

Abstract
Inference in a high-dimensional situation may involve regularization of a certain form to treat overparameterization, imposing challenges to inference. The common practice of inference uses either a regularized model, as in inference after model selection, or bias-reduction known as “debias.” While the first ignores statistical uncertainty inherent in regularization, the second reduces the bias inbred in regularization at the expense of increased variance. In this article, we propose a constrained maximum likelihood method for hypothesis testing involving unspecific nuisance parameters, with a focus of alleviating the impact of regularization on inference. Particularly, for general composite hypotheses, we unregularize hypothesized parameters whereas regularizing nuisance parameters through a L0-constraint controlling the degree of sparseness. This approach is analogous to semiparametric likelihood inference in a high-dimensional situation. On this ground, for the Gaussian graphical model and linear regression, we derive conditions under which the asymptotic distribution of the constrained likelihood ratio is established, permitting parameter dimension increasing with the sample size. Interestingly, the corresponding limiting distribution is the chi-square or normal, depending on if the co-dimension of a test is finite or increases with the sample size, leading to asymptotic similar tests. This goes beyond the classical Wilks phenomenon. Numerically, we demonstrate that the proposed method performs well against it competitors in various scenarios. Finally, we apply the proposed method to infer linkages in brain network analysis based on MRI data, to contrast Alzheimer’s disease patients against healthy subjects. Supplementary materials for this article are available online.
Keywords: Brain networks; Generalized Wilks phenomenon; High-dimensionality; L0-regularization; (p, n)-asymptotics; Similar tests
1. Introduction
High-dimensional analysis has become increasingly important in modern statistics, where a model’s size may greatly exceed the sample size. For instance, in studying the brain activity, a brain network is often examined, which consists of structurally and functionally interconnected regions at many scales. At the macroscopic level, networks can be studied noninvasively in healthy and disease subjects with functional MRI (fMRI) and other modalities such as MEG and EEG. In such a situation, inferring the structure of a network becomes critically important, which is one kind of high-dimensional inference. Yet, high-dimensional inference remains largely under-studied. In this article, we develop a full likelihood inferential method, particularly for a Gaussian graphical model and high-dimensional linear regression.
In the literature, a great deal of effort has been devoted to estimation. For the linear model, many methods focus on estimation with sparsity-inducing convex and nonconvex regularization such as Lasso, SCAD, MCP, and TLP (Tibshirani 1996; Fan and Li 2001; Zhang 2010; Shen, Pan, and Zhu 2012), among others. For the Gaussian graphical model, methods include the regularized likelihood approach (Rothman et al. 2008; Friedman, Hastie, and Tibshirani 2008; Yuan and Lin 2007; Fan, Feng, and Wu 2009; Shen, Pan, and Zhu 2012) and the nodewise regression approach (Meinshausen and Bühlmann 2006), and their extensions, such as conditional Gaussian graphical (Li, Chun, and Zhao 2012; Yin and Li 2013) and multiple Gaussian graphical models (Zhu, Shen, and Pan 2014; Lin et al. 2017). Despite progress, there is a paucity of inferential methods for high-dimensional models, although some have been recently proposed in Zhang and Zhang (2014), Van de Geer et al. (2014), Javanmard and Montanari (2014), and Janková and Van de Geer (2017), where CI are constructed based on a bias-reduction method called “debias” (Zhang and Zhang 2014). One potential issue of this kind of approach is not asymptotically similar with its null distribution depending on unknown nuisance parameters to be estimated, and most critically the variance is likely to increase after debias, resulting in an increased length of a CI.
In this article, we propose a maximum likelihood method subject to certain constraints for hypothesis testing involving unspecific nuisance parameters, referred to as the constrained maximum likelihood ratio (CMLR) test, which regularizes the degree of sparsity of un-hypothesized parameters in a high-dimensional model, whereas hypothesized parameters are not regularized. This is an analogy of semiparametric inference with respect to the parametric component, which enables to alleviate the inherited bias problem due to regularization. For computation, we employ a surrogate of the L0-function, a truncated L1-function, for the constraints. On this ground, we develop the CMLR test, which is asymptotically similar with its null distribution independent of unspecific nuisance parameters. Moreover, we derive the asymptotic distributions of the test in the presence of growing parameter dimensions for the Gaussian graphical model and linear model. Most importantly, the corresponding distribution for the CMLR test statistic converges to the chis-quare distribution when the co-dimension, or the difference in dimensionality between the full and null spaces, is finite, and converges to normal (after proper centering and scaling) when the co-dimension tends to infinity. This occurs in a situation roughly when and , respectively, in the Gaussian graphical model and linear regression, where |B| and |A0| are the numbers of the hypothesized parameters and the nonzero unhypothesized parameters. Such a critical assumption is in contrast to a requirement of for sparse feature selection Shen et al. (2013), which has been used in Portnoy (1988) for the maximum likelihood estimation in a different context. Empirically, the asymptotic approximation becomes inadequate when departure from this assumption occurs in a less sparse situation. To our knowledge, our result is the first of this kind, providing a multivariate likelihood test in the presence of high-dimensional nuisance parameters. This is in contrast to a univariate debias test Zhang and Zhang (2014), Van de Geer et al. (2014), Javanmard and Montanari (2014), and Janková and Van de Geer (2017). When specializing the CMLR test to a single parameter in the Gaussian graphical model and linear regression, we show that it has asymptotic power, that is, no less than that of the debias test; see, Theorem 3. This is anticipated since the debias test does not capture all the information contained in the likelihood, whereas the full likelihood takes into account component to component dependencies. This aspect is illustrated by our second numerical example in which a null hypothesis involves a row (column) of offdiagonals of the precision matrix. Of course, a multivariate likelihood test as ours may require stronger conditions than a univariate non-likelihood test, which is analogous to the classical situation of the maximum likelihood versus the method of moments in inference. Throughout this article, we shall focus our attention to the CMLR test as opposed to the corresponding Wald test based on the constrained maximum likelihood, which not asymptotically similar, given that it is rather challenging to invert a high-dimensional Fisher information matrix.
Computationally, we relax the nonconvex minimization using an L0-surrogate function by solving a sequence of convex relaxations as in Shen, Pan, and Zhu (2012). For each convex relaxation, we employ the alternating direction method of multipliers algorithm Boyd et al. (2011), permitting a treatment of problems of medium to large size. Moreover, we study the operating characteristics of the proposed inference method and compare against the debias methods through numerical examples. In simulations, we demonstrate that the proposed method performs well under various scenarios, and compares favorably against its competitors. Finally, we apply the proposed method to confirm that a reduced level of connectivity is observed in certain brain regions in the default mode network (DMN) but an increased level in others for Alzheimer’s disease (AD) patients as compared to healthy subjects.
The rest of the article is organized as follows. Section 2 proposes a constrained likelihood ratio test, and gives specific conditions under which the asymptotic approximation of the sampling distribution of the test is valid for the Gaussian graphical model and linear regression. Section 3 performs the power analysis for the CMLR test. Section 4 discusses computational strategies for the proposed test. Section 5 performs numerical studies, followed by an application of the tests to detect the structural changes in brain network analysis for AD subjects versus healthy subjects in Section 6. Section 7 is devoted to technical proofs.
2. Constrained Likelihood Ratios
Given an iid sample X1,...,Xn from a probability distribution with density pθ, consider a testing problem H0 : θi = 0; i ∈ B versus Ha : θi ≠ 0 for some i ∈ B, with unspecific nuisance parameters θj for j ∈ Bc, possibly high-dimensional, where , and B ⊆ {1,...,d}. Here, we allow the dimension of θ and size of |B| to grow as a function of the sample size n. For a problem of this type, we construct a constrained likelihood ratio with a sparsity constraint on nuisance parameters . Specifically, define
| (1) |
| (2) |
where is the log-likelihood, pτ(x) = min(x/τ, 1) is the truncated L1-function Shen, Pan, and Zhu (2012) as a surrogate of the L0-function, and (K, τ) are nonnegative tuning parameters. In this situation, without the sparsity constraint, and in (1) and (2) are exactly the maximum likelihood estimates under H0 and Ha, respectively. Now, we define the constrained likelihood ratio as: . In what is to follow, we derive the asymptotic distribution of Λn(B) in a high-dimensional situation for the Gaussian graphical model and linear regression. On this ground, an asymptotically similar test is derived, whose null distribution is independent of nuisance parameters.
Tuning parameters K and τ in (1) and (2) are estimated using a cross-validation (CV) criterion based on the full model (1). Choosing the same values of (K, τ) in (1) and (2) ensures the nestedness property of Λn(B) ≥ 0 because the constrained set in (1) is a subset of that in (2). With K = ∞, the test statistic Λn(B) reduces to the classical likelihood ratio test statistic.
2.1. Asymptotic Distribution of Λn(B) in Graphical Models
This subsection is devoted to a Gaussian graphical model, where X1,...,Xn follow from a p-dimensional normal distribution N(0, Ω−1), with Ω a precision matrix, or the inverse of the covariance matrix ∑. In this case, θ = Ω. The log-likelihood is , where is the sample covariance matrix, and tr(·) denotes the trace of a matrix.
In the foregoing testing framework, the null and alternative hypotheses can be written as: H0 : ΩB = 0 versus Ha : ΩB ≠ 0 for some prespecified index set B. Then the constrained log-likelihood ratio becomes , where and are the constrained maximum likelihood estimates (CMLE)s based on the null and full spaces of the test.
To establish the asymptotic distribution of Λn(B), we first introduce some notations to be used. For any symmetric matrix M, let λmax(M) and λmin(M) be the maximum and minimum eigenvalues of M, and ||M||F be the Frobenius norm of M. Let \ and | · | denote the set difference and the size of a set. For any vector , let . Denote by an approximating point in a space to the true Ω0, where is the Kullback–Leibler information. Let be the Fisher-norm between Ω0 and Ω Shen (1997). Moreover, let be the support of true parameter θ0, κ0 = λmax(Ω0)/λmin(Ω0) be the condition number of Ω0, and , where . Let . Let be the minimum nonzero offdiagonals of Ω0 representing the signal strength. The following technical conditions are made.
Assumption 1 (Degree of separation).
| (3) |
where C1 > 0 is a constant.
Assumption 1 requires that the degree of separation Cmin exceeds a certain threshold level, roughly , which measures the level of difficulty of the task of removing zero components of the nuisance (un-hypothesized) parameters of Ω by the constrained likelihood with the L0-constraint. To better understand (3) of Assumption 1, we consider a sufficient condition of (3) as follows:
Note that . Consequently, a simpler but stronger condition of (3) in terms of γmin is
| (4) |
for some constant C2 > 0.
Assumption 2 (Dimension restriction for Λn(B).
Assume that
Assumption 2 restricts the size p for an asymptotic approximation of the sampling distribution of the likelihood ratio tests, which is closely related to that in Portnoy (1988) for a different problem. Note that if |A0| = O(p) and |B| = O(p) then Assumption 2 roughly requires that .
Theorem 1 gives the asymptotic distribution of when |B| is either fixed or grows with n, referred to as Wilks phenomenon and generalized Wilks phenomenon, respectively.
Theorem 1 (Asymptotic sampling distribution of Λn(B).
Under Assumptions 1–2, there exists optimal tuning parameters (K, τ) with K |A0| and such that under H0
-
(i)Wilks phenomenon: If with |B| fixed, then
-
(ii)Generalized Wilks phenomenon: If with |B| → ∞, then
Concerning Assumptions 1 and 2, we remark that the degree of separation assumption (3) or (4) is necessary for the result of Theorem 1. Without Assumption 1, the result may break down, as suggested by a counter example in Lemma 1 for a parallel condition—Assumption 3 in linear regression in Section 2.2. This is expected because when the constrained likelihood cannot be over-selection consistency when Assumption 1 breaks down in view of the result of Shen, Pan, and Zhu (2012). That means that any under-selected component yields a bias of order . As a result, the foregoing results are not generally expected to hold. Moreover, Assumption 2 is intended for joint inference of multiple parameters, for instance, testing zero offdiagonals of one row or column of Ω as in the second simulation example of Section 4. These assumptions, as we believe, are needed for multivariate tests based on a full likelihood although we have not proved so, which appear stronger than those required for a univariate debias test based on a pseudo likelihood Janková and Van de Geer (2017). This is primarily due to the full likelihood approach estimating component to component dependencies in lieu of a marginal approach without them, leading to higher efficiency when possible. This is evident from Corollary 1 that the CMLR gives more precise inference than the debias test under these conditions.
The result of Theorem 1 depends on the optimal tuning parameter K = K0 and τ, both of which are unknown in practice. Therefore, K is estimated by cross-validation through tuning, and the exact knowledge of the value K is not necessary, whereas τ is usually set to be a small number, say 10−2, in practice.
2.2. Asymptotic Distribution of Λn(B) in Linear Regression
In linear regression, a random sample follows
| (5) |
where β = (β1,..., βp)T and xi = (xi1,..., xip)T are p-dimensional vectors of regression coefficients and predictors, and xi is independent of random error ϵi. In (5), it is known priori that β is sparse in that , and , where .
In this case, θ = (β, σ). Our focus is to test H0 : βB = 0 versus Ha = βB ≠ 0 for some index set B. The log-likelihood is , and the constrained log-likelihood ratio is accordingly defined as are the CMLE based on the null and full spaces of the test.
A parallel condition of Assumption 1 is made in Assumption 3.
Assumption 3 (Degree of separation condition, Shen et al. 2013).
| (6) |
for some absolute constant C0 that may depend on the design matrix X.
A parallel result of Theorem 1 is established for linear regression.
Theorem 2 (Sampling distribution of Λn(B).
Assume that . Under Assumptions 3, there exists optimal tuning parameters (K, τ) with K = |A0| and such that under H0
-
(i)Wilks phenomenon: If βi = 0 for i ∈ B with |B| fixed, then
-
(ii)Generalized Wilks phenomenon: If βi = 0 for i ∈ B with |B| → ∞, then
Note of worthy is that the requirement in linear regression appears weaker than that in the Gaussian graphical model. This is primarily because the error for the likelihood ratio approximation in the former is smaller in magnitude.
Next we provide a counter example to show that the result in Theorem 2 breaks down when Assumption 3 is violated in the absence of a strong signal strength. In other words, such an assumption is necessary for such a full likelihood approach to gain the test efficiency, which is in contrast to a pseudo-likelihood approach.
Lemma 1 (A counter example).
In (5), we write y = β0 + β⊤ x, where x = (x1,...,xp) are independently distributed from N(μi, 1) with μ1 = 0 and μj = 1; 2 ≤ j ≤ p, and ϵ is N(0, 1 − n−1), independent of x. Assume that β0 = 0 and β = (n−1/2, 0,...,0), or, y = n−1/2x1 + ϵ. Then Assumption 3 is violated. Now consider a hypothesis test of H0 : β0 = 0 versus as n, p → ∞, then as n, p → ∞, with B = {0}.
3. Power Analysis
This section analyzes the local limiting power function of the CMLR test and compare it with that of the debias test of Janková and Van de Geer (2017) in Gaussian graphical model. To that the null H0 for fixed index set B for the Gaussian graphical end, we first establish the asymptotic distribution of under model and linear model. Then, we use those results to carry out a local power analysis for both models.
3.1. Asymptotic Normality
We first introduce some notations before presenting the asymptotic normality results for Gaussian graphical model. Let is a sub-vector of vec(C) excluding components with indices not in B, is a scaled vectorization of a p × p symmetric matrix C (Alizadeh et al. 1998) and is the indicator. For the Fisher information, we need the symmetric Kronecker product Alizadeh et al. (1998) for a p × p symmetric matrix C to treat derivatives of the log-likelihood with respect to a matrix. Define the symmetric Kronecker product of as for any symmetric matrix Δ, and define the Fisher information matrix for the -dimensional vector as , c.f., Lemma 2. Given an index set B, we define a |B| × |B| submatrix IB,B as , extracting the corresponding |B| × |B| submatrix from I. Theorem 1 gives the asymptotic distribution of .
Proposition 1 (Asymptotic distribution of CMLE ).
for Gausian graphical model). Under Assumptions 1 and 2, if |B| is fixed, there exists a pair of tuning parameters (K, τ) with K = |A0| and satisfies
| (7) |
where extracts a |B| × |B| submatrix from .
For linear regression, a similar asymptotic result can be derived.
Proposition 2 (Asymptotic distribution of CMLE).
Assume that is inevitable. Under Assumptions 3, if |B| is fixed, there exists a pair of tuning parameters (K, τ) with K = |A0| and such that satisfies
| (8) |
where MB,B extracts a |B| × |B| submatrix from a matrix M.
3.2. Local Power Analysis
Consider a local alternative with , for any , with is fixed, , for some constant h. Let . Subsequently, we study the behavior of the local limiting power function for the proposed CMLR test is fixed and lim . Let the corresponding of the debias test in Janková and Van de Geer (2017) in the Gaussian graphical model as a result for linear regression is similar.
Theorem 3.
If for any θn = Ωn the Assumptions 1 and 2 for the Gaussian graphical model are met and further assume that |B|3/2/n → 0, then for any nuisance parameters ,
where α > 0 is the level of significance, Z ∼ N(0, I|B| × |B|) is a multivariate normal random variable, Z ∼ N(0, 1), and JB,B is the asymptotic variance of in (7). In particular, . Moreover, in the one-dimensional situation with |B| = 1, for any h and ,
| (9) |
Theorem 3 suggests that the proposed CMLR test has the desirable power properties, which dominates the corresponding debias tests, which is attributed to optimality of the corresponding CMLE and likelihood ratio, as suggested by Theorem 1. Note that the debias test requires Assumption 2.
Next, we compare the asymptotic variance of our estimator to that of Janková and Van de Geer (2017) for the one-dimensional case with |B| = 1. As indicated by Corollary 1, our estimator has asymptotic variance, that is, no larger than that of its debias counterpart.
Corollary 1 (Comparison of asymptotic variances).
Under the assumption of Theorem 1, the asymptotic covariance matrix of is upper bounded by the matrix , where is the ijth element of the . When specializing the above result to the one-dimensional case, it implies that the asymptotic variance of is no larger than , the asymptotic variance of the regression estimator in Janková and Van de Geer (2017).
A parallel result of Theorem 3 is established for linear regression.
Theorem 4.
If for any θn = βn the Assumptions 1 and 2 for the linear regression model are met. Then
| (10) |
where with columns being the eigenvalues of , and Z is a |B| dimensional normal random vector. Hence, for any nuisance parameters .
4. Computation
To compute the CMLEs under the null and full spaces in (1) and (2), we approximately solve constrained nonconvex optimization through difference convex (DC) programming. Particularly, we follow the DC approach of Shen, Pan, and Zhu (2012) to approximate the nonconvex constraint by a sequence of convex constraints based on a difference convex decomposition iteratively. This leads to an iterative method for solving a sequence of relaxed convex problems. The reader may consult Shen, Pan, and Zhu (2012) for convergence of the method.
For (1) and (2), at the mth iteration, we solve
| (11) |
to yield , where A1 = B and A2 = ∅ for (1) and A1 = A2 = B for (2). Iteration continues until two adjacent iterates are equal. To solve (11), we employ the alternating direction method of multipliers algorithm (Boyd et al. 2011), which amounts to the following iterative updating scheme
| (12) |
| (13) |
where
denotes the projection onto the set and ρ > 0 is fixed or can be adaptively updated using a strategy in Zhu (2017). Note that in both cases, the θ-update (12) can be solved using an analytic formula involving a singular value decomposition for the Gaussian graphical model (see Section 6.5 of Boyd et al. 2011) and solving a linear system for the linear model, while (13) is performed using the L1-projection algorithm of Liu and Ye (2009) whose complexity is almost linear in a problem’s size. Specifically, consider a generic problem of projection onto a weighted L1-ball subject to equality constraint:
where ci ≥ 0; i = 1,..., d and A is a subset of {1,...,d}. The solution of this problem is otherwise, where λ★ is a root of . This root-finding problem is solved efficiently by bisection.
5. Numerical Examples
This section investigates operating characteristics of the proposed CMLR test with regard to the size and power of a test through simulations and compare with several strong competitors in the literature.
For the Gaussian graphical model, we examine three different types of graphs—a chain graph, a hub graph, and a random graph, as displayed in Figure 1. For a given graph , Ω is generated based on connectivity of the graph, that is, ωij ≠ 0 iff there exists a connection between nodes i and j for i ≠ j. Moreover, we set ωij = 0.3 if i and j are connected and diagonals equal to 0.3 + c with c chosen so that the smallest eigenvalue of the resulting matrix equals to 0.2. Finally, a random sample of size n = 200 is drawn from N(0, Ω−1).
Figure 1.
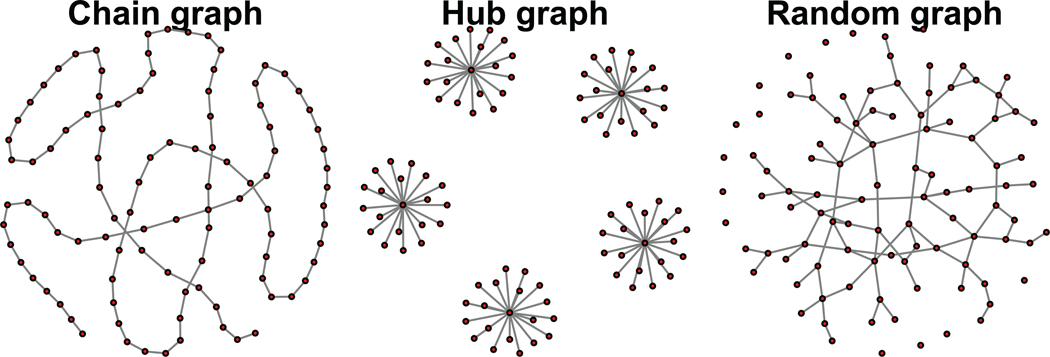
Three types of graphs used in our simulations.
In what follows, we consider two hypothesis testing problems concerning conditional independence of components of a Gaussian random vector X = (X1,...,Xp). The first concerns null hypothesis versus its alternative , for testing conditional independence between and . The second deals with versus for some j ≠ i0, for testing conditional independence of component i0 with the rest. In either case, we apply the proposed CMLR test in Section 2 and compare it with the univariate debias test of Janková and Van de Geer (2017) in terms of the empirical size and power only in the first problem. To our knowledge, no competing methods are available for the second problem in the present situation.
For the size of a test, we calculate its empirical size as the percentage of times rejecting H0 out of 1000 simulations when H0 is true. For the power of a test, we consider four different alternatives: . Under each alternative, we compute the power as the percentage of times rejecting H0 out of 1000 simulations when Ha is true.
With regard to tuning, we fix τ = 0.001 and propose to use a vanilla cross-validation to choose the optimal tuning parameter K for our test by minimizing a prediction criterion using a 5-fold CV. Specifically, we divide the dataset into five roughly equal parts denoted by . Define and , respectively, as the sample covariance matrices calculated based on samples in and . Similarly, define to be the precision matrix calculated based on sample covariance matrix . The 5-fold CV criterion is . Then the optimal tuning parameter is obtained by minimizing CV(K) over a set of grids in the domain of K. Finally, K★ = arg min K CV(K) is used to compute the final estimator based on the original data.
For the first testing problem, the nominal size of a test is set to 0.05 for our CMLR test and the univariate debias test of Janková and Van de Geer (2017), denoted as CMLR-chi-square and JG, where the confidence interval in Janková and Van de Geer (2017) is converted to a two-sided test. For each graph type, three different graph sizes p = 50, 100, 200 are examined. As indicated in Table 1, the empirical size of the CMLR test is under or close to the nominal size 0.05. Moreover, as suggested in Table 1, the power of the likelihood ratio test is uniformly higher across all the 12 scenarios with four alternatives and three different dimensions, where the largest improvements are seen for the hub graph, particularly with p = 100, 200 for an amount of improvement of 50% or more. This result is anticipated because the likelihood method is more efficient than a regression approach.
Table 1.
Empirical size and power comparisons of the proposed CMLR test and test of Janková and Van de Geer (2017), denoted by CMLR-chi-square and JG, in the first testing problem for the Gaussian graphical model based on 1000 simulations.
| CMLR-chi-square |
JG |
||||
|---|---|---|---|---|---|
| Graph | (n, p) | Size | Power | Size | Power |
| Band | (200,50) | 0.054 | (0.27, 0.78, 0.98, 1.0) | 0.043 | (0.24, 0.77, 0.99, 1.0) |
| (200,100) | 0.055 | (0.30, 0.79, 0.98, 1.0) | 0.042 | (0.24, 0.75, 0.99, 1.0) | |
| (200,200) | 0.048 | (0.29, 0.80, 0.99, 1.0) | 0.036 | (0.23, 0.74, 0.98, 1.0) | |
| Hub | (200,50) | 0.019 | (0.10, 0.36, 0.74, 0.95) | 0.005 | (0.06, 0.27, 0.66, 0.92) |
| (200,100) | 0.028 | (0.12, 0.43, 0.81, 0.96) | 0.005 | (0.02, 0.17, 0.54, 0.86) | |
| (200,200) | 0.031 | (0.16, 0.55, 0.86, 0.98) | 0.001 | (0.02, 0.15, 0.50, 0.86) | |
| Random | (200,50) | 0.034 | (0.15, 0.51, 0.86, 0.98) | 0.025 | (0.14, 0.49, 0.83, 0.98) |
| (200,100) | 0.041 | (0.21, 0.68, 0.94, 1.0) | 0.018 | (0.11, 0.53, 0.92, 0.99) | |
| (200,200) | 0.049 | (0.15, 0.47, 0.81, 0.96) | 0.034 | (0.14, 0.41, 0.78, 0.95) | |
To study operating characteristics of the constrained likelihood test, we focus on the validity of asymptotic approximations based on the chi-square or normal distribution under H0. For the first problem, Figure 2 indicates that the chi-square approximation on one degree of freedom is adequate for the likelihood ratio test. Similarly, for the second testing problem involving a column/row of Ω, Figure 3 confirms that the normal approximation is again adequate for the CMLR test. Overall, the asymptotic approximations appear adequate.
Figure 2.
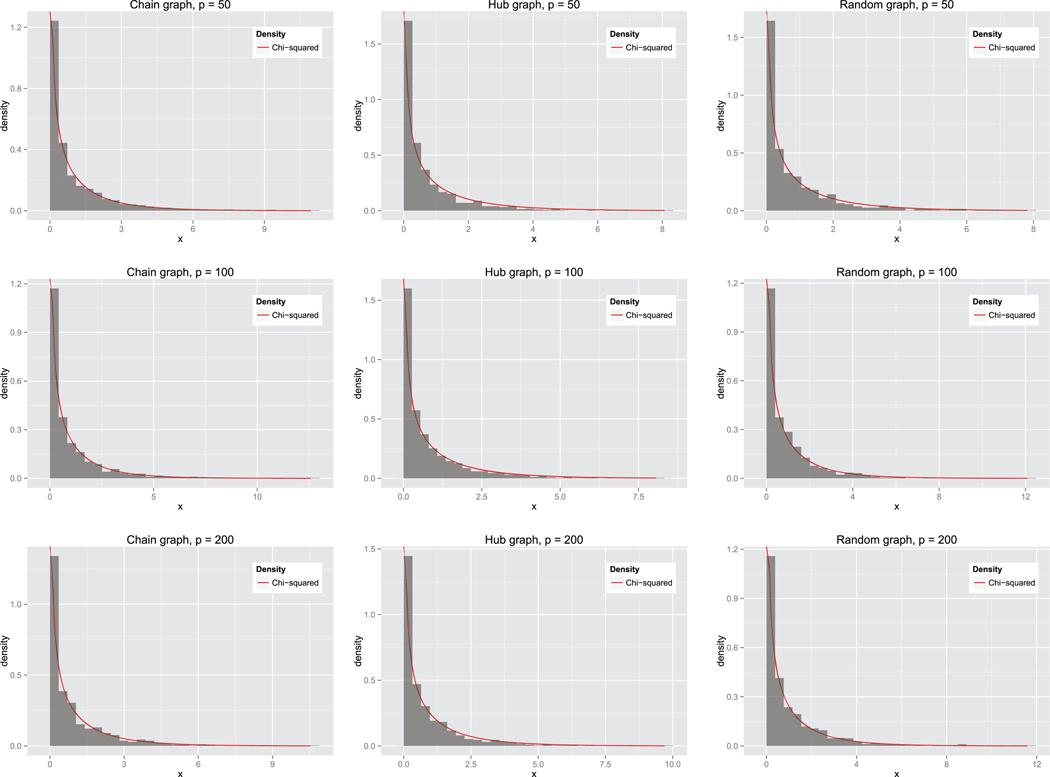
Empirical null distribution of the proposed CMLR test based on the chi-square approximation with n = 200.
Figure 3.
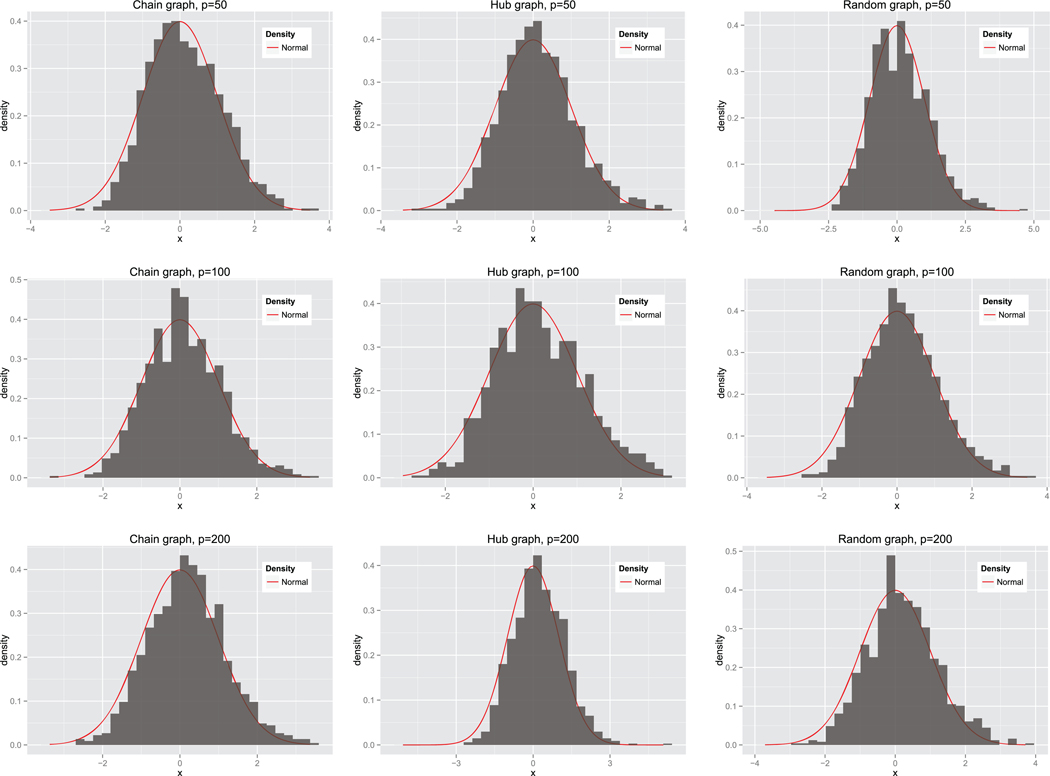
Empirical null distribution of our likelihood ratio test based on the normal approximation for the second testing problem involving a single column/row.
For the linear model, we perform a parallel simulation study to compare the CMLR test with the debiased lasso test (Zhang and Zhang 2014; Van de Geer et al. 2014) and the method of Zhang and Cheng (2017). In (5), we examine (n, p) = (100, 50), (100, 200), (100, 500), (100, 1000), in which predictors xij and the error ϵi are generated independently from N(0, 1), where and ; l = 0, 1,...,4. Now consider a hypothesis test with null hypothesis H0 : βB = 0 versus its alternative Ha : βB ≠ 0, where we let |B| ≠ 1, 5, 10. With regard to size, power, and tuning, we follow the same scheme as in the Gaussian graphical model.
As indicated in Table 2, the empirical size of CMLR-chi-square and CMLR-normal are close to the target size 0.05, while the former does better than the latter for |B| is small and worse for large |B|, which corroborates with the result of Theorem 2. Moreover, the power of CMLR-chi-square is uniformly higher across all the three scenarios with four alternatives compared to the other two competing methods. Interestingly, when |B| is large, the method of Zhang and Cheng (2017) seems to control the size closer to the nominal level than the CMLR test, but the situation is just the opposite when |B| is not large. Additional simulations also suggest that similar results are obtained with additional correlation among covariates, which are not displayed in here.
Table 2.
Empirical size and power comparisons in linear regression as well as estimated tuning parameter by a 5-fold cross-validation over 1000 simulations.
| |B| | n | p | Method | Size | Power | ||
|---|---|---|---|---|---|---|---|
| 1 | 100 | 50 | CMLR-chi-square | 0.057 | (0.165, 0.489, 0.837, 0.972) | 3.36 (1.08) | |
| CMLR-normal | 0.061 | (0.17, 0.495, 0.84, 0.972) | NA | ||||
| Zhang and Cheng | 0.039 | (0.109, 0.262, 0.579, 0.788) | NA | ||||
| DL | 0.033 | (0.132, 0.404, 0.724, 0.917) | NA | ||||
| 200 | CMLR-chi-square | 0.055 | (0.17, 0.524, 0.829, 0.974) | 3.191 (0.591) | |||
| CMLR-normal | 0.058 | (0.176, 0.532, 0.834, 0.975) | NA | ||||
| Zhang and Cheng | 0.013 | (0.042, 0.116, 0.306, 0.476) | NA | ||||
| DL | 0.052 | (0.144, 0.358, 0.694, 0.888) | NA | ||||
| 500 | CMLR-chi-square | 0.051 | (0.175, 0.509, 0.838, 0.963) | 3.159 (0.583) | |||
| CMLR-normal | 0.051 | (0.179, 0.513, 0.84, 0.963) | NA | ||||
| Zhang and Cheng | NA | NA | NA | ||||
| DL | NA | NA | NA | ||||
| 1000 | CMLR-chi-square | 0.056 | (0.165, 0.512, 0.828, 0.962) | 3.115 (0.371) | |||
| CMLR-normal | 0.058 | (0.17, 0.522, 0.83, 0.964) | NA | ||||
| Zhang and Cheng | NA | NA | NA | ||||
| DL | NA | NA | NA | ||||
| 5 | 100 | 50 | CMLR-chi-square | 0.058 | (0.11, 0.328, 0.63, 0.865) | 3.33 (0.94) | |
| CMLR-normal | 0.052 | (0.109, 0.322, 0.619, 0.862) | NA | ||||
| Zhang and Cheng | 0.05 | (0.063, 0.115, 0.226, 0.346) | NA | ||||
| DL | NA | NA | NA | ||||
| 200 | CMLR-chi-square | 0.066 | (0.114, 0.297, 0.601, 0.878) | 3.188 (0.606) | |||
| CMLR-normal | 0.063 | (0.112, 0.289, 0.592, 0.878) | NA | ||||
| Zhang and Cheng | 0.037 | (0.052, 0.111, 0.153, 0.253) | NA | ||||
| DL | NA | NA | NA | ||||
| 500 | CMLR-chi-square | 0.064 | (0.124, 0.321, 0.625, 0.895) | 3.153 (0.56) | |||
| CMLR-normal | 0.061 | (0.118, 0.315, 0.618, 0.893) | NA | ||||
| Zhang and Cheng | NA | NA | NA | ||||
| DL | NA | NA | NA | ||||
| 1000 | CMLR-chi-square | 0.059 | (0.118, 0.304, 0.612, 0.872) | 3.11 (0.355) | |||
| CMLR-normal | 0.057 | (0.112, 0.3, 0.604, 0.869) | NA | ||||
| Zhang and Cheng | NA | NA | NA | ||||
| DL | NA | NA | NA | ||||
| 10 | 100 | 50 | CMLR-chi-square | 0.068 | (0.094, 0.252, 0.528, 0.794) | 3.41 (1.20) | |
| CMLR-normal | 0.059 | (0.085, 0.233, 0.503, 0.775) | NA | ||||
| Zhang and Cheng | 0.054 | (0.055, 0.085, 0.146, 0.21) | NA | ||||
| DL | NA | NA | NA | ||||
| 200 | CMLR-chi-square | 0.086 | (0.115, 0.253, 0.514, 0.786) | 3.193 (0.618) | |||
| CMLR-normal | 0.079 | (0.104, 0.238, 0.487, 0.767) | NA | ||||
| Zhang and Cheng | 0.049 | (0.055, 0.089, 0.106, 0.152) | NA | ||||
| DL | NA | NA | NA | ||||
| 500 | CMLR-chi-square | 0.093 | (0.123, 0.286, 0.54, 0.773) | 3.159 (0.585) | |||
| CMLR-normal | 0.078 | (0.113, 0.262, 0.516, 0.76) | NA | ||||
| Zhang and Cheng | NA | NA | NA | ||||
| DL | NA | NA | NA | ||||
| 1000 | CMLR-chi-square | 0.073 | (0.123, 0.252, 0.526, 0.779) | 3.11 (0.355) | |||
| CMLR-normal | 0.066 | (0.112, 0.23, 0.497, 0.766) | NA | ||||
| Zhang and Cheng | NA | NA | NA | ||||
| DL | NA | NA | NA | ||||
NOTES: Here “CMLR-chi-square,” “CMLR-normal,” “DL,” and “Zhang and Cheng” denote the proposed test based on a chi-square approximation, a normal approximation, the debias method of Zhang and Zhang (2014), and the method of Zhang and Cheng (2017). Note that the nominal size is 0.05, DL is a test converted from a CI, and NA means that a result is not applicable or the code fail to return a result after a code’s runtime exceeds one week.
Concerning sensitivity of the choice of tuning parameters (K, τ) for the proposed method, as illustrated in Figure 4, the choice of τ is much less sensitive than that of K. Moreover, when K ≥ K0, both the size and power become less sensitive to a change of K. With regard to the estimated K by cross-validation, the estimator is close to K0 = 3 in the linear regression example, as suggested by Table 2.
Figure 4.
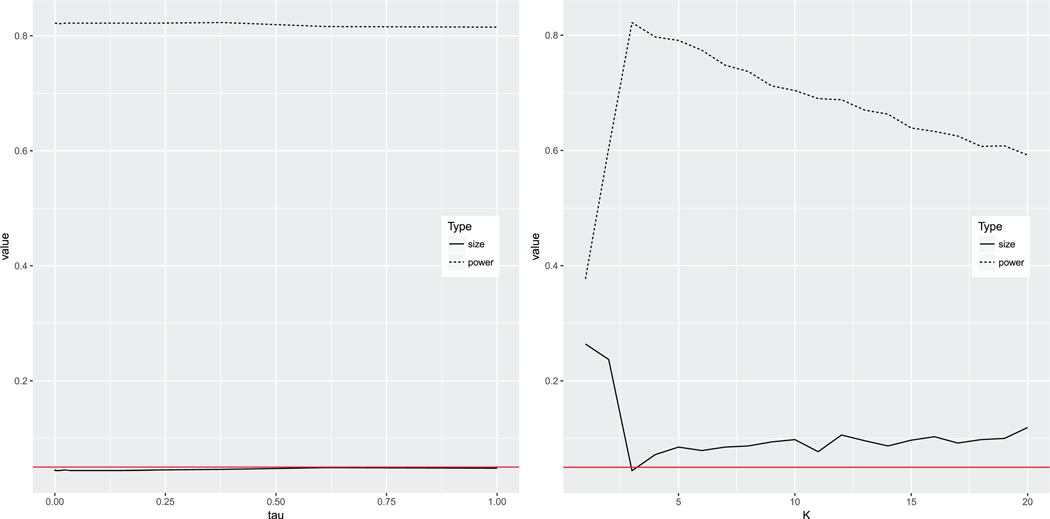
Sensitivity study of power as a function of tuning parameters τ and K, when n = 100, p = 100, and K0 = 3 in the linear regression problem based on 1000 simulations. Dotted and black lines represent empirical power and sizes of the proposed method, while red lines serve as a reference of the nominal size α = 0.05.
In summary, our simulation results suggest that the proposed method achieves high power compared to its competitors Janková and Van de Geer (2017), Zhang and Zhang (2014), Van de Geer et al. (2014), and Zhang and Cheng (2017). Moreover, the asymptotic approximation seems adequate in all the examples.
6. Brain Network Analysis
Alzheimer’s disease is the most common dementia without cure, while the prevalence is projected to continuously increase with an estimated 11% of the US senior population in 2015 to 16% in 2050, costing over 1.1 trillion in 2050 Alzheimer’s Association (2016). AD is now widely believed to be a disease with disrupted brain networks, and cortical networks based in structural MRI have been constructed to contrast with that of normal/healthy controls (He, Chen, and Evans 2008). Using the ADNI-1 baseline data (adni.loni.usc.edu), we extracted the cortical thicknesses for p = 68 regions of interest (ROIs) based on the Desikan–Killany atlas Desikan et al. (2006). Since previous studies (e.g., Greicius et al. 2004; Montembeault et al. 2015) have identified the DMN to be associated with AD, we will pay particular attention to this subnetwork, which includes 12 ROIs in our dataset. As in He, Chen, and Evans (2008), we first regress the cortical thickness on five covariates (gender, handedness, education, age, and intercranial volume measured at baseline), then use the residuals to estimate precision matrices, for 145 AD patients and 182 normal controls (CNs), respectively. Our approach here differs from previous studies He, Chen, and Evans (2008) and Montembeault et al. (2015) not only in estimating precision matrices, instead of covariance matrices, but also in rigorous inference.
For this data, we consider a hypothesis test of H0 : ωij = 0 versus Ha : ωij ≠ 0; 1 ≤ i ≠ j ≤ 12. For each estimated network for the two groups, significant edges under the overall error rate α = 0.05, after Bonferroni correction, are reported for the proposed CMLR test and the debias test of Janková and Van de Geer (2017) or JG. As indicated in Figure 5, the CMLR test yields 28 and 33 signif icant edges for the two groups of CN and AD, which is in contrast to 29 and 28 significant edges by the JG test. In other words, the CMLR test detects slightly more edges than the JG test, which is in agreement of the simulation results in Table 1.
Figure 5.
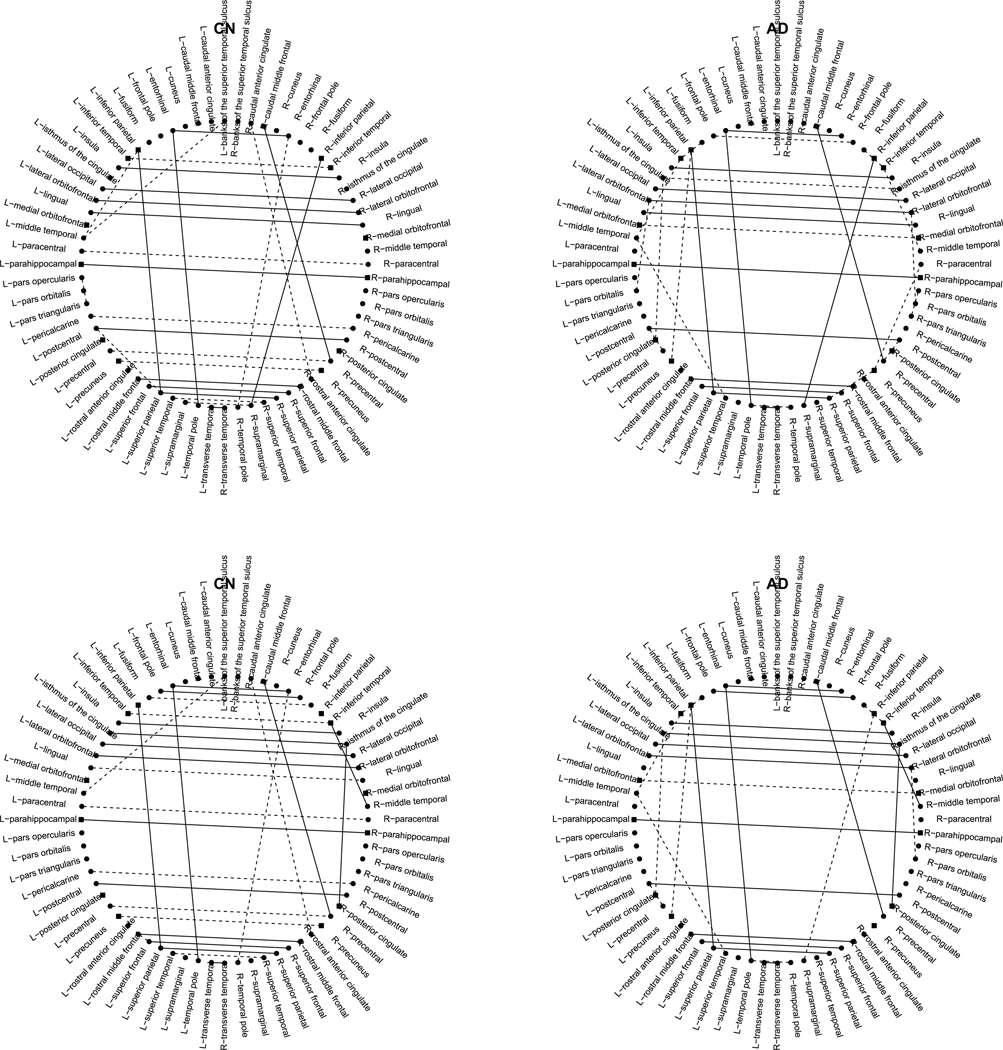
Estimated networks by the proposed method (first row) and the method Janková and Van de Geer (2017) (second row) for the CN (left) and AD (right) groups, where reported edges are significant under a p-value of 0.05 after Bonferroni correction. Nodes with square shape belong to DMN. The solid edges denote those that are shared by the two groups, whereas the dashed edges denote those that are only present within one group.
In what follows, we will focus on scientific interpretations of the statistical findings by the CMLR test. As shown in Montembeault et al. (2015), it is confirmed that for the AD patients, as compared to the normal controls, there seems to be reduced connectivity within DMN, but increased connectivity for some other ROIs, that is, the salience network and the executive network reported in Montembeault et al. (2015). Moreover, it seems that connectivity between the left and right brain within DMN somewhat deteriorates for the AD patients. To further explore the latter point, we then separately test the independence between each node in DMN and the other nodes outside DMN using the proposed CMLR test with the standard normal approximation. Specifically, for node i in DMN, we test H0 : ωij = 0 for all versus Ha : ωij ≠ 0 for some j ∈ DMN, where DMN denotes the set of 12 nodes in DMN. This amounts to 2 × 12 = 24 tests, with 12 tests for each group. Specifically, it is confirmed that for the group AD, only L-parahippocampal (left side) is independent of all the other nodes outside DMN; in contrast, for the CN group, in addition to L-parahippocampal, three other ROIs in DMN, L-medial prefrontal cortex, R-parahippocampal, and R-precuneus are independent of all the other nodes outside DMN.
Supplementary Material
Acknowledgments
The authors thank the editors, the associate editor, and anonymous referees for helpful comments and suggestions.
Funding
Research supported in part by NSF grants DMS-1415500, DMS-1712564, DMS-1721216, DMS-1712580, DMS-1721445, and DMS-1721445, NIH funding: NIH grants 1R01GM081535-01, 1R01GM126002, HL65462, and R01HL105397.
Appendix
The following lemmas provide some key results to be used subsequently. Detailed proofs of Lemmas 2–8 are provided in a online Supplementary materials due to space limit. Before proceeding, we introduce some notations. Given an index set , define CMLE as , with indicating positive definiteness of a matrix. Worthy of note is that becomes the oracle estimator when is the index set including all the indices corresponding to nonzero entries of the true precision matrix
Lemma 2.
For any symmetric matrices C1 and C2, . Moreover, for any positive definite matrix ,
| (A.1) |
| (A.2) |
| (A.3) |
| (A.4) |
Lemma 3.
For any symmetric matrix T and ν > 0
| (A.5) |
where . Furthermore, for T1,...,TK such that with c0 > 0 and any ν > 0, we have that
| (A.6) |
which implies that . Particularly, for any ν > 0 and any index set B,
| (A.7) |
implying that
Lemma 4.
(The Kullback–Leibler divergence and Fisher-norm) For a positive definite matrix , a connection between the Kullback–Leibler divergence K(Ω0, Ω) and the Fisher-norm can be established:
| (A.8) |
| (A.9) |
Lemma 5.
(Rate of convergence of constrained MLE). Let be an index set. For , we have that
| (A.10) |
on the event that . Moreover, if , then
| (A.11) |
Lemma 6.
(Selection consistency). If
| (A.12) |
as n → ∞ under Assumptions 1 and 2, where , and Cmin are as defined in (1)–(3).
Lemma 7.
Let be iid random vectors with var(γ1) = Im×m. If m is fixed, then
| (A.13) |
Otherwise, if max (m, m2m/n, m3/n, m3m3/2/n2 → 0), where , then
| (A.14) |
Lemma 8.
Let X ∼ N(0, Σ0) and with T a symmetric matrix. Then
| (A.15) |
Lemma 9.
(Asymptotic distribution for log-likelihood ratios). The log-likelihood ratio statistic , where is the MLE over index set with . Denote by κ0 the condition number of Σ0. If with p ≥ 2, then,
where follows a chi-square distribution χ2 on |B| degrees of freedom and Z ∼ N(0, 1), respectively.
Proof of Theorem 1.
By Lemma 6, ; , as n → ∞ under Assumptions 1 and 2. Then, the asymptotic distribution of the likelihood ratio follows immediately from Lemma 9. □
Proof of Proposition 1.
Let . By Lemma 6, , as n → ∞. Asymptotic normality of follows from an expansion of the score equation. Specifically, note that
where . Let be as defined in (B.33) of the online supplementary material. Multiplying on both sides of this identity, we obtain
| (A.16) |
Next, we show that the first term tends to in distribution and the second term tends to 0 in probability. For the second term, following similar calculations as in (B.34) of the online supplementary material, we have that for any . This, together with (B.37) of the online supplementary material, implies that
| (A.17) |
under Assumption 2. For the first term, note that
where the second last equality uses the property of exponential family Brown (1986). Hence, by the central limit theorem, . Finally, by Slutsky’s Theorem, we obtain that . This completes the proof. □
Proof of Proposition 2.
By Theorem 3 of Shen et al. (2013), , as n, p → ∞. Hence, with probability tending to 1,
Simple moment generating function calculations show that when |B| is fixed,
Hence, . This completes the proof. □
Proof of Corollary 1.
Let . The result follows directly from Theorem 1. Specifically, we bound the asymptotic covariance matrix of for any B of fixed size. Note that the asymptotic covariance matrix of can be bounded: . Moreover, for any can be written as
Using , the asymptotic variance of is upper bounded by a |B| × |B| matrix . Particularly, when B = {(i, j)}, this reduces to an upper bound on the asymptotic variance . This completes the proof. □
Proof of Theorem 2.
By Theorem 3 of Shen et al. (2013), , as n, p → ∞, by Assumption 1, where is the least square estimate over A. Hence, in what follows, we focus our attention to event .
Easily, after profiling out σ, we have . Then an application of Taylor’s expansion of log(1 − x) yields that
| (A.18) |
where δ = β − β0. Moreover, on the event ,
implying that and . Consequently, replacing , the right-hand of (A.18) reduces to
Similarly, replacing δ by , (A.18) becomes . Taking the difference leads to that , where R(ϵ) is
Note that is idempotent with the rank |B|. Moreover, . Thus, R(ϵ) is no greater than
on the event that . This, together with the facts that , implies that when |B| is fixed, and when |B| → ∞ and , because
provided that and |B| → ∞. This completes the proof. □
Footnotes
Supplementary materials for this article are available online. Please go to www.tandfonline.com/r/JASA.
Supplementary Materials
The technical details of the counter example in Section 2.2 and the proofs of Lemma 2–9 are provided.
References
- Alizadeh F, Haeberly JA, and Overton ML (1998), “Primal-Dual Interior-Point Methods for Semidefinite Programming: Convergence Rates, Stability and Numerical Results,” SIAM Journal on Optimization, 8, 746–768. [220] [Google Scholar]
- Alzheimer’s Association (2016). “Changing the Trajectory of Alzheimer’s Disease: How a Treatment by 2025 Saves Lives and Dollars,” [225] [Google Scholar]
- Boyd S, Parikh N, Chu E, Peleato B, and Eckstein J (2011), “Distributed Optimization and Statistical Learning Via the Alternating Direction Method of Multipliers,” Foundations and Trends in Machine Learning, 3, 1–122. [218,221] [Google Scholar]
- Brown LD (1986), Fundamentals of Statistical Exponential Families With Applications in Statistical Decision Theory (Lecture Notes-Monograph Series), Durham, NC: Duke University Press, pp. 1–279. [228] [Google Scholar]
- Desikan RS, Ségonne F, Fischl B, Quinn BT, Dickerson BC, Blacker D, Buckner RL, Dale AM, Maguire RP, and Hyman BT (2006), “An Automated Labeling System for Subdividing the Human Cerebral Cortex on MRI Scans Into Gyral Based Regions of Interest,” Neuroimage, 31, 968–980. [225] [DOI] [PubMed] [Google Scholar]
- Fan J, Feng Y, and Wu Y (2009), “Network Exploration via the Adaptive LASSO and SCAD Penalties,” The Annals of Applied Statistics, 3, 521–541. [217] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, and Li R (2001), “Variable Selection via Nonconcave Penalized Likelihood and Its Oracle Properties,” Journal of the American Statistical Association, 96, 1348–1360. [217] [Google Scholar]
- Friedman J, Hastie T, and Tibshirani R (2008), “Sparse Inverse Covariance Estimation With the Graphical Lasso,” Biostatistics, 9, 432–441. [217] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greicius MD, Srivastava G, Reiss AL, and Menon V (2004), “Default-Mode Network Activity Distinguishes Alzheimer’s Disease From Healthy Aging: Evidence From Functional MRI,” Proceedings of the National Academy of Sciences of the United States of America, 101, 4637–4642. [225] [DOI] [PMC free article] [PubMed] [Google Scholar]
- He Y, Chen Z, and Evans A (2008), “Structural Insights Into Aberrant Topological Patterns of Large-Scale Cortical Networks in Alzheimer’s Disease,” The Journal of Neuroscience, 28, 4756–4766. [225,226] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Janková J, and Van de Geer S (2017), “Honest Confidence Regions and Optimality in High-Dimensional Precision Matrix Estimation,” TEST, 26, 143–162. [217,218,219,220,221,222,223,226] [Google Scholar]
- Javanmard A, and Montanari A (2014), “Confidence Intervals and Hypothesis Testing for High-Dimensional Regression,” Journal of Machine Learning Research, 15, 2869–2909. [217,218] [Google Scholar]
- Li B, Chun H, and Zhao H (2012), “Sparse Estimation of Conditional Graphical Models With Application to Gene Networks,” Journal of the American Statistical Association, 107, 152–167. [217] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin Z, Wang T, Yang C, and Zhao H (2017), “On Joint Estimation of Gaussian Graphical Models for Spatial and Temporal Data,” Biometrics, 73, 769–779. [217] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu J, and Ye J (2009), “Efficient Euclidean Projections in Linear Time,” in Proceedings of the 26th Annual International Conference on Machine Learning, pp. 657–664, ACM; [221] [Google Scholar]
- Meinshausen N, and Bühlmann P (2006), “High-Dimensional Graphs and Variable Selection With the Lasso,” The Annals of Statistics, 34, 1436–1462. [217] [Google Scholar]
- Montembeault M, Rouleau I, Provost JS, and Brambati SM (2015), “Altered Gray Matter Structural Covariance Networks in Early Stages of Alzheimer’s Disease,” Cerebral Cortex, 26, 2650–2662. [225,226] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Portnoy S (1988), “Asymptotic Behavior of Likelihood Methods for Exponential Families When the Number of Parameters Tends to Infinity,” The Annals of Statistics, 16, 356–366. [218,219] [Google Scholar]
- Rothman A, Bickel P, Levina E, and Zhu J (2008), “Sparse Permutation Invariant Covariance Estimation,” Electronic Journal of Statistics, 2, 494–515. [217] [Google Scholar]
- Shen X (1997), “On Methods of Sieves and Penalization,” The Annals of Statistics, 25, 2555–2591. [219] [Google Scholar]
- Shen X, Pan W, and Zhu Y (2012), “Likelihood-Based Selection and Sharp Parameter Estimation,” Journal of American Statistical Association, 107, 223–232. [217,218,219,221] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen X, Pan W, Zhu Y, and Zhou H(2013), “On Constrained and Regularized High-Dimensional Regression,” Annals of the Institute of Statistical Mathematics, 65, 807–832. [218,220,228] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tibshirani R (1996), “Regression Shrinkage and Selection Via the Lasso,” Journal of the Royal Statistical Society, Series B, 58, 267–288. [217] [Google Scholar]
- Van de Geer S, Bühlmann P, Ritov Y, and Dezeure R (2014), “On Asymptotically Optimal Confidence Regions and Tests for High-Dimensional Models,” The Annals of Statistics, 42, 1166–1202. [217,218,223] [Google Scholar]
- Yin J, and Li H (2013), “Adjusting for High-Dimensional Covariates in Sparse Precision Matrix Estimation by 1-Penalization,” Journal of Multivariate Analysis, 116, 365–381. [217] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuan M, and Lin Y (2007), “Model Selection and Estimation in the Gaussian Graphical Model,” Biometrika, 94, 19–35. [217] [Google Scholar]
- Zhang C (2010), “Nearly Unbiased Variable Selection Under Minimax Concave Penalty,” The Annals of Statistics, 38, 894–942. [217] [Google Scholar]
- Zhang C, and Zhang S (2014), “Confidence Intervals for Low Dimensional Parameters in High Dimensional Linear Models,” Journal of the Royal Statistical Society, Series B, 76, 217–242. [217,218,223,225] [Google Scholar]
- Zhang X, and Cheng G (2017), “Simultaneous Inference for High-Dimensional Linear Models,” Journal of the American Statistical Association, 112, 757–768. [223,225] [Google Scholar]
- Zhu Y (2017), “An Augmented ADMM Algorithm With Application to the Generalized Lasso Problem,” Journal of Computational and Graphical Statistics, 26, 195–204. [221] [Google Scholar]
- Zhu Y, Shen X, and Pan W (2014), “Structural Pursuit Over Multiple Undirected Graphs,” Journal of the American Statistical Association, 109, 1683–1696. [217] [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.