

Summary
Single-cell RNA-sequencing (scRNA-seq) is a set of technologies used to profile gene expression at the level of individual cells. Although the throughput of scRNA-seq experiments is steadily growing in terms of the number of cells, large datasets are not yet commonly generated owing to prohibitively high costs. Integrating multiple datasets into one can improve power in scRNA-seq experiments, and efficient integration is very important for downstream analyses such as identifying cell-type-specific eQTLs. State-of-the-art scRNA-seq integration methods are based on the mutual nearest neighbor paradigm and fail to both correct for batch effects and maintain the local structure of the datasets. In this paper, we propose a novel scRNA-seq dataset integration method called BATMAN (BATch integration via minimum-weight MAtchiNg). Across multiple simulations and real datasets, we show that our method significantly outperforms state-of-the-art tools with respect to existing metrics for batch effects by up to 80% while retaining cell-to-cell relationships.
Subject Areas: Algorithms, Bioinformatics, Transcriptomics
Graphical Abstract
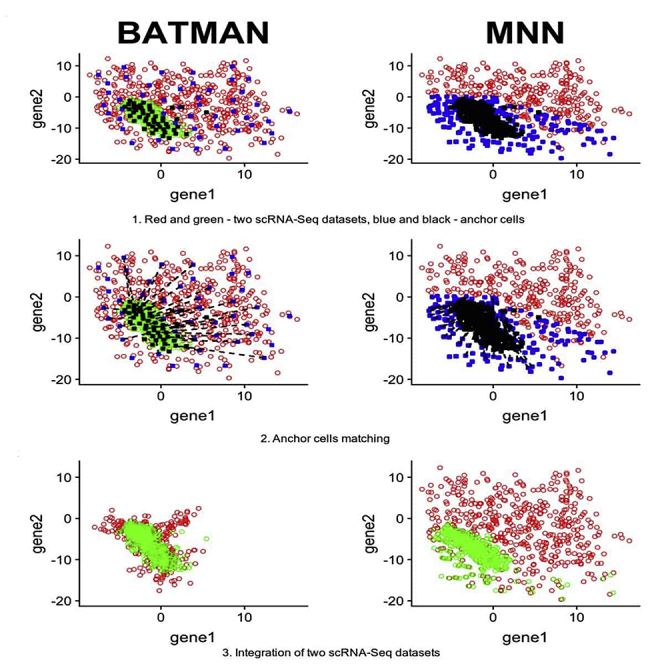
Highlights
-
•
Current methods for scRNA-seq dataset integration are based on MNN paradigm
-
•
MNN paradigm has drawbacks, e.g., it fails in case of non-orthogonal batch effects
-
•
BATMAN proposes a new paradigm based on minimum-weight bipartite matching
-
•
BATMAN outperforms the existing scRNA-seq integration methods in the gene space
Algorithms; Bioinformatics; Transcriptomics
Introduction
Single-cell RNA sequencing (scRNA-seq) has revolutionized transcriptomics as it enables the computational inference of cell types, the discovery of new cell states, and the reconstruction of cellular differentiation trajectories (Angerer et al., 2017). Although the scale of the datasets produced by scRNA-seq is continuously growing (Svensson et al., 2018), the demand for sequencing an even larger number of cells greatly exceeds the current throughput of sequencing experiments (Brennecke et al., 2013) and, therefore, cells must be processed in multiple sequencing runs, or batches. Owing to the high level of technical noise, systematic differences between sequencing instruments, and other confounding factors, simple concatenation is a suboptimal approach to integrate multiple batches of a dataset. Furthermore, batch effects have been shown to cause an increased number of false positives in downstream analyses (Goh et al., 2017). To mitigate the level of false discoveries, a proper integration of multiple batches must eliminate the differences caused by batch effects.
Current methods for merging scRNA-seq datasets can conventionally be divided into two categories: batch correction and integration methods (Hie et al., 2019). Batch correction is the adjustment of gene expression in the high-dimensional gene space to account for confounding variation between technical scRNA-seq replicates—in other words, batch correction operates on the gene expression levels themselves. Integration methods operate instead in a latent low-dimensional space, such as canonical correlation analysis (CCA) embeddings or embeddings learned from neural networks (Lopez et al., 2018), and are applied to the problem of merging multiple datasets across different technologies or biological conditions. Batch correction methods are more interpretable since they allow for a wider range of downstream analyses including differential gene expression and pseudo-time trajectory inference. On the other hand, integration methods enjoy a limited spectrum of applications, the most frequently used being visualization and cell-type classification. Throughout this paper, we will use the term “integration” for combining scRNA-seq datasets into one as it is more general.
In this paper, we present a method for integration of single-cell datasets called BATMAN (BATch integration via minimum weight MAtchiNg), based on a parsimonious one-to-one matching of representative cells across datasets that maintains local structure. BATMAN operates in the high-dimensional gene space and uses the minimal total correction necessary to remove discrepancies between datasets. We show that BATMAN not only significantly outperforms state-of-the-art tools in terms of widely used integration quality metrics on a wide range of simulated and real datasets (by 80%) but also maintains the local structure of each dataset.
Background
Given two scRNA-seq datasets, a query dataset D1 and a reference dataset D2, the goal of integration is to align the query to the reference dataset by removing the confounding variation between them (Stuart et al., 2019). Usually after alignment only the query dataset is modified, i.e., the gene expression values of the cells in D1 are modified, whereas the cells in D2 remain intact. The quality of the alignment is generally measured by a metric of how well mixed the two cell populations are after modification. D1 and D2 are considered well mixed if the local dataset-label distribution in the neighborhood of each cell (in the context of the integrated dataset D3) matches the global dataset label distribution, i.e., every ball containing cells of D3 contains cells from D1 and D2 in the same proportion as given by their cell counts (Büttner et al., 2019). The alignment is constrained by the local structure of each dataset; after integration, the neighborhood relationship among the cells in the query dataset must be preserved. If the datasets consist of several cell types, then the above definition applies to each cell type separately, i.e., cells of cell type x of dataset D1 should only be mixed with cells of cell type x of dataset D2.
scRNA-seq dataset integration by maximizing the mixing quality of two datasets under the constraint of local structure preservation is a challenging task as there are no straightforward or trivial objective functions to optimize over. Current state-of-the-art scRNA-seq integration metrics such as kBET (Büttner et al., 2019) (k-nearest neighbor batch effect test) measure the quality of mixing through the concordance of the global and local dataset label distributions among the nearest k neighbors. Using such metrics as objectives in the integration problem prevents any standard optimization techniques from being applicable. Although it is possible to find a perfect mixing with respect to the aforementioned metrics by random assignment of cells in the dataset D1 to the cells of dataset D2, the biological signal of each dataset would be compromised as the local structure of each dataset would be destroyed.
One approach for solving the integration problem for scRNA-seq datasets is to use tools designed for bulk RNA-seq data. In this case, each cell in an scRNA-seq dataset is viewed as a single bulk RNA-seq sample. Nonetheless, integration methods that are borrowed from bulk RNA-seq analysis depend on normalization techniques and usually assume that the data comes from a particular distribution. For example, ComBat (Johnson et al., 2007) and limma (Ritchie et al., 2015) assume that the observed expression values come from a Gaussian distribution. These assumptions may not hold true for some real datasets (Pierson and Yau, 2015, Risso et al., 2018). Additionally, ComBat and limma were not designed to handle datasets consisting of multiple cell types (Wang et al., 2019). As it has been previously shown, in more complicated scenarios characteristic to single-cell datasets, these methods perform poorly (Wang et al., 2019).
Many methods have recently been proposed for integration of scRNA-seq data, primarily based on clustering or deep neural networks, for example, BERMUDA (Wang et al., 2019), SAUCIE (Amodio et al., 2019), and Harmony (Korsunsky et al., 2019). BERMUDA uses a deep neural network architecture called an autoencoder to learn a low-dimensional representation of the data in an unsupervised manner. The autoencoder network is trained to minimize the loss between the original gene expression values and the reconstructed values after performing the dimensionality reduction, as well as the maximum mean discrepancy (MMD) between similar clusters from different batches. Like BERMUDA, SAUCIE also uses a sparse autoencoder to learn a low-dimensional representation of the data. The approach adds several novel regularization methods to the network activations to encourage the network to learn representations which are useful for several tasks in single-cell analyses such as clustering and integration. Harmony is an integration method that uses soft clustering after projecting the cells into a low-dimensional space by principal components analysis (PCA) to iteratively find cluster centroids, which are then used to calculate a cell-specific correction factor. The downside of these methods is that they operate in latent space, which limits their interpretability and use in downstream analyses such as differential gene expression and single-cell eQTL analyses.
Another group of integration methods that operate in gene space includes Seurat v3.0 (Stuart et al., 2019), MNNcorrect (Haghverdi et al., 2018), and Scanorama (Hie et al., 2019). MNNcorrect finds similar pairs of cells across batches where both cells are contained in each other's set of nearest neighbors (mutual nearest neighbors, or MNN). The average difference in the gene expression between many pairs of mutual nearest neighbors estimates the batch effect, and this estimate can be used to correct the expression values. Seurat (version 3.0) builds on the MNN methodology, using MNN to determine “anchor points.” For dimensionality reduction, Seurat uses canonical correlation analysis (CCA) to find a subspace common to all datasets, which should be void of technical variation that is local to each dataset (Stuart et al., 2019, Thompson et al., 2019). Scanorama also uses MNN for integration and batch correction, but the MNN search is performed in a low-dimensional space after randomized singular value decomposition (SVD) and uses a faster approximate nearest neighbor search to improve scalability. Additionally, Scanorama was designed to handle the alignment of multiple datasets without being sensitive to the ordering of alignment.
Results
We compared BATMAN with three other state-of-the-art tools that operate in the gene space: Seurat v3.0, MNNcorrect, and Scanorama. We did not include tools such as limma and ComBat in the comparison, as they are more appropriate for bulk RNA-seq analysis and have been shown to fail in more complicated scenarios characteristic of single-cell datasets (Wang et al., 2019). We also compared BATMAN with Harmony, which is the state-of-the-art integration tool in PC space.
Evaluation Metrics
Traditionally, scRNA-seq dataset integration quality has been assessed visually using UMAP and/or tSNE plots. However, there are multiple quantitative evaluation metrics available (Haghverdi et al., 2018, Stuart et al., 2019, Wang et al., 2019). All of the metrics are based on scanning local neighborhoods of the cells in the combined dataset (i.e., after integration) and testing if the proportion of cells from the two datasets is the same as globally, for example, using the entropy mixing score. A novel test, kBET (Büttner et al., 2019), was designed independently of all the batch correction and integration methods and tests whether the local dataset label distribution is concordant with the global. As noted in (Büttner et al., 2019), kBET has an issue: it fails to measure batch effects properly when the datasets have different cell-type compositions. Additionally, the more standard metrics such as entropy mixing score lack interpretability. To overcome these issues, we use LISI (Local Inverse Simpson Index), a novel recently proposed metric (Korsunsky et al., 2019). To compute LISI score, one has to build Gaussian kernel-based distributions of neighborhoods. Then, for each neighborhood the Inverse Simpson Index is computed:
where p(b) refers to the probability of batch b in the local neighborhood. LISI score is then reported as the average value of S across all neighborhoods. Its value ranges from 1 to 2, and it has a simple interpretation as the expected number of cells needed to be sampled before two are drawn from the same dataset. In our evaluations, we use two versions of LISI: integration LISI (iLISI; 1 is perfect separability, 2 is perfect mixing) and cell-type LISI (cLISI; 1, all cell types are separable; 2, cell types are mixed with each other).
To quantify how well a method preserves the local structure of datasets after integration, we measure the average percentage of retained nearest neighbors. Intuitively, if a cell and its neighbors are not perturbed by a batch correction method, then they will have the same set of nearest neighbors before and after applying the correction. This quantity is computed as follows: given two datasets D1 and D2, for each cell we determine the top-k nearest neighbors in the original dataset. Next, for each cell we determine the top-k nearest neighbors after integration (again, in the context of its original dataset). We report the average percentage of retained nearest neighbors across all the cells in the union of D1 and D2. We will refer to this metric as k-RNN (retained nearest neighbors).
Integration of Simulated Datasets
We simulated scRNA-seq datasets based on a gamma-Poisson distribution using the splatter (Zappia et al., 2017) simulator (version 1.10.0) to compare BATMAN with Seurat V3.0, MNNcorrect (from scran R package, version 1.12.1), and Scanorama (version 1.5) across five different scenarios:
-
1.
Large batch effects (LB)
-
2.
Large batch effects with large dropout rate (LB-DR)
-
3.
Large batch effects with unequal batch sizes (LB-UB)
-
4.
Small batch effects (SB)
-
5.
Large batch effects—two cell types (LB-CT)
Within Splatter, the magnitude of batch effects is controlled with two parameters: batch.facLoc and batch.facScale. Per Splatter's documentation, for large batch effects scenarios in simulations we set both parameters to 0.5 and for small batch effects we set both to 0.001. The dropout.shape parameter controls the magnitude of dropout rate; setting this parameter to larger values produces sparser scRNA-seq datasets. This parameter was set to 2 for the LB-DR scenario and set to 1 in all other scenarios. In all five scenarios, we simulated 1,000 genes. Batches in the LB-UB scenario consist of 200 and 1,000 cells, whereas in the other scenarios each batch has 1,000 cells. Finally, in the LB-CT scenario, each dataset consists of two cell types (80% and 20% cell type frequency in both batches).
For each scenario, we simulated 100 datasets and ran BATMAN alongside the other three tools. We computed the average values of iLISI and 50-RNN across the 100 runs and along with confidence intervals (CI) for each metric. The lower bound of the CIs were computed as the average of the second and the third value in the sorted list of 100 values, and the upper bound of the CIs were computed as the average of the 97th and the 98th values correspondingly. All the tools were run with their default parameters. In all the experiments, we used Seurat V3.0 pre-processing steps to obtain log-counts for each dataset.
In the LB scenario, a visual inspection of the datasets in the space of the top 2 principal components (see Figure 1) suggests that Seurat V3.0 slightly undercorrected for the batch effects. MNNcorrect and Scanorama, although correctly shifting the datasets toward the centers of each other, failed to properly account for the variance of the datasets as evidenced by Figure 1. However, BATMAN is the only tool that properly integrated two datasets; we show that the iLISI score of the integrated dataset is higher after integration only when applying BATMAN and the other tools failed to properly correct for the differences between the datasets as evidenced by very low iLISI scores (see Table 1). For example, although the PCA plot of Seurat V3.0 shows that the batch effects were mostly removed (Figure 1), its low iLISI score suggests that, in fact, it failed to properly integrate the two datasets. To investigate this discrepancy between the iLISI results and the PCA plots, for each integration result, we computed iLISI scores based on different numbers of top principal components (Figure 2A). When we consider top 2 principal components, the iLISI scores of Seurat V3.0 are high. However, as we increase the dimensionality of the dataset by projecting it to a larger number of principal components, the integration quality of Seurat V3.0 is constantly decreasing and in the limit it tends to 1. On the contrary, the original datasets look linearly separated in the top 2 principal components and the iLISI score is 1. However, when considering more top principal components, Figure 2A shows that the two original datasets become better mixed with each other. BATMAN has the highest performance not only when considering the top two principal components but also when considering more top principal components. It is the only method that manages to efficiently maintain a high iLISI score in a larger number of dimensions.
Figure 1.

Simulated Datasets with Large Batch Effects (LB Scenario)—PCA Plots
Each dataset consists of 1,000 cells and 1,000 genes. The top two PCs are plotted.
Table 1.
Integration Results in LB Scenario (Large Batch Effects): iLISI and 50-RNNscores
| Metric | Original | BATMAN | Seurat V3.0 | MNNcorrect | Scanorama |
|---|---|---|---|---|---|
| Mean iLISI | 1.82 | 1.84 | 1.00 | 1.00 | 1.01 |
| CI iLISI | (1.57, 1.92) | (1.51, 1.96) | (1.00, 1.02) | (1.00, 1.01) | (1.00, 1.01) |
| Mean 50-RNN | 1.00 | 0.92 | 0.58 | 0.51 | 0.14 |
| CI 50-RNN | (1.00, 1.00) | (0.90, 0.95) | (0.56, 0.61) | (0.51, 0.52) | (0.11, 0.16) |
The best results are emphasized in bold. CI stands for confidence interval.
Figure 2.

Evaluation of Integration with Large Batch Effects (LB Scenario)
(A) iLISI score as a function of the number of top principal components. (B) k-RNN score for different values of k.
Notably, BATMAN is the only tool that not only properly corrected for the batch effects but also preserved the biological signal characteristic to each dataset before integration (see Table 1). The 50-RNN of BATMAN equal to 0.92 means that, on average, BATMAN preserves 92% of each cell's 50 nearest neighbors after integration. Seurat V3.0 and MNN each preserves 58% and 51% correspondingly, whereas Scanorama integrates two datasets without keeping their local structure resulting in a poor 50-RNN score of 0.14. BATMAN, Seurat V3.0, and Scanorama display a consistent k-RNN score across multiple values of k, whereas Scanorama has very poor results for smaller values of k (reflecting that it destroys local structure in each small neighborhood of the two datasets; Figure 2B).
Higher dropout rates (the LB-DR scenario) do not seem to drastically change the results of integration across the four methods (Figure S5) as compared with the LB scenario. Again, BATMAN significantly outperformed the other tools on iLISI and 50-RNN scores (see Table S1).
When the two datasets consist of different numbers of cells (the LB-UB scenario), BATMAN is the only method that demonstrates any improvement in the iLISI score after integration (see Figure S6 and Table S2). Notably, both BATMAN and Seurat V3.0 preserved the local structure of the datasets with a 50-RNN score above 0.7 (see Figure S6 and Table S2).
We also measured the ability of the four methods to properly correct for very small batch effects (the SB scenario, see Figure S7, Supplemental Information). In this case, the two datasets were well mixed even before integration with an initial iLISI score of 1.88. Given that any integration method will attempt to correct for batch effects even when the datasets are perfectly mixed, in this scenario a decreased iLISI score after integration indicates an overcorrection. As expected, the iLISI score for each of the four methods is smaller than the score before integration (see Table S3). However, the smallest overcorrection is achieved by BATMAN (iLISI = 1.87), whereas the other methods' overcorrection introduced large batch effects.
Finally, when two cell types are simulated (the LB-CT scenario), MNNcorrect, BATMAN, and Scanorama achieve high iLISI scores (of at least 1.6), whereas Seurat V3.0 fails to properly integrate the two datasets. Interestingly, MNNcorrect slightly outperformed BATMAN both in terms of iLISI and 50-RNN scores (see Figure S8 and Table S4).
The analysis of iLISI and k-RNN scores in PCA embeddings suggest that, in most of the simulation scenarios, MNN-based methods only work well in latent spaces of up to 100 principal components, whereas BATMAN successfully maintains a high quality of integration in higher dimensions. BATMAN also retains the local structure by preserving cell-to-cell relationships for each integrated dataset, whereas the MNN-based methods perform worse (see Figures S9–S12).
Integration of Real Datasets across Different Technologies
To compare BATMAN with the other tools in the case of real datasets across different single-cell technologies, we downloaded two pancreatic datasets: a CEL-Seq2 dataset consisting of 2,285 cells (Muraro et al., 2016) and a Smart-Seq2 dataset consisting of 2,394 cells (Segerstolpe et al., 2016). Both datasets include 13 pancreatic cell types with different cell-type composition (see Table S5 for cell-type composition and Figure S13 for UMAP plots).
To examine how different methods correct for batch effects and match cell-type populations, we performed two experiments: (1) integration of full datasets (“all cell types”) and (2) integration with one cell type missing from one of the datasets (“1-held-out”). The second experiment evaluates whether the integration methods can align cells of the same cell types across datasets. For maximum stringency, we excluded the most abundant cell type (alpha cells, 37% of cells in CEL-Seq2 dataset and 42% of cells in Smart-Seq2 dataset—see Table S5) from CEL-Seq2 dataset.
First, when all cell types are present across the two datasets, all four methods perform well on matching cell-type populations; the cell types are initially well separable (cLISI score 1.05, Table 2) and they remain so after the integration of all four methods. However, there are large batch effects between the two datasets (iLISI score 1.07). Despite the fact that the integration results look successful upon visual inspection for all methods (see UMAP plots of Figures 3 and S14 of Supplemental Information), BATMAN outperformed the MNN-based methods (iLISI of 1.55 for BATMAN versus next highest iLISI of 1.35 for Seurat V3.0).
Table 2.
Integration Results for Real Pancreas Dataset
| Experiment | Score | No Correction | BATMAN | Seurat V3.0 | MNNcorrect | Scanorama |
|---|---|---|---|---|---|---|
| All cell types | iLISI | 1.07 | 1.55 | 1.35 | 1.18 | 1.22 |
| cLISI | 1.05 | 1.08 | 1.03 | 1.08 | 1.04 | |
| 1-Held-out | iLISI | 1.09 | 1.39 | 1.23 | 1.20 | 1.21 |
| cLISI | 1.04 | 1.07 | 1.03 | 1.09 | 1.05 |
The best results (of four methods) are marked in bold. For iLISI, higher corresponds to higher quality of integration; for cLISI, lower scores correspond to better separation of cell types.
Figure 3.

Integration of the Two Pancreatic Datasets across Different Technologies—UMAP Plots (“All Cell Types” Scenario)
(A) BATMAN; (B) Seurat V3.0; (C) MNNcorrect; (D) Scanorama.
Notably, BATMAN is outperformed by Seurat V3.0 and MNNcorrect in lower dimensions as iLISI scores for BATMAN are slightly worse than those for Seurat V3.0 and MNNcorrect in top-50 to top-170 principal components (Figure 4A). However, as the number of dimensions grows, BATMAN's iLISI score increases and the iLISI scores of MNN-based methods decrease. BATMAN showed significantly higher k-RNN scores compared with the other methods (Figure 4B), which demonstrates that BATMAN better preserves the local structure of each dataset.
Figure 4.

Integration of the Two Pancreatic Datasets across Different Technologies: Integration Quality and Local Structure Preserving
(A) iLISI score as a function of top principal components; (B) k-RNN metric across different values of k.
Second, in the 1-held-out experiment, all methods correctly matched the cell types leaving alpha cells from Smart-Seq2 dataset unmatched (Table 2 and Figures S15 and S16). The cLISI scores of all the methods are approximately the same, whereas the iLISI scores vary. BATMAN achieves the best iLISI score (1.39), whereas the worst iLISI scores are produced by MNNcorrect and Scanorama integration results. Again, BATMAN introduced the least deformation to the local structure of the datasets compared with the MNN-based methods (Figure S17).
In terms of runtime, BATMAN and Scanorama perform best. In the “all cell types'' experiment, BATMAN and Scanorama integrated the two datasets in 9 and 14 s, whereas Seurat V3.0 and MNNcorrect, in 22.3 and 228.6 s correspondingly. In the 1-held-out experiment, the runtimes were slightly smaller: BATMAN, 4 s; Scanorama, 11.8 s; Seurat V3.0, –16.3 s; and MNNcorrect, 190.8 s. All the experiments were performed on a MacBook Pro laptop (16 GB RAM, 8 core 2.3 GHz Intel Core i9 processor).
Integration of Real 10X Genomics Datasets
Current trends in scRNA-seq suggest that droplet-based technologies such as 10X Genomics will become the state of the art in single-cell data acquisition owing to their ability to simultaneously profile large numbers of cells in one experiment. Also, their cost-effectiveness makes them more attractive for large-scale experiments. Therefore, it is crucial for integration methods to be able to handle massive and sparse datasets like those of 10X Genomics, which have a higher dropout rate.
We sought to assess the ability of BATMAN to integrate two 10X Genomics datasets with different numbers of cells and different cell-type composition. For this purpose, we downloaded the PBMC 8k dataset (8,381 peripheral blood mononuclear cells) and the “Pan T cells” dataset (3,555 T cells) from 10X Genomics' official website. The cells in the PBMC 8k dataset belong to multiple cell types such as CD4 T cells, B cells, dendritic cells, and more; thus, we expect the Pan T cells dataset to be biologically similar to a subset of the PBMC 8k dataset. Indeed, the PCA plots reveal that the PBMC 8k dataset consists of three clusters (Figure 5A; “pbmc8k_0,” “pbmc8k_1,” and “pbmc8k_2”), whereas the Pan T cells dataset consists of a single cluster (Figure 5B; “t_3k”). On a PCA plot of the combined dataset without integration in Figure 5C, t_3k is closer to pbmc8k_0. The expression plots of two immune marker genes IL7R and NKG7 (Figure 5D) reveal a shared biological signal between the two clusters. However, large batch effects are present (Figure 5C).
Figure 5.

PBMC 8k and Pan T Cells Datasets (10X Genomics)
(A) PCA plot of PBMC 8k dataset reveals three clusters: pbmc8k_0, pbmc8k_1, and pbmc8k_2. (B) PCA plot of Pan T cells dataset reveals one cluster—t_3k. (C) PCA plot of both datasets with no integration shows significant batch effects between cluster pbmc8k_0 of PBMC 8k dataset and t_3k cluster of Pan T cells dataset. (D) Feature plot showing co-expression of IL7R and NKG7 marker genes. Pan T cells dataset corresponds to cluster pbmc8k_0 of PBMC 8k dataset. A proper integration of these two datasets should mix these two clusters.
We integrated the two datasets using BATMAN and the three MNN-based methods. BATMAN not only had the highest iLISI score of the four methods but also better preserved cell-to-cell relationships (Figure 6A). MNNcorrect performed slightly worse than BATMAN in terms of both integration and local structure preserving (Figure 6C). Although Scanorama had a good iLISI score, it destroyed much of the cell-to-cell relationships (Figure 6D). Finally, Seurat V3.0 failed to properly match the biological state of the cells between the two datasets (Figure 6B), which resulted in lower quality of integration.
Figure 6.

Integration of PBMC 8k and Pan T Cells Datasets (10X Genomics)
(A) BATMAN; (B) Seurat V3.0; (C) MNNcorrect; (D) Scanorama.
In terms of runtime, BATMAN and Scanorama were the fastest tools finishing the integration task of the two 10X Genomics datasets in 20.1 and 31.0 s correspondingly. Seurat V3.0 used 211.2 s, whereas MNNcorrect was the slowest tool—1,099.5 s.
Integration in PCA Space
We compared BATMAN against Harmony (version 0.1) on integrating the two PBMC datasets in the PCA space (Figure 7). Harmony is a method that is designed to work specifically with PCA embeddings, and on these 10X datasets it shows a slightly better performance than BATMAN both in terms of iLISI and 10-RNN scores. Both BATMAN and Harmony were able to correctly match the cell populations between the two datasets. In terms of runtime, both tools performed in 14 s.
Figure 7.

Integration of PBMC 8k and Pan T Cells Datasets (10X Genomics) in the PCA Space
(A) BATMAN; (B) Harmony.
Discussion
We present BATMAN, a novel method for scRNA-seq dataset integration. It shows significantly better performance than state-of-the-art methods for mixing two datasets in the gene space while efficiently matching cell-type populations and preserving the cell-to-cell relationships of each dataset. It also shows comparable performance against the state-of-the-art tool Harmony in the PCA space. The underlying principle of BATMAN is novel and has never been applied before in scRNA-seq integration. Our parsimonious formulation based on minimum-weight matching not only finds a minimal correction needed to integrate two datasets but also preserves the intrinsic structure of the two datasets.
We show that BATMAN achieves better performance than the state-of-the-art methods in terms of widely used metrics such as LISI on a wide range of datasets in the gene space.
Limitations of the Study
The current implementation of BATMAN works only with two datasets. However, in principle, it can be used to integrate multiple datasets (similar to multiple integration in MNNcorrect).
Resources Availability
Lead Contact
Igor Mandric (imandric@ucla.edu)
Materials Availability
This study did not generate new unique reagents.
Data and Code Availability
BATMAN is available at https://github.com/mandricigor/batman.
Methods
All methods can be found in the accompanying Transparent Methods supplemental file.
Acknowledgments
E.H., M.T., and B.L.H. were partially supported by the National Science Foundation (Grant No. 1705197). E.H. and M.T. were also partially supported by NIH/NHGRI HG010505-02. E.H., I.M., and M.T. were also partially funded by NIH 1R56MD013312. I.M. and M.K.F. were also partially supported by NIH R01HG009120, NIH R01MH115676, and NIH U01CA194393. E.H. was also partially supported by NIH 1R01MH115979, NIH 5R25GM112625, and NIH 5UL1TR001881.
Author Contributions
Conceptualization, E.H., I.M.; Methodology, I.M.; Writing, I.M., B.L.H., M.K.F., M.T., E.H.; Supervision, E.H.
Declaration of Interests
The authors declare no competing interests.
Published: June 26, 2020
Footnotes
Supplemental Information can be found online at https://doi.org/10.1016/j.isci.2020.101185.
Contributor Information
Igor Mandric, Email: imandric@ucla.edu.
Eran Halperin, Email: ehalperin@cs.ucla.edu.
Supplemental Information
References
- Amodio M., van Dijk D., Srinivasan K., Chen W.S., Mohsen H., Moon K.R., Campbell A., Zhao Y., Wang X., Venkataswamy M. Exploring single-cell data with deep multitasking neural networks. Nat. Methods. 2019;16:1139–1145. doi: 10.1038/s41592-019-0576-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Angerer P., Simon L., Tritschler S., Wolf A., Fischer D., Theis F. Single cells make big data: new challenges and opportunities in transcriptomics. Curr. Opin. Syst. Biol. 2017:85–91. [Google Scholar]
- Brennecke P., Anders S., Kim J.K., Kołodziejczyk A.A., Zhang X., Proserpio V., Baying B., Benes V., Teichmann S.A., Marioni J.C., Heisler M.G. Accounting for technical noise in single-cell RNA-Seq experiments. Nat. Methods. 2013;10:1093–1095. doi: 10.1038/nmeth.2645. [DOI] [PubMed] [Google Scholar]
- Büttner M., Miao Z., Wolf F.A., Teichmann S.A., Theis F.J. A test metric for assessing single-cell RNA-Seq batch correction. Nat. Methods. 2019;16:43–49. doi: 10.1038/s41592-018-0254-1. [DOI] [PubMed] [Google Scholar]
- Goh W.W.B., Wang W., Wong L. Why batch effects matter in omics data, and how to avoid them. Trends Biotechnol. 2017;35:498–507. doi: 10.1016/j.tibtech.2017.02.012. [DOI] [PubMed] [Google Scholar]
- Haghverdi L., Lun A.T.L., Morgan M.D., Marioni J.C. Batch effects in single-cell RNA-sequencing data are corrected by matching mutual nearest neighbors. Nat. Biotechnol. 2018;36:421–427. doi: 10.1038/nbt.4091. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hie B., Bryson B., Berger B. Efficient integration of heterogeneous single-cell transcriptomes using Scanorama. Nat. Biotechnol. 2019;37:685–691. doi: 10.1038/s41587-019-0113-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson W.E., Li C., Rabinovic A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics. 2007:118–127. doi: 10.1093/biostatistics/kxj037. [DOI] [PubMed] [Google Scholar]
- Korsunsky I., Millard N., Fan J., Slowikowski K., Zhang F., Wei K., Baglaenko Y., Brenner M., Loh P.R., Raychaudhuri S. Fast, sensitive, and accurate integration of single cell data with Harmony. Nat. Methods. 2019;36:1289–1296. doi: 10.1038/s41592-019-0619-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lopez R., Regier J., Cole M.B., Jordan M.I., Yosef N. Deep generative modeling for single-cell transcriptomics. Nat. Methods. 2018;15:1053–1058. doi: 10.1038/s41592-018-0229-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Muraro M.J., Dharmadhikari G., Grün D., Groen N., Dielen T., Jansen E., van Gurp L., Engelse M.A., Carlotti F., de Koning E.J., van Oudenaarden A. A single-cell transcriptome atlas of the human pancreas. Cell Syst. 2016;3:385–394.e3. doi: 10.1016/j.cels.2016.09.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pierson E., Yau C. ZIFA: dimensionality reduction for zero-inflated single-cell gene expression analysis. Genome Biol. 2015;16:241. doi: 10.1186/s13059-015-0805-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Risso D., Perraudeau F., Gribkova S., Dudoit S., Vert J.P. A general and flexible method for signal extraction from single-cell RNA-Seq data. Nat. Commun. 2018;9:284. doi: 10.1038/s41467-017-02554-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ritchie M.E., Phipson B., Wu D., Hu Y., Law C.W., Shi W., Smyth G.K. Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015;43:e47. doi: 10.1093/nar/gkv007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Segerstolpe Å., Palasantza A., Eliasson P., Andersson E.M., Andréasson A.C., Sun X., Picelli S., Sabirsh A., Clausen M., Bjursell M.K. Single-cell transcriptome profiling of human pancreatic islets in health and type 2 diabetes. Cell Metab. 2016;24:593–607. doi: 10.1016/j.cmet.2016.08.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stuart T., Butler A., Hoffman P., Hafemeister C., Papalexi E., Mauck W.M., 3rd, Hao Y., Stoeckius M., Smibert P., Satija R. Comprehensive integration of single-cell data. Cell. 2019;177:1888–1902.e21. doi: 10.1016/j.cell.2019.05.031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Svensson V., Vento-Tormo R., Teichmann S.A. Exponential scaling of single-cell RNA-seq in the past decade. Nat. Protoc. 2018:599–604. doi: 10.1038/nprot.2017.149. [DOI] [PubMed] [Google Scholar]
- Thompson M., Chen Z.J., Rahmani E., Halperin E. CONFINED: distinguishing biological from technical sources of variation by leveraging multiple methylation datasets. Genome Biol. 2019;20:138. doi: 10.1186/s13059-019-1743-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang T., Johnson T.S., Shao W., Lu Z., Helm B.R., Zhang J., Huang K. BERMUDA: a novel deep transfer learning method for single-cell RNA sequencing batch correction reveals hidden high-resolution cellular subtypes. Genome Biol. 2019;20:165. doi: 10.1186/s13059-019-1764-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zappia L., Phipson B., Oshlack A. Splatter: simulation of single-cell RNA sequencing data. Genome Biol. 2017;18:174. doi: 10.1186/s13059-017-1305-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
BATMAN is available at https://github.com/mandricigor/batman.