

Abstract
Background:
The analysis of health effects of exposure to mixtures is a critically important issue in human epidemiology, and increasing effort is being devoted to developing methods for this problem. A key feature of environmental mixtures is that some components can be highly correlated, raising the issues of confounding by coexposure and colinearity. A relatively unexplored topic in epidemiologic analysis of mixtures is the impact of residual confounding bias due to unmeasured or unknown variables.
Objectives:
This paper examines the potential amplification of such biases when correlated exposure variables are included in regression models.
Methods:
We use directed acyclic graphs (DAGs) to describe different simple scenarios involving residual confounding. We derive expressions for the expected value of the resulting bias using linear models and multiple linear regression.
Results:
Approaches to the analysis of mixtures that involve regressing the outcome on several exposures simultaneously can in some cases amplify rather than reduce confounding bias.
Discussions:
The problem of bias amplification can worsen with stronger correlation between mixture components or when more mixture components are included in the model.
Conclusions:
Investigators must consider steps to minimize possible bias amplification in the design and analysis of epidemiologic studies of multiple correlated exposures. This may be particularly important when biomarkers of exposure are used. https://doi.org/10.1289/EHP2450
Introduction
The analysis of health effects of exposure to mixtures is a critically important issue in environmental epidemiology—we are not exposed to one factor at a time. This is an area of growing interest and different approaches to handle this challenging issue are being pursued. The National Institute of Environmental Health Sciences held a workshop in July 2015 on this specific topic (Taylor et al. 2016). Questions of interest for the epidemiologic analysis of mixtures include identifying exposures that contribute to the outcome, identifying interactions between exposures, and construction of exposure summary measures. Like all analytical epidemiology, mixtures methods must be able to deal with confounding (Braun et al. 2016). We focus here on the issue of confounding and describe a previously underappreciated additional source of bias that may be particularly problematic for the epidemiologic analysis of mixtures; our results are informed by recent work on instrumental variables and Z amplification bias (Pearl 2010), a topic that has received little attention in environmental epidemiology.
A number of statistical methods for the epidemiologic analysis of mixtures include an entire set of exposure variables in a statistical model and let the method determine which are important; many of these methods are fundamentally based on multivariable regression (Taylor et al. 2016). Such agnostic approaches may appear reasonable in many situations. For example, polybrominated diphenyl ethers (PBDEs) are a class of compounds widely found in human sera with moderate to high correlation (Makey et al. 2014; Sjödin et al. 2008). PBDEs are structurally related to thyroid hormones; previous research suggests that some may cause changes in serum thyroid hormone levels (among other health effects), but it is not known with certainty which PBDEs are responsible (Makey et al. 2016). One might therefore try to analyze the mixture by including a whole group of these compounds in a model. Nevertheless, we will argue that in a number of important cases agnostic approaches may produce highly biased results.
Epidemiologists generally want to identify and accurately measure causal associations between exposures and outcomes. This goal differs from predictive methods that do not necessarily distinguish between causal and noncausal associations. In this paper, we use a number of examples to show that causal methods are crucial to our goal as epidemiologists investigating effects of exposure to mixtures. In particular, we focus on confounding by variables that are unknown or unmeasured, which pose a special threat because the inclusion of multiple exposure variables together in a model can sometimes—depending on the causal structure—make things worse, amplifying the amount of bias in a regression estimate compared with analyzing single exposures. The degree of bias amplification depends in part on the amount of correlation between exposure variables; in environmental epidemiology, groups of exposure variables can be highly correlated. As we will discuss, the vastly increased availability of exposure biomarkers makes the study of the health effects of mixtures more feasible, but their use as exposure variables in such studies can introduce confounding by physiological or behavioral factors that are unknown or poorly understood. Finally, we argue that this set of problems cannot be resolved based on statistics alone but requires expert knowledge of the problem under study combined with careful analysis. We therefore caution against including large sets of exposure variables in models without careful consideration.
Causal Methods and Directed Acyclic Graphs
Although ideas about causality have a long history in epidemiology, the application of directed acyclic graphs (DAGs) has greatly influenced the field in the last few decades. DAGs are essentially a graphical method for showing causal assumptions. DAGs consist of variables and arrows. Arrows between variables mean causality (which runs in one direction, hence directed). DAGs cannot contain causal pathways (defined below) that are loops (hence, acyclic).
In discussing DAGs and relationships between variables, we use causal DAG terminology that has been described elsewhere (Glymour and Greenland 2008; Greenland et al. 1999; Hernán and Robins 2017). Here we briefly, and in somewhat simplified fashion, explain some of the key terms, using Figures 1 and 2a as examples that contain the elements of interest. Causal effects are represented by directed arrows; for example, indicates a causal effect of on Y. That is, if were changed, the risk of Y would change. A pathway is any connection between two variables made by following arrows in any direction (possibly through other intermediate variables). A backdoor pathway from variable to another variable is a pathway between the two that starts along an arrow pointing into , for example, . A collider in any pathway is a variable into which two arrows of the pathway point: For example, in Figure 2a, is a collider in the pathway . An open pathway is one that results in statistical (causal or noncausal) correlation between two variables in a regression model. A blocked pathway is one that results in no statistical correlation between two variables in a regression model. Here is the point of this terminology: Pathways are blocked by uncontrolled colliders or control for noncolliders in the pathway. Pathways can be opened by control of colliders and failure to control noncolliders. By control, we mean adjustment, stratification, and restriction. For example, in Figure 2a, the backdoor pathway is blocked if U′ (a noncollider on this pathway) is controlled but open if it is not. The backdoor pathway is blocked if (a collider on this pathway) is not controlled, but opened if it is.
Figure 1.
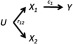
Directed acyclic graph (DAG) for simple confounding by coexposure. Causal pathways are denoted by arrows and causal coefficients by . In this example, only causes the outcome. The two exposures (, ) have a common source (U), with causal coefficients omitted. is the bivariate correlation coefficient for and .
Figure 2.

a) Directed acyclic graph (DAG) for coexposure amplification bias. To Figure 1 we have added an unknown variable (U′) that affects the outcome and only one exposure. Adjustment for both exposures causes bias amplification of the association and reversal for the association. is the bivariate correlation coefficient for and . b) DAG for Z amplification bias. Z is an instrumental variable for . Coexposure amplification bias is an extension of this idea.
Although DAG methods may seem complicated when first encountered, they are increasingly considered as essential for proper interpretation of epidemiologic results. As one prominent example, the properties of colliders were not known by most epidemiologists until DAGs became more popular (e.g., Hernández-Diaz et al. 2006). As we will see, DAGs and colliders are crucial for epidemiology of mixtures.
In what follows, we examine a series of scenarios with different causal assumptions. We focus on estimating effects of individual mixture components from regression models under the assumptions of additivity (ignoring interaction) and no measurement error (often an issue in environmental epidemiology). Our interest is in potential biases in effect estimates for the individual components, not precision of the estimates or overall prediction of the outcome. Neither do we address whole mixture methods, an approach used in toxicology that sometimes applies in epidemiology (e.g., Simmons et al. 2004). We begin with a simple example with two mixture components and then build additional complexity including unmeasured confounding.
Confounding by Coexposures
Two well-known problems facing the epidemiologic analysis of mixtures are confounding by coexposures and colinearity (Braun et al. 2016). These two problems—and exposure variable selection—are linked and arise because subsets of exposures are often moderately to highly positively correlated due to shared causes, such as shared sources, exposure routes, metabolic pathways or other factors (Webster 2016).
Suppose for example that two exposure variables are both associated with the outcome in separate, single-exposure analyses and positively correlated with each other (we will discuss multiple exposures later). Figure 1 shows one (of many) DAGs that are consistent with these correlations. The two exposures and are correlated because of a shared cause U, assumed unknown or unmeasured. For example, the two exposures might be two PBDE congeners measured in serum with common exposure to house dust contaminated by a commercial flame retardant containing these compounds. Thus, although epidemiologists would typically use DAGs that focus on one exposure, epidemiologic analysis of mixtures would be interested in both. Suppose, as in Figure 1—and unknown to the analyst—that only causes the outcome Y. How well will an agnostic mixtures procedure fare in this case?
Although the structure of DAGs can yield qualitative answers, quantitative determination of bias requires more information. For simplicity we will assume throughout this paper that outcomes are continuous, associations are linear, and variables are standardized. We will apply multivariable linear regression because closed-form results are straightforward to derive. We distinguish between causal coefficients, (e.g., , the causal effect of a 1-unit change of on Y in the DAG of Figure 1), and simple bivariate correlation coefficients, (e.g., , the bivariate correlation between and in Figure 1). For simplicity, we will assume, unless otherwise noted, that the and are positive; this need not always be true, but it reduces the proliferation of cases (some care may be needed in extrapolating to other situations when inequalities are discussed). We derive the expected value of regression coefficients in the Supplemental Material, and summarize them in Table 1; in some cases, results can be read directly from DAGs.
Table 1.
Expected values of the single-exposure and mutually adjusted regression coefficients () for the exposure ()–outcome associations for the different DAGs.
| Exposure variable | Estimate | Expected valuesa | ||
|---|---|---|---|---|
| Single-exposure modelsb | Mutually adjusted for and | Mutually adjusted for , , and | ||
| DAG 1 | ||||
| 0 | ||||
| DAG 2a | ||||
| DAG 2b | ||||
| Z | ||||
| DAG 3a | ||||
| 0 | ||||
| DAG 3b | ||||
| DAG 4a | ||||
| DAG 4b | ||||
| DAG 5ac | ||||
| DAG 5bc | ||||
| DAG 5cd | ||||
| DAG 5dd | ||||
Note: DAG, directed acyclic graph.
For derivations, see Supplemental Material. Variables are assumed to be standardized. The c’s refer to causal effects; the r’s refer to correlations.
Effect estimates are derived from models that only include one exposure at a time.
In 5a, and in 5b, .
In 5c and 5d, is the bivariate correlation due to the common source U plus a correlation induced by U′.
Given the DAG in Figure 1, regressing Y on alone yields the correct causal coefficient (Table 1), because there are no other open pathways connecting and Y. Regressing Y on alone will be confounded through the open backdoor pathway . Suppose we regress Y on both and . The regression coefficients for both are unbiased: the estimate for () is still ; the estimate for () is now null because the backdoor pathway is blocked by conditioning on . Thus, to obtain an unbiased estimate for , both terms must be included in the model. If is high, then this colinearity can increase standard errors in real-world analyses and make the estimates unstable, although not biased in the statistical sense of expectation (Schisterman et al. 2017). In sum, the single-exposure analysis of was confounded by coexposure to , whereas the mutually adjusted analysis produces the correct results for both exposure variables, that is, the agnostic approach worked. The latter would also be true if both exposures caused the outcome.
Confounding by Unknown or Unmeasured Variables
Epidemiologists examining mixtures must, of course, also consider confounding by variables not considered exposures, including the potential impact of uncontrolled confounding. As discussed elsewhere (Weisskopf and Webster 2017), the vastly expanded ability to measure biomarkers of exposure is a boon to exposure science and environmental epidemiology, capable of providing assessment of a large number of exposures. Indeed this capability has spurred interest in the epidemiology of exposure mixtures. However, it raises the specter of uncontrolled confounding by novel or poorly understood behavioral or physiological factors that affect processes like how blood concentrations of a compound relate to levels in external media (air, dust, food, etc.) or how urinary concentrations relate to blood. For example, indoor dust containing PBDEs can get on hands and via hand-to-mouth activity into the body where it is measured in blood. Greater frequency of hand washing can reduce blood levels of PBDEs, presumably via reducing the ingestion of contaminated indoor dust (Watkins et al. 2011). If frequency of hand washing is also related to a given health outcome, it would introduce confounding into an analysis of blood PBDEs and that health outcome. Use of an external measure of exposure such as PBDE concentrations in dust would not be confounded by hand washing (although it may measure exposure less well).
In some cases confounding may be related to only one (or a subset) of the coexposures as shown in Figure 2a (some other possibilities will be discussed below). For example, serum concentrations of different compounds ( and ) that share a source could have high correlation, but there may be some enzymatic activity that affects the serum concentration of only one of the compounds (), but not the other. Suppose that such a factor U′ (e.g., genetic, physiological, behavioral) also affects the outcome directly. Again considering PBDEs, it is at least conceivable that an enzyme might affect serum levels of both thyroid hormones and preferentially one PBDE congener.
If U′ in Figure 2a is measured, then it can in principle be controlled, for example, by including it in the regression model. If U′ is unknown or unmeasured, then it will confound the association. In a single-exposure model, U′ will not confound the association given that is a collider on the pathway . However, is still confounded due to coexposure by via the pathway . Separate single-exposure analyses thus lead to biased effect estimates for both exposures.
One might expect mutual adjustment to at least partially mitigate the problem illustrated in Figure 2a. Alas! Regressing on both exposures (without U′ in the model) eliminates the coexposure confounding of by , but it creates a bias in the association because of conditioning on a collider (here ). As shown in Table 1, the direction of the effect estimate () is now negative, reversed from the single-exposure model estimate (provided that , ). This phenomenon is related to what has been called the reversal paradox in statistics (Hernán et al. 2011; Pearl 2014; Tu et al. 2008).
Perhaps even more unexpected is what happens to the effect estimate when we adjust for in Figure 2a (without U′ in the model). In the single-exposure model with only, the estimate () of the causal effect of () is biased due to confounding by U′ (the causal effect of U′ on times the causal effect of U′ on Y, that is, ). Thus, the biased estimate for equals (DAG 2a in Table 1). Mutually adjusting for amplifies the bias () by the factor
| [1] |
such that the total bias in the estimate of () is now equal to (see Supplemental Material, DAG 2a mutually adjusted estimate). The amplification factor [1] is always greater than one and becomes larger as increases, that is, the more correlated the components of the mixture are, the greater the bias. Thus, contrary to a perhaps naïve expectation, including both exposure variables in the model made results worse.
As an example, in DAG 2a suppose and are highly correlated (). For simplicity, assume that the causal effect of on Y, U′ on Y, and U′ on are all the same (). The association between and Y from a single-exposure model is confounded ( instead of 0.2) as is the association between and Y from a single-exposure model ( instead of 0). Adjusting for both exposures makes the confounding of much worse () and reverses the sign for (). Bias amplification has been noted before in statistics, although its dependence on uncontrolled confounding not always recognized (e.g., Hernán et al. 2011; Tu et al. 2008). But its importance was underappreciated in the causal inference literature until recently where it emerged in discussions of instrumental variables (Pearl 2010).
Instrumental Variables and Z-Amplification Bias
Instrumental variables are a statistical tool that can be extremely useful in causal inference and have been described in detail (Glymour 2006; Greenland 2000; Hernán and Robins 2006; Martens et al. 2006). Suppose an exposure ()–outcome (Y) relation is subject to unmeasured confounding (by U′). An ideal instrumental variable (Z) can eliminate this bias if it has the following properties: a) Z is associated with , b) Z does not cause Y except through , and c) Z does not share any causes with Y. A DAG that describes this situation is shown in Figure 2b. In instrumental variable analysis, Y is regressed on Z in place of . But suppose that we regress Y on both and Z. Recent literature has demonstrated that the bias of the effect estimate () due to U′ is amplified (termed Z-amplification bias) (Bhattacharya and Vogt 2007; Pearl 2010; Wooldridge 2009).
Although the model in Figure 2b is a canonical diagram of an instrumental variable, other models will also satisfy the requirements. For example, in our simple two-exposure mixture model of Figure 2a the coexposure meets the requirements for an instrumental variable for the association. Thus, using as an instrumental variable for would avoid the confounding caused by U′ in a direct analysis. But including both and in the same model (something not done in an instrumental variable analysis) causes bias amplification of the estimate. The algebraic solution for Figure 2b is the same as for Figure 2a with taking the place of (see Supplemental Material DAG 2a and 2b). Hence the bias amplification observed for Figure 2a is an extension of Z amplification bias. Because we are interested in the bias of the effect estimates of both exposures, we will use a broader term: coexposure amplification bias.
We assume that the variable U in Figure 2a—the common source of and —is unknown or unmeasured. If it were measured, it would meet the requirements of an instrumental variable for (taking the place of Z in Figure 2b), and could be used in instrumental variable analyses as described above to avoid confounding of by U′. Note that the structure of Figure 2a also describes Mendelian randomization in which a gene () in linkage disequilibrium with a gene (U) that affects (i.e., linked to via U rather than causally related) is used as an instrumental variable for .
Variations on Causation by the Exposures
We will now discuss some variations of the basic DAG of Figure 2a. As noted earlier, epidemiologists may not have sufficient information a priori to know exactly which, if any, of the exposures cause the outcome. Figure 3a shows a special case of Figure 2a where neither exposure causes the outcome, that is, . The main difference from the earlier case is that now the estimate for () from a single-exposure model is unbiased (and equal to zero), as there is no longer an open pathway through . The biases for the mutually adjusted model are the same as in Figure 2a: bias amplification for and a negative bias for (Table 1).
Figure 3.

Variations of the directed acyclic graph (DAG) in Figure 2a: differences in causation by exposures. a) Neither nor causes Y. Bias amplification still occurs. is the bivariate correlation coefficient for and . b) Both exposures cause the outcome. Here there is no optimal solution: Both single-exposure and mutually adjusted regression coefficients are biased.
Alternatively, both exposures may cause the outcome as shown in Figure 3b. In the single-exposure analyses, both exposures are confounded by the other; the estimate for () is also confounded by U′ (Table 1). Adjustment for both exposures produces the same biases as in Figure 2a. Which is preferred: the single-exposure or mutually adjusted estimates? For , the decision of whether or not to condition on requires balancing between the uncontrolled confounding bias through () versus the amplified confounding bias through U′. Controlling for would be warranted (i.e., confounding by is worse than the amplification of bias through U′ by conditioning on ) if
| [2] |
(See Supplemental Material, DAG 3b). Note that the right-most factor increases as increases; thus, as the correlation between and increases, it can get quite difficult for this inequality to favor adjustment for . However, a strong causal link between and the outcome (a large ) would favor including in the model with . Unfortunately, the correlation between coexposures can often be quite high, typically driven by shared sources for the exposures. The same condition [2] also implies that the regression effect estimate for () from a model mutually adjusted for will be positive but biased toward zero, whereas the single-exposure model estimate for is biased upward (see Supplemental Material, DAG 3b). Similar results have been derived for imperfect instrumental variables (Pearl 2010).
More than Two Exposures
So far we have examined two exposures, but mixtures can obviously be much more complicated. For example, at least four PBDE congeners have high detection rates in human serum from the United States and are positively correlated with each other (Makey et al. 2014; Sjödin et al. 2008).
Correlation of exposures due to a shared cause.
Suppose for simplicity that we are examining three positively correlated exposures, that is, , , are all positive as a result of a shared source, U (Figure 4a). Table 1 summarizes the results for separate single-exposure analyses, mutual adjustment for combinations of two-exposure variables ( and or ) and mutual adjustment for all three. Unfortunately, mutual adjustment for all three exposure variables further amplifies the bias of () beyond just adjusting for one ( or ). The amplification factor is now the determinant of the exposure correlation matrix. When mutually adjusting for all three exposures, the direction of bias for () and () can be in either direction, depending on the relative magnitudes of , , and (see Supplemental Material, DAG 4a).
Figure 4.

Variations of the directed acyclic graph (DAG) in Figure 2a: three exposures. Bivariate correlations between exposures are for , for , and for . a) Assume all three exposures are (positively) correlated due to causation by the same source. b) There are two different sources and no correlation between and : . This simplifies the bias equations. In both cases, the bias amplification for the association caused by adjusting for one other exposure ( or ) will be further amplified when adjusting for all three. This is also true for the and associations for 4b.
Correlation of exposures with separate causes.
Figure 4b presents a DAG for a different kind of mixture: exposure to comes about via two different processes ( and ), one associated with and the other associated with . Unlike Figure 4a, and are not associated with each other. Although this situation should not occur for compounds with the same source, it is not impossible more generally. For example, people can be exposed to PBDEs via both indoor exposure and diet (Wu et al. 2007). If these sources are not associated with each other in a population [e.g., not related via socioeconomic status (SES), or rendered unrelated by appropriate control for SES], then a PBDE congener might be associated with different groups of compounds, one group via indoor exposure and another group via diet. As shown in Table 1 for DAG 4b, under these conditions adjusting for an additional exposure will always increase the bias amplification of (); the bias of () will always become even more negative when we further adjust for (and vice versa).
One can imagine more complex scenarios. For example, suppose we add an arrow (causal link) from to Y in Figure 4b. Similar to what we found for Figure 3b, the decision to adjust the analysis of the association for and requires balancing uncontrolled confounding through versus the possibility of the confounding bias through U′ (see Supplemental Material, DAG 4a and 4b).
Different Types of Unmeasured Confounding
In Figures 2–4, the unmeasured variable U′ introduces confounding to only one exposure. Although potentially important because of coexposure amplification bias, other causal structures should be considered; some may be more common.
Confounding of both exposure variables by a shared cause.
Suppose as in Figure 5a that U′ affects the common source (U) of both exposures. For example, SES might be related to both the health outcome and to purchasing decisions that affect exposure to sources of the PBDE mixture. In this case, including the coexposure in the model with is beneficial because conditioning on partially conditions on U′ (conditioning on a descendant partially conditions on the parent variable) and thus it reduces confounding of () by U′ (Greenland 1980; Ogburn and Vanderweele 2013) (Table 1; see also Supplemental Material, DAG 5a). (This is true regardless of whether causes Y directly). Similarly, adjusting for reduces the bias of () caused by U′ (unlike Figure 2a, is no longer a collider between and U′).
Figure 5.

Variations of the directed acyclic graph (DAG) in Figure 2a: U′ affects both exposures. a) U′ affects the exposures via the common source U. b) U′ and U are combined. c) U′ and U are independent; both affect both exposures. d) To 5c, this case adds a causal link from to Y (parallel to case 3b). In a and b, the casual coefficients linking the common source to and are explicit. In c and d, is the bivariate correlation due to the common source U plus a correlation induced by U′.
A slight variation on the example of Figure 5a is shown in Figure 5b, where the same variable (U′) that causes the outcome also directly causes the correlation between and . Adjustment for both and is again beneficial. The algebraic solution is a simplified version of that for Figure 5a (Table 1; see also Supplemental Material, DAG 5b). In air pollution epidemiology different air pollutants, for example, (particulate matter micrometers in diameter) and (nitrogen dioxide), are often correlated because some of the drivers of those pollutants are the same, for example, temperature. Let in Figure 5b stand for , for , and U′ for temperature. If temperature is associated with the outcome (other than through ), then confounding of the association may exist. Although an oversimplified example—current air pollution studies typically control for temperature—we use it to illustrate our point, which would apply to any such uncontrolled variable, even ones not recognized. Assuming temperature is not controlled, adjusting for does not cause coexposure amplification bias. As depicted in Figure 5b, () functions as a proxy for the unmeasured variable U′. Thus, instead of amplifying bias, adjustment for in this case helps control confounding of the association through U′.
Confounding of both exposure variables by two shared causes.
Both types of U variables may independently affect the two exposures as illustrated in Figure 5c. In this case, the bias amplification of the association () introduced by adjusting for that we discussed for Figure 2a is multiplied by the term
| [3] |
such that the total bias in the estimate of () is now equal to
| [4] |
(DAG 5c in Table 1; see also Supplemental Material, mutually adjusted estimate). In this case is the marginal bivariate correlation between and , which is not quite the same as the earlier : Now the correlation between and depends on both and . If U′ does not affect (), then this multiplicative term reduces to [1].
When U′ affects both and as in Figure 5c, the effect of the bias multiplier [3] is trickier to intuit, especially given that , and are interrelated. In many cases, adjustment for will be beneficial: This occurs if [3] is positive but less than 1, reducing overall bias for the reasons described for Figure 5a. However, the effect of [3] could make the bias amplification worse: If is positive and and are of opposite signs, then the bias amplification of [1] will be increased given that [3] will be even larger than 1. The same condition will lead to an even more negative bias for the coefficient (see Supplemental Material, DAG 5c). This scenario is not far-fetched. In a study of children 12–36 months of age in North Carolina (Stapleton et al. 2012), the sum of the highly correlated PBDE congeners BDE 47, BDE 99, and BDE 100 () in children’s sera was positively correlated with BDE 153. In contrast, SES factors like parents’ education were negatively correlated with , but positively correlated with BDE 153. Suppose, for example, that the SES factors were also related to an outcome of interest. If we include both and BDE 153 in the same model of that outcome, but not the SES factors, then the bias of the effect estimates for and BDE 153 by the SES factors would both be more amplified than in Figure 2a. Again, this bias amplification will occur independent of whether there are direct causal effects of on Y.
If there are true causal effects of both exposure variables on Y (Figure 5d), then whether or not to include a second exposure (e.g., ) in a model to estimate the effect of the other (e.g., ) requires balancing of amplified confounding through U′ versus uncontrolled confounding through similar to what was discussed above for the inequality in [2] (see Supplemental Material, DAG 5d).
Note that in Figures 2–5, U′ is treated as unknown or unmeasured. In practice, if such U′ variables are known and measured (e.g., health behaviors, SES), it is always best to adjust for them. Unfortunately, they are not always measured or even known.
What Is to Be Done? Some Considerations for the Epidemiology of Exposure to Mixtures
For all of the DAGs we have shown, crude associations would be found between all exposures and the outcome in single-exposure models, with the exception of in Figure 3a. Thus, there is no empirical way to determine the true underlying causal structure—and the implications it has for bias—on the basis of associations alone. Construction of a DAG (or a set of plausible DAGs) ultimately requires content-specific knowledge. As such knowledge does not guarantee construction of the correct DAG, it can be useful to construct more than one DAG as a way of understanding how results from the same model would be interpreted under different assumptions of relations between variables. One should interpret the regression model results based on a DAG, rather than constructing a DAG based on results of regression models. Our most basic advice is a familiar one: Proper interpretation of results depends on assumptions about causation (Greenland et al. 1999; Hernán et al. 2002, 2011). But this advice is perhaps even more important for mixtures epidemiology because of bias amplification.
We therefore advise caution about blindly including multiple exposure variables in a model. Sometimes, including multiple variables is appropriate: for example, if the causal structure corresponds with Figure 1a. Also, if the causal structure corresponds with Figure 5a,b, adjustment would help mitigate the effect of the unknown confounding through U′. But in other cases, for example, scenarios represented by Figures 2a or 4b, adjustment makes things worse; whereas in still other cases, for example, scenarios represented by Figures 3b or 5c,d, the consequences of adjustment vary.
There are several key general considerations. First, epidemiologists examining exposure mixtures need to consider the impact of possible residual confounding by unmeasured variables. To the extent that variables that introduce confounding to an exposure–outcome relation (the U′ variables in the figures) are known and measured, control of them should be done. As shown here, it makes a difference if such variables (U′) affect only one exposure (Figures 2–4)—where they can lead to bias amplification—or whether they affect both (Figure 5). We hypothesize that similar considerations will apply to situations with larger numbers of exposures where only a subset is affected. Answering such questions for physiological factors may require detailed input from toxicology and other disciplines. We suspect that variables such as SES that affect exposure to a common source (e.g., Figure 5a) may be easier to understand and control. Exploration of these different scenarios appears to be a very important line of research. We also urge epidemiologists studying exposure mixtures to consider use of quantitative bias assessment to explore the potential impact of unknown confounding (Lash et al. 2011). The results we present may provide a useful starting place.
Second, the problem of coexposure amplification bias can sometimes be avoided by using an instrumental variable to measure exposure. As noted earlier in this paper, the vastly increased use of exposure biomarkers may bring with it the threat of unknown confounding (e.g., behavioral, physiological). Measurement of the common source variable U (e.g., in Figure 2a), if external, would avoid confounding by physiology and its amplification. As we state elsewhere (Weisskopf and Webster 2017), use of such exposure variables may sometimes pose tradeoffs between bias due to confounding and bias due to exposure measurement error.
Third, the correlation structure of the exposures matters, whether it is the strength of the correlation between two exposures (which influences the degree of bias amplification in Figure 2a) or the pattern of correlations when there are more (e.g., Figure 4). Although we have focused on nonnegative correlations in this paper—because they are common in environmental epidemiology due to shared sources—negative correlations are possible, for example, if one compound is a replacement for or a metabolite of another. Although the equations in Table 1 still apply, the direction of inequalities may change, for example, [2] (see Supplemental Material DAG 2a).
Fourth, it makes a difference how many exposures cause the outcome, one (e.g., Figure 2a) or more (e.g., Figure 3b). Unfortunately, we often do not know this a priori. Even if we did, neglecting noncausal exposures is not always the best strategy. For example, in Figure 2a, could be used as an instrumental variable for , avoiding the confounding of by U′. In Figure 3b when both and cause the outcome Y, the choice between adjustment or not poses a tradeoff: The better solution depends on the parameters in inequality [2], which unfortunately are typically not known.
We explored the implications of the combination of confounding and highly correlated exposures in models using linear models with standardized variables. The assumption of standardized variables can be relaxed by expanding the derivations in the Supplemental Material (see the derivation for Figure 1). Bias amplification has been explored in nonlinear models in the context of instrumental variables (Pearl 2010). More research is needed to explore the implications for nonlinear models (e.g., logistic regression) as well as interactions between exposure variables.
We analyzed the various causal scenarios using multivariable linear regression because derivation of closed-form results is relatively straightforward. An important research question is the degree to which other proposed mixtures methods (e.g., Taylor et al. 2016) have similar properties.
Lastly, as any field advances, the understanding of an exposure–outcome relation, and of variables that can potentially introduce confounding, improves. With new information past results must be reevaluated with an eye towards possible confounding that may have not been appreciated at the time of the original study. When doing this, the possibility that coexposure amplification bias contributed to past findings must be kept in mind.
Conclusions
In environmental epidemiology of mixtures, some exposures are often highly correlated, for example, because of shared sources or metabolic pathways. In the absence of unmeasured confounding, including correlated components of a mixture in the same regression model can in principle avoid confounding by coexposures and identify the independent effect of each component; colinearity can make this difficult in practice because of effects on precision. However, if there is unmeasured confounding of some individual components of the mixture, then including correlated exposures in the same regression model can in many cases increase the confounding, a problem we have called coexposure amplification bias. Identification and control of the unknown confounders is one remedy. Another option is the use of instrumental variables, or proxy exposures that approach instrumental variables (Weisskopf and Webster 2017). Other study designs (e.g., panel studies, case-crossover studies) also can avoid certain types of confounding. Thus, careful consideration of the study setting and choice of study design can potentially eliminate confounding even by unknown or unmeasured variables.
Progress on epidemiology of exposure to mixtures will greatly benefit from interdisciplinary research. The correlations between exposures are one determinant of how coexposure amplification bias will affect results. Detailed exposure assessment studies are needed to understand the strength and basis for correlations between exposures, including common sources of exposure. It may sometimes be useful to treat well-defined mixtures as a whole rather than as components. Physiological and toxicological information will assist in the development of causal models that are necessary for proper interpretation of regression results. Researchers developing statistical approaches to identify critical exposures out of many—a key goal of the epidemiologic analysis of exposure mixtures—need to consider the possibility that including many correlated exposures simultaneously in analytic models could make bias worse.
The problem of coexposure amplification bias is not, however, restricted to toxicants in an exposure mixture. Any variables included in a model could result in this problem, and in fact this issue has been considered in the context of adjusting for propensity scores that often include a wide variety of variables (Rosenbaum 2002; Rubin 2007, 2009; Weitzen et al. 2004). Nonetheless, environmental toxicant exposure mixtures often have much higher correlations between exposures than many other variables, potentially making this issue particularly relevant for such exposure settings.
Supplemental Material
Acknowledgments
We thank the reviewers for many helpful comments. This work was supported in part by National Institutes of Health (NIH) grants P42 ES007381, R01ES028800, R01ES027813, R01ES024165, R21NS099910, and P30 ES000002. R.M.S. was supported by NIH grant T32 NS 048005.
References
- Bhattacharya J, Vogt WB. 2007. Do instrumental variables belong in propensity scores? (Tech Rep NBER Technical Working Paper 343) . Cambridge, MA:National Bureau of Economic Research. [Google Scholar]
- Braun JM, Gennings C, Hauser R, Webster TF. 2016. What can epidemiological studies tell us about the impact of chemical mixtures on human health? Environ Health Perspect 124(1):A6–A9, PMID: 26720830, 10.1289/ehp.1510569. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glymour MM. 2006. Natural experiments and instrumental variable analyses in social epidemiology. In: Methods in Social Epidemiology. Oakes JM, Kaufman JS, eds San Francisco, CA:John Wiley & Sons, Inc, 429–468. [Google Scholar]
- Glymour M, Greenland S. 2008. Causal Diagrams. In: Modern Epidemiology. 3rd Edition, Part 2. Rothman KJ, Greenland S, Lash TL, eds Philadelphia, PA:Wolters Kluwer Health/Lippincott Williams & Wilkins, 183–209. [Google Scholar]
- Greenland S. 1980. The effect of misclassification in the presence of covariates. Am J Epidemiol 112(4):564–569, PMID: 7424903, 10.1093/oxfordjournals.aje.a113025. [DOI] [PubMed] [Google Scholar]
- Greenland S. 2000. An introduction to instrumental variables for epidemiologists. Int J Epidemiol 29(4):722–729, PMID: 10922351, 10.1093/ije/29.4.722. [DOI] [PubMed] [Google Scholar]
- Greenland S, Pearl J, Robins JM. 1999. Causal diagrams for epidemiologic research. Epidemiology 10(1):37–48, PMID: 9888278, 10.1097/00001648-199901000-00008. [DOI] [PubMed] [Google Scholar]
- Hernán MA, Clayton D, Keiding N. 2011. The Simpson's paradox unraveled. Int J Epidemiol 40(3):780–785, PMID: 21454324, 10.1093/ije/dyr041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hernán MA, Hernández-Díaz S, Werler MM, Mitchell AA. 2002. Causal knowledge as a prerequisite for confounding evaluation: an application to birth defects epidemiology. Am J Epidemiol 155(2):176–184, PMID: 11790682, 10.1093/aje/155.2.176. [DOI] [PubMed] [Google Scholar]
- Hernán MA, Robins JM. 2006. Instruments for causal inference: an epidemiologist's dream? Epidemiology 17(4):360–372, PMID: 16755261, 10.1097/01.ede.0000222409.00878.37. [DOI] [PubMed] [Google Scholar]
- Hernán MA, Robins JM. 2017. Causal Inference. Boca Raton:Chapman & Hall/CRC, forthcoming. [Google Scholar]
- Hernández-Diaz S, Schisterman EF, Hernán MA. 2006. The birth weight “paradox” uncovered? Am J Epidemiol 164(11):1115–1120, PMID: 16931543, 10.1093/aje/kwj275. [DOI] [PubMed] [Google Scholar]
- Lash TL, Fox MP, Fink AK. 2011. Applying Quantitative Bias Analysis to Epidemiologic Data. New York, NY:Springer Science & Business Media. [Google Scholar]
- Makey CM, McClean MD, Braverman LE, Pearce EN, He XM, Sjödin A, et al. 2016. Polybrominated diphenyl ether exposure and thyroid function tests in North American adults. Environ Health Perspect 124(4):420–425, PMID: 26372669, 10.1289/ehp.1509755. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Makey CM, McClean MD, Sjödin A, Weinberg J, Carignan CC, Webster TF. 2014. Temporal variability of polybrominated diphenyl ether (PBDE) serum concentrations over one year. Environ Sci Technol 48(24):14642–14649, PMID: 25383963, 10.1021/es5026118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martens EP, Pestman WR, de Boer A, Belitser SV, Klungel OH. 2006. Instrumental variables: application and limitations. Epidemiology 17(3):260–267, PMID: 16617274, 10.1097/01.ede.0000215160.88317.cb. [DOI] [PubMed] [Google Scholar]
- Ogburn EL, Vanderweele TJ. 2013. Bias attenuation results for nondifferentially mismeasured ordinal and coarsened confounders. Biometrika 100(1):241–248, PMID: 24014285, 10.1093/biomet/ass054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pearl J. 2010. On a class of bias-amplifying variables that endanger effect estimates. In: Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence (UAI 2010) Grünwald P, Spirtes P, eds. 8–11 July 2010, Corvallis, OR. Corvallis, OR:Association for Uncertainty in Artificial Intelligence, 425–432. [Google Scholar]
- Pearl J. 2014. Comment: understanding Simpson’s paradox. Am Stat 68(1):8–13, 10.1080/00031305.2014.876829. [DOI] [Google Scholar]
- Rosenbaum PR. 2002. Observational Studies. 2nd Edition. New York, NY:Springer Verlag, Publishers. [Google Scholar]
- Rubin DB. 2007. The design versus the analysis of observational studies for causal effects: parallels with the design of randomized trials. Stat Med 26(1):20–36, PMID: 17072897, 10.1002/sim.2739. [DOI] [PubMed] [Google Scholar]
- Rubin DB. 2009. Should observational studies be designed to allow lack of balance in covariate distributions across treatment groups? Stat Med 28(9):1420–1423, 10.1002/sim.3565. [DOI] [Google Scholar]
- Schisterman EF, Perkins NJ, Mumford SL, Ahrens KA, Mitchell EM. 2017. Collinearity and causal diagrams: a lesson on the importance of model specification. Epidemiology 28(1):47–53, PMID: 27676260, 10.1097/EDE.0000000000000554. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simmons JE, Teuschler LK, Gennings C, Speth TF, Richardson SD, Miltner RJ, et al. 2004. Component-based and whole-mixture techniques for addressing the toxicity of drinking-water disinfection by-product mixtures. J Toxicol Environ Health A 67(8–10):741–754, PMID: 15192866, 10.1080/15287390490428215. [DOI] [PubMed] [Google Scholar]
- Sjödin A, Wong LY, Jones RS, Park A, Zhang Y, Hodge C, et al. 2008. Serum concentrations of polybrominated diphenyl ethers (PBDEs) and polybrominated biphenyl (PBB) in the United States population: 2003–2004. Environ Sci Technol 42(4):1377–1384, PMID: 18351120, 10.1021/es702451p. [DOI] [PubMed] [Google Scholar]
- Stapleton HM, Eagle S, Sjödin A, Webster TF. 2012. Serum PBDEs in a North Carolina toddler cohort: associations with handwipes, house dust, and socioeconomic variables. Environ Health Perspect 120(7):1049–1054, PMID: 22763040, 10.1289/ehp.1104802. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor KW, Joubert BR, Braun JM, Dilworth C, Gennings C, Hauser R, et al. 2016. Statistical approaches for assessing health effects of environmental chemical mixtures in epidemiology: lessons from an innovative workshop. Environ Health Perspect 124(12):A227–A229, PMID: 27905274, 10.1289/EHP547. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tu YK, Gunnell D, Gilthorpe MS. 2008. Simpson’s Paradox, Lord’s Paradox, and suppression effects are the same phenomenon – the reversal paradox. Emerg Themes Epidemiol 5:2, PMID: 18211676, 10.1186/1742-7622-5-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watkins DJ, McClean MD, Fraser AJ, Weinberg J, Stapleton HM, Sjödin A, et al. 2011. Exposure to PBDEs in the office environment: evaluating the relationships between dust, handwipes, and serum. Environ Health Perspect 119(9):1247–1252, PMID: 21715243, 10.1289/ehp.1003271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Webster TF. 2016. Analyzing patterns of co-exposure in exposure space. In: International Society for Exposure Science 2016 Annual Meeting 9–13 October 2016, Utrecht, Netherlands. Utrecht, Netherlands:International Society of Exposure Science (ISES), 201. [Google Scholar]
- Weisskopf MG, Webster TF. 2017. Trade-offs of personal versus more proxy exposure measures in environmental epidemiology. Epidemiology 28(5):635–643, PMID: 28520644, 10.1097/EDE.0000000000000686. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weitzen S, Lapane KL, Toledano AY, Hume AL, Mor V. 2004. Principles for modeling propensity scores in medical research: a systematic literature review. Pharmacoepidemiol Drug Saf 13(12):841–853, PMID: 15386709, 10.1002/pds.969. [DOI] [PubMed] [Google Scholar]
- Wooldridge JM. 2009. “Should instrumental variables be used as matching variables?” (Technical Report). East Lansing, MI:Michigan State University. [Google Scholar]
- Wu N, Herrmann T, Paepke O, Tickner J, Hale R, Harvey LE, et al. 2007. Human exposure to PBDEs: associations of PBDE body burdens with food consumption and house dust concentrations. Environ Sci Technol 41(5):1584–1589, PMID: 17396645, 10.1021/es0620282. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.