

Abstract
Background
Emerging interest in precision health and the increasing availability of patient- and population-level data sets present considerable potential to enable analytical approaches to identify and mitigate the negative effects of social factors on health. These issues are not satisfactorily addressed in typical medical care encounters, and thus, opportunities to improve health outcomes, reduce costs, and improve coordination of care are not realized. Furthermore, methodological expertise on the use of varied patient- and population-level data sets and machine learning to predict need for supplemental services is limited.
Objective
The objective of this study was to leverage a comprehensive range of clinical, behavioral, social risk, and social determinants of health factors in order to develop decision models capable of identifying patients in need of various wraparound social services.
Methods
We used comprehensive patient- and population-level data sets to build decision models capable of predicting need for behavioral health, dietitian, social work, or other social service referrals within a safety-net health system using area under the receiver operating characteristic curve (AUROC), sensitivity, precision, F1 score, and specificity. We also evaluated the value of population-level social determinants of health data sets in improving machine learning performance of the models.
Results
Decision models for each wraparound service demonstrated performance measures ranging between 59.2%% and 99.3%. These results were statistically superior to the performance measures demonstrated by our previous models which used a limited data set and whose performance measures ranged from 38.2% to 88.3% (behavioural health: F1 score P<.001, AUROC P=.01; social work: F1 score P<.001, AUROC P=.03; dietitian: F1 score P=.001, AUROC P=.001; other: F1 score P=.01, AUROC P=.02); however, inclusion of additional population-level social determinants of health did not contribute to any performance improvements (behavioural health: F1 score P=.08, AUROC P=.09; social work: F1 score P=.16, AUROC P=.09; dietitian: F1 score P=.08, AUROC P=.14; other: F1 score P=.33, AUROC P=.21) in predicting the need for referral in our population of vulnerable patients seeking care at a safety-net provider.
Conclusions
Precision health–enabled decision models that leverage a wide range of patient- and population-level data sets and advanced machine learning methods are capable of predicting need for various wraparound social services with good performance.
Keywords: social determinants of health, supervised machine learning, delivery of health care, integrated, wraparound social services
Introduction
Background
The combination of precision health [1] and population health initiatives in the United States have raised awareness about how clinical, behavioral, social risk, and social determinants of health factors influence an individual’s use of medical services and their overall health and well-being [2]. Large-scale adoption of health information systems [3], increased use of interoperable health information exchange, and the availability of socioeconomic data sets have led to unprecedented and ever increasing accessibility to various patient- and population-level data sources. The availability of these data sets, together with a focus on mitigating patient social factors and uptake of machine learning solutions for health care present considerable potential for predictive modeling in support of risk prediction and intervention allocation [4,5]. This is particularly significant for wraparound services that can enhance primary care by utilizing providers who are trained in behavioral health, social work, nutritional counseling, patient navigation, health education, and medical legal partnerships in order to mitigate the effects of social risk and to address social needs [6].
Wraparound services focus on the socioeconomic, behavioral, and financial factors that typical medical care encounters cannot address satisfactorily [7,8], and when used, can result in improved health care outcomes, reduced costs [6,9], and better coordination of care. As such, these services are of significant importance to health care organizations that are incentivized by United States reimbursement policies to mitigate the effects of social issues that influence poor health outcomes and unnecessary utilization of costly services [10].
Previous Work
In a previous study [11], we integrated patient-level clinical, demographic, and visit data with population-level social determinants of health measures to develop decision models that predicted patient need for behavioral health, dietitian, social work, or other wraparound service referrals. We also compared the performance of models built with and without population-level social determinants of health indicators. These models achieved reasonable performance with area under the receiver operating characteristic curve values between 70% and 78%, and sensitivity, specificity, and accuracy values ranging between 50% and 77%. We integrated these models into nine federally qualified health center sites operated by Eskenazi Health, a county-owned safety-net provider located in Indianapolis, Indiana. A subsequent trial identified increased rates of referral when predicted-need scores were shared with primary care end users [12]. Nevertheless, there were several limitations in our previous study such as limited patient-level measures, a level of aggregated data that was too coarse, poor optimization, lack of consideration of data temporality, and limited generalizability.
Our previous models included a wide range of patient-level clinical, behavioral, and encounter-based data elements as well as population-level social determinants of health measures; however, the models might have performed better with the inclusion of additional data elements such as medication data, insurance information, narcotics or substance abuse data, mental and behavioral disorders information inferred from diagnostic data, and patient-level social risk factors extracted from diagnostic data using ICD-10 classification codes [13].
Our previous use of population-level social determinants of health factors measured at the zip-code level did not contribute to any statistically significant performance improvements. A wider range of measures of social determinants of health captured at smaller geographic areas might have yielded more discriminative power and have led to significant performance improvements.
We used Youden J-index [14] which optimizes sensitivity and specificity to determine optimal cutoff thresholds; however, this resulted in poor precision (positive predictive values that ranged between 15% and 50%). Given the importance of optimizing precision, which represents a model’s ability to return only relevant instances, alternate optimization techniques should be used.
Our previous models included all data captured during the period under study, and not exclusively data elements that occurred prior to the outcome of interest. Failing to omit data elements that occurred after the outcomes of interest may have influenced the performance of these decision models [15].
We developed our previous approach using data that was extracted from a homegrown electronic health record system [16]. This limited its ability to be replicated across other settings that could support other widely used commercial electronic health record systems. Since our previous study, Eskenazi Health has transitioned to a commercial electronic health record system enabling us to adapt our solution to be vendor neutral and applicable to any electronic health record system.
Objective
This study addressed the aforementioned limitations by using additional patient- and population-level data elements as well as more advanced analytical methods to develop decision models to identify patients in need of referral to providers that can address social factors. We evaluated the contribution of these enhancements by recreating the original models that had been developed during the previous study (phase 1) and comparing their performance to that of new models developed during this study (phase 2). Furthermore, during each phase, we evaluated the contribution of small-area population-level social determinants of health measures to improving model performance.
Methods
Patient Sample
We included adults (18 years of age or older) with at least one outpatient visit at Eskenazi Health between October 1, 2016 and May 1, 2018.
Data Extraction
Primary data sources for the patient cohort were Eskenazi Health’s Epic electronic health record system and the statewide health information exchange data repository known as the Indiana Network for Patient Care [17], which provided out-of-network encounter data from hospitals, laboratory systems, long-term care facilities, and federally qualified health centers across the state. These data were supplemented with population-level social determinants of health measures derived from the US Census Bureau, the Marion County Public Health Department vital statistics system, and various community health surveys.
Feature Extraction
To recreate the models developed during phase 1, we extracted a subset of features that had been used to train the original models [11]. We also extracted additional features for phase 2 enhancements. Table 1 presents an outline of the feature sets for each phase of model development.
Table 1.
Comparison of the patient- and population-level data sets that were used for each phase.
| Feature type | Phase 1 | Added in phase 2 |
| Demographics | Age, ethnicity, and gender | Insurance (Medicare, Medicaid, self-pay) |
| Weight and nutrition | None | BMI, hemoglobin A1c |
| Encounter frequency | Outpatient visits, emergency department encounters, and inpatient admissions | None |
| Chronic conditions | 20 most common chronic conditions [18] | None |
| Addictions and narcotics use | Tobacco and opioid use | Alcohol abuse, opioid overdose, use disorders |
| Medications | None | 145 categories of medication (categorized by therapeutic and pharmaceutical codes) [19] |
| Patient-level social risk | None | 12 patient-level measures [20] |
| Population-level social determinants of health | 48 social determinants of health measures [11] | 60 social determinants of health measures [20] |
Preparation of the Gold Standard
We sought to predict the need for referrals to behavioral health services, dietitian counseling, social work services, and all other wraparound services, which included respiratory therapy, financial planning, medical-legal partnership assistance, patient navigation, and pharmacist consultations. We used billing, encounter, and scheduling data extracted from the Indiana Network for Patient Care and Eskenazi Health to identify patients who had been referred to supplementary services between October 1, 2016 and May 1, 2018. We assumed that a patient with a referral had been in need of that referral even if the patient subsequently canceled or failed to keep the appointment.
Data Vector Preparation
We prepared two data vectors for each wraparound service for phase 1 modeling—a clinical data vector consisting of only patient-level data elements and a master data vector consisting of both patient- and population-level elements. Next, we created two more data vectors for each wraparound service for phase 2 data—a clinical data vector consisting of only patient-level data elements and a master data vector consisting of both patient- and population-level elements. For each patient, we included only data for events that had occurred at least 24 hours prior to the final outcome of interest. Features such as age (discrete by whole years); weight- or nutrition-based (categorical); gender (categorical); ethnicity (categorical); encounter frequency (number of each type per patient); and addictions or use of narcotics, chronic conditions, medications, and patient-level social risk (binary indicating presence or absence).
Population-level social determinants of health measures were categorized into three groups—socioeconomic status, disease prevalence, and other miscellaneous factors (such as data on calls made by those who were seeking public assistance). Measures that were reported from across 1150 census tracts were used to calculate z scores (a numerical measurement relating a given value to the mean in a group of values) for each of the three categories. The z scores were grouped into clusters using the k-means algorithm [21] and the elbow method [22].
As requested by dietitians who consulted on our efforts, for dietitian referrals, prediction of need was restricted to a subset of patients with specific risk conditions (Multimedia Appendix 1). Thus, data vectors for dietitian referrals included only patients with one or more of these conditions, which were identified by ICD-10 classification codes.
Machine Learning Process for Phase 1 Models
We randomly split each data vector into groups of 80% (training and validation data set) and 20% (test set). We replicated the same processes that were used during phase 1 [11] to recreate a new set of models to be used for comparison.
Machine Learning Process for Phase 2 Models
We split each data vector into random groups of 80% (training and validation data set) and 20% (test set). We applied randomized lasso-based [23] feature selection to the 80% training and validation data set to identify the most relevant features for each outcome of interest. We used machine learning in Python (version 3.6.1; scikit-learn library, version 0.21.0) [24] to build extreme gradient boosting [25] classification models to predict the need for referrals. The extreme gradient boosting algorithm is an implementation of gradient boosted decision trees [26] designed for speed and performance. It has demonstrated a strong track record of outperforming other decision trees and other classification algorithms in machine learning competitions [27]. The extreme gradient boosting algorithm consisted of multiple parameters, each of which could affect model performance. Thus, we decided to perform hyperparameter tuning on the training and validation data set using randomized search and 10-fold cross-validation. Decision model parameters that were modified as part of the hyperparameter tuning process are listed in Multimedia Appendix 2. The best performing models, parameterized using hyperparameter tuning, were applied to the test data sets.
Analysis
We assessed the performance of each decision model using the test set. For each record in the test set, each decision model produced a binary outcome (referral needed or referral not needed) and a probability score. We used these scores to calculate area under the receiver operating characteristic curve (AUROC), sensitivity, precision, F1 score, and specificity for each model. These measures were calculated using thresholds that optimized sensitivity and precision scores. We also calculated 95% confidence intervals for each measure using bootstrap methods [28]. P values were calculated using guidelines presented by Altman and Bland [29]. P values<.05 were deemed statistically significant. For the models trained during each phase, we evaluated the contribution of population-level measures by comparing the performance of models trained using master (with population-level measures) vector models to the performance of clinical (without population-level measures) vector models. Next, we evaluated the value of the additional data sets and analytical methods that were used to train phase 2 models by comparing their performance to that of models trained in phase 1. Figure 1 presents a flowchart that describes the approach.
Figure 1.
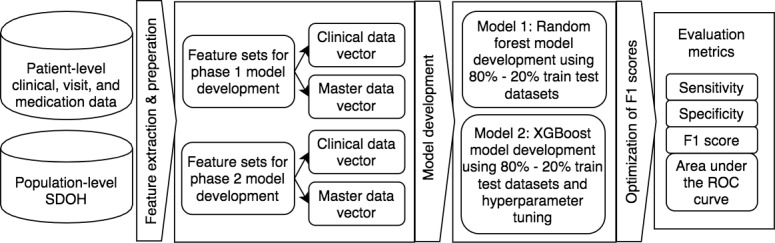
The complete study approach from data collection and decision-model building to evaluation of results. ROC: receiver operating characteristic; SDOH: social determinants of health; XGBoost: extreme gradient boosting.
Results
Our patient sample consisted of 72,484 adult patients (Table 2). Of these patients, 15,867 (21.9%) met the dietitian referral criteria. Similar to that of phase 1, our patient population reflected an adult, urban, low-income primary care safety-net population; patients ranged in age from 18 to 107 years and were predominantly female (47,187/72,484, 65.1%). Referral types, which constituted our gold standard reference, were behavioral health (12,162/72,484, 16.8%), social work (4104/72,484, 5.7%), dietitian counseling (4330/15,867, 27.3%), and other services (17,877/72,484, 24.7%).
Table 2.
Characteristics of the adult, primary care patient sample whose data were used in phase 2 risk predictive modeling.
| Demographic characteristics | Values | |
| Age (years), mean (SD) | 44.1 (16.6) | |
| Gender (N=72,484), n (%) | ||
| Male | 25,297 (34.9) | |
| Female | 47,187 (65.1) | |
| Insurance provider (N=72,484), n (%) | ||
| Medicaid or public insurance | 41,316 (57.0) | |
| Private | 31,168 (43.0) | |
| BMI category (N=72,484), n (%) | ||
| BMI<18.5 | 6379 (8.8) | |
| 18.5≤BMI<25 | 8698 (12.0) | |
| 25≤BMI<30 | 10,148 (14.0) | |
| BMI≥30 | 20,875 (28.8) | |
| Missing | 26,384 (36.4) | |
| Ethnicity (N=72,484), n (%) | ||
| White, non-Hispanic | 18,266 (25.2) | |
| African American, non-Hispanic | 34,575 (47.7) | |
| Hispanic | 15,149 (20.9) | |
| Other | 4494 (6.2) | |
As with our previous effort, use of population-level social determinants of health measures led to only minimal changes in each performance metric across models trained under phases 1 and 2, and were not statistically significant (behavioural health: F1 score P=.08, AUROC P=.09; social work: F1 score P=.16, AUROC P=.09; dietitian: F1 score P=.08, AUROC P=.14; other: F1 score P=.33, AUROC P=.21). Thus, we evaluated the contribution of the additional data sets, classification algorithms, and analytical approaches leveraged in phase 2 by comparing clinical vector models developed during phase 1 to those developed during phase 2.
Table 3 presents a comparison of clinical vector model performance for phase 1 and phase 2. Phase 2 models yielded significantly better results than those of phase 1 models across all performance metrics except sensitivity for social work services (phase 1: 67.0%, 95% CI 63.4%-72.2%; phase 2: 72.4%, 95% CI 69.1%-75.6%; P=.07). Phase 2 decision models reported performance measures ranging from 59.2% to 99.3% which were statistically superior to performance measures reported by phase 1 models which ranged from 38.2% to 88.3%. For every clinical vector, phase 2 models reported significantly better area under the receiver operating characteristic curve values than those reported for phase 1 models (behavioral health: P=.01; social work: P=.03; dietitian: P=.001; other: P=.02). Furthermore, phase 2 precision scores were significantly greater than those reported in phase 1 (behavioral health: P<.001; social work: P<.001; dietitian: P=.02; other: P<.001). We also evaluated model fit using logarithmic loss (log loss), which measures the performance of a classification model where prediction input is a probability between 0 and 1, and using lift curves [30], which compares a decision model to a random model for the given percentile of top scored predictions. Log loss values were 0.09 (behavioral health), 0.07 (social work), 0.32 (dietitian), and 0.34 (other). Lift scores for each decision model are shown in a figure in Multimedia Appendix 3.
Table 3.
Comparison of clinical vector model performance for phase 1 and phase 2.
| Clinical vector performance measures | Model performance, % (95% CI) |
|
|||||
|
|
Phase 1 | Phase 2 | P valuea | ||||
| Behavioral health services | |||||||
|
|
Sensitivity | 70.2 (68.0, 72.5) | 86.3 (83.1, 88.9) | <.001 | |||
|
|
Specificity | 78.5 (78.0, 78.9) | 99.1 (98.5, 99.7) | <.001 | |||
|
|
F1 score | 56.6 (53.6, 58.9) | 90.4 (87.4, 93.4) | <.001 | |||
|
|
Precision (positive predictive value) | 47.4 (44.2, 49.6) | 95.0 (92.0, 98.3) | <.001 | |||
|
|
AUROCb | 88.3 (87.4, 89.2) | 98.0 (97.6, 98.5) | .01 | |||
| Social work services | |||||||
|
|
Sensitivity | 67.0 (63.4, 72.2) | 72.4 (69.1, 75.6) | .07 | |||
|
|
Specificity | 79.6 (79.1, 79.8) | 99.3 (99.2, 99.6) | <.001 | |||
|
|
F1 score | 48.6 (45.0, 52.5) | 82.5 (79.7, 85.3) | <.001 | |||
|
|
Precision (positive predictive value) | 38.2 (34.8, 41.2) | 95.8 (93.8, 97.8) | <.001 | |||
|
|
AUROC | 87.6 (86.1, 89.2) | 93.7 (92.5, 95.0) | .03 | |||
| Dietitian counseling services | |||||||
|
|
Sensitivity | 60.7 (56.5, 64.7) | 73.6 (70.5, 77.0) | .02 | |||
|
|
Specificity | 73.2 (71.9, 74.9) | 93.3 (90.8, 94.6) | <.001 | |||
|
|
F1 score | 61.5 (57.3, 66.0) | 76.4 (73.3, 80.4) | .001 | |||
|
|
Precision (positive predictive value) | 62.2 (58.1, 67.4) | 79.4 (76.4, 84.2) | .02 | |||
|
|
AUROC | 82.5 (81.5, 83.6) | 91.5 (90.3, 92.6) | .001 | |||
| Other wraparound services | |||||||
|
|
Sensitivity | 44.5 (42.7, 46.1) | 59.2 (56.5, 63.8) | .002 | |||
|
|
Specificity | 78.5 (77.5, 79.3) | 92.9 (89.7, 96.1) | <.001 | |||
|
|
F1 score | 43.2 (40.0, 45.7) | 65.5 (62.9, 67.6) | .01 | |||
|
|
Precision (positive predictive value) | 41.9 (37.7, 45.2) | 73.4 (70.5, 77.7) | <.001 | |||
|
|
AUROC | 77.2 (76.2, 78.1) | 85.3 (84.4, 86.0) | .02 | |||
aP values were calculated using confidence intervals [29].
bAUROC: area under the receiver operating characteristic curve.
Discussion
Principal Findings
Our study expanded upon our previous efforts to demonstrate the feasibility of predicting the need for wraparound services such as behavioral health, dietitian, social work and other services using a range of readily available patient- and population-level data sets that represent an individual’s well-being as well as their socioeconomic environment. Specifically, we demonstrated that inclusion of additional patient-level data sets that represented medication history, addiction and mental disorders, and patient-level social risk factors, as well as use of the extreme gradient boosting classification algorithm and advanced analytical methods for model development led to statistically superior performance measures. Furthermore, improved precision scores were made possible by additional data elements and alternate optimization techniques that maximized precision and recall scores and which greatly improved the practical application of our solution. Each decision model reported area under the receiver operating characteristic curve scores from 85% to 98%, which are superior to the global performance of prediction models on mortality [31], hospital readmissions [4], and disease development [32]; however, inclusion of additional population-level aggregate social determinants of health measures in our low-income population did not contribute significantly toward performance improvements despite the introduction of additional indicators, more granular geographic measurement units (by switching from zip code to census tract level), and vectorization methods that converted these to standardized scores to emphasize variance and create indices.
The inability of population-level social determinants of health measures to improve model performance may be because our patient population was comprised of an urban safety-net group with relatively little variability in socioeconomic, policy, and environmental conditions. Thus, it is possible that machine learning studies using larger, more diverse populations may benefit from the use of population-level data [33]. Moreover, the lack of improvement may be related to our choice of prediction outcome. Wraparound service providers work to address the social needs and risk factors of individual patients and not population-level social determinants. Likewise, social determinants of health factors influence social risk [34], but these population conditions are not the reason for referral to a wraparound service provider. It is likely that social factors are more relevant to, and observed by, the referring provider. Nevertheless, the continued lack of meaningful contribution to our models prompts questions regarding how to best leverage aggregate social determinants of health measures for decision making. This is an important and unanswered question, as census-based aggregate measures are the most widely available and easily accessible indicators of social determinants of health available to researchers and health organizations [35]. In contrast, several patient-level social and behavioral factors measures were influential in the models. This indicates the need for more widespread use and collection of social factors in clinical settings [36]. Electronic health record organizations seeking to identify patients with social risk factors and in need of social services must integrate the collection of social risk data into their workflow [37].
Limitations
This work has limitations. Notably, the phase 2 model development approach leveraged the same urban safety-net population that was used to develop phase 1 models. Thus, though the phase 2 demonstrate superior performance, the results may not be generalizable to other commercially insured or broader populations. In addition, we only leveraged structured data that had been extracted from the Indiana Network for Patient Care or from Eskenazi Health for the machine learning process. These methods may not be utilized at other health care settings that are not part of a large, robust health information exchange. Expanding our approaches to different geographic regions would require standardization of population-level sources as well as infrastructure and interoperability measures to effectively store and exchange such data sets [38]. Also, we did not utilize any unstructured data sets for machine learning. This is a significant issue as up to 80% of health data may be collected in an unstructured format [39,40]. Despite these limitations, the considerable performance enhancements demonstrated by these models suggest significant potential to enable access to various social services; however, it must be noted that social determinants of health risk factors are often confounded with one another. Thus, mitigating a social need that arises from several social determinants of health risk factors may not result in any positive improvements to a patient [41].
Future Work
Our next steps include expanding our models to predict additional wraparound services of interest. Furthermore, we believe that there is an acute need to improve the explainability and actionability of machine learning predictions using novel methods such as counterfactual reasoning [42]. We perceive that similar predictive models for minors and the services available to these patients would be of significant value for health care decision making. Our inability to utilize unstructured data sets for machine learning is a significant concern. Various natural language processing toolkits can leverage unstructured data sets for machine learning; however, integrating these toolkits into inproduction systems is challenging due to infrastructure and maintenance costs. Moreover, searching and indexing the massive quantities of free-text reports that are collected statewide would require additional computational effort, and may significantly increase computation time. We are currently engaged in efforts to utilize the Regenstrief Institute’s nDepth tool [43] to evaluate the ability to extract actionable elements at a production setting.
Integration Into Electronic Health Record Systems
As noted, this work built upon existing risk prediction efforts. We have integrated the updated decision models into the existing platform for all scheduled and walk-in appointments. Model results are presented to end users using a customized interface within the electronic health record with metadata on which features drove the extreme gradient boosting decision-making process, and with predicted probabilities categorized as low, rising, or high risk [12] (Figure 2). This study’s methodological work sets the foundation for our future evaluations of our intervention’s impact on patient outcomes.
Figure 2.
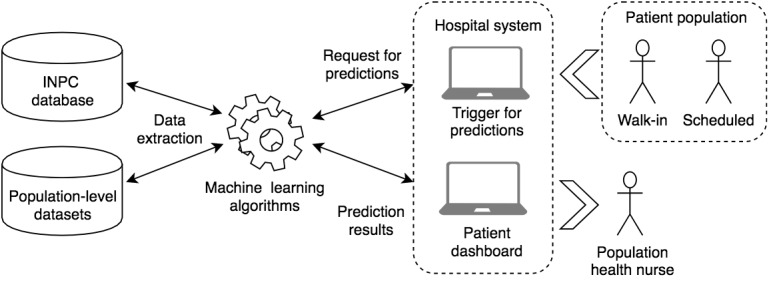
Integration of decision models into hospital workflow. INPC: Indiana Network for Patient Care.
Conclusions
This study developed decision models that integrate a wide range of individual and population data elements and advanced machine learning methods that are capable of predicting need for various wraparound social services; however, population-level data may not contribute to improvements in predictive performance unless they represent larger, diverse populations.
Acknowledgments
Support for this research was provided by the Robert Wood Johnson Foundation. The views expressed herein do not necessarily reflect the views of the Robert Wood Johnson Foundation. The authors also wish to thank Jennifer Williams (Regenstrief Institute), Amber Blackmon (Indiana University), the Regenstrief data core team, and Eskenazi Health of Indiana for their assistance.
Abbreviations
- AUROC
area under the receiver operating characteristic curve
- ICD-10
International Statistical Classification of Diseases, 10th Revision
List of risk conditions used to identify a subpopulation for predicting dietitian referrals.
Parameters that were modified as part of the hyperparameter tuning process for phase 2.
Lift scores reported by each decision model.
{kind=link}
Footnotes
Conflicts of Interest: SNK, SG, PKH, NM, and JRV are cofounders of Uppstroms LLC, a commercial entity established to disseminate the artificial intelligence models discussed in this paper.
References
- 1.Collins FS, Varmus H. A new initiative on precision medicine. N Engl J Med. 2015 Feb 26;372(9):793–5. doi: 10.1056/NEJMp1500523. http://europepmc.org/abstract/MED/25635347 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Martin Sanchez F, Gray K, Bellazzi R, Lopez-Campos G. Exposome informatics: considerations for the design of future biomedical research information systems. J Am Med Inform Assoc. 2014;21(3):386–90. doi: 10.1136/amiajnl-2013-001772. http://europepmc.org/abstract/MED/24186958 .amiajnl-2013-001772 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Charles D, Gabriel M, Searcy T. Adoption of electronic health record systems among US non-federal acute care hospitals. ONC data brief. 2013;9:2008–2012. https://www.healthit.gov/sites/default/files/oncdatabrief16.pdf . [Google Scholar]
- 4.Kansagara D, Englander H, Salanitro A, Kagen D, Theobald C, Freeman M, Kripalani S. Risk prediction models for hospital readmission: a systematic review. JAMA. 2011 Oct 19;306(15):1688–98. doi: 10.1001/jama.2011.1515. http://europepmc.org/abstract/MED/22009101 .306/15/1688 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Vuik SI, Mayer EK, Darzi A. Patient segmentation analysis offers significant benefits for integrated care and support. Health Aff (Millwood) 2016 May 01;35(5):769–75. doi: 10.1377/hlthaff.2015.1311.35/5/769 [DOI] [PubMed] [Google Scholar]
- 6.Vest JR, Harris LE, Haut DP, Halverson PK, Menachemi N. Indianapolis provider's use of wraparound services associated with reduced hospitalizations and emergency department visits. Health Aff (Millwood) 2018 Oct;37(10):1555–1561. doi: 10.1377/hlthaff.2018.0075. [DOI] [PubMed] [Google Scholar]
- 7.Lewis JH, Whelihan K, Navarro I, Boyle KR, SDH Card Study Implementation Team Community health center provider ability to identify, treat and account for the social determinants of health: a card study. BMC Fam Pract. 2016 Aug 27;17:121. doi: 10.1186/s12875-016-0526-8. https://bmcfampract.biomedcentral.com/articles/10.1186/s12875-016-0526-8 .10.1186/s12875-016-0526-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Fenton M. Health care's blind side: the overlooked connection between social needs and good health. Princeton: Robert Wood Johnston Foundation. 2011 [Google Scholar]
- 9.Fitzpatrick T, Rosella L, Calzavara A, Petch J, Pinto A, Manson H, Goel V, Wodchis W. Looking beyond income and education: socioeconomic status gradients among future high-cost users of health care. Am J Prev Med. 2015 Aug;49(2):161–71. doi: 10.1016/j.amepre.2015.02.018. https://linkinghub.elsevier.com/retrieve/pii/S0749-3797(15)00082-3 .S0749-3797(15)00082-3 [DOI] [PubMed] [Google Scholar]
- 10.Kaufman A. Theory vs practice: should primary care practice take on social determinants of health now? yes. Ann Fam Med. 2016 Mar;14(2):100–1. doi: 10.1370/afm.1915. http://www.annfammed.org/cgi/pmidlookup?view=long&pmid=26951582 .14/2/100 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Kasthurirathne S, Vest J, Menachemi N, Halverson P, Grannis S. Assessing the capacity of social determinants of health data to augment predictive models identifying patients in need of wraparound social services. J Am Med Inform Assoc. 2018 Jan 01;25(1):47–53. doi: 10.1093/jamia/ocx130.4645255 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Vest JR, Menachemi N, Grannis SJ, Ferrell JL, Kasthurirathne SN, Zhang Y, Tong Y, Halverson PK. Impact of risk stratification on referrals and uptake of wraparound services that address social determinants: a stepped wedged trial. Am J Prev Med. 2019 Apr;56(4):e125–e133. doi: 10.1016/j.amepre.2018.11.009.S0749-3797(18)32433-4 [DOI] [PubMed] [Google Scholar]
- 13.ICD-10 adds more detail on the social determinants of health. LaBrec P. 2016. [2019-02-24]. https://www.3mhisinsideangle.com/blog-post/icd-10-adds-more-detail-on-the-social-determinants-of-health/
- 14.Youden WJ. Index for rating diagnostic tests. Cancer. 1950 Jan;3(1):32–5. doi: 10.1002/1097-0142(1950)3:1<32::aid-cncr2820030106>3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- 15.Choi E, Bahadori M, Schuetz A, Stewart W, Sun J. Doctor ai: predicting clinical events via recurrent neural networks. arXiv preprint arXiv. 2015:151105942. [PMC free article] [PubMed] [Google Scholar]
- 16.Duke JD, Morea J, Mamlin B, Martin DK, Simonaitis L, Takesue BY, Dixon BE, Dexter PR. Regenstrief Institute's Medical Gopher: a next-generation homegrown electronic medical record system. Int J Med Inform. 2014 Mar;83(3):170–9. doi: 10.1016/j.ijmedinf.2013.11.004.S1386-5056(13)00245-1 [DOI] [PubMed] [Google Scholar]
- 17.McDonald CJ, Overhage JM, Barnes M, Schadow G, Blevins L, Dexter PR, Mamlin B, INPC Management Committee The Indiana network for patient care: a working local health information infrastructure. Health Aff (Millwood) 2005;24(5):1214–20. doi: 10.1377/hlthaff.24.5.1214.24/5/1214 [DOI] [PubMed] [Google Scholar]
- 18.Goodman RA, Posner SF, Huang ES, Parekh AK, Koh HK. Defining and measuring chronic conditions: imperatives for research, policy, program, and practice. Prev Chronic Dis. 2013 Apr 25;10:E66. doi: 10.5888/pcd10.120239. https://www.cdc.gov/pcd/issues/2013/12_0239.htm .E66 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Nelson SJ, Zeng K, Kilbourne J, Powell T, Moore R. Normalized names for clinical drugs: RxNorm at 6 years. J Am Med Inform Assoc. 2011 Jul 01;18(4):441–448. doi: 10.1136/amiajnl-2011-000116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Beyond health care: the role of social determinants in promoting health and health equity. Artiga S, Hinton E. 2018. [2020-06-03]. http://files.kff.org/attachment/issue-brief-beyond-health-care .
- 21.Jain AK. Data clustering: 50 years beyond K-means. Pattern Recognition Letters. 2010 Jun;31(8):651–666. doi: 10.1016/j.patrec.2009.09.011. [DOI] [Google Scholar]
- 22.Kodinariya T, Makwana P. Review on determining number of Cluster in K-Means Clustering. International Journal. 2013;1(6):90–5. [Google Scholar]
- 23.Tang J, Alelyani S, Liu H. Feature selection for classification: a review. In: Aggarwal CC, editor. Data Classification: Algorithms and Applications. New York: Chapman and Hall/CRC; 2014. Jul 25, p. A. [Google Scholar]
- 24.Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D. Scikit-learn: Machine learning in Python. Journal of machine learning research. (Oct) 2011;12:2825–30. http://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf . [Google Scholar]
- 25.Chen T, Guestrin C. XGBoost: A Scalable Tree Boosting System. 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; August 2016; San Francisco. 2016. Aug 1, [Google Scholar]
- 26.Ye J, Chow J, Chen J, Zheng Z, editors Stochastic gradient boosted distributed decision trees. Proceedings of the 18th ACM conference on Information and Knowledge management; : ACM; 2009; Hong Kong. 2019. Dec 1, [DOI] [Google Scholar]
- 27.Nielsen D. NTNU Open. Trondheim: NTNU; 2016. Tree Boosting With XGBoost - Why Does XGBoost Win "Every" Machine Learning Competition? [Google Scholar]
- 28.Calonico S, Cattaneo MD, Titiunik R. Robust nonparametric confidence intervals for regression-discontinuity designs. Econometrica. 2014 Dec 23;82(6):2295–2326. doi: 10.3982/ecta11757. [DOI] [Google Scholar]
- 29.Altman Douglas G, Bland J Martin. How to obtain the P value from a confidence interval. BMJ. 2011;343:d2304. doi: 10.1136/bmj.d2304. [DOI] [PubMed] [Google Scholar]
- 30.Vuk M, Curk T. ROC curve, lift chart and calibration plot. Metodoloski zvezki. 2006;3(1):89. [Google Scholar]
- 31.Alba AC, Agoritsas T, Jankowski M, Courvoisier D, Walter SD, Guyatt GH, Ross HJ. Risk prediction models for mortality in ambulatory patients with heart failure: a systematic review. Circ Heart Fail. 2013 Sep 01;6(5):881–9. doi: 10.1161/CIRCHEARTFAILURE.112.000043.CIRCHEARTFAILURE.112.000043 [DOI] [PubMed] [Google Scholar]
- 32.Echouffo-Tcheugui JB, Batty GD, Kivimäki Mika, Kengne AP. Risk models to predict hypertension: a systematic review. PLoS One. 2013;8(7):e67370. doi: 10.1371/journal.pone.0067370. http://dx.plos.org/10.1371/journal.pone.0067370 .PONE-D-13-08187 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Dalton JE, Perzynski AT, Zidar DA, Rothberg MB, Coulton CJ, Milinovich AT, Einstadter D, Karichu JK, Dawson NV. Accuracy of cardiovascular risk prediction varies by neighborhood socioeconomic position: a retrospective cohort study. Ann Intern Med. 2017 Oct 03;167(7):456–464. doi: 10.7326/M16-2543. http://europepmc.org/abstract/MED/28847012 .2652557 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Alderwick Hugh, Gottlieb Laura M. Meanings and misunderstandings: a social determinants of health lexicon for health care systems. Milbank Q. 2019 Jun;97(2):407–419. doi: 10.1111/1468-0009.12390. http://europepmc.org/abstract/MED/31069864 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Golembiewski E, Allen KS, Blackmon AM, Hinrichs RJ, Vest JR. Combining nonclinical determinants of health and clinical data for research and evaluation: rapid review. JMIR Public Health Surveill. 2019 Oct 07;5(4):e12846. doi: 10.2196/12846. https://publichealth.jmir.org/2019/4/e12846/ v5i4e12846 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Institute of Medicine . National Academies Press (US) Capturing social and behavioral domains and measures in electronic health records: phase 2: National Academies Press; 2014. p. 0309312434. [PubMed] [Google Scholar]
- 37.Gold R, Bunce A, Cowburn S, Dambrun K, Dearing M, Middendorf M, Mossman N, Hollombe C, Mahr P, Melgar G, Davis J, Gottlieb L, Cottrell E. Adoption of social determinants of health EHR tools by community health centers. Ann Fam Med. 2018 Sep;16(5):399–407. doi: 10.1370/afm.2275. http://www.annfammed.org/cgi/pmidlookup?view=long&pmid=30201636 .16/5/399 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Kasthurirathne S, Cormer K, Devadasan N, Biondich P. editors. Development of a FHIR Based Application Programming Interface for Aggregate-Level Social Determinants of Health. : AMIA Informatics summit Conference Proceedings; 2019; San Francisco. 2019. Mar 25, [DOI] [Google Scholar]
- 39.Wang Y, Kung L, Byrd TA. Big data analytics: understanding its capabilities and potential benefits for healthcare organizations. Technological Forecasting and Social Change. 2018 Jan;126:3–13. doi: 10.1016/j.techfore.2015.12.019. [DOI] [Google Scholar]
- 40.Hubbard W N, Westgate C, Shapiro L M, Donaldson R M. Acquired abnormalities of the tricuspid valve--an ultrasonographic study. Int J Cardiol. 1987 Mar;14(3):311–8. doi: 10.1016/0167-5273(87)90201-4.0167-5273(87)90201-4 [DOI] [PubMed] [Google Scholar]
- 41.Castrucci B, Auerbach J. Meeting individual social needs falls short of addressing social determinants of health. Health Affairs Blog. [2019-01-01]. https://www.healthaffairs.org/do/10.1377/hblog20190115.234942/full/?utm_campaign=HASU&utm_ medium=email&utm_content=Health+Affairs+In+2018%3A+Editor+s+Picks%3B+The+2020+Proposed+Payment+Notice%3B+ Persistently+High-Cost+Medicare+Patients&utm_source=Newsletter& .
- 42.Pearl J. Theoretical impediments to machine learning with seven sparks from the causal revolution. arXiv preprint arXiv. 2018:180104016. doi: 10.1145/3159652.3176182. [DOI] [Google Scholar]
- 43.Regenstrief Institute Inc. nDepth. regenstrief.org. 2019. [2019-01-01]. https://www.regenstrief.org/implementation/ndepth/
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
List of risk conditions used to identify a subpopulation for predicting dietitian referrals.
Parameters that were modified as part of the hyperparameter tuning process for phase 2.
Lift scores reported by each decision model.