

Abstract
Colorectal cancer screening modalities, such as optical colonoscopy (OC) and virtual colonoscopy (VC), are critical for diagnosing and ultimately removing polyps (precursors of colon cancer). The non-invasive VC is normally used to inspect a 3D reconstructed colon (from CT scans) for polyps and if found, the OC procedure is performed to physically traverse the colon via endoscope and remove these polyps. In this paper, we present a deep learning framework, Extended and Directional CycleGAN, for lossy unpaired image-to-image translation between OC and VC to augment OC video sequences with scale-consistent depth information from VC, and augment VC with patient-specific textures, color and specular highlights from OC (e.g, for realistic polyp synthesis). Both OC and VC contain structural information, but it is obscured in OC by additional patient-specific texture and specular highlights, hence making the translation from OC to VC lossy. The existing CycleGAN approaches do not handle lossy transformations. To address this shortcoming, we introduce an extended cycle consistency loss, which compares the geometric structures from OC in the VC domain. This loss removes the need for the CycleGAN to embed OC information in the VC domain. To handle a stronger removal of the textures and lighting, a Directional Discriminator is introduced to differentiate the direction of translation (by creating paired information for the discriminator), as opposed to the standard CycleGAN which is direction-agnostic. Combining the extended cycle consistency loss and the Directional Discriminator, we show state-of-the-art results on scale-consistent depth inference for phantom, textured VC and for real polyp and normal colon video sequences. We also present results for realistic pendunculated and flat polyp synthesis from bumps introduced in 3D VC models.
1. Introduction
Colon cancer is one of the most commonly diagnosed cancers with 1.8 million new cases (and subsequent 750,000 deaths) reported worldwide every year [1]. Optical colonoscopy (OC) is the most prevalent colon cancer screening procedure. In this invasive procedure, polyps (precursors of colon cancer) can be found and removed using an endoscope. In contrast, virtual colonoscopy (VC) is a non-invasive screening procedure where the colon is 3D reconstructed from computed tomography (CT) scans and inspected for polyps with a virtual flythrough (simulating the OC endoscope traversal). Due to its non-invasive, inexpensive, and low-risk (no sedation required) nature, VC is becoming a commonplace tool for colon cancer screening. In fact, the US Multi-Society Task Force on Colorectal Cancer recommends VC screenings every 5 years and OC every 10 years for average-risk patients above the age of 50 [22].
Both VC and OC provide complementary information. OC endoscope videos are comprised of individual frames capturing complex real-time dynamics of the colon with important texture information (e.g., veins, blood clots, stool, etc). VC, on the other hand, provides complete 3D geometric information of the colon including polyps. This complementary nature of OC and VC motivates our current work to find ways of translating information between these two modalities. The geometric information from VC images can aid in 3D reconstruction and surface coverage (percentage of colon inspected) during the OC procedure; lower the surface coverage higher the polyp miss rate. Inferring scale-consistent depth maps for given OC video sequences enables 3D reconstruction through established simultaneous localization and mapping (SLAM) algorithms [23, 25], which can help deduce the surface coverage during OC. Augmenting VC with texture and specular highlights from OC can be used to generate realistic virtual training simulators for gastroenterologists as well as realistic polyps. Shin et al. [24] have presented a method to produce polyps from edge maps and binary polyp masks. This generates realistic polyps, but the 3D shape and endoscope orientation are hard to control making it difficult to produce specific polyp shapes, for example, flat polyps. VC to OC translation, in our context, provides full control over the 3D shape and endoscope orientation making it easy to generate pendunculated and flat polyps.
The task of translating between OC and VC can be generalized to image-to-image domain translation. Since there is no ground truth paired data for OC and VC, CycleGAN [27] is suited to this problem, but it cannot handle lossy transformations, for example, between VC (structure) and OC (structure + color + texture + specular highlights), as shown by Chu et al. [3]. Porav et al. [20] have presented a method to handle the lossy CycleGAN translation by adding a denoiser to reduce high frequencies with low amplitudes. As seen in Figure 1, specular highlights and textures are not embedded as high frequency/low amplitude signals, hence the denoiser will not help in our context.
Figure 1.

Two examples of standard CycleGAN lossy transformation problem [3]. In OC to VC translation, standard CycleGAN stores the textures and specular reflections in the VC domain as depicted in the histogram-equalized output.
Thus, we introduce a novel extended cycle consistency loss for lossy image domain translation. This frees the network from needing to hide information in the lossy domain by replacing OC comparisons with VC comparisons. Stronger removal of these specular reflections and textures are handled via a Directional Discriminator that differentiates the direction of translation as opposed to the standard CycleGAN which is direction-agnostic. This Directional Discriminator acts like a discriminator in a conditional GAN and deals with paired data thus giving the network, as a whole, a better understanding of the relationship between the two domains.
The contributions of this work are as follows:
A lossy image-to-image translation model via a novel extended cycle consistency loss to remove texture, color and specular highlights from VC.
A Directional Discriminator to create a stronger link between OC and VC for removing remaining textures and lighting.
The same framework can synthesize realistic OC (flat and pendunculated) images.
Scale-consistent depth inference from OC video sequences.
2. Related Work
Generative Adversarial Networks:
GANs [6] introduced the concept of adversarial learning and have shown promising results in image generation, segmentation [10], super resolution [9], video prediction [14] and more. The idea behind GANs revolves around two networks playing a game against each other.
Image-to-Image Translation:
This task maps an image in one domain to another. OC and VC image translation, in our context, can be reframed as an image-to-image translation problem. The pix2pix network is a deep learning model that solves this problem using a conditional GAN with an additional L1 loss [7]. This model requires paired ground truth data from two given domains, which is not available in our context.
Recent deep learning approaches that tackle unpaired image-to-image domain translation include CycleGAN [27] and similar approaches [8, 26]. In this paper, we modify CycleGAN for unpaired lossy image-to-image translation between OC and VC, and further alter it to create a stronger link between the two input domains. CycleGANs, have been shown to hallucinate features [24], which is problematic if used directly for patient diagnosis. We, however, use it as an add-on to the real data rather than for diagnostic purposes.
CycleGANs, when dealing with lossy image translations, tend to hide information in the lossy images. The cycle consistency loss requires the network to embed extra information in the lossy domain, in order to reconstruct the image [3]. Porav et al. [20] have proposed a possible solution to the lossy domain translation by adding a denoiser to reduce high frequencies with low amplitudes. In our case, the network simply tries to blend in texture and lighting artifacts with the colon wall, so their method is not helpful.
Mirza et al. [16] have introduced the idea of conditioning the output of the generator with all or part of the input. This extra information is passed to the discriminator and provides a stronger link between the input and the output. Conditional CycleGAN [11] employs this same concept, where a label or another image are used to drive the direction of translation. In other words, the CycleGAN allows for extra input to drive the translation but requires ground truth pair between the label and the input. Our Directional Discriminator is similar to conditional GANs, but unlike conditional GANs does not require the ground truth labels and input.
Donahue et al. [4] and Dumoulin et al. [5] have presented approaches that are similar to ours as they use paired input and output of two networks to train a single discriminator, but instead of pairing images (like in our case), they pair latent vectors and images. As shown by Zhu et al. [27], these approaches did not work well by themselves in the image-to-image domain translation task and resulted in heavy artifacts and unrealistic images. More recently, Pajot et al. [19] have discussed a similar extended cycle consistency loss to ours for reconstructing noisy images. We differ from their method as we only take one step forward in the cycle to allow for a one-to-many image translation (requirement for our application), rather than two steps forward in their case.
Depth Reconstruction:
Due to complexities in texture and lighting, traditional computer vision techniques do not work well for OC depth inference. Nadeem et al. [18] have introduced a non-parametric dictionary learning approach to infer depth information for a given OC video frame using only a VC RGB-Depth dictionary. However, due to the non-realistic rendering of depth cues in the VC RGB images, the inferred depth was inaccurate. Mahmood et al. [13] have overcome this limitation by incorporating realistic depth cues, using inverse intensity fall-off in the rendered images. They created a transformer network that is trained on synthetic colon images. Given OC images, a GAN is used to first transform these images into a synthetic-like environment, which are then used to generate depth maps using a separate deep learning network. While this approach does a good job in removing patient-specific textures without requiring paired image data, it has difficulties removing specular reflections from the OC images. In addition, the resulting depth maps are not smooth and scale-consistent.
Rau et al. [21] have introduced a variant of pix2pix called extended pix2pix to produce OC depth maps. The extended pix2pix is a variant of the pix2pix model applied to colonoscopy depth reconstruction. Since a phantom and VC data was used to create paired depth and colon images, the network struggled with real OC data. To alleviate this problem, an extension was introduced that included real OC images for the GAN loss. Due to a lack of ground truth the L1 loss in pix2pix is ignored for these OC inputs. This allows the network to partially train on real colon images while not needing the corresponding ground truth. Their method, however, assumes a complete endoluminal view (tube-like structure) and fails otherwise. Chen et al. [2] have also used a pix2pix network to produce depth maps from a phantom model. They trained on VC with various realistic renderings that did not include any complex textures or specular reflections found in OC. Still, they were able to produce scale-consistent depth maps for a phantom and a porcine colon video sequence.
A deep learning method based on visual odometry has been presented by Ma et al. [12] to infer scale-consistent depth maps from OC video sequences. These scale-consistent depth maps are then passed into a SLAM algorithm [23] to 3D reconstruct a colon mesh for surface coverage computation. Like most other methods, however, they assume a cylindrical topology and only caters to the endoluminal view. Furthermore, their method cannot handle specular highlights, occlusion and large camera movements, and requires preprocessing to mask these aspects.
3. Data
The OC and VC data was acquired at Stony Brook University for 10 patients who underwent VC followed by OC (for polyp removal). The OC data contained 10 videos from OC procedures. These do not provide ground truth as the shape of the colon is different between VC and OC. The images taken from the videos were cropped to the borders of the frames. A cleansed 3D triangular mesh colon model was extracted from the 10 abdominal CT patient scans using a pipeline similar to Nadeem et al. [18]. The virtual colon was then loaded into the Blender1 graphics software, and centerline flythrough videos of size 256×256 pixels were rendered with two light sources on the sides of the virtual camera in order to replicate the endoscope and its environment. To incorporate more realistic depth cues, the inverse square fall-off property for the virtual lights was enabled [13]. When training the network, both VC and OC images were downsampled to a size of 256×256 pixels for computational efficiency. In total, 10 OC and VC videos were used with 5 of these used for training and the remaining three for testing and two for validation purposes. We captured 300 images from each OC and VC video, resulting in 1500 for training, 900 for testing and 600 for validation. Figure 2 shows our end-to-end pipeline.
Figure 2.
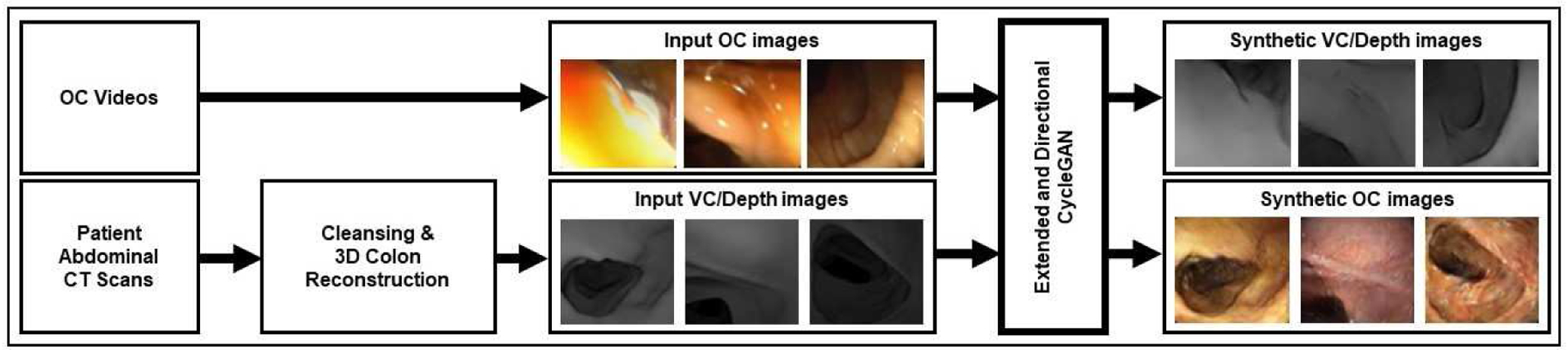
Pipeline for generating realistic VC and OC images from their counterpart. OC and VC images are extracted from videos. VC videos are created from reconstructing CT scans and then rendering a flythrough of the colon. This data is passed into the generators of the Extended and Directional CycleGAN and produce VC and OC images.
4. Method
The CycleGAN network [27] consists of two GANs with additional losses to combine the GANs into one model. We define G as a generator, Goc as the generator from the GAN that produces OC images, and Gvc as the generator that produces VC images. D, Doc, and Dvc represents discriminators for their corresponding generators. Similar to Zhu et al. [27], we represent the data distribution of domain A as y ~ p(A) and the distribution of domain B as x ~ p(B). The adversarial loss that is applied in GANs is as follows:
| (1) |
The cycle consistency loss in CycleGANs links the two GANs to handle the image-to-image domain translation task. The cycle consistency loss is as follows:
| (2) |
where ‖·‖1 is the ℓ1 norm, and x ∈ a. This loss is depicted on the left in Figure 3. The cycle consistency loss is used for translating in both directions (i.e., A to B and B to A). The lossy transformations as seen in Figure 1 are not handled by the CycleGAN (as is previously shown [3, 20]). The cycle consistency loss requires OC images to be reconstructed from synthetic VC, Gvc(OC). In order to handle this task, the network requires synthetic VC to store color, texture, and specular reflections so the synthetic VC can reconstruct the OC. To address this problem, we introduce the extended cycle consistency loss to help the network perform lossy translations. Still, there are textures and reflections that are passed into the VC domain and hence, a stronger link between OC and VC is required which is established via our Directional Discriminator that pairs OC and VC images.
Figure 3.
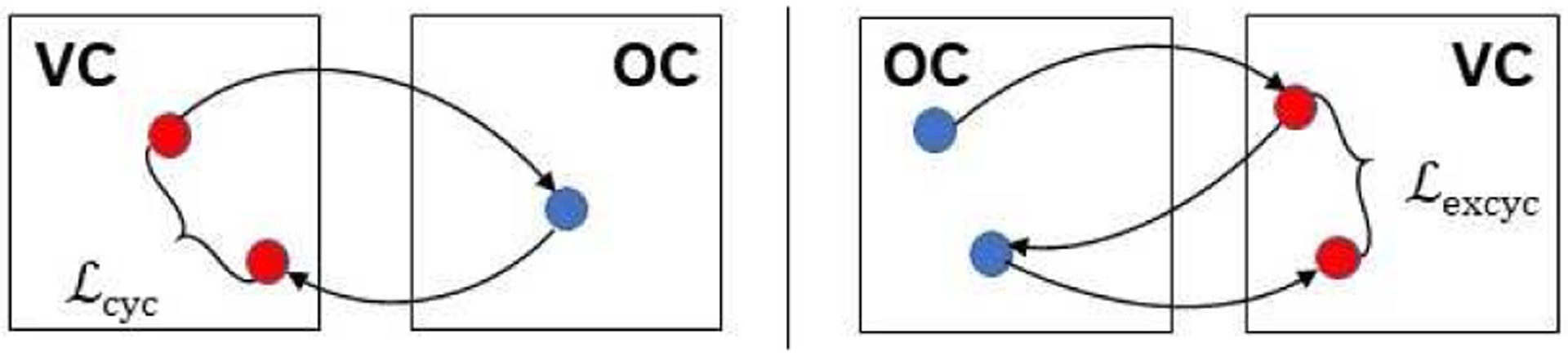
The image on the left depicts the cycle consistency loss used for VC to OC translation from Zhu et al’s CycleGAN [27]. The image on the right shows the extended cycle consistency loss that we used for OC to VC translation.
4.1. Extended Cycle Consistency Loss
To address the OC features being embedded in VC, we propose a new loss to replace the cycle consistency loss in the OC domain, which we call the extended cycle consistency loss (Figure 3):
| (3) |
This loss has synthetic VC, Gvc(OC), compared with reconstructed synthetic VC, Gvc(Goc(Gvc(OC))). In other words, the extended cycle consistency loss is enforcing the structure captured in the VC domain to be the same between OC and the reconstructed OC, Goc(Gvc(OC)). This loss is depicted pictorially on the right in Figure 3. Figure 4 shows how the extended cycle consistency loss allows the reconstructed OC to have different textures and lighting than the original OC input. When applying this loss to the CycleGAN, we call it the extended CycleGAN (XCycleGAN).
Figure 4.
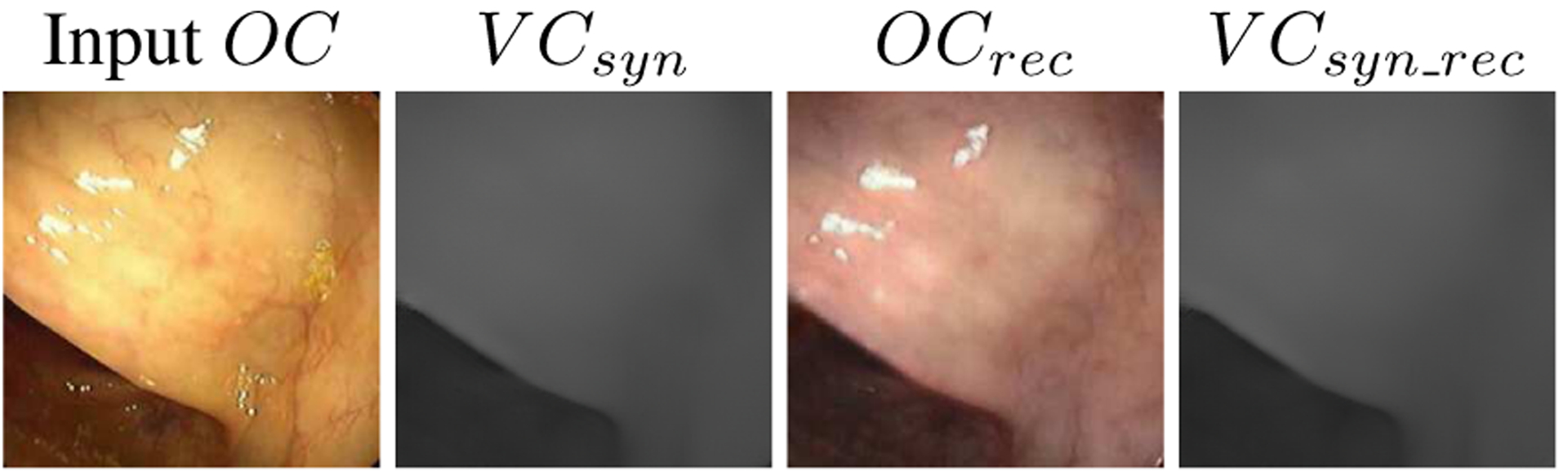
The first image is the input OC image. The input image is passed through GVC resulting in a synthetic VC, VCsyn. OCrec is VCsyn passed through GOC. Notice how this image does not have the same texture or the specular reflections as the input OC image. Rather only the geometry between the two are the same. This geometry is reflected in VCsyn_rec which is obtained by passing OCrec through GVC.
The network, the way it is, has the reconstructed OC, Goc(Gvc(OC)), unrestrained. Since this image is supposed to look like an OC image, an additional OC discriminator is added and a GAN loss is applied. In addition, Zhu et al. [27] have mentioned the use of an identity loss that compares OC and GOC(OC) to retain color when reconstructing. This loss is removed as we do not wish to retain color information for OC but is kept on the VC side to retain the color there. Thus, , is a loss included for the XCycleGAN.
4.2. Directional Discriminator
To create a stronger link between OC and VC, our approach uses a single Directional Discriminator rather than two as shown in Figure 5. Since only the number of input channels of the discriminator is changed, the Directional Discriminator reduces the memory needed for the network. Our Directional Discriminator only required 17.4 MB, whereas a single CycleGAN discriminator required 11.1 MB (altogether 22.2MB).
Figure 5.
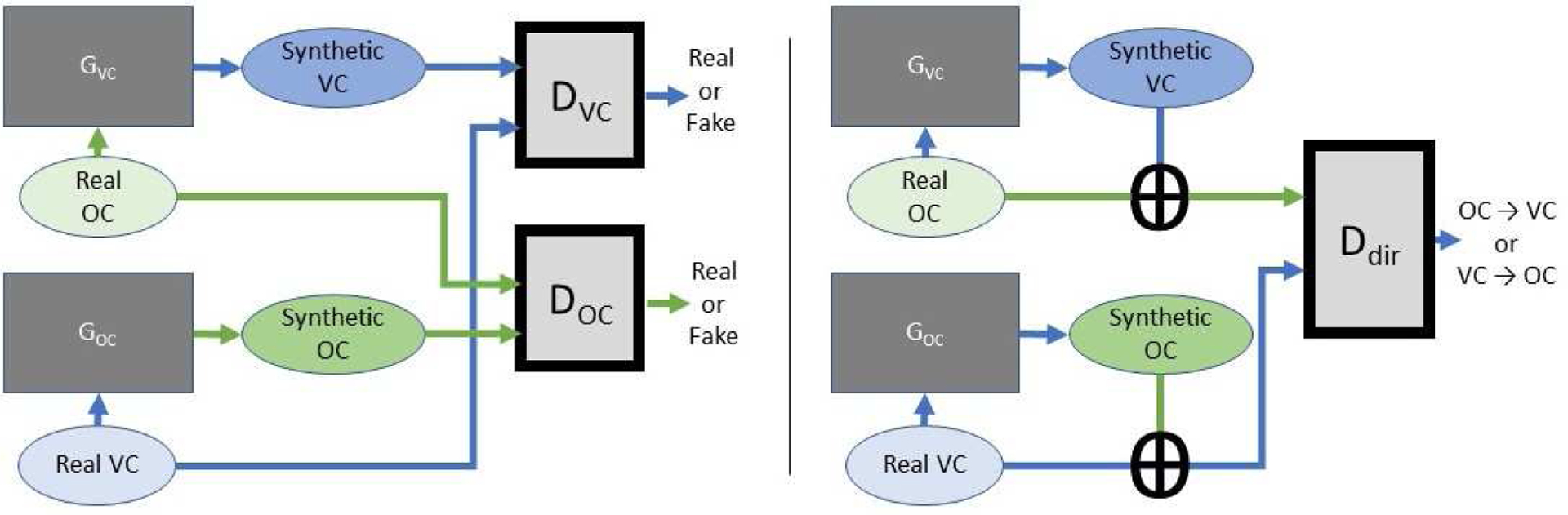
The left image shows adversarial portion of CycleGAN to handle two GANs. Each generator acts independently without the cycle consistency losses included. The right image displays the architecture layout with a Directional Discriminator. Real OC and synthetic VC are concatenated and passed into the Directional Discriminator along with the concatenation of synthetic OC and real VC, creating a stronger connection between the two. This allows the Directional Discriminator to work with the paired information. In both cases, the discriminators only take into consideration the real distribution of real OC and VC along with the synthetic distributions produced by the generator from real OC and VC. Reconstructed images are not taken into account by the adversarial losses from these discriminators.
GANs are based around the idea of creating a two player adversarial game between the generator and the discriminator. In our model, we wish to create a stronger relationship between the image generators by creating a three player game. The players of this game are two generators (Ga,Gb) and a discriminator (D). Similar to conditional GANs, Ga will give its input and output to D trying to convince D that its output came from Gb. Gb does the same task except it makes its input-output pair resemble Ga’s. Since, Ga’s input domain is GB’s output domain and Ga’s output domain is Gb’s input domain, the discriminator ends up discerning which generator is used since the input domains are fixed as shown on the right in Figure 5. By trying to differentiate the generators, the discriminator is essentially differentiating the direction of the translation. For example, if we look at OC and VC image translation, the discriminator would be differentiating the following pairs {OC, synthetic VC} and {synthetic OC, VC}. Thus, the discriminator ends up discerning the direction of the translation. When this model converges, the synthesized images will need to reflect the real distribution of their corresponding domains, while also giving the discriminator paired information to work with. This creates a stronger connection between the two generators, while eliminating the need for two discriminators. The loss for this Directional Discriminator is:
| (4) |
The combination of our Directional Discriminator and extended cycle consistency loss produces the Extended and Directional CycleGAN (XDCycleGAN). The total objective loss function for XDCycleGAN is:
| (5) |
where α, λ, and γ are constant weights. For both OC to VC rendering and OC to scale consistent depth maps, we train the network for 200 epochs with α = 0.5, λ = 10, and γ = 5. We add spectral normalization [17] to each layer of the discriminators for better network stability.
5. Experimental Results
To clearly emphasize the texture and specular highlights in OC to VC translation, we show our results in Figure 6 by training the CycleGAN, XCycleGAN, and XDCycleGAN on OC and rendered VC data; in depth maps the texture and highlights are slightly difficult to visualize. To further highlight the embedding of the textures and lighting, histogram equalization is applied to the output VC images. For all the OC images, it is clearly seen that the histogram-equalized CycleGAN images embed the specular reflection and textures. In most cases these artifacts are visible in the VC images. We further point out that there are textures and lighting seen in the histogram-equalized XCycleGAN which are retained from the input, which the XDCycleGAN is able to remove. These cases are marked by the blue boxes. The last two rows in Figure 6 show how our network is able to recreate the polyps in VC. In the third last row, the XDCycleGAN shows its superior understanding of the geometry from OC. It recovers the shape of the polyp better than the XCycleGAN, which makes it appear much flatter. In the last row the more intricate geometry of the polyp is captured by the XDCycleGAN and is highlighted with a red box.
Figure 6.
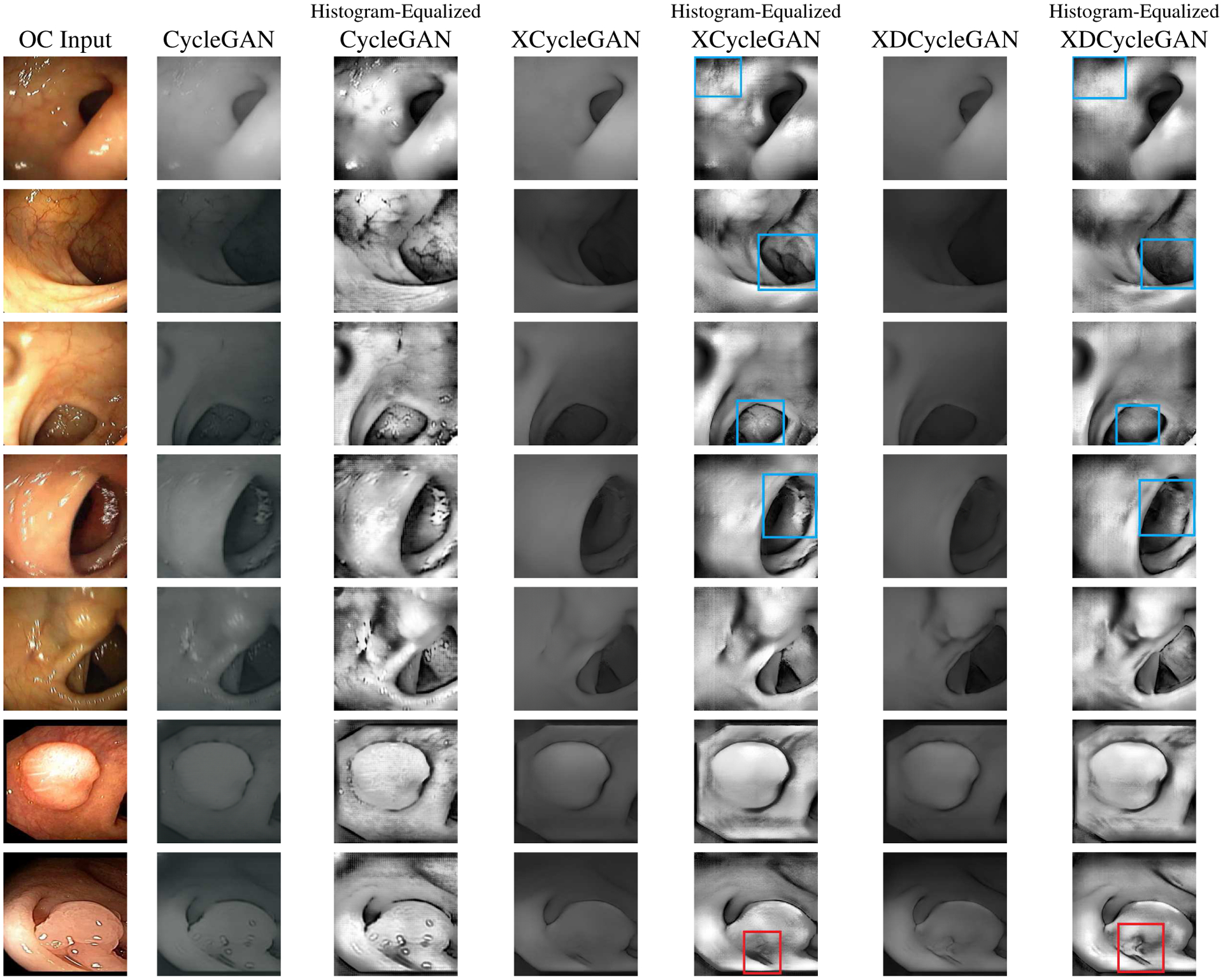
Results from OC to VC. Blue boxes show areas where the XCycleGAN is unable to completely remove the specular reflections and texture, whereas the XDCycleGAN is able to remove these. The last two rows show polyps from [15] that XDCycleGAN can recreate polyps in VC.
In the VC to OC image translation, our network also does better than CycleGAN, as seen in Figure 7. We observe that CycleGAN takes structures in the VC domain and turns these into texture, whereas the XDCycleGAN retains all of the structure in the VC domain. In order to demonstrate the benefits of the VC to OC translation, we generate polyps by adding bumps with specific shapes and endoscope orientations in VC and augment them with textures and specular reflection also shown in Figure 7. The cycle consistency accuracy for depth in the VC → OC → VC case for the CycleGAN is 7.74±6.07, for the XCycleGAN is 6.84±5.39, and for the XDCycleGAN is 6.34±3.73.
Figure 7.
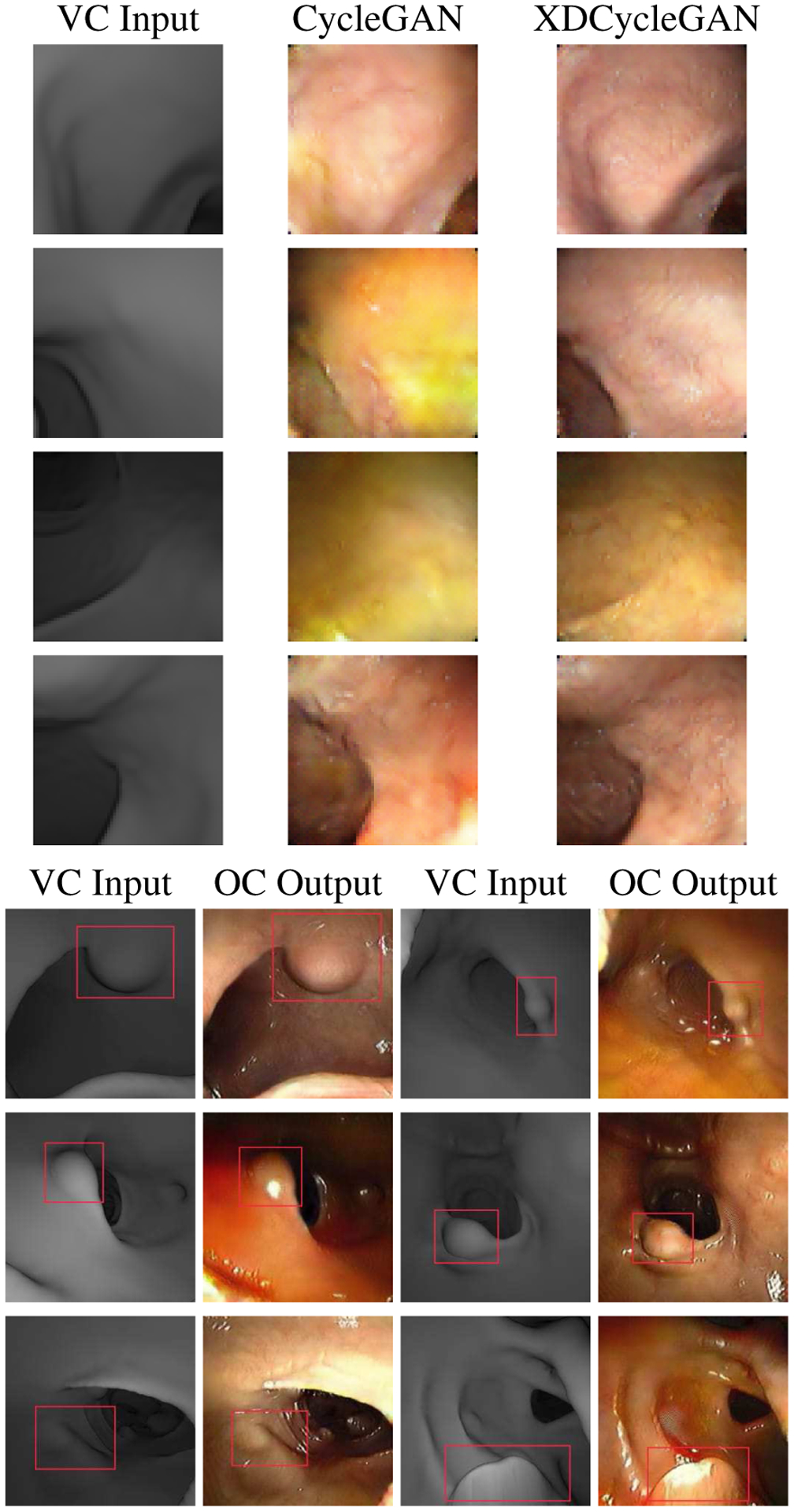
Results from VC to OC image translation. The synthetic OC images from the CycleGAN turn structures into texture where the XDCycleGAN does not do this. Below that, we display polyps created in VC with augmneted textures, colors, and specular reflections by our XDCycleGAN.
Scale-Consistent Depth Inference
We train our XDCycleGAN on VC depth maps to demonstrate its ability to infer scale-consistent depth information. This depth inference is a first step for 3D reconstruction, and once these depth maps are attained, standard SLAM algorithms [23, 25] can be used. Figure 8 shows various time sequences and our results on that input. In our first test, we compare with Mahmood et al. [13] and show that our depth maps are much smoother. Their method shows issues by treating some of the specular reflections as a change in depth and failing in scale consistency. The XDCycleGAN, on the other hand, ignores these reflections and produces smoother depth maps.
Figure 8.
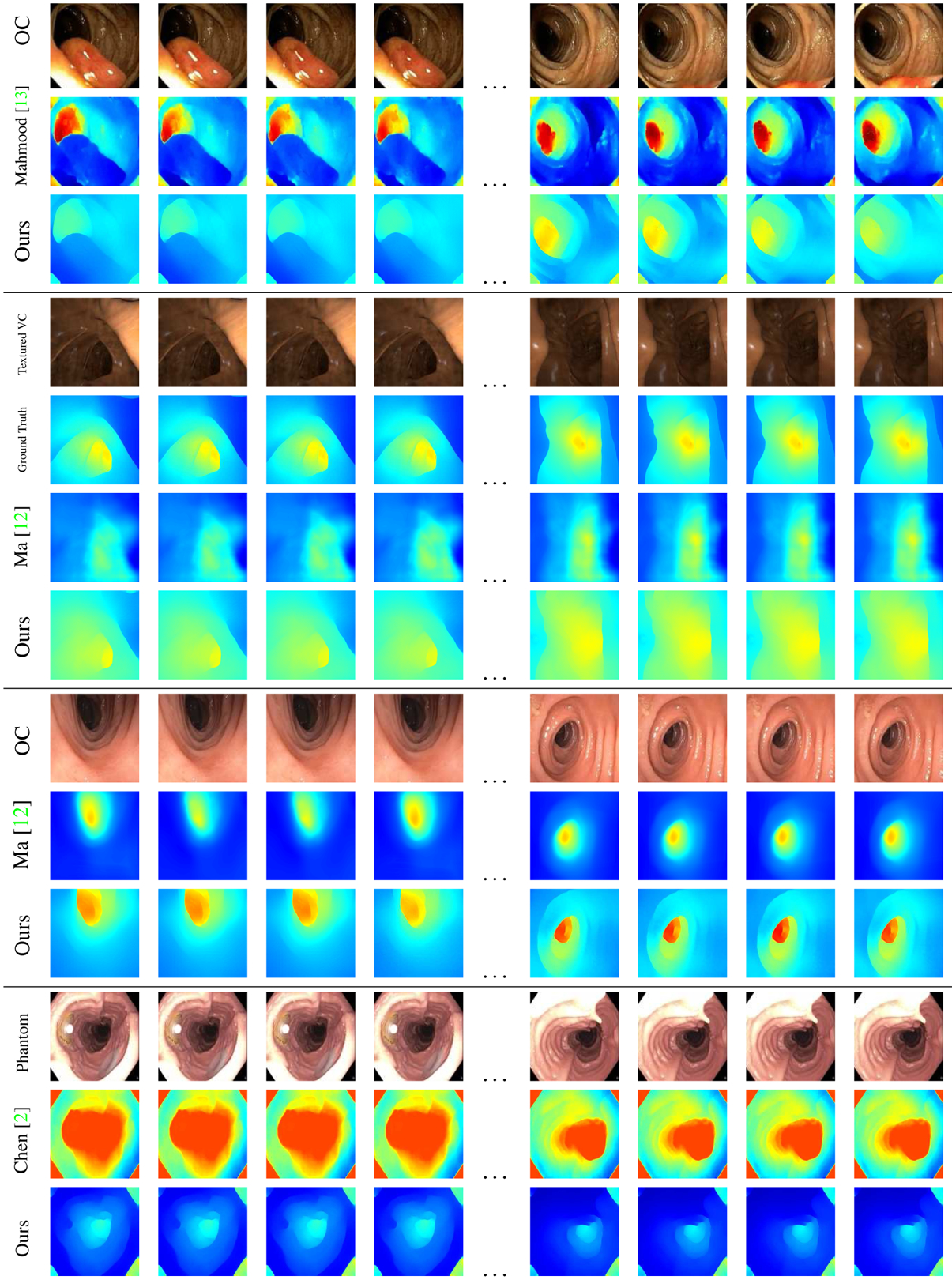
Scale-consistent depth inference on video sequences. The first (top) dataset contains a polyp video sequence with Mahmood et al.’s [13] and our results. The second dataset is successive frames from our textured VC video flythrough and the corresponding results from Ma et al. [12] and ours. The SSIM for Ma et al.’s approach is 0.637, whereas ours is 0.918. Ma et al. assume as input a chunk of successive video frames with cylindrical topology (endoluminal) view with the specular reflections and occlusions masked out. The third dataset show another sequence assuming Ma et al.’s input [12] and our corresponding results. The final dataset, shows Chen et al.’s phantom model [2] along with their results and our results. Complete videos and additional sequences are shown in the supplementary material.
For our second test, we use 2000 video frames produced from a manually textured virtual colon from VC. The colon is textured by blending various snapshots of textures found in OC, and ground truth can be attained. For quantitative analysis, we analyze the average SSIM score across the 2000 frames to test structural similarity. Our approach got an average SSIM score of 0.918, which indicates that our network is able to capture the structure of these frames rather well. We also ran Ma et al.’s approach [12] on our ground truth. The SSIM score was 0.637. Their score is low as the depth maps are smoothed out and most of the critical geometry/structures are lost. They also assume the endoluminal view which, if invalidated, propagates the error to the following frames. In addition to SSIM, RMSE for the depth maps with our approach is 31.25±6.76 as compared to 92.67±10.32 for Ma et al. [12].
To be fair, we also compared Ma et al.’s approach [12] on OC video sequences where their input assumptions hold. The depth maps produced from their pipeline does not recover the geometry of most haustral folds as accurately as XDCycleGAN. Finally, we compare with Chen et al.’s method [2] on their phantom colon and show that our model is robust, and is comparable even on data that we did not cater for during training.
6. Limitations and Future work
As with most deep learning frameworks there are failure cases with this network, as shown in Figure 9. When there is heavy occlusion, blurring, or fluid motion the network tries to reconstruct the image regardless and infers random geometry. To address these artifacts, in the future we will incorporate an image quality control framework to detect and remove these frames. Moreover, our pipeline does not cater to the instruments in the OC images since our VC counterpart does not have equivalent representation. Adding instrument models in the VC domain may be one way to recognize instruments in the OC images. Furthermore, if a polyp strongly blends in with the textures of the colon wall and its protrusion from the wall is hard to notice, the XDCycleGAN removes both the polyp and the texture. The polyp, however, may be visible in the earlier frames and a temporal component may resolve this. Finally, we will undertake a more through analysis of polyp detection and segmentation pipelines with our polyp data augmentation/synthesis.
Figure 9.
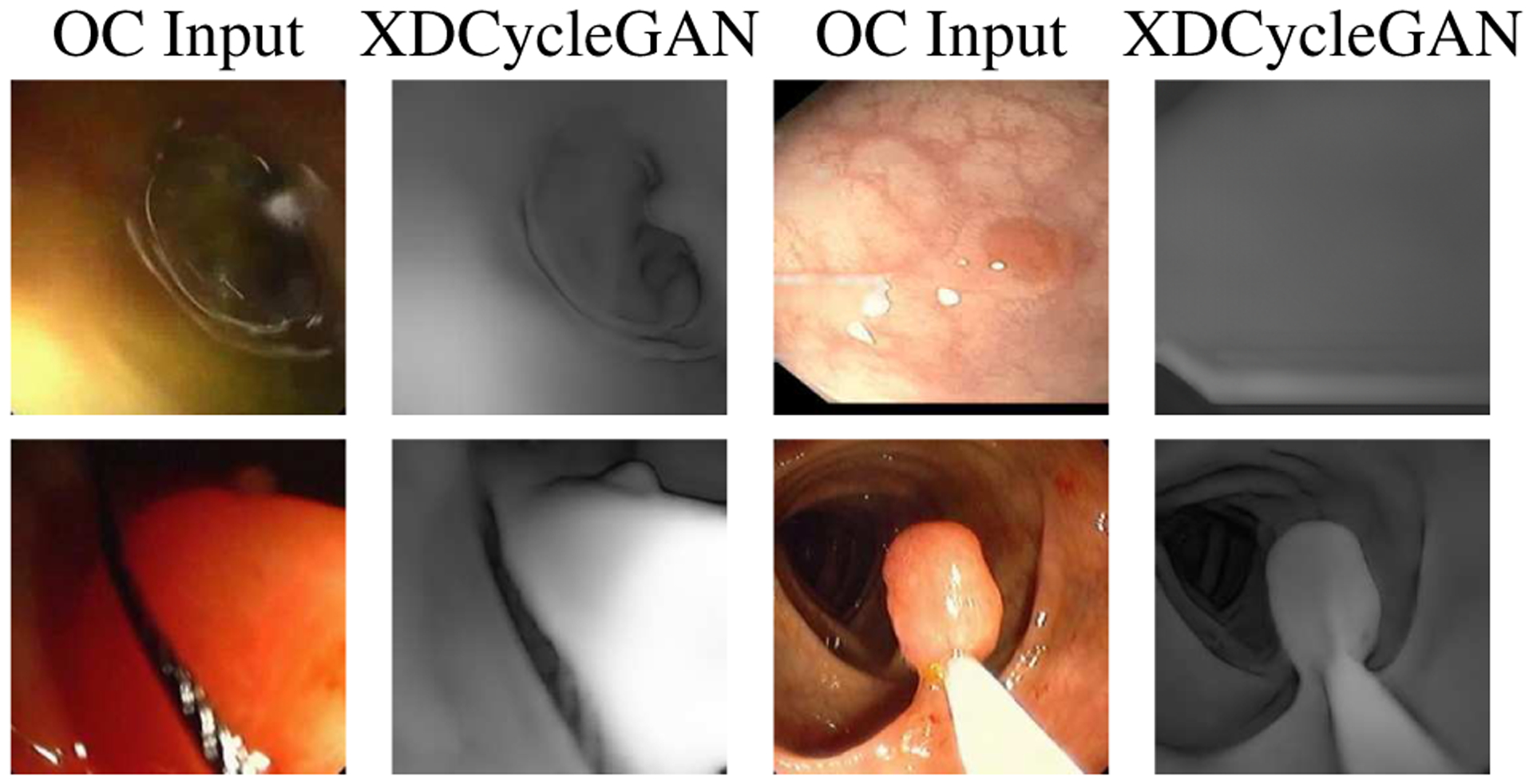
Failure cases of the XDCycleGAN. These include frames with fluid movement, motion blur or occlusion, as well as instruments. The top-right image (from [15]) shows how our network can mistake polyps for texture if it is surrounded by texture.
Supplementary Material
Acknowledgement
We would like to thank Dr. Sarah K. McGill (UNC Chapel Hill) for granting access to the OC videos and to Ruibin Ma for comparisons. This research was funded by NSF grants NRT1633299, CNS1650499, OAC1919752, and ICER1940302, the NIH/NCI Cancer Center Support Grant P30 CA008748, NIH/NHLBI under Award U01HL127522, the Center for Biotechnology NY State Center for Advanced Technology, Stony Brook University, Cold Spring Harbor Lab, Brookhaven National Lab, Feinstein Institute for Medical Research, and NY State Department of Economic Development under Contract C14051. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
Footnotes
References
- [1].Bray Freddie, Ferlay Jacques, Soerjomataram Isabelle, Siegel Rebecca L, Torre Lindsey A, and Jemal Ahmedin. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: A Cancer Journal for Clinicians, 68(6):394–424, 2018. [DOI] [PubMed] [Google Scholar]
- [2].Chen Richard J, Bobrow Taylor L, Athey Thomas, Mahmood Faisal, and Durr Nicholas J. Slam endoscopy enhanced by adversarial depth prediction. arXiv preprint arXiv:1907.00283, 2019. [Google Scholar]
- [3].Chu Casey, Zhmoginov Andrey, and Sandler Mark. Cyclegan, a master of steganography. arXiv preprint arXiv:1712.02950, 2017. [Google Scholar]
- [4].Donahue Jeff, Krähenbuhl Philipp, and Darrell Trevor. Adversarial feature learning. International Conference on Learning Representations (ICLR), 2017. [Google Scholar]
- [5].Dumoulin Vincent, Belghazi Ishmael, Poole Ben, Mastropietro Olivier, Lamb Alex, Arjovsky Martin, and Courville Aaron. Adversarially learned inference. International Conference on Learning Representations (ICLR), 2017. [Google Scholar]
- [6].Goodfellow Ian, Jean Pouget-Abadie Mehdi Mirza, Xu Bing, David Warde-Farley Sherjil Ozair, Courville Aaron, and Bengio Yoshua. Generative adversarial nets. Advances in neural information processing systems, pages 2672–2680, 2014. [Google Scholar]
- [7].Isola Phillip, Zhu Jun-Yan, Zhou Tinghui, and Efros Alexei A. Image-to-image translation with conditional adversarial networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1125–1134, 2017. [Google Scholar]
- [8].Kim Taeksoo, Cha Moonsu, Kim Hyunsoo, Lee Jung Kwon, and Kim Jiwon. Learning to discover cross-domain relations with generative adversarial networks. Proceedings of the 34th International Conference on Machine Learning, 70:1857–1865, 2017. [Google Scholar]
- [9].Ledig Christian, Theis Lucas, Ferenc Huszár Jose Caballero, Cunningham Andrew, Acosta Alejandro, Aitken Andrew, Tejani Alykhan, Totz Johannes, Wang Zehan, and Shi Wenzhe. Photo-realistic single image super-resolution using a generative adversarial network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4681–4690, 2017. [Google Scholar]
- [10].Long Jonathan, Shelhamer Evan, and Darrell Trevor. Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431–3440, 2015. [DOI] [PubMed] [Google Scholar]
- [11].Lu Yongyi, Tai Yu-Wing, and Tang Chi-Keung. Attribute-guided face generation using conditional cyclegan. Proceedings of the European Conference on Computer Vision (ECCV), pages 282–297, 2018. [Google Scholar]
- [12].Ma Ruibin, Wang Rui, Pizer Stephen, Rosenman Julian, McGill Sarah K, and Frahm Jan-Michael. Real-time 3d reconstruction of colonoscopic surfaces for determining missing regions. International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 573–582, 2019. [Google Scholar]
- [13].Mahmood Faisal, Chen Richard, and Durr Nicholas J. Unsupervised reverse domain adaptation for synthetic medical images via adversarial training. IEEE Transactions on Medical Imaging, 37(12):2572–2581, 2018. [DOI] [PubMed] [Google Scholar]
- [14].Mathieu Michael, Couprie Camille, and LeCun Yann. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015. [Google Scholar]
- [15].Mesejo Pablo, Pizarro Daniel, Abergel Armand, Rouquette Olivier, Beorchia Sylvain, Poincloux Laurent, and Bartoli Adrien. Computer-aided classification of gastrointestinal lesions in regular colonoscopy. IEEE Transactions on Medical Imaging, 35(9):2051–2063, 2016. [DOI] [PubMed] [Google Scholar]
- [16].Mirza Mehdi and Osindero Simon. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014. [Google Scholar]
- [17].Miyato Takeru, Kataoka Toshiki, Koyama Masanori, and Yoshida Yuichi. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018. [Google Scholar]
- [18].Nadeem Saad and Kaufman Arie. Computer-aided detection of polyps in optical colonoscopy images. SPIE Medical Imaging, 9785:978525, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Pajot Arthur, de Bezenac Emmanuel, and Gallinari Patrick. Unsupervised adversarial image reconstruction. International Conference on Learning Representations (ICLR), 2019. [Google Scholar]
- [20].Porav Horia, Musat Valentina, and Newman Paul. Reducing steganography in cycle-consistency gans. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 78–82, 2019. [Google Scholar]
- [21].Rau Anita, Edwards PJ Eddie, Ahmad Omer F, Riordan Paul, Janatka Mirek, Lovat Laurence B, and Stoyanov Danail. Implicit domain adaptation with conditional generative adversarial networks for depth prediction in endoscopy. International Journal of Computer Assisted Radiology and Surgery, 14(7):1167–1176, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Rex Douglas K, C Richard Boland, Dominitz Jason A, Giardiello Francis M, Johnson David A, Kaltenbach Tonya, Levin Theodore R, Lieberman David, and Robertson Douglas J. Colorectal cancer screening: Recommendations for physicians and patients from the US Multi-Society Task Force on Colorectal Cancer. The American Journal of Gastroenterology, 112(7):1016, 2017. [DOI] [PubMed] [Google Scholar]
- [23].Thomas Schöps, Torsten Sattler, and Pollefeys Marc. Surfelmeshing: Online surfel-based mesh reconstruction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019. [DOI] [PubMed] [Google Scholar]
- [24].Shin Younghak, Qadir Hemin Ali, and Balasingham Ilangko. Abnormal colon polyp image synthesis using conditional adversarial networks for improved detection performance. IEEE Access, 6:56007–56017, 2018. [Google Scholar]
- [25].Whelan Thomas, Salas-Moreno Renato F, Glocker Ben, Davison Andrew J, and Leutenegger Stefan. Elasticfusion: Real-time dense slam and light source estimation. The International Journal of Robotics Research, 35(14):1697–1716, 2016. [Google Scholar]
- [26].Yi Zili, Zhang Hao, Tan Ping, and Gong Minglun. DualGAN: Unsupervised dual learning for image-to-image translation. Proceedings of the IEEE International Conference on Computer Vision, pages 2849–2857, 2017. [Google Scholar]
- [27].Zhu Jun-Yan, Park Taesung, Isola Phillip, and Efros Alexei A. Unpaired image-to-image translation using cycle-consistent adversarial networks. Proceedings of the IEEE International Conference on Computer Vision, pages 2223–2232, 2017. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.