

Abstract
Motivation
Minimizers are methods to sample k-mers from a string, with the guarantee that similar set of k-mers will be chosen on similar strings. It is parameterized by the k-mer length k, a window length w and an order on the k-mers. Minimizers are used in a large number of softwares and pipelines to improve computation efficiency and decrease memory usage. Despite the method’s popularity, many theoretical questions regarding its performance remain open. The core metric for measuring performance of a minimizer is the density, which measures the sparsity of sampled k-mers. The theoretical optimal density for a minimizer is , provably not achievable in general. For given k and w, little is known about asymptotically optimal minimizers, that is minimizers with density .
Results
We derive a necessary and sufficient condition for existence of asymptotically optimal minimizers. We also provide a randomized algorithm, called the Miniception, to design minimizers with the best theoretical guarantee to date on density in practical scenarios. Constructing and using the Miniception is as easy as constructing and using a random minimizer, which allows the design of efficient minimizers that scale to the values of k and w used in current bioinformatics software programs.
Availability and implementation
Reference implementation of the Miniception and the codes for analysis can be found at https://github.com/kingsford-group/miniception.
Supplementary information
Supplementary data are available at Bioinformatics online.
1 Introduction
The minimizer (Roberts et al., 2004a, b; Schleimer et al., 2003), also known as winnowing, is a method to sample positions or k-mers (substrings of length k) from a long string. Given two strings that share long enough exact substrings, the minimizer selects the same k-mers in the identical substrings, making it suitable to quickly estimate how similar two strings are, and to quickly locate shared substrings. The minimizers method is very versatile and is used in various ways in many bioinformatics programs [see the reviews (Marçais et al., 2019; Rowe, 2019) for examples] to reduce the total computation cost or the memory usage.
A minimizer has three parameters: . k is the length of the k-mers of interest while w is the length of the window: a least one k-mer in any window of w consecutive k-mers, or equivalently in any substring of length , must be selected. Finally, is a total order (i.e. a permutation) of all the k-mers, and it determines how the k-mers are selected: in each window the minimizer selects the minimum k-mer according to the order (hence the name minimizer), and in case of multiple minimum k-mers, the leftmost one is selected. The main measure of performance for minimizer is the density: the expected number of positions selected divided by the length of the string. In general, minimizers with lower densities are desirable as fewer selected positions imply a further reduction in the run time or memory usage of applications using minimizers, while preserving the guarantee that for similar strings the same k-mers are selected. For given parameters w and k, the choice of the order changes the expected density.
For example, a long-read aligner like Minimap2 (Li and Birol, 2018) stores the positions of every selected k-mers of a reference genome, to find exact match anchors for seed-and-extent alignment. The parameters k and w are constrained by the required sensitivity of alignment. Any choice of order provides the same guarantees, but an order with a lower density reduces the size of the storage and computation time by lowering the number of anchors to consider.
The density of a minimizer is lower bounded by , where exactly one position per window is selected, and upper bounded by 1, where every position is selected. A minimizer with a density of may not exist for every choice of w and k, and how to find an order with the smallest possible density for any w and k efficiently is still an open question. We are interested in constructing minimizers with density of —that is, within constant factor of optimal density—and avoid minimizers with density of .
Schleimer et al. gave two results about the density of minimizers: under some simplifying assumptions, (i) the expected density obtained by a randomly chosen order on a random input string is and (ii) the density is lower bounded by . Although these estimates are useful in practice, they are dependent on some hidden assumptions and do not represent the behavior of minimizers in all cases.
In previous publications we refined these results in multiple ways by looking at the asymptotic behavior of minimizers, by considering the cases where k is fixed and and where w is fixed and . First, when w is fixed and , we gave a construction of a minimizers with density of , for some (Marçais et al., 2018). That is, density arbitrarily close to the optimal is achievable for large values of k. The apparent contradiction between this result and Schleimer’s lower bound stems from a hidden assumption: k should not be too large compared to w. Second, we showed that when k is fixed and , the density of any minimizer is . Hence, a density of , or even , as proposed for a random order does not apply for large w and fixed k (Marçais et al., 2018). In other words, this original density estimate relies on a hidden assumption: k should not be too small compared to w.
Examples of minimizers with density < exist in practice, but these examples are one-off construction for a particular choice of parameters w and k (Marçais et al., 2017). Methods to construct minimizers that have density lower than and work for any w exist: a density of is obtained by Marçais et al. and Zheng et al. improves the result to . But neither of them reaches the desired asymptotically optimal density. This naturally raises the question on whether a minimizer with density or is possible assuming that both parameters k and w can be arbitrarily large.
This paper has three main contributions. First, in Section 2.2, we prove that as w grows asymptotically, the condition that is both a necessary and sufficient condition for the existence of minimizers with density of . In other words, to construct asymptotically optimal minimizers, it is sufficient and necessary that the length of the k-mers grows at least as fast as the logarithm of the window size.
Second, in Section 2.3, by slightly strengthening the constraint on k—i.e. , for any fixed —we show that a random minimizer has expected density of . This theorem is a direct extension of the result by Schleimer et al. as it removes any hidden assumptions and gives a sufficient condition for the result to hold.
Third, in Section 2.4, we give a construction of minimizers, called the Miniception, with expected density on a random string of when . This is an example of minimizers with guaranteed density that works for infinitely many w and k, not just an ad hoc example working for one or a small number of parameters w and k. This is also the first example of a family of minimizers with guaranteed expected density that works when instead of the less practical case of . Moreover, unlike other methods with low density in practice (DeBlasio et al., 2019; Ekim et al., 2020; Orenstein et al., 2016), the Miniception does not require the use of expensive heuristics to precompute and store a large set of k-mers. Selecting k-mers with the Miniception is as efficient as a selecting k-mers with a random minimizer using a hash function, and does not require any additional storage.
2 Materials and Methods
2.1 Preliminary
In this section, we restate several theorems from existing literature that are useful for later sections. Most definitions follow existing literatures (Roberts et al., 2004b; Schleimer et al., 2003). In the following, is an alphabet (mapped to integers) of size σ and we assume that and is fixed. If is a string, we use to denote the length of S.
Definition 1
(Minimizer and Windows). A ‘minimizer’ is characterized by where w and k are integers and is a complete order of . A ‘window’ is a string of length , consisting of exactly w overlapping k-mers. Given a window as input, the minimizer outputs the location of the smallest k-mer according to , breaking ties by preferring leftmost k-mer.
When is the dictionary order, it is called a lexicographic minimizer. A minimizer created by randomly choosing a permutation of uniformly over all possible permutations is called a random minimizer. (See Fig. 1 for an illustration of these and the following concepts.)
Definition 2
(Density). Given a string and a minimizer, a position in S is selected if the minimizer picks the k-mer at that position in any window of w consecutive k-mers. The specific density of a minimizer on S is the number of selected positions divided by the total number of k-mers in S. The density of a minimizer is the expected specific density on a sufficiently long random string.
Fig. 1.

The string S is broken into k-mers. In each window (w consecutive k-mers), the position of the lowest (smallest according to ) k-mer is selected. The gray context (two consecutive windows) is an example of a charged window because the first and second windows selected different positions. There are a total of three charged contexts in this example
Note that the density is calculated by expectation over random strings and is independent from S. For the ease of comparison, we will also use the concept of contexts and density factors:
Definition 3
(Contexts and Charged Contexts). A ‘context’ of S is a substring of length , or equivalently, two overlapping windows. The minimizer is applied to both the first and last windows, and a context is ‘charged’ if different positions are picked.
Definition 4
(Density Factor). The density factor of a minimizer is its density multiplied by . Intuitively, this is the expected number of selected locations in a random context.
The idea for charged contexts is to attribute picked k-mers to the window that first picked it (it is charged for picking a new k-mer). To determine whether a window is actually picking a new k-mer, it is sufficient to look back exactly one window due to the fact that minimizers pick k-mers in a forward manner, and the context is the union of the two windows necessary to determine whether this happens. This means counting picked k-mers in a string is equivalent to counting charged contexts (in other words, only charged contexts contribute to the density). Consequently, the (non-specific) density of a minimizer equals the probability that a context drawn from uniform distribution over is a charged one.
We denote by the set of all possible windows and the set of all contexts. The following lemma gives a slightly stronger condition on the positions of selected k-mers in a charged context. A similar lemma was proved by Schleimer et al. (2003) and a proof is given here for clarity.
Lemma 1
(Charged Contexts of Minimizers). For a minimizer, a context is charged if and only if the minimizer picks either the first k-mer of the first window or last k-mer in the last window.
Proof. On one hand, if the minimizer picks either the first or the last k-mer in the context, it cannot be picked in both windows. On the other hand, if the minimizer does not pick either the first or the last k-mer, it will pick the same k-mer in both windows. Assuming otherwise, both picked k-mers are in both window so this means one of them is not minimal, leading to a contradiction. □
A related concept is universal hitting sets (UHS) (Orenstein et al., 2016), which is central to the analysis of minimizers (Ekim et al., 2020; Marçais et al., 2017, 2018).
Definition 5
(Universal Hitting Sets). Assume . If U intersects with every w consecutive k-mers (or equivalently, the set of k-mers in every ), it is a UHS over k-mers with path length w and relative size .
Lemma 2
(Minimal Decycling Sets) (Mykkeltveit, 1972). Any UHS over k-mers has relative size at least .
2.2 Condition for asymptotically optimal minimizers
In this section, culminating with Theorem 2, we prove that to have asymptotically optimal minimizers (i.e. minimizers with density of ), the value k (for the k-mers) must be sufficiently large compared to the length w of the windows, and that this condition is necessary and sufficient. To be more precise, we treat k as a function of w, and study the density as w grows to infinity. We show that the lexicographic minimizers are asymptotically optimal provided that k is large enough: . This result may be surprising as in practice the lexicographic minimizers have high density (Marçais et al., 2017; Roberts et al., 2004a; and see Section 4). One interpretation of Theorem 2 is that asymptotically, all minimizers behave the same regarding density.
2.2.1 Minimizers with exceedingly small k
If k is exceedingly small, in the sense that k does not even grow as fast as the logarithm of w—i.e. as w grows—no minimizer will obtain density . To see this, for any order , let y be the smallest of all k-mers. Any context starting with y is charged, and the proportion of such context is . The density calculated from these contexts only is already , as .
For this reason, in the following we are only interested in the case where k is large enough. That is, there exists a fixed constant c such that for all sufficiently large w.
2.2.2 Lexicographic minimizers
We first prove the special case that the lexicographic minimizer achieves density with parameter . Recall is the set of all windows, and is the set of all contexts. Let be a window, be the minimizer function, and be the set of charged contexts for this minimizer. Let , the set of windows where the minimizer picks the first k-mer, and similarly . By Lemma 1, we know .
We now use the notion to denote any non-zero character of Σ, and to denote d consecutive zeroes. Let be the set of windows whose first k-mer is , and for , let , that is, the set of windows that starts with exactly i – 1 zeros and have the minimizer function pick the first k-mer. All and A+ are mutually disjoint. Since the minimizer always pick at the start of the window, we have .
Lemma 3
For , where , that is, the set of windows that starts with and does not contain in the next w−1 bases.
Proof. We need to show that if a window z starts with and is not in . As , there is a stretch of in z before the last k−i characters. This means that there is a k-mer of form in z, and since the first k-mer is of form , the minimizer will never pick the first k-mer. □
In our previous paper (Zheng et al., 2020), we proved that.
Lemma 4
The probability that a random string of length does not contain anywhere is at most .
Setting and d = i and noting there are choices for t in Bi, we know for every i. This is sufficient to prove the following:
Lemma 5
.
Proof. Let , combined with the fact that , we know . It remains to bound the summation term.
We next prove for :
Note that we also use the fact and in the last line. The right-hand side is minimum when i = k. By our choice of k, , so the term is lower bounded by 2.
This implies , and since , we have . □
The bound for is computed similarly. It is different from W+ as in case of ties for the minimal k-mer, the leftmost one is picked. Hence, we define as the set of windows such that the last k-mer is one of the minimal k-mers in the window. We have , as the last k-mer needs to be the minimal, with no ties, for the minimizer to pick it.
Similarly, we define as the set of windows that ends with . For , we define . This is the set of windows whose last k-mer starts with while satisfying the condition for . Again, and all are mutually disjoint, and we have . There is an analogous lemma for bounding :
Lemma 6
For , where .
Proof. We need to show that if a window ends with a k-mer of form and contains before last k-mer, it is not in . In that case the window contains a k-mer of form , which is strictly smaller than the last k-mer of the form , violating the condition of . □
Note that and have highly similar expressions. In fact, we can simply bound the size of by bi (defined in the proof of Lemma 5) using the identical argument. This immediately means that we have the exactly same bound for and , as also has the same size as .
Theorem 1The lexicographic minimizer with has density .
Proof. We have , and the density is . □
Next, we extend this result to show that this bound holds for all k as long as for some constant c. As , the following lemmas establish our claim for small and large k:
Lemma 7
The lexicographic minimizer with for constant has density .
Lemma 8
The lexicographic minimizer with has density .
We prove both lemmas in Supplementary Section S1. Combining everything we know, we have the following theorem.
Theorem 2For with constant c, the lexicographic minimizer achieves density of . Otherwise, no minimizer can achieve density of .
2.3 Density of random minimizers
We now study the density of random minimizers. Random minimizers are of practical and theoretical interest. In practice, implementing a random minimizer is relatively easy using a hash function, and these minimizers usually have lower density than lexicographic minimizers. Consequently, most software programs using minimizers use a random minimizer. The constant hidden in the big-O notation of Theorem 2 may also be too large for practical use, while later in Theorem 3, we guarantee a density of with a slightly more strict constraint over k.
Schleimer et al. (2003) estimated the expected density of random minimizers to be with several assumptions on the string (which do not strictly hold in practice), and our main theorem (Theorem 3) achieves the same result up to with a single explicit hypothesis between w and k. Combined with our previous results on connecting UHS to minimizers, we also provide an efficient randomized algorithm to construct compact UHS with approximation ratio.
2.3.1 Random minimizers
In the estimation of the expected density for random minimizers, there are two sources of randomness: (i) the order on the k-mers is selected at random among all the permutations of and (ii) the input string is a very long random string with each character chosen IID. The key tool to this part is the following lemma to control the number of ‘bad cases’ when a window contains two or more identical k-mers. Chikhi et al. (2016) proved a similar statement with slightly different methods.
Lemma 9
For any , if , the probability that a random window of -mers contains two identical k-mers is .
Proof. We start with deriving the probability that two k-mers in fixed locations i and j are identical in a random window. Without loss of generality, we assume i < j. If , the two k-mers do not share bases, so given they are both random k-mers independent of each other, the probability is .
Otherwise, the two k-mers intersect. We let , and mi to denote ith k-mer of the window. We use x to denote the substring from the start of mi to the end of mj with length k + d (or equivalently, the union of mi and mj). If mi = mj, the nth character of mi is equal to the nth character of mj, meaning for all . This further means that x is a repeating sequence of period d, so x is uniquely determined by its first d characters and there are σd possible configurations of x. The probability a random x satisfies mi = mj is then , which is also the probability of mi = mj for a random window.
The event that the window contains two identical k-mers is the union of events of form mi = mj for i < j, and each of these events happens with probability . Since there are events, by the union bound, the probability that any of them happens is upper bounded by . □
We are now ready to prove the main theorem of this section.
Theorem 3For , the expected density of a random minimizer is .
Proof. Given a context , we use I(c) to denote the event that c has two identical k-mers. As c has -mers, by Lemma 9, assuming that c is a random context.
Recall that a random minimizer means the order is randomized, and is the set of charged contexts. For any context c that does not have duplicate k-mers, we claim . This is because given all k-mers in c are distinct, under the randomness of , each k-mer has probability of exactly to be the minimal. By Lemma 1, if and only if the first or the last k-mer is the minimal, and as these two events are mutually exclusive, the probability of either happening is . The expected density of the random minimizer then follows:
□
2.3.2 Approximately optimal UHS
One interesting implication of Theorem 3 is on construction and approximation of compact UHS. In our previous paper (Zheng et al., 2020), we proved a connection between UHS and forward schemes. We restate it with minimizers, as follows.
Theorem 4For any minimizer , the set of charged contexts over a de Bruijn sequence of order w + k is a UHS over -mers with path length w, and with relative size identical to the density of the minimizer.
This theorem, combined with the density bound derived last section, allows efficient construction of approximately optimal UHS. We say that an algorithm for constructing UHS is efficient if it runs in time, as the output length of such algorithms is already at least .
Theorem 5For sufficiently large k and for arbitrary w, there exists an efficient randomized algorithm to generate a -approximation of a minimum size UHS over k-mers with path length w.
We prove this by discussing the case with k > w and k < w separately, as shown in Supplementary Section S2. This is also the first known efficient algorithm to achieve constant approximation ratio, as previous algorithms (DeBlasio et al., 2019; Ekim et al., 2020; Orenstein et al., 2016) use path cover heuristics with approximation ratio dependent on w and k.
2.4 The Miniception
In this section, we develop a minimizer (or rather, a distribution of minimizers) with expected density strictly below . The construction works as long as w < xk for some constant x. One other method exists to create minimizers with density below (Marçais et al., 2018), but it requires , a much more restrictive condition.
The name ‘Miniception’ is shorthand for ‘Minimizer Inception’, a reference to its construction that uses a smaller minimizer to construct a larger minimizer. In the estimation of the expected density of Miniception minimizers, there are multiple sources of randomness: the choice of orders in the small and in the large minimizers, and the chosen context. The construction and the proof of Miniception use these sources of randomness to ensure its good performance on average.
2.4.1 A tale of two UHS
UHS are connected to minimizers in two ways. The first connection, via the charged context set of a minimizer, is described in Theorem 4. The second and more known connection is via the idea of compatible minimizers. Detailed proof of the following properties are available in Marçais et al. (2017, 2018).
Definition 6
(Compatibility). A minimizer is said to be compatible with a UHS U, if the path length of U is at most w and for any under .
Lemma 10
(Properties of Compatible Minimizers). If a minimizer is compatible with a UHS, (i) any k-mer outside the UHS will never be picked by the minimizer, and (ii) the relative size of the UHS is an upper bound to the density of the minimizer.
Theorem 6Any minimizer is compatible with the set of selected k-mers over a de Bruijn sequence of order w + k.
The Miniception is a way of constructing minimizers that uses the UHS in both ways. Assume that we have a minimizer . By Theorem 4, its charged context set is a UHS over -mers with path length w0. According to Definition 6 and Theorem 6, we can construct a minimizer that is compatible with , where and any k-mer in is less than any k-mer outside according to .
We assume that the smaller minimizer is a random minimizer and that the larger minimizer is a random compatible minimizer (meaning the order of k-mers within is random in ). The Miniception is formally defined as follows:
Definition 7
(The Miniception). Given parameters w, k and k0, set . The Miniception is a minimizer with parameters w and k constructed as follows:
A random minimizer called the ‘seed’ is generated.
The set of charged contexts is calculated from the seed minimizer (note that ).
The order of the resulting minimizer is constructed by generating a random order within , and having every other k-mer compare larger than any k-mers in .
Note that by Lemma 10, the order within k-mers outside does not matter in constructing . In the following three sections, we will prove the following theorem:
Theorem 7With and , the expected density of the Miniception is upper bounded by .
As , for large values of w0, we can take for example , meaning in these cases. This makes the Miniception the only known construction with guaranteed density and with practical parameters.
Figure 2 provides an example of the Miniception. The Miniception can be implemented efficiently in practice. Assuming that a random order is computed with a hash function in O(k) time for a k-mer, determining the set of picked k-mers in a string S in takes time. This is as fast as a random minimizer. In particular, there is no need to precompute the set . We discuss the implementation in more detail in Supplementary Section S4 and provide a reference implementation in the GitHub repository.
Fig. 2.

An example of running the Miniception in a window. The k0-mers and -mers are displayed by their order in and , where the minimal elements appear at the top. We take to be lexicographic order for simplicity, and is a random order. The idea of sorting k0-mers will be important in deriving the theoretical guarantees of the Miniception
2.4.2 The permutation argument
We now focus on the setup outlined in Theorem 7. Our goal is to measure the density of the Miniception, which is equivalent to measuring the expected portion of charged contexts, that is, . There are three sources of randomness here: (i) the randomness of the seed minimizer, (ii) the randomness of the order within (which we will refer to as the randomness of ), and (iii) the randomness of the context.
A context of the Miniception is a -mer, which contains -mers. By our choice of k0 and Lemma 9, the probability that the context contains two identical k0-mers is (as ). Similar to our reasoning in proving Theorem 3, let I0 denote the event of duplicate k0-mers in a Miniception context:
We now consider a fixed context that has no duplicate k0-mers. Recall the way we determine whether a k-mer is in : we check whether it is a charged context of the seed minimizer, which involves only comparisons between its constituent k0-mers. This means that given a context of the Miniception, we can determine whether each of its k-mer is in the UHS only using the order between all k0-mers. We use to denote the order of k0-mers within c according to . Conditioned on any c with , over the randomness of , the order of the k0-mers inside c now follows a random permutation of , which we denote as .
Next, we consider fixing both c and (the only randomness is in ) and calculate probability that the context is charged. Note that fixing c and means fixed , and fixed set of k-mers in . The order of the k-mers is still random due to randomness in . For simplicity, if a k-mer is in , we call it a UHS k-mer. A boundary UHS k-mer is a UHS k-mer that is either the first or the last k-mer in the context c.
Lemma 11
Assume a fixed context c with no duplicate k0-mers and a fixed . Denote as the number of boundary UHS k-mers () and let be the number of total UHS k-mers in the context. The probability that the context is charged, over the randomness of , is .
Proof. We first note that for any context and any , due to being a UHS over k-mers with path length , so the expression is always valid. Furthermore, there are also no duplicate k-mers as . As is random, every UHS k-mer in the window has equal probability to be the minimal k-mer. The context is charged if one of the boundary UHS k-mers is chosen in this process, and the probability is for each boundary UHS k-mer, so the total probability is . □
This proof holds for every c and satisfying . In this case, both and are only dependent on . This means that we can write the probability of charged context conditioned on with a single source of randomness, as follows:
Next, we use E0 to denote the event that the first k-mer in the context is a UHS k-mer, and E1 to denote the event for the last k-mer. These two events are also only dependent on . We then have . By linearity of expectation, we have the following:
As the problem is symmetric, it suffices to solve one term. We have , because E0 is true if and only if the minimal k0-mer in the first k-mer is either the first or the last one, and there are -mers in a k-mer. The only term left is .
In the next two sections, we will upper bound this last term, which in turn bounds . It helps to understand why this argument achieves a bound better than a purely random minimizer, even though the Miniception looks very randomized. The context contains two UHS k-mers on average, because the relative size of is , so it may appear that the expectation term is close to 0.5, which leads to a density bound of , identical to a random minimizer. However, conditioned on E0, the context provably contains at least one other UHS k-mer, and with strictly positive chance contains two or more other UHS k-mers, which brings the expectation down strictly below 0.5.
2.4.3 Deriving the unconditional distribution
In this section, we bound the quantity by deriving the distribution of , where is sampled from conditioned on E0. We emphasize that at this point the actual k0-mers are not important and only their order matters. It is beneficial to view the sequence simply as the order . To prepare for the actual bound, we will first derive the distribution of assuming without extra conditions.
We are interested in the asymptotic bound, meaning , so we use the following notation. Let denote the distribution of random order of xw elements. This is consistent with previous definition of , as a context contains -mers. The relative length of a sequence is defined by its number of k0-mers divided by w. Given a sequence of relative length x, where the order of its constituent k0-mers follows , let denote the probability that the sequence contains exactly n UHS k-mers. As a context is a sequence of relative length 2, we are interested in the value of for .
We derive a recurrence for . Fix x, the relative length of the sequence. We iterate over the location of the minimal k0-mer and let its location be tw where .
There are two kinds of UHS k-mers for this sequence. The first kind contains the minimal k0-mer of the sequence, and there can be at most two of them: one starting with that k0-mer and one ending with that k0-mer. The second kind does not contain the minimal k0-mer, so it is either to the left of the minimal k0-mer or to the right of the minimal k0-mer, in the sense that it does not contain the minimal k0-mer in full. Precisely, it is from the substring that contains exactly the set of k0-mers left to the minimal k0-mer or from the substring that contains exactly the set of k0-mers right to the minimal k0-mer: these two substrings have an overlap of bases but do not share any k0-mer, and neither contain the minimal k0-mer. We refer to these sequences as the left and right substring for conciseness.
This divides the problem of finding n UHS k-mers into two subproblems: finding UHS k-mers left of location tw and finding UHS k-mers right of location tw. If we sample an order from , conditioned on the minimal k0-mer on location tw, the order of the k0-mers left of the minimal k0-mer follows , and similarly for the k0-mers right of the minimal k0-mer. As we assume , we ignore that two substrings combined have one less k0-mer. We prove in Supplementary Section S3.6 that this simplification introduces a negligible error. This means that the subproblems have an identical structure to the original problem.
We start with the boundary conditions. For x < 1, corresponding to a sequence with relative length <1, it contains no k-mer so with probability 1 the sequence contains no UHS k-mer. This means that and for . We now derive the value of , that is, the probability the sequence contains no UHS k-mer for . Define the middle region as the set of k0-mer locations that are at most -mers away from both the first and the last k0-mer. The sequence contains no UHS k-mer if and only if the minimal k0-mer falls within the middle region, as only in this case every k-mer contains the minimal k0-mer but none has it at the boundary. The relative length of the middle region is , as we assume (see Fig. 3). As the order of k0-mers follows , every k0-mer has equal probability to be the minimal and it is in the middle region with probability .
Fig. 3.

Setup for derivation of with and . The text denotes the relative length of the corresponding substrings. If the minimal k0-mer falls into the middle region (left panel), there are zero UHS k-mers in the sequence. Otherwise (right panel), there is at least one UHS k-mer with possibility for more from the substring
For , we next derive the recurrence for with (as seen in Fig. 3). We define the middle region in an identical way as in last lemma, whose relative length is again . If the minimal k0-mer is in the middle region, the sequence has exactly zero UHS k-mers. Otherwise, by symmetry we assume that it is to the left of the middle region (that is, at least -mers away from the last k0-mer in the sequence), with location tw where . The sequence now always has one UHS k-mer, that is the k-mer starting with the minimal k0-mer, and all other UHS k-mers come from the substring right to the minimal k0-mer. The substring has relative length x – t, and as argued above, the probability of observing exactly UHS k-mers from the substring is . Averaging over t, we have the following:
Given , we can solve for the next few Pn for as described in Supplementary Section S3.3. Recall our goal is to upper bound . For this purpose, is not sufficient as the expectation is conditioned on E0.
2.4.4 Deriving the conditional distribution
We now define the events and . is the event that the first k-mer of the Miniception context is a UHS k-mer, because inside the first k-mer the minimal k0-mer is at the front. Similarly, is the event where the first k-mer is a UHS k-mer, because the last k0-mer in the first k-mer is minimal. These events are mutually exclusive and have equal probability of , so .
Definition 8
(Restricted Distribution). for is the distribution of random permutations of xw elements, conditioned on the event that the first element is minimum among first w elements. Similarly, for is the distribution of random permutations of xw elements, conditioned on the event that the last element is minimum among first w elements.
We now have the following:
Based on this, we define to be the probability that a sequence of relative length xw, where the order of k0-mers inside the sequence follows , contains exactly n UHS k-mers. Our goal now is to determine for , which also bounds .
The general idea of divide-and-conquer stays the same in deriving a recurrence for . It is, however, trickier to apply this idea with a conditional distribution. We solve this issue by defining the following:
Definition 9
(Restricted Sampling). With fixed x and w, the restricted sampling process samples a permutation of length xw, then swap the minimum element in the first w element with the first element.
Lemma 12
Denote the distribution generated by the restricted sampling process as , then .
We prove this in Supplementary Section S3.1. As the distributions are the same, we redefine with . The boundary condition for is for all x, because the first k-mer is guaranteed to be a UHS k-mer (note that is defined only with ).
For and , from the process of restricted sampling, we know with probability the minimal k0-mer in the sequence is the first k0-mer overall. In this case, the first k-mer is the only UHS k-mer that contains the minimal k0-mer, and all other UHS k-mers come from the substring without the first k0-mer whose relative length is still x as we assume . We claim the following:
Lemma 13
Given an order of k0-mers sampled from , conditioned on the first k0-mer being overall minimal, the k0-mer order excluding the first k0-mer follows the unrestricted distribution .
This is proved in Supplementary Section S3.1. This lemma means that the probability of observing UHS k-mers outside the first k0-mer is . Otherwise, we use the same argument as before by setting the location of the minimal k0-mer to be tw, where . Only one UHS k-mer contains the minimal k0-mer with probability 1 (if x = 2, t = 2 happens with probability 0), and all other UHS k-mers come from the substring to the left of the minimal k0-mer. By a similar argument, the order of k0-mers within the left substring follows . These arguments are also shown in Figure 4. Averaging over t, we have the following recurrence for , valid for and :
Fig. 4.

Setup for derivation of with and . The text denotes the relative length of the corresponding substrings. If the minimal k0-mer is in the first k-mer, it will be the first k0-mer overall. In this case, there is one guaranteed UHS k-mer and possibility more in the substring without first k0-mer. Otherwise, the analysis is similar to the derivation of
Replacing with , we can similarly define and derive the recurrence for given . The process is highly symmetric to the previous case for , and we leave it to Supplementary Section S3.2. Similar to , we can derive the analytical solution to these integrals (see Supplementary Section S3.3). By definition of , we now bound by truncating the distribution’s tail, as follows (omitting the condition for clarity):
We can derive a similar formula for the symmetric term . For both Q+ and Q-, at n = 6 the tail probability , so we bound both terms using n = 6, resulting in the following:
Finally, we bound the density of the Miniception, now also using the symmetry conditions (omitting the condition for clarity):
2.4.5 Density bounds beyond x = 2
We can derive the recurrence for and for x > 2, corresponding to the scenario where . By similar techniques, with suitably chosen n, we can upper bound the density of the Miniception from the values of and with . The resulting bound has form of , where D(x) is the density factor bound. The detailed derivations can be found in Supplementary Section S3.4. We then have the following theorem:
Theorem 8With and , the expected density of the Miniception is upper bounded by .
3 Results
3.1 Asymptotic performance of the Miniception
We use a dynamic programming formulation (Supplementary Section S3.5) to calculate the density factor of the Miniception given , with a large value of k = 2500. As analyzed in Supplementary Section S3.6, this accurately approximates D(x), which in turn approximates the density factor of the Miniception with other values of k up to an asymptotically negligible error. Figure 5 shows estimated D(x) for .
Fig. 5.
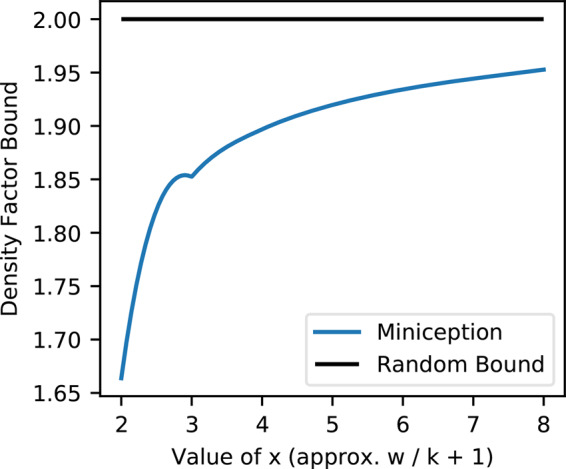
Density factor for the Miniception when and k = 2500. The random minimizer achieves density factor of constant 2 and is plotted for comparison
Consistent with Section 2.4, , as x = 2 corresponds to the case . There is no analytical form for D(x) with x > 2, but this experiment suggests that as x grows, D(x) increases while staying below 2, the density factor of a random minimizer. That is, as w gets increasingly larger than k, the Miniception performance regresses to that of a random minimizer. We conjecture that as x grows.
3.2 Designing minimizers with large k
As seen in the implementation of Miniception (Supplementary Section S4), the run time of the Miniception minimizer is the same as a random minimizer. Therefore, it can be used even for large values of k and w. This contrasts to PASHA (Ekim et al., 2020), the most efficient minimizer design algorithm, which only scales up to k = 16.
We implemented the Miniception and calculated its density by sampling 1 000 000 random contexts to estimate the probability of a charged context (which is equivalent to estimating the density as discussed before). The Miniception has a single tunable parameter k0. It is important to pick an appropriate value of k0: too small value of k0 invalidates the assumption that most k0-mers are unique in a window, and too large value of k0 increases the value of x. In general, we recommend setting k0 close to k - w if k is larger than w (which corresponds roughly to x = 2 in our analysis of the Miniception), and a constant multiple of if w is larger than k (roughly corresponding to in our analysis).
We tune this parameter in our experiments by setting if k is larger than w + 3. If this does not hold, we test the scheme with and report the best-performing one. We show the results for Miniception against lexicographic and random minimizers in four setups: two with fixed w and two with fixed k (Fig. 6). These parameter ranges encompass values used by bioinformatics software packages.
Fig. 6.
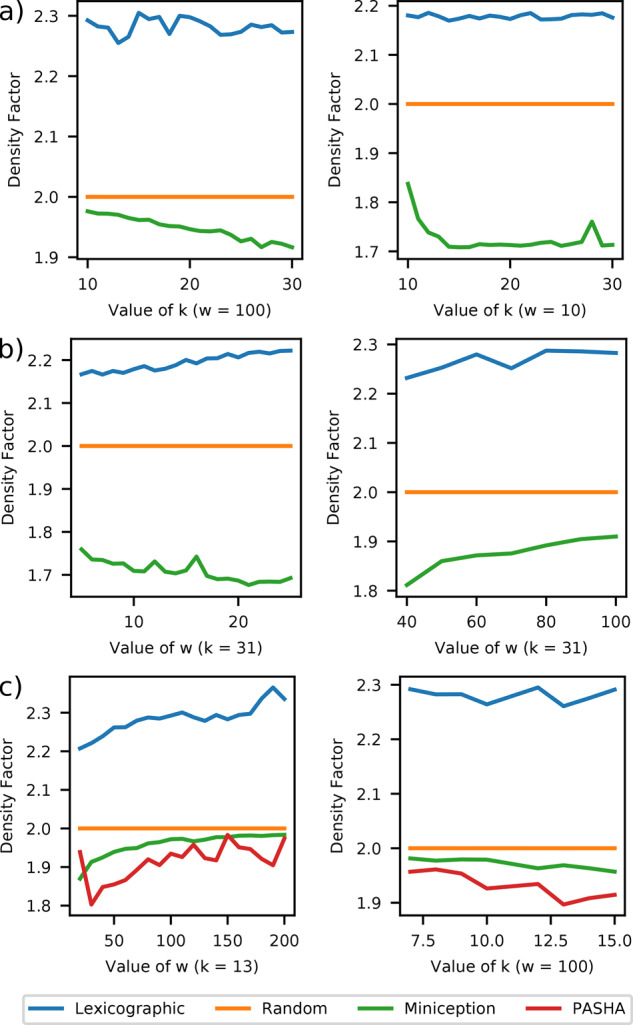
Comparing density of the Miniception against lexicographic, random and PASHA minimizers. Two setups are considered: fixed w and varying k in a), and fixed w and varying k in b) and c). PASHA is computationally limited to and is therefore not included in b)
The Miniception consistently performs better than the lexicographic and random minimizers in all tested scenarios. For the setups with fixed w = 10, k is larger than w and the Miniception achieves density factor of for . Given that , our bound on the density factor of holds relatively well for these experiments. Same conclusion holds for the setup with fixed k = 31 and .
For w = 100, w is larger than k and we observe the same behavior as in Section 3.1: the performance degrades when k becomes smaller than w. Same conclusion holds for the setup with fixed k = 31 and . Our theory also correctly predicts this behavior, as the decrease of improves the density bound as seen in Section 2.4.
3.3 Comparison with PASHA
In Figure 6c, we compare the Miniception with PASHA. We downloaded the PASHA-generated UHS from the project website and implemented the compatible minimizers according to Ekim et al. (2020). Our test consists of two parts. For the first part, we fix k = 13 and vary w from 20 to 200. For the second part, we fix w = 100 and vary k from 7 to 15. This setup features some of the largest minimizers designed by PASHA, the state of the art in large minimizer design (we are unable to parse the UHS file for k = 16).
The Miniception still performs better than the random minimizers for these configurations, but PASHA, even though it is a heuristic without a density guarantee, overall holds the edge. We also perform experiments on the hg38 human reference genome sequence, where we observe similar results with a smaller performance edge for PASHA, as shown in Supplementary Section S5.
Although PASHA has lower density than Miniception, it is limited to . Moreover, computing minimizers with PASHA requires storing in memory a relatively large set of k-mers (5–10 million mers for k = 13). Miniception does not need any to store any set.
4 Discussion
4.1 Limitations and alternatives to minimizers
The bound is not the only density lower bound for minimizers. Specifically, Marçais et al. (2018) proved the following lower bound:
| (1) |
As w grows compared to k, this implies that the density factor of the minimizers is lower bounded by a constant up to 1.5. We also observed that performance of minimizers, both the Miniception and the PASHA compatible ones, regresses to that of a random minimizer when w increases. Unfortunately, this is inherent to minimizers. With a fixed k, as the window size w grows, the k-mers become increasingly decoupled from each other and the ordering plays less of a role in determining the density.
The minimizers are not the only class of methods to sample k-mers from strings. Local schemes are generalizations of minimizers that are defined by a function with no additional constraints. They may not be limited by existing lower bounds ((1) for example), and developing local schemes can lead to better sampling methods with densities closer to .
4.2 Perfect schemes and beyond
This work answers positively the long-standing question on the existence of minimizers that are within a constant factor of optimal. Even though the original papers introducing the winnowing and minimizer methods proposed a density of , their analysis only applied to particular choices of k and w. Theorems 2 and 3 give the necessary and sufficient conditions for k and w to be able to achieve density. Theorem 2 also results in the first constant factor approximation algorithm for a minimum size UHS, which improves on our previous result of a factor approximation (Zheng et al., 2020). These theorems also settle the question on existence of asymptotically perfect forward and local schemes.
In general, studies on the asymptotic behavior of minimizers have proven very fruitful to deepen our understanding of the minimizers and of the associated concepts (structure of the de Bruijn graph, decycling sets and UHS). However, there is a sizable gap between the theory and the practice of minimizers.
One example of this gap is the way we prove Theorem 2: the density of the lexicographic minimizers reaches whenever it is possible for any minimizer. This means that the lexicographic minimizers are optimal for asymptotic density. However, in practice, they are usually considered the worst minimizers and are avoided. Another example is the fact that heuristics such as PASHA, while unable to scale as our proposed methods and being computationally extensive, achieves better density in practice (for the set of parameters it is able to run on) with worse theoretical guarantee. Now that we have mostly settled the problem of asymptotical optimality for minimizers, working on bridging the theory and the practice of minimizers is an exciting future direction.
The core metric for minimizers, the density, is measured over assumed randomness of the string. In many applications, especially in bioinformatics, the string is usually not completely random. For example, when working with a read aligner, the minimizers are usually computed on a reference genome, which is known to contain various biases. Moreover, this string may be fixed (e.g. the human genome). In these cases, a minimizer with low density on average may not be the best choice. Instead, a minimizer which selects a sparse set of k-mers specifically on these strings would be preferred. The idea of ‘sequence specific minimizers’ is not new (DeBlasio et al. 2019); however, it is still largely unexplored.
Funding
This work was partially supported in part by the Gordon and Betty Moore Foundation’s Data-Driven Discovery Initiative [GBMF4554 to C.K.]; the US National Science Foundation [CCF-1256087, CCF-1319998]; and the US National Institutes of Health [R01GM122935].
Conflict of Interest: C.K. is a co-founder of Ocean Genomics, Inc. G.M. is a V.P. of software development at Ocean Genomics, Inc.
Supplementary Material
Contributor Information
Hongyu Zheng, Computational Biology Department, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, USA .
Carl Kingsford, Computational Biology Department, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, USA .
Guillaume Marçais, Computational Biology Department, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, USA .
References
- Chikhi R. et al. (2016) Compacting de Bruijn graphs from sequencing data quickly and in low memory. Bioinformatics, 32, i201–i208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DeBlasio D. et al. (2019) Practical universal k-mer sets for minimizer schemes. In: Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, BCB ‘19, ACM, New York, NY, USA, pp. 167–176.
- Ekim B. et al. (2020) A randomized parallel algorithm for efficiently finding near-optimal universal hitting sets. In: Schwartz,R. (ed.), Research in Computational Molecular Biology, Springer International Publishing, Cham, pp.37--53. [DOI] [PMC free article] [PubMed]
- Li H., Birol I. (2018) Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics, 34, 3094–3100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marçais G. et al. (2017) Improving the performance of minimizers and winnowing schemes. Bioinformatics, 33, i110–i117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marçais G. et al. (2018) Asymptotically optimal minimizers schemes. Bioinformatics, 34, i13–i22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marçais G. et al. (2019) Sketching and sublinear data structures in genomics. Annu. Rev. Biomed. Data Sci., 2, 93–118. [Google Scholar]
- Mykkeltveit J. (1972) A proof of Golomb’s conjecture for the de Bruijn graph. J. Comb. Theory B, 13, 40–45. [Google Scholar]
- Orenstein Y. et al. (2016) Compact universal k-mer hitting sets. In: Frith,M. and Pedersen,C.(eds), Algorithms in Bioinformatics. Lecture Notes in Computer Science. Springer, Cham, pp.257–268. [Google Scholar]
- Roberts M. et al. (2004. a) A preprocessor for shotgun assembly of large genomes. J. Comput. Biol., 11, 734–752. [DOI] [PubMed] [Google Scholar]
- Roberts M. et al. (2004. b) Reducing storage requirements for biological sequence comparison. Bioinformatics, 20, 3363–3369. [DOI] [PubMed] [Google Scholar]
- Rowe W.P.M. (2019) When the levee breaks: a practical guide to sketching algorithms for processing the flood of genomic data. Genome Biol., 20, 199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schleimer S. et al. (2003) Winnowing: local algorithms for document fingerprinting. In: Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, SIGMOD ‘03, ACM, pp. 76–85. [Google Scholar]
- Zheng H. et al. (2020) Lower density selection schemes via small universal hitting sets with short remaining path length. In: Schwartz,R. (ed.), Research in Computational Molecular Biology, Springer International Publishing, Cham, pp.202--217. [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.