

Abstract
Researchers and educators have long wrestled with the question of how best to teach their clients be they humans, non-human animals or machines. Here, we examine the role of a single variable, the difficulty of training, on the rate of learning. In many situations we find that there is a sweet spot in which training is neither too easy nor too hard, and where learning progresses most quickly. We derive conditions for this sweet spot for a broad class of learning algorithms in the context of binary classification tasks. For all of these stochastic gradient-descent based learning algorithms, we find that the optimal error rate for training is around 15.87% or, conversely, that the optimal training accuracy is about 85%. We demonstrate the efficacy of this ‘Eighty Five Percent Rule’ for artificial neural networks used in AI and biologically plausible neural networks thought to describe animal learning.
Subject terms: Learning algorithms, Psychology, Human behaviour, Computer science
Is there an optimum difficulty level for training? In this paper, the authors show that for the widely-used class of stochastic gradient-descent based learning algorithms, learning is fastest when the accuracy during training is 85%.
Introduction
When we learn something new, like a language or musical instrument, we often seek challenges at the edge of our competence—not so hard that we are discouraged, but not so easy that we get bored. This simple intuition, that there is a sweet spot of difficulty, a ‘Goldilocks zone’1, for motivation and learning is at the heart of modern teaching methods2 and is thought to account for differences in infant attention between more and less learnable stimuli1. In the animal learning literature it is the intuition behind shaping3 and fading4, whereby complex tasks are taught by steadily increasing the difficulty of a training task. It is also observable in the nearly universal ‘levels’ feature in video games, in which the player is encouraged, or even forced, to a higher level of difficulty once a performance criterion has been achieved. Similarly in machine learning, steadily increasing the difficulty of training has proven useful for teaching large scale neural networks in a variety of tasks5,6, where it is known as ‘Curriculum Learning’7 and ‘Self-Paced Learning’8.
Despite this long history of empirical results, it is unclear why a particular difficulty level may be beneficial for learning nor what that optimal level might be. In this paper we address this issue of optimal training difficulty for a broad class of learning algorithms in the context of binary classification tasks, in which ambiguous stimuli must be classified into one of two classes (e.g., cat or dog).
In particular, we focus on the class of stochastic gradient-descent based learning algorithms. In these algorithms, parameters of the model (e.g., the weights in a neural network) are adjusted based on feedback in such a way as to reduce the average error rate over time9. That is, these algorithms descend the gradient of error rate as a function of model parameters. Such gradient-descent learning forms the basis of many algorithms in AI, from single-layer perceptrons to deep neural networks10, and provides a quantitative description of human and animal learning in a variety of situations, from perception11, to motor control12 to reinforcement learning13. For these algorithms, we provide a general result for the optimal difficulty in terms of a target error rate for training. Under the assumption of a Gaussian noise process underlying the errors, this optimal error rate is around 15.87%, a number that varies slightly depending on the noise in the learning process. That is the optimal accuracy for training is around 85%. We show theoretically that training at this optimal difficulty can lead to exponential improvements in the rate of learning. Finally, we demonstrate the applicability of the Eighty Five Percent Rule to artificial one- and two-layer neural networks9,14, and a model from computational neuroscience that is thought to describe human and animal perceptual learning11.
Results
Optimal training difficulty for binary classification tasks
In a standard binary classification task, an animal or machine ‘agent’ makes binary decisions about simple stimuli. For example, in the classic Random Dot Motion paradigm from Psychology and Neuroscience15,16, stimuli consist of a patch of moving dots—most moving randomly but a small fraction moving coherently either to the left or the right—and participants must decide in which direction the coherent dots are moving. A major factor in determining the difficulty of this perceptual decision is the fraction of coherently moving dots, which can be manipulated by the experimenter to achieve a fixed error rate during training using a procedure known as ‘staircasing’17.
We assume that agents make their decision on the basis of a scalar, subjective decision variable, h, which is computed from a stimulus that can be represented as a vector x (e.g., the direction of motion of all dots)
| 1 |
where Φ(⋅) is a function of the stimulus and (tunable) parameters ϕ. We assume that this transformation of stimulus x into the subjective decision variable h yields a noisy representation of the true decision variable, Δ (e.g., the fraction of dots moving left). That is, we write
| 2 |
where the noise, n, arises due to the imperfect representation of the decision variable. We further assume that this noise, n, is random and sampled from a zero-mean Gaussian distribution with standard deviation σ (Fig. 1a).
Fig. 1.
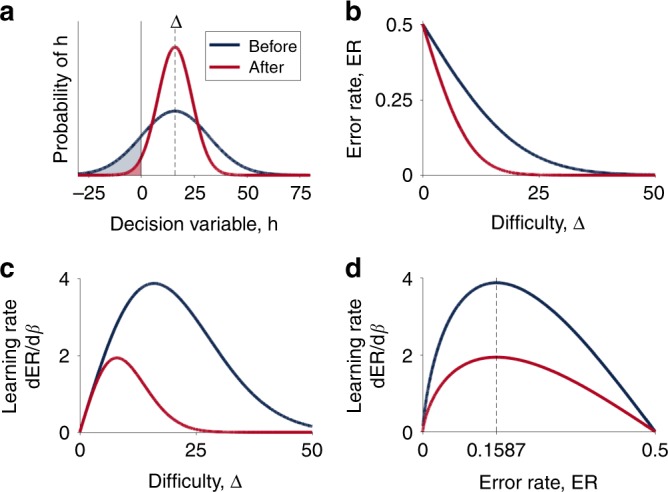
Illustration of the model. a Distributions over decision variable h given a particular difficulty, Δ = 16, with lower precision before learning and higher precision after learning. The shaded regions corresponds to the error rate—the probability of making an incorrect response at each difficulty. b The error rate as a function of difficulty before and after learning. c The derivative that determines the rate of learning as a function of difficulty before and after learning showing that the optimal difficulty for learning is lower after learning than before. d The same derivative as in c re-plotted as a function of error rate showing that the optimal error rate (at 15.87% or ~85% accuracy) is the same both before and after learning
If the decision boundary is set to 0, such that the model chooses option A when h > 0, option B when h < 0 and randomly when h = 0, then the noise in the representation of the decision variable leads to errors with probability
| 3 |
where F(x) is the cumulative density function of the standardized noise distribution, p(x) = p(x|0, 1), and β = 1/σ quantifies the precision of the representation of Δ and the agent’s skill at the task. As shown in Fig. 1b, this error rate decreases as the decision gets easier (Δ increases) and as the agent becomes more accomplished at the task (β increases).
The goal of learning is to tune the parameters ϕ such that the subjective decision variable, h, is a better reflection of the true decision variable, Δ. That is, the model should aim to adjust the parameters ϕ so as to decrease the magnitude of the noise σ or, equivalently, increase the precision β. One way to achieve this tuning is to adjust the parameters using gradient descent on the error rate, i.e. changing the parameters over time t according to
| 4 |
where η is the learning rate and ∇ϕER is the derivative of the error rate with respect to parameters ϕ. This gradient can be written in terms of the precision, β, as
| 5 |
Note here that only the first term on the right hand side of Eq. (5) depends on the difficulty Δ, while the second describes how the precision changes with ϕ. Note also that Δ itself, as the ‘true’ decision variable, is independent of ϕ. This means that the optimal difficulty for training, that maximizes the change in the parameters, ϕ, at this time point, is the value of the decision variable Δ* that maximizes ∂ER/∂β. Of course, this analysis ignores the effect of changing ϕ on the form of the noise—instead assuming that it only changes the scale factor, β, an assumption that likely holds in the relatively simple cases we consider here, although whether it holds in more complex cases will be an important question for future work.
In terms of the decision variable, the optimal difficulty changes as a function of precision (Fig. 1c) meaning that the difficulty of training must be adjusted online according to the skill of the agent. Using the monotonic relationship between Δ and ER (Fig. 1b) it is possible to express the optimal difficulty in terms of the error rate, ER* (Fig. 1d). Expressed this way, the optimal difficulty is constant as a function of precision, meaning that optimal learning can be achieved by clamping the error rate during training at a fixed value, which, for Gaussian noise is
| 6 |
That is, the optimal error rate for learning is 15.87%, and the optimal accuracy is around 85%. We call this the Eighty Five Percent Rule for optimal learning.
Dynamics of learning
While the previous analysis allows us to calculate the error rate that maximizes the rate of learning, it does not tell us how much faster learning occurs at this optimal error rate. In this section we address this question by comparing learning at the optimal error rate with learning at a fixed error rate, ERf (which may be suboptimal), and, alternatively, a fixed difficulty, Δf. If stimuli are presented one at a time (i.e., not batch learning), in both cases, gradient-descent based updating of the parameters, ϕ, (Eq. (4)) implies that the precision β evolves in a similar manner, i.e..
| 7 |
For fixed error rate, ERf, as shown in the Methods, integrating Eq. (7) gives
| 8 |
where t0 is the initial time point, β0 is the initial value of β and Kf is the following function of the training error rate
| 9 |
Thus, for fixed training error rate the precision grows as the square root of time with the exact rate determined by Kf which depends on both the training error rate and the noise distribution.
For fixed decision variable, Δf, integrating Eq. (7) is more difficult and the solution depends more strongly on the distribution of the noise. In the case of Gaussian noise, there is no closed form solution for β. However, as shown in the Methods, an approximate form can be derived at long times where we find that β grows as
| 10 |
i.e., exponentially slower than Eq. (38).
Simulations
To demonstrate the applicability of the Eighty Five Percent Rule we simulated the effect of training accuracy on learning in three cases, two from AI and one from computational neuroscience. From AI we consider how training at 85% accuracy impacts learning in the the simple case of a one-layer Perceptron14 with artificial stimuli, and in the more complex case of a two-layer neural network9 with stimuli drawn from the MNIST (Modified National Institute of Standards and Technology) dataset of handwritten digits18. From computational neuroscience we consider the model of Law and Gold11, that accounts for both the behavior and neural firing properties of monkeys learning the Random Dot Motion task. In all cases we see that learning is maximized when training occurs at 85% accuracy.
Perceptron with artificial stimuli
The Perceptron is a classic one-layer neural network model that learns to map multidimensional stimuli x onto binary labels, y via a linear threshold process14. To implement this mapping, the Perceptron first computes the decision variable h as
| 11 |
where w are the weights of the network, and then assigns the label according to
| 12 |
The weights, w, which constitute the parameters of the model, are updated based on feedback about the true label t by a the learning rule,
| 13 |
This learning rule implies that the Perceptron only updates its weights when the predicted label y does not match the actual label t—that is, the Perceptron only learns when it makes mistakes. Naively then, one might expect that optimal learning would involve maximizing the error rate. However, because Eq. (13) is closely related (albeit not identical) to a gradient descent based rule (e.g., Chapter 39 in ref. 19), the analysis of the previous sections applies and the optimal error rate for training is 15.87%.
To test this prediction we simulated the Perceptron learning rule for a range of training error rates between 0.01 and 0.5 in steps of 0.01 (1000 simulations per error rate, 1000 trials per simulation). Error rate was kept constant by varying the difficulty, and the degree of learning was captured by the precision β (see Methods). As predicted by the theory, the network learns most effectively when trained at the optimal error rate (Fig. 2a) and the dynamics of learning are well described, up to a scale factor, by Eq. (38) (Fig. 2b).
Fig. 2.
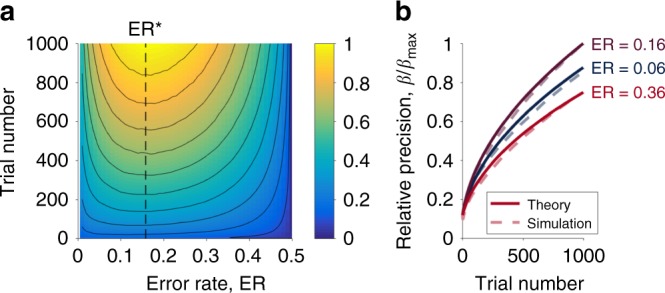
The Eighty Five Percent Rule applied to the Perceptron. a The relative precision, β/βmax, as a function of training error rate and training duration. Training at the optimal error rate leads to the fastest learning throughout. b The dynamics of learning agree well with the theory
Two-layer network with MNIST stimuli
As a more demanding test of the Eighty Five Percent Rule, we consider the case of a two-layer neural network applied to more realistic stimuli from the Modified National Institute of Standards and Technology (MNIST) dataset of handwritten digits18. The MNIST dataset is a labeled dataset of 70,000 images of handwritten digits (0 through 9) that has been widely used as a test of image classification algorithms (see ref. 20 for a list). The dataset is broken down into a training set consistent of 60,000 images and a test set of 10,000 images. To create binary classification tasks based on these images, we trained the network to classify the images according to either the parity (odd or even) or magnitude (less than 5 or not) of the number.
The network itself consisted of 1 input layer, with 400 units corresponding to the pixel values in the images, 1 hidden layer, with 50 neurons, and one output unit. Unlike the Perceptron, activity of the output unit was graded and was determined by a sigmoid function of the decision variable, h
| 14 |
where the decision variable was given by
| 15 |
where w2 were the weights connecting the hidden layer to the output units and a was the activity in the hidden layer. This hidden-layer activity was also determined by a sigmoidal function
| 16 |
where the inputs, x, corresponds to the pixel values in the image and w1 were the weights from the input layer to the hidden layer.
All weights were trained using the Backpropagation algorithm9 which takes the error,
| 17 |
and propagates it backwards through the network, from output to input stage, as a teaching signal for the weights. This algorithm implements stochastic gradient descent and, if our assumptions are met, should optimize learning at a training accuracy of 85%.
To test this prediction we trained the two-layer network for 5000 trials to perform either the Parity or the Magnitude Task while clamping the training error rate between 5 and 30% (Fig. 3). After training, performance was assessed on the entire test set and the whole process was repeated 1000 times for each task. As shown in Fig. 3, training error rate has a relatively large effect on test accuracy, around 10% between the best and worse training accuracies. Moreover, for both tasks, the optimal training occurs at 85% training accuracy. This suggests that the 85% rule holds even for learning of more realistic stimuli, by more complex multi-layered networks.
Fig. 3.
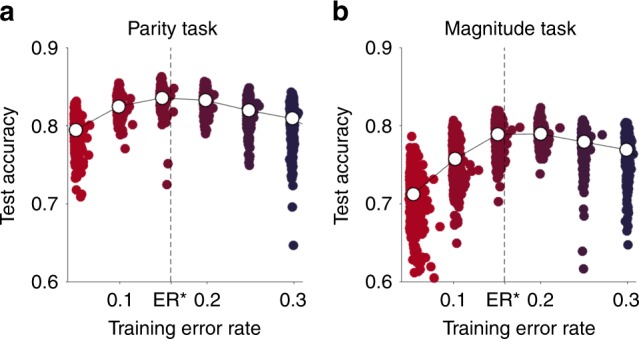
The Eighty Five Percent Rule applied to a multilayered neural network. Test accuracy vs training error rate on the MNIST dataset for the a Parity and b Magnitude tasks for 1000 different simulations. In both cases the test accuracy peaks at or near the optimal error rate. Each color corresponds to a different target training accuracy
Biologically plausible model of perceptual learning
To demonstrate how the Eighty Five Percent Rule might apply to learning in biological systems, we simulated the Law and Gold model of perceptual learning11. This model has been shown to capture the long term changes in behavior, neural firing and synaptic weights as monkeys learn to perform the Random Dot Motion task.
Specifically, the model assumes that monkeys make the perceptual decision between left and right on the basis of neural activity in area MT—an area in the dorsal visual stream that is known to represent motion information15. In the Random Dot Motion task, neurons in MT have been found to respond to both the direction θ and coherence COH of the dot motion stimulus such that each neuron responds most strongly to a particular ‘preferred’ direction and that the magnitude of this response increases with coherence. This pattern of firing is well described by a simple set of equations (see “Methods”) and thus the noisy population response, x, to a stimulus of arbitrary direction and coherence is easily simulated.
From this MT population response, Law and Gold proposed that animals construct a decision variable in a separate area of the brain (lateral interparietal area, LIP) as the weighted sum of activity in MT; i.e.,
| 18 |
where w are the weights between MT and LIP neurons and ϵ is random neuronal noise that cannot be reduced by learning. The presence of this irreducible neural noise is a key difference between the Law and Gold model (Eq. 18) and the Perceptron (Eq. 11) as it means that no amount of learning can lead to perfect performance. However, as shown in the Methods section, the presence of irreducible noise does not change the optimal accuracy for learning which is still 85%.
Another difference between the Perceptron and the Law and Gold model is the form of the learning rule. In particular, weights are updated according to a reinforcement learning rule based on a reward prediction error
| 19 |
where r is the reward presented on the current trial (1 for a correct answer, 0 for an incorrect answer) and E[r] is the predicted reward
| 20 |
where B is a proportionality constant that is estimated online by the model (see “Methods”). Given the prediction error, the model updates its weights according to
| 21 |
where C is the choice (−1 for left, +1 for right) and η is the learning rate. Despite the superficial differences with the Perceptron learning rule (Eq. (13)) the Law and Gold model still implements stochastic gradient descent on the error rate13 and learning should be optimized at 85%.
To test this prediction we simulated the model at a variety of different target training error rates. Each target training rate was simulated 100 times with different parameters for the MT neurons (see “Methods”). The precision, β, of the trained network was estimated by fitting simulated behavior of the network on a set of test coherences that varied logarithmically between 1 and 100%. As shown in Fig. 4a the precision after training is well described (up to a scale factor) by the theory. In addition, in Fig. 4b, we show the expected difference in behavior—in terms of psychometric choice curves—for three different training error rates. While these differences are small, they are large enough that they could be distinguished experimentally.
Fig. 4.
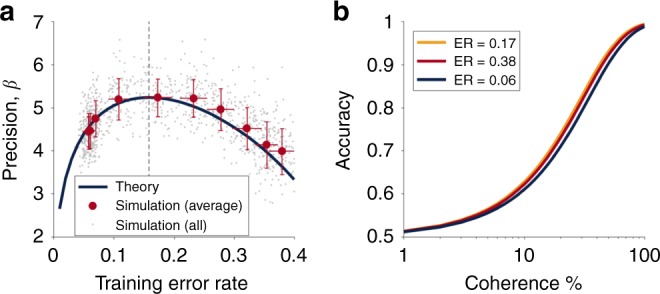
The Eighty Five Percent Rule applied to the Law and Gold model of perceptual learning. a Precision of the trained network as function of training error rate. Gray dots represent the results of individual simulations—note that the empirical error rate on each run often differs slightly from the target error rate due to noise. Red dots correspond to the average precision and empirical error rate for each target error rate (error bars ± standard deviation in both measures). b Accuracy as a function of coherence for the network trained at three different error rates corresponding to near optimal (ER = 0.17), too high (ER = 0.38) and too low (ER = 0.06)
Discussion
In this article we considered the effect of training accuracy on learning in the case of binary classification tasks and stochastic gradient-descent-based learning rules. We found that the rate of learning is maximized when the difficulty of training is adjusted to keep the training accuracy at around 85%. We showed that training at the optimal accuracy proceeds exponentially faster than training at a fixed difficulty. Finally we demonstrated the efficacy of the Eighty Five Percent Rule in the case of artificial and biologically plausible neural networks.
Our results have implications for a number of fields. Perhaps most directly, our findings move towards a theory for identifying the optimal environmental settings in order to maximize the rate of gradient-based learning. Thus the Eighty Five Percent Rule should hold for a wide range of machine learning algorithms including multilayered feedforward and recurrent neural networks (e.g. including ‘deep learning’ networks using backpropagation9, reservoir computing networks21,22, as well as Perceptrons). Of course, in these more complex situations, our assumptions may not always be met. For example, as shown in the Methods, relaxing the assumption that the noise is Gaussian leads to changes in the optimal training accuracy: from 85% for Gaussian, to 82% for Laplacian noise, to 75% for Cauchy noise (Eq. (31) in the “Methods”).
More generally, extensions to this work should consider how batch-based training changes the optimal accuracy, and how the Eighty Five Percent Rule changes when there are more than two categories. In batch learning, the optimal difficulty to select for the examples in each batch will likely depend on the rate of learning relative to the size of the batch. If learning is slow, then selecting examples in a batch that satisfy the 85% rule may work, but if learning is fast, then mixing in more difficult examples may be best. For multiple categories, it is likely possible to perform similar analyses, although the mapping between decision variable and categories will be more complex as will be the error rates which could be category specific (e.g., misclassifying category 1 as category 2 instead of category 3).
In Psychology and Cognitive Science, the Eighty Five Percent Rule accords with the informal intuition of many experimentalists that participant engagement is often maximized when tasks are neither too easy nor too hard. Indeed it is notable that staircasing procedures (that aim to titrate task difficulty so that error rate is fixed during learning) are commonly designed to produce about 80–85% accuracy17. Similarly, when given a free choice about the difficulty of task they can perform, participants will spontaneously choose tasks of intermediate difficulty levels as they learn23. Despite the prevalence of this intuition, to the best of our knowledge no formal theoretical work has addressed the effect of training accuracy on learning, a test of which is an important direction for future work.
More generally, our work closely relates to the Region of Proximal Learning and Desirable Difficulty frameworks in education24–26 and Curriculum Learning and Self-Paced Learning7,8 in computer science. These related, but distinct, frameworks propose that people and machines should learn best when training tasks involve just the right amount of difficulty. In the Desirable Difficulties framework, the difficulty in the task must be of a ‘desirable’ kind, such as spacing practice over time, that promotes learning as opposed to an undesirable kind that does not. In the Region of Proximal Learning framework, which builds on early work by Piaget27 and Vygotsky28, this optimal difficulty is in a region of difficulty just beyond the person’s current ability. Curriculum and Self-Paced Learning in computer science build on similar intuitions, that machines should learn best when training examples are presented in order from easy to hard. In practice, the optimal difficulty in all of these domains is determined empirically and is often dependent on many factors29. In this context, our work offers a way of deriving the desired difficulty and the region of proximal learning in the special case of binary classification tasks for which stochastic gradient-descent learning rules apply. As such our work represents the first step towards a more mathematical instantiation of these theories, although it remains to be generalized to a broader class of circumstances, such as multi-choice tasks and different learning algorithms.
With regard to different learning algorithms, it is important to note that not all models will exhibit a sweet spot of difficulty for learning. As an example, consider how a Bayesian learner with a perfect memory would infer parameters ϕ by computing the posterior distribution given past stimuli, x1:t, and labels, y1:t,
| 22 |
where the last line holds when the label depends only on the current stimulus. Clearly this posterior distribution over parameters is independent of the ordering of the trials meaning that a Bayesian learner (with perfect memory) would learn equally well if hard or easy examples are presented first. This is not to say that Bayesian learners cannot benefit from carefully constructed training sets, but that for a given set of training items the order of presentation has no bearing on what is ultimately learned. This contrasts markedly with gradient-based algorithms, many of which try to approximate the maximum a posteriori solution of a Bayesian model, whose training is order dependent and whose learning is optimized with ∂ER/∂β.
Finally, we note that our analysis for maximizing the gradient, ∂ER/∂β, not only applies to learning but to any process that affects the precision of neural representations, such as attention, engagement, or more generally cognitive control30,31. For example, attention is known to improve the precision with which sensory stimuli are represented in the brain, e.g., ref. 32. If exerting control leads to a change in precision of δβ, then the change in error rate associated with exerting this control is
| 23 |
This predicts that the benefits of engaging cognitive control should be maximized when ∂ER/∂β is maximized, that is at ER*. More generally this relates to the Expected Value of Control theory30,31,33 which suggests that the learning gradient, ∂ER/∂β, is monitored by control-related areas of the brain such as anterior cingulate cortex.
Along similar lines, our work points to a mathematical theory of the state of ‘Flow’34. This state, ‘in which an individual is completely immersed in an activity without reflective self-consciousness but with a deep sense of control’ [ref. 35, p. 1], is thought to occur most often when the demands of the task are well matched to the skills of the participant. This idea of balance between skill and challenge was captured originally with a simple conceptual diagram (Fig. 5) with two other states: ‘anxiety’ when challenge exceeds skill and ‘boredom’ when skill exceeds challenge. These three qualitatively different regions (flow, anxiety, and boredom) arise naturally in our model. Identifying the precision, β, with the level of skill and the level challenge with the inverse of true decision variable, 1/Δ, we see that when challenge equals skill, flow is associated with a high learning rate and accuracy, anxiety with low learning rate and accuracy and boredom with high accuracy but low learning rate (Fig. 5b, c). Intriguingly, recent work by Vuorre and Metcalfe, has found that subjective feelings of Flow peaks on tasks that are subjectively rated as being of intermediate difficulty36. In addition work on learning to control brain computer interfaces finds that subjective, self-reported measures of ‘optimal difficulty’, peak at a difficulty associated with maximal learning, and not at a difficulty associated with optimal decoding of neural activity37. Going forward, it will be interesting to test whether these subjective measures of engagement peak at the point of maximal learning gradient, which for binary classification tasks is 85%.
Fig. 5.

Proposed relationship between the Eighty Five Percent Rule and Flow. a Original model of flow as a state that is achieved when skill and challenge are well balanced. Normalized learning rate, ∂ER/∂β, b and accuracy c as a function of skill and challenge suggests that flow corresponds to high learning and accuracy, boredom corresponds to low learning and high accuracy, while anxiety is associated with low learning and low accuracy
Methods
Optimal error rate for learning
In order to compute the optimal difficulty for training, we need to find the value of Δ that maximizes the learning gradient, ∂ER/∂β. From Eq. (3) we have
| 24 |
From here the optimal difficulty, Δ*, can be found by computing the derivative of the gradient with respect to Δ, i.e.,
| 25 |
Setting this derivative equal to zero gives us the following expression for the optimal difficulty, Δ*, and error rate, ER*
| 26 |
where p′(x) denotes the derivative of p(x) with respect to x. Because β and Δ* only ever appear together in these expressions, Eq. (26) implies that βΔ* is a constant. Thus, while the optimal difficulty, Δ*, changes as a function of precision (Fig. 1c), the optimal training error rate, ER* does not (Fig. 1d). That is, training with the error rate clamped at ER* is guaranteed to maximize the rate of learning.
The exact value of ER* depends on the distribution of noise, n, in Eq. (2). In the case of Gaussian noise, we have
| 27 |
which implies that
| 28 |
and that the optimal difficulty is
| 29 |
Consequently the optimal error rate for Gaussian noise is
| 30 |
Similarly for Laplacian noise () and Cauchy noise (p(x) = (π(1 + x2))−1) we have optimal error rates of
| 31 |
Optimal learning with endogenous noise
The above analyses for optimal training accuracy also applies in the case where the decision variable, h, is corrupted by endogenous, irreducible noise, ϵ, in addition to representation noise, n, that can be reduced by learning; i.e.,
| 32 |
In this case we can split the overall precision, β, into two components, one based on representational uncertainty that can be reduced, βn, and another based on endogenous uncertainty that cannot, βϵ. For Gaussian noise, these precisions are related to each other by
| 33 |
More generally, the precisions are related by some function, G, such that β = G(βn, βϵ). Since only n can be reduced by learning, it makes sense to perform stochastic gradient descent on βn such that the learning rule should be
| 34 |
Note that ∂β/∂βn is independent of Δ so maximizing learning rate w.r.t. Δ means maximizing ∂ER/∂β as before. This implies that the optimal training difficulty will be the same, e.g., 85% for Gaussian noise, regardless whether endogenous noise is present or not.
Dynamics of learning
To calculate the dynamics of learning we need to integrate Eq. (7) over time. This, of course depends on the learning gradient, ∂ER/∂β, which varies depending on the noise and whether the error rate or the true decision variable is fixed during training.
In the fixed error rate case, we fix the error rate during training to ERf. This implies that the difficulty should change over time according to
| 35 |
where F−1(⋅) is the inverse cdf. This implies that β evolves over time according to
| 36 |
where we have introduced Kf as
| 37 |
Integrating Eq. (36) and solving for β(t) we get
| 38 |
where t0 is the initial time point, and β0 is the initial value of β. Thus, for fixed error rate the precision grows as the square root of time with the rate determined by Kf which depends on both the training error rate and the noise distribution. For the optimal error rate we have, Kf = p(−1).
In the fixed decision variable case, the true decision variable is fixed at Δf and the error rate varies as a function of time. In this case we have
| 39 |
Formally, this can be solved as
| 40 |
However, the exact form for β(t) will depend on p(x).
In the Gaussian case we cannot derive a closed form expression for β(t). The closest we can get is to write
| 41 |
For long times, and large β, we can write
| 42 |
which implies that for long times β grows slower than , which is exponentially slower than the fixed error rate case.
In contrast to the Gaussian case, the Laplacian case lends itself to closed form analysis and we can derive the following expression for β
| 43 |
Again this shows logarithmic dependence on t indicating that learning is much slower with a fixed difficulty.
In the case of Cauchy noise we can compute the integral in Eq. (40) and find that β is the root of the following equation
| 44 |
For long training times this implies that β grows as the cube root of t. Thus in the Cauchy case, while the rate of learning is still greatest at the optimal difficulty, the improvement is not as dramatic as in the other cases.
Application to the perceptron
To implement the Perceptron example, we assumed that true labels t were generated by a ‘Teacher Perceptron’38 with normalized weight vector, e. Learning was quantified by decomposing the learned weights w into two components: one proportional to e and a second orthogonal to e, i.e.,
| 45 |
where θ is the angle between w and e, and e⊥ is the unit vector perpendicular to e in the plane defined by e and w. This allows us to write the decision variable h in terms of signal and noise components as
| 46 |
where the difficulty Δ = |e ⋅ x| is the distance between x and the decision boundary, and the (2t − 1) term simply controls which side of the boundary x is on. This implies that the precision β is proportional to cot θ, with a constant of proportionality determined by the dimensionality of x.
In the case where the observations x are sampled from distributions that obey the central limit theorem, then the noise term is approximately Gaussian implying that the optimal error rate for training the Perceptron, ER* = 15.87%.
To test this prediction we simulated the Perceptron learning rule for a range of training error rates between 0.01 and 0.5 in steps of 0.01 (1000 simulations per error rate). Stimuli, x, were 100 dimensional and independently sampled from a Gaussian distribution with mean 0 and variance 1. Similarly, the true weights e were sampled from a mean 0, variance 1 Gaussian. To mimic the effect of a modest degree of initial training, we initialized the weight vector w randomly with the constraint that |θ| < 1.6π. The difficulty Δ was adjusted on a trial-by-trial basis according to
| 47 |
which ensures that the training error rate is clamped at ER. The degree of learning was captured by the precision β.
Application to the two-layer neural network
To implement the two-layer network, we built a sigmoidal neural network with one hidden layer (of 50 neurons) and one output neuron. The weights between the input layer and the hidden layer and between the hidden layer and output layer were trained using the standard Backpropagation algorithm.
In order to clamp the error rate during training we first had to rate the images according to their ‘difficulty’. To this end, we trained a teacher network with the same basic architecture (i.e., 50 hidden units and 1 output unit) until its performance was near perfect (training error rate = 99.6% for the Parity Task and 99.4% for the Magnitude Task; test error rate = 97% for the Magnitude Task and 95.6% for the Parity Task). We then used the absolute value of the decision variable from this network, |hteacher| as a proxy for the true difficulty, Δ—with larger values of |hteacher| indicating easier stimuli to classify.
Weights in the network were initialized randomly from a Gaussian distribution (mean 0, variance 1). To achieve a fixed error rate during training, on each trial, we selected a stimulus that was closest to a target difficulty, htarget. This target difficulty was adjusted based on the performance of the network during training—increasing if the network classified the stimulus incorrectly, and decreasing if the network classified the stimulus correctly. More specifically, the target difficulty was adjusted as
| 48 |
where D is the step size (=1), Atarget is the target training accuracy and Aav is the running average of the accuracy from the last 50 trials.
On each trial we selected the ‘eligible’ stimulus whose value of hteacher was closest to htarget. To ensure that a given stimulus was not selected too often during training, stimuli were only eligible to be chosen if they had not been used in the last 50 trials.
Each initial state of the network was trained on either the Parity or Magnitude Task at a fixed training error rate between 5 and 30% in steps of 5%. At the end of training performance was assessed on the whole test set. This process was repeated 1000 times, with a new set of initial random weights each time.
Application to Law and Gold model
The model of perceptual learning follows the exposition in Law and Gold11. To aid comparison with that paper we retain almost all of their notation, with the three exceptions being their β parameter, which we rename as B to avoid confusion with the precision, their ϕi parameter which we rename as Fi to avoid confusion with the parameters of the learner, and their learning rate parameter α which we write as η.
Following Law and Gold11, the average firing rate of an MT neuron, i, in response to a moving dot stimulus with direction θ and coherence COH is
| 49 |
where T is the duration of the stimulus, is the response of neuron i to a zero-motion coherence stimulus, is the response to a stimulus moving in the preferred direction and is the response to a stimulus in the null direction. f(θ|Θi) is the tuning curve of the neuron around its preferred direction Θi
| 50 |
where σθ (=30 degrees) is the width of the tuning curve which is assumed to be identical for all neurons.
Neural activity on each trial was assumed to be noisily distributed around this mean firing rate. Specifically the activity, xi, of each neuron is given by a rectified (to ensure xi > 0) sample from a Gaussian with mean mi and variance vi
| 51 |
where Fi is the Fano factor of the neuron.
Thus each MT neuron was characterized by five free parameters. These free parameters were sampled randomly for each neuron such that , , , and . Note that is set between − and 0 to ensure that the minimum average firing rate never dips below zero. Each trial was defined by three task parameters: T = 1 s, Θ = ±90 degrees and COH which was adjusted based on performance to achieve a fixed error rate during training (see below). As in the original paper, the number of neurons was set to 7200 and the learning rate, η was 10−7.
The predicted reward E[r] was computed according to Eq. (20). In line with Law and Gold (Supplementary Fig. 2 in ref. 11), the proportionality constant B was computed using logistic regression on the accuracy and absolute value of the decision variable, |h|, from last L trials, where L = min(300, t).
In addition to the weight update rule (Eq. (21)), weights were normalized after each update to keep the sum of the squared weights, a constant (=0.02). While this normalization has only a small overall effect (see Supplementary Material in ref. 11), we replicate this weight normalization here for consistency with the original model.
To initialize the network, the first 50 trials of the simulation had a fixed coherence COH = 0.9. After this initialization period, the coherence was adjusted according to the difference between the target accuracy, Atarget, and actual accuracy in the last L trials, AL, where L = min(300, t). Specifically, the coherence on trial t was set as
| 52 |
where Γt was adjusted according to
| 53 |
and dΓ was 0.1.
To estimate the post-training precision parameter, β, we simulated behavior of the trained network on a set of 20 logarithmically spaced coherences between 10−3 and 1. Behavior at each coherence was simulated 100 times and learning was disabled during this testing phase. The precision parameter, β, was estimated using logistic regression between accuracy on each trial (0 or 1) and coherence; i.e.,
| 54 |
Supplementary information
Acknowledgements
This project was made possible through the support of a grant from the John Templeton Foundation to J.D.C., a Center of Biomedical Research Excellence grant P20GM103645 from the National Institute of General Medical Sciences to A.S., and National Institute on Aging grant R56 AG061888 to R.C.W. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the funders.
Author contributions
R.C.W., A.S., M.S., and J.D.C. developed the idea and wrote the paper. R.C.W. derived mathematical results and ran simulations.
Data availability
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Code availability
All code is publicly available on GitHub at https://github.com/bobUA/EightyFivePercentRule
Competing interests
The authors declare no competing interests.
Footnotes
Peer review information Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information is available for this paper at 10.1038/s41467-019-12552-4.
References
- 1.Kidd C, Piantadosi ST, Aslin RN. The goldilocks effect: Human infants allocate attention to visual sequences that are neither too simple nor too complex. PLoS ONE. 2012;7:e36399. doi: 10.1371/journal.pone.0036399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Metcalfe J. Metacognitive judgments and control of study. Curr. Directions Psychological Sci. 2009;18:159–163. doi: 10.1111/j.1467-8721.2009.01628.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Skinner B. The Behavior of Organisms: An Experimental Analysis. New York: D. appleton-century company; 1938. [Google Scholar]
- 4.Lawrence DH. The transfer of a discrimination along a continuum. J. Comp. Physiological Psychol. 1952;45:511. doi: 10.1037/h0057135. [DOI] [PubMed] [Google Scholar]
- 5.Elman JL. Learning and development in neural networks: the importance of starting small. Cognition. 1993;48:71–99. doi: 10.1016/0010-0277(93)90058-4. [DOI] [PubMed] [Google Scholar]
- 6.Krueger KA, Dayan P. Flexible shaping: how learning in small steps helps. Cognition. 2009;110:380–394. doi: 10.1016/j.cognition.2008.11.014. [DOI] [PubMed] [Google Scholar]
- 7.Bengio, Y., Louradour, J., Collobert, R. & Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, 41–48 (ACM, 2009).
- 8.Kumar, M. P., Packer, B. & Koller, D. In Advances in Neural Information Processing Systems, 1189–1197 (2010).
- 9.Rumelhart DE, et al. Learning representations by back-propagating errors. Cogn. modeling. 1988;5:1. [Google Scholar]
- 10.LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521:436–444. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 11.Law C-T, Gold JI. Reinforcement learning can account for associative and perceptual learning on a visual-decision task. Nat. Neurosci. 2009;12:655–663. doi: 10.1038/nn.2304. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Schöllhorn W, Mayer-Kress G, Newell K, Michelbrink M. Time scales of adaptive behavior and motor learning in the presence of stochastic perturbations. Hum. Mov. Sci. 2009;28:319–333. doi: 10.1016/j.humov.2008.10.005. [DOI] [PubMed] [Google Scholar]
- 13.Williams RJ. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992;8:229–256. [Google Scholar]
- 14.Rosenblatt F. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Rev. 1958;65:386. doi: 10.1037/h0042519. [DOI] [PubMed] [Google Scholar]
- 15.Newsome WT, Pare EB. A selective impairment of motion perception following lesions of the middle temporal visual area (mt) J. Neurosci. 1988;8:2201–2211. doi: 10.1523/JNEUROSCI.08-06-02201.1988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Britten KH, Shadlen MN, Newsome WT, Movshon JA. The analysis of visual motion: a comparison of neuronal and psychophysical performance. J. Neurosci. 1992;12:4745–4765. doi: 10.1523/JNEUROSCI.12-12-04745.1992. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Garca-Pérez MA. Forced-choice staircases with fixed step sizes: asymptotic and small-sample properties. Vis. Res. 1998;38:1861–1881. doi: 10.1016/S0042-6989(97)00340-4. [DOI] [PubMed] [Google Scholar]
- 18.LeCun Y, et al. Gradient-based learning applied to document recognition. Proc. IEEE. 1998;86:2278–2324. doi: 10.1109/5.726791. [DOI] [Google Scholar]
- 19.MacKay, D. J. Information Theory, Inference and Learning Algorithms (Cambridge University Press, 2003).
- 20.LeCun, Y., Cortes, C. & Burges, C. J. The mnist database of handwritten digits. http://yann.lecun.com/exdb/mnist/.
- 21.Jaeger H. The echo state approach to analysing and training recurrent neural networks-with an erratum note. Bonn., Ger.: Ger. Natl. Res. Cent. Inf. Technol. GMD Tech. Rep. 2001;148:13. [Google Scholar]
- 22.Maass W, Natschläger T, Markram H. Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 2002;14:2531–2560. doi: 10.1162/089976602760407955. [DOI] [PubMed] [Google Scholar]
- 23.Baranes AF, Oudeyer P-Y, Gottlieb J. The effects of task difficulty, novelty and the size of the search space on intrinsically motivated exploration. Front. Neurosci. 2014;8:317. doi: 10.3389/fnins.2014.00317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Metcalfe J, Kornell N. A region of proximal learning model of study time allocation. J. Mem. Lang. 2005;52:463–477. doi: 10.1016/j.jml.2004.12.001. [DOI] [Google Scholar]
- 25.Bjork, R. A. in Metacognition: Knowing about Knowing (eds Metcalfe, J. & Shimamura, A.)185–205 (MIT Press, Cambridge, MA, 1994).
- 26.Schnotz W, Kürschner C. A reconsideration of cognitive load theory. Educ. Psychol. Rev. 2007;19:469–508. doi: 10.1007/s10648-007-9053-4. [DOI] [Google Scholar]
- 27.Piaget J, Cook M. The Origins of Intelligence in Children. New York: International Universities Press; 1952. [Google Scholar]
- 28.Vygotsky, L. S. The Collected Works of LS Vygotsky: Problems of the Theory and History of Psychology, vol. 3 (Springer Science & Business Media, 1997).
- 29.Metcalfe J. Learning from errors. Annu. Rev. Psychol. 2017;68:465–489. doi: 10.1146/annurev-psych-010416-044022. [DOI] [PubMed] [Google Scholar]
- 30.Shenhav A, Botvinick MM, Cohen JD. The expected value of control: an integrative theory of anterior cingulate cortex function. Neuron. 2013;79:217–240. doi: 10.1016/j.neuron.2013.07.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Shenhav A, et al. Toward a rational and mechanistic account of mental effort. Annu. Rev. Neurosci. 2017;40:99–124. doi: 10.1146/annurev-neuro-072116-031526. [DOI] [PubMed] [Google Scholar]
- 32.Briggs F, Mangun GR, Usrey WM. Attention enhances synaptic efficacy and the signal-to-noise ratio in neural circuits. Nature. 2013;499:476–480. doi: 10.1038/nature12276. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Brown JW, Braver TS. Learned predictions of error likelihood in the anterior cingulate cortex. Science. 2005;307:1118–1121. doi: 10.1126/science.1105783. [DOI] [PubMed] [Google Scholar]
- 34.Csikszentmihalyi, M. Beyond Boredom and Anxiety (Jossey-Bass, 2000).
- 35.Engeser, S. Advances in Flow Research (Springer, 2012).
- 36.Vuorre M, Metcalfe J. The relation between the sense of agency and the experience of flow. Conscious. Cognition. 2016;43:133–142. doi: 10.1016/j.concog.2016.06.001. [DOI] [PubMed] [Google Scholar]
- 37.Bauer R, Fels M, Royter V, Raco V, Gharabaghi A. Closed-loop adaptation of neurofeedback based on mental effort facilitates reinforcement learning of brain self-regulation. Clin. Neurophysiol. 2016;127:3156–3164. doi: 10.1016/j.clinph.2016.06.020. [DOI] [PubMed] [Google Scholar]
- 38.Kinzel W, Rujan P. Improving a network generalization ability by selecting examples. Europhys. Lett. 1990;13:473–477. doi: 10.1209/0295-5075/13/5/016. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
All code is publicly available on GitHub at https://github.com/bobUA/EightyFivePercentRule