of choosing a gamble increased as the probability of reward for its larger magnitude outcome increased, indicating that monkeys did incorporate the length of a given colored portion (i.e., reward probability) in their choices.
Figure 4.

Monkeys' choices were sensitive to reward probability during both tasks. a, Plotted is the probability of choosing a gamble versus sure option as a function of the probability of the nonzero reward outcome (medium or large) of the gamble during the juice-gambling task. Selection of the gamble increased monotonically as the probability of nonzero reward outcome increased. b, Each panel plots the probability of choosing a gamble with the nonzero reward outcome indicated on the x-axis as a function of the reward probability of the nonzero outcome of that gamble and the competing gamble (indicated on the y-axis) during the juice-gambling task. c, Same as b, but for the token-gambling task. Each panel plots the probability of choosing gamble 1 as a function of the reward probability of the larger magnitude outcome of gamble 1 (x-axis) and gamble 2 (y-axis) for a set of gambles with a specific pairs of reward magnitudes. As indicated in the inset, the outcome reward magnitudes of gamble 1 and gamble 2 are shown next to the x-axis and y-axis, respectively. Gamble 1: M1, P1; m1, 1 − P1; gamble 2: M2, P2; m2, 1 − P2. Overall, the probability of choosing a gamble increased as the probability of reward for its larger magnitude outcome increased, indicating the sensitivity of monkeys to reward probabilities provided by the length of different portions of each bar.
Finally, we investigated whether monkeys understood the structure of the token-gambling task and were sensitive to the information about collected tokens that was presented at the bottom of the screen. We reasoned that, if monkeys understood this information, then they would necessarily show systematic changes in behavior as a function of token number; for example, they would exhibit more motivation to perform the task as the number of tokens grows and the probability of winning a jackpot reward immediately increases. To test this, we calculated psychometric functions separately for different numbers of collected tokens at the beginning of each trial (Fig. 5). The psychometric function measures the preference between each pair of gambles as a function of the difference in EVs of gambles and thus reflects the sensitivity of the animal to the presented information (Eq. 11). We found that both monkeys became less stochastic (smaller σ corresponding to a steeper psychometric function) in their decisions or equivalently more sensitive to the presented information, as they gathered more tokens (p = 0.04 for Monkey B and p = 0.0003 for Monkey J; two-sided t test). This result reflects higher levels of motivation in performing the task and supports the premise that monkeys can use the token information as a symbolic scoreboard of future rewards.
Monkeys exhibit convex utility curves for both gains and losses and a task-dependent S-shaped PW
Our subjects' overall risk-seeking and loss-seeking behavior suggests utility and PW functions different from those predicted by prospect theory. More specifically, there are three main characteristics that describe the core risk attitudes of humans in prospect theory (Kahneman and Tversky, 1979). First, the utility curve is concave for gains but convex for losses, indicating risk aversion and risk-seeking behavior for gains and losses, respectively (Fig. 3a, blue curve). The opposing risk attitudes for gains and losses is known as the reflection effect. Second, the slope of the utility curve for losses is steeper than the one for gains. This pattern produces loss aversion, the tendency for losses to have a more negative impact on subjective value than equivalent gains. Third, the PW function has an inverse S-shape, resulting in overweighting of the value of options with small reward probability and underweighting of options with large reward probability (Fig. 3b, blue curve). To assess risk attitudes in monkeys directly based on prospect theory, we first used four base models to fit choice behavior and estimated utility and PW functions in each of the two experiments (see Materials and Methods). The behavior that we observed in our subjects better fits the red curves in Figure 3, a and b, where a convex curve for gains as well as losses explains risk-seeking behavior in both domains and the PW function (where significant) is S-shaped, suggesting that subjects underweight options with a low probability and overweight options with a high probability. We examine these behavioral patterns in detail below.
Fitting choices based on cross-validation showed that the SU model (the model with nonlinear utility and PW functions) provided the best fit in the juice-gambling task (Fig. 6a). Session-by-session estimates of the utility functions based on this model revealed a convex utility function (Fig. 6b, Table 1). This convexity was reflected in the median of the exponent of the utility curve (ρG; see Eq. 4 in Materials and Methods) being larger than 1 (median ± IQR = 2.95 ± 0.94, two-sided sign test; p = 6.3 × 10−28, d = 3.15, N = 146). Monkeys also exhibited a prominent S-shaped PW function (Fig. 6c) reflected in the distortion parameter (γ; see Eq. 5 in Materials and Methods) being larger than 1 (median ± IQR = 1.57 ± 0.76, two-sided sign test; p = 3.5 × 10−14, d = 1.13, N = 146). Importantly, these results were not model specific because fitting based on the models with either a nonlinear utility function (EU) or the PW function (EV+PW) also produced convex utility curves (ρG median ± IQR = 2.57 ± 0.57, two-sided sign test; p = 2.3 × 10−28, d = 3.59, N = 146; Fig. 6d) or a prominent S-shaped PW (γ median ± IQR = 2.50 ± 1.68, two-sided sign test; p = 3.7 × 10−14, d = 0.87, N = 146; Fig. 6-1a, respectively.
Figure 6.

Fitting of choice behavior reveals a task-dependent pattern of risk attitudes different than what is predicted by prospect theory. a, Comparison of the goodness-of-fit for choice behavior during the juice-gambling task using four different models of subjective value: EV, EV+PW, EU, and SU. Plotted is the average negative log likelihood (−LL) per trial over all cross-validation instances (a smaller value corresponds to a better fit). The SU model provided the best fit. b, Estimated utility function based on the SU model as a function of the reward juice. Each curve shows the result of the fit for one session of the experiment; the thick magenta curve is based on the median of the fitting parameter. The dashed line is the unity line normalized by 100 μL. The insets show the distribution of estimated parameters for the utility curve for gains (ρG). The dashed lines show the medians and a star indicates that the median of the distribution is significantly different from 1 (two-sided sign test; p < 0.05). c, Estimated PW function based on the SU model. The inset shows the distribution of estimated parameters for the PW function (γ). The dashed line is the unity line. Subjects exhibited a pronounced S-shaped PW function. Figure 6-1) shows consistent results for fitting based on the EV+PW model. d, Estimated utility function based on the EU model. Conventions are the same as in b. e–h, Same as a–d, but for the token-gambling task. The EU and SU models provided the best fits and subjects exhibited a slightly S-shaped PW function based on the SU model. The reward magnitude in this task corresponds to the juice equivalent of a given number of tokens. The insets in f show the distribution of estimated parameters for the utility curves in the gain domain (ρG) and loss domain (ρL), as well as the loss aversion coefficient (λ). On average, subjects exhibited a convex utility function for both gains and losses and thus were loss seeking and violated the reflection effect.
Table 1.
Summary of the estimated risk preference parameters during the juice-gambling task
| SU with cross-option DW by magnitude | SU | EU | EV + PW | |
|---|---|---|---|---|
| ρG | 1.74 ± 1.00 | 2.95 ± 0.94 | 2.57 ± 0.57 | N/A |
| γ | 1.55 ± 0.78 | 1.57 ± 0.76 | N/A | 2.50 ± 1.68 |
Reported are medians ± IQR of the distribution of estimated parameters in a given model.
N/A, Not applicable.
Estimated utility and probability weighting functions based on the EV+PW model. (a) Estimated probability weighting function based on the EV+PW model for the juice-gambling task. Each curve shows the result of the fit for one session of the experiment and the thick green curve is based on the median of the fitting parameter. The dashed line is the unity line. The inset shows the distribution of estimated parameters for the probability weighting function (γ). The dashed lines show the medians, and a star indicates that the median of the distribution is significantly different from 1 (two-sided sign-test; p < 0.05). (b) The same as in (a) but for the token-gambling task. Download Figure 6-1, TIF file (284.3KB, tif)
We next examined choice behavior during the token-gambling task. Fitting choice based on cross-validation showed that the EU and SU models provided the best fit for choice during this task (Fig. 6e). Fits for the two models were nearly equal, suggesting that inclusion of the PW function did not improve the fit and thus the absence of any probability distortion. Session-by-session estimates of the utility functions based on the SU model revealed that monkeys adopted a convex utility function for both gains and losses (Fig. 6f, Table 2). This convexity was reflected in the median of the exponent of the gain utility curve being larger than 1 (median ± IQR = 1.58 ± 0.51, two-sided sign test; p = 2.7 × 10−24, d = 1.59, N = 140; Fig. 6f, bottom inset), and the median of the exponent of the loss utility curve (ρL; see Eq. 4 in Materials and Methods) being smaller than 1 (median ± IQR = 0.64 ± 1.02, two-sided sign test; p = 1.0 × 10−4, d = 0.25, N = 140). In addition, monkeys were loss seeking: the loss aversion coefficient (λ; see Eq. 4 in Materials and Methods) was significantly smaller than 1 (median ± IQR = 0.46 ± 0.84, p = 3.3 × 10−9, d = 0.56, N = 140; Fig. 6f, top inset). Finally, monkeys exhibited a slightly S-shaped PW function (γ median ± IQR = 1.14 ± 0.37, two-sided sign test; p = 5.7 × 10−5, d = 0.57, N = 140; Fig. 6g). This result is consistent with the finding that the PW function did not improve the fit in the token-gambling task (Fig. 6e).
Table 2.
Summary of the estimated risk preference parameters during the token-gambling task
| SU with within-option DW by magnitude | SU | EU | EV + PW | EV | |
|---|---|---|---|---|---|
| ρG | 1.43 ± 0.46 | 1.58 ± 0.51 | 1.49 ± 0.49 | N/A | N/A |
| ρL | 0.48 ± 0.73 | 0.64 ± 1.02 | 0.55 ± 1.05 | N/A | N/A |
| λ | 0.58 ± 1.51 | 0.46 ± 0.84 | 0.46 ± 0.84 | N/A | (βL/βG) 0.13 ± 0.17 |
| γ | 1.11 ± 0.4 | 1.14 ± 0.37 | N/A | 1.48 ± 0.58 | N/A |
Reported are medians ± IQR of the distribution of estimated parameters in a given model.
N/A, Not applicable.
As with the juice-gambling task, these results were not model specific: fitting based on the models with either a nonlinear utility function (EU) or the PW function (EV+PW) produced a qualitatively similar pattern of risk preference for the token-gambling task. More specifically, parameter estimates of the utility function based on the EU model showed convex utility curves for both gains and losses that were steeper for the gain than the loss domain (Fig. 6h, Table 2). This was reflected in: the median of ρG being larger than 1 (median ± IQR = 1.49 ± 0.49, two-sided sign test; p = 1.2 × 10−23, d = 1.50, N = 140; Fig. 6h, bottom inset); the median of ρL being smaller than 1 (median ± IQR = 0.55 ± 1.05, two-sided sign test; p = 4.5 × 10−4, d = 0.34, N = 140); and the median of λ being significantly smaller than 1 (median ± IQR = 0.46 ± 0.84, two-sided sign test; p = 3.4 × 10−8, d = 0.69, N = 140; Fig. 6h, top inset). Finally, parameter estimates of the PW function based on the EV+PW model revealed an S-shaped weighting function (γ median ± IQR = 1.48 ± 0.58, two-sided sign test; p = 3.2 × 10−16, d = 1.16, N = 140; Fig. 6-1b). Together, these results show that the observed shape of the estimated utility and PW functions were general and not model specific.
We also considered the possibility that the observed loss-seeking behavior was caused by monkeys not considering losing a token as a real loss because, in each trial, they were provided with a small “motivation” reward regardless of the outcome of the gamble (see Materials and Methods). To test for this possibility, we fit choice behavior with four base models similar to those used above with the difference that a loss of two and one tokens were considered as zero loss or a gain of one token, respectively. The goodness-of-fit based on these models did not reach those of the models in which losing any token was considered as loss (Fig. 7). This result strongly suggests that monkeys treated losing tokens as a genuine loss and thus the observed loss seeking was not due to a shift in the reference point.
Figure 7.

Observed loss-seeking behavior was not due to a shift in the reference point. a, Comparison of the goodness-of-fit for choice behavior during the token-gambling task using four different models of subjective value in which a loss of two and one tokens were considered as zero loss or gain of one, respectively, due to the small “motivation” reward (equivalent to two tokens) provided in each trial. Conventions are the same as in Figure 6. Dashed line indicates the average negative log likelihood (−LL) for the best model that considers losing any token as a loss (correspond to the cyan and magenta bars in Fig. 6e). The EU model provided the best fit, but its goodness-of-fit was worse than the best model that considered losing any token as a loss. b, Estimated utility function based on the SU model as a function of the reward juice. Each curve shows the result of the fit for one session of the experiment; the thick magenta curve is based on the median of the fitting parameter. The dashed line is the unity line normalized by 100 μL. The insets show the distribution of estimated parameters for the utility curve for gains (ρG). The dashed lines show the medians and a star indicates that the median of the distribution is significantly different from 1 (two-sided sign test; p < 0.05). c, Estimated PW function based on the SU model. The inset shows the distribution of estimated parameters for the PW function (γ). The dashed line is the unity line.
Finally, we compared the estimated utility and probability functions in the two experiments. The utility function for gains was significantly more convex in the juice-gambling task than in the token-gambling task (comparison of ρG values, two-sided Wilcoxon rank-sum test; p = 7.4 × 10−37, d = 2.75, N = 284). Crucially, this difference was significant even for each of the two monkeys who performed both experiments (Monkey B: p = 1.3 × 10−21, d = 3.81, N = 140, Monkey C: p = 1.0 × 10−8, d = 2.24, N = 93; Fig. 8a,c). The PW function was more distorted in the juice-gambling task than in the token-gambling task (comparison of γ values, two-sided Wilcoxon rank-sum test; p = 3.5 × 10−10, d = 0.96, N = 284). This pattern held true for each of the two monkeys that performed both experiments as well (Monkey B: p = 4.9 × 10−6, d = 1.04, N = 140, Monkey C: p = 0.02, d = 0.63, N = 93; Fig. 8b,d).
Figure 8.
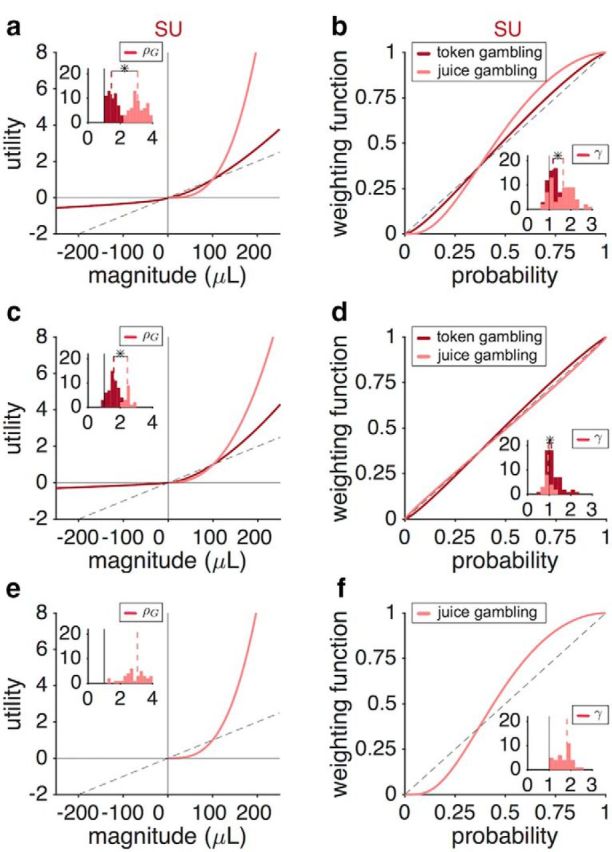
Different utility and PW functions in the two tasks in individual monkeys. a, Estimated utility functions based on the SU model in the juice-gambling and token-gambling tasks. Plot shows the utility curves based on the median of the fitting parameter in the juice (pink) and token (magenta) gambling tasks for monkey B. The dashed line is the unity line normalized by 100 μL. The insets show the distributions of estimated parameters for the utility curve for gains (ρG) in the two tasks. The dashed lines show the medians and a star indicates that the medians of the two distributions are significantly different (two-sided Wilcoxon rank-sum test; p < 0.05). b, Estimated PW function based on the SU model in the two tasks. Plot shows the PW functions based on the median of the fitting parameter in the two tasks for monkey B. The dashed line is the unity line. The insets show the distribution of γ values in the two tasks. c, d, Same as a and b, but for monkey J. Both monkey B and J exhibited a much steeper utility curve in the juice-gambling task. Although both monkeys exhibited different probability distortion in the two tasks, this effect was stronger in monkey B. e, f, Same as in a and b, but for Monkey C, which only performed the juice-gambling task. The overall behavior of monkey C was similar to that of monkey B in the juice-gambling task.
These findings show that risk attitudes, especially in terms of the curvature of the utility function, are flexible and task dependent. To further explore potential mechanisms underlying this flexibility, we next examined additional components involved in the construction of subjective value that could account for some of the observed differences in risk attitudes during the two tasks.
DW can partially account for the difference in utility functions across experiments
To explore additional factors that could influence the construction of subjective value and choice, we considered two sets of mechanisms for weighting possible outcomes. First, we hypothesized that the two gamble outcomes could be weighted differently before they are combined to form the overall subjective value. In other words, the two possible outcomes of a given gamble compete to influence the overall gamble value. To test this hypothesis, we considered three possible “within-option” DW mechanisms by which the gamble outcome with a larger reward magnitude, reward probability, or EV could influence the overall value more so than the alternative outcome (see Materials and Methods and Fig. 2a–c for more details). Second, we hypothesized that, when comparing two gambles, the value of the better outcome of each gamble could influence its overall value relative to the other gamble. To test this hypothesis, we considered alternative “cross-option” DW mechanisms based on the magnitude, probability, or EV of the better outcome in each gamble (see Materials and Methods and Fig. 2d–i for more details). We used all of these models to fit choice behavior in the two experiments.
We found that the SU model with cross-option DW based on reward magnitude provided the best fit in the juice-gambling task (Fig. 9a). To study the contribution of DW to flexible risk attitudes, we next compared the session-by-session estimates of the DW factor (see Materials and Methods) and risk preference parameters based on the SU model with and without DW. This analysis revealed a strong DW of the two gambles based on reward magnitude of the better outcome (DW factor median ± IQR = 0.63 ± 0.18, two-sided sign test; p = 1.1 × 10−26, d = 1.30, N = 146; Fig. 9d) corresponding to ∼102% larger weight for the value of the gamble with the larger magnitude relative to the other gamble. More importantly, the estimated utility function was less steep in the SU model with DW than in the SU model without DW (ρG median ± IQR = 1.74 ± 1.00 and 2.95 ± 0.94 for the model with and without DW, respectively; two-sided sign test; p = 1.1 × 10−15, d = 1.18, N = 146; Figs. 9b, 10a). This finding suggests that DW accounts for some portion of behavior that, unless modeled explicitly, results in an overestimation of the convexity of the SU function. However, there was no difference between probability distortion estimates based on the model with and without DW (γ median ± IQR = 1.55 ± 0.78 and 1.57 ± 0.76 for the model with and without DW, respectively; two-sided sign test, p = 0.12, d = 0.17, N = 146; Figs. 9c, 10b), suggesting that DW may not influence estimates of this function, at least not in this task.
Figure 9.

DW of gamble outcomes can account for part of the convexity of the utility functions. a, Comparison of the goodness-of-fit for choice behavior during the juice-gambling task using four different models for the construction of reward value for each possible outcome (convention the same as in Fig. 6) and three different types of DW mechanisms (cross-opt: cross-option). Plotted is the average negative log likelihood (−LL) per trial over all cross-validation instances (a smaller value corresponds to a better fit). Overall, the SU model with cross-option DW by magnitude provided the best fit in the juice-gambling task. Dashed line indicates the average −LL for the best model without DW. b, c, Distributions of the estimated parameters for the utility (b) and PW function (c) using the SU model with DW. The black dashed lines show the medians and a black star indicates that the median of a given distribution is significantly different than 1.0 in b and c and 0.5 in d (two-sided sign test; p < 0.05). The blue dashed line shows the median of the best model without DW (the same medians as in Fig. 6b,c). A blue star indicates that the estimated parameter was significantly different between the best models with and without DW (two-sided sign-rank test; p < 0.05). DW can account for part of the convexity of the utility function because the model with this mechanism is less convex. d, Distribution of estimated DW factors using the SU model with DW. There was a significant DW in favor of the gamble with the larger reward magnitude. e–h, Same as a–d, but for the token-gambling task. Overall, the EU and SU with within-option DW by magnitude models provided the best fit. Moreover, all models with cross-option DW by magnitude were provided worse fits than corresponding models with within-option DW.
Figure 10.

Estimated utility and PW functions for the SU model with DW by reward magnitude. a, b, Estimated utility function (a) and PW function (b) based on the SU model with within-option DW by magnitude for the juice-gambling task. Each curve shows the result of the fit for one session of the experiment and the thick red curve is based on the median of the fitting parameter. For comparison, the black curves show the utility function (a) and PW functions (b) based on the SU model without DW. The PW curves are indistinguishable in the two models. The dashed line is the unity line normalized by 100 μL in a and the unity line in b. c, d, Same as a and b, but for the token-gambling task using the SU model with cross-option DW.
In contrast to the juice-gambling task, models with within-option DW provided better fit compared with models with cross-option DW in the token-gambling task (cf. bottom and top four bars in Fig. 9e). Overall, the EU and SU models with within-option DW based on reward magnitude provided the best fit among all models with DW. The improvement of fit based on these models relative to the best models without DW (base EU and SU models) was minimal (Fig. 6e). These results indicate that DW did not strongly influence choice behavior in the token-gambling task. Nevertheless, the session-by-session estimate of the DW factor in the SU with DW model revealed a significant effect of DW on valuation; DW factors were significantly larger than 0.5 (median ± IQR = 0.57 ± 0.22; two-sided sign test; p = 2.3 × 10−7, d = 0.67, N = 140; Fig. 9h), corresponding to ∼33% larger weight for the value of the outcome with the larger magnitude relative to the outcome with the smaller reward magnitude.
Moreover, the utility functions for both gains and losses were less steep in the SU model with DW than in the SU model without DW (Figs. 9f, 10c, Table 2). The estimated exponents of the utility function for gains (ρG) were significantly smaller after considering DW (median ± IQR = 1.43 ± 0.46 and 1.58 ± 0.51 for the model with and without DW, respectively; two-sided sign test; p = 1.3 × 10−4, d = 0.52, N = 140). Similarly, the estimated exponents of the utility function for losses (ρL) were significantly smaller after considering DW (median ± IQR = 0.48 ± 0.73 and 0.64 ± 1.02 for the model with and without DW, respectively; two-sided sign test; p = 0.048, d = 0.17, N = 140). The estimated loss aversion coefficients, however, were larger in the model with DW (λ median ± IQR = 0.58 ± 1.51 and 0.46 ± 0.84 for the model with and without DW, respectively; two-sided sign test; p = 9.1 × 10−6, d = 0.23, N = 140) corresponding to more loss seeking in this model. Finally, the PW function was slightly less distorted in the model with DW (γ median ± IQR = 1.11 ± 0.40 and 1.14 ± 0.37 for the model with and without DW, respectively; two-sided sign test; p = 9.1 × 10−6, d = 0.32, N = 140; Figs. 9g, 10d). These results demonstrate that within-option DW can account for some of the observed convexity of the utility functions in the token-gambling task.
To demonstrate that our fitting procedure can actually distinguish between alternative models and identify the correct model and to estimate model parameters accurately, we generated choice data using all the presented models and over a wide range of model parameters and subsequently fit the simulated data with all of the models (see Materials and Methods). We found that data generated with certain models were easier to fit than other models. For example, models without DW were in general easier to fit and, within a given family of models, data generated with models with nonlinear utility functions (EU and SU) were easier to fit (Fig. 2-1a,c. Nevertheless, the same model used to generate a given set of data provided the best overall fit (Fig. 2-1b,d. We also computed the relative estimation error (i.e., difference between the estimated and actual parameters after normalizing each estimated parameter by its actual value; see Materials and Methods) and found that fitting based on the model used to generate a given set of data provided an unbiased estimate of model parameters (Fig. 2-2a,c). Moreover, we found the minimum value of the average absolute estimation error (as a more robust measure of variance in estimation error) for the same model used to generate a given set of data (Fig. 2-2b,d). Together, these results demonstrate that our fitting method is able to identify correctly the model used to generate a given set of data and thus can distinguish between the alternative models. In addition, our fitting yields unbiased estimates of model parameters with relatively small error.
These results illustrate that DW could account for part of the observed convexity of the utility function in both experiments. Interestingly, the amount of change in the convexity after including DW was larger in the juice-gambling task than in the token-gambling task (juice task: ΔρG median ± IQR = −1.09 ± 1.52; token task: ΔρG median ± IQR = −0.09 ± 0.20; two-sided Wilcoxon rank-sum test, p = 1.8 × 10−21, d = 1.55, N = 284), making the utility functions more similar after the inclusion of DW (Fig. 11a). We did not observe similar changes in the estimates of probability distortion parameters after the inclusion of DW (juice task: Δγ median ± IQR = 0.02 ± 0.13; token task: Δγ median ± IQR = −0.03 ± 0.10; two-sided Wilcoxon rank-sum test, p = 0.27, d = 0.45, N = 284; Fig. 11b). These results demonstrate that the DW mechanisms can partially account for the observed difference in utility function across the two tasks. Moreover, they explain how such additional mechanisms enable flexible risk attitudes according to the task.
Figure 11.

Comparison of the estimated utility and PW functions in the juice-gambling and token-gambling tasks based on the SU model with DW. a, Estimated utility functions based on the best SU model with DW in the juice-gambling and token-gambling tasks. Plot shows the utility curves based on the median of the fitting parameter in the juice (pink) and token (magenta) gambling tasks. The dashed line is the unity line normalized by 100 μL. The insets show the distributions of estimated parameters for the utility curve for gains (ρG) in the two tasks. The dashed lines show the medians. There was a small but significant difference between the two distributions (two-sided Wilcoxon rank-sum test; p < 0.05). b, Estimated PW function based on the SU model with DW in the juice-gambling and token-gambling tasks. Plot shows the PW functions based on the median of the fitting parameter in the two tasks. The dashed line is the unity line. Other conventions are the same as in a. The star indicates that the medians of the two distributions are significantly different (two-sided Wilcoxon rank-sum test; p < 0.05). Correlations between estimated model parameters are plotted in Figure 11-1 and Figure 11-2 and errors in the estimation of model parameters are shown in Figure 11-3.
Correlation between model parameters using the inverse of the Hessian matrix. The matrix of correlation coefficients between a given model parameters is calculated from the inverse of the Hessian matrix. (a-b) Color of each square indicates the correlation coefficient between each pair of parameters for the SU (a) and the SU with DW models (b) during the juice-gambling task. Correlation coefficients are reported for values larger than 0.1 or smaller than -0.1 only. (c-d) The same as in (a-b) but for the token-gambling task. Download Figure 11-1, TIF file (373.3KB, tif)
Correlation between model parameters using session-by-session estimates. For each model and between the pair of models, the matrix of correlation coefficients between model parameters is calculated using estimated model parameters in each session. (a-c) Color of each square indicates the correlation coefficient between each pair of parameters of the SU model (a), the SU with DW models (b), and between the parameters of the two models (c) during the juice-gambling task. Correlation coefficients are only reported for statistically significant values (p < .05, using Bonferroni correction to adjust critical p-value in each panel). (d-f) The same as in (a-c) but for the token-gambling task. Download Figure 11-2, TIF file (677.8KB, tif)
Error in the values of estimated parameters in the best models with and without differential weighting. (a) The left column shows the minimum eigenvalue and the corresponding eigenvector for the SU model in the juice-gambling task. The right column shows the estimated percent error for each model parameter. (b) The same as in (a) but for the SU model with differential weighting. (c-d) The same as in (a-b) but for the token-gambling task. Download Figure 11-3, TIF file (505.1KB, tif)
We also calculated the correlations between the estimated parameters of the best models (the SU models with and without DW) to test whether some of the observed effects of DW could be captured by changes in other parameters. We calculated these correlations using two different methods: the Hessian matrix and session-by-session values of fitting parameters (see Materials and Methods). These analyses revealed that, in both models, the exponent of utility function power law (ρG) and the stochasticity in choice (σ) were significantly correlated with each other, indicating that a larger amplification of reward magnitude by the utility function can be offset with a larger value for the stochasticity in choice (Fig. 11-1, and Fig. 11-2). This correlation could be evidence for normalization in value construction. In addition, we found that, in the SU model with DW, the DW factor was significantly correlated with ρG and σ. Moreover, in the juice-gambling task, the DW factor was significantly correlated with ρG and to a lower extent with σ. In the token-gambling task, we also found a correlation between DW and σ and between DW and the loss aversion coefficient (λ). It is worth noting that the observed correlations should not be concerning for the interpretation of best-fitting models because we used cross-validation for identifying those models. Cross-validation would reveal if any of the fitting parameters in our best models were redundant.
One possible concern could be that because of the correlation between ρ and σ, some of the observed change in ρ (i.e., the convexity of the utility function) between the two tasks could be caused by changes in σ and not DW. To rule out such possibility, we defined a single quantity for measuring the effect of reward magnitude on choice behavior equal to xρG/σ (and λxρL/σ for losses), where x is one of the possible reward magnitudes. The value of xρG/σ determines the influence of reward magnitudes on choice in a given model considering the stochasticity in choice in that model. We then computed the distributions of xρG/σ for the best models with and without DW and found that xρG/σ (and λxρL/σ) values were significantly larger in the SU with DW model (two-sided sign test; juice task: p = 7.4 × 10−24, 4.9 × 10−23, 4.9 × 10−23; d = 1.98, 2.28, 2.13, for small, medium, and large rewards, respectively; N = 146; token task: p = 5.7 × 10−26, 1.1 × 10−22, 5.7 × 10−26, 5.7 × 10−26, 4.0 × 10−25; d = 0.23, 0.41, 1.74, 1.58, 1.33; for −1, −2, 1, 2, and 3 tokens, respectively; N = 140; Fig. 12). These results show that, despite correlations between DW and ρG and σ, DW results in enhanced value of reward magnitude relative to the stochasticity in choice. This indicates that DW of possible outcomes based on the magnitude increases the overall effect of magnitude on choice and thus can capture some of risk-seeking behavior that is otherwise attributed to the convexity of the utility function.
Figure 12.

DW of possible outcomes enhances the overall effect of magnitude on choice. a, b, Distribution of estimated values of stochasticity in choice (σ) during the juice-gambling task (a) and the token-gambling task (b). The SU models with and without DW are shown in blue and black, respectively. The dashed lines show medians and a blue star indicates that the medians of two distributions are significantly different from each other (two-sided sign test; p < 0.05). The stochasticity in choice was significantly smaller in the SU with DW model. c, Distributions of xρ/σ values for small, medium, and larger rewards during the juice-gambling task. d, e, Distribution of λxρL/σ values for loss tokens (d) and xρG/σ values for gain tokens (e) during the token-gambling task. In all cases, the xρ/σ values were significantly larger in the SU with DW model, indicating that DW of possible outcomes based on the magnitude increases the overall effect of magnitude on choice.
Finally, we also examined the likelihood surface of the best models to calculate the error associated with the estimated parameters. Overall, we found small errors in the estimation of model parameters, expect for a few parameters that were correlated with other parameters: σ in the SU with DW model in the juice-gambling task, ρL in the SU model in the token-gambling task, and ρL and λ in the SU with DW model in the token-gambling task (Fig. 11-3). Importantly, estimation errors in these parameters do not affect our results.
Discussion
Flexible risk attitudes in monkeys
We investigated risky choices in monkeys performing two different gambling tasks: a token-gambling task (with both gains and losses) and a juice-gambling task (with gains only). Fitting choice behavior with alternative models revealed convex utility curves for both the gain and loss domains, a pattern that is inconsistent with the reflection effect. Macaques thus deviated from humans and capuchins (Lakshminarayanan et al., 2011; Santos and Rosati, 2015). Moreover, our monkeys showed a steeper utility curve for gains than for losses, making them loss seeking; a deviation from the loss aversion observed in humans and capuchins (Chen et al., 2006). Finally, monkeys showed a prominent S-shaped PW function in the juice-gambling task and nearly linear (albeit slightly S-shaped) PW in the token-gambling task. These patterns deviate from each other, from previous human studies, and from rhesus macaques in two other studies (Yamada et al., 2013; Stauffer et al., 2015).
Together, our results challenge the idea that rhesus monkeys have a fixed and stable set of risk attitudes that are consistent across tasks. This variety in responses to risk challenges the idea that these risk attitudes have not changed since the time of our most recent ancestor. Instead, our results support an alternative view in which natural selection in the primate order has led to robust cognitive flexibility. This flexibility, presumably, would prevent us from having risk attitudes that are so ingrained that we would fail to adjust our utility curves or PW rapidly to changing task conditions. In contrast, the flexibility requires mechanisms that can be adjusted to the task at hand; for example, different utility and PW functions for different tasks.
Neural mechanisms of flexibility in risk attitudes
A major goal of neuroeconomics has been to understand how our responses to uncertainty are determined by, presumably, specially dedicated neural mechanisms. It is often assumed that risk attitudes are stable and that the goal of neuroeconomics is thus to understand how relevant neural operations lead to these preferences. Our work points to a different possibility: if preferences are not stable, then the neural processes that produce them may be similarly flexible. Indeed, our results suggest a somewhat different desideratum: that neuroeconomics ought to focus on how the brain regulates risk attitudes in response to context and adjusts them rapidly and adaptively when demands change. More broadly, and more speculatively, our findings suggest that risk attitudes may be seen as a consequence of general neural mechanisms that support rapid adjustment, presumably in contexts divorced from risk, rather than of a special and dedicated uncertainty module in the brain. Our results point to attentional modulation as a plausible mechanism (see below). All of these results are relevant for future studies into neural mechanisms of value computations and how they are adjusted.
Standard approaches to modeling choice, especially in the neural domain, hold that different prospective outcomes of a single offer are weighted equally in evaluation (i.e., after all, the normative strategy as well as the simpler one). It is surprising then that our results point to two types of DW based on reward magnitude: a within-option weighting for outcomes within a risky option and a cross-option weighting for the two options. These findings can be explained by the idea that the weighting processes that determine value are biased by the greater attentional weight assigned to some prospects (Busemeyer and Townsend, 1993; Roe et al., 2001; Shimojo et al., 2003; Hayden and Platt, 2007; typically the more salient outcomes, Hayden et al., 2008; Ludvig et al., 2014). In the juice-gambling task, in which there is only one nonzero outcome per gamble, competitive DW occurs between the two gambles, perhaps via spatial attention. In the token-gambling task, in which there could be two nonzero outcomes in each gamble, the competitive DW occurs within a gamble, perhaps via feature-based attention. Even though models with a DW mechanism only minimally improved the quality of fit in this task, the result of the comparison of fitting parameters indicates that this mechanism can account for part of the convexity of the utility function. Our results therefore illustrate how attentional mechanisms can influence economic decisions and make them more flexible. Empirically, modeling the influence of attention on evaluation is essential because some of the variance attributed to utility curves may actually reflect DW instead. Traditional approaches that do not take this possibility into account may overestimate the convexity of the utility function.
Stable versus constructed values and comparison with previous studies
One tradition in behavioral economics holds that preferences are constructed at the time of elicitation and do not reveal stable values (Lichtenstein and Slovic, 2006). The set of computations involved in preference construction include, not only a value function, but also editing, reference dependence, reweighting, and so on. Our results appear to be consistent with this view. These patterns are not likely to be restricted to the domain of risk; they are also consistent, for example, with an emerging body of work showing that preferences in the time domain are highly dependent on seemingly irrelevant contextual factors (Stephens and Anderson, 2001; Pearson et al., 2010; Blanchard and Hayden, 2015; for review, see Hayden, 2016). Together, these results suggest that both risky and temporal preferences are constructed in animals and thus extend the concept of preference construction beyond humans.
We have argued previously that, when playing fast repeated gambles for small amounts, monkeys are more likely to focus on the win than on the loss (Hayden and Platt, 2007; Heilbronner et al., 2009; Hayden et al., 2010) and that humans may do the same when confronted with those contexts (Hayden and Platt, 2009). Our results here provide three pieces of evidence for this argument. First, a convex utility curve that became steeper from losses to gains showed how larger wins were valued more. Second, we found a strong DW based on reward magnitude across gambles in the juice-gambling task, indicating that, indeed, a larger win strongly influenced the behavior. Third, in the task with both gains and losses (token-gambling task), monkeys again differentially weighted possible outcomes of each gamble based on reward magnitude.
One factor that could explain the shape of the PW function is the difference between description and experience in communicating the properties of the gamble (Hertwig et al., 2004; Hertwig and Erev, 2009; Ludvig and Spetch, 2011; Camilleri and Newell, 2013). Humans, like our monkeys, exhibit S-shaped curves in experienced gambles. It may be that monkeys in our tasks treated the gambles as more experienced-like than described-like, especially in the juice-gambling task, in which we used a much higher resolution for reward probability (0.02 vs 0.2 in the juice vs token task, respectively). Monkeys could trust a larger set of reward probabilities less and therefore rely more on experience to evaluate corresponding gambles. Reliance on experience is a useful strategy for tackling reward uncertainty (Farashahi et al., 2017). In a recent study showing an inverse S-shape for probability distortion in monkeys, only six values of reward probability were used, which could have made the gambles act as described previously (Stauffer et al., 2015). Note also that, in that study, only one value for the reward magnitude was used in gambles. This limitation could result in degeneracy in fitting solutions, causing the inverse-S-shaped PW to absorb some the convexity of the utility function.
Ultimately, these results serve as a testament to the cognitive flexibility and adaptiveness of rhesus monkeys, which are among the most successful primate species (Strier, 2016). Indeed, the success of the rhesus macaque is in part attributable to its ability to adjust to changing environments, including an omnivorous diet and a willingness to live in a variety of climates, ranging from warm to cold and locations in both city and country. That is, regardless of the dietary richness of the environment in which they evolved, rhesus monkeys have thrived because they can adjust to new environments rapidly. Therefore, in our view, it should not be surprising that they do not have a stable set of risk attitudes. It remains an open question how these ideas relate to species with narrower niches.
Footnotes
This work is supported by the National Science Foundation (CAREER Award BCS1253576 to B.H. and EPSCoR RII Track-2 FEC Grant to A.S.) and the National Institutes of Health (Grant R01 DA038615 to B.H.). We thank Meghan Castagno, Marc Mancarella, and Caleb Strait for assistance with data collection and Rei Akaishi, Ben Eisenreich, Clara Guo, Daeyeol Lee, and Katherine Rowe for helpful comments on the manuscript.
The authors declare no competing financial interests.
References
- Abe H, Lee D (2011) Distributed coding of actual and hypothetical outcomes in the orbital and dorsolateral prefrontal cortex. Neuron 70:731–741. 10.1016/j.neuron.2011.03.026 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Azab H, Hayden BY (2017) Correlates of decisional dynamics in the dorsal anterior cingulate cortex. PLoS Biol 15:e2003091. 10.1371/journal.pbio.2003091 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Azab H, Hayden BY (2018) Correlates of economic decisions in the dorsal and subgenual anterior cingulate cortices. Eur J Neurosci. In press. 10.1111/ejn.13865 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beran MJ, Perdue BM, Smith JD (2014) What are my chances? closing the gap in uncertainty monitoring between rhesus monkeys (Macaca mulatta) and capuchin monkeys (Cebus apella). J Exp Psychol Anim Learn Cogn 40:303–316. 10.1037/xan0000020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blanchard TC, Wilke A, Hayden BY (2014a) Hot-hand bias in rhesus monkeys. J Exp Psychol Anim Learn Cogn 40:280–286. 10.1037/xan0000033 [DOI] [PubMed] [Google Scholar]
- Blanchard TC, Wolfe LS, Vlaev I, Winston JS, Hayden BY (2014b) Biases in preferences for sequences of outcomes in monkeys. Cognition 130:289–299. 10.1016/j.cognition.2013.11.012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blanchard TC, Strait CE, Hayden BY (2015) Ramping ensemble activity in dorsal anterior cingulate neurons during persistent commitment to a decision. J Neurophysiol 114:2439–2449. 10.1152/jn.00711.2015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blanchard TC, Hayden BY (2015) Monkeys are more patient in a foraging task than in a standard intertemporal choice task. PLoS One 10:e0117057. 10.1371/journal.pone.0117057 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brainard DH. (1997) The psychophysics toolbox. Spat vis 10:433–436. [PubMed] [Google Scholar]
- Busemeyer JR, Townsend JT (1993) Decision field theory: a dynamic-cognitive approach to decision making in an uncertain environment. Psychol Rev 100:432–459. 10.1037/0033-295X.100.3.432 [DOI] [PubMed] [Google Scholar]
- Camilleri AR, Newell BR (2013) Mind the gap? description, experience, and the continuum of uncertainty in risky choice. Prog Brain Res 202:55–71. 10.1016/B978-0-444-62604-2.00004-6 [DOI] [PubMed] [Google Scholar]
- Chen MK, Lakshminarayanan V, Santos LR (2006) How basic are behavioral biases? Evidence from capuchin monkey trading behavior. J Political Econ 114:517–537. 10.1086/503550 [DOI] [Google Scholar]
- Chen X, Stuphorn V (2015) Sequential selection of economic good and action in medial frontal cortex of macaques during value-based decisions. Elife 4:e09418. 10.7554/eLife.09418 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cornelissen FW, Peters EM, Palmer J (2002) The Eyelink Toolbox: eye tracking with MATLAB and the Psychophysics Toolbox. Behavior Research Methods, Instruments, & Computers 34:613–617. [DOI] [PubMed] [Google Scholar]
- De Petrillo F, Ventricelli M, Ponsi G, Addessi E (2015) Do tufted capuchin monkeys play the odds? Flexible risk preferences in Sapajus spp. Anim Cogn 18:119–130. 10.1007/s10071-014-0783-7 [DOI] [PubMed] [Google Scholar]
- Diamond A. (2013) Executive functions. Annu Rev Psychol 64:135–168. 10.1146/annurev-psych-113011-143750 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Egan LC, Santos LR, Bloom P (2007) The origins of cognitive dissonance: evidence from children and monkeys. Psychol Sci 18:978–983. 10.1111/j.1467-9280.2007.02012.x [DOI] [PubMed] [Google Scholar]
- Farashahi S, Donahue CH, Khorsand P, Seo H, Lee D, Soltani A (2017) Metaplasticity as a neural substrate for adaptive learning and choice under uncertainty. Neuron 94:401–414.e6. 10.1016/j.neuron.2017.03.044 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayden BY. (2016) Time discounting and time preference in animals: a critical review. Psychon Bull Rev 23:39–53. 10.3758/s13423-015-0879-3 [DOI] [PubMed] [Google Scholar]
- Hayden BY, Platt ML (2007) Temporal discounting predicts risk sensitivity in rhesus macaques. Curr Biol 17:49–53. 10.1016/j.cub.2006.10.055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayden BY, Platt ML (2009) Gambling for gatorade: risk-sensitive decision making for fluid rewards in humans. Anim Cogn 12:201–207. 10.1007/s10071-008-0186-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayden BY, Heilbronner SR, Nair AC, Platt ML (2008) Cognitive influences on risk seeking by rhesus macaques. Judgm Decis Mak 3:389–395. [PMC free article] [PubMed] [Google Scholar]
- Hayden BY, Pearson JM, Platt ML (2009) Fictive reward signals in the anterior cingulate cortex. Science 324:948–950. 10.1126/science.1168488 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayden BY, Heilbronner SR, Platt ML (2010) Ambiguity aversion in rhesus macaques. Front Neurosci 4:166. 10.3389/fnins.2010.00166 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heilbronner SR. (2017) Modeling risky decision-making in nonhuman animals: shared core features. Curr Opin Behav Sci 16:23–29. 10.1016/j.cobeha.2017.03.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heilbronner SR, Hayden BY (2013) Contextual factors explain risk seeking preferences in rhesus monkeys. Front Neurosci 7:7. 10.3389/fnins.2013.00007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heilbronner SR, Hayden BY (2016) The description-experience gap in risky choice in nonhuman primates. Psychon Bull Rev 23:593–600. 10.3758/s13423-015-0924-2 [DOI] [PubMed] [Google Scholar]
- Heilbronner SR, Hayden BY, Platt ML (2009) Neuroeconomics of risk-sensitive decision making. Impulsivity: Theory, Science, and Neuroscience of Discounting. Available at https://www.researchgate.net/publication/232469128_Neuroeconomics_of_risk-sensitive_decision_making
- Heilbronner SR, Rosati AG, Stevens JR, Hare B, Hauser MD (2008) A fruit in the hand or two in the bush? divergent risk preferences in chimpanzees and bonobos. Biol Lett 4:246–249. 10.1098/rsbl.2008.0081 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hertwig R, Erev I (2009) The description–experience gap in risky choice. Trends Cogn Sci 13:517–523. 10.1016/j.tics.2009.09.004 [DOI] [PubMed] [Google Scholar]
- Hertwig R, Barron G, Weber EU, Erev I (2004) Decisions from experience and the effect of rare events in risky choice. Psychol Sci 15:534–539. 10.1111/j.0956-7976.2004.00715.x [DOI] [PubMed] [Google Scholar]
- Kacelnik A, Bateson M (1997) Risk-sensitivity: crossroads for theories of decision-making. Trends Cogn Sci 1:304–309. 10.1016/S1364-6613(97)01093-0 [DOI] [PubMed] [Google Scholar]
- Kahneman D, Tversky A (1979) Prospect theory: an analysis of decision under risk. Econometrica 47:263–292. 10.2307/1914185 [DOI] [Google Scholar]
- Kahneman D, Tversky A (2000) Choices, values, and frames. In: Handbook of the fundamentals of financial decision making (MacLean LC, Ziemba WT, ed), pp 269–278. Cambridge, UK: Cambridge UP. [Google Scholar]
- Lakshminarayanan VR, Chen MK, Santos LR (2011) The evolution of decision-making under risk: framing effects in monkey risk preferences. J Exp Soc Psychol 47:689–693. 10.1016/j.jesp.2010.12.011 [DOI] [Google Scholar]
- Lichtenstein S, Slovic P (2006) The construction of preference. Cambridge: Cambridge UP. [Google Scholar]
- Ludvig EA, Spetch ML (2011) Of black swans and tossed coins: is the description-experience gap in risky choice limited to rare events? PLoS One 6:e20262. 10.1371/journal.pone.0020262 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ludvig EA, Madan CR, Pisklak JM, Spetch ML (2014) Reward context determines risky choice in pigeons and humans. Biol Lett 10:20140451. 10.1098/rsbl.2014.0451 [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCoy AN, Platt ML (2005) Risk-sensitive neurons in macaque posterior cingulate cortex. Nat Neurosci 8:1220–1227. 10.1038/nn1523 [DOI] [PubMed] [Google Scholar]
- Mendelson TC, Fitzpatrick CL, Hauber ME, Pence CH, Rodríguez RL, Safran RJ, Stevens JR (2016) Cognitive phenotypes and the evolution of animal decisions. Trend Ecol Evol 31:850–859. 10.1016/j.tree.2016.08.008 [DOI] [PubMed] [Google Scholar]
- O'Neill M, Schultz W (2010) Coding of reward risk by orbitofrontal neurons is mostly distinct from coding of reward value. Neuron 68:789–800. 10.1016/j.neuron.2010.09.031 [DOI] [PubMed] [Google Scholar]
- Paglieri F, Addessi E, De Petrillo F, Laviola G, Mirolli M, Parisi D, Petrosino G, Ventricelli M, Zoratto F, Adriani W (2014) Nonhuman gamblers: lessons from rodents, primates, and robots. Front Behav Neurosci 8:33. 10.3389/fnbeh.2014.00033 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pearson JM, Hayden BY, Platt ML (2010) Explicit information reduces discounting behavior in monkeys. Front Psychol 1:237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pearson JM, Watson KK, Platt ML (2014) Decision making: the neuroethological turn. Neuron 82:950–965. 10.1016/j.neuron.2014.04.037 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Platt ML, Huettel SA (2008) Risky business: the neuroeconomics of decision making under uncertainty. Nat Neurosci 11:398–403. 10.1038/nn2062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roe RM, Busemeyer JR, Townsend JT (2001) Multialternative decision field theory: a dynamic connectionist model of decision making. Psychol Rev 108:370–392. 10.1037/0033-295X.108.2.370 [DOI] [PubMed] [Google Scholar]
- Santos LR, Rosati AG (2015) The evolutionary roots of human decision making. Annu Rev Psychol 66:321–347. 10.1146/annurev-psych-010814-015310 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seo H, Lee D (2009) Behavioral and neural changes after gains and losses of conditioned reinforcers. J Neurosci 29:3627–3641. 10.1523/JNEUROSCI.4726-08.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seo H, Cai X, Donahue CH, Lee D (2014) Neural correlates of strategic reasoning during competitive games. Science 346:340–343. 10.1126/science.1256254 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shimojo S, Simion C, Shimojo E, Scheier C (2003) Gaze bias both reflects and influences preference. Nat Neurosci 6:1317–1322. 10.1038/nn1150 [DOI] [PubMed] [Google Scholar]
- So NY, Stuphorn V (2010) Supplementary eye field encodes option and action value for saccades with variable reward. J Neurophysiol 104:2634–2653. 10.1152/jn.00430.2010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- So N, Stuphorn V (2012) Supplementary eye field encodes reward prediction error. J Neurosci 32:2950–2963. 10.1523/JNEUROSCI.4419-11.2012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stauffer WR, Lak A, Bossaerts P, Schultz W (2015) Economic choices reveal probability distortion in macaque monkeys. J Neurosci 35:3146–3154. 10.1523/JNEUROSCI.3653-14.2015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stephens DW, Anderson D (2001) The adaptive value of preference for immediacy: when shortsighted rules have farsighted consequences. Behav Ecol 12:330–339. 10.1093/beheco/12.3.330 [DOI] [Google Scholar]
- Stevens JR, Rosati AG, Ross KR, Hauser MD (2005) Will travel for food: spatial discounting in two new world monkeys. Curr Biol 15:1855–1860. 10.1016/j.cub.2005.09.016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait CE, Blanchard TC, Hayden BY (2014) Reward value comparison via mutual inhibition in ventromedial prefrontal cortex. Neuron 82:1357–1366. 10.1016/j.neuron.2014.04.032 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait CE, Sleezer BJ, Hayden BY (2015) Signatures of value comparison in ventral striatum neurons. PLoS Biol 13:e1002173. 10.1371/journal.pbio.1002173 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait CE, Sleezer BJ, Blanchard TC, Azab H, Castagno MD, Hayden BY (2016) Neuronal selectivity for spatial positions of offers and choices in five reward regions. J Neurophysiol 115:1098–1111. 10.1152/jn.00325.2015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strier KB. (2016) Primate behavioral ecology. New York: Routledge. [Google Scholar]
- Trepel C, Fox CR, Poldrack RA (2005) Prospect theory on the brain? toward a cognitive neuroscience of decision under risk. Brain Res Cogn Brain Res 23:34–50. 10.1016/j.cogbrainres.2005.01.016 [DOI] [PubMed] [Google Scholar]
- Yamada H, Tymula A, Louie K, Glimcher PW (2013) Thirst-dependent risk preferences in monkeys identify a primitive form of wealth. Proc Natl Acad Sci U S A 110:15788–15793. 10.1073/pnas.1308718110 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Fitting procedure is able to identify the model used for simulating data correctly. (a) Plot shows the goodness-of-fit (in terms of the average AIC over a set parameters) for fitting choice data generated with a given model and fit with the same or different models (total 16 models) for the juice-gambling task. The models used to generate and fit data are indicated on the x- and y-axis, respectively. (b) The same as in (a), but the AIC values for data generated with a given model (each column) are rescaled by first subtracting the minimum AIC value obtained by fitting a given set of data and then dividing the outcome by the difference between the maximum and minimum values of AIC for that set of data. As a result, rescaled AIC values for each set of simulated data fall between 0 and 1. (c-d) The same as in (a-b) but for the token-gambling task. Overall, the same model used to generate a given set of data provided the best overall fit. Download Figure 2-1, TIF file (1.6MB, tif)
Fitting procedure is able to estimate model parameters accurately and with relatively small error. (a) Plotted is the average relative estimation error (i.e. the difference between the estimated and actual parameter values divided by the actual value) in fitting choice data generated with a given model and fit with the same or different models (total 16 models) for the juice-gambling task. The fit using the same model used to generate a given set of data provided unbiased estimates of model parameters. (b) Plotted is average of the absolute value of relative estimation error (as a more robust measure of variance in estimation error) in fitting choice data generated with a given model and fit with the same or different models. The variance in estimated parameters was the minimum for fit using the same model used to generate a given set of data. (c-d) The same as in (a-b) but for the token-gambling task. Download Figure 2-2, TIF file (1.5MB, tif)
Estimated utility and probability weighting functions based on the EV+PW model. (a) Estimated probability weighting function based on the EV+PW model for the juice-gambling task. Each curve shows the result of the fit for one session of the experiment and the thick green curve is based on the median of the fitting parameter. The dashed line is the unity line. The inset shows the distribution of estimated parameters for the probability weighting function (γ). The dashed lines show the medians, and a star indicates that the median of the distribution is significantly different from 1 (two-sided sign-test; p < 0.05). (b) The same as in (a) but for the token-gambling task. Download Figure 6-1, TIF file (284.3KB, tif)
Correlation between model parameters using the inverse of the Hessian matrix. The matrix of correlation coefficients between a given model parameters is calculated from the inverse of the Hessian matrix. (a-b) Color of each square indicates the correlation coefficient between each pair of parameters for the SU (a) and the SU with DW models (b) during the juice-gambling task. Correlation coefficients are reported for values larger than 0.1 or smaller than -0.1 only. (c-d) The same as in (a-b) but for the token-gambling task. Download Figure 11-1, TIF file (373.3KB, tif)
Correlation between model parameters using session-by-session estimates. For each model and between the pair of models, the matrix of correlation coefficients between model parameters is calculated using estimated model parameters in each session. (a-c) Color of each square indicates the correlation coefficient between each pair of parameters of the SU model (a), the SU with DW models (b), and between the parameters of the two models (c) during the juice-gambling task. Correlation coefficients are only reported for statistically significant values (p < .05, using Bonferroni correction to adjust critical p-value in each panel). (d-f) The same as in (a-c) but for the token-gambling task. Download Figure 11-2, TIF file (677.8KB, tif)
Error in the values of estimated parameters in the best models with and without differential weighting. (a) The left column shows the minimum eigenvalue and the corresponding eigenvector for the SU model in the juice-gambling task. The right column shows the estimated percent error for each model parameter. (b) The same as in (a) but for the SU model with differential weighting. (c-d) The same as in (a-b) but for the token-gambling task. Download Figure 11-3, TIF file (505.1KB, tif)