

Abstract
Background
Meta-analysis is a statistical method to synthesize evidence from a number of independent studies, including those from clinical studies with binary outcomes. In practice, when there are zero events in one or both groups, it may cause statistical problems in the subsequent analysis.
Methods
In this paper, by considering the relative risk as the effect size, we conduct a comparative study that consists of four continuity correction methods and another state-of-the-art method without the continuity correction, namely the generalized linear mixed models (GLMMs). To further advance the literature, we also introduce a new method of the continuity correction for estimating the relative risk.
Results
From the simulation studies, the new method performs well in terms of mean squared error when there are few studies. In contrast, the generalized linear mixed model performs the best when the number of studies is large. In addition, by reanalyzing recent coronavirus disease 2019 (COVID-19) data, it is evident that the double-zero-event studies impact the estimate of the mean effect size.
Conclusions
We recommend the new method to handle the zero-event studies when there are few studies in a meta-analysis, or instead use the GLMM when the number of studies is large. The double-zero-event studies may be informative, and so we suggest not excluding them.
Supplementary Information
The online version contains supplementary material available at (10.1186/s40779-021-00331-6).
Keywords: Continuity correction, Coronavirus disease 2019 data, Meta-analysis, Relative risk, Zero-event studies
Background
Meta-analysis is a statistical method to synthesize evidence from a number of independent studies that addressed the same scientific questions [1, 2]. In clinical studies, experimental data are commonly composed of binary outcomes, and consequently, meta-analyses of binary data have attracted increasing attention in evidence-based medicine [3, 4]. For each study, an effect size is reported to quantify the treatment effect by comparing the event probabilities between the treatment group and the control group, including the odds ratio (OR), the relative risk (RR), and the risk difference (RD). In meta-analysis, when the study-specific effect size is estimated based on a two-by-two contingency table, the zero-event problem in one or both groups frequently occurs, which may cause an unexpected calculation complication in the statistical inference of the effect size. If the study involves a zero event in one group, we refer to it as a single-zero-event study; and if the study involves zero events in both groups, we refer to it as a double-zero-event study [5]. Vandermeer et al. [6] and Kuss [7] applied random sampling techniques and found that 30% of meta-analyses from the 500 sampled Cochrane reviews included one or more single-zero-event studies, while 34% of the reviews involved at least one meta-analysis with a double-zero-event study.
As a recent example, Chu et al. [8] conducted several meta-analyses to evaluate the effectiveness of physical distancing, face masks, and eye protection on the spread of three coronaviruses, which caused severe acute respiratory syndrome (SARS), Middle East respiratory syndrome (MERS) or coronavirus disease 2019, also known as COVID-19 [9, 10]. Specifically, they considered RR as the effect size and applied the random-effects model to pool the observed effect sizes with an inverse-variance weight assigned to each study [11, 12]. As a result, for their meta-analysis on physical distancing, they concluded that the risk of infection will be significantly decreased with a further physical distance. We note, however, that there are 8 single-zero-event studies and 7 double-zero-event studies among a total of 32 studies. In particular for the 7 studies on COVID-19 data, 4 of them are single-zero-event studies and 2 of them are double-zero-event studies. To escape the zero-event problem, Chu et al. [8] excluded the double-zero-event studies from their meta-analyses, which, however, may introduce an estimation bias to the overall effect size [7]. More recently, Xu et al. [13] revisited 442 meta-analyses with or without the double-zero-event studies, and then by a comparative study, they concluded that the double-zero-event studies do contain valuable information and should not be excluded from the meta-analysis.
Inspired by the aforementioned examples, we provide a selective review on the existing methods for meta-analysis that can handle the zero-event studies. For ease of presentation, we will mainly focus on the random-effects model with RR as the effect size, whereas the same comparison also applies to OR and RD. For more details on meta-analysis of OR and RD with the zero-event studies, one may refer to [7] and the references therein, in which the author discussed the methods applicable to all the three effect sizes as well as some methods only applicable to one of them. For a given study, we let n1 be the number of samples in the treatment group with X1 being the number of events, and n2 be the number of samples in the control group with X2 being the number of events. Let also X1 follow a binomial distribution with parameters n1 and p1>0, and X2 follow a binomial distribution with parameters n2 and p2>0. We further assume that X1 and X2 are independent of each other. Then to estimate RR=p1/p2, the maximum likelihood estimator is known as
| 1 |
Note that is often right-skewed. To derive the statistical inference on RR, researchers frequently apply the log scale so that the resulting estimator can be more normally distributed. Specifically by Agresti [14], the approximate variance of is
| 2 |
By (1) and (2), when there are zero events in one or both groups, the classic method for estimating RR suffers from the zero-event problem and will no longer be applicable.
To have a valid estimate of RR, originated from Haldane [15], one often recommends to add 0.5 to the counts of events and non-events if some count is zero [16, 17]. This method is referred to a correction method and has been extensively used in meta-analysis to deal with the zero-event studies. For further developments on the continuity correction, one may refer to Sweeting et al. [18], Carter et al. [19], and the references therein. On the other side, there are also statistical models without the continuity correction to handle meta-analysis with the zero-event studies, such as the generalized linear mixed models [4, 20, 21].
The remainder of this paper is organized as follows. In “Methods with the continuity correction” section, we first review the random-effects model and the existing methods with the continuity correction, and then propose a new method of the continuity correction for estimating RR. In “The generalized linear mixed models” section, we review the generalized linear mixed models for meta-analysis. In “Simulation studies” section, we conduct simulation studies to evaluate the performance of the reviewed methods and our new method. In “Application to COVID-19 data” section, we apply all the well performed methods to a recent meta-analysis on COVID-19 data for further evaluation of their performance. We then conclude the paper in “Discussion” and “Conclusions” sections with some interesting findings, and provide the supplementary materials in the Appendix.
Methods
Methods with the continuity correction
Suppose that there are k studies in the meta-analysis, and yi for are the observed effect sizes for each study. By DerSimonian and Laird [22], the random-effects model can be expressed as
| 3 |
where θ is the mean effect size, ζi are the deviations of each study from θ, and εi are the sampling errors. We further assume that ζi are independent and identically distributed random variables from N(0,τ2),εi are independent random errors from , and that they are independent of each other. In addition, τ2 is referred to as the between-study variance, and are referred to as the within-study variances.
For the random-effects model in (3), by the inverse-variance method the mean effect size θ can be estimated by
| 4 |
where are the weights assigned to each individual study [23]. In meta-analysis, the within-study variances are routinely estimated by the variances of the observed effect sizes, denoted by var(yi). While for the between-study variance, DerSimonian and Laird [22] proposed the method of moments estimator as
| 5 |
where is known as the Q statistic, and with for .
We note, however, that the random-effects model may suffer from the zero-event problem. Taking RR as an example, if we apply the random-effects model for meta-analysis, then the effect sizes yi will be the observed ln(RR) values. Now for estimating ln(RR), if we plug in from formula (1) directly, then ln will not be well defined when the studies involve the zero events, and so is for the variance estimate of in formula (2). Consequently, without a valid estimate of the effect size and of its within-study variance, the random-effects model cannot be applied to estimate the mean effect size by the inverse-variance method. This shows that a correction on is often desired in meta-analysis with some studies involving zero events.
Existing methods with the continuity correction
Let c1>0 and c2>0 be two values for the continuity correction. To overcome the zero-event problem, one common approach is to estimate p1 by (X1+c1)/(n1+2c1) and estimate p2 by (X2+c2)/(n2+2c2). Plugging them into (1) and (2), we have
| 6 |
Accordingly, the 95% confidence interval (CI) of RR is
| 7 |
For the values of c1 and c2 in (6), there are mainly three suggestions in the literature that are widely used for the random-effects meta-analysis.
-
(i)When c1=c2=0.5, it yields the Haldane estimator [15] as
8 -
(ii)When c1=n1/(n1+n2) and c2=n2/(n1+n2), it yields the TACC estimator [18] as
9 For the balanced case when n1=n2, the TACC estimator is equivalent to the Haldane estimator. Also to implement this estimator, one may apply metabin in the R package “meta” with the setting incr=“TACC” [24].
-
(iii)When c1=c2=1, it yields the Carter estimator [19] as
10
Besides the continuity correction methods in family (6), another alternative is to estimate p1 by (X1+c1)/(n1+c1) and estimate p2 by (X2+c2)/(n2+c2). Then with c1=c2=0.5, it yields the Pettigrew estimator [25] as
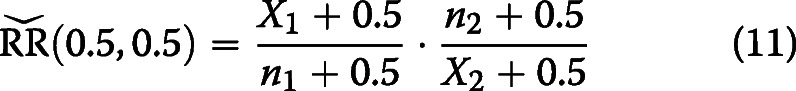 and the 95% CI of RR as
and the 95% CI of RR as
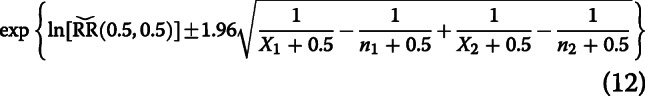
Moreover, to avoid a zero standard error, Hartung and Knapp [26] suggested not to correct X1 and X2 when X1=n1 and X2=n2.
A hybrid method with the continuity correction
Note that the existing methods are all constructed to first estimate p1 and p2, and then take their ratio as an estimate of RR=p1/p2. Nevertheless, noting that p2 is in the denominator rather than in the numerator, inverting an optimal estimate for p2 may not necessarily yield an optimal estimate for 1/p2. In this section, we propose a hybrid method that is to estimate p1 and 1/p2 directly, and then take their product to estimate RR.
For the estimation of p1, we show in Appendix 1 that the mean squared error (MSE) of (X1+c1)/(n1+2c1) is smaller than the MSE of (X1+c1)/(n1+c1) in most settings. We thus consider to apply (X1+c1)/(n1+2c1) to estimate p1 in RR. While to estimate the reciprocal of p2, one may consider (n2+2c2)/(X2+c2) as in (6). Or instead, another option can be to consider (n2+c2)/(X2+c2) as originated in (??), see also [27] and [28] for more discussion. And if we take the latter one, then a hybrid estimator of RR can be constructed as
| 11 |
For the optimal values of c1 and c2 in (11), our simulation studies in Appendices 2 and 3 show that c1=0.5 and c2=0.5 are among the best options. In view of this, our new hybrid estimator is taken as follows:
| 12 |
whereas the 95% CI of RR is given as
| 13 |
Comparison of the continuity correction methods
In this section, we conduct a numerical study to compare the finite sample performance of the existing and new methods. For ease of presentation, we refer to the confidence intervals associated with (8), (9), (10), (??) and (12) as the Haldane interval, the TACC interval, the Carter interval, the Pettigrew interval, and the hybrid interval, respectively.
To generate the data, we let p2=0.05, 0.15, 0.85 or 0.95, and p1=p2×RR with RR ranging from 0.2 to min{5,1/p2}. We also consider different combinations of the sample sizes. For the sake of brevity, only the results for balanced samples with n1=n2=10 or 50 are presented, whereas the results for the unbalanced samples are postponed to Appendix 4. Recall that the Haldane and TACC intervals are the same when n1=n2, and we thus present the results for the Haldane interval only. With N=100,000 repetitions for each setting, we generate random numbers from the binomial distributions with parameters (p1,n1) and (p2,n2) to yield the estimates of RR and their CIs. We then compute the frequencies of the true RR falling in the CIs as the coverage probability estimates. Moreover, the expected lengths of the CIs on the log scale are computed by , where ULs and LLs are the upper and lower limits of the sth CI.
For p2=0.05 or 0.15, the top four panels of Figs. 1 and 2 show that the Haldane interval is the most conservative interval in most settings, and it provides the longest expected lengths compared to the other three intervals. The Carter interval may have downward spikes in the left or right tail, although it leads to the shortest expected lengths. We also note that the simulation results of the Pettgrew interval and the hybrid interval are nearly the same. Their coverage probabilities and expected lengths are intermediate between those of the other two intervals in most settings.
Fig. 1.

Comparison of the four CIs of RR with p2=0.05, 0.15, 0.85 or 0.95, and n1=n2=10. The dot-dashed lines represent the simulation results of the Haldane interval, the dashed lines represent the simulation results of the Carter interval, the dotted lines represent the simulation results of the Pettigrew interval, and the solid lines represent the simulation results of the hybrid interval. CI: Confidence interval, RR: Relative risk
Fig. 2.

Comparison of the four CIs of RR with p2=0.05, 0.15, 0.85 or 0.95, and n1=n2=50. The dot-dashed lines represent the simulation results of the Haldane interval, the dashed lines represent the simulation results of the Carter interval, the dotted lines represent the simulation results of the Pettigrew interval, and the solid lines represent the simulation results of the hybrid interval. CI: Confidence interval, RR: Relative risk
From the bottom four panels of Figs. 1 and 2 with p2=0.85 or 0.95, it is evident that the Haldane interval has a satisfactory performance in most settings with the coverage probabilities around the nominal level. In contrast, the Carter interval fails to provide enough large coverage probabilities in most settings, so does the Pettgrew interval when n1 and n2 are small. Note also that the coverage probabilities of the hybrid interval are comparable to the Haldane interval as long as p2 is not extremely large. Moreover, the hybrid interval yields shorter expected lengths than the Haldane interval.
To sum up, when p2 is small, the Pettgrew interval and the hybrid interval are less conservative than the Haldane interval in most settings. While for large p2, the Haldane interval and the hybrid interval perform better than the Pettgrew interval in terms of coverage probability. In addition, the expected lengths of the hybrid interval are always shorter than the Haldane interval. This shows that the hybrid interval can serve as a good alternative for the interval estimation of RR.
The generalized linear mixed models
The generalized linear mixed models (GLMMs) are extensions of the generalized linear model, which include both the fixed and random effects as linear predictors [14]. Different types of the GLMMs have been proposed in the literature including a few reviews and comparison studies [4, 29]. Among the existing models, the bivariate GLMM has been well recognized and being recommended for estimating RR in meta-analysis [20].
Let pi1 and pi2 be the event probabilities in the treatment and control groups of the ith study, respectively. The bivariate GLMM is represented as
| 14 |
where g(·) is the link function, Ω1 and Ω2 are the fixed effects, and the random effects are given by
The mean effect size based on model (14) was defined as
| 15 |
where E(p1) and E(p2) are the mean event probabilities in the control and treatment groups, g−1(·) is the inverse function of the link, and ϕ(·) is the probability density function of the standard normal distribution [30]. For the logit link, Zeger et al. [31] proposed an approximate formula with . For the probit link, , where j=1 or 2, and Φ(·) is the cumulative distribution function of the standard normal distribution. While for the other links, there does not exist a closed form of formula (15) and so a numerical approximation is often needed [32].
For the parameter estimation in model (14), Jackson et al. [4] provided a detailed introduction for the implementation based on the R package “lme4” in their model 6. Alternatively, one may also apply the function meta.biv in the R package “altmeta” maintained by Lin and Chu [33], in which the 95% CI of RR can be derived by the bootstrap resampling method.
Results
Simulation studies
In this section, we compare the performance of the reviewed methods on handling meta-analysis with the zero-event studies, including the continuity correction methods and the generalized linear mixed models. Among the existing continuity correction methods, we note that the Haldane and TACC estimators are comparable and among the best when estimating the mean effect size, in contrast to the other two methods including the Carter and Pettigrew estimators. Hence, for the sake of brevity, we only present the results of the Haldane and TACC estimators in the main text but provide the simulation results for all four methods in Appendix 5. Besides the Haldane and TACC estimators, we also consider the newly introduced hybrid estimator and the GLMM with the logit link for further comparison.
To conduct the meta-analysis, we consider k=3, 6 and 12 as three different numbers of studies. Also by (3), we let θ=ln(RR) be the mean effect size that ranges from ln(0.2) to ln(5), and then generate the random effects ζi from N(0,τ2) with τ2= 0.25 or 1. Next, we randomly generate ni2 from the log-normal distribution based on the assumption that [34]. It is also assumed by [34] that the ratios between ni1 and ni2 follow the uniform distribution with values from 0.84 to 2.04. In addition, we generate the event probabilities of the control group pi2 from the uniform distribution with values from 0.01 to min{0.99,1/exp(θ)}. Then accordingly, the event probabilities of the treatment group are given by pi1=exp(θ+ζi)pi2, where exp(θ+ζi)pi2≥1 will be discarded. Finally, we generate Xi1 and Xi2 from the binomial distributions with parameters (ni1,pi1) and (ni2,pi2), respectively. Note that the data will be re-generated if the number of events or non-events in one group are both zero. Finally, with N=10,000 repetitions for each setting, we compute the mean squared errors (MSEs) between the estimated RR and the true RR to evaluate the accuracy of the methods.
From the top two panels of Fig. 3, it is evident that the three continuity correction methods perform much better than the GLMM in nearly all settings when k is small. Moreover, the hybrid estimator is consistently better than the Haldane and TACC estimators. The middle two panels show that, when k is moderate, the three continuity correction methods still perform better than the GLMM in most settings. Finally, the bottom two panels indicate that the GLMM performs the best in most settings when k is large. To conclude, the accuracy of the different methods depends on the number of studies. In particular, for meta-analysis with few studies, the random-effects model with the hybrid estimator is more reliable for handling the zero-event studies than the other methods; and for meta-analysis with large studies, we recommend the GLMM to handle the random-effects meta-analysis.
Fig. 3.

Comparison of the four methods with k=3, 6 or 12, τ2=0.25 or 1. “1” represents the results of the random-effects model with the Haldane estimator, “2” represents the results of the random-effects model with the TACC estimator, “3” represents the results of the random-effects model with the hybrid estimator, and “4” represents the results of the GLMM. TACC: Treatment arm continuity correction, GLMM: Generalized linear mixed model, MSE: Mean squared error
Application to COVID-19 data
As mentioned earlier, Chu et al. [8] conducted a systematic review that revealed the connections of physical distancing, face masks, and eye protection with the transmission of SARS, MERS, and COVID-19. It is noteworthy that their analytical results have attracted more and more attention. As an evidence, their paper has received a total of 1236 citations in Google Scholar as of 16 March 2021. In this section, we propose to reanalyze COVID-19 data and compare the performance of the different methods with or without the double-zero-event studies, including the Haldane estimator, the TACC estimator, the hybrid estimator, and the GLMMs.
Note that the treatment group represents a further physical distance and the control group represents a shorter physical distance. As shown in the top panel of Fig. 4, [8] applied the random-effects model with the Haldane estimator and removed the double-zero-event studies from their meta-analysis. The overall effect size of 0.15 with the 95% CI being [0.03,0.73] indicates that the infection risk will be significantly reduced with a further physical distance. The middle panel of Fig. 4 reports that the random-effects model with the TACC estimator yields the overall effect size of 0.12 with the 95% CI being [0.03,0.50]. Moreover, the bottom panel of Fig. 4 shows that the random-effects model with the hybrid estimator yields the overall effect size of 0.13 with the 95% CI being [0.03,0.72]. Note also that the study-specific CIs here are always narrower than the CIs in the top panel, which coincides with the simulation results that the expected lengths of the CI associated with the hybrid estimator are shorter than the Haldane estimator. In addition, the GLMM in (14) does not provide the estimates of the study-specific effect sizes, so the results are listed as follows. By the bootstrap resampling with 1000 replicates, the GLMM with the logit link yields the overall effect size of 0.20 with the 95% bootstrap CI being [0.05,0.55]. Also, the GLMM with the probit link yields the overall effect size of 0.18 with the 95% CI being [0.04,0.55].
Fig. 4.

Meta-analyses of COVID-19 data without the double-zero-event studies by applying the Haldane estimator (top), the TACC estimator (middle), and the hybrid estimator (bottom). COVID-19: Coronavirus disease 2019, TACC: Treatment arm continuity correction, RR: Relative risk, CI: Confidence interval
To reanalyze COVID-19 data, we now include the double-zero-event studies. The top panel of Fig. 5 shows that the random-effects model with the Haldane estimator yields the overall effect size of 0.22 with 95% CI being [0.06,0.82]. The middle panel of Fig. 5 presents that the random-effects model with the TACC estimator provides the overall effect size of 0.18 with the 95% CI being [0.06,0.57]. While for the hybrid estimator, it is shown by the bottom panel that the overall effect size is 0.21 with 95% CI being [0.05, 0.81]. At last, the GLMM with the logit link provides the overall effect size of 0.29 with the 95% CI being [0.10,0.64], and the GLMM with the probit link provides the overall effect size of 0.28 with the 95% CI being [0.10,0.56].
Fig. 5.

Meta-analyses of COVID-19 data with the double-zero-event studies by applying the Haldane estimator (top), the TACC estimator (middle), and the hybrid estimator (bottom). COVID-19: Coronavirus disease 2019, TACC: Treatment arm continuity correction, RR: Relative risk, CI: Confidence interval
Discussion
To handle the zero-event studies in meta-analysis of binary data, researchers often apply the random-effects model with the continuity correction, or instead, the GLMMs. From the simulation results, we note that the performance of the different methods depends on the number of studies. For meta-analysis with few studies, the random-effects model with the continuity correction is able to perform better than the GLMM, especially the hybrid continuity correction. We also note that the hybrid continuity correction can yield a reliable confidence interval for a single RR. Although the continuity correction does show some advantages, it should be used with caution since an arbitrary correction may lead to a bias or even reverse the result of a meta-analysis, especially when the numbers of samples in the two groups are fairly unbalanced [7, 13]. When the number of studies is large, the GLMM is preferable to the random-effects model with the continuity correction. In other words, the performance of the GLMM relies on a sufficient number of studies [35]. Also as shown in Ju et al. [34], the GLMM also requires enough total events in the two groups, e.g., larger than 10.
Besides the random-effects model we have compared, it is noteworthy that there are also other models for meta-analysis that can handle the zero-event studies including, for example, the beta-binomial model [36–38]. Most meta-analyses with rare events have a small degree of heterogeneity, and so the common-effect model may be more suitable than the random-effects model [39]. In addition, Li and Rice [40] showed that the fixed-effects model can also provide an accurate CI for meta-analysis of OR with the zero-event studies. Apart from that, it is also noteworthy that the fixed-effects model can serve as a convincing model for meta-analysis with few studies [12, 41–43]. As a future work, it can be interesting to investigate the best model for meta-analysis with few studies which include the zero-event studies as well.
For the double-zero-event studies in meta-analysis, we have shown by reanalyzing COVID-19 data that they do impact the estimate of the mean effect size, and so they may not be uninformative. As noted by Friedrich et al. [44], including the double-zero-event studies moves the mean effect size estimate toward the direction of the null hypothesis. If one arbitrarily excluded the informative double-zero-event studies, there would be a risk of overstating the treatment effect such that the conclusion would be less reliable. As recommended by the literature [7, 13] and the references therein, we suggest including the double-zero-event studies in meta-analysis.
Apart from model comparison, the selection of effect sizes has attracted more and more attention in the literature. In particular, there is a recent debate on the choice of RR or OR in clinical epidemiology, in which a number of important properties of RR or OR together with their pros and cons were discussed including, for example, portability and collapsibility [45–47]. In view of this, we have also analyzed COVID-19 data with OR being the effect size and present the results in Appendix 6 with R code in Appendix 7. To handle the zero-event studies, we apply four methods that have been reviewed in this paper, including Haldane’s continuity correction, TACC, the GLMM, and the empirical continuity correction proposed by Sweeting et al. [18]. For more techniques on meta-analysis of OR with the zero-event studies, one may refer to [4, 7, 18, 29, 34] and the references therein.
Conclusions
In this paper, we revisited the existing methods that are widely used to handle the zero-event problem in meta-analysis of binary data, in particular with RR as the effect size which is also known as the risk ratio. For the methods with the continuity correction, we reviewed four existing estimators of RR and also introduced a new hybrid estimator with their applications to the random-effects model. Apart from those, the GLMM was also included which is a state-of-the-art method without the continuity correction. By a comparative study and also a real data analysis on COVID-19 data, we found that the random-effects model with the hybrid estimator can serve as a more reliable method for handling the zero-event studies when there are few studies in a meta-analysis, and recommend using the GLMM when the number of studies is large. This paper also provides a useful addition to Chu et al. [8], and meanwhile, it also calls for further observational studies in this field.
Supplementary Information
Additional file 1 Supplementary information: Appendix
Acknowledgements
The authors sincerely thank the Editor, Associate Editor, and two anonymous reviewers for their insightful comments and suggestions.
Abbreviations
- OR
Odds ratio
- RR
Relative risk
- RD
Risk difference
- SARS
Severe acute respiratory syndrome
- MERS
Middle East respiratory syndrome
- COVID-19
Coronavirus disease 2019
- CI
Confidence interval
- MSE
Mean squared error
- GLMMs
Generalized linear mixed models
- TACC
Treatment arm continuity correction
Authors’ contributions
TJT, JJW, EXL, and XTZ reviewed the literature and designed the methods. TJT, JJW, and JDS conducted the simulation studies. TJT, JJW, KY, and ZLH conducted the experiments and analyzed the real data. All authors contributed to the manuscript preparation. All authors read and approved the final manuscript.
Funding
This study was supported by grants awarded to Tie-Jun Tong from the General Research Fund (HKBU12303918), the National Natural Science Foundation of China (1207010822), and the Initiation Grants for Faculty Niche Research Areas (RC-IG-FNRA/17-18/13, RC-FNRA-IG/20-21/SCI/03) of Hong Kong Baptist University.
Availability of data and materials
Not applicable.
Declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Jia-Jin Wei, Email: 20482051@life.hkbu.edu.hk.
En-Xuan Lin, Email: linenxuan@cuhk.edu.cn.
Jian-Dong Shi, Email: 18481701@life.hkbu.edu.hk.
Ke Yang, Email: yang_ke17@163.com.
Zong-Liang Hu, Email: zlhu@szu.edu.cn.
Xian-Tao Zeng, Email: zengxiantao1128@163.com.
Tie-Jun Tong, Email: tongt@hkbu.edu.hk.
References
- 1.Borenstein M, Hedges LV, Higgins JPT, Rothstein HR. Introduction to Meta-Analysis. Chichester, UK: John Wiley & Son; 2011. [Google Scholar]
- 2.Ma LL, Wang YY, Yang ZH, Huang D, Weng H, Zeng XT. Methodological quality (risk of bias) assessment tools for primary and secondary medical studies: what are they and which is better? Mil Med Res. 2020;7:7. doi: 10.1186/s40779-020-00238-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Davey J, Turner RM, Clarke MJ, Higgins JPT. Characteristics of meta-analyses and their component studies in the cochrane database of systematic reviews: a cross-sectional, descriptive analysis. BMC Med Res Methodol. 2011;11:160. doi: 10.1186/1471-2288-11-160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Jackson D, Law M, Stijnen T, Viechtbauer W, White IR. A comparison of seven random–effects models for meta-analyses that estimate the summary odds ratio. Stat Med. 2018;37(7):1059–85. doi: 10.1002/sim.7588. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Ren Y, Lin L, Lian Q, Zou H, Chu H. Real-world performance of meta-analysis methods for double-zero-event studies with dichotomous outcomes using the cochrane database of systematic reviews. J Gen Intern Med. 2019;34(6):960–8. doi: 10.1007/s11606-019-04925-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Vandermeer B, Bialy L, Hooton N, Hartling L, Klassen TP, Johnston BC, Wiebe N. Meta-analyses of safety data: a comparison of exact versus asymptotic methods. Stat Methods Med Res. 2009;18(4):421–32. doi: 10.1177/0962280208092559. [DOI] [PubMed] [Google Scholar]
- 7.Kuss O. Statistical methods for meta-analyses including information from studies without any events–add nothing to nothing and succeed nevertheless. Stat Med. 2015;34(7):1097–116. doi: 10.1002/sim.6383. [DOI] [PubMed] [Google Scholar]
- 8.Chu DK, Akl EA, Duda S, Solo K, Yaacoub S, Schünemann HJ, study authors C-SURGES. Physical distancing, face masks, and eye protection to prevent person-to-person transmission of SARS-CoV-2 and COVID-19: a systematic review and meta-analysis. Lancet. 2020;395(10242):1973–87. doi: 10.1016/S0140-6736(20)31142-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Jin YH, Cai L, Cheng ZS, Cheng H, Deng T, Fan YP, et al. A rapid advice guideline for the diagnosis and treatment of 2019 novel coronavirus (2019-ncov) infected pneumonia (standard version) Mil Med Res. 2020;7:4. doi: 10.1186/s40779-020-0233-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Jin YH, Zhan QY, Peng ZY, Ren XQ, Yin XT, Cai L, et al. Chemoprophylaxis, diagnosis, treatments, and discharge management of COVID-19: An evidence-based clinical practice guideline (updated version) Mil Med Res. 2020;7:41. doi: 10.1186/s40779-020-00270-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Borenstein M, Hedges LV, Higgins JP, Rothstein HR. A basic introduction to fixed-effect and random-effects models for meta–analysis. Res Synth Methods. 2010;1(2):97–111. doi: 10.1002/jrsm.12. [DOI] [PubMed] [Google Scholar]
- 12.Lin E, Tong T, Chen Y, Wang Y. Fixed-effects model: the most convincing model for meta-analysis with few studies. Preprint at https://arxiv.org/abs/2002.04211. 2020.
- 13.Xu C, Li L, Lin L, Chu H, Thabane L, Zou K, Sun X. Exclusion of studies with no events in both arms in meta-analysis impacted the conclusions. J Clin Epidemiol. 2020;123:91–9. doi: 10.1016/j.jclinepi.2020.03.020. [DOI] [PubMed] [Google Scholar]
- 14.Agresti A. Categorical Data Analysis, 2nd Edition. Hoboken: John Wiley & Son; 2003. [Google Scholar]
- 15.Haldane JB. The estimation and significance of the logarithm of a ratio of frequencies. Ann Hum Genet. 1956;20(4):309–11. doi: 10.1111/j.1469-1809.1955.tb01285.x. [DOI] [PubMed] [Google Scholar]
- 16.Schwarzer G. meta: An r package for meta-analysis. R News. 2007;7:40–5. [Google Scholar]
- 17.Weber F, Knapp G, Ickstadt K, Kundt G, Glass Ä. Zero–cell corrections in random–effects meta–analyses. Res Synth Methods. 2020;11(6):913–9. doi: 10.1002/jrsm.1460. [DOI] [PubMed] [Google Scholar]
- 18.Sweeting MJ, Sutton AJ, Lambert PC. What to add to nothing? use and avoidance of continuity corrections in meta–analysis of sparse data. Stat Med. 2004;23(9):1351–75. doi: 10.1002/sim.1761. [DOI] [PubMed] [Google Scholar]
- 19.Carter RE, Lin Y, Lipsitz SR, Newcombe RG, Hermayer KL. Relative risk estimated from the ratio of two median unbiased estimates. J Royal Stat Soc: Ser C Appl Stat. 2010;59(4):657–71. doi: 10.1111/j.1467-9876.2010.00711.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Chu H, Nie L, Chen Y, Huang Y, Sun W. Bivariate random effects models for meta-analysis of comparative studies with binary outcomes: methods for the absolute risk difference and relative risk. Stat Methods Med Res. 2012;21(6):621–33. doi: 10.1177/0962280210393712. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Chen Y, Hong C, Ning Y, Su X. Meta–analysis of studies with bivariate binary outcomes: a marginal beta–binomial model approach. Stat Med. 2016;35(1):21–40. doi: 10.1002/sim.6620. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.DerSimonian R, Laird N. Meta-analysis in clinical trials. Control Clin Trials. 1986;7(3):177–88. doi: 10.1016/0197-2456(86)90046-2. [DOI] [PubMed] [Google Scholar]
- 23.Laird NM, Mosteller F. Some statistical methods for combining experimental results. Int J Technol Assess Heal Care. 1990;6(1):5–30. doi: 10.1017/S0266462300008916. [DOI] [PubMed] [Google Scholar]
- 24.Balduzzi S, Rücker G, Schwarzer G. How to perform a meta-analysis with R: a practical tutorial. Evid Based Ment Health. 2019;22(4):153–60. doi: 10.1136/ebmental-2019-300117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Pettigrew HM, Gart JJ, Thomas DG. The bias and higher cumulants of the logarithm of a binomial variate. Biometrika. 1986;73(2):425–35. doi: 10.1093/biomet/73.2.425. [DOI] [Google Scholar]
- 26.Hartung J, Knapp G. A refined method for the meta–analysis of controlled clinical trials with binary outcome. Stat Med. 2001;20(24):3875–89. doi: 10.1002/sim.1009. [DOI] [PubMed] [Google Scholar]
- 27.Fattorini L. Applying the Horvitz-Thompson criterion in complex designs: a computer-intensive perspective for estimating inclusion probabilities. Biometrika. 2006;93(2):269–78. doi: 10.1093/biomet/93.2.269. [DOI] [Google Scholar]
- 28.Seber GAF. Statistical Models for Proportions and Probabilities. Heidelberg: Springer; 2013. [Google Scholar]
- 29.Bakbergenuly I, Kulinskaya E. Meta-analysis of binary outcomes via generalized linear mixed models: a simulation study. BMC Med Res Methodol. 2018;18(1):70. doi: 10.1186/s12874-018-0531-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.McCullagh P. Sampling bias and logistic models. J R Stat Soc Ser B Stat Methodol. 2008;70(4):643–77. doi: 10.1111/j.1467-9868.2007.00660.x. [DOI] [Google Scholar]
- 31.Zeger SL, Liang KY, Albert PS. Models for longitudinal data: a generalized estimating equation approach. Biometrics. 1988;44(4):1049–60. doi: 10.2307/2531734. [DOI] [PubMed] [Google Scholar]
- 32.Lin L, Chu H. Meta-analysis of proportions using generalized linear mixed models. Epidemiology. 2020;31(5):713–7. doi: 10.1097/EDE.0000000000001232. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Lin L, Chu H. altmeta: Alternative Meta-Analysis Methods. 2020. https://CRAN.R-project.org/package=altmeta.
- 34.Ju J, Lin L, Chu H, Cheng LL, Xu C. Laplace approximation, penalized quasi-likelihood, and adaptive gauss-hermite quadrature for generalized linear mixed models: towards meta-analysis of binary outcome with sparse data. BMC Med Res Methodol. 2020;20(1):152. doi: 10.1186/s12874-020-01035-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Gronsbell J, Hong C, Nie L, Lu Y, Tian L. Exact inference for the random–effect model for meta–analyses with rare events. Stat Med. 2020;39(3):252–64. doi: 10.1002/sim.8396. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Sarmanov O. Generalized normal correlation and two-dimensional fréchet classes. Sov Math Dokl. 1966;7:596–9. [Google Scholar]
- 37.Chen Y, Luo S, Chu H, Su X, Nie L. An empirical Bayes method for multivariate meta-analysis with an application in clinical trials. Commun Stat Theory Methods. 2014;43(16):3536–51. doi: 10.1080/03610926.2012.700379. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Luo S, Chen Y, Su X, Chu H. mmeta: an R package for multivariate meta-analysis. J Stat Softw. 2014;56(11):11. doi: 10.18637/jss.v056.i11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Jia P, Lin L, Kwong JSW, Xu C. Many meta-analyses of rare events in the cochrane database of systematic reviews were underpowered. J Clin Epidemiol. 2021;131:113–22. doi: 10.1016/j.jclinepi.2020.11.017. [DOI] [PubMed] [Google Scholar]
- 40.Li QK, Rice K. Improved inference for fixed–effects meta–analysis of 2×2 tables. Res Synth Methods. 2020;11(3):387–96. doi: 10.1002/jrsm.1401. [DOI] [PubMed] [Google Scholar]
- 41.Bender R, Friede T, Koch A, Kuss O, Schlattmann P, Schwarzer G, Skipka G. Methods for evidence synthesis in the case of very few studies. Res Synth Methods. 2018;9(3):382–92. doi: 10.1002/jrsm.1297. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Rice K, Higgins JP, Lumley T. A re–evaluation of fixed effect(s) meta–analysis. J R Stat Soc Ser A Stat Methodol. 2018;181(1):205–27. doi: 10.1111/rssa.12275. [DOI] [Google Scholar]
- 43.Yang K, Kwan HY, Yu Z, Tong T. Model selection between the fixed-effects model and the random-effects model in meta-analysis. Stat Interface. 2020;13(4):501–10. doi: 10.4310/SII.2020.v13.n4.a7. [DOI] [Google Scholar]
- 44.Friedrich JO, Adhikari NK, Beyene J. Inclusion of zero total event trials in meta-analyses maintains analytic consistency and incorporates all available data. BMC Med Res Methodol. 2007;7:5. doi: 10.1186/1471-2288-7-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Doi SA, Furuya-Kanamori L, Xu C, Lin L, Chivese T, Thalib L. Questionable utility of the relative risk in clinical research: a call for change to practice. J Clin Epidemiol. 2020. 10.1016/j.jclinepi.2020.08.019. [DOI] [PubMed]
- 46.Xiao M, Chen Y, Cole SR, MacLehose R, Richardson D, Chu H. Is OR “portable” in meta-analysis? Time to consider bivariate generalized linear mixed model. 2020. Preprint at https://www.medrxiv.org/content/10.1101/2020.11.05.20226811v1. [DOI] [PMC free article] [PubMed]
- 47.Doi SA, Furuya-Kanamori L, Xu C, Chivese T, Lin L, Musa OA, Hindy G, Thalib L, Harrell Jr FE. The OR is “portable” but not the RR: time to do away with the log link in binomial regression. J Clin Epidemiol. 2021. 10.13140/RG.2.2.31631.10407. [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional file 1 Supplementary information: Appendix
Data Availability Statement
Not applicable.