

Abstract
Cryo-electron microscopy (cryo-EM) has become a leading technology for determining protein structures. Recent advances in this field have allowed for atomic resolution. However, predicting the backbone trace of a protein has remained a challenge on all but the most pristine density maps (<2.5 Å resolution). Here we introduce a deep learning model that uses a set of cascaded convolutional neural networks (CNNs) to predict Cα atoms along a protein’s backbone structure. The cascaded-CNN (C-CNN) is a novel deep learning architecture comprised of multiple CNNs, each predicting a specific aspect of a protein’s structure. This model predicts secondary structure elements (SSEs), backbone structure, and Cα atoms, combining the results of each to produce a complete prediction map. The cascaded-CNN is a semantic segmentation image classifier and was trained using thousands of simulated density maps. This method is largely automatic and only requires a recommended threshold value for each protein density map. A specialized tabu-search path walking algorithm was used to produce an initial backbone trace with Cα placements. A helix-refinement algorithm made further improvements to the α-helix SSEs of the backbone trace. Finally, a novel quality assessment-based combinatorial algorithm was used to effectively map protein sequences onto Cα traces to obtain full-atom protein structures. This method was tested on 50 experimental maps between 2.6 Å and 4.4 Å resolution. It outperformed several state-of-the-art prediction methods including Rosetta de-novo, MAINMAST, and a Phenix based method by producing the most complete predicted protein structures, as measured by percentage of found Cα atoms. This method accurately predicted 88.9% (mean) of the Cα atoms within 3 Å of a protein’s backbone structure surpassing the 66.8% mark achieved by the leading alternate method (Phenix based fully automatic method) on the same set of density maps. The C-CNN also achieved an average root-mean-square deviation (RMSD) of 1.24 Å on a set of 50 experimental density maps which was tested by the Phenix based fully automatic method. The source code and demo of this research has been published at https://github.com/DrDongSi/Ca-Backbone-Prediction.
Subject terms: Computational science, Protein structure predictions, Cryoelectron microscopy
Introduction
Proteins perform a vast array of functions within organisms. From molecule transportation, to mechanical cellular support, to immune protection, proteins are the central building blocks of life in the universe1. Despite each protein being composed from a combination of the same 20 naturally occurring amino acids, a protein’s functionality is mainly derived from its unique three-dimensional (3D) shape. Therefore, learning the details of a protein’s 3D structure is a prerequisite to understanding its biological function.
Cryo Electron Microscopy (Cryo-EM)
Currently, one of the leading techniques for determining the atomic structure of proteins is cryo-electron microscopy (cryo-EM)2–4. Briefly, samples are fast frozen in liquid-nitrogen cooled liquid ethane and imaged in an electron microscope at cryogenic temperatures. When there are many identical copies of the macromolecule in the sample (different views of the macromolecule are present in the collected images), single particle reconstruction can be carried out to reconstruct the 3D density map of the macromolecules. A 3D density map is represented as values on a 3D grid. There is a density value associated with each voxel (volume pixel) of the map. When the copies of the macromolecule/assembly are different from each other, cryo-electron tomography (cryo-ET) can be carried out (the sample needs to be rotated and images at different rotating angles will be collected). Due to the averaging of many identical copies of the same macromolecule in single-particle reconstruction, the achieved resolution can be very high, even beyond 2 Å resolution5,6. In the past five years, more than 1,000 protein structures have been determined at 4 Å resolution or better in the EM databank using single-particle reconstruction7–11. The cryo-EM field is slowly moving to allow many high-resolution maps produced in one project or study12,13. Some of these studies involve very large protein assemblies of many subunits. Thus, a highly automated backbone generation method and software tool will be essential for further expanding the throughput of cryo-EM approach.
Protein backbone structure
From clean, high-resolution EM density maps (<5 Å) it is possible to distinguish the backbone structure of a protein14–16. A protein’s backbone is a continuous chain of atoms that runs throughout the length of a protein, see Fig. 1A. The backbone structure consists of a repeated sequence of three atom (nitrogen, alpha-carbon, carbon). Of these three atoms, the alpha-carbon (Cα) is particularly important as it is the central point for each amino acid residue within the protein. Therefore, predicting not only a protein’s backbone but also the locations of each Cα along that backbone can help determine where specific amino acids are located throughout the protein structure.
Figure 1.

Simulated density maps from protein 1aqh at different resolutions. (A) shows a high-resolution map (2.5 Å) with underlying backbone trace. (B) shows a medium-resolution map (4.5 Å) with underlying ribbon structure. α-helix structures are colored red, β-sheets are colored blue, and the loops/turns are colored yellow. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure51.
Protein secondary structure detection
In addition to the backbone features of a protein, some of the most visually dominate features of cryo-EM density maps are the secondary structure elements (SSEs), see Fig. 1B. The three SSEs are α-helices, β-sheets, and turns/loops. At medium resolution, α-helices appear as long cylinders with a radius of approximately 2.3 Å. β-sheets consist of multiple parallel beta strands that connect laterally by hydrogen bonds. While only distinguishable at 6 Å resolution or better, β-sheets appear as flat or slightly wavy sheets. Turns/Loops are the final SSE. They occur in locations where the polypeptide chain of the protein reverses its overall direction. When imaged with cryo-EM, turns/loops often appear faint due to their relatively low electron density. This makes them one of the most challenging SSE to classify. There are many methods for identifying SSEs at medium resolutions17–23. At near-atomic resolution, in general one can still easily recognize β-sheets and α-helix pitches.
Current protein prediction models
Ever since the first experimental density maps were released for protein structures, researchers have been developing software models to predict the various structural elements from each map. Some of the leading software models are now able to predict the atomic structure of a protein from its electron density map.
Phenix is a widely used macromolecular structure determination software suite that has often been used in research since its initial release in 200224. A recent 2018 paper introduced a new molecular prediction method that combined the Phenix prediction software along with advanced post-processing techniques25. This method, henceforth referred to as the Phenix method, produced some of the most-complete predicted protein structures. As a result, we used this method as a metrics benchmark for this research.
The Phenix method is a fully-autonomous prediction method which only requires a density map and a nominal resolution value as input. This method first sharpens the input density map using an automated map sharpening algorithm which aims to maximize the connectivity of high-density regions26. Then, for each part of the structure, various atomic structures are generated using several independent prediction models, including one for SSEs and one for backbone tracing, among others27–29. The results from these predictions are ensembled and used to produce an initial predicted structure. This structure is then refined using any symmetry that is present in the protein. The Phenix method was tested on 476 experimental density maps and has, to date, produced the most complete predicted structures. This method also uses a unique set of metrics to measure the effectiveness of the prediction method. The RMSD method uses a one-to-one mapping of predicted to ground-truth Cα atom but only includes atoms that are within 3 Å of the ground truth model. The ground truth is defined as the resolved atomic structure of a protein, which can be downloaded from the Protein Data Bank (PDB). To measure predicted structure completeness, the Phenix method calculates the percentage of matching Cα atoms between the predicted and ground-truth model within the same 3 Å space. We use the same metrics when evaluating our deep-learning prediction technique.
Rosetta de-novo is a protein modeling software tool first developed at the University of Washington. Rosetta de-novo employs a modeling technique which consists of two general components: conformation sampling and energy evaluation30,31. Conformational sampling uses well-established physical characteristics of molecular structure as guides for prediction. Examples of such characteristics include: the common torsion angles of atoms in the backbone structure, or the radius of α-helix secondary structures. Each of these structures has a very narrow band of potential values making them excellent constants to use when modeling protein structure. The energy evaluation process calculates the total energy of a predicted protein based on each predicted atom position along with each bonding angle between them. This value is compared to the expected lowest-energy state, which can be calculated from sequence information. Given that the lowest-energy state is likely closest to the native state of the protein, slight adjustments are made to the predicted protein structure to minimize the energy within its atomic structure thereby optimizing the predicted structure for the protein.
Another leading backbone prediction model is the MAINMAST algorithm developed by researchers at Purdue University32. MAINMAST produces a backbone trace, consisting of a set of Cα atoms, from high density regions of an electron density map. This algorithm first identifies regions of high-density (high-density points are likely to be backbone structure) using mean shifting and then transforms them into a minimum spanning tree (MST). A Tabu search algorithm is applied to find a few thousand possible MSTs. For each MST, the amino acid sequence is mapped on the longest path in the tree using areas of high density as likely Cα atom locations. Each MST is rated based on the best fit. The highest scoring tree is chosen as the final prediction of the protein structure.
In designing our experimental method, we leveraged techniques from each of these leading prediction methods. We employed a new conformational sampling technique similar to the Rosetta de-novo method. Our technique used constants such as: standardized distance between Cα atoms, mean α-helix radius, and common torsion angles between backbone atoms. Using these constants, we also invented a new Tabu-search scoring algorithm, similar to the one used in the MAINMAST method and our previous graph-based search33. Our Tabu-search was primarily used as a backbone path-walking algorithm. Finally, we employed the multi-prediction model approach of the Phenix method by creating a different CNN to predict the SSEs, backbone, and Cα atoms of each density map before stitching them together to form a final prediction map.
Deep learning semantic segmentation
This research aimed to use deep learning to create a predictive model capable of detecting the SSEs, backbone structure, and Cα atoms from electron density maps. The field of deep learning has proven to be very successful in the fields of image recognition and image classification34–36. This research used a specific image classification method known as semantic segmentation. With semantic segmentation each 2D-pixel or 3D-voxel of an image is classified independently rather than the entire image as a whole.
Until recently, semantic segmentation was accomplished through patch classification. Patch classification takes a slice of the input data and runs it through a convolution neural network (CNN). However, patch classification only classifies the center pixel of each patch meaning that the CNN would have to process a new patch for each pixel in the image. This technique is preferred when computing resources are limited because processing a small patch is much less computationally expensive than processing a full image.
However, with the recent advances in GPU technology, fully connected end-to-end networks are now able to perform semantic segmentation on full images in one pass. In 2014, research at UC Berkley used a Fully Convolutional Network (FCN) to perform semantic segmentation on the PASCAL-Context dataset37. Their method used an encoder-decoder architecture that removed the need for patch classification by essentially combining the calculations of the overlapping patch regions into a single end-to-end network. In 2015, the network Segnet aimed to improve the encoder-decoder architecture by forwarding the max-pooling indices from the encoder layer to the decoder layer to prevent the loss of global information in the image38. Later that year, researchers at Princeton University used a technique called dilated convolution which made it possible to perform semantic segmentation without the encoder-decoder architecture39. Dilated convolutions are preferred when a convolution needs to increase the field of view without reducing the resolution of the image. We attempted to use Segnet and other architectures but none of them produced high-quality results because they focused on different image features, instead of the protein backbone structure features and local Cα atom features in our problem.
In this paper, we leveraged the architecture of each of these semantic segmentation classifiers. Previous deep learning methods that were used for SSE prediction used patch classification. Our model levered the Fully Connected Network design to eliminate the need for patch classification and instead use semantic segmentation to classify a full 3D image in a single pass. It also used data forwarding, inspired by Segnet, to allow for segregated learning. Finally, this model used dilated convolutions to increase the field of view while maintaining the input image dimensionality.
Methods
Data collection/generation
Predictive models are only successful if they are trained with representative data. Since high-quality high-resolution experimental cryo-EM maps are still scarce, we trained our model using simulated cryo-EM maps instead of experimental maps. This design decision allowed us to utilize a large number of simulated data and save all the experimental maps for verification and final evaluation.
The experimental cryo-EM density maps and the corresponding PDB entries were downloaded from Electron Microscopy Data Bank (EMDB) for the purpose of final evaluation on experimental data. Simulated cryo-EM maps can be generated from PDB files using a script from the EMAN2 package called pdb2mrc40. This script takes each atom in a PDB file and produces a 3D Gaussian electron density (Gaussian is applied with the same width for every atom regardless of B-factors). It then sums the Gaussian density of all the simulated atoms on a 3D grid to produce a complete electron density map for the entire protein. This simulation method produces electron density maps that are very representative of their experimental counterparts with the primary difference being that a simulated map has no experimental inaccuracies.
To produce a large enough dataset for training, we used 7,024 PDB files to generate simulated density maps using the pdb2mrc script. Each map was simulated at a different resolution to produce a higher amount of variance in the training set and prevent overfitting in the model. When selecting PDB files, we considered proteins with sequence identity less than 35% to be in the training set. This ensured that our training data was diverse and well-representative of the large range of protein with different function or structure in nature, and it also prevent overfitting to specific structure. In addition to simulating the density maps, we also had to generate the labeled data for each map. This was done by editing the PDB file to retain only atoms that fit a specific label (e.g. Cα atoms or other backbone atoms) and then running pdb2mrc to produce a corresponding density map. This way we can create different density maps from a single PDB file representing the different types of atom that we want the model to predict.
The data generation pipeline is outlined in Fig. 2. The output of this pipeline was two HDF5 files: one training file and one validation file. The training data was used to train the neural network while the validation data was used to measure accuracy as the model was trained. Both the training and validation data sets were generated from simulated density maps. The test data, which this research used to measure the success of the trained model, consists of experimental density maps. Each test map was structurally unique relative to each protein in the training and validation data sets. The training and validation data were split randomly from the total 7,024 PDB files mentioned previously to form a five-fold cross validation. The validation set was reserved only for validating the model after each epoch to track training progress and prevent overfitting. We further increased the training data size using data augmentation (rotated by 0°, 90°, 180° and 270° to increase the training data size by 4x). Corresponding SSE, backbone, and Cα labeled maps for each protein were generated for each density map. All test maps were unique, and no map rotation was performed to increase the test data size.
Figure 2.

Simulated data generation pipeline including details about the data normalization process. The output of this pipeline was an HDF5 file containing all the data used to train the prediction model.
To ensure uniformity among each electron density map, extensive data normalization was used to produce a common input data format. There were five data normalization steps, see Fig. 2. First, all voxels with an electron density less than a threshold were zeroed out to remove low intensity noise. This removed low intensity areas of the simulated maps which differed significantly from their experimental counterparts. It also allowed the neural network to exclusively train with voxels of high-intensity, which are often more representative of protein structures. The third step of data normalization involved dividing all voxels by the median voxel value in the electron density map. This step normalized the voxel values and ensured that each map had a similar data range. After this, data outliers were removed by capping all voxels at the 98th-percentile voxel intensity. These high-intensity voxels were not consistent with any common molecular structure and often occurred as an artifact of the pdb2mrc simulation. We noticed that capping these extremely high values produced a higher prediction accuracy because it prevented the trained model from overemphasizing the inconsistent high-intensity voxels. Finally, each training map was copied and rotated by a varied angle to increase the total training data size.
Cascaded convolutional neural network
Building off the previous semantic segmentation convolutional neural networks, we designed a cascaded convolutional neural network (C-CNN) consisting of three feedforward dilated neural networks. The high-level architecture is shown in Fig. 3. This design allowed us to train all the neural networks simultaneously. The input to the C-CNN was a 64 × 64 × 64 tensor representing the 3D electron density of a protein. However, because density maps vary greatly in size across each dimension, an extra step was required before the model could process maps of a different size. Each map was split into 64 × 64 × 64 cubes that overlapped by 7 voxels on each face. Each cube was evaluated by the C-CNN independently and then the resulting output cubes were stitched back together to reconstruct the full image. However, only the center 50 × 50 × 50 voxels were used to reconstruct the image. At each face the 7-voxel overlap region was disregarded. This method allowed us to process density maps of any size without losing spatial information at each cube’s boundary.
Figure 3.

Cascaded Convolutional Neural Network. The input/output of each stage is shown as a gray cube with the given dimensions. Each CNN is represented by a tapered salmon rectangle. Results from each CNN are forwarded along with previous input data to the next CNN.
Inside the C-CNN, the input map was forwarded to each of the three neural networks. The first network was the SSE CNN. It predicted voxels as α-helices, β-sheets, or loops/turns and output a confidence map for each SSE. The three SSE maps along with the input electron density map were forwarded to the backbone CNN which produced two confidence maps representing whether each voxel was part of the backbone structure of the protein or not. The final CNN in the C-CNN was the Cα-Atom CNN. This network took all the previous maps and produced two output maps representing the confidence of a voxel being part of a Cα atom or not.
The paper is mainly focused on achieving an accurate prediction of the Cα atom locations. The backbone and SSE predictions are the intermediate steps to help the positioning of the Cα atoms. Therefore, their accuracy is relevant to the end result but not determinant. Since there are also other steps involved in the prediction, such as pre-processing and post-processing, that help improve the accuracy of Cα atom placements.
Convolutional neural network architecture
The three neural networks were very similar, each having the same number of layers and same type of layers. Their detailed structure is illustrated in Fig. 4. Each neural network had four layers. The first and fourth layers were regular 3-D convolutional layers with a stride of one. The second and third layers were dilated convolutions, also with a stride of one. Each dilated convolutional layer used a dilation rate of two. Following each dilated convolution was a leaky ReLU activation function. A leaky ReLU was preferred over a standard ReLU activation function in order to solve the dying ReLU problem41. Dilated convolutional layers were used to increase the receptive field while maintaining the image size. This is crucial for semantic segmentation because it maintains a one-to-one ratio of input voxel to output voxel.
Figure 4.

Detailed architecture of each of the 3D convolutional neural networks (CNN). (A) contains the Secondary Structure Elements (SSE) CNN. (B) contains the Backbone CNN. (C) contains the Cα-Atom CNN. Each CNN, including all its layers, are shown within the salmon colored boxes. The input to each CNN is noted by the yellow cubes. The Backbone CNN (B) and the Cα-Atom CNN (C) take input that is a contamination of various maps. The size of each input is noted by the dimensions listed at the base of each input cube. Each layer in each CNN is denoted by its name/function, kernel size (NxNxN), and finally the output number of filters (inside parenthesis) for that layer. Each leaky ReLU activation function used an alpha value of 0.1. The output of each CNN is noted by the purple cube. The dimensions for each output are listed at the base of the cube.
Each of the three neural networks used the same number of filters per layer for the first three layers: 1st layer: 32 filters, 2nd layer: 64 filters, and 3rd layer: 64 filters. The 4th and final layer differed for each network, but it was always equal to the number of output classes. Using more filters usually leads to higher accuracy. However, even a small increase from these numbers greatly slowed the network training. Therefore, we settled with these values as it was an optimal compromise between accuracy and speed. Other than the slight difference in filters per layer, the only other difference among the networks was a small difference in kernel size in the standard convolutional layers. The kernel size was larger (5 × 5 × 5 vs. 4 × 4 × 4) in the backbone and SSE CNNs to account for the need for a larger receptive field to better predict those structural elements.
End-to-end model pipeline
The cascaded convolutional neural network is only a piece of the full backbone prediction model. The full model is shown in Fig. 5. The primary input to the full model was an MRC file or MAP file containing a 3D tensor of the electron density of the protein. A threshold which was used to zero out low-density voxels and noises. Optionally, one could use hideDust in Chimera to remove density outliers. Selecting a proper threshold is challenging because each experimental density map is very different in intensity. However, the recommended contour level on the EM Databank is a good value to start with. The final output of the entire prediction model was a PDB file containing a set of traces where each trace is a set of connected Cα atoms. This PDB file also contains SSE labels for each Cα atom. These labels are determined from both the SSE output maps and the helix-refinement. Using the final output file the RMSD and the Percentage of Matched Cα atoms metrics were calculated.
Figure 5.

Full Backbone Prediction Model. Model includes data preprocessing, the cascaded convolutional neural network (after training), and post-processing.
Pre-processing
The goal of pre-processing experimental density maps before sending them into the cascaded convolutional neural network is to make them as similar as possible to the simulated maps that the C-CNN was trained with. Unlike simulated maps, experimental maps have large variance in local classified resolutions, electron density values, and molecular shapes. This can be attributed to the wide range in flexibility of biological molecules, cryo-EM imaging devices, different experimental procedures, and small natural artifacts that appear as part of the cryo-EM imaging process. Combined, these issues make experimental maps difficult to normalize.
The first step of the preprocessing was to filter the outliers if necessary (see supplementary for more details on cleaning the map). Once cleaned, the density map was resampled so that each dimension (x, y, z) had a voxel-size of exactly 1 Å. There is a wide range of voxel-sizes for each experimental map and many often have a different value for each axis. Therefore, resampling was crucial because the C-CNN was trained with simulated maps that had a voxel-size of exactly 1Å × 1Å × 1Å. This step was easily accomplished by using the UCSF Chimera tool along with the internal Chimera command vop resample.
After resampling, the new map was preprocessed using the method as outlined in Fig. 5.
Network output
After the C-CNN processed the input map it produced confidence maps for the protein’s SSEs, backbone, and Cα atom locations. The output maps for EMD-8410 (chain-A) are shown in Fig. 6. Each voxel in the map was assigned a confidence value by the network. The final classification of a voxel was determined by the max confidence value of each of the output maps for a given neural network.
Figure 6.
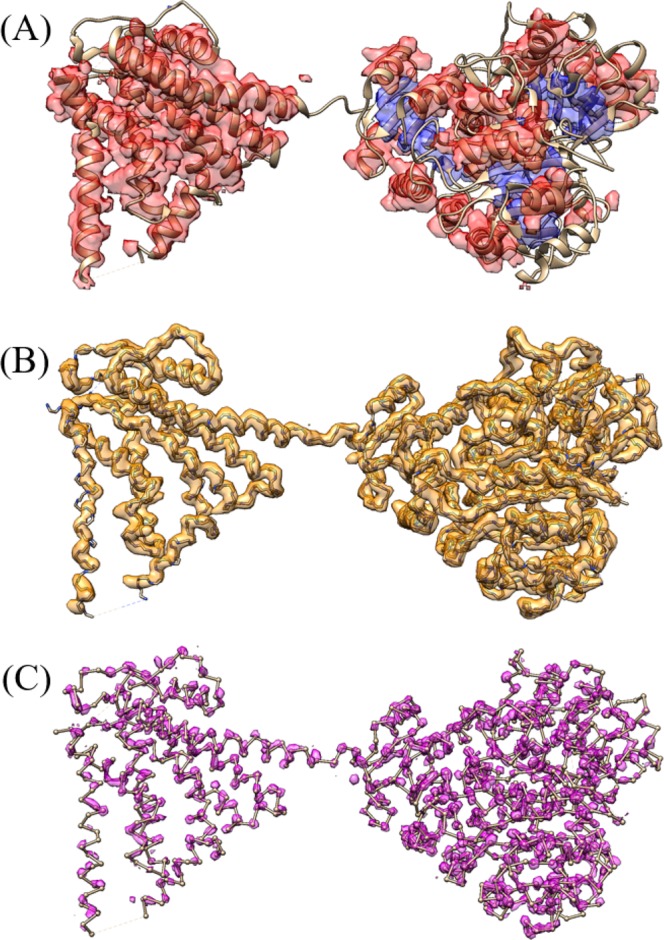
Confidence map output for EMD-8410 (chain-A). (A) is the combination of the α-helix and β-sheet prediction map after applying the max function, (loops/turns map omitted for readability). (B) is the backbone confidence map (>40% confidence) with the ground truth backbone structure shown for reference. (C) is the Cα-Atom confidence map (>50% confidence) with the ground truth ball and stick representation of EMD-8410 shown for reference. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Path-walking algorithm
Although the C-CNN assigns confidence values to specific features of the protein, post-processing algorithms were required to piece together that information and generate a final prediction trace. This was accomplished with a path-walking technique that processed the confidence maps to produce a final PDB file that contained exact Cα atom locations along the protein’s backbone.
The path-walking technique walked through high-confidence areas of the backbone map and connected areas of high Cα atom confidence using a novel tabu-search algorithm designed specifically for this research. The tabu-search algorithm scored each potential future movement based on a location’s local density prediction confidence and distance. Additionally, it also incorporated the backbone atom torsion angles and common radius of α-helix secondary structures as weights when finding the optimal next Cα atom.
The path-walking algorithm walked until it either reached an area of the protein that had already been processed or until it reached an area of the protein where no more suitable Cα atoms could be found. Upon reaching the end of a single trace, the path-walking algorithm would search the Cα confidence map for any other areas of the protein that might contain additional untraced Cα atoms and, if found, would walk each additional trace. This process was repeated until all high-confidence areas of the Cα prediction map had been explored. The output of the path-walking algorithm was a PDB file consisting of a series of disconnected traces where each trace contained a chain of Cα atoms.
Graph refinement
The disconnected traces from the path-walking algorithm represented partial backbone traces in the protein. However, there were many false positive traces that were the result of side chains and shortcuts between backbone structures being incorrectly classified as backbone traces. To remedy this issue, two refinement steps were required to improve the predicted traces: path combination and backbone refinement. In order to complete these two steps, the backbone traces were converted from a list of Cα locations and connections into a graph where each Cα atom was represented by a node and each connection to another Cα atom was represented by an edge.
The goal of the path combination step was to combine a set of disjoint graphs (formerly traces) into a fully connected graph that is more representative of the protein’s backbone structure. We used a depth first search to walk from any given Cα atom within a disjoint graph to both end points of that trace. Using these endpoints, this algorithm would then examine all other Cα nodes in the protein graph to determine if another Cα atom was within 3 Å of the end point Cα atom. If it was, then the end point Cα atom’s location was reassigned to be equal to the other Cα atom. This process helped combine neighboring disjoint graphs (traces) into a fully connected graph.
After path combination, the fully connected graph resembled a protein’s backbone structure, but it still had many side chain and backbone trace shortcut connections. These false-positive connections meant that many Cα nodes in the graph had three or even four edge connections to other Cα atoms. The next step in the graph refinement process was to remove the false-positive connections so that the remaining graph only contained true-positive Cα node and Cα edge connections. This refinement process was broken down into three steps: side chain removal, loop removal, dead-end point removal.
Side chain removal involved examining every Cα node in the graph to determine if it might be part of a false-positive side chain connection. If a node had three or more edges (trinary node), it was likely that one of the three edges was a side-chain connection. This algorithm would use a depth first search (DFS) to walk along each of the three paths leading from a trinary node and stop once it found either an ending node (only one edge), or another node with three or more edges. It would compare the total depth reached for each of the three DFS edge walks. If one path had a depth of three or less while the other two paths both had depths greater than the shortest path, then the shortest path was considered a side chain connection and removed from the graph. This algorithm proved to be very effective at removing side chain and false-positive shortcut connections between true parallel backbone traces.
After removing the side chains from the fully connected graph, it was necessary to remove small loops within the graph. These loops were the result of false-positive shortcut traces within α-helix elements of the protein. The goal of this method was to remove the false-positive half of each loop leaving the true backbone structure in place. The approach was similar to side chain removal. It would find any Cα nodes that contained three or more edges and then path walk each trace until it reached an end-node or trinary connection. However, in this case, if two paths terminated in the same trinary node then the combined two paths were considered a loop. To remove the false-positive side of the loop, this method would calculate the density along each path using a 1 Å radius cylinder and remove the path with the lower average density value. This approach made the assumption that the backbone structure of the protein had a higher density than another false-positive path.
The final step of the graph refinement process was to remove dead-end nodes. These resulted from side-chains that did not connect to another backbone trace of the protein but did nonetheless protrude off the true backbone structure. Removing these was accomplished by finding all trinary Cα nodes in the graph and then walking down each trace extending from that node. If any path had a depth of two or less and ended in a dead-end node then it was considered a side-chain and removed from the graph.
Helix refinement
In the final post-processing step, we tackled prediction inaccuracies for α-helix backbone structures. Due to their geometrical shape, the neural network had, in some cases, difficulties accurately predicting the location of Cα atoms belonging to an α-helix. In order to improve the prediction, we exploited the fact that the shape of an α-helix has a general definition which is valid across proteins42. Since the neural network predicted the confidence of secondary structure elements, as described in Network Output section, we know which Cα atoms belong to an α-helix based on the confidence of their region in space. We combined this knowledge of α-helix locations and their shape attributes in order to adjust the appropriate Cα atoms to better fit the shape of a natural α-helix structure.
For an α-helix which centers around the z-axis, we can use Eq. 1 to model its shape where the variables s and r represent the initial shift and rotation of the helix. The values 2.11 and 1.149 are constants that define the radius and pitch of the helix to best match those of an α-helix.
| 1 |
Equation 1 however, cannot be used to describe an α-helix which does not center around the z-axis or whose shape is not a straight cylinder. Since this is the case for most α-helices, it is necessary to adjust the equation in such way that it will address these issues. With the aim of doing so, we first locate the screw axis, the center line around which the helix winds itself, for each α-helix. This is achieved by calculating the centroid of consecutive intervals of the α-helix and then connecting them to approximate the true curve. An example of an α-helix and its calculated screw axis can be seen in Fig. 7.
Figure 7.
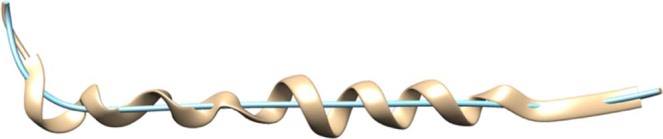
Alpha-helix extracted from the backbone prediction of the 5u70 protein map in tan color and its screw axis in teal color. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Now that we know the location and shape of the screw axis for the α-helix, we need to incorporate this information into Eq. 1. This is achieved by interpreting t as the distance that we travelled on the screw axis and use the unit direction vector of the screw axis at a certain point t as the new z axis. Next, we can find the new y-axis by calculating the cross product of the x-axis and the new z-axis and then normalizing it. Finally, we can get the new x-axis by calculating the cross product of the new z and y-axis and normalizing it again. By concatenating the three new axes we can get a rotation matrix RM with which we can calculate the point of the α-helix for any value t as shown in Eq. 2.
| 2 |
Now, we need to know the values t at which we have to insert Cα atoms. Since we know that an α-helix has a rise of 1.5 Å per residue42 we can increase t in steps of 1.5 and add a new Cα atom at α-helix(t).
In the final step we minimize the average distance from the Cα atoms of the refined α-helix to the Cα atoms of the original prediction. This is done by applying a minimization algorithm over the variables s and r to try different initial shifts and rotations. The final results of the α-helix refinement step are shown in Fig. 8.
Figure 8.
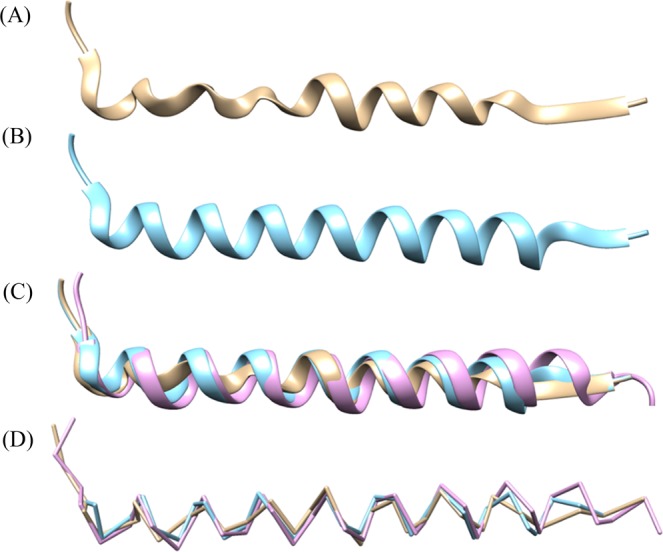
Alpha-helix extracted from the backbone prediction of the 5u70 protein density map. (A) Original prediction before the helix-refinement step. (B) Alpha-helix after the refinement. (C) Direct comparison of original prediction in tan color, refined prediction colored in teal, and the ground truth in pink color. (D) Direct comparison without ribbon. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Mapping protein sequences onto Cα traces
After an imperfectly reconstructed Cα trace is reconstructed, the next important problem is to assign amino acids in the protein sequence onto its correct location in the trace. This problem is non-trivial because a protein may have extra or disordered residues that do not have corresponding positions in the trace. Additionally, the trace contains noisy, false or missing Cα positions that do not match with residues in the protein well. Therefore, simply copying a protein sequence onto a Cα trace does not work. To address this challenge, we design a quality assessment-based combinatorial algorithm to map a protein sequence onto each reconstructed Cα trace from the previous steps.
As shown in Fig. 9, given the Cα trace of a target protein and its whole sequence, the algorithm first extracts all continuous Cα segments with length greater than a threshold (i.e. >50 residues). For each Cα trace segment, the full-atom structure including the position of backbone atoms and side-chain atoms is reconstructed by using Pulchra43 and Scwrl44 according to the Cα coordinate of each segment. For each segment, the structure of segment trace is aligned to different positions from N-terminal to C-terminal in the protein sequence to rebuild possible full-chain structures using comparative modeling method45. During the process, the structure of each segment is considered as a template structure so that the Cα coordinate information of segment trace can be directly transferred into full-length model according to the pairwise sequence alignment between segment sequence and protein sequence. Different pairwise sequence alignments are generated according to the different positions in the protein sequence that the segment trace is assigned to. The quality of the rebuilt full-chain structures, i.e. the fitness between the Cα trace and sub-regions in the full-length protein sequence, is assessed by a protein single-model quality assessment method Qprob46, which utilizes several structural and physicochemical features from feature-based probability density functions to predict the structure quality score (GDT-TS). Finally, the sequence region whose assigned structure has the best structural quality is selected to map to the Cα trace. The selected segments are evaluated one by one according to the segment size from largest to smallest to identify their best-matching sequence region. The Cα-trace of the current segment is aligned to those regions in protein sequence that has not been assigned to one of previous segments. The region with largest quality score is then selected for the current segment. For each segment, both forward direction and backward direction in the segment trace are examined by using the same protocol to assign protein sequence onto Cα traces.
Figure 9.

The algorithm of mapping a protein sequence onto a Cα trace. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Computation
The C-CNN was trained with 25,000 simulated protein maps, each with a size of 64 × 64 × 64 voxels. Training was accomplished with the Python TensorFlow Library on a Nvidia GTX 1070 GPU. Training was stopped after 15 epochs to prevent overfitting and took about 24 hours. Density map prediction, which involved running a preprocessed density map through the saved C-CNN only, was completed using the same GPU and took about 15 seconds to produce the five output prediction maps (three SSEs, backbone, and Cα atoms) for a map size of approximately 100 × 100 × 100 voxels. The path-walking algorithm was the most time-consuming aspect of the prediction process. A map of approximately 1000 Cα atoms took about 20 minutes to compute. All computation used a machine with an Intel 6 core i7-8700K CPU clocked at 3.7 GHz with 16GB of RAM. To increase throughput, batch predictions of multiple density maps were executed in parallel by spawning a new process for each map.
Results
This method was tested with both simulated and experimental maps. Simulated density maps were generated using Chimera’s molmap command with grid spacing of 1 at resolutions 3 Å, 4 Å, and 5 Å while experimental maps were downloaded from the EM Databank at various high resolutions. The experimental maps underwent the pre-processing steps as outlined in the previous section Pre-Processing before being evaluated.
Metrics
A variety of metrics were used to measure the effectiveness of our method. One primary metric was the root-mean-squared-deviation (RMSD) which measures the standard deviation of the distance between atoms in two structures. In this case, the two structures were the predicted Cα atoms and the ground truth Cα atoms as defined in the PDB file. The output from our model often consisted of partial backbone traces when the confidence was not high enough to form a complete backbone trace. With partial backbone traces it is difficult to use traditional RMSD algorithms to measure the effectiveness of a prediction method. As a result, we decided to follow the same calculation used by the fully autonomous Phenix method25 which compares each Cα atom in the ground truth structure to the closest Cα atom in the predicted structure using a one-to-one mapping. This RMSD method walks each predicted backbone trace and pairs it with the closest Cα atom in the ground truth structure. This produces slightly lower/better RMSD values than other methods because it allows for Cα skips in the ground truth backbone trace.
Another primary metric that we focus on in this research is the percentage of predicted Cα atoms within 3 Å (% Cα in 3 Å) of the ground truth structure. This metric is a good measure of prediction completeness because higher values mean that a higher percentage of the ground truth atoms were found. This metric is calculated in a similar way to the RMSD metric: by walking down each predicted trace and pairing each predicted Cα atom with its closest ground truth Cα atom. This metric requires a one-to-one mapping. We compare our results for this metric to the Phenix method which used the exact same metric and metric calculation method.
In addition to these metrics, we also include for each tested density map: the number of predicted Cα atoms, the number of actual Cα atoms, and the number of false positive Cα atoms.
Simulated density maps
Table 1 shows the results for seven simulated density maps. Each density map was generated from the Chimera’s molmap command at 3 Å, 4 Å, and 5 Å. (Please see supplementary Table S1 for 4 Å and 5 Å results.) We concluded that at a higher resolution our model got better RMSD scores on average while maintaining the percentage of Cα atoms being within 3 Å of a predicted Cα atom. This is a result of higher resolution density maps having much more dust (i.e. outliers) that we were able to eliminate through our preprocessing steps.
Table 1.
Results of simulated data at 3 Å resolution.
| PDB ID | Pred. Cα | Native Cα | RMSD (Å) | % Cα in 3 Å | FP% |
|---|---|---|---|---|---|
| 3i2n | 358 | 346 | 1.00 | 99.1 | 1.4 |
| 3n2t | 338 | 327 | 0.93 | 100.0 | 0.3 |
| 3qc7 | 173 | 172 | 0.98 | 95.9 | 0.0 |
| 5i68 | 669 | 662 | 0.84 | 99.5 | 1.0 |
| 6ahv | 349 | 345 | 0.83 | 100.0 | 0.0 |
| 6eyw | 388 | 381 | 0.97 | 99.0 | 0.8 |
| 6g61 | 117 | 111 | 0.96 | 100.0 | 1.7 |
| Avg. | 0.93 | 99.1 | 0.7 |
The simulated results proved to be very accurate relative to the true protein structure. With an average RMSD of 0.93 Å per Cα atom at 3 Å, 0.99 Å per Cα atom at 4 Å, and 0.97 Å per Cα atom at 5 Å. The predicted backbone structure was almost a perfect match to the true structure. Additionally, the predicted results produced nearly complete backbone traces as evident by an average of 99.1% of ground truth Cα atoms being within 3 Å of a predicted Cα atom for 3 Å resolution, 99.0% of ground truth Cα atoms being within 3 Å of a predicted Cα atom for 4 Å resolution, and 98.6% of ground truth Cα atoms being within 3 Å of a predicted Cα atom for 5 Å resolution. Finally, the false positive rate was very low for each prediction. This translates to a very high sensitivity for each prediction. Figure 10 shows the final prediction of both the Cα-only backbone structure along with the ribbon representation of 6eyw.
Figure 10.

Backbone prediction from the simulated 6eyw protein density map at 3 Å. Ground Truth is colored teal while the predicted structures are colored tan. (A) Contains the Cα only backbone structures with the input density map overlaid on the image for reference. (B) Displays the final ribbon prediction. The ribbon was enhanced using the secondary structure output maps from the Cascaded Convolutional Neural Network. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
The low RMSD values, minimal false positive Cα atoms, and high matching percentage of Cα atoms within 3 Å of the real structure demonstrates the effectiveness of this method with simulated density maps. However, these maps have the advantage over experimental maps in that they do not contain any experimental inaccuracies or real-world noise to distort the image. Additionally, these simulated maps were generated with Chimera’s molmap command which is based on pdb2mrc script that the training data was generated with. This means that the C-CNN likely learned local features of simulated maps very accurately and possibly overfit the data thereby leading to the high accuracy metrics.
Experimental density maps
The real test of our backbone prediction model involved experimental density maps which were evaluated using our backbone prediction model (Table 2). In order to test the model’s performance on maps at various high resolutions, we constructed the test set such that it would incorporate a range of resolutions from 2.6 Å to 4.4 Å. The protein structures deposited in PDB were used as the native reference structures. Note that many protein structures contain multiple chains. Table 2 tabulates the results for each experimental density map. Each density map was downloaded from the EM databank.
Table 2.
Backbone Cα atom prediction results from the evaluation of experimental density maps.
| EMDB ID | PDB ID | Res. (Å) | Pred. Cαa | Native Cαb | FP%c | % Cα in 3 Å | RMSD (Å) | Phenix % Cα in 3 Å | Phenix RMSD (Å) |
|---|---|---|---|---|---|---|---|---|---|
| 2513 | 4ci0 | 3.36 | 911 | 893 | 3.5 | 96.6 | 1.06 | 62.5 | 1.33 |
| 3061 | 5a63 | 3.4 | 1243 | 1223 | 3.0 | 95.6 | 1.10 | 73.9 | 1.15 |
| 3121 | 5aco | 4.36 | 2416 | 2415 | 10.4 | 83.4 | 1.45 | 57.0 | 1.63 |
| 3222 | 5flu | 3.8 | 1998 | 2119 | 1.1 | 86.6 | 1.60 | 62.0 | 1.76 |
| 3238 | 5fn3 | 4.1 | 1163 | 1318 | 3.6 | 79.5 | 1.48 | 56.1 | 1.50 |
| 3601 | 5n8o | 3.9 | 1416 | 1433 | 6.6 | 85.8 | 1.37 | 50.0 | 1.29 |
| 3785 | 5odv | 4.0 | 5415 | 4968 | 10.0 | 91.5 | 1.46 | 40.1 | 1.73 |
| 4054 | 5lij | 4.2 | 153 | 152 | 1.3 | 90.8 | 1.44 | 84.2 | 1.44 |
| 4062 | 5ljv | 3.64 | 2033 | 1950 | 3.8 | 95.8 | 1.10 | 48.3 | 1.21 |
| 4128 | 5lzp | 3.5 | 6007 | 6182 | 0.8 | 93.2 | 1.16 | 77.1 | 1.13 |
| 5623 | 3j9i | 3.3 | 5899 | 5978 | 0.8 | 95.9 | 1.05 | 72.4 | 0.87 |
| 5778 | 3j5p | 3.28 | 1875 | 2368 | 1.2 | 74.7 | 1.29 | 55.6 | 1.15 |
| 5995 | 3j7h | 3.2 | 4123 | 4088 | 1.5 | 96.9 | 1.10 | 72.9 | 1.12 |
| 6224 | 3j9c | 2.9 | 414 | 423 | 0.5 | 95.3 | 1.05 | 71.9 | 0.99 |
| 6239 | 3j9d | 3.3 | 754 | 746 | 1.9 | 98.1 | 1.01 | 74.8 | 0.99 |
| 6240 | 3j9e | 3.3 | 441 | 520 | 0.2 | 83.5 | 1.02 | 69.4 | 0.82 |
| 6272 | 3j9s | 2.6 | 394 | 397 | 0.0 | 99.0 | 0.85 | 88.9 | 0.69 |
| 6324 | 3ja7 | 3.6 | 4625 | 5136 | 2.0 | 83.2 | 1.30 | 69.4 | 1.13 |
| 6346 | 3jaf | 3.8 | 1629 | 1710 | 1.5 | 91.7 | 1.20 | 72.8 | 1.10 |
| 6408 | 3jb6 | 3.3 | 1727 | 1731 | 1.3 | 96.6 | 0.97 | 79.3 | 0.83 |
| 6488 | 3jby | 3.7 | 2021 | 1802 | 14.4 | 92.6 | 1.19 | 57.3 | 1.18 |
| 6551 | 3jcf | 3.8 | 1710 | 1745 | 1.3 | 93.8 | 1.17 | 74.2 | 1.15 |
| 6630 | 3jcz | 3.26 | 2844 | 2976 | 0.6 | 91.8 | 1.09 | 66.1 | 1.05 |
| 6631 | 3dj0 | 3.47 | 2802 | 2976 | 1.9 | 89.4 | 1.16 | 59.5 | 1.07 |
| 6676 | 5wq8 | 3.26 | 6320 | 7440 | 1.3 | 80.7 | 1.12 | 54.2 | 0.93 |
| 6703 | 5 × 58 | 3.2 | 2996 | 3159 | 5.2 | 84.5 | 1.31 | 53.1 | 1.27 |
| 6744 | 5xno | 3.5 | 1027 | 854 | 25.9 | 85.7 | 1.25 | 55.4 | 1.22 |
| 6770 | 5xsy | 4.0 | 1326 | 1312 | 7.4 | 88.7 | 1.32 | 68.5 | 1.21 |
| 7063 | 6b7n | 3.3 | 3009 | 2898 | 4.1 | 96.4 | 1.14 | 71.3 | 1.21 |
| 8015 | 5gaq | 3.1 | 2612 | 2592 | 0.5 | 99.0 | 0.91 | 79.2 | 1.1 |
| 8069 | 5i08 | 4.04 | 2816 | 2874 | 3.4 | 87.9 | 1.36 | 66.7 | 1.51 |
| 8072 | 5i68 | 3.37 | 686 | 662 | 3.4 | 94.9 | 1.14 | 84.6 | 1.07 |
| 8200 | 5k47 | 4.22 | 1809 | 1936 | 1.9 | 89.2 | 1.24 | 71.7 | 1.29 |
| 8331 | 5szs | 3.4 | 3911 | 3531 | 8.6 | 96.5 | 1.17 | 68.6 | 1.04 |
| 8405 | 5tfy | 3.4 | 3611 | 4264 | 1.9 | 82.5 | 1.20 | 70.7 | 1.25 |
| 8410 | 5tj6 | 3.5 | 886 | 890 | 2.6 | 95.3 | 1.09 | 67.6 | 1.07 |
| 8515 | 5u70 | 3.76 | 881 | 902 | 0.6 | 95.5 | 1.08 | 76.5 | 1.19 |
| 8637 | 5v6p | 4.1 | 482 | 540 | 3.5 | 79.6 | 1.47 | 80 | 1.37 |
| 8642 | 5v7v | 3.9 | 613 | 613 | 4.2 | 90.7 | 1.33 | 76.3 | 1.28 |
| 8651 | 5va2 | 3.8 | 453 | 558 | 2.6 | 75.1 | 1.50 | 69.7 | 1.43 |
| 8658 | 5vc7 | 3.9 | 2846 | 3264 | 3.4 | 80.3 | 1.48 | 68.2 | 1.49 |
| 8697 | 5vjh | 4.0 | 3091 | 3485 | 4.2 | 80.0 | 1.43 | 72.5 | 1.39 |
| 8712 | 5vms | 3.7 | 456 | 484 | 1.1 | 90.7 | 1.20 | 64.9 | 1.22 |
| 8764 | 5w3s | 2.94 | 1632 | 1940 | 3.4 | 77.5 | 1.14 | 66.6 | 0.97 |
| 8767 | 5w5f | 3.4 | 2928 | 2934 | 1.0 | 97.5 | 1.37 | 52.8 | 1.43 |
| 8782 | 5w81 | 3.37 | 1163 | 1173 | 5.2 | 89.8 | 1.48 | 66.7 | 1.38 |
| 8784 | 5w9i | 3.6 | 3553 | 3618 | 4.9 | 87.6 | 1.31 | 53.8 | 1.25 |
| 8794 | 5wc0 | 4.4 | 1459 | 1660 | 4.4 | 76.2 | 1.59 | 64.3 | 1.53 |
| 8882 | 5wpt | 3.75 | 1606 | 1816 | 2.2 | 83.5 | 1.15 | 68.5 | 1.02 |
| 9515 | 5gjw | 3.9 | 2337 | 2678 | 5.1 | 76.7 | 1.44 | 54.6 | 1.40 |
| Avg. | 3.7 | 88.9 | 1.24 | 66.8 | 1.22 |
Results from the Phenix method25 are listed alongside each evaluated map to compare the RMSD and % matching metrics of each method. Combined metrics for each method are plotted in Figs. 14 and 15. (Results are continued on the next page).
aThe number of Cα atoms modeled by our C-CNN method.
bThe number of Cα atoms in the ground-truth PDB structure.
cThe percentage of Cα atoms in the predicted structure that are more than 3 Å away from any ground-truth Cα atom.
Our results were compared to the fully automatic Phenix method25 in two categories: RMSD and % Cα Matching within 3 Å. The Phenix method results are listed alongside our results in Table 2. Both methods were tested on the same set of 50 experimental density maps.
The results on experimental data show that our method was very similar to the automatic Phenix method with respect to RMSD. Our C-CNN was able to achieve a mean RMSD of 1.24 Å while the Phenix method achieve a mean RMSD of 1.22 Å. Our method was able to produce a much higher average Cα percentage matching within 3 Å than the Phenix method (88.9% vs. 66.8%). Phenix’s RMSD calculation only considers predicted Cα atoms within 3 Å distance to the ground truth Cα atoms. Since our method predicted more Cα atoms within 3 Å. When we evaluate the results following Phenix’s method, the mean RMSD is similar but our average Cα matching percentage is much higher. This significant improvement is primarily a result of our method’s ability to predict backbone structure in relatively low-confident regions while the automatic Phenix made no prediction in these areas. By achieving similar RMSD metrics but improved Cα matching percentages our method has clearly demonstrated an improvement over the automatic Phenix method in terms of Cα/backbone prediction. Figure 11 shows the final predicted map for three experimental density maps using our deep learning method. Additional comparisons with Rosetta and MAINMST are included in Supplementary Tables S2 and S3.
Figure 11.

Backbone prediction for various density maps. (A) EMD-6272 (chain-A) at resolution 2.6 Å. (B) EMD-8410 (chain-A) at resolution 3.5 Å. (C) EMD-5778 (chain-A), resolution 3.3 Å. The left map in each subfigure contains the predicted vs. actual backbone structure. The right subfigure contains the predicted vs. actual ribbon structure of the protein which specify the SSE classification. The pink trace is the predicted structures while the blue trace is the actual structure. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Impact of Helix Refinement
In the Helix Refinement section we discussed the final post-processing step which was responsible for adjusting predicted α-helices to model the true structure of an α-helix. The refinement step improved the percentage of Cα atoms predicted within 3 Å of their actual location by 0.6% and the average RMSD value by 0.01 from 1.25 to 1.24. In this section we want to highlight specific protein maps where the helix refinement yielded significantly improved results. In Table 3 we can see a comparison of results before and after the application of the helix refinement.
Table 3.
Results from the evaluation of experimental density maps before and after the helix refinement was applied.
| EMDB ID | RMSD before refinement | RMSD after refinement | % Cα in 3 Å before refinement | % Cα in 3 Å after refinement |
|---|---|---|---|---|
| 8637 | 1.71 | 1.47 | 68.5 | 79.6 |
| 3238 | 1.52 | 1.48 | 77.2 | 79.5 |
| 6744 | 1.28 | 1.25 | 85.2 | 85.7 |
| 8200 | 1.27 | 1.24 | 86.0 | 89.2 |
| 8405 | 1.20 | 1.20 | 82.1 | 82.5 |
From Table 3 we can see that the helix refinement was particularly effective in increasing the percentage of Cα atoms predicted within 3 Å of their actual location with up to ~11% in the case of the EMD-8637 map. In Fig. 12 we can see a comparison before and after the helix refinement step for this map. Improvements in RMSD values were less significant, especially if we consider all test results. This can be attributed to the number of Cα atoms originally predicted within α-helices which is almost always lower than the actual number of Cα atoms. This means that the average inaccuracy in α-helices, which is usually high, has less of an impact to the overall average RMSD value. In the helix refinement process new Cα atoms are added to the predicted α-helices in an attempt to approximate their true structure. As a result, the average RMSD value within the α-helix improves. However, since there are now more Cα atoms belonging to the α-helices, their average inaccuracy has a larger impact to the overall average RMSD dampening improvements.
Figure 12.
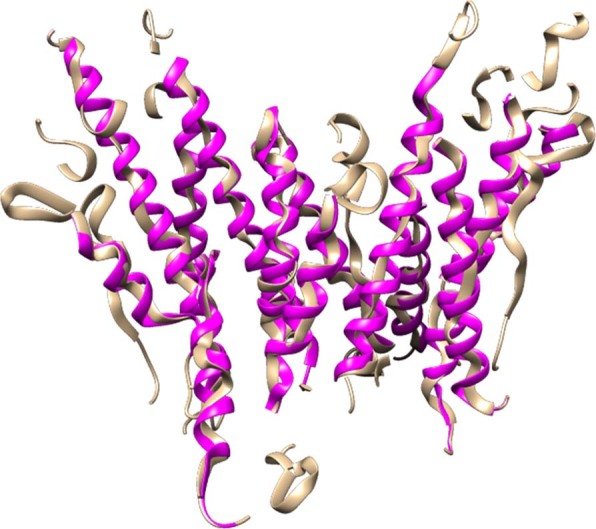
Comparison of predicted structure for EMD-8637 before the helix refinement step in tan color and after the refinement in pink color. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Comparison of prediction methods
As introduced in the Current Protein Prediction Models section, there are three other leading backbone prediction methods: Phenix, MAINMAST, and Rosetta de-novo. We compared our deep learning method to the other leading prediction methods by evaluating on EMD-6272. The predicted structures for each method are shown in Fig. 13. Additional comparisons on simulated and experimental maps, version and detail usage of other tools could be found at the end of supplementary document.
Figure 13.

Final predicted structure for EMD-6272. (A) The ground truth structure. Each figure overlays the input density map on top of the predicted structure. (B) Our method. (C) Automatic Phenix method. (D) Rosetta de-novo. (E) MAINMAST. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Table 4 compares the prediction metrics of all four prediction methods on EMD-6272. The Rosetta de-novo model produced a relatively accurate structure in terms of RMSD but it was only able to predict 64.0% of the Cα atoms from the ground-truth structure. The MAINMAST method, which only predicts backbone structure and not SSEs, has the highest RMSD of 1.55 Å. Among the three former prediction methods the Phenix method performed well in percentage of matching Cα atom and has the lowest RMSD, but produced a higher false positive Cα atom percentage. Our deep-learning method produced much higher percent Cα atom matching (99.0%), a lower RMSD of 0.85 Å and the lowest false positive rate compare with the other three prediction methods.
Table 4.
Comparison of EMD-6272 among leading backbone prediction methods.
| Method | % Cα in 3 Å | RMSD (Å) | FP% |
|---|---|---|---|
| Our method | 99.0 | 0.85 | 0.0 |
| Phenix | 88.9 | 0.69 | 3.0 |
| MAINMAST | 89.7 | 1.55 | 0.3 |
| Rosetta de-novo | 64.0 | 0.84 | 1.9 |
Each method had specific strengths, however the our deep learning method produced the most complete structure as measured by the Cα matching percentage.
Computation time of prediction models
While our C-CNN model took about 24 hours to train on a single machine with a GTX 1070 GPU, after the training had completed, the full end-to-end prediction for a density map with approximately 1000 Cα Atoms took about 20 minutes to complete. The C-CNN prediction software was running on the same GTX 1070 GPU with a single CPU core. In contrast, the existing methods usually required a lot of computing resources and were also very time-consuming. In our experiments, Rosetta de-novo took 5 days with 20 CPUs to complete, MAINMAST finished in about 18 hours with 1 CPU, and Phenix method took several hours with 6 CPUs.
Comparison of Deep-Learning C-CNN and the fully automatic phenix method
The results for each density map in Table 2 are plotted and shown in Figs. 14 and 15. Figure 14 plots the RMSD vs. the labeled resolution for each density map. The mean RMSD of our deep-learning method was 1.24 Å which is similar to the Phenix method’s RMSD of 1.22 Å for the same set of experimental density maps. Figure 14 shows that the performance of our deep-learning method was very similar to the Phenix method across all resolution values. Figure 14 also clearly shows how the RMSD for both prediction methods increased as a function of the labeled resolution. This is to be expected as higher resolution maps usually have better defined structure to aid the prediction models.
Figure 14.
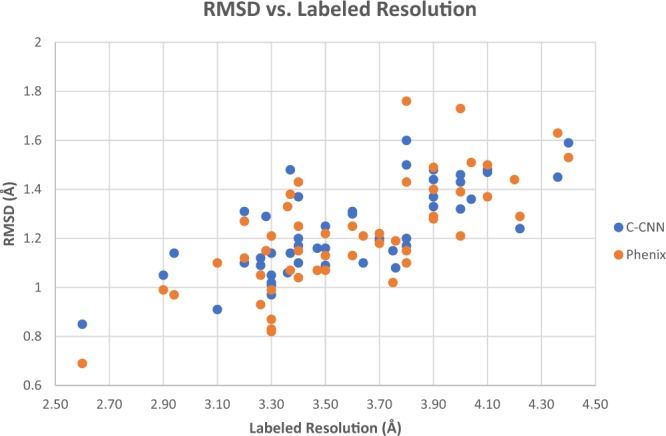
Plot of RMSD as a function of resolution for the 50 experimental density maps. This compares our deep learning C-CNN method and the fully automatic Phenix Method.
Figure 15.
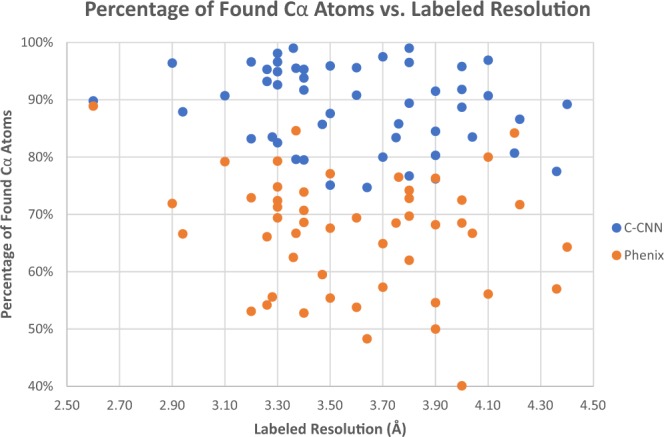
Plot of Percentage of Found Cα atoms as a function of resolution for the 50 experimental density maps. This compares our deep learning C-CNN method and the fully automatic Phenix Method.
Figure 15 plots the percentage of matching Cα atoms vs. labeled resolution of each density map for both the C-CNN method and the Phenix method. This figure shows how our deep-learning method found a higher percentage of Cα atoms than the Phenix method across all resolutions. Our method found a mean of 88.9% of the Cα atoms for the 50 experimental density maps. This is significantly better that the Phenix method which only found a mean of 66.8% Cα atoms from the same 50 experimental maps.
Evaluating the results of mapping protein sequences onto Cα traces
To validate the effectiveness of our sequence-to-trace mapping algorithm, we evaluated the structural similarity between the predicted structure of the Cα-trace segment and its real structure for the mapped sequence fragment in the known experimental structure of the protein in terms of the TM-score and GDT-TS metrics. TM-score47 and GDT-TS48 are two structural similarity measurements with values in (0, 1], where higher value indicates better accuracy and 1 means the perfect match between two protein structures. The two metrics measure the match of the residues with Cα-atom distances within a certain distance cutoff of their positions in two structures for the same protein sequence, which is suitable for the method evaluation in our study. A perfect Cα trace segment matched with a completely correct sequence fragment will match perfectly with its corresponding counterpart in the experimental structure, leading to a prefect similarity score (TM-score or GDT-TS) of 1, otherwise a score between 0 and 1. We validated our mapping algorithm on fragment traces derived from three experimental density maps (EMD-6272, EMD-5778 and EMD-8410), and seven simulated density maps. For EMD-6272, our method predicts one Cα trace segment (397 residues) that is well mapped by the sequence, and has a TM-score of 0.932 and a GDT-TS of 0.809. The alignment of the mapped structure of the segment with its counterpart, which was superimposed by the sequence-dependent alignment program – TM-score, is illustrated in Fig. 16(A). For EMD-5778, the longest Cα trace segment (329 residues) among the predicted Cα segments is well mapped by the sequence segment and has a TM-score of 0.702 and a GDT-TS of 0.509 as shown in Fig. 16(B). The TM-score of the second mapped Cα segment is 0.402, suggesting its incorrect topology when the TM-score is less than 0.5. The structural errors result from either the noise in the Cα trace or inaccuracy of the mapping algorithm, or both factors. For EMD-8410, the longest Cα trace segment (483 residues) is mapped reasonably well, which has a TM-score of 0.786. However, the other mapped Cα trace segments have TM-scores below the 0.5, indicating the structures are not predicted correctly. The superposition of the mapped structure and its counterpart for the longest trace of EMD-8410 is illustrated in Fig. 16(C). The analysis demonstrates that our mapping strategy is able to identify the correct sequence fragment for the Cα trace if the segment is well predicted by C-CNN and long enough for mapping sequence to structure using quality assessment methods. We also compared our final predicted structures with the predictions of three top-performance methods: Phenix, Rosetta-denovo, and MAINMAST, and the results were summarized in Table S4 for simulated data and Table S5 for experimental data.
Figure 16.

(A) Visualization of superposition between the mapped Cα Segment 1 of EMD-6272 (brown) and its counterpart in the experimental structure (blue). “:” in the sequence-dependent structure alignment denotes the residue pairs whose distance is less than 5 Angstrom. (B). Visualization of superposition between the mapped Cα Segment 1 of EMD-5778(brown) and its counterpart in the experimental structure (blue). “:” in the sequence-dependent structure alignment denotes the residue pairs whose distance is less than 5 Angstrom. (C). Visualization of the superposition between the mapped Cα segment 1 of EMD-8410 (brown) and its counterpart experimental structure (blue). “:” denotes the residue pairs of distance is less than 5 Angstrom. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Discussion
False positive Cα error rate
The RMSD metric in conjunction with the percentage of matching Cα metric is useful to determine the accuracy of Cα atom placements that are in-line with Cα atoms within the ground truth structure. However, as is often the case with backbone prediction, side-chains or other noise in a density map will appear as backbone structure to a prediction model. This can cause the model to produce false positive Cα atoms that are clearly not in alignment with the true backbone structure of the protein, see Fig. 17. An effective prediction model will limit the number of false positive Cα atoms by correctly distinguishing side-chains or other noise from the true backbone structure and not place Cα atoms in these areas. In this research, we measure the number of false positive Cα atom for each density map which is listed in Tables 1 and 2. A false positive is defined as any Cα atom that is placed more than 3 Å from any Cα atom within the ground truth structure.
Figure 17.

Ball and stick representation of the predicted structure (pink) and the ground truth structure (blue) of EMD-8642, resolution 3.9 Å. This map had a relatively low RMSD value of 1.33 Å but also had a false positive Cα rate of 4.2%. The expanded areas show examples of side chains that were incorrectly predicted as backbone structure resulting in false-positive Cα placements. UCSF Chimera v1.13 (www.cgl.ucsf.edu/chimera) was used to create this figure.
Normalizing the number of false positive Cα atoms by the size of a protein produces a false positive rate for Cα atom placement. This is called the Cα atom error rate. This metric can be derived from the number of false-positive Cα atoms and the total number of predicted Cα atoms, see Eq. 3.
| 3 |
Figure 18 plots the Cα atom error rate as a function of resolution for the 50 experimental density maps evaluated by our model. The error rate of Cα atom prediction is inversely related to the labeled resolution of a density map. However, our deep learning model produced a relatively low error rate (<~5%) for most density maps with a labeled resolution value of 3.3 Å or better. The error rate of density maps with a lower resolution than 3.3 Å had a high variance and thus had lower prediction confidence.
Figure 18.
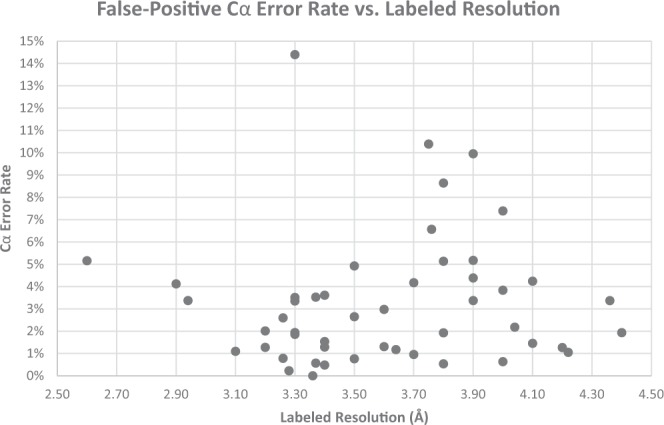
Error-rate vs. resolution for each experimental density map.
Future improvements
We found during development that the biggest improvements in accuracy came as the result of adding more convolutional neural networks to the C-CNN. Originally, this method used only one network, the Cα-Atom prediction network. It was only after adding the SSE and Backbone CNNs that we were able to achieve the results outlined in this paper. Future work might be able to incorporate other Deep Learning techniques into the C-CNN such as structural learning, amino acid network or atom network. Adding these networks might also help match the protein sequence to the density map.
As the number of publicly available experimental density maps continues to grow, it may become possible to train neural networks using experimental data instead of simulated data in the future. Our research utilized a large number of simulated data to train the network, but experimental training data may improve results further. This change would give the model a wider, more representative data set to train with and could potentially enable the model to recognize various patterns of noise. Also, by adding an additional 1 × 1 scalar input to the network to denote the resolution of an experimental map, the C-CNN could train to differentiate between map resolution. This change would allow the network to learn each resolution with more independence.
Similar to other methods, a selected threshold value is required to normalize each experimental density map before evaluating it. We have shown that the structure prediction accuracy is only affected by the selected threshold to a limited extend (Supplementary Table S6). We recently developed an automatic method which use traits such as map surface area or resolution to automatically estimate a threshold value for density map49.
There are still many challenges that exist in experimental cryo-EM data processing. For example, local resolution or local density quality issues, resolution validation and verification issues50, and many more. We believe further investigations and research in the related fields will make the atomic structure prediction from cryo-EM more accurate and promising.
Conclusion
In summary, we presented an effective method for protein backbone prediction from high resolution cryo-EM density maps using deep learning. This approach used three cascaded convolutional neural networks to produce confidence maps for some of the major structural components of proteins. These confidence maps were processed using a variety of novel method including a Tabu-search path-walking algorithm to construct backbone traces and a helix-refinement step to improve the structure of α-helices. Additionally, a new protein sequence mapping algorithm was used to build up full atomic structures. Our method out-performed the Phenix based fully automatic structure building method by producing backbone traces that were more complete (88.9% vs. 66.8%) as measured by percentage of matching Cα atoms. Further research may improve this research field by incorporating other structural aspects of protein molecules within the cascaded convolutional neural network or training the networks with experimental data.
Supplementary information
Acknowledgements
This research was funded by the Graduate Research Award of Computing and Software Systems division and the startup fund 74-0525 of the University of Washington Bothell. We gratefully acknowledge the support of NVIDIA Corporation (Santa Clara, CA, USA) with the donation of the GPU used for this research. We thank Michael Ryan Harlich for assistance and comments that improved the manuscript. Molecular graphics and analyses performed with UCSF Chimera, developed by the Resource for Biocomputing, Visualization, and Informatics at the University of California, San Francisco, with support from NIH P41-GM103311.
Author contributions
Conceptualization: D.S. Data curation: S.M., J.P., J.H. and D.S. Formal analysis: D.S., S.M., J.P., J.H. and R.C. Funding acquisition: D.S. Investigation: D.S., S.M., J.P., J.H. and T.W. Methodology: D.S. and S.M. Project administration: D.S. Resources: D.S. and J.C. Software: D.S., S.M., J.P., J.H., T.W. and J.C. Supervision: D.S. Validation: J.P., J.H., R.C. and D.S. Visualization: S.M. and J.P. Writing – original draft: D.S., S.M., J.P., T.W. and L.W. Writing – review & editing: D.S., J.P., R.C. and L.W.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
is available for this paper at 10.1038/s41598-020-60598-y.
References
- 1.Berg, J. M. et al. Biochemisty: International version (hardcover). (W. H. Freeman, New York, 2002).
- 2.Bai XC, McMullan G, Scheres SH. How cryo-EM is revolutionizing structural biology. Trends in Biochemical Sciences. 2015;40(1):49–57. doi: 10.1016/j.tibs.2014.10.005. [DOI] [PubMed] [Google Scholar]
- 3.Nogales E, Scheres SH. Cryo-EM: A Unique Tool for the Visualization of Macromolecular Complexity. Molecular Cell. 2015;58(4):677–689. doi: 10.1016/j.molcel.2015.02.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Wang L, Sigworth FJ. Cryo-EM and single particles. Physiology. 2006;21(1):13–18. doi: 10.1152/physiol.00045.2005. [DOI] [PubMed] [Google Scholar]
- 5.Merk A, et al. Breaking Cryo-EM Resolution Barriers to Facilitate Drug Discovery. Cell. 2016;165(7):1698–1707. doi: 10.1016/j.cell.2016.05.040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Bartesaghi A, et al. Atomic Resolution Cryo-EM Structure of beta-Galactosidase. Structure. 2018;26(6):848–856. doi: 10.1016/j.str.2018.04.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Liao M, Cao E, Julius D, Cheng Y. Structure of the TRPV1 ion channel determined by electron cryo-microscopy. Nature. 2013;504:107–112. doi: 10.1038/nature12822. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Yan Z, et al. Structure of the rabbit ryanodine receptor RyR1 at near-atomic resolution. Nature. 2015;517:50–55. doi: 10.1038/nature14063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Hite RK, et al. Cryo-electron microscopy structure of the Slo2. 2 Na+-activated K+ channel. Nature. 2015;527:198–203. doi: 10.1038/nature14958. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Hite RK, MacKinnon R. Structural Titration of Slo2.2, a Na(+)-Dependent K(+) Channel. Cell. 2017;168(3):390–399. doi: 10.1016/j.cell.2016.12.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Tao X, Hite RK, MacKinnon R. Cryo-EM structure of the open high-conductance Ca 2+-activated K+ channel. Nature. 2017;541:46–51. doi: 10.1038/nature20608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Zhang K, et al. Cryo-EM structures of Helicobacter pylori vacuolating cytotoxin A oligomeric assemblies at near-atomic resolution. PNAS. 2019;116(14):6800–6805. doi: 10.1073/pnas.1821959116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Dong, Y. et al. Cryo-EM structures and dynamics of substrate-engaged human 26S proteasome. Nature565 (7737) (2019). [DOI] [PMC free article] [PubMed]
- 14.Domanska A, et al. A 2.8-angstrom-resolution cryo-electron microscopy structure of human parechovirus 3 in complex with Fab from a neutralizing antibody. Journal of virology. 2019;93(4):e01597–18. doi: 10.1128/JVI.01597-18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Martynowycz, M. W. et al. Collection of Continuous Rotation MicroED Data from Ion Beam-Milled Crystals of Any Size. Structure (2019). [DOI] [PMC free article] [PubMed]
- 16.Zhu L, et al. Structures of Coxsackievirus A10 unveil the molecular mechanisms of receptor binding and viral uncoating. Nature communications. 2018;9(1):4985. doi: 10.1038/s41467-018-07531-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Si D, Ji S, Nasr KA, He J. A Machine Learning Approach for the Identification of Protein Secondary Structure Elements from Electron Cryo‐Microscopy Density Maps. Biopolymers. 2012;97(9):698–708. doi: 10.1002/bip.22063. [DOI] [PubMed] [Google Scholar]
- 18.Li, R., Si, D., Zeng, T., Ji, S. & He, J. Deep convolutional neural networks for detecting secondary structures in protein density maps from cryo-electron microscopy, presented at 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 2016 (unpublished). [DOI] [PMC free article] [PubMed]
- 19.Si, D. & He, J. Combining image processing and modeling to generate traces of beta-strands from cryo-EM density images of beta-barrels, presented at 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, 2014 (unpublished). [DOI] [PubMed]
- 20.Palu, A. D., He, J. & Pontelli, E. Identification of α-helices from low resolution protein density maps, presented at Computational Systems Bioinformatics, 2006 (unpublished). [PubMed]
- 21.Si, D. & He, J. Beta-sheet Detection and Representation from Medium Resolution Cryo-EM Density Maps, presented at In Proceedings of the International Conference on Bioinformatics, Computational Biology and Biomedical Informatics, 2013 (unpublished).
- 22.Si D, He J, Si D, Jing H. Tracing beta strands using StrandTwister from cryo-EM density maps at medium resolutions. Structure. 2014;22(11):1665–1676. doi: 10.1016/j.str.2014.08.017. [DOI] [PubMed] [Google Scholar]
- 23.Ng, A. & Si, D. Beta-Barrel Detection for Medium Resolution Cryo-EM Density Maps using Genetic Algorithms and Ray Tracing. Journal of Computational Biology, 326–336. 10.12017.0155 (2018). [DOI] [PubMed]
- 24.Adams, P. D. et al. PHENIX: building new software for automated crystallographic structure determination. Acta Crystallographica Section D: Biological Crystallography58 (1) (2002). [DOI] [PubMed]
- 25.Terwilliger TC, Adams PD, Afonine PV, Sobolev OV. A fully automatic method yielding initial models from high-resolution electron cryo-microscopy maps. Nature methods. 2018;15(11):905–908. doi: 10.1038/s41592-018-0173-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Terwilliger Thomas C., Sobolev Oleg V., Afonine Pavel V., Adams Paul D. Automated map sharpening by maximization of detail and connectivity. Acta Crystallographica Section D Structural Biology. 2018;74(6):545–559. doi: 10.1107/S2059798318004655. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Terwilliger TC. Rapid model building of α-helices in electron-density maps. Acta Crystallographica Section D: Biological Crystallography. 2010;66(3):268–275. doi: 10.1107/S0907444910000314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Terwilliger TC. Automated main-chain model building by template matching and iterative fragment extension. Acta Crystallographica Section D. 2003;59(1):38–44. doi: 10.1107/S0907444902018036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Terwilliger TC. Rapid chain tracing of polypeptide backbones in electron-density maps. Acta Crystallographica Section D: Biological Crystallography. 2010;66(3):285–294. doi: 10.1107/S0907444910000272. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Wang Ray Yu-Ruei, Kudryashev Mikhail, Li Xueming, Egelman Edward H, Basler Marek, Cheng Yifan, Baker David, DiMaio Frank. De novo protein structure determination from near-atomic-resolution cryo-EM maps. Nature Methods. 2015;12(4):335–338. doi: 10.1038/nmeth.3287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Song Yifan, DiMaio Frank, Wang Ray Yu-Ruei, Kim David, Miles Chris, Brunette TJ, Thompson James, Baker David. High-Resolution Comparative Modeling with RosettaCM. Structure. 2013;21(10):1735–1742. doi: 10.1016/j.str.2013.08.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Terashi, G. & Kihara, D. De novo main-chain modeling for EM maps using MAINMAST. Nature (2018). [DOI] [PMC free article] [PubMed]
- 33.Si, D. & Collins, P. A Graph Based Method for the Prediction of Backbone Trace from Cryo-EM Density Maps. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics (ACM-BCB ‘17), 691-867. 10.1145/3107411.3107501 (2017).
- 34.Kaiming H, X. Z. S. R. J. S. Deep residual learning for image recognition, presented at Proceedings of the IEEE conference on computer vision and pattern recognition, 2016 (unpublished).
- 35.Socher, D., Huval, B., Bhat, B., Manning, C. D. & Ng, A. Y. Convolutional-Recursive Deep Learning for 3D Object Classification. Advances in neural information processing systems (2012).
- 36.Yann LeCun YBGH. Deep learning. Nature. 2015;521(7553):436. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 37.Jonathan Long ESTD. Fully Convolutional Networks for Semantic Segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition. 2015;1:3431–3440. [Google Scholar]
- 38.Badrinarayanan, V., Kendall, A. & Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv1 (2015). [DOI] [PubMed]
- 39.Yu, F. a. V. K. Multi-scale context aggregation by dilated convolutions. arXiv1 (2015).
- 40.Tang G, et al. EMAN2: An extensible image processing suite for electron microscopy. Journal of Structural Biology. 2007;157:38–46. doi: 10.1016/j.jsb.2006.05.009. [DOI] [PubMed] [Google Scholar]
- 41.Pedamonti, D. Comparison of non-linear activation functions for deep neural networks on MNIST classification task. arXiv e-prints (2018).
- 42.Langel, U. et al. In Introduction to Peptides and Proteins, pp. 40–45 (CRC Press, 2009).
- 43.Rotkiewicz PJS. Fast procedure for reconstruction of full-atom protein models from reduced representations. Journal of computational chemistry. 2008;29(9):1460–1465. doi: 10.1002/jcc.20906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Krivov GG, Shapovalov MV, Dunbrack RL., Jr. Improved prediction of protein side‐chain conformations with SCWRL4. Proteins: Structure, Function, and Bioinformatics. 2009;77(4):778–795. doi: 10.1002/prot.22488. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Li, J. & Cheng, J. A Stochastic Point Cloud Sampling Method for Multi-Template Protein Comparative Modeling. Scientific reports6 (2016). [DOI] [PMC free article] [PubMed]
- 46.Cao, R. & Cheng, J. Protein single-model quality assessment by feature-based probability density functions. Scientific reports6 (23990) (2016). [DOI] [PMC free article] [PubMed]
- 47.Zhang Y, Skolnick J. TM-align: a protein structure alignment algorithm based on the TM-score. Nucleic acids research. 2005;33(7):2302–2309. doi: 10.1093/nar/gki524. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Zemla A. LGA: a method for finding 3D similarities in protein structures. Nucleic acids research. 2003;31(13):3370–3374. doi: 10.1093/nar/gkg571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Pfab, J. & Si, D. Automated Threshold Selection for Cryo-EM Density Maps. bioRxiv, 10.1101/657395 (2019).
- 50.Avramov TK, et al. Deep Learning for Validating and Estimating Resolution of Cryo-Electron Microscopy Density Maps. Molecules. 2019;24(6):1181. doi: 10.3390/molecules24061181). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Pettersen Eric F., Goddard Thomas D., Huang Conrad C., Couch Gregory S., Greenblatt Daniel M., Meng Elaine C., Ferrin Thomas E. UCSF Chimera?A visualization system for exploratory research and analysis. Journal of Computational Chemistry. 2004;25(13):1605–1612. doi: 10.1002/jcc.20084. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.