

Abstract
Purpose
The population and spatial characteristics of COVID-19 infections are poorly understood, but there is increasing evidence that in addition to individual clinical factors, demographic, socioeconomic, and racial characteristics play an important role.
Methods
We analyzed positive COVID-19 testing results counts within New York City ZIP Code Tabulation Areas with Bayesian hierarchical Poisson spatial models using integrated nested Laplace approximations.
Results
Spatial clustering accounted for approximately 32% of the variation in the data. There was a nearly five-fold increase in the risk of a positive COVID-19 test (incidence density ratio = 4.8, 95% credible interval 2.4, 9.7) associated with the proportion of black/African American residents. Increases in the proportion of residents older than 65 years, housing density, and the proportion of residents with heart disease were each associated with an approximate doubling of risk. In a multivariable model including estimates for age, chronic obstructive pulmonary disease, heart disease, housing density, and black/African American race, the only variables that remained associated with positive COVID-19 testing with a probability greater than chance were the proportion of black/African American residents and proportion of older persons.
Conclusions
Areas with large proportions of black/African American residents are at markedly higher risk that is not fully explained by characteristics of the environment and pre-existing conditions in the population.
Keywords: COVID-19, Disparity, Spatial analysis
Introduction
The SARS-Cov-2 poses unprecedented clinical and public health challenges worldwide. Although much of the attention has been rightfully focused on the clinical aspects of the disease, epidemiological studies and prevention research are becoming of increasing importance, particularly as no effective therapeutic has yet been identified [1]. Epidemiological and population-based studies can contribute to the identification of patient risk factors for disease severity. Recent studies of observational registry data have found COVID-19 mortality to be independently associated with coronary artery disease (odds ratio [OR] for mortality = 2.7; 95% CI: 2.1, 3.5), chronic obstructive pulmonary disease (COPD) (OR = 3.0; 95% CI, 2.0 to 4.4), and age greater than 65 years (OR = 1.9; 95% CI, 1.6 to 2.4) [2]. In one case series, 68% of laboratory-confirmed COVID-19 ICU patients had at least one comorbidity, of which hypertension was most common [3].
Not all risks, however, are physiologic. As the COVID-19 pandemic continues to ravage communities across the United States and the world, attention is increasingly turning to population-level demographic, socioeconomic, racial, and environmental risk factors for COVID-19. Blacks/African Americans have been reported to contract and die from COVID-19 at higher rates than others [4]. In Chicago, a large number of COVID-19 deaths are concentrated in five largely black neighborhoods [5]. A similar mortality concentration among black/African American persons has been reported in New Orleans [6]. At the built-environmental level, drivers of disease include population density [7] and housing density, with urban counties in the United States having the highest COVID-19 death rates [8].
Few regions of the United States have been more grievously affected than the five boroughs of New York City. A neighborhood-level analysis of New York City found higher rates of COVID-19 disease in areas with higher population shares of black/African American and Hispanic persons, and in areas with higher population density [9]. Although it certainly is possible that those affected have higher rates of underlying health conditions that may increase their susceptibility to the virus, the authors speculate that “residents of these neighborhoods are less likely to be able to work from home, disproportionately rely on public transit during the crisis, are less likely to have internet access,” and “have higher rates of overcrowding at the household level.”
In this study, we analyze positive COVID-19 testing result counts within New York City ZIP Code Tabulation Areas (ZCTAs) using Bayesian hierarchical Poisson spatial models with integrated nested Laplace approximations. We attempt to quantify the amount of spatial clustering in New York City neighborhoods, and the association of positive test counts in a neighborhood with population-level estimates of demographic, socioeconomic, health, and built environmental variables. The results quantify and provide insights into the complex interplay of individual and ecologic risks for COVID-19 spread and may be helpful in the effective allocation of testing resources and interventions in similar urban settings.
Methods
Data
COVID-19 test result data were obtained from the New York City Department of Health and Mental Hygiene (NYC DOHMH) GitHub Page. Variables consisted of ZCTA designation, total number of positive tests, and total number of tests performed. Files are updated approximately every 2 days. The data in these analyses were current as of 22 April 2020.
ZCTA-level data for total population, proportion of persons older than 65 years, number of persons self-identifying as black/African American, Asian, or Hispanic, number of persons older than 5 years, speaking a language other than English, population density, housing density, school density (number of people, housing structures, and schools per square mile, respectively), proportion of persons receiving public assistance, were obtained from or derived from the U.S. Census [10].
We created a social fragmentation index based on the work of Congdon [11] which combines four variables extracted from U.S. Census variables: the proportion of total housing units in a ZCTA that are not owner occupied, the proportion of vacant housing units, the proportion of individuals living alone, and the proportion of units into which someone recently moved. Based on Census definitions, a “recent” move is defined as anytime in the previous 9 years (since the last decennial census). Variables are standardized and added with equal weight. The resulting variable is normally distributed with mean zero and 95% quantiles −2.5 and 2.2.
Data on ZCTA health metrics were derived from shapefiles downloaded from the Simply Analytics company [12] and consisted of the number of persons in a ZCTA with heart disease or congestive heart failure (which are combined as a metric) and the number of persons with COPD. The estimates are based on SimmonsLOCAL data, which are local approximations of national survey results of individual responses to questions regarding recent health events. A full description of the methodology has previously been described [13].
Spatial shapefiles of New York City ZCTAs were downloaded and derived from the New York City Department of City Planning [14]. The testing and covariate data were merged to the spatial shapefile data and restricted to ZCTAs with valid data entries. An adjacency matrix was created from the map file using the R tool spdep::poly2nb() and manually edited to create adjacencies between New York City boroughs using spdep::edit.nb().
Statistical analysis
After merging the testing to the covariate data, descriptive statistics consisted of counts, means and medians, and maps of the number of positive COVID-19 tests per 10,000 total population and 10,000 tests performed in a ZCTA.
Counts of positive COVID-19 test results in New York City ZCTAs were spatially modeled in accordance with Besag-York-Mollie as described by Lawson [[15], [16], [17]].
where,
-
1.
the y i counts in area i are independently identically Poisson distributed and have an expectation in area i of e i, the expected count, times θ i, the risk for area i.
-
2.
a logarithmic transformation (log (λ i)) allows a linear, additive model of regression terms (βx i), along with
-
3.
a spatially random effects component (υ i) that is i.i.d normally distributed with mean zero (~nl (0, τ η)), and
-
4.
a conditional autoregressive spatially structured component in which a “neighborhood” consisting of spatially adjacent shapes is characterized by the normally distributed mean of the spatially structured random effect terms for the spatial shapes that make up the neighborhood , and the standard deviation of that mean divided by the number of spatial shapes in the neighborhood (τ η/n δ). This spatially structured conditional autoregression component is also sometimes described as a Gaussian process where W represents the matrix of neighbors that defines the neighborhood structure, and the conditional distribution of each λ i , given all the other λ i is normal with μ = the average λ of it,s neighbors and a precision (τ λ).
A baseline convolution model that consisted solely of an intercept term with unstructured and spatially structured random effect terms was extended to include univariate association of explanatory variables with the number of positive COVID-19 tests in a ZCTA. Important and likely associations were chosen for inclusion in a multivariable model with the primary exposure variable being the proportion of black/African American residents in an area and additional explanatory variables included as potential confounders.
The final linear model consisted of an intercept (β 0); a vector of scaled ZCTA-level explanatory variables for the proportion of persons in a ZCTA identifying as black/African American, with COPD, heart disease, older than 65 years, a measure of housing density, a spatially unstructured random effect term (υ i), and a spatially structured conditional autoregression term (η i). An offset variable for the total number of tests was included in all models. Model selection was based on deviance information criteria and number of effective parameters.
The spatially unstructured random effect term captures normally distributed or Gaussian random variation around the mean or intercept. The spatially structured conditional autoregression term accounts for local geographic influence. The intercept is interpreted as the average citywide risk on the log scale adjusted for the covariates, random effects and spatial terms. The exponentiated coefficients for the explanatory covariates are interpreted as incidence density ratios. Coefficient results are presented with 95% Bayesian credible intervals (95% Cr I).
Spatial risk, controlling for or holding the covariates constant, was calculated as ζ i = υ i + η i [18], and is interpreted as the residual spatial risk for each area (compared with all of New York City) after covariates and spatial clustering are taken into account. Finally, the proportion of spatially explained variance was calculated as the proportion of total spatial heterogeneity accounted for by the spatially structured conditional autoregression variance.
Spatial modeling was conducted using integrated nested Laplace approximations (INLA) with the R INLA package [19] using approaches described by Blangiardo et al. [18] Code to reproduce the analyses is available at: http://www.injuryepi.org/resources/Misc/covidINLA_onlineCode.html.
The study protocol was exempted as not human research by the New York University School of Medicine Institutional Review Board.
Results
Descriptive statistics
There were 177 ZCTAs in the data set. The mean COVID-19 rate of positive tests per 10,000 ZCTA population was 166.2 (95% CI: 156.7, 175.7). The mean COVID-19 rate of positive tests per 10,000 tests was 5176.0 (95% CI 5045.9, 5306.1) and appeared skewed and peaked, indicating that a relatively small number of ZCTAs accounted for the highest rates (Fig. 1 ). The 5 ZCTAs with the highest positive COVID-19 test numbers per 10,000 population were the same as those with the highest proportion per 10,000 tests (10464, 10470, 10455, 10473, 11234, and 11210). The 5 lowest ZCTAs were also the same for both measures (11103, 11102, 11693, 11369, 11363, and 10308). Table 1 presents comparative statistics for the ZCTAs with the highest and lowest quantiles for population-based rates of positive tests. Figure 2 presents a choropleth of positive COVID-19 tests per 10,000 per 10,000 positive tests.
Fig. 1.
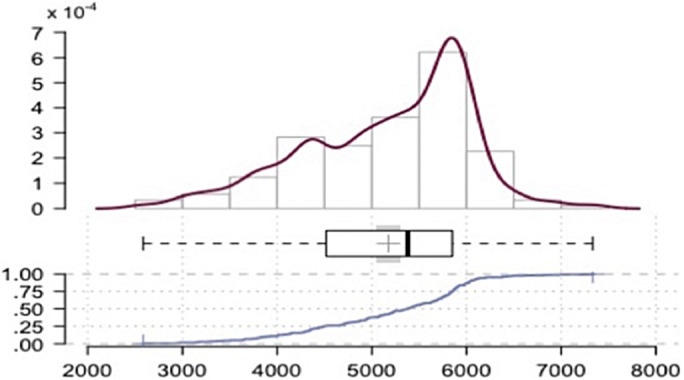
Rate of positive COVID-19 tests per 10,000 tests. New York City, April 3–22, 2020.
Table 1.
Comparative descriptive statistics high versus low quantile COVID-19 ZIP Code Tabulation Areas (New York City, April 3–22, 2020)
| Variable | All (SE) | High (SE) | Low (SE) | P-value difference |
|---|---|---|---|---|
| Median household income | 57,758.7 (24,986.7) | 55,314.5 (19,700.6) | 82,917 (27,557.0) | .001 |
| School density | 5.1 (4.6) | 2.7 (2.0) | 7.289 (5.4) | .001 |
| Population density | 16,584.9 (11,770.9) | 9486.7 (7238.2) | 26,000.1 (13,418.6) | .001 |
| Housing density | 18,165.2 (19,748.0) | 8784.8 (6788.2) | 37,361.7 (33,665.0) | .001 |
| Congdon index | −0.089 (2.0) | −1.1 (2.0) | 1.603 (2.0) | .001 |
| Proportion black | 0.23 (0.26) | 0.36 (0.31) | 0.070 (0.13) | .001 |
| Proportion hispanic | 0.12 (0.05) | 0.13 (0.05) | 0.12 (0.05) | .06 |
| Heart disease | 0.11 (0.21) | 0.17 (0.27) | 0.07 (0.16) | .1 |
| Chronic obstructive Pulmonary disease | 2.01 (1.93) | 2.23 (2.48) | 1.55 (1.42) | .2 |
Fig. 2.

Choropleth quintiles number of positive COVID-19 tests per 10,000 tests. New York City, April 3–22, 2020.
Spatial models
A frailty model consisting of only a random effect term and no explicit spatial component returned a deviance information criterion of 1831.58, with 174.5 effective parameters. The random effect term was normally distributed around the mean value of 64.9 (SD = 1.1; 95% Cr I: 55.5, 75.6) reflecting the random nature of the distribution of the unstructured heterogeneity or variance.
A convolution model with a spatially structured conditional autoregression term added to the spatially unstructured heterogeneity random effect term of the frailty model, returned a deviance information criterion of 1807.60 (with 175.98 effective parameters) reflecting an improvement over the baseline unstructured heterogeneity frailty model, and indicating the spatial component added information to the simple unstructured model. In Figure 3 , the spatial risk estimate is calculated as the sum of the unstructured and spatially structured variance components (ζ = υ + ν). Finally, we estimate the proportion of the variance explained by geographic variation or place, which for this model is approximately 32%.
Fig. 3.

Choropleth quantiles spatial risk estimates (sum of unstructured and spatially structured variance) positive COVID-19 tests per 10,000 tests. New York City, April 3–22, 2020.
Simple and multivariable models
The convolution model is extended to include a series of simple, single-variable, ecological-level models examining the unadjusted bivariate association of population, housing, income, social fragmentation, population characteristics, and clinical conditions with positive COVID-19 test counts. Table 2 summarizes the results of this series of unadjusted single covariate models of associations with positive COVID-19 test counts. The single strongest unadjusted bivariate association is for the proportion of persons in a ZCTA with COPD, which returned an incidence density ratio (IDR) of 8.2 (95% Cr I: 3.7, 18.3), indicating that for each single unit increase in the standardized proportion of persons in a ZCTA with COPD, there was an eight-fold increased risk of an additional positive COVID-19 test in that ZCTA. The proportion of black/African American residents in a ZCTA was also strongly associated with the risk of positive COVID-19 tests. For every one unit increase in a scaled standardized measure of the proportion of black/African American residents, there was a nearly five-fold increase in the risk of a positive COVID-19 test (IDR = 4.8; 95% Cr I: 2.4, 9.7).
Table 2.
Summary series of unadjusted single covariate Bayesian hierarchical Poisson models for association with positive COVID-19 tests counts in New York city ZIP Code Tabulation Areas, April 3–22, 2020
| Model | IDR∗ | 2.5% | 97.5% |
|---|---|---|---|
| Population density | 1.5 | 1.1 | 2.2 |
| Median household income | 0.5 | 0.4 | 0.7 |
| School density | 0.8 | 0.6 | 1.2 |
| Older than 65 years | 1.9 | 1.6 | 2.4 |
| Asian | 0.4 | 0.2 | 0.8 |
| Housing density | 2.0 | 1.2 | 3.2 |
| Congdon index | 0.8 | 0.8 | 0.9 |
| Language | 1.3 | 0.9 | 1.8 |
| Black/African American | 4.8 | 2.4 | 9.7 |
| Hispanic | 1.2 | 0.9 | 1.6 |
| Heart disease | 2.1 | 1.5 | 2.9 |
| COPD† | 8.2 | 3.7 | 18.3 |
Incidence Density Ratio for bivariate association of explanatory covariates with Positive Test Counts in ZIP Code Tabulation Area.
Chronic obstructive pulmonary disease.
Variables for population density, proportion of residents older than 65 years, housing density, and heart disease were also associated with increased risk of positive COVID-19 testing rates. Median household income in a ZCTA community was inversely related to positive COVID-19 tests. For each unit increase in a standardized measure of median household income in a ZCTA, there is an approximately 46% decrease in the number of positive COVID-19 tests (IDR = 0.54; 95% Cr I: 0.43, 0.69). Other variables that were associated with lower positive tests were proportion of Asian and proportion of Hispanic residents and increased measures of social fragmentation. School density, proportion of persons not speaking English, and the proportion of persons on public assistance were not associated with positive COVID-19 testing rates.
Single-variable models were followed by multivariable models. In a multivariable model including COPD, heart disease, proportion of black/African American residents, housing density, and age greater than 65 years, the only 2 variables that remained associated with positive COVID-19 testing with a probability greater than chance were the proportion of black/African American residents and older persons (Table 3). Proportion of black/African American residents was the strongest predictor of higher positive testing rates in a community regardless of other factors.
Table 3.
Summary multivariable Bayesian hierarchical Poisson modes for association with positive COVID-19 tests counts in New York City ZIP Code Tabulation Areas, April 3–22, 2020
| Variable | IDR∗ | 2.5% | 97.5% |
|---|---|---|---|
| Intercept | 353.82 | 197.66 | 632.23 |
| COPD† | 2.32 | 0.92 | 5.85 |
| Heart disease | 1.27 | 0.88 | 1.83 |
| Black/African American | 2.29 | 1.13 | 4.68 |
| Older than 65 years | 1.50 | 1.17 | 1.92 |
| Housing density | 1.08 | 0.65 | 1.78 |
Incidence density ratio for bivariate association of explanatory covariates with positive test counts in ZIP Code Tabulation Area.
Chronic obstructive pulmonary disease.
Discussion
Despite the recent onset of the current COVID-19 pandemic, there is already growing evidence about both individual risk factors and population-level drivers of disease and mortality. Our results are consistent with recent reports of a correlation between the percentage of black/African Americans living in a U.S. county and the percentage of confirmed COVID-19 cases and deaths [20], a nearly 3X greater risk of hospitalization for COVID-19 for black/African Americans in northern California [21], and that counties with higher proportions of black residents had an appreciably greater risk of COVID-19 diagnoses (RR = 1.24, CI 1.17–1.33) [22]. This study adds to a number of very recent similar spatial analyses of ZCTA-level testing data released by the New York City Department of Health and Mental Hygeiene [[23], [24], [25]] and illustrates the importance of sharing these kinds of data, as well as the informative nature of spatial epidemiology as the pandemic evolves across the nation and the world. Consistent with prior reports, we find that the clustering of positive COVID-19 testing results in New York City are unlikely to be due to chance [9,24] and is driven in large measure by socioeconomics, age distribution [25], and race [9,24].
Our study adds to this by demonstrating that the proportion of residents self-identifying as black/African American is among the single strongest unadjusted bivariate predictors of the proportion of positive tests in a community. The only stronger such predictor is the proportion of residents with COPD, which at 8 times the risk of areas with less COPD is stunning. But perhaps the more unexpected finding is that when black/African American race and COPD are considered jointly, it is race that appears to be the stronger predictor. Unlike a previous New York City–based report [9], we did not find an independent risk associated with the proportion of Hispanic residents. It may be that census estimates of black/African American persons includes persons who also identify as Hispanic. Three of the 5 ZCTAs with highest positive COVID-19 test numbers per 10,000 population were in areas of the Bronx with large proportions of Hispanic and Latino residents. And, it may be that disparities may vary depending in part on how well-established Hispanic communities are within cities and states [26].
The question of why COVID-19 affects one community more severely than another may provide clues to crucial questions about who is a risk and why [27]. Our study indicates place is important. We find about a third of the variance in a simple spatial model can be accounted for by place. We found risk to be approximately doubled by environmental characteristics such as population and housing density. This complements a report of a nonspatial, linear multivariable regression model of similar data that reported that 72% of variance could be attributed to individual characteristics such as household size, gender, age, race, and immigration status [23].
If ecologic and spatial analyses can provide clues, those clues cannot on the basis of these analyses necessarily point to individual-level or biological risk factors. While there are preliminary reports that infection with SARS-Cov-2 may be associated with the type A blood group [28], and that severe COVID-19 is driven in part by coagulopathies that may be associated with Factor VIII and von Willebrand factor [29], the relationship of such factors with race is [30] complex and cannot be supported by these results. These results must be interpreted in the context of place. Predominantly nonwhite neighborhoods are likely to be poorer, with less access to routine health services which can lead to greater risks of many disease outcomes. Largely nonwhite neighborhoods may also have a larger proportion of persons at increased risk of exposure. Black/African Americans make up a large proportion of persons providing direct services to COVID-19 patients in New York City. By one account, 80% of nonmedical staff in New York City's hard-hit public hospitals are black/African American or Hispanic. It would be consistent with our findings that the neighborhoods in which these persons live have higher rates of disease, and may point toward an increased emphasis on personal protective equipment for essential workers [31].
Interestingly, the proportion of comorbidities in a community, which are associated with disease severity, were associated with disease acquisition in simple bivariate models. However, they generally fell out of significance when race was added to the model. The odds ratio for the association of the rate of positive tests with an important risk like COPD dropped from eight to nonsignificance when race was included in the model, indicating that race may be more strongly associated with positive tests. Placing risk factors in context, both within and across populations, may be key. New York City and Chicago appear to differ in the factors associated with disease clusters and hot spots. New York City hot spots may be associated with service workers. Chicago hot spots are in neighborhoods with high poverty rates [24]. It will be increasingly important to conduct comparative studies.
Ecological studies can offer a view of disease processes in a community, but it may be a fractured view. Measures such as school density and social fragmentation may not be measuring what we think they are measuring; the number of schools in an area, rather than acting as a disease multiplier, may be a measure of the strength of the tax base. Similarly, the Congdon index treats empty houses as a measure of disorder which can be correlated with a number of social ills. But, empty houses may indicate less dense neighborhoods which may be inversely correlated with less person-to-person disease spread. The proportion of non-English speakers in a given ZCTA may be biased by a lack of self-reporting by undocumented immigrants. And, as in any ecologic study, it is not certain that the persons with the risk factor being studied are those who are developing the outcome.
SARS-Cov-2 testing results are imperfect, with numbers likely to be biased by the availability of testing. But, we would expect that bias, to be in the direction of increased counts in areas with higher socioeconomic status. Consistent with our findings, a recent geographic analysis reported that persons in poorer New York City neighborhoods were less likely to be tested but once tested, were more likely to test positive [22]. It is partly for this reason, we chose to base most of our analyses on the proportion of positive tests, rather than the population-based rates of positive tests, an approach taken by others [22].
Despite these caveats, it is difficult to overlook the interplay of race and COVID-19. Race appears to be an indicator of risk independent of social status, income, built environment, or even underlying health. This finding has implications not only for justice and equity, but for an effective response to the pandemic.
Footnotes
Charles DiMaggio: Conceptualization, Methodology, Data curation; Michael Klein: Writing - reviewing & editing, Conceptualization; Cherisse Berry: Conceptualization, Reviewing and Editing; Spiros Frangos: Conceptualization, Reviewing and Editing.
References
- 1.Information for Clinicians on Investigational Therapeutics for Patients with COVID-19. Centers for Disease Control and Prevention: Coronavirus Disease 2019 (COVID-19) 2020. https://www.cdc.gov/coronavirus/2019-ncov/hcp/therapeutic-options.html
- 2.Mehra M.R., Desai S.S., Kuy S., Henry T.D., Patel A.N. Cardiovascular disease, drug therapy, and mortality in covid-19. N Engl J Med. 2020;382:e102. doi: 10.1056/NEJMoa2007621. [DOI] [PMC free article] [PubMed] [Google Scholar] [Retracted]
- 3.Grasselli G., Zangrillo A., Zanella A., Antonelli M., Cabrini L., Castelli A. Baseline characteristics and outcomes of 1591 patients infected with SARS-Cov-2 admitted to ICUs of the Lombardy region, Italy. JAMA. 2020;323:1574–1581. doi: 10.1001/jama.2020.5394. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Yancy C.W. COVID-19 and African Americans. JAMA. 2020;323:1891–1892. doi: 10.1001/jama.2020.6548. [DOI] [PubMed] [Google Scholar]
- 5.Reyes C., Gutowski C., Husain N. Chicago's coronavirus disparity: Black Chicagoans are dying at nearly six times the rate of white residents, data show. Chicago Tribune. 2020. https://www.chicagotribune.com/coronavirus/ct-coronavirus-chicago-coronavirus-deaths-demographics-lightfoot-20200406-77nlylhiavgjzb2wa4ckivh7mu-story.html
- 6.M D. Louisiana data: Virus hits Blacks, people with hypertension. US News World Report. 2020. https://www.usnews.com/news/best-states/louisiana/articles/2020-04-07/louisiana-data-virus-hits-blacks-people-with-hypertension
- 7.CDC COVID-19 Response Team Geographic differences in covid-19 cases, deaths, and incidence - united states, February 12 - April 7, 2020. MMWR Morb Mortal Wkly Rep. 2020;69(15):465–471. doi: 10.15585/mmwr.mm6915e4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.R F. The geography of coronavirus. Bloomberg CityLab. 2020. https://www.citylab.com/equity/2020/04/coronavirus-spread-map-city-urban-density-suburbs-rural-data/609394/
- 9.COVID-19 cases in New York City, a neighborhood-level analysis. The Stoop: NYU Furman Center Blog. 2020. https://furmancenter.org/thestoop/entry/covid-19-cases-in-new-york-city-a-neighborhood-level-analysis
- 10.US Census Bureau. Washington, DC. 2010. https://data.census.gov/cedsci/
- 11.Congdon P. Bayesian models for suicide monitoring. Eur J Popul. 2001;15(3):1–34. [Google Scholar]
- 12.SimplyAnalytics. https://simplyanalytics.com/
- 13.Experian Marketing Services SimmonsLOCAL Methodology Overview. 2013. https://business.library.emory.edu/documents/databases/simplymap-3.0-simmons-local-methodology.pdf
- 14.New York City Department of City Planning Bytes of the Big Apple. 2011. https://www1.nyc.gov/site/planning/data-maps/open-data.page#:∼:text=BYTES%20of%20the%20BIG%20APPLE,be%20downloaded%20here%20for%20free
- 15.Besag J., York J., Mollie A. Bayesian image restoration, with two applications in spatial statistics. Ann Inst Stat Math. 1991;43(1):1–59. [Google Scholar]
- 16.Lawson A., Biggeri A., Boehning D., Lesaffre E., Viel J.F., Clark A. Disease mapping models: An empirical evaluation. Disease mapping collaborative group. Stat Med. 2000;19(17-18):2217–2241. doi: 10.1002/1097-0258(20000915/30)19:17/18<2217::aid-sim565>3.0.co;2-e. [DOI] [PubMed] [Google Scholar]
- 17.Lawson A.B. Second ed. (Chapman & Hall/CRC Interdisciplinary Statistics). Chapman; Hall/CRC; 2013. Bayesian Disease Mapping: Hierarchical Modeling in Spatial Epidemiology; p. 396. [Google Scholar]
- 18.Blangiardo M., Cameletti M., Baio G., Rue H. Spatial and spatio-temporal models with r-INLA. Spat Spatiotemporal Epidemiol. 2013;7:39–55. doi: 10.1016/j.sste.2013.07.003. [DOI] [PubMed] [Google Scholar]
- 19.Rue H., Martino S., Lindgren F., Simpson D., Riebler A. INLA: Functions which allow to perform full Bayesian analysis of latent Gaussian models using integrated nested Laplace approximation. 2013. https://rdrr.io/github/andrewzm/INLA/man/INLA-package.html
- 20.Mahajan U.V., Larkins-Pettigrew M. Racial demographics and COVID-19 confirmed cases and deaths: a correlational analysis of 2886 US counties. J Public Health (Oxf) 2020;42:445–447. doi: 10.1093/pubmed/fdaa070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Azar K.M.J., Shen Z., Romanelli R.J., Lockhart S.H., Smits K., Robinson S. Disparities in outcomes among COVID-19 patients in a large health care system in California. Health Aff (Millwood) 2020;39(7):1253–1262. doi: 10.1377/hlthaff.2020.00598. [DOI] [PubMed] [Google Scholar]
- 22.Millett G.A., Jones A.T., Benkeser D. Assessing Differential Impacts of COVID-19 on Black Communities. Ann Epidemiol. 2020;47:37–44. doi: 10.1016/j.annepidem.2020.05.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Borjas G.J. Demographic Determinants of Testing Incidence and Covid-19 Infections in New York City Neighborhoods. National Bureau of Economic Research. 2020. https://www.hks.harvard.edu/publications/demographic-determinants-testing-incidence-and-covid-19-infections-new-york-city
- 24.Maroko A.R., Nash D., Pavilonis B. Covid-19 and inequity: a comparative spatial analysis of New York City and Chicago hot spots. medRxiv. 2020. https://www.medrxiv.org/content/10.1101/2020.04.21.20074468v1 [DOI] [PMC free article] [PubMed]
- 25.Whittle R.S., Diaz-Artiles A. An ecological study of socioeconomic predictors in detection of covid-19 cases across neighborhoods in New York City. medRxiv. 2020. https://www.medrxiv.org/content/10.1101/2020.04.17.20069823v1 [DOI] [PMC free article] [PubMed]
- 26.Jordon M., Oppel R.A. For Latinos and COVID-19, Doctors are Seeing an “Alarming” Disparity. New York Times. 2020. https://www.nytimes.com/2020/05/07/us/coronavirus-latinos-disparity.html?referringSource=articleShare
- 27.Beech H., Rubin A.J., Kurmanaev A., Maclean R. The covid-19 riddle: Why does the virus wallop some places and spare others? New York Times. 2020. https://www.nytimes.com/2020/05/03/world/asia/coronavirus-spread-where-why.html
- 28.Zhao J., Yang Y., Huang H.-P., Li D., Gu D.F., Lu X.F. Relationship between the ABO blood group and the covid-19 susceptibility. medRxiv. 2020. https://www.medrxiv.org/content/10.1101/2020.03.11.20031096v2
- 29.Panigada M., Bottino N., Tagliabue P., Grasselli G., Novembrino C., Chantarangkul V. Hypercoagulability of covid-19 patients in intensive care unit. A report of thromboelastography findings and other parameters of hemostasis. J Thromb Haemost. 2020;18:1738–1742. doi: 10.1111/jth.14850. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Miller C.H., Dilley A., Richardson L., Hooper W.C., Evatt B.L. Population differences in von willebrand factor levels affect the diagnosis of von willebrand disease in african-american women. Am J Hematol. 2001;67(2):125–129. doi: 10.1002/ajh.1090. [DOI] [PubMed] [Google Scholar]
- 31.Hong N. 3 hospital workers gave out masks. Weeks later, they all were dead. New York Times. 2020. https://www.nytimes.com/2020/05/04/nyregion/coronavirus-ny-hospital-workers.html