

Abstract
This paper proposes nonparametric two-sample tests for the direct comparison of the probabilities of a particular transition between states of a continuous time non-homogeneous Markov process with a finite state space. The proposed tests are a linear nonparametric test, an L2-norm-based test and a Kolmogorov–Smirnov-type test. Significance level assessment is based on rigorous procedures, which are justified through the use of modern empirical process theory. Moreover, the L2-norm and the Kolmogorov–Smirnov-type tests are shown to be consistent for every fixed alternative hypothesis. The proposed tests are also extended to more complex situations such as cases with incompletely observed absorbing states and non-Markov processes. Simulation studies show that the test statistics perform well even with small sample sizes. Finally, the proposed tests are applied to data on the treatment of early breast cancer from the European Organization for Research and Treatment of Cancer (EORTC) trial 10854, under an illness-death model.
Keywords: Competing risks, Illness-death model, Missing absorbing states, Multi-state model, State occupation probabilities
1. Introduction
Continuous time nonhomogeneous Markov processes with a finite state space are important in many areas of science and particularly in medicine and public health (Tattar and Vaman, 2014; Bakoyannis et al., 2019). Consideration of specific transitions between two states of a multi-state process can provide a deeper and more detailed insight about the treatment effect in clinical trials compared to the analysis of standard survival outcomes, such as event-free survival (Le-Rademacher et al., 2018). Important special cases of a Markov process are the univariate survival model, the competing risks model, and the Markov illness-death model (Andersen et al., 2012).
The stochastic behavior of a Markov process can be described by either the transition intensities, which represent the instantaneous rates of transition between two states, or the transition probabilities. The transition probabilities are also known as survival functions in the framework of the univariate survival model, and as cumulative incidence functions in the competing risks model. It is important to note that, in general, a difference in the transition intensities between two groups does not necessarily imply a difference in the corresponding transition probabilities and vice versa. This phenomenon has been well documented for the special case of the competing risks model (Gray, 1988; Pepe, 1991; Putter et al., 2007; Bakoyannis and Touloumi, 2012). Nonparametric tests for comparing transition intensities between groups in general Markov multi-state processes have been well developed (Andersen et al., 2012). However, the issue of nonparametric comparison of transition probabilities in general Markov multi-state processes has not received much attention. Nevertheless, transition probabilities, unlike transition intensities, directly quantify clinical prognosis (Bakoyannis et al., 2019), which is the target of scientific interest in many applications.
Nonparametric estimation of the transition probabilities of a general Markov process can be performed using the Aalen–Johansen estimator (Aalen and Johansen, 1978). The issue of nonparametric comparison of transition probabilities under the univariate survival model has been extensively studied in the literature. For a review of these methods see Kalbfleisch and Prentice (2011) and Andersen et al. (2012). A number of researchers have proposed nonparametric tests for the comparison of transition probabilities for the special case of the competing risks model (Gray, 1988; Pepe and Mori, 1993; Lin, 1997). Dabrowska and Ho (2000) proposed a graphical procedure based on simultaneous confidence bands to test for differences between transition probabilities in a general Markov process. However, their method imposes proportional hazards assumptions for the transition intensities and, thus, it is not fully nonparametric. Also, this approach does not provide the actual level of statistical significance. Tattar and Vaman (2014) proposed two nonparametric tests for the comparison of the whole transition probability matrices between k groups, by comparing all the possible transition intensities. The first test only compares the transition probability matrices at a specific time point t0, while the second test is a Kolmogorov–Smirnov-type test based on the supremum norm. However, the tests proposed by Tattar and Vaman (2014) do not provide a direct comparison of the transition probability of a particular transition, which is frequently of scientific interest (Le-Rademacher et al., 2018). A statistically significant result with these tests only indicates a difference in any transition between groups. Recently, Bluhmki et al. (2018) proposed a wild bootstrap approach for the Aalen–Johansen estimator, which can be used to construct a simultaneous confidence band for the difference between the transition probabilities of two independent groups. This approach, which is related to a Kolmogorov–Smirnov-type test, can be used as a graphical two-sample comparison procedure at a predetermined α level. However, this approach does not provide the actual level of statistical significance and, also, a Kolmogorov–Smirnov-type test may not be the most powerful nonparametric test for every alternative hypotheses. Additionally, there is no rigorous justification about the consistency of this graphical hypothesis testing procedure against any fixed alternative hypothesis (Van der Vaart, 2000). Last but not least, the proposed approach is not readily adaptable to more complex situations such as cases with missing data.
This paper addresses the issue of direct nonparametric two-sample comparison of the transition probabilities of a particular transition in a general continuous-time nonhomogeneous Markov process with a finite state space. For this, we propose a linear nonparametric test, an L2-norm-based test and a Kolmogorov–Smirnov-type test. The asymptotic null distributions of the tests are derived. The evaluation of the actual level of statistical significance is based on rigorous procedures justified through the use of modern empirical process theory. Moreover, the L2-norm-based and Kolmogorov–Smirnov-type tests are shown to be consistent against any fixed alternative hypothesis (Van der Vaart, 2000). It has to be noted that the linear nonparametric test can be inconsistent under some alternative hypotheses with crossing transition probability curves. This is because, in such cases, the corresponding test statistic can be equal to zero, since positive and negative differences of the same magnitude cancel out. In less extreme cases with crossing, the linear test is expected to be less powerful compared to the L2-norm-based and Kolmogorov–Smirnov-type tests. We also propose extensions related to interesting practical problems such as cases with missing absorbing states (Bakoyannis et al., 2019) and non-Markov processes (Putter and Spitoni, 2018). The proposed tests exhibit good small sample properties as illustrated in our simulation experiments. Finally, the tests are applied to data on the treatment of early breast cancer from the European Organization for Research and Treatment of Cancer (EORTC) trial 10854.
Compared to the previous work by Bluhmki et al. (2018), which used counting process theory arguments in their derivations, we justify the properties of the proposed tests through the use of modern empirical process theory (Van Der Vaart and Wellner, 1996; Kosorok, 2008). As it will be argued later in the text, the practical advantage of our derivations lies on the fact that our proposed tests can be straightforwardly adapted to more complex settings such as cases with incompletely observed absorbing states (Bakoyannis et al., 2019). This can be done by replacing the influence function of the standard Aalen–Johansen estimator with the influence function of any other well-behaved and asymptotically linear estimator of the transition probabilities in our proposed testing procedures. Such adaptations are not trivial within the framework of the graphical testing procedure proposed by Bluhmki et al. (2018). An important reason for this is that with more complex estimators, certain predictability conditions assumed by counting process and martingale theory techniques are violated. For such situations, empirical process theory provides a powerful alternative tool. Moreover, we provide two additional tests, a linear test and an L2-norm-based test, which may be more powerful compared to a Kolmogorov–Smirnov-type test in certain settings. Additionally, we argue about the consistency of our L2-norm-based and Kolmogorov–Smirnov-type tests against any fixed alternative hypothesis. Finally, our tests provide the actual level of statistical significance which is useful in practical applications.
The structure of this paper is as follows. In Section 2 we introduce some notation about Markov processes, provide the proposed nonparametric tests, and consider extensions to more complex situations that are frequently met in practice. Section 3 presents a simulation study to evaluate the small sample performance of the proposed tests. Section 4 illustrates the use of the proposed tests using data from the EORTC trial 10854. Finally, Section 5 concludes the article with some key remarks. Outlines of the asymptotic theory proofs are provided in the Appendix.
2. Two-sample nonparametric tests
2.1. Nonparametric estimation of transition probabilities
The stochastic behavior of a Markov process {X(t) : t ≥ 0} with a finite state space can be described by the q × q transition probability matrix P0(s, t) = (P0,hj(s, t)) whose elements are the transition probabilities
where is the event history prior to time s, with Nhj (t) being the number of direct transitions from state h to state j, h ≠ j, in [0, t], , and , is the transition intensity at time t. The conditional independence between the probability of X(t) and the prior history , conditionally on X(s), is the so-called Markov assumption. Because Po(s, t) is a stochastic matrix we have that
The observed data from a sample of i.i.d. observations of a Markov process are the counting processes {Nihj (t) : h ≠ j, t ∈ [0, τ]}, i = 1, … , n, which represent the number of direct transitions of the ith observation from the state h to the state j by time t, and the at-risk processes which are the indicator functions of whether the ith observation is at the state just before time t ∈ [0, τ]. Based on such a sample, the transition probability matrix of a nonhomogeneous Markov process can be estimated using the nonparametric Aalen–Johansen estimator (Aalen and Johansen, 1978):
where ∏ is the product integral and Ân(t) a q×q matrix whose elements are the Nelson–Aalen estimates of the cumulative transition intensities
2.2. Linear nonparametric tests
First consider the two-sample problem of comparing the transition probabilities and , s ∈ [0, τ), of two populations of interest, for a particular transition h → j, with . In many applications the starting point is being set to s = 0, but here we will use an arbitrary s ∈ [0, τ) for the sake of generality. Based on two independent random samples of n1 and n2 observations from the two populations, define the pointwise weighted difference
where is a weight function and and are the nonparametric Aalen–Johansen estimates of the transition probabilities of the two populations under comparison. Examples of weight function choices are
and
where I(·) is the indicator function, is a transient state that can be visited during the transition h → j} and, The latter choice assigns more weight to times with more observations at risk. This is useful for assigning less weight for times with a very small number of observations, such as times close to the end of the study period, where the transition probability estimates can be highly unstable. A natural linear test for the null hypothesis for a given starting point s ∈ [0, τ) and all t ∈ [s, τ], or, equivalently, for a given starting point s ∈ [0, τ), is the area under the weighted difference curve
where m is the Lebesgue measure on the Borel σ-algebra . To establish the asymptotic distributions of the proposed test statistics, we assume the following conditions.
C1. The potential right censoring and left truncation are independent of the counting processes {Nhj(t) : h ≠ j, t ∈ [0, τ]} and noninformative about P0(s, t).
C2. n1/(n1 + n2) → λ ∈ (0,1) as min(n1, n2) → ∞.
C3. The counting processes {Nhj(t) : h ≠ j, t ∈ [0, τ]} satisfy E[Nhj(τ)]2 < ∞ for all h ≠ j.
C4. inft∈[0, τ] E[Yh(t)] > 0 for all the transient states.
C5. The cumulative transition intensities {A0,hj(t) : h ≠ j, t ∈ [0, τ]} are continuous functions.
C6. The weight converges uniformly, in probability, to a nonnegative uniformly bounded function Whj(t) on [0, τ].
Remark 1. In some applications condition C4 may not be satisfied for some time points for one or more transient states . In such cases, provided that the conditions for the uniform consistency of the Aalen–Johansen estimator hold, one can restrict the comparison interval to [τ1, τ2] with 0 < τ1 < τ2 < τ, such that inft∈[τ1, τ2] E[Yh(t)] > 0 for the transient states, and then use nonparametric bootstrap for inference. In such cases the test statistic becomes
for a fixed s ∈ [τ1, τ2).
Before stating the theorem about the asymptotic distribution of test statistic we define the functions
where and are the counting and at-risk processes of the ith observation in the pth sample at time t. Also, define to be the subset of which contains the potential absorbing states. For non-absorbing Markov processes .
Theorem 1 provides the asymptotic distribution of under the null hypothesis . In this work, we adopt the convention that 0 · ∞ = 0 as in Athreya and Lahiri (2006).
Theorem 1. Suppose that conditions C1-C6 hold. Then under the null hypothesis for some (fixed) s ∈ [0, τ),
where and
with
for i = 1, …, np
Remark 2. The functions in Theorem 1 are the influence functions of the Aalen–Johansen estimator of
A consistent (in probability) estimator of the variance is
where are estimated by replacing the expectations with sample averages and the unknown parameters with their uniform consistent estimates. Now, Theorem 1 and can be used to construct a Z-test for the null hypothesis as:
The actual significance level can then be evaluated under the standard normal distribution as usual.
In some applications it may not be desirable to fix the starting point s. In such cases the scientific interest is on comparing and for all s ∈ [0, τ). The null hypothesis in this case is or, more compactly, The following test statistic can be used for this hypothesis testing problem:
Theorem 2 below provides the asymptotic null distribution of the above test statistic.
Theorem 2. Suppose that conditions C1-C6 hold. Then under the null hypothesis
where and
A consistent (in probability) estimator of can be obtained by replacing the expectations by sample averages, λ by n1/(n1 + n2), and Whj(t) and by and , respectively.
2.3. L2-norm-based and Kolmogorov–Smirnov-type tests
A linear test is not the optimal choice when the two transition probability curves under comparison cross at one or more time points. In this section, we propose alternative tests for such situations. The first test is a test based on an L2 norm
for any (fixed) s ∈ [0, τ), while the second test is a Kolmogorov–Smirnov-type test
The Kolmogorov–Smirnov-type test is related to the graphical hypothesis testing procedure proposed by Bluhmki et al. (2018). For applications where it is not desirable to fix the starting point s, the following test statistics can be used:
and
The asymptotic null distributions of these tests are complicated. However, significance level can be easily calculated numerically by proper simulation realizations from the null distribution of these test statistics. Theorem 3 provides the basis for an approach to properly simulate realizations from the null distributions of , and . Before stating Theorem 3 define the estimated functions
where , p = 1, 2, are independent draws from N(0, 1).
Theorem 3. Suppose that conditions C1-C6 hold. Then, the following are true:
-
(i)Under the null hypothesis , for any (fixed) s ∈ [0, τ),
and, conditionally on the observed data,
where and are two independent tight zero-mean Gaussian processes with covariance functions
for any t1, t2 ∈ [s, τ]. -
(ii)Under the null hypothesis
and, conditionally on the observed data,
where and are two independent tight zero-mean Gaussian processes with covariance functions at the points v1 = (s1, t1) and v2 = (s2, t2) equal to
Corollary 1. By Theorem 3 and the continuous mapping theorem it follows that under the null hypothesis
and
for any fixed s ∈ [0, τ). Similarly, under the null hypothesis
and
The asymptotic null distributions of the omnibus tests are quite complicated and, thus, they are of limited use in practical applications. However, Theorem 3 provides justification about a way to numerically calculate p-values through a simple simulation technique. This can be performed as follows. In light of Theorem 3, one can simulate from the asymptotic null asymptotic distributions of the tests and , for a fixed s ∈ [0, τ], by simulating multiple versions of and independently from N(0,1) for r = 1, … , R, and then calculating a sample for the corresponding null distributions of and as
and , r = 1, …, R, respectively, where
Generating samples from the null distributions of the test statistics and , given in Corollary 1, can be performed in a similar manner. Now, the significance level for each test can be calculated as the proportion of realizations from the corresponding null distribution that is greater than or equal to the calculated test statistic value from the observed data.
The tests and , for a given s ∈ [0, τ), are consistent for every fixed alternative hypothesis with . This follows from Theorem 2, the uniform consistency of the Aalen–Johansen estimator of the transition probabilities (Aalen and Johansen, 1978), condition C6, the continuity of these tests in , and Lemma 14.15 in Van der Vaart (2000). The same conclusion also holds for the test statistics and .
2.4. Extensions to more complex settings
Many complications that frequently occur in practice make the application of the proposed tests improper. An important example is the problem of incompletely observed absorbing states, where missingness occurs either due to the usual nonresponse or by the study design (Bakoyannis et al., 2019). A special case of this is the issue of missing causes of death in biomedical applications. In such cases, a complete case analysis, which discards cases with a missing cause of death, is well known to lead to biased estimates (Gao and Tsiatis, 2005; Lu and Liang, 2008; Bakoyannis et al., 2019). In general, more complicated cases require extensions of the standard Aalen–Johansen estimator, denoted by , to consistently estimate the transition probabilities of interest over an interval [τ1, τ2] ⊂ [0, τ]. In such cases, one can replace the standard Aalen–Johansen estimator with another appropriate estimator in the testing procedures. Then, the linear test becomes
for any (fixed) s ∈ [τ1, τ2), where
while the L2-norm based and Kolmogorov–Smirnov-type tests become
and
The following conditions ensure the validity of the proposed testing procedures for the null hypothesis in more complex settings.
D1. The estimator is consistent in the sense
for any (fixed) s ∈ [τ1, τ2).
D2. The estimator is an asymptotically linear estimator with
with {ϕhj(s, t) : t ∈ [s, τ2]} being a P-Donsker class for any s ∈ [τ1, τ2].
D3. The empirical versions of the influence functions satisfy
where ξi are independent random draws from N(0, 1).
Remark 3. Condition D2 is sufficient for establishing the weak convergence of the estimator to a tight mean-zero Gaussian process. Condition D3 along with the conditional multiplier central limit theorem (Van Der Vaart and Wellner, 1996; Kosorok, 2008) and condition D2, provide a simulation approach for the construction of simultaneous confidence bands (Kosorok, 2008). Therefore, conditions D1-D3 are expected to have been established in works extending the standard Aalen–Johansen estimator to more complex settings. This is the case, for example, for the nonparametric estimator of the transition probability matrix with incompletely observed absorbing states (Bakoyannis et al., 2019).
Hypothesis testing in more complex settings can be simply performed by replacing the influence functions of the standard Aalen–Johansen estimator with the influence functions of the estimator . The theorems stated below justify the direct use of the proposed tests in more complex situations. Before stating those theorems define the functions
where are independent draws from N(0, 1).
Theorem 4. Suppose that conditions C2, C6, D1 and D2 hold. Then under the null hypothesis
for any (fixed) s ∈ [τ1, τ2), where and
The proof of Theorem 4 involves the same arguments to those used in the proof of Theorem 1 given in the Appendix.
Theorem 5. Assume that conditions C2, C6, and D1-D3 are satisfied. Then, under the null hypothesis and for s ∈ [τ1, τ2)
and, conditionally on the observed data,
where and are two independent tight zero-mean Gaussian processes with covariance functions
The proof of Theorem 5 follows from similar arguments to those used in the proof of Theorem 3 given in the Appendix.
2.4.1. Missing absorbing states
In many settings one can observe that a process has arrived at some absorbing state, but the actual absorbing state is unobserved for some study participants, such as in cases with missing causes of death. For such situations, Bakoyannis et al. (2019) proposed a nonparametric maximum pseudolikelihood estimator (NPMPLE) under a missing at random assumption. To review this estimator, let Δij be an indicator variable with Δij = 1 if the ith observation arrived at the absorbing state , and Δij = 0 otherwise. Also, let Ri be another indicator variable with Ri = 1 indicating that the absorbing state of the ith observation has been successfully observed. Finally, let πj(Oi, β0) be the probability that Δij = 1 given the fully observed data Oi, under a parametric model indexed by an unknown Euclidean parameter β0. In this setting, the cumulative transition intensities can be estimated using the NPMPLE:
where
with being a consistent estimator of β0. The transition probability matrix can then be estimated as
where the components of the matrix are . By Theorems 1 and 2 in Bakoyannis et al. (2019) and calculations provided in the proof of Theorem 2 in the same source, the NPMPLE estimator satisfies the conditions D1-D3 above. Therefore, if the conditions in Bakoyannis et al. (2019) and the conditions C2 and C6 above are satisfied, two-sample comparison can be performed by utilizing the NPMPLE of the transition probabilities along with the corresponding influence functions in the proposed tests. This is justified by Theorems 4 and 5 above.
2.4.2. Non-Markov processes
Trivially, the Aalen–Johansen estimator is uniformly consistent for the transition probability Phj(0, ·) even under a non-Markov process (Datta and Satten, 2001; Titman, 2015). When the interest lies on the marginal Pr(X(t) = j|X(s) = h), i.e. unconditionally on the prior history , for some s > 0, under a non-Markov process, then the landmark Aalen–Johansen estimator is consistent for Pr(X(t) = j|X(s) = h) (Putter and Spitoni, 2018) under the conditions of Datta and Satten (2001) and, also, the assumption that Pr(X(s) = h) > 0. The landmark Aalen–Johansen estimator is essentially equivalent to the standard Aalen–Johansen estimator, except for the fact that only observations with X(s) = h are considered. This is achieved by considering the modified counting and at-risk processes and , for t ≥ s. Therefore, the influence functions of the landmark Aalen–Johansen estimator are the same to that of the standard Aalen–Johansen estimator, with the only exception that the former involves the modified and instead of the standard counting and at-risk processes Nihj(t) and Yih(t). Consequently, it is clear that conditions D1–D3 are satisfied if Pr(X(s) = h) > 0 and, also, if the conditions in Datta and Satten (2001) hold. Thus, in light of Theorems 4 and 5, the proposed nonparametric tests can be used with non-Markov processes by utilizing the landmark Aalen–Johansen estimator.
2.4.3. Comparison of state occupation probabilities
The proposed tests can be easily adapted for the comparison of state occupation probabilities , as these are simple linear combinations of the transition probabilities. The state occupation probabilities describe the marginal behavior, i.e. unconditional on the prior history, of the processes and are of interest in many applications, such as in HIV studies focusing on the event history of patients in HIV care (Lee et al., 2018). It is important to note that these probabilities can be consistently estimated based on the Aalen–Johansen estimator of the transition probabilities even in non-Markov processes (Datta and Satten, 2001). An obvious consistent estimator of P0,h(0) is
By the continuous mapping theorem and the uniform consistency of the Aalen–Johansen estimator, the estimator of the state occupation probabilities , is uniformly consistent for P0,j(t). Also, it is not hard to see that, by the asymptotic linearity of the Aalen–Johansen estimator, is an asymptotically linear estimator with
The class {ψj(t) : t ∈ [0, τ]} formed by the influence functions is P-Donsker. This property is a consequence of the Donsker property of the classes {γhj(0, t) : t ∈ [0, τ]} for all and , as it is argued in the proof of Theorem 1 in the Appendix, the total boundedness of the class of fixed functions {P0,hj(0, t) : t ∈ [0, τ]} as a result of condition C5, and Corollary 9.32 in Kosorok (2008). Therefore, conditions D1 and D2 are satisfied. Finally, condition D3 is also satisfied by the fact the ψij(t), , is a linear combination of γihj (0, t), , the triangle inequality, and arguments similar to those used in the proof of Theorem 3 in the Appendix. Consequently, Theorems 4 and 5 provide a rigorous justification about the use of the proposed tests for comparing state occupation probabilities based on the aforementioned estimator.
3. Simulation studies
To evaluate the finite sample performance of the proposed test statistics, we conducted a simulation study. We considered a Markov process with 2 transient states {1, 2} and 1 absorbing state {3}, under the illness-death model without recovery (Andersen et al., 2012). This model is illustrated in Figure 1. In this simulation study, we focused on the null hypothesis . Initially, we independently generated the times from state 1 to states 2 and 3 by assuming the cumulative transition intensities , for p = 1, 2, and . For observations that first arrived at the transient state 2, we generated the time from state 2 to the absorbing state 3, assuming a cumulative transition intensity Under this set-up the transition probability of interest was
Different scenarios were considered according to the parameter values α1 = (α11, α21) and α2 = (α12, α22). In simulation scenarios 1 to 4 we simulated data under the null hypothesis with α1 = α2 ≡ α. This common parameter was set to (1, 0.5), (1.4, 0.75), (1.2, 0.25), and (0.6, 0.25) under scenarios 1, 2, 3, and 4, respectively. In simulation scenarios 5 to 8 we simulated data under the alternative hypothesis. In these cases, the parameter α1 was set to (0.6, 0.25), (0.6, 0.25), (1, 0.5), and (0.8, 0.25) for scenarios 5, 6, 7, and 8, respectively. The corresponding figures for the parameter α2 were (0.9, 0.25), (1.2, 0.25), (1.4, 0.75), and (1.4, 0.75). Right censoring times were independently simulated from Exp(0.25). Different sample sizes np, p = 1, 2, of the two groups were also considered. 2000 datasets were simulated for each scenario, and the L2 distance test and Kolmogorov–Smirnov-type test were calculated using 1000 independent simulations of and from N(0, 1). Finally, we considered the weight function
in all cases. We also provide simulation results based on the weight function in the Supplemental Online Material.
Figure 1:
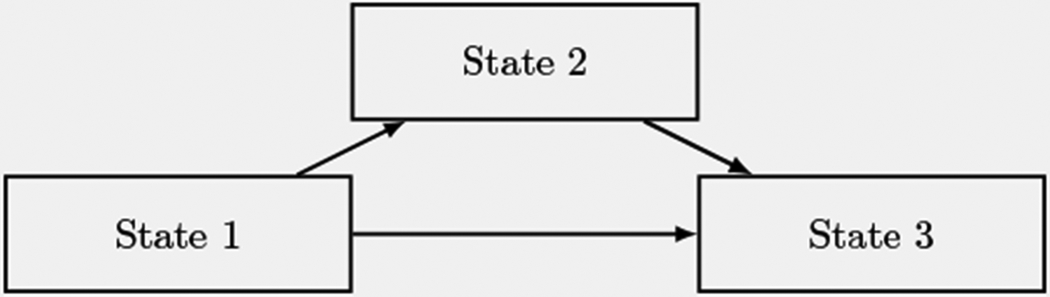
Illness-death model without recovery assumed in the simulation study.
Simulation results regarding the empirical type I error rates are presented in Tables 1 and 2, respectively. Under these scenarios, the empirical type I errors rates for all tests were close to the nominal α levels, even in situations with small sample sizes. Thus, these results provide numerical evidence for the validity of the proposed hypothesis testing procedures under H0. Simulation results regarding the empirical power levels under alternative hypotheses with non-crossing transition probabilities are presented in Table 3. Under these scenarios, the empirical power levels increased with sample size and, also, with a more pronounced difference between the two groups, as expected. These results provide numerical evidence for the consistency of the proposed tests with non-crossing transition probabilities. The linear test exhibited more power compared to the Kolmogorov–Smirnov-type test in such cases. Simulation results regarding the empirical power levels under alternative hypotheses with crossing transition probabilities are presented in Table 4. These scenarios illustrate numerically that the linear test can exhibit substantially lower power levels compared to the omnibus tests, for alternative hypotheses with crossing transition probability curves. The empirical power of the tests increased with sample size and with a more pronounced difference between the two groups.
Table 1:
Simulation results about empirical type I error rates for the linear test (Linear), the L2-norm-based test (L2), and the Kolmogorov–Smirnov-type test (KS) for testing , under simulation scenarios 1 and 2.
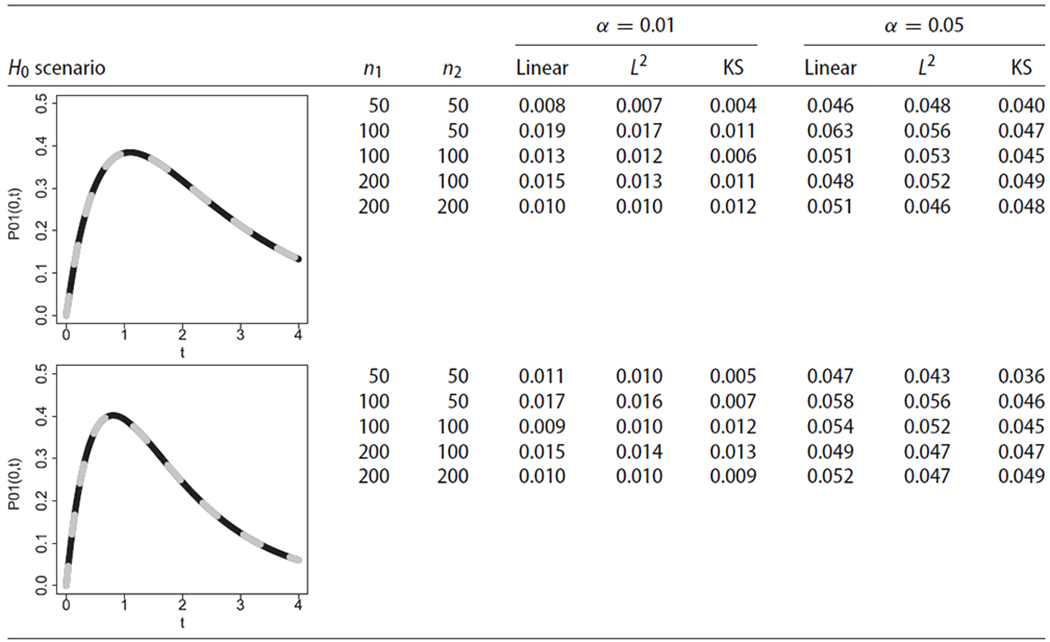 |
Note: The weight function was
Table 2:
Simulation results about empirical type I error rates for the linear test (Linear), the L2-norm-based test (L2), and the Kolmogorov–Smirnov-type test (KS) for testing , under simulation scenarios 3 and 4.
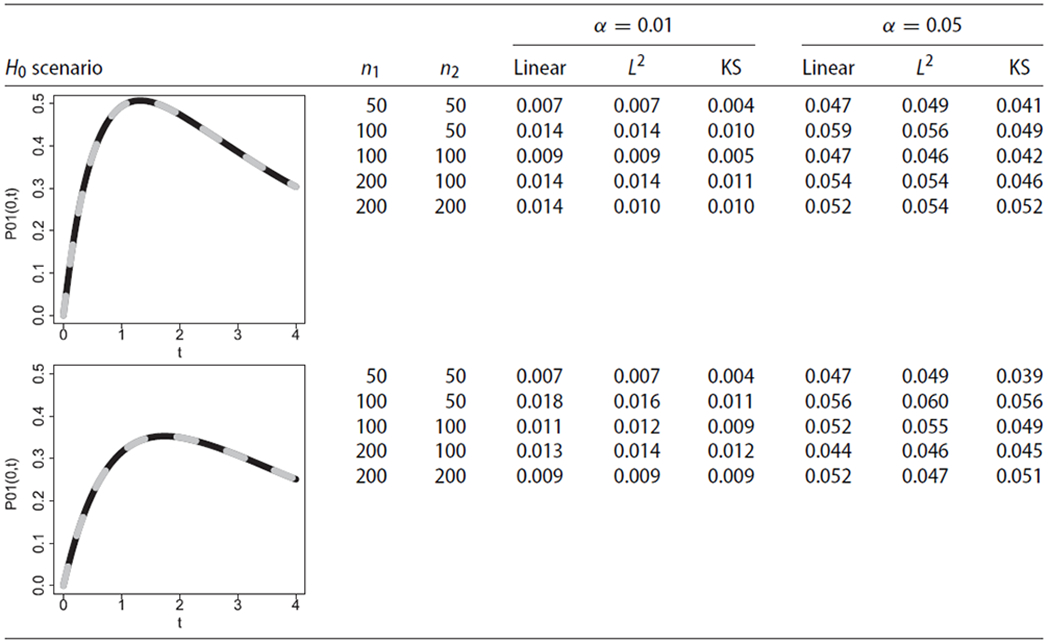 |
Note: The weight function was
Table 3:
Simulation results about empirical power levels for the linear test (Linear), the L2-norm-based test (L2), and the Kolmogorov–Smirnov-type test (KS) for testing under simulation scenarios 5 and 6.
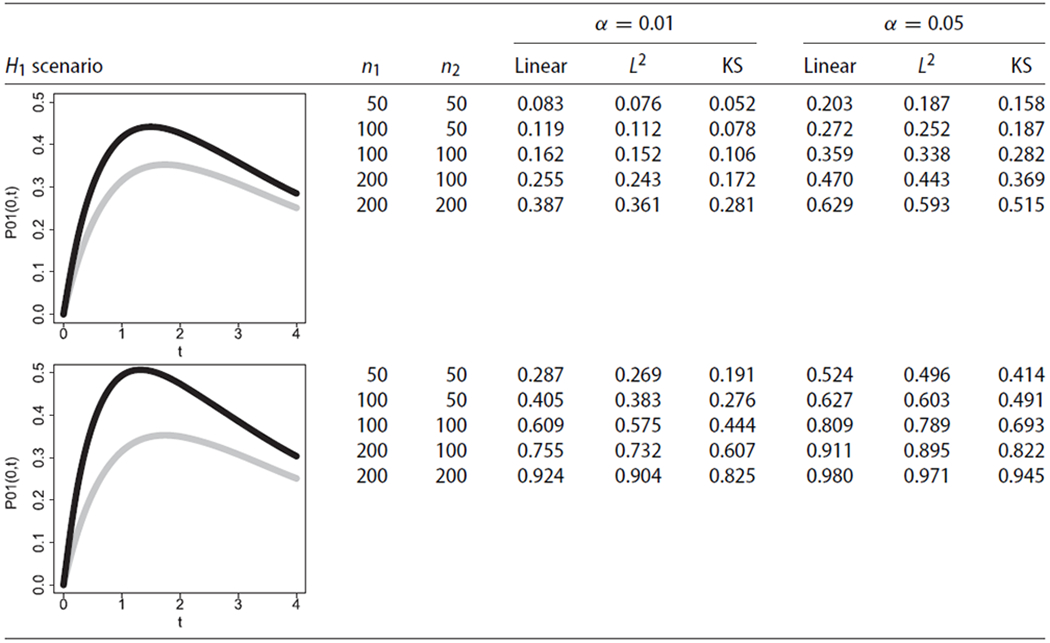 |
Note: The weight function was
Table 4:
Simulation results about empirical power levels for the linear test (Linear), the L2-norm-based test (L2), and the Kolmogorov–Smirnov-type test (KS) for testing under simulation scenarios 7 and 8. The weight function was
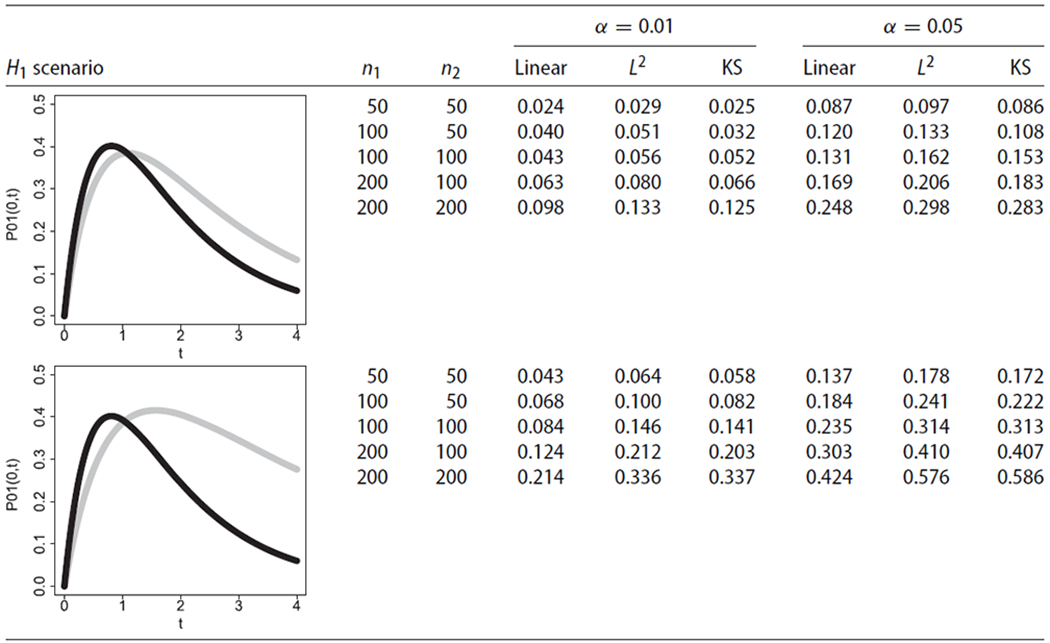 |
Simulation results based on the weight function are provided in the Supplemental Online Material. These results are similar to those presented here. However, with the latter weight choice, the Kolmogorov–Smirnov-type test appears to exhibit higher power levels for scenarios with non-crossing transition probability curves. Moreover, the L2-norm-based test appears to be the most powerful test in scenarios with crossing transition probability curves, particularly under a smaller difference between the two groups.
4. Data analysis
In this section we analyze the data on treatment of early breast cancer from the European Organization for Research and Treatment of Cancer (EORTC) trial 10854. This randomized clinical trial was conducted to evaluate whether the combination of surgery with polychemotherapy is beneficial to early breast cancer patients compared to surgery alone. The original analysis of this clinical trial was presented in Van der Hage et al. (2001).
In this trial, 1395 patients where randomly assigned to the surgery group and 1398 to the surgery plus polychemotherapy group. The data set contains information about the time to cancer relapse or death. Therefore, an illness-death model is a natural choice for this data set. It is important to note that the transition probability to relapse, which was not analyzed in the original analysis of this trial, is a non-monotonic function of time as patients can move to the “death” state after relapse. Thus, standard survival and competing risks analysis methods are not applicable for this transition probability. Here, we focus on this probability which can be interpreted as the probability of being alive and in relapse. The estimated transition probabilities of relapse in the two intervention groups are presented in Figure 2. Based on Figure 2, the probability of being alive and in relapse was lower in the group that received polychemotherapy during surgery. To perform hypothesis testing here we considered the weight function . For the L2-norm-based and Kolmogorov–Smirnov-type tests we considered 1000 standard normal simulation realizations. The p-value from the linear test was 0.001, while the p-values from the L2-norm-based and Kolmogorov–Smirnov-type tests were both equal to 0.002. These results provide evidence for the superiority of the surgery plus polychemotherapy combination with respect to the transition probability of relapse, in early breast cancer patients.
Figure 2:
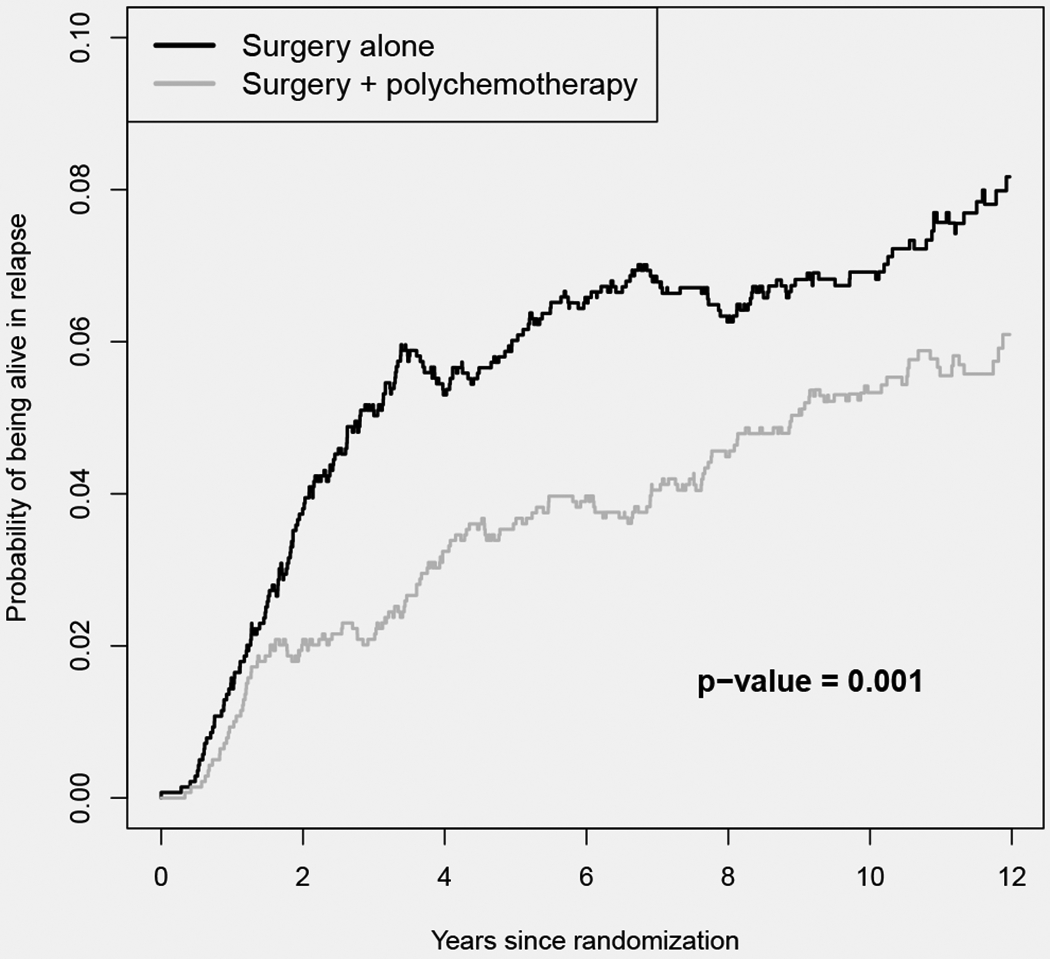
Transition probabilities of being alive in relapse by intervention group in the EORTC Trial 10854.
5. Concluding remarks
This paper addressed the issue of direct nonparametric two-sample comparison of transition probabilities P0,hj(s, ·), for some (fixed) s ∈ [0, τ), for a particular transition h → j in a continuous time nonhomogeneous Markov process with a finite state space. The proposed tests were a linear nonparametric test, an L2-norm-based test and a Kolmogorov–Smirnov-type test. Rigorous approaches to evaluate the significance level grounded on modern empirical process theory were provided. Moreover, the L2-norm-based and Kolmogorov–Smirnov-type tests were argued to be consistent against any fixed alternative hypothesis. Additionally, we proposed versions of the tests for the null hypothesis , that is for all s ∈ [0, τ) and t ∈ [s, τ]. We also considered extensions of the tests to more complex situations such as cases with missing absorbing states (Bakoyannis et al., 2019) and non-Markov processes (Putter and Spitoni, 2018). The simulation study provided numerical evidence for the validity of the proposed testing procedures, which exhibited good performance even with small sample sizes. Finally, a data analysis of a clinical trial on early breast cancer illustrated the utility of the proposed tests in practice.
The importance of the weight function Whj(t) in the proposed test statistics lies on the fact that it essentially restricts the comparison time interval to a time interval where the risk set sizes are non-zero for both groups under comparison. Moreover, a weight function can be used to assign less weight to time points with less observations at risk, where the estimated transition probabilities can be unstable.
It has to be noted that the linear nonparametric test can be inconsistent under some alternative hypotheses with crossing transition probability curves. This is because, in such cases, the true area under the weighted difference curve can be equal to zero, since positive and negative differences of the same magnitude cancel out. In less extreme cases with crossing, the linear test is expected to be less powerful compared to the L2-norm-based and Kolmogorov–Smirnov-type tests. This phenomenon was illustrated numerically in our simulation studies.
The issue of nonparametric comparison of transition probabilities in general nonhomogeneous Markov processes has received little attention in the literature. To the best of our knowledge, the only fully nonparametric approach for comparing the transition probabilities for a particular transition in general nonhomogeneous Markov processes is a graphical procedure proposed by Bluhmki et al. (2018). This proposal is based on the construction of a simultaneous confidence band for the difference between the transition probabilities of two groups. This approach relies on the same statistic as our Kolmogorov–Smirnov-type test, that is the supremum of the absolute weighted difference between the Aalen–Johansen estimators of the two groups, and thus it involves the same sampling distribution. Estimation of the 1 − α percentile of the corresponding asymptotic null distribution is achieved through a resampling procedure which is similar to ours. As Bluhmki et al. (2018) state “The confidence band for the difference can also be viewed as a Kolmogorov–Smirnov-type asymptotic level α test”. Thus, evaluating whether a (1 − α)% confidence band for the difference of the two transition probabilities by Bluhmki et al. (2018) does not fully include the line y = 0, is equivalent to assessing whether p-value<α based our Kolmogorov–Smirnov-type test, under the same weight function. However, the graphical approach by Bluhmki et al. (2018) does not provide the exact level of statistical significance and, also, our linear and L2-norm tests can be more powerful compared to the Kolmogorov–Smirnov-type test in certain settings, as shown in the simulation studies. More importantly, the justification of this approach was based on counting process theory arguments and not on modern empirical process theory. A consequence of that is that this approach cannot be directly adapted to more complex settings that are frequently occur in practice, such as cases with missing absorbing states. An important reason for this is that with more complex estimators, certain predictability conditions assumed by counting process and martingale theory techniques are violated. On the contrary, our proposed methods can be trivially adapted to many other complex settings, provided that appropriate estimators, in the sense of conditions D1–D3, of the transition probabilities exist. Such adaptations can be theoretically justified using the Theorems 4 and 5 provided in our manuscript. Such extensions, which are useful in many applications, include the situation with missing absorbing states and the case of nonparametric two-sample comparison of state occupation probabilities, presented in subsections 2.4.1 and 2.4.3, respectively.
An important future task from a practical standpoint is the implementation of the proposed tests in standard statistical software, such as R, for general use. While calculations for the proposed tests of , for some (fixed) s ∈ [0, τ), can be fast, the tests of are quite computationally intensive, particularly with larger sample sizes. This is because they require calculating the influence functions for all the combinations of times s and t, with s < t, evaluated at the observed transition times. For this case, efficient code implementation along with parallel computing would be useful in practice.
Supplementary Material
Acknowledgement
The authors thank the reviewers for their insightful comments that led to a significant improvement of this manuscript. This project was supported, in part, by the Indiana Clinical and Translational Sciences Institute funded, in part by Grant Number UL1TR002529 from the National Institutes of Health, National Center for Advancing Translational Sciences, Clinical and Translational Sciences Award, and the National Institute of Allergy and Infectious Diseases under award number R21AI145662. We would like to thank the European Organisation for Research and Treatment of Cancer (EORTC) for sharing with us the data from the EORTC trial 10854. The content of this manuscript is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health and the EORTC.
A. Outlines of proofs
Outlines of the proofs of Theorems 1 and 2 are provided below. The proofs of Theorems 3 and 4 follow from similar arguments and, therefore, are omitted. The proofs rely on empirical process theory techniques (Van Der Vaart and Wellner, 1996; Kosorok, 2008). Before providing the proofs it is useful to introduce some notation. First, let be the sample space, and O an arbitrary sample point in . Now, define for some measurable function . Also, define to be the expectation of f under the probability measure P on the measurable space , where is a σ-algebra on . For simplicity, but without loss of generality, we set the starting point s = 0 in the following proofs. It has to be noted that conditions C1 and C3–C5 imply the uniform consistency of the standard Aalen–Johansen estimator. This can be shown using similar arguments to those used in the proof of Theorem 1 in Bakoyannis et al. (2019). In what follows, C will denote a universal constant that may vary from place to place. Before providing the proofs of Theorems 1 and 2, we state and prove two useful lemmas.
Lemma 1. Let h(t) be a fixed and uniformly bounded function on [0, τ] and N(t) be an arbitrary counting process with P[N(τ)]2 < ∞. Then, the class of functions
is P-Donsker.
Proof. Let for any probability measure Q. Now, for any probability measure Q and any s1, s2 ∈ [0, τ], t1 ∈ [s1, τ], and t2 ∈ [s2, τ] it follows that
By Lemma 22.4 in Kosorok (2008), it follows that the class Φ1 = {N(t) : t ∈ [0, τ]} has a bounded uniform entropy integral (BUEI) with envelope 2N(τ), and is also pointwise measurable (PM). This implies that, for any s ∈ [0, τ] and t ∈ [s, τ] there exist an sj ∈ [0, τ], j = 1, …, N(ϵ2‖ N(τ)‖Q,2, Φ1, L2(Q)), and a ti ∈ [s, τ], i = 1, …, N(ϵ2‖N(τ)‖Q,2, Φ1, L2(Q)), such that ‖N(s) − N(sj)‖Q,2 < ϵ2‖N(τ)‖Q,2 and ‖N(t) − N(ti)‖Q,2 < ϵ2‖N(τ)‖Q,2, for any ϵ > 0 and any finitely discrete probability measure Q. Therefore, for any member of , there exist a , for i, j = 1, … , N(ϵ, Φ1, L2(Q)), such that
for any ϵ > 0 and any finitely discrete probability measure Q. Consequently, by the minimality of the covering number it follows that for any ϵ > 0 and any finitely discrete probability measure Q, we have that
which yields a BUEI for with envelope 4CN(τ). Using similar arguments to those used in the example of page 142 of Kosorok (2008), it can be shown that the class is also PM. Therefore, by Theorem 2.5.2 in Van Der Vaart and Wellner (1996), the class is P-Donsker. □
Lemma 2. Let h(t) be a fixed and uniformly bounded function, Y(t) be an arbitrary at-risk process, and A(t) a continuous cumulative transition intensity function on [0, τ]. Then, the class of functions
is P-Donsker.
Proof. It is not hard to show that for any probability measure Q and any s1, s2 ∈ [0, τ], t1 ∈ [s1, τ], and t2 ∈ [s2, τ] it follows that
Now, the class of fixed functions Φ2 = {A(t) : t ∈ [0, τ]} is a compact subset of as it consists of continuous functions defined on the compact set [0, τ]. Therefore, this class of fixed functions can be covered by C(1/ϵ) ϵ-balls and, thus, N(ϵ, Φ2, | · |) ≤ C(1/ϵ). Consequently, for any s ∈ [0, τ] and t ∈ [s, τ] there exist an sj ∈ [0, τ], j = 1, … , N (ϵ, Φ2, | · |), and a ti £ [s, τ], i = 1, … , N(ϵ, Φ2, | · |), such that |A(s) − A(sj)| < ϵ and |A(t) − A(tj)| < ϵ, for any ϵ > 0 and any finitely discrete probability measure Q. Therefore, for any member of , there exist a , for i, j = 1, … , N(ϵ, Φ2, | · |), such that
for any ϵ > 0 and any finitely discrete probability measure Q. Consequently, by the minimality of the covering number it follows that for any ϵ > 0 and any finitely discrete probability measure Q, we have that
which yields a BUEI for . Finally, similar arguments to those used in the proof of Lemma 1 lead to the conclusion that the class is P-Donsker. □
A.1. Proof of Theorem 1
Theorem 1 relies on the asymptotic linearity of the estimators . This can be established by first utilizing the asymptotic linearity of the Nelson–Aalen estimators of the cumulative transition intensities and then by applying the functional delta method (Van der Vaart, 2000). The steps to achieve this utilize conditions C1 and C3–C5 and arguments similar to those used in the proof of Theorem 2 of Bakoyannis et al. (2019). After this analysis it can be shown that
for 0 ≤ s ≤ t ≤ τ, where
| (1) |
The first integral in the brackets in the right side of (1) forms a P-Donsker class of functions indexed by s ∈ [0, τ] and t ∈ [s, τ], as a consequence of Lemma 1 and conditions C3 and C4. The second integral in the bracket in (1) also forms a P-Donsker class indexed by s ∈ [0, τ] and t ∈ [s, τ], by Lemma 2 and conditions C4 and C5. Therefore, the class
is P-Donsker by Corollary 9.32 in Kosorok (2008), as it is formed by the union of the classes and which consist of finite sums of functions that belong to P-Donsker classes. This implies that the Aalen–Johansen estimator converges weakly to a tight zero mean Gaussian process. Next, by condition C6 and the weak convergence of the Aalen–Johansen estimator it follows that
for any (fixed) s ∈ [0, τ). Now, it is not hard to see that under the null hypothesis and by condition C2, the asymptotic linearity of the transition probability estimators, and the continuous mapping theorem:
| (2) |
for any (fixed) s ∈ [0, τ). By the Donsker property of the class and Lemma 15.10 in Kosorok (2008), it follows that the classes {}, p = 1, 2, are P-Donsker for any fixed s ∈ [0, τ). This implies that for t = τ,
is asymptotically normally distributed with variance
Finally, the statement of Theorem 1 follows from the independence between the two terms in the right side of (2), as a consequence of the fact that the two samples are independent.
A.2. Proof of Theorem 2
First, the estimators , are consistent uniformly in s ∈ [0, τ] and t ∈ [s, τ] by a continuity result for the Duhamel equation (Andersen et al., 2012) and the continuous mapping theorem (Kosorok, 2008). Next, by condition C6 and the weak convergence of the Aalen–Johansen estimator, as a consequence of its asymptotic linearity and the Donsker property of the class , it follows that
Similarly to the proof of Theorem 2, under the null hypothesis and due to the asymptotic linearity of the transition probability estimators, and the continuous mapping theorem, it follows that
| (3) |
By the Donsker property of the class and Lemma 15.10 in Kosorok (2008), it follows that the classes {}, p = 1, 2, are P-Donsker. Thus, for s = 0,
is asymptotically normally distributed with variance
Now, the statement of Theorem 2 follows from (3) and the independence of the two samples.
A.3. Proof of Theorem 3
As it was argued in the proof of Theorem 1
for any (fixed) s ∈ [0, τ]. Due to the asymptotic linearity of the transition probability estimators , for p = 1, 2, as argued in the proof of Theorem 1, along with condition C2, it follows that
Now, by the Donsker property of the class and condition C6, it follows that is a P-Donsker class for any (fixed) s ∈ [0, τ). Therefore, by the independence between the two samples, it follows that
where and are two independent tight zero-mean Gaussian processes with covariance functions
Now, define
where ξ(p), p = 1, 2, are independent random draws from N(0,1). By the Donsker property of the class for and any (fixed) s ∈ [0, τ), and the conditional multiplier central limit theorem (Van Der Vaart and Wellner, 1996) it follows that
conditionally on the observed data. Therefore
for any (fixed) s ∈ [0, τ), conditionally on the observed data. Now it remains to argue that for any fixed s ∈ [0, τ), unconditionally on the observed data. By the triangle inequality it follows that
for any (fixed) s ∈ [0, τ). By similar calculations to those in the proof of Theorem 2 in Bakoyannis et al. (2019) and conditions C1-C6 it follows that both normed terms in right side the above inequality are op(1). This concludes the proof of part (i) of Theorem 3.
The first statement of part (ii) of Theorem 3 follows from condition C6, the fact that under the null hypothesis
as it was argued in the proof of Theorem 2, and the Donsker property of the class . The second statement of part (ii) of Theorem 3 follows from the uniform consistency of the estimators , p = 1, 2 in s ∈ [0, τ] and t ∈ [s, τ] as it was argued in the proof of Theorem 2, and arguments similar to those used for the proof of part (i) of Theorem 3.
References
- Aalen OO and Johansen S (1978). An empirical transition matrix for non-homogeneous markov chains based on censored observations. Scandinavian Journal of Statistics 5 (3), 141–150. [Google Scholar]
- Andersen PK, Borgan O, Gill RD, and Keiding N (2012). Statistical models based on counting processes. Springer Science & Business Media. [Google Scholar]
- Athreya KB and Lahiri SN (2006). Measure theory and probability theory. Springer Science & Business Media. [Google Scholar]
- Bakoyannis G and Touloumi G (2012). Practical methods for competing risks data: a review Statistical Methods in Medical Research 21 (3), 257–272. [DOI] [PubMed] [Google Scholar]
- Bakoyannis G, Zhang Y, and Yiannoutsos CT (2019). Nonparametric inference for Markov processes with missing absorbing state. Statistica Sinica 29 (4) 2083–2104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bluhmki T, Schmoor C, Dobler D, Pauly M, Finke J, Schumacher M, and Beyersmann J (2018). A wild bootstrap approach for the Aalen–Johansen estimator. Biometrics If (3), 977–985. [DOI] [PubMed] [Google Scholar]
- Dabrowska DM and Ho W.-t. (2000). Confidence bands for comparison of transition probabilities in a markov chain model. Lifetime Data Analysis 6(1), 5–21. [DOI] [PubMed] [Google Scholar]
- Datta S and Satten GA (2001). Validity of the Aalen–Johansen estimators of stage occupation probabilities and Nelson-Aalen estimators of integrated transition hazards for non-Markov models. Statistics & Probability Letters 55 (4), 403–411. [Google Scholar]
- Gao G and Tsiatis AA (2005). Semiparametric estimators for the regression coefficients in the linear transformation competing risks model with missing cause of failure. Biometrika 92 (4), 875–891. [Google Scholar]
- Gray RJ (1988). A class of k-sample tests for comparing the cumulative incidence of a competing risk. The Annals of Statistics 16(3), 1141–1154. [Google Scholar]
- Kalbfleisch JD and Prentice RL (2011). The statistical analysis of failure time data, Volume 360 John Wiley & Sons. [Google Scholar]
- Kosorok MR (2008). Introduction to empirical processes and semiparametric inference. Springer. [Google Scholar]
- Le-Rademacher JG, Peterson RA, Therneau TM, Sanford BL, Stone RM, and Mandrekar SJ (2018). Application of multi-state models in cancer clinical trials. Clinical Trials 15 (5), 489–498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee H, Hogan JW, Genberg BL, Wu XK, Musick BS, Mwangi A, and Braitstein P (2018). A state transition framework for patient-level modeling of engagement and retention in hiv care using longitudinal cohort data. Statistics in Medicine 37(2), 302–319. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin D (1997). Non-parametric inference for cumulative incidence functions in competing risks studies. Statistics in Medicine 16(8), 901–910. [DOI] [PubMed] [Google Scholar]
- Lu W and Liang Y (2008). Analysis of competing risks data with missing cause of failure under additive hazards model. Statistica Sinica 18(1), 219–234. [Google Scholar]
- Pepe MS (1991). Inference for events with dependent risks in multiple endpoint studies. Journal of the American Statistical Association 86(415), 770–778. [Google Scholar]
- Pepe MS and Mori M (1993). Kaplan–meier, marginal or conditional probability curves in summarizing competing risks failure time data? Statistics in Medicine 12 (8), 737–751. [DOI] [PubMed] [Google Scholar]
- Putter H, Fiocco M, and Geskus RB (2007). Tutorial in biostatistics: competing risks and multi-state models. Statistics in Medicine 26(11), 2389–2430. [DOI] [PubMed] [Google Scholar]
- Putter H and Spitoni C (2018). Non-parametric estimation of transition probabilities in non-Markov multi-state models: The landmark Aalen–Johansen estimator. Statistical Methods in Medical Research 27(7), 2081–2092. [DOI] [PubMed] [Google Scholar]
- Tattar PN and Vaman H (2014). The k-sample problem in a multi-state model and testing transition probability matrices. Lifetime Data Analysis 20(3), 387–403. [DOI] [PubMed] [Google Scholar]
- Titman AC (2015). Transition probability estimates for non-Markov multi-state models. Biometrics 71 (4), 1034–1041. [DOI] [PubMed] [Google Scholar]
- Van der Hage J, van De Velde C, Julien J-P, Floiras J-L, Delozier T, Vandervelden C, Duchateau L, et al. (2001). Improved survival after one course of perioperative chemotherapy in early breast cancer patients: long-term results from the european organization for research and treatment of cancer (eortc) trial 10854. European Journal of Cancer 37(17), 2184–2193. [DOI] [PubMed] [Google Scholar]
- Van der Vaart AW (2000). Asymptotic statistics. Cambridge University Press. [Google Scholar]
- Van Der Vaart AW and Wellner JA (1996). Weak convergence and empirical processes with applications to Statistics. Springer. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.