

Abstract
We study additive function-on-function regression where the mean response at a particular time point depends on the time point itself, as well as the entire covariate trajectory. We develop a computationally efficient estimation methodology based on a novel combination of spline bases with an eigenbasis to represent the trivariate kernel function. We discuss prediction of a new response trajectory, propose an inference procedure that accounts for total variability in the predicted response curves, and construct pointwise prediction intervals. The estimation/inferential procedure accommodates realistic scenarios, such as correlated error structure as well as sparse and/or irregular designs. We investigate our methodology in finite sample size through simulations and two real data applications. Supplementary Material for this article is available online.
Keywords: Functional data analysis, Eigenbasis, Nonlinear models, Orthogonal projection, Penalized B-splines, Prediction
1 Introduction
Regression models where both the response and the covariate are curves have become common in many scientific fields such as medicine, finance, and agriculture. These models are often called function-on-function regression. One of the commonly known models is the functional concurrent model where the current response relates to the current values of the covariate/s; see for example, Ramsay and Silverman (2005); Sentürk and Nguyen (2011); Kim et al. (2016). When the current response depends on the past values of the covariate/s, the historical functional linear model (Malfait and Ramsay, 2003) is more appropriate.
We consider functional regression models that relate the current response to the full trajectory of the covariate. The functional linear model (Ramsay and Silverman, 2005; Yao et al., 2005b; Wu et al., 2010) assumes that the relationship is linear: the effect of the full covariate trajectory is modeled through a weighted integral using an unknown bivariate coefficient function as the weights. The linearity assumption was extended to the functional additive model (FAM) of Müller and Yao (2008), which models the effect of the covariate by a sum of smooth functions of the functional principal component scores of the covariate. A limitation of this approach is that the estimated effects are not easily interpretable. This paper considers flexible nonlinear regression models that can capture complex relationships between the response and the full covariate trajectory more directly.
Additive models have enjoyed great popularity since they were introduced by Friedman and Stuetzle (1981) for a scalar response and scalar predictors. Their model replaces the linear model Yi = β0 +β1Xi,1 + ⋯ +βpXi,p +εi, where each of Yi, Xi,1, …, Xi,p, i = 1, …, n, is scalar by, Yi = β0 + f1(Xi,1) + ⋯ fp(Xi,p) + εi. Here f1, …, fp are smooth functions. Additive models allow nonparametric modeling of the relationship between the response and the predictors while avoiding the so-called curse of dimensionality and being easily interpreted. Additive and generalized additive models for a scalar response and functional predictors were introduced by McLean et al. (2014) and Müller et al. (2013).
Additive function-on-function regression models where the current mean response depends on the time point itself as well as the full covariate trajectory were introduced by Scheipl et al. (2015), but the present paper is the first to investigate them fully. We develop a novel estimation procedure that is an order of magnitude faster than the existing algorithm and discuss inference for the predicted response curves. The methodology is applicable for realistic scenarios involving densely and/or sparsely observed functional responses and predictors, as well as various residual dependence structures.
There are three major contributions in this paper. First, we combine B-spline bases for the covariate function, X(s), and for its argument, s, (Marx and Eilers, 2005; Wood, 2006; McLean et al., 2014) with a functional principal component basis for the argument, t, of the response function; see (2) below. The replacement of the spline basis used by Scheipl et al. (2015) for the argument of the response function with an eigenbasis is a key step to creating a computationally efficient algorithm. Second, we develop inferential methods for out-of-sample prediction of the full response trajectories, accounting for correlation in the error process. Finally, our method accommodates realistic scenarios such as densely or sparsely observed functional responses and covariates, possibly corrupted by measurement error. We show numerically that when the true relationship is nonlinear, our model provides improved predictions over the functional linear model. At the same time, when the true relationship is linear, our model maintains prediction accuracy and its fit is comparable to that of a functional linear model.
Section 2 introduces our modeling framework and a novel estimation procedure, that we call AFF-PC (additive function-on-function regression with a principal component basis). Additionally it discusses implementation details and extensions. Section 3 discusses out-of-sample prediction inference. In Section 4, we investigate the performance of AFF-PC through simulations. Section 5 presents an application of AFF-PC to a bike share study. A second application, to yield curves, is in the Supplementary Material. Section 6 provides a brief discussion.
2 Methodology
2.1 Statistical Framework and Modeling
Suppose for i = 1, …, n we observe {(Xik, sik) : k = 1, …, mi} and {(Yij, tij) : j = 1, …, mY,i}, where Xik and Yij are the covariate and response observed at time points sik and tij, respectively. We assume that for all i and k and for all i and j, where and are compact intervals. It is assumed that Xik = Xi(sik), where Xi(·) is a square-integrable, true smooth signal defined on . It is further assumed that Yij = Yi(tij), where Yi(·) is defined on . For convenience, we assume that the response has zero-mean. In practice, this is achieved by de-meaning, that is, by subtracting the response sample mean from the individual response curves.
To illustrate our ideas, we assume that both the response and the predictor are observed on a fine, regular, and common grid of points so that sik = sk with k = 1, …, m and tij = tj with j = 1, …, mY for all i. This assumption, as well as the assumption that the functional covariate is observed on a fine grid and without noise are made for illustration only; our methodology can accommodate more general situations, as we show in Section 4.
We consider a general additive function-on-function regression model
| (1) |
where F(·, ·, t) is an unknown smooth trivariate function defined on , and εi(·) is an error process with mean zero and unknown autocovariance function R(t, t′) and is independent of the covariate Xi(s). Model (1) was introduced by Scheipl et al. (2015). The form F(·, ·, t) quantifies the unknown dependence between the current response Yi(t) and the full covariate trajectory Xi(·). If F(x, s, t) = β(s, t)x, then model (1) reduces to the standard functional linear model. In principle, this allows us to study whether an additive rather than a linear functional model is necessary, but this topic is left for future research.
One possible approach for modeling F is using a tensor product of univariate B-spline basis functions for x, s, and t. This approach was proposed by Scheipl et al. (2015) and implemented in the R package refund (Goldsmith et al., 2016), although the accuracy of their estimation approach has been investigated neither numerically nor theoretically. As expected, and also as observed in our numerical results, using a trivariate spline basis imposes a heavy computational burden. The main reason for the high computational cost is that the trivariate spline basis requires a large number of basis functions. For example, if F is modeled using a tensor product of 10 basis functions per dimension, then there are 103 = 1000 basis functions in total. Secondly, this estimation methodology requires selection of three smoothing parameters, one for each spline basis, which is computationally very expensive. Thirdly, the associated penalized criterion uses the response data directly, rather than the projection of the data onto a lower dimension basis. In this paper we consider an alternative approach that uses a low-rank representation of the response data and, since we have only two spline bases, fewer smoothing parameters. The low-dimensional representation of the response curves, especially, leads to computationally efficient estimation. We will refer to the Scheipl et al. (2015) algorithm as AFF-S, where “S” refers to the spline basis for t in F(x, s, t). Our algorithm uses a principal component basis for t and so is called AFF-PC.
For some insight, consider a smooth function and let be the projection of Yi onto ϕ(·). Model (1) implies that , where and , assuming these integrals exist. The implied final model is exactly the one proposed by McLean et al. (2014); thus the unknown bivariate function Gϕ(·, ·) can be estimated by modeling it using a tensor product of two univariate known bases functions and controlling its smoothness through two tuning parameters.
Inspired by this result, let {ϕk(·)}k be an orthogonal basis in if k = k′ and 0 otherwise. We represent the function F(x, s, t) as . Here, , k = 1, …, are unknown basis coefficients that vary smoothly over x and s. We model Gk(·, ·) as a tensor product of spline bases, , where and are orthogonalized B-spline bases (Redd, 2012) of dimensions Kx and Ks, respectively. Combining these expansions, the trivariate “kernel” function F can be written as
| (2) |
where are the unknown parameters. In practice, we truncate the summation in k at some finite K. Thus, this representation uses trivariate basis functions obtained by the tensor product of univariate B-spline bases functions in directions x and s and orthogonal basis functions, ϕk(·). Let ℤi be the KxKs-column vector of and let Θk be the KxKs-column vector of unknown coefficients , where l = 1, …, Kx, l′ = 1, …, Ks. Then, model (1) can be approximated as
| (3) |
2.2 Estimation and Prediction
2.2.1 Estimation
We estimate the unknown Θk’s parameters in (3) by penalized least squares. However, unlike the standard penalized likelihood approaches (Ruppert et al. 2003; Wood 2006), which penalize the basis coefficients in all directions, we use quadratic penalties for the directions x and s, and control the roughness in the direction t by the number of orthogonal basis functions, K. Here ⊗ is the Kronecker product, and IK is the identity matrix of dimension K. Specifically, the curvature in the x-direction is measured through , where ℙx is the Kx × Kx penalty matrix with the (l, r) entry equal to l, r = 1, …, Kx. Using the orthogonality of {ϕk, k = 1, …, K}, the curvature in the s-direction is
and ℙs is the Ks×Ks penalty matrix with the (l, r) entry equal to (l′, r′ = 1, …, Ks). The penalized criterion to be minimized is
| (4) |
where ||·||2 is the L2-norm corresponding to the inner product < f, g >=∫ fg, and λx and λs are smoothness parameters that control the tradeoff between the roughness of the function F and the goodness of fit. The smoothness parameters λx and λs, in fact, also control the smoothness of the coefficient functions Gk(x, s) in directions x and s, respectively.
One convenient way to calculate the first term in (4) is to expand Yi(·) using the same basis functions {ϕk(·)}k. Specifically, if {ϕk(·)}k is the eigenbasis of the marginal covariance of Yi(·), then Karhunen-Loève (KL) expansion yields where eit is a zero-mean error and ; recall that the marginal mean of Yi(·) is assumed to be zero. Here “marginal” means marginalized over the covariate function. Criterion (4) can be equivalently written as
| (5) |
Using the eigenbasis of the response covariance allows a low-dimensional representation of (4) that improves computation time and yet preserves model complexity. Our numerical results show that AFF-PC is orders of magnitude faster than its closest competitor, AFF-S; see Table 2.
Table 2.
Comparison of FAM and AFF-S by root means squared prediction errors (1) RMSPEin and (2) RMSPEout, and (3) computation time (in seconds) averaged over 1000 simulations. Results correspond to n = 50.
| F(x, s, t) | method | dense design | sparse design | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
||||||||||||
| (1) | (2) | (3) | (1) | (2) | (3) | (1) | (2) | (3) | (1) | (2) | (3) | ||||
| FAM | 0.45 | 0.17 | 94.0 | 0.37 | 0.18 | 92.9 | 0.45 | 0.21 | 687.9 | 0.38 | 0.21 | 920.5 | |||
| F1(x, s, t) | AFF-S | 0.44 | 0.15 | 99.4 | 0.36 | 0.21 | 82.3 | 0.45 | 0.16 | 43.0 | 0.37 | 0.19 | 38.7 | ||
| AFF-PC | 0.44 | 0.14 | 10.2 | 0.37 | 0.15 | 8.7 | 0.45 | 0.17 | 10.2 | 0.38 | 0.17 | 8.9 | |||
|
| |||||||||||||||
| FAM | 0.43 | 0.12 | 93.9 | 0.36 | 0.13 | 93.4 | 0.44 | 0.17 | 564.2 | 0.36 | 0.17 | 697.7 | |||
| F2(x, s, t) | AFF-S | 0.43 | 0.06 | 143.5 | 0.34 | 0.12 | 116.4 | 0.42 | 0.08 | 39.0 | 0.34 | 0.10 | 37.5 | ||
| AFF-PC | 0.43 | 0.09 | 6.1 | 0.35 | 0.10 | 7.8 | 0.43 | 0.11 | 7.1 | 0.35 | 0.12 | 9.9 | |||
|
| |||||||||||||||
| FAM | 0.48 | 0.28 | 94.4 | 0.41 | 0.29 | 92.7 | 0.49 | 0.32 | 687.2 | 0.42 | 0.33 | 656.3 | |||
| F3(x, s, t) | AFF-S | 0.45 | 0.21 | 130.3 | 0.37 | 0.27 | 124.1 | 0.45 | 0.23 | 50.6 | 0.38 | 0.26 | 31.0 | ||
| AFF-PC | 0.45 | 0.19 | 10.5 | 0.37 | 0.21 | 10.1 | 0.46 | 0.23 | 9.7 | 0.39 | 0.23 | 9.9 | |||
We set Kx and Ks to be sufficiently large to capture the complexity of the model and penalize the basis coefficients to balance the bias and the variance. The smoothness parameters λx and λs can be chosen based on appropriate criteria, such as generalized cross validation (GCV) (see e.g., Ruppert et al., 2003; Wood, 2006) or restricted maximum likelihood (REML) (see e.g., Ruppert et al., 2003; Wood, 2006). In our numerical studies, we let Kx and Ks be as large as possible, while ensuring that KxKs < n, and select the smoothness parameters using REML.
The penalized criterion (5) uses the true functional principal component (FPC) scores. In practice, we use estimates of FPC scores from functional principal component analysis (FPCA), as we show next. Using the eigenbasis of the marginal covariance of the response, rather than a spline basis, is appealing because of the resulting parsimonious representation of the response and has been often used in the literature; see for example, Aston et al. (2010); Jiang and Wang (2010); Park and Staicu (2015). This choice of orthogonal basis also allows us to formulate the mean model for the conditional response profile, given scalar/vector covariates, based on mean models for the conditional FPC scores given the covariates: , where , Gk(·, ·) are unknown bivariate functions and ξik are the FPC scores of response. The representation is novel and extends ideas of Aston et al. (2010) and Pomann et al. (2015) to the case of a functional covariate. Also, it is related to Müller and Yao (2008) for , where fkm(·) are unknown smooth functions for m = 1, …, M and are the FPC scores of the functional covariate Xi(·), and M is a finite truncation.
2.2.2 Prediction
We use the following notation: ‘ˆ’ for prediction based on the function-on-function regression model and ‘~’ for estimation based on the marginal analysis of response Yi(·). Estimation and prediction of the response curves Yi(·) follows a three-step procedure: 1) reconstruct the smooth trajectory of the response by smoothing the data for each I (Zhang and Chen, 2007) and de-mean it, where is the estimated mean function; 2) use functional principal components analysis (PCA) to estimate the eigenbasis of the (marginal) covariance of , and then obtain the functional PCA scores ; and 3) Obtain estimates , k = 1, …, K, of the basis coefficients by minimizing the penalized criterion (5) with respect to Θk’s, and using in place of ξik. The truncation point K is determined through a pre-specified percent of variance explained; in our numerical work we use 95%. For fixed smoothness parameters, the minimizer of (5) has a closed form:
| (6) |
where , , and λ = (λx, λs)T. Once the basis coefficients are estimated, F(·, ·, ·) can be estimated by
Furthermore, for any X(s), the response curve can be predicted by the estimated E[Y |X(·)],
| (7) |
which is obtained by plugging in the expression of into the integral term of (1).
2.3 Implementation and Extensions
Implementation of our method requires transformation of the covariate as a preliminary step since the realizations of the covariate functions {Xi(sk): k, i} may not be dense over the entire domain of the B-spline basis functions for x. In this situation, some of the B-spline basis functions may not have observed data on their support. This problem has been addressed by McLean et al. (2014) and Kim et al. (2016) with different strategies. This paper uses pointwise center/scaling transformation of the functional covariate proposed by Kim et al. (2016). For completeness, we present the full details in Section B of the Supplementary Material.
We have presented our methodology for the case where, for each subject, the functional covariate is observed on a fine grid and without measurement error. The approach can be easily modified to accommodate a variety of other realistic settings such as noisy functional covariates observed on either a dense or sparse grid of points for each subject, or a functional response observed on a sparse grid of points for each subject. Details on the necessary modifications are provided in the Supplementary Material, Section A. Our numerical investigation, to be discussed in Section 4, considers settings where the functional covariates are observed at dense or moderately sparse grids of points and the measurements are corrupted with noise.
3 Out-of-Sample Prediction
In this section, we focus on out-of-sample prediction and its associated inference. For example, in the capital bike share study (Fanaee-T and Gama, 2013), an important research objective is to understand better how the hourly temperature profile for a weekend day affects the bike rental patterns for that day. The idea is that nowadays with reasonably accurate weather forecasts, AFF-PC could be applied to the next day’s weather forecast to predict bike rental demand that day; this could help the company avoid deploying too many or too few bikes for rental.
Inference for predicted response curves is not straightforward due to two important sources of variability: (1) uncertainty produced by predicting response curves conditional on the particular estimate of the orthogonal basis {ϕk(·)}k and (2) uncertainty induced by estimating the eigenbasis {ϕk(·)}k. Ignoring the second source of variability could cause underestimation of total variance. Inspired by the ideas of Goldsmith et al. (2013), we assess the total variability of the predicted response curves by combining the two sources of variability. As the two sources are assessed based on the estimated error covariance, we first describe the estimation of the error covariance in Section 3.1, and then discuss the out-of-sample prediction inference in Section 3.2.
Let be the projection of the de-meaned full response curve onto ; recall that the are obtained from the spectral decomposition of the estimated marginal covariance of the response. Define , , and . For notational simplicity, let be the set of all parameters that describe the marginal covariance of the response.
3.1 Estimation of Error Covariance
For inference about the model parameters, we account for dependence of the errors using ideas similar to those of Kim et al. (2016). We assume that the covariance function of ε(t), denoted by R(t, t′), can be decomposed as R(t, t′) = Σ(t, t′) + σ2I(t = t′), where Σ(t, t′) is a continuous covariance function, σ2 > 0, and I(·) is the indicator function. Estimation of R(t, t′) follows two steps: 1) fit the additive function-on-function model using a working independence assumption and obtain residuals, where ; and 2) apply standard functional PCA based methods (see e.g., Yao et al., 2005a; Di et al., 2009) to the residual curves and estimate a finite rank approximation of ; this yields estimated eigencomponents and estimated error variance, .
3.2 Inference
We now discuss the variability of the predicted response curves when new covariate profiles are observed. Let X0(·) be the new functional covariate and assume as in (1). Let be the right-hand side of (7) with X = X0. We measure the uncertainty in the prediction by the prediction error (Ruppert et al., 2003), which is defined as
| (8) |
Assume that the error process ε0(t) has the same distribution as εi(t) in (1) and is independent of X0(s). Then, the variance of ε0(t) can be estimated by ; here is obtained as in the previous section. We approximate using the iterated variance formula:
| (9) |
where is the estimator of η.
We begin by deriving a model-based variance estimate of . From (7),
where ℤ0 is the KxKs-column vector of for l = 1, …, Kx, l′ = 1, …, Kx. Next, and . The conditional variance of is
| (10) |
where and where implicitly this variance is conditioned on X0(s). We estimate by plugging estimates of νkk and into (10). When the response curve is observed on a fine and regular grid of points, we estimate νkk by , where is the estimated marginal covariance function of response, and is approximately 0 for k ≠ k′, since is the eigenbasis of and therefore orthogonal. When the response curve is observed at sparse and irregular grid of points, modification is needed to obtain and ; see Section A of the Supplementary Material.
To account for the second source of variability, we use bootstrapping of subjects. We approximate the total variance of using the iterated variance formula in (9); the first term, , can be estimated by averaging the model-based conditional variances across bootstrap samples. The second term, , is estimated by the sample variance of the predicted responses obtained from the bootstrap samples. Algorithm 1, displayed below, computes the total variance of . Using this result, we can construct a 100(1 − α)% pointwise prediction interval for the new response Y0(t) as , where zα/2 is the α/2 upper quantile of the standard normal distribution and is obtained by bootstrapping the subjects using Algorithm 1.
Our inferential procedure has two advantages. First, the procedure accommodates complex correlation structure within the subject. Second, the iterated expectation and variance formula combines the model-based prediction variance and the variance of , and better captures the total variance of the predicted response curves; our numerical study confirms the standard error characteristics in finite samples. One possible alternative for estimating the error covariance function R(t, t′) is to use where is estimated using the bth bootstrap sample, and our numerical study is based on this approach. Our numerical experience is that using the latter estimate of the covariance yields similar results as using the estimated model covariance derived in Section 3.1.
Algorithm 1.
Bootstrap of subjects
| 1: | for b = 1 to B do |
| 2: | Resample the subjects with replacement. Let {b1, …, bn} be the subject index of the bootstrap resample. |
| 3: | Define the covariate and the response curves in the bth bootstrap sample as and , respectively. The bootstrap data for the ith subject is obtained by collecting the trajectories and . |
| 4: | Apply FPCA to and obtain an estimate of the eigenbasis , where K(b) is the finite truncation that explains a pre-specified percent of variance. |
| 5: | For l = 1, …, Kx, l′ = 1, …, Ks, and k = 1, …, K(b), obtain parameter estimates by applying AFF-PC to and . |
| 6: | For a new covariate X0(s), obtain the predicted response by . |
| 7: | Compute using the model-based formula in (10). |
| 8: | end for |
| 9: | Approximate the marginal variance of predicted response by , |
| where is the sample mean of . |
As the Associate Editor pointed out, the proposed approach to construct prediction bands relies on the validity of the involved bootstrap approximations. We use resampling of the subjects (see also Benko et al. (2009); Park et al. (2017)) to approximate both the unconditional model-based variance component and the variance of the predicted trajectories. But a rigorous study of the bootstrap techniques is somewhat limited in the functional data analysis. In particular, there is no consistency result about the bootstrap procedure involved here. While our numerical investigation, based on the coverage of the prediction bands (see Table 3), confirms that the methodology has desired property in the settings considered here, there is no guarantee that it is generally valid and the approach is for illustration.
Table 3.
Summary of average coverage probabilities for predicting a new response Y0(t)|X0(·) at nominal significance levels 1 − α = 0.85, 0.90, and 0.95. Results are based on 1000 simulated data sets with 100 bootstrap replications per data.
| F(x, s, t) = F2(x, s, t), dense design | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||||
| n |
|
|
|
|
||||||||||||
| 0.85 | 0.90 | 0.95 | 0.85 | 0.90 | 0.95 | 0.85 | 0.90 | 0.95 | 0.85 | 0.90 | 0.95 | |||||
| 50 | 0.904 | 0.942 | 0.976 | 0.883 | 0.926 | 0.966 | 0.880 | 0.926 | 0.967 | 0.883 | 0.925 | 0.965 | ||||
| 100 | 0.884 | 0.928 | 0.967 | 0.869 | 0.916 | 0.960 | 0.866 | 0.916 | 0.961 | 0.869 | 0.915 | 0.959 | ||||
| 300 | 0.868 | 0.915 | 0.960 | 0.859 | 0.908 | 0.955 | 0.856 | 0.908 | 0.957 | 0.858 | 0.908 | 0.953 | ||||
|
| ||||||||||||||||
| F(x, s, t) = F2(x, s, t), sparse design | ||||||||||||||||
|
| ||||||||||||||||
| 50 | 0.910 | 0.946 | 0.977 | 0.882 | 0.926 | 0.965 | 0.888 | 0.930 | 0.969 | 0.887 | 0.928 | 0.967 | ||||
| 100 | 0.887 | 0.930 | 0.969 | 0.870 | 0.916 | 0.960 | 0.870 | 0.918 | 0.963 | 0.873 | 0.918 | 0.961 | ||||
| 300 | 0.867 | 0.915 | 0.960 | 0.860 | 0.909 | 0.956 | 0.858 | 0.910 | 0.958 | 0.862 | 0.910 | 0.955 | ||||
|
| ||||||||||||||||
| F(x, s, t) = F3(x, s, t), dense design | ||||||||||||||||
|
| ||||||||||||||||
| 50 | 0.936 | 0.963 | 0.986 | 0.914 | 0.948 | 0.978 | 0.912 | 0.947 | 0.978 | 0.911 | 0.946 | 0.977 | ||||
| 100 | 0.913 | 0.949 | 0.979 | 0.895 | 0.935 | 0.970 | 0.895 | 0.935 | 0.972 | 0.893 | 0.933 | 0.970 | ||||
| 300 | 0.880 | 0.924 | 0.966 | 0.871 | 0.917 | 0.961 | 0.870 | 0.916 | 0.962 | 0.869 | 0.914 | 0.959 | ||||
|
| ||||||||||||||||
| F(x, s, t) = F3(x, s, t), sparse design | ||||||||||||||||
|
| ||||||||||||||||
| 50 | 0.949 | 0.971 | 0.989 | 0.913 | 0.947 | 0.977 | 0.931 | 0.958 | 0.982 | 0.932 | 0.959 | 0.983 | ||||
| 100 | 0.923 | 0.954 | 0.982 | 0.895 | 0.936 | 0.971 | 0.903 | 0.941 | 0.975 | 0.903 | 0.940 | 0.974 | ||||
| 300 | 0.889 | 0.931 | 0.970 | 0.877 | 0.922 | 0.964 | 0.879 | 0.923 | 0.966 | 0.878 | 0.921 | 0.963 | ||||
4 Simulation Study
We investigate the finite sample performance of our method through simulations. We generate N = 1000 samples from model (1) with the true functional covariate given by where a1, a2, and a3 vary independently across subjects, specifically, ap ~ Normal(0, 2(1−p)2) for p = 1, 2, 3. Also, the covariate is observed with noise, Wik = Xi(sik) + δik where the δik are independent Normal(0, 0.5). For each sample we generate training sets of size n = 50, 100, and 300 and a test set of size 50; also . The training sets include two different scenarios for the sampling of s and t. (i) Dense design - the grids of points {sik: k = 1, …, mi} and {tik : k = 1, …, mY,i} are the same across i, mi = m and mY,i = mY, and are defined as the set of 81 and 101 equidistant points in [0, 1] respectively. (ii) Sparse design - for each i the number of observation points mi ~ Uniform(45, 54) and mY,i ~ Uniform(35, 44); the time-points {sik : k = 1, …, mi} and {tik : k = 1, …, mY,i} are randomly sampled without replacement from a set of 81 and 101 equidistant points in [0, 1] respectively.
The test set is generated using the set of 81 and 101 equispaced points in [0, 1] for s and t, respectively. We denote realizations of the error process by and generate them using four different covariance structures; these cases are denoted by , , , , where assumes a simple independent error structure, and other cases have correlated structure with increasing complexity and are described in Section C of the Supplementary Material. We consider three forms of true function F: linear function F1(x, s, t), simple nonlinear function F2(x, s, t), and complex nonlinear function F3(x, s, t); they too are defined in the Supplementary Material, Section C. Figure 1 shows the true surface of F3(x, s, t) along with x and s at fixed points t = 0.05, 0.5, and 1. The thick solid line is F3 evaluated at fixed values for t and s so that only x varies; the nonlinearity of this curve indicates a departure from a functional linear model where F(x, s, t) would be linear in x. The remaining details about the simulation are in the Supplementary Material, Section C. The R packages Matrix (Bates and Maechler, 2017) and MASS (Venables and Ripley, 2002) were used to generate data.
Figure 1.
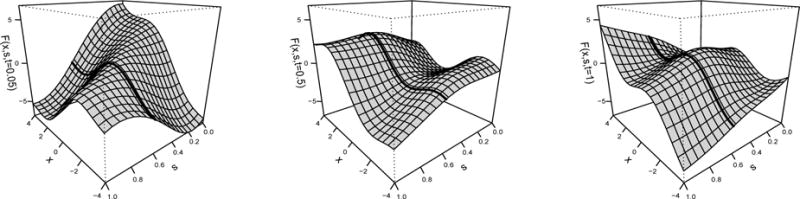
The three panels show the complex nonlinear function F3(·). Plotted are F3(x, s, 0.05) (left), F3(x, s, 0.5) (middle), and F3(x, s, 1) (right). The thick solid line represents the curve obtained by fixing s at 0.6. Notice its nonlinearity as a function of x.
The performance of AFF-PC was assessed in terms of in-sample and out-of-sample predictive accuracy, as measured by the root mean squared prediction error (RMSPE), average computation time, and coverage probabilities of prediction intervals. The in-sample and out-of-sample root mean squared prediction error (RMSPE) are denoted by RMSPEin and RMSPEout, respectively. We define the in-sample RMSPE by
where and its estimate are from the rth Monte Carlo simulation. The out-of-sample RMSPE, denoted by RMSPEout, is defined similarly. For each prediction we calculate the average coverage probability of the pointwise prediction intervals.
4.1 Competitive Methods
We compare our method to three other approaches: the functional linear model, the functional additive model of Müller and Yao (2008), which we label FAM, and the B-spline based estimation of Scheipl et al. (2015), AFF-S. Our approach is implemented using the R packages refund (Goldsmith et al., 2016) and mgcv (Wood, 2011, 2004, 2003). Details about the selection of the tuning parameters for our approach and the competitive approaches are in Section C of the Supplementary Material. We assess the prediction accuracy of the proposed approach and three competitive alternatives and compare their computational efficiency. Due to the high computational cost of the functional additive model and AFF-S, we restrict our comparisons with these methods to the case where n = 50 and the error process is either or as described in Section C of the Supplementary Material. For the functional linear model, we consider a model defined by . Implementation details of our method and the three other approaches are summarized in the Supplementary Material, Section C.3.
4.2 Simulation Results
4.2.1 Prediction Performance
The comparison with the functional linear model is summarized in Table 1. For in-sample prediction accuracy, we report the relative percent gain in prediction with respect to functional linear model by computing , where and are the in-sample prediction errors obtained by fitting the AFF-PC and functional linear model, respectively. Relative improvement for out-of-sample prediction is measured similarly. Thus, values closer to 0 indicate similar prediction performance between the two models, while larger positive values are indicative of AFF-PC having greater prediction accuracy than the functional linear model. The top part of Table 1 contains the case when the underlying true model is linear in x; the true relationship is described by F1. Both AFF-PC and the functional linear model, provide relatively similar in-sample and out-of-sample prediction performance in all scenarios. The number of subjects, the sampling design of the grid points, and the error structure slightly affect the numerical results. The results confirm that when the true relationship is linear, then AFF-PC has similar prediction performance to the functional linear model, although there are few cases, especially for sparse designs and smaller sample sizes, where AFF-PC is slightly worse with respect to out-of-sample prediction.
Table 1.
Relative percent gain in prediction accuracy of the AFF-PC compared to the functional linear model. The percent improvements are measured for (1) in-sample and (2) out-of-sample. The functions are a linear function F1(x, s, t), a simple nonlinear function F2(x, s, t), and a complex nonlinear function F3(x, s, t) and are four correlation structures, with being independent.
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (1) | (2) | (1) | (2) | (1) | (2) | (1) | (2) | (1) | (2) | (1) | (2) | (1) | (2) | (1) | (2) | |||||||||
| n | F(x, s, t) = F1(x, s, t), dense design | F(x, s, t) = F1(x, s, t), sparse design | ||||||||||||||||||||||
|
| ||||||||||||||||||||||||
| 50 | 0.00 | −0.71 | 0.22 | −1.41 | 0.27 | −0.67 | 0.27 | −2.04 | −0.29 | −5.81 | 0.00 | −6.37 | 0.00 | −4.37 | 0.00 | −5.66 | ||||||||
| 100 | 0.31 | −0.88 | 0.00 | −0.87 | 0.00 | −0.84 | 0.00 | −0.85 | −0.30 | −3.88 | 0.00 | −4.58 | −0.27 | −3.79 | −0.27 | −3.79 | ||||||||
| 300 | 0.00 | 0.00 | 0.00 | −1.06 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | −1.98 | −0.23 | −2.94 | 0.00 | −1.96 | −0.27 | −1.96 | ||||||||
|
| ||||||||||||||||||||||||
|
| ||||||||||||||||||||||||
| n | F(x, s, t) = F2(x, s, t), dense design | F(x, s, t) = F2(x, s, t), sparse design | ||||||||||||||||||||||
|
| ||||||||||||||||||||||||
| 50 | 5.20 | 31.97 | 3.38 | 38.51 | 6.74 | 44.81 | 5.93 | 35.95 | 5.47 | 29.80 | 3.15 | 26.80 | 5.91 | 32.91 | 4.84 | 22.29 | ||||||||
| 100 | 6.36 | 41.84 | 4.04 | 50.00 | 6.95 | 56.55 | 6.67 | 50.34 | 6.65 | 41.67 | 3.59 | 37.93 | 6.13 | 45.58 | 5.59 | 36.05 | ||||||||
| 300 | 6.97 | 55.80 | 4.26 | 63.04 | 6.91 | 66.19 | 6.65 | 64.75 | 7.53 | 55.40 | 4.03 | 52.52 | 6.63 | 60.00 | 6.10 | 53.57 | ||||||||
|
| ||||||||||||||||||||||||
|
| ||||||||||||||||||||||||
| n | F(x, s, t) = F3(x, s, t), dense design | F(x, s, t) = F3(x, s, t), sparse design | ||||||||||||||||||||||
|
| ||||||||||||||||||||||||
| 50 | 34.38 | 58.77 | 24.32 | 58.21 | 30.61 | 56.21 | 30.61 | 55.34 | 31.71 | 52.37 | 22.69 | 51.18 | 28.60 | 50.86 | 28.60 | 50.21 | ||||||||
| 100 | 36.36 | 65.30 | 25.59 | 64.61 | 31.99 | 63.33 | 31.99 | 62.64 | 34.16 | 59.68 | 24.38 | 58.43 | 30.07 | 58.20 | 30.07 | 57.75 | ||||||||
| 300 | 37.57 | 70.19 | 26.38 | 69.95 | 32.60 | 69.32 | 32.60 | 68.85 | 35.88 | 67.29 | 25.33 | 66.59 | 31.41 | 66.67 | 31.23 | 66.43 | ||||||||
The prediction results for the case where the true model in nonlinear are shown in the middle and bottom parts of the table: the true relationship is described by F2 (simple nonlinear, middle) and F3 (complex nonlinear, bottom). The results confirm that if the true model is nonlinear, then AFF-PC shows a dramatic improvement in prediction accuracy over the functional linear model. Depending on the complexity of the mean model, AFF-PC improves prediction accuracy compared to the functional linear model by over 50%. This improvement increases as the sample size gets larger.
Next, we compare AFF-PC to the AFF-S estimator (Scheipl et al., 2015), which uses B-splines rather than an eigenbasis to represent the trajectories. The results are presented in Table 2. Comparing the columns labeled (1) and (2) in the two panels, we observe that the two estimators have similar accuracy, with accuracy varying slightly with the complexity of the relationship. Column labeled (3) shows the average computation time (in seconds), indicating an order of magnitude improvement by AFF-PC over AFF-S. The models were run on a 2.3GHz AMD Opteron Processor.
Table 2 also compares AFF-PC and FAM. As the model complexity increases, the out-of-sample prediction accuracy of AFF-PC increases compared to FAM. Also, FAM takes much more computation time than AFF-PC, especially when the grid points are sparsely sampled. Computation time is less affected by the error covariance structure than is prediction accuracy.
In summary, AFF-PC better captures complex nonlinear relationships than the functional linear model, and yet AFF-PC performs as well as the functional linear model when the latter is true. The B-spline based estimator, AFF-S, and AFF-PC have similar prediction performance, while AFF-S and FAM are much slower than AFF-PC.
4.2.2 Performance of the Prediction Intervals
Next, we assess coverage accuracy of the pointwise prediction intervals. These intervals are approximated using the method described in Section 3 with 100 bootstrap samples per simulated data set. Table 3 reports the average coverage probability for both the dense and sparse design at nominal levels of 85%, 90%, and 95%. When the sample size is small (e.g., n = 50), the prediction intervals are conservative, providing greater coverage probabilities than the nominal values. However, the coverage probabilities approach the nominal levels as the sample size increases. The complexity of the true function F(x, s, t) affects the coverage performance slightly. If the true function is complex, e.g., F(x, s, t) = F3(x, s, t), the coverage probability converges more slowly to the nominal levels as n increases compared to when the true function is simple, e.g., F(x, s, t) = F2(x, s, t). The number of subjects, the sampling design of the grid points, and the error covariance structure also affect the coverage performance slightly.
Remark
Section D.1 of the Supplementary Material includes additional simulation results corresponding to another level of sparseness, and the results indicate that our approach still maintains prediction accuracy. Section D.2 of the Supplementary Material illustrates numerically that our method is not sensitive to the choice of K.
5 Capital Bike Share Data
We now turn to the capital bike share study (Fanaee-T and Gama, 2013). The data were collected from the Capital Bike Share system in Washington, D.C., which offers bike rental services on an hourly basis. In recent years, there has been an increased demand for bicycle rentals; renting is viewed as an attractive alternative to owing bicycles. Ensuring a sufficient bike supply represents an important factor for a successful business in this area. In this paper we try to gain a better understanding of the customers’ rental behavior during a weekend day in relation to the weather condition for that day. We are interested in casual rentals, which are rentals to cyclists without membership in the Capital Bike Share program. The counts of casual bike rentals are recorded at every hour of the day, during the period from January 1, 2011 to December 31, 2012, for a total of 105 weeks. Also collected are weather information such as temperature (°C) and humidity on an hourly basis.
Bike rentals have different dynamics on weekends compared to weekends. We restrict our study to Saturday rentals, when there is a particularly high demand for casual bike rentals. Our focus is on how Saturday rentals relate to the temperature, while accounting for humidity. Understanding the nature of this association could help one predict the casual rental demand based on the weather forecast available on the previous day. Figure 2 shows the counts of casual bike rentals (left panel) and hourly temperature (right panel) on Saturdays; each curve corresponds to a particular week. The solid, dotted, and dashed lines are the observations for three different Saturdays. On weekends, many renters can be flexible about when during the day to rent, so it is assumed that the entire temperature curve affects the number of casual bikes rental at any time on Saturday. To remove skewness, we log-transform the response data, x → log(x + 1), before we proceed with our analysis.
Figure 2.
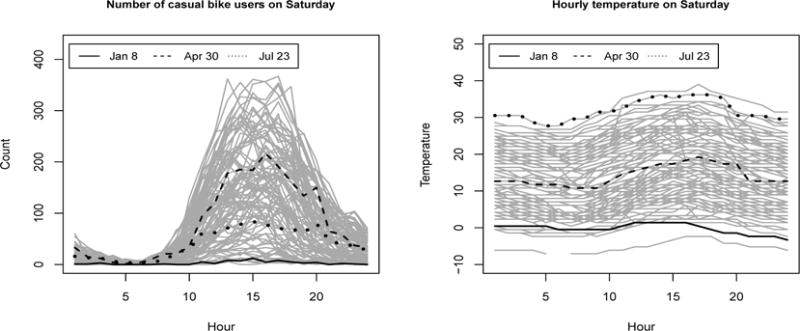
The number of casual bike users (left panel) and hourly temperatures (°C, right panel) collected every Saturday. The measurements taken in three different days on January, April, and July in 2011 are indicated by solid, dashed, and dotted lines, respectively.
Let CBi(t) be the number of casual bikes rented recorded, on the log-scale, for the ith Saturday at the tth hour of the day; also let Tempi(t) denote the true temperature for the ith Saturday at the tth hour of the day and let AHumi be the average humidity for the corresponding Saturday. We consider the general additive function-on-function regression AFF-PC model
| (11) |
where α(·) is the marginal mean of the response, F(·, ·, ·) is an unknown trivariate function capturing the effect of the daily temperature and γ(·) is a smooth univariate function that quantifies the time-varying effect of the average humidity.
The temperature and the counts of bike rentals have a small amount of missingness. Therefore, we smoothed the temperature profiles using functional principal component analysis before applying the center/scaling transformation. We assessed both in-sample and out-of-sample prediction accuracy by splitting the data into training and test sets of size 89 and 16, respectively. To model the function F, we used Kx = Ks = 7 cubic B-splines for the x- and s-directions and selected K, the number of eigenfunctions for modeling F in the t direction, by fixing the percentage of explained variance to 95%; this resulted in K = 3. These choices for the tuning parameters are supported by additional sensitivity analysis included in Section E.2 of the Supplementary Material. We also used to model the marginal mean function α(·) and the smooth effect of average humidity γ(t), and , where βk and ζk are the unknown basis coefficients. Such a representation allows us to use K also to control the smoothness of the fitted coefficient function, . Parameter estimation was done as described in Section 2.2 with minor modifications due to the additional covariate, average humidity. Briefly, to estimate the unknown parameters, βk, ζk and , we constructed , , and and then minimized the penalized criterion (5) using and in place of and , respectively.
Figure 3 shows the estimated parameter functions: the top two plots illustrate the estimated intercept function and . On average the number of casual bike rentals decreases until 5AM (t = 5 on the plot) and then increases steadily peaking at about 3:00PM (t = 15). As expected, humidity is negatively associated with the bike rentals; the effect seems to be largest at 3:00PM. The bottom panels show the contour plots of the function for three values of t, t = 0 (midnight), t = 12 (noon) and t = 20 (evening, 8PM); the values of x have a standardized interpretation. For example, x = 1 is interpreted as one standard deviation away from the mean temperature profile. The plots were produced using the R packages gridExtra (Auguie, 2016) and lattice (Sarkar, 2008).
Figure 3.
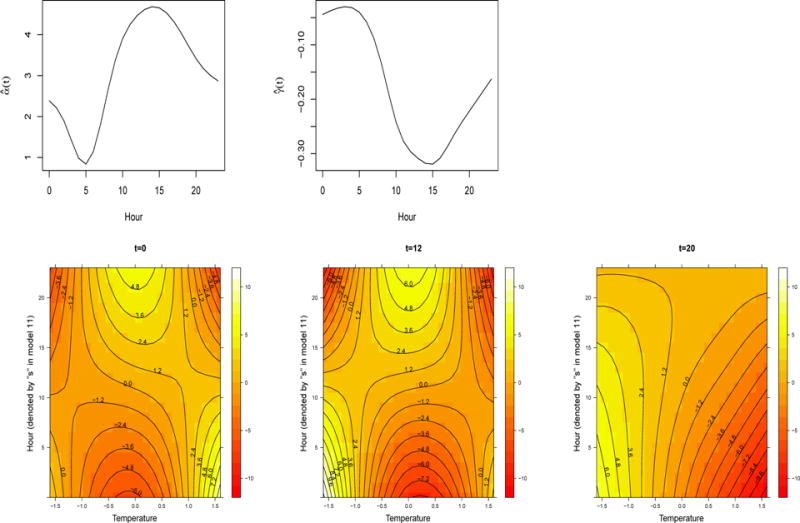
Displayed are the estimated parameter functions obtained by regressing log(1+countij) on the transformed temperature (°C) and average humidity. Top panels: marginal mean, and the effect of average humidity, . Bottom panels: contour plots of the estimated surface, (left), (middle) and (right).
As mentioned in Section 2.1, the functional linear model is the special case of (1) where F(x, s, t) = β(s, t)x, which implies that ∂F(x, s, t)/∂x does not depend on x. The nonlinearity of in x can be noted in all these plots but in particular in the middle bottom panel (t = 12). Consider the case when s = 10; simple calculations yield that the partial derivative of F with respect to x at x = −1 is different from the one for x = 1, and thus that is not linear in x.
Table 4 compares AFF-PC, AFF-S, and the functional linear model in terms of prediction accuracy. AFF-PC results in better prediction performance than functional linear model for both in-sample and out-of sample. As expected, AFF-PC and AFF-S have similar accuracy but AFF-PC is much faster than AFF-S.
Table 4.
Results from the Capital Bike Share study described in Section 5. Displayed are the summaries of (1) RMSPEin, (2) RMSPEout and (3) computation time (in seconds) obtained by regressing log(1+countij) on temperature and average humidity.
| Method | (Kx, Ks, Kt) | log-transformed data | original data | |||
|---|---|---|---|---|---|---|
| (1) | (2) | (1) | (2) | (3) | ||
| FLM | (NA, 7,7) | 0.740 | 0.606 | 62.079 | 43.603 | 2.12 |
| AFF-S | (7,7,7) | 0.637 | 0.494 | 37.275 | 28.826 | 25.36 |
| AFF-PC | (7,7, K b = 3) | 0.635 | 0.493 | 38.184 | 31.715 | 1.97 |
Furthermore, we can construct bootstrap-based prediction intervals for the predicted trajectories in the test set, by slightly modifying the bootstrap procedure included in Section 3.2. For completeness, the algorithm is provided in the Supplementary Material, Section E.3. Figure 4 illustrates the 95% prediction bands constructed for three different Saturdays in the test set. Finally, we assessed the coverage probability of the prediction intervals. AFF-PC tended to produce conservative prediction intervals. For example, using 1000 bootstrap replications, the actual coverage probability of the 95% prediction intervals was 0.988 with a standard error of 0.003.
Figure 4.
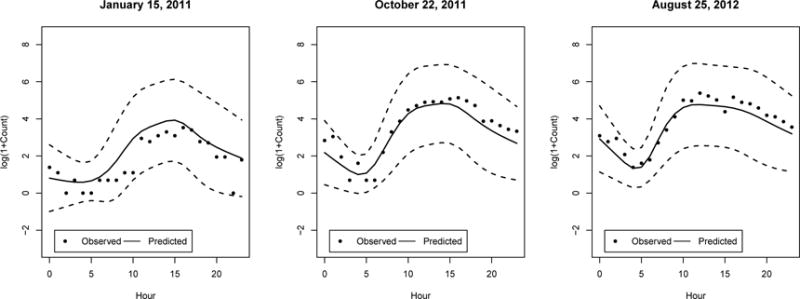
95% prediction bands constructed for three subject-level trajectories in the bike data. “●” are the observed response trajectories, solid lines are predicted response. Dashed lines are the prediction bands obtained by applying the method of AFF-PC.
6 Discussion
This article considered additive regression models for functional responses and functional covariates. These models are a generalization of the functional linear model and allow for a nonlinear relationship between the response and the covariate. We proposed a novel estimation technique, AFF-PC, that is computationally very fast. We developed prediction inference for a future functional outcome when the functional covariate is known. As illustrated by the bike share study, AFF-PC can accommodate additional scalar or vector covariates. Furthermore, AFF-PC can easily be extended to accommodate multiple functional covariates. We showed through numerical study that when the true model is linear, AFF-PC’s performance is very close to that of the functional linear model, but if the true model is nonlinear, AFF-PC can yield considerably improved prediction performance. The capital bike share data is available at: https://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset. The R code used in the simulation is available at: http://www4.stat.ncsu.edu/~staicu/Code/affpccode.zip.
Supplementary Material
Acknowledgments
Staicu’s research was funded by National Science Foundation grant DMS 1454942 and National Institute of Health grants R01 NS085211 and R01 MH086633. Maity’s research was partially funded by National Institutes of Health award R00 ES017744 and a North Carolina State University Faculty Research and Professional Development award. Carroll’s research was supported by a grant from the National Cancer Institute (U01-CA057030). The research of Ruppert was partially supported by National Science Foundation grant AST 1312903 and by a grant from the National Cancer Institute (U01-CA057030).
Footnotes
Supplementary Material
Supplementary Material: Additional descriptions for methodology extensions, simulation setup, and simulation results are provided. (pdf file)
R code: The R code developed for the simulation. (zip file)
References
- Aston JAD, Chiou JM, Evans JP. Linguistic pitch analysis using functional principal component mixed effect models. Journal of the Royal Statistical Society, Series C. 2010;59:297–317. [Google Scholar]
- Auguie B. gridExtra: Miscellaneous Functions for ”Grid” Graphics. 2016. (R package version 2.2.1). [Google Scholar]
- Bates D, Maechler M. Matrix: Sparse and Dense Matrix Classes and Methods. 2017. (R package version 1.2.8). [Google Scholar]
- Benko M, Härdle W, Kneip A, et al. Common functional principal components. The Annals of Statistics. 2009;37(1):1–34. [Google Scholar]
- Di CZ, Crainiceanu CM, Caffo B, Punjabi NM. Multilevel functional principal component analysis. Annals of Applied Statistics. 2009;3:458–488. doi: 10.1214/08-AOAS206SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fanaee-T H, Gama J. Event labeling combining ensemble detectors and background knowledge. Progress in Artificial Intelligence. 2013:1–15. [Google Scholar]
- Friedman JH, Stuetzle W. Projection pursuit regression. Journal of the American statistical Association. 1981;76(376):817–823. [Google Scholar]
- Goldsmith J, Greven S, Crainiceanu C. Corrected confidence bands for functional data using principal components. Biometrics. 2013;69:41–51. doi: 10.1111/j.1541-0420.2012.01808.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goldsmith J, Scheipl F, Huang L, Wrobel J, Gellar J, Harezlak J, McLean MW, Swihart B, Xiao L, Crainiceanu C, Reiss PT. refund: Regression with Functional Data. 2016. (R package version 0.1.16). [Google Scholar]
- Jiang CR, Wang J-L. Covariate adjusted functional principal components analysis for longitudinal data. Annals of Statistics. 2010;38:1194–1226. [Google Scholar]
- Kim J, Maity A, Staicu AM. General functional concurrent model. 2016 doi: 10.4310/SII.2018.v11.n4.a11. Unpublished manuscript (under review) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Malfait N, Ramsay JO. The historical functional linear model. The Canadian Journal of Statistics. 2003;31:115–128. [Google Scholar]
- Marx BD, Eilers PHC. Multivariate penalized signal regression. Technometrics. 2005;47:13–22. [Google Scholar]
- McLean MW, Hooker G, Staicu AM, Scheipl F, Ruppert D. Functional generalized additive models. Journal of Computational and Graphical Statistics. 2014;23:249–269. doi: 10.1080/10618600.2012.729985. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Müller HG, Wu Y, Yao F. Continuously additive models for nonlinear functional regression. Biometrika. 2013;103:607–622. [Google Scholar]
- Müller HG, Yao F. Functional additive models. Journal of the American Statistical Association. 2008;103:1534–1544. [Google Scholar]
- Park SY, Staicu AM. Longitudinal functional data analysis. Stat. 2015;4:212–226. doi: 10.1002/sta4.89. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Park SY, Staicu A-M, Xiao L, Crainiceanu CM. Inference on fixed effects in complex functional mixed models. 2017 doi: 10.1093/biostatistics/kxx026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pomann GM, Staicu A-M, Ghosh S. Two sample hypothesis testing for functional data. 2015 Unpublished manuscript (submitted) [Google Scholar]
- Ramsay JO, Silverman BW. Functional Data Analysis. 2nd. New York: Springer; 2005. [Google Scholar]
- Redd A. A comment on the orthogonalization of b-spline basis functions and their derivatives. Statistics and Computing. 2012;22:251–257. [Google Scholar]
- Ruppert D, Wand MP, Carroll RJ. Semiparametric Regression. Cambridge, New York: Cambridge University Press; 2003. [Google Scholar]
- Sarkar D. Lattice: Multivariate Data Visualization with R. New York: Springer; 2008. [Google Scholar]
- Scheipl F, Staicu A-M, Greven S. Functional additive mixed models. Journal of Computational and Graphical Statistics. 2015;24:477–501. doi: 10.1080/10618600.2014.901914. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sentürk D, Nguyen DV. Varying coefficient models for sparse noise-contaminated longitudinal data. Statistica Sinica. 2011;21:1831–1856. doi: 10.5705/ss.2009.328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venables WN, Ripley BD. Modern Applied Statistics with S. Fourth. New York: Springer; 2002. [Google Scholar]
- Wood SN. Thin-plate regression splines. Journal of the Royal Statistical Society (B) 2003;65(1):95–114. [Google Scholar]
- Wood SN. Stable and efficient multiple smoothing parameter estimation for generalized additive models. Journal of the American Statistical Association. 2004;99(467):673–686. [Google Scholar]
- Wood SN. Generalized Additive Models: An Introduction with R. Boca Raton, Florida: Chapman and Hall/CRC; 2006. [Google Scholar]
- Wood SN. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. Journal of the Royal Statistical Society (B) 2011;73(1):3–36. [Google Scholar]
- Wu Y, Fan J, Müller H-G. Varying-coefficient functional linear regression. Bernoulli. 2010;16:730–758. [Google Scholar]
- Yao F, Müller H-G, Wang J-L. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005a;100:577–590. [Google Scholar]
- Yao F, Müller H-G, Wang J-L. Functional linear regression analysis for longitudinal data. Annals of Statistics. 2005b;33:2873–2903. [Google Scholar]
- Zhang JT, Chen J. Statistical inference for functional data. Annals of Statistics. 2007;35:1052–1079. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.