

Abstract
Topological data analysis and its main method, persistent homology, provide a toolkit for computing topological information of high-dimensional and noisy data sets. Kernels for one-parameter persistent homology have been established to connect persistent homology with machine learning techniques with applicability on shape analysis, recognition and classification. We contribute a kernel construction for multi-parameter persistence by integrating a one-parameter kernel weighted along straight lines. We prove that our kernel is stable and efficiently computable, which establishes a theoretical connection between topological data analysis and machine learning for multivariate data analysis.
Keywords: Topological Data Analysis, Machine Learning, Persistent Homology, Multivariate Analysis
1. Introduction
Topological data analysis (TDA) is an active area in data science with a growing interest and notable successes in a number of applications in science and engineering [1, 2, 3,4, 5, 6, 7, 8]. TDA extracts in-depth geometric information in amorphous solids [5], determines robust topological properties of evolution from genomic data sets [2] and identifies distinct diabetes subgroups [6] and a new subtype of breast cancer [9] in high-dimensional clinical data sets, to name a few. In the context of shape analysis, TDA techniques have been used in the recognition, classification [10, 11], summarization [12], and clustering [13] of 2D/3D shapes and surfaces. Oftentimes, such techniques capture and highlight structures in data that conventional techniques fail to treat [11, 13] or reveal properly [5].
TDA employs the mathematical notion of simplicial complexes [14] to encode higher order interactions in the system, and at its core uses the computational framework of persistent homology [15, 16, 17, 18, 19] to extract multi-scale topological features of the data. In particular, TDA extracts a rich set of topological features from high-dimensional and noisy data sets that complement geometric and statistical features, which offers a different perspective for machine learning. The question is, how can we establish and enrich the theoretical connections between TDA and machine learning?
Informally, homology was developed to classify topological spaces by examining their topological features such as connected components, tunnels, voids and holes of higher dimensions; persistent homology studies homology of a data set at multiple scales. Such information is summarized by the persistence diagram, a finite multi-set of points in the plane. A persistence diagram yields a complete description of the topological properties of a data set, making it an attractive tool to define features of data that take topology into consideration. Furthermore, a celebrated theorem of persistent homology is the stability of persistence diagrams [20] – small changes in the data lead to small changes of the corresponding diagrams, making it suitable for robust data analysis.
However, interfacing persistence diagrams directly with machine learning poses technical difficulties, because persistence diagrams contain point sets in the plane that do not have the structure of an inner product, which allows length and angle to be measured. In other words, such diagrams lack a Hilbert space structure for kernel-based learning methods such as kernel SVMs or PCAs [21]. Recent work proposes several variants of feature maps [22, 21, 23] that transform persistence diagrams into L2-functions over . This idea immediately enables the application of topological features for kernel-based machine learning methods as establishing a kernel function implicitly defines a Hilbert space structure [21].
A serious limit of standard persistent homology and its initial interfacing with machine learning [22, 21, 23, 24, 25] is the restriction to only a single scale parameter, thereby confining its applicability to the univariate setting. However, in many real-world applications, such as data acquisition and geometric modeling, we often encounter richer information described by multivariate data sets [26, 27, 28]. Consider, for example, climate simulations where multiple physical parameters such as temperature and pressure are computed simultaneously; and we are interested in understanding the interplay between these parameters. Consider another example in multivariate shape analysis, various families of functions carry information about the geometry of 3D shape objects, such as mesh density, eccentricity [29] or Heat Kernel Signature [30]; and we are interested in creating multivariate signatures of shapes from such functions. Unlike the univariate setting, very few topological tools exist for the study of multivariate data [31, 32, 29], let alone the integration of multivariate topological features with machine learning.
The active area of multi-parameter persistent homology [26] studies the extension of persistence to two or more (independent) scale parameters. A complete discrete invariant such as the persistence diagram does not exist for more than one parameter [26]. To gain partial information, it is common to study slices, that is, one-dimensional affine subspaces where all parameters are connected by a linear equation. In this paper, we establish, for the first time, a theoretical connection between topological features and machine learning algorithms via the kernel approach for multi-parameter persistent homology. Such a theoretical underpinning is necessary for applications in multivariate data analysis.
Our contribution.
We propose the first kernel construction for multi-parameter persistent homology. Our kernel is generic, stable and can be approximated in polynomial time. For simplicity, we formulate all our results for the case of two parameters, although they extend to more than two parameters.
Our input is a data set that is filtered according to two scale parameters and has a finite description size; we call this a bi-filtration and postpone its formal definition to Section 2. Our main contribution is the definition of a feature map that assigns to a bi-filtration a function , where Δ(2) is a subset of . Moreover, is integrable over Δ(2), effectively including the space of bi-filtrations into the Hilbert space L2(Δ(2)). Therefore, based on the standard scalar product in L2(Δ(2)) a 2-parameter kernel is defined such that for two given bi-filtrations and we have
| (1) |
We construct our feature map by interpreting a point of Δ(2) as a pair of (distinct) points in that define a unique slice. Along this slice, the data simplifies to a mono-filtration (i.e., a filtration that depends on a single scale parameter), and we can choose among a large class of feature maps and kernel constructions of standard, one-parameter persistence. To make the feature map well-defined, we restrict our attention to a finite rectangle R.
Our inclusion into a Hilbert space induces a distance between bi-filtrations as
| (2) |
We prove a stability bound, relating this distance measure to the matching distance and the interleaving distance (see the paragraph on related work below). We also show that this stability bound is tight up to constant factors (see Section 4).
Finally, we prove that our kernel construction admits an efficient approximation scheme. Fixing an absolute error bound ϵ, we give a polynomial time algorithm in 1/ϵ and the size of the bi-filtrations and to compute a value r such that . On a high level, the algorithm subdivides the domain into boxes of smaller and smaller width and evaluates the integral of (1) by lower and upper sums within each subdomain, terminating the process when the desired accuracy has been achieved. The technical difficulty lies in the accurate and certifiable approximation of the variation of the feature map when moving the argument within a subdomain.
Related work.
Our approach heavily relies on the construction of stable and efficiently computable feature maps for mono-filtrations. This line of research was started by Reininghaus et al. [21], whose approach we discuss in some detail in Section 2. Alternative kernel constructions appeared in [24, 33]. Kernel constructions fit into the general framework of including the space of persistence diagrams in a larger space with more favorable properties. Other examples of this idea are persistent landscapes [22] and persistent images [34], which can be interpreted as kernel constructions as well. Kernels and related variants defined on mono-filtrations have been used to discriminate and classify shapes and surfaces [21, 25]. An alternative approach comes from the definition of suitable (polynomial) functions on persistence diagrams to arrive at a fixed-dimensional vector in on which machine learning tasks can be performed; see [35, 36, 37, 38].
As previously mentioned, a persistence diagram for multiparameter persistence does not exist [26]. However, bi-filtrations still admit meaningful distance measures, which lead to the notion of closeness of two bi-filtrations. The most prominent such distance is the interleaving distance [39], which, however, has recently been proved to be NP-complete to compute and approximate [40]. Computationally attractive alternatives are (multi-parameter) bottleneck distance [41] and the matching distance [42, 43], which compares the persistence diagrams along all slices (appropriately weighted) and picks the worst discrepancy as the distance of the bi-filtrations. This distance can be approximated up to a precision ϵ using an appropriate subsample of the lines [42], and also computed exactly in polynomial time [43]. Our approach extends these works in the sense that not just a distance, but an inner product on bi-filtrations, is defined with our inclusion into a Hilbert space. In a similar spirit, the software library RIVET [44] provides a visualization tool to explore bi-filtrations by scanning through the slices.
2. Preliminaries
We introduce the basic topological terminology needed in this work. We restrict ourselves to the case of simplicial complexes as input structures for a clearer geometric intuition of the concepts, but our results generalize to more abstract input types (such as minimal representations of persistence modules) without problems.
Mono-filtrations.
Given a vertex set V, an (abstract) simplex is a non-empty subset of V, and an (abstract) simplicial complex is a collection of such subsets that is closed under the operation of taking non-empty subsets. A subcomplex of a simplicial complex X is a simplicial complex Y with Y ⊆ X. Fixing a finite simplicial complex X, a mono-filtration of X is a map that assigns to each real number α, a subcomplex of X, with the property that whenever α ≤ β, . The size of is the number of simplices of X. Since X is finite, changes at only finitely many places when α grows continuously from −∞ to +∞; we call these values critical. More formally, α is critical if there exists no open neighborhood of α such that the mono-filtration assigns the identical subcomplex to each value in the neighborhood. For a simplex σ of X, we call the critical value of σ the infimum over all α for which . For simplicity, we assume that this infimum is a minimum, so every simplex has a unique critical value wherever it is included in the mono-filtration.
Bi-filtrations.
For points in , we write (a, b) ≤ (c, d) if a ≤ c and b ≤ d. Similarly, we say (a, b) < (c, d) if a < c and b < d. For a finite simplicial complex X, a bi-filtration of X is a map that assigns to each point a subcomplex of X, such that whenever p ≤ q, . Again, a point p = (p1, p2) is called critical for if, for any ϵ > 0, both and are not identical to . Note that unlike in the mono-filtration case, the set of critical points might not be finite. We call a bi-filtration tame if it has only finitely many such critical points. For a simplex σ, a point is critical for σ if, for any ϵ > 0, σ is neither in nor in , whereas σ is in both and . Again, for simplicity, we assume that in this case. A consequence of tameness is that each simplex has a finite number of critical points. Therefore, we can represent a tame bi-filtration of a finite simplicial complex X by specifying the set of critical points for each simplex in X. The sum of the number of critical points over all simplices of X is called the size of the bi-filtration. We henceforth assume that bi-filtrations are always represented in this form; in particular, we assume tameness throughout this paper.
A standard example to generate bi-filtrations is by an arbitrary function with the property that if τ ⊂ σ are two simplices of X, F(τ) ≤ F(σ). We define the sublevel set as
and let denote its corresponding sublevel set bi-filtration. It is easy to verify that yields a (tame) bi-filtration and F(σ) is the unique critical value of σ in the bi-filtration.
Slices of a bi-filtration.
A bi-filtration contains an infinite collection of mono-filtrations. Let be the set of all nonvertical lines in with positive slope. Fixing any line , we observe that when traversing this line in positive direction, the subcomplexes of the bi-filtration are nested in each other. Note that ℓ intersects the anti-diagonal x = −y in a unique base point b. Parameterizing ℓ as b + λ · a, where a is the (positive) unit direction vector of ℓ, we obtain the mono-filtration
We will refer to this mono-filtration as a slice of along ℓ (and sometimes also call ℓ itself the slice, abusing notation). The critical values of a slice can be inferred by the critical points of the bi-filtration in a computationally straightforward way. Instead of a formal description, we refer to Figure 1 for a graphical description. Also, if the bi-filtration is of size n, each of its slices is of size at most n.
Figure 1.
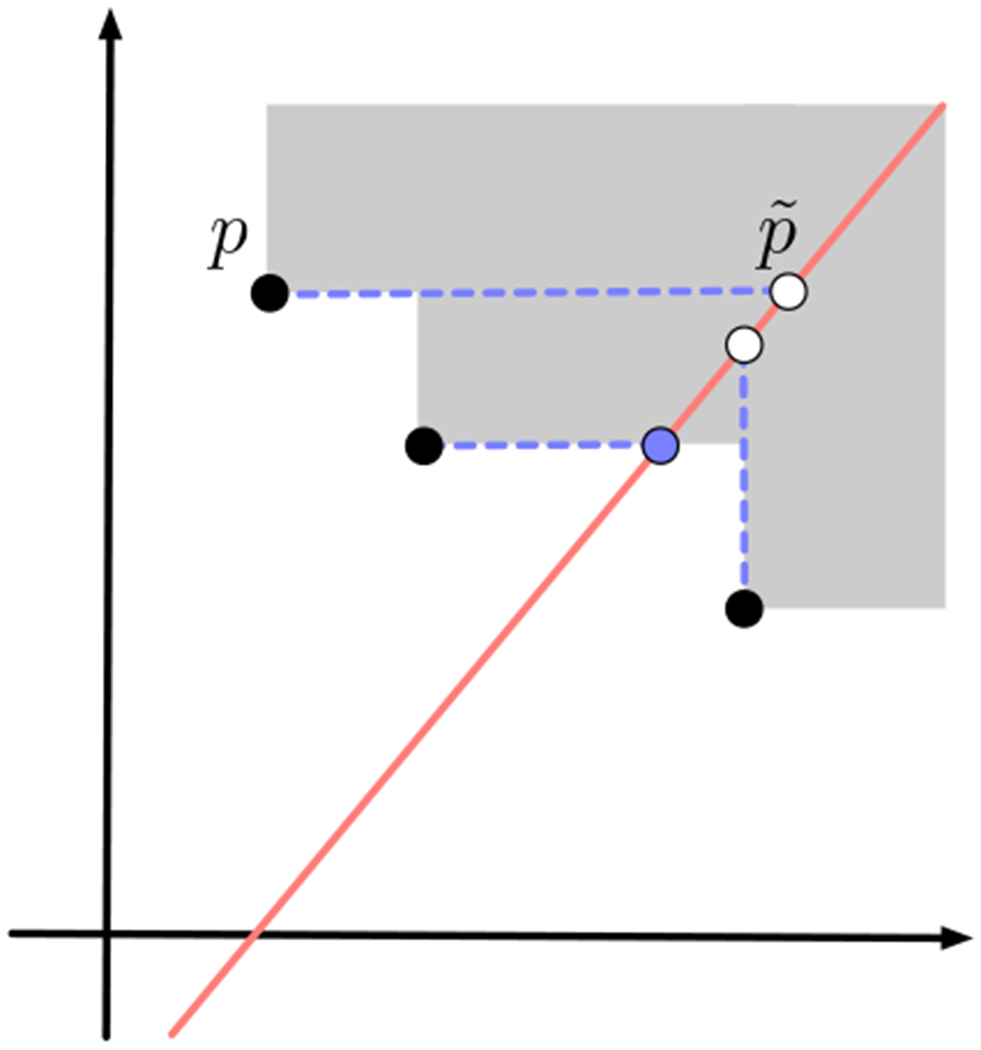
The three black points mark the three critical points of some simplex σ in X. The shaded area denotes the positions at which σ is present in the bi-filtration. Along the given slice (red line), the dashed lines denote the first position where the corresponding critical point “affects” the slice. This position is either the upper-vertical, or right-horizontal projection of the critical point onto the slice, depending on whether the critical point is below or above the line. For σ, we see that it enters the slice at the position marked by the blue point.
Persistent homology.
A mono-filtration gives rise to a persistence diagram. Formally, we obtain this diagram by applying the homology functor to , yielding a sequence of vector spaces and linear maps between them, and splitting this sequence into indecomposable parts using representation theory. Instead of rolling out the entire theory (which is explained, for instance, in [45]), we give an intuitive description here.
Persistent homology measures how the topological features of a data set evolve when considered across a varying scale parameter α. The most common example involves a point cloud in , where considering a fixed scale α means replacing the points by balls of radius α. As α increases, the data set undergoes various topological configurations, starting as a disconnected point cloud for α = 0 and ending up as a topological ball when α approaches ∞; see Figure 2(a) for an example in .
Figure 2.
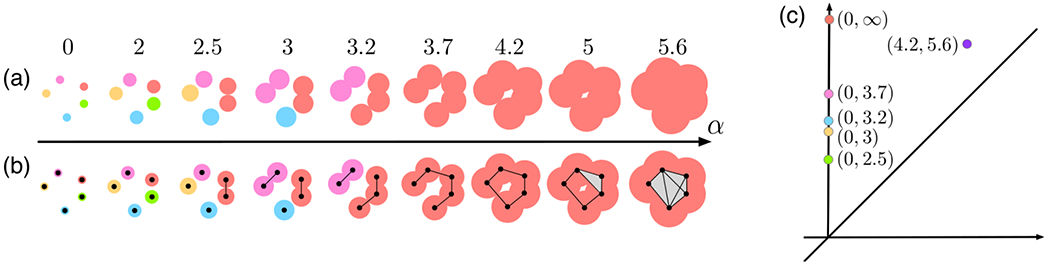
Computing persistent homology of a point cloud in . (a) A nested sequence of topological spaces formed by unions of balls at increasing parameter values. (b) A mono-filtration of simplicial complexes that captures the same topological information as in (a). (c) 0-dimensional and 1-dimensional persistence diagrams combined.
The topological information of this process can be summarized as a finite multi-set of points in the plane, called the persistence diagram. Each point of the diagram corresponds to a topological feature (i.e., connected components, tunnels, voids, etc.), and its coordinates specify at which scales the feature appears and disappears in the data. As illustrated in Figure 2(a), all five (connected) components are born (i.e., appear) at α = 0. The green component dies (i.e., disappears) when it merges with the red component at α = 2.5; similarly, the orange, blue and pink components die at scales 3, 3.2 and 3.7, respectively. The red component never dies as α goes to ∞. The 0-dimensional persistence diagram is defined to have one point per component with birth and death value as its coordinates (Figure 2(c)). The persistence of a feature is then merely its distance from the diagonal. While we focus on the components, the concept generalizes to higher dimensions, such as tunnels (1-dimensional homology) and voids (2-dimensional homology). For instance, in Figure 2(a), a tunnel appears at α = 4.2 and disappears at α = 5.6, which gives rise to a purple point (4.2, 5.6) in the 1-dimensional persistence diagram (Figure 2(c)).
From a computational point of view, the nested sequence of spaces formed by unions of balls (Figure 2(a)) can be replaced by a nested sequence of simplicial complexes by taking their nerves, thereby forming a mono-filtration of simplicial complexes that captures the same topological information but has a much smaller footprint (Figure 2(b)).
In the context of shape analysis, we apply persistent homology to capture the topological information of 2D and 3D shape objects by employing various types of mono-filtrations. A simple example is illustrated in Figure 3: we extract point clouds sampled from the boundary of 2D shape objects and compute the persistence diagrams using Vietoris-Rips complex filtrations.
Figure 3.
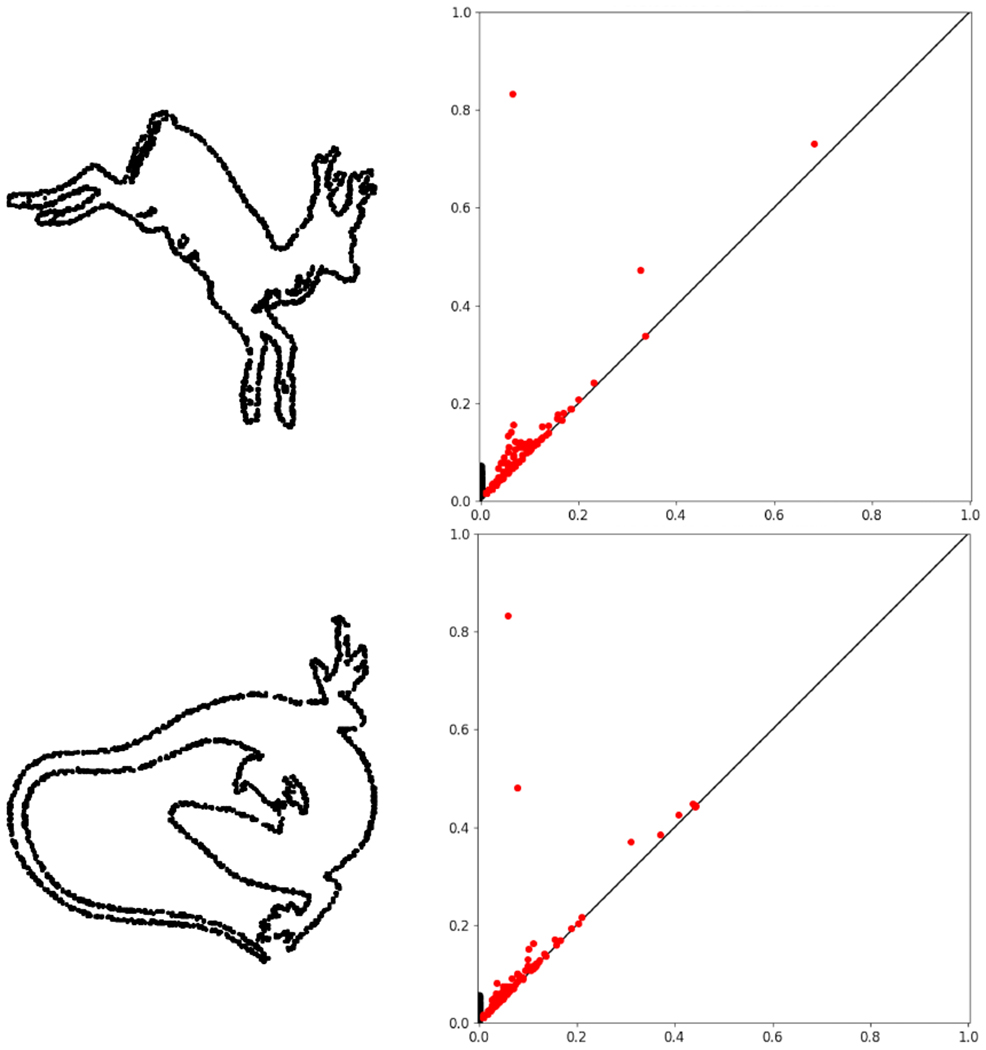
The persistence diagrams of 2D shape objects. Black and red points are 0-dimensional and 1-dimensional features respectively (ignoring points with ∞ persistence).
Stability of persistent homology.
Bottleneck distance represents a similarity measure between persistence diagrams. Let D, D′ be two persistence diagrams. Without loss of generality, we can assume that both contain infinitely many copies of the points on the diagonal. The bottleneck distance between D and D′ is defined as
| (3) |
where γ ranges over all bijections from D to D′. We will also use the notation for two mono-filtrations instead of
A crucial result for persistent homology is the stability theorem proven in [46] and re-stated in our notation as follows. Given two functions whose sublevel sets form two mono-filtrations of a finite simplicial complex X, the induced persistence diagrams satisfy
| (4) |
Feature maps for mono-filtrations.
Several feature maps aimed at the construction of a kernel for mono-filtrations have been proposed in the literature [22, 23, 21]. We discuss one example: the persistence scale-space kernel [21] assigns to a mono-filtration an L2-function defined on . The main idea behind the definition of is to define a sum of Gaussian peaks, all of the same height and width, with each peak centered at one finite off-diagonal point of the persistence diagram of . To make the construction robust against perturbations, the function has to be equal to 0 across the diagonal (the boundary of Δ(1)). This is achieved by adding negative Gaussian peaks at the reflections of the off-diagonal points along the diagonal. Writing for the reflection of a point z, we obtain the formula,
| (5) |
where t is the width of the Gaussian, which is a free parameter of the construction. See Figure 4 (b) and (c) for an illustration of a transformation of a persistence diagram to the function . The induced kernel enjoys several stability properties and can be evaluated efficiently without explicit construction of the feature map; see [21] for details.
Figure 4.
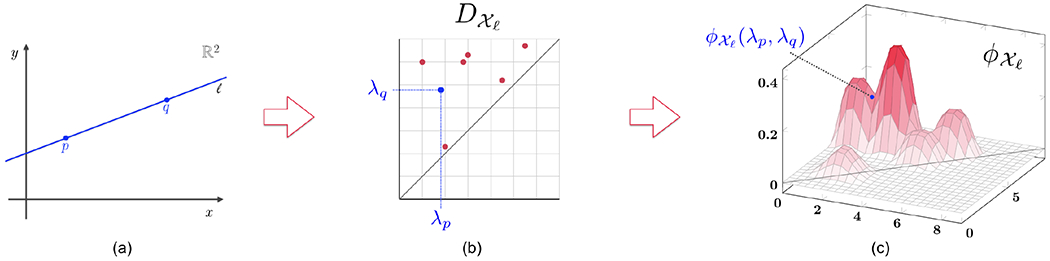
An illustration of the construction of a feature map for multi-parameter persistent homology. (a) Given a bi-filtration X and a point (p, q) ∈ Δ(2), the line ℓ passing through them is depicted and the parameter λp and λq computed. (b) The point (λp,λq) is embedded in the persistence diagram of the mono-filtration obtained as the slice of along ℓ. (c) The point (λp, λq) is assigned the value via the feature map ϕ.
More generally, in this paper, we look at the class of all feature maps that assign to a mono-filtration a function in L2(Δ(1)). For such a feature map , we define the following properties:
Absolutely boundedness. There exists a constant v1 > 0 such that, for any mono-filtration of size n and any x ∈ Δ(1), .
Lipschitzianity. There exists a constant v2 > 0 such that, for any mono-filtration of size n and any x, x′ ∈ Δ(1), .
Internal stability. There exists a constant v3 > 0 such that, for any pair of mono-filtrations , of size n and any x ∈ Δ(1),
Efficiency. For any x ∈ Δ(1), can be computed in polynomial time in the size of , that is, in O(nk) for some k ≥ 0.
It can be verified easily that the scale-space feature map from above satisfies all these properties. The same is true, for instance, if the Gaussian peaks are replaced by linear peaks (that is, replacing the Gaussian kernel in (5) by a triangle kernel).
3. A feature map for multi-parameter persistent homology
Let ϕ be a feature map (such as the scale-space kernel) that assigns to a mono-filtration a function in L2(Δ(1)). Starting from ϕ, we construct a feature map Φ on the set of all bi-filtrations Ω that has values in a Hilbert space.
The feature map Φ assigns to a bi-filtration a function . We set
as the set of all pairs of points where the first point is smaller than the second one. Δ(2) can be interpreted naturally as a subset of , but we will usually consider elements of Δ(2) as pairs of points in .
Fixing (p, q) ∈ Δ(2), let ℓ denote the unique slice through these two points. Along this slice, the bi-filtration gives rise to a mono-filtration , and consequently a function using the considered feature map for mono-filtrations. Moreover, using the parameterization of the slice ℓ as b + λ · a from Section 2, there exist real values λp, λq such that b + λpa = p and b + λqa = q. Since p < q and λp < λq, hence (λp, λq) ∈ Δ(1). We define to be the weighted function value of at (λp, λq) (see also Figure 4), that is,
| (6) |
where w(p, q) is a weight function defined below.
The weight function w has two components. First, let R be a bounded axis-aligned rectangle in ; its bottom-left corner coincides with the origin of the coordinate axes. We define w such that its weight is 0 if p or q is outside of R. Second, for pairs of points within R × R, we assign a weight depending on the slope of the induced slices. Formally, let ℓ be parameterized as b + λ·a as above, and recall that a is a unit vector with non-negative coordinates. Write a = (a1, a2) and set . Then, we define
where χR is the characteristic function of R, mapping a point x to 1 if x ∈ R and 0 otherwise.
The factor ensures that slices that are close to being horizontal or vertical attain less importance in the feature map. The same weight is assigned to slices in the matching distance [42]. is not important for obtaining an L2-function, but its meaning will become clear in the stability results of Section 4. We also remark that the largest weight is attained for the diagonal slice with a value of . Consequently, w is a non-negative function upper bounded by .
To summarize, our map Φ depends on the choice of an axis-aligned rectangle R and a choice of feature map for mono-filtrations, which itself might have associated parameters. For instance, using the scale-space feature map requires the choice of the width t (see (5)). It is only left to argue that the image of the feature map Φ is indeed an L2-function.
Theorem 1. If ϕ is absolutely bounded, then is in L2(Δ(2)).
Proof. Let be a bi-filtration of size n. As mentioned earlier, each slice is of a size at most n. By absolute boundedness and the fact that the weight function is upper bounded by , it follows that for all (p, q). Since the support of is compact (R × R), the integral of over Δ(2) is finite, being absolutely bounded and compactly supported. □
Note that Theorem 1 remains true even without restricting the weight function to R, provided we consider a weight function that is square-integrable over Δ(2). We skip the (easy) proof.
4. Stability
An important and desirable property for a kernel is its stability. In general, stability means that small perturbations in the input data imply small perturbations in the output data. In our setting, small changes between multi-filtrations (with respect to matching distance) should not induce large changes in their corresponding feature maps (with respect to L2 distance).
Adopted to our notation, the matching distance is defined as
where is the set of non-vertical lines with positive slope [47].
Theorem 2. Let and be two bi-filtrations. If ϕ is absolutely bounded and internally stable, we have
for some constant C.
Proof. Absolute boundedness ensures that the left-hand side is well-defined by Theorem 1. Now we use the definition of ‖·‖L2 and the internal stability of ϕ to obtain
Since w(p, q) is zero outside R × R, the integral does not change when restricted to Δ(2) ∩ (R × R). Within this set, w(p, q) simplifies to , with ℓ the line through p and q. Hence, we can further bound
The claimed inequality follows by noting that the final integral is equal to . □
As a corollary, we get the the same stability statement with respect to interleaving distance instead of matching distance [48, Thm.1]. Furthermore, we obtain a stability bound for sublevel set bi-filtrations of functions [47, Thm.4]:
Corollary 3. Let be two functions that give rise to sublevel set bi-filtrations and , respectively. If ϕ is absolutely bounded and internally stable, we have
for some constant C.
We remark that the appearance of n in the stability bound is not desirable as the bound worsens when the complex size increases (unlike, for instance, the bottleneck stability bound in (4), which is independent of n). The factor of n comes from the internal stability property of ϕ, so we have to strengthen this condition on ϕ. However, we show that such an improvement is impossible for a large class of “reasonable” feature maps.
For two bi-filtrations , we define by setting for all . A feature map Φ is additive if for all bi-filtrations , . Φ is called non-trivial if there is a bi-filtration such that ‖Φ‖L2 ≠ 0. Additivity and non-triviality for feature maps ϕ on mono-filtrations is defined in the analogous way. Note that, for instance, the scale space feature map is additive. Moreover, because for every slice ℓ, a feature map Φ is additive if the underlying ϕ is additive.
For mono-filtrations, no additive, non-trivial feature map ϕ can satisfy
with , mono-filtrations and δ ∈ [0, 1); the proof of this statement is implicit in [21, Thm 3]. With similar ideas, we show that the same result holds in the multi-parameter case.
Theorem 4. If Φ is additive and there exists C > 0 and δ ∈ [0, 1) such that
for all bi-filtrations and , then Φ is trivial.
Proof. Assume to the contrary that there exists a bi-filtration such that . Then, writing for the empty bifiltration, by additivity we get . On the other hand, . Hence, with C and δ as in the statement of the theorem,
a contradiction. □
5. Approximability
We provide an approximation algorithm to compute the kernel of two bi-filtrations and up to any absolute error ϵ > 0. Recall that our feature map Φ depends on the choice of a bounding box R. In this section, we assume R to be the unit square [0, 1] × [0, 1] for simplicity. We prove the following theorem that shows our kernel construction admits an efficient approximation scheme that is polynomial in 1/ϵ and the size of the bi-filtrations.
Theorem 5. Assume ϕ is absolutely bounded, Lipschitz, internally stable and efficiently computable. Given two bi-filtrations and of size n and ϵ > 0, we can compute a number r such that in polynomial time in n and 1/ϵ.
The proof of Theorem 5 will be illustrated in the following paragraphs, postponing most of the technical details to Appendix A.
Algorithm. Given two bi-filtrations and of size n and ϵ > 0, our goal is to efficiently approximate by some number r. On the highest level, we compute a sequence of approximation intervals (with decreasing lengths) J1, J2, J3,…, each containing the desired kernel value . The computation terminates as soon as we find some Ji of width at most ϵ, in which case we return the left endpoint as an approximation to r.
For ( being the set of natural numbers), we compute Js as follows. We split R into 2s × 2s congruent squares (each of side length 2−s) which we refer to as boxes. See Figure 5(a) for an example when s = 3. We call a pair of such boxes a box pair. The integral from (1) can then be split into a sum of integrals over all 24s box pairs. That is,
For each box pair, we compute an approximation interval for the integral, and sum them up using interval arithmetic to obtain Js.
Figure 5.
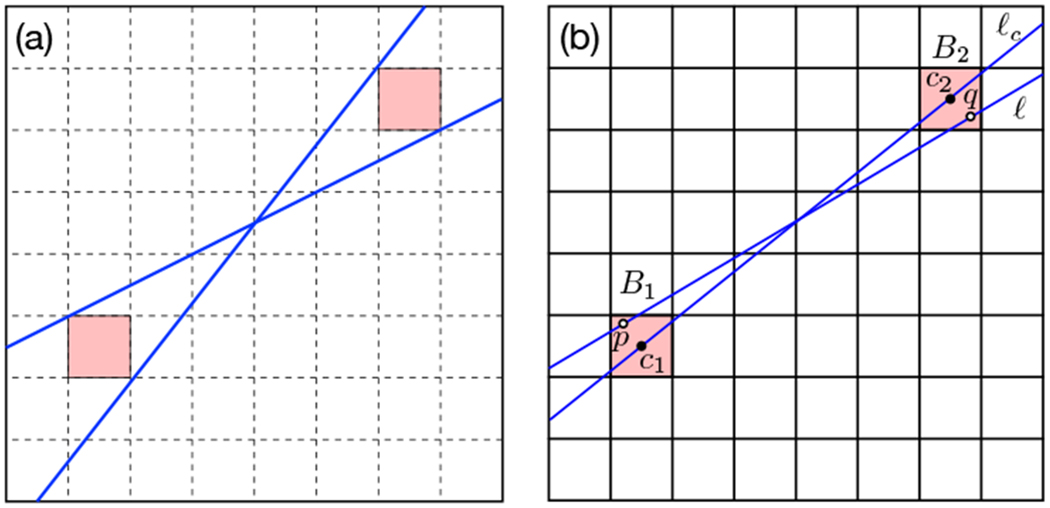
(a) The two given slices realize the largest and smallest possible slope among all slices traversing the pink box pair. It can be easily seen that the difference of the unit vector of the center line to one of the unit vectors of these two lines realizes A for the given box pair. (b) Computing variations for the center slice and a traversing slice of a box pair.
We first give some (almost trivial) bounds for . Let (B1, B2) be a box pair with centers located at c1 and c2, respectively. By construction, vol(B1 × B2) = 2−4s. By the absolute boundedness of ϕ, we have
| (7) |
| (8) |
where is the maximal weight. Let . If c1 ≤ c2, then we can choose [0, U] as approximation interval. Otherwise, if c1 ≰ c2, then Δ(2) ∩ (B1 × B2) = ∅; we simply choose [0, 0] as approximation interval.
We can derive a second lower and upper bound for as follows. We evaluate and at the pair of centers (c1, c2), which is possible due to the efficiency hypothesis of ϕ. Let and . Then, we compute variations relative to the box pair, with the property that, for any pair (p, q) ∈ B1 × B2, , and . In other words, variations describe how far the value of ${ \Phi_{ \cal{ X \cal} _} $} (or ${ \Phi_{ \cal{ Y \cal} _} $}) deviates from its value at (c1, c2) within B1 × B2. Combined with the derivations starting in (7), we have for any pair (p, q) ∈ B1 × B2,
| (9) |
| (10) |
| (11) |
By multiplying the bounds obtained in (9) by the volume of Δ(2) ∩ (B1 × B2), we get a lower and an upper bound for the integral of over a box pair (B1, B2). By summing over all possible box pairs, the obtained lower and upper bounds are the endpoints of Js.
Variations.
We are left with computing the variations relative to a box pair. For simplicity, we set δ ≔ δx and explain the procedure only for ; the treatment of is similar.
We say that a slice ℓ traverses (B1, B2) if it intersects both boxes in at least one point. One such slice is the center slice ℓc, which is the slice through c1 and c2. See Figure 5(b) for an illustration. We set D to be the maximal bottleneck distance of the center slice and every other slice traversing the box pair (to be more precise, of the persistence diagrams along the corresponding slices). We set W as the maximal difference between the weight of the center slice and any other slice traversing the box pair, where the weight w is defined as in Section 3. Write λc1 for the parameter value of c1 along the center slice. For every slice ℓ traversing the box pair and any point p ∈ ℓ ∩ B1, we have a value λp, yielding the parameter value of p along ℓ. We define L1 as the maximal difference of λp and λc1 among all choices of p and ℓ. We define L2 in the same way for B2 and set L ≔ max{L1, L2}. With these notations, we obtain Lemma 6 below.
Lemma 6. For all (p, q) ∈ B1 × B2,
Proof. Plugging in (6) and using triangle inequality, we obtain
and bound the three parts separately. The first summand is upper bounded by because of internal stability of the feature map ϕ and because for any slice ℓ. The second summand is upper bounded by v1nW by the absolute boundedness of ϕ. The third summand is bounded by v2nL, because and by ϕ being Lipschitz, and . The result follows. ■
Next, we bound D by simple geometric quantities. We use the following lemma, whose proof appeared in [48]:
Lemma 7 ([48]). Let ℓ and ℓ′ be two slices with parameterizations b + λa and b′ + λa′, respectively. Then, the bottleneck distance of the two persistence diagrams along these slices is upper bounded by
We define A as the maximal infinity distance of the directional vector of the center slice ℓc and any other slice ℓ traversing the box pair. We define B as the maximal infinity distance of the base point of ℓc and any other ℓ. Finally, we set M as the minimal weight among all slices traversing the box pair. Using Lemma 7, we see that
and we set
| (12) |
It follows from Lemma 6 and Lemma 7 that δ indeed satisfies the required variation property.
We remark that δ might well be equal to ∞, if the box pair admits a traversing slice that is horizontal or vertical, in which case the lower and upper bounds derived from the variation are vacuous. While (12) looks complicated, the values v1, v2, v3 are constants coming from the considered feature map ϕ, and all the remaining values can be computed in constant time using elementary geometric properties of a box pair. We only explain the computation of A in Figure 5(a) and skip the details of the other values.
Analysis.
At this point, we have not made any claim that the algorithm is guaranteed to terminate. However, its correctness follows at once because Js indeed contains the desired kernel value. Moreover, handling one box pair has a complexity that is polynomial in n, because the dominant step is to evaluate at the center (c1, c2). Hence, if the algorithm terminates at iteration s0, its complexity is
This is because in iteration s, 24s box pairs need to be considered. Clearly, the geometric series above is dominated by the last iteration, so the complexity of the method is O(24s0poly(n)). The last (and technically most challenging) step is to argue that , which implies that the algorithm indeed terminates and its complexity is polynomial in n and 1/ϵ.
To see that we can achieve any desired accuracy for the value of the kernel, i.e., that the interval width tends to 0, we observe that, if the two boxes B1, B2 are sufficiently far away and the resolution s is sufficiently large, the magnitudes A, B, W, and L in (12) are all small, because the parameterizations of two slices traversing the box pair are similar (see Lemmas 11, 12, 13 and 14 in Appendix A). Moreover, if every slice traversing the box pair has a sufficiently large weight (i.e., the slice is close to the diagonal), the value M in (12) is sufficiently large. These two properties combined imply that the variation of such a box pair (which we refer to as the good type) tends to 0 as s goes to ∞. Hence, the bound based on the variation tends to the correct value for good box pairs.
However, no matter how high the resolution, there are always bad box pairs for which either B1, B2 are close, or are far but close to horizontal and vertical, and hence yield a very large variation. For each of these box pairs, the bounds derived from the variation are vacuous, but we still have the trivial bounds [0, U] based on the absolute boundedness of ϕ. Moreover, the total volume of these bad box pairs goes to 0 when s goes to ∞ (see Lemma 9, Lemma 10 in Appendix A). So, the contribution of these box pairs tends to 0. These two properties complete the proof of Theorem 5.
A more careful investigation of our proof shows that the complexity of our algorithm is O(n80+k(1/ϵ)40), where k is the efficiency constant of the feature map (Section 2). We made little effort to optimize the exponents in this bound.
6. Conclusions and future developments
We restate our main results for the case of a multi-filtration with d parameters: there is a feature map that associates to a real-valued function whose domain is of dimension 2d, and introduces a kernel between a pair of multi-filtrations with a stable distance function, where the stability bounds depend on the (2d-dimensional) volume of a chosen bounding box. The proofs of these generalized results carry over from the results of this paper. Moreover, assuming that d is a constant, we claim that the kernel can be approximated in polynomial time to any constant (with the polynomial exponent depending on d). A proof of this statement requires to adapt the definitions and proofs of Appendix A to the higher-dimensional case; we omit details.
Other generalizations include replacing filtrations of simplicial complexes with persistence modules (with a suitable finiteness condition), passing to sublevel sets of a larger class of (tame) functions and replacing the scale-space feature map with a more general family of single-parameter feature maps. All these generalizations will be discussed in subsequent work.
The next step is an efficient implementation of our kernel approximation algorithm. We have implemented a prototype in C++, realizing a more adaptive version of the described algorithm. We have observed rather poor performance due to the sheer number of box pairs to be considered. Some improvements under consideration are to precompute all combinatorial persistence diagrams (cf. the barcode templates from [44]), to refine the search space adaptively using a quad-tree instead of doubling the resolution and to use techniques from numerical integration to handle real-world data sizes. We hope that an efficient implementation of our kernel will validate the assumption that including more than a single parameter will attach more information to the data set and improve the quality of machine learning algorithms using topological features.
Acknowledgments
This work was initiated at the Dagstuhl Seminar 17292 “Topology, Computation and Data Analysis”. We thank all members of the breakout session on multi-dimensional kernel for their valuable suggestions. RC, UF, and MK acknowledge support by the Austrian Science Fund (FWF) grant P 29984-N35. CL is partially supported by ARCES (University of Bologna), and FAR 2017 (University of Modena and Reggio Emilia). BW is partially supported by NSF grant DBI-1661375, IIS-1513616 and NIH grant R01-1R01EB022876-01. Fig. 3 is generated by Lin Yan.
Appendix A. Details on the Proof of Theorem 5
Overview.
Recall that our approximation algorithm produces an approximation interval Js for by splitting the unit square into 2s × 2s boxes. For notational convenience, we write u ≔ 2−s for the side length of these boxes.
We would like to argue that the algorithm terminates after iterations, which means that after that many iterations, an interval of width ϵ has been produced. The following Lemma 8 gives an equivalent criterion in terms of u and n.
Lemma 8. Assume that there are constants e1, e2 > 0, such that width(Js) = O(ne1ue2). Then, width(Js0) ≤ ϵ for some .
Proof. Assume that width(Js) ≤ cne1ue2 for constants c and s sufficiently large. Since u = 2−s, a simple calculation shows that cne1 ue2 ≤ ϵ if and only if . Hence, choosing
ensures that width(Js0) ≤ ϵ. □
In the rest of this section, we will show that width(Js) = O(n2 u0.1).
Classifying box pairs.
For the analysis, we partition the box pairs considered by the algorithm into 4 disjoint classes. We call a box pair (B1, B2):
null if c1 ≰ c2,
close if c1 ≤ c2 such that ,
non-diagonal if c1 ≤ c2 such that and any line ℓ that traverses (B1, B2) satisfies ,
good if it is of neither of the previous three types.
According to this notation, the integral from (1) can then be split as
where, is defined and analogously for the other ones. We let Js,null, Js,close, Js,non–diag, Js,good denote the four approximation intervals obtained from our algorithm when summing up the contributions of the corresponding box pairs. Then clearly, Js is the sum of these four intervals. For simplicity, we will write Jnull instead of Js,null when s is fixed, and likewise for the other three cases.
We observe first that the algorithm yields Jnull = [0, 0], so null box pairs can simply be ignored. Box pairs that are either close or non-diagonal are referred to as bad box pairs in Section 5. We proceed by showing that the width of Jclose, Jnon–diag, and Jgood are all bounded by O(n2u0.1).
Bad box pairs.
We start with bounding the width of Jclose. Let be the union of all close box pairs. Note that our algorithm assigns to each box pair (B1, B2) an interval that is a subset of [0, U]. Recall that . U can be rewritten as , where vol(B1 × B2) is the 4-dimensional volume of the box pair (B1, B2). It follows that
| (A.1) |
Lemma 9. For , .
Proof. Fixed a point p ∈ R, for each point q ∈ R such that and p < q, there exists a unique close box pair (B1, B2) that contains (p, q). By definition of close box pair, we have that:
Moreover, for , , and so . Equivalently, q belongs to the 2-ball centered at p and of radius . Then,
Consequently, combined with (A.1), we have
Note that u < 1 and hence, u ≤ u0.1.
For the width of Jnon–diag, we use exactly the same reasoning, making use of the following Lemma 10. Let be the union of all non-diagonal box pairs.
Lemma 10. For , .
Proof. Fixed a point p ∈ R, for each point q ∈ R such that and p < q, there exists a unique non-diagonal box pair (B1, B2) that contains (p, q). We have that q lies in:
Triangle T1(p) of vertices p = (p1, p2), (1, p2), and , if the line ℓ of maximum slope passing through B1 × B2 is such that where a = (a1, a2) is the (positive) unit direction vector of ℓ;
Triangle T2(p) of vertices p = (p1, p2), (p1, 1), and , if the line ℓ of minimum slope passing through B1 × B2 is such that where a = (a1, a2) is the (positive) unit direction vector of ℓ.
Let us bound the area of the two triangles. Since the calculations are analogous, let us focus on T1(p). By definition, the basis of T1(p) is smaller than 1 while its height is bounded by . The maximum value for the height of T1(p) is achieved for . So, by exploiting the identity , we have
Under the conditions and we have
Therefore, . Similarly, . Finally,
Good box pairs.
For good box pairs, we use the fact that the variation of a box pair yields a subinterval of as an approximation, so the width is bounded by . Let be the union of all good box pairs. Since the volumes of all good box pairs sum up to at most one, that is, , it follows that the width of Jgood is bounded by . By absolute boundedness, and are in O(n), and recall that by definition,
based on the fact that . The same bound holds for . Hence,
It remains to show that . Note that because the box pair is assumed to be good. We will show in the next lemmas that A, B, W, and L are all in , proving that the term is indeed in O(u0.1). This completes the proof of the complexity of the algorithm.
Lemma 11. Let (B1, B2) be a good box pair. Let a, a′ be the unit direction vectors of two lines that pass through the box pair. Then, . In particular, .
Proof. Since (B1, B2) is a good box pair, the largest value for ‖a − a′‖∞ is achieved when ℓ and ℓ′ correspond to the lines passing through the box pair(B1, B2) with minimum and maximum slope, respectively. By denoting as c1 = (c1,x, c1,y), c2 = (c2,x, c2,y) the centers of B1, B2, we define ℓ to be the line passing through the points , . Similarly, let us call ℓ′ the line passing through the points , . So, the unit direction vector a of ℓ can be expressed as
Similarly, the unit direction vector a′ of ℓ′ is described by
Then, by denoting as (·, ·) the scalar product,
By an elementary calculation, one can prove that
Then,
Since (B1, B2) is a good box pair, . So,
Since , we have that
Therefore,
Lemma 12. Let (B1, B2) be a good box pair. Let ℓ = aλ + b, ℓ′ = a′λ + b′ be two lines that pass through the box pair such that a, a′ are unit direction vectors and b, b′ are the intersection points with the diagonal of the second and the fourth quadrant. Then . In particular, .
Proof. Since (B1, B2) is a good box pair, the largest value for ‖b − b′‖∞ is achieved when ℓ and ℓ′ correspond to the lines passing through the box pair(B1, B2) with minimum and maximum slope, respectively. By denoting the centers of B1 and B2 by c1 and c2, we define ℓ to be the line passing through the points , . Similarly, let us call ℓ′ the line passing through the points , . So, ℓ can be expressed as
where t is a parameter running on . By intersecting ℓ with the line y = −x, we get:
which can be written as
letting us deduce that
So, by replacing t in the equation of ℓ we retrieve b:
Similarly,
So,
Since (B1, B2) is a good box pair,
Finally,
Lemma 13. Let (B1, B2) be a good box pair. Let , be the weights of two lines ℓ and ℓ′ that pass through the box pair. Then . In particular, .
Proof. If and , then, by applying Lemma 11,
On the other hand, if and , then there exists a line ℓ″ passing through the box pair (B1, B2) such that . By applying twice Lemma 11,
The cases , and , can be treated analogously to the previous ones. □
Lemma 14. Let (p, q), (p′, q′) be two points in a good box pair (B1, B2) and let ℓ, ℓ′ be the lines passing through p, q and p′, q′, respectively. In accordance with the usual parametrization, we have that and . As a consequence, .
Proof. Thanks to the definition of λp, the triangular inequality and Lemma 12, we have that:
So, we have that , and, similarly, . Then,
Analogously, it can be proven that
References
- [1].Carstens CJ, Horadam KJ. Persistent homology of collaboration networks. Mathematical Problems in Engineering 2013;2013:7. [Google Scholar]
- [2].Chan JM, Carlsson G, Rabadan R Topology of viral evolution. Proceedings of the National Academy of Sciences of the United States of America 2013;110(46):18566–18571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Giusti C, Pastalkova E, Curto C, Itskov V Clique topology reveals intrinsic geometric structure in neural correlations. Proceedings of the National Academy of Sciences of the United States of America 2015;112(44):13455–13460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Guo W, Banerjee AG. Toward automated prediction of manufacturing productivity based on feature selection using topological data analysis. In: IEEE International Symposium on Assembly and Manufacturing 2016, p. 31–36. [Google Scholar]
- [5].Hiraoka Y, Nakamura T, Hirata A, Escolar EG, Matsue K, Nishiura Y Hierarchical structures of amorphous solids characterized by persistent homology. Proceedings of the National Academy of Sciences of the United States of America 2016;113(26):7035–7040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Li L, Cheng WY, Glicksberg BS, Gottesman O, Tamler R, Chen R, et al. Identification of type 2 diabetes subgroups through topological analysis of patient similarity. Science Translational Medicine 2015;7(311):311ra174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Wang Y, Ombao H, Chung MK. Topological data analysis of single-trial electroencephalographic signals. Annals of Applied Statistics 2017;12(3):1506–1534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Yoo J, Kim EY, Ahn YM, Ye JC. Topological persistence vineyard for dynamic functional brain connectivity during resting and gaming stages. Journal of Neuroscience Methods 2016;267(15):1–13. [DOI] [PubMed] [Google Scholar]
- [9].Nicolau M, Levine AJ, Carlsson G Topology based data analysis identifies a subgroup of breast cancers with a unique mutational profile and excellent survival. Proceedings National Academy of Sciences of the United States of America 2011;108(17):7265–7270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Turner K, Mukherjee S, Boyer DM. Persistent homology transform for modeling shapes and surfaces. Information and Inference: A Journal of the IMA 2014;3(4):310–344. [Google Scholar]
- [11].Li C, Ovsjanikov M, Chazal F Persistence-based structural recognition. In: IEEE Conference on Computer Vision and Pattern Recognition 2014, p. 2003–2010. [Google Scholar]
- [12].Biasotti S, Falcidieno B, Spagnuolo M Extended Reeb graphs for surface understanding and description. In: Proceedings of the 9th International Conference on Discrete Geometry for Computer Imagery 2000, p. 185–197. [Google Scholar]
- [13].Skraba P, Ovsjanikov M, Chazal F, Guibas L Persistence-based segmentation of deformable shapes. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition - Workshop on Non-Rigid Shape Analysis and Deformable Image Alignment 2010, p. 45–52. [Google Scholar]
- [14].Munkres JR. Elements of algebraic topology. Redwood City, CA, USA: Addison-Wesley; 1984. [Google Scholar]
- [15].Edelsbrunner H, Letscher D, Zomorodian AJ. Topological persistence and simplification. Discrete and Computational Geometry 2002;28:511–533. [Google Scholar]
- [16].Zomorodian A, Carlsson G Computing persistent homology. Discrete and Computational Geometry 2005;33(2):249–274. [Google Scholar]
- [17].Edelsbrunner H, Harer J Persistent homology - a survey. Contemporary Mathematics 2008;453:257–282. [Google Scholar]
- [18].Edelsbrunner H, Harer J Computational Topology: An Introduction. Providence, RI, USA: American Mathematical Society; 2010. [Google Scholar]
- [19].Edelsbrunner H, Morozov D Persistent homology: Theory and practice In: Proceedings of the European Congress of Mathematics. European Mathematical Society Publishing House; 2012, p. 31–50. [Google Scholar]
- [20].Cohen-Steiner D, Edelsbrunner H, Harer J Stability of persistence diagrams. Discrete and Computational Geometry 2007;37(1):103–120. [Google Scholar]
- [21].Reininghaus J, Huber S, Bauer U, Kwitt R A stable multi-scale kernel for topological machine learning. In: IEEE Conference on Computer Vision and Pattern Recognition 2015, p. 4741–4748. [Google Scholar]
- [22].Bubenik P Statistical topological data analysis using persistence landscapes. The Journal of Machine Learning Research 2015;16(1):77–102. [Google Scholar]
- [23].Kwitt R, Huber S, Niethammer M, Lin W, Bauer U Statistical topological data analysis - a kernel perspective In: Cortes C, Lawrence ND, Lee DD, Sugiyama M, Garnett R, editors. Advances in Neural Information Processing Systems 28. Curran Associates, Inc.; 2015, p. 3070–3078. [Google Scholar]
- [24].Kusano G, Fukumizu K, Hiraoka Y Persistence weighted Gaussian kernel for topological data analysis. Proceedings of the 33rd International Conference on Machine Learning 2016;48:2004–2013. [Google Scholar]
- [25].Hofer C, Kwitt R, Niethammer M, Uhl A Deep learning with topological signatures In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, et al. , editors. Advances in Neural Information Processing Systems 30. Curran Associates, Inc.; 2017, p. 1634–1644. [Google Scholar]
- [26].Carlsson G, Zomorodian A The theory of multidimensional persistence. Discrete and Computational Geometry 2009;42(1):71–93. [Google Scholar]
- [27].Carlsson G, Mémoli F Multiparameter hierarchical clustering methods In: Locarek-Junge H, Weihs C, editors. Classification as a Tool for Research. Springer Berlin; Heidelberg; 2010, p. 63–70. [Google Scholar]
- [28].Chazal F, Cohen-Steiner D, Guibas LJ, Mémoli F, Oudot SY. Gromov-Hausdorff stable signatures for shapes using persistence. Eurographics Symposium on Geometry Processing 2009;28(5):1393–1403. [Google Scholar]
- [29].Singh G, Mémoli F, Carlsson G Topological methods for the analysis of high dimensional data sets and 3D object recognition. In: Eurographics Symposium on Point-Based Graphics 2007, p. 91–100. [Google Scholar]
- [30].Sun J, Ovsjanikov M, Guibas L A concise and provably informative multi-scale signature based on heat diffusion. Computer Graphics Forum 2009;28(5):1383–1392. [Google Scholar]
- [31].Edelsbrunner H, Harer J Jacobi sets of multiple Morse functions In: Cucker F, DeVore R, Olver P, Süli E, editors. Foundations of Computational Mathematics, Minneapolis 2002. Cambridge University Press; 2002, p. 37–57. [Google Scholar]
- [32].Edelsbrunner H, Harer J, Patel AK. Reeb spaces of piecewise linear mappings. In: Proceedings of the 24th Annual Symposium on Computational Geometry 2008, p. 242–250. [Google Scholar]
- [33].Carriére M, Cuturi M, Oudot S Sliced Wasserstein kernel for persistence diagrams. In: Proceedings of the 34th International Conference on Machine Learning; vol. 70 2017, p. 664–673. [Google Scholar]
- [34].Adams H, Chepushtanova S, Emerson T, Hanson E, Kirby M, Motta F, et al. Persistence images: A stable vector representation of persistent homology. The Journal of Machine Learning Research 2017;18(1):218–252. [Google Scholar]
- [35].Adcock A, Rubin D, Carlsson G Classification of hepatic lesions using the matching metric. Computer Vision and Image Understanding 2014;121:36–42. [Google Scholar]
- [36].Di Fabio B, Ferri M Comparing persistence diagrams through complex vectors. In: V., M E, P editors. International Conference on Image Analysis and Processing Springer, Cham; 2015, p. 294–305. [Google Scholar]
- [37].Adcock A, Carlsson E, Carlsson G The ring of algebraic functions on persistence bar codes. Homology, Homotopy and Applications 2016;18:381–402. [Google Scholar]
- [38].Kališnik S Tropical coordinates on the space of persistence barcodes. Foundations of Computational Mathematics 2018;19(1):1–29. [Google Scholar]
- [39].Lesnick M The theory of the interleaving distance on multidimensional persistence modules. Foundations of Computational Mathematics 2015;15(3):613–650. [Google Scholar]
- [40].Bjerkevik HB, Botnan MB, Kerber M Computing the interleaving distance is NP-hard. ArXiv: 1811.09165; 2018. [Google Scholar]
- [41].Dey TK, Xin C Computing Bottleneck Distance for 2-D Interval Decomposable Modules. In: Proceedings of the 34th International Symposium on Computational Geometry 2018, p. 32:1–32:15. [Google Scholar]
- [42].Biasotti S, Cerri A, Frosini P, Giorgi D A new algorithm for computing the 2-dimensional matching distance between size functions. Pattern Recognition Letters 2011;32(14):1735–1746. [Google Scholar]
- [43].Kerber M, Lesnick M, Oudot S Exact computation of the matching distance on 2-parameter persistence modules. In: Proceedings of the 35th International Symposium on Computational Geometry 2019, p. 46:1–46:15. [Google Scholar]
- [44].Lesnick M, Wright M Interactive visualization of 2-D persistence modules. arXiv:1512.00180; 2015. [Google Scholar]
- [45].Oudot S Persistence theory: From Quiver Representation to Data Analysis; vol. 209 of Mathematical Surveys and Monographs. American Mathematical Society; 2015. [Google Scholar]
- [46].Cohen-Steiner D, Edelsbrunner H, Harer J Stability of persistence diagrams. Discrete and Computational Geometry 2007;37(1):103–120. [Google Scholar]
- [47].Biasotti S, Cerri A, Frosini P, Giorgi D, Landi C Multidimensional size functions for shape comparison. Journal of Mathematical Imaging and Vision 2008;32(2):161. [Google Scholar]
- [48].Landi C The rank invariant stability via interleavings In: Chambers EW, Fasy BT, Ziegelmeier L, editors. Research in Computational Topology; vol. 13 Springer; 2018, p. 1–10. [Google Scholar]