

Abstract
Introduction:
Over the past 2 decades, drug-related deaths have grown to be a major U.S. population health problem. County-level differences in drug-related mortality rates are large. The relative contributions of social determinants of health to this variation, including the economic, social, and healthcare environments, are unknown.
Methods:
Using data from the U.S. Centers for Disease Control and Prevention Multiple-Cause of Death Files (2006–2015, analyzed in 2017), U.S. Census Bureau, U.S. Department of Agriculture Economic Research Service, Agency for Healthcare Research and Quality, and Northeast Regional Center for Rural Development, this paper modeled associations between county-level drug-related mortality rates and economic, social, and healthcare environments. Spatial autoregressive models controlled for state fixed effects and county demographic characteristics.
Results:
The average county-level age-adjusted drug-related mortality rate was 16.6 deaths per 100,000 population (2006–2015), but there were substantial geographic disparities in rates. Net of state effects and demographic characteristics, average mortality rates were significantly higher in counties with greater economic and family distress and in counties economically dependent on mining. Average mortality rates were significantly lower in counties with a larger presence of religious establishments, a greater percentage of recent in-migrants, and counties with economies reliant on public (government) sector employment. Healthcare supply factors did not contribute to between-county disparities in mortality rates.
Conclusions:
Drug-related mortality rates are not randomly distributed across the U.S. Future research should consider the specific pathways through which economic, social, and healthcare environments are associated with drug-related mortality.
INTRODUCTION
From 2006 to 2015, a total of 515,060 people in the U.S. died from drug overdoses and other drug-related causes.1 A large share (42.3%) involved opioids, but other drugs, including benzodiazepines (12.1%) and cocaine (12%) also contributed.1 The economic, social, and emotional tolls of these deaths are substantial, but some parts of the U.S. are bearing heavier burdens than others.2–5 Empirical explanations for this geographic heterogeneity are lacking. Most existing studies of drug mortality examine temporal trends rather than geographic differences,3–7 and those that examine geographic disparities are largely descriptive, emphasizing differences in population composition (e.g., age, race) rather than the “fundamental” social determinants of health8 known to contribute to geographic differences in other types of mortality and morbidity.9–13
This study employs the WHO social determinants of health14 and socioecological15 frameworks to develop hypotheses about factors that contribute to between-county disparities in drug-related mortality rates. Social determinants of health are the structural conditions in which populations live, work, and socialize that influence stress, relationships, health behaviors, and mortality, including economic resources, the social environment, and the healthcare infrastructure. Based on these frameworks, this study tests the hypothesis that counties’ economic, social, and healthcare environments contribute to between-county variation in drug-related mortality rates.
Environmental features can be derived or integral.16 Derived measures capture aggregate characteristics of individuals, families, and households, reflecting county composition. But they also shape residents’ health environments. Economic disadvantages like unemployment, poverty, low education, and housing challenges are associated with increased risk of family conflict, social isolation, stress, and substance misuse.17–22 Concentrated economic disadvantage can contribute to collective frustration and hopelessness,23 out-migration, community disinvestments, and social disorders like substance misuse.23–30 Therefore, counties with greater economic, housing, and family distress should have higher drug-related mortality rates.
Integral measures capture structural (contextual) characteristics external to individuals. Features like the healthcare environment and opportunities for social interaction are inversely associated with all-cause mortality,9–12 whereas unstable labor markets and manually labor intensive occupations have been found to be associated with mental health problems, injuries, and chronic pain.13,14,20 Studies have yet to examine whether these same factors contribute to geographic differences in drug-related mortality rates. Counties reliant on heavy manual labor industries, like mining and manufacturing, that have suffered substantial employment downturns and wage stagnation in recent decades, may have higher drug-related mortality rates.22,33 Opportunities for social interaction through community associations, recreational facilities, and churches facilitate trust, goodwill, and social cohesion, which may buffer against isolation, depression, and substance misuse.31,32 Therefore, counties with more of these social capital–promoting establishments may have lower drug-related mortality rates. Access to physical health care may help protect against injury risk or long-term chronic pain and disability for which opioids are commonly prescribed. Access to mental health care may facilitate necessary substance abuse treatment. Counties lacking these services may have higher drug-related mortality rates.
Ultimately, distinguishing which (if any) of these social determinants of health contribute to geographic disparities in drug-related mortality is an essential step toward developing place-level targeted interventions. Therefore, these analyses test associations between county-level social determinants of health and drug-related mortality rates.
METHODS
Study Sample
A pooled cross-section of county-level mortality rates (2006–2015) were extracted from the U.S. Centers for Disease Control and Prevention’s Wide-Ranging Online Data for Epidemiologic Research (WONDER) multiple cause-of-death (MCD) files.1 Categorization of drug-related deaths used ICD-10 codes including: accidental poisoning, intentional self-poisoning, and poisoning of undetermined intent by exposure to drugs, drug-induced diseases, drugs in the blood, and mental/behavioral disorders due to drugs. Appendix A provides specific codes.
There are practical and conceptual reasons for using MCD versus underlying cause-of-death files. Data suppression for counties with <10 deaths results in suppressed mortality rates for more than one third of counties in the underlying cause-of-death data, even when pooling 10 years of data. Suppressed counties have smaller populations. Excluding them would limit study generalizability and could bias results. Because all contributing causes of death are included in the MCD files, fewer counties have suppressed mortality rates in the MCD data (note that deaths were counted only once, even if multiple drug-related causes contributed to the death). Second, using MCD data reduces risk of undercounting because of misclassification, which has been especially pronounced for drug-related suicides.34,35 Third, identifying a single factor as the underlying cause of death is an oversimplification of the clinical and pathologic processes that led to death36 and ignores the possibility that the death may not have occurred if drugs were not involved (e.g., motor vehicle accident).
Measures
County-level predictors were selected based on the social determinants of health14 and socioecological frameworks.10,15 When possible, analyses used measures for the working-age population because drug-related mortality rates are highest in that group, and that age group makes the largest contributions to county economies. Data availability prevented matching age ranges for some variables. Analyses used measures that captured conditions pre-2006 to reduce reverse causality bias (i.e., possibility that high drug abuse rates created the county-level conditions used as predictors). Sensitivity analyses were conducted using variables that captured more recent county conditions.
The economic environment was measured with indicators for county economic distress, housing distress, and labor market structure. Economic distress included the U.S. Census 200037 percentage aged 25–54 years in poverty, aged 25–54 years unemployed/not in labor force, aged 21–64 years with disability affecting employment, aged ≥25 years with less than 4-year college degree, households with supplemental security income, households with public assistance income, gini coefficient of income inequality, and aged 18–64 years without health insurance in 2008.38 Housing distress included the percentage of vacant housing units and renter-occupied housing units spending >30% of income on rent in 2000.37 Industrial dependence came from the U.S. Department of Agriculture Economic Research Service’s economic dependency typology that categorizes counties as dependent upon manufacturing, mining, farming, services, public sector (government), or nonspecialized based on the sector’s contribution to the county’s economy.39 Social environment was measured with family distress (residents aged ≥15 years separated/divorced and single-parent families in 2000),37 percentage of residents living in a different county 5 years earlier in 2000,37 and social capital–promoting establishments (religious establishments, nonprofit organizations, membership associations, and sports/recreation establishments per 10,000 population) in 2005.40 The social capital measures were not normally distributed (even when logged), so they were recoded into quartiles. Healthcare environment included indicators from the Area Health Resource Files designating the county as a primary healthcare or mental healthcare professional shortage area in 2000–2004 and number of active patient care physicians per 10,000 population in 2000.41 Ideally, analyses would have included the supply of mental health and substance abuse professionals/facilities, but those data are not available for all counties for the necessary years. The Area Health Resource Files capture county-level counts of specific types of healthcare providers (e.g., psychiatrists, psychologists), but prior to the 2013–2014 Area Health Resource Files release, counties with missing values were designated with values of zero. Therefore, users are unable to identify which counties have missing counts versus which counties truly have none.
Control variables were demographic factors likely to be related to geographic differences in mortality rates, based on existing literature4,42–44: metropolitan status, racial composition (percentage non-Hispanic black, Hispanic, American Indian), age composition (percentage aged ≥65 years), and percentage of residents in the military/veterans.11,12 The racial composition variables were highly skewed, leading to heteroscedasticity, so they were recoded into quartiles. All continuous variables were standardized (mean 0, SD=1) to enable comparisons of regression coefficient magnitude across predictors. Appendix B provides details about all data sources.
Statistical Analysis
Analyses included 3,106 of the 3,143 U.S. counties. All counties in Alaska (29) and Hawaii (5) and Loving County, Texas were excluded due to data availability. Broomfield County, Colorado and Bedford City, Virginia were excluded due to county boundary changes. Mortality data were suppressed for 623 counties (20%). Therefore, analyses used multiple imputation with the Markov Chain Monte Carlo method (Appendix C).45 Sensitivity analyses compared results from multiple imputation models with those from models that excluded suppressed counties (i.e., complete case analysis). Minor differences between these models are described in Appendix D.
Exploratory spatial data analysis revealed significant spatial autocorrelation in mortality rates (Moran’s I of 0.560). Generalized spatial two-stage least squares autoregressive models were used to model logged county-level mortality rates. These models accounted for correlated residuals between neighboring counties by fitting the model with a correlation parameter of the residuals. The spatial weight matrix was based on first order queens contiguity. Spatial lag models for the dependent variable and continuous independent variables were also tested, but the spatial lag coefficients were not significant in the fully adjusted models.
The first stage of analyses involved separately regressing each predictor on the logged mortality rate to assess each variable’s independent relationship with mortality. Models controlled for state fixed effects to adjust SEs that are downwardly biased because of the clustering of counties within states and account for unobserved state-level differences in factors that may influence drug mortality. Several variables were strongly correlated, preventing their inclusion in multivariate regression models (Appendix E). Confirmatory factor analysis was used to create factor-weighted indices combining the economic distress variables (α=0.891) and family distress variables (α=0.784). Factor loadings are presented in Appendix F. Maps showing the geographic distribution of index values are presented in Appendix G Variables that did not load highly onto factors (≥0.40) and were not collinear with other variables were included in the regression models as individual predictors. The second stage of analysis involved fitting a multivariate regression model that simultaneously incorporated all three groups of predictors (economic, social, health care), while controlling for demographic characteristics and state fixed effects.
Sensitivity analyses included models on only nonsuppressed counties (n=2,484) and models with temporally overlapping predictors from the 2010–2014 American Community Survey rather than the temporally prior variables from 2000. Coefficients for all models are presented in Appendix D.
Statistical significance is reported at p<0.05. Regression analyses were conducted in Stata/SE, version 15.1. Analysis of secondary data is exempt from IRB review by Syracuse University.
RESULTS
The mean county-level age-adjusted drug-related mortality rate (AAMR) 2006–2015 was 16.6 deaths per 100,000 population (min=2.8, max=102.5). There was significant spatial variation in rates (Figure 1). A Local Indicator of Spatial Association map revealed high mortality rate clusters in Appalachia, Oklahoma, parts of the Southwest, and northern California. Low mortality rate clusters were observed in parts of the Northeast, the Black Belt, Texas, and the Great Plains. There was also substantial within-state variation (Figure 2), with West Virginia having the largest disparity between the highest and lowest rate counties. A null multilevel model with counties nested within states was run to assess how much variation in rates was due to state versus county-level differences. Imputation models produced an average intra-class correlation coefficient of 0.32, indicating that about a third of county-level variation in drug mortality rates was due to differences between states.
Figure 1.
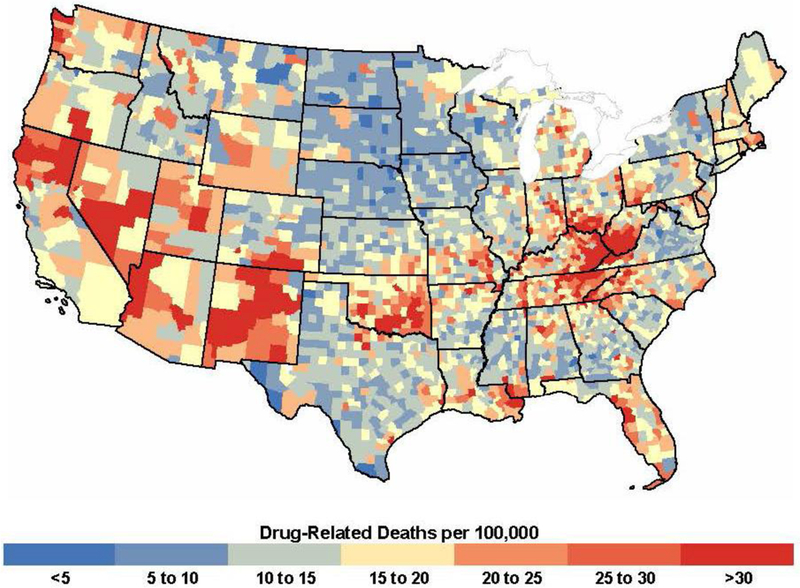
County-level age-adjusted drug-related mortality rates, 2006–2015.
Figure 2.
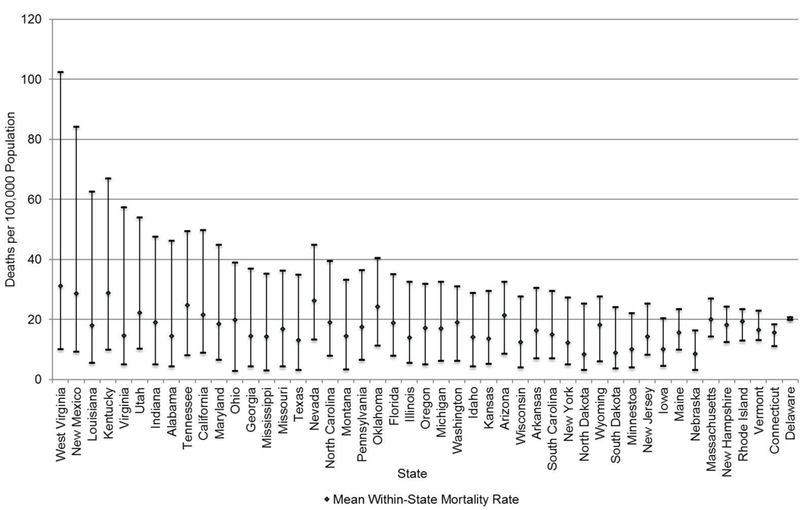
Within-state range between counties with highest and lowest drug-related mortality rates, 2006–2015.
Note: States are ordered by magnitude of difference between highest and lowest county mortality rates. Line caps represent county maximum and minimum drug-related mortality rates in each state.
Table 1 shows that nearly all of the hypothesized economic and social variables were significantly associated with county-level drug mortality rates, net of state fixed effects. The healthcare environment variables were not statistically significant.
Table 1.
Variables Included in Regression Analysis With Summary Statistics and Bivariate Regression Results
| Summary statistics | Bivariate regression results | |||||
|---|---|---|---|---|---|---|
| Variable | ||||||
| Mean (SD) | Range | Est. (SE) | p-value | |||
| Drug-related mortality rate (deaths per 100,000) | 16.6 (8.9) | 2.8–102.5 | NA | |||
| Drug-related mortality rate, logged | 2.7 (0.5) | 1.0–4.6 | NA | |||
| Economic environment | ||||||
| Economic distress index | 0.0 (4.5) | –11.7–23.8 | 11.53 (1.11) | <0.001 | ||
| Population below the poverty line, age 25–54 years, % | 11.3 (5.7) | 1.7–53.1 | 8.57 (1.06) | <0.001 | ||
| Civilian non-institutionalized population unemployed or not in labor force, age 25–54 years, % | 24.4 (8.2) | 5.3–66.3 | 5.70 (1.06) | <0.001 | ||
| Civilian non-institutionalized population with a work disability, age 21–64 years, % | 13.0 (3.6) | 3.7–33.9 | 9.60 (1.01) | <0.001 | ||
| Population with <4-year college degree, age >25 years, % | 83.5 (7.8) | 36.3–95.1 | 6.64 (0.85) | <0.001 | ||
| Households with supplemental security income, % | 5.1 (2.7) | 0–26.6 | 10.81 (1.16) | <0.001 | ||
| Households with public assistance income, % | 3.4 (1.9) | 0–18.6 | 9.53 (0.97) | <0.001 | ||
| Population without health insurance, age 18–64 years, % | 20.9 (6.6) | 4.1–50.9 | 1.35 (1.64) | 0.410 | ||
| Gini coefficient | 43.3 (3.6) | 32.6–60.1 | 2.70 (0.90) | 0.003 | ||
| Housing distress | ||||||
| Vacant housing units, % | 14.1 (9.5) | 1.5–77.0 | 3.23 (1.04) | 0.002 | ||
| Renter-occupied housing units with rent >30% of household income, % | 29.6 (7.2) | 0–56.1 | 5.41 (1.08) | <0.001 | ||
| Labor market dependence, % | ||||||
| Services | 10.8 | 2.14 (2.62) | 0.413 | |||
| Public sector | 11.9 | –11.70 (2.51) | <0.001 | |||
| Manufacturing | 29.0 | –4.86 (1.98) | 0.014 | |||
| Mining | 4.0 | 9.67 (4.29) | 0.024 | |||
| Farming | 14.1 | –16.34 (3.89) | <0.001 | |||
| Non-specialized (ref) | 30.2 | |||||
| Social environment | ||||||
| Family distress index | 0.0 (1.8) | –6.9–7.3 | 16.29 (1.16) | <0.001 | ||
| Persons separated/divorced, age >15 years, % | 11.3 (2.3) | 3.7–21.2 | 15.66 (1.15) | <0.001 | ||
| Families with children headed by single parent, % | 26.1 (7.3) | 2.5–63.0 | 13.51 (1.10) | <0.001 | ||
| Social capital | 0.0 (1.8) | –3.3–11.2 | ||||
| Religious establishments per 10,000 population (Q4 vs Q1) | 9.4 (5.1) | 0–49.3 | –5.13 (2.79) | 0.066 | ||
| Nonprofit organizations per 10,000 population (Q4 vs Q1) | 59.8 (34.6) | 1.7–360.3 | 0.48 (3.23) | 0.883 | ||
| Membership associations per 10,000 population (Q4 vs Q1) | 3.0 (2.5) | 0–29.2 | 10.26 (2.54) | <0.001 | ||
| Sports establishments per 10,000 population (Q4 vs Q1) | 2.0 (1.6) | 0–18.0 | –3.07 (2.51) | 0.221 | ||
| Residents living in different county 5 years ago, % | 20.0 (6.8) | 4.8–71.2 | –5.92 (0.90) | <0.001 | ||
| Healthcare environment | ||||||
| Physicians per 10,000 population | 12.0 (13.6) | 0–204.0 | 0.94 (0.75) | 0.210 | ||
| County designated as a primary healthcare professional shortage area | 63.3 | 0.46 (1.60) | 0.775 | |||
| County designated as a mental healthcare professional shortage area | 55.0 | 3.47 (1.94) | 0.074 | |||
| Population characteristics | ||||||
| Nonmetropolitan county | 62.7 | –1.11 (1.75) | 0.524 | |||
| Age >65 years, % | 14.8 (4.1) | 1.8–34.7 | 6.28 (1.07) | <0.001 | ||
| Veterans or currently in armed forces, % | 14.3 (3.7) | 3.3–69.3 | 4.61 (0.88) | <0.001 | ||
| Black population, % (Q4 vs Q1) | 8.7 (14.5) | 0–86.1 | –1.85 (3.53) | 0.601 | ||
| Hispanic population, % (Q4 vs Q1) | 6.1 (12.0) | 0–98.1 | –1.52 (3.33) | 0.648 | ||
| American Indian population, % (Q4 vs Q1) | 1.6 (6.3) | 0–93.7 | 14.04 (3.10) | <0.001 | ||
Notes: Boldface indicates statistical significance (p<0.05). Coefficients are from spatial autoregressive models with spatial error and control only for state fixed effects. Regression coefficients represent the percentage change in the age-adjusted mortality rate (AAMR, deaths per 100,000 population). All interval-ratio variables (except the four social capital variables, percent non-Hispanic black, percent Hispanic, and percent American Indian) are standardized at a mean of 0 and SD of 1, so the coefficient represents the percentage change in the AAMR for a one SD increase in the predictor variable. The four social capital variables, percent non-Hispanic black, percent Hispanic, and percent American Indian were not normally distributed, so they were transformed into quartiles for regression analysis to avoid problems with non-normality of residuals. For those seven variables, the coefficient estimates represent the percent difference in the AAMR between quartile 4 (the top 25th percentile) and quartile 1 (the bottom 25th percentile). In the interest of space, the coefficient estimates are not shown for quartiles 2 and 3. The coefficients for the labor market dependence categories represent the percentage difference in the AAMR between each respective category and counties with non-specialized economies.
NA, Not applicable; Q, Quartile; Est., Estimate
Table 2 presents coefficients from the fully adjusted multivariate model. Among the economic variables, economic distress, rental stress, and labor market dependence were significant. An SD increase in economic distress was associated with a 6.4% increase in the AAMR (p<0.001), whereas an SD increase in rental stress was associated with a 3.9% increase in the AAMR (p=0.001). Compared with diversified economies, mining dependent counties had a 13% higher average AAMR (p=0.001), and public sector dependent counties had an 11.8% lower average AAMR (p<0.001). Manufacturing and farming dependence were also associated with lower AAMRs, but the p-values fell just short of the p<0.05 threshold. Among the social factors, family distress, recent in-migration, and religious establishments were significant. Net of all other factors, an SD increase in family distress was associated with a 13.6% increase in the AAMR (p<0.001). Counties with higher percentages of residents living in a different county 5 years earlier had significantly lower AAMRs. More religious establishments was associated with significantly lower AAMRs; compared with counties with the fewest religious establishments per capita (Quartile1), those with the most (Quartile 4) had an 8% lower average AAMR. None of the other social capital variables, or the healthcare environment variables, were significant.
Table 2.
Multivariate Regression Results From Spatial Autoregressive Model
| Model 1 | ||
|---|---|---|
| Variable | Est. (SE) | P value |
| Economic environment | ||
| Economic distress index | 6.39 (1.68) | <0.001 |
| Housing distress | ||
| Vacant housing units, % | –0.12 (1.26) | 0.924 |
| Rent >30% of household income, % | 3.90 (1.19) | 0.001 |
| Labor market dependence | ||
| Services | 1.91 (2.62) | 0.466 |
| Public sector | –11.81 (2.59) | <0.001 |
| Manufacturing | –3.53 (1.90) | 0.064 |
| Mining | 13.05 (4.03) | 0.001 |
| Farming | –6.62 (3.69) | 0.093 |
| Non-specialized (ref) | 0.00 | |
| Social environment | ||
| Family distress index | 13.56 (1.46) | <0.001 |
| Residents living in different county 5 years ago, % | –2.79 (1.11) | 0.012 |
| Social capital (all per 10,000 population) | ||
| Religious establishments (Q4 vs Q1) | –8.14 (2.97) | 0.006 |
| organizations (Q4 vs Q1) | –4.28 (3.90) | 0.273 |
| Membership associations (Q4 vs Q1) | 3.50 (2.75) | 0.204 |
| Sports establishments (Q4 vs Q1) | –1.89 (2.61) | 0.468 |
| Healthcare environment | ||
| Physicians per 10,000 population | 0.42 (0.86) | 0.624 |
| Primary healthcare professional shortage area | –2.32 (1.52) | 0.126 |
| Mental healthcare professional shortage area | 1.50 (1.85) | 0.417 |
| Spatial autocorrelation parameter | 0.547 (0.03) | <0.001 |
Notes: Coefficients are from a generalized spatial two-stage least squares autoregressive model with a spatial lag of the error. Average pseudo R-square from multiple imputation models=.50. Boldface indicates statistical significance (p<0.05). Regression coefficients represent the percentage change in the age-adjusted mortality rate (AAMR, deaths per 100,000 population). Economic distress, housing distress, family distress, % residents living in different county, and physicians per 10,000 population are standardized (mean of 0 and SD of 1), so the coefficient represents the percentage change in the AAMR for a one SD increase in the predictor variable. The coefficients for the labor market dependence categories represent the percentage difference in the AAMR between each respective category and counties with non-specialized economies. The coefficients for the four social capital variables represent the percent difference in the AAMR between quartile 4 (the top 25th percentile) and quartile 1 (the bottom 25th percentile). In the interest of space, the coefficients are not shown for quartiles 2 and 3, but all coefficients are shown in the Appendix. The spatial autocorrelation parameter represents the correlated residuals from neighboring counties. It has a range of –1 to 1, with 0 representing no spatial autocorrelation.
AAMR, age-adjusted mortality rate; Q, Quartile; Est., Estimate
DISCUSSION
This is the first national study to identify specific economic and social factors contributing to between-county differences in U.S. drug-related mortality rates. Consistent with recent research on drug overdose trends,2,3,5 this study found significant geographic disparities, including large within-state disparities, in drug-related mortality rates. Average drug-related mortality rates were higher among counties characterized by greater economic and family distress, including rates of poverty, unemployment, disability, no college degree, public assistance, rental stress, divorce/separation, and single-parent families. This is consistent with research showing associations between county-level economic deprivation and drug use30,48 and research on SES as a major social determinant of health and fundamental cause of preventable disease disparities.13,49,50 Although the causal mechanisms driving these associations are unclear, economic insecurity contributes to family breakdown and social disorganization,20,24,26,29–31 undermining important supports against depression and substance misuse.
Drug-related mortality rates were also higher in counties with labor markets dependent on mining, but lower in counties dependent on the government sector. The mining industry has experienced significant declines in recent decades, displacing many workers, but also adversely impacting secondary service industries in these areas.23,29 Macro-level labor market stressors are community-level traumas that can manifest in collective psychosocial distress21,33 and social disorders, like substance misuse.30–34 The proliferation of illicit high-volume opioid clinics (i.e., pill mills) and aggressive OxyContin marketing throughout the 1990s and 2000s likely contributed to drug deaths in these same counties,29,51,52 but lack of historic prescribing data prevents testing this hypothesis. Public sector employment is often more stable than other industries and involves less physical stress and injury than manual-labor dependent jobs, which may explain lower average mortality rates in public sector–dependent counties.
This study also demonstrates that economic conditions alone do not fully explain geographic differences in drug-related mortality. Social factors are important. Specifically, counties with a larger presence of religious establishments have lower drug-related mortality rates. Opportunities for fellowship and civic engagement through religious organizations may facilitate social interactions, trust, and social cohesion, and increase residents’ sense of belonging.31,32 The other social capital establishment measures were not significant in the fully adjusted model. Future research should examine whether these institutions are more protective in specific types of counties (e.g., low-income, rural) or in different regions. Percentage of residents living in a different county 5 years ago was associated with lower AAMRs. In-migration may reflect community vibrancy, including good employment and social opportunities, and strong public service infrastructure that can help buffer against widespread substance misuse.
Healthcare supply factors were not significant. County designation as a mental health professional shortage area was associated with higher AAMRs, but it did not meet the threshold for significance (p<0.05). Future research should incorporate more comprehensive indicators of mental health and substance abuse treatment, when/if such indicators become publicly available for all counties.
State-level differences accounted for about a third of the between-county variation in mortality rates. State policy and economic contexts structure residents’ lives and influence the ability of counties to provide services.10,13 Current evidence is mixed on whether state-level factors like prescribing regulations, medical cannabis laws, and insurance treatment mandates are associated with overdose rates.56–60 Identifying the relative contributions of these and other state factors to between-county differences in drug-related mortality rates was beyond the scope of this study. Future research should examine specific state laws and other factors, such as Medicaid generosity, prescription drug monitoring programs, and austerity measures that may explain the pathways through which states influence county-level differences in rates. The magnitude and significance of the spatial error term representing correlated residuals among neighboring counties reflects the importance of correctly accounting for spatial autocorrelation in analyses on county-level differences in mortality rates. Analyses that do not correct for spatial autocorrelation risk producing biased or inaccurate results.
Limitations
Analyses were ecologic and cannot account for decedent characteristics, including duration of county residence. Data suppression prevented disaggregating by race/ethnicity, sex, and age. There is significant demographic variation in drug-related mortality.53 Associations between the factors considered here and mortality rates may vary across groups. Likewise, suppression prevented examining changes in drug mortality and comparing potentially related types of mortality (e.g., suicide, alcohol-related). The necessity to pool multiple years of data prevented exploring possible cohort effects across years. Given the rapid increase in deaths in recent years (e.g., 2014, 2015), these years may be driving geographic variation in rates. Death certificates may misclassify causes of death. Using MCD files reduces the likelihood of undercounting because of misclassification.35 Results may be biased by heterogeneity in cause-of-death reporting, but state-level reporting variation was controlled with state fixed effects. State fixed effects also accounted for heterogeneity in state programs/policies that may affect drug access. A non-exhaustive list of variables was used to represent social determinants and surely did not capture all relevant factors. County-level data on opioid prescriptions, drug arrests, and other potentially important factors associated with drug supply are unavailable at the national level. There is also heterogeneity within counties that cannot be accounted for in these analyses. Moreover, associations between county environments and mortality rates likely play out over an extended period, but these analyses incorporated only recent county conditions and did not consider temporal changes in environments. Finally, the specific types of drugs and the underlying mechanisms driving drug-related mortality may play out differently across different regions of the country. Future research should examine geographic heterogeneity in the relationships between drug-related mortality and the social determinants considered here.
CONCLUSIONS
Drug deaths are not randomly distributed across the U.S. Failing to consider the substantial geographic variation in drug-related mortality rates may lead to failure to target the hardest hit areas. Social and economic environments are important for prevention because they affect stress, healthcare investment, residents’ knowledge about and access to services, self-efficacy, social support, and opportunities for social interaction.55 Findings from this study suggest that communities with significant economic and family distress are important targets for interventions. Moreover, religious establishments may play an important social capital–promoting role in the fight against the current U.S. drug epidemic.
ACKNOWLEDGMENTS
The author acknowledges funding from the U.S. Department of Agriculture Economic Research Service (Cooperative Agreement 58–6000-6–0028) and The Institute for New Economic Thinking (INO17–00003) and support from the Lerner Center for Public Health Promotion and Center for Policy Research at Syracuse University and the U.S. Department of Agriculture Agricultural Experiment Station Multistate Research Project: W4001: Social, Economic, and Environmental Causes and Consequences of Demographic Change in Rural America.
APPENDIX
Appendix A.
Appendix Table A.1.
ICD-10 Codes Included in the Drug-related Mortality Rate
| Category | Code |
|---|---|
| accidental poisoning, intentional self-poisoning | X60–X64 |
| poisoning of undetermined intent by exposure to drugs | X40–X44, Y10–Y14 |
| drug-induced diseases | D52.1, D59.0, D59.2, D61.1, D64.2, E06.4, E16.0, E23.1, E24.2, E27.3, E66.1, G21.1, G24.0, G25.1, G25.4, G25.6, G44.4, G62.0, G72.0, I95.2, J70.2–J70.4, K85.3, L10.5, L27.0, L27.1, M10.2, M32.0, M80.4, M81.4, M83.5, M87.1, R50.2 |
| drugs in the blood | R78.1–R78.5 |
| mental/behavioral disorders due to drugs | F11.0–F11.5, F11.7–F11.9, F12.0–F12.5, F12.7–F12.9, F13.0–F13.5, F13.7–F13.9, F14.0–F14.5, F14.7–F14.9, F15.0–F15.5, F15.7–F15.9, F16.0–F16.5, F16.7–F16.9, F18.0–F18.5, F18.7–F18.9, F19.0–F19.5, F19.7–F19.9 |
Appendix B.
Appendix Table B.1.
Data Sources and Variables Used in Regression Analysis of Variation in Drug-related Mortality Rates
| Data sources for main analysis | Data sources for sensitivity analysis | |
|---|---|---|
| Population below the poverty line, age 25–54 years, % | 1 | 2 |
| Civilian non-institutionalized population unemployed or not in labor force, age 25–54 years, % | 1 | 2 |
| Civilian non-institutionalized population with a work disability, age 21–64 years, % | 1 | 2 |
| Population with <4-year college degree, age >25 years, % | 1 | 2 |
| Households with supplemental security income, % | 1 | 2 |
| Households with public assistance income, % | 1 | 2 |
| Population without health insurance, age 18–64 years, % | 7a | 2 |
| Gini coefficient of income inequality | 1 | 2 |
| Vacant housing units, % | 1 | 2 |
| Renter-occupied housing units with rent >30% of household income, % | 1 | 2 |
| Economic/employment dependence typology | 3 | 3 |
| Persons separated/divorced, age >15, % | 1 | 2 |
| Families with children headed by single parent, % | 1 | 2 |
| Religious establishments per 10,000 population | 4 | 5 |
| Nonprofit organizations per 10,000 population | 4 | 5 |
| Membership (civic, business, labor, political, professional) associations per 10,000 population | 4 | 5 |
| Sports (bowling, golf, sports, fitness) establishments per 10,000 population | 4 | 5 |
| Residents living in different county 5 years earlier, % | 1 | 2 |
| Physicians per 10,000 population, 2000b | 6 | 6 |
| County designated as a primary healthcare professional shortage areab | 6 | 6 |
| County designated as a mental healthcare professional shortage areab | 6 | 6 |
| Metropolitan status (metropolitan vs nonmetropolitan) | 3 | 4 |
| Population age >65 years, % | 1 | 2 |
| Veterans or currently in armed forces, % | 1 | 2c |
| Black population, % | 1 | 2 |
| Hispanic population, % | 1 | 2 |
| American Indian population, % | 1 | 2 |
aHealth insurance estimates are from 2008. County-level health insurance rates for 2000 are unavailable. American Community Survey (ACS) health insurance rates first became available in the 2010–2014 ACS release. Insurance rates prior to 2010–2014 are available only from the Small Area Health Insurance Estimates (SAHIE). SAHIE estimates for 2005 and 2006 are based on the Current Population Survey (CPS) and have wide margins of error, making them unreliable for national county-level analyses. SAHIE estimates for 2008 and later are based on restricted ACS data and provide estimates that are more consistent with the 2010–2014 estimates produced by the ACS than with estimates produced from CPS data.
bCounties are designated as primary and/or mental health professional shortage areas based on a formula derived by the Health Resources & Services Administration that considers multiple factors, including the population-to-provider ratio and travel time to the nearest source of care outside of the county. Ideally, I would have included indicators that capture the pre-2006 supply of healthcare professionals and facilities in the area of mental health and substance abuse services, but those data are not available nationally at the county level. The Area Health Resource File (AHRF) captures county-level measures for specific types of healthcare providers (e.g., psychiatrists, psychologists, social workers, occupational, physical, and recreational therapists), but prior to the 2013–2014 AHRF release, counties with missing values on any measures were designated with values of 0, thereby making those measures unreliable (users are unable to identify which counties are missing vs. which counties truly have values of 0 on these measures). For more information, see User Documentation for the County Area Health Resource File 2015–2016 release, page 148. (https://datawarehouse.hrsa.gov/data/datadownload.aspx#MainContent_ctl00_gvDD_lbl_dd_topic_ttl_0).
cThe variable available in the 2010–2014 ACS measures percent veterans only, not percent currently in armed forces. Therefore, coefficients from the 2000 and 2010–2014 models are not comparable for this variable.
Appendix C. Description of Multiple Imputation and Listing of Auxiliary Variables
Justification for Multiple Imputation: CDC WONDER suppresses mortality data (including death counts and rates) for groupings with fewer than ten deaths. Counties with suppressed data have much smaller population sizes. Importantly, this does not mean that counties with suppressed data have low mortality rates than counties with at least ten deaths. For example, a county with a population of 10,000 and eight deaths would have a mortality rate of 80 per 100,000 (well above the mean mortality rate). In 2010, the mean county population size was 6,404 for counties with fewer than ten deaths versus 121,831 for counties with at least ten deaths. Based on examinations of correlation tables and t-tests, there are a number of other important differences between counties with suppressed data and those with death counts above ten. Demographically, counties with suppressed data have an older age composition, higher percent married, and are more likely to be designated as nonmetropolitan and as persistent population loss counties by the USDA Economic Research Service. Economically, counties with suppressed data are more likely to be farming dependent, have higher percentages of workers employed in management and farming, fishing, and forestry occupations, are more economically distressed, and have a higher percentage of vacant housing units. Socially, suppressed counties have more religious establishments, residents with religious affiliations, and non-profit organizations per capita. However, suppression is also inversely correlated with poor health outcomes; counties with suppressed mortality rates have lower mean poor mental health and poor physical health days (based on data from the 2016 County Health Rankings). As a result of these differences, excluding suppressed counties from the analysis could potentially bias the results, and simply combining them with neighboring counties ignores major economic, demographic, and social differences between neighboring counties.
Multiple Imputation Process: The drug-related mortality rate was Missing at Random (MAR). A variable is MAR if other variables in the dataset can be used to predict its missingness. As described above, this is the case with the mortality variable (several variables in the data set predict “missingness”. Multiple imputation is superior to traditional imputation methods (e.g., unconditional/conditional mean imputation, stochastic imputation) because instead of filling in a single value, the distribution of observed data is used to estimate multiple values that reflect uncertainty around the true value (See Enders, Craig K. 2010. Applied Missing Data Analysis). Each imputed value includes a random component, building uncertainty into the imputed values, and upwardly adjusting SEs to reflect that uncertainty. These values are then used to produce regression models, and the results from all imputations are pooled. Therefore, multiple imputation produces unbiased coefficient estimates and SEs that account for uncertainty around the “actual value” of the dependent variable (See Allison, Paul. 2002. Missing Data. Sage Publications). Also see Multiple Imputation in Stata: https://stats.idre.ucla.edu/sas/seminars/multiple-imputation-in-sas/mi_new_1/ for more information.
For these analyses, 50 imputation models were produced. The imputation models included all variables that were included in the main regression analysis (this is a requirement of multiple imputation) and several auxiliary variables (listed in Appendix Table C.1 below) that were correlated with both drug-related mortality and suppression. Relative variance efficiency (RE) values (a measure of how well the true population parameters are estimated) ranged from 0.989 to 0.999.
Appendix Table C.1.
Auxiliary Variables and Data Sources Used in Multiple Imputation Modela
| Variable | Data source |
|---|---|
| Population size, logged, 2010 | 1 |
| Population density, logged, 2010 | 1 |
| Religious congregations per 1,000 population, logged, 2010 | 2 |
| Residents with religious affiliations per 1,000 population, logged, 2010 | 2 |
| Residents living in same house 5 years earlier, %, 2000 | 1 |
| Persistent population loss (county lost population 1980–1990 and 1990–2000) | 4 |
| Average number of days of poor mental health among adults age >18 years, 2014 | 3 |
| Average number of days of poor physical health among adults age >18 years, 2014 | 3 |
| Adults age >18 years who report heavy or binge drinking, %, 2014 | 3 |
| Adults age >18 years who are current smokers, %, 2014 | 3 |
| Population who is married, age >15 years, %, 2000 | 1 |
| Median household income, 2000 | 1 |
| Middle income households (HH with income between the 25th and 75th percentile of the national income distribution), % | 1 |
| Voter turnout rate, 2004 | 5 |
| Workers employed in administrative occupations, %, 2000 | 1 |
| Workers employed in construction occupations, %, 2000 | 1 |
| Workers employed in farming, fishing, and forestry occupations, %, 2000 | 1 |
| Workers employed in healthcare support occupations, %, 2000 | 1 |
| Workers employed in management occupations, %, 2000 | 1 |
| Workers employed in production occupations, %, 2000 | 1 |
| Workers employed in professional occupations, %, 2000 | 1 |
| Workers employed in protective service occupations, %, 2000 | 1 |
| Workers employed in sales occupations, %, 2000 | 1 |
HH, household
Appendix D.
Appendix Table D.1.
All Regression Coefficients From Final Model and Supplemental Sensitivity Models)
| Final model (Model 1) | Model 2 | |||
|---|---|---|---|---|
| Variable | Est. (SE) | p-value | Est. (SE) | p-value |
| Economic environment | ||||
| Economic distress index | 6.39 (1.68) | <0.001 | 4.54 (1.51) | 0.003 |
| Housing distress | ||||
| Vacant housing units, % | –0.12 (1.26) | 0.924 | 0.30 (1.13) | 0.788 |
| Rent >30% of household income, % | 3.90 (1.19) | 0.001 | 3.16 (1.06) | 0.003 |
| Labor market dependence | ||||
| Non-specialized (ref) | 0.00 | 0.00 | ||
| Services | 1.91 (2.62) | 0.466 | 1.71 (2.33) | 0.463 |
| Public sector | –11.81 (2.59) | <0.001 | –8.57 (2.29) | <0.001 |
| Manufacturing | –3.53 (1.90) | 0.064 | –2.83 (1.68) | 0.092 |
| Mining | 13.05 (4.03) | 0.001 | 12.89 (3.65) | <0.001 |
| Farming | –6.25 (3.69) | 0.093 | –0.51 (3.23) | 0.874 |
| Social environment | ||||
| Family distress index | 13.56 (1.46) | <0.001 | 14.42 (1.26) | <0.001 |
| Residents living in different county 5 years ago, % | –2.79 (1.11) | 0.012 | –2.64 (0.99) | 0.008 |
| Social capital | ||||
| Religious establishments per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –3.78 (2.12) | 0.074 | –1.86 (1.92) | 0.331 |
| 50th–75th percentile | –7.39 (2.47) | 0.003 | –6.16 (2.25) | 0.006 |
| Top 25th percentile | –8.14 (2.97) | 0.006 | –5.78 (2.72) | 0.034 |
| Nonprofit organizations per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –2.51 (2.22) | 0.260 | –4.24 (1.97) | 0.031 |
| 50th–75th percentile | –3.72 (2.83) | 0.189 | –6.93 (2.51) | 0.006 |
| Top 25th percentile | –4.28 (3.90) | 0.273 | –9.44 (3.34) | 0.005 |
| Membership associations per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –0.56 (2.01) | 0.780 | –0.75 (1.81) | 0.678 |
| 50th–75th percentile | 1.41 (2.30) | 0.540 | 1.19 (2.15) | 0.578 |
| Top 25th percentile | 3.50 (2.75) | 0.204 | 3.92 (2.61) | 0.132 |
| Sports establishments per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 0.21 (2.06) | 0.918 | –0.47 (1.81) | 0.794 |
| 50th–75th percentile | 0.70 (2.22) | 0.754 | –0.31 (2.01) | 0.877 |
| Top 25th percentile | –1.89 (2.61) | 0.468 | –3.56 (2.40) | 0.138 |
| Healthcare environment | ||||
| Physicians per 10,000 population | 0.42 (0.86) | 0.624 | 0.74 (0.78) | 0.347 |
| Primary healthcare professional shortage area | –2.32 (1.52) | 0.126 | –1.67 (1.44) | 0.244 |
| Mental healthcare professional shortage area | 1.50 (1.85) | 0.417 | 2.81 (1.70) | 0.099 |
| Population characteristics | ||||
| Nonmetro county | –6.58 (1.92) | 0.001 | –5.63 (1.74) | 0.001 |
| Age >65 years, % | 6.45 (1.31) | <0.001 | 8.79 (1.20) | <0.001 |
| Veterans or currently in armed forces, % | 5.87 (1.01) | <0.001 | 5.18 (0.89) | <0.001 |
| Black population, % | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 1.08 (2.26) | 0.634 | 0.49 (2.02) | 0.806 |
| 50th–75th percentile | –2.21 (2.70) | 0.414 | –1.51 (2.45) | 0.538 |
| Top 25th percentile | –23.72 (3.59) | <0.001 | –19.78 (3.30) | <0.001 |
| Hispanic population, % | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 3.65 (2.11) | 0.083 | 3.31 (1.92) | 0.085 |
| 50th–75th percentile | 4.25 (2.51) | 0.091 | 3.10 (2.29) | 0.176 |
| Top 25th percentile | –2.32 (3.12) | 0.458 | –3.26 (2.92) | 0.265 |
| American Indian population, % | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –1.74 (2.06) | 0.398 | –0.95 (1.84) | 0.603 |
| 50th–75th percentile | 0.42 (2.37) | 0.859 | 1.03 (2.13) | 0.628 |
| Top 25th percentile | 5.38 (2.95) | 0.069 | 4.14 (2.78) | 0.137 |
| Spatial autocorrelation parameter | 0.547 (0.03) | <0.001 | 0.658 (0.02) | <0.001 |
| N | 3,106 | 2,484 | ||
Notes: Boldface indicates statistical significance (p<0.05). All models control for state fixed effects. Model 1 is the final fully adjusted model shown in Table 2. Model 2 is the same as Model 1, but does not use multiple imputation. This model is conducted only on complete cases (i.e., counties with at least ten drug-related deaths, N=2,484). Though the magnitude of some of the coefficients vary slightly, there was only one substantive difference between these two models. Nonprofit organizations were not significant in Model 1, but there were significant and negative in this model; counties with a greater presence of non-profit organizations have significantly lower AAMR in Model 2. This is because counties with suppressed data (i.e., counties with smaller populations) have a significantly larger presence of non-profit associations per capita than counties with at least ten deaths. More than 68% of counties with suppressed data are in the top quartile of non-profit organizations (compared to only 14% of counties without suppressed data). Therefore, excluding the counties with the most non-profit organizations per capita (as is the case when excluding counties with suppressed mortality data), over-estimates the association of non-profit organizations with drug-related mortality rates.
AAMR, Age-Adjusted Mortality Rate; Est., Estimate
Appendix Table D.2.
Regression Coefficients From Supplemental Sensitivity Models Using 2010–2014 ACS Estimates
| Model 3 | Model 4 | |||
|---|---|---|---|---|
| Variable | Est. (SE) | p-value | Est. (SE) | p-value |
| Economic environment | ||||
| Economic distress index | 12.55 (1.60) | <0.001 | 9.62 (1.47) | <0.001 |
| Housing distress | ||||
| Vacant housing units, % | 0.87 (1.20) | 0.468 | 2.79 (1.11) | 0.012 |
| Rent >30% of household income, % | 2.51 (1.11) | 0.024 | 3.31 (1.08) | 0.002 |
| Labor market dependence | ||||
| Non-specialized (ref) | 0.00 | 0.00 | ||
| Services | 4.99 (2.65) | 0.060 | 3.95 (2.36) | 0.094 |
| Public sector | –9.27 (2.56) | <0.001 | –7.37 (2.29) | 0.001 |
| Manufacturing | –3.69 (1.89) | 0.050 | –3.33 (1.68) | 0.048 |
| Mining | 13.09 (4.05) | 0.001 | 12.77 (3.69) | 0.001 |
| Farming | –9.74 (3.71) | 0.010 | –4.02 (3.24) | 0.215 |
| Social environment | ||||
| Family distress index | 7.14 (1.35) | <0.001 | 8.73 (1.22) | <0.001 |
| Residents living in different county 5 years ago, % | –1.86 (1.05) | 0.077 | –2.87 (0.95) | 0.003 |
| Social capital | ||||
| Religious establishments per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –3.47 (2.13) | 0.104 | –2.06 (1.94) | 0.288 |
| 50th–75th percentile | –7.92 (2.46) | 0.001 | –6.33 (2.27) | 0.005 |
| Top 25th percentile | –8.79 (2.93) | 0.003 | –6.08 (2.70) | 0.024 |
| Nonprofit organizations per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –0.24 (2.21) | 0.912 | –2.18 (1.98) | 0.272 |
| 50th–75th percentile | –0.62 (2.82) | 0.826 | –4.29 (2.52) | 0.089 |
| Top 25th percentile | –0.25 (3.86) | 0.949 | –5.86 (3.35) | 0.080 |
| Membership associations per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 1.21 (2.02) | 0.548 | 1.44 (1.82) | 0.430 |
| 50th–75th percentile | 3.44 (2.30) | 0.135 | 3.69 (2.15) | 0.087 |
| Top 25th percentile | 6.25 (2.74) | 0.023 | 8.39 (2.61) | 0.001 |
| Sports establishments per 10,000 population | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 3.18 (2.06) | 0.122 | 2.10 (1.82) | 0.248 |
| 50th–75th percentile | 3.04 (2.22) | 0.172 | 1.65 (2.03) | 0.415 |
| Top 25th percentile | –1.14 (2.59) | 0.661 | –3.08 (2.41) | 0.203 |
| Healthcare environment | ||||
| Physicians per 10,000 population | 2.07 (0.87) | 0.017 | 2.26 (0.79) | 0.004 |
| Primary healthcare professional shortage area | –2.57 (1.53) | 0.093 | –2.26 (1.45) | 0.120 |
| Mental healthcare professional shortage area | 0.49 (1.87) | 0.793 | 1.84 (1.72) | 0.283 |
| Population characteristics | ||||
| Nonmetro county | –10.46 (1.92) | <0.001 | –9.58 (1.76) | <0.001 |
| Age >65 years, % | 6.12 (1.20) | <0.001 | 6.48 (1.10) | <0.001 |
| Military veterans, % | 2.23 (0.92) | 0.015 | 2.60 (0.81) | 0.001 |
| Black population, % | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 4.41 (2.09) | 0.035 | 5.69 (2.00) | 0.004 |
| 50th–75th percentile | 0.72 (2.63) | 0.784 | 3.13 (2.38) | 0.188 |
| Top 25th percentile | –15.06 (3.57) | <0.001 | –11.64 (3.20) | <0.001 |
| Hispanic population, % | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | 2.92 (2.18) | 0.181 | 2.26 (2.10) | 0.282 |
| 50th–75th percentile | 3.15 (2.56) | 0.217 | 2.03 (2.42) | 0.401 |
| Top 25th percentile | –1.04 (3.26) | 0.749 | –3.70 (3.07) | 0.228 |
| American Indian population, % | ||||
| Bottom 25th percentile (ref) | 0.00 | 0.00 | ||
| 25th–50th percentile | –1.09 (1.93) | 0.573 | 0.88 (1.79) | 0.624 |
| 50th–75th percentile | 1.73 (2.18) | 0.428 | 2.60 (2.05) | 0.204 |
| Top 25th percentile | 6.69 (2.67) | 0.012 | 7.12 (2.56) | 0.005 |
| Spatial autocorrelation parameter | 0.524 (0.027) | <0.001 | 0.630 (0.03) | <0.001 |
| N | 3,106 | 2,484 | ||
Notes: Boldface indicates statistical significance (p<0.05). All models control for state fixed effects. Model 3 is the same as Model 1 (N=3,106), but uses temporally proximate/overlapping demographic, economic distress, housing distress, and family distress variables from the American Community Survey 5-year estimates (2010–2014). These estimates represent more current conditions, whereas Model 1 is based on county conditions from 2000. The direction and significance (p<0.05) of coefficients are generally consistent between Model 1 and Model 3, and when there are differences in significance, it is usually because the p-value was between 0.05 and 0.10, thereby failing to meet the conventional p<0.05 threshold. There was one important difference that reflects the importance of current economic conditions on drug mortality rates. The magnitude of the economic distress coefficient is nearly twice as large in Model 3 compared to Model 1, suggesting that economic conditions from 2000, while important, may be underestimating the true impact of economic distress on county mortality rates. Importantly, this differences could also be the result of reverse causality bias; high rates of substance abuse could lead to increases in poverty, unemployment, and disability rates, for example. The only other major difference is that counties in the top quartile of membership associations had a significantly higher average AAMR than counties in the bottom quartile in this model. It is unclear why substituting economic, demographic, and family predictors from 2000 with those from 2010–2014 would result in this change. T-tests showed that counties in the top quartile of non-profit associations had lower average economic distress in both 2000 and 2010–2014, higher average percentages of vacant housing units, lower average rental stress, lower average family distress, and higher average percent aged >65 years in both 2000 and 2010–2014. The only difference between these two time periods was that percent veterans in 2000 was higher in counties in the top quartile of non-profit associations, but percent veteran in 2010–2014 was significantly lower in counties in the top quartile of nonprofit organizations than in the other 75% of counties. Model 4 is the same as Model 3, but does not use multiple imputation. This model is conducted only on complete cases (i.e., counties with at least ten drug-related deaths, N=2,484) and uses the 2010–2014 ACS estimates. Again, model results are consistent with the exception that vacant housing units is positive and significant in Model 4. This is because counties with suppressed mortality rates had a significantly higher average percentage of vacant housing units in 2010–2014 than counties without suppressed mortality rates. Excluding these counties from the analysis overestimates the relationship between vacant housing units and drug mortality rates.
Est., Estimate; AAMR, Age-Adjusted Mortality Rate
Appendix E.
Appendix Table E.1.
Correlation Matrix for Variables Included in Regression Analysis
| Pearson Correlation Coefficient | |||||
| <0.10 | 0.11 to 0.30 | 0.31 to 0.50 | 0.51 to 0.70 | >0.70 | |
| Variable | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | |
|---|---|---|---|---|---|---|---|---|---|---|
| (1) | Black population, % | 1.00 | ||||||||
| (2) | Hispanic population, % | –0.11 | 1.00 | |||||||
| (3) | American Indian population, % | –0.10 | –0.01 | 1.00 | ||||||
| (4) | Age >65 years, % | –0.21 | –0.16 | –0.10 | 1.00 | |||||
| (5) | Veterans or currently in armed forces, % | –0.15 | –0.14 | 0.03 | 0.19 | 1.00 | ||||
| (6) | Population below the poverty line, age 25–54 years, % | 0.34 | 0.24 | 0.33 | 0.05 | –0.19 | 1.00 | |||
| (7) | Unemployed or not in labor force, age 25–54 years, % | 0.40 | 0.23 | 0.17 | –0.15 | –0.11 | 0.73 | 1.00 | ||
| (8) | Population with a work disability, age 21–64 years, % | 0.42 | 0.09 | 0.02 | 0.05 | –0.09 | 0.58 | 0.63 | 1.00 | |
| (9) | Population with <4-year college degree, age >25 years, % | 0.09 | –0.03 | 0.04 | 0.30 | 0.00 | 0.42 | 0.42 | 0.51 | 1.00 |
| (10) | Population without health insurance, age 18–64 years, % | 0.19 | 0.51 | 0.12 | 0.02 | –0.08 | 0.60 | 0.51 | 0.46 | 0.35 |
| (11) | Households with supplemental security income, % | 0.43 | 0.05 | 0.09 | –0.01 | –0.24 | 0.78 | 0.73 | 0.70 | 0.50 |
| (12) | Households with public assistance income, % | 0.17 | 0.26 | 0.46 | –0.08 | –0.11 | 0.73 | 0.60 | 0.45 | 0.32 |
| (13) | Persons separated/divorced, age >15, % | 0.32 | 0.01 | 0.06 | –0.24 | 0.17 | 0.25 | 0.43 | 0.47 | 0.12 |
| (14) | Families with children headed by single parent, % | 0.71 | 0.01 | 0.21 | –0.16 | –0.05 | 0.49 | 0.49 | 0.48 | 0.10 |
| (15) | Vacant housing units, % | –0.05 | 0.05 | 0.11 | 0.43 | 0.21 | 0.37 | 0.25 | 0.25 | 0.32 |
| (16) | Renter-occupied with rent >30% of HH income, % | 0.18 | 0.07 | –0.06 | –0.32 | –0.05 | 0.04 | 0.15 | 0.04 | –0.38 |
| (17) | Manufacturing industry dependent | 0.07 | –0.17 | –0.09 | –0.09 | –0.11 | –0.14 | –0.06 | 0.09 | 0.20 |
| (18) | Mining industry dependent | –0.06 | 0.11 | 0.03 | –0.04 | –0.05 | 0.14 | 0.17 | 0.11 | 0.10 |
| (19) | Farming industry dependent | –0.09 | 0.08 | 0.05 | 0.30 | –0.08 | 0.15 | –0.11 | –0.11 | 0.12 |
| (20) | Services industry dependent | –0.02 | 0.03 | –0.04 | –0.05 | 0.01 | –0.16 | –0.11 | –0.10 | –0.44 |
| (21) | Public sector industry dependent | 0.12 | 0.08 | 0.10 | –0.20 | 0.23 | 0.07 | 0.20 | –0.02 | –0.17 |
| (22) | Non-specialized industry dependent | –0.05 | –0.02 | 0.00 | 0.05 | 0.03 | 0.03 | 0.00 | 0.03 | 0.08 |
| (23) | Gini coefficient | 0.37 | 0.18 | 0.06 | 0.07 | –0.24 | 0.60 | 0.46 | 0.42 | –0.02 |
| (24) | Primary healthcare professional shortage area | 0.12 | 0.07 | 0.08 | –0.04 | 0.03 | 0.25 | 0.26 | 0.21 | 0.18 |
| (25) | Mental healthcare professional shortage area | –0.04 | 0.03 | 0.09 | 0.25 | –0.04 | 0.25 | 0.12 | 0.17 | 0.29 |
| (26) | Physicians per 10,000 population | 0.06 | 0.00 | –0.06 | –0.16 | –0.05 | –0.20 | –0.15 | –0.18 | –0.59 |
| (27) | Religious establishments per 10,000 population | –0.06 | –0.15 | –0.08 | 0.54 | –0.03 | –0.07 | –0.24 | –0.10 | 0.18 |
| (28) | Membership associations per 10,000 population | –0.17 | –0.08 | –0.03 | 0.28 | 0.03 | –0.17 | –0.27 | –0.23 | –0.14 |
| (29) | Nonprofit organizations per 10,000 population | –0.28 | –0.07 | 0.00 | 0.49 | 0.08 | –0.10 | –0.38 | –0.34 | –0.19 |
| (30) | Sports establishments per 10,000 population | –0.24 | –0.12 | –0.06 | 0.29 | 0.06 | –0.28 | –0.38 | –0.32 | –0.17 |
| (31) | Living in different county 5 years earlier, age >5 years, % | –0.10 | 0.01 | –0.03 | –0.27 | 0.34 | –0.27 | –0.10 | –0.24 | –0.42 |
| (32) | Nonmetropolitan county | –0.09 | –0.02 | 0.10 | 0.41 | –0.05 | 0.31 | 0.14 | 0.14 | 0.37 |
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) |
Appendix Table E.2.
Correlation Matrix for Variables Included in Regression Analysis
| Variable | (10) | (11) | (12) | (13) | (14) | (15) | (16) | (17) | (18) | |
|---|---|---|---|---|---|---|---|---|---|---|
| (10) | Population without health insurance, age 18–64 years, % | 1.00 | ||||||||
| (11) | Households with supplemental security income, % | 0.38 | 1.00 | |||||||
| (12) | Households with public assistance income, % | 0.36 | 0.65 | 1.00 | ||||||
| (13) | Persons separated/divorced, age >15 years, % | 0.22 | 0.36 | 0.31 | 1.00 | |||||
| (14) | Families with children headed by single parent, % | 0.19 | 0.50 | 0.47 | 0.64 | 1.00 | ||||
| (15) | Vacant housing units, % | 0.40 | 0.20 | 0.18 | 0.05 | 0.03 | 1.00 | |||
| (16) | Renter-occupied w/rent >30% of HH income, % | –0.09 | 0.10 | 0.17 | 0.38 | 0.44 | –0.25 | 1.00 | ||
| (17) | Manufacturing industry dependent | –0.17 | 0.03 | –0.11 | 0.11 | 0.07 | 0.48 | –0.23 | 1.00 | |
| (18) | Mining industry dependent | 0.11 | 0.11 | 0.12 | 0.03 | –0.03 | 0.08 | –0.01 | –0.13 | 1.00 |
| (19) | Farming industry dependent | 0.22 | –0.06 | –0.01 | –0.37 | –0.26 | –0.21 | –0.28 | –0.26 | –0.08 |
| (20) | Services industry dependent | –0.12 | –0.16 | –0.11 | 0.11 | 0.05 | –0.33 | 0.36 | –0.22 | –0.07 |
| (21) | Public sector industry dependent | 0.03 | 0.02 | 0.09 | 0.10 | 0.16 | –0.22 | 0.14 | –0.23 | –0.08 |
| (22) | Non-specialized industry dependent | 0.00 | 0.06 | 0.07 | 0.01 | 0.00 | 0.03 | 0.10 | –0.42 | –0.13 |
| (23) | Gini coefficient | 0.43 | 0.52 | 0.38 | 0.26 | 0.45 | –0.06 | 0.08 | –0.14 | 0.04 |
| (24) | Primary healthcare professional shortage area | 0.21 | 0.21 | 0.19 | 0.13 | 0.15 | 0.21 | 0.03 | –0.06 | 0.06 |
| (25) | Mental healthcare professional shortage area | 0.18 | 0.19 | 0.14 | –0.08 | –0.03 | 0.28 | –0.19 | –0.03 | 0.02 |
| (26) | Physicians per 10,000 population | –0.26 | –0.18 | –0.10 | 0.10 | 0.17 | –0.31 | 0.40 | –0.09 | –0.05 |
| (27) | Religious establishments per 10,000 population | –0.03 | –0.11 | –0.17 | –0.32 | –0.20 | 0.14 | –0.39 | 0.00 | –0.03 |
| (28) | Membership associations per 10,000 population | –0.22 | –0.24 | –0.13 | –0.17 | –0.09 | 0.06 | –0.09 | –0.06 | –0.01 |
| (29) | Nonprofit organizations per 10,000 population | –0.12 | –0.32 | –0.18 | –0.34 | –0.25 | 0.26 | –0.27 | –0.21 | –0.02 |
| (30) | Sports establishments per 10,000 population | –0.26 | –0.32 | –0.24 | –0.29 | –0.23 | 0.08 | –0.11 | –0.08 | –0.05 |
| (31) | Living in different county 5 years earlier, age >5 years, % | 0.04 | –0.34 | –0.23 | 0.04 | –0.14 | –0.01 | 0.16 | –0.20 | –0.07 |
| (32) | Nonmetropolitan county | 0.22 | 0.23 | 0.17 | –0.12 | –0.04 | 0.49 | –0.31 | –0.01 | 0.10 |
| (10) | (11) | (12) | (13) | (14) | (15) | (16) | (17) | (18) |
Appendix Table E.3.
Correlation Matrix for Variables Included in Regression Analysis
| Variable | (19) | (20) | (21) | (22) | (23) | (24) | (25) | (26) | (27) | |
|---|---|---|---|---|---|---|---|---|---|---|
| (19) | Farming industry dependent | 1.00 | ||||||||
| (20) | Services industry dependent | –0.14 | 1.00 | |||||||
| (21) | Public sector industry dependent | –0.15 | –0.13 | 1.00 | ||||||
| (22) | Non-specialized industry dependent | –0.27 | –0.23 | –0.24 | 1.00 | |||||
| (23) | Gini coefficient | 0.03 | 0.10 | 0.07 | –0.03 | 1.00 | ||||
| (24) | Primary health care professional shortage area | 0.06 | –0.02 | 0.03 | –0.01 | 0.12 | 1.00 | |||
| (25) | Mental health care professional shortage area | 0.16 | –0.16 | –0.04 | 0.04 | 0.10 | 0.11 | 1.00 | ||
| (26) | Physicians per 10,000 population | –0.20 | 0.38 | 0.12 | –0.08 | 0.18 | –0.13 | –0.23 | 1.00 | |
| (27) | Religious establishments per 10,000 population | 0.34 | –0.20 | –0.14 | –0.02 | –0.04 | –0.14 | 0.18 | –0.13 | 1.00 |
| (28) | Membership associations per 10,000 population | 0.10 | 0.00 | 0.02 | –0.03 | –0.06 | –0.12 | –0.02 | 0.16 | 0.29 |
| (29) | Nonprofit organizations per 10,000 population | 0.38 | 0.00 | –0.05 | –0.04 | –0.05 | –0.10 | 0.11 | 0.06 | 0.46 |
| (30) | Sports establishments per 10,000 population | 0.17 | 0.05 | –0.10 | 0.00 | –0.16 | –0.14 | 0.03 | 0.11 | 0.30 |
| (31) | Living in different county 5 years earlier, age >5 years, % | –0.07 | 0.13 | 0.28 | 0.00 | –0.14 | –0.07 | –0.12 | 0.10 | –0.17 |
| (32) | Nonmetropolitan county | 0.23 | –0.24 | –0.06 | 0.00 | 0.12 | 0.01 | 0.32 | –0.31 | 0.32 |
| (19) | (20) | (21) | (22) | (23) | (24) | (25) | (26) | (27) |
Appendix Table E.4.
Correlation Matrix for Variables Included in Regression Analysis
| Variable | (28) | (29) | (30) | (31) | (32) | |
|---|---|---|---|---|---|---|
| (28) | Membership associations per 10,000 population | 1.00 | ||||
| (29) | Nonprofit organizations per 10,000 population | 0.49 | 1.00 | |||
| (30) | Sports establishments per 10,000 population | 0.33 | 0.44 | 1.00 | ||
| (31) | Living in different county 5 years earlier, age >5 years, % | –0.07 | 0.00 | 0.00 | 1.00 | |
| (32) | Nonmetropolitan county | 0.15 | 0.31 | 0.13 | –0.21 | 1.00 |
| (28) | (29) | (30) | (31) | (32) |
Note: Correlations are reported for all variables included in the main regression models.
Appendix F.
Appendix Table F.1.
Factor Loadings for Variables Included in Economic Distress and Family Distress Indices
| Variable | Factor loading |
|---|---|
| Factor loadings and Cronbach’s alpha for variables included in economic distress index | |
| Population below the poverty line, age 25–54 years, % | 0.9045 |
| Households with supplemental security income, % | 0.8753 |
| Households with public assistance income, % | 0.7125 |
| Civilian non-institutionalized population unemployed or not in labor force, age 25–54 years, % | 0.8187 |
| Civilian non-institutionalized population with a work disability, age 21–64 years, % | 0.7410 |
| Population with <4-year college degree, age >25 years, % | 0.5134 |
| Population without health insurance, age 18–64 years, % | 0.6098 |
| Gini coefficient of income inequality | 0.5848 |
| Cronbach’s alpha | 0.891 |
| Factor loadings Cronbach’s alpha for variables included in family distress index | |
| Persons separated/divorced, age >15 years, % | 0.728 |
| Families with children headed by single parent, % | 0.728 |
| Cronbach’s alpha | 0.784 |
Appendix G.
Appendix Figure G.1.
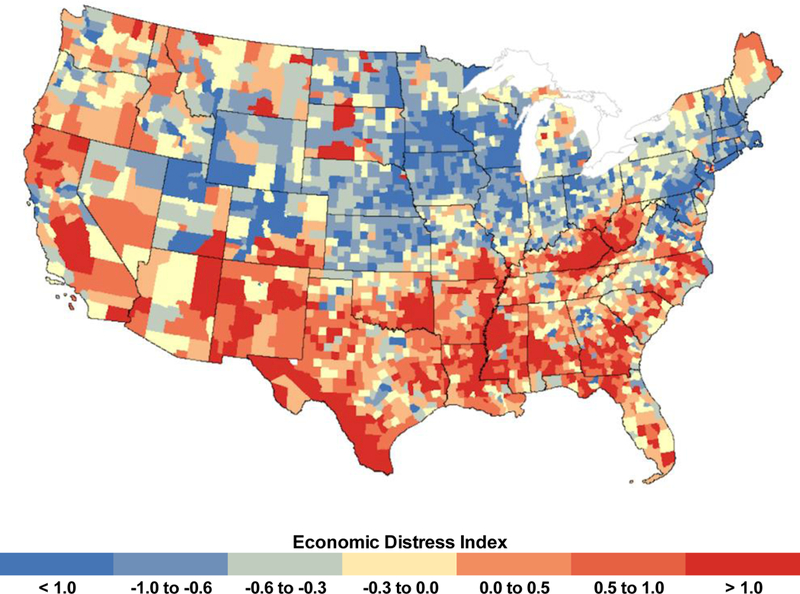
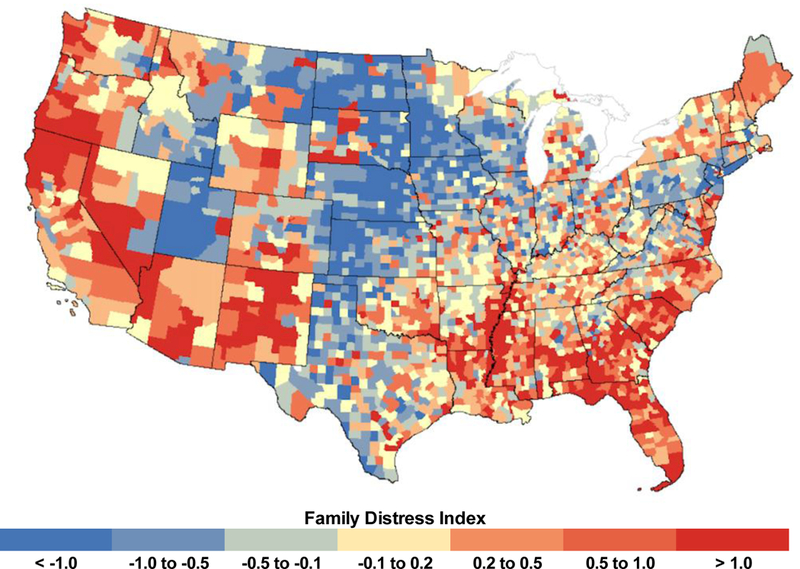
County-level distribution of economic distress index and family distress index.
A. County-level distribution of economic distress index, 2000.
Note: Factor-weighted standardized (z-score) index combing percent poverty (age 25–54 years), percent unemployment/not in labor force (age 25–54 years), percent with a work disability (age 21–64 years), percent without a 4-year college degree (age >25 years), percent households with supplemental security income, percent households with public assistance income, Gini coefficient of income inequality, percent without health insurance (age 18–64 years); categories are represented as quintiles.
B. County-level distribution of family distress index, 2000.
Note: Standardized (z-score) index combing percent divorced/separated (age >15 years) and percent single-parent families; categories are represented as quintiles.
Footnotes
No financial disclosures were reported by the author of this paper.
REFERENCES
- 1. U.S. CDC. Wide-Ranging Online Data for Epidemiologic Research. http://wonder.cdc.gov/. Accessed January 25, 2016.
- 2. Rossen LM, Khan D, Warner M. Trends and geographic patterns in drug-poisoning death rates in the U.S., 1999–2009. Am J Prev Med. 2013;45(6):e19–e25. https://doi.org/10.1016/j.amepre.2013.07.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Rossen LM, Bastian B, Warner M, Khan D, Chong Y. Drug poisoning mortality: United States, 1999–2014. National Center for Health Statistics. https://blogs.cdc.gov/nchs-data-visualization/drug-poisoning-mortality/. Accessed January 20, 2016. [Google Scholar]
- 4. Shiels MS, Chernyavskiy P, Anderson WF, et al. Trends in premature mortality in the USA by sex, race, and ethnicity from 1999 to 2014: an analysis of death certificate data. Lancet. 2017;389(10073):1043–1054. https://doi.org/10.1016/S0140–6736(17)30187–3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Buchanich JM, Balmert LC, Pringle JL, Williams KE, Burke DS, Marsh GM. Patterns and trends in accidental poisoning death rates in the U.S., 1979–2014. Prev Med. 2016;89:317–323. https://doi.org/10.1016/j.ypmed.2016.04.007. [DOI] [PubMed] [Google Scholar]
- 6. Case A, Deaton A. Rising morbidity and mortality in midlife among white non-Hispanic Americans in the 21st century. JAMA. 2015;112(49):15078–15083. https://doi.org/10.1073/pnas.1518393112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Case A, Deaton A. Morbidity and mortality in the 21st century. Brookings Papers on Economic Activity. The Brookings Institution; 2017. www.brookings.edu/bpea-articles/mortality-and-morbidity-in-the-21st-century/. Accessed March 23, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Link BG, Phelan JC. Social conditions as fundamental causes of disease. J Health Soc Behav. 1995;35:80–94. https://doi.org/10.2307/2626958. [PubMed] [Google Scholar]
- 9. McLaughlin DK, Stokes CS, Smith PJ, Nonoyama A. Differential mortality across the United States: the influence of place-based inequality In: Lobao LM, Hooks G, Tickamyer A, eds. The Sociology of Spatial Inequality. Albany, NY: State University of New York Press; 2007. [Google Scholar]
- 10. Montez JK, Zajacova A, Hayward MD. Explaining inequalities in women’s mortality between U.S. states. SSM Popul Health. 2016;2:561–571. https://doi.org/10.1016/j.ssmph.2016.07.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Yang TC, Jensen L. Exploring the inequality-mortality relationship in the U.S. with Bayesian spatial modeling. Popul Res Policy Rev. 2015;34(3):437–460. https://doi.org/10.1007/s11113–014-9350–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Pierce JR, Schott PK. Trade liberalization and mortality: evidence from U.S. counties. Finance and Economics Discussion Series 2016–094 Washington, DC: Board of Governors of the Federal Reserve System. www.federalreserve.gov/econresdata/feds/2016/files/2016094pap.pdf. Accessed February 2, 2017. [Google Scholar]
- 13. Karas Montez J, Zajacova A, Hayward M. Contextualizing the social determinants of health: disparities in disability by educational attainment across U.S. states. Am J Public Health. 2017;107(7):1101–1108. https://doi.org/10.2105/AJPH.2017.303768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Solar O, Irwin A. A conceptual framework for action on the social determinants of health Social determinants of health discussion paper 2 (policy and practice). Geneva: WHO; 2010. [Google Scholar]
- 15. Macintyre S, Ellaway A, Cummins S. Place effects on health: how can we conceptualize, operationalise and measure them? Soc Sci Med. 2002;55(1):125–139. https://doi.org/10.1016/S0277–9536(01)00214–3. [DOI] [PubMed] [Google Scholar]
- 16. Diez-Roux AV. The examination of neighborhood effects on health: conceptual and methodological issues related to the presence of multiple levels of organization In: Kawachi I, Berkman LF, eds. Neighborhood Effects and Health. New York, NY: Oxford University Press; 2003. https://doi.org/10.1093/acprof:oso/9780195138382.003.0003. [Google Scholar]
- 17. Frasquilho D, Matos MG, Salonna F, et al. Mental health outcomes in times of economic recession: a systematic literature review. BMC Public Health. 2016;16:115. https://doi.org/10.1186/s12889–016-2720-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Kerr WC, Kaplan MS, Huguet N, Caetana R, Giesbrecht N, McFarland BH. Economic recession, alcohol, and suicide rates: comparative effects of poverty, foreclosure, and job loss. Am J Prev Med. 2017;52(4):469–475. https://doi.org/10.1016/j.amepre.2016.09.021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Chen VT. Cut Loose: Jobless and Hopeless in an Unfair Economy. Oakland, CA: University of California Press; 2015. [Google Scholar]
- 20. Sherman J Those Who Work, Those Who Don’t: Poverty, Morality, and Family in Rural America. Minneapolis, MN: University of Minnesota Press; 2009. [Google Scholar]
- 21. Ananat E, Gassman-Pines A, Francis DV, Gibson-Davis C. Linking job loss, inequality, mental health, and education. Science. 2017:356(6343):1127–1128. https://doi.org/10.1126/science.aam5347. [DOI] [PubMed] [Google Scholar]
- 22. McLean K “There’s nothing here”: deindustrialization as risk environment for overdose. Int J Drug Policy. 2016;29:19–26. https://doi.org/10.1016/j.drugpo.2016.01.009. [DOI] [PubMed] [Google Scholar]
- 23. Bailey C, Jensen L, Ransom E. Rural America in a Globalizing World: Problems and Prospects for the 2010s. Morgantown, WV: West Virginia University Press; 2014. [Google Scholar]
- 24. Smith KE, Tickamyer AR. Economic Restructuring and Family Well-Being in Rural America. University Park, PA: Pennsylvania State University Press; 2011. [Google Scholar]
- 25. Brown DL, Swanson LE. Challenges for Rural America in the Twenty-First Century. University Park, PA: Pennsylvania State University Press; 2003. [Google Scholar]
- 26. Goldstein A Janesville: An American Story. New York, NY: Simon & Schuster; 2017. [Google Scholar]
- 27. Kaplan MS, Huguet N, Caetano R, Giesbrecht N, Kerr WC, McFarland BH. Economic contraction, alcohol intoxication and suicide: analysis of the National Violent Death Reporting System. Inj Prev. 2015;21(1):35–41. https://doi.org/10.1136/injuryprev-2014–041215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Alexander B Glass House: The 1% Economy and the Shattering of the All-American Town. New York, NY: Macmillan St. Martin’s Press; 2017. [Google Scholar]
- 29. Quinones S Dreamland: The True Tale of America’s Opiate Epidemic. New York, NY: Bloomsbury Press; 2015. [Google Scholar]
- 30. Nandi A, Galea S, Ahern J, Bucciarelli A, Vlahov D, Tardiff K. What explains the association between neighborhood-level income inequality and the risk of fatal overdose in New York City? Soc Sci Med. 2006;63(3):662–674. https://doi.org/10.1016/j.socscimed.2006.02.001. [DOI] [PubMed] [Google Scholar]
- 31. Yen IH, Syme SL. The social environment and health: a discussion of the epidemiologic literature. Annu Rev Public Health. 1999;20:287–308. https://doi.org/10.1146/annurev.publhealth.20.1.287. [DOI] [PubMed] [Google Scholar]
- 32. Putnam RD. Bowling Alone: The Collapse and Revival of American Community. New York, NY: Touchstone Books; 2001. [Google Scholar]
- 33. Keyes KM, Cerda M, Brady JE, Havens JR, Galea S. Understanding the rural-urban difference in nonmedical prescription opioid use and abuse in the United States. Am J Public Health. 2014;104(2):e52–59. https://doi.org/10.2105/AJPH.2013.301709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Kapusta ND, Tran US, Rockett IR, et al. Declining autopsy rates and suicide misclassification. Arch Gen Psychiatry. 2011;68(1):1050–1057. https://doi.org/10.1001/archgenpsychiatry.2011.66. [DOI] [PubMed] [Google Scholar]
- 35. Rockett IR, Kapusta ND, Coben JH. Beyond suicide: action needed to improve self-injury mortality accounting. JAMA Psychiatry. 2014;71(3):231–232. https://doi.org/10.1001/jamapsychiatry.2013.3738. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Fedeli U, Zoppini G, Goldoni CA, Avossa F, Mastrangelo G, Saugo M. Multiple cause of death analysis of chronic diseases: the example of diabetes. Popul Health Metr. 2015;13:21. https://doi.org/10.1186/s12963–015-0056-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. U.S. Census Bureau. Decennial Census 2000. https://factfinder.census.gov/faces/nav/jsf/pages/index.xhtml. Accessed January 15, 2016.
- 38. U.S. Census Bureau. Small Area Health Insurance Estimates. https://www.census.gov/programs-surveys/sahie.html. Published 2008. Accessed June 14, 2017.
- 39. U.S. Department of Agriculture, Economic Research Service. County Typology Codes, 2015 Edition. www.ers.usda.gov/data-products/county-typology-codes/. Accessed January 15, 2016.
- 40. Rupasingha A, Goetz SJ, Freshwater D. County-Level Measure of Social Capital. Northeast Regional Center for Rural Development. http://aese.psu.edu/nercrd/community/social-capital-resources. Accessed June 30, 2016. [Google Scholar]
- 41. U.S. DHHS, Health Resources and Services Administration. Area Health Resource Files Database. http://ahrf.hrsa.gov/download.htm. Accessed May 13, 2016.
- 42. Garcia MC, Faul M, Massetti G, et al. Reducing potentially excess deaths from the five leading causes of death in the rural United States. MMWR Morb Mortal Wkly Rep. 2017;66(2):1–7. https://doi.org/10.15585/mmwr.ss6602a1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. West NA, Severtson SG, Green JL, Dart RC. Trends in abuse and misuse of prescription opioids among older adults. Drug Alcohol Depend. 2015;149:117–121. https://doi.org/10.1016/j.drugalcdep.2015.01.027. [DOI] [PubMed] [Google Scholar]
- 44. Tanielian T, Jaycox LH, Schell T, et al. Invisible wounds: mental health and cognitive needs of America’s returning veterans. RAND Corporation. www.rand.org/pubs/research_briefs/RB9336.html. Accessed February 8, 2017. [Google Scholar]
- 45. Allison PD. Missing Data. Thousand Oaks, CA: Sage University Press; 2002. https://doi.org/10.4135/9781412985079. [Google Scholar]
- 46. ESRI. The American Community Survey: An ESRI White Paper; Redland, CA; 2014. www.esri.com/~/media/Files/Pdfs/library/whitepapers/pdfs/the-american-community-survey.pdf#page=6. Accessed February 2, 2017. [Google Scholar]
- 47. Anselin L Exploring Spatial Data with GeoDa: A Workbook . Santa Barbara, CA: Center for Spatially Integrated Social Science; 2005. [Google Scholar]
- 48. Furr-Holden CD, Milam AJ, Reynolds EK, Macpherson L, Lejuez CW. Disordered neighborhood environments and risk-taking propensity in late childhood through adolescence. J Adolesc Health. 2012;50(1):100–102. https://doi.org/10.1016/j.jadohealth.2011.04.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Catalano R, Dooley D. Health effects of economic instability: a test of economic stress hypothesis. J Health Soc Behav. 1983;24(1):46–60. https://doi.org/10.2307/2136302. [PubMed] [Google Scholar]
- 50. Adler NE, Newman K. Socioeconomic disparities in health: pathways and policies. Health Aff (Millwood) . 2002;21(2):60–76. https://doi.org/10.1377/hlthaff.21.2.60. [DOI] [PubMed] [Google Scholar]
- 51. Wininger PJ. Pharmaceutical overpromotion liability: the legal battle over rural prescription drug abuse. KY Law J. 2005;93(1):269. [Google Scholar]
- 52. Leukefeld CG, Walker R, Havens JR, Leedham VT. What does the community say: key informant perceptions of rural prescription drug use. J Drug Issues. 2007;37(3):503–524. https://doi.org/10.1177/002204260703700302. [Google Scholar]
- 53. Monnat SM. Drugs, alcohol, and suicide represent growing share of U.S. mortality. Carsey School of Public Policy. https://carsey.unh.edu/publication/drugs-alcohol-suicide. Accessed February 8, 2017.
- 54. Young FW, Lyson TA. Structural pluralism and all-cause mortality. Am J Public Health. 2001;91(1):136–138. https://doi.org/10.2105/AJPH.91.1.136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Frohlich KL, Corin E, Potvin L. A theoretical proposal for the relationship between context and disease. Soc Health Illness. 2001;23(6):776–797. https://doi.org/10.1111/1467–9566.00275. [Google Scholar]
- 56. Johnson H, Paulozzi L, Porucznik C, Mack K, Herter B. Decline in drug overdose deaths after state policy changes – Florida, 2010–2012. MMWR Morb Mortal Wkly Rep . 2014;63(26):569–574. [PMC free article] [PubMed] [Google Scholar]
- 57. Selby RJ. The impact of substance abuse insurance mandates. Working Paper; 2017. http://pages.uoregon.edu/rebekahs/rebekahselby_jmp.pdf. Accessed July 17, 2017. [Google Scholar]
- 58. Paulozzi LJ, Stier DD. Prescription drug laws, drug overdoses, and drug sales in New York and Pennsylvania. J Public Health Policy . 2010;31(4):422–432. https://doi.org/10.1057/jphp.2010.27. [DOI] [PubMed] [Google Scholar]
- 59. Bachhuber MA, Saloner B, Cunningham CO, Barry CL. Medical cannabis laws and opioid analgesic overdose mortality in the United States, 1999–2010. JAMA Intern Med. 2014;174(10):1668–1673. https://doi.org/10.1001/jamainternmed.2014.4005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60. Dowell D, Zhang K, Noonan RK, Hockenberry JM. Mandatory provider review and pain clinic laws reduce the amounts of opioids prescribed and overdose death rates. Health Aff (Millwood). 2016;35(10):1876–1883. https://doi.org/10.1377/hlthaff.2016.0448. [DOI] [PMC free article] [PubMed] [Google Scholar]
Data Sources
- U.S. Census Bureau. Decennial Census, 2000. https://factfinder.census.gov/faces/nav/jsf/pages/index.xhtml. Accessed January 15, 2016.
- U.S. Census Bureau. American Community Survey, 2010–14. https://factfinder.census.gov/faces/nav/jsf/pages/index.xhtml. Accessed January 15, 2016.
- U.S. Department of Agriculture, Economic Research Service. County Typology Codes, 2004 Edition. www.ers.usda.gov/data-products/county-typology-codes/. Accessed January 15, 2016.
- Rupasingha A, Goetz SJ, Freshwater D. County-Level Measures of Social Capital, 2005. Northeast Regional Center for Rural Development. http://aese.psu.edu/nercrd/community/social-capital-resources. Accessed June 30, 2016.
- Rupasingha A, Goetz SJ, Freshwater D. County-Level Measures of Social Capital, 2009. Northeast Regional Center for Rural Development. http://aese.psu.edu/nercrd/community/social-capital-resources. Accessed June 30, 2016.
- U.S. DHHS, Health Resources and Services Administration. Area Health Resource Files Database. http://ahrf.hrsa.gov/download.htm. Accessed May 13, 2016.
- U.S. Census Bureau. Small Area Health Insurance Estimates. 2008. https://www.census.gov/programs-surveys/sahie.html. Accessed June 14, 2017.
Data Sources
- U.S. Census Bureau. Decennial Censuses, 2000 and 2010. https://factfinder.census.gov/faces/nav/jsf/pages/index.xhtml. Accessed January 15, 2016.
- The Association of Religion Data Archives. 2010. www.thearda.com/Archive/ChCounty.asp. Accessed January 15, 2016.
- Robert Wood Johnson Foundation. County Health Rankings. 2015. www.countyhealthrankings.org/rankings/data. Accessed January 15, 2016.
- U.S. Department of Agriculture, Economic Research Service. County Typology Codes, 2004 Edition. www.ers.usda.gov/data-products/county-typology-codes/. Accessed January 15, 2016.
- Rupasingha A, Goetz SJ, Freshwater D. County-Level Measures of Social Capital, 2005. Northeast Regional Center for Rural Development. http://aese.psu.edu/nercrd/community/social-capital-resources. Accessed June 30, 2016.