

Assessing the importance of each connection in a network for the spreading of epidemics allows the largest containment up to date.
Abstract
Epidemic containment is a major concern when confronting large-scale infections in complex networks. Many studies have been devoted to analytically understand how to restructure the network to minimize the impact of major outbreaks of infections at large scale. In many cases, the strategies are based on isolating certain nodes, while less attention has been paid to interventions on the links. In epidemic spreading, links inform about the probability of carrying the contagion of the disease from infected to susceptible individuals. Note that these states depend on the full structure of the network, and its determination is not straightforward from the knowledge of nodes’ states. Here, we confront this challenge and propose a set of discrete-time governing equations that can be closed and analyzed, assessing the contribution of links to spreading processes in complex networks. Our approach allows a scheme for the containment of epidemics based on deactivating the most important links in transmitting the disease. The model is validated in synthetic and real networks, yielding an accurate determination of epidemic incidence and critical thresholds. Epidemic containment based on link deactivation promises to be an effective tool to maintain functionality of networks while controlling the spread of diseases, such as disease spread through air transportation networks.
INTRODUCTION
The problem of modeling the spread of a disease among individuals has been studied in depth over many years (1–4). The development of compartmental models, models that divide the individuals among a set of possible states, has given rise to a new collection of techniques that enable, for instance, analysis of the onset of epidemics (5–15) or study of the impact of a vaccination campaign (16–20). Previous studies have relied heavily on a mathematical approach to the study of epidemic spreading (21), and we follow a similar approach here in the same spirit.
The design of effective containment strategies constitutes a major challenge. Measures such as vaccination, improved hygiene, biosecurity, cattle culling, or education to prevent contagions operate on the biological aspects of the disease. On the other hand, isolation or mobility restrictions act on the physical routes or patterns of disease spread, which may transform a local event into a pandemic. Here, we concentrate on the role of the links of the spreading network. For example, if we identify the edges that are more involved in the propagation of a disease, then it is possible to design targeted countermeasures that affect only specific links instead of whole nodes while being more effective. This approach can be illustrated by a hypothetical pandemic disease propagated using the air transportation network: The isolation of one airport is a dramatic measure that is socially and politically difficult to accept and put into practice, but the suspension of only a few connections between selected airports could be more easily assumed and could also achieve a better containment of the disease.
Previous studies have directed their attention mostly toward schemes based on the actuation on single nodes, either randomly or according to node properties such as their degree, betweenness, PageRank, or eigenvector centrality (22–25). Following the same idea, some authors have introduced link removal using properties of the adjacent nodes (degrees or centralities) or of the link itself (edge betweenness) (22, 26, 27). A model of coevolution of epidemics with permanent and temporal link removals was proposed in (28), and methods from optimization and control have been applied to minimize the impact of the epidemics (29–31). The core of what is currently considered to be the optimal approach is built upon finding the minimum set of edges whose removal leads to a maximum decrease in the spectral radius of the network, that is, the largest eigenvalue of the adjacency matrix (27, 32, 33). Because the epidemic threshold is, at first-order approximation of a susceptible-infected-susceptible (SIS) epidemic dynamics, inverse to the spectral radius, it seems the best and more mathematically grounded option. Unfortunately, it turns out to be an NP-complete problem; thus, only heuristics are available for large networks (27).
It must be emphasized that all the previous approaches make use only of the structural characteristics of the network to decide which nodes or edges have to be removed; the characteristics or parameters of the epidemic process are ignored. Even the spectral radius, which is closely related to the epidemic threshold, does not depend on the infection or recovery rates, the expected number of infected neighbors around a certain node, or any other local or global information of the spreading process.
Our proposal concentrates on the role of the links in the spreading of the epidemics, quantifying the importance of each link (34) and thus enabling containment strategies based on their removal. To this end, we first define the epidemic importance of a link as its capacity to infect other individuals once this link has been used to propagate the disease. The determination of this link epidemic importance requires the development of a mathematical model that is able to cope with the infection propagation at the level of links in complex networks. We will show that the proposed model facilitates the determination of the epidemics incidence and threshold with high accuracy. Moreover, the quantification of the epidemic importance of the edges leads to a link removal strategy that, in many cases, outperforms the previous approaches, even those based on minimizing the spectral radius, and also preserves most of the connectivity of the network.
The contributed model is built upon the relationships between the states of nodes connected by links, thus being related to pairwise approximations (35–41). However, our model is microscopic, at the level of individual links as in (40), thus allowing a clear identification of maximally infectious links, but with the additional advantage of being able to easily calculate not only the epidemic threshold but also the incidence of the epidemics and the importance of the links.
RESULTS
Link epidemic importance
Let us consider a discrete-time SIS dynamics that runs on top of a complex network of N nodes and L edges, with adjacency matrix A, and where each node i can be in one of two different states σi, either susceptible (S) or infected (I), that is, σi ∈ {S, I}. We can say that a link (i, j) between nodes i and j is in state SI if σi = S and σj = I. The parameters of the SIS dynamics are the infection and recovery probabilities, β and μ, respectively.
Our objective is to find an effective strategy to contain the SIS epidemic process through bond percolation. To determine which link should be removed first, we need a measure of the importance of each link in the spreading of the epidemics. A possible option would be to use the edge importance defined in (34), which accounts for the relative change of the spectral radius when the edge is removed. However, this constitutes an indirect way of containment, because we aim at lowering the incidence of the epidemics as much as possible, whereas the actuation on the spectral radius is directed to increase the epidemic threshold; both are different targets. In addition, the spectral radius only depends on the structure of the network, but not on the epidemic parameters of the process or the participation of the link in the spreading of the disease.
We assume that the system has reached the stationary state, which does not mean that the nodes remain in a certain fixed state, only that the average incidence of the epidemics is basically constant; thus, there is still margin for applying a containment strategy to minimize this incidence. In this regime, we can measure the probabilities of nodes and links in each of the epidemic states, for example, the probability P(σi = I) of node i being infected or the joint probability P(σi = I, σj = S) of link (i, j) being in state IS.
Consider we have a link in state SS or II. In both cases, the next step of the epidemic dynamics is not going to use this link because, in the former, there is no infected node to propagate the disease and, in the latter, both nodes are already infected. Thus, to propagate the epidemics, a link must be in an either SI or IS state. Let us suppose we have a link (i, j) in state IS. First, with probability β, node i can infect node j through this link, changing to state II. Next, infected node j may transmit the disease to some of its neighbors. Thus, if we had removed link (i, j), then we would have cut this path of infections initiated at node i. This means that the larger the expected number of infected neighbors of node j, the largest the impact of removing link (i, j) for the spreading of the epidemics. Note that the degree of j, as well as the probability of its neighbors being susceptible when j is infected, is relevant, because you cannot infect nodes that are already infected. For example, if j is surrounded by many infected nodes, then cutting link (i, j) is not going to have too much effect on the overall incidence of the epidemics. The expected number of infected nodes produced in this way can be expressed as
| (1) |
where P(σr = S|σj = I) is the conditional probability that node r is susceptible when its neighbor j is infected. Because this measure is asymmetric, and removing an edge affects the propagation of the disease in both directions, we define the link epidemic importance of a link, Iij, as
| (2) |
Now, the problem reduces to finding the joint and conditional probabilities for each link, and this is accomplished using our epidemic link equations (ELE). It can be shown that this definition of link epidemic importance has the property of trying to preserve the connectivity of the network (see section S1 and fig. S1), unlike other options such as edge betweenness, which quickly tend to produce a large number of disconnected components, thus hindering the functionality of the network.
Epidemic link equations
To simplify the notation, we first denote the previous joint probability as Φij = P(σi = S, σj = I); the higher the Φij, the larger the likelihood that the disease propagates from node j to node i. It is worth mentioning that this feature is generally asymmetrical, meaning that the propagation of the illness can be more probable from j to i than the other way around. In the same way, the epidemic is restrained by edges where the nodes are in the same state; thus, it is convenient to define the probabilities and for all pairs of neighboring nodes.
The evolution of the joint probability Φij of one link depends on the probabilities Φ, ΘI, and ΘS to the rest of the neighboring links and on the infection rules of the SIS dynamics. Thus, we can write the following equation for each link
| (3) |
where qij(t) stands for the probability that a susceptible node i is not infected by any of its neighbors (excluding node j). We have taken into account all the possible changes of state of the nodes i and j. The first term considers the probability that both nodes are in a susceptible state; then, node i remains susceptible, while node j is infected by any of its other neighbors. The second term accounts for both nodes remaining in the same state; node i is not infected by any of its neighbors, and node j is not recovered from the infection. Then, the third term represents the transition in which node i is infected and recovers, while node j is susceptible and is infected by any of its other neighbors. Last, in the fourth term, both nodes are infected, but node i recovers, while node j does not. The asymmetry of probability Φij multiplies the number of equations by two, because, for each link between nodes i and j, we need an equation for Φij(t + 1) and another for Φji(t + 1).
Similarly, we can obtain an expression for probability
| (4) |
In this case, we have only L equations, one per link, because of its symmetry. There is no need for extra equations for probability , because the normalization leads to .
qij(t) in Eqs. 3 and 4 can be expressed as
| (5) |
where hij defines the hostility of j against i, that is, the probability that node j is infected when node i is susceptible, hij = P(σj = I|σi = S). The hostility can be obtained in terms of and Φij as
| (6) |
Note that the denominator in Eq. 6 is a property of node i, given that for all neighboring nodes j of vertex i.
We call this system of 3L equations and unknowns our ELE model. It can be solved by iteration, starting from any meaningful initial condition, for example, and Φij(0) = Φji(0) = ρ0(1 − ρ0) (for any 0 < ρ0 ≤ 1), until a fixed point is found. Apart from the solution where all nodes are susceptible, for all the links, a nontrivial one appears when the system is above the critical value of the epidemic spreading (see Methods for the analytic derivation of the epidemic threshold from ELE model). Last, the incidence of the epidemic process, the average number of infected nodes in the whole system, can be computed as
| (7) |
where ki is the degree of node i.
To test the agreement between our approach and empirical simulations, we have analyzed the incidence of the epidemics, ρ, in different synthetic and real network structures, covering the full range of infection probabilities, β (see Fig. 1). The results show a marked agreement between our ELE model and the Monte Carlo simulations and a good prediction of the epidemic threshold for all synthetic and real networks, pointing out the validity of our model to describe the global impact of the epidemics. Note that all networks, except the first one, have a large clustering coefficient, making the determination of the incidence difficult for standard mean field methods because of the effect of dynamical correlations.
Fig. 1. Incidence of the epidemic process ρ as a function of the infection probability β.
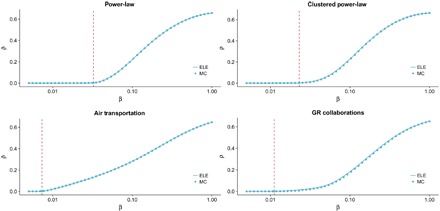
We show the incidence level for the ELE model (solid lines) and for Monte Carlo (MC) simulations (circles). The theoretical epidemic threshold calculated using Eq. 19 is marked with a vertical line. We have made use of two synthetic and two real networks: two scale-free networks (top) with an exponent of 3, one of them with high clustering coefficient; the world air transportation network; and the network of scientific collaborations in the field of general relativity (GR). We have set the recovery rate for all the networks to μ = 0.5 (see Methods for the description of the networks and the details of the MC simulations).
Epidemic containment
Our approach for effective epidemic containment is based on removing the links with the largest link epidemic importance. This is possible once we have solved the ELE model, computing the Iij for all the links in the network using Eq. 2, which can be expressed as
| (8) |
Note that the value of β does not affect the ranking of the links, but we do not remove it from Eq. 8 to preserve the semantics of Iij. Because the structure of the network changes after each link removal, it is convenient to recalculate the solution of the ELE model to ensure that we really remove the current link with the largest link epidemic importance.
We show the results of our approach for epidemic containment in Fig. 2. For comparison purposes, we also test four additional containment strategies. First, we consider two strategies that only make use of the structure of the network: removal based on maximum edge betweenness (22) and targeting the link with the highest eigenscore, that is, the product of the eigenvector centralities of the nodes connected by the link (27). Then, we consider a measure based on the epidemic process at the level of nodes, the removal of all the links of the node that has the maximum probability of being infected. Last, we carried out a simple random edge removal. As in the case of our strategy, we recalculate all the measures after each removal (see Methods for further details). We have also checked a promising approach based on communicability distances (42); however, the computational costs involved in computing communicability angles and distances for large networks preclude this approach to be used in large networks. For this reason, we have not included results on this one.
Fig. 2. Targeted bond percolation.
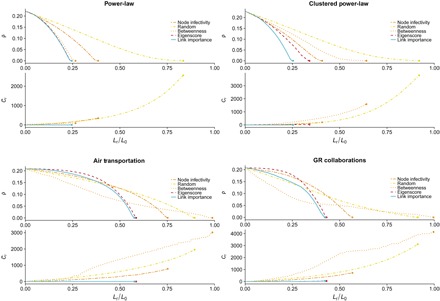
We show the incidence of the epidemics, (ρ), and the number of connected components, (Cr), as functions of the occupation probability, (Lr/L0), where L0 is the number of links of the network and Lr is the number of removed edges in the bond percolation process. We compare five different epidemic containment strategies: removing the edges of the node with the highest probability of being infected, P(σi = I) (orange dash-dash lines); a random edge removal (yellow dash-dot lines); removing the edge with the highest edge betweenness (light orange dotted lines); targeting the edge with the highest eigenscore (red dashed line); and, last, removing the edge that has the largest link epidemic importance (blue solid line). We apply these processes to the same networks as in Fig. 1 (see Methods). We have set the recovery rate to μ = 0.5 and have chosen the infection probability β such that the stationary incidence of the epidemics is about ρini ≈ 0.2 for all the networks, that is, β = 0.1 for both power-law networks, β = 0.06 for air transportation network, and β = 0.11 for the collaboration network. The dots mark the achievement of total containment.
We observe in Fig. 2 that link epidemic importance leads to the fastest extinction of the epidemics for the four considered networks, and it is the only method that preserves their connectivity (thus, functionality). Note that the strategy based on node infectivity, though better than the random removal, performs poorly for all the networks despite having information about the epidemic process. This means that the use of information at the level of links is crucial to contain the epidemics.
For the power-law network, our approach using link epidemic importance yields the best performance, but the results are very similar to the those obtained using eigenscore and edge betweenness strategies [equivalent results hold for Erdős-Rényi (ER) networks; see fig. S6]. However, when the transitivity of the network is increased, we can see the benefits of using link epidemic importance, both in epidemic containment and on preservation of the connectivity of the network (see figs. S2 and S3 for more details on the containment process for each method).
The effect of the clustering coefficient is also present when we look at the epidemic containment results for the two empirical networks in Fig. 2. Moreover, as in most real networks, the air transportation and the scientific collaboration networks have a significant modular structure. This plays an important role on the epidemic containment process. Here, we can see how the strategy based on edge betweenness apparently performs better when few links are removed because of the fact that links with higher edge betweenness are those connecting different modules (43). When the bond percolation process isolates modules, each module may sustain its own epidemic process, and thus, it may happen that some of the modules are subcritical for the given infection probability β. This will lead to a decrease of the global prevalence of the epidemics at the expense of losing the connectivity of the network. Furthermore, if we look at the prevalence on the giant connected component, an important increase above the initial average number of infected individuals is revealed (see figs. S4 and S5). A consequence of this fragmentation process is the appearance of multiple isolated supercritical components, for which the removal of a link in one of them does not affect the incidence on the other components. As a result, the edge betweenness procedure needs to remove more links to arrive to the total epidemic extinction than any of the other methods, even the random one. For the sake of completeness, we have analyzed two benchmark networks with community structure, obtaining similar results (see figs. S7 and S8).
In Fig. 3 (top), we illustrate the survival links in the air transportation network after 33.3% of the edges have been removed according to our epidemic containment strategy proposal (see fig. S9 for the original network before the containment process). As it is observed, the global connectivity, and thus functionality, of the worldwide connections is preserved (links of the same color are part of the same connected component). In Fig. 3 (bottom), we plot the network after deactivating the same fraction of links (33.3%) using the recursive deactivation of links according to edge betweenness. The edge betweenness containment method, in contrast with our proposal, generates two kinds of components: small or sparsely connected subcritical modules such as the ones in Australia, Africa, or South America, where the epidemics vanishes, and large supercritical communities in Europe, North America, and East Asia, with a large prevalence of the epidemics. This means that, for instance, there is no path to go from London to New York, or from Tokyo to Los Angeles, thus disconnecting the world by air transportation.
Fig. 3. Epidemic containment on the air transportation network.
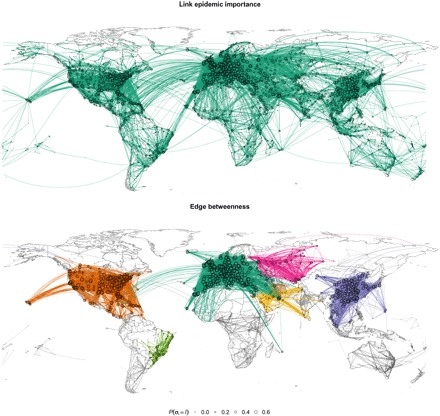
We show the networks after 33.3% of the links have been removed using link epidemic importance (top) and edge betweenness (bottom). Nodes and edges with the same color belong to the same connected component, with subcritical components in gray scale and using darker gray for larger components. The area of the nodes is proportional to their probability of being infected P(σi = I) from 0.0 to 0.6. We have set the epidemic probabilities to μ = 0.5 and β = 0.06.
For a better assessment of the performance of the different containment strategies, we show in Fig. 4 their comparison in terms of the required fraction of removed links to attain total containment, LTC/L0, when applied to a large set of synthetic networks and epidemic parameters. The results point to a clear advantage of the link epidemic importance method over the node infectivity and random approaches, and better or equal results with respect to edge betweenness and eigenscore. Only eigenscore achieves results comparable to link epidemic importance, with a slight advantage for our method. When applied to a set of 27 real networks (see Methods), the differences between link epidemic importance and eigenscore become more evident, showing again the effectiveness of our approach, but with some exceptions in which eigenscore performs better (see Fig. 5). In addition, we plot in figs. S10 and S11 the comparison of the number of connected components between the different containment strategies, which show the better performance of link epidemic importance to keep the number of components low, with only a few exceptions.
Fig. 4. Fraction of links removed for total epidemic containment on synthetic networks.
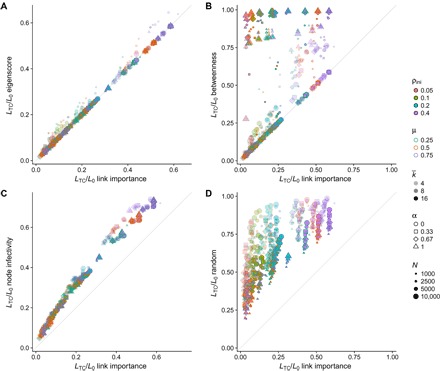
We show the fraction of links that have to be removed to obtain total epidemic containment using link epidemic importance, compared with the fractions for the other four strategies: (A) eigenscore, (B) edge betweenness, (C) node infectivity, and (D) random removal. Each point represents a configuration consisting of a network and a set of epidemic parameters. The networks have been generated with the model in (48), which interpolates between ER (α = 1) and BA networks (α = 0). We use four values of the interpolating parameter: α = 0.0, 0.33, 0.67, and 1.0. These networks are generated in four sizes (N = 1000, 2500, 5000, and 10, 000) and three average degrees (〈k〉 = 4, 8, and 16), thus amounting to 48 different networks. For each network, we apply the five containment strategies for three different values of the recovery probability (μ = 0.25, 0.50, and 0.75) and four values of the infection probability β selected such that, before removing links, the incidence of the epidemics at the stationary state is equal to ρini = 0.05, 0.1, 0.2, and 0.4. Therefore, each plot contains 576 different configurations.
Fig. 5. Fraction of links removed for total epidemic containment on real networks.
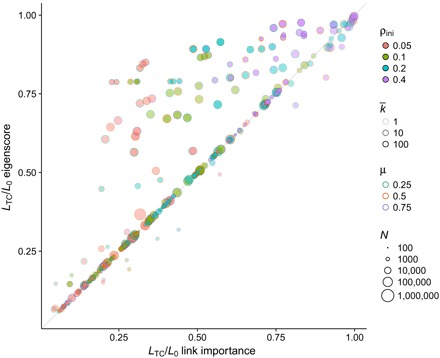
We compare the link epidemic importance and eigenscore methods on a set of 27 real networks selected from the Network Repository (49) (see Methods), with sizes ranging from 410 to 404,719 nodes. The epidemic parameters are the same as in Fig. 4, thus amounting to 324 different configurations.
DISCUSSION
We have presented a methodology for assessing epidemic spreading based on links instead of nodes. The model, named ELE, allows the determination of the epidemic importance of each link in transmitting the disease. The method accounts for the first-order correlations between links, although it could be extended to higher orders, assuming a larger analytical and computational cost. The results are used to develop an epidemic containment strategy built on deactivating recursively the links with the largest link epidemic importance while preserving the connectivity of the full network, that is, avoiding fragmentation. We have validated our proposal in synthetic and empirical networks, comparing with other alternative containment strategies, which show its better performance, with few exceptions. In the empirical case of the worldwide air transportation network, we identify the most important connections between airports for the spreading of epidemics and evaluate the epidemic incidence after its deactivation, considering an SIS epidemic spreading dynamics. Our results open the door to new approaches in the analysis of dynamical diffusive-like models on complex networks at the level of links instead of nodes.
METHODS
Epidemic threshold
The determination of the epidemic threshold was performed by considering a state of the system in which the epidemic incidence is very small (, for all links); thus, the system of equations can be linearized (see section S2 for full details), resulting in
| (9) |
| (10) |
Here, we removed the dependence on time to emphasize that we are considering the steady state. From Eq. 9, we can write
| (11) |
Now, calling , which does not depend on node j because P(σi = I, σj = S) + P(σi = I, σj = I) = P(σi = I), we made the following ansatz
| (12) |
| (13) |
where ϒ, X, and Z are constants independent of the link. These ansatz include the assumptions of symmetry of and asymmetry of Φij, respectively. We can determine the constants by substitution in Eq. 11 and using the definition of εi, which leads to
| (14) |
| (15) |
| (16) |
Last, we built equations for εi by substituting Eqs. 9 and 10 in and using the ansatz. The result is
| (17) |
where B is a matrix whose elements depend on the adjacency matrix of the network, on ϒ, and on the degrees ki of the nodes
| (18) |
δij stands for the Kronecker delta function, which is 1 if i = j and 0 otherwise. If μ/β is an eigenvalue of matrix B, then Eq. 17 has nontrivial solutions. Hence, the onset of the epidemics βc, the lowest value of β that yields nontrivial solutions of Eq. 17, is given by
| (19) |
where Λmax(B) is the largest eigenvalue of matrix B. Note that matrix B depends on β and μ; thus, Eq. 19 is implicit for βc, which can be solved by iteration (see section S3 for a discussion on the determination of the epidemic threshold).
Estimation of the incidence of the epidemic from numerical simulations
The numerical incidence of the epidemics, ρ, is calculated using discrete-time and synchronous Monte Carlo simulations. We made use of the quasistationary (QS) approach (44, 45) to avoid the effect that a large number of realizations end up in the absorbing state with no infected individuals in the system. Basically, the QS method focuses the simulation on active configurations, that is, with one or more infected individuals. Every time the system reaches the absorbing state, this state is replaced by one of the previously stored active states of the system. We kept 50 active configurations with an update probability of 0.20. We gave the systems a transient time of 105 time steps and then calculated ρ as an average over a relaxation time of 2 × 104 time steps.
Networks
In this work, we evaluated our methodology on synthetic and empirical networks. We built a network with power-law degree distribution P(k) ~ k−γ with exponent γ = 3 and 〈k〉 = 6 using the configuration model. To evaluate the impact of transitivity, we also built another network with the same characteristics of the previous one but with a clustering coefficient of 0.6 using the algorithm of Holme and Kim (46) with a parameter p = 0.8.
We considered also two empirical networks: the air transportation network and the network of scientific collaborations in the field of general relativity. The air transportation network was constructed using data from the website openflights.org, which has information about the traffic between airports updated to 2012. This network accounts for the largest connected component, with 3154 nodes and 18,592 edges (see data file S1). The network of scientific collaborations was obtained from (47); it is composed of 5242 nodes linked by 14,496 edges.
The synthetic networks in Fig. 4 were generated with the model in (48), which interpolates between ER and Barabási-Albert (BA) networks. In this way, we were able to evaluate the performance of the containment strategies on networks with degree distributions that range from Poisson (ER) to power-law (BA). By construction, these networks have no community structure and low transitivity.
The 27 real networks in Fig. 5 were obtained from the Network Repository (49), selecting only the largest connected component. They cover wide ranges of number of nodes (from 410 to 404,719), number of links (from 1043 to 713,319), average degree (between 2.04 and 84.82), average clustering coefficient (from 0.0023 to 0.1105), and assortativity (between −0.88 and 0.64) (see section S4).
Containment process
To perform the deactivation of links, we imposed an adiabatic process: After each removal step, we let the system converge to the meta-stable equilibrium before removing any other link. For a fair comparison between different containment strategies, we removed on each deactivation step as many edges as we have removed using the node infectivity strategy. In the case of the real networks in Fig. 5, we set the maximum number of adiabatic processes to 1000 because of its large computational cost on the largest networks. This means that, if the network has 20,000 links, we removed 20 links at each deactivation step. We considered that we reached total containment when the incidence of the epidemics becomes lower than 1/N. The computational cost of calculating the links to remove for each containment strategy is shown in fig. S13.
Supplementary Material
Acknowledgments
We acknowledge comments on the manuscript by C. Granell, M. Barahona, and P. Hövel. Funding: J.T.M., A.A., and S.G. were supported by the Generalitat de Catalunya project 2017-SGR-896, Spanish MINECO project FIS2015-71582-C2-1, and Universitat Rovira i Virgili project 2017PFR-URV-B2-41. A.A. acknowledges financial support from the ICREA Academia and the James S. McDonnell Foundation (220020325). J.T.M. acknowledges an FI-2015 grant from the Generalitat de Catalunya AGAUR. Author contributions: All authors have contributed equally to this manuscript. Competing interests: All authors declare that they have no competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and/or the Supplementary Materials. Additional data related to this paper may be requested from the authors.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/4/12/eaau4212/DC1
Section S1. Link epidemic importance and connected components
Section S2. Linearization of the ELE model
Section S3. Epidemic threshold
Section S4. Data description
Fig. S1. Ratio between the link epidemic importance IA of a link in a subnetwork A and the link epidemic importance IAB of a link that acts as the only bridge between subnetworks A and B.
Fig. S2. Epidemic containment for a network with 5000 nodes, power-law degree distribution of exponent 3, and average degree 〈k〉 = 6.
Fig. S3. Epidemic containment for a network with 5000 nodes, power-law degree distribution of exponent 3, high clustering coefficient, and average degree 〈k〉 = 6.
Fig. S4. Epidemic containment for the air transportation network.
Fig. S5. Epidemic containment for the general relativity collaborations network.
Fig. S6. Epidemic containment for an ER network with 5000 nodes and average degree 〈k〉 = 6.
Fig. S7. Epidemic containment for a network with 5000 nodes generated with a stochastic block model, with four blocks of 250 nodes, two blocks of 1000 nodes, and one block of 2000 nodes, average degree of 5, and mixing probability of 0.3.
Fig. S8. Epidemic containment for a network with 5000 nodes generated using the LFR algorithm, with average degree of 6, exponent of 3, and mixing probability of 0.1.
Fig. S9. Original air transportation network (top) and the results after a removal of 33.3% of the links using link epidemic importance (middle) and edge betweenness (bottom).
Fig. S10. Comparison of the number of connected components after total containment between the link epidemic importance strategy and the other four methods, calculated for the synthetic networks and parameters as in Fig. 4.
Fig. S11. Comparison of the number of connected components after total containment between the link epidemic importance and eigenscore strategies, calculated for the real networks and parameters as in Fig. 5.
Fig. S12. Graphical representation of the determination of the epidemic threshold.
Fig. S13. Computational time invested for each method to perform a single ranking and removal for BA networks ranging from 100 to 400,000 nodes, averaged over 36 repetitions.
Table S1. Structural characteristics of the 27 real networks obtained from the Network Repository (http://networkrepository.com) and used in Fig. 6 and fig. S11.
Data file S1. Air transportation network data.
REFERENCES AND NOTES
- 1.R. M. Anderson, R. M. May, B. Anderson, Infectious Diseases of Humans: Dynamics and Control (Wiley Online Library, 1992), vol. 28. [Google Scholar]
- 2.Hethcote H. W., The mathematics of infectious diseases. SIAM Rev. 42, 599–653 (2000). [Google Scholar]
- 3.D. J. Daley, J. Gani, J. M. Gani, Epidemic Modelling: An Introduction (Cambridge Univ. Press, 2001), vol. 15. [Google Scholar]
- 4.Pastor-Satorras R., Castellano C., Van Mieghem P., Vespignani A., Epidemic processes in complex networks. Rev. Mod. Phys. 87, 925 (2015). [Google Scholar]
- 5.Pastor-Satorras R., Vespignani A., Epidemic spreading in scale-free networks. Phys. Rev. Lett. 86, 3200–3203 (2001). [DOI] [PubMed] [Google Scholar]
- 6.Newman M. E., Spread of epidemic disease on networks. Phys. Rev. E 66, 016128 (2002). [DOI] [PubMed] [Google Scholar]
- 7.Hufnagel L., Brockmann D., Geisel T., Forecast and control of epidemics in a globalized world. Proc. Natl. Acad. Sci. U.S.A. 101, 15124–15129 (2004). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Y. Wang, D. Chakrabarti, C. Wang, C. Faloutsos, Proceedings of the 22nd International Symposium on Reliable Distributed Systems (IEEE, 2003), pp. 25–34. [Google Scholar]
- 9.Chakrabarti D., Wang Y., Wang C., Leskovec J., Faloutsos C., Epidemic thresholds in real networks. ACM Trans. Inform. Syst. Security 10, 13 (2008). [Google Scholar]
- 10.Gómez S., Arenas A., Borge-Holthoefer J., Meloni S., Moreno Y., Discrete-time Markov chain approach to contact-based disease spreading in complex networks. Europhys. Lett. 89, 38009 (2010). [Google Scholar]
- 11.Gómez S., Gómez-Gardenes J., Moreno Y., Arenas A., Nonperturbative heterogeneous mean-field approach to epidemic spreading in complex networks. Phys. Rev. E 84, 036105 (2011). [DOI] [PubMed] [Google Scholar]
- 12.Brockmann D., Helbing D., The hidden geometry of complex, network-driven contagion phenomena. Science 342, 1337–1342 (2013). [DOI] [PubMed] [Google Scholar]
- 13.Cai C.-R., Wu Z.-X., Guan J.-Y., Effective degree Markov-chain approach for discrete-time epidemic processes on uncorrelated networks. Phys. Rev. E 90, 052803 (2014). [DOI] [PubMed] [Google Scholar]
- 14.Cai C.-R., Wu Z.-X., Chen M. Z. Q., Holme P., Guan J.-Y., Solving the dynamic correlation problem of the susceptible-infected-susceptible model on networks. Phys. Rev. Lett. 116, 258301 (2016). [DOI] [PubMed] [Google Scholar]
- 15.P. E. Paré, B. E. Kirwan, J. Liu, T. Başar, C. L. Beck, 2018 Annual American Control Conference (ACC) (IEEE, 2018), pp. 404–409. [Google Scholar]
- 16.Earn D. J. D., Rohani P., Bolker B. M., Grenfell B. T., A simple model for complex dynamical transitions in epidemics. Science 287, 667–670 (2000). [DOI] [PubMed] [Google Scholar]
- 17.Pastor-Satorras R., Vespignani A., Immunization of complex networks. Phys. Rev. E 65, 036104 (2002). [DOI] [PubMed] [Google Scholar]
- 18.Madar N., Kalisky T., Cohen R., ben-Avraham D., Havlin S., Immunization and epidemic dynamics in complex networks. Eur. Phys. J. B 38, 269–276 (2004). [Google Scholar]
- 19.Gómez-Gardeñes J., Echenique P., Moreno Y., Immunization of real complex communication networks. Eur. Phys. J. B 49, 259–264 (2006). [Google Scholar]
- 20.Hébert-Dufresne L., Allard A., Young J.-G., Dubé L. J., Global efficiency of local immunization on complex networks. Sci. Rep. 3, 2171 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Lofgren E. T., Halloran M. E., Rivers C. M., Drake J. M., Porco T. C., Lewis B., Yang W., Vespignani A., Shaman J., Eisenberg J. N. S., Eisenberg M. C., Marathe M., Scarpino S. V., Alexander K. A., Meza R., Ferrari M. J., Hyman J. M., Meyers L. A., Eubank S., Opinion: Mathematical models: A key tool for outbreak response. Proc. Natl. Acad. Sci. U.S.A. 111, 18095–18096 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Holme P., Kim B. J., Yoon C. N., Han S. K., Attack vulnerability of complex networks. Phys. Rev. E 65, 056109 (2002). [DOI] [PubMed] [Google Scholar]
- 23.Cohen R., Havlin S., ben-Avraham D., Efficient immunization strategies for computer networks and populations. Phys. Rev. Lett. 91, 247901 (2003). [DOI] [PubMed] [Google Scholar]
- 24.Chung F., Horn P., Tsiatas A., Distributing antidote using PageRank vectors. Internet Math. 6, 237–254 (2009). [Google Scholar]
- 25.B. A. Prakash, L. Adamic, T. Iwashyna, H. Tong, C. Faloutsos, Proceedings of the 2013 SIAM International Conference on Data Mining (SIAM, 2013), pp. 659–667. [Google Scholar]
- 26.Schneider C. M., Mihaljev T., Havlin S., Herrmann H. J., Suppressing epidemics with a limited amount of immunization units. Phys. Rev. E 84, 061911 (2011). [DOI] [PubMed] [Google Scholar]
- 27.Van Mieghem P., Stevanović D., Kuipers F., Li C., van de Bovenkamp R., Liu D., Wang H., Decreasing the spectral radius of a graph by link removals. Phys. Rev. E 84, 016101 (2011). [DOI] [PubMed] [Google Scholar]
- 28.Zanette D. H., Risau-Gusmán S., Infection spreading in a population with evolving contacts. J. Biol. Phys. 34, 135–148 (2008). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Preciado V. M., Zargham M., Enyioha C., Jadbabaie A., Pappas G. J., Optimal resource allocation for network protection against spreading processes. IEEE Trans. Control Netw. Syst. 1, 99–108 (2014). [Google Scholar]
- 30.M. Zargham, V. Preciado, 2014 48th Annual Conference on Information Sciences and Systems (CISS) (IEEE, 2014), pp. 1–6. [Google Scholar]
- 31.Nowzari C., Preciado V. M., Pappas G. J., Analysis and control of epidemics: A survey of spreading processes on complex networks. IEEE Control Syst. Mag. 36, 26–46 (2016). [Google Scholar]
- 32.Bishop A. N., Shames I., Link operations for slowing the spread of disease in complex networks. Europhys. Lett. 95, 18005 (2011). [Google Scholar]
- 33.S. Saha, A. Adiga, B. A. Prakash, A. K. S. Vullikanti, Proceedings of the 2015 SIAM International Conference on Data Mining (Society for Industrial and Applied Mathematics, 2015), pp. 568–576. [Google Scholar]
- 34.Restrepo J. G., Ott E., Hunt B. R., Characterizing the dynamical importance of network nodes and links. Phys. Rev. Lett. 97, 094102 (2006). [DOI] [PubMed] [Google Scholar]
- 35.Van Mieghem P., Omic J., Kooij R., Virus spread in networks. IEEE ACM Trans. Netw. 17, 1–14 (2009). [Google Scholar]
- 36.Taylor M., Simon P. L., Green D. M., House T., Kiss I. Z., From Markovian to pairwise epidemic models and the performance of moment closure approximations. J. Math. Biol. 64, 1021–1042 (2012). [DOI] [PubMed] [Google Scholar]
- 37.Cator E. A., Van Mieghem P., Second-order mean-field susceptible-infected-susceptible epidemic threshold. Phys. Rev. E 85, 056111 (2012). [DOI] [PubMed] [Google Scholar]
- 38.Kiss I. Z., Berthouze L., Taylor T. J., Simon P. L., Modelling approaches for simple dynamic networks and applications to disease transmission models. Proc. R. Soc. A 468, 1332–1355 (2012). [Google Scholar]
- 39.Gleeson J. P., Binary-state dynamics on complex networks: Pair approximation and beyond. Phys. Rev. X 3, 021004 (2013). [Google Scholar]
- 40.Mata A. S., Ferreira S. C., Pair quenched mean-field theory for the susceptible-infected-susceptible model on complex networks. Europhys. Lett. 103, 48003 (2013). [Google Scholar]
- 41.Szabó-Solticzky A., Berthouze L., Kiss I. Z., Simon P. L., Oscillating epidemics in a dynamic network model: Stochastic and mean-field analysis. J. Math. Biol. 72, 1153–1176 (2016). [DOI] [PubMed] [Google Scholar]
- 42.Estrada E., Vargas-Estrada E., Ando H., Communicability angles reveal critical edges for network consensus dynamics. Phys. Rev. E 92, 052809 (2015). [DOI] [PubMed] [Google Scholar]
- 43.Newman M. E., Girvan M., Finding and evaluating community structure in networks. Phys. Rev. E 69, 026113 (2004). [DOI] [PubMed] [Google Scholar]
- 44.Ferreira S. C., Castellano C., Pastor-Satorras R., Epidemic thresholds of the susceptible-infected-susceptible model on networks: A comparison of numerical and theoretical results. Phys. Rev. E 86, 041125 (2012). [DOI] [PubMed] [Google Scholar]
- 45.Binder K., Heermann D., Roelofs L., Mallinckrodt A. J., McKay S., Monte Carlo simulation in statistical physics. Comput. Phys. 7, 156 (1993). [Google Scholar]
- 46.Holme P., Kim B. J., Growing scale-free networks with tunable clustering. Phys. Rev. E 65, 026107 (2002). [DOI] [PubMed] [Google Scholar]
- 47.Leskovec J., Kleinberg J., Faloutsos C., Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data 1, 2 (2007). [Google Scholar]
- 48.Gómez-Gardeñes J., Moreno Y., From scale-free to Erdős-Rényi networks. Phys. Rev. E 73, 056124 (2006). [DOI] [PubMed] [Google Scholar]
- 49.R. A. Rossi, N. K. Ahmed, Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI, 2015), vol. 15, pp. 4292–4293. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/4/12/eaau4212/DC1
Section S1. Link epidemic importance and connected components
Section S2. Linearization of the ELE model
Section S3. Epidemic threshold
Section S4. Data description
Fig. S1. Ratio between the link epidemic importance IA of a link in a subnetwork A and the link epidemic importance IAB of a link that acts as the only bridge between subnetworks A and B.
Fig. S2. Epidemic containment for a network with 5000 nodes, power-law degree distribution of exponent 3, and average degree 〈k〉 = 6.
Fig. S3. Epidemic containment for a network with 5000 nodes, power-law degree distribution of exponent 3, high clustering coefficient, and average degree 〈k〉 = 6.
Fig. S4. Epidemic containment for the air transportation network.
Fig. S5. Epidemic containment for the general relativity collaborations network.
Fig. S6. Epidemic containment for an ER network with 5000 nodes and average degree 〈k〉 = 6.
Fig. S7. Epidemic containment for a network with 5000 nodes generated with a stochastic block model, with four blocks of 250 nodes, two blocks of 1000 nodes, and one block of 2000 nodes, average degree of 5, and mixing probability of 0.3.
Fig. S8. Epidemic containment for a network with 5000 nodes generated using the LFR algorithm, with average degree of 6, exponent of 3, and mixing probability of 0.1.
Fig. S9. Original air transportation network (top) and the results after a removal of 33.3% of the links using link epidemic importance (middle) and edge betweenness (bottom).
Fig. S10. Comparison of the number of connected components after total containment between the link epidemic importance strategy and the other four methods, calculated for the synthetic networks and parameters as in Fig. 4.
Fig. S11. Comparison of the number of connected components after total containment between the link epidemic importance and eigenscore strategies, calculated for the real networks and parameters as in Fig. 5.
Fig. S12. Graphical representation of the determination of the epidemic threshold.
Fig. S13. Computational time invested for each method to perform a single ranking and removal for BA networks ranging from 100 to 400,000 nodes, averaged over 36 repetitions.
Table S1. Structural characteristics of the 27 real networks obtained from the Network Repository (http://networkrepository.com) and used in Fig. 6 and fig. S11.
Data file S1. Air transportation network data.