

Abstract
Young people’s life chances can be predicted by characteristics of their neighborhood1. Children growing up in disadvantaged neighborhoods exhibit worse physical and mental health and suffer poorer educational and economic outcomes compared to children growing up in advantaged neighborhoods. Increasing recognition that aspects of social inequalities tend, in fact, to be geographic inequalities2–5 is stimulating research and focusing policy interest on the role of place in shaping health, behavior, and social outcomes. Where neighborhood effects are causal, neighborhood-level interventions can be effective. Where neighborhood effects reflect selection of families with different characteristics into different neighborhoods, interventions should instead target families/individuals directly. To test how selection may affect different neighborhood-linked problems, we linked neighborhood data with genetic, health, and social-outcome data for >7,000 European-descent UK and US young people in the E-Risk and Add Health Studies. We tested selection/concentration of genetic risks for obesity, schizophrenia, teen-pregnancy, and poor educational outcomes in high-risk neighborhoods, including genetic analysis of neighborhood mobility. Findings argue against genetic selection/concentration as an explanation for neighborhood gradients in obesity and mental-health problems. In contrast, modest genetic selection/concentration was evident for teen-pregnancy and poor educational outcomes, suggesting neighborhood effects for these outcomes should be interpreted with care.
A challenge in interpreting neighborhood-effects research is distinguishing causal effects of neighborhood features from processes of selection in which individuals with different characteristics come to live in different neighborhoods 6,7 There is growing evidence that at least some neighborhood effects are causal; in a natural experiment arising from immigration policy in Sweden and in a randomized trial of a housing voucher program in the United States, people assigned to better-off neighborhoods tended to have some better health outcomes 8,9 Economic benefits of neighborhood interventions are less clear, but may be present for children whose neighborhoods are changed relatively early in life 10,11. But selection effects are also apparent. For example, in one study of hurricane survivors, those in poorer health prior to the disaster tended to relocate to higher-poverty communities in its aftermath 12. Selection and causation in neighborhood effects are not mutually exclusive; both can occur 13. Better understanding of how selection may contribute to apparent neighborhood effects is needed to guide intervention design and policy. Where selection can be ruled out as an explanation of neighborhood effects, neighborhood-level interventions could be prioritized. In instances where apparent neighborhood effects reflect selection processes, interventions delivered to individuals or families directly might prove more effective.
To evaluate the size and scope of selection effects in neighborhood research, methods are needed that quantify selection factors and that are not influenced by neighborhood conditions. The ideal approach is to compare fixed characteristics between children growing up in high-risk neighborhoods and peers growing up in better-off neighborhoods. Because neighborhoods may affect individuals as early as the very beginnings of their lives 3,14, traditional social-science measurements are problematic. Recent discoveries from genome-wide association studies (GWAS) provide a new opportunity to quantify selection effects at the level of the individual: polygenic scores. DNA sequence is fixed at conception and never altered by neighborhood environments. Because children inherit their DNA sequence from their parents, measures of genetic risk form a conceptual link between familial characteristics, such as parental education, that may influence selection into neighborhoods, and children’s health and social outcomes. In this article, we report proof-of-concept polygenic score analysis to quantify genetic selection into neighborhoods.
We analyzed polygenic scores and neighborhood conditions in 1,999 young people from the E-Risk Longitudinal Study, a birth cohort ascertained from a birth registry in England and Wales and followed prospectively through age 18 years. We studied phenotypes that represent substantial public health and economic burdens, have been linked with neighborhood risk in prior studies, are prevalent among 18-year-olds in England and Wales, and have been subject to large-scale genome-wide association study meta-analyses: obesity, mental health problems, teen pregnancy, and poor educational outcomes. We measured children’s genetic risk using four polygenic scores computed based on results from published GWAS of obesity, schizophrenia, age at first birth, and educational attainment 15–18. We measured their neighborhoods using administrative, survey, and systematic-social-observation 19 data collected during their childhoods. We tested for the expected associations of polygenic and neighborhood risk with E-Risk children’s development of obesity and mental-health problems, teen pregnancy, earning poor educational qualifications, and not being in education, employment, or training (NEET), as measured during home visits at age 18 years. To test for genetic selection effects, we tested for gene-environment correlations in which young people who carried elevated burdens of polygenic risk tended to have grown up in more disadvantaged neighborhoods. To test if gene-environment correlations reflected the passive inheritance of genetics and neighborhood conditions from parents, we also analyzed the genetics of the children’s mothers. Finally, to test how genetics might become correlated with neighborhood conditions, we tested genetic associations with neighborhood mobility using data from 5,325 participants in the US-based National Longitudinal Study of Adolescent to Adult Health, a nationally representative longitudinal study of American adolescents followed prospectively through their late 20s/early 30s.
As anticipated by the genetics literature, E-Risk children with higher genetic risk had more health and social problems by age 18 years.
We computed polygenic scores from published GWAS results for obesity, schizophrenia, age-at-first birth, and educational attainment 15–18 using the methods described by Dudbridge 20. This method proceeds as follows: First, SNPs in the E-Risk database were matched with SNPs reported in the GWAS publications. Second, for each matched SNP, a weight is calculated equal to the number of phenotype-associated alleles multiplied by the effect-size estimated in the GWAS. Finally, the average weight across all SNPs in a Study member’s genome is calculated to compute their polygenic score. Scores were transformed to have cohort-wide mean=0, standard deviation=1 for analysis.
18-year-olds with higher polygenic risk for obesity were at increased risk for obesity (RR=1.26 [1.14–1.38]); those with higher polygenic risk for schizophrenia were at increased risk for mental-health problems (RR=1.13 95%CI [1.02–1.26]); those with higher polygenic risk of young-age-at-first-birth were at increased risk for teen pregnancy (RR=1.40 95%CI [1.19–1.63]); and those with higher polygenic risk for low educational attainment were at increased risk for poor educational qualifications (RR=1.46 95%CI [1.34–1.59]) and becoming NEET (RR=1.32 [1.15–1.51]) (Figure 1, Supplementary Table 1 Panel A).
Figure 1. Children with higher genetic risk had more health and social problems by age 18 years.
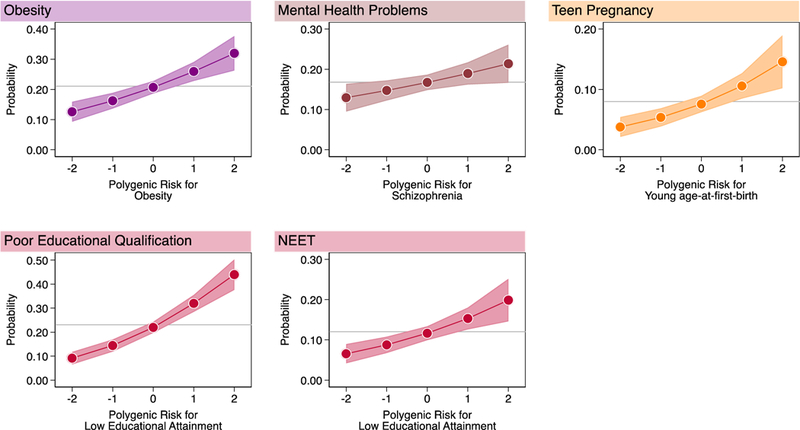
Graphs show fitted probabilities of each health and social problem across the distribution of polygenic risk. Models were adjusted for sex. Gray lines intersecting the Y-axis show the frequency of the health or social problem in E-Risk. Shaded areas around the fitted slopes show 95% Confidence intervals. Probability of obesity is graphed against polygenic risk for obesity (RR=1.26 [1.14–1.38], n=1,837); probability of mental-health problems is graphed against polygenic risk for schizophrenia (RR=1.13 [1.02–1.26], n=1,863); probability of teen pregnancy is graphed against polygenic risk for young age-at-first-birth 1.40 [1.19–1.64], n=1,825); probabilities of poor educational qualification and NEET (Not in Education, Employment, or Training) status are graphed against polygenic risk for low educational attainment (poor educational qualification RR=1.47 [1.34–1.60], n=1,860; NEET RR 1.32 [1.15–1.52], n=1,863) (Supplementary Table 1). Effect-sizes are reported for a 1-SD increase in polygenic risk.
An advantage of using genetics to test for potential selection effects is that genotypes cannot be caused by the neighborhoods where children live, ruling out reverse causation. A second advantage is that genetics may provide new information over and above what can be measured from children’s families 21–23. To evaluate whether the polygenic scores we studied provided new information over and above family-history risk information, we repeated our polygenic score analysis, adding covariate adjustment for family-history measures. After covariate adjustment for family history, associations of young people’s polygenic scores with their health and social problems were modestly attenuated. Family history analysis is reported in Supplementary Table 1 Panels B and C.
As anticipated from the neighborhood-effects literature, children growing up in more disadvantaged neighborhoods were at increased risk for health and social problems by age 18 years.
Because there is no single standard to quantify neighborhood risks 6,24, we used two different approaches to measure E-Risk children’s exposure to neighborhood disadvantage.
The first approach characterized the neighborhoods as they are seen by businesses and the public sector, using a consumer-classification system called ACORN (“A Classification of Residential Neighborhoods”). We computed the average ACORN classification across children’s home addresses when they were aged 5, 7, 10, and 12 years. According to ACORN, 22% of E-Risk cohort children grew up in “Wealthy Achiever” neighborhoods, 33% grew up in “Urban Prosperity/ Comfortably Off” neighborhoods, 19% grew up in “Moderate Means” neighborhoods, and 26% grew up in “Hard Pressed” neighborhoods. This distribution matched overall distributions for the United Kingdom. As an example, ACORN distributions for E-Risk families at the time of the age-12 assessment are compared to the national distribution in Figure 2, Panel A.
Figure 2. Quantification of E-Risk families’ neighborhood disadvantage using ACORN and a composite Ecological-Risk Index.
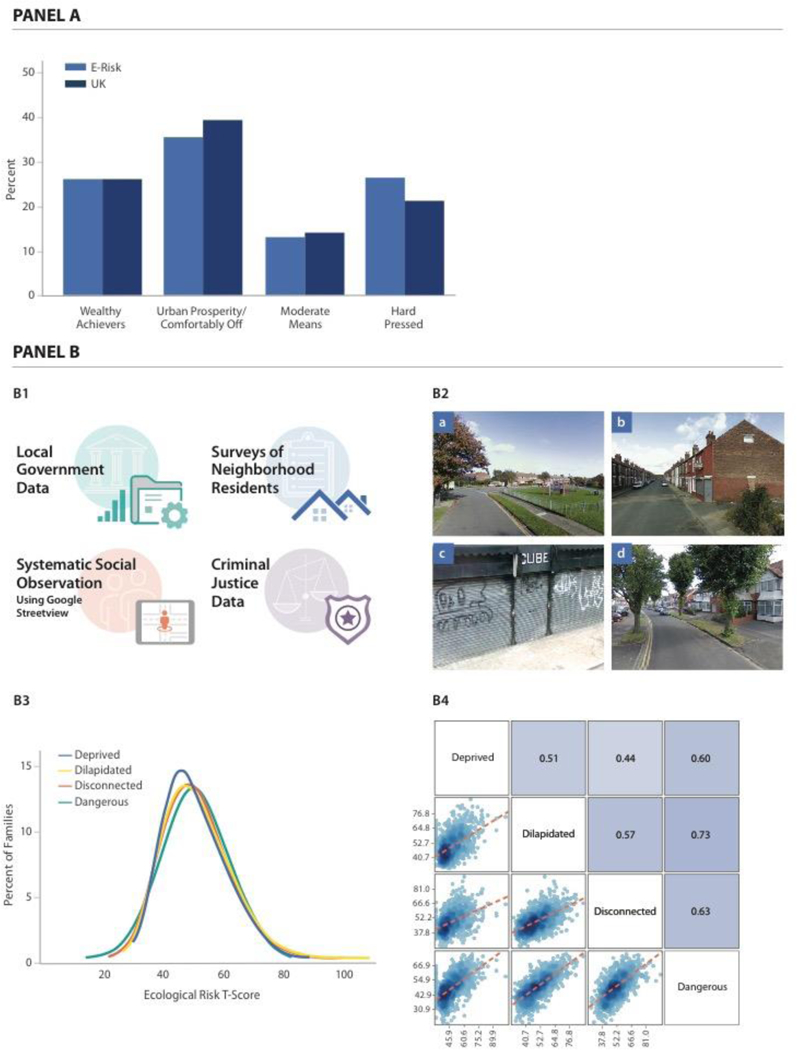
Panel A of the Figure shows distributions of ACORN (“A Classification of Residential Neighborhoods”) classifications for E-Risk families at the time of the age-12 interview (n=1,008 families with genetic data, light blue bars) and the corresponding distribution for the United Kingdom obtained from http://doc.ukdataservice.ac.uk/doc/6069/mrdoc/pdf/6069 acorn userguide.pdf (dark blue bars). Panel B of the Figure contains 4 cells. Cell B1 depicts the four sources of data used for ecological-risk assessment: from top to bottom, these are geodemographic data from local governments, official crime data, Google Street View Systematic Social Observation (SSO), and resident surveys. Image created by Motsavage Design. Cell B2 shows images illustrating (a) Well-kept neighborhood; visible play area for children; roads and sidewalks in good condition. (b) Evidence of graffiti; poorly kept sidewalk and trash container; sidewalks in fair condition. (c) Deprived residential area; vacant lot in poor condition; heavy amount of litter; sidewalks and road in poor condition. (d) Comfortably-off residential area; roads and sidewalks in good conditions; no signs of litter, graffiti or other signs of disorder. Images: Google Street View. Cell B3 shows distributions of four ecological-risk measures derived from these data: economic deprivation, physical dilapidation, social disconnectedness, and danger. Values of the ecological-risk measures are expressed as T scores (M=50, SD=10) (n=987 families with genetic data). Cell B4 shows a matrix of the ecological-risk measures illustrating their correlation with one another (see Supplementary Table 2). Matrix cells below and to the left of measures show scatterplots of their association. Matrix cells above and to the right of measures show their correlation expressed as Pearson’s r (n=973 families with genetic data and data on all four ecological risk measures).
The second approach characterized neighborhoods as they are seen by social scientists and public health researchers. Ecological risk measures were constructed from (a) geodemographic data from local governments, (b) official crime data accessed as part of an open data sharing effort about crime and policing in England and Wales, (c) Google Streetview Virtual Systematic Social Observation 19, and (d) data from surveys of neighborhood residents (Figure 2, Panel B). We used these data to score neighborhoods on their economic deprivation, physical dilapidation, social disconnection, and dangerousness. We standardized scores to have M=50, SD=10 (“T” scores). We summed these four ecological-risk measures to compute one composite Ecological-Risk Index (M=198, SD=33) (Supplementary Figure 1). Ecological-risk measures were correlated with ACORN classifications (for the Ecological-Risk Index r=0.65; correlations for all measures reported in Supplementary Table 2 and Supplementary Figure 1).
18-year-olds who grew up in neighborhoods with more disadvantaged ACORN classifications or with higher scores on the Ecological-Risk Index were at increased risk for obesity, mental-health problems, teen pregnancy, poor educational qualifications, and NEET status (obesity ACORN RR=1.20 [1.10–1.31], Ecological-Risk Index RR=1.15 [1.03–1.29]; mental health problems ACORN RR=1.19 [1.08–1.31], Ecological-Risk Index RR=1.30 [1.14–1.47]; teen pregnancy ACORN RR=1.56 [1.34–1.83], Ecological-Risk Index RR=1.55 [1.30–1.85]; poor educational qualifications ACORN RR=1.53 [1.40–1.67], Ecological-Risk Index RR=1.47 [1.33–1.62]; NEET ACORN RR=1.52 [1.33–1.74], Ecological-Risk Index RR=1.59 [1.36–1.85]). Figure 3 Panel A plots risk for each health and social problem by childhood neighborhood disadvantage. Results for all neighborhood measures are reported in Supplementary Table 3.
Figure 3. Neighborhood gradients in obesity, mental health problems, teen pregnancy, poor educational qualifications, and NEET status, and in genetic risk for these phenotypes.
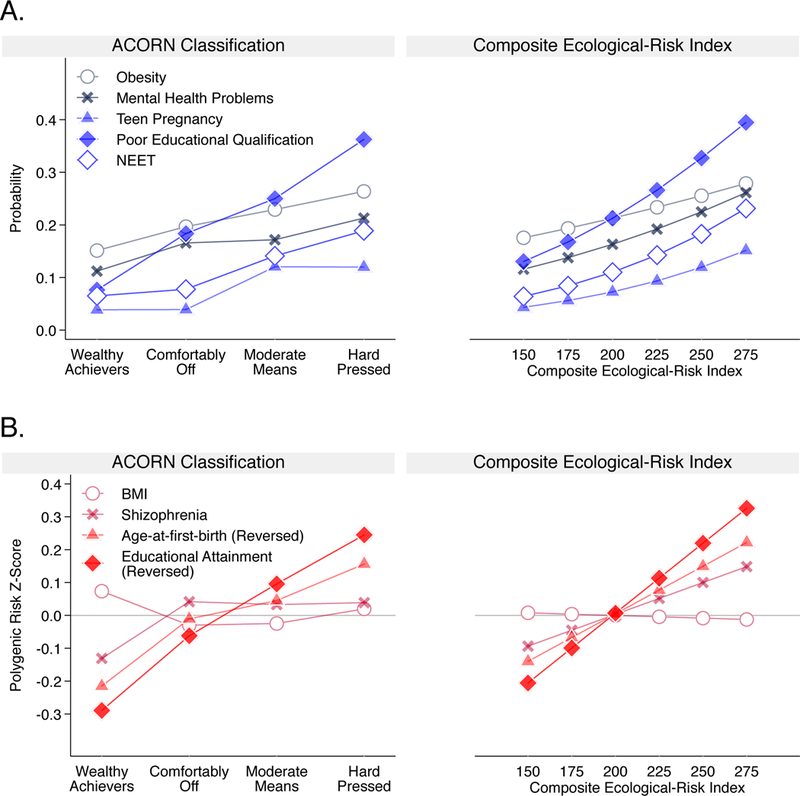
Panel A shows the neighborhood risk gradient for each health and social problem. The y-axis shows the probability of having a given problem at varying levels of neighborhood risk. The left-side graph plots probabilities by ACORN Classification (n=1,857). The right-side graph plots predicted probabilities for a series of values of the composite Ecological-Risk Index (n=1,822). Effect-sizes (in terms of relative risk [95% CI]) associated with a 1-category increase in disadvantage defined by ACORN and with a 1-standard deviation increase in disadvantage defined by the Ecological-Risk Index, respectively, were: obesity (RR=1.20 [1.10–1.31], / 1.15 [1.03–1.29]); mental health problems (RR=1.19 [1.08–1.31]/ 1.30 [1.14–1.47]); having a teen pregnancy (RR=1.56 [1.34– 1.83]/ 1.55 [1.30–1.85]); poor educational qualifications (RR=1.53 [1.40–1.67]/ 1.47 [1.33–1.62]) and NEET (RR=1.52 [1.33–1.74]/ 1.59 [1.36–1.85]) (Supplementary Table 3). Panel B shows the neighborhood risk gradient for each polygenic score. The y-axis shows polygenic risk on a Z-score scale (M=0, SD=1) at varying levels of neighborhood risk. The left-side graph plots polygenic risk by ACORN Classification (n=1,441). The right-side graph plots polygenic risk for a series of values of the composite Ecological-Risk Index (n=1,414). Effect-sizes (in terms of Pearson r correlation [95% CI]) with disadvantage defined by ACORN and by the Ecological-Risk Index, respectively, were: body-mass index polygenic score (r=−0.01 [−0.07, 0.04] / −0.01 [−0.08, 0.07]); schizophrenia polygenic score (r=0.04 [−0.01, 0.10] / 0.08 [0.01, 0.15]); age-at-first-birth polygenic score (r=0.12 [0.06–0.17] / 0.12 [0.04, 0.19]); educational-attainment polygenic score (r=0.18 [0.12, 0.23] / 0.17 [0.09, 0.25]) (Supplementary Table 4). Sample sizes in Panel B are smaller than sample sizes in Panel A because polygenic score analysis shown in Panel B included only one member of each monozygotic twin pair.
We found little evidence that genetic selection/concentration explained neighborhood risk for obesity or mental health problems.
Although children’s genetic risk and their neighborhood disadvantage separately predicted their increased risk of obesity and mental health problems, polygenic risks for obesity and schizophrenia were not consistently related to neighborhood disadvantage. Figure 3 show this result graphically. Whereas the blue slopes in Panel A document positive associations between neighborhood disadvantage and risk for obesity and mental health problems, the red slopes in Panel B reveal null associations between neighborhood disadvantage and polygenic risk for obesity and null or weak associations between neighborhood disadvantage and polygenic risk for schizophrenia. In the E-Risk cohort, children raised in disadvantaged neighborhoods more often became obese by age 18; but we found no evidence for concentration of children with high polygenic risk in disadvantaged neighborhoods (ACORN r=−0.01 [−0.07, 0.04]; Ecological-Risk Index r=−0.01 [−0.08, 0.07]). Results were similar for analysis of genetic risk for schizophrenia, although the association between children’s polygenic scores and their neighborhood Ecological-Risk Index was statistically significant at the α=0.05 level (ACORN r=0.04 [−0.01, 0.10]; Ecological-Risk Index r=0.08 [0.01, 0.15]). Results for all neighborhood measures are reported in Supplementary Table 4. These findings argue against neighborhood selection/composition as a source of neighborhood gradients in obesity and mental health problems and encourage more research to unravel the possible causal effects of neighborhood conditions on physical and mental health.
We found evidence of genetic selection/concentration in disadvantaged neighborhoods of children at high polygenic risk of teen pregnancy, poor educational attainment, and NEET.
We tested if children at higher polygenic risk for young age-at-first-birth and poor educational attainment tended to grow up in more disadvantaged neighborhoods. They did, as measured by both ACORN classification and the composite Ecological-Risk Index. Figure 3 shows this result graphically. The blue slopes in Panel A document positive associations between neighborhood disadvantage and risk for teen pregnancy, poor educational outcomes, and NEET status. In parallel, the red slopes in Panel B reveal positive associations between neighborhood risk and polygenic risk for young age-at-first-birth (reversed values of the age-at-first-birth polygenic score, right-side y-axis; ACORN r=0.12 [0.06, 0.17]; Ecological-Risk Index r=0.12 [0.04, 0.19]) and low educational attainment (reversed values of the education polygenic score, right-side y-axis; ACORN r=0.18 [0.12, 0.23]; Ecological-Risk Index r=0.17 [0.09, 0.25]). Results for all neighborhood measures are reported in Supplementary Table 4. These findings suggest that neighborhood selection/composition may be relevant to neighborhood-teen pregnancy and neighborhood-achievement gradients and encourage research to understand selection processes.
Children inherited genetic and neighborhood risks from their parents.
E-Risk children were aged 5–12 years during the period when neighborhood data were collected. It is unlikely that they actively selected themselves into different types of neighborhoods. Instead, a hypothesis for why children’s polygenic and neighborhood risks are correlated is that both risks are inherited from their parents. According to this hypothesis, genetics influence parents’ characteristics and behaviors, which in turn affect where they live. Children subsequently inherit their parents’ genetics and their neighborhoods. As an initial test of this hypothesis, we analyzed genetic data that we collected in the E-Risk study from children’s mothers (N=858 with children included in analysis). (E-Risk did not collect fathers’ DNA.) As expected, polygenic scores were correlated between E-Risk participants and their mothers (r=0.50–0.52). We first tested if mothers’ polygenic scores were associated with neighborhood disadvantage. Parallel to results from analysis of children’s genetics, we did not detect associations of mothers’ obesity and schizophrenia polygenic scores with neighborhood disadvantage (r=0.00–0.04). Also consistent with analysis of children, mother’s age-at-first-birth and educational-attainment polygenic scores were associated with neighborhood disadvantage (effect-sizes r=0.14–0.21; Supplementary Table 5). Next, we repeated analysis of association between children’s polygenic scores and neighborhood disadvantage, this time including a covariate for the mother’s polygenic score. Consistent with the hypothesis that children’s polygenic and neighborhood risks are correlated because both risks are inherited from their parents, covariate adjustment for mothers’ polygenic scores reduced magnitudes of associations between children’s polygenic scores and their neighborhood disadvantage by more than half (Supplementary Table 6, Supplementary Figure 2).
Polygenic risk for teen pregnancy and low educational attainment predicted downward neighborhood mobility among participants in the US National Longitudinal Study of Adolescent to Adult Health.
If children’s genetic and neighborhood risks are correlated because they inherit both risks from their parents, the next question is how parents’ genetics come to be correlated with neighborhood risks. A hypothesis is that parents’ genetics influence their characteristics and behavior in ways that affect where they are able to live. To test this hypothesis, data are needed that observe the neighborhood mobility process in which people leave the homes where they grew up and selectively end up in new neighborhoods. Because the E-Risk study began collecting information on children’s mothers only after the children were born, data were not collected on the mothers’ own childhood neighborhoods. Therefore, to test how polygenic risks might influence patterns of neighborhood mobility, we turned to a second dataset, the US National Longitudinal Study of Adolescent to Adult Health (Add Health). Add Health first surveyed participants when they were secondary-school students living with their parents. Add Health has since followed participants into their late 20s and early 30s 25, when most were living in new neighborhoods (N=5,325 with genetic and neighborhood data; 86% lived >1km from the address where they first surveyed). We used the Add Health genetic database and neighborhood measures derived from US Census data to test if polygenic risk for obesity, schizophrenia, teen-pregnancy, and low educational attainment predicted downward neighborhood mobility, i.e. young adults coming to live in more disadvantaged neighborhoods relative to the one where they lived with their parents.
Add Health participants’ polygenic risks for obesity and schizophrenia showed weak or null associations with neighborhood disadvantage when they were first surveyed in their parents’ homes as secondary school students (polygenic risk for obesity r=0.03 [0.00, 0.06]; polygenic risk for schizophrenia r=−0.01 [−0.03–0.02]) and when they were followed-up in their 20s and 30s (polygenic risk for obesity r=0.04 [0.01–0.07]; polygenic risk for schizophrenia r=-0.03 [−0.05–0.00]). Findings were similar in neighborhood mobility analysis (polygenic risk for obesity r=0.03 [0.00–0.05]; polygenic risk for schizophrenia r=−0.02 [−0.05–0.00]). These findings bolster conclusions from E-Risk analysis that genetic selection/concentration is likely to be a trivial factor in neighborhood gradients in obesity and mental health problems, although the obesity polygenic score association with neighborhood risk was statistically significant at the α=0.05 level in Add Health, and therefore not a full replication of findings in E-Risk.
In contrast, Add Health participants with higher polygenic risk for teen pregnancy and low educational attainment tended to have grown up in more disadvantaged neighborhoods (r=0.07 [0.05–0.10] for the age-at-first-birth polygenic score and r=0.17 [0.14–0.19] for the educational-attainment polygenic score) and to live in more disadvantaged neighborhoods when they were followed-up in their 20s and 30s (adult neighborhood r=0.09 [0.06–0.11] for the age-at-first-birth polygenic score and r=0.13 [0.10–0.16] for the educational attainment polygenic score). In neighborhood mobility analysis, participants with higher polygenic risk for teen pregnancy and low educational attainment tended to move to more disadvantaged neighborhoods relative to the neighborhoods where they lived with their parents when they were first surveyed (downward mobility r=0.06 [0.03–0.08] for the age-at-first-birth polygenic score and r=0.07 [0.05–0.09] for the educational-attainment polygenic score; Figure 4). These finding bolster conclusions from E-Risk analysis that genetic selection/concentration may contribute to neighborhood gradients in teen pregnancy and poor educational outcomes, although this contribution may be small.
Figure 4. Age-at-first-birth and education polygenic score association with neighborhood mobility in the Add Health Study.
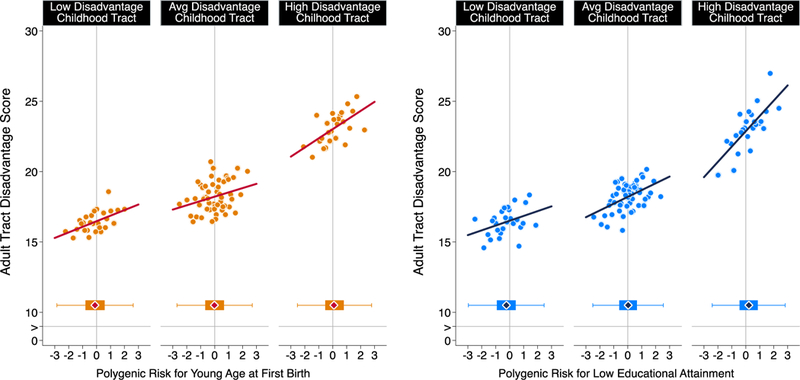
The figure plots polygenic risk associations with adult neighborhood disadvantage at the Census tract level for Add Health Participants who grew up in low-, middle-, and high-disadvantage Census tracts (n=5,325). For the figure, low-, middle-, and high-disadvantage Census tracts were defined as the bottom quartile, middle 50%, and top quartiles of the childhood tract disadvantage score distribution. The individual graphs show binned scatterplots in which each plotted point reflects average X- and Y- coordinates for a “bin” of 50 Add Health participants. The regression lines are plotted from the raw data. The box-and-whisker plots at the bottom of the graphs show the distribution of polygenic risk for each childhood-neighborhood-disadvantage category. The blue diamond in the middle of the box shows the median; the box shows the interquartile range; and the whiskers show upper and lower bounds defined by the 25th percentile minus 1.5x the interquartile range and the 75th percentile plus 1.5x the interquartile range, respectively. The vertical line intersecting the X-axis shows the cohort average polygenic risk. The figure illustrates three findings. First, adult participants tended to live in Census tracts with similar levels of disadvantage to the ones where they grew up. Second, children’s polygenic risks and their neighborhood disadvantage were correlated; the box plots show polygenic risk tended to be lower for participants who grew up in low-disadvantage tracts and higher for participants who grew up in high disadvantage tracts. Third, across strata of childhood neighborhood disadvantage, children at higher polygenic risk tended to move to more disadvantaged Census tracts no matter where they grew up.
To put polygenic score-neighborhood associations in context, we conducted a SNP heritability analysis to estimate the upper-bound of the information polygenic scores could contain about participants’ neighborhoods. Traditional heritability analysis compares phenotypic similarity between more and less closely related relatives, e.g. monozygotic twins who share 100% of their DNA and dizygotic twins who share 50% of their DNA. Analysis of how much more similar monozygotic twins are as compared to dizygotic twins can be used estimate how much of the variation in the phenotype can be attributed to genetic differences between people. This estimate is called heritability. SNP heritability analysis operates on the same principle, but instead of using known genetic similarities of relatives, SNP heritability analysis uses measured genetic similarity derived from the same genome-wide SNP data used to construct polygenic scores 26. An advantage of SNP heritability is that it can be estimated from samples of unrelated individuals. We estimated SNP heritability of neighborhood disadvantage in the Add Health Study using the GCTA software 27. We tested if Add Health participants who were more genetically similar to one another also tended to live in neighborhoods with more similar levels of disadvantage. We focused GCTA analysis on the neighborhoods Add Health participants had moved to by the time of the 2008 follow-up, when the participants were in their 20s and 30s. Analysis included unrelated (GRM<0.05) participants with available neighborhood and genotype data (N=4,655). (We did not conduct GCTA analysis in the E-Risk sample because power calculations suggested plausible SNP heritabilities could not be distinguished from zero in that cohort; Methods). The result showed that neighborhood disadvantage was heritable; about 16% of the variance in Add Health participants’ adult neighborhood disadvantage could be explained by their genetics (95% CI [0.01, 0.32]). Neighborhood mobility was somewhat less heritable; 9% of the variance in neighborhood mobility could be explained by genetics, but the confidence interval for the estimate overlapped zero (95% CI [−0.06, 0.24]). Comparing the results of our polygenic score analysis with this analysis of SNP heritability suggests that, in the Add Health Study, participants’ age-at-first birth polygenic scores explain about 5% of the SNP heritability in neighborhood disadvantage and their education polygenic scores explain about 11% of the SNP heritability in neighborhood disadvantage. For mobility, these fractions were 4% and 6% for age-at-first-birth-and education-polygenic scores, respectively.
Summary.
Sociogenomic analyses testing the concentration of polygenic risks for health, behavior, and social problems in children growing up in disadvantaged neighborhoods yielded three findings: First, we found little consistent evidence for the concentration of polygenic risk for obesity or polygenic risk for mental health problems in children growing up in disadvantaged neighborhoods. Second, in contrast, we found consistent evidence for the concentration of polygenic risks for teen pregnancy and low achievement. Concentration of polygenic risks was mostly explained by children’s inheritance of both neighborhood and polygenic risks from their parents. Third, selective mobility may contribute to concentrations of risks. In neighborhood mobility analysis that followed young people living with their parents during adolescence to where they lived as adults nearly two decades later, participants with higher polygenic risk for teen pregnancy and low achievement exhibited downward neighborhood mobility, moving to more disadvantaged neighborhoods across follow-up.
Large investments are being made in neighborhood-level policies and programs intended to improve the health and wellbeing of residents. These investments are based on exciting new findings demonstrating causal long-term impacts of local neighborhoods on health and possibly economic outcomes for children moving out of poverty 9–11. The promise of place-based intervention efforts is that they can improve, at scale, the lives of residents and, for children, break the intergenerational transmission of poverty and lack of opportunity. At the same time, genome-wide association studies (GWAS) are revealing genetic predictors of the health outcomes, behaviors, and attainments that place-based interventions seek to modify. We carried out a study of genetic selection into neighborhoods to test how genes and geography combine.
We did not find consistent evidence of genetic selection effects into neighborhoods for obesity and mental health problems.
A previous Swedish study detected evidence of gene-neighborhood correlation between the schizophrenia polygenic score and a commercial database measure of neighborhood deprivation (r=0.04, N~7,000) 28. The magnitude of the association was about the same as we observed for the E-Risk twins (r=0.04) using the commercial-database ACORN measure. However, this association was not replicated in the Add Health Study, where the association was not statistically significant and was in the opposite direction (r=−.01 to −.03). It is possible that selective non-participation in research related to genetic liability for schizophrenia could limit ability to detect these associations in some datasets 29,30. Our results nevertheless document consistent evidence (across measures and samples) of gene-neighborhood correlation for GWAS discoveries for age-at-first-birth and educational attainment, and less so for GWAS discoveries for obesity and schizophrenia.
We found consistent evidence of genetic selection effects into neighborhoods for teen pregnancy, poor educational qualifications, and NEET status.
These findings are consistent with recent findings in sociology about how neighborhood residents come to be both physically and economically “stuck in place” across generations 31,32. Teen pregnancy and poor outcomes in education and the workplace can trap parents and their children in disadvantaged neighborhoods, causing a clustering of individual-level and neighborhood-level risks. This has led to calls for multi-generational and multi-level intervention efforts to break the cycle of disadvantage. While our findings show that selection is at work for these key outcomes, the effects documented are unlikely to be large enough to fully account for neighborhood gradients. Consistent evidence for both selection (from us) and social causation (in the larger literature) means that policies and interventions will need to target resources at both people and place to be effective.
Our findings make three contributions. First, they make a methodological and conceptual contribution by integrating genetics and social science in the rapidly developing field of social geography. We know that the places where children grow up are associated with whether they thrive. The challenge in neighborhood research is to sort out selection from causation. Here, we take a fresh look at this classic problem using new information from genomics research. DNA-sequence differences between people index differences in liability to health and social outcomes, and DNA cannot be influenced by neighborhoods. As the price of generating genetic data continues to fall, measurements of these DNA differences can provide tools to advance social science research into effects of place.
Second, findings shed light on how genetics and environments combine to influence children’s development. Genetics contribute to the effects of place by influencing where people choose to live, are forced to live, or otherwise end up living. For E-risk and Add Health young people, some genetic risks were patterned across neighborhoods, presumably reflecting the children’s inheritance of genetics that influenced where their parents were able to live. This patterning was apparent for genetics linked to teen pregnancy and poor education, but not with genetics linked to mental health problems or obesity. One interpretation is that teen pregnancy and poor education are more proximate causes of economic circumstances that determine where one can live as compared to, for example, obesity. Consistent with this interpretation, Add Health young people who carried higher levels of polygenic risk for teen pregnancy and poor educational outcomes showed patterns of downward neighborhood mobility, tending to move in young adulthood to worse-off neighborhoods relative to the ones where they grew up. In contrast, Add Health participants’ polygenic risk for obesity and schizophrenia showed trivial or null associations with their neighborhood mobility. Findings document that even though risk for highly heritable health problems such as obesity and schizophrenia may be patterned across neighborhoods, genetic risks for these conditions may not be. More broadly, findings highlight that a phenotype being heritable does not imply that social risk factors are necessarily genetically confounded.
Third, findings provide evidence that many children are growing up subject to correlated genetic and place-related risks, particularly for teen pregnancy and attainment failure. The polygenic score-neighborhood correlations we observed are too small to account entirely for neighborhood effects, but genetic and neighborhood risks may act in combination. Neighborhood interventions can thus be conceptualized, in part, as breaking up geneenvironment correlations, lending urgency to the development of effective place-based interventions. To this end, genetically-informed designs may offer opportunities to advance intervention research. For example, comparative studies could test if correlations between genetic and neighborhood risks vary across cities governed by different urban planning strategies. Intervention studies could also actively incorporate genetic information: Trials of neighborhood interventions can improve precision of their treatment-effect estimates by including polygenic score measurements as control variables to account for unmeasured differences between participants 33.
We acknowledge limitations. Foremost, our measures of genetic risk are imprecise. They explain only a fraction of the genetic variance in risk estimated from family-based genetic models; the polygenic score for educational attainment explains >10% of phenotypic variance, polygenic scores for body-mass index and schizophrenia explain 6–7% of phenotypic variance, and the age-at-first-birth polygenic score explains one percent of phenotypic variance 15–18, whereas heritabilities of these traits and behaviors estimated in family-based studies tend to be much higher 34. As a consequence, our estimates of gene-neighborhood correlations should be considered lower-bound estimates. Second, a related limitation is that the different polygenic scores had different amounts of power to detect associations with neighborhood risk, with the education polygenic score having more power than the others. Nevertheless, we had more power for body-mass index and schizophrenia polygenic score analysis than we did for age-at-first-birth polygenic score analysis, and yet genetic associations with neighborhood risk were much larger for the age-at-first-birth polygenic score than for the body-mass index and schizophrenia polygenic scores. This pattern of results held in both the E-Risk and Add Health studies. This pattern of results was also consistent with a previous analysis that used the LD-Score Regression method to test genetic correlations of an area-level measure of social deprivation with health and social outcomes35. Third, the magnitudes of observed gene-neighborhood correlations in our study were small. For example, the strongest gene-neighborhood correlations we observed were for the educational attainment polygenic score (r~0.17). Based on our analysis, neighborhood differences in this polygenic score between the highest and lowest risk neighborhoods could account for, at most, only about 15% of the observed differences in poor educational qualifications and about 10% of the observed differences in NEET status between these neighborhoods (Supplementary Methods). As GWAS sample sizes continue to grow, more precise measurements will become available 36. More predictive polygenic scores could potentially strengthen measured gene-neighborhood correlations and explain increasing fractions of neighborhood gradients in health and social outcomes.
An additional limitation is that E-Risk data come from a single birth cohort in a single country, and thus reflect a relatively specific geographic and historical context. Findings that polygenic risk of teen pregnancy and low educational attainment were correlated with neighborhood disadvantage did replicate in the US-based Add Health Study. Add Health neighborhood risk was measured from tract-level US Census data describing broad social and economic conditions and is thus less geographically precise than the small-area ACORN and Ecological-Risk Assessment data analyzed in E-Risk. Therefore, Add Health analysis is not a direct replication of our E-Risk findings. Instead, the consistent results across two studies of different populations measured using different methods argues for the overall robustness of our findings.
Our analysis in both the E-Risk and Add Health studies was limited to European-descent individuals. This restriction was necessary to match the ancestry of our analytic sample with the ancestry of the samples studied in the GWAS used to calculate polygenic scores, which is the recommended approach 37. As polygenic scores are developed for populations of non-European ancestry, replication in these populations should be a priority.
Finally and fundamentally, our results cannot establish causal relationships between genetics, neighborhood risk, and health, behavior, and attainment outcomes. It could be that genetics influence reproductive behavior and educational attainment in ways that affect neighborhood mobility. But there are alternative possibilities. For example, if neighborhood risks cause teen pregnancy and school failure, GWAS of age-at-first-birth and educational attainment could identify genetics that influence exposure to those causal neighborhood risks. If and when large-scale GWAS of neighborhood mobility are conducted, emerging statistical methods, such as two-sample Mendelian Randomization 38,39 may be able to clarify this important causal question.
The observation of gene-neighborhood correlations does not suggest that residents in disadvantaged neighborhoods will not benefit from neighborhood-level interventions. It simply means policy-makers should not over-interpret neighborhood effects in purely causal terms. For example, people observed to live in a friendly suburb, remote ranch, quaint village, and luxury high-rise are not found in those neighborhoods randomly by accident; people end up in such locations selectively. But regardless of location they all respond to incentives and opportunities. More precise quantifications of selection processes influencing where people live can help inform policies and programs to craft incentives and opportunities that promote healthy development for everyone.
METHODS
Environmental Risk Longitudinal Study (E-Risk)
Sample.
Participants were members of the Environmental Risk (E-Risk) Longitudinal Twin Study, which tracks the development of a birth cohort of 2,232 British children. The sample was drawn from a larger birth register of twins born in England and Wales in 1994–1995 40. Full details about the sample are reported elsewhere 41. Briefly, the E-Risk sample was constructed in 1999–2000, when 1,116 families (93% of those eligible) with same-sex 5-year-old twins participated in home-visit assessments. The sample includes 56% monozygotic and 44% dizygotic twin pairs; sex is evenly distributed within zygosity (49% male). Families were recruited to represent the UK population of families with newborns in the 1990s, on the basis of residential location throughout England and Wales, and mother’s age. Teenaged mothers with twins were over-selected to replace high-risk families who were selectively lost to the register through nonresponse. Older mothers having twins via assisted reproduction were under-selected to avoid an excess of well-educated older mothers. These strategies ensured that the study sample represents the full range of socioeconomic conditions in Great Britain 19.
Follow-up home visits were conducted when the children were aged 7 (98% participation), 10 (96% participation), 12 (96% participation), and, in 2012–2014, 18 years (93% participation). There were no differences between those who did and did not take part at age 18 in terms of socioeconomic status (SES) assessed when the cohort was initially defined (χ2 = 0.86, p = .65), age- 5 IQ scores (t = 0.98, p = .33), or age- 5 internalizing or externalizing behavior problems (t = 0.40, p = .69 and t = 0.41, p = .68, respectively). Home visits at ages 5, 7, 10, and 12 years included assessments with participants as well as their mother; the home visit at age 18 included interviews only with the twin participants. All interviews at the age-18 assessment were conducted after the 18th birthday. Each twin participant was assessed by a different interviewer. The joint Research and Development Office of South London and Maudsley and the Institute of Psychiatry Research Ethics Committee approved each phase of the study. Parents gave informed consent and twins gave assent between ages 5 and 12 years; twins gave informed consent at age 18 years.
Genetic Data.
We used Illumina HumanOmni Express 12 BeadChip arrays (Version 1.1; Illumina, Hayward, CA) to assay common single-nucleotide polymorphism (SNP) variation in the genomes of cohort members. We imputed additional SNPs using the IMPUTE2 software (Version 2.3.1; https://mathgen.stats.ox.ac.uk/impute/impute v2.html; 42) and the 1000 Genomes Phase 3 reference panel 43. Imputation was conducted on autosomal SNPs appearing in dbSNP (Version 140; http://www.ncbi.nlm.nih.gov/SNP/; 44) that were “called” in more than 98% of the samples. Invariant SNPs were excluded. Pre-phasing and imputation were conducted using a 50-million-base-pair sliding window. We analyzed SNPs in Hardy-Weinberg equilibrium (p >.01). The resulting genotype databases included genotyped SNPs and SNPs imputed with 90% probability of a specific genotype among European-descent E-Risk Study members (n=1,999 children in 1,011 families). The same procedure was used to construct the genetic database for Study members’ mothers. Genetic data were available for N=860 mothers of the Study members in our genetic analysis sample.
Polygenic Scoring.
We computed polygenic scores for obesity (body-mass index), schizophrenia, age-at-first birth, and educational attainment from published genome-wide association study (GWAS) results 15–18. We computed these polygenic scores because the GWAS on which they are based are among the largest and most comprehensive available and their target phenotypes are established as having strong geographic gradients in risk. For example, in the case of schizophrenia, there is a long-running debate about hypotheses of social causation, in which ecological risks contribute to schizophrenia pathogenesis, and social drift, in which genetic liability to schizophrenia causes downward social mobility45,46.
Polygenic scoring was conducted following the method described by Dudbridge 20 using the PRSice software 47. Briefly, SNPs reported in GWAS results were matched with SNPs in the E-Risk database. For each SNP, the count of phenotype-associated alleles (i.e. alleles associated with higher body-mass index, increased risk of schizophrenia, younger age at first birth, or less educational attainment, depending on the score being calculated) was weighted according to the effect estimated in the GWAS. Weighted counts were summed across SNPs to compute polygenic scores. We used all matched SNPs to compute polygenic scores irrespective of nominal significance in the GWAS.
Polygenic score analysis may be biased by population stratification, the nonrandom patterning of allele frequencies across ancestry groups 37,48. To address residual population stratification within the European-descent members of the E-Risk sample, we conducted principal components analysis 49. We computed principal components from the genome-wide SNP data with the PLINK software 50 using the command ‘pca’. One member of each twin pair was selected at random from each family for this analysis. SNP-loadings for principal components were applied to co-twin genetic data to compute principal component values for the full sample. We residualized polygenic scores for the first ten principal components estimated from the genome-wide SNP data 51 and standardized residuals to have mean=0, SD=1 for analysis.
Neighborhood Disadvantage.
We characterized the neighborhoods in which E-Risk participants grew up using two approaches. The first approach characterized the neighborhoods as they are seen by businesses and the public sector, using a consumer-classification system called ACORN (“A Classification of Residential Neighborhoods”). The second approach characterized neighborhoods as they are seen by social scientists and public health researchers, using ecological-risk assessment methods.
Neighborhood Disadvantage Measured by Consumer Classification.
We used a geodemographic classification system, ACORN, developed as a tool for businesses interested in market segmentation by CACI (CACI, UK, http://www.caci.co.uk/). This is a proprietary algorithm that is sold to businesses, but which CACI made available to our research group. ACORN classifications were derived from analysis of census and consumer research databases. ACORN classifies neighborhoods, in order of least disadvantaged to most disadvantaged as “Wealthy Achievers”, “Urban Prosperity”, “Comfortably Off”, “Moderate Means”, or “Hard Pressed”. For analysis, we combined neighborhoods classified in the “Urban Prosperity” and “Comfortably Off” categories because very few children lived in “Urban Prosperity” neighborhoods. (Nationally, fewer children live in neighborhoods characterized by “Urban Prosperity”.) We obtained ACORN classifications for the Output Areas in which E-Risk families’ lived 19. Output Areas are the smallest unit at which UK Census data are provided and they reflect relatively small geospatial units of about 100–125 households. Households were classified based on street address at the time of the age-5, age-7, age-10, and age-12 in-home visits. We assigned children the average neighborhood classification across these four measurements. ACORN classifications were available for N=1,993 children in 1,008 families in the genetic sample.
Neighborhood Disadvantage Measured by Ecological-Risk Assessment.
Ecological risk assessment was conducted by combining information from four independent sources of data: Geodemographic data from local governments, official crime data from the UK police, Google Streetview-based Systematic Social Observation (SSO), and surveys of neighborhood residents conducted by the E-Risk investigators when the E-Risk children were aged 13–14. These data sources are described in detail in the Supplementary Methods.
We used these four data sources to measure neighborhood ecological risk in four domains: deprivation, dilapidation, disconnection, and danger. Deprivation was measured with the Department of Community and Local Government Index of Multiple Deprivation. Dilapidation was measured from resident ratings of problems in their neighborhood (e.g. litter, vandalized public spaces, vacant storefronts) and independent raters’ assessments of these same problems based on the “virtual walk-through” using Google Streetview. Disconnection was measured from resident surveys assessing neighborhood collective efficacy and social connectedness. Neighborhood collective efficacy was assessed via the resident survey using a previously validated 10-item measure of social control and social cohesion 52. Residents were asked about the likelihood that their neighbors could be counted on to intervene in various ways if, for example: ‘children were skipping school and hanging out on a street corner,’ ‘children were spray-painting graffiti on a local building’. They were also asked how strongly they agreed that, for example: ‘people around here are willing to help their neighbors,’ ‘this is a close-knit neighborhood’ (item responses: 0–4). Social connectedness was assessed based on indicators of intergenerational closure (“If any of your neighbors’ children did anything that upset you would you feel that you could speak to their parents about it?”), reciprocated exchange (e.g., Would you be happy to leave your keys with a neighbor if you went away on holiday?) and friendship ties (e.g., Do you have any close friend that live in your neighborhood) among neighbors developed in prior research 53. Dangerousness was measured from police records of crime incidence, from neighborhood residents’ ratings of how much they feared for their safety and whether they had been victimized, and from independent raters’ assessments of neighborhood safety based on the “virtual walk-through” using Google Streetview (Figure 2 Panel B).
For each of the four domains, we constructed a measure of ecological risk as follows. First, variables with skewed distribution were log transformed. Second, values were standardized to have M=50, SD=10. (For domains in which multiple resident survey or systematic-social-observation measures were available, we combined values within measurement method before standardizing.) Finally, scores were averaged across measurement method within each domain. The resulting scales of deprivation, dilapidation, disconnection, and danger were approximately normally distributed (Figure 2 Panel B). Neighborhoods’ ecological risk levels on these four measures were correlated (Pearson’s r=0.4–0.7, Figure 2 Panel B). We computed the composite Ecological-Risk Index by summing values across the four risk domains. Values were pro-rated for families with data on at least three of the four domains. Ecological-Risk Index values were available for N=1,954 children in 987 families in the genetic sample.
Phenotypes.
We selected phenotypes for analysis that represented substantial public health and economic burden, had been linked with neighborhood risk in prior studies, were prevalent among 18-year-olds in the United Kingdom at the time data were collected, and had been subject to large-scale genome-wide association study meta-analyses: obesity, mental health problems, teen pregnancy, and poor educational outcome.
Obesity.
Trained research workers took anthropometric measurements of study members when they were aged 18 years. BMI was computed as weight in kilograms over squared height in meters. Waist\hip ratio was calculated by dividing waist circumference by hip circumference. We defined obesity using the US Centers for Disease Control and Prevention threshold of BMI>30 and the World Health Organization recommendation of waist-hip ratio >0.90 for men and >0.85 for women 54. 21% of the analysis sample met at least one of these criteria, similar to prevalence for 16–24 year olds in the UK 55.
Mental Health Problems.
Our measure of mental health problems is a general factor of psychopathology, the ‘p-factor,’ derived from confirmatory factor analysis of symptom-level psychopathology data collected at age 18 years, when E-Risk participants were assessed in private interviews about alcohol dependence, tobacco dependence, cannabis dependence, conduct disorder, attention-deficit hyperactivity disorder, depression, generalized anxiety disorder, post-traumatic stress disorder, eating disorder and thought/psychotic disorders 56. The ‘p factor’ indexes liability to develop a wide spectrum of mental-health problems 57. We classified E-Risk Study members reporting psychiatric symptoms one standard deviation or more above the cohort norm as having mental health problems. 17% of the analysis sample met this criterion.
Teen pregnancy.
Getting pregnant (for women) and getting someone pregnant (for men) was assessed as part of a computer-assisted interview about reproductive behavior at the age-18 interview. 8% of the analysis sample (6% of men and 9% of women) reported a teen pregnancy.
Poor Educational Qualifications.
Poor educational qualification was assessed by whether participants did not obtain or scored a low average grade (grade D-G) on their General Certificate of Secondary Education (GCSE). GSCEs are a standardized examination taken at the end of compulsory education at age 16 years. 23% of the analysis sample met criteria for poor educational qualifications.
NEET.
NEET is an initialization for “Not in Education, Employment, or Training.” NEET status was assed at in-person interviews 58. As of the age-18 interview, 12% of Study members were NEET, similar to the UK population (as of 2010, about 14% of UK 19 year olds reported being NEET for at least one year 59.
National Longitudinal Study of Adolescent to Adult Health (Add Health)
Sample.
The National Longitudinal Study of Adolescent to Adult Health (Add Health) is an ongoing, nationally-representative longitudinal study of the social, behavioral, and biological linkages in health and developmental trajectories from early adolescence into adulthood. The cohort was drawn from a probability sample of 144 middle and high schools and is representative of American adolescents in grades 7–12 in 1994–1995. Since the start of the project, participants have been interviewed in home at four data collection waves (numbered I-IV), most recently in 2007–2008, when 15,701 Study members took part 25.
Genotyping.
At the Wave IV interview in 2007–2008, saliva and capillary whole blood were collected from respondents. 15,159 of 15,701 individuals interviewed consented to genotyping, and 12,254 agreed to genetic data archiving. DNA extraction and genotyping was conducted on this archive sample using two platforms (Illumina Omni1 and Omni2.5). After quality controls, genotype data were available for 9,975 individuals. We analyzed data from the N=5,690 participants with genetically European ancestry. Imputation was conducted on SNPs “called” in more than 98% of the samples with minor allele frequency >1% using the Michigan Imputation Server (http://imputationserver.readthedocs.io/en/latest/pipeline/) and the Haplotype Reference Consortium (HRC) reference panel 60.
Polygenic Scoring.
We computed polygenic scores for body-mass-index, schizophrenia and age-at-first-birth following the method described by Dudbridge 61 according to the procedure used in previous studies 62. Briefly, SNPs in the genotype database were matched to published GWAS results 16,17. For each of these SNPs, a loading was calculated as the number of phenotype-associated alleles multiplied by the effect-size estimated in the original GWAS. Loadings were then averaged across the SNP set to calculate the polygenic score. The Add Health Study was included in the most recent GWAS of educational attainment 18. We therefore obtained the polygenic score for educational attainment directly from the Social Science Genetic Association Consortium (SSGAC). SSGAC computed the score according to the methods described in the GWAS article based on a GWAS that did not include any Add Health samples.
To account for any residual population stratification within the European-descent analysis sample, we residualized polygenic scores for the first ten principal components estimated from the genome-wide SNP data 51 and standardized residuals to have mean=0, SD=1 to compute polygenic scores for analysis. Principal components for the Add Health European-descent sample were provided by the SSGAC.
Neighborhood Characteristics.
We measured neighborhood-level socioeconomic disadvantage using Census-tract-level data linked to Add Health participants’ addresses when they were first interviewed in 1994–1995 and when they were most recently followed-up in 2007–8. Participants’ 1994–1995 addresses were linked with tract-level data from the 1990 Decennial Census 63. Participants’ addresses in 2007–2008 were linked with tract-level data from the 2005–2009 panels of the American Community Survey 64. For each tract, we coded proportions of female-headed households, individuals living below the poverty threshold, individuals receiving public assistance, adults with less than a high school education, and adults who were unemployed using the following system: We computed tract deciles based on the full set of tracts from which Add Health participants were sampled at Wave 1. We then scored each tract on a scale of 1–10 corresponding to the Wave 1 decile containing the tract’s value on the variable. We calculated neighborhood deprivation as the sum of decile scores across the five measures resulting in a score ranging from 0 to 50. Values were Z-transformed to have M=0 SD =1 for analysis.
Add Health analysis included all European-descent Add Health participants with available genetic and neighborhood data (N=5,325).
Statistical Analysis.
We analyzed continuous dependent variables using linear regression models. We analyzed dichotomous dependent variables using Poisson regression models to estimate risk ratios (RR). In models testing polygenic and neighborhood risks for health and social problems, health and social problems were specified as the dependent variables and polygenic and neighborhood risks were specified as predictor variables. We tested statistical independence of polygenic risk information from family history risk information using multivariate regression with family history measures included as covariates alongside polygenic scores. In models testing for association between polygenic and neighborhood risks, polygenic scores were specified as dependent variables and neighborhood risks were specified as predictor variables. We tested if associations between children’s neighborhood risks and polygenic risks were correlated because both were inherited from their parents using multivariate regression with mother’s polygenic scores included as covariates alongside neighborhood risk measures. We tested polygenic risk associations with neighborhood mobility using the mobility model from previous work 65; participants adulthood neighborhood disadvantage scores were regressed on their polygenic scores, their childhood neighborhood disadvantage scores, and covariates. For all models, we accounted for non-independence of observations of siblings within families by clustering standard errors at the family level. For models testing polygenic score associations with neighborhood conditions in the E-Risk data, only one member of each monozygotic twin pair was included in analysis. (For these models, monozygotic twins would have identical values for predictors and outcomes.) All models were adjusted for sex. Add Health models were adjusted for year of birth. (Year of birth did not vary in the E-Risk cohort.)
We conducted post-hoc power analyses to provide context for interpretation of the associations we observed. We conducted power analysis using the “power” command in the Stata software66. Both the E-Risk and Add Health samples had >80% power to detect associations with effect-size r=0.1 in all analyses. Power analysis for tests of polygenic score associations with neighborhood risk is shown in Supplementary Figure 3. We conducted power analysis for GCTA using the online power calculator provided by Hemani and Yang (http://cnsgenomics.com/shiny/gctaPower/). In the Add Health sample, power was >80% to detect SNP heritability estimates of 0.2 or greater. We did not conduct GCTA analysis in the E-Risk sample because power calculations suggested only SNP heritabilities >0.9 could be distinguished from zero in that sample.
Supplementary Material
Acknowledgement.
The E-Risk Study is funded by the Medical Research Council (UKMRC grant G1002190). Additional support was provided by NICHD grant HD077482, Google, and by the Jacobs Foundation. The Add Health Study is supported by Eunice Kennedy Shriver National Institute of Child Health and Human Development grants P01HD31921, R01HD073342, and R01HD060726, with cooperative funding from 23 other federal agencies and foundations. DWB & CLO were supported by fellowships from Jacobs Foundation. CLO is supported by the Canadian Institute for Advanced Research. BWD is supported by Russell Sage Foundation award 961704. We are grateful to the E-Risk Study mothers and fathers, the twins, and the twins’ teachers and the Add Health Study participants and their parents for their participation. Our thanks to CACI, Google Streetview, and to members of the E-Risk team for their dedication, hard work, and insights. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Footnotes
Data Availability Statement. The E-Risk dataset reported in the current article is not publicly available due to lack of informed consent and ethical approval, but is available on request by qualified scientists. Requests require a concept paper describing the purpose of data access, ethical approval at the applicant’s institution, and provision for secure data access. We offer secure access on the Duke University, and King’s College London campuses. All data analysis scripts and results files are available for review. The Add Health data can be accessed through the Add Health Study. Details are available through the Carolina Population Center as described here: https://www.cpc.unc.edu/projects/addhealth/documentation. Genotype data are available through dbGaP.
Code Availability Statement. All data analysis scripts and results files are available for review.
Competing Interests. The authors declare no competing interests.
REFERENCES
- 1.Woods LM et al. Geographical variation in life expectancy at birth in England and Wales is largely explained by deprivation. J. Epidemiol. Community Health 59, 115–120 (2005). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Chetty R, Stepner M, Abraham S & et al. THe association between income and life expectancy in the united states, 2001–2014. JAMA (2016). doi: 10.1001/jama.2016.4226 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Luo Z-C et al. Disparities in birth outcomes by neighborhood income: temporal trends in rural and urban areas, british columbia. Epidemiol. Camb. Mass 15, 679–686 (2004). [DOI] [PubMed] [Google Scholar]
- 4.Sampson RJ Urban sustainability in an age of enduring inequalities: Advancing theory and ecometrics for the 21st-century city. Proc. Natl. Acad. Sci. 201614433 (2017). doi: 10.1073/pnas.1614433114 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Newton JN et al. Changes in health in England, with analysis by English regions and areas of deprivation, 1990–2013: a systematic analysis for the Global Burden of Disease Study 2013. The Lancet 386, 2257–2274 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Sampson RJ, Morenoff JD & Gannon-Rowley T Assessing ‘Neighborhood Effects’: Social Processes and New Directions in Research. Annu. Rev. Sociol. 28, 443–478 (2002). [Google Scholar]
- 7.Oakes JM The (mis)estimation of neighborhood effects: causal inference for a practicable social epidemiology. Soc. Sci. Med. 58, 1929–1952 (2004). [DOI] [PubMed] [Google Scholar]
- 8.White JS et al. Long-term effects of neighbourhood deprivation on diabetes risk: quasi-experimental evidence from a refugee dispersal policy in Sweden. Lancet Diabetes Endocrinol. 4, 517–524 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Ludwig J et al. Long-Term Neighborhood Effects on Low-Income Families: Evidence from Moving to Opportunity. Am. Econ. Rev. 103, 226–231 (2013). [Google Scholar]
- 10.Chetty R & Hendren N The Impacts of Neighborhoods on IntergenerationalMobility II: County-Level Estimates. (National Bureau of Economic Research, 2016). doi : 10.3386/w23002 [DOI] [Google Scholar]
- 11.Chetty R, Hendren N & Katz LF The Effects of Exposure to Better Neighborhoods on Children: New Evidence from the Moving to Opportunity Experiment. Am. Econ. Rev. 106, 855–902 (2016). [DOI] [PubMed] [Google Scholar]
- 12.Arcaya MC et al. Role of health in predicting moves to poor neighborhoods among Hurricane Katrina survivors. Proc. Natl. Acad. Sci. 111, 16246–16253 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Oakes JM, Andrade KE, Biyoow IM & Cowan LT Twenty Years of Neighborhood Effect Research: An Assessment . Curr. Epidemiol. Rep. 2, 80–87 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Buka SL, Brennan RT, Rich-Edwards JW, Raudenbush SW & Earls F Neighborhood Support and the Birth Weight of Urban Infants. Am. J. Epidemiol. 157, 1–8 (2003). [DOI] [PubMed] [Google Scholar]
- 15.Locke AE et al. Genetic studies of body mass index yield new insights for obesity biology. Nature 518, 197–206 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Schizophrenia Working Group of the Psychiatric Genomics Consortium. Biological insights from 108 schizophrenia-associated genetic loci. Nature advance online publication, (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Barban N et al. Genome-wide analysis identifies 12 loci influencing human reproductive behavior. Nat. Genet. 48, 1462–1472 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Lee JJ et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat. Genet. 50, 1112–1121 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Odgers CL, Caspi A, Bates CJ, Sampson RJ & Moffitt TE Systematic social observation of children’s neighborhoods using Google Street View: a reliable and cost-effective method. J. Child Psychol. Psychiatry 53, 1009–17 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Dudbridge F Power and predictive accuracy of polygenic risk scores. PLoS Genet. 9, e1003348 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Belsky DW et al. Polygenic Risk, Rapid Childhood Growth, and the Development of Obesity: Evidence from a 4-Decade Longitudinal Study. Arch. Pediatr. Adolesc. Med. 166, 515–521 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Belsky DW et al. Polygenic risk and the developmental progression to heavy, persistent smoking and nicotine dependence: Evidence from a 4-decade longitudinal study. JAMA Psychiatry 70, 534–542 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Agerbo E et al. Polygenic Risk Score, Parental Socioeconomic Status, Family History of Psychiatric Disorders, and the Risk for Schizophrenia: A Danish Population-Based Study and Meta-analysis. JAMA Psychiatry 72, 635–641 (2015). [DOI] [PubMed] [Google Scholar]
- 24.Mujahid MS, Roux D, V A, Morenoff JD & Raghunathan T Assessing the Measurement Properties of Neighborhood Scales: From Psychometrics to Ecometrics. Am. J. Epidemiol. 165, 858–867 (2007). [DOI] [PubMed] [Google Scholar]
- 25.Harris KM et al. Social, behavioral, and genetic linkages from adolescence into adulthood. Am. J. Public Health 103, S25–S32 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Yang J et al. Genome partitioning of genetic variation for complex traits using common SNPs. Nat. Genet. 43, 519–25 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Yang J, Lee SH, Goddard ME & Visscher PM GCTA: A Tool for Genome-wide Complex Trait Analysis. Am. J. Hum. Genet. 88, 76–82 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Sariaslan A et al. Schizophrenia and subsequent neighborhood deprivation: revisiting the social drift hypothesis using population, twin and molecular genetic data. Transl. Psychiatry 6, e796 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Martin J et al. Association of Genetic Risk for Schizophrenia With Nonparticipation Over Time in a Population-Based Cohort Study. Am. J. Epidemiol. 183, 1149–1158 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Gage SH, Smith GD & Munafô MR Schizophrenia and neighbourhood deprivation. Transl. Psychiatry 6, e979 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Sharkey P Neighborhoods, Cities, and Economic Mobility. RSF 2, 159–177 (2016). [Google Scholar]
- 32.Sharkey P Stuck in place: Urban neighborhoods and the end of progress toward racial equality. (University of Chicago Press, 2013). [Google Scholar]
- 33.Okbay A et al. Genome-wide association study identifies 74 loci associated with educational attainment. Nature 533, 539–542 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Polderman TJC et al. Meta-analysis of the heritability of human traits based on fifty years of twin studies. Nat. Genet. 47, 702–709 (2015). [DOI] [PubMed] [Google Scholar]
- 35.Hill WD et al. Molecular Genetic Contributions to Social Deprivation and Household Income in UK Biobank. Curr. Biol. 26, 3083–3089 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Visscher PM, Brown MA, McCarthy MI & Yang J Five years of GWAS discovery. Am. J. Hum. Genet. 90, 7–24 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Martin AR et al. Human Demographic History Impacts Genetic Risk Prediction across Diverse Populations. Am. J. Hum. Genet. 100, 635–649 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Burgess S, Butterworth A & Thompson SG Mendelian Randomization Analysis With Multiple Genetic Variants Using Summarized Data. Genet. Epidemiol. 37, 658–665 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Hartwig FP, Davies NM, Hemani G & Davey Smith G Two-sample Mendelian randomization: avoiding the downsides of a powerful, widely applicable but potentially fallible technique. Int. J. Epidemiol. 45, 1717–1726 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Trouton A, Spinath FM & Plomin R Twins Early Development Study (TEDS): A Multivariate, Longitudinal Genetic Investigation of Language, Cognition and Behavior Problems in Childhood. Twin Res. Hum. Genet. 5, 444–448 (2002). [DOI] [PubMed] [Google Scholar]
- 41.Moffitt TE & E-risk Team. Teen-aged mothers in contemporary Britain. J. Child Psychol. Psychiatry 43, 727–742 (2002). [DOI] [PubMed] [Google Scholar]
- 42. Howie BN, Donnelly P & Marchini J A flexible and accurate genotype imputation method for the next generation of genome-wide association studies. Plos Genet. 5, e1000529 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.1000 Genomes Project Consortium et al. An integrated map of genetic variation from 1,092 human genomes. Nature 491, 56–65 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Sherry ST et al. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res. 29, 308–311 (2001). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Lapouse R, Monk MA & Terris M The Drift Hypothesis and Socioeconomic Differentials in Schizophrenia. Am. J. Public Health Nations Health 46, 978–986 (1956). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Murray RM, Jones PB, Susser E, Os JV & Cannon M The Epidemiology of Schizophrenia. (Cambridge University Press, 2002). [Google Scholar]
- 47.Euesden J, Lewis CM & O’Reilly PF PRSice: Polygenic Risk Score software. Bioinforma. Oxf. Engl. 31, 1466–1468 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Hamer D & Sirota L Beware the chopsticks gene. Mol. Psychiatry 5, 11–13 (2000). [DOI] [PubMed] [Google Scholar]
- 49.Price AL, Zaitlen NA, Reich D & Patterson N New approaches to population stratification in genome-wide association studies. Nat. Rev. Genet. 11, 459–463 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Chang CC et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience 4, 7 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Conley D et al. Assortative mating and differential fertility by phenotype and genotype across the 20th century. Proc. Natl. Acad. Sci. 113, 6647–6652 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Sampson RJ, Raudenbush SW & Earls F Neighborhoods and Violent Crime: A Multilevel Study of Collective Efficacy. Science 277, 918–924 (1997). [DOI] [PubMed] [Google Scholar]
- 53.Sampson RJ, Morenoff JD & Earls F Beyond Social Capital: Spatial Dynamics of Collective Efficacy for Children. Am. Sociol. Rev. 64, 633–660 (1999). [Google Scholar]
- 54.WHO Expert Consultation. Waist circumference and waist-hip ratio: Report of a WHO Expert Consultation. WHO; (2008; ). Available at: mailto:http://www.who.int/nutrition/publications/obesity/WHO_report_waistcircumference_and_waisthip_ratio/en/. (Accessed: 5th December 2016) [Google Scholar]
- 55.Scantlebury R & Moody A Health Survey for England, 2014, Chapter 9. Adult obesity and overweight. (The Health and Social Care Information Centre, 2014). [Google Scholar]
- 56. Schaefer JD et al. Adolescent Victimization and Early-Adult Psychopathology: Approaching Causal Inference Using a Longitudinal Twin Study to Rule Out Noncausal Explanations. Clin. Psychol. Sci. 2167702617741381 (2017). doi: 10.1177/2167702617741381 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Caspi A & Moffitt TE All for One and One for All: Mental Disorders in One Dimension. Am. J. Psychiatry 175, 831–844 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Goldman-Mellor S et al. Committed to work but vulnerable: self-perceptions and mental health in NEET 18-year olds from a contemporary British cohort. J. Child Psychol. Psychiatry 57, 196–203 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Brown J NEET: Young people not in education, employment or training. (House of Commons, 2016). [Google Scholar]
- 60.Consortium, the H. R. et al. A reference panel of 64,976 haplotypes for genotype imputation. Nat. Genet. 48, 1279–1283 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Dudbridge F Power and Predictive Accuracy of Polygenic Risk Scores. PLOS Genet. 9, e1003348 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Domingue BW et al. The social genome of friends and schoolmates in the National Longitudinal Study of Adolescent to Adult Health. Proc. Natl. Acad. Sci. 201711803 (2018). doi: 10.1073/pnas.1711803115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Billy JO, Wenzlow AT & Grady WR User documentation for the add health contextual database. Seattle Battelle Cent . Public Health Res. Eval. (1998). [Google Scholar]
- 64.Morales L & Monbureau T Add Health Wave IV Contextual Data. (2013). [Google Scholar]
- 65.Belsky DW et al. The Genetics of Success: How Single-Nucleotide Polymorphisms Associated With Educational Attainment Relate to Life-Course Development. Psychol. Sci. 27, 957–972 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Stata Corp. Power and sample size | Stata. Power and Sample Size (2017). Available at: https://www.stata.com/features/power-and-sample-size/. (Accessed: 26th December 2017) [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.