

Abstract
Diffusion magnetic resonance imaging (DMRI) is a powerful imaging modality due to its unique ability to extract microstructural information by utilizing restricted diffusion to probe compartments that are much smaller than the voxel size. Quite commonly, a mixture of models is fitted to the data to infer microstructural properties based on the estimated parameters. The fitting process is often non-linear and computationally very intensive. Recent work by Daducci et al. has shown that speed improvement of several orders of magnitude can be achieved by linearizing and recasting the fitting problem as a linear system, involving the estimation of the volume fractions associated with a set of diffusion basis functions that span the signal space. However, to ensure coverage of the signal space, sufficiently dense sampling of the parameter space is needed. This can be problematic because the number of basis functions increases exponentially with the number of parameters, causing computational intractability. We propose in this paper a method called iterative subspace screening (ISS) for tackling this ultrahigh dimensional problem. ISS requires only solving the problem in a medium-size subspace with a dimension that is much smaller than the original space spanned by all diffusion basis functions but is larger than the expected cardinality of the support of the solution. The solution obtained for this subspace is used to screen the basis functions to identify a new subspace that is pertinent to the target problem. These steps are performed iteratively to seek both the solution subspace and the solution itself. We apply ISS to the estimation of the fiber orientation distribution function (ODF) and demonstrate that it improves estimation robustness and accuracy.
1 Introduction
Microstructural tissue properties can be inferred with the help of diffusion MRI (DMRI) thanks to its sensitivity to the restricted motion of water molecules owing to barriers such as cellular membranes. Microstructural information is typically obtained from diffusion parameters estimated via fitting to the acquired data some biophysical models. Fitting models such as the tensor model [1] is relatively simple and straightforward. But fitting models that are more sophisticated, such as the multi-compartmental models used in AxCaliber [2] and NODDI [3], is much more involved with significantly greater computational load. Computational complexity is further increased when certain structure is imposed on the solution, such as sparsity [4,5].
In a recent work called AMICO [6], the authors show that it is possible to speed up AxCaliber and NODDI estimation several orders of magnitude by re-formulating the fitting problem as a linear system that can be efficiently solved using very fast algorithms. However, this work is limited to a sparse sampling of the parameter space (30 basis functions for AxCaliber and 145 basis functions for NODDI) and is also limited to voxels containing only a single principal diffusion direction. When extending AM-ICO for the more realistic case of multiple white matter (WM) directions per voxel [7], the number of the basis functions would need to be significantly increased, causing the optimization problem to be very high dimensional and computationally very expensive. A similar situation occurs in the estimation of the fiber orientation distribution function (ODF), as in [5], when one needs to increase the number of angular directions of the basis functions for improving accuracy.
In this paper, we propose a method called iterative subspace screening (ISS) to solve this kind of ultrahigh dimension problem more efficiently. ISS requires only solving the target problem in a medium-size subspace with a dimension that is much smaller than the original space spanned by all the basis functions, but is larger than the expected cardinality of the support of the solution. ISS is a subspace pursuit algorithm [8] involving the following iterative steps:
Subspace Selection: Select a potential solution subspace by screening out irrelevant basis functions. This is done by element-wise regression of the fitting residual similar to iterative sure independence screening (ISIS) [9] and subspace pursuit (SP) [8].
Subspace Solution: Solve for the solution, assumed sparse, in the selected subspace and compute the fitting residual. The fitting residual is then used in the subspace selection step above to refine the subspace so that irrelevant basis functions can be discarded and relevant ones can be included.
Such subspace selection approach allows us to remove from consideration many basis functions that might never be active and contribute to the solution. This is motivated by the fact that, in our case, the solution is sparse and hence resides in a small subspace. Since the dimension of the ISS subspace is typically much smaller, the solution can be obtained much faster with potentially lesser local minima that may result from the high dimensionality. We demonstrate the effectiveness of ISS on the problem of fiber ODF estimation and show that significant speed up can be achieved. Extension of ISS for AxCaliber and NODDI, similar to AMICO, should be straightforward.
2 Approach
2.1 Problem Description
The problem we are interested in solving has the following form:
| (1) |
where in our case is a smooth and convex data fidelity term with respect to observation vector and .(f) is a sparsity-inducing regularization term that is not necessarily smooth or convex. In diffusion MRI, one would typically fill the columns of basis matrix with the set of basis functions derived from diffusion models with varying parameters, such as orientation and diffusivity. The vector consists of the corresponding volume fractions associated with the basis functions. For example, for estimating the fiber ODF as in [5], one would fill the columns of A with the signal vectors sampled from tensor models oriented uniformly in all directions. For fast AxCaliber [2] and NODDI [3] estimation using a linear system as described in AMICO [6], one would fill the columns of A with signal vectors from compartment models orientated in a direction estimated via fitting a diffusion tensor. If the parameter space is sampled densely, the above estimation would be computationally very expensive and can be susceptible to local minima due to the high dimensionality and high correlation between the basis functions.
Algorithm 1.
Iterative Subspace Screening
| Input : A, s, . |
| Initialization: |
| 1.
= {. indices of the entries with the largest magnitudes in vector ATs} 2. r(0) = residual 3. f(0) = 0 |
| Iteration : At iterations . = 1, 2, …, go through the following steps: |
| 1.
= {. indices of the non-zeros entries of f(.−1) and the entries with the largest magnitudes in vector ATr(.−1)} 2. Set f(.) = solve 3. r(.) = residual 4. If ‖r(.)‖>‖r(.−1)‖, quit the iteration. |
| Output : The solution f = f(.−1). |
2.2 Iterative Subspace Screening (ISS)
We propose a method called iterative subspace screening (ISS) to tackle this kind of ultrahigh dimension problem more efficiently. ISS requires only solving the target problem (1) in a medium-size subspace with a dimension that is much smaller than the original space spanned by all the basis functions, but is larger than the expected cardinality of the support of the solution. This is based on the observation that the problem (1) can be rewritten as
| (2) |
subject to . ≤ . is larger than the expected cardinality of the support of the solution. Here, with being the subvector formed by the elements of f indexed by set and being the sub-matrix formed the columns of A indexed by . The regularization term now penalizes only the elements in f that are indexed by . We can think of problem (2) as concurrently solving for the solution subspace and the solution itself. This problem is clearly non-convex, non-smooth, and discontinuous; but decoupling subspace identification from the problem allows us to devise an algorithm that focuses on determining the solution in a subspace that actually contains the solution and not in the original subspace, especially when the original problem (1) is very high dimensional (i.e., . is large). As we shall see later, this subspace can be progressively refined by including basis functions that will contribute to the solution and by discarding those that will not. Since the solution is sparse, most basis functions are irrelevant to the solution and can be removed from consideration, reducing significantly the computation cost. Note that if the solution to (1) resides in the identified subspace, solving for (2) will give the same solution as (1).
Proposed Solution
We propose to solve (2) by alternating between solving for and solving for f. At each iteration, one only needs to solve for f in a medium-size subspace with dimension . ≤ .. To select the subspace, we perform an element-wise regression of the fitting residual with the basis functions. That is, at the .-th iteration, we first compute the fitting residual r(.−1) = residual and then use it to determine a subspace of dimension .. This subspace is spanned by the basis functions corresponding to the non-zero elements of f(.−1) and, in addition, the basis functions corresponding to the largest entries of ATrk−1. Based on this new subspace, with the constituent basis functions indexed by , we solve for f(.), i.e., f(.) = solve , via (2) with fixed. This solution can then be used to recompute the residual and refine the subspace. Since at each iteration, the residual vector will be used to screen out a significant number of basis functions, thus removing a big portion of the original subspace, we call our method iterative subspace screening (ISS). See Algorithm 1 for a step-by-step summary of ISS. In addition to reducing significantly the computation time by not having to solve the problem in the original high-dimensional space, ISS can also deal with collinearity between basis functions. By performing subspace screening using the residual vector, some unimportant basis functions that are highly correlated with the important basis functions can be discarded, as observed in [9].
Grouped Variant
We can take advantage of the relationships between basis functions by grouping them [9]. We can divide the pool of . basis functions into disjoint groups, each with a number of basis functions. ISS can then be applied to the selection of basis function groups instead of the individual basis functions. This will reduce the chance of missing important basis functions by taking advantage of the joint information among them, making the estimation more reliable. This can be achieved by modifying Step 1 in the .-loop of Algorithm 1 to select the top . groups of basis functions with the greatest ℓ2-norm of inner products with the residual vector. We shall show how grouping can be used in ISS to help solve sparse-group approximation problem similar to the one described in [10].
A Specific Case
To demonstrate the utility of ISS, we select to use the general sparse-group regularization , where is an indicator function returning 1 if z ≠ 0 or 0 if otherwise. The ℓ0-“norm” gives the cardinality of the support, i.e., . Parameters α ∈ [0,1] and γ> 0 are for penalty tuning, analogous to those used in the sparse-group LASSO [10]. Note that α = 1 gives the ℓ0 fit, whereas α = 0 gives the group ℓ0 fit. Note that in contrast to the more commonly used ℓ1-norm penalization, we have chosen here to use ℓ0-“norm” cardinality-based penalization. As reported in [11], ℓ1-norm penalization [5] conflicts with the unit sum requirement of the volume fractions and hence results in suboptimal solutions.
3 Experiments
3.1 Data
Synthetic Data
For quantitative evaluation, we generated a synthetic dataset for evaluation of ISS. The dataset was generated using a mixture of four tensor models. Two of which are anisotropic and represent two white matter (WM) compartments that are at an angle of 60° with each other. The other two are isotropic and represent the gray matter (GM) and cerebrospinal fluid (CSF) compartments. The generated diffusion-attenuated signals therefore simulate the partial volume effects resulting from these compartments. The volume fractions and the diffusivities of the compartments were allowed to vary in ranges that mimic closely the real data discussed in the next section. Various levels of noise (SNR=10, 20, 30, with respect to the signal value at . = 0 s/mm2) was added.
Real Data
Diffusion weighted (DW) data from the Human Connectome Project (HCP) [12] were used. The 1.25 × 1.25 1.25 mm3 data were acquired with diffusion weightings . = 1000, 2000, and 3000 s/mm2 each applied in 90 directions. 18 baseline images with low diffusion weighting . = 5 s/mm2 were also acquired. All images were acquired with reversed phase encoding for correction of EPI distortion.
3.2 Methods of Evaluation
For the synthetic data, our aim is to estimate the fiber ODFs [13] and evaluate their accuracy by comparing their peaks (local maxima) with respect to the ground truth. The orientational discrepancy (OD) measure defined in [14] was used as a metric for evaluating the accuracy of peak estimation. For the real data, we want to evaluate whether consistent results are given by ISS compared with the original problem (1).
The fiber ODF was estimated by fitting to the data the compartment models for WM, GM, and CSF. Similar to [15], the WM is represented by a large number of anisotropic single-tensor models with orientations distributed evenly on a unit sphere. Dissimilar to [15], however, we allow the axial and radial diffusivities to vary. The GM and CSF are represented using isotropic tensor models with GM having a lower range of diffusivities compared with CSF. Mathematically, this is realized by filling the columns of A with the above models with different parameters, i.e., orientations and diffusivities, and then solving problem (1) (or (2)) for the corresponding volume fractions f. Structure is imposed on the problem by grouping the WM models for each direction as well as the GM models and the CSF models. The tuning parameters were set as follows: γ = 1 × 10−4 and α = 0.05. . was set to about 15% of ..
3.3 Results
Synthetic Data
To show that ISS improves the speed of estimation, we evaluated the computation time of ISS in comparison with solving the original problem (1). We perform this for different numbers of subdivisions of the icosahedron, giving different numbers of directions for the WM models and hence different numbers of columns. for A. 3, 4, 5, and 6 subdivisions of the icosahedron give respectively 321, 1281, 5121, and 20481 directions on a hemisphere. Figure 1 shows that ISS improves the speed of convergence remarkably.
Fig. 1.
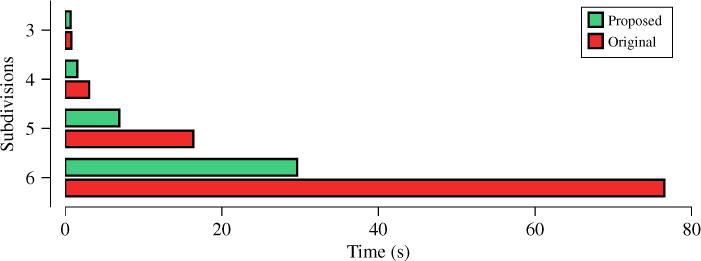
Computation times.
Next, we proceeded to evaluate whether such increase in speed implies a decrease in ODF estimation accuracy. Figure 2, perhaps surprisingly, indicate that ISS actually improves ODF estimation accuracy. This can be explained from the fact that solving the problem in a lower-dimensional subspace can help alleviate the problem of local minima, especially when the problem is non-convex as in our case.
Fig. 2.
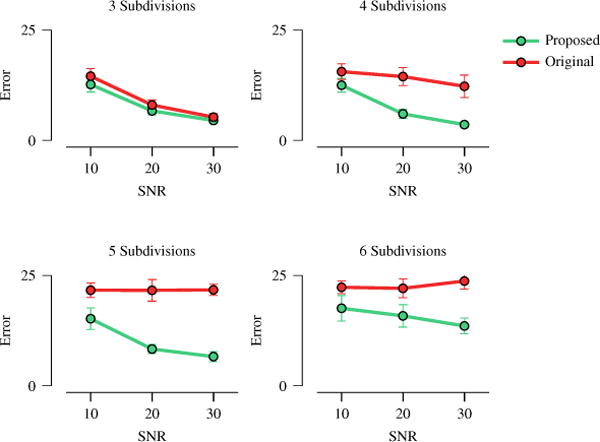
ODF estimation error measured via orientational discrepancy (OD). The error bars indicate the standard deviations.
Real Data
Figure 3 shows the WM ODF glyphs at a portion of the centrum semiovale. The images show that the centrum semiovale contains elements of the corticospinal tract (blue), corpus callosum (red), and superior longitudinal fasciculus (green), including voxels with two- and three-way intersections of these elements. The images indicate that ISS gives consistent results comparable to the original problem. However, we could observe that ISS in fact improves ODF estimation in some voxels (marked by white boxes) and gives ODF estimates that are more coherent and match better with the underlying anatomy.
Fig. 3.
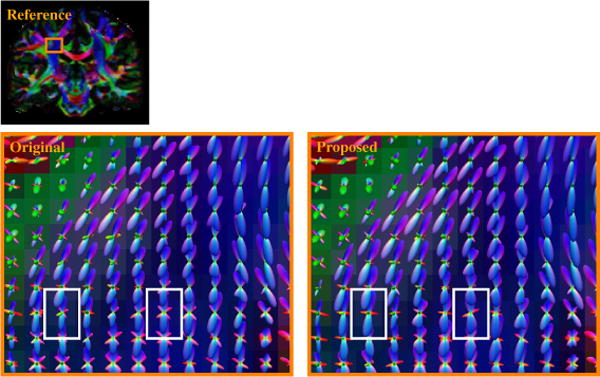
WM ODF glyphs at the centrum semiovale. White boxes mark examples of improvements given by ISS.
4 Conclusion
We have proposed a method for improving the speed and robustness of solving least-squares problems that are regularized by sparse inducing norms. We applied our method called iterative subspace screening (ISS) to ODF estimation and showed that better and faster estimates of the fiber orientations can be obtained. In the future, ISS will be applied to improve the speed and accuracy of estimation techniques for microstructure, such as AxCaliber and NODDI.
Acknowledgments
This work was supported in part by a UNC BRIC-Radiology start-up fund and NIH grants (EB006733, EB009634, AG041721, MH100217, and 1UL1TR001111).
References
- 1.Basser PJ, Pierpaoli C. Microstructural and physiological features of tissues elucidated by quantitative-diffusion-tensor MRI. Journal of Magnetic Resonance Series B. 1996;111(3):209–219. doi: 10.1006/jmrb.1996.0086. [DOI] [PubMed] [Google Scholar]
- 2.Alexander DC, Hubbard PL, Hall MG, Moore EA, Ptito M, Parker GJ, Dyrby TB. Orientationally invariant indices of axon diameter and density from diffusion MRI. NeuroImage. 2010;52:1374–1389. doi: 10.1016/j.neuroimage.2010.05.043. [DOI] [PubMed] [Google Scholar]
- 3.Zhang H, Schneider T, Wheeler-Kingshott CA, Alexander DC. NODDI: Practical in vivo neurite orientation dispersion and density imaging of the human brain. NeuroImage. 2012;61:1000–1016. doi: 10.1016/j.neuroimage.2012.03.072. [DOI] [PubMed] [Google Scholar]
- 4.Landman BA, Bogovic JA, Wan H, ElShahaby FEZ, Bazin PL, Prince JL. Resolution of crossing fibers with constrained compressed sensing using diffusion tensor MRI. NeuroImage. 2012;59:2175–2186. doi: 10.1016/j.neuroimage.2011.10.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Ramirez-Manzanares A, Rivera M, Vemuri BC, Carney P, Mareci T. Diffusion basis functions decomposition for estimating white matter intra-voxel fiber geometry. IEEE Transactions on Medical Imaging. 2007;26(8):1091–1102. doi: 10.1109/TMI.2007.900461. [DOI] [PubMed] [Google Scholar]
- 6.Daducci A, Canales-Rodríguez EJ, Zhang H, Dyrby TB, Alexander DC, Thiran JP. Accelerated microstructure imaging via convex optimization (AMICO) from diffusion MRI data. NeuroImage. 2015;105:32–44. doi: 10.1016/j.neuroimage.2014.10.026. [DOI] [PubMed] [Google Scholar]
- 7.Zhang H, Dyrby TB, Alexander DC. Axon diameter mapping in crossing fibers with diffusion MRI. In: Fichtinger G, Martel A, Peters T, editors. MICCAI 2011, Part II. LNCS. Vol. 6892. Springer; Heidelberg: 2011. pp. 82–89. [DOI] [PubMed] [Google Scholar]
- 8.Dai W, Milenkovic O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Transactions on Information Theory. 2009;55(5):2230–2249. [Google Scholar]
- 9.Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space. Journal of the Royal Statistical Society, Series B. 2008;70(Part 5):849–911. doi: 10.1111/j.1467-9868.2008.00674.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Simon N, Friedman J, Hastie T, Tibshirani R. A sparse-group lasso. Journal of Computational and Graphical Statistics. 2013;22(2):231–245. [Google Scholar]
- 11.Daducci A, Ville DVD, Thiran JP, Wiaux Y. Sparse regularization for fiber ODF reconstruction: From the suboptimality of ℓ2 and ℓ1 priors to ℓ0. Medical Image Analysis. 2014;18:820–833. doi: 10.1016/j.media.2014.01.011. [DOI] [PubMed] [Google Scholar]
- 12.Essen DCV, Smith SM, Barch DM, Behrens TE, Yacoub E, Ugurbil K. The WU-Minn human connectome project: An overview. NeuroImage. 2013;80:62–79. doi: 10.1016/j.neuroimage.2013.05.041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Tournier JD, Calamante F, Gadian DG, Connelly A. Direct estimation of the fiber orientation density function from diffusion-weighted MRI data using spherical deconvolution. NeuroImage. 2004;23(3):1176–1185. doi: 10.1016/j.neuroimage.2004.07.037. [DOI] [PubMed] [Google Scholar]
- 14.Yap PT, Chen Y, An H, Yang Y, Gilmore JH, Lin W, Shen D. SPHERE: SPherical Harmonic Elastic REgistration of HARDI data. NeuroImage. 2011;55(2):545–556. doi: 10.1016/j.neuroimage.2010.12.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Jian B, Vemuri BC. A unified computational framework for deconvolution to reconstruct multiple fibers from diffusion weighted MRI. IEEE Transactions on Medical Imaging. 2007;26(11):1464–1471. doi: 10.1109/TMI.2007.907552. [DOI] [PMC free article] [PubMed] [Google Scholar]