

Abstract
Cluster randomized trials (CRTs) refer to experiments with randomization carried out at the cluster or the group level. While numerous statistical methods have been developed for the design and analysis of CRTs, most of the existing methods focused on testing the overall treatment effect across the population characteristics, with few discussions on the differential treatment effect among subpopulations. In addition, the sample size and power requirements for detecting differential treatment effect in CRTs remain unclear, but are helpful for studies planned with such an objective. In this article, we develop a new sample size formula for detecting treatment effect heterogeneity in two-level CRTs for continuous outcomes, continuous or binary covariates measured at cluster or individual level. We also investigate the roles of two intraclass correlation coefficients (ICCs): the adjusted ICC for the outcome of interest and the marginal ICC for the covariate of interest. We further derive a closed-form design effect formula to facilitate the application of the proposed method, and provide extensions to accommodate multiple covariates. Extensive simulations are carried out to validate the proposed formula in finite samples. We find that the empirical power agrees well with the prediction across a range of parameter constellations, when data are analyzed by a linear mixed effects model with a treatment-by-covariate interaction. Finally, we use data from the HF-ACTION study to illustrate the proposed sample size procedure for detecting heterogeneous treatment effects.
Keywords: cluster randomized trials, heterogeneous treatment effect, interaction, intraclass correlation coefficient, power formula, sample size estimation
1 |. INTRODUCTION
Cluster randomized trials (CRTs), or sometimes called group randomized trials (GRTs), refer to experiments with randomization carried out at the cluster or the group level.1 CRTs are conducted because the intervention is naturally performed at the group level (e.g., a clinical decision support system delivered to the entire clinic), because the investigators wish to minimize the risk of treatment contamination within the same cluster, or because it is more ethical if the same treatment is applied to individuals in the same geographical unit (e.g., village or county), among others. Such trials are common in epidemiology, social science, and medicine. Over the past decade, CRTs are also adopted for studies embedded in the healthcare delivery systems, where there is a great interest in learning the real-world effectiveness of a system-based intervention.2 Numerous statistical methods have been developed for the design and analysis of CRTs; see, for example, the recent methodological reviews by Turneretal.3,4 However, these previous methods have primarily focused on the overall treatment effect (OTE) averaged over the population characteristics, and little discussion has been offered to address the differential treatment effect among subpopulations. A recent systematic review by Starks et al5 also found that only 18 out of 64 health-related CRTs published between 2010 and 2016 examined heterogeneity of treatment effect (HTE) in subgroups. Although not as commonly seen in previous CRTs, the investigation of HTE has received increasing attention because cluster randomized designs are gaining popularity in intervention studies embedded in healthcare systems, where patient-level information is routinely collected and readily available.6,7 Responding to the lack of guidance on HTE analysis in CRTs,5 this article provides a model-based approach to design CRTs that allows investigators to detect HTE for continuous outcomes, with a particular emphasis on sample size and power requirements. Our method applies to two-level CRTs with continuous or binary covariates that are measured at the individual or cluster level.
The concept of HTE refers to potentially variable treatment effects between patient subgroups that can arise due to different reasons, such as different responses to treatment, different vulnerability to certain diseases, and adverse effects.8 When HTE is present, the treatment of interest may provide benefit to some patients, but could be neutral or harmful to others.8 HTE is usually identified by separate subgroup analysis, or formalized by parametric statistical interaction terms in individually randomized trials. Systematic reviews of individually randomized trials suggest that HTE tends to be overlooked and inadequately reported.9–11 In particular, the sample size estimates provided in the design stage are usually specific to testing the OTE in the study population, and it is unknown whether the trial has adequate power to detect the HTE. Furthermore, separate subgroup analyses are frequently conducted in an ad hoc fashion and could involve multiple comparisons that are subject to false positive results. Similar concerns translate into the design and analysis of CRTs, with the caveat that CRTs usually require a larger sample size for detecting the OTE due to within-cluster correlations.
Because the unit of randomization is each cluster, another distinguishing feature of CRTs is that the individual-level outcomes are correlated within the same cluster, possibly due to social connections or shared healthcare resources. The intraclass correlation coefficient (ICC) characterizes the similarity of values (e.g., outcomes) for pairs of individuals in the same cluster, and plays an important role in determining the sample size for CRTs. The sample size requirements for testing the OTE in CRTs have been well studied;1 a typical strategy is to inflate standard sample size estimate obtained under individual randomization by a design effect (also called the variance inflation factor),
| (1) |
where ρy is the ICC for individual-level outcomes and m is the cluster size.12–14 In CRTs, the number of clusters and the cluster size jointly determine the total sample size. Based on this simple expression of design effect, others have also studied the trade-off between increasing cluster sizes vs increasing the number of clusters, and provided insights on optimal design of CRTs to reach the maximum statistical efficiency.15,16 While these results are particularly powerful in designing CRTs to evaluate the OTE, they do not take into account additional covariates (either cluster-level or patient-level), and so do not apply directly for HTE analysis. On the other hand, the sample size methodology for detecting HTE in individually randomized trials has been formalized either as examining the cross-site difference in treatment effect17 or as testing the statistical interaction between the treatment and covariates; see, for example, Brookes et al18 and Shieh19 for continuous outcomes, Greenland20 and Demidenko21 for binary outcomes, and Kang et al22 for censored time-to-event outcomes. We take the latter approach by formalizing the detection of HTE as a test for treatment-by-covariate interaction in a random-effects model that accounts for within-cluster correlations, and aim to clarify the essential ingredients for appropriate sample size planning with HTE analysis in CRTs.
In the educational statistics literature, several authors have previously studied power formulas for HTE analysis in CRTs. For example, Spybrook et al23 proposed power formulas for detecting treatment-by-covariate interaction effects in CRTs with a binary covariate. They also extended the formula to account for additional adjustment variables which further improve the test power. Dong et al24 extended these formulas to three-level CRTs under both fixed-slope and random-slope models. While these previous results explicitly involve the ICCs of the outcome, the impact of the clustering of the covariate on power has not been explicitly considered. In addition, these previous sample size formulas have not been empirically validated in Monte Carlo simulation studies, and their finite-sample operating characteristics remain to be explored. On the other hand, sample size procedures for testing interaction terms have been discussed in individually randomized studies with repeated measures, namely studies where treatment is randomized to individuals and repeated measurements are then taken for each individual across several time points. In that context, the target parameter that describes the intervention effect is the change in slopes of the individual outcome trajectory, and is parameterized as the statistical interaction between treatment and time (in continuous scale). For continuous outcomes, Heo and Leon25 provided a sample size formula to detect the two-way and three-way slope change over time; their test statistic is based on method of moments and the intraclass correlation for repeated measurements has only been considered in variance estimation. Jung and Ahn26 derived a sample size formula for the slope change based on continuous outcomes analyzed by independence generalized estimating equations.27 Our interaction test for detecting HTE in CRTs is related to and generalizes the results developed for the slope test in longitudinal studies. While the interaction is defined as the product between the treatment and a time variable in longitudinal studies, the interaction term can be defined as the product between the treatment and a general covariate. The general covariate could be either continuous or binary, and could be either measured at the cluster level or individual level, depending on the scientific question. These considerations motivate us to formalize a sample size procedure applicable to the interaction test used to describe HTE in CRTs for continuous outcomes.
The remainder of this article is organized as follows. In Section 2, we introduce the linear mixed effects model with a treatment-by-covariate interaction. In Section 3, we develop a closed-form sample size formula for testing the treatment-by-covariate interaction and provide extensions to multiple covariates. We present numerical evidence in Section 4 to illustrate the proposed sample size formula, and conduct a Monte Carlo simulation study in Section 5 to investigate the accuracy of the proposed power formula. In Section 6, we use data obtained from the HF-ACTION study to illustrate the new sample size formula to detect HTE. Section 7 concludes with a discussion.
2 |. STATISTICAL MODEL
We consider a parallel CRT with n clusters randomly assigned to two arms or conditions. Typically, individuals are recruited in each cluster and the outcomes will be measured for each individual. Let Yij be a continuous outcome for the jth individual (j=1, … , mi) in the ith cluster (i=1, … , n). The linear mixed effects model is commonly used to analyze individual-level outcomes in CRTs, with a random cluster intercept that accounts for the outcome ICC.4 When the focus is on the overall intervention effect, a linear mixed effects model with a treatment indicator and a random intercept is written as:
| (2) |
where α1 is the grand mean, Wi is the binary treatment indicator (Wi =1 if cluster i is assigned to intervention and Wi =0 otherwise), α2 is the OTE, is the random cluster effect, and is the residual error, independent of the random cluster effect.
Individual-level covariates are often collected at baseline in CRTs embedded within the healthcare delivery systems.6,28 In addition to testing for the OTE, investigators may wish to test possible treatment effect heterogeneity with respect to some covariates. In this case, as the power and sample size requirements for the OTE are relatively well known, it would be important to understand the sample size and power requirements with respect to the interaction effect parameter describing treatment effect heterogeneity. Assume that Xij is a p-dimensional vector of individual-level covariates, such as age, gender, and race among others, we could extend model (2) for the analysis of individual-level outcomes as
| (3) |
where Xij =(Xij1, … , Xijp)T is the set of covariates measured for individual j in cluster i, Wi is defined in model (2), XijWi represents a vector of interactions between treatment and covariates, β1 is the grand mean, β2 is the main treatment effect, β3 = (β31, … , β3p)T and β4 = (β41, … , β4p)T are regression coefficients for the covariates and the interaction terms. For example, assuming Xij is a binary covariate, race, and Xij =1 denotes black while Xij =0 white. The parameter β1 represents the mean response among white patients in the control arm, β2 represents the treatment effect for white patients, β1 + β3 represents the mean response among black patients in the control arm, and β4 represents the difference in treatment effect among black and white patients, which could be the parameter of interest. Similar to the assumptions in model (2), we assume in model (3) and , and independence between γi and ϵij. This same model has also been discussed in Spybrook et al,23 where Xij is binary. Of note, model (3) is a direct extension of those studied in Raudenbush,29 Li et al,30 and Yang et al,31 where only main effects of Wi and Xij are considered. Further extensions of model (3) to allow for random coefficients for Xij can be found in Jaciw et al32 and Dong et al.24
To proceed, we let denote the proportion of clusters that are randomized to the intervention group. When half of clusters are randomized to the intervention arm, , but our results allow to be any value in (0,1). We reparameterize model (3) by subtracting from the treatment variable, and obtain
| (4) |
where the coefficients are , b2 = β2, , and b4 = β4. From model (4), the total variance of Yij adjusting for Xij is , and , where is the indicator function. The outcome ICC adjusting for Xij is then defined as29
| (5) |
Following the terminology in Murray and Blitstein,33 we define , as the adjusted variance components, and ρy|x as the adjusted outcome ICC. Furthermore, the joint covariance matrix of within-cluster observations is compound symmetric. In other words, if we define , we can write in matrix notations that , where is the mi × mi identity matrix, is the mi × mi matrix of ones, and Ri is the exchangeable correlation matrix.
Define the collection of design points and . Given the values of and , the covariance matrix and the correlation matrix of Yi are known. The best linear unbiased estimator (BLUE) of b =(b1,b2,b3,b4)T is given by the generalized least squares (GLS)
| (6) |
When n is large, is approximately normally distributed with mean b and variance matrix
| (7) |
In practice, both and are unknown, and therefore will be estimated from the data. The restricted maximum likelihood (REML) approach can be used to estimate both b and variance components; additional technical details for estimation can be found in Pinheiro and Bates.34
3 |. SAMPLE SIZE AND POWER CALCULATION
3.1 |. Basic setting with one covariate
We first derive the sample size formula when the treatment effect heterogeneity concerns one covariate. In other words, p =1; this is the case, for example, when the covariate of interest is race (a binary covariate) or age (a continuous covariate). We keep the race variable as a running example through this section. The interaction effect, β4 is a scalar, and we are interested in testing the null hypothesis H0 : β4 = 0 using a two-sided test. In our running example, we would be interested in testing whether the treatment effect differs between two different racial groups. Based on the linear mixed effects model (4), the scaled GLS estimator is asymptotically normal with mean zero and variance equal to the lower right element of Σ = limn→∞nΣn, which we denote by . This suggests the use of the z-test statistic, , which will be referenced to the standard normal distribution. For a prespecified test size β4 = Δ, it then follows that the required number of clusters with a nominal test size α and power 1 – λ is given by
| (8) |
To derive an expression for , we examine the expression for U = limn→∞n−1Un (readers who want to skip the technical intermediate steps can jump to Equation (9) without loss of continuity). Following the conventions in designing CRTs, here we make the simplification assumption that the cluster sizes are equal, namely, mi = m for all i. With this assumption, the inverse of the exchangeable working correlation structure can be written as35
where we define c = 1/(1 – ρy|x), and d = −ρy|x/[(1 – ρy|x){1 + (m − 1)ρy|x}]. This allows us to write Un = cSn + dTn, where
and
where for l =1,2 represent the cluster-specific moment values for the covariate. Next, define , as the limits of covariate moments and as the variation in the treatment assignment, we can obtain the limits
and
These calculations allow us to obtain the structure of the limit of the precision matrix in a block form as
 |
Notice that each block in U is actually a diagonal matrix, which permits a simple closed-form derivation of the lower right element of U−1 via block matrix inversion. Specifically, we observe , and B = C, then the lower right block becomes (D − CA−1B)−1 = (D − CC−1μ1B)−1 = (D − μ1B)−1. It follows that the lower-right element of becomes
| (9) |
where in most CRTs due to balanced allocation of treatment.
Equations (8) and (9) provide a simple approach to calculate the required number of clusters to power the test of treatment effect heterogeneity. Given information on the cluster size m, adjusted ICC of the outcome ρy|x, and moment values μ1, μ2, and η2, one could obtain the required number of clusters n by simple calculation. On the other hand, if we have information on the maximum number of clusters n, Equations (8) and (9) imply a quadratic function of the cluster sizes required to achieve the desired level of power, and therefore m can be obtained by the quadratic formula. To get further insights on the sample size formula, it is possible to simplify Equation (9) by introducing a new quantity, ρx, which measures the intraclass correlation for the covariate of interest. The concept of covariate ICC has been previously mentioned in Raudenbush,29 and can be viewed as the counterpart of outcome ICC. In our running example, ρx measures the degree of similarity between within-cluster individuals in terms of their racial groups. Formally, we define
where Xij, Xik are measured for pairs of individuals in the same cluster. With this quantity, it follows that
Plugging this expression into (9), and notice that the marginal variance of the covariate Xij is , we have
| (10) |
and the required total number of individuals in a CRT satisfies
| (11) |
Sample size formula (11) depends on the marginal variance of the covariate and the two ICC parameters ρy|x and ρx. Compared with the conventional CRT powered to test for the overall treatment effect, we require information of the adjusted outcome ICC, and information of Xij through two second-order parameters and ρx. The above expression allows us to study the relationship between sample size and distributions of Xij. Particularly, larger values of marginal variance reduce the required sample size for fixed outcome ICC, while larger values of covariate ICC ρx increase the required sample size for fixed outcome ICC. This is intuitive since larger marginal variability of Xij and smaller covariate ICC imply more per unit information on estimating the treatment effect heterogeneity and hence improve the efficiency. On the other hand, the relationship between the required number of clusters and the adjusted outcome ICC seems less clear, and we will conduct numerical studies in Section 4.1 to assess such relationships. Another noticeable feature of sample size formula (11) is that it does not depend on the grand mean term or main effect sizes of the treatment and covariate, which suggests that knowledge of the effect size for the interaction term suffices.
The above sample size formula can be inverted to obtain the minimum detectable effect size (MDES) given the available number of clusters n and the cluster size m. In this case, we can easily see that the study would have 1 − λ power to detect an interaction effect size of at least |Δ|, where
It is important to notice that sample size formula (11) includes two interesting special cases.
Case 1 (cluster-level covariate). When the covariate of interest is at the cluster-level (e.g., proportion of black patients in each clinic) and hence Xij = Xi for all j, we naturally have ρx = 1 (because the covariate is perfectly correlated with itself in each cluster), and the above formulas reduce to
| (12) |
| (13) |
from which we immediately recognize that the term, 1 + (m − 1)ρy|x, corresponds to the usual design effect in a parallel CRT powered for testing OTE, except that the adjusted outcome ICC is used. This is expected because XiWi degenerates to a cluster-level covariate, and the variance inflation for XiWi due to clustering resembles that for the treatment, which is also a cluster-level covariate. Furthermore, under equal treatment allocation and when Xi is a binary cluster-level covariate with prevalence 1/2, Equation (13) reduces to equation (10) in Spybrook et al.23 In this regard, formula (13) generalizes equation (10) in Spybrook et al23 to allow for unequal allocation and an arbitrary cluster-level covariate.
Case 2 (no residual clustering). If there is no residual clustering and that we are interested in testing treatment effect heterogeneity in an individually randomized trial, then we must have ρy|x = 0. The variance expression and required sample size can be shown to be
| (14) |
| (15) |
where N now represents the total number of individuals, and is the adjusted total variance. This sample size formula is closely connected with the one provided in Shieh et al,19 although they did not provide an explicit expression and focused on the t-test statistic.
The forms of Equations (13) and (15) provide the basis for formally defining the design effect due to clustering with respect to testing treatment effect heterogeneity. That is, the design effect for testing treatment heterogeneity with respect to a cluster-level covariate has the same form as that defined for testing OTE,
| (16) |
while the design effect for testing treatment effect heterogeneity with respect to an individual-level covariate is implied from Equations (11) and (15),
| (17) |
Unlike θ1(m), which diverges to infinity as cluster size increases indefinitely, the design effect θ2(m) converges to a finite constant θ2(∞) = (1 − ρy|x)/(1 − ρx). Hence, depending on the relative magnitude of the two ICCs, the limit of the design effect θ2(∞) may be either greater or smaller than one, which represents a distinguishing feature between θ1(m) and θ2(m). In addition, the limit of the design effect θ2(∞) decreases as ρy|x increases and ρx decreases, while θ1(m) is monotone in ρy|x. Finally, when the adjusted outcome ICC equals to the covariate ICC, there is no efficiency loss due to clustering in testing the treatment effect heterogeneity, because θ2(m) = 1 for any m.
3.2 |. Extensions to multiple covariates
Although we mainly focus on the basic scenario, it is possible to extend the above sample size procedure for jointly testing the interactions with multiple covariates. In this case, Xij =(Xij1, Xij2, … , Xijp)T is the set of p ≥ 2 covariates, and the interaction parameters of interest are β4 = (β41, β42, … , β4p)T. We are interested in testing the global null hypothesis H0 : β4 = 0 based on a Wald test. In the context of the running example, we could have access to p =2 covariates: race and gender, and would be interested in jointly testing whether race and gender modify the treatment effect. From the linear mixed effects model (4), the scaled GLS estimator is asymptotically normal with mean zero and variance equal to the lower-right p × p block of Σ = limn→∞nΣn, which we denote by Ω4. This motivates the Wald test statistics , which converges to a Chi-squared distribution χ2(p, ϑ) with p degrees of freedom and the noncentrality parameter . For fixed effect size vector β4, the corresponding power equation of the Wald test is approximated by
| (18) |
where f(x;p,ϑ) is the probability density function of the χ2(p, ϑ) distribution. Fixing n or m, solving Equation (18) for m or n then gives the required sample size.
An explicit sample size equation with multiple covariates now requires the derivation of the variance matrix Ω4, which determines the noncentrality parameter. We show in Web Appendix A that
| (19) |
In this expression, information on covariates has been represented by two matrix expressions. The first matrix summarizes the marginal correlation between p covariates and is defined as
where , , is the diagonal matrix containing the marginal variances of all covariates. Therefore, the diagonal element of is one and the off-diagonal elements represent the marginal correlation between each pair of covariates. The second matrix is defined as
which could be regarded as a multivariate extension of the scalar covariate ICC. Specifically, the diagonal element of is the ICC of each covariate, while the off-diagonal elements are the intraclass cross-correlations between two different covariates. To further aid the interpretations of the two correlation matrices in Equation (19), we provide in Web Appendix A a simple example where Xij is generated from a multilevel model, from which we derive explicit forms of and . When p=2 covariates are considered, we additionally derive a more explicit expression of Equation (19) in Web Appendix A, as a function of scalar correlation parameters. Finally, we notice that the variance expression (10) is a special case of (19) when p=1. In that case, , , and is obtained.
Similar to Section 3.1, the expression (19) shed lights on two special cases. For example, when the multiple covariates of interest are all measured at the cluster-level (e.g., proportion of Black patients and proportion of female patients in each clinic), it is easy to verify that , and so the variance expression simplifies to
| (20) |
where we again see the expression 1 + (m − 1)ρy|x as the design effect due to clustering. Finally, in an individually randomized trial, one could similarly show that the variance becomes
| (21) |
which happens to be the expression (19) evaluated at ρy|x = 0.
4 |. NUMERICAL ILLUSTRATIONS
In this section, we present some numerical evidence to further illustrate the variance expression (10) in the univariate case. In particular, we aim to study (i) how the power for testing H0 : β4 = 0, or equivalently changes as we vary the two ICC parameters and (ii) the comparisons between the required sample sizes for testing HTE vs those for testing OTE in CRTs.
4.1 |. Roles of the ICC parameters
Because the variance expression involves two ICC parameters, ρy|x for the outcome of interest, and ρx for the covariate of interest, it is of particular interest to understand how the values of these two parameters affect the and hence the power for testing H0 : β4 = 0. In Figure 1, we plot values of over the range of either ρx (upper panels) or ρy|x (lower panels), with cluster sizes varied from m∈{20,50,100}, and , . Notice that we allow the largest ρx to be 1 and the largest ρy|x to be 0.5. The largest value ρx = 1 is observed when the covariate is measured at the cluster| level; this scenario allows us to compare the efficiency between the interaction test with an individual-level covariate and that with a cluster-level covariate. The largest ρy|x, however, may be unlikely to be seen in real-world CRT contexts. We include those values merely to illustrate the relationship between and ρy|x. From the upper panels, it is clear that larger values of the covariate ICC ρx inflate the variance , and therefore reduce the power of the interaction test, when all other parameters are held fixed. This pattern confirms the analytical result in Section 3.1. When the adjusted outcome ICC is small (ρy|x = 0.01), the relationship between and covariate ICC ρx is relatively flat, indicating that the power (which is inversely related to ) is not sensitive to ρx. But as the adjusted outcome ICC grows larger (ρy|x = 0.1), the power of the test becomes increasingly sensitive to changes in ρx, especially when ρx is larger than 0.5. Because ρx = 1 corresponds to the scenario with a cluster-level covariate, it is evident that the power to detect the cluster-level interaction effect could be much smaller than that to detect the individual-level interaction effect, when the adjusted outcome ICC is nontrivial (say, ρy|x ≥ 0.05) and the cluster size is not large. From the lower panels, we observe a parabolic relationship between and ρy|x. In general, as the adjusted outcome ICC increases, the variance first increases to its maximum and then decreases monotonically. In fact, we can use the quadratic formula to show that the value of ρy|x that gives the largest variance (stationary or critical point) is
| (22) |
which clearly depends on both the covariate ICC and cluster size. As the covariate ICC becomes smaller or the cluster sizes become larger, moves toward zero. This underlies the reason why is nearly monotonically decreasing in ρy|x when ρx = 0.05. Web Figure 4 presents the analogous results for m=10 (extremely small cluster sizes) and m=200. Results for m=10 and m =200 are qualitatively similar to those for m=20 and m=100, respectively. Therefore, the patterns seen in Figure 1 extend to smaller and larger cluster sizes.
FIGURE 1.
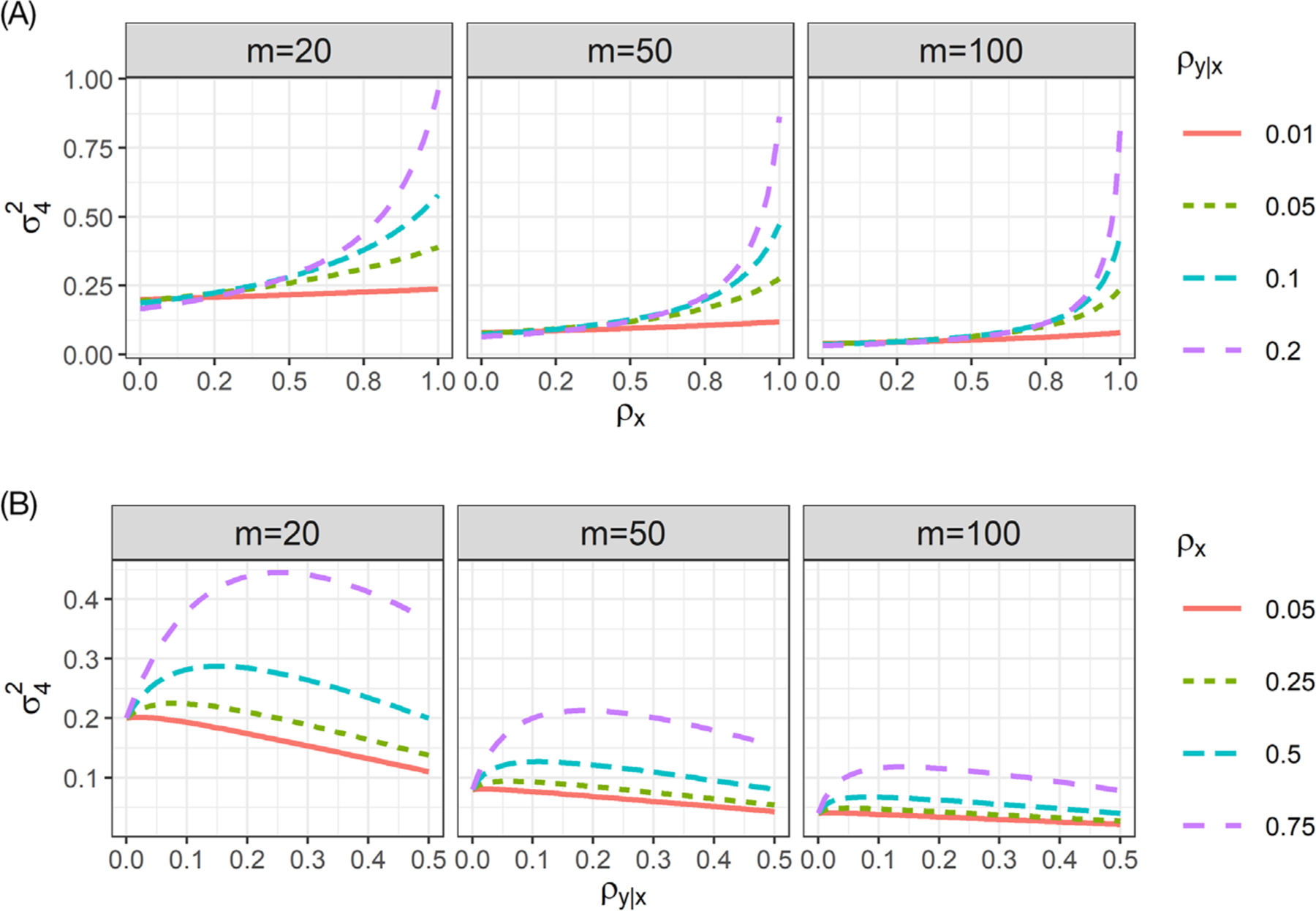
Variance of the GLS estimator for the treatment-by-covariate interaction, , as a function of the, A, covariate ICC ρx and, B, adjusted outcome ICC ρy|x with cluster sizes m∈{20,50,100}, assuming , and
4.2 |. Sample size requirements for testing HTE vs testing OTE
Most current CRTs are powered to detect the OTE, parameterized by α2 in model (2). It is unknown whether such studies have adequate power to detect the treatment-by-covariate interaction, parameterized by β4 in model (3). In this section, we use a simple example to numerically evaluate how many additional information is required to power the interaction test vs the overall treatment effect test. That is, the sample size difference between testing the null hypothesis H0 : β4 = 0 in model (3) vs H0 : α2 = 0 in model (2), when the true data generating process follows model (3).
A complication of this evaluation is that when β4 is nonzero, models (2) and (3) may not hold simultaneously (see Web Appendix B for further details). However, when the true model follows (3), it is possible to approximate the unadjusted model of form (2). To do so, we assume a single continuous covariate generated from a multilevel model such that Xij = μ + μi + τij, where μ is the marginal mean, , , and τij is independent of μi. We further assume the covariate is mean-centered such that μ = 0. The marginal variance of Xij is , and the covariate ICC is . We can then rewrite model (3) with this mean-centered covariate as
where we treat α1 = β1, α2 = β2, λi = β3μi + β4Wiμi + γi, and ξij = β3τij + β4Wiτij + ϵij. The approximate model (2) can then be identified once we compute the induced variance components for λi and ξij. In Web Appendix B, we show that
and cov(λi, ξij) = 0, where . Define and recall that , the unadjusted outcome ICC can be reasonably approximated by (see Web Appendix B for additional details)
| (23) |
which appears as a weighted combination of the adjusted outcome ICC ρy|x and covariate ICC ρx (with weight ω). Specifically, when all the ICCs are nonnegative, ρy ≥ ρy|x if and only if ρx ≥ ρy|x. Furthermore, if the adjusted total variance is substantially larger than , then the unadjusted outcome ICC tends to be similar to the adjusted outcome ICC, ρy ≈ ρy|x.
These derivations allow us to approximate the asymptotic variance of , which is given by . We further define the ratio of detectable effect size (RDES) as RDES = Δ/ΔOTE, where Δ is the hypothesized value of β4, and ΔOTE is the hypothesized value of α2 = β2. Based on expression (8), the ratio of total sample size required for testing HTE vs OTE is given by
| (24) |
where the last equality results from the relationship (23), and . A more detailed analytical investigation of Θ(m) as a function of covariate ICC can be found in Web Appendix B.
Figure 2 presents the values of Θ(20), Θ(50), and Θ(100), with various values of ρx and ρy|x, and fixing , β2 = β3 = 0.5 and (equal randomization). This scenario corresponds to a CRT with both main effects as half the magnitude of the total adjusted standard deviation. We vary the RDES ∈{0.1,0.25,0.5,1} to represent scenarios where the interaction effect is one-tenth of, a quarter of, half as and identical to the OTE. Three patterns emerge from the Figure 2. First, Θ(m) appears mostly as a decreasing function of ρx, with a few exceptions when ρy|x is large. When the adjusted outcome ICC is small (ρy|x = 0.01), the variance inflation factor Θ(m) is sensitive to covariate ICC, and decreases sharply as covariate ICC increases. However, as the adjusted outcome ICC increases, the relationship between Θ(m) and covariate ICC ρx becomes relatively flat. The total sample size required for the interaction test is more likely to exceed those required for the OTE test when the covariate ICC and outcome ICC are both small. For example, when the interaction effect is one half of the OTE, the total sample size required for testing HTE can be 2.5 times that required for testing the OTE, when the covariate ICC is close to 0, the adjusted outcome ICC is 0.01 and m=20. When the interaction effect is the same as the OTE, however, the total sample size required for testing HTE is smaller than that required for testing the OTE. For individually randomized trials, Brookes et al18 previously suggested that the sample size should be inflated at least 4- or 16-folds for testing the interaction effect with the same or half magnitude of the OTE with a binary covariate (in their case ). Extrapolating our results to a binary covariate with , we find that the sample size should be inflated at most 3- and 10-fold for testing the interaction effect with the same or half the magnitude of the OTE in CRTs (these numbers are calculated by four times the numbers in the “worst case scenarios” where the covariate ICC is zero, adjusted outcome ICC is 0.01, , and cluster size is 20). Such indirect comparisons suggest that the sample size inflation for testing an interaction term in CRTs may be no larger than that in individually randomized trials, among the scenarios we considered. Second, Θ(m) becomes smaller as cluster size increases, which indicates that the total sample size required for the two tests are likely to be more comparable when the study involves clusters with more participants. Finally, the determining factor for power of the interaction test is still the RDES. When the RDES is very small (say 0.1), the variation inflation factor Θ(m) can be more than 50 when the cluster size is not large, and any realistic sample sizes used in current CRTs will not be able to power an interaction test with such small effect sizes. Nevertheless, when the interaction effect size is close to OTE (RDES=1), the required sample size for the interaction test is frequently smaller than that for the overall effect test, across the ranges of ICC values we have considered. In the Web Appendix, we have varied the main effect of the covariate β3 ∈ {0.25,1} and the cluster size m∈{10,200}; the results are presented in Web Figures 5 to 8. Overall, those additional results are similar to Figure 2 and confirm that the patterns observed here extend to small and larger covariate main effect and cluster sizes.
FIGURE 2.
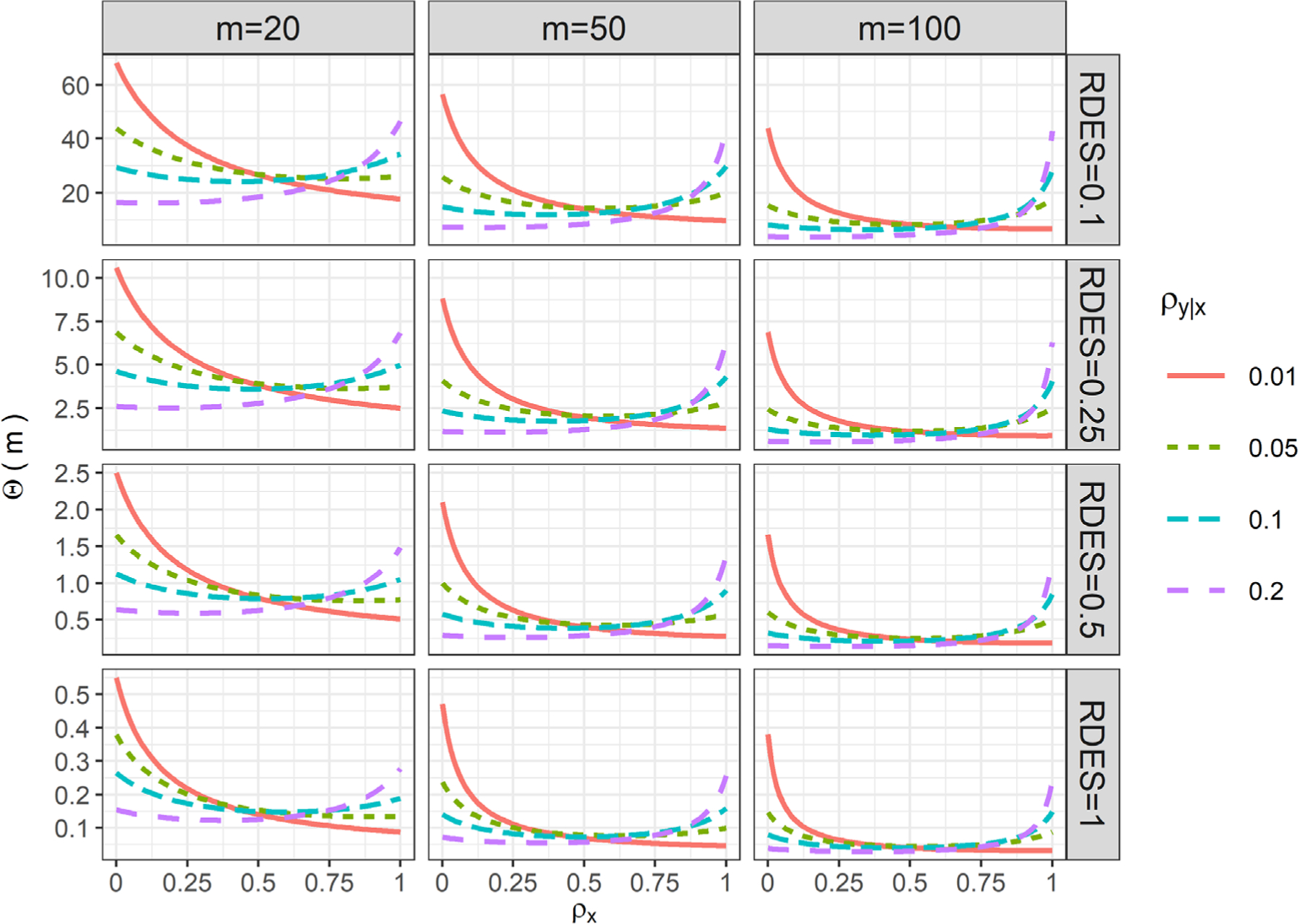
Ratio of total sample size required for testing HTE vs OTE as a function of the cluster size m, covariate ICC ρx, adjusted outcome ICC ρy|x, and ratio of detectable effect sizes (RDES), assuming , β2 = β3 = 0.5, and W = 1/2
5 |. SIMULATIONS
5.1 |. Simulation design
We investigate the performance of the new sample size formula for detecting treatment effect heterogeneity in finite samples via simulations. We focus on a cross-sectional CRT with clusters randomized to two arms in a 1:1 ratio, so that . For simplicity, we consider a single individual-level covariate Xij, which could be either continuous or binary. From Equation (11), the total sample size depends on the following parameters: type I error rate, power, the total adjusted variance and the marginal variance of covariate , adjusted outcome ICC and covariate ICC, cluster size, and the effect size for the treatment-by-covariate interaction. Throughout we fix , nominal type I error at 5%, desired level of power at 80%, and vary the remaining parameters in a factorial design. We consider four levels of cluster sizes m∈{10,20,50,100}, representing small to large cluster sizes; three levels of adjusted outcome ICC ρy|x ∈ {0.01,0.05,0.1}, representing values commonly reported in the CRT literature;1,36 three levels of covariate ICC ρx ∈ {0.1,0.25,0.5}, mimicking values considered in the illustrative example in Section 6. We fix the interaction effect size at zero to examine the empirical type I error rate, and choose the interaction effect size among {0.10,0.15,0.25} for the continuous covariate scenario and among {0.25,0.35,0.45} for the binary covariate scenario. The differences in the choice of effect size in the continuous and binary covariate scenarios are to offset the differences in the marginal variance and to obtain comparable sample size estimates. To summarize, for each type of covariate, there are in total 4×3×3×3=108 scenarios. We have also investigated additional scenarios when ρx = 0.01 and 0.05, and find similar results. Those results are omitted for brevity.
In the continuous covariate scenario, we fix the marginal variance , and generate Xij from Xij = 1/2 + μi + τij, where , and . In the binary covariate scenario, we simulated Xij from the beta-binomial model, where the cluster-specific prevalence πi ~ Beta(q1, q2), and Xij ~ Bernoulli(πi). The implied marginal prevalence across all clusters from this model is q1/(q1 + q2), and the covariate ICC can be analytically shown as ρx = (1 + q1 + q2)−1. We choose q1 and q2 to ensure the marginal prevalence of Xij is 30% and to maintain the desired level of covariate ICC. The implied marginal variance is therefore . In each of the above scenario, we use our sample size formula (11) to estimate the required number of clusters, n, rounded to the nearest even integer above. Then given the value of n, we simulate individual-level outcomes Yij from model (3), where we choose β2 = 0.25 and β3 = 0.1. As we have explained in Section 3.1, these regression parameters are ancillary to sample size determination as they are not part of Equation (11). A total of 5000 data replicates are generated for each scenario, and the linear mixed effects model (3) is fit to each data set using the restricted maximum likelihood estimation (REML). In the null scenario where β4 = 0, we calculate the empirical type I error rate (ψ0) as the proportion of false rejections to ensure the test carries a nominal size in finite samples. In the nonnull scenario where β4 ≠ 0, we calculate the empirical power (ϕ0) as the proportion of correct rejections and compare with the analytical prediction (ϕ). All analyses are conducted in R (version 3.4.4) using the nlme package.34
5.2 |. Simulation results
Table 1 summarizes the estimated required number of clusters (n), the empirical type I error rate (ψ0), the empirical power (ϕ0), and the predicted power (ϕ), when the cluster size m ∈{10,20,50,100}, and three levels of effect sizes Δ for the continuous covariate Xij. Table 2 parallels Table 1 and summarizes the corresponding results when the covariate Xij is binary. In the null scenario, the test for HTE maintains the nominal type I error rate across the parameter constellations, indicating that the test is valid. This ensures the validity of the subsequent comparisons between the empirical and predicted power. Across all levels of nonzero effect sizes, the predicted power obtained from our sample size formula is fairly close to the empirical power. Note since the required number of clusters are rounded to the nearest even integer above, the predicted power could be slightly greater than 0.80 in some cases. The mean absolute difference between the empirical and analytical power is 0.007 (IQR=0.008) when Xij is continuous and 0.01 (IQR=0.011) when Xij is binary. Overall, our sample size formula performs well since the analytical prediction agrees with empirical power, based on a two-sided test that maintains the nominal type I error rate, even when the number of clusters is as small as 6. It is worth noting that with a small cluster size (eg, m=10), the required number of clusters to power the HTE test could be over 300, which is substantially larger than most current CRTs. However, with a relatively large cluster size (ie, m=50 or m=100), even a small HTE could be detected with enough power when the number of cluster is fewer than 40, which falls into the range of sample size used in most CRTs.
TABLE 1.
Estimated required number of clusters n, empirical type I error Ψ0, empirical power ϕ0, and predicted power ϕ obtained from sample size formula, when Xij is continuous
| Δ = 0.10 | Δ = 0.15 | Δ = 0.25 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ρx | ρy|x | n | Ψ0 | ϕ0 | ϕ | n | Ψ0 | ϕ0 | ϕ | n | Ψ0 | ϕ0 | ϕ | |
| m = 10 | 0.10 | 0.01 | 318 | 0.06 | 0.80 | 0.80 | 142 | 0.05 | 0.80 | 0.80 | 52 | 0.05 | 0.81 | 0.81 |
| 0.05 | 320 | 0.05 | 0.80 | 0.80 | 142 | 0.06 | 0.79 | 0.80 | 52 | 0.05 | 0.80 | 0.81 | ||
| 0.10 | 314 | 0.05 | 0.80 | 0.80 | 140 | 0.05 | 0.80 | 0.80 | 52 | 0.05 | 0.81 | 0.81 | ||
| 0.25 | 0.01 | 322 | 0.05 | 0.80 | 0.80 | 144 | 0.05 | 0.80 | 0.80 | 52 | 0.05 | 0.79 | 0.81 | |
| 0.05 | 336 | 0.05 | 0.80 | 0.80 | 150 | 0.05 | 0.80 | 0.80 | 54 | 0.05 | 0.79 | 0.80 | ||
| 0.10 | 342 | 0.05 | 0.80 | 0.80 | 152 | 0.05 | 0.80 | 0.80 | 56 | 0.05 | 0.80 | 0.81 | ||
| 0.50 | 0.01 | 328 | 0.05 | 0.80 | 0.80 | 146 | 0.05 | 0.79 | 0.80 | 54 | 0.05 | 0.79 | 0.81 | |
| 0.05 | 370 | 0.05 | 0.80 | 0.80 | 164 | 0.05 | 0.80 | 0.80 | 60 | 0.06 | 0.80 | 0.81 | ||
| 0.10 | 398 | 0.05 | 0.81 | 0.80 | 178 | 0.05 | 0.80 | 0.80 | 64 | 0.06 | 0.80 | 0.80 | ||
| m = 20 | 0.10 | 0.01 | 160 | 0.05 | 0.80 | 0.80 | 72 | 0.05 | 0.80 | 0.81 | 26 | 0.05 | 0.80 | 0.81 |
| 0.05 | 162 | 0.05 | 0.81 | 0.80 | 72 | 0.06 | 0.81 | 0.80 | 26 | 0.05 | 0.79 | 0.80 | ||
| 0.10 | 158 | 0.05 | 0.80 | 0.80 | 70 | 0.05 | 0.81 | 0.80 | 26 | 0.05 | 0.82 | 0.81 | ||
| 0.25 | 0.01 | 164 | 0.05 | 0.79 | 0.80 | 74 | 0.05 | 0.80 | 0.81 | 28 | 0.05 | 0.81 | 0.83 | |
| 0.05 | 176 | 0.04 | 0.80 | 0.80 | 78 | 0.05 | 0.80 | 0.80 | 28 | 0.06 | 0.80 | 0.80 | ||
| 0.10 | 178 | 0.05 | 0.80 | 0.80 | 80 | 0.06 | 0.81 | 0.81 | 30 | 0.05 | 0.81 | 0.82 | ||
| 0.50 | 0.01 | 172 | 0.05 | 0.81 | 0.80 | 76 | 0.05 | 0.79 | 0.80 | 28 | 0.05 | 0.78 | 0.81 | |
| 0.05 | 206 | 0.05 | 0.80 | 0.80 | 92 | 0.05 | 0.80 | 0.81 | 34 | 0.05 | 0.79 | 0.82 | ||
| 0.10 | 222 | 0.05 | 0.80 | 0.80 | 100 | 0.05 | 0.79 | 0.81 | 36 | 0.05 | 0.80 | 0.81 | ||
| m = 50 | 0.10 | 0.01 | 66 | 0.05 | 0.81 | 0.81 | 30 | 0.06 | 0.81 | 0.82 | 12 | 0.05 | 0.85 | 0.85 |
| 0.05 | 66 | 0.05 | 0.80 | 0.80 | 30 | 0.06 | 0.81 | 0.81 | 12 | 0.06 | 0.85 | 0.85 | ||
| 0.10 | 64 | 0.05 | 0.81 | 0.81 | 28 | 0.05 | 0.80 | 0.80 | 12 | 0.05 | 0.86 | 0.86 | ||
| 0.25 | 0.01 | 70 | 0.05 | 0.81 | 0.81 | 32 | 0.06 | 0.81 | 0.82 | 12 | 0.05 | 0.82 | 0.84 | |
| 0.05 | 74 | 0.04 | 0.81 | 0.80 | 34 | 0.05 | 0.81 | 0.81 | 12 | 0.06 | 0.80 | 0.81 | ||
| 0.10 | 74 | 0.06 | 0.80 | 0.81 | 34 | 0.05 | 0.81 | 0.82 | 12 | 0.05 | 0.81 | 0.81 | ||
| 0.50 | 0.01 | 76 | 0.06 | 0.80 | 0.80 | 34 | 0.06 | 0.80 | 0.81 | 12 | 0.06 | 0.75 | 0.80 | |
| 0.05 | 96 | 0.05 | 0.80 | 0.81 | 44 | 0.06 | 0.81 | 0.82 | 16 | 0.06 | 0.80 | 0.82 | ||
| 0.10 | 100 | 0.05 | 0.80 | 0.80 | 46 | 0.05 | 0.81 | 0.81 | 16 | 0.06 | 0.78 | 0.80 | ||
| m = 100 | 0.10 | 0.01 | 34 | 0.05 | 0.81 | 0.81 | 16 | 0.05 | 0.83 | 0.83 | 6 | 0.05 | 0.84 | 0.85 |
| 0.05 | 34 | 0.05 | 0.83 | 0.81 | 16 | 0.05 | 0.84 | 0.83 | 6 | 0.05 | 0.83 | 0.85 | ||
| 0.10 | 32 | 0.05 | 0.81 | 0.81 | 14 | 0.05 | 0.80 | 0.80 | 6 | 0.04 | 0.86 | 0.86 | ||
| 0.25 | 0.01 | 36 | 0.05 | 0.80 | 0.80 | 16 | 0.06 | 0.80 | 0.80 | 6 | 0.06 | 0.80 | 0.82 | |
| 0.05 | 40 | 0.05 | 0.82 | 0.82 | 18 | 0.05 | 0.82 | 0.82 | 8 | 0.06 | 0.88 | 0.90 | ||
| 0.10 | 38 | 0.05 | 0.81 | 0.81 | 18 | 0.05 | 0.83 | 0.83 | 6 | 0.06 | 0.80 | 0.80 | ||
| 0.50 | 0.01 | 42 | 0.06 | 0.80 | 0.80 | 20 | 0.06 | 0.80 | 0.83 | 8 | 0.05 | 0.82 | 0.87 | |
| 0.05 | 52 | 0.05 | 0.80 | 0.80 | 24 | 0.05 | 0.81 | 0.82 | 10 | 0.05 | 0.86 | 0.87 | ||
| 0.10 | 54 | 0.06 | 0.80 | 0.81 | 24 | 0.05 | 0.81 | 0.81 | 10 | 0.05 | 0.86 | 0.86 | ||
Note: Δ is the effect size, ρy|x is the adjusted outcome ICC, and ρx is the covariate ICC. The results are based on 5000 simulations.
TABLE 2.
Estimated required number of clusters n, empirical type I error Ψ0, empirical power ϕ0, and predicted power ϕ obtained from sample size formula, when Xij is binary
| Δ = 0.10 | Δ = 0.15 | Δ = 0.25 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ρx | ρy|x | n | Ψ0 | ϕ0 | ϕ | n | Ψ0 | ϕ0 | ϕ | n | Ψ0 | ϕ0 | ϕ | |
| m = 10 | 0.10 | 0.01 | 242 | 0.05 | 0.80 | 0.80 | 124 | 0.05 | 0.80 | 0.80 | 76 | 0.05 | 0.81 | 0.81 |
| 0.05 | 244 | 0.05 | 0.80 | 0.80 | 126 | 0.05 | 0.81 | 0.81 | 76 | 0.05 | 0.81 | 0.80 | ||
| 0.10 | 240 | 0.05 | 0.80 | 0.80 | 124 | 0.05 | 0.80 | 0.81 | 74 | 0.04 | 0.80 | 0.80 | ||
| 0.25 | 0.01 | 246 | 0.06 | 0.80 | 0.80 | 126 | 0.05 | 0.80 | 0.80 | 76 | 0.05 | 0.80 | 0.80 | |
| 0.05 | 256 | 0.05 | 0.79 | 0.80 | 132 | 0.05 | 0.79 | 0.80 | 80 | 0.05 | 0.79 | 0.80 | ||
| 0.10 | 260 | 0.05 | 0.80 | 0.80 | 134 | 0.05 | 0.81 | 0.80 | 82 | 0.05 | 0.80 | 0.81 | ||
| 0.50 | 0.01 | 250 | 0.05 | 0.80 | 0.80 | 128 | 0.05 | 0.80 | 0.80 | 78 | 0.05 | 0.79 | 0.81 | |
| 0.05 | 282 | 0.05 | 0.82 | 0.80 | 144 | 0.05 | 0.80 | 0.80 | 88 | 0.05 | 0.80 | 0.81 | ||
| 0.10 | 304 | 0.05 | 0.80 | 0.80 | 156 | 0.05 | 0.80 | 0.80 | 94 | 0.05 | 0.79 | 0.80 | ||
| m = 20 | 0.10 | 0.01 | 122 | 0.05 | 0.80 | 0.80 | 62 | 0.05 | 0.80 | 0.80 | 38 | 0.05 | 0.80 | 0.81 |
| 0.05 | 124 | 0.05 | 0.81 | 0.80 | 64 | 0.05 | 0.80 | 0.81 | 38 | 0.06 | 0.79 | 0.80 | ||
| 0.10 | 120 | 0.05 | 0.80 | 0.80 | 62 | 0.05 | 0.79 | 0.81 | 38 | 0.06 | 0.81 | 0.81 | ||
| 0.25 | 0.01 | 126 | 0.05 | 0.81 | 0.80 | 64 | 0.05 | 0.80 | 0.80 | 40 | 0.05 | 0.81 | 0.82 | |
| 0.05 | 134 | 0.06 | 0.80 | 0.80 | 68 | 0.05 | 0.79 | 0.80 | 42 | 0.05 | 0.79 | 0.81 | ||
| 0.10 | 136 | 0.06 | 0.79 | 0.81 | 70 | 0.05 | 0.81 | 0.81 | 42 | 0.05 | 0.80 | 0.81 | ||
| 0.50 | 0.01 | 130 | 0.05 | 0.80 | 0.80 | 68 | 0.05 | 0.79 | 0.81 | 42 | 0.06 | 0.81 | 0.82 | |
| 0.05 | 156 | 0.05 | 0.80 | 0.80 | 80 | 0.05 | 0.79 | 0.80 | 48 | 0.06 | 0.79 | 0.80 | ||
| 0.10 | 170 | 0.05 | 0.80 | 0.80 | 88 | 0.05 | 0.81 | 0.81 | 54 | 0.05 | 0.80 | 0.81 | ||
| m = 50 | 0.10 | 0.01 | 50 | 0.05 | 0.80 | 0.81 | 26 | 0.05 | 0.80 | 0.81 | 16 | 0.06 | 0.80 | 0.82 |
| 0.05 | 50 | 0.05 | 0.79 | 0.80 | 26 | 0.05 | 0.81 | 0.81 | 16 | 0.05 | 0.80 | 0.82 | ||
| 0.10 | 48 | 0.05 | 0.80 | 0.80 | 26 | 0.05 | 0.83 | 0.82 | 16 | 0.06 | 0.81 | 0.83 | ||
| 0.25 | 0.01 | 52 | 0.05 | 0.79 | 0.80 | 28 | 0.05 | 0.81 | 0.82 | 18 | 0.05 | 0.83 | 0.84 | |
| 0.05 | 58 | 0.04 | 0.81 | 0.81 | 30 | 0.06 | 0.81 | 0.82 | 18 | 0.05 | 0.80 | 0.81 | ||
| 0.10 | 56 | 0.05 | 0.80 | 0.80 | 30 | 0.05 | 0.82 | 0.82 | 18 | 0.05 | 0.81 | 0.82 | ||
| 0.50 | 0.01 | 58 | 0.05 | 0.79 | 0.81 | 30 | 0.06 | 0.80 | 0.81 | 18 | 0.06 | 0.76 | 0.81 | |
| 0.05 | 74 | 0.05 | 0.80 | 0.81 | 38 | 0.05 | 0.81 | 0.81 | 24 | 0.05 | 0.81 | 0.83 | ||
| 0.10 | 76 | 0.05 | 0.79 | 0.80 | 40 | 0.05 | 0.80 | 0.81 | 24 | 0.05 | 0.78 | 0.81 | ||
| m = 100 | 0.10 | 0.01 | 26 | 0.05 | 0.82 | 0.81 | 14 | 0.05 | 0.83 | 0.83 | 8 | 0.06 | 0.80 | 0.81 |
| 0.05 | 26 | 0.05 | 0.81 | 0.81 | 14 | 0.05 | 0.82 | 0.84 | 8 | 0.05 | 0.81 | 0.81 | ||
| 0.10 | 24 | 0.05 | 0.80 | 0.80 | 14 | 0.05 | 0.85 | 0.85 | 8 | 0.05 | 0.83 | 0.83 | ||
| 0.25 | 0.01 | 28 | 0.05 | 0.80 | 0.81 | 14 | 0.06 | 0.79 | 0.80 | 10 | 0.06 | 0.84 | 0.86 | |
| 0.05 | 30 | 0.05 | 0.81 | 0.81 | 16 | 0.05 | 0.81 | 0.83 | 10 | 0.05 | 0.82 | 0.84 | ||
| 0.10 | 30 | 0.05 | 0.81 | 0.82 | 16 | 0.04 | 0.83 | 0.84 | 10 | 0.05 | 0.83 | 0.85 | ||
| 0.50 | 0.01 | 32 | 0.06 | 0.79 | 0.80 | 18 | 0.06 | 0.81 | 0.84 | 10 | 0.04 | 0.76 | 0.81 | |
| 0.05 | 40 | 0.05 | 0.79 | 0.81 | 22 | 0.06 | 0.81 | 0.83 | 14 | 0.06 | 0.81 | 0.85 | ||
| 0.10 | 42 | 0.05 | 0.82 | 0.82 | 22 | 0.05 | 0.81 | 0.83 | 14 | 0.05 | 0.80 | 0.85 | ||
Note: Δ is the effect size, ρy|x is the adjusted outcome ICC, and ρx is the covariate ICC. The results are based on 5000 simulations.
The results obtained in Tables 1 and 2 further allow us to evaluate the impact of different design parameters on the estimated required number of clusters n. We fit a multiple linear regression model, where n is the response variable, and cluster size m, covariate ICC ρx, adjusted outcome ICC ρy|x, and effect size Δ are four covariates (linear term only). Although we know from Equation (11) that their relationship is not necessarily linear, this approach may provide additional insights on the determining factors for sample size calculation for testing HTE in CRTs. We report the unstandardized and standardized regression coefficients and z-score values in Table 3. The standardized regression coefficient, also known as the β-coefficient or β-weight, are obtained from a regression analysis where the variances of the response and independent variables are all scaled to unity, and is therefore invariant to unit of measurement for the original variables. Comparing the standardized coefficients could inform which design parameter has a greater effect on the required sample size. From Table 3, it is evident that both the cluster size m and interaction effect size Δ have a major impact on the required number of clusters. In addition, the impact of covariate ICC ρx on sample size n appears larger than that of the adjusted outcome ICC ρy|x. The standardized coefficient of ρx is two times that of ρy|x, highlighting the important role of ρx in powering the interaction test in CRTs.
TABLE 3.
Effect of design parameters on the sample size n: results from multiple linear regression analysis
| Design parameter | Unstandardized coefficient | Standardized coefficient | Standard error | z-score | P-value |
|---|---|---|---|---|---|
| ρx | 41.00 | 0.08 | 24.39 | 1.68 | .09 |
| ρy|x | 85.31 | 0.04 | 109.30 | 0.78 | .44 |
| m | −1.39 | −0.59 | 0.11 | −12.11 | <.001 |
| Δ | −255.26 | −0.36 | 34.41 | −7.42 | <.001 |
6 |. THE HF-ACTION DATA EXAMPLE
We illustrate our sample size procedure using data collected from the HF-ACTION study.37 The HF-ACTION study is an individually randomized trial that aimed to test the efficacy and safety of exercise training program among patients with chronic heart failure and reduced ejection fraction. In the study, patients recruited from 82 sites (heart clinics or heart and vascular centers) were randomized to receive either usual care plus aerobic exercise training, or usual care alone. In Yang et al,31 we have previously used the outcome and covariate data from the HF-ACTION study to recreate a CRT to assess the bias in estimating the OTE due to baseline imbalance. In this section, we use the same context and baseline covariate data from HF-ACTION to inform the design parameters and exemplify how to estimate the required sample size and power for testing HTE, were the investigators to conduct a CRT using the HF-ACTION population.
Suppose the investigators are interested in conducting a CRT to evaluate the benefit of exercise training program among patients with chronic heart failure and reduced ejection fraction. In this case, each participating site will be randomized to either the aerobic exercise arm or the usual care arm, and . Suppose the primary outcome of the study is the change of 6-minute walk test distance from baseline to 3 months. From the HF-ACTION baseline data, we estimate the marginal standard deviation of primary outcome to be σy ≈ 71 m, and the unadjusted outcome ICC to be ρy = 0.04. In the HF-ACTION study, the overall treatment effect size is estimated to be ΔOTE = 18.85 (P <.001) m. Using the classical sample size calculation based on the design effect (1), and given each site is able to recruit m=27 patients for the study, we found that about n=34 sites are required to ensure 80% power to detect the overall treatment effect size similar to that reported in the HF-ACTION study.
In addition to powering the OTE test, we are also interested in finding out how many more clusters are required to ensure 80% power to detect treatment effect heterogeneity. We use age as an example for the continuous covariate and race as an example for the binary covariate. The considerations for HTE with respect to race is particularly common, as previous studies suggest that black patients respond differently to therapies for heart failure,38 and that there is a statistically significant interaction between black race and exercise training for the 6-minute walk test outcome.39 From the baseline data of HF-ACTION, the mean age is 59.3 years (σx = 12.7), and 34.4% are black race (σx = 0.48). Figure 3 presents the cluster-specific average age and proportion of black population, and clearly shows substantial variability of both covariates across clusters. We estimate the covariate ICC for age to be ρx = 0.08 and that for black race to be ρx = 0.22 (the binary ICC was estimated using the ANOVA method40). In this case, because σy|x ≈ 69 m for both age and race and is substantially larger than σx, adjusting for either age or race does not change the outcome ICC so that ρy x ≈ ρy = 0.04. This observation is consistent with the analytical insight provided by Equation (23). Suppose that the effect size for the treatment-by-age interaction is Δ = 0.05ΔOTE, which implies that one unit change in age (in years) translates into around 1 m difference in 6-minute walk distance. We require about 41 sites to ensure 80% power for the interaction test. Using the race variable as another example, suppose that the treatment-by-black-race interaction effect is the same as that of OTE, which implies a Δ ≈ 19 m difference between the black and white populations. We require 80 sites to ensure 80% power to detect the in a CRT. Equivalently, based on expression (24), we can see that the number of clusters required for the OTE test needs to be increased by a factor of Θ(27) ≈ 1.19 and Θ(27) ≈ 2.36 to obtain the same power for testing differential treatment effect by age and race, respectively. In particular, if the 82 sites included in the HF-ACTION study all agree to participate in a CRT, the study would be adequately powered for both the analysis of overall treatment effect as well as treatment-by-age, treatment-by-race interactions, with respect to the change of 6-minute walk distance outcome.
FIGURE 3.
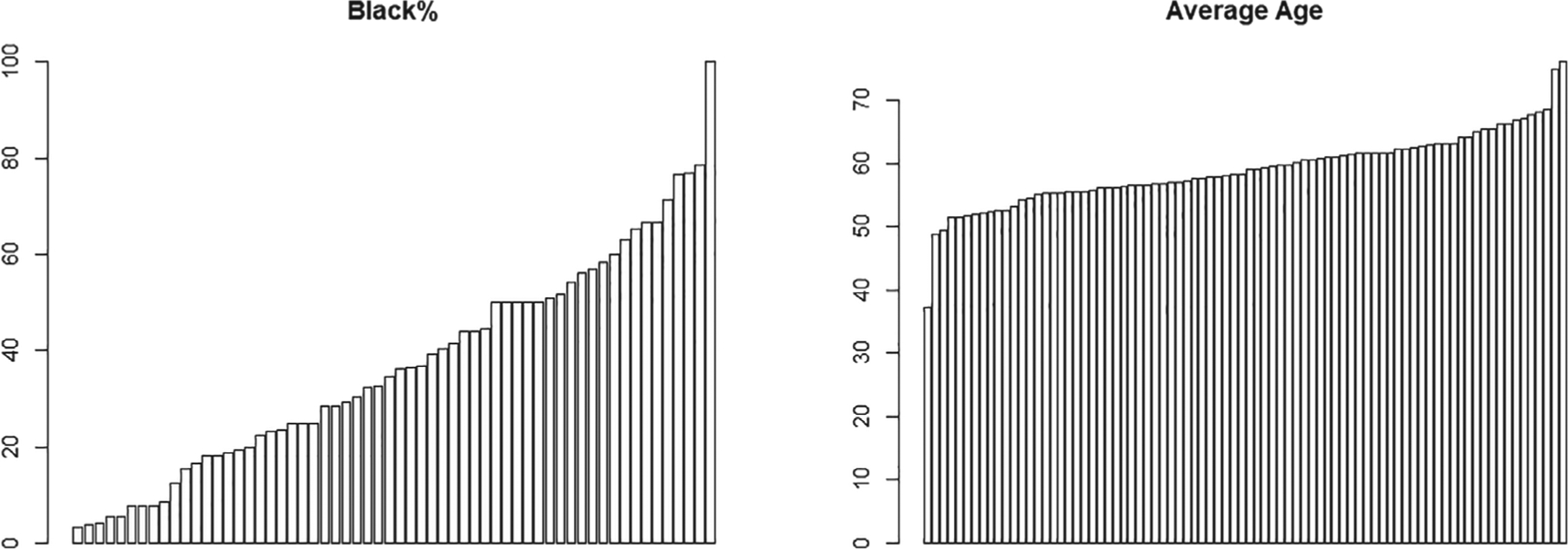
Distributions of proportion of black population and mean age across 82 sites (clusters) in the HF-ACTION study
7 |. DISCUSSION
Current cluster randomized trials are designed to evaluate the OTE, frequently using a random-effects model that includes only the treatment indicator. In recent years, investigating differential treatment effect among patient subgroups has become increasingly popular, but there has not been extensive discussion on the sample size requirements for testing HTE in CRTs, except in Spybrook et al23 and Dong et al.24 In this article, we develop a closed-form sample size formula that allows investigators to calculate the required number of clusters or patients to power the interaction test, while accounting for the intraclass correlation coefficients of both the outcome and the covariate. The proposed formula can accommodate an interaction test concerning either individual-level or cluster-level covariates. We realize that many CRTs include the analysis of OTE as their primary analysis, and therefore may not be designed to power the analysis of treatment-by-covariate interaction. In those context, however, our sample size procedure may also be useful in ad hoc power calculation to clarify the sample size requirements in secondary analysis that targets such treatment effect heterogeneity. Although the interaction test may require a larger sample size than the overall test in some scenarios (as in our data example of Section 6), we also demonstrate in Figure 2 that their sample size requirements could be comparable in regions where the adjusted outcome ICC is not too small and the cluster size is large. In any case, the proposed procedure provides a principled approach to identify such scenarios where the sample size requirements are similar for both analyses, and offers an opportunity to enhance the credibility of the analysis of treatment effect heterogeneity in CRTs. Notice that we have adopted a model-based framework and assume the covariate-adjusted linear mixed model (3) holds. However, the results may be somewhat different if one adopts a design-based perspective to the analysis of randomized trials as in Schochet et al41,42 and Ding et al.43
Although Equation (11) suggests a direct approach to calculate the required sample size for the interaction test, those who are more familiar with the traditional design effect θ1(m) could use the following three-step approach to obtain the same sample size result. Given the nominal type I error rate and power to detect an overall effect, one could obtain the number of patients (Nind) required for an individually randomized controlled trial (RCT). This can be done by using the general formula (8), but replacing with the total variance of the outcome. By assuming the number of patients that would be recruited in each cluster, the second step is to inflate Nind by the traditional design effect θ1(m), and obtain NOTE = Nind × θ1(m), which is the number of patients required in a CRT. The required number of clusters for detecting the overall treatment effect is then NOTE/m, rounded to the nearest integer above. The above two steps are no different from the common practice used in designing CRTs. To calculate the sample size for detecting HTE, one could further inflate (or deflate) NOTE by a second design effect, Θ(m), defined in Equation (24). This requires knowledge of the relative effect sizes (RDES), the covariate ICC, the adjusted outcome ICC, and the adjusted total variance. The required number of patients to power the test for HTE is given by
| (25) |
and the required number of clusters would simply be NHTE/m, rounded to the nearest integer above. Depending on whether Θ(m) is greater than one, we may require more or fewer patients for detecting HTE than for detecting OTE in a CRT.
We have studied how the design parameters influence the sample size determination and power of the interaction test. We have highlighted the roles of the two ICC parameters: ρy|x and ρx. First, while larger values of the covariate ICC reduce the power of the interaction test, it may reduce the power of the overall treatment effect even more when the outcome ICC is relatively small (see Figure 2 when ρy|x=0.01). Second, larger values of the adjusted outcome ICC may not necessarily lead to smaller power in testing the HTE. As a result, the role of the adjusted outcome ICC in testing HTE is strikingly different from the role of unadjusted outcome ICC in testing OTE. We have observed a parabolic relationship between the power of the HTE test and adjusted outcome ICC; the power of the test first reduces and then increases as the adjusted outcome ICC becomes larger. The critical point that leads to the smallest power is given in Equation (22) and depends on both the covariate ICC and cluster size. In particular, the outcome ICC (either adjusted or unadjusted) commonly reported in the CRT literature only occasionally exceeds 0.1.33,44 In Figure 1, we observe that when the covariate ICC larger than 0.5 and the cluster size is relatively small (say smaller than 50), the critical point is usually no smaller than 0.1; in those case, the adjusted outcome ICC still inflates the required sample size for testing HTE. However, as the covariate ICC moves toward zero, the critical point also moves toward zero, suggesting that larger values of the adjusted outcome ICC may actually increase the power of the HTE test. This is actually the case in our data example of Section 6, because the covariate ICC for either age or race was estimated to be no larger than 0.25 and the anticipated cluster size is only 27. The important role of the covariate ICC has also been highlighted in Table 3, where the multiple linear regression analysis produces a much larger standardized coefficient for ρx than for ρy|x. Although it is currently recommended to report outcome ICC values in parallel CRTs,45,46 reporting covariate ICCs has not become standard practice. In scenarios where pilot studies are carried out or baseline information is readily available, the estimation of ICC for covariates can proceed using standard procedures developed for outcome ICC.3,47 Because the covariate ICC is an essential ingredient of the sample size formula, we advocate future CRTs that examine treatment effect heterogeneity to start reporting ICCs for the covariates of interest. Just like the outcome ICCs, values of covariate ICCs can provide useful information for designing future trials that plan to assess the treatment-by-covariate interaction. In the absence of covariate ICC information, however, our power formula still provides a useful approach for sensitivity analysis, provided a plausible range of ρx can be elicited in the design phase.
It is important to notice that the new variance expression derived in this article (Equation (10)) differs from those studied in Spybrook et al23 and Dong et al.24 Within the same setting of a two-level CRT, the previous work has provided (or indirectly implied) an alternative variance expression for , which depends on both the residual variance of the unadjusted model and that of the adjusted model . An R-squared parameter is further introduced to parameterize the sample size formula and represents the explained variation of the outcome due to covariates. By contrast, our variance expression only assumes knowledge from the adjusted model (3), and does not involve assumptions of the unadjusted model (2). These different assumptions could underlie the different forms of the variance expressions. On the other hand, it remains unclear from previous work whether the covariate ICC ρx plays a role in and hence the sample size determination. Our approximate derivation in Section 4.2 and Web Appendix B shows that there may be cases where , as a function of only and , is invariant to ρx, whereas our analytical and simulation results clearly indicate ρx plays a major role in determining the required sample size for the interaction test. A keen reviewer also pointed out that the model used in Spybrook et al23 and Dong et al24 assumed that the covariates were centered around the cluster mean, which may help avoid the complication due to the covariate ICC. From this perspective, an important major contribution of this article is that it facilitates power calculation when the covariates are not centered around the cluster mean. In any case, additional further research is required to formally compare our sample size procedure with the previous procedures via extensive Monte Carlo simulations. These additional comparisons may be able to fully clarify the differences and make recommendations on appropriate use of different sample size formulas in different scenarios.
There are several potential limitations of this article, some of which will be addressed in our future work. Above all, although we provided the extension of the sample size procedure to accommodate multiple covariates, we have mainly focused our discussion and simulation experiments on a single covariate. We recognize that more efforts are required to come up with sensible effect sizes for multiple interaction terms in the design stage, and those values could possibly be informed once more treatment-by-covariate interaction effects are reported in CRTs. Second, we have only considered the interaction test between treatment and covariates in the absence of additional adjustment variables. There are scenarios where additional pretest variables are considered in addition to the treatment-by-covariate interactions to further improve precision; those scenarios have been addressed in Spybrook et al23 and Dong et al,24 and will be considered in our future work. Third, we have assumed the outcome to be a continuous variable, and therefore the proposed sample size formula could only approximate the required sample size for a binary or count outcome. Additional work is required to develop formal sample size procedures for categorical outcomes, based on the generalized linear mixed model or the generalized estimating equations; section 3 of Li et al48 reviews technical details of these models commonly used in CRTs with a binary outcome. Fourth, we have limited our attention to parallel CRTs, while other recent CRTs have considered the crossover49 or stepped wedge designs.35,50,51 It would be interesting to extend the existing sample size procedures developed for these unidirectional designs to similarly accommodate an interaction test. Finally, we have assumed equal cluster sizes to simplify the derivation of the sample size formula. It remains to be explored whether unequal cluster sizes would drastically reduce the efficiency for testing the HTE as it does for testing the OTE in CRTs.13 We plan to carry out future work to investigate the impact of variable cluster sizes for testing HTE, and develop a modified sample size formula that adjusts for cluster size variability.
Supplementary Material
ACKNOWLEDGEMENTS
This work was supported by research supplements from the NIH Common Fund to promote diversity in health-related research under award number 3U54AT007748-02S4, from the Health Care Systems Research Collaboratory Coordinating Center under award number 1U54AT007748-04, and from the National Center for Complementary and Alternative Medicine, a center of the National Institutes of Health. Fan Li’s work was also supported within the National Institutes of Health (NIH) Health Care Systems Research Collaboratory by the NIH Common Fund through cooperative agreement U24AT009676 from the Office of Strategic Coordination within the Office of the NIH Director and cooperative agreement UH3DA047003 from the National Institute on Drug Abuse, and by the administrative supplement 3-UH3-DA047003-02S2 from the NIH Office of Disease Prevention. The content is solely the responsibility of the author and does not necessarily represent the official views of the National Institutes of Health.
Funding information
National Center for Complementary and Alternative Medicine, Grant/Award Number: 1U54AT007748-04; National Institute on Drug Abuse, Grant/Award Number: UH3DA047003; National Institutes of Health, Grant/Award Numbers: 3U54AT007748-02S4, U24AT009676; Office of Disease Prevention, Grant/Award Number: 3-UH3-DA047003-02S2
Footnotes
DATA AVAILABILITY STATEMENT
The HF-ACTION data that is used as an illustrative example in this study can be accessed through NIH at https://biolincc.nhlbi.nih.gov/studies/hf_action/
SUPPORTING INFORMATION
Additional supporting information may be found online in the Supporting Information section at the end of this article.
REFERENCES
- 1.Murray D. Design and Analysis of Group-Randomized Trials. New York, NY: Oxford University Press; 1998. [Google Scholar]
- 2.Cook AJ, Delong E, Murray DM, Vollmer WM, Heagerty PJ. Statistical lessons learned for designing cluster randomized pragmatic clinical trials from the NIH health care systems collaboratory biostatistics and design core. Clin Trials. 2016;13(5):504–512. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Turner EL, Li F, Gallis JA, Prague M, Murray DM. Review of recent methodological developments in group-randomized trials: Part 1 design. Am J Publ Health. 2017;107(6):907–915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Turner EL, Prague M, Gallis JA, Li F, Murray DM. Review of recent methodological developments in group-randomized trials: Part 2 analysis. Am J Publ Health. 2017;107(7):1078–1086. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Starks MA, Sanders GD, Coeytaux RR, et al. Assessing heterogeneity of treatment effect analyses in health-related cluster randomized trials: a systematic review. PLoS One. 2019;14(8):1–13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Concannon TW, Guise JM, Dolor RJ, et al. A national strategy to develop pragmatic clinical trials infrastructure. Clin Transl Sci. 2014;7(2):164–171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Weinfurt KP, Hernandez AF, Coronado GD, et al. Pragmatic clinical trials embedded in healthcare systems: generalizable lessons from the NIH collaboratory. BMC Med Res Methodol. 2017;17(1):1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Kravitz RL, Duan N, Braslow J. Evidence-based medicine, heterogeneity of treatment effects, and the trouble with averages. Milbank Quart. 2004;82(4):661–687. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Garcia FYE, Nguyen H, Duan N, Gabler NB, Kravitz RL. Assessing heterogeneity of treatment effects: are authors misinterpreting their results? Health Serv Res. 2010;45(1):283–301. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Gabler NB, Duan N, Liao D, Elmore JG, Ganiats TG, Kravitz RL. Dealing with heterogeneity of treatment effects: is the literature up to the challenge? Trials. 2009;10(1):43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Fan J, Song F, Bachmann MO. Justification and reporting of subgroup analyses were lacking or inadequate in randomized controlled trials. J Clin Epidemiol. 2019;108:17–25. [DOI] [PubMed] [Google Scholar]
- 12.Donner A, Birkett N, Buck C. Randomization by cluster: sample size requirements and analysis. Am J Epidemiol. 1981;114(6):906–914. [DOI] [PubMed] [Google Scholar]
- 13.Eldridge SM, Ashby D, Kerry S. Sample size for cluster randomized trials: effect of coefficient of variation of cluster size and analysis method. Int J Epidemiol. 2006;35(5):1292–1300. [DOI] [PubMed] [Google Scholar]
- 14.Rutterford C, Copas A, Eldridge S. Methods for sample size determination in cluster randomized trials. Int J Epidemiol. 2015;44(3):1051–1067. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Hemming K, Eldridge S, Forbes G, Weijer C, Taljaard M. How to design efficient cluster randomised trials. BMJ. 2017;358:j3064. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Breukelen VGJ, Candel MJ. Calculating sample sizes for cluster randomized trials: we can keep it simple and efficient! J Clin Epidemiol. 2012;65(11):1212–1218. [DOI] [PubMed] [Google Scholar]
- 17.Bloom HS, Spybrook J. Assessing the precision of multisite trials for estimating the parameters of a cross-site population distribution of program effects. J Res Educ Effectiv. 2017;10(4):877–902. [Google Scholar]
- 18.Brookes ST, Whitely E, Egger M, Smith GD, Mulheran PA, Peters TJ. Subgroup analyses in randomized trials: risks of subgroup-specific analyses: power and sample size for the interaction test. J Clin Epidemiol. 2004;57(3):229–236. [DOI] [PubMed] [Google Scholar]
- 19.Shieh G Detecting interaction effects in moderated multiple regression with continuous variables power and sample size considerations. Org Res Methods. 2009;12(3):510–528. [DOI] [PubMed] [Google Scholar]
- 20.Greenland S Tests for interaction in epidemiologic studies: a review and a study of power. Stat Med. 1983;2(2):243–251. [DOI] [PubMed] [Google Scholar]
- 21.Demidenko E Sample size and optimal design for logistic regression with binary interaction. Stat Med. 2008;27(1):36–46. [DOI] [PubMed] [Google Scholar]
- 22.Kang S, Lu W, Song R. Subgroup detection and sample size calculation with proportional hazards regression for survival data. Stat Med. 2017;36(29):4646–4659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Spybrook J, Kelcey B, Dong N. Power for detecting treatment by moderator effects in two-and three-level cluster randomized trials. J Educ Behav Stat. 2016;41(6):605–627. [Google Scholar]
- 24.Dong N, Kelcey B, Spybrook J. Power analyses for moderator effects in three-level cluster randomized trials. J Exper Educ. 2018;86(3):489–514. [Google Scholar]
- 25.Heo M, Leon AC. Sample sizes required to detect two-way and three-way interactions involving slope differences in mixed-effects linear models. J Biopharmaceut Stat. 2010;20(4):787–802. [DOI] [PubMed] [Google Scholar]
- 26.Jung SH, Ahn CW. Sample size for a two-group comparison of repeated binary measurements using GEE. Stat Med. 2005;24(17):2583–2596. [DOI] [PubMed] [Google Scholar]
- 27.Liang KY, Zeger SL. Longitudinal data analysis using generalized linear models. Biometrika. 1986;73(1):13–22. [Google Scholar]
- 28.Wright N, Ivers N, Eldridge S, Taljaard M, Bremner S. A review of the use of covariates in cluster randomized trials uncovers marked discrepancies between guidance and practice. J Clin Epidemiol. 2015;68(6):603–609. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Raudenbush SW. Statistical analysis and optimal design for cluster randomized trials. Psychol Methods. 1997;2(2):173–185. [DOI] [PubMed] [Google Scholar]
- 30.Li F, Lokhnygina Y, Murray DM, Heagerty PJ, DeLong ER. An evaluation of constrained randomization for the design and analysis of group-randomized trials. Stat Med. 2016;35(10):1565–1579. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Yang S, Starks MA, Hernandez AF, et al. Impact of baseline covariate imbalance on bias in treatment effect estimation in cluster randomized trials: race as an example. Contemp Clin Trials. 2019;88:105775. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Jaciw AP, Lin L, Ma B. An empirical study of design parameters for assessing differential impacts for students in group randomized trials. Evaluat Rev. 2016;40(5):410–443. [DOI] [PubMed] [Google Scholar]
- 33.Murray DM, Blitstein JL. Methods to reduce the impact of intraclass correlation in group-randomized trials. Evaluat Rev. 2003;27(1):79–103. [DOI] [PubMed] [Google Scholar]
- 34.Pinheiro J, Bates D. Mixed-Effects Models in S and S-PLUS. New York, NY: Springer Science & Business Media; 2006. [Google Scholar]
- 35.Li F, Turner EL, Preisser JS. Sample size determination for GEE analyses of stepped wedge cluster randomized trials. Biometrics. 2018;74(4):1450–1458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Eldridge SM, Ashby D, Feder GS, Rudnicka AR, Ukoumunne OC. Lessons for cluster randomized trials in the twenty-first century: a systematic review of trials in primary care. Clin Trials. 2004;1(1):80–90. [DOI] [PubMed] [Google Scholar]
- 37.O’Connor CM, Whellan DJ, Lee KL, et al. Efficacy and safety of exercise training in patients with chronic heart failure: HF-ACTION randomized controlled trial. Jama. 2009;301(14):1439–1450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Taylor AL, Ziesche S, Yancy C, et al. Combination of isosorbide dinitrate and hydralazine in blacks with heart failure. New Engl J Med. 2004;351(20):2049–2057. [DOI] [PubMed] [Google Scholar]
- 39.Mentz RJ, Bittner V, Schulte PJ, et al. Race, exercise training, and outcomes in chronic heart failure: findings from heart failure-a controlled trial investigating outcomes in exercise training (HF-ACTION). Am Heart J. 2013;166(3):488–495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Ridout MS, Demetrio CG, Firth D. Estimating intraclass correlation for binary data. Biometrics. 1999;55(1):137–148. [DOI] [PubMed] [Google Scholar]
- 41.Schochet PZ. Statistical theory for the” RCT-YES” software: design-based causal inference for RCTs. NCEE 2015–4011. National Center for Education Evaluation and Regional Assistance; Washington, DC: US Department of Education, Institute of Education Sciences; 2015. http://ies.ed.gov/ncee/edlabs. [Google Scholar]
- 42.Schochet PZ. Design-based estimators for average treatment effects for multi-armed RCTs. J Educ Behav Stat. 2018;43(5):568–593. [Google Scholar]
- 43.Ding P, Feller A, Miratrix L. Decomposing treatment effect variation. J Am Stat Assoc. 2019;114(525):304–317. [Google Scholar]
- 44.Preisser JS, Reboussin BA, Song EY, Wolfson M. The importance and role of intracluster correlations in planning cluster trials. Epidemiology. 2007;18(5):552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Campbell MK, Elbourne DR, Altman DG. CONSORT statement: extension to cluster randomised trials. BMJ. 2004;328(7441):702–708. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Campbell MK, Piaggio G, Elbourne DR, Altman DG. Consort 2010 statement: extension to cluster randomised trials. BMJ. 2012;345:e5661. [DOI] [PubMed] [Google Scholar]
- 47.Eldridge SM, Ukoumunne OC, Carlin JB. The intra-cluster correlation coefficient in cluster randomized trials: a review of definitions. Int Stat Rev. 2009;77(3):378–394. [Google Scholar]
- 48.Li F, Turner EL, Heagerty PJ, Murray DM, Vollmer WM, DeLong ER. An evaluation of constrained randomization for the design and analysis of group-randomized trials with binary outcomes. Stat Med. 2017;36(24):3791–3806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Li F, Forbes AB, Turner EL, Preisser JS. Power and sample size requirements for GEE analyses of cluster randomized crossover trials. Stat Med. 2019;38(4):636–649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Li F, Turner EL, Preisser JS. Optimal allocation of clusters in cohort stepped wedge designs. Stat Probab Lett. 2018;137:257–263. [Google Scholar]
- 51.Design Li F. and analysis considerations for cohort stepped wedge cluster randomized trials with a decay correlation structure. Stat Med. 2020;39(4):438–455. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.