

Abstract
Frequently, clinical trials and observational studies involve complex event history data with multiple events. When the observations are independent, the analysis of such studies can be based on standard methods for multistate models. However, the independence assumption is often violated, such as in multicenter studies, which makes standard methods improper. This work addresses the issue of nonparametric estimation and two‐sample testing for the population‐averaged transition and state occupation probabilities under general multistate models with cluster‐correlated, right‐censored, and/or left‐truncated observations. The proposed methods do not impose assumptions regarding the within‐cluster dependence, allow for informative cluster size, and are applicable to both Markov and non‐Markov processes. Using empirical process theory, the estimators are shown to be uniformly consistent and to converge weakly to tight Gaussian processes. Closed‐form variance estimators are derived, rigorous methodology for the calculation of simultaneous confidence bands is proposed, and the asymptotic properties of the nonparametric tests are established. Furthermore, I provide theoretical arguments for the validity of the nonparametric cluster bootstrap, which can be readily implemented in practice regardless of how complex the underlying multistate model is. Simulation studies show that the performance of the proposed methods is good, and that methods that ignore the within‐cluster dependence can lead to invalid inferences. Finally, the methods are illustrated using data from a multicenter randomized controlled trial.
Keywords: multistate model, multicenter, nonparametric test, state occupation probability, transition probability
1. INTRODUCTION
Frequently, clinical trials and observational studies involve complex multistate event histories. An example is cancer clinical trials where patient event histories typically involve three or more clinical states, such as “cancer‐free,” “cancer,” and “death.” Another example is observational studies on coronavirus disease 2019 (COVID‐19) progression. In such studies, patients may be hospitalized, then placed to an intensive care unit, on a ventilator, be discharged from the hospital, or die. With independent observations, nonparametric estimation of the transition probabilities for such multistate processes can be performed using the Aalen‐Johansen estimator (Aalen and Johansen, 1978). Calculation of confidence bands and nonparametric two‐sample tests can be performed using the approaches by Bluhmki et al. (2018) and Bakoyannis (2020), respectively.
The independent observations assumption is often violated in medical research. This is typical in multicenter studies, where the events of individuals within the same center are expected to be associated. Such a multicenter study was the European Organization for Research and Treatment of Cancer (EORTC) trial 10854, which evaluated the effectiveness of the combination of surgery with polychemotherapy compared to surgery alone as a treatment for early breast cancer, and involved 15 hospitals (ie, centers/clusters). Another example is studies involving multiple family members. For example, in a study of COVID‐19 progression, members of the same family are expected to have correlated outcomes. When the observations exhibit within‐cluster dependence, the traditional Greenwood standard error estimators for the transition probabilities, the simultaneous confidence bands by Bluhmki et al. (2018), and the nonparametric tests by Bakoyannis (2020) are not valid.
Several parametric methods have been proposed for the analysis of multistate models based on clustered observations (Cook et al., 2004; Li and Zhang, 2015; Yiu et al., 2018). However, these methods impose strong parametric assumptions about the underlying multistate processes that are expected to be violated in practice. Chen and Zhou (2013) proposed a semiparametric random‐effects approach for cluster‐specific inference about nonhomogeneous Markov processes. This approach, which also allows for nonignorable missingness, utilizes a Monte Carlo Expectation Maximization (MCEM) algorithm. Recently, O'Keeffe et al. (2018) proposed a nonparametric approach for cluster‐specific inference based on correlated observations from a general multistate model. This approach, similar to the Chen and Zhou (2013) method, accounts for the within‐cluster dependence by incorporating random effects. Estimation in this case relies on numerical integration. There are no other nonparametric approaches for clustered multistate data that utilize random effects that I am aware of. The current semiparametric and nonparametric proposals for clustered observations that utilize random effects (Chen and Zhou, 2013; O'Keeffe et al., 2018) have several limitations. First, they impose strong parametric assumptions on the random effects. Also, these random effects introduce only a restrictive positive within‐cluster association. Second, they tend to be computationally intensive, which may restrict their use with larger data sets. Third, they do not establish the asymptotic properties of the proposed estimators for the transition probabilities. Moreover, they do not provide methodology for confidence bands and nonparametric hypothesis testing. Fourth, they do not consider the case of informative cluster size (ICS), where there is an association between cluster size and observed events. Finally, in many applications, population‐averaged inference is more scientifically relevant than cluster‐specific inference. This is the case with the EORTC trial 10854. To our knowledge, only Lan et al. (2017) proposed a method for nonparametric population‐averaged inference about state occupation probabilities in general multistate models, allowing for ICS. However, this approach is for current status data and not the usual right‐censored or left‐truncated multistate data. Moreover, the asymptotic properties of this method have not been established, and there is no methodology for confidence bands and nonparametric tests.
To the best of my knowledge, the issue of nonparametric population‐averaged inference for event probabilities in general multistate models with cluster‐correlated, right‐censored, and/or left‐truncated observations has not been addressed so far. In this work, I address this issue by proposing rigorous estimators and methodology for standard error estimation, simultaneous confidence bands, and nonparametric two‐sample Kolmogorov‐Smirnov–type tests. The asymptotic properties of the proposed methods are rigorously established using modern empirical process theory and closed‐form variance estimators are provided. In addition, I establish the validity of the nonparametric cluster bootstrap and show how it can be used for the calculation of simultaneous confidence bands and P‐values. This is particularly useful in practice, since it provides a convenient way to conduct inference using off‐the‐shelf software. The proposed methods do not impose restrictive parametric assumptions or assumptions regarding the within‐cluster dependence. I additionally allow for ICS and nonhomogeneous processes that are non‐Markov. Simulation studies show that the methods perform well and that standard methods for independent observations provide severely under‐estimated standard errors and confidence bands with a poor coverage rate. Finally, the methods are illustrated using data from the multicenter EORTC trial 10854.
2. NONPARAMETRIC ESTIMATION
2.1. Nonhomogeneous Markov processes
Consider a Markov multistate process , for some , with a finite set of states and a subset that includes the possible absorbing states (eg, death). For situations without absorbing states set . The Markov assumption will be relaxed later in Section 2.6. Let be the number of direct transitions from state h to state j, for , which occurred by time t (in the absence of right censoring and left truncation). Also, let be the at‐risk process for state h, with if the process is at state h just before time t, and otherwise. A key quantity of interest is the transition probability which is defined as , , , where is the event history prior to time s. The subindex 0 is used to indicate the true (unknown) parameter value. Note that the conditional independence from the prior history above is the Markov assumption. Another key quantity is the cumulative transition intensity which is defined as , , , with , by the Kolmogorov forward equation (Aalen et al., 2008). The matrix , , of transition probabilities can be defined based on the matrix of cumulative transition intensities as  , where
, where 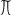 is the product integral and is the identity matrix. Finally, the state occupation probability is defined as , , .
is the product integral and is the identity matrix. Finally, the state occupation probability is defined as , , .
2.2. Clustered observations
Suppose that a study involves n clusters of observations of the Markov process , with observations in the ith cluster. The observable data are the possibly right‐censored and/or left‐truncated counting processes and at‐risk processes , for and . The process represents the number of observed direct transitions from state h to state j, , in [0, t] (which occurred after the left truncation time and prior to the right censoring time), for the mth observation in the ith cluster. The process is equal to 1 if the mth observation in the ith cluster is at state h and under observation just before time t, and otherwise. The corresponding complete (ie, not right‐censored and not left‐truncated) counterparts are denoted as and . The processes and are assumed i.i.d. across clusters. However, an arbitrary within‐cluster dependence for the individual observations is allowed. In this article, it is assumed that the cluster sizes , are either constant or i.i.d. random positive integers. Furthermore, for the latter case, the counting and at‐risk processes are allowed to depend on cluster size (informative or nonignorable cluster size). For the sake of generality, is treated as random and informative in this article. However, the methods presented here are trivially applicable to simpler situations where cluster size is either noninformative or fixed. The right censoring and left truncation times are assumed to be independent of both multistate process of interest and cluster size . Also, the main i.i.d. observations assumption implies that, marginally, censoring and truncations times are i.i.d. across clusters. However, between‐cluster heterogeneity (eg, different hospitals can have different censoring distributions, conditionally on some hospital‐specific random effect) and an arbitrary within‐cluster dependence are allowed for censoring and truncation.
When cluster size is random and informative, there are typically two populations of interest (Seaman et al., 2014). The first one is the population of all cluster members (ACM), eg, the population of all teeth in dental studies or the population of all patients in multicenter studies. Larger clusters are overrepresented in this population. The second is the population of typical cluster members (TCM). This population is formed by selecting one representative member from each cluster (eg, a typical tooth from each patient in dental studies or a typical patient from each center in multicenter studies). Thus, each cluster is equally represented in this population. The population‐averaged state occupation probabilities over the ACM population are defined, similar to marginal generalized linear models (Seaman et al., 2014), as , , , for a randomly selected cluster member m. These can be seen as weighted averages where larger clusters have a larger influence on these probabilities. The population‐averaged state occupation probabilities over the TCM population are defined as , , for a randomly selected cluster member m. In this case, all clusters contribute a single (randomly selected) member and, therefore, all clusters have the same weight on the resulting probabilities. The two versions of population‐averaged transition probabilities can be defined similarly. This leads to the population‐averaged cumulative transition intensities , , with , and , , with . Based on the corresponding matrices and , the population‐averaged transition probability matrices can be expressed as the product integrals (by the Kolmogorov forward equations) 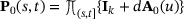 and
and 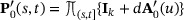 , . If cluster size is either noninformative or constant then and , for . However, if cluster size is informative, it is expected that and , . If the probability of a particular event over the ACM population is higher (lower) than the probability of that event over the TCM population, then the proportion of this event is larger (smaller) in larger clusters. This is because a population‐averaged probability over the ACM population is dominated by larger clusters under ICS. Depending on the setting, the difference between the two probabilities may be attributed to systematic differences in important individuals' characteristics between larger and smaller clusters of observations. For example, in multicenter studies, patients with more advanced disease, and thus more prone to poor health outcomes, may tend to choose (or be advised to attend) larger clinics. When clusters are health care facilities or providers, another reason for the difference between the two population‐averaged probabilities may be systematic differences in the performance of facilities or providers with more patients.
, . If cluster size is either noninformative or constant then and , for . However, if cluster size is informative, it is expected that and , . If the probability of a particular event over the ACM population is higher (lower) than the probability of that event over the TCM population, then the proportion of this event is larger (smaller) in larger clusters. This is because a population‐averaged probability over the ACM population is dominated by larger clusters under ICS. Depending on the setting, the difference between the two probabilities may be attributed to systematic differences in important individuals' characteristics between larger and smaller clusters of observations. For example, in multicenter studies, patients with more advanced disease, and thus more prone to poor health outcomes, may tend to choose (or be advised to attend) larger clinics. When clusters are health care facilities or providers, another reason for the difference between the two population‐averaged probabilities may be systematic differences in the performance of facilities or providers with more patients.
In the EORTC 10854 trial, the population‐averaged probabilities of cancer and death over the ACM population provide information about the effectiveness of the combined intervention on a typical patient from the population of all patients. In these probabilities, hospitals with more patients are naturally overweighted as they account for a larger portion of patients in the population. On the other hand, the population‐averaged probabilities over the TCM population provide information about the effectiveness of the combined intervention on a typical patient from a typical hospital setting. These probabilities weight each hospital equally and, thus, they are not dominated by hospitals with more patients, which may have different performance and/or patient characteristics compared to those with less patients. Thus, they provide information about effectiveness on a typical patient from an average performing hospital.
2.3. Estimation of transition probabilities
To nonparametrically estimate the population‐averaged transition probability matrices and , we first estimate the population‐averaged cumulative transition intensity matrices and , and then utilize the relationships 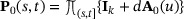 and
and 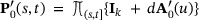 , . Let , for , and , for . In Web Appendix B.2, it is shown that , . Therefore, a natural estimator of is , , . Similar arguments lead to the conclusion that , , and thus a natural nonparametric estimator of is , , . Then, the proposed plug‐in estimators of and are
, . Let , for , and , for . In Web Appendix B.2, it is shown that , . Therefore, a natural estimator of is , , . Similar arguments lead to the conclusion that , , and thus a natural nonparametric estimator of is , , . Then, the proposed plug‐in estimators of and are 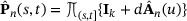 and
and 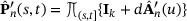 , where and are the matrices with off‐diagonal elements and , and diagonal elements and , , respectively. In the special case with fixed cluster size, . The estimator can be seen as the working independence Aalen‐Johansen estimator. We call the weighted by cluster size working independence Aalen‐Johansen estimator. The following theorem states the uniform consistency of and .
, where and are the matrices with off‐diagonal elements and , and diagonal elements and , , respectively. In the special case with fixed cluster size, . The estimator can be seen as the working independence Aalen‐Johansen estimator. We call the weighted by cluster size working independence Aalen‐Johansen estimator. The following theorem states the uniform consistency of and .
Theorem 1
Suppose that conditions C1 to C5 in Web Appendix B.1 hold and define the norm for some matrix . Then, for any , as
The proof of Theorem 1 can be found in Web Appendix B.2. Note that, even though the standard Aalen‐Johansen estimator is consistent for , the usual standard error estimators are invalid with clustered data as they ignore the within‐cluster dependence.
Next, the asymptotic distributions of the estimators are studied. Let and denote the influence functions of the estimators and , , respectively. Explicit formulas for the influence functions are provided in Web Appendix A. Next, define the estimated process , for and , where , , are i.i.d. standard normal random variables, and is the estimated version of (see Web Appendix A for details). Similarly, define the estimated process , for and . These estimated processes will be used for the calculation of simultaneous confidence bands. An alternative method for inference is the nonparametric cluster bootstrap. Calculation of a bootstrap version of and , denoted by and , respectively, can be easily performed by randomly sampling n clusters with replacement from the original data set, and then calculating the proposed estimators based on the resulting bootstrap data set.
Theorem 2
Suppose that conditions C1 to C6 in Web Appendix B.1 hold. Then, for any , , and ,
- (i)
and , . Moreover, the classes of functions and are P‐Donsker;
- (ii)
and in , conditionally on the observed data, where is the limiting process of ;
- (iii)
and in , conditionally on the observed data, where is the limiting process of .
The proof of Theorem 2 can be found in Web Appendix B.3. In Web Appendix B.5, condition C6 is relaxed. By Theorem 2, and converge weakly to the mean‐zero Gaussian processes and , respectively. The covariance functions of and at the time points t 1 and t 2 are and . These covariance functions can be consistently estimated by and , respectively. Theorem 2 also implies that the asymptotic distributions of the estimators can be easily approximated by generating realizations of the processes and (through simulating a large number of sets of standard normal variates ) or by cluster bootstrap realizations and .
These results can be used for the calculation of pointwise confidence intervals and simultaneous confidence bands. For these procedures consider a differentiable transformation g, such as , to ensure that the limits of the confidence interval and the confidence band lie in the interval (0,1). For the calculation of confidence bands for , , , and , it is useful to consider a weight function that converges uniformly (in probability) to a bounded nonnegative function on an interval . A choice is , where, as argued above, is consistent for the true asymptotic variance of . By Theorem 2, the functional delta method, and the continuous mapping theorem it follows that and , have the same asymptotic distribution. The percentile of this distribution, denoted by , can be estimated as the sample percentile of a large number of simulation realizations of the process . Alternatively, one can use cluster bootstrap realizations . Based on this , a simultaneous confidence band can be calculated as , . In general, simultaneous confidence bands can be unstable toward the earlier or later times of the observation interval (Nair, 1984). To avoid this issue in practice it is suggested to restrict the domain of the confidence band to a set with limits the 10th and 90th or the 5th and 95th percentile of the distribution of transition times from state h to state j. Calculation of confidence bands for can be performed similarly.
2.4. Estimation of state occupation probabilities
Natural estimators of the state occupation probabilities and are , , where , and , . In these estimators, is a consistent estimator of the probability of being under observation at time , denoted as π0. Here, it is also assumed that . In the absence of left truncation . In the special case with fixed cluster size, , . Based on Theorem 1, it can be easily shown that and are uniformly consistent.
In light of Theorem 2, the state occupation probability estimators are asymptotically linear of the form , , and , , , where the influence functions and are provided in Web Appendix A. It follows that, and converge weakly to zero‐mean Gaussian processes, with covariance functions and , for . As with the case of transition probabilities, the estimated influence functions can be used to consistently estimate these covariance functions. Moreover, the estimated processes and and the cluster bootstrap processes and can be used to calculate confidence bands, as described for the transition probabilities.
2.5. Two‐sample Kolmogorov‐Smirnov–type tests
In many settings, the scientific interest is on comparing the transition probabilities for a particular transition, or the state occupation probabilities for a particular state, between two groups, say groups 1 and 2. For example, consider a multicenter randomized controlled trial where the goal is to assess whether the probability of cancer relapse differs between those receiving an experimental treatment and those receiving a control treatment. Depending on what is the most relevant population‐averaged quantity for the given context, the null hypothesis in terms of the transition probability is either or , for some . In terms of the state occupation probability, the null hypothesis is either or . Let and be the number of observations from the ith cluster, which belong to groups 1 and 2, respectively, with , . Here, the situation where is considered, that is each cluster contains at least one observation from both groups. Finally, let , , and , be the counting and at‐risk processes for the mth observation in the pth group in the ith cluster.
Based on this setup, define the estimators of the pointwise between‐group difference of the transition probabilities as , , where , , is the estimator of from the pth group and , , where , , is the estimator of from the pth group, for some . Similarly, define the differences between the population‐averaged state occupation probabilities as , , where , , is the estimator of from the pth group, and , , where , , is the estimator of from the pth group. The corresponding nonparametric cluster bootstrap realizations of the above differences are denoted by , , , and . It is important to note that these nonparametric cluster bootstrap realizations are generated by randomly sampling n clusters with replacement, as described in Sections 2.3. Based on these differences, define the Kolmogorov‐Smirnov–type test statistics , for some appropriate weight function and some , and . The corresponding tests for and , denoted by and , are defined in the same manner. The weights , , , and are assumed to be uniformly consistent (in probability) for the nonnegative and uniformly bounded fixed functions , , , and . The importance of the weight functions lies on the fact that they can restrict the comparison interval to a set of times where both groups under comparison have nonzero observations at risk for the transition of interest. An example of such a weight function is , where is a transient state that can be visited during the transition and , for the group , with denoting the sum of the at‐risk process for state h in the ith cluster and the pth group. Similarly, this type of weight can be defined for the state occupation probabilities as . The weights and are defined similarly. The weight functions can also be used to assign less weight to observation times with a smaller number of observations, where the estimated difference tends to be unstable. An example of such weight functions is and . The corresponding weights and can be similarly defined by replacing with , for the group . In practice, the use of this latter type of weight functions is suggested. The calculation of P‐values can be based on nonparametric cluster bootstrap or the influence functions for the group‐specific estimators and , . These influence functions, denoted by and , respectively, are provided in Web Appendix A. Now, define the estimated processes , , for some , where , are independent standard normal variables and the influence functions are estimated as described in Web Appendix A, and , . Similarly, one can define the estimated processes and which correspond to the tests for and .
Theorem 3
Suppose that conditions C1, C2, C3′, C4′, C5, and C6′ in Web Appendix B.1 hold. Then, under the null hypothesis and for any , , and ,
- (i)
in , where is a tight zero‐mean Gaussian process with covariance function , for . Moreover, and in , conditionally on the observed data.
- (ii)
in , where is a tight zero‐mean Gaussian process with covariance function , for . Moreover, and in , conditionally on the observed data.
The proof of Theorem 3 can be found in Web Appendix B.4. There, it is also shown that the tests are consistent against any fixed alternative hypothesis. A relaxation of condition C6′ is considered in Web Appendix B.5. It can be easily shown that a similar version of Theorem 3 holds for the differences and . Based on Theorem 3 and the continuous mapping theorem it follows that, under the null hypothesis, , for any , and . These asymptotic null distributions are complicated to use in practice for the calculation of P‐values. However, by Theorem 3, one can simulate realizations from these null distributions by simulating a sufficiently large number of sets of standard normal variables and then calculating samples from these null distributions as and . Alternatively, one can use a sufficiently large number of nonparametric cluster bootstraps , , and , and, then, calculate realizations from the asymptotic null distributions as and . The P‐value can then be estimated as the proportion of these simulation realizations, which are greater than or equal to the actual value of the test statistic based on the observed data.
2.6. Non‐Markov processes
When the multistate process is non‐Markov, the transition probabilities and transition intensities depend on the prior event history . In this case, the population‐averaged transition intensities defined in Section 2.2 are the partly conditional transition intensities, which are not conditional on the prior history . Such marginal intensities have been argued to be meaningful quantities even for non‐Markov processes because they describe the marginal (ie, unconditional on the prior history) behavior of the process (Datta and Satten, 2001; Glidden, 2002). With independent observations from a non‐Markov process, Datta and Satten (2001) showed that the Nelson‐Aalen estimator of the cumulative transition intensities and the Aalen‐Johansen estimator of the state occupation probabilities are consistent for the corresponding marginal quantities. Using the same arguments to those presented by Datta and Satten (2001) it can be shown that, with clustered observations from a non‐Markov process, the proposed estimators of the (marginal) population‐averaged cumulative transition intensities and state occupation probabilities are consistent. Similarly, as in the case with independent observations (Titman, 2015), the proposed estimators and are consistent for the population‐averaged and under right censoring, even for non‐Markov processes. In the presence of left truncation, consistent estimation requires calculating and using only the subset of individuals who were under observation at . However, for , the proposed estimators and are not consistent in general for non‐Markov processes, as in the case with independent observations (Titman, 2015). In such cases, following the idea of landmarking by Putter and Spitoni (2018), I propose estimating and , for and , via the proposed estimators but using only individuals who were at the transient state h at time s. More precisely, I propose using the modified counting and at‐risk processes , , and , , instead of the original and , when estimating and , . These landmark estimators can be shown to be consistent using the same arguments to those used in Putter and Spitoni (2018). Inference with non‐Markov processes can be performed as indicated in Theorems 2 and 3, with the exception that the influence functions for the landmark versions of and involve the modified processes , , and , . A remark on using Theorems 2 and 3 for inference with non‐Markov processes is provided in Web Appendix B.6.
3. SIMULATION STUDIES
To evaluate the small‐sample performance of the proposed methods I conducted a series of simulation experiments under a non‐Markov illness‐death model with states and absorbing state , in a study with ICS. These experiments focused on the population‐averaged probabilities , , , and . Note that, for the illness‐death model where state 1 (healthy) is the unique initial state, and . Scenarios with clusters were considered. These sample sizes are considered small or relatively small. The cluster sizes , , were simulated from either of the discrete uniform distributions and , producing scenarios with 5 to 15 and 10 to 30 observations per cluster, respectively. To simulate non‐Markov illness‐death processes, which are correlated within clusters, cluster‐specific frailties , , were simulated from the Gamma distribution with shape and scale parameters equal to 1. Conditionally on the frailty values and the cluster sizes , the non‐Markov illness‐death processes were simulated based on the cumulative transition intensities , , and , . Note that the dependence of on cluster size produced data with ICS. The resulting population‐averaged probabilities of interest are depicted in Figure 1 in Web Appendix D. In this simulation study, two scenarios regarding right censoring and left truncation were considered; the first involved right censoring only while the second considered both right censoring and left truncation. In both scenarios, independent right censoring times were simulated from the uniform distribution U(0, 3). In the first scenario, the simulation settings led on average to 57.5% right‐censored observations (a), 24.4% observations at the illness state (b) (45.9% of those arrived later at the death state), and 18.1% at the death state (c) without a prior visit to the illness state. In the second scenario, left truncation times were independently simulated from the beta distribution Beta(1,2). For the simulations evaluating the estimators of and , this data generation scheme led on average to 67% of the individuals being under observation and at state 1 at time . For simulations evaluating state occupation probability estimators, left truncation time was set to 0 with a probability equal to 2/3. This is because estimation of and for non‐Markov processes under left truncation, involves only individuals who were under observation at time (see Section 2.6). Therefore, in both cases, around 33% of the observations were excluded from the analysis due to left truncation. Under this setup, a two‐arm multicenter randomized controlled trial was also simulated with a 1:1 arm allocation ratio within clusters. To simulate data under the alternative hypothesis, the cumulative intensity , , was assumed depending on the treatment arm p. Estimation of the transition probabilities was performed using the landmark version of the proposed estimators as described in Section 2.6. Simultaneous confidence bands and P‐values from the Kolmogorov‐Smirnov–type tests were based on 1000 simulated sets of standard normal variates or 1000 nonparametric cluster bootstrap realizations. Moreover, as described in Section 2.3, the range of the confidence bands was restricted for each data set to the 10th and 90th percentile of the distribution of transition times from state 1 to state 2. We also present simulation results for the one‐sample case under the working‐independence Aalen‐Johansen estimator using the usual Greenwood standard error estimates and a wild bootstrap approach for confidence bands that ignores the within‐cluster dependence.
FIGURE 1.

Overall population‐averaged state occupation probabilities of the three states (black lines) over the population of all hospital patients in the multicenter EORTC trial 10854, along with the 95% simultaneous confidence bands (gray areas)
Pointwise simulation results for the state occupation probability estimators under right censoring are presented in Tables 1 and 2. Ignoring the within‐cluster dependence was associated with underestimated standard errors and poor coverage probabilities of the 95% confidence intervals. Also, the working independence Aalen‐Johansen estimator of exhibited a small bias as a result of the ICS (relative bias around −7%). The proposed estimators of and were both virtually unbiased, the standard error estimates based on the influence functions and the nonparametric cluster bootstrap were both close to the Monte Carlo standard deviation (MCSD) of the estimates, and the corresponding 95% pointwise confidence intervals were close to the nominal level, except for the case with a very small number of clusters (n=20) and only 5 to 15 individuals per cluster. It is important to note that the weighted by cluster size working independence estimator exhibited a larger MCSD compared to the working independence estimator (variance ratio range: 1.15 to 1.21), as a result of the additional variability of the weights.
TABLE 1.
Simulation results for the analysis of and , where τ0.4 is the 40th percentile of the follow‐up time, based on the standard approach which ignores the within‐cluster dependence (naïve) and the proposed method with (i) the influence function‐based variance estimator (IF) and (ii) the nonparametric cluster bootstrap (CB)
|
|
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n |
|
Method | Biasa | MCSDa | ASEa | CP | Biasa | MCSDa | ASEa | CP | ||
| 20 |
|
Naïve | 0.006 | 3.229 | 2.625 | 0.890 | −1.022 | 3.226 | 2.623 | 0.859 | ||
| IF | 0.006 | 3.229 | 3.018 | 0.927 | −0.063 | 3.517 | 3.311 | 0.926 | ||||
| CB | 0.006 | 3.229 | 3.040 | 0.928 | −0.063 | 3.517 | 3.316 | 0.923 | ||||
|
|
Naïve | 0.069 | 2.559 | 1.857 | 0.842 | −0.928 | 2.558 | 1.855 | 0.816 | |||
| IF | 0.069 | 2.559 | 2.483 | 0.939 | 0.077 | 2.787 | 2.702 | 0.940 | ||||
| CB | 0.069 | 2.559 | 2.494 | 0.935 | 0.077 | 2.787 | 2.698 | 0.939 | ||||
| 40 |
|
Naïve | 0.105 | 2.204 | 1.866 | 0.909 | −0.939 | 2.199 | 1.863 | 0.866 | ||
| IF | 0.105 | 2.204 | 2.196 | 0.944 | 0.080 | 2.403 | 2.411 | 0.948 | ||||
| CB | 0.105 | 2.204 | 2.198 | 0.943 | 0.080 | 2.403 | 2.407 | 0.947 | ||||
|
|
Naïve | 0.006 | 1.811 | 1.312 | 0.846 | −1.003 | 1.808 | 1.310 | 0.779 | |||
| IF | 0.006 | 1.811 | 1.782 | 0.945 | −0.012 | 1.940 | 1.941 | 0.946 | ||||
| CB | 0.006 | 1.811 | 1.786 | 0.944 | −0.012 | 1.940 | 1.940 | 0.945 | ||||
| 80 |
|
Naïve | −0.037 | 1.557 | 1.314 | 0.903 | −1.083 | 1.551 | 1.312 | 0.820 | ||
| IF | −0.037 | 1.557 | 1.557 | 0.942 | −0.055 | 1.699 | 1.715 | 0.940 | ||||
| CB | −0.037 | 1.557 | 1.556 | 0.942 | −0.055 | 1.699 | 1.711 | 0.940 | ||||
|
|
Naïve | 0.044 | 1.287 | 0.929 | 0.844 | −0.962 | 1.286 | 0.928 | 0.732 | |||
| IF | 0.044 | 1.287 | 1.271 | 0.945 | 0.025 | 1.399 | 1.382 | 0.944 | ||||
| CB | 0.044 | 1.287 | 1.273 | 0.944 | 0.025 | 1.399 | 1.382 | 0.946 | ||||
Abbreviations: ASE, average estimated standard error; CP, coverage probability; , discrete uniform distribution of the cluster size; MCSD, Monte Carlo standard deviation of the estimates; n, number of clusters.
Note. Results under right censoring.
Indicates × 102.
TABLE 2.
Simulation results for the analysis of and , where τ0.6 is the 60th percentile of the follow‐up time, based on the standard approach that ignores the within‐cluster dependence (naïve) and the proposed method with (i) the influence function–based variance estimator (IF) and (ii) the nonparametric cluster bootstrap (CB)
|
|
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n |
|
Method | Biasa | MCSDa | ASEa | CP | Biasa | MCSDa | ASEa | CP | ||
| 20 |
|
Naïve | 0.160 | 3.657 | 3.040 | 0.904 | −0.939 | 3.656 | 3.033 | 0.888 | ||
| IF | 0.160 | 3.657 | 3.348 | 0.921 | 0.077 | 3.963 | 3.651 | 0.924 | ||||
| CB | 0.160 | 3.657 | 3.378 | 0.916 | 0.077 | 3.963 | 3.663 | 0.920 | ||||
|
|
Naïve | 0.116 | 2.731 | 2.146 | 0.869 | −0.940 | 2.740 | 2.140 | 0.854 | |||
| IF | 0.116 | 2.731 | 2.679 | 0.935 | 0.078 | 2.978 | 2.899 | 0.935 | ||||
| CB | 0.116 | 2.731 | 2.693 | 0.940 | 0.078 | 2.978 | 2.899 | 0.933 | ||||
| 40 |
|
Naïve | 0.015 | 2.360 | 2.143 | 0.935 | −1.060 | 2.364 | 2.140 | 0.896 | ||
| IF | 0.015 | 2.360 | 2.399 | 0.955 | 0.027 | 2.592 | 2.635 | 0.953 | ||||
| CB | 0.015 | 2.360 | 2.407 | 0.957 | 0.027 | 2.592 | 2.636 | 0.953 | ||||
|
|
Naïve | 0.035 | 1.956 | 1.513 | 0.866 | −1.020 | 1.943 | 1.509 | 0.818 | |||
| IF | 0.035 | 1.956 | 1.915 | 0.936 | −0.011 | 2.100 | 2.075 | 0.937 | ||||
| CB | 0.035 | 1.956 | 1.919 | 0.941 | −0.011 | 2.100 | 2.075 | 0.936 | ||||
| 80 |
|
Naïve | −0.063 | 1.745 | 1.513 | 0.913 | −1.152 | 1.738 | 1.510 | 0.845 | ||
| IF | −0.063 | 1.745 | 1.714 | 0.943 | −0.084 | 1.894 | 1.885 | 0.949 | ||||
| CB | −0.063 | 1.745 | 1.716 | 0.945 | −0.084 | 1.894 | 1.885 | 0.948 | ||||
|
|
Naïve | 0.076 | 1.436 | 1.073 | 0.856 | −0.972 | 1.433 | 1.070 | 0.775 | |||
| IF | 0.076 | 1.436 | 1.369 | 0.939 | 0.045 | 1.543 | 1.487 | 0.942 | ||||
| CB | 0.076 | 1.436 | 1.372 | 0.940 | 0.045 | 1.543 | 1.488 | 0.945 | ||||
Abbreviations: ASE, average estimated standard error; CP, coverage probability; n, number of clusters; , discrete uniform distribution of the cluster size; MCSD: Monte Carlo standard deviation of the estimates.
Note. Results under right censoring.
Indicates × 102.
Simulation results regarding the coverage probabilities of the 95% simultaneous confidence bands are presented in Table 3. The wild bootstrap approach for confidence band calculation that ignores the within‐cluster dependence exhibited poor coverage rates in all cases. This phenomenon was more pronounced for the population‐averaged state occupation probability over the TCM population, and is attributed to the bias of the working independence Aalen‐Johansen estimator in addition to the variability underestimation. On the contrary, the coverage probabilities of the proposed approaches were close to the nominal level, except for the case with only 20 clusters and 5 to 15 observations per cluster, where the coverage rate was somewhat lower. Finally, simulation results about the empirical rejection rates of the proposed tests are presented in Table 4. Under H 0, the type I error rate of the tests was close to the nominal level in all cases. Under H 1, the empirical power was increasing with sample size and this provides numerical evidence for the consistency of the proposed tests.
TABLE 3.
Simulation results regarding the coverage probabilities of the 95% simultaneous confidence bands for and based on the standard method that ignores the within‐cluster dependence (naïve) and the proposed method with (i) the estimated processes and (IF) and (ii) the nonparametric cluster bootstrap (CB)
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|
| n |
|
Naïve | IF | CB | Naïve | IF | CB | ||
| 20 |
|
0.856 | 0.922 | 0.930 | 0.826 | 0.917 | 0.911 | ||
|
|
0.798 | 0.944 | 0.952 | 0.771 | 0.946 | 0.938 | |||
| 40 |
|
0.892 | 0.948 | 0.951 | 0.849 | 0.945 | 0.940 | ||
|
|
0.802 | 0.941 | 0.942 | 0.750 | 0.945 | 0.946 | |||
| 80 |
|
0.878 | 0.945 | 0.943 | 0.788 | 0.940 | 0.942 | ||
|
|
0.820 | 0.941 | 0.944 | 0.689 | 0.945 | 0.940 | |||
Abbreviations: : discrete uniform distribution of the cluster size; n, number of clusters.
Note. Results under right censoring.
TABLE 4.
Simulation results regarding the empirical type I error (H 0) and the empirical power (H 1) of the proposed two‐sample Kolmogorov‐Smirnov–type tests for and at the level
| , | , | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| H 0 | H 1 | H 0 | H 1 | |||||||
| n |
|
IF | CB | IF | CB | IF | CB | IF | CB | |
| 20 |
|
0.045 | 0.042 | 0.352 | 0.339 | 0.049 | 0.050 | 0.331 | 0.337 | |
|
|
0.040 | 0.039 | 0.634 | 0.625 | 0.044 | 0.040 | 0.598 | 0.601 | ||
| 40 |
|
0.044 | 0.041 | 0.666 | 0.659 | 0.037 | 0.039 | 0.612 | 0.603 | |
|
|
0.048 | 0.046 | 0.905 | 0.906 | 0.044 | 0.046 | 0.874 | 0.873 | ||
| 80 |
|
0.048 | 0.046 | 0.916 | 0.917 | 0.049 | 0.047 | 0.870 | 0.864 | |
|
|
0.053 | 0.053 | 0.995 | 0.994 | 0.059 | 0.055 | 0.991 | 0.990 | ||
Abbreviations: , distribution of the cluster size; n: number of clusters.
Note. Significance levels were calculated based on either the estimated processes and (IF) or the nonparametric cluster bootstrap (CB). Results under right censoring.
Simulation results regarding the estimators of the population‐averaged transition probabilities and under right censoring are presented in Web Appendix D.1. Results under both right censoring and left truncation are presented in Web Appendix D.2. Finally, simulation experiments evaluating the proposed methods under a larger cluster size variability (cluster size range: 5 to 200) and a very small number of clusters ( and 20), are presented in Web Appendix D.3. In all cases, the naïve methods performed poorly. However, this poor performance was less pronounced under both right censoring and left truncation as a result of the fact that, in this case, there were fewer observations per cluster, which led to a less pronounced intracluster dependence issue. The performance of the proposed methods was satisfactory in all cases, with the exception of somewhat lower coverage probabilities (reaching 91% in a few cases) with a very small number of clusters.
4. DATA EXAMPLE
The proposed methods are illustrated using data from the EORTC trial 10854 (Van der Hage et al., 2001). In total, 2792 early breast cancer patients from 15 hospitals (clusters) were recruited in this trial. Of them, 1398 (50.1%) were randomly assigned to the group receiving the combination therapy approach. In this multicenter trial, cluster sizes ranged from 6 to 902 patients. The trial involved only clusters and thus the analysis based on the proposed large sample inference methods may provide biased results. In this analysis we assumed that the data from the different hospitals are i.i.d. However, the number of patients in one hospital might be correlated with the number of patients in another hospital. This could lead to biased variance estimation and incorrect P‐values. After surgery, 1146 (41.0%) patients experienced locoregional relapse, distant metastasis, or secondary cancer, and 810 (29.0%) died throughout the follow‐up period. Among the deceased patients, 710 (87.7%) died after having experienced a locoregional relapse, distant metastasis, or secondary cancer, while the remaining 100 deceased patients died without prior evidence for these events. The patient event history in this trial can be described by an illness‐death model with the states “cancer‐free” (state 1), “cancer” (state 2), and “death” (state 3). Throughout the follow‐up period, 1546 (55.4%) patients were right‐censored while being in the “cancer‐free” state and 436 (15.6%) were right‐censored while being in the “cancer” state. There was no left truncation in this data set. In this analysis, the focus was on the between‐arm comparison of the population‐averaged state occupation probabilities of cancer and (for the population undergoing surgery only), and and (for the population receiving the combination of surgery plus polychemotherapy). The overall state occupation probability estimates for the three states over the population of all hospital patients along with the associated 95% simultaneous confidence bands are presented in Figure 1. These confidence bands were calculated based on 1000 nonparametric cluster bootstrap realizations. Figure 1 provides significant information about the natural history of early breast cancer patients undergoing surgery. The corresponding probabilities for the population of typical hospital patients were approximately the same, with the exception that the probability of cancer was slightly lower in this case (data not shown). The arm‐specific state occupation probabilities of cancer for both population of all hospital patients and population of typical hospital patients are presented in Figure 2. To compare these population‐averaged probabilities between arms, the proposed Kolmogorov‐Smirnov–type test was used based on 1000 nonparametric cluster bootstrap realizations. The tests for both versions of population‐averaged probabilities were not statistically significant at the level and, therefore, the null hypothesis that the population‐averaged probabilities of cancer do not differ between arms cannot be rejected. Among those in the surgery only group, the estimated population‐averaged probability of cancer over the population of typical hospital patients was lower compared to that for the population of all hospital patients (Figure 2). This indicates that larger hospitals had more cancer events among patients with surgery only, which may be attributed to the fact that patients with more advanced disease choose (or are advised to attend) larger hospitals. To evaluate this difference, the modified Kolmogorov‐Smirnov–type test described in Web Appendix C was used. The result of this test was statistically significant (P‐value = .046), which provides evidence for ICS in this group. The corresponding test for the group of patients receiving the combination therapy approach was not statistically significant (P‐value = .416).
FIGURE 2.
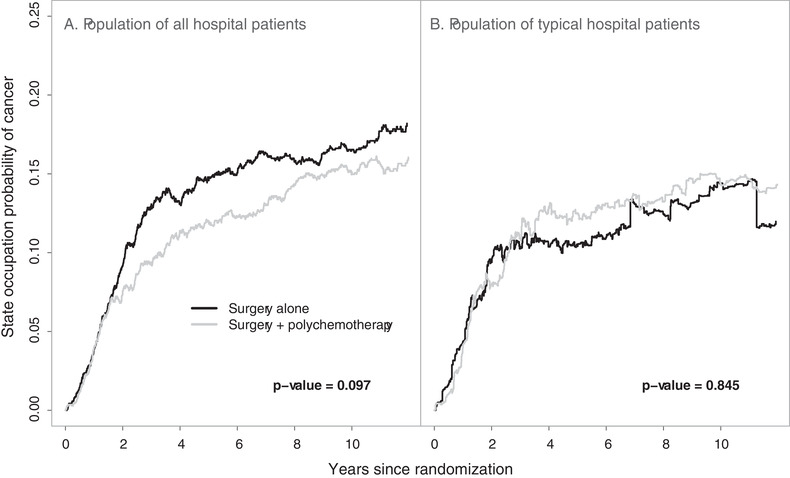
Population‐averaged state occupation probabilities of cancer (locoregional relapse, distant metastasis, or secondary cancer) over the population of all hospital patients (A) and the population of typical hospital patients (B) for the two arms in the multicenter EORTC trial 10854, along with the P‐values from the Kolmogorov‐Smirnov–type test
5. DISCUSSION
This work addressed the issue of nonparametric population‐averaged inference for multistate models with right‐censored and/or left‐truncated clustered observations. The estimators for the transition and state occupation probabilities were shown to be uniformly consistent and asymptotically normal with explicit formulas for the corresponding covariance functions. Additionally, rigorous methodology for the calculation of simultaneous confidence bands and a class of Kolmogorov‐Smirnov–type tests were proposed. Inference can be performed using either the explicit formulas for the influence functions of the estimators or the nonparametric cluster bootstrap. The latter is particularly useful in practice since it can be used for inference using off‐the‐shelf software. In this work, I did not impose restrictive distributional assumptions or assumptions regarding the within‐cluster dependence. Moreover, I allowed for ICS and nonhomogeneous multistate processes which are non‐Markov. Simulation results indicated that the performance of the proposed methods is satisfactory even for non‐Markov processes and under ICS. On the contrary, ignoring the within‐cluster dependence leads to invalid inference.
The proposed nonparametric estimators of the transition probability matrix and the influence function‐based methodology for the calculation of simultaneous confidence bands are extensions of the Aalen‐Johansen estimator (Aalen and Johansen, 1978; Andersen et al., 2012) and the wild bootstrap approach for independent data by Bluhmki et al. (2018) to the cluster‐correlated data setting. However, these extensions were not trivial given that I allowed for random and ICS. Moreover, I established the asymptotic properties of the proposed methods using empirical process theory instead of martingale theory that was used for the aforementioned methods for independent data (Andersen et al., 2012; Bluhmki et al., 2018). I also considered the nonparametric cluster bootstrap by Field and Welsh (2007). These authors dealt with the case of a simple linear random‐intercept model. Even though I used the cluster bootstrap algorithm of Field and Welsh (2007) for the one‐sample problem, I proved its consistency for the more complicated nonparametric estimators in Theorem 2. Moreover, for the two‐sample problem, the nonparametric cluster bootstrap approach proposed here is slightly different because the weight is being kept fixed (at its estimated value based on the original data set) across the bootstrap samples, since its variability does not affect the asymptotic null distributions of the test statistics.
It has to be noted that the proposed methods provide large sample inference, as do the typical methods for multistate models. Large sample in the clustered data setting means large number of clusters. Following general recommendations for the central limit theorem, it is suggested to use the proposed methods with at least 30 clusters. However, the extensive simulation studies presented in this article provide some numerical evidence for the satisfactory performance of the proposed methods, and their superiority over the naïve methods that ignore the within‐cluster dependence, even with 20 clusters.
I can see two useful extensions of the proposed framework. First, developing an estimation approach for semiparametric regression on the state occupation probabilities would be crucial in practice for the estimation of risk factor effects. This could be achieved by extending the inverse probability of censoring weighting approach by Scheike and Zhang (2007) to the clustered data setting. Second, relaxing the i.i.d. assumption across clusters imposed in this article is important from both theoretical and applied perspective. One situation where this assumption is violated is when there is a dependence between cluster sizes or counting processes from different clusters. A way to deal with this issue is to introduce weak dependence (such as mixing conditions) or long‐range dependence assumptions over space or time for the clusters, and use appropriate central limit theorems for such dependent data (Dehling et al., 2002) to establish the asymptotic distributions of the estimators.
6.
Supporting information
Web Appendices A, B, C, and D, referenced in Sections 2, 3, and 4, are available with this paper at the Biometrics website on Wiley Online Library. R code for the illness‐death model without recovery, example data, and a README file are also available there. R code for more general processes is available at https://github.com/gbakoyannis/clustered‐multistate.
ACKNOWLEDGMENTS
The author thanks the Associate Editor and the two anonymous referees for their insightful comments that led to a significant improvement of this manuscript. The author also thanks the EORTC for sharing the data from the EORTC trial 10854. This project was supported by the National Institute of Allergy and Infectious Diseases, grant number R21AI145662, and the Indiana Clinical and Translational Sciences Institute funded, in part by grant number UL1TR002529 from the National Institutes of Health (NIH), National Center for Advancing Translational Sciences, Clinical and Translational Sciences Award. The content of this manuscript is solely the responsibility of the author and does not necessarily represent the official views of the NIH and the EORTC.
Bakoyannis G. Nonparametric analysis of nonhomogeneous multistate processes with clustered observations. Biometrics. 2021;77:533–546. 10.1111/biom.13327
DATA AVAILABILITY STATEMENT
The data used in the Data Example section are available from European Organization for Research and Treatment of Cancer (EORTC). Restrictions apply to the availability of these data, which were used under license in this paper. Data are available from the author with the permission of EORTC.
References
- Aalen, O., Borgan, O. and Gjessing, H. (2008) Survival and Event History Analysis: a Process Point of View. Berlin: Springer Science & Business Media. [Google Scholar]
- Aalen, O.O. and Johansen, S. (1978) An empirical transition matrix for non‐homogeneous Markov chains based on censored observations. Scandinavian Journal of Statistics, 5, 141–150. [Google Scholar]
- Andersen, P.K., Borgan, O., Gill, R.D. and Keiding, N. (2012) Statistical Models Based on Counting Processes. Berlin: Springer Science & Business Media. [Google Scholar]
- Bakoyannis, G. (2020) Nonparametric tests for transition probabilities in nonhomogeneous Markov processes. Journal of Nonparametric Statistics, 32, 131–156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bluhmki, T., Schmoor, C., Dobler, D., Pauly, M., Finke, J., Schumacher, M. et al. (2018) A wild bootstrap approach for the Aalen–Johansen estimator. Biometrics, 74, 977–985. [DOI] [PubMed] [Google Scholar]
- Chen, B. and Zhou, X.‐H. (2013) A correlated random effects model for non‐homogeneous Markov processes with nonignorable missingness. Journal of Multivariate Analysis, 117, 1–13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cook, R., Yi, G., Lee, K.‐A. and Gladman, D. (2004) A conditional Markov model for clustered progressive multistate processes under incomplete observation. Biometrics, 60, 436–443. [DOI] [PubMed] [Google Scholar]
- Datta, S. and Satten, G.A. (2001) Validity of the Aalen–Johansen estimators of stage occupation probabilities and Nelson–Aalen estimators of integrated transition hazards for non‐Markov models. Statistics & Probability Letters, 55, 403–411. [Google Scholar]
- Dehling, H., Mikosch, T. and Sørensen, M. (2002) Empirical Process Techniques for Dependent Data. Berlin: Springer. [Google Scholar]
- Field, C.A. and Welsh, A.H. (2007) Bootstrapping clustered data. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 69, 369–390. [Google Scholar]
- Glidden, D.V. (2002) Robust inference for event probabilities with non‐Markov event data. Biometrics, 58, 361–368. [DOI] [PubMed] [Google Scholar]
- Lan, L., Bandyopadhyay, D. and Datta, S. (2017) Non‐parametric regression in clustered multistate current status data with informative cluster size. Statistica Neerlandica, 71, 31–57. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li, Y. and Zhang, Q. (2015) A Weibull multi‐state model for the dependence of progression‐free survival and overall survival. Statistics in Medicine, 34, 2497–2513. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nair, V.N. (1984) Confidence bands for survival functions with censored data: a comparative study. Technometrics, 26, 265–275. [Google Scholar]
- O'Keeffe, A., Su, L. and Farewell, V. (2018) Correlated multistate models for multiple processes: an application to renal disease progression in systemic lupus erythematosus. Journal of the Royal Statistical Society. Series C: Applied Statistics, 67, 841–860. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Putter, H. and Spitoni, C. (2018) Non‐parametric estimation of transition probabilities in non‐Markov multi‐state models: the landmark Aalen–Johansen estimator. Statistical Methods in Medical Research, 27, 2081–2092. [DOI] [PubMed] [Google Scholar]
- Scheike, T.H. and Zhang, M.‐J. (2007) Direct modelling of regression effects for transition probabilities in multistate models. Scandinavian Journal of Statistics, 34, 17–32. [Google Scholar]
- Seaman, S.R., Pavlou, M. and Copas, A.J. (2014) Methods for observed‐cluster inference when cluster size is informative: a review and clarifications. Biometrics, 70, 449–456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Titman, A.C. (2015) Transition probability estimates for non‐Markov multi‐state models. Biometrics, 71, 1034–1041. [DOI] [PubMed] [Google Scholar]
- Van der Hage, J., van De Velde, C., Julien, J.‐P., Floiras, J.‐L., Delozier, T., Vandervelden, C. et al. (2001) Improved survival after one course of perioperative chemotherapy in early breast cancer patients: long‐term results from the European Organization for Research and Treatment of Cancer (EORTC) Trial 10854. European Journal of Cancer, 37, 2184–2193. [DOI] [PubMed] [Google Scholar]
- Yiu, S., Farewell, V. and Tom, B. (2018) Clustered multistate models with observation level random effects, mover–stayer effects and dynamic covariates: modelling transition intensities and sojourn times in a study of psoriatic arthritis. Journal of the Royal Statistical Society. Series C: Applied Statistics, 67, 481–500. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Web Appendices A, B, C, and D, referenced in Sections 2, 3, and 4, are available with this paper at the Biometrics website on Wiley Online Library. R code for the illness‐death model without recovery, example data, and a README file are also available there. R code for more general processes is available at https://github.com/gbakoyannis/clustered‐multistate.
Data Availability Statement
The data used in the Data Example section are available from European Organization for Research and Treatment of Cancer (EORTC). Restrictions apply to the availability of these data, which were used under license in this paper. Data are available from the author with the permission of EORTC.