

Analog machine learning computations are performed passively by propagating light and sound waves through programmed materials.
Abstract
Analog machine learning hardware platforms promise to be faster and more energy efficient than their digital counterparts. Wave physics, as found in acoustics and optics, is a natural candidate for building analog processors for time-varying signals. Here, we identify a mapping between the dynamics of wave physics and the computation in recurrent neural networks. This mapping indicates that physical wave systems can be trained to learn complex features in temporal data, using standard training techniques for neural networks. As a demonstration, we show that an inverse-designed inhomogeneous medium can perform vowel classification on raw audio signals as their waveforms scatter and propagate through it, achieving performance comparable to a standard digital implementation of a recurrent neural network. These findings pave the way for a new class of analog machine learning platforms, capable of fast and efficient processing of information in its native domain.
INTRODUCTION
Recently, machine learning has had notable success in performing complex information processing tasks, such as computer vision (1) and machine translation (2), which were intractable through traditional methods. However, the computing requirements of these applications are increasing exponentially, motivating efforts to develop new, specialized hardware platforms for fast and efficient execution of machine learning models. Among these are neuromorphic hardware platforms (3–5), with architectures that mimic the biological circuitry of the brain. Furthermore, analog computing platforms, which use the natural evolution of a continuous physical system to perform calculations, are also emerging as an important direction for implementation of machine learning (6–10).
In this work, we identify a mapping between the dynamics of wave-based physical phenomena, such as acoustics and optics, and the computation in a recurrent neural network (RNN). RNNs are one of the most important machine learning models and have been widely used to perform tasks such as natural language processing (11) and time series prediction (12–14). We show that wave-based physical systems can be trained to operate as an RNN and, as a result, can passively process signals and information in their native domain, without analog-to-digital conversion, which should result in a substantial gain in speed and a reduction in power consumption. In this framework, rather than implementing circuits that deliberately route signals back to the input, the recurrence relationship occurs naturally in the time dynamics of the physics itself, and the memory and capacity for information processing are provided by the waves as they propagate through space.
RESULTS
Equivalence between wave dynamics and an RNN
In this section, we introduce the operation of an RNN and its connection to the dynamics of waves. An RNN converts a sequence of inputs into a sequence of outputs by applying the same basic operation to each member of the input sequence in a step-by-step process (Fig. 1A). Memory of previous time steps is encoded into the RNN’s hidden state, which is updated at each step. The hidden state allows the RNN to retain memory of past information and to learn temporal structure and long-range dependencies in data (15, 16). At a given time step, t, the RNN operates on the current input vector in the sequence, xt, and the hidden state vector from the previous step, ht−1, to produce an output vector, yt, as well as an updated hidden state, ht.
Fig. 1. Conceptual comparison of a standard RNN and a wave-based physcal system.
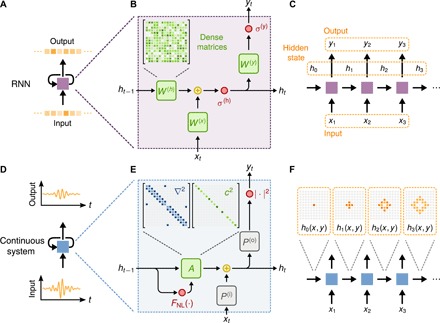
(A) Diagram of an RNN cell operating on a discrete input sequence and producing a discrete output sequence. (B) Internal components of the RNN cell, consisting of trainable dense matrices W(h), W(x), and W(y). Activation functions for the hidden state and output are represented by σ(h) and σ(y), respectively. (C) Diagram of the directed graph of the RNN cell. (D) Diagram of a recurrent representation of a continuous physical system operating on a continuous input sequence and producing a continuous output sequence. (E) Internal components of the recurrence relation for the wave equation when discretized using finite differences. (F) Diagram of the directed graph of discrete time steps of the continuous physical system and illustration of how a wave disturbance propagates within the domain.
While many variations of RNNs exist, a common implementation (17) is described by the following update equations
| (1) |
| (2) |
which are diagrammed in Fig. 1B. The dense matrices defined by W(h), W(x), and W(y) are optimized during training, while σ(h)( · ) and σ(y)( · ) are nonlinear activation functions. The operation prescribed by Eqs. 1 and 2, when applied to each element of an input sequence, can be described by the directed graph shown in Fig. 1C.
We now discuss the connection between the dynamics in the RNN as described by Eqs. 1 and 2 and the dynamics of a wave-based physical system. As an illustration, the dynamics of a scalar wave field distribution u(x, y, z) are governed by the second-order partial differential equation (Fig. 1D)
| (3) |
where is the Laplacian operator, c = c(x, y, z) is the spatial distribution of the wave speed, and f = f(x, y, z, t) is a source term. A finite difference discretization of Eq. 3, with a temporal step size of Δt, results in the recurrence relation
| (4) |
Here, the subscript, t, indicates the value of the scalar field at a fixed time step. The wave system’s hidden state is defined as the concatenation of the field distributions at the current and immediately preceding time steps, ht ≡ [ut, ut−1]T, where ut and ut−1 are vectors given by the flattened fields, ut and ut−1, represented on a discretized grid over the spatial domain. Then, the update of the wave equation may be written as
| (5) |
| (6) |
where the sparse matrix, A, describes the update of the wave fields ut and ut−1 without a source (Fig. 1E). The derivation of Eqs. 5 and 6 is given in section S1.
For sufficiently large field strengths, the dependence of A on ht−1 can be achieved through an intensity-dependent wave speed of the form c = clin + ut2 · cnl, where cnl is exhibited in regions of material with a nonlinear response. In practice, this form of nonlinearity is encountered in a wide variety of wave physics, including shallow water waves (18), nonlinear optical materials via the Kerr effect (19), and acoustically in bubbly fluids and soft materials (20). Additional discussion and analysis of the nonlinear material responses are provided in section S2. Similar to the σ(y)( · ) activation function in the standard RNN, a nonlinear relationship between the hidden state, ht, and the output, yt, of the wave equation is typical in wave physics when the output corresponds to a wave intensity measurement, as we assume here for Eq. 6.
Similar to the standard RNN, the connections between the hidden state and the input and output of the wave equation are also defined by linear operators, given by P(i) and P(o). These matrices define the injection and measuring points within the spatial domain. Unlike the standard RNN, where the input and output matrices are dense, the input and output matrices of the wave equation are sparse because they are nonzero only at the location of injection and measurement points. Moreover, these matrices are unchanged by the training process. Additional information on the construction of these matrices is given in section S3.
The trainable free parameter of the wave equation is the distribution of the wave speed, c(x, y, z). In practical terms, this corresponds to the physical configuration and layout of materials within the domain. Thus, when modeled numerically in discrete time (Fig. 1E), the wave equation defines an operation that maps into that of an RNN (Fig. 1B). Similar to the RNN, the full time dynamics of the wave equation may be represented as a directed graph, but in contrast, the nearest-neighbor coupling enforced by the Laplacian operator leads to information propagating through the hidden state with a finite velocity (Fig. 1F).
Training a physical system to classify vowels
We now demonstrate how the dynamics of the wave equation can be trained to classify vowels through the construction of an inhomogeneous material distribution. For this task, we use a dataset consisting of 930 raw audio recordings of 10 vowel classes from 45 different male speakers and 48 different female speakers (21). For our learning task, we select a subset of 279 recordings corresponding to three vowel classes, represented by the vowel sounds ae, ei, and iy, as contained in the words had, hayed, and heed, respectively (Fig. 2A).
Fig. 2. Schematic of the vowel recognition setup and the training procedure.
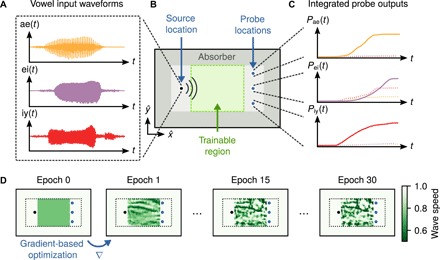
(A) Raw audio waveforms of spoken vowel samples from three classes. (B) Layout of the vowel recognition system. Vowel samples are independently injected at the source, located at the left of the domain, and propagate through the center region, indicated in green, where a material distribution is optimized during training. The dark gray region represents an absorbing boundary layer. (C) For classification, the time-integrated power at each probe is measured and normalized to be interpreted as a probability distribution over the vowel classes. (D) Using automatic differentiation, the gradient of the loss function with respect to the density of material in the green region is computed. The material density is updated iteratively, using gradient-based stochastic optimization techniques until convergence.
The physical layout of the vowel recognition system consists of a two-dimensional domain in the x-y plane, infinitely extended along the z direction (Fig. 2B). The audio waveform of each vowel, represented by x(i), is injected by a source at a single grid cell on the left side of the domain, emitting waveforms that propagate through a central region with a trainable distribution of the wave speed, indicated by the light green region in Fig. 2B. Three probe points are defined on the right-hand side of this region, each assigned to one of the three vowel classes. To determine the system’s output, y(i), we measured the time-integrated power at each probe (Fig. 2C). After the simulation evolves for the full duration of the vowel recording, this integral gives a non-negative vector of length 3, which is then normalized by its sum and interpreted as the system’s predicted probability distribution over the vowel classes. An absorbing boundary region, represented by the dark gray region in Fig. 2B, is included in the simulation to prevent energy from building up inside the computational domain. The derivation of the discretized wave equation with a damping term is given in section S1.
For the purposes of our numerical demonstration, we consider binarized systems consisting of two materials: a background material with a normalized wave speed c0 = 1.0 and a second material with c1 = 0.5. We assume that the second material has a nonlinear parameter, cnl = − 30, while the background material has a linear response. In practice, the wave speeds would be modified to correspond to different materials being used. For example, in an acoustic setting, the material distribution could consist of air, where the sound speed is 331 m/s, and porous silicone rubber, where the sound speed is 150 m/s (22). The initial distribution of the wave speed consists of a uniform region of material with a speed that is midway between those of the two materials (Fig. 2D). This choice of starting structure allows for the optimizer to shift the density of each pixel toward either one of the two materials to produce a binarized structure consisting of only those two materials. To train the system, we perform back-propagation through the model of the wave equation to compute the gradient of the cross-entropy loss function of the measured outputs with respect to the density of material in each pixel of the trainable region. This approach is mathematically equivalent to the adjoint method (23), which is widely used for inverse design (24–25). Then, we use this gradient information to update the material density using the Adam optimization algorithm (26), repeating until convergence on a final structure (Fig. 2D).
The confusion matrices over the training and testing sets for the starting structure are shown in Fig. 3 (A and B), averaged over five cross-validated training runs. Here, the confusion matrix defines the percentage of correctly predicted vowels along its diagonal entries and the percentage of incorrectly predicted vowels for each class in its off-diagonal entries. The starting structure cannot perform the recognition task. Figure 3 (C and D) shows the final confusion matrices after optimization for the testing and training sets, averaged over five cross-validated training runs. The trained confusion matrices are diagonally dominant, indicating that the structure can indeed perform vowel recognition. More information on the training procedure and numerical modeling is provided in Materials and Methods.
Fig. 3. Vowel recognition training results.
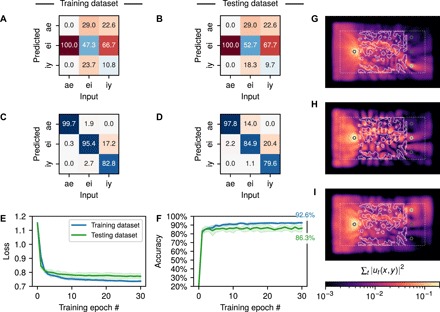
Confusion matrix over the training and testing datasets for the initial structure (A and B) and final structure (C and D), indicating the percentage of correctly (diagonal) and incorrectly (off-diagonal) predicted vowels. Cross-validated training results showing the mean (solid line) and SD (shaded region) of the (E) cross-entropy loss and (F) prediction accuracy over 30 training epochs and five folds of the dataset, which consists of a total of 279 total vowel samples of male and female speakers. (G to I) The time-integrated intensity distribution for a randomly selected input (G) ae vowel, (H) ei vowel, and (I) iy vowel.
Figure 3 (E and F) shows the cross-entropy loss value and the prediction accuracy, respectively, as a function of the training epoch over the testing and training datasets, where the solid line indicates the mean and the shaded regions correspond to the SD over the cross-validated training runs. We observe that the first epoch results in the largest reduction of the loss function and the largest gain in prediction accuracy. From Fig. 3F, we see that the system obtains a mean accuracy of 92.6 ± 1.1% over the training dataset and a mean accuracy of 86.3 ± 4.3% over the testing dataset. From Fig. 3 (C and D), we observe that the system attains near-perfect prediction performance on the ae vowel and is able to differentiate the iy vowel from the ei vowel but with less accuracy, especially in unseen samples from the testing dataset. Figure 3 (G to I) shows the distribution of the integrated field intensity, ∑t ut2, when a representative sample from each vowel class is injected into the trained structure. We thus provide visual confirmation that the optimization procedure produces a structure that routes most of the signal energy to the correct probe. As a performance benchmark, a conventional RNN was trained on the same task, achieving comparable classification accuracy to that of the wave equation. However, a larger number of free parameters were required. In addition, we observed that a comparable classification accuracy was obtained when training a linear wave equation. More details on the performance are provided in section S4.
DISCUSSION
The wave-based RNN presented here has a number of favorable qualities that make it a promising candidate for processing temporally encoded information. Unlike the standard RNN, the update of the wave equation from one time step to the next enforces a nearest-neighbor coupling between elements of the hidden state through the Laplacian operator, which is represented by the sparse matrix in Fig. 1E. This nearest-neighbor coupling is a direct consequence of the fact that the wave equation is a hyperbolic partial differential equation in which information propagates with a finite velocity. Thus, the size of the analog RNN’s hidden state, and therefore its memory capacity, is directly determined by the size of the propagation medium. In addition, unlike the conventional RNN, the wave equation enforces an energy conservation constraint, preventing unbounded growth of the norm of the hidden state and the output signal. In contrast, the unconstrained dense matrices defining the update relationship of the standard RNN lead to vanishing and exploding gradients, which can pose a major challenge for training traditional RNNs (27).
We have shown that the dynamics of the wave equation are conceptually equivalent to those of an RNN. This conceptual connection opens up the opportunity for a new class of analog hardware platforms, in which evolving time dynamics play a major role in both the physics and the dataset. While we have focused on the most general example of wave dynamics, characterized by a scalar wave equation, our results can be readily extended to other wave-like physics. Such an approach of using physics to perform computation (9, 28–32) may inspire a new platform for analog machine learning devices, with the potential to perform computation far more naturally and efficiently than their digital counterparts. The generality of the approach further suggests that many physical systems may be attractive candidates for performing RNN-like computations on dynamic signals, such as those in optics, acoustics, or seismics.
MATERIALS AND METHODS
Training method for vowel classification
The procedure for training the vowel recognition system was carried out as follows. First, each vowel waveform was downsampled from its original recording, with a 16-kHz sampling rate, to a sampling rate of 10 kHz. Next, the entire dataset of (3 classes) × (45 males + 48 females) = 279 vowel samples was divided into five groups of approximately equal size.
Cross-validated training was performed with four of the five sample groups forming a training set and one of the five sample groups forming a testing set. Independent training runs were performed with each of the five groups serving as the testing set, and the metrics were averaged over all training runs. Each training run was performed for 30 epochs using the Adam optimization algorithm (26) with a learning rate of 0.0004. During each epoch, every sample vowel sequence from the training set was windowed to a length of 1000, taken from the center of the sequence. This limits the computational cost of the training procedure by reducing the length of the time through which gradients must be tracked.
All windowed samples from the training set were run through the simulation in batches of nine, and the categorical cross-entropy loss was computed between the output probe probability distribution and the correct one-hot vector for each vowel sample. To encourage the optimizer to produce a binarized distribution of the wave speed with relatively large feature sizes, the optimizer minimizes this loss function with respect to a material density distribution, ρ(x, y), within a central region of the simulation domain, indicated by the green region in Fig. 2B. The distribution of the wave speed, c(x, y), was computed by first applying a low-pass spatial filter and then a projection operation to the density distribution. The details of this process are described in section S5. Figure 2D illustrates the optimization process over several epochs, during which the wave velocity distribution converges to a final structure. At the end of each epoch, the classification accuracy was computed over both the testing and training sets. Unlike the training set, the full length of each vowel sample from the testing set was used.
The mean energy spectrum of the three vowel classes after downsampling to 10 kHz is shown in Fig. 4. We observed that the majority of the energy for all vowel classes is below 1 kHz and that there is a strong overlap between the mean peak energy of the ei and iy vowel classes. Moreover, the mean peak energy of the ae vowel class is very close to the peak energy of the other two vowels. Therefore, the vowel recognition task learned by the system is nontrivial.
Fig. 4. Frequency content of the vowel classes.
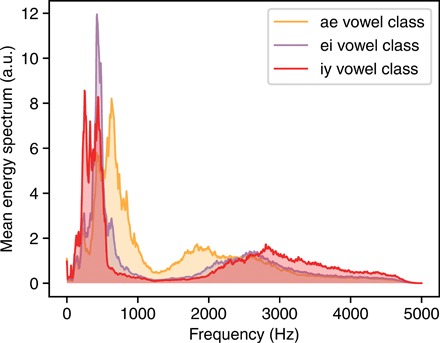
The plotted quantity is the mean energy spectrum for the ae, ei, and iy vowel classes. a.u., arbitrary units.
Numerical modeling
Numerical modeling and simulation of the wave equation physics were performed using a custom package written in Python. The software was developed on top of the popular machine learning library, PyTorch (33), to compute the gradients of the loss function with respect to the material distribution via reverse-mode automatic differentiation. In the context of inverse design in the fields of physics and engineering, this method of gradient computation is commonly referred to as the adjoint variable method and has a computational cost of performing one additional simulation. We note that related approaches to numerical modeling using machine learning frameworks have been proposed previously for full-wave inversion of seismic datasets (34). The code for performing numerical simulations and training of the wave equation, as well as generating the figures presented in this paper, may be found online at www.github.com/fancompute/wavetorch/.
Supplementary Material
Acknowledgments
Funding: This work was supported by a Vannevar Bush Faculty Fellowship from the U.S. Department of Defense (N00014-17-1-3030), by the Gordon and Betty Moore Foundation (GBMF4744), by a MURI grant from the U.S. Air Force Office of Scientific Research (FA9550-17-1-0002), and by the Swiss National Science Foundation (P300P2_177721). Author contributions: T.W.H. conceived the idea and developed it with I.A.D.W., with input from M.M. The software for performing numerical simulations and training of the wave equation was developed by I.A.D.W. with input from T.W.H. and M.M. The numerical model for the standard RNN was developed and trained by M.M. S.F. supervised the project. All authors contributed to analyzing the results and writing the manuscript. Competing interests: T.W.H., I.A.D.W., M.M., and S.F. are inventors on a patent application related to this work filed by Leland Stanford Junior University (no. 62/836328, filed 19 April 2019). The authors declare no other competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and/or the Supplementary Materials. Additional data related to this paper may be requested from the authors. The code for performing numerical simulations and training of the wave equation, as well as generating the figures presented in this paper are available online at www.github.com/fancompute/wavetorch/.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/5/12/eaay6946/DC1
Section S1. Derivation of the wave equation update relationship
Section S2. Realistic physical platforms and nonlinearities
Section S3. Input and output connection matrices
Section S4. Comparison of wave RNN and conventional RNN
Section S5. Binarization of the wave speed distribution
Fig. S1. Saturable absorption response.
Fig. S2. Cross-validated training results for an RNN with a saturable absorption nonlinearity.
Table S1. Comparison of a scalar wave model and a conventional RNN on a vowel recognition task.
References and Notes
- 1.Russakovsky O., Deng J., Su H., Krause J., Satheesh S., Ma S., Huang Z., Karpathy A., Khosla A., Bernstein M., Berg A. C., Fei-Fei L., Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115, 211–252 (2015). [Google Scholar]
- 2.I. Sutskever, O. Vinyals, Q. V. Le, Sequence to sequence learning with neural networks, in Advances in Neural Information Processing Systems, NIPS Proceedings, Montreal, CA, 2014. [Google Scholar]
- 3.Shainline J. M., Buckley S. M., Mirin R. P., Nam S. W., Superconducting optoelectronic circuits for neuromorphic computing. Phys. Rev. Appl. 7, 034013 (2017). [Google Scholar]
- 4.Tait A. N., Lima T. F. D., Zhou E., Wu A. X., Nahmias M. A., Shastri B. J., Prucnal P. R., Neuromorphic photonic networks using silicon photonic weight banks. Sci. Rep. 7, 7430 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Romera M., Talatchian P., Tsunegi S., Abreu Araujo F., Cros V., Bortolotti P., Trastoy J., Yakushiji K., Fukushima A., Kubota H., Yuasa S., Ernoult M., Vodenicarevic D., Hirtzlin T., Locatelli N., Querlioz D., Grollier J., Vowel recognition with four coupled spin-torque nano-oscillators. Nature 563, 230–234 (2018). [DOI] [PubMed] [Google Scholar]
- 6.Shen Y., Harris N. C., Skirlo S., Prabhu M., Baehr-Jones T., Hochberg M., Sun X., Zhao S., Larochelle H., Englund D., Soljačić M., Deep learning with coherent nanophotonic circuits. Nat. Photonics 11, 441–446 (2017). [Google Scholar]
- 7.Biamonte J., Wittek P., Pancotti N., Rebentrost P., Wiebe N., Lloyd S., Quantum machine learning. Nature 549, 195–202 (2017). [DOI] [PubMed] [Google Scholar]
- 8.Laporte F., Katumba A., Dambre J., Bienstman P., Numerical demonstration of neuromorphic computing with photonic crystal cavities. Opt. Express 26, 7955–7964 (2018). [DOI] [PubMed] [Google Scholar]
- 9.Lin X., Rivenson Y., Yardimci N. T., Veli M., Luo Y., Jarrahi M., Ozcan A., All-optical machine learning using diffractive deep neural networks. Science 361, 1004–1008 (2018). [DOI] [PubMed] [Google Scholar]
- 10.Khoram E., Chen A., Liu D., Ying L., Wang Q., Yuan M., Yu Z., Nanophotonic media for artificial neural inference. Photon. Res. 7, 823–827 (2019). [Google Scholar]
- 11.K. Yao, G. Zweig, M.-Y. Hwang, Y. Shi, D. Yu, Recurrent neural networks for language understanding (Interspeech, 2013), pp. 2524–2528; https://www.microsoft.com/en-us/research/publication/recurrent-neural-networks-for-language-understanding/.
- 12.Hüsken M., Stagge P., Recurrent neural networks for time series classification. Neurocomputing 50, 223–235 (2003). [Google Scholar]
- 13.Dorffner G., Neural networks for time series processing. Neural Net. World 6, 447–468 (1996). [Google Scholar]
- 14.Connor J. T., Martin R. D., Atlas L. E., Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 5, 240–254 (1994). [DOI] [PubMed] [Google Scholar]
- 15.Elman J. L., Finding structure in time. Cognit. Sci. 14, 179–211 (1990). [Google Scholar]
- 16.Jordan M. I., Serial order: A parallel distributed processing approach. Adv. Physcol. 121, 471–495 (1997). [Google Scholar]
- 17.I. Goodfellow, Y. Bengio, A. Courville, Deep Learning (MIT Press, 2016). [Google Scholar]
- 18.Ursell F., The long-wave paradox in the theory of gravity waves. Math. Proc. Camb. Philos. Soc. 49, 685–694 (1953). [Google Scholar]
- 19.R. W. Boyd, Nonlinear Optics (Academic Press, 2008). [Google Scholar]
- 20.T. Rossing, Springer Handbook of Acoustics (Springer Science & Business Media, 2007). [Google Scholar]
- 21.Hillenbrand J., Getty L. A., Clark M. J., Wheeler K., Acoustic characteristics of American English vowels. J. Acoust. Soc. Am. 97, 3099–3111 (1995). [DOI] [PubMed] [Google Scholar]
- 22.Ba A., Kovalenko A., Aristégui C., Mondain-Monval O., Brunet T., Soft porous silicone rubbers with ultra-low sound speeds in acoustic metamaterials. Sci. Rep. 7, 40106 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hughes T. W., Minkov M., Shi Y., Fan S., Training of photonic neural networks through in situ backpropagation and gradient measurement. Optica 5, 864–871 (2018). [Google Scholar]
- 24.Molesky S., Lin Z., Piggott A. Y., Jin W., Vucković J., Rodriguez A. W., Inverse design in nanophotonics. Nat. Photonics 12, 659–670 (2018). [Google Scholar]
- 25.Elesin Y., Lazarov B. S., Jensen J. S., Sigmund O., Design of robust and efficient photonic switches using topology optimization. Photonics Nanostruct. Fund. Appl. 10, 153–165 (2012). [Google Scholar]
- 26.D. P. Kingma, J. Ba, Adam: A method for stochastic optimization. arXiv:1412.6980 [cs.LG] (22 December 2014).
- 27.L. Jing, Y. Shen, T. Dubcek, J. Peurifoy, S. Skirlo, Y. LeCun, M. Tegmark, M. Soljačić, Tunable Efficient Unitary Neural Networks (EUNN) and their application to RNNs, Proceedings of the 34th International Conference on Machine Learning-Volume 70 (JMLR.org, 2017), pp. 1733–1741. [Google Scholar]
- 28.Silva A., Monticone F., Castaldi G., Galdi V., Alù A., Engheta N., Performing mathematical operations with metamaterials. Science 343, 160–163 (2014). [DOI] [PubMed] [Google Scholar]
- 29.Hermans M., Burm M., Van Vaerenbergh T., Dambre J., Bienstman P., Trainable hardware for dynamical computing using error backpropagation through physical media. Nat. Commun. 6, 6729 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Guo C., Xiao M., Minkov M., Shi Y., Fan S., Photonic crystal slab Laplace operator for image differentiation. Optica 5, 251–256 (2018). [Google Scholar]
- 31.Kwon H., Sounas D., Cordaro A., Polman A., Alù A., Nonlocal metasurfaces for optical signal processing. Phys. Rev. Lett. 121, 173004 (2018). [DOI] [PubMed] [Google Scholar]
- 32.Estakhri N. M., Edwards B., Engheta N., Inverse-designed metastructures that solve equations. Science 363, 1333–1338 (2019). [DOI] [PubMed] [Google Scholar]
- 33.A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, A. Lerer, Automatic differentiation in PyTorch, Workshop on Autodiff (NIPS, 2017).
- 34.A. Richardson, Seismic full-waveform inversion using deep learning tools and techniques. arXiv:1801.07232 [physics.geo-ph] (22 January 2018).
- 35.Oskooi A. F., Zhang L., Avniel Y., Johnson S. G., The failure of perfectly matched layers, and towards their redemption by adiabatic absorbers. Opt. Express 16, 11376–11392 (2008). [DOI] [PubMed] [Google Scholar]
- 36.W. C. Elmore, M. A. Heald, Physics of Waves (Courier Corporation, 2012). [Google Scholar]
- 37.Lamont M. R., Luther-Davies B., Choi D.-Y., Madden S., Eggleton B. J., Supercontinuum generation in dispersion engineered highly nonlinear (γ = 10 /W/m) As2S3 chalcogenide planar waveguide. Opt. Express 16, 14938–14944 (2008). [DOI] [PubMed] [Google Scholar]
- 38.Hartmann N., Hartmann G., Heider R., Wagner M., Ilchen M., Buck J., Lindahl A., Benko C., Grünert J., Krzywinski J., Liu J., Lutman A. A., Marinelli A., Maxwell T., Miahnahri A. A., Moeller S. P., Planas M., Robinson J., Kazansky A. K., Kabachnik N. M., Viefhaus J., Feurer T., Kienberger R., Coffee R. N., Helml W., Attosecond time–energy structure of x-ray free-electron laser pulses. Nat. Photonics 12, 215–220 (2018). [Google Scholar]
- 39.Jiang X., Gross S., Withford M. J., Zhang H., Yeom D.-I., Rotermund F., Fuerbach A., Low-dimensional nanomaterial saturable absorbers for ultrashort-pulsed waveguide lasers. Opt. Mater. Express 8, 3055–3071 (2018). [Google Scholar]
- 40.Christiansen R. E., Sigmund O., Experimental validation of systematically designed acoustic hyperbolic meta material slab exhibiting negative refraction. Appl. Phys. Lett. 109, 101905 (2016). [Google Scholar]
- 41.Pinton G. F., Dahl J., Rosenzweig S., Trahey G. E., A heterogeneous nonlinear attenuating full- wave model of ultrasound. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 56, 474–488 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Hochreiter S., Schmidhuber J., Long short-term memory. Neural Comput. 9, 1735–1780 (1997). [DOI] [PubMed] [Google Scholar]
- 43.J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv:1412.3555 [cs.NE] (11 December 2014).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/5/12/eaay6946/DC1
Section S1. Derivation of the wave equation update relationship
Section S2. Realistic physical platforms and nonlinearities
Section S3. Input and output connection matrices
Section S4. Comparison of wave RNN and conventional RNN
Section S5. Binarization of the wave speed distribution
Fig. S1. Saturable absorption response.
Fig. S2. Cross-validated training results for an RNN with a saturable absorption nonlinearity.
Table S1. Comparison of a scalar wave model and a conventional RNN on a vowel recognition task.