

Abstract
Placenta‐origin pregnancy complications, including preeclampsia (PE), gestational diabetes mellitus (GDM), fetal growth restriction (FGR), and macrosomia (MA) are common occurrences in pregnancy, resulting in significant morbidity and mortality for both mother and fetus. However, despite their frequency, there are no reliable methods for the early diagnosis of these complications. Since cfDNA is mainly derived from placental trophoblasts and maternal hematopoietic cells, it might have information for gene expression which can be used for disease prediction. Here, low coverage whole‐genome sequencing on plasma DNA from 2,199 pregnancies is performed based on retrospective cohorts of 3,200 pregnant women. Read depth in the promoter regions is examined to define read‐depth distribution patterns of promoters for pregnancy complications and controls. Using machine learning methods, classifiers for predicting pregnancy complications are developed. Using these classifiers, complications are successfully predicted with an accuracy of 80.3%, 78.9%, 72.1%, and 83.0% for MA, FGR, GDM, and PE, respectively. The findings suggest that promoter profiling of cfDNA may be used as a biological biomarker for predicting pregnancy complications at early gestational age.
Keywords: cell‐free DNA, early prediction, pregnancy complications, promoter profiling, whole‐genome sequencing
Cell free DNA (cfDNA) comprises a nucleosome footprint that carries information of its tissue of origin. Different pregnancy complications show distinct patterns of promoter profiling. Based on promoter profiling and machine learning methods, the prediction classifiers can forecast four types of pregnancy complications, such as macrosomia, fetal growth restriction, gestational diabetes, and preeclampsia at early gestational age.
1. Introduction
Placenta‐origin pregnancy complications are common, with preeclampsia (PE) observed in 3–8%,[[qv: 1]] gestational diabetes mellitus (GDM) in approximately 10%,[[qv: 2,3]] fetal growth restriction (FGR) in 5–10%,[[qv: 4]] and macrosomia (MA) in 3–15% of pregnancies.[[qv: 5,6]] These complications often lead to adverse maternal and fetal outcomes during as well as subsequent pregnancies, including abnormal fetal development, thromboembolic complications, and an increased risk of diabetes for mothers and their offspring.[[qv: 7]] Multivariate screening methods based on ultrasound examination and the quantification of diverse maternal urine and serum biomarkers have recently been proposed.[[qv: 8–11]] Some researchers have developed metabolomic biomarkers for the early pregnancy prediction of preeclampsia.[[qv: 12,13]] More reliable biomarkers for pregnancy complications are therefore needed to predict potential complications at early gestational age.
Elevated levels of cell‐free DNA (cfDNA) has been first reported in lupus patients[[qv: 14]] and later in cancer patients.[[qv: 15]] Since then, elevated cfDNA levels have been observed for a wide range of conditions, including pregnancy, infection, inflammation, ischemic stroke, myocardial infarction, and hemodialysis.[[qv: 16–20]] Of these conditions, higher median maternal serum cfDNA concentrations have been reported in pregnancies with pregnancy complications, such as PE.[[qv: 21]] Taken together, these observations indicate that cfDNA is a potential noninvasive biomarker of diverse diseases, including pregnancy‐related complications. However, it is necessary to distinguish the disease‐specific cfDNA patterns of different diseases before applying it to predict pregnancy complications in early pregnancy.
Plasma cfDNA fragments are released by apoptotic cells after enzymatic processing of chromatin. DNA that remains bound to nucleosomes is retained, whereas naked DNA regions between nucleosomes are digested.[[qv: 22–24]] The resulting cfDNA, therefore, comprises a nucleosome footprint carrying information about its tissues of origin.[[qv: 25]] For example, analysis of cfDNA fragment derived from cancers revealed that the promoter regions of active genes exhibited depleted coverage, which implied that less nucleosome‐binding occurred in these regions along with increased gene expression.[[qv: 26]] In pregnant women, the majority of cfDNA is derived from maternal hematopoietic cells and placental trophoblasts.[[qv: 27]] In addition, common pregnancy complications such as PE, GDM, FGR, and MA, have a root cause in the placenta, and involve the maternal immune system.[[qv: 20,28]] Therefore, we hypothesized that cfDNA fragment distribution patterns may carry information regarding source tissues of origin, particularly placental trophoblasts and maternal hematopoietic cells, and that global profiling of cfDNA fragments in promoter regions can be used to identify biomarkers that can predict pregnancy complications.
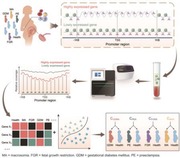
Here, we carried out a large‐scale, retrospective study using whole‐genome sequencing of plasma cfDNA from pregnant women at three independent hospitals, which included data from 3200 pregnant women (Figure 1 ). According to their follow‐up results, 2199 participants (including 578 women with pregnancy complications and 1621 controls) were selected for promoter profiling analysis. Specific promoter profiling was found for MA, FGR, GDM, and PE. We then applied logistic regression to develop classifiers that could predict the occurrence of each complication. Using these classifiers, MA, FGR, GDM, and PE were successfully predicted with an accuracy of 80.3% (CMA‐A), 78.9% (CFGR‐A), 72.1% (CGDM‐A), and 83.0% (CPE‐A), respectively. Our findings suggested that cfDNA coverage across certain promoter regions detected at early gestational age may be used to develop simple and precise methods for predicting placenta‐origin pregnancy complications.
Figure 1.
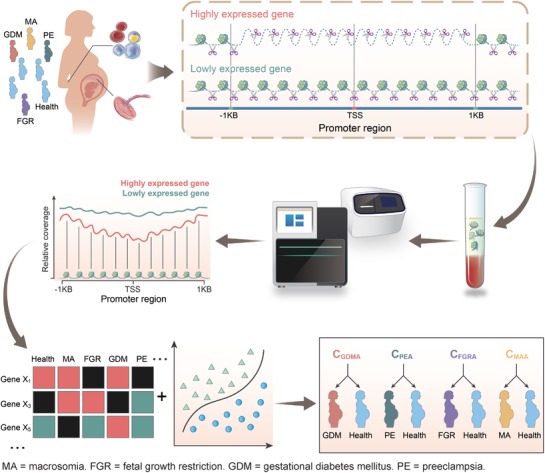
Schematic overview of predicting pregnancy complications. During pregnancy, the plasma cell free DNA (cfDNA) is primarily derived from placental trophoblasts and maternal hematopoietic cells. Exposed DNA not bound to a nucleosome is digested, whereas nucleosome‐bound DNA escapes digestion and enters into maternal circulation. Therefore, cfDNA comprises a nucleosome footprint that carries information of its tissue of origin and could reflect its gene expression pattern. As pregnancy complications are closely related to dysfunction of the placenta and maternal immune system, the read coverage of cfDNA may be used to predict the occurrence of pregnancy complications. We used whole‐genome sequencing data of cfDNA derived from 2199 pregnancies to develop classifiers for predicting four pregnancy complications—macrosomia (MA), fetal growth restriction (FGR), gestational diabetes mellitus (GDM), and preeclampsia (PE)—at early gestational age. To show greater differences, all nucleosome in the promoter regions (−1 KB to +1 KB around the transcription start site [TSS]) of highly expressed genes are depleted; however, the nucleosome‐depleted region is usually found within the nucleosome upstream of the TSS.
2. Results
2.1. Read Depth in Promoter Regions of Plasma DNA Infers Gene Expression Levels in Maternal Blood and Placenta Tissues
Read depths in the promoter regions detected using plasma cfDNA reflect the promoter activity of their respective genes in the tissues of origin and are negatively correlated with gene expression.[[qv: 26]] The transcriptional activity of genes varies according to nucleosome occupancy at promoter regions, with decreased occupancy at the primary transcription start site (pTSS, defined as the region ranging from −1 to +1 KB around the transcriptional start site) of the active genes. Decreased nucleosome occupancy also leads to increased accessibility by DNA nucleases. As most of cfDNA in pregnancies was derived from maternal blood cells and placenta, we want to confirm whether the coverage of plasma cfDNA in promoter regions could reflect gene expression patterns of placenta and maternal blood. We carried out whole genome sequencing of cfDNA in 300 healthy pregnancies (Table S2, Supporting Information) to obtain promoter profiling on the read depths at the pTSS. In addition, the gene expression profiles of the placenta and maternal blood from healthy pregnancies were downloaded from Gene Expression Omnibus (GEO).
By comparing cfDNA coverage at the pTSS for the most 500 highest and 500 lowest expressed genes in the placenta and maternal blood (Figure 2 a,e), we confirmed that gene expression levels had negatively correlation with the read depths across the promoter regions. Highly expressed genes in the placenta exhibited lower read depth, whereas lowly expressed genes exhibited greater read depth (Figure 2b). Similar patterns were also evident for genes with high or low expression levels in the maternal blood (Figure 2f). As merely approximately 10% of total cfDNA was derived from placenta with the rest majorly derived from maternal blood cells, the promoter profiling of placenta may be affected by their common genes. Therefore, we further compared promoter profiling of placenta and whole blood specific genes and unexpressed genes. And we obtained similar results (Figure 2c, d, g, and h). Since most of pregnancy complications were correlated with the dysfunctions of placenta and maternal immune system, these results suggested that cfDNA distribution may reflect expression levels in the tissues of origin in pregnant women, meaning that cfDNA coverage at gene promoters can be applied as a biomarker to predict pregnancy complications. Using the expression profiles of placenta and whole blood cells derived from pregnancies with complications (see Section 4), we also found that the top 500 of highly expressed genes showed low coverage in the promoter regions and the bottom 500 of lowly expressed genes showed high coverage in the promoter regions (Figure S1, Supporting Information).
Figure 2.
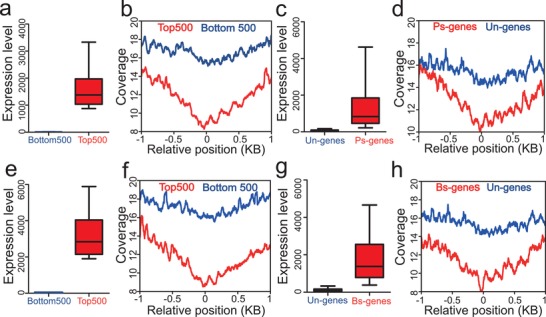
Promoter read depth patterns of highly and lowly expressed genes. a) Mean expression levels of the 500 most‐ (Top500, red) and least‐expressed (Bottom500, blue) genes in the placenta. b) Promoter coverage patterns for the 500 most‐ (Top500, red line) and least‐expressed (Bottom500, blue line) genes in the placenta. c) Mean expression levels of the placenta‐specific (Ps‐genes, red) and unexpressed (Un‐genes, blue) genes in the placenta. d) Promoter coverage patterns for the placenta‐specific (Ps‐genes, red) and unexpressed (Un‐genes, blue) genes in placenta. e) Mean expression levels of the most‐ 500 (Top500, red) and least‐expressed (Bottom500, blue) genes in the maternal blood. f) Promoter coverage patterns for the most‐ (Top500, red line) and least‐expressed (Bottom500, blue line) genes in the maternal blood. g) Mean expression levels of the whole blood‐specific (Bs‐genes, red) and unexpressed (Un‐genes, blue) genes in the maternal blood. h) Promoter coverage patterns for the whole blood‐specific (Bs‐genes, red) and unexpressed (Un‐genes, blue) genes in the maternal blood. Additional details about tissue‐specific and unexpressed genes can be found in Method section.
2.2. Promoter Profiling of cfDNA Reveals Disease‐Associated Patterns
To validate the potentials of cfDNA for predicting pregnancy complications, our study selected low coverage sequencing data of cfDNA derived from 2199 samples (119 MA, 132 FGR, 267 GDM, 60 PE and 1621 healthy controls) from three independent hospitals of China according to the gestational age of plasma collection and their follow‐up results (Figure 3 ). For each complication, the gestational age of their controls was well matched in each cohort (Table S1, Supporting Information). There was no significant difference of the gestational age between cases and controls (p‐value: 0.76 for PE, 0.5 for GDM, 0.41 for FGR, 0.78 for MA, Table 1 ). We developed a pipeline to search for effective classifiers (Figure 3), which included three stages: exploration of genes with differential promoter profiling (discovery stage), identification of classifiers (training stage) and validation of classifiers (validation stage). At the discovery stage, we first selected the low coverage whole‐genome sequencing data of cfDNA on ten complication cases and ten gestational age‐matched controls for each of the four pregnancy complications (MA, FGR, GDM, and PE). By comparing the promoter profiling of each pregnancy complication and their matched controls, we identified sets of genes with significant differential coverages (|Log2 fold change| ≥ 1 and FDR ≤ 0.1): 718 gene transcripts for MA, 808 for FGR, 800 for GDM, and 672 for PE, respectively (Figure 4 a–d and Table S6, Supporting Information). Next, we performed unsupervised clustering analysis on the coverages for these pregnancy complications. We found distinctive coverage patterns for MA (Figure 4e), FGR (Figure 4f), GDM (Figure 4g), and PE (Figure 4h), revealing distinctive coverage patterns for MA (Figure 4e), FGR (Figure 4f), GDM (Figure 4g), and PE (Figure 4h). The heatmaps show distinct patterns of promoter coverage between healthy pregnancies and pregnancies with complications (Figure 4e–h).
Figure 3.

Pipeline used to develop classifiers for predicting pregnancy complications. To develop classifiers for predicting pregnancy complications, the plasma samples of pregnant women were collected before the diagnosis of pregnancy complications. The samples used for classifier construction were selected according to the gestational age of sampling and their follow‐up results. Additional details regarding the definition of pregnancy complications and corresponding controls are presented in Methods section. GA means gestational age. a, b, and c indicate participants from the Nanfang Hospital of Southern Medical University, Third Affiliation Hospital of Sun Yat‐Sen University, and Cangzhou People's Hospital, respectively. Plasma cfDNA samples collected from Nanfang Hospital were analyzed using the Illumina sequencing platform. Plasma cfDNA samples collected from The Third Affiliation Hospital of Sun Yat‐Sen University and Cangzhou People′s Hospital were analyzed using the Ion Proton sequencing platform.
Table 1.
Maternal and pregnancy characteristics of study pregnancies
| Macrosomia | FGR | GDM | PE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case(n = 119) | Control(n = 476) | p‐value | Case(n = 132) | Control(n = 518) | p‐value | Case(n = 267) | Control(n = 801) | p‐value | Case(n = 60) | Control(n = 240) | p‐value | |
| Gestational age at sampling (weeks) | 16.9 ± 3.6 | 17.0 ± 3.6 | 0.78 | 18.3 ± 4.0 | 17.9 ± 3.7 | 0.41 | 15.9 ± 2.4 | 16.0 ± 2.6 | 0.5 | 17.9 ± 4.2 | 18.0 ± 4.2 | 0.76 |
| Age (years) | 33.1 ± 4.1 | 32.1 ± 4.7 | 0.052 | 31.1 ± 5.3 | 31.3 ± 5.1 | 0.67 | 34.0 ± 4.5 | 32.7 ± 4.8 | 1.6E‐03 | 34.1 ± 4.9 | 33.3 ± 4.4 | 0.17 |
| BMI (kg m−2) | 23.0 ± 2.3 | 21.2 ± 1.9 | 2.2E‐16 | 20.6 ± 3.1 | 21.5 ± 2.0 | 2.8E‐07 | 22.5 ± 2.8 | 21.3 ± 2.5 | 2.0E‐13 | 24.2 ± 3.5 | 21.3 ± 2.4 | 1.3E‐11 |
| Weight gain (kg) | 13.8 ± 4.3 | 13.9 ± 2.3 | 0.21 | 12.3 ± 3.2 | 13.7 ± 2.5 | 1.8E‐08 | 11.1 ± 3.1 | 13.4 ± 3.0 | 2.2E‐16 | 12.3 ± 3.5 | 13.0 ± 2.9 | 0.078 |
| Baby weight (kg) | 4.3 ± 0.6 | 3.3 ± 0.3 | 2.2E‐16 | 2.3 ± 0.3 | 3.3 ± 0.3 | 2.2E‐16 | 3.3 ± 0.5 | 3.2 ± 0.3 | 0.17 | 2.7 ± 0.6 | 3.2 ± 0.3 | 7.1E‐11 |
| History of adverse pregnancy outcomes | ||||||||||||
| Yes | 19 | 19 | 4.9E‐06 | 15 | 23 | 4.8E‐03 | 26 | 59 | 0.27 | 4 | 13 | 0.76* |
| No | 100 | 457 | 117 | 495 | 241 | 742 | 56 | 227 | ||||
Data are mean ± standard deviation. Age = maternal age. BMI = pre‐pregnancy body mass index. Weight gain = weight gain during pregnancy. FGR = fetal growth restriction. GDM = gestational diabetes mellitus. PE = preeclampsia. Mann–Whitney U‐test was used for the comparison of continuous variables. χ2 test and Fisher exact test (*) were used for the comparison of categorical variables.
Figure 4.
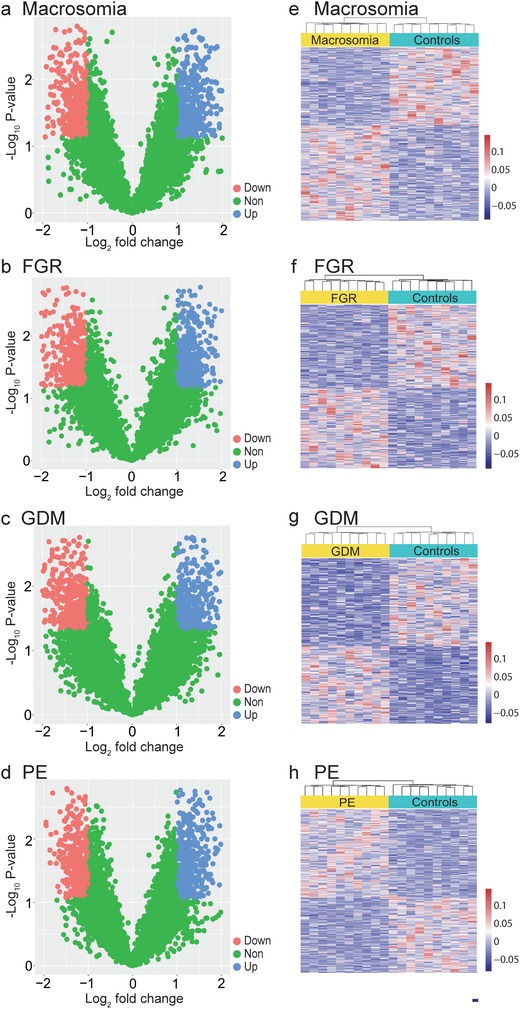
Gene transcripts with differential read coverages at primary TSS (pTSS). Volcano plots of gene transcripts with differential read coverages at the pTSS (|log2 fold change| ≥ 1 and false discovery rate [FDR] ≤ 0.1) at the pTSS detected using whole‐genome sequencing for a) macrosomia, b) FGR, c) GDM, and d) PE. The red, blue, and green dots indicate gene promoters though to be downregulated, upregulated, and exhibiting non‐differential coverage, respectively. Heat map of the z‐scores of promoters with differential read coverages for e) macrosomia, f) FGR, g) GDM, and h) PE.
We searched the literature for the functional relevance of the top enriched pathways to the diseases, and found that each set of enriched pathways were associated with to the corresponding complication (Figure S2, Supporting Information and Table S7, Supporting Information). As one example, the PI3K‐Akt pathway regulates the expression of sFlt1, which is an important marker of PE in clinic.[[qv: 29]]
2.3. Identification and Validation of Classifiers Based on Genes with Differential Coverage at pTSS
To further validate the potentials of cfDNA for predicting complications, we applied more samples of whole‐genome sequencing of cfDNA to develop and validate prediction classifiers. At training stage, we focused on the gene transcripts with significant differential coverage at pTSS identified in the discovery stage. Using a logistic regression model and stepwise method for feature selection, a set of 12 genes, denoted by CMA‐A (set‐A classifier), performed well as a predictor of MA (accuracy = 80.0%) and exhibited the largest AUC value (Table S8, Supporting Information). The probability of pregnancies with MA was calculated using CMA‐A as follow:
| (1) |
Where SMC3, MASTL, CREM, C1QTNF12, MLXIP, MAP3K9, IGSF6, APC2, GPM6A, TMEM128, NIPBL, and TMEM184A are genes in the CMA‐A. In this equation, each gene was represented by a value of 1 when the normalized gene promoter coverage was higher than the corresponding cutoff (Table S9, Supporting Information); otherwise, the gene was represented by 0. Then the p‐value was calculated by logit transformation. If the p‐value was higher than the corresponding threshold (Table S13, Supporting Information), the pregnancy was predicted to have MA, otherwise the pregnancy was predicted to not have MA. In the training cohort, CMA‐A had an AUC of 0.766 with a 95% confidence interval (95% CI of 0.678–0.854), which was used to determine whether individuals would develop MA or not. The accuracy of CMA‐A was 80.0%, with a sensitivity of 71.0% and specificity of 82.3% in the training cohort (Figure 5 ; Table S8, Supporting Information). Consistent with the results of the training cohort, the internal validation cohort and two external cohorts produced AUCs of 0.817 (0.689–0.945), 0.791 (0.721–0.861), and 0.762 (0.675–0.848), respectively, for the CMA‐A (Figure 5; Table S8, Supporting Information).
Figure 5.
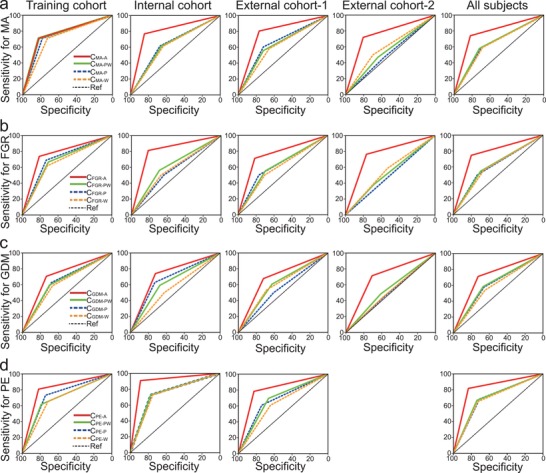
Performance of classifiers in predicting pregnancy complications. Receiver operating characteristic (ROC) curves for predicting a) macrosomia, b) FGR, c) GDM, and d) PE occurrences in the training, internal, and external cohorts for set‐A classifiers based on gene promoters with differential read coverages—CMA‐A, CFGR‐A, CGDM‐A, and CPE‐A; set‐P classifiers based on the promoter profiling of placenta‐specific genes—CMA‐P, CFGR‐P, CGDM‐P, and CPE‐P; set‐W classifiers based on the promoter profiling of whole blood‐specific genes—CMA‐W, CFGR‐W, CGDM‐W, and CPE‐W; and set‐PW classifiers based on the combination of placenta‐ and whole blood‐specific genes—CMA‐PW, CFGR‐PW, CGDM‐PW, and CPE‐PW. The X‐ and Y‐axes indicate classifier sensitivity and specificity, respectively.
For the other three pregnancy complications, the procedures for classifier construction and validation were similar to those used for MA (CMA‐A). For FGR, a set with 13 genes, denoted by CFGR‐A, performed well as predictor of FGR (accuracy = 79.5%; AUC = 0.774) during the training (Figure 5; Table S10, Supporting Information). The internal cohort and two external validation cohorts for CFGR‐A produced AUCs of 0.813 (0.703–0.922), 0.763 (0.684–0.843), and 0.765 (0.684–0.845), respectively (Figure 5; Table S8, Supporting Information). For GDM, a set of 11 genes, denoted by CGDM‐A, performed well as predictor of GDM (accuracy = 72.6%; AUC = 0.720) during training (Figure 5; Table S11, Supporting Information). The internal cohort and two external validation cohorts for CGDM‐A produces AUCs of 0.732 (0.663–0.800), 0.699 (0.604–0.794), and 0.711 (0.642–0.780), respectively (Figure 5; Table S8, Supporting Information). For PE, a set of ten genes, denoted by CPE‐A, performed well as predictor for PE (accuracy = 81.5% and AUC = 0.813) during training (Figure 5; Table S12, Supporting Information). The internal cohort and external validation cohorts for CPE‐A produced AUCs of 0.898 (0.797–0.999) and 0.804 (0.710–0.899), respectively (Figure 5; Table S8, Supporting Information). All equations are shown in Table S13, Supporting Information.
2.4. Classifiers Based on Placenta‐ and Whole Blood‐Specific Genes
As the four complications examined in this study are associated with the dysfunctions of placenta and maternal immune system,[[qv: 28]] placenta‐specific and blood‐specific genes may be better at predicting these complications. We thus developed three additional sets of classifiers: 1) set‐P classifiers, which were selected promoters of placenta‐specific genes; 2) set‐W classifiers, which were selected promoters of whole blood‐specific genes; and 3) set‐PW classifiers, which were selected promoters of placenta‐ and whole blood‐specific genes. Their procedures of classifier construction and validation were similar with those of set‐A classifiers. For whole blood‐specific genes, the optimal classifiers for MA (CMA‐W), FGR (CFGR‐W), GDM (CGDM‐W), and PE (CPE‐W) produced AUCs of 0.640 (0.591–0.689), 0.611 (0.563–0.658), 0.593 (0.559–0.627), and 0.69 (0.623–0.757), respectively (Figure 5; Table S13, Supporting Information). For placenta‐specific genes, the optimal classifiers for MA (CMA‐P), FGR (CFGR‐P), GDM (CGDM‐P), and PE (CPE‐P) produced AUCs of 0.644 (0.595–0.693), 0.616 (0.569–0.664), 0.618 (0.584–0.651), and 0.696 (0.63–0.762), respectively (Figure 5; Table S14, Supporting Information). For combination two types of tissue‐specific genes, the optimal classifiers for MA (CMA‐PW), FGR (CFGR‐PW), GDM (CGDM‐PW), and PE (CPE‐PW) produced AUCs of 0.649 (0.600–0.698), 0.621 (0.574–0.668), 0.626 (0.592–0.660), and 0.702 (0.636–0.768), respectively (Figure 5; Table S14, Supporting Information).
Although only approximately 10% of total cfDNA is derived from the placenta, with the rest majorly derived from maternal blood cells,[[qv: 27]] the overall AUC of set‐P classifiers of four pregnancy complications was slightly higher than that of set‐W classifiers (Table S14, Supporting Information), indicating that placenta dysfunction may be one of the most factors underlying the occurrence of these four pregnancy complications, consistent with previous studies.[[qv: 28]] We next compared the overall performance of the set‐A classifiers (derived from differential read depths of promoters without considering their tissues of origin) with those of the other three classifier sets for each pregnancy complication. Set‐A classifiers predicted complications more accurately than the other three classifier sets (Table S15, Supporting Information; all p‐value < 0.05), suggesting that factors other than dysfunctions of the placenta and maternal immune system may be related to the occurrence of these pregnancy complications.
2.5. Classifiers Combined with Clinical Features
Previous studies have reported that certain clinical features may be used to predict pregnancy complications, such as BMI before pregnancy. In our data, we found that their AUCs were significantly lower than set‐A classifiers for each complication (Table S16, Supporting Information; all p‐value < 0.05). To attempt to improve the performance of our classifiers, we further combined BMI with set‐A classifier of each complication (CMA‐A, CFGR‐A, CGDM‐A, and CPE‐A). But the AUC of the combined classifiers for predicting MA, GDM, and PE was decreased, whereas that of predicting FGR was slightly increased (Table S16, Supporting Information).
3. Discussion
In this study, we used promoter profiling of whole‐genome sequencing of cfDNA from pregnant women to assess the transcription activity of its tissues of origin. We found that differential read depths at the pTSS were indicative of differential gene expression in the tissues of origin, primarily the placenta and maternal blood (Figure 2). Therefore, we hypothesized that the differential read‐depth patterns of cfDNA at promoters should carry information regarding placenta‐origin diseases at an early stage, before any clinical symptoms become noticeable (Figure 1). To develop reliable predictors of subsequent pregnancy complications, we searched the genome for candidate promoters and implemented machine learning to select optimal classifiers for each pregnancy complication. Performance of the optimal classifiers for predicting MA (CMA‐A), FGR (CFGR‐A), GDM (CGDM‐A), and PE (CPE‐A) with an overall accuracy of 80.3%, 78.9%, 72.1%, and 83.0%, respectively (Table S8, Supporting Information). These findings highlight the potential predictive value of cfDNA read depth patterns as a non‐invasive assessment for predicting pregnancy complications at early gestational age.
The classifiers contained genes that may be correlated with the dysfunctions of pregnancy complications. For MA, the classifier CMA‐A contained 12 genes APC2, C1QTNF12, CREM, GPM6A, IGSF6, SMC3, MAP3K9, MASTL, MLXIP, NIPBL, TMEM128, and TMEM184A (Table S9, Supporting Information). Previous studies have reported a close relationship between glucose metabolism and MA.[[qv: 30]] Accordingly, MLXIP play a role in gene regulation in response to cellular glucose levels;[[qv: 31]] C1QTNF12 regulates glucose metabolism in liver and adipose tissues;[[qv: 32]] and CREM is associated with Type 1 diabetes mellitus.[[qv: 33]] For FGR, CFGR‐A (Table S10, Supporting Information) included CD63, which is involved in different levels of platelet activation in preeclamptic, normotensive pregnant, and non‐pregnant women.[[qv: 34]] For GDM, the classifier CGDM‐A (Table S10, Supporting Information) included CLOCK, which may be associated with obesity and metabolic syndrome.[[qv: 35]] For PE, the classifier CPE‐A (Table S12, Supporting Information) contained NFKB, which is involved in inflammation and immune function, and associated with preterm birth.[[qv: 36]] Further details regarding the function of individual genes in each classifier along with supporting citations can be found in Table S17, Supporting Information.
A useful biomarker for disease prediction requires low cost, easy detection and pervasive application. So far, no published studies have recruited more than 2000 pregnancies, began with high throughput screen, and performed validation in two independent external cohorts for predicting pregnancy complications. Our method was based on low‐coverage DNA sequencing data to predict pregnancy complications. The workflow of current noninvasive prenatal test (NIPT) procedures need not to change, therefore, our method can be easily adapted for preclinical tests based on current NIPT data. In addition, our method could simultaneously predict these four pregnancy complications based on the same sequencing data. With the accumulation of more NIPT data, this method might be applied to predict other severe pregnancy complications, such as preterm birth. Although the AUC, accuracy, sensitivity and specificity of our classifiers is robust in all cohorts, the positive prediction rate were approximately 0.5 (Table S18, Supporting Information). The low rate of positive prediction may come from the genetic heterogeneity of the diseases. For example, according to our recent study, the differentially expressed genes (DEGs) in clinical subtypes of PE are different: 2977 DEGs in early‐onset PE, 375 in late‐onset PE and 42 in late‐onset mild PE.[[qv: 37]] The finer classification of the heterogeneous diseases may help improve the positive prediction. In addition, the performance of classifiers might be different among different ethnic groups. Previous studies have revealed that the risk factors of some pregnancy complications between different ethnic backgrounds were significantly different.[[qv: 38]] In this study, we only validated the performance of our classifiers with one internal cohort and two external cohorts in Chinese. Therefore, such classifiers may be only applicable to Chinese patients.
The cfDNA and cfRNA have been taken as an important non‐invasive tool for the prediction of pregnancy complications. For cfDNA, it has been used to detect fetal chromosomal abnormalities in clinic,[[qv: 27]] because detection of such abnormalities would not depend on the gene expression. In our study, we have developed classifiers using the promoter profiling of cfDNA for the prediction of pregnancy complications, based on the hypothesis that the promoter profiling of cfDNA may infer the gene expression patterns of maternal blood and placental tissues. The cfRNA can directly represent the expressed genes of maternal blood and placental tissues and thus may be used in the prediction of premature delivery.[[qv: 39]]
4. Conclusions
In summary, our data suggest that promoter‐profiling based classifiers provide high predictive capabilities for predicting multiple placenta‐origin pregnancy complications at early gestational age. The techniques required for low‐coverage DNA sequencing without additional tests, are easily applicable to routinely NIPT data, the results of classifiers are easy to interpret, and the costs of reagents and consumables are relatively low. Therefore, application of our classifiers in clinical practice should be feasible.
5. Experimental Section
Study Design and Participants
In this nested case‐control study, the authors developed classifiers for predicting pregnancy complication based on low coverage whole‐genome sequencing on the plasma cfDNA of 2199 participants. These participants included 578 pregnancies who developed MA (119 cases), FGR (132 cases), GDM (267 cases), and PE (60 cases) later on. In addition, 1621 controls were also sequenced, including controls for MA (476 cases), FGR (518 cases), GDM (801 cases), and PE (240 cases) (Table 1). Participants were enrolled at three independent hospitals of China, including Nanfang Hospital of Southern Medical University (SMU), The Third Affiliated Hospital of Sun Yat‐sen University (SYSU), and Cangzhou People's Hospital. The plasma used in the discovery and training cohort was collected between May 1, 2013, and Dec 31, 2016, at Nanfang Hospital. The samples used at the discovery stage were contained in the training cohort. The validation stage has three cohorts: 1) the internal validation cohort, enrolled at Nanfang Hospital from Jan 1, 2017, to Dec 31, 2017; 2) external validation cohort‐1, enrolled at The Third Affiliated Hospital from Jan 1, 2016, to Dec 31, 2017; 3) external validation cohort‐2 enrolled at Cangzhou People's Hospital from Jan 1, 2016 to Dec 31, 2017.
The DNA sequencing samples were selected from retrospective cohorts of 3200 participants according to their gestational age of plasma collection and follow‐up results. To develop classifiers for disease prediction, plasma samples had to be collected before the time period of each pregnancy complication diagnosis. All selected samples were collected at 12–28 weeks' gestation and the selected participants were singleton pregnancies. For MA and FGR, plasma was collected at 12–28 weeks' gestation. For GDM and PE, plasma samples were collected at <18 and <20 weeks' gestation, respectively. For healthy controls, their gestational age at the time of sample collection was matched with that of each pregnancy complication (Table S1, Supporting Information; p > 0.05, Mann–Whiney U‐test). According to the follow‐up results, we defined five groups of pregnancies including MA, FGR, GDM, PE, and healthy pregnancies. The detailed eligibility criteria of each group was listed in Supporting Information. Briefly, MA was defined as a birth weight ≥ 4000 g.[[qv: 40]] FGR was defined as birth weight below the 10th percentile for gestational age[[qv: 41]] and gestational age was ≥ 37 weeks. GDM was diagnosed according to International Association of Diabetes and Pregnancy Study Groups (IADPSG) criteria, with universal testing for GDM at 24–28 weeks' gestation with the 75 g 2 h OGTT. The PE definition was taken from the International Society for the Study of Hypertension in Pregnancy (ISSHP), which required blood pressure > 90 mmHg with proteinuria > 0.3 g in a 24 h collection > 20 weeks' gestation. Healthy control samples were collected from full‐term singleton pregnancies without pregnancy complications, in which the fetus was appropriately grown at birth with no obstetric, medical, or surgical complications in pregnancy. In addition, 300 healthy pregnancies in 1621 controls were selected to compare their promoter profiling with tissue expression profiles (Table S2, Supporting Information).
The institutional ethical review boards of all included hospitals approved this retrospective analysis and the requirement for informed consent was waived by the ethics review boards (NFEC‐2016‐093).
Sequence Analysis and Promoter Profiling
The procedure of DNA preparation, isolation and DNA sequencing are in the Supporting Information. Raw reads were aligned to the hg19 human reference genome using bwa‐mem,[[qv: 42]] with PCR duplicates removed using the rmdup function of SAMtools (ver. 1.2).[[qv: 43]] Gene information was obtained from the RefSeq of University of California Santa Cruz.[[qv: 44]] For each transcript, the region ranging from −1 to +1 KB around the transcriptional start site defined as the primary transcription start site (pTSS) was identified. After alignment, read counts for each base at the pTSS were calculated from the aligned BAM files using SAMtools. The read coverage at the pTSS was extracted from the aligned BAM files using bedtools (ver. 2.17.0). The read counts were normalized using the reads per kilobase per million mapped reads (RPKM) method.
Microarray Data on the Placenta and Maternal Blood
Placenta and maternal blood expression profiles of healthy pregnancies (GSE85307 and GSE24129)[[qv: 45,46]] and pregnancies with complications (GSE85307, GSE92772, GSE24129, and GSE70493)[[qv: 45–48]] were downloaded from the GEO database. Normalized gene expression values were processed using GEO query in R (ver. 3.3.1). The 500 highest and lowest expressed genes in the placenta and maternal blood were identified (Table S3, Supporting Information). According to the methods adopted by previous studies,[[qv: 49]] the Human 133A/GNF1H Gene Atlas Database (GSE1133)[[qv: 50]] was analyzed using the MGFM package of R with default settings to identify placenta‐ and whole blood‐specific genes (Table S4, Supporting Information). The list of unexpressed genes in all tissues were downloaded from the Supporting Information of a previous study.[[qv: 26]]
Procedure of Classifiers Construction
At the discovery stage, we selected 10 cases of each pregnancy complication (MA, FGR, GDM, and PE) and 10 gestational age‐matched controls. Whole‐genome sequencing of cfDNA was then performed on each of these samples. Following alignment and normalization, promoter coverages at the pTSS were compared between each pregnancy complication and their corresponding controls, and a p‐value was calculated using the Wilcoxon rank sum test. P‐value was then adjusted to the false discovery rate (FDR) using the Benjamini–Hochberg procedure. Gene transcripts with FDR ≤ 0.1 and |log2 fold change| ≥ 1 were considered to have significant differential coverages at the pTSS (Table S6, Supporting Information).
At the training stage, we selected genes with significant differential coverages to develop promoter profiling‐based classifiers that could differentiate MA, FGR, GDM, and PE from healthy controls. The ten cases with complications and ten healthy controls used during the discovery stage were also included at the training stage. As a considerable amount of studies have reported that discrete data may improve classifier performance,[[qv: 51]] the normalized read count of each promoter was discretized according to the optimal cut‐off point before classifier construction. The optimal cut‐off point of each promoter was defined as the maximum value of (sensitivity + specificity)/2 in the training cohort. The read depth of each promoter found in each subject was then set to one when it was larger than the corresponding optimal cut‐off; otherwise, it was set to zero. At the training stage, a stepwise method for feature selection was used to select the promoter combinations to construct classifiers. The robustness of these classifiers was assessed using the leave‐one‐out cross validation method. Briefly, each subject in the training cohort was withheld in turn, and the remaining subjects were submitted to train the model. The trained model was then used to predict the class (pregnancies with complications or healthy controls) of the withheld subject. This procedure went on until all subjects in the training cohort were judged. Receiver operating characteristic (ROC) analysis was used to evaluate the performance of each classifier, including area under curve (AUC), accuracy, sensitivity, and specificity. The classifiers which performed well and displayed the largest AUC in the training cohort were chosen as the optimal classifiers for each pregnancy complication (set‐A classifiers). The performance of these classifiers was then further validated using three independent validation cohorts, including one internal cohort and two external cohorts.
Apart from the set‐A classifiers (genes with significant differential coverages between pregnancy complication and healthy controls), another three sets of classifiers were developed to predict individual pregnancy complications: 1) set‐P classifiers selected promoters of placenta‐specific genes; 2) set‐W classifiers selected promoters of whole blood‐specific genes; and 3) set‐PW classifiers selected promoters of placenta‐ and whole blood‐specific genes. The procedure for selecting optimal classifiers for these sets was similar to that of the set‐A classifiers.
Previous studies have revealed that overweight and obesity were taken as significant contributors to disease.[[qv: 52]] Therefore, pre‐pregnancy BMI potential for predicting pregnancy complications was also elevated. We first assessed BMI performance for predicting complications and compared its performance with set‐A classifiers. Then BMI was taken as a feature of set‐A classifiers to test whether the performance of combined classifiers would be increased.
Statistical Analyses
ROC curves and the significance of differences in the AUC, sensitivity and specificity were plotted and calculated using the pROC package in R.[[qv: 53]] Maternal and gestational ages were compared between groups using the Mann–Whitney U‐test. The Wilcoxon rank sum test was used to identify genes with differential read coverages at the pTSS. χ2 test and Fisher exact test were used for comparison of categorical variables. p‐values < 0.05 for two sided tests were considered statistically significant. Hierarchical clustering was applied to the coverage data, using the average‐linkage clustering algorithms in Cluster (ver. 3.0). Heat maps were plotted using the pheatmap package in R. Function enrichment analysis was performed using Metascape with default setting.[[qv: 54]] Then top ten enriched terms were visualized using ggplot2 and annotated by searching the literature.
Conflict of Interest
The authors declare no conflict of interest.
Supporting information
Supporting Information
Acknowledgements
Z.G., F.Y., J.Z., and Z.Z. contributed equally to this work. This work was supported by project grants from National Natural Science Foundation of China (81871177, 81802435); Natural Science Foundation of Guangdong Province (2018A030313286); Science and Technology Planning Project of Guangdong Province [2015B020233009]; Guangzhou Municipal Science and Technology Project (201604020104, 201803040009); China Postdoctoral Science Foundation funded project (2016M602486, 2019T120742).
Guo Z., Yang F., Zhang J., Zhang Z., Li K., Tian Q., Hou H., Xu C., Lu Q., Ren Z., Yang X., Lv Z., Wang K., Yang X., Wu Y., Yang X., Whole‐Genome Promoter Profiling of Plasma DNA Exhibits Diagnostic Value for Placenta‐Origin Pregnancy Complications. Adv. Sci. 2020, 7, 1901819 10.1002/advs.201901819
Contributor Information
Xinping Yang, Email: xpyang1@smu.edu.cn.
Yingsong Wu, Email: wg@smu.edu.cn.
Xuexi Yang, Email: yxx1214@smu.edu.cn.
References
- 1. Sibai B., Dekker G., Kupferminc M., The Lancet 2005, 365, 785. [DOI] [PubMed] [Google Scholar]
- 2. Xu Y., Wang L., He J., Bi Y., Li M., Wang T., Jiang Y., Dai M., Lu J., Xu M., Li Y., Hu N., Li J., Mi S., Chen C. S., Li G., Mu Y., Zhao J., Kong L., Chen J., Lai S., Wang W., Zhao W., Ning G., JAMA 2013, 310, 948.24002281 [Google Scholar]
- 3. Guariguata L., Whiting D. R., Hambleton I., Beagley J., Linnenkamp U., Shaw J. E., Diabetes Res. Clin. Pract. 2014, 103, 137. [DOI] [PubMed] [Google Scholar]
- 4. Froen J. F., Gardosi J. O., Thurmann A., Francis A., Stray‐Pedersen B., Acta Obstet. Gynecol. Scand. 2004, 83, 801. [DOI] [PubMed] [Google Scholar]
- 5. Mohammadbeigi A., Farhadifar F., Soufi Zadeh N., Mohammadsalehi N., Rezaiee M., Aghaei M., Ann. Med. Health Sci. Res. 2013, 3, 546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Asplund C. A., Seehusen D. A., Callahan T. L., Olsen C., Ann. Fam. Med. 2008, 6, 550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Damm P., Int J Gynaecol Obstet 2009, 104, S25. [DOI] [PubMed] [Google Scholar]
- 8. Lo Y. M., Leung T. N., Tein M. S., Sargent I. L., Zhang J., Lau T. K., Haines C. J., Redman C. W., Clin. Chem. 1999, 45, 184. [PubMed] [Google Scholar]
- 9. Wright D., Gallo D. M., Gil Pugliese S., Casanova C., Nicolaides K. H., Ultrasound Obstet. Gynecol. 2016, 47, 554. [DOI] [PubMed] [Google Scholar]
- 10. Zhong Y., Zhu F., Ding Y., BMC Pregnancy and Childbirth 2015, 15, 191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Diaz S. O., Pinto J., Graca G., Duarte I. F., Barros A. S., Galhano E., Pita C., Almeida Mdo C., Goodfellow B. J., Carreira I. M., Gil A. M., J. Proteome Res. 2011, 10, 3732. [DOI] [PubMed] [Google Scholar]
- 12. Kenny L. C., Broadhurst D. I., Dunn W., Brown M., North R. A., McCowan L., Roberts C., Cooper G. J., Kell D. B., Baker P. N., Hypertension 2010, 56, 741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Bahado‐Singh R. O., Akolekar R., Mandal R., Dong E., Xia J., Kruger M., Wishart D. S., Nicolaides K., Am. J. Obstet. Gynecol. 2013, 208, 58.e1. [DOI] [PubMed] [Google Scholar]
- 14. Tan E. M., Schur P. H., Carr R. I., Kunkel H. G., J. Clin. Invest. 1966, 45, 1732. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Leon S. A., Shapiro B., Sklaroff D. M., Yaros M. J., Cancer Res 1977, 37, 646. [PubMed] [Google Scholar]
- 16. Yi J., Zhang Y., Ma Y., Zhang C., Li Q., Liu B., Liu Z., Liu J., Zhang X., Zhuang R., Jin B., Viruses 2014, 6, 2723. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Garnacho‐Montero J., Huici‐Moreno M. J., Gutierrez‐Pizarraya A., Lopez I., Marquez‐Vacaro J. A., Macher H., Guerrero J. M., Puppo‐Moreno A., Crit. Care 2014, 18, R116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Tsai N. W., Lin T. K., Chen S. D., Chang W. N., Wang H. C., Yang T. M., Lin Y. J., Jan C. R., Huang C. R., Liou C. W., Lu C. H., Clinica Chimica Acta 2011, 412, 476. [DOI] [PubMed] [Google Scholar]
- 19. Tovbin D., Novack V., Wiessman M. P., Abd Elkadir A., Zlotnik M., Douvdevani A., Nephrol. Dial. Transplant. 2012, 27, 3929. [DOI] [PubMed] [Google Scholar]
- 20. Sur Chowdhury C., Hahn S., Hasler P., Hoesli I., Lapaire O., Giaglis S., Fetal Diagn. Ther. 2016, 40, 263. [DOI] [PubMed] [Google Scholar]
- 21. Rafaeli‐Yehudai T., Imterat M., Douvdevani A., Tirosh D., Benshalom‐Tirosh N., Mastrolia S. A., Beer‐Weisel R., Klaitman V., Riff R., Greenbaum S., Alioshin A., Rodavsky Hanegbi G., Loverro G., Catalano M. R., Erez O., PLoS One 2018, 13, e0200360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Lo Y. M., Chan K. C., Sun H., Chen E. Z., Jiang P., Lun F. M., Zheng Y. W., Leung T. Y., Lau T. K., Cantor C. R., Chiu R. W., Sci. Transl. Med. 2010, 2, 61ra91. [DOI] [PubMed] [Google Scholar]
- 23. Diehl F., Li M., Dressman D., He Y., Shen D., Szabo S., Diaz L. A. Jr., David K. A., Juhl H., Kinzler K. W., Vogelstein B., Proc. Natl. Acad. Sci. 2005, 102, 16368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Ramachandran S., Henikoff S., Sci. Adv. 2015, 1, e1500587. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Snyder M. W., Kircher M., Hill A. J., Daza R. M., Shendure J., Cell 2016, 164, 57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Ulz P., Thallinger G. G., Auer M., Graf R., Kashofer K., Jahn S. W., Abete L., Pristauz G., Petru E., Geigl J. B., Heitzer E., Speicher M. R., Nat. Genet. 2016, 48, 1273. [DOI] [PubMed] [Google Scholar]
- 27. Lo Y. M., Tein M. S., Lau T. K., Haines C. J., Leung T. N., Poon P. M., Wainscoat J. S., Johnson P. J., Chang A. M., Hjelm N. M., Am. J. Hum. Genet. 1998, 62, 768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Huynh J., Dawson D., Roberts D., Bentley‐Lewis R., Placenta 2015, 36, 101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Park J. K., Jeong J. W., Kang M. Y., Baek J. C., Shin J. K., Lee S. A., Choi W. S., Lee J. H., Paik W. Y., Placenta 2010, 31, 621. [DOI] [PubMed] [Google Scholar]
- 30. Kc K., Shakya S., Zhang H., Ann Nutr Metab 2015, 2, 14. [DOI] [PubMed] [Google Scholar]
- 31. Richards P., Rachdi L., Oshima M., Marchetti P., Bugliani M., Armanet M., Postic C., Guilmeau S., Scharfmann R., Diabetes 2018, 67, 461. [DOI] [PubMed] [Google Scholar]
- 32. Enomoto T., Ohashi K., Shibata R., Higuchi A., Maruyama S., Izumiya Y., Walsh K., Murohara T., Ouchi N., J. Biol. Chem. 2011, 286, 34552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Nejentsev S., Smink L. J., Smyth D., Bailey R., Lowe C. E., Payne F., Masters J., Godfrey L., Lam A., Burren O., Stevens H., Nutland S., Walker N. M., Smith A., Twells R., Barratt B. J., Wright C., French L., Chen Y., Deloukas P., Rogers J., Dunham I., Todd J. A., BMC Genetics 2007, 8, 24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Holthe M. R., Staff A. C., Berge L. N., Lyberg T., Am. J. Obstet. Gynecol. 2004, 190, 1128. [DOI] [PubMed] [Google Scholar]
- 35. Sookoian S., Gemma C., Gianotti T. F., Burgueno A., Castano G., Pirola C. J., Am. J. Clin. Nutr. 2008, 87, 1606. [DOI] [PubMed] [Google Scholar]
- 36. Velez D. R., Fortunato S. J., Thorsen P., Lombardi S. J., Williams S. M., Menon R., PLoS One 2008, 3, e3283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Ren Z, Gao Y, Liang G, Chen Q, Jiang S, Yang X, Fan C, Wang H, Wang J, Shi Yi‐Wu, Xiao C, Zhong M, Yu Y, Yang X, bioRxiv 2019, 10.1101/787796. [DOI] [Google Scholar]
- 38. Hedderson M., Ehrlich S., Sridhar S., Darbinian J., Moore S., Ferrara A., Diabetes Care 2012, 35, 1492. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Ngo T. T. M., Moufarrej M. N., Rasmussen M. H., Camunas‐Soler J., Pan W., Okamoto J., Neff N. F., Liu K., Wong R. J., Downes K., Tibshirani R., Shaw G. M., Skotte L., Stevenson D. K., Biggio J. R., Elovitz M. A., Melbye M., Quake S. R., Science 2018, 360, 1133. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Walsh J. M., McAuliffe F. M., Eur. J. Obstet. Gynecol. Reprod. Biol. 2012, 162, 125. [DOI] [PubMed] [Google Scholar]
- 41. Yudkin P. L., Aboualfa M., Eyre J. A., Redman C. W., Wilkinson A. R., Early Hum. Dev. 1987, 15, 45. [DOI] [PubMed] [Google Scholar]
- 42. Langmead B., Trapnell C., Pop M., Salzberg S. L., Genome Biol. 2009, 10, R25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Li H., Handsaker B., Wysoker A., Fennell T., Ruan J., Homer N., Marth G., Abecasis G., Durbin R., Bioinformatics 2009, 25, 2078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Casper J., Zweig A. S., Villarreal C., Tyner C., Speir M. L., Rosenbloom K. R., Raney B. J., Lee C. M., Lee B. T., Karolchik D., Hinrichs A. S., Haeussler M., Guruvadoo L., Navarro Gonzalez J., Gibson D., Fiddes I. T., Eisenhart C., Diekhans M., Clawson H., Barber G. P., Armstrong J., Haussler D., Kuhn R. M., Kent W. J., Nucleic Acids Res. 2018, 46, D762. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Mirzakhani H., Litonjua A. A., McElrath T. F., O'Connor G., Lee‐Parritz A., Iverson R., Macones G., Strunk R. C., Bacharier L. B., Zeiger R., Hollis B. W., Handy D. E., Sharma A., Laranjo N., Carey V., Qiu W., Santolini M., Liu S., Chhabra D., Enquobahrie D. A., Williams M. A., Loscalzo J., Weiss S. T., J. Clin. Invest. 2016, 126, 4702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Nishizawa H., Ota S., Suzuki M., Kato T., Sekiya T., Kurahashi H., Udagawa Y., Reprod. Biol. Endocrinol. 2011, 9, 107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Stirm L., Huypens P., Sass S., Batra R., Fritsche L., Brucker S., Abele H., Hennige A. M., Theis F., Beckers J., Hrabe de Angelis M., Fritsche A., Haring H. U., Staiger H., Sci. Rep. 2018, 8, 1366. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Binder A. M., LaRocca J., Lesseur C., Marsit C. J., Michels K. B., Clin. Epigenet. 2015, 7, 79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Koh W., Pan W., Gawad C., Fan H. C., Kerchner G. A., Wyss‐Coray T., Blumenfeld Y. J., El‐Sayed Y. Y., Quake S. R., Proc. Natl. Acad. Sci. 2014, 111, 7361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Su A. I., Wiltshire T., Batalov S., Lapp H., Ching K. A., Block D., Zhang J., Soden R., Hayakawa M., Kreiman G., Cooke M. P., Walker J. R., Hogenesch J. B., Proc. Natl. Acad. Sci. 2004, 101, 6062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Lin X. J., Chong Y., Guo Z. W., Xie C., Yang X. J., Zhang Q., Li S. P., Xiong Y., Yuan Y., Min J., Jia W. H., Jie Y., Chen M. S., Chen M. X., Fang J. H., Zeng C., Zhang Y., Guo R. P., Wu Y., Lin G., Zheng L., Zhuang S. M., Lancet Oncol. 2015, 16, 804. [DOI] [PubMed] [Google Scholar]
- 52. Ezzati M., Lopez A. D., Rodgers A., Vander Hoorn S., Murray C. J., The Lancet 2002, 360, 1347. [DOI] [PubMed] [Google Scholar]
- 53. Robin X., Turck N., Hainard A., Tiberti N., Lisacek F., Sanchez J. C., Muller M., BMC Bioinformatics 2011, 12, 77. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Zhou Y., Zhou B., Pache L., Chang M., Khodabakhshi A. H., Tanaseichuk O., Benner C., Chanda S. K., Nat. Commun. 2019, 10, 1523. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting Information