

Abstract
Adaptation is a fundamental process crucial for the efficient coding of sensory information. Recent evidence suggests that similar coding principles operate in decision-related brain areas, where neural value coding adapts to recent reward history. However, the circuit mechanism for value adaptation is unknown, and the link between changes in adaptive value coding and choice behavior is unclear. Here we show that choice behavior in nonhuman primates varies with the statistics of recent rewards. Consistent with efficient coding theory, decision-making shows increased choice sensitivity in lower variance reward environments. Both the average adaptation effect and across-session variability are explained by a novel multiple timescale dynamical model of value representation implementing divisive normalization. The model predicts empirical variance-driven changes in behavior despite having no explicit knowledge of environmental statistics, suggesting that distributional characteristics can be captured by dynamic model architectures. These findings highlight the importance of treating decision-making as a dynamic process and the role of normalization as a unifying computation for contextual phenomena in choice.
Previous work has shown that the neural representation of value adapts to the recent history of rewards. Here, the authors report that a computational model based on divisive normalization over multiple timescales can explain changes in value coding driven by changes in the reward statistics.
Introduction
Behaving organisms face complex and constantly changing environments, requiring the processing of vast amounts of information. However, information capacity is limited in neural systems, which face intrinsic physiological constraints such as finite numbers of neurons and bounded dynamic ranges in spiking activity. How such intrinsically limited neural systems represent near-limitless quantities of information has long been a fundamental question in neuroscience1–3. The efficient coding hypothesis proposes that neural systems exploit statistical regularities within their inputs, reducing redundancy to maximize the information carried in neural responses1. Information-maximizing coding strategies for capacity-limited systems have been extensively documented in sensory processing2,4–8, but whether these principles extend to higher-order processes like decision-making is not fully known.
A key element in the efficient coding of sensory information is the contextual modulation of neural responses7,9,10. Under contextual modulation, responses to a stimulus depend on both the stimulus and the surrounding sensory context. Functionally, context effects can be grouped into two broad domains, driven by either spatial context or temporal context. In spatial contextual modulation, neurons encode stimulus-specific sensory information relative to surrounding contemporaneous sensory information10,11. In temporal contextual modulation, neurons adjust their sensitivity in response to recent sensory history to encode information relative to recent stimuli12–15. Such adaptation to stimulus history is a widespread feature of sensory physiology and perception. Critically, both spatial and temporal contextual modulation are thought to contribute to the efficient coding of sensory information, allowing the brain to minimize redundancy by accounting for spatial and temporal regularities in the sensory environment2,7,10.
In contrast to sensory systems, less is known about how contextual modulation and efficient coding principles operate in the neural systems underlying economic decision-making. While context-dependent preferences have a prominent history in the behavioral choice literature16–18, the responsible neural mechanisms have not yet been identified. Recent work suggests that spatial contextual modulation in value coding plays an important role in value representation and spatial choice effects. Neurons in monkey parietal and premotor regions represent the value of actions in a relative manner, normalizing firing rates to the spatial context defined by the value of the current choice set19–21. Similar relative value coding has been observed in human parietal cortex using electroencephalography22 and functional magnetic resonance imaging23. This relative value coding is believed to be mediated by divisive normalization, a canonical neural computation prevalent in sensory brain areas. Normalization thus provides a unifying computational mechanism for contextual modulation in both sensory and decision processing. Importantly, normalized value coding also explains spatial contextual effects in value-driven decision-making23,24, linking contextual modulation in neural coding to context-dependent choice.
While temporal context also controls value-coding activity, the underlying neural mechanism is less well understood and the link between mechanism and behavior remains unclear. Adaptation in value coding has, however, been observed in a number of brain regions involved in reward learning and value representation25–28. In the orbitofrontal cortex (OFC), an area implicated in the representation of option and outcome values25,29–31, neurons represent value information independent of the current choice context32 but dependent on the statistical structure of recent rewards. OFC value coding adapts to the range or variance of recent rewards26,33, with less variable reward environments generating stronger value coding. Similar adaptive responses are exhibited by midbrain dopamine neurons28, suggesting that adaptive value coding is a general feature of reward-processing in the brain. Such adaptation dynamically reallocates neuronal coding sensitivity to represent the most likely rewards, as determined by the recent reward history. A common theoretical assumption is that this sensitivity retuning should improve discriminability at the behavioral level; however, despite ample evidence for adaptation effects in sensory neurons, empirical evidence for adaptation-induced changes in perceptual discriminability is varied, subtle, and conflicting13,34,35. In decision-making, most previous experiments demonstrating adaptive value coding have not examined choice behavior26,33 and the relationship between adaptation in neural coding and changes in empirical decision-making is unclear. While recent evidence suggests that choice behavior can vary with the mean and range of rewards36–38 as well as the tendency to repeat choices39 (hysteresis), little is known about the neural mechanisms responsible for adaptive changes in value coding and their potential role in choice behavior outside of an explicit learning context40,41. Thus a critical open question is whether and how value-based decision-making adapts to time-varying changes in the statistics of the reward environment.
Here we propose a general computational mechanism for adaptive value coding based on the principles of dynamic divisive normalization and examine the ability of this model to predict adapting choice behavior. Normalization is a canonical computational mechanism in which the activity of a neuron is divided by a summed common factor, usually comprising the summed activity of a neighboring pool of neurons3. Given the ubiquity of normalization in sensory modulation and its proposed role in economic spatial context effects, we hypothesize that normalization, as implemented in dynamic networks, also mediates temporal context effects in value coding and choice behavior. To test our hypothesis, we extend the normalization model to a fully dynamic form capable of capturing the effects of past reward information. This extended mechanism implements a dynamic, cascaded form of normalization42 that can bridge spatial and temporal context effects in a generalized framework.
To test this proposed mechanism, we examine nonhuman primate choice behavior in environments with varying reward statistics. These findings show for the first time that economic choice behavior adapts to the local reward environment in a manner consistent with efficient coding theory. Furthermore, both the extent and across-session variability in adaptive choice behavior is captured by the dynamic normalization model, without any explicit knowledge of the underlying reward statistics. These findings indicate that normalization can account for both spatial as well as temporal context effects in choice and suggest that the underlying biophysical mechanism, even though unknown at a circuit level, may serve a common purpose: efficient coding of value representations.
Results
Dynamic normalization model of value adaptation
To examine the neural basis of temporal context effects in choice, we implemented a dynamic divisive normalization model incorporating multiple timescales of integration. Divisive normalization is a neural computation widely observed in both early sensory coding and higher-order cognitive processes including visual attention, multi-sensory integration, and decision-making3,24,43–45. The characteristic feature of normalization is a divisive scaling, in which the input-driven response of a neuron is divided by the summed activity of a large pool of other neurons. This divisive scaling introduces an intrinsic relativity in neural coding and is thought to play a key role in contextual modulation3,46. If the divisive term includes information about immediate past inputs or neuronal responses, normalization has been demonstrated to characterize key features of adaptation in sensory processing5,47.
Our dynamic model simulates the time-evolving activity of value-coding neurons using a set of normalization-based differential equations. In decision-making, dynamic normalization models can reproduce temporal aspects of normalized value coding seen in the monkey lateral intraparietal (LIP) area, including phasic responses at choice onset, time-varying value coding, and a delayed onset of contextual information representation48. This model features paired excitatory (rate coding, R) and inhibitory (gain control, G) neurons for each choice option, with divisive normalization implemented via recurrent inhibition: each gain control neuron sums network excitatory activity and inhibits its paired output neuron via divisive scaling. In this model, evolving neural activity is governed by a set of N pairs of differential equations:
| 1 |
| 2 |
where i = 1,..,N are individual choice options, Vi is the value of option i, Ri and Gi are the activity of the excitatory and inhibitory neurons representing option i, respectively, the parameters ωij weight the input Rj to gain neuron Gi, and the timescale τ governs the timescale of system dynamics. Together, these equations capture the cross-option normalization that underlies spatial context effects on value coding as well as their underlying dynamics. Note that these dynamics are intra-trial dynamics (when τ is short as in our original model), describing activity changes in a decision-related brain area over the course of a single choice. However, these fast dynamics are unable to capture processes such as adaptation that occurs over multiple trials, necessitating an extension to the previous model.
In order to capture longer timescale phenomena while retaining the ability of the model to capture fast firing rate dynamics, such as those in area LIP, we extended the dynamic normalization model with an additional circuit capturing inter-trial (slower) dynamics. Inter-trial dynamics are required because empirically observed adaptive value coding is sensitive to distributional parameters like the mean, range, and standard deviation of past rewards25,26,33, which can only be estimated across multiple trials. Our model utilizes the same general circuit architecture as the previously published model48 but incorporates cascaded circuits operating at long and short timescales, generating both slow and fast dynamics (Fig. 1a). As in the previous model, each fast network gain control neuron (GiF) computes a weighted sum of excitatory output neurons and inhibits its paired output neuron via divisive inhibition:
| 3 |
| 4 |
Fig. 1.

Cascaded normalization model and example model behavior. a Cascaded dynamic normalization model. Circuits are arranged into separate slow (bottom) and fast (top) subcircuits. Model units are either excitatory (R) or inhibitory (G); arrows depict excitatory and dots inhibitory connections. b–e The network behavior using a simple input structure emulating consecutive trials over time (e); panels on the right show an expanded view of a small time interval (dashed boxes). b Dynamic activity of the fast circuit excitatory units. These units show fast transients and subsequent sustained responses to value input in single trials. c Dynamic activity of fast (pink) and slow (teal) circuit inhibitory units. Note that, in the model architecture, inhibitory neurons within a subcircuit (fast or slow) act as a single pool and are plotted together. d Dynamic activity of slow circuit excitatory units. Over trials, slower adaptation-like effects within the slow circuit are propagated to the fast subcircuit. Contrasting the first and second half of the stimulation demonstrates the profound differences in value coding elicited by the temporal context despite having the exact same input structure (b). e Simulated value inputs. In this simulation, V2 was kept constant while V1 was changed across blocks; values were turned on during each trial and set to zero between trials
However, in addition to fast circuit excitatory neurons (RF), fast circuit inhibitory neurons also receive input from excitatory neurons (RS) in an upstream slow circuit. Like the fast circuit, the slow circuit comprises excitatory output neurons and inhibitory gain control neurons mediating a recurrent divisive inhibition but in this case at a much slower timescale (longer time constant):
| 5 |
| 6 |
Together, this system of differential equations (Eqs. 3–6) describes how the neural activity of each unit in the circuit changes over time as a function of activity levels and option values Vi. Both the fast and slow circuits utilize the same internal architecture: feedforward value inputs, lateral connectivity within a circuit, and recurrent inhibition. As in previous work48, the fast circuit operates at a short timescale (τF) to capture intra-trial dynamics, modeling value-coding activity in a brain area implementing choice. In contrast, the slow circuit operates at a long timescale (τS) to capture inter-trial dynamics, modeling value responses that integrate responses over multiple trials and rewards. Critically, slow circuit activity modulates fast circuit activity via inputs to fast circuit gain control neurons, resulting in cascaded circuits operating at different timescales that influence both value coding and choice behavior via the output of the fast network.
Example model behavior
To demonstrate the multiple timescale characteristics of the cascaded model, we show model behavior in a simulation with values that change over long timescales (Fig. 1). In this simulation, we examined a two option network receiving information about two choice option values in individual trials. Within a block, the two option values were held constant; across blocks, the value of one option (V1) stepped through 3 values (20, 40, 60 arbitrary units) twice, while the value of the other option (V2) was constant (Fig. 1e). To signify individual trials, value inputs were turned on for a constant amount of time and switched off between trials. Time constants were set to 1 for the fast and 1000 for the slow subnetworks in arbitrary units of time.
Two important model characteristics are evident in the faster dynamic subcircuit of the network (Fig. 1b), which represents neurons in a value-coding output area (i.e., decision-related area). First, the fast dynamics in response to a single value input reflect previously studied dynamic normalization models and closely resemble aspects of value modulation in LIP area neurons48. Value-coding RF neurons in the fast network exhibit peak transients and subsequent steady-state plateaus during option presentation. Second, longer timescale changes in the system produce a change in the pattern of fast activity over time, despite constant patterns of input. This longer timescale adaptation is evident in changes in RF activity within each block. These adaptive changes in the fast network are driven by longer timescale changes in the slow network (Fig. 1c,d), not by changes in the inputs. Both excitatory (RS) and inhibitory (GS) units in the slow network operate at a longer timescale and integrate value information over multiple trials. Because inhibitory units in the fast network receive inputs from the slow network, their activity also exhibits longer timescale dynamics. This network architecture thus incorporates an interaction between the two dynamic components of the slow and the fast network.
These dynamics imply that the model can integrate information over multiple trials and thus reflect the statistics of the reward environment. In this model, we quantify choice formally by comparing the RF value-coding activity in the fast network for each of the options under consideration48. In the simulation shown in Fig. 1, RF activity representing the values of the two individual options changes over trials. Even with constant value inputs, the difference between these activities governing model choice also changes on a similar timescale (Fig. 1b, inset). Given these predicted neural and behavioral signatures of adaptation, we next examined whether the cascaded dynamic normalization model captures temporal context effects in empirical monkey choice behavior.
Behavioral results
To examine how temporal reward context affects empirical decision-making, we quantified choice behavior in monkeys performing a delayed two alternative forced choice task (Fig. 2a). In each trial, monkeys chose between options delivering different amounts and types of juice reward. Trials were organized into one of the two different kinds of blocks (narrow, wide; counterbalanced across sessions). Both blocks included identical test trials, which paired a fixed quantity of one juice type with varying quantities of a second juice type (Fig. 2b). The two juice types used were held constant for each animal. Within each block, these test trials always quantified choice behavior across a fixed set of value differences. In addition to these fixed test trials, each block included adapter trials, which paired varying quantities of the second juice type. Critically, the statistics of the adapter juice distribution differed between blocks of trials, exhibiting lower variance in the narrow block and higher variance in the wide block (while preserving a common mean). In each block, test trials and adapter trials were randomly interleaved; therefore, the statistical distribution of all presented rewards differed between blocks. This design allowed us to examine how choice behavior in test trials—which were identical between blocks—depended on the background reward statistics controlled by adapter trials.
Fig. 2.

Choice task with varying background reward statistics. a Task design. Top, single trial timeline. Animals made saccadic choices between two rewards, with juice type and amount indicated by the color and number of squares, respectively. Bottom, block design. Individual test trials were presented in narrow or wide context blocks. b Trial types and block structure. Test trials were held constant between both conditions while adapter choice trials exhibited a larger standard deviation (same mean) of randomly presented reward options. c Illustrative data representing the hypothesized influence of a narrow and wide adapter distribution on neural coding and choice probability in the test distribution
We first examined how average choice behavior varied between blocks with different reward statistics. In sensory processing, the efficient coding hypothesis postulates a straightforward relationship between sensory statistics and neural stimulus coding1,7. Given a fixed dynamic range, neurons adapt to wider stimulus distributions with shallower firing rate response curves, a phenomenon that has been observed in value-coding areas of the brain26. We hypothesized that—if value-coding neurons adapt to narrow and wide reward distributions by changing the slope of their firing rate response curves—choice behavior for a fixed set of value differences should exhibit steeper choice curves in narrow reward contexts (Fig. 2c). For each session, we fit separate sigmoid functions to test trial choice data from the narrow and wide blocks (see Methods). In both monkeys, we observed a significant (Monkey H: t(38) = 2.638, p = 0.012; Monkey B: t(29) = 2.199, p = 0.036; t test two tailed) change in average choice slope between the two adaptation conditions; this difference was also significant when tested in a non-parametric manner (p < 0.05; permutation testing). Choice slopes were on average higher in the narrow (smaller variance) condition compared to the wide (larger variance) condition (Fig. 3b). Notably, this change in choice stochasticity was not accompanied by a change in relative juice preference: neither animal exhibited a significant change between conditions in choice curve indifference points, the magnitudes at which juices are chosen with equal probability (Monkey H, t(38) = 0.190, p = 0.850; Monkey B: t(29) = 0.603, p = 0.551; t test two tailed). We also found no significant difference in the root mean square error of the choice curve fits across block conditions (Monkey B: t(29) = 1.405, p = 0.170, Monkey H: t(38) = 0.652, p = 0.518; t test two tailed); thus differences in model fit quality do not account for the adaptation-related difference in choice performance. This block-dependent difference in choice behavior demonstrates the influence of distributional context on choice stochasticity. Consistent with the predictions of efficient coding theory, adaptation to a larger distribution of value options leads to decreased choice performance on fixed test trial choices.
Fig. 3.

Individual choice data and aggregate behavioral performance. a Example single session monkey choice curves. Each choice curve is fit to data from single session test choice data from narrow (light blue line) and wide (dark blue line) blocks; dots show session average choice data. Data from two sessions in each animal are shown. Example sessions consistent with (right panel in each pair: narrow slope > wide slope) and contrary to the efficient coding prediction (left panel in each pair: narrow slope < wide slope) are displayed. b Normalized slope difference (narrow−wide) of all sessions performed by each animal. Left, Monkey B (n = 30 sessions); right, Monkey H (n = 39 sessions). A significant mean shift toward positive slope differences (narrow > wide) can be observed (arrow, mean slope difference)
In addition to the significant average change in choice performance, adaptation effects demonstrated a large variability across individual sessions, each of which presented the adapters and test trials in a different random order. As evident in example daily sessions (Fig. 3a) and across all data (Fig. 3b), slope differences exhibited a range of adaptation effects: while most session differences occurred in the expected direction (narrow > wide), a minority exhibited either no difference (narrow ∼ wide) or differences in the opposite direction (narrow < wide). This variability was unrelated to either varying indifference points or other potentially confounding behavioral measures. There was no significant relationship between narrow–wide slope differences and indifference point differences across sessions (Monkey H, r(38) = 0.09, p = 0.56; Monkey B, r(29) = 0.20, p = 0.30; Pearson correlation). Furthermore, a simple regression analysis showed no relationship between narrow–wide choice slope difference and various session variables (percentage of correct trials, experiment time, average saccade response time, mean received reward, standard deviation of received reward) across sessions (Monkey H, F(38) = 1.68, p = 0.16; Monkey B, F(29) = 1.16, p = 0.35; multiple linear regression). Thus the aggregate behavioral adaptation effect, which matches the prediction of efficient coding theory, masks a considerable variability in the effects of reward statistics on session-level data. Notably, because experimental reward distributions were identical across sessions, this session-by-session variability cannot be explained by the effect of average reward statistics. However, such variability might reflect the effect of more local reward statistics (i.e., the specific order in which adapters were presented), a possibility we next examined with the cascaded normalization model.
Modelling adapting choice behavior
To test the ability of the cascaded model to explain adapting choice behavior, we examined whether it could reproduce two key features of the empirical data: (1) average choice performance across blocks, and (2) session-by-session variability in the extent of adaptation. Neither of these effects can be captured by static normalization models that ignore the trial history. To assess model performance, for each session the model was fed the identical trial sequence experienced by the monkey, trial-by-trial predicted choices were identified, and narrow and wide block choice curves were quantified. The inputs to the model thus comprised the exact experimental sequence of option values presented to a monkey, delivered with the same timing as in experimental sessions. Because the dynamic model utilizes differential equations, which evaluate the activity of a given unit as a function of both input and the activity of other units at each time step, both the magnitude and timing of value inputs control model activity and influence predicted choice behavior. In this approach, the temporal sequence of potential rewards encountered by the animals—but not the explicit underlying reward statistics—is available to the model; in order to adapt to block-wise reward statistics, the model must effectively extract this information from the dynamic sequence of trial values.
For each individual behavioral session, we determined predicted model choice on each trial and constructed probabilistic choice curves for the two block conditions (narrow, wide). As in our analysis of the monkey behavior, the difference in block-specific choice curves served as a measure of session-by-session adaptation in model-predicted choice behavior (Fig. 4a). Note that the dynamic model was not fit in a traditional sense to the choice data; the only free parameters in the model are the time constants τS and τF. Only the ratio of these slow and fast time constants affects the behavior of the model. Rather than optimize parameter values, we examined model predictions at different fixed τS and τF ratios. Given that previous work suggests that fast normalization dynamics operate with a τF ~ 100 ms48, we assessed model predictions with τ ratios (τS/τF) ranging from 100 to 2500 consistent with a τS = 10–250 s. At these slow timescales, the model incorporates information from several to many trials in the past (average trial length = 2.5 s).
Fig. 4.

Individual model choice data and aggregate model performance. a Example single session model choice curves. Each choice curve is fit to model-predicted choices in single session test trials from narrow (light blue) and wide (dark blue) blocks. Model data from two sessions in each animal are shown. As in Fig. 3, example sessions consistent with (right panel in each pair: narrow slope > wide slope) and contrary to the efficient coding prediction (left panel in each pair: narrow slope < wide slope) are displayed. b Normalized slope difference of all sessions for the simulations. As in the empirical choice data (Fig. 3), a significant mean shift toward positive slope differences (narrow > wide) can be observed (arrow, mean slope difference). Example model-predicted choice curves in each monkey were based on optimal simulation timescales (Monkey B: τS = 75 s; Monkey H: τS = 60 s), as shown in Fig. 5b
We found that the cascaded dynamic normalization model captured both the mean adaptation effect and its session-by-session variability. Averaged across sessions (Fig. 4b), model predictions in both monkeys exhibit steeper choice curves in narrow versus wide block conditions (p < 0.05; permutation testing). The direction of model-predicted adaptation effects do not significantly differ from that observed in the behavioral data (monkey B: χ2 = 1.36, monkey H: χ2 = 0.35), indicating that the model and the monkeys exhibit analogous average responses to background reward statistics.
More importantly, as in the empirical data, model behavior exhibited across-session variability in adaptation. Figure 4a shows two example model-predicted choice curves in each monkey for the same sessions displayed in Fig. 3 (Monkey B: τS = 75 s; Monkey H: τS = 60 s). Across all sessions (Fig. 4b), model-predicted adaptation effects qualitatively matched observed adaptation effects, with slope differences consistent with the average effect (narrow > wide) and in the opposite direction (narrow < wide). The example choice curves and the distributions of slope differences indicate that model and animal behavior exhibit a similar pattern of across-session variability in adaptation. Moreover, the extent of adaptation in monkey and model behavior was significantly correlated across sessions (Fig. 5a; Monkey B: r(29) = 0.453, p = 0.012; Monkey H: r(38) = 0.314, p = 0.046; Pearson correlation). This correlation shows that the dynamic normalization model captures session-specific changes to the extent of adaptation: sessions that exhibited stronger adaptation in observed behavior generated stronger adaptation in model choice.
Fig. 5.
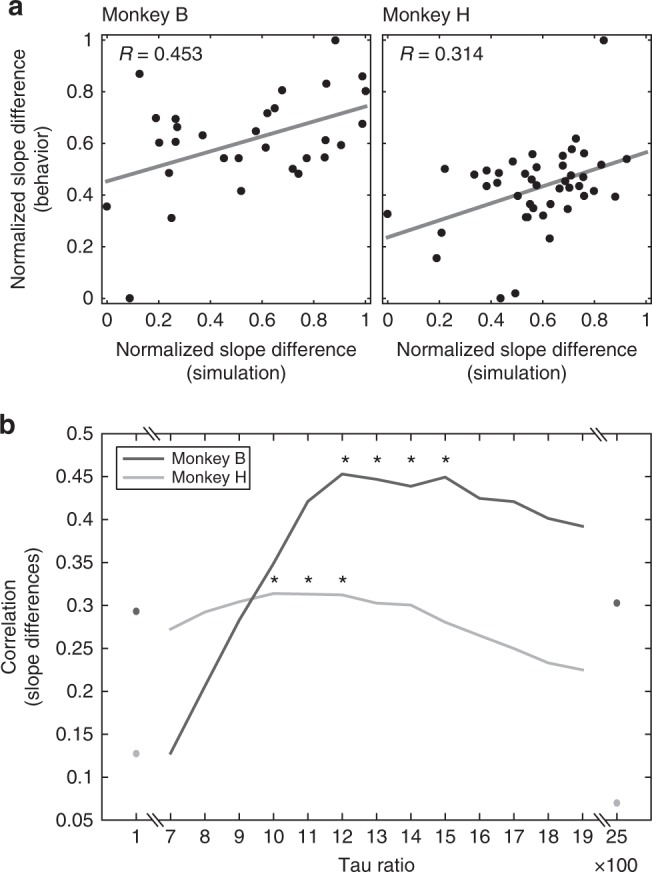
Across-session variability of adaptation strength captured by normalization model. a Correlation between strength of adaptation effect in monkey and model choices across sessions. Each point plots the difference in model choice stochasticity (narrow−wide) versus the difference in monkey choice stochasticity (narrow−wide) in a single session. Model performance evaluated using the best fitting tau ratio in each monkey. b Model performance at different slow circuit timescales. Each line shows correlation between model and monkey adaptation effects across all sessions (asterisk, Pearson's correlations significant at p < 0.05)
In order to differentially respond to distributional reward statistics, our normalization model relies on a slow circuit that integrates value information over multiple trials. To examine how model performance depends on the balance of slow (τS) and fast (τF) circuit timescales, we performed independent simulations of our model using a range of different τ ratio values (Fig. 5b). Model-predicted choice slope differences at each τ ratio were compared to empirical observations using correlational analyses, as described above. Significant correlations between model predictions and monkey behavior were only observed at intermediate τ ratios, corresponding to τS values of ~50–80 s in both animals (assuming τF = 100 ms, based on previous work). These intermediate slow circuit integration times suggest that model dynamics must match the timescale of the relevant environmental statistics: at very fast integration times, the model is unable to capture across-trial reward statistics; at very slow integration times, the model is insensitive to across-block changes in reward statistics.
Finally, we examined which aspects of the reward environment contribute to model performance. In the primary analysis above, input to the dynamic normalization model comprised the exact sequence and timing of option values presented to the monkey in each session. To determine the contribution of reward sequence and timing to model performance, we examined model predictions with shuffled versions of the empirical data (see Methods and Fig. 6a). These shuffled data retained the choices associated with each presentation of options but varied either the sequence of presented options or their timing information. In the magnitude permutation, we shuffled the order of presented trials but retained the temporal characteristics of each session (trial and inter-trial interval (ITI) durations). In the ITI permutation, we shuffled the timing information but retained the sequence of presented trials. For each shuffled data set, model predictions and performance were determined at the best fitting τS for each animal, and the distribution of shuffled-data model performances quantified (n = 1000 repetitions each). Figure 6b shows the distribution of correlations for both magnitude and ITI permutations. In both animals, our observed correlations (black line) are significantly different from the permuted null distribution (p < 0.01) for the magnitude shuffles and significantly different for the ITI shuffle in animal B (p < 0.05). The relatively small impact of timing information in model performance is expected given the experimental design: ITI variability was small (600–900 ms) compared to the timescale of the model slow circuit (~60 s). The ability of the ITI shuffles to decrease model performance is likely driven by post-error time-outs, which increased the interval between successive trials following aborted trials; consistent with this idea, the animal that exhibited a significant ITI shuffle effect also exhibited more time-outs on average (Supplementary Fig. 1). These findings show that the reward sequence, and to a lesser degree the precise timing, are necessary for the model to replicate empirical adaptation effects, suggesting that the influence of reward statistics on choice behavior may be implemented by the dynamical behavior of neural valuation circuits.
Fig. 6.
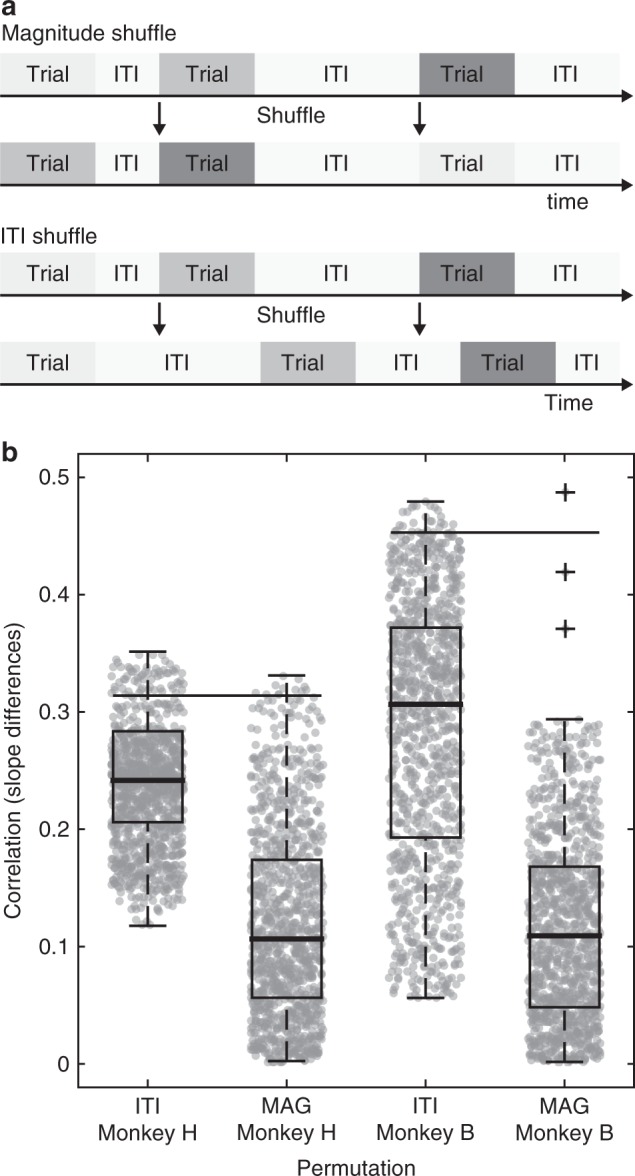
Permutation testing for monkey-model correspondence. a Illustration of permutation procedures. In the magnitude shuffle (top), the sequence of juice types and magnitudes option was permuted for each behavioral session. In the ITI shuffle (bottom), the sequence of reward magnitudes trial was kept intact but the exact timing of the presentation was shuffled by permuting the ITI intervals of each behavioral session (ITIs included timeouts that occurred following aborted trials). Each permuted dataset was then input to the dynamic normalization model. b Model–monkey correspondence on permuted data (n = 1000 permutations for each shuffle and monkey). Correlation determined in the same manner as in Fig. 5. Boxplot center line depicts the median, surrounding box 25th to 95th percentile, and shaded gray dots are underlying data distribution. Horizontal black lines show the correlation value obtained with the original non-permuted data
Discussion
How intrinsically constrained neural systems efficiently represent the wide range of behaviorally relevant information is a fundamental question in neural coding. In sensory systems, spatial and temporal contextual modulation of neural responses are thought to optimize neural coding for static and dynamic regularities in the sensory environment2,3,10. Importantly, these described coding changes predict behavioral changes at the perceptual level such as the tilt illusion and the motion aftereffect10. The extent to which these neural computational principles apply to value coding, and what influence they have on choice behavior, is relatively less understood. Here we demonstrate a value adaptation effect on mean choice behavior in nonhuman primates. Consistent with efficient coding principles, the steepness of stochastic choice functions varies with the width of the recent value distribution. Notably, this adaptation effect displays a substantial amount of variability in both its magnitude and direction. We find that this adapting choice behavior can be explained by a dynamic value normalization model incorporating slow and fast timescale circuits. Dynamic normalization accounts for both the average adaptation effect as well as a considerable proportion of its variability, suggesting that value adaptation is driven by local reward changes rather than global reward statistics. While reinforcement learning processes in theory can produce sequential trial effects on valuation and generate choice stochasticity, the task used here is entirely deterministic in reward structure and a simple reinforcement learning model does not explain either the observed choice behavior or across-session variability in the extent of adaptation (Supplementary Fig. 2).
Adaptation is a characteristic feature of single neuron computation in sensory processing7 and extends to value coding in reward-related brain areas, including midbrain dopaminergic nuclei and OFC26,33,36. Our results extend these neural findings to the behavioral domain, showing that—consistent with recent theoretical findings36—value-guided choice behavior also adapts to the recent reward environment. These adaptive changes in choice performance follow in principle from previously demonstrated value-coding changes, though establishing a definitive link between adaptation in value-coding activity and in choice behavior will require further study. In sensory processing, adaptation does not always reliably improve discriminability for stimuli similar to the adapter and often drives other changes in perceptual performance34 (e.g., biases). While our results show a change in value-guided discriminability, adaptation to reward statistics could also produce other changes in choice behavior such as preference biases, particularly under different adaptation conditions (see Supplementary Discussion).
Regardless of the underlying biophysical mechanism, the slow temporal dynamics evident in our behavioral results emphasizes that the brain integrates information over real time rather than discrete trials. As our permutation tests demonstrate, merely shuffling the temporal structure reduces the predictive power of our model. This establishes that the actual temporal structure, and not merely the trial order, determines how reward history is integrated into an estimate of the reward environment. This finding is additionally supported by the fact that shuffling the temporal structure has a more detrimental effect on the behavior–model correspondence in the animal that has a larger variability in their temporal trial order.
Our modeling results also emphasize the importance of treating decision-making as a dynamic rather than a stationary process and demonstrate the power of a dynamic approach for explaining variability in choice behavior. The empirical adaptation effects we observed were variable across sessions despite identical average reward statistics, suggesting that adaptation responds to local, within-block fluctuations in reward environments. This variability in strength of adaptation was captured by a dynamic normalization model whose only input was the stream of observed rewards, indicating that behaviorally driven reward adaptation does not require explicit knowledge of distributional characteristics. A crucial element of this normalization model is the existence of two timescales of operation: a fast timescale in the choice behavior circuit and a slow timescale in the circuit integrating reward information over multiple trials. This dual timescale network is consistent with recent evidence that neurons exhibit a diversity of time constants49,50. In our data, optimal slow circuit time constants were comparable between both animals (60–75 s); however, it is possible that environmental characteristics could influence the temporal integration process51,52.
Our model follows from previous proposals of context dependent choice mechanisms24,46,53 and can be seen as an approximation to a general mechanism for implementing flexible decision-making through context dependence. While previous work has demonstrated19,48 that the fast dynamic circuit in our model corresponds well with electrophysiological characteristics of area LIP neurons, we remain open to the exact implementation and localization of the slow dynamic circuit. Our model implements a form of divisive normalization, a computation proposed to be a canonical cortical operation3 that operates in many different neural processes, brain regions, and species. Our current model extends previously used normalization equations to incorporate both spatial and temporal context, further supporting the idea that normalization is a general neural computation. Many flavors of normalization models can potentially be conceived and the exact biophysical mechanisms are still under debate3,54,55 but the importance of the implied computational mechanism lies in its simplicity and generality. Our approach extends this generality and reconciles adaptation-like processes under the umbrella of normalization (for limitations, see Supplementary Discussion).
In summary, we present here behavioral evidence demonstrating the effect of value adaptation on choice stochasticity. These adaptive changes in choice behavior are explained by a dynamic cascaded normalization model that captures session-by-session variability in the extent of adaptation and uncovers the behaviorally appropriate timescale integrating past reward information. Since decisions are rarely conducted in isolation, it is of crucial behavioral importance to understand how organisms adapt to the value context defined by the local temporal history. Establishing the dynamics of value coding and representation yields behavioral insights into choice behavior impossible to capture with traditional choice models.
Methods
Subjects
Two male rhesus monkeys (Macaca mulatta) were used as subjects (Monkey H, 11.3 kg; Monkey B, 7.8 kg). All experimental procedures were performed in accordance with the United States Public Health Service’s Guide for the Care and Use of Laboratory Animals and approved by the New York University Institutional Use and Care Committee. Experiments were conducted in a dimly lit, sound-attenuated room using standard techniques. Briefly, the monkeys were head restrained and seated in a custom-built Plexiglas primate chair that permitted arm and leg movements. Visual stimuli were generated using a liquid-crystal display (240 Hz) placed 67 cm in front of the animal. Monkeys' eye movements were monitored using the Oculomatic video-based system56. Monkey H’s eye movements were also recorded using a scleral search coil, with horizontal and vertical eye position sampled at 600 Hz using a quadrature phase detector (Riverbend Electronics). Presentation of visual stimuli and juice reinforcement delivery were controlled with integrated software and hardware systems, controlled by a customized MonkeyLogic57 package.
Task
Trained monkeys were offered a choice between two options differing in reward magnitude and juice type (delayed two alternative forced choice task). Monkeys were trained to fixate on a central fixation spot for 500 ms after which a choice display comprised of colored squares indicating the juice type and magnitude of the options was presented at 16° eccentricity. Monkeys had to maintain fixation for an additional 1200 ms until the fixation dot disappeared and a saccade toward one of the option targets could then be initiated. Monkeys’ gaze had to reach the target within 500 ms and hold fixation on the target for an additional 400 ms to obtain the chosen juice reward (Fig. 2a). Time intervals between trials (ITI) were jittered between 600 and 900 ms. Juices were delivered through a multi-line juice tube. Each juice line was controlled by an independent solenoid valve. Routine calibrations were performed to match the juice quantity (~80 µl) to solenoid opening times. Magnitude of juice reward was realized by opening and closing (75 ms dead time) the solenoid according to the magnitude of the reward stimulus selected by the monkey.
Block of trials were presented that were composed of a mixture of adapter trials and test trials. Trial composition was assigned to be 60% adapter trials and 40% test trials, with individual trial identity determined randomly. In test trials, fixed in structure across all blocks, monkey chose between an unvarying reference reward (fixed reward magnitude and juice type) and one of the five variable rewards (Fig. 2b). These responses allowed us to plot the monkey’s probability of choosing the reference reward as a function of the magnitude of the variable reward: a choice curve. What we systematically varied across blocks was the structure of the adapter trials. The structure was comprised of a narrow versus a wide standard deviation in the magnitude of randomly presented adapter trial options. We then examined the effects of the standard deviation of adapter variability on the slopes of these choice curves. Monkeys were required to complete both condition blocks within a single session. Thus, on a given testing day, animals were required to complete both one wide and one narrow block. Block order was randomized over recording days. Only days in which monkeys performed >230 trials per block correctly were included in the analysis. On average, animals performed 289 trials per block leading to an average of total of 578 trials per daily session. An additional accuracy criterion of 80% correct trials was used for data inclusion. A total of 9 days of data collection had to be discarded from analysis of which 5 days were due to poor animal performance (below 80%) and 4 days due to equipment failure. The average accuracy over both animals was 85%. Switches between blocks within a testing day were not overtly signaled to the animal. However, we note that, since offer quantities were unique between blocks, it is possible that the animal could identify block changes from this indirect signal.
Data analysis and modeling
Analysis of behavioral data and model performance used a total of 69 sessions (Monkey B, n = 30; Monkey H, n = 39). Only choice data from test trials (which were constant across conditions) were used for the following analysis. To examine the effect of adapter block identity on choice performance, we independently fit choice data from test trials in each block to a standard sigmoidal function (y = 1/(1 + 10(x50−x) × s)) and used the resulting slope of the choice curve as the parameter representing overall choice stochasticity. We then tested for systematic differences in choice stochasticity between the two behavioral conditions both on a mean aggregate level (all choices over days combined) or on a daily basis (all choices within daily conditions) and assessed the significance of the differences using permutation testing. We additionally ran a control regression analysis predicting condition choice stochasticity as a function of number of trials correct, condition completion time, and average response latency. For the modeling, we extended well-studied previous models of static divisive normalization to the temporal domain as a set of cascaded differential equations.
Our model uses a two-stage cascaded approach in which the incoming value information is first normalized with respect to the other concurrent value option via lateral inhibition. In a second stage, value information is normalized by a time discounted version of previously encountered value options. To estimate the predictive accuracy of this model, we used a two-fold approach. First, we individually solved the set of equations using the Runge–Kutta method for each behavioral time series. Behavioral time series were evaluated at a millisecond level with reward magnitudes and timing determined from the actual monkey experience in each session; note that model ITIs also included time-outs implemented following any aborted trials. Fixed parameters were used for evaluation (ω = 1, β = 1, α = 1 for all i and j). These parameters were chosen to produce the simplest form of the model in which no a priori knowledge of excitation to inhibition weighting is known, baseline activity is zero, and inhibition is global to the cascade stage level. Excitatory and inhibitory τ values within a given circuit (slow, fast) were set to be equal. Previous work48 has demonstrated that a network with equivalent excitatory and inhibitory time constants accurately characterizes value-coding activity in decision circuits; more broadly, standard mean-field approaches generally assume equivalent or approximately equivalent timescales within a network58–60. Temporal integration dynamics were modeled by explicitly setting a τ-ratio between the fast and slow components of our network. We independently re-evaluated our model for a range of τ-ratios spanning from short (5 s) timescales of about one trial to long (125 s) timescales encompassing many trials.
The resulting raw network activity was used to construct a probabilistic choice curve similar to the fitting of the behavioral results. The simple difference in modeled firing rate between the two presented options was used as a metric of choice output on a given trial. This means that, if the network consistently produces a large difference between concurrent presentations of the same options, the resulting choice probability becomes less stochastic. Variations in the firing rate differences over trials and time, as well as small differences in firing rates on the other hand, indicate larger stochasticity. In a final step, we aggregated the resulting modeled choice data and related the change in choice stochasticity over the experimental conditions to the changes observed in the actual behavioral data.
Code availability
The code used for data analysis and simulations is available from the corresponding author upon reasonable request.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Electronic supplementary material
Acknowledgements
We thank all members of the P.W.G. Laboratory, especially Kai Steverson for helpful comments and discussions. We also thank Rushell Dixon and Echo Wang for help with animal husbandry. This work was supported by grants from the National Institute of Health (R01MH104251 to K.L., R01DA038063 to P.W.G. and T32EY007136 to J.Z.).
Author contributions
All the authors designed the experiment and wrote the manuscript. J.Z. collected and analyzed the data.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
9/5/2018
This Article was originally published without the accompanying Peer Review File. This file is now available in the HTML version of the Article; the PDF was correct from the time of publication.
Electronic supplementary material
Supplementary Information accompanies this paper at 10.1038/s41467-018-05507-8.
References
- 1.Barlow, H. B. Possible Principles Underlying the Transformation of Sensory Messages. Sensory Communication (MIT Press, Cambridge, MA, 1961).
- 2.Simoncelli EP, Olshausen BA. Natural image statistics and neural representation. Annu. Rev. Neurosci. 2001;24:1193–1216. doi: 10.1146/annurev.neuro.24.1.1193. [DOI] [PubMed] [Google Scholar]
- 3.Carandini M, Heeger DJ. Normalization as a canonical neural computation. Nat. Rev. Neurosci. 2011;13:51–62. doi: 10.1038/nrn3136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Laughlin S. A simple coding procedure enhances a neuron’s information capacity. Z. Naturforsch. C. Biosci. 1981;36:910–912. doi: 10.1515/znc-1981-9-1040. [DOI] [PubMed] [Google Scholar]
- 5.Heeger DJ. Normalization of cell responses in cat striate cortex. Vis. Neurosci. 1992;9:181–197. doi: 10.1017/S0952523800009640. [DOI] [PubMed] [Google Scholar]
- 6.Gutnisky DA, Dragoi V. Adaptive coding of visual information in neural populations. Nature. 2008;452:220–224. doi: 10.1038/nature06563. [DOI] [PubMed] [Google Scholar]
- 7.Wark B, Lundstrom BN, Fairhall A. Sensory adaptation. Curr. Opin. Neurobiol. 2007;17:423–429. doi: 10.1016/j.conb.2007.07.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Brenner N, Bialek W, de Ruyter van Steveninck R. Adaptive rescaling maximizes information transmission. Neuron. 2000;26:695–702. doi: 10.1016/S0896-6273(00)81205-2. [DOI] [PubMed] [Google Scholar]
- 9.Atick JJ, Redlich AN. Towards a theory of early visual processing. Neural Comput. 1990;2:308–320. doi: 10.1162/neco.1990.2.3.308. [DOI] [Google Scholar]
- 10.Schwartz O, Hsu A, Dayan P. Space and time in visual context. Nat. Rev. Neurosci. 2007;8:522–535. doi: 10.1038/nrn2155. [DOI] [PubMed] [Google Scholar]
- 11.Angelucci A, et al. Circuits and mechanisms for surround modulation in visual cortex. Annu. Rev. Neurosci. 2017;40:425–451. doi: 10.1146/annurev-neuro-072116-031418. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Smirnakis SM, Berry MJ, Warland DK, Bialek W, Meister M. Adaptation of retinal processing to image contrast and spatial scale. Nature. 1997;386:69–73. doi: 10.1038/386069a0. [DOI] [PubMed] [Google Scholar]
- 13.Kohn A. Visual adaptation: physiology, mechanisms, and functional benefits. J. Neurophysiol. 2007;97:3155–3164. doi: 10.1152/jn.00086.2007. [DOI] [PubMed] [Google Scholar]
- 14.Shapley R, Enroth-Cugell C. Visual adaptation and retinal gain controls. Progress. Retin. Res. 1984;9:263–346. doi: 10.1016/0278-4327(84)90011-7. [DOI] [Google Scholar]
- 15.Carandini M. Visual cortex: fatigue and adaptation. Curr. Biol. 2000;10:R605–R607. doi: 10.1016/S0960-9822(00)00637-0. [DOI] [PubMed] [Google Scholar]
- 16.Tversky A. Elimination by aspects: a theory of choice. Psychol. Rev. 1972;79:281–299. doi: 10.1037/h0032955. [DOI] [Google Scholar]
- 17.Huber J, Payne JW, Puto C. Adding asymmetrically dominated alternatives: violations of regularity and the similarity hypothesis. J. Consum. Res. 1982;9:90–98. doi: 10.1086/208899. [DOI] [Google Scholar]
- 18.Simonson I. Choice based on reasons: the case of attraction and compromise effects. J. Consum. Res. 1989;16:158–174. doi: 10.1086/209205. [DOI] [Google Scholar]
- 19.Louie K, Grattan LE, Glimcher PW. Reward value-based gain control: divisive normalization in parietal cortex. J. Neurosci. 2011;31:10627–10639. doi: 10.1523/JNEUROSCI.1237-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Rorie AE, Gao J, McClelland JL, Newsome WT. Integration of sensory and reward information during perceptual decision-making in lateral intraparietal cortex (LIP) of the macaque monkey. PLoS ONE. 2010;5:e9308. doi: 10.1371/journal.pone.0009308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Pastor-Bernier A, Cisek P. Neural correlates of biased competition in premotor cortex. J. Neurosci. 2011;31:7083–7088. doi: 10.1523/JNEUROSCI.5681-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Itthipuripat S, Cha K, Rangsipat N, Serences JT. Value-based attentional capture influences context-dependent decision-making. J. Neurophysiol. 2015;114:560–569. doi: 10.1152/jn.00343.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hunt LT, Dolan RJ, Behrens TEJ. Hierarchical competitions subserving multi-attribute choice. Nat. Neurosci. 2014;17:1613–1622. doi: 10.1038/nn.3836. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Louie K, Khaw MW, Glimcher PW. Normalization is a general neural mechanism for context-dependent decision making. Proc. Natl. Acad. Sci. USA. 2013;110:6139–6144. doi: 10.1073/pnas.1217854110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Tremblay L, Schultz W. Relative reward preference in primate orbitofrontal cortex. Nature. 1999;398:704–708. doi: 10.1038/19525. [DOI] [PubMed] [Google Scholar]
- 26.Kobayashi S, Pinto de Carvalho O, Schultz W. Adaptation of reward sensitivity in orbitofrontal neurons. J. Neurosci. 2010;30:534–544. doi: 10.1523/JNEUROSCI.4009-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Wise RA. Dopamine, learning and motivation. Nat. Rev. Neurosci. 2004;5:483–494. doi: 10.1038/nrn1406. [DOI] [PubMed] [Google Scholar]
- 28.Tobler PN, Fiorillo CD, Schultz W. Adaptive coding of reward value by dopamine neurons. Science. 2005;307:1642–1645. doi: 10.1126/science.1105370. [DOI] [PubMed] [Google Scholar]
- 29.Padoa-Schioppa C, Assad JA. Neurons in the orbitofrontal cortex encode economic value. Nature. 2006;441:223–226. doi: 10.1038/nature04676. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Padoa-Schioppa C, Assad JA. The representation of economic value in the orbitofrontal cortex is invariant for changes of menu. Nat. Neurosci. 2008;11:95–102. doi: 10.1038/nn2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Grattan LE, Glimcher PW. Absence of spatial tuning in the orbitofrontal cortex. PLoS One. 2014;9:e112750. doi: 10.1371/journal.pone.0112750. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Padoa-Schioppa C. Neurobiology of economic choice: a good-based model. Annu. Rev. Neurosci. 2011;34:333–359. doi: 10.1146/annurev-neuro-061010-113648. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Padoa-Schioppa C. Range-adapting representation of economic value in the orbitofrontal cortex. J. Neurosci. 2009;29:14004–14014. doi: 10.1523/JNEUROSCI.3751-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Solomon SG, Kohn A. Moving sensory adaptation beyond suppressive effects in single neurons. Curr. Biol. 2014;24:R1012–R1022. doi: 10.1016/j.cub.2014.09.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Snow M, Coen-Cagli R, Schwartz O. Adaptation in the visual cortex: a case for probing neuronal populations with natural stimuli. F1000Res. 2017;6:1246. doi: 10.12688/f1000research.11154.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Rustichini A, Conen KE, Cai X, Padoa-Schioppa C. Optimal coding and neuronal adaptation in economic decisions. Nat. Commun. 2017;8:1208. doi: 10.1038/s41467-017-01373-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Rigoli F, Friston KJ, Dolan RJ. Neural processes mediating contextual influences on human choice behaviour. Nat. Commun. 2016;7:12416. doi: 10.1038/ncomms12416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Rigoli F, Rutledge RB, Dayan P, Dolan RJ. The influence of contextual reward statistics on risk preference. Neuroimage. 2016;128:74–84. doi: 10.1016/j.neuroimage.2015.12.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Padoa-Schioppa C. Neuronal origins of choice variability in economic decisions. Neuron. 2013;80:1322–1336. doi: 10.1016/j.neuron.2013.09.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Walton ME, Behrens TEJ, Noonan MP, Rushworth MFS. Giving credit where credit is due: orbitofrontal cortex and valuation in an uncertain world. Ann. NY Acad. Sci. 2011;1239:14–24. doi: 10.1111/j.1749-6632.2011.06257.x. [DOI] [PubMed] [Google Scholar]
- 41.Palminteri S, Khamassi M, Joffily M, Coricelli G. Contextual modulation of value signals in reward and punishment learning. Nat. Commun. 2015;6:195. doi: 10.1038/ncomms9096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.LoFaro T, Louie K, Webb R, Glimcher PW. The temporal dynamics of cortical normalization models of decision-making. Lett. Biomath. 2014;1:209–220. doi: 10.1080/23737867.2014.11414481. [DOI] [Google Scholar]
- 43.Olsen SR, Bhandawat V, Wilson RI. Divisive normalization in olfactory population codes. Neuron. 2010;66:287–299. doi: 10.1016/j.neuron.2010.04.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Kaliukhovich DA, Vogels R. Divisive normalization predicts adaptation-induced response changes in macaque inferior temporal cortex. J. Neurosci. 2016;36:6116–6128. doi: 10.1523/JNEUROSCI.2011-15.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Reynolds JH, Heeger DJ. The normalization model of attention. Neuron. 2009;61:168–185. doi: 10.1016/j.neuron.2009.01.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Louie K, Glimcher PW. Efficient coding and the neural representation of value. Ann. NY Acad. Sci. 2012;1251:13–32. doi: 10.1111/j.1749-6632.2012.06496.x. [DOI] [PubMed] [Google Scholar]
- 47.Westrick ZM, Heeger DJ, Landy MS. Pattern adaptation and normalization reweighting. J. Neurosci. 2016;36:9805–9816. doi: 10.1523/JNEUROSCI.1067-16.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Louie K, LoFaro T, Webb R, Glimcher PW. Dynamic divisive normalization predicts time-varying value coding in decision-related circuits. J. Neurosci. 2014;34:16046–16057. doi: 10.1523/JNEUROSCI.2851-14.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Murray JD, et al. A hierarchy of intrinsic timescales across primate cortex. Nat. Neurosci. 2014;17:1661–1663. doi: 10.1038/nn.3862. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Chaudhuri R, Bernacchia A, Wang XJ. A diversity of localized timescales in network activity. eLife. 2014;3:e01239. doi: 10.7554/eLife.01239. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Behrens TEJ, Woolrich MW, Walton ME, Rushworth MFS. Learning the value of information in an uncertain world. Nat. Neurosci. 2007;10:1214–1221. doi: 10.1038/nn1954. [DOI] [PubMed] [Google Scholar]
- 52.Farashahi S, et al. Metaplasticity as a neural substrate for adaptive learning and choice under uncertainty. Neuron. 2017;94:401–414.e6. doi: 10.1016/j.neuron.2017.03.044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Louie K, Glimcher PW, Webb R. Adaptive neural coding: from biological to behavioral decision-making. Curr. Opin. Behav. Sci. 2015;5:91–99. doi: 10.1016/j.cobeha.2015.08.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Sato TK, Haider B, Häusser M, Carandini M. An excitatory basis for divisive normalization in visual cortex. Nat. Neurosci. 2016;19:568–570. doi: 10.1038/nn.4249. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Pouille F, Marin-Burgin A, Adesnik H, Atallah BV, Scanziani M. Input normalization by global feedforward inhibition expands cortical dynamic range. Nat. Neurosci. 2009;12:1577–1585. doi: 10.1038/nn.2441. [DOI] [PubMed] [Google Scholar]
- 56.Zimmermann J, Vazquez Y, Glimcher PW, Pesaran B, Louie K. Oculomatic: high speed, reliable, and accurate open-source eye tracking for humans and non-human primates. J. Neurosci. Methods. 2016;270:138–146. doi: 10.1016/j.jneumeth.2016.06.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Asaad WF, Eskandar EN. A flexible software tool for temporally-precise behavioral control in Matlab. J. Neurosci. Methods. 2008;174:245–258. doi: 10.1016/j.jneumeth.2008.07.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Wilson HR, Cowan JD. Excitatory and inhibitory interactions in localized populations of model neurons. Biophys. J. 1972;12:1–24. doi: 10.1016/S0006-3495(72)86068-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Humanski RA, Wilson HR. Spatial frequency mechanisms with short-wavelength-sensitive cone inputs. Vision. Res. 1992;32:549–560. doi: 10.1016/0042-6989(92)90247-G. [DOI] [PubMed] [Google Scholar]
- 60.Cowan JD, Neuman J, van Drongelen W. Wilson-Cowan equations for neocortical dynamics. J. Math. Neurosci. 2016;6:1. doi: 10.1186/s13408-015-0034-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.