

Abstract
The intraclass correlation coefficient (ICC) is a classical index of measurement reliability. With the advent of new and complex types of data for which the ICC is not defined, there is a need for new ways to assess reliability. To meet this need, we propose a new distance‐based ICC (dbICC), defined in terms of arbitrary distances among observations. We introduce a bias correction to improve the coverage of bootstrap confidence intervals for the dbICC, and demonstrate its efficacy via simulation. We illustrate the proposed method by analyzing the test‐retest reliability of brain connectivity matrices derived from a set of repeated functional magnetic resonance imaging scans. The Spearman‐Brown formula, which shows how more intensive measurement increases reliability, is extended to encompass the dbICC.
Keywords: functional connectivity, intraclass correlation coefficient, Spearman‐Brown formula, test‐retest reliability
1. INTRODUCTION
With the increasing availability of new and complex forms of data, there is a corresponding need for new ways to assess measurement reliability. This article aims to help meet this need by reformulating the intraclass correlation coefficient (ICC), a standard index of reliability, in terms of distances between observations.
We begin by defining the ICC as developed in classical test theory (Lord and Novick, 1968; Fleiss, 1986; Mair, 2018), which views a measured scalar quantity X as the sum of an underlying true score T and an error term E. Suppose we have a sample of I individuals with true real‐valued scores drawn from a population with variance ; and that for each i, the ith individual is measured times, yielding observations
| (1) |
, where the 's are drawn from a distribution with mean 0 and variance , independently of each other and of the 's. Then for distinct , the correlation between the j 1th and j 2th observations for individual i is easily shown to be
| (2) |
This quantity is the classical ICC.
Reliability measures for more complex settings include replacing model (1) with the generalizability theory model of Cranford et al. (2006), as well as generalizations of (2) to multivariate data (Alonso et al., 2010), including high‐dimensional data (Shou et al., 2013). All of these extensions assume a model that is more complex than (1), but still of an additive (signal plus noise) form. However, for complex objects that are measured or estimated in modern biomedical research, such as motion patterns or brain networks, such an additive representation is typically inapplicable. There is thus a need for a new reliability index appropriate for general data objects.
Our work was motivated by the study of functional connectivity in the human brain by means of resting‐state functional magnetic resonance imaging (fMRI). Briefly, fMRI produces a time series of brain activity, known as the blood oxygen‐level‐dependent (BOLD) signal, at each of a set of regions of interest (ROIs). Resting‐state fMRI means that the participants in the study were not performing any particular task or viewing a stimulus during the brain scan. Functional connectivity refers to association among activity levels in different parts of the brain, and can be measured in many ways (Yan et al., 2013). One of the most common functional connectivity measures is a simple Pearson correlation matrix of regional BOLD signals. Figure 1 displays two such correlation matrices, along with associated brain graphs, for a set of 80 ROIs to be discussed in Section 4. These particular examples were chosen to illustrate high and low connectivity, according to a metric described in Web Appendix A.
FIGURE 1.
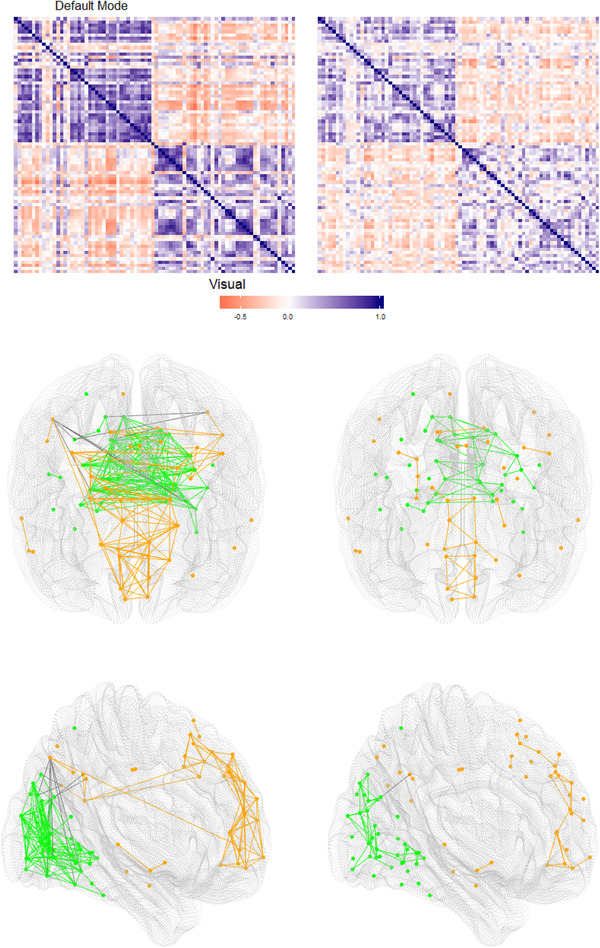
Top: Matrices of correlations among 80 ROIs comprising the default mode network and visual network in our fMRI data set. The left and right matrices, respectively, attain the highest and lowest connectivity scores observed in our data set. Middle: Brain maps (axial view) corresponding to the same two correlation matrices, and displaying pairs of regions with absolute correlation above 0.6. Orange nodes and links refer to the default mode network; green nodes and links refer to the visual network; links between the two networks are shown in black. Bottom: Same brain maps, sagittal view. The fMRI data are presented in Section 4, and the connectivity score is discussed briefly in Web Appendix A
In order to be confident that such correlation matrices, and the scientific conclusions derived from them, are trustworthy and reproducible, it is necessary first to be able to assess their reliability (Noble et al., 2019). Our proposed methodology offers a means to that end.
Our basic proposal, a reformulation of the ICC based on distances between observations, is outlined in Section 2, and estimation of the resulting reliability index is discussed in Section 3. An application to an fMRI data set is presented in Section 4. In Sections 5‐7, we extend the Spearman‐Brown (SB) formula, a fundamental result in reliability theory, to our distance‐based ICC, and revisit our fMRI data set in light of this extension. A concluding discussion appears in Section 8.
2. DISTANCE‐BASED RELIABILITY MEASUREMENT
A novel reliability index applicable to general data objects can be defined by rederiving the ICC (2) in terms of squared distances among observations. Let and be the mean squared differences for measurements between and within individuals, respectively. Then and , and thus, the ICC (2) can be reexpressed as
| (3) |
The advantage of expression (3) is that, unlike (2), it extends straightforwardly to general data objects (curves, networks, etc), as long as a distance or dissimilarity between such objects is defined. One simply redefines MSDb and MSDw in (3) in a more general sense, as the between‐ and within‐individual mean squared distances
| (4) |
Henceforth, we shall refer to (3), with given by (4), as the distance‐based intraclass correlation coefficient, or dbICC.
We note that the same general strategy, of rederiving variance‐based formulas in terms of sums of squared distances, has previously been used to formulate distance‐based hypothesis tests (McArdle and Anderson, 2001; Mielke and Berry, 2007; Reiss et al., 2010).
A simple example of extending (1) beyond the scalar real‐valued case is to let be mutually independent random vectors, with covariance matrices , respectively, and let d be the Euclidean distance. Then (3) reduces straightforwardly to
| (5) |
the multivariate reliability measure referred to as (Alonso et al., 2010), and as I2C2 (Shou et al., 2013) for images viewed as vectors. Thus, the dbICC is an extension of these measures to more general distances and data types.
3. ESTIMATING THE dbICC
3.1. Point estimation
Like the classical ICC (2), the proposed dbICC (3) can be estimated in practice by plugging in consistent estimates of the population quantities (4), as follows:
| (6) |
where
| (7) |
| (8) |
Figure 2 illustrates this schematically for a distance matrix with rows and columns grouped by individuals: one estimates by averaging the between‐ and within‐individual distances (B and W), respectively.
FIGURE 2.
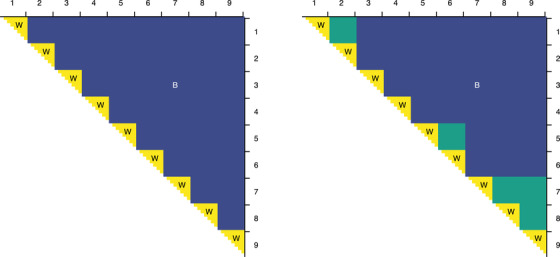
Left: Schematic diagram of a matrix of distances among repeated observations of nine individuals, with rows and columns grouped by individual. Distances in the half‐squares along the diagonal are within‐individual (W), while the rest are between‐individual (B). Right: A similar diagram, but for a bootstrap sample with repeated observations. Distances shown in green are nominally between‐individual, but in reality, they are within‐individual
3.2. Bootstrap confidence intervals
The dbICC is intended for distance functions whose distribution may not be known. It is thus natural to turn to nonparametric bootstrapping as a distribution‐free approach to interval estimation for the dbICC. For with suitably large B, let be a sample with replacement from ; then the rth bootstrap sample consists of for and . The resulting ICC estimate is
| (9) |
where are bootstrap analogues of (7) and (8):
| (10) |
The interval from the to the quantile of the 's can then be used as a % confidence interval.
These bootstrap estimates , however, suffer from negative bias (over and above the well‐known negative bias of the classical ICC; Atenafu et al., 2012). Returning to the example in Figure 2, consider a bootstrap sample in which individuals 1 and 2 are duplicates, as are individuals 5 and 6 and individuals 7‐9. Then the blocks shown in the right subfigure in green nominally refer to between‐individual differences, but, in fact, represent within‐individual differences. Assuming , counting these entries as between‐individual will tend to result in underestimation of MSDb and hence in negative bias in (9). The diagonal entries of these blocks are zero, thereby compounding the bias. To remove this bias, we can simply exclude such blocks from the summations in (10); formally, we replace each occurrence of with .
3.3. A simulation study
Using multivariate data with Euclidean distance (the example from the end of Section 2), we conducted a simulation study to assess the accuracy of our point and interval estimates of the dbICC. Values were drawn from (1) where and with . By (5), the (population) dbICC is then , which equals 0.2, 0.5, and 0.8 for the above three values of c. The number of subjects I was set to 10, 40, and 70, and the number of measurements per subject fixed at 4. We took 500 replicates with each combination of the above values of ρ and I. Boxplots of the dbICC estimates are displayed in Figure 3. The classical negative bias of ICC estimates (Atenafu et al., 2012) is noticeable for when , but not for the other settings.
FIGURE 3.
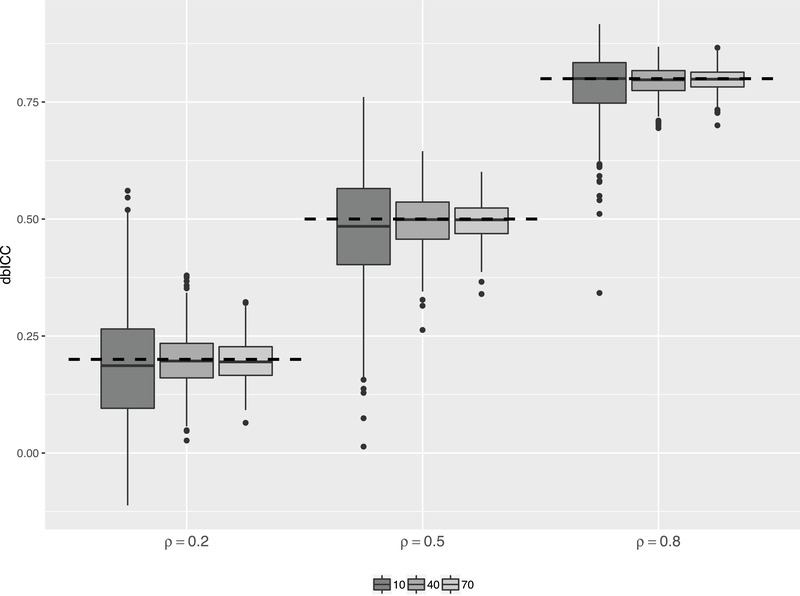
Boxplots of point estimates of dbICC, for true values (indicated by dashed lines) and for
Next, we considered bootstrap confidence intervals, with , without and with the bias correction of the previous subsection. We performed 500 replicates for each combination of the same ρ and I values as above, again with fixed at 4. Boxplots of the median of the 1200 bootstrap estimates within each replicate are presented in Figure 4. For and to some extent for , the correction yields a marked reduction in the observed negative bias. Accordingly, the coverage of 95% confidence intervals is improved by the correction, as can be seen in Table 1. As noted above, however, a small‐sample negative bias (unrelated to bootstrapping) occurs for point estimates of dbICC as for the classical ICC, and hence the coverage remains quite poor for .
FIGURE 4.
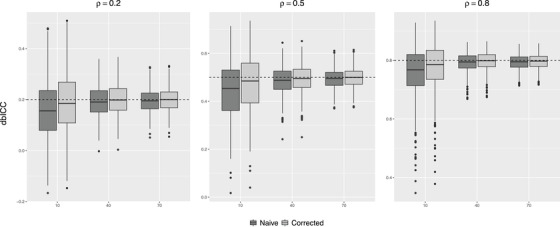
Boxplots of median bootstrap estimate of dbICC, for true values (indicated by dashed lines) and for
TABLE 1.
Percent coverage of bootstrap 95% confidence intervals, naïve (N) and corrected (C)
|
|
|
|
|||||||
|---|---|---|---|---|---|---|---|---|---|
| N | C | N | C | N | C | ||||
|
|
86.0 | 90.8 | 91.6 | 93.2 | 92.2 | 92.6 | |||
|
|
84.8 | 90.6 | 91.4 | 92.0 | 94.0 | 94.6 | |||
|
|
85.2 | 89.6 | 90.6 | 92.6 | 92.8 | 94.2 | |||
4. FUNCTIONAL CONNECTIVITY IN THE HUMAN BRAIN
As noted in the introduction, the dbICC was originally conceived as a way to evaluate the reliability of functional connectivity measures. To demonstrate how dbICC can be so applied, here we reexamine part of a data set presented by Shehzad et al. (2009) in an early study of the test‐retest reliability of resting‐state functional connectivity. These authors, followed by others (eg, Somandepalli et al., 2015; Choe et al., 2017), focused on ordinary ICC at each of a set of brain locations or connections. The dbICC, by contrast, offers an overall index of reliability for fMRI‐based correlation matrices, viewed as gestalt measures of functional connectivity.
The data include BOLD time series of length 197, within each of 333 ROIs derived by Gordon et al. (2016), for individuals, with such fMRI scans per individual; further details are provided in the Appendix. We then computed the distance between each pair of matrices among the correlation matrices thus derived, using each of three distance measures:
-
(i)
the ℓ2 distance (square root of sum of squared differences) between and ;
-
(ii)
the ℓ1 distance (sum of absolute differences) between and ; and
-
(iii)
, where r is the correlation between the lower triangular elements of and those of (correlation of correlations); the rationale for this distance is explained in Web Appendix B.
We stress that (i) and (ii) are not the distances induced by the matrix 2‐ and 1‐norms, since here we are interested in entry‐wise differences as opposed to treating the matrices as operators. Distance (i) is, rather, the distance induced by the Frobenius norm, which, in turn, is induced by an inner product; consequently, this distance fits with the generalized true score model presented below in Section 5.2. Since the matrices are treated here as vectors, dbICC based on distance (i) is equivalent to the I2C2 estimator of Shou et al. (2013) cited at the end of Section 2, although these authors focused on MRI‐based images as opposed to regional connectivity matrices.
The dbICC estimates (6) based on distances (i)‐(iii), along with 95% bootstrap CIs, are given in the first row of Table 2. While fairly consistent with the results of Shou et al. (2013), these reliabilities are very low by classical standards.
TABLE 2.
Point estimates and 95% bootstrap CIs for dbICC, based on three sets of ROIs and three distance measures
| ℓ2 | ℓ1 |
|
||
|---|---|---|---|---|
| All 333 ROIs | 0.378 (0.329,0.424) | 0.382 (0.335,0.426) | 0.382 (0.338,0.426) | |
| Default mode network | 0.488 (0.403,0.562) | 0.493 (0.404,0.570) | 0.487 (0.414,0.555) | |
| Visual network | 0.434 (0.362,0.508) | 0.435 (0.354,0.515) | 0.451 (0.401,0.500) |
We also examined two subsets of the 333 ROIs: 41 ROIs constituting the default mode network of the brain (DMN; Raichle et al., 2001), and 39 ROIs making up the brain's visual network. Correlations among the ROIs within each of these networks tend to be high, as illustrated in Figure 1. Hence, it comes as no surprise that dbICC values within each of these two networks, presented in the second and third rows of Table 2, are markedly higher than for the complete set of ROIs. For each set of ROIs, the dbICC values are quite consistent across the three distances.
A likely explanation for the relatively low dbICCs for the complete set of 333 ROIs is that many pairs of regions are essentially uncorrelated, and thus, their correlation estimates largely reflect noise. This suggests that it might be possible to boost dbICC by thresholding small correlations. Figure 5 shows the effect on dbICC of soft‐thresholding. Somewhat contrary to our expectation, soft‐thresholding generally increased dbICC only slightly at best, and often decreased it.
FIGURE 5.
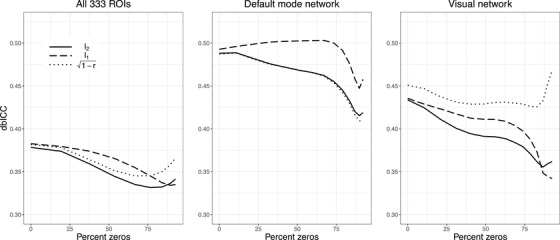
Estimated dbICC, for the same distances and sets of ROIs as in Table 2, but with soft‐thresholding of the correlation values. The horizontal axis denotes the average percentage of the correlations that are shrunk to zero, as the threshold increases
5. GENERALIZING THE SPEARMAN‐BROWN FORMULA
Is there a way to improve upon the low reliabilities found for the functional connectivity data? A general approach to boosting reliability, suggested by classical psychometrics, is to take more measurements: for example, to average over replicates of a measure, or to increase the number of questions on a test. A well‐known relation between the number of measurements and the reliability appeared in Spearman (1910) and, in a more familiar form, in Brown (1910). In this section, we extend this relation to the distance‐based ICC, and in Section 6, we reexamine the fMRI data results in light of our generalization of the Spearman‐Brown (SB) formula.
5.1. Measurement intensity and its effect on reliability
The SB formula states that averaging each score over m replicates transforms the classical ICC from ρ to . If we let , respectively, denote the raw ICC and the ICC based on m replicates, the formula can be written as , which with some rearrangement becomes
or alternatively
| (11) |
Lord and Novick (1968) refer to as the signal‐to‐noise ratio (SNR), and accordingly, (11) may be paraphrased as: the SNR is proportional to the number of measurements whose average is taken.
Averaging over m real‐valued measurements can be viewed as just one example of a broader notion of increasing measurement intensity and thereby boosting reliability. Other instances of measurement intensity m include:
-
(E1)
An estimated covariance or correlation matrix based on a sample of m multivariate observations. For functional connectivity matrices as considered above in Section 4, m would be the number of time points recorded by fMRI.
-
(E2)
A curve estimate obtained by penalized spline smoothing with m observations.
Our goal in the next subsection is to derive a distance‐based SB relation, ie, an analogue of (11) in which m denotes measurement intensity and is the resulting dbICC. To do this, we need a more general formulation of the true score model (1).
5.2. A true score model for general Hilbert spaces
The classical setting of real‐valued measures, as well as examples (E1) and (E2), can all be viewed as instances of a general setup in which the observations are of the form (1), but the 's are a random sample of true scores in a Hilbert space , while the 's are random measurement errors in . We define distance in by , where is the norm induced by the inner product on . Define
| (12) |
and
| (13) |
for and for , where denotes expectation for measurement intensity equal to m. Note that the measurement intensity affects only the expected distance between errors , but not that between scores . We make two assumptions, of which the first is implicit in (13):
-
(a1)
The expectation in (13) is the same for versus for .
-
(a2)For all ,
(14)
Then
and therefore
| (15) |
In the classical case where is the mean of m measurements, is the mean of m independent errors with mean 0 and common variance, so that
plugging this into (15) leads directly to the rearranged SB formula (11). In other cases, such as (E2), , and hence, the generalized SB formula (15) does not reduce to (11).
6. APPLYING THE GENERALIZED SB FORMULA TO THE fMRI DATA
Our goal in this section is to study the implications of the generalized SB formula (15) for correlation matrices such as those used in Section 4 as measures of functional connectivity. In Section 6.1 we show that, in the simpler setting of covariance matrix estimation, the relationship between measurement intensity and reliability is essentially the same as in the classical case of scalar measures. In Sections 6.2 and 6.3, we investigate the extent of agreement between what is expected theoretically and what is observed with simulated and real data.
6.1. An SB formula for covariance matrix estimation
Let be a random sample of covariance matrices, and for , let be sample covariance matrices, each based on m independent and identically distributed (IID) observations from a p‐variate normal distribution with covariance matrix . These belong to the Hilbert space of real symmetric matrices, equipped with inner product ; the norm induced by this inner product is the Frobenius (entry‐wise ℓ2) norm used in the fMRI example of Section 4. Note that here, unlike in the classical true score model, and are not independent since must be such that is nonnegative definite. But as shown in the Appendix, assumptions (a1) and (a2) of Section 5.2 hold, and consequently,
| (16) |
Thus by (15),
| (17) |
this is almost exactly the classical SB relation (11), but with in place of m.
6.2. Log‐log plots with simulated data
Suppose that, for a given collection of covariance matrices, we repeatedly generate sets of sample covariances as in Section 6.1, but with varying values of m, and obtain a dbICC estimate , based on the ℓ2 distance, for each m. Then the relation (17) suggests that the points
| (18) |
should lie approximately along a line with slope 1. To test this suggestion with simulated data resembling the fMRI data analyzed in Sections 4 and 6.3, we followed the above recipe with
, and ;
() taken to be the mean of the two sample covariance matrices from the ith participant's two fMRI scans; and
a range of m values from 25 to 197, approximately equally spaced on the log scale.
A plot of the resulting points (18) appears in the left panel of Figure 6 (black dots), and the best‐fit line through these points has slope 0.997 with standard error 0.010, in agreement with the theoretical slope 1.
FIGURE 6.
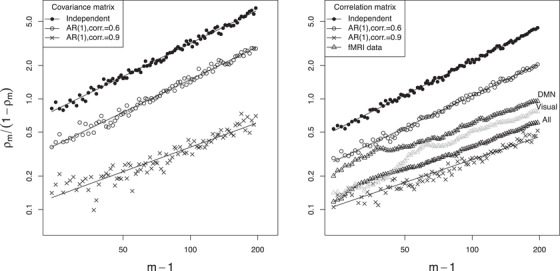
Left: Effect of measurement intensity on SNR for covariance matrix estimation with simulated data. Both axes are plotted on the log scale since, as explained at (18), this is expected to yield a linear relation with slope 1 for independent observations. Right: Simulation results for correlation matrix estimation, along with results based on subsets of the fMRI time series
Many aspects of the fMRI data reliability analysis in Section 4 are not captured by the above simulation setup. Two of the most prominent disparities are that for the real data, (a) we computed dbICC for correlation, rather than covariance, matrices, and (b) the multivariate observations are autocorrelated rather than independent (see Arbabshirani et al., 2014 and Zhu and Cribben, 2018, regarding the impact of such autocorrelation).
The simulation study was expanded to partially address these discrepancies. Using a standard implementation (Barbosa, 2012) for vector autoregressive models of order 1 (VAR(1); Lütkepohl, 2005), we conducted further simulations in which the jth multivariate time series for the ith individual was given by (), with independent innovations having zero mean and 333 × 333 covariance matrix . The lag‐1 autocorrelation ϕ was set to the values 0.6 and 0.9, which are near the low and high ends of the range of AR(1)‐model‐based estimates for individual ROIs in our fMRI data. The resulting points (18), with derived from sample covariance matrices, are displayed in the left panel of Figure 6. The right panel is analogous, but here is derived from sample correlation matrices. A comparison of the two panels indicates that, for given autocorrelation settings, both the estimated SNR and its dependence on m are very similar for covariance versus correlation matrix estimation. Autocorrelation is seen to reduce reliability and thus to shift the SNR markedly downward. Moreover, autocorrelation seems to attenuate the linear relationship between m and SNR: whereas in the IID setting, the slope is 1.018 for the sample correlation matrix, again very close to the theoretical value 1, the slopes are smaller with autocorrelation 0.6 (0.986 for covariance, 0.960 for correlation) and even smaller for autocorrelation 0.9 (0.736 for covariance, 0.687 for correlation). In Web Appendix C, we present plots that are analogous to Figure 6, but based on the ℓ1 and distances, and we report the intercepts and slopes of the best‐fit lines for all cases.
6.3. Reliability based on subsets of the fMRI time series
Next, we constructed log‐log plots as above but based on subsets of the real fMRI time series of Section 4 rather than on simulated data. For values of m ranging from 25 to the full time series length 197, we took the middle m observations from each of the fMRI time series, and thus computed correlation matrices () using the same three sets of ROIs as in Section 4: all 333 ROIs proposed by Gordon et al. (2016), the default mode network, and the visual network. Log‐log plots for the resulting dbICC values appear in the right panel of Figure 6. For smaller m, these plots are quite nonlinear and distinct from each other, but for , they each appear to stabilize with a linear pattern that is roughly parallel to the best‐fit line for the simulations with lag‐1 autocorrelation .9.
This degree of agreement with the simulation results of Section 6.2 is probably as much as can be expected, given the significant discrepancies between the settings of the simulated‐ and real‐data analyses, which include the following: (a) The simulations for different m are independent, whereas with the real data, for increasing m, we consider a nested sequence of increasingly large subsets of the same time series. (b) The real time series may not be multivariate normal and presumably have more complex patterns of autocorrelations and cross‐correlations than the simulated data.
At any rate, it seems clear that the theoretical log‐log plot slope of 1 cannot be expected to characterize the reliability improvement attainable via longer fMRI time series. Our results offer hope that a slope around 0.7 might be attained, but at least two further caveats are in order. One is that we cannot extrapolate beyond , the full time series length for our data. A second, subtler caveat concerns the true score model (1), in the specific form outlined in Section 6.1. That model assumes that for each i, the two sample covariance matrices are estimates of a common true covariance . But if, in fact, the underlying covariance matrix differs between the two fMRI scans for at least some of the participants, this is an additional source of within‐subject distance that is not removed by increasing the time series length m, and thus, may tend to level off rather than increasing linearly with . In summary, while longer fMRI scans might make correlation matrices more reliable as measures of functional connectivity, the improvement would likely be less dramatic than the results reported here might lead us to expect.
7. FURTHER APPLICATION AND EXTENSION OF THE SB FORMULA
Log‐log plots like those in Figure 6 are a broadly applicable tool for examining the relationship between measurement intensity m and reliability. As discussed in Web Appendix D, for penalized spline smoothing (example (E2) of Section 5.1), . Thus, arguing as in Section 6.2, a linear model fit to the points should have slope , a prediction that is borne out with simulated data.
Some distances, such as the dynamic time warping distance between signatures considered in Web Appendix E, do not arise from the true score model (1), even in the generalized (Hilbert space‐valued) form of Section 5.2. Whether or not the true score model applies, the dbICC (3) satisfies
| (19) |
The key to the derivation of (15) is simply that, by (12)‐(14),
-
(i)
,
-
(ii)
, which does not depend on m.
The same argument works more generally (ie, not only in Hilbert spaces): as long as MSDw can be written as a function of m whereas does not change with m, it follows from (19) that
| (20) |
generalizing (15), which is itself a generalization of (11).
Log‐log plots might be used in this more general setting to estimate the effect of measurement intensity m on , as opposed to confirming a theoretical relationship. By (20), if it is expected that for some unknown β, then we can regress values of on the corresponding values of , and the resulting slope serves as an estimate of β. A similar approach is used to estimate the Hurst exponent of a long memory process (Beran, 1994).
8. DISCUSSION
In this paper, we have redefined the intraclass correlation coefficient in terms of distances, and thereby extended this reliability index to arbitrary data objects for which a distance is defined. The proposed distance‐based ICC leads to two extensions of the SB formula, namely, (15) for Hilbert space‐valued data including covariance matrices, and (20) for more general data objects.
In an early paper on extending the ICC to multivariate data, Fleiss (1966) wrote that a classical (univariate) ICC value less than about 0.70 “is, for most purposes, taken to indicate insufficient reliability.” The much lower dbICC values that we report for functional connectivity data, along with similar results reported by others (eg, Shou et al., 2013), are a sobering indication that in some cases, as technology has advanced, the reliability of complex new measures has retreated. This might help to explain the recently‐much‐discussed difficulties surrounding scientific reproducibility, a desideratum that is closely related to reliability (Yu, 2013).
While our presentation has focused on test‐retest data, the dbICC might also be applied to assess the reliability of results obtained by algorithms, such as bootstrapping, which have a stochastic component (cf. Philipp et al., 2018).
While we have developed a distance‐based analog of the intraclass correlation coefficient, the distance correlation of Székely et al. (2007) is comparable to interclass correlation coefficients. Extending ideas from distance correlation research to the intraclass setting may be an interesting avenue for future work.
9.
Supporting information
Web Appendix A, referenced in Section 1, Web Appendix B, referenced in Section 4, Web Appendix C, referenced in Section 6.2, and Web Appendices D and E, referenced in Section 7, along with a brief guide to the R code, are available with this paper at the Biometrics website on Wiley Online Library. A package for R (R Core Team, 2019) implementing the methods of this paper is available at https://github.com/wtagr/dbicc.
ACKNOWLEDGMENTS
The authors thank the Co‐Editor, the Associate Editor, and the reviewers for very helpful and thoughtful feedback. Thanks are due as well to Eva Petkova and Don Klein for inspiring this work, by calling attention to the need for reliable measurement in the early days of resting‐state fMRI connectivity research. The work of M. Xu and P. T. Reiss was supported by Israel Science Foundation grants 1777/16 and 1076/19. The work of I. Cribben was supported by Natural Sciences and Engineering Research Council (Canada) grant RGPIN‐2018‐06638 and the Xerox Faculty Fellowship, Alberta School of Business.
fMRI data description and preprocessing
The resting‐state fMRI data set, downloaded from http://www.nitrc.org/projects/nyu_trt, includes 25 participants (mean age 29.44 ± 8.64, 10 males) scanned at New York University. A Siemens Allegra 3.0‐Tesla scanner was used to obtain three resting‐state scans for each participant, although for this analysis, we considered only the second and third scans, which were less than 1 hour apart. Each scan consisted of 197 contiguous EPI functional volumes with time repetition (TR) = 2000 ms; time echo (TE) = 25 ms; flip angle (FA) = 90°; 39 number of slices, matrix = 64 × 64; field of view (FOV) = 192 mm; voxel size mm3. During each scan, the participants were asked to relax and remain still with eyes open. For spatial normalization and localization, a high‐resolution T1‐weighted magnetization prepared gradient echo sequence was obtained (MPRAGE, TR = 2500 ms; TE = 4.35 ms; inversion time = 900 ms; FA = 8°, number of slices = 176; FOV = 256 mm).
The data were preprocessed using the FSL (http://www.fmrib.ox.ac.uk) and AFNI (http://afni.nimh.nih.gov/afni) software packages. The images were (a) motion corrected using FSL's mcflirt (rigid body transform; cost function normalized correlation; reference volume the middle volume) and then (b) normalized into the Montreal Neurological Institute space using FSL's flirt (affine transform; cost function mutual information). (c) FSL's fast was then used to obtain a probabilistic segmentation of the brain to acquire white matter and cerebrospinal fluid (CSF) probabilistic maps, thresholded at 0.99. (d) AFNI's 3dDetrend was then used to remove the nuisance signals, namely, the six motion parameters, white matter and CSF signals, and the global signal. (e) Finally, using FSL's fslmaths, the volumes were spatially smoothed using a Gaussian kernel with FWHM = 6 mm.
The ROIs for our connectivity analysis are derived from the work of Gordon et al. (2016), who parcellated the cortical surface into 333 areas within which homogeneous connectivity patterns are observed. Time courses for these 333 ROIs were obtained for each subject by averaging over all of the voxels within each region. Each regional time course was then detrended and standardized to unit variance, and then we applied a fourth‐order Butterworth filter with passband 0.01‐0.10 Hertz.
(a1), (a2), and for sample covariance matrices
Sample covariance matrices of multivariate normal samples are a special case of the true score model of Section 5.2 in which, for each i, , a covariance matrix, and for each ,
| (A.1) |
where is the sample covariance matrix of an IID random sample . Here, we verify assumptions (a1) and (a2) of Section 5.2 for this case, and derive expression (16) for .
By (A.1), in (13) are independent mean‐zero matrices, implying that
For , since are independent mean‐zero matrices. On the other hand, if , then are independent and of mean zero, conditionally on , and thus again
Hence, the expectation defining does not depend on whether or not , ie, (a1) holds; and
| (A.2) |
for as in (A.1).
For (a2), it suffices to show that . This follows since
while since is independent of and of mean zero.
By a standard result in multivariate analysis, conditionally on , has a Wishart distribution with degrees of freedom; thus by Theorem 2.2.6 of Fujikoshi et al. (2010),
These results lead to
Combining this with (A.2) gives
where the expectation is with respect to the distribution of the true covariance matrices . This confirms (16).
Xu M, Reiss PT, Cribben I. Generalized reliability based on distances. Biometrics. 2021;77:258–270. 10.1111/biom.13287
DATA AVAILABILITY STATEMENT
The data that support the findings in this paper are available in the Supporting Information. These data were derived from the public‐domain NYU CSC TestRetest resource at http://www.nitrc.org/projects/nyu_trt.
REFERENCES
- Alonso, A. , Laenen, A. , Molenberghs, G. , Geys, H. and Vangeneugden, T. (2010) A unified approach to multi‐item reliability. Biometrics, 66, 1061–1068. [DOI] [PubMed] [Google Scholar]
- Arbabshirani, M.R. , Damaraju, E. , Phlypo, R. , Plis, S. , Allen, E. , Ma, S. et al. (2014) Impact of autocorrelation on functional connectivity. NeuroImage, 102, 294–308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Atenafu, E.G. , Hamid, J.S. , To, T. , Willan, A.R. , Feldman, B.M. and Beyene, J. (2012) Bias‐corrected estimator for intraclass correlation coefficient in the balanced one‐way random effects model. BMC Medical Research Methodology, 12, 126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbosa, S.M. (2012) mAr: Multivariate AutoRegressive Analysis . R package version 1.1‐2.
- Beran, J. (1994) Statistics for Long‐Memory Processes. Boca Raton, FL: CRC Press. [Google Scholar]
- Brown, W. (1910) Some experimental results in the correlation of mental abilities. British Journal of Psychology, 3, 296–322. [Google Scholar]
- Choe, A.S. , Nebel, M.B. , Barber, A.D. , Cohen, J.R. , Xu, Y. , Pekar, J.J. , Caffo, B. and Lindquist, M.A. (2017) Comparing test‐retest reliability of dynamic functional connectivity methods. NeuroImage, 158, 155–175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cranford, J.A. , Shrout, P.E. , Iida, M. , Rafaeli, E. , Yip, T. and Bolger, N. (2006) A procedure for evaluating sensitivity to within‐person change: can mood measures in diary studies detect change reliably? Personality and Social Psychology Bulletin, 32, 917–929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fleiss, J.L. (1966) Assessing the accuracy of multivariate observations. Journal of the American Statistical Association, 61, 403–412. [Google Scholar]
- Fleiss, J.L. (1986) Design and Analysis of Clinical Experiments. New York: John Wiley & Sons. [Google Scholar]
- Fujikoshi, Y. , Ulyanov, V.V. and Shimizu, R. (2010) Multivariate Statistics: High‐Dimensional and Large‐Sample Approximations. Hoboken, NJ: John Wiley & Sons. [Google Scholar]
- Gordon, E.M. , Laumann, T.O. , Adeyemo, B. , Huckins, J.F. , Kelley, W.M. and Petersen, S.E. (2016) Generation and evaluation of a cortical area parcellation from resting‐state correlations. Cerebral Cortex, 26, 288–303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lord, F.M. and Novick, M.R. (1968) Statistical Theories of Mental Test Scores. Reading, MA: Addison‐Wesley. [Google Scholar]
- Lütkepohl, H. (2005) New Introduction to Multiple Time Series Analysis. New York: Springer Science & Business Media. [Google Scholar]
- Mair, P. (2018) Modern Psychometrics with R. Cham, Switzerland: Springer. [Google Scholar]
- McArdle, B.H. and Anderson, M.J. (2001) Fitting multivariate models to community data: a comment on distance‐based redundancy analysis. Ecology, 82, 290–297. [Google Scholar]
- Mielke, P.W. and Berry, K.J. (2007) Permutation Methods: A Distance Function Approach. New York: Springer. [Google Scholar]
- Noble, S. , Scheinost, D. and Constable, R.T. (2019) A decade of test‐retest reliability of functional connectivity: a systematic review and meta‐analysis. Neuroimage, 203, 116157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Philipp, M. , Rusch, T. , Hornik, K. and Strobl, C. (2018) Measuring the stability of results from supervised statistical learning. Journal of Computational and Graphical Statistics, 27, 685–700. [Google Scholar]
- R Core Team (2019) R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. [Google Scholar]
- Raichle, M.E. , MacLeod, A.M. , Snyder, A.Z. , Powers, W.J. , Gusnard, D.A. and Shulman, G.L. (2001) A default mode of brain function. Proceedings of the National Academy of Sciences, 98, 676–682. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reiss, P.T. , Stevens, M.H.H. , Shehzad, Z. , Petkova, E. and Milham, M.P. (2010) On distance‐based permutation tests for between‐group comparisons. Biometrics, 66, 636–643. [DOI] [PubMed] [Google Scholar]
- Shehzad, Z. , Kelly, A.C. , Reiss, P.T. , Gee, D.G. , Gotimer, K. , Uddin, L.Q. et al. (2009) The resting brain: unconstrained yet reliable. Cerebral Cortex, 19, 2209–2229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shou, H. , Eloyan, A. , Lee, S. , Zipunnikov, V. , Crainiceanu, A. , Nebel, M. et al. (2013) Quantifying the reliability of image replication studies: the image intraclass correlation coefficient (I2C2). Cognitive, Affective, & Behavioral Neuroscience, 13, 714–724. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Somandepalli, K. , Kelly, C. , Reiss, P.T. , Zuo, X.‐N. , Craddock, R.C. , Yan, C.‐G. , Petkova, E. , Castellanos, F.X. , Milham, M.P. and Di Martino, A. (2015) Short‐term test–retest reliability of resting state fMRI metrics in children with and without attention‐deficit/hyperactivity disorder. Developmental Cognitive Neuroscience, 15, 83–93. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spearman, C. (1910) Correlation calculated from faulty data. British Journal of Psychology, 3, 271–295. [Google Scholar]
- Székely, G.J. , Rizzo, M.L. and Bakirov, N.K. (2007) Measuring and testing dependence by correlation of distances. Annals of Statistics, 35, 2769–2794. [Google Scholar]
- Yan, C.‐G. , Craddock, R.C. , Zuo, X.‐N. , Zang, Y.‐F. and Milham, M.P. (2013) Standardizing the intrinsic brain: towards robust measurement of inter‐individual variation in 1000 functional connectomes. NeuroImage, 80, 246–262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu, B. (2013) Stability. Bernoulli, 19, 1484–1500. [Google Scholar]
- Zhu, Y. and Cribben, I. (2018) Sparse graphical models for functional connectivity networks: best methods and the autocorrelation issue. Brain Connectivity, 8, 139–165. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Web Appendix A, referenced in Section 1, Web Appendix B, referenced in Section 4, Web Appendix C, referenced in Section 6.2, and Web Appendices D and E, referenced in Section 7, along with a brief guide to the R code, are available with this paper at the Biometrics website on Wiley Online Library. A package for R (R Core Team, 2019) implementing the methods of this paper is available at https://github.com/wtagr/dbicc.
Data Availability Statement
The data that support the findings in this paper are available in the Supporting Information. These data were derived from the public‐domain NYU CSC TestRetest resource at http://www.nitrc.org/projects/nyu_trt.