

Abstract
We report an evaluation of a semi-empirical quantum chemical method PM7 from the perspective of uncertainty quantification. Specifically, we apply Bound-to-Bound Data Collaboration, an uncertainty quantification framework, to characterize (a) variability of PM7 model parameter values consistent with the uncertainty in the training data and (b) uncertainty propagation from the training data to the model predictions. Experimental heats of formation of a homologous series of linear alkanes are used as the property of interest. The training data are chemically accurate, i.e., they have very low uncertainty by the standards of computational chemistry. The analysis does not find evidence of PM7 consistency with the entire data set considered as no single set of parameter values is found that captures the experimental uncertainties of all training data. A set of parameter values for PM7 was able to capture the training data within ±1 kcal/mol, but not to the smaller level of uncertainty in the reported data. Nevertheless, PM7 was found to be consistent for subsets of the training data. In such cases, uncertainty propagation from the chemically accurate training data to the predicted values preserves error within bounds of chemical accuracy if predictions are made for the molecules of comparable size. Otherwise, the error grows linearly with the relative size of the molecules.
Introduction
Uncertainty quantification (UQ) is a critical diagnostic for the models that are positioned as a source of actionable predictions. Computational models of this kind are abundant in chemistry. One can think of kinetic models1–3, classical force-fields4,5, semi-empirical Hamiltonians6–8, approximate density functionals9–13 and the blossoming field of machine learning/deep learning models14–19.
One of the challenges of the model selection and curation is their tendency to proliferate uncontrollably if there is flexibility in the model’s form and fitting to reference data is involved. The rich landscape of approximate density functionals20 is a case to the point. Models produced within data-centric framework that are application-oriented will inevitably face the same challenge at a much larger scale21,22.
Currently, models that require parameter fitting are compared on the basis of some form of the fitting error23. Our goal here is to develop a framework for model-data diagnostics, that informs users about the model from the point of view of the UQ. First, given a set of training data with known, presumably low, uncertainty, we want to be able to establish if there is a domain of the model parameters that captures all training data within their uncertainty. Second, knowing the domain of parameter values that are consistent with the training data, we want to establish how the variance in the parameter values propagates into the uncertainty of the model predictions.
There is a noticeable growth of interest in the assessment of uncertainty of the models used in computational chemistry (see e.g., refs24–27 and citations therein). A recent analysis of the error assessment in computational chemistry arrives at the following conclusion28: “… a procedure for quantifying the uncertainty associated with computational models, in particular with quantum chemical calculations, is mandatory despite their first-principles character. Otherwise, it may be difficult to draw meaningful conclusions. Unfortunately, this procedure is neither well established nor straightforward.” Earlier we demonstrated how applying the Bound-to-Bound Data Collaboration framework24,29,30 for UQ can be incorporated into DFT framework in order to quantify and improve uncertainty of the predictions31. In the present study, we apply the same framework as a diagnostic tool for semi-empirical quantum chemical model PM732.
Semi-empirical model chemistries are popular because of the low computational overhead that makes it possible to tackle large systems in a relatively short time. Interpretable mechanistic nature of these methods and straight-forward manner in which empirical data can be incorporated are the reasons why semi-empirical quantum chemistry finds a wide range of ubiquitous applications and sees ongoing development33,34.
The goal of the presented study is to determine if (a) there is a single set, i.e., feasible set, of PM7 parameter values that satisfies uncertainty bounds of the training data and (b) it is possible to achieve predictions outside the training data with the uncertainty as low as the uncertainty of the training data.
Methods and Data
Bound-to-Bound Data Collaboration
This section provides a brief overview of Bound-to-Bound Data Collaboration (B2BDC), with a focus on the methodological details specific to the present study. A more detailed discussion can be found elsewhere24,29,30,35,36.
B2BDC is a deterministic framework for uncertainty quantification, where uncertain parameters are constrained by combining models and experimental data. Let {Me(x)}e = 1, …, N denote a collection of models mapping from a common parameter space to various scalar-valued quantities of interest (QOIs). For a given parameter vector x ∈ n, the expression Me(x) evaluates the model prediction for e-th QOI. Experimental observations of the QOIs come in B2BDC in the form {[Le,Ue]}e = 1, …, N, where the uncertainty is characterized by a lower bound, Le and a upper bound Ue for the e-th QOI. Oftentimes, there is prior knowledge to confine the parameters, x, to a set ⊂ n. Prior knowledge can be represented as a set of constraints on either individual model parameters, e.g., −1 ≤ x1 ≤ 1, or can represent relationships between parameters, e.g., 0 ≤ 5x1 + x2 ≤ 2. Constrained by both prior knowledge on x and experimental uncertainty bounds, each QOI has an associated feasible set of parameters for which model evaluations agree with the corresponding experimental bounds:
| 1 |
Naturally, one is often interested in the set of parameters which satisfies multiple observations:
| 2 |
where I ⊂ {1, 2, …, N} is the index set of the QOIs. For example, 1:3,5 denotes the feasible set associated with QOIs, e = 1, 2, 3, 5. If the set 1:N is nonempty, the models and data are said to be consistent. Consistency is a form of model validation, ensuring that a model parameter vector exists that evaluates within the experimental uncertainty bounds for all N QOIs. When such a parameter vector does not exist the set 1:N is empty, the models and data are said to be inconsistent. If the models can be accurately represented by polynomial surrogates, this notion of consistency can be efficiently and provably quantified through constrained optimization35. A polynomial surrogate is a model which mimics the behavior of an underlying simulation model as close as possible, while being computationally cheaper to evaluate37. In cases where the models are not well characterized by simple surrogates but are computationally inexpensive to evaluate, direct sampling can provide a means of assessing consistency. To prove consistency, we must find at least one parameter vector x in 1:N. However, this becomes very challenging when the prior parameter space is large and there are many QOI models whose experimental bounds must be satisfied.
In B2BDC, the prediction for a particular model, say Mp(x), amounts to establishing bounds on the range of a model prediction, subject to model parameters being within a feasible set, I:
| 3 |
The prediction model need not be a member of the collection of models {Me(x)}e = 1, …, N. In certain cases, Eq. 3 can be efficiently solved via constrained optimization30. Note, inner approximations to the prediction interval can be found by evaluating the prediction model for a set of parameter values in ℱI. The inner approximation can be interpreted as saying the prediction model can be no more predictive than the computed bounds and a wider prediction interval indicates greater uncertainty in the prediction.
As an illustrative example of the B2BDC methodology, pertinent to the present work, we select a case investigated recently31. The problem is stated as estimating the ionization potential (IP) of water hexamer and its uncertainty interval, given ionization potentials and their respective uncertainties of water dimer, trimer, tetramer and pentamer. In this problem, there are four QOI models for the training-set of water clusters, consisting of dimer, trimer, tetramer and pentamer. A theoretical model of the ionization potential was constructed based on the double-hybrid form of the Density Functional Theory (DFT). Two model parameters, referred here as x1 and x2, encapsulated the model variability over their allowable prior ranges (each 0 to 1). Initial sampling over the parameter space and building surrogate models produced individual feasible regions (Eq. 1), for each of the four training-set water clusters labeled 1 through 4. The top-left panel of Fig. 1 shows the individual feasible sets of dimer and trimer water clusters, 1 and 2 respectively and their intersection 1:2 shown in dark red. Every point of this red region guarantees predictions of the dimer and trimer IPs within their respective uncertainty bounds. The top-right panel adds the feasible set for tetramer water clusters, 3 and the bottom-left panel adds further the feasible set for pentamer water clusters, 4. The intersection of all the individual feasible regions produces a feasible region, 1:4 which is the feasible set of the B2BDC framework described in Eq. 2; shown in dark red in the bottom-left panel of Fig. 1. Every point of 1:4 is a combination of the two model parameters that maps to a value for the property we seek to predict, i.e., the ionization potential of the water hexamer, which is consistent with the ionization potentials of the training data. Collectively, all points in 1:4 result in an interval of predicted hexamer IP values, shown in the bottom-right panel of Fig. 1. The predicted uncertainty interval encompasses all the uncertainties of the input data and turned out to be significantly smaller, by about a factor of 2, compared to the high-theory calculations.
Figure 1.

Illustration of the B2BDC methodology, specifically the intersection of feasible sets, for the problem described in Edwards et al.31. The shaded regions shown in Panels a, b and c are individual feasible set, e, which are a set of model parameters that can predict the ionization potential of a particular water cluster within its respective uncertainty. Panel a: individual feasible sets for dimer and trimer configurations of water, 1 and 2 respectively. The intersection of these two regions is the feasible set 1:2, shown in dark red. Panel b: the addition of the feasible set for the tetramer configuration of water, 3, shown in teal. The intersection is shown in dark red, 1:3. Panel c: the feasible set of pentamer configuration of water, shown in dark grey, primarily overlaps with 3. The intersection of all individual feasible sets forms 1:4, shown in dark red. Panel d: prediction of the ionization potential of a hexamer water cluster on feasible set 1:4. Prediction establishes a range of a prediction model as seen in Eq. 3. The resulting prediction interval for the ionization potential is shown on the right-hand side in red.
Selection of QOIs and experimental data for PM7
There are a multitude of approaches available for validating a computational model to experimental data. The two most important factors when validating a model is the choice of validation data and the specific experimental feature to validate the model by.
In this study, we will be considering a single homologous series, namely linear alkanes. We chose this homologous series for its simplicity and accumulated knowledge. There are 27 adjustable model parameters in PM7 which are used to parameterize the interactions of carbon and hydrogen atoms. Given the problem choice, we should expect the “best case scenario” from the results.
For a given parameterization, PM7 as a model provides many output responses, e.g., vibrational frequencies, ionization potential, HOMO-LUMO energies, heat of formation, etc. Due to the sheer number of model responses, the availability of accurate experimental data will be used to guide the choice of a quantity of interest. We also keep in mind that the primary output value of PM7 is standard heat of formation. Ruscic et al.38, employing a thermochemical network approach, reported accurate thermochemical values for a set of molecules, including members of linear alkanes, methane to octane (Table 1). Uncertainties listed in Table 1 represents the reported 95% confidence intervals, in conformity to the accepted standard in thermochemistry39. Despite the reported values not being purely experimental, the terms “experimental uncertainty” and “experimental bounds” will be used to describe the data in Table 1. In the present study, heats of formation of linear alkanes will be used as our QOIs. The experimental bounds used for the training data are the the reported heat of formation ± the uncertainty. Table 1 also shows the QOI models used in the study, namely the heat of formation of methane, ethane to octane. For sake of simplicity, each QOI model is indexed by the number of carbon atoms.
Table 1.
List of the QOI models Me, the associated index e (equivalent to the number of carbon atoms in the alkane), the reported heat of formation and uncertainty38.
| e | M e | (kcal/mol) | Uncertainty |
|---|---|---|---|
| 1 | −17.81 | ±0.01 | |
| 2 | −20.06 | ±0.03 | |
| 3 | −25.10 | ±0.05 | |
| 4 | −30.10 | ±0.06 | |
| 5 | −34.98 | ±0.07 | |
| 6 | −39.90 | ±0.08 | |
| 7 | −44.82 | ±0.11 | |
| 8 | −49.78 | ±0.16 |
Motivation for direct sampling
B2BDC typically employs surrogate models to represent an underlying simulation. The use of surrogates makes tasks like optimization and sensitivity analysis much more efficient due to inexpensive evaluations. When the surrogates are polynomials, consistency and prediction can be addressed efficiently and provably. However, we have found constructing surrogates for PM7 particularly challenging for two reasons, as we will detail below with the serving as our example.
First, we do not have a well-defined prior domain, , to confine our search for feasible parameters as no bounds are specified for these parameters. To address this, we constructed an initial prior domain by centering the domain around the PM7 nominal parameter vector32, xnom, which is listed in Supplementary Table S1. The bounds of the prior domain were constructed by selecting perturbations ±δi to the i-th parameter with all other parameters remained fixed such that the interval defined by xnom,i + δi produced a 10 kcal/mol change in . We denote this initial region by , as shown in Supplementary Table S1.
Second, our experience has shown that surrogate models are only accurate (to within the experimental uncertainty) on small domains. To illustrate this, we compare the fitting error of a quadratic polynomial and Gaussian process surrogate model on shrinking domains, where k ∈ [0, 1], as shown in Fig. 2. The surrogate model fitting error is the absolute difference between an evaluation of PM7 and an evaluation of the surrogate model over a domain k. For each k, 7500 Latin Hypercube samples were generated in k to construct both surrogate models. 10-fold cross validation was used to estimate the surrogate model fitting error over each domain. The Gaussian process was implemented by using MATLAB’s fitrgp function40. As seen in Fig. 2, the Gaussian process deviated by approximately 0.8 kcal/mol from PM7 on the domain 1, which is significant given the accuracy of the training data. In order to attain a surrogate model fitting error below our target, the experimental uncertainty, the initial region needed to be reduced by the factor of k = 0.4. The reduced domain 0.4 is 5.5 × 1010 times smaller by volume as compared to the original domain 1. Based on this result, we concluded that it would require an intractable number of surrogate models to mimic the behavior of PM7 over the prior region within the desired accuracy. Therefore, PM7 will be evaluated directly and forgo any surrogate modeling.
Figure 2.
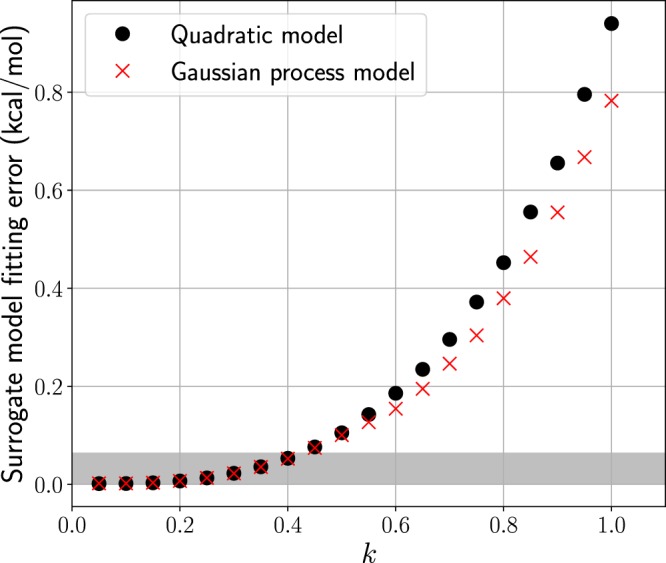
Surrogate model fitting error for the heat of formation of C4H10 evaluated on a shrinking domain , with k ∈ [0, 1]. The nominal PM7 value, xnom and δ are reported in Supplementary Table S1. As the domain shrinks, by reducing k, the surrogate model fitting error, that is the difference between PM7 and the surrogate model, decreases to a point where the error falls below the experimental uncertainty (shown in grey) of 0.06 kcal/mol. Comparison between a quadratic surrogate (black dots) and a Gaussian process model (red crosses) with a constant mean and a squared exponential covariance function is shown. 10-fold cross-validation was used to estimate the fitting error.
Direct Sampling for Consistency
In light of the challenges discussed in the preceding section, we approached consistency and prediction by directly sampling . Still, despite PM7’s fast evaluation time, particularly for fixed geometries, evaluating consistency for multiple QOIs remains a computational challenge. We break this challenge into two tasks: (1) allocating computational resources to sample ; and (2) determining a prior region to confine our search for feasible parameters.
Computational burden of direct sampling PM7
One of the limitations encountered in the present study was the number of samples we could evaluate for PM7 with the computational resources available. Evaluating PM7 for millions of parameter combinations is an embarrassingly parallel task, but computational efficiency can be improved by reducing an input/output (I/O) bottleneck occurring in the evaluation process.
Throughout the study, the input molecular geometries were obtained via optimization with the PM7 nominal parameter vector, which remained frozen afterwards, during the subsequent direct sampling. The freezing of the molecules geometries was done to avoid any unphysical reorganization or distortion. The consequences of freezing the molecular geometries with the nominal PM7 parameter vector are two-fold. First, using geometry optimization for a given parameter vector can (and usually does) result in different heats of formation as compared to the fixed geometry. Second, parameter vectors which are feasible with respect to the heats of formation, do not guarantee reaching a physically meaningful geometry. All feasible parameter vectors, which would produce unphysical geometries, should ultimately be removed from the feasible set.
The computational chemistry program MOPAC41 was used for evaluation of PM7 parameter sets. One of the practical aspects to be solved in working with MOPAC is handling efficiently multiple reading and writing of text files for each execution, which creates a bottleneck in I/O when parallelizing the direct sampling approach. To reduce I/O time, a memory based file system was used, that enabled all files to be read and written into system memory (RAM) instead of a hard disk drive (HDD). For example, using a Seagate 7200 RPM SATA HDD, read and write speeds were 204.0 and 194.9 MB/s, respectively. Using a memory based file system we could read and write at 6020.7 and 5840.6 MB/s, respectively. To relate this to sampling performance, the time to evaluate 104 different parameter values for C4H10 on a workstation equipped with an Intel Core i7-6700 K processor took 305.0 seconds using the Seagate hard drive and 215.7 using the memory based file system, a speed up of 41%. This speedup in reading and writing MOPAC text files directly translates into more evaluations of PM7 per second.
The MATLAB Parallel Computing Toolbox40 was used to write input files, execute PM7 and read output files in parallel. Two workstations, each with an Intel Core-i7 6700 K processor were used to directly sample PM7 and evaluate the heats of formation of a series of alkanes, methane to nonane.
Determination of a prior search region
The choice of the prior parameter domain, , determines all subsequent analysis and hence it needs to be well motivated. Our goal is to assess the predictivity of PM7 for large alkanes while being consistent with experimental data available for small alkanes. Due to limited data, we set aside heptane and octane, the two largest alkanes for which we have experimental bounds, to assess predictivity. Conversely, we also set aside methane and ethane so as not to bias the result. Although the physical properties of methane and ethane may be representative of the homologous series, the chemical properties, i.e., the energetics, are very different as seen through group additivity42. Propane and butane were also not included in the initial region search, since a priori it was not known if a parameter vector exist that could simultaneously evaluate the heats of formation of propane, butane, heptane and hexane within the uncertainty in the training data. Based on these considerations, we prioritized our determination of on feasible samples for pentane and hexane, 5:6.
A non-linear programming solver, fmincon40, was used to minimize the following objective function, , where, M5:6(x) are the heats of formation of pentane and hexane computed by PM7 at the parameter vector x. y5:6 are the reported heats of formation for pentane and hexane from Table 1. The local optimal parameter vector found, xopt, was feasible for pentane and hexane, therefore . A volume was taken around xopt in order to collect samples of 5:6. For each sampled point, the heats of formation of pentane and hexane were computed by PM7. 2 × 105 samples were generated by employing a Latin Hypercube design from the volume [xopt ± xopt × 1 × 10−3] and 65 samples were found to be within 5:6.
Principal component analysis (PCA) was conducted to identify a rotated coordinate system around the samples of 5:6, where all principal components were preserved. Considering the arbitrary choice of the volume used in the sampling of 5:6, each PCA direction was extended ten times of that of the 5:6 samples. This allowed for an even larger sample region to be considered. A Latin Hypercube design was used to generate uniform samples in the rotated and extended volume.
In total, 5.76 million samples were generated uniformly within the PCA-rotated volume and were used to evaluate PM7 for the heats of formation of nine alkanes, CH4 to C9H20. Shown in Table 2 are the extreme parameter values from the generated samples. There were 164,569 samples which were feasible for at least one alkane in the training set. The number of feasible samples found quickly dropped when considering feasibility with multiple alkanes. For example, there were 19167 samples that were feasible with at least two alkanes, 6193 samples feasible with at least three alkanes, 3110 samples feasible with at least four alkanes, 1989 samples feasible with at least five alkanes and 169 samples feasible with at least six alkanes.
Table 2.
Extreme parameter values from the search region.
| Parameter | min(x) | max(x) |
|---|---|---|
| USSH | −14.815 | −9.5475 |
| BETASH | −10.444 | −6.383 |
| ZSH | 0.85244 | 1.5053 |
| GSSH | 10.953 | 15.822 |
| FN11H | 0.14962 | 0.23173 |
| FN21H | 1.2161 | 1.4849 |
| FN31H | 0.83875 | 1.0458 |
| ALPBH | 3.9629 | 4.8467 |
| XFACH | 2.3077 | 2.7852 |
| USSC | −52.553 | −45.61 |
| UPPC | −43.679 | −37.301 |
| BETASC | −15.285 | −11.804 |
| BETAPC | −9.2246 | −6.7715 |
| ZSC | 1.5914 | 2.2229 |
| ZPC | 1.501 | 2.0466 |
| GSSC | 10.314 | 13.662 |
| GSPC | 9.7585 | 13.092 |
| GPPC | 9.3945 | 12.464 |
| GP2C | 8.6452 | 11.014 |
| HSPC | 0.66956 | 0.77601 |
| FN11C | 0.045528 | 0.055036 |
| FN21C | 4.3632 | 5.1283 |
| FN31C | 1.4298 | 1.7154 |
| ALPBHC | 0.76974 | 1.1501 |
| XFACHC | 0.15181 | 0.21488 |
| ALPCC | 2.3296 | 3.0615 |
| XFACC | 0.71959 | 0.96953 |
Results
Feasible Set Search
For each of the eight alkanes, a feasible parameter vector could be found that would predict its heat of formation within the experimental bounds. Feasible parameters were also found for all pairwise combinations of alkanes, i.e., a parameter vector could be found that would predict the heat of formation for any two alkanes within their respective experimental bounds. The percentage of feasible samples found for each pair of alkanes in the training data set is reported in Supplementary Table S3. Methane had the smallest percentage of feasible samples for a single alkane and the largest was for octane. This difference in percentages of feasible samples could be due to the uncertainty bounds associated to octane being nearly an order of magnitude larger than that of methane and the difference in molecular structure of methane compared to all others in the homologous series.
From the generated samples, there were 4020 samples of 5:6, the alkanes which we had focused our search on. However, from the generated samples, there was no single parameter vector that was able to simultaneously satisfy the uncertainty bounds of all the training data, i.e., . Thus the PM7 model and the training data are found to be mutually inconsistent.
The inability to find a parameter vector feasible for all alkanes does not prove the non-existence of such a point. In fact, parameter values that are feasible for all alkanes could lead to potential biases in the prediction because methane and ethane are sufficiently different from the rest of the homologous series with respect to their atomic bonding and hence the energetics. Using parameter values feasible for methane and/or ethane in the prediction of larger alkane properties can result in a prediction interval with smaller uncertainty but in disagreement with experimental data, a problem similar to the bias-variance tradeoff43.
Direct sampling the search region led to a fraction of samples being consistent with the experimental data for three alkanes (Supplementary Table S4), 4250 samples were found from 6:8. Prediction of all alkanes by 6:8 is shown in Supplementary Fig. S2. Feasible sets formed by consecutive alkanes, i.e., adjacent members of the homologous series, where only a few or no samples were found are shown in Supplementary Table S5. The feasible set with the largest number of consecutive alkanes was 3:8. Prediction of all alkanes by 3:8 is shown in Supplementary Fig. S3. No samples were found from 2:8 from direct sampling. Using a genetic algorithm via MATLAB’s ga function (and 750 + cpu hours), we were able to obtain a single parameter vector from 2:8 (Supplementary Table S2).
For PM7 to predict the heats of formation of eight alkanes to within the uncertainty in the training data turned out to be a challenging task. There exists a set of parameter vectors, specifically 28,696 such sets, each of them simultaneously predicting the heats of formation of all eight alkanes with 95%-confidence chemical accuracy, i.e., within ±1 kcal/mol. Since there is no justification for expanding the uncertainty of the training data, the feasible sets used throughout this study are defined by the reported experimental uncertainties, those reported in Table 1.
To better understand the shape of a feasible set over the search region, consider two feasible points for C6H14. The heat of formation of C6H14 was calculated along the line segment connecting the two feasible points. Figure 3(a) shows that points along the line segment do not remain feasible, thus proving the feasible set is non-convex. Interestingly, if the line segment is extended further, beyond the initial sample region, another intersection with the experimental bounds occurs at t = −0.65, shown in Fig. 3(b). This proves that there exist more feasible points for C6H14 which are outside of the sampled search region.
Figure 3.

Blue curve is the heat of formation of C6H14 from PM7 calculations along the line segment defined as x = (1 − t)x1 + tx2, where x1 and x2 are two feasible points for C6H14. The black dashed lines are the respective experimental bounds (see Table 1). Panel a: line segment between two feasible points is not entirely feasible, thus the feasible set of C6H14 is non-convex. Panel b: extending the line segment beyond x1, to the left, a new intersection with the experimental bounds is found at t = −0.65.
Uncertainty of Predictions
In this section, we examine the uncertainty of predictions for larger alkanes using samples consistent with experimental data for smaller alkanes. Prediction of the heat of formation of heptane, octane and nonane were investigated. In the case of heptane and octane, experimental data are available for comparison, but for nonane there are not. In each case, samples consistent with the experimental data for smaller alkanes were used for prediction of the larger alkane forming the histograms shown in Fig. 4. The width of the histograms constitute the prediction uncertainty. The predictions are only inner approximations as the samples were only generated from a portion of the parameter space. Thus, the predicted uncertainty can be no smaller than that which is presented below.
Figure 4.

Heat of formation of a larger alkane, predicted from the feasible parameter set of smaller alkanes. The grey shaded region is the experimental interval for the respective alkane from Table 1. Panel a: heat of formation of heptane predicted from samples of 5:6, 4:6 and 3:6. Panel b: heat of formation of octane predicted from samples of 6:7, 5:7 and 4:7. Panel c: heat of formation of nonane predicted from samples of 7:8, 6:8 and 5:8; this case is without experimental data.
Figure 4(a) depicts the prediction of the heat of formation of heptane. In blue are samples from 5:6, i.e, parameter vectors that were feasible for both C5H12 and C6H14. The width of the histogram is 0.5 kcal/mol, which is larger than that of the experimental uncertainty of 0.2 kcal/mol (shown in grey), but still within the chemical accuracy (1 kcal/mol in terms of a 95% confidence interval). To further reduce the prediction uncertainty, we can impose additional constraints by considering samples that are also feasible with smaller alkanes. Samples of 4:6 and 3:6, shown in red and yellow, respectively, are indeed capable of reducing the predicted uncertainty and in the case of 3:6 producing a prediction 52.5% smaller than that of 5:6.
Following a similar analysis, we examined the prediction for octane, the largest alkane that we had experimental data for comparison. To predict the heat of formation of C8H18, we considered feasible samples from the preceding two, three and four smaller alkanes, i.e., samples from 6:7, 5:7 and 4:7. The results are shown in Fig. 4(b). The heat of formation of octane predicted by 6:7, shown in blue, yielded uncertainty of 0.62 kcal/mol, again within the chemical accuracy. Using samples which were feasible with the preceding three alkanes, 5:7, resulted in a prediction uncertainty of 0.42 kcal/mol, a reduction of 31% compared to the prediction by 6:7.
The computational results for the alkane without any experimental data for comparison, nonane, are shown in Fig. 4(c). Using samples of 7:8, the prediction uncertainty for nonane is 0.85 kcal/mol. We were able to reduce the prediction uncertainty for nonane by 44%, to 0.48 kcal/mol, by considering feasible samples from 5:8. Prediction of the heat of formation of nonane using 3:8, the feasible set with the largest number of consecutive alkanes found, is given in Supplementary Fig. S1.
The predictions for alkanes beyond nonane are shown in Fig. 5. The displayed uncertainty was predicted by using samples of 3:8. Two interesting observations can be made from these results. First, using samples from 3:8 produces a predicted uncertainty of nearly 5 kcal/mol for methane. This observation is consistent with the fact that methane is sufficiently different from the larger members of the homologous series. Parameter vectors feasible for larger alkanes are not capable of predicting the heat of formation for methane with chemical accuracy. Second, for larger alkanes prediction uncertainty grows linearly with the alkane size. The linearly increasing prediction uncertainty can also be seen in Fig. 6 where C2H6 through n-C20H42 are compared against the available experimental data and the nominal PM7 evaluation. Predictions made with samples of 3:8 overlap with the experimental bounds from C3H8 through C8H18 (by definition of the feasible set 3:8), but the nominal parameterization of PM7 deviates by nearly 2 kcal/mol. The PM7 results with the nominal parameter vector intersects with the predicted interval for alkanes C14H30 through C19H40.
Figure 5.
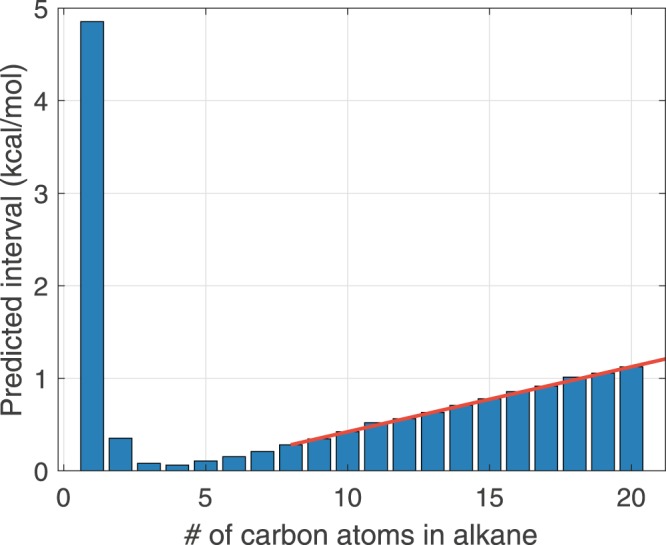
Predicted intervals for alkanes outside of the training data. Prediction was made using samples of 3:8. Interval length is defined as the absolute value of the , where Mp(x) is the evaluation of PM7 of the p-th alkane with the parameter vector, x. The red line shown is a linear fit between n-C8H18 and n-C20H42.
Figure 6.
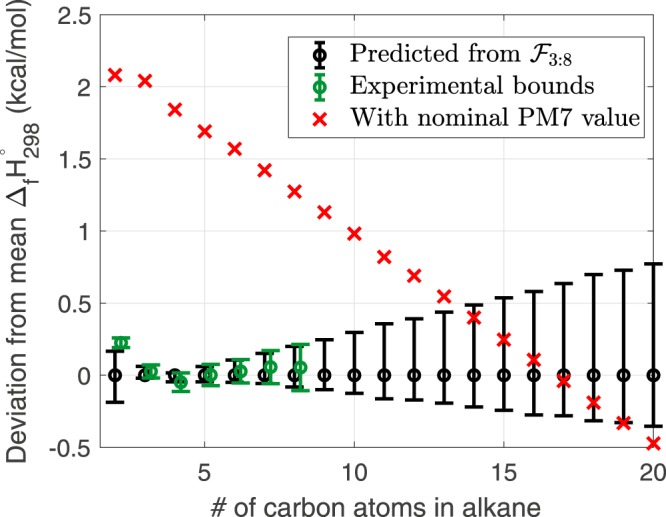
Uncertainty intervals of the heat of formation of ethane to icosane predicted by samples of 3:8. The black intervals are prediction by 3:8 and with the computed mean positioned at zero and marked with a black circle, the green intervals are the experimental bounds (Table 1) and the red crosses are the heats of formation computed with the PM7 nominal parameter vector.
Classification of Feasible Points
As was established in Fig. 3, the feasible set of PM7 is non-convex. For a convex feasible set it suffices to map out its boundary in order to determine if any combination of parameters is feasible or not. In the case of PM7, explicitly mapping of the boundary of the feasible set is computationally expensive due to the dimensionality of the problem and the feasible set being non-convex; a viable alternative is to use the data collected via direct sampling and train a binary classifier that distinguishes a “feasible” class of parameter values from the “infeasible” one. As there was no parameter vector found feasible for all alkanes, it is unclear what parameter vectors should be assigned to the “feasible” class. One approach is to only consider parameter values belonging to a specific feasible set, such as 4:7, as the “feasible” class. An alternative approach would be to consider the “feasible” class as all parameter vectors that are feasible for at least one alkane. Given the unbalanced nature of the feasible and infeasible classes, i.e., over 5 × 106 samples which are infeasible and only a few thousand samples belonging to any specific feasible set, we choose the latter option and constructed the “feasible” class from all points that are feasible for at least one alkane in the training set.
Binary classification was performed using a Random Forest classifier, as implemented in Scikit-learn library44, with equal misclassification costs. A Random Forest classifier is capable of emulating the decision boundary for non-convex and even non-contiguous feasible domains. Both classes were down-sampled to 105 to handle the class imbalance. Down-sampling was performed by using a randomly drawn 105 samples from each class. Performance of the classifier is evaluated in a 5-fold cross-validation via construction of the Receiver Operating Curve (ROC) and computation of the Area Under Curve (AUC) (see Fig. 7). The ROC allows one to gauge the performance of a binary classifier by comparing the true positive and false positive rate across all possible decision thresholds. The true positive rate is the number of feasible samples correctly identified as the “feasible” class over the total number of feasible samples. The false positive rate is the number of samples incorrectly identified as the “feasible” class over the total number of infeasible samples. A perfect classifier would have an ROC curve at the top-left corner of Fig. 7, with a true positive rate of 1 and a false positive rate of 0. For this to occur, all feasible samples would be correctly identified as part of the “feasible” class without misclassifying any infeasible samples as the “feasible” class.
Figure 7.
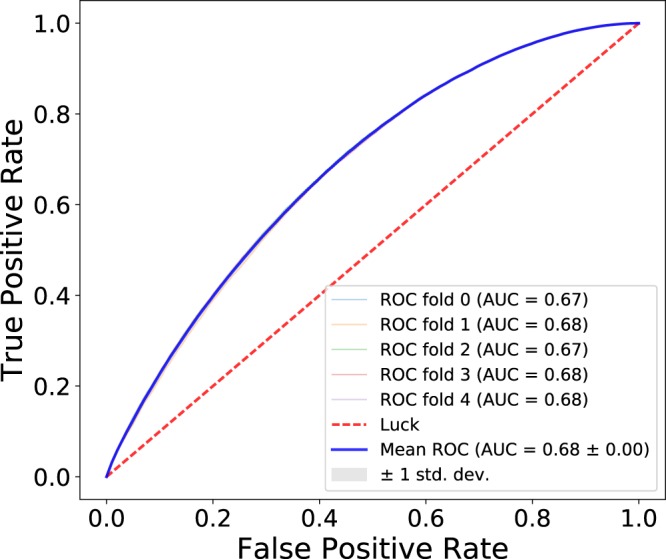
ROC curves and their corresponding AUC for binary classification using a Random Forest model. Classification was between the classes, “feasible” and “infeasible” with the samples obtained via direct sampling. “Feasible” class includes samples that are feasible for at least one alkane. “Infeasible” class includes samples that are not feasible for any alkane. Both classes were down-sampled to 105 samples. Classification performance was assessed by 5-fold cross-validation using 5 × 103 ensemble of random trees.
One figure of merit for binary classification is the area under the ROC curve (AUC). The AUC varies between 0 and 1 where a perfect classifier has an AUC of 1 and randomly guessing (luck) would have an AUC of 0.5. With an AUC value of 0.68, we found that there is indeed a non-random structure in the feasible set recovered via direct sampling. Therefore, it is possible to train a classifier that fulfills the same function as the boundary to a feasible set. Of course, for this assessment to be practical, a better performance metric of the classifier should be achieved. One route toward this goal is to collect a sample in the parameter space that conveys a better representation of the spatial extents of the non-convex feasible set found via sampling on a Latin hyper-cube. The inset of Fig. 3(b) depicts a region where a line segment passes through the experimental bounds. This region (and all other intersections) is a 27 dimensional space. Samples in these regions, near the experimental bounds, can help improve the characterization of the feasible set for classification.
Conclusion
Uncertainty quantification of semi-empirical quantum chemical model PM7 was performed using the B2BDC framework. The obtained results did not show evidence of model consistency even in the “best case” scenario, when we considered heats of formation of a small family of linear alkanes. This finding, however, requires a cautious interpretation.
Lack of evidence of the model consistency with experimental data may imply that either the experimental data has some bias or the model has a deficiency. Given the quality of the experimental data, we tend to think the model inconsistency resides with the parameterization of PM7. To ultimately resolve this question, would require a significantly more engaged investigation of PM7 parameter space whose dimensionality exceeds 27 for organic molecules that include hetero-atoms. The practical lesson of the study is that we could not find a parameter vector feasible for all the training data having searched a finite volume and consumed a certain amount of the computational resources and time. The cost of establishing model consistency is, in itself, a diagnostic that can be used to compare various data-centric models and make an informed selection among them.
Another practical lesson is the source of the encountered lack of consistency. The “problematic” QOIs found were the shortest alkanes, methane and ethane, whose chemical properties are known to be different from the rest of the homologous series. The value of PM7 comes from the low computational cost to evaluate larger molecules. In our study, the heats of formation of larger molecules were found to be consistency with the experimental data. The reported results demonstrate B2BDC’s capability for a deeper analysis into PM7 by evaluating the limits of model consistency in a data-centric setting.
One clear challenge in this study was the inability to accurately represent a significant volume of the parameter space with a surrogate model. The encountered difficulties motivated the development of a tool-set for uncertainty quantification of models with high-dimensional parameter spaces that can have non-convex and even non-contiguous feasible sets. Incorporation of machine learning techniques with the B2BDC framework was shown to be a viable strategy to efficiently tackle cases of this type. Our basic attempt to learn the geometric structure of the identified feasible sets showed encouraging results. Possibility of the accurate binary classification of feasible/infeasible classes suggests a route to sampling strategies that are more efficient than brute-force direct sampling and could rely on a semi-supervised model to search for feasible points.
An equally important aspect of our study concerns uncertainty propagation from the training data that have sub-chemical accuracy to PM7 predictions. We observed that predictions remained within bounds of chemical accuracy for the molecules whose size is close to the size of the molecules in the training set. As expected, improvement of the quality of the feasible sets, i.e., attaining consistency with more alkanes, led to the reduction of the prediction uncertainty. Growth of the prediction error with the difference in the size between the test and training molecules agrees with the size-extensive nature of the selected QOI. This result reinforces intuition that there is a price to switching from interpolation to extrapolation regime. It motivates a large-scale uncertainty quantification study of semi-empirical quantum chemical models where both the size and chemical diversity of the dataset are significantly expanded. In order to facilitate such an effort we are including the parameter vectors and current feasibility labels in the Supplementary Information.
Electronic supplementary material
Acknowledgements
The authors would like to thank the anonymous reviewers for their insightful comments, especially in regards to geometry optimization. The work at UCB was supported by the Department of Energy, National Nuclear Security Administration, under Award Number(s) DE-NA0002375. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof.
Author Contributions
M.F., D.Z. and A.P. conceived the project and planned the experiments. J.O., Z.L., A.H., W.L. and D.Z. conducted computational experiments and analyzed data. All authors contributed to writing and approved the manuscript.
Competing Interests
The authors declare no competing interests.
Footnotes
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Supplementary information accompanies this paper at 10.1038/s41598-018-31677-y.
References
- 1.Miller JA, Kee RJ, Westbrook CK. Chemical kinetics and combustion modeling. Annu. Rev. Phys. Chem. 1990;41:345–387. doi: 10.1146/annurev.pc.41.100190.002021. [DOI] [Google Scholar]
- 2.Battin-Leclerc F, et al. Towards cleaner combustion engines through groundbreaking detailed chemical kinetic models. Chem. Soc. Rev. 2011;40:4762–4782. doi: 10.1039/c0cs00207k. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Frenklach M. Transforming data into knowledge–process informatics for combustion chemistry. Proc. Combust. Inst. 2007;31:125–140. doi: 10.1016/j.proci.2006.08.121. [DOI] [Google Scholar]
- 4.Lemkul JA, Huang J, Roux B, MacKerell AD. An empirical polarizable force field based on the classical drude oscillator model: Development history and recent applications. Chem. Rev. 2016;116:4983–5013. doi: 10.1021/acs.chemrev.5b00505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Warshel A, Kato M, Pisliakov AV. Polarizable force fields: History, test cases and prospects. J. Chem. Theory Comput. 2007;3:2034–2045. doi: 10.1021/ct700127w. [DOI] [PubMed] [Google Scholar]
- 6.Christensen AS, Kubař T, Cui Q, Elstner M. Semiempirical quantum mechanical methods for noncovalent interactions for chemical and biochemical applications. Chem. Rev. 2016;116:5301–5337. doi: 10.1021/acs.chemrev.5b00584. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Yilmazer ND, Korth M. Comparison of molecular mechanics, semi-empirical quantum mechanical and density functional theory methods for scoring protein-ligand interactions. J. Phys. Chem. B. 2013;117:8075–8084. doi: 10.1021/jp402719k. [DOI] [PubMed] [Google Scholar]
- 8.Thiel W. Semiempirical quantum-chemical methods. WIREs Comput. Mol. Sci. 2013;4:145–157. doi: 10.1002/wcms.1161. [DOI] [Google Scholar]
- 9.Burke K. Perspective on density functional theory. J. Chem. Phys. 2012;136:150901. doi: 10.1063/1.4704546. [DOI] [PubMed] [Google Scholar]
- 10.Wiitala KW, Hoye TR, Cramer CJ. Hybrid density functional methods empirically optimized for the computation of 13C and 1H chemical shifts in chloroform solution. J. Chem. Theory Comput. 2006;2:1085–1092. doi: 10.1021/ct6001016. [DOI] [PubMed] [Google Scholar]
- 11.Karton A, Tarnopolsky A, Lamère J-F, Schatz GC, Martin JML. Highly accurate first-principles benchmark data sets for the parametrization and validation of density functional and other approximate methods. derivation of a robust, generally applicable, double-hybrid functional for thermochemistry and thermochemical kinetics. J. Phys. Chem. A. 2008;112:12868–12886. doi: 10.1021/jp801805p. [DOI] [PubMed] [Google Scholar]
- 12.Zhao Y, Schultz NE, Truhlar DG. Design of density functionals by combining the method of constraint satisfaction with parametrization for thermochemistry, thermochemical kinetics and noncovalent interactions. J. Chem. Theory Comput. 2006;2:364–382. doi: 10.1021/ct0502763. [DOI] [PubMed] [Google Scholar]
- 13.Cui Q, Elstner M. Density functional tight binding: values of semi-empirical methods in an ab initio era. Phys. Chem. Chem. Phys. 2014;16:14368–14377. doi: 10.1039/C4CP00908H. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Xue LC, Dobbs D, Bonvin AM, Honavar V. Computational prediction of protein interfaces: A review of data driven methods. FEBS letters. 2015;589:3516–3526. doi: 10.1016/j.febslet.2015.10.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Lusci A, Pollastri G, Baldi P. Deep architectures and deep learning in chemoinformatics: The prediction of aqueous solubility for drug-like molecules. J. Chem. Inf. Model. 2013;53:1563–1575. doi: 10.1021/ci400187y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Schütt KT, Arbabzadah F, Chmiela S, Müller KR, Tkatchenko A. Quantum-chemical insights from deep tensor neural networks. Nat. Commun. 2017;8:13890. doi: 10.1038/ncomms13890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Hegde G, Bowen RC. Machine-learned approximations to density functional theory hamiltonians. Sci. Rep. 2017;7:42669. doi: 10.1038/srep42669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Goh GB, Hodas NO, Vishnu A. Deep learning for computational chemistry. J. Comput. Chem. 2017;38:1291–1307. doi: 10.1002/jcc.24764. [DOI] [PubMed] [Google Scholar]
- 19.McGibbon RT, et al. Improving the accuracy of møller-plesset perturbation theory with neural networks. J. Chem. Phys. 2017;147:161725. doi: 10.1063/1.4986081. [DOI] [PubMed] [Google Scholar]
- 20.Medvedev MG, Bushmarinov IS, Sun J, Perdew JP, Lyssenko KA. Density functional theory is straying from the path toward the exact functional. Sci. 2017;355:49–52. doi: 10.1126/science.aah5975. [DOI] [PubMed] [Google Scholar]
- 21.Cherkasov A, et al. Qsar modeling: Where have you been? where are you going to? J. Med. Chem. 2014;57:4977–5010. doi: 10.1021/jm4004285. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Mansouri K, Grulke CM, Richard AM, Judson RS, Williams AJ. An automated curation procedure for addressing chemical errors and inconsistencies in public datasets used in qsar modelling. SAR and QSAR Environ. Res. 2016;27:911–937. doi: 10.1080/1062936X.2016.1253611. [DOI] [PubMed] [Google Scholar]
- 23.Peverati R, Truhlar DG. Quest for a universal density functional: the accuracy of density functionals across a broad spectrum of databases in chemistry and physics. Phil. Trans. R. Soc. A. 2014;372:20120476. doi: 10.1098/rsta.2012.0476. [DOI] [PubMed] [Google Scholar]
- 24.Russi T, Packard A, Frenklach M. Uncertainty quantification: Making predictions of complex reaction systems reliable. Chem. Phys. Lett. 2010;499:1–8. doi: 10.1016/j.cplett.2010.09.009. [DOI] [Google Scholar]
- 25.Faver JC, Yang W, Merz KM., Jr. The effects of computational modeling errors on the estimation of statistical mechanical variables. J. Chem. Theory Comput. 2012;8:3769–3776. doi: 10.1021/ct300024z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Yang X, et al. Atomic radius and charge parameter uncertainty in biomolecular solvation energy calculations. J. Chem. Theory Comput. 2018;14:759–767. doi: 10.1021/acs.jctc.7b00905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Simm, G. N. & Reiher, M. Error-controlled exploration of chemical reaction networks with gaussian processes. arXiv preprint available at, https://arxiv.org/abs/1805.09886 (2018). [DOI] [PubMed]
- 28.Simm GN, Proppe J, Reiher M. Error assessment of computational models in chemistry. Chimia. 2017;71:202–208. doi: 10.2533/chimia.2017.202. [DOI] [PubMed] [Google Scholar]
- 29.Frenklach, M., Packard, A. & Seiler, P. Prediction uncertainty from models and data. In Proceedings of the American Control Conference, vol. 5, 4135–4140 (IEEE, 2002).
- 30.Seiler P, Frenklach M, Packard A, Feeley R. Numerical approaches for collaborative data processing. Optim. Eng. 2006;7:459–478. doi: 10.1007/s11081-006-0350-4. [DOI] [Google Scholar]
- 31.Edwards DE, Zubarev DY, Packard A, Lester WA, Frenklach M. Interval prediction of molecular properties in parametrized quantum chemistry. Phys. Rev. Lett. 2014;112:253003. doi: 10.1103/PhysRevLett.112.253003. [DOI] [PubMed] [Google Scholar]
- 32.Stewart JJ. Optimization of parameters for semiempirical methods VI: more modifications to the NDDO approximations and re-optimization of parameters. J. Mol. Model. 2013;19:1–32. doi: 10.1007/s00894-012-1667-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Dral PO, et al. Semiempirical quantum-chemical orthogonalization-corrected methods: Theory, implementation and parameters. J. Chem. Theory Comput. 2016;12:1082–1096. doi: 10.1021/acs.jctc.5b01046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dral PO, Wu X, Spörkel L, Koslowski A, Thiel W. Semiempirical quantum-chemical orthogonalization-corrected methods: Benchmarks for ground-state properties. J. Chem. Theory Comput. 2016;12:1097–1120. doi: 10.1021/acs.jctc.5b01047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Feeley R, Seiler P, Packard A, Frenklach M. Consistency of a reaction dataset. J. Phys. Chem. A. 2004;108:9573–9583. doi: 10.1021/jp047524w. [DOI] [Google Scholar]
- 36.Frenklach M, Packard A, Garcia-Donato G, Paulo R, Sacks J. Comparison of statistical and deterministic frameworks of uncertainty quantification. SIAM/ASA J. Uncertainty Quantif. 2016;4:875–901. doi: 10.1137/15M1019131. [DOI] [Google Scholar]
- 37.Box, G. E. & Draper, N. R. Empirical model-building and response surfaces. (John Wiley & Sons, 1987).
- 38.Ruscic, B. & Bross, D. Active thermochemical tables (ATcT) values based on ver. 1.122 of the thermochemical network, 2016. avaliable at ATcT.anl.gov (2017).
- 39.Ruscic B. Uncertainty quantification in thermochemistry, benchmarking electronic structure computations and active thermochemical tables. Int. J. Quantum Chem. 2014;114:1097–1101. doi: 10.1002/qua.24605. [DOI] [Google Scholar]
- 40.MATLAB, statistics and machine learning toolbox, parallel computing toolbox and optimization toolbox release 2017b, The MathWorks Inc. Natick, MA (2002).
- 41.Stewart, J. J. MOPAC2016. Stewart Computational Chemistry, Colorado Springs, CO. available at, http://openmopac.net (2016).
- 42.Benson SW, et al. Additivity rules for the estimation of thermochemical properties. Chem. Rev. 1969;69:279–324. doi: 10.1021/cr60259a002. [DOI] [Google Scholar]
- 43. Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning, vol. 2 (Springer Series in Statistics, 2009).
- 44.Pedregosa F, et al. Scikit-learn: Machine learning in Python. J. Machine Learning Research. 2011;12:2825–2830. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.