

Visual Abstract

Keywords: aging, Alzheimer’s diseases, connectome, dataset completion, fMRI, whole-brain modelling
Abstract
Large neuroimaging datasets, including information about structural connectivity (SC) and functional connectivity (FC), play an increasingly important role in clinical research, where they guide the design of algorithms for automated stratification, diagnosis or prediction. A major obstacle is, however, the problem of missing features [e.g., lack of concurrent DTI SC and resting-state functional magnetic resonance imaging (rsfMRI) FC measurements for many of the subjects]. We propose here to address the missing connectivity features problem by introducing strategies based on computational whole-brain network modeling. Using two datasets, the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset and a healthy aging dataset, for proof-of-concept, we demonstrate the feasibility of virtual data completion (i.e., inferring “virtual FC” from empirical SC or “virtual SC” from empirical FC), by using self-consistent simulations of linear and nonlinear brain network models. Furthermore, by performing machine learning classification (to separate age classes or control from patient subjects), we show that algorithms trained on virtual connectomes achieve discrimination performance comparable to when trained on actual empirical data; similarly, algorithms trained on virtual connectomes can be used to successfully classify novel empirical connectomes. Completion algorithms can be combined and reiterated to generate realistic surrogate connectivity matrices in arbitrarily large number, opening the way to the generation of virtual connectomic datasets with network connectivity information comparable to the one of the original data.
Significance Statement
Personalized information on anatomic connectivity (structural connectivity; SC) or coordinated resting state activation patterns (functional connectivity; FC) is a source of powerful neuromarkers to detect and track the development of neurodegenerative diseases. However, there are often “gaps” in the available information, with only SC (or FC) being known but not FC (or SC). Exploiting whole-brain modeling, we show that gap in databases can be filled by inferring the other connectome through computational simulations. The generated virtual connectomic data carry information analogous to the one of empirical connectomes, so that machine learning algorithms can be trained on them. This opens the way to the release in the future of cohorts of “virtual patients,” complementing traditional datasets in data-driven predictive medicine.
Introduction
One of the greatest challenges today is to develop approaches allowing the useful exploitation of large-scale datasets in biomedical research in general (Margolis et al., 2014) and neuroscience and neuroimaging in particular (Van Horn and Toga, 2014). Progress in this direction is made possible by the increasing availability of large public datasets in the domain of connectomics (Van Essen et al., 2013; Poldrack and Gorgolewski, 2014; Horien et al., 2021). This is true, in particular, for research in Alzheimer’s disease (AD), in which, despite decades of massive investment and a daunting literature on the topic, the partial and, sometimes contradictory nature of the reported results (Patterson, 2018) still prevents a complete understanding of the factors governing the progression of the disease (Braak and Braak, 1991; Braak et al., 2006; Komarova and Thalhauser, 2011; Henstridge et al., 2019) or of the diversity of cognitive deficits observed in different subjects (Iacono et al., 2009; Mungas et al., 2010; Allen et al., 2016). In AD research, datasets that compile rich and diverse genetic, biomolecular, cognitive, and neuroimaging (structural and functional) features for a large number of patients are playing an increasingly important role (Rathore et al., 2017; Iddi et al., 2019). Example applications include: the early diagnosis and prognosis by using magnetic resonance imaging (MRI) images (Dennis and Thompson, 2014; Chiesa et al., 2017; de Vos et al., 2018), the use of machine learning for automated patient classification (Cuingnet et al., 2011; Zhang et al., 2012; Moore et al., 2019), or prediction of the conversion from early stages to fully developed AD (Rombouts et al., 2005; Moradi et al., 2015; Casanova et al., 2018), with signs of pathology difficult to distinguish from “healthy aging” effects (Doan et al., 2017), the extraction of decision networks based on the combination of semantic knowledge bases and data mining of the literature (Sanchez et al., 2011; Kodamullil et al., 2015; Iyappan et al., 2016).
Among the factors contributing to the performance of prediction and inference approaches in AD, and, more in general, other neurologic or psychiatric diseases (Walter et al., 2019) or studies of aging (Cole and Franke, 2017), are not only the large size of datasets but also the multiplicity of features jointly available for each patient. Indeed, one can take advantage not only of the complementary information that different features could bring but also capitalize on possible synergies arising from their simultaneous knowledge (Wang et al., 2015; Zimmermann et al., 2016; Iddi et al., 2019). Unfortunately, even gold standard publicly available datasets in AD, such as the datasets released by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) consortium (Wyman et al., 2013; Beckett et al., 2015; Weiner et al., 2017), have severe limitations. Indeed, if they include neuroimaging features of different types, structural DTI and functional MRI (fMRI), these features are simultaneously available for only a substantial minority of the subjects in the dataset (i.e., the feature coverage is not uniform over the dataset). In addition, if the number of subjects included is relatively large (hundreds of subjects), it still is too small to properly qualify as “big data.” Furthermore, the connectomic data themselves have an imperfect reliability, with a test/retest variability that can be quite large, making potentially difficult subject identifiability and, thus, personalized information extraction (Termenon et al., 2016).
Here, we will introduce a new solution aiming at relieving the problems of partially missing features and limited sample size and illustrate their validity on the two independent example datasets. Specifically, we will focus on two examples of structural and functional neuroimaging datasets, as important proofs of concept: a first one addressing AD, mediated from the previously mentioned ADNI databases (Wyman et al., 2013; Beckett et al., 2015), and a second one investigating a cohort of healthy subjects over a broad span of adult age, to analyze the effects of normal aging (Zimmermann et al., 2016; Battaglia et al., 2020). It is important to stress however that the considered issues may broadly affect any other connectomic dataset gathered for data mining intents.
To cope with missing connectomic features (and “filling the gaps” in neuroimaging datasets), we propose to build on the quickly maturating technology of mean-field whole-brain network modeling (for review, see Deco et al., 2011). Indeed, computational modeling provides a natural bridge between structural and functional connectivity (FC), the latter emerging as the manifestation of underlying dynamical states, constrained but not entirely determined by the underlying anatomy (Ghosh et al., 2008; Kirst et al., 2016). Theoretical work has shown that average FC properties in the resting-state can be accounted for by the spontaneous collective activity of brain networks informed by empirical structural connectivity (SC) when the system is tuned to operate slightly below a critical point of instability (Deco et al., 2011; Deco and Jirsa, 2012). Based on this finding, simulations of a model constructed from empirical DTI connectomes and then tuned to a suitable slightly subcritical dynamic working point are expected to provide a good rendering of resting-state FC. Such whole-brain simulations are greatly facilitated by the availability of dedicated neuroinformatic platforms, such as The Virtual Brain (TVB; Sanz-Leon et al., 2013, 2015; Woodman et al., 2014), and data preprocessing pipelines (Schirner et al., 2015; Proix et al., 2016), enabling brain model personalization and clinical translation (Jirsa et al., 2017; Proix et al., 2017). It thus becomes possible to complete the missing information in a dataset about BOLD fMRI FC by running a TVB simulation in the right regime, embedding the available empirical DTI SC (SC-to-FC completion). Analogously, algorithmic procedures based on mean-field modeling (MFM) steps (“effective connectivity” approaches by Gilson et al., 2016, 2018), here used for a different purpose) can be used to address the inverse problem of inferring a reasonable ersatz of SC from resting state FC (FC-to-SC completion). In this study we will demonstrate the feasibility of both types of completion (SC-to-FC and FC-to-SC), applying alternative linear and nonlinear simulation pipelines to both the ADNI and the healthy aging proof-of-concept datasets.
Beyond a single step of virtual completion, by combining completion procedures, to map, e.g., from an empirical SC (or FC) to a virtual FC (or SC) and then, however, to a “twice virtual” SC (or FC), we can generate for each given empirical connectome a surrogate replacement, i.e., map every empirical SC or FC to a matching dual (bivirtual) connectome of the same nature. We show then that pairs of empirical and bivirtual dual connectivity matrices display highly correlated network topology features, such as node-level strengths or clustering and centrality coefficients (Bullmore and Sporns, 2009). We demonstrate along the example of relevant classification tasks [stratification of mild cognitive impairment (MCI) or AD patients from control subjects on the ADNI dataset and age-class prediction on the healthy aging dataset] that close performance can be reached using machine learning algorithms trained on actual empirical connectomes or on their duals. Furthermore, empirical connectomes can be correctly categorized by classifiers trained uniquely on virtual duals.
To conclude, we provide systematic recipes for generating realistic surrogate connectomic data via data-constrained MFMs. We show that the information that we can extract from computationally inferred connectivity matrices are only moderately degraded with respect to the one carried by the original empirical data. This opens the way to the design and sharing of veritable “virtual cohorts” data, ready for machine-learning applications in clinics, that could complement actual empirical datasets, facilitating learning through “data augmentation” (Yaeger et al., 1997; Taylor and Nitschke, 2018), or, even, potentially, fully replace them, e.g., when the sharing of real data across centers is restricted because of byzantine regulation issues (not applying to their totally synthetic but operationally equivalent ersatz, the virtual and bivirtual duals).
Materials and Methods
Two datasets for proof of concept
We applied our data completion pipelines in this study to two different and independent neuroimaging datasets, from which SC and FC connectivity matrices could be extracted for at least a part of the subjects. A first dataset was obtained from the ADNI database (adni.loni.usc.edu). The ADNI was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI has been to test whether serial MRI, positron emission tomography (PET), other biological markers, and clinical and neuropsychological assessment can be combined to measure the progression of MCI and early AD. We refer in the following to this first dataset as to the ADNI dataset.
A second dataset was generated by Petra Ritter and co-workers at the Charité Hospital in Berlin, with the aim of studying and investigating changes of structural and static and dynamic FC occurring through healthy aging. This dataset was previously investigated in Zimmermann et al. (2016) and Battaglia et al. (2020) among others. We refer to this second dataset in the following as to the healthy aging dataset.
ADNI dataset
Data sample
Raw neuroimaging data from the ADNI GO/2 studies (Wyman et al., 2013; Beckett et al., 2015) were downloaded for 244 subjects. These included T1w images for all subjects, as well as DWI and resting-state fMRI (rsfMRI) images for separate cohorts of subjects. An additional 12 subjects for which both DWI and rsfMRI were acquired in the same session were identified and their data also downloaded.
A volumetric 96-ROI parcellation was defined on the MNI template and consisted of 82 cortical ROIs from the regional map parcellation (Kötter and Wanke, 2005) and an additional 14 subcortical ROIs spanning the thalamus and basal ganglia. Details on the construction of the 96-ROI parcellation can be found in Bezgin et al. (2017).
Among the 244 subjects we downloaded, 74 were control subjects, while the others were patients at different stages of the pathology progression. In this study, we performed a rough coarse-graining of the original ADNI labels indicating the stage or type of pathology. We thus overall labeled 119 patients as MCI (grouping together the labels four patients as MCI, 64 as EMCI and 41 as LMCI) and 51 patients as AD (overall 170 patients for the simple classification experiments of Fig. 6).
Figure 6.

Intersubject distances for empirical-bivirtual pairs. We show here the distances between the empirical SCemp (or FCemp) of different subjects and the intersubject distances for their corresponding pairs of subjects from bivirtual SCbi-MFM (or FCbi-MFM). A, B, For the ADNI dataset the correlation between the intersubject distances in real and dual spaces for SC (between SCemp and SCbi-MFM) were significant and equal to 0.39, and for FC pairs (between FCemp and FCbi-MFM) equal to 0.43. C, D, The same intersubject distances for the healthy aging dataset were measured, with correlation values equal to 0.53 and 0.40 for SC and FC empirical-bivirtual pairs, respectively.
Overall, T1 and DTI were jointly available for 88 subjects (allowing to reconstruct SC matrix), and T1 and fMRI for 178 (allowing to reconstruct FC). However, among the 244 subjects we downloaded, only 12 subjects (referred to as the SCemp + FCemp subset) had a complete set of structural and functional images (T1, DTI, fMRI), hinting at how urgently needed is data completion.
Data preprocessing
Neuroimaging data preprocessing was done using a custom Nipype pipeline implementation (Gorgolewski et al., 2011). First, raw neuroimaging data were reconstructed into NIFTI format using the dcm2nii software package (https://www.nitrc.org/projects/dcm2nii/). Skull stripping was performed using the Brain Extraction Tool (BET) from the FMRIB Software Library package (FSL v5) for all image modalities before all other preprocessing steps. Brain extraction of T1w images using BET was generally suboptimal and was supplemented by optiBET (Lutkenhoff et al., 2014), an iterative routine that improved brain extractions substantially by applying transformations and back-projections between the native brain mask and MNI template space. Segmentation of the T1w images was performed using FSL’s FAT tool with bias field correction to obtain into three distinct tissue classes.
To improve the registration of the ROI parcellation to native space, the parcellation was first nonlinearly registered to a publicly-available older adult template (aged 70–74 years; Fillmore et al., 2015) using the Advanced Normalization Tools (ANTS; Avants et al., 2011) software package before subsequent registrations.
Diffusion-weighted images were preprocessed using FSL’s eddy and bedpostx tools. The ROI parcellation was first nonlinearly registered to each subject’s T1w structural image and then linearly registered to the DWI image using ANTS.rsfMRI data were preprocessed using FSL’s FEAT toolbox. Preprocessing included motion correction, high-pass filtering, registration, normalization, and spatial smoothing (FWHM: 5 mm). Subjects with excessive motion were excluded from our sample. Global white matter and cerebrospinal fluid signals (but not global mean signal) were linearly regressed from the rsfMRI data.
All images were visually inspected following brain extraction and registrations to ensure correctness.
SC construction
Details of tractography methods for reconstructing each subject’s structural connectome can be found in Shen et al. (2019a,b). Briefly, FSL’s probtrackx2 was used to perform tractography between all ROIs. The set of white matter voxels adjacent to a gray matter ROI was defined as the seed mask for that particular ROI. Gray matter voxels adjacent to each seed mask were used to define an exclusion mask. For intra-hemispheric tracking, an additional exclusion mask of the opposite hemisphere was additionally defined. Tractography parameters were set to a curvature threshold of 0.2, 5000 seeds per voxel, a maximum of 2000 steps, and a 0.5-mm step length. The connection weight between each pair of ROIs was computed as the number of streamlines detected between the ROIs, divided by the total number of streamlines sent from the seed mask. This connectivity information was compiled for every subject in a matrix of empirical SC SCemp.
rsfMRI timeseries and FC construction
Empirical rsfMRI time series for each ROI were computed using a weighted average approach that favored voxels nearer the center of each ROI (Shen et al., 2012). Each subject’s matrix of empirical FC FCemp was determined by Pearson correlation of these recorded rsfMRI time series.
Healthy aging dataset
Data sample
Forty-nine healthy subjects between the ages of 18 and 80 (mean 42.16 ± 18.37; 19 male/30 female) were recruited as volunteers. Subjects with a self-reported history of neurologic, cognitive, or psychiatric conditions were excluded from the experiment. Research was performed in compliance with the Code of Ethics of the World Medical Association (Declaration of Helsinki). Written informed consent was provided by all subjects with an understanding of the study before data collection, and was approved by the local ethics committee in accordance with the institutional guidelines at Charité Hospital, Berlin.
Acquisition procedures
Acquisition procedures for these data (magnetic resonance acquisition procedure, dwMRI data preprocessing and tractography, fMRI data preprocessing, computation of SC and FC connectome matrices) have been described by Zimmermann et al. (2016), where we redirect the reader interested in full detail.
Briefly, functional and structural image acquisition was performed on a 3T Siemens Tim Trio Scanner MR equipped with a 12-channel Siemens head coil. After anatomic and dwMRI measurements, subjects were removed from the scanner and again put in later for the functional measurements. Data were obtained from subjects at resting state; subjects were asked to close their eyes, relax, and avoid falling asleep.
Anatomical and diffusion images were preprocessed using a fully automated open-source pipeline for extraction of functional and structural connectomes (Schirner et al., 2015). The pipeline performed the following steps. Using the FreeSurfer software toolbox (http://surfer.nmr.mgh.harvard.edu/), anatomic T1-weighted images were motion corrected and intensity normalized, nonbrain tissue was removed, and a brain mask was generated. White matter and subcortical segmentation was performed, and a cortical parcellation based on the probabilistic Desikan– Killiany FreeSurfer atlas divided the gray matter into 68 ROIs (regions of interest, 34 per hemisphere; Desikan et al., 2006). The diffusion data were further corrected (for head movement, eddy current distortions, etc.). Probabilistic fiber tracking was performed using MRTrix streamtrack algorithm.
The fMRI resting-state preprocessing was performed using the FEAT (fMRI Expert Analysis Tool) version 6.0 first-level analysis software tool from the FMRIB (fMRI of the brain) Software Library (www.fmrib.ox.ac.uk). MCFLIRT motion correction was used to adjust for head movement. Nuisance variables were regressed from the BOLD signal, including the six motion parameters, mean white matter, and CSF signals. Regression of global mean was not performed.
Two types of computational whole brain models
To bridge between SC and FC via dynamics, we relied on computational modeling of whole-brain intrinsic dynamics. We used two categories of models differing in their complexity, stochastic linear models (SLMs) and fully nonlinear MFMs. SLM procedures are used for linear SC-to-FC and FC-to-SC completions, while MFM procedures are used for analogous but nonlinear completions.
SLM models
The SLM model used in this study is a linear stochastic system of coupled Ornstein–Uhlenbeck processes which is deeply investigated in (Saggio et al., 2016). For each brain region, neural activity is modeled as a linear stochastic model, coupled to the fluctuations of other regions:
| (1) |
where A is the coupling matrix, is a normal Gaussian white noise, and the SD of the local drive noise. The coupling matrix A can be written as:
| (2) |
where I is the identity matrix, G is the global coupling parameter and W is a weight matrix set to match SCemp. The negative identity matrix guarantees that the nodes have a stable equilibrium point. If all the eigenvalues of A are negative, which happens for all positive values of G < Gcritic = (where are the eigenvalues of W), the system will be in an equilibrium state. After some mathematical steps (Saggio et al., 2016), the covariance matrix between regional fluctuations can be analytically expressed at this critical point Gcritic as:
| (3) |
whose normalized entries provide the strength of FC between different regions. The noise strength can be arbitrarily set at the critical point since it provides only a scaling constant to be reabsorbed into the Pearson correlation normalization. However, the only parameter that needs to be explored is , whose range goes from Gmin = 0, i.e., uncoupled nodes, to slightly before Gcritic = , or Gmax = Gcritic–. In Extended Data Figure 3-1A, running explicit simulations of SLM models for different values of coupling G and evaluating on the FCemp + SCemp subset of ADNI subjects the match between the simulated and empirical activity correlation matrices, we confirm (Hansen et al., 2015) that the best match (max of Pearson correlation between the upper-triangular parts of the empirical and virtual FCs) is obtained at a slightly subcritical point for G* = Gcritic–.
Linear SC-to-FC and FC-to-SC completion
To infer FCSLM from SCemp, we chose to always use a common value G*ref = 0.83, which is the median of G* for all 12 FCemp + SCemp subjects in the ADNI and healthy ageing dataset (the error made in doing this approximation is estimated to be <1% in Extended Data Fig. 3-1C). When the connectome FCemp is not known, Equations 2, 3 can directly be used to evaluate the covariance matrix C (setting σ = 1 and G = G*ref). We then estimate the regional fluctuation covariance from these inferences and normalize it into a Pearson correlation matrix to infer FCSLM (see pseudo-code in Extended Data Table 1-1). Linear FCSLM completions for our ADNI dataset and for the healthy aging dataset can be downloaded as MATLAB workspace within Extended Data 1 FC_SLM.mat (available at the address https://github.com/FunDyn/VirtualCohorts).
provides a pseudo-code for the linear SC-to-FC completion procedure (see Materials and Methods for all details). Linear SC-to-FC completions for the DTI-only subjects in the considered ADNI dataset and the healthy ageing dataset can be downloaded as part of Extended Data 1 FC_SLM. Download Table 1-1, DOCX file (16.6KB, docx) .
MATLAB scripts for connectome generation and workspaces including virtual SC and FC connectomes generated with our data completion pipelines as well as virtual cohorts. All workspaces available at https://github.com/FunDyn/VirtualCohorts. Download Extended Data 1, ZIP file (63.8MB, zip) .
To infer SCSLM from FCemp, we invert the analytical expressions of Equations 2, 3 and always set σ = 1 and G = G*ref leading to:
| (4) |
,where C is the covariance matrix estimated from empirical BOLD time series. The linearly completed SCSLM is then set to be identical to W* setting its diagonal to zero to avoid offsets, which would be meaningless given the conventional choice of noise σ which we have made (see Extended Data Table 2-1). Note that all the free parameters of the SLM model appear uniquely as scaling factors and do not affect the (normalized) correlation of the inferred SCSLM with the SCemp. However, the absolute strengths of inferred structural connections remain arbitrary, with only the relative strengths between different connections being reliable (since unaffected by arbitrary choices of scaling parameters; see pseudo-code in Extended Data Table 2-1). Linear SCSLM completions for the ADNI dataset and for the healthy aging dataset can be downloaded as MATLAB workspace within Extended Data 1 SC_SLM.mat (available at the address https://github.com/FunDyn/VirtualCohorts).
Pseudo-code for linear FC-to-SC completion procedure (see Materials and Methods for all details). Linear FC-to-SC completions for the DTI-only subjects in the considered ADNI dataset and the healthy ageing dataset can be downloaded as part of Extended Data 1 SC_SLM. Download Table 2-1, DOCX file (16.6KB, docx) .
MFM models
For nonlinear completion algorithms, we performed simulations of whole-brain MFMs analogous to Deco et al. (2013) or Hansen et al. (2015). We used a modified version of the MFM designed by Wong and Wang (2006), to describe the mean neural activity for each brain region, following the reduction performed in (Deco et al., 2013). The resulting neural mass equations are given by:
| (5) |
| (6) |
| (7) |
,where represents NMDA synaptic input currents and the NMDA decay time constant; is collective firing rates; is a kinetic parameter; , , are parameters values for the input-output function; are the total synaptic inputs to a regions; is an intensity scale for synaptic currents; is the relative strength of recurrent connections within the region; are the entries of the SCemp matrix reweighted by global scale of long-range connectivity strength G as a control parameter; is the noise amplitude, and is a stochastic Gaussian variable with a zero mean and unit variance. Finally, represents the external input and sets the level of regional excitability. Different sets of parameters yield different neural network dynamics and, therefore, patterns of FCMFM non-stationarity.
To emulate BOLD fMRI signals, we then transformed the raw model output activity
through a standard Balloon–Windkessel hemodynamic model. All details of the hemodynamic model are set according to Friston et al. (2003).
Non-linear SC-to-FC completion
In general, our simple MFM model has three free parameters at the level of the local neural mass dynamics (τ and I0) and one free global parameter G. Since changing the values of and I0 had lesser effects on the collective dynamics of the system (see Extended Data Fig. 3-2), we set their values to ω = 0.9 and I0 = 0.32, respectively, and remain then just two free parameters which we allow to vary in the ranges G [1 3] and τ [1 100] ms when seeking for an optimal working point of the model. As revealed by the analyses of Figure 3, the zone in this restricted parameter space associated with the best FC-rendering performance can be identified through the joint inspection of three scores, varying as a function of both G and τ. The first criterion is the spatial heterogeneity of activation (see Table 1, line 2.5) computed by taking the coefficient of variation of BOLDMFM time series.
Figure 3.

Non-linear SC-to-FC data completion. Simulations of a nonlinear model embedding a given input SCemp matrix can be used to generate surrogate FCMFM matrices. A, Systematic exploration (here shown for a representative subject) of the dependency of the correlation between FCemp and FCMFM on the MFM parameters G (interregional coupling strength) and τ (synaptic time-constant of within-region excitation) indicates that the best fitting performances are obtained when parameters are concentrated in a narrow concave stripe across the G/τ plane. B, Enlarged zoom of panel A over the range G ∈ [1 3] and τ ∈ [10 30]. C, For a value of τ = 25, representatively chosen here for illustration, we identify a value G* for which the Pearson correlation between FCemp and FCMFM reaches a clear local maximum. Panels A–C thus indicate that it makes sense speaking of a best-fit zone and that reliable nonlinear SC-to-FC completion should be performed using MFM parameters within this zone. Three criteria help us identifying parameter combinations in this best fitting zone when the actual FCemp is unknown. D, First criterion: we define the spatial coefficient of variation of the time series of simulated BOLD activity TSMFM as the ratio between the variance and the mean across regions of the time-averaged activation of different regions. The best fit zone is associated with a peaking of this spatial coefficient of variation, associated with a maximally heterogeneous mix or low and high activation levels for different regions (see time series in lower cartoons). E, Second criterion: in the best fitting zone, the resulting FCMFM is neither randomly organized nor excessively regular (synchronized) but presents a complex clustering structure (see lower cartoons), which can be tracked by a peak in the clustering coefficient of the FCMFM, seen as weighted adjacency matrix. F, Third criterion: in the best fitting zone, resting-state FCMFM display a relatively richer dynamics than in other sectors of the parameter space. This gives rise to an “dFC matrix” (correlation between time-resolved FC observed at different times) which is neither random nor too regular but displays a certain degree of clustering (see lower cartoons). The emergence of complex dynamics of FC can be tracked by an increase in the clustering coefficient of the dFC matrix extracted from simulated resting-state dynamics. G, The boxplot shows the distribution of correlations between the actual FCemp and FCMFM estimated within the best fitting zone for all subjects from the SCemp + FCemp ADNI subset and the aging dataset. See Extended Data Figure 3-1 for linear SC-to-FC completion and Extended Data Figure 3-2 for dependency of MFM best fit zone on additional parameters.
Table 1.
Pseudo-code for nonlinear SC-to-FC completion (FC virtual duals to SC)
| Algorithm non-linear SC-to-FC completion is |
| External input: empirical SC (SCemp) |
| Output: non-linear virtual FC (FCMFM) |
| Fixed parameters: noise level (), simulation time (T), range to scan Gstart ≤ G ≤ Gstop, range to scan τstart ≤ τ ≤ τstop, other frozen Wong-Wang neural mass parameters |
| Begin |
| 1. Construct a MFM embedding SCemp and the default frozen Wong-Wang neural mass parameters |
| For Gstart ≤ G ≤ Gstop |
| For τstart ≤ τ ≤ τstop |
| 2.1 Simulate the MFM with current parameter values for a short time 0.2*T (discarding an initial transient) |
| 2.2 Compute surrogate BOLD from MFM time series via Balloon–Windkessel model |
| 2.3 Compute Corr(BOLD), i.e. the time-averaged FC matrix |
| 2.4 Compute stream of time-resolved FC(t) and the associated dFC matrix |
| 2.5 Compute and store Crit1[G, τ] (Spatial heterogeneity of activations) |
| 2.6 Compute and store Crit2[G, τ] (Clustering coefficient of time-averaged FC matrix) |
| 2.7 Compute and store Crit3[G, τ] (Clustering coefficient of dFC matrix) |
| End |
| End |
| 3. Identify G* and τ* for which Crit1[G, τ], Crit2[G, τ] and Crit3[G, τ] are jointly optimum |
| 4. Simulate the MFM with parameter values G* and τ* for a time T (discarding an initial transient) |
| 5. Compute surrogate BOLD from MFM time series via Balloon–Windkessel model |
| 6. Compute C = Corr(BOLD), i.e. the time-averaged FC matrix at G* and τ* |
| Return FCMFM = C |
| End |
By computing the Pearson correlation coefficient of upper-triangular between FCMFM and FCemp for every subject from SCemp + FCemp subset in the ADNI dataset (see Table 1, line 2.3), we obtained a best-fitting zone in a narrow concave stripe (see Fig. 3A for one subject), (G*, τ*) parameter set, bring the system to this best-fitting zone and values lower than this is set and higher values are . Qualitatively analogous results are found for the healthy aging dataset. This non-monotonic behavior of yellow zone in G/τ plane occurs where three criteria are jointly met; the second criterion is the clustering coefficient of time-average FCMFM matrices (see Table 1, line 2.6) and finally, the third criterion is the clustering coefficient of dFCMFM matrices (see Table 1, line 2.6), where the dFC matrices were computed for an arbitrary window using the dFCwalk toolbox (Arbabyazd et al., 2020; https://github.com/FunDyn/dFCwalk.git). By knowing the optimal working point of the system where all three criteria are jointly optimum (see Table 1, line 2), we freeze the algorithm and finally run a last simulation with the chosen parameters to perform nonlinear SC-to-FC data completion (see Table 1, lines 3–5). Non-linear FCMFM completions for our ADNI dataset and for the healthy aging dataset can be downloaded as a MATLAB workspace within Extended Data 1 FC_MFM.mat (available at the address https://github.com/FunDyn/VirtualCohorts).
Non-linear FC-to-SC completion
We implemented a heuristic approach to infer the most likely connectivity matrix (i.e., effective connectivity) that maximizes the similarity between empirical and simulated FC. As an initial point, we considered a random symmetric matrix and removed diagonal as SC*(0) (see Table 2, line 1) and run the algorithm in Table 1 to simulate the FC*(0). Then iteratively we adjusted the SC as a function of the difference between the current FC and empirical FC (see Table 2, line 2), in other words SC*(1) = SC*(0) + λΔFC(0), where ΔFC(0) = FCemp – FC*(0) and λ is the learning rate (see Table 2, line 3). The iteration will stop when the correlation between FCemp and FC*(k) reaches to the threshold CCtarget = 0.7 and giving the SC*(k) as SCMFM. All the parameter used in this section is identical to the nonlinear SC-to-FC completion procedure. Nonlinear SCMFM completions for our ADNI and healthy aging datasets can be downloaded as a MATLAB workspace within Extended Data 1 SC_MFM.mat (available at the address https://github.com/FunDyn/VirtualCohorts).
Table 2.
Pseudo-code for nonlinear FC-to-SC completion (SC virtual duals to FC)
| Algorithm non-linear FC-to-SC completion is |
| External input: empirical FC (FCemp) |
| Output: non-linear virtual SC (SCMFM) |
| Fixed parameters: FC* fitting quality (CCtarget), initial guess SC*(0), learning rate λ, noise level (σ), simulation time (T), range to scan Gstart ≤ G ≤ Gstop, range to scan τstart ≤ τ ≤ τstop, other frozen Wong-Wang neural mass parameters |
| Begin |
| 1. FC*(0) = non-linear SC-to-FC completion starting from SC*(0) |
| 2. Dist = corr(FC*(0), FCemp) |
| 3. Iteration = 0 |
| While (Dist ≤ CCtarget) |
| Iteration = iteration + 1 |
| SC*(iteration) = SC*(iteration – 1) + λ*(FC*(iteration) – FC*(iteration)) |
| FC*(iteration) = non-linear SC-to-FC completion starting from SC*(iteration) |
| Dist = corr(FC*(iteration), FCemp) |
| End |
| Return SCMFM = SC*(iteration) |
| End |
Trivial completion using the “other connectome”
In the case in which one of the two connectomes is missing (e.g., just SC available but not FC) one may think to use the available connectome (in this example, SC) as a “good guess” for the missing one (in this example, FC). We refer to this trivial procedure as a completion using the other connectome. If the match quality between surrogate connectomes obtained via more complex procedures and the target empirical connectome to reconstruct happened to be comparable with the one that one can get via the trivial completion, then it would not be worth using more sophisticated methods. We assessed then, for comparison with other strategies, the performance of such trivial completion approach on the SCemp + FCemp subset of the ADNI dataset and on the whole healthy aging dataset. In order for a completion approach to be considered viable, it is necessary that it outperforms significantly this trivial completion via the “other type” connectome, which can be quantified by a relative improvement coefficient:
Bivirtual data completion
The pipelines for data completion described above can be concatenated, by performing. e.g., FC-to-SC completion on a virtually FC or SC-to-FC completion on a virtual SC (rather than actual FCemp or SCemp, respectively). In this way, one can create bivirtual dual counterparts SCbi-MFM (FCbi-MFM) or SCbi-SLM (FC bi-SLM) for any of the available empirical SCemp (FCemp) by applying in sequence nonlinear MFM-based or linear SLM-based procedures for SC-to-FC and then FC-to-SC completion (or, conversely, FC-to SC followed by SC-to-FC completions). Linear and nonlinear bivirtual completions for our ADNI and healthy aging datasets can be downloaded as MATLAB workspaces within Extended Data 1 SC_bivirt.mat and FC_bivirt.mat (available at the address https://github.com/FunDyn/VirtualCohorts).
For every pair of subjects, we computed the correlation distance between the respective empirical connectomes (pairs of FCemp or SCemp) and the corresponding bivirtual duals (pairs of FCbi-MFM or SCbi-MFM) and plotted the empirical-empirical distances versus the corresponding bivirtual-bivirtual distances (compare Fig. 6) to reveal the large degree of metric correspondence between real and bivirtual dual spaces. This correspondence was also quantified computing Pearson correlation between empirical and bivirtual pairwise distances. These correlations (computed as well for virtual connectomes, beyond the bivirtual duals) are tabulated in Table 3 and Table 4.
Table 3.
Single-subject correlations between network features in real and bivirtual dual connectomes for the ADNI dataset
| SC | FC | |||
|---|---|---|---|---|
| Median and range Within subject cross-subject |
Δ% | Median and range Within subject cross-subject |
Δ% | |
| Strength | 0.16 ±0.20 | 25 ± 18 | 0.77 ± 0.18 | 342 ± 8 |
| 0.13 ± 0.17 | 0.17 ± 0.20 | |||
| Clustering | −0.05 ± 0.12 | −17 ± 24 | 0.65 ± 0.24 | 359 ± 13 |
| −0.06 ± 0.11 | 0.14 ± 0.21 | |||
| Centrality | 0.21 ± 0.18 | 24 ± 12 | 0.66 0.20 | 312 10 |
| 0.16 ± 0.15 | 0.16 0.18 | |||
| Communities | 59 10% | 23 2 | 45 10% | 260 6 |
| 47 8% | 12 6% | |||
Indicated values for real/bivirtual dual correlations (for strength, clustering, and centrality coefficients) or relative mutual information (for communities) are mean ± SD of the mean over subjects.
Table 4.
Single-subject correlations between network features in real and bivirtual dual connectomes for the healthy aging dataset
| SC | FC | |||
|---|---|---|---|---|
| Median and range Within subject cross-subject | Δ% | Median and range Within subject cross-subject | Δ% | |
| Strength | 0.80 0.04 | 5 1 | 0.65 0.18 | 75 7 |
| 0.76 0.07 | 0.37 0.16 | |||
| Clustering | 0.83 0.06 | 6 1 | 0.64 0.22 | 70 8 |
| 0.79 0.08 | 0.38 0.19 | |||
| Centrality | 0.80 0.05 | 4 1 | 0.63 0.18 | 65 7 |
| 0.76 0.06 | 0.38 0.16 | |||
| Communities | 44 8% | 16 3 | 53 10% | 10 3 |
| 38 8% | 48 12% | |||
Indicated values for real/bivirtual dual correlations (for strength, clustering, and centrality coefficients) or relative mutual information (for communities) are mean ± SD of the mean over subjects.
Improvement by personalization
Completion procedures map a connectome for a given subject to subject-specific virtual and bivirtual dual connectomes. The question is whether the similarity between empirical and completed connectomes is better when considering connectome pairs formed by an empirical and its subject-specific dual connectomes, or pairs made by an empirical and a generic virtual or bivirtual connectome, not specific to the considered subject. We expect that empirical-to-virtual match is improved by personalization. To quantify it, we introduce an Improvement by Personalization coefficient ΔPers, evaluating it for all the types of completion.
For simulated data one can define CCpersonalized = CC[Connectomevirt(a subject), Connectomeemp(same subject)], where “connectome” refers to the considered connectome matrix (of either the SC or the FC type) and the ondex “virt” to any type of completion (SLM or MFM based, virtual or bivirtual). Analogously, we define CCgeneric = group average of CC[Connectomevirt(same subject), Connectomeemp(a different subject)]. The Improvement by personalization coefficient is then defined as ΔPers = (CCpersonalized – CCgeneric)/CCgeneric. This coefficient significantly larger than zero denotes that completion pipelines get to improved results when completion is personalized.
At least for FC, we can estimate from empirical data how much the improvement by personalization could be expected to be in the case in which a first FC extraction for a given subject had to be replaced by a second one coming from a second scan from the same subject versus a scan for another generic subject. To obtain such an estimate, we focus on a dataset mediated from the Human Connectome Project and conceived to probe test/retest variability (Termenon et al., 2016). In this dataset, 100 subjects underwent two resting state scans, so that two FCemp can be extracted for each of them. If we redefine CCpersonalized = CC[FCemp(same subject first scan), FCemp(same subject second scan)] and CCgeneric = Group average of CC[FCemp(same subject, first scan), FCemp(a different subject, first scan)], then we can evaluate an empirical ΔPers = (CCpersonalized – CCgeneric)/CCgeneric. For empirical FCs from the Termenon et al. (2016) dataset we obtain an improvement by personalization of ∼+22%, to be used as a comparison level when looking at improvements by personalization in virtual and bivirtual connectomes.
Network topology features and their personalized preservation through data completion
To evaluate the correspondence between empirical and bivirtual connectomes we evaluated a variety of graph-theoretical descriptors of the connectomes and compared them within pairs of empirical and bivirtual dual adjacency matrices. Every connectome, functional or structural, was described by a weighted undirected matrix Cij, where i and j are two brain regions, and the matrix entries denote the strength of coupling, anatomic or at the level of activity correlations, between them. For each brain region i, we then computed: its strength Si = Σj Cij, indicating how strongly a given region is connected to its local neighborhood; its clustering coefficient Clui = |triangles involving i|/|pairs of neighbors of i| (with denoting the count of a type of object), determining how densely connected are between them the neighbors of the considered region; and its centrality coefficient, quantifying the tendency for paths interconnecting any two nodes in the networks to pass through the considered node. In particular, we computed here centrality using a version of the PageRank algorithm (Brin and Page, 1998) for weighted undirected networks in an implementation from the Brain Connectivity Toolbox (Bullmore and Sporns, 2009), with a typical damping parameter of 0.9. Without entering in the details of the algorithm (for details, see Brin and Page, 1998), a node is deemed important according to PageRank centrality if it receives strong links from other important nodes sending selective and parsimonious in their connections, i.e., sending only a few strong links. Strengths, clustering, and centrality measures provide together a rich and detailed portrait of complementary aspects of network topology and on how it varies across brain regions. We computed then the correlations between the above graph theoretical features for matching regions in empirical connectomes and their bivirtual counterparts. Note that the number of network nodes were different for connectomes in the ADNI and in the healthy aging datasets, since the used reference parcellations included a different number of regions in the two cases. However, graph theoretical metrics can be computed in precisely the same way and we perform in this study uniquely within-dataset analyses. In Figure 8, we show point clouds for all subjects of the ADNI dataset pooled together. Analogous plots for the healthy aging dataset are shown in Extended Data Figure 8-1.
Figure 8.

Correspondence of network topology between empirical and their bivirtual dual connectomes (ADNI dataset). The bivirtual dual connectomes share the same nature (SC or FC) of the corresponding empirical connectome. Therefore, network topology can be directly compared between empirical and bivirtual SCs or empirical and bivirtual FCs. A, B, We show here scatter plots of connectivity strengths (top center), local clustering coefficients (top right) and local centrality coefficients (bottom center) for different brain regions and subjects, plotting feature values for empirical connectomes versus their bivirtual counterparts. We also show histograms over different subjects of the relative mutual information (normalized between 0 and 1, the latter corresponding to perfect matching) between the community structures (bottom right) of empirical connectomes and their bivirtual duals. Results are shown in panel A for SC and in panel B for FC connectomes for the ADNI dataset (see Extended Data Fig. 8-1 for analogous results holding for the healthy aging dataset). In both cases, there is a remarkable correlation at the ensemble level between network topology features for empirical bivirtual connectomes (see Table 3 for the even superior correspondence at the single subject level for the ADNI dataset).
We then computed correlations between vectors of graph-theoretical features over the different brain regions within specific subjects. This analysis is an important probe of the personalization quality in data completion, since every subject may have a different spectrum of graph-theoretical properties across the different regions and that it is important that information about these topological specificities is maintained by completion. These within-subject correlations, often higher than global population correlations, since not disturbed by variations of mean feature values across subjects, are summarized in Table 3 for the ADNI dataset and in Extended Data Table 3-1 for the healthy aging dataset. In these tables, we provide both absolute correlation values and the indication of how each correlation is improved by computing it within subjects rather than across the whole sample. Correlations were evaluated over data points belonging to the interquartile range of empirical data and then extrapolated to the whole range to avoid estimation to be fully dominated by cloud tails of extreme outliers.
We extracted then the community structure of empirical and bivirtual dual connectomes using the Louvain algorithm (Blondel et al., 2008), with default parameter Γ = 1 and “negative symmetric” treatment of negative matrix entries (once again, in the implementation of the Brain Connectivity Toolbox). To compare the resulting community assignments to different regions across pairs of dual empirical and bivirtual connectomes we computed the mutual information between the respective labelings and normalized it in the unit range by dividing it by the largest among the entropies of the community labelings of each connectome. Such normalized mutual information measure is not sensitive to changes in names of the labels and can be applied independently on the number of retrieved communities. Chance levels for relative mutual information can be estimated by permuting randomly the labels and finding the 99th percentile of values for shuffled labels. Average mutual information between community labels are tabulated as well in Table 3 for the ADNI dataset and in Extended Data Table 3-1 for the healthy aging dataset, once again giving absolute values and relative improvements of personalized with respect to generic correspondence.
Supervised subject classification
To show the possibility to extract personalized information relevant for subject characterization, we performed different machine-learning supervised classification tasks using as input features derived from empirical and (bi)virtual connectomes. The input and target features to predict were different for the ADNI and the healthy aging datasets.
Concerning the ADNI dataset, we separated subjects in two subgroups: controls and patients (MCI or AD). Subjects (the actual ones or their associated virtual counterparts) are thus labeled as “positive” when belonging to the patient subgroup or negative otherwise. Note that our classifiers were not sufficiently powerful to reliably discriminate subjects in three classes (control, MCI, and AD) on this dataset, at least under the simple classification strategies we used. For illustration, we constructed classifiers predicting subject category from input vectors compiling the total connectivity strengths (in either SC or FC connectomes, real, virtual, or bivirtual) of different brain regions. The dimension of the input space was thus limited to the number of regions in the used 96-ROIs parcellation, which is of the same order of the number of available subjects in the overall dataset.
Concerning the healthy aging dataset, we separated subjects in four age classes with 13 subjects in Class I (age = 18–25), and 12 subjects in Classes II (age = 26–39), III (age = 40–57), and IV (age = 58–80) and used as target labels for classification the ordinal of the specific age class of each subject. As input vectors we used in this case the top 10 PCA of upper-triangular of connectome. In both cases, we chose as classifier a boosted ensemble of 50 shallow decision trees. For the ADNI dataset, we trained it using the RUSBoost algorithm (Seiffert et al., 2010), particularly adapted to data in which the number of input features is large with respect to the training dataset size and in which positive and negative labels are unbalanced. For the healthy aging dataset, we used a standard random forest method (Breiman, 2001). For both datasets, for training and testing we split the dataset into five folds, each of them with a proportion of labels maintained identical to the one of the full dataset and performed training on three of the five folds and testing on the remaining two folds (generalization performance). We considered classifiers in which the training features were of the same type of the testing features (e.g., classifiers trained on SCemp and tested on SCemp data; or classifiers trained on FCMFM and tested on FCMFM data in Figure 7D, center, E, right; etc.). We also considered classifiers in which the type of data differed in training and testing (e.g., classifiers trained on SCbi-MFM and tested on SCemp data, in Fig. 7F). In all cases, generalization performance was assessed on data from different subjects than the ones used for training (i.e., prediction performed on the folds of data not actually used for training). The split in random folds was repeated 1000 times, so to be able to evaluate median performances and their confidence intervals, given by 5th and 95th percentile performances over the 1000 repetitions of training and testing. We measured performance based on confusion matrices between predicted and actual class labels and, just for the binary classification problem on the ADNI dataset, on the receiver operator curve (ROC) analysis as well. For ROC analysis, we quantified fractions of true and false positives (numbers of true or false positives over the total number of actual positives) during generalization, which depend on an arbitrary threshold to be applied to the classifier ensemble output to decide for positivity of not of the input data. ROCs are generated by smoothly growing this threshold. An area under the curve (AUC) was then evaluated as a summary performance indicator, being significantly larger than 50% in the case of performance above chance level. The ROC curves plotted in Figure 7B,C, as well as their associated 95% confidence range of variation are smoothed using a cubic smoothing spline based on the cloud of TP and FP values at different thresholds over the 1000 individual training and testing classification runs. We report confidence intervals for AUCs only for “direct” classifications (pooling performances for classifiers trained on either SCemp or FCemp and tested on same-type empirical connectomes) and “virtual” classifications (pooling performances for classifiers trained on any type of virtual or bivirtual connectomes and tested on same nature virtual or empirical connectomes) since confidence intervals for more specific types of classifiers were largely overlapping.
Figure 7.
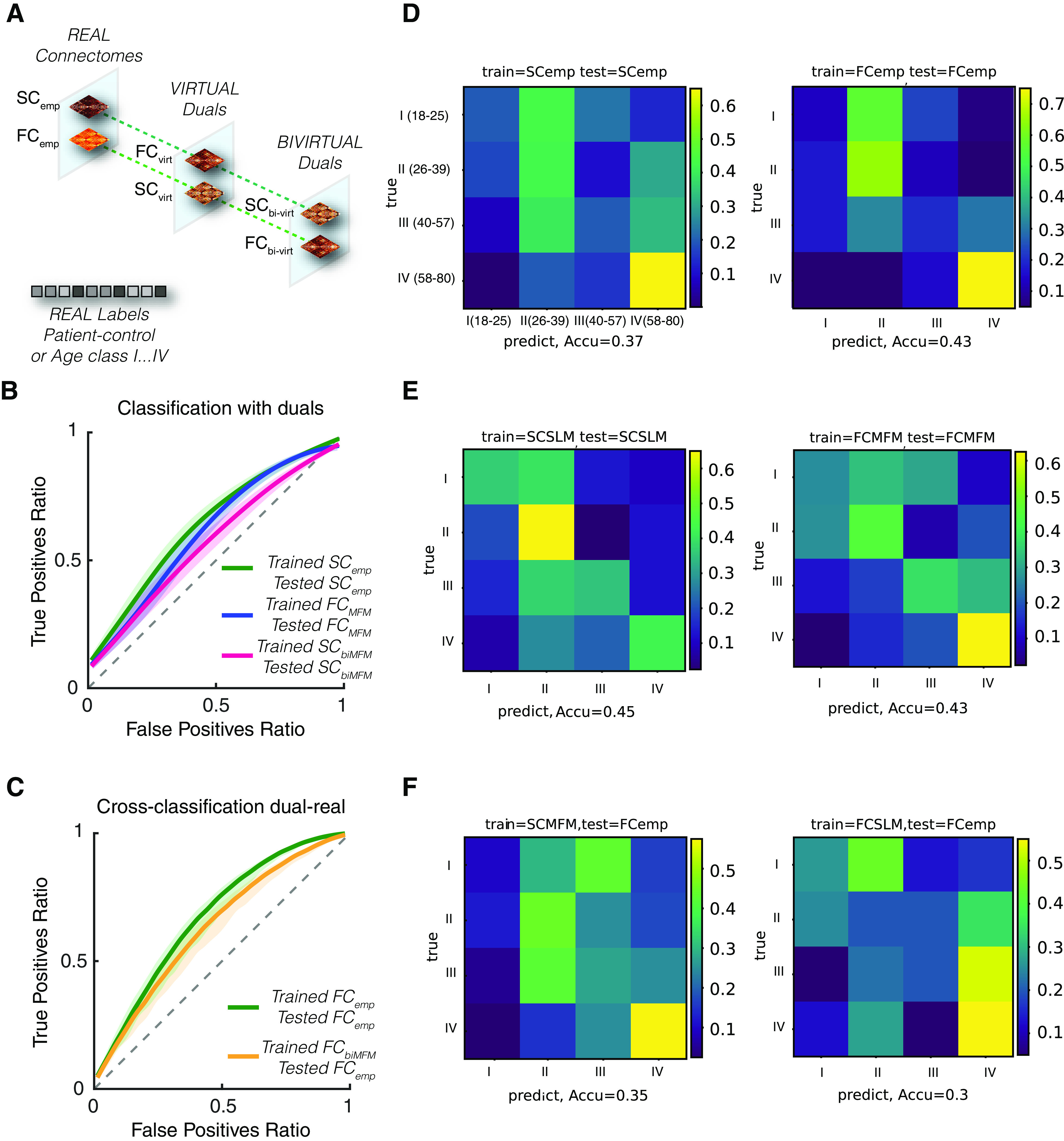
Classification of MCI patients based on empirical and virtual connectomes and virtual cohorts. A, Data completion procedures can be seen as bridges between different connectome spaces, mapping empirical connectomes in real space to subject-specific dual connectomes in virtual or bivirtual spaces, depending on the number of virtualization steps applied to the original connectome. Subjects classifications into controls (light blue) or MCI (yellow) and AD (red) patients are shared between empirical connectomes and their virtual and bivirtual duals. Virtual duals have a different nature than their associated empirical connectomes (empirical SCs are mapped to virtual FCs and vice versa), while bivirtual duals have the same nature. B, C, Performance of tree ensemble classifiers discriminating control from patient subjects, evaluated via ROC analysis (fractions of true vs false positive, as a function of applied decision threshold; generalization performance via crossvalidation; thick lines indicate median performance, shaded regions 95% confidence intervals). In panel B, we show example of classification in dual space, compared with a real connectome space classification: in green, classification with classifiers trained on empirical SCs evaluated on other empirical SCs; in blue, classifiers trained on virtual FCs evaluated on other virtual FCs (or the virtual duals of other empirical SCs); in magenta, classifiers trained on bivirtual SCs evaluated on other bivirtual SCs (or the bivirtual duals or other empirical SCs). In panel B, we show an example of cross-space classification, compared with a real connectome space classification: in green classification with classifiers trained on empirical FCs evaluated on other empirical FCs; and in orange, classification with classifiers trained on bivirtual FCs evaluated directly on other empirical FCs, without prior “lifting” into bivirtual dual space. In all the shown cases, classifications performed with classifiers trained in virtual or bivirtual connectomes are slightly less performing than for classifiers trained on empirical data, but the drop in performance is not significant for most thresholds. D–F, The confusion matrix for classification of four age classes of the healthy aging database using the random forest Breiman algorithm is shown. D, When the classifier was trained and tested on the empirical SC and FC connectome, the accuracy was closed to ∼0.37 and ∼0.43, respectively. E, The classification accuracy for the classifier which was trained and tested on the virtual connectomes was above the chance level (∼0.25) with ∼0.43 for SCSLM and ∼0.43 for FCMFM connectomes which the performance was better or equivalent to the empirical connectome (D). F, Here, we shown the classification performance of cross-training, when the classifier was trained on SCMFM and tested on FCemp with accuracy equal to ∼0.35 (F-center) and when the classifier was trained on FCSLM and tested on FCemp with accuracy of ∼0.30 (F-right; see Extended Data Fig. 7-1 for the classification performances on other virtual connectomes from healthy aging dataset).
Virtual cohorts
To generate virtual cohorts, i.e., synthetic datasets made of a multitude of virtual connectomes beyond individual subject or patient data completion, we artificially boosted the size of the original dataset by generating a much larger number of virtual subjects with multiple alternative (but all equally valuable) completions of the missing connectomic data. Concretely, to generate the virtual cohort dataset illustrated in Figure 9A, we took the 88 subjects in the SCemp only plus the 12 subjects in the SCemp + FCemp subsets of the ADNI dataset (including 21 AD subjects, 35 MCI, and 32 control subjects) and run for each of them the nonlinear SC-to-FC completion algorithm 100 times, using each time a different random seed. The net result was a group of 100 alternative FCMFM instances for each of the subjects, yielding in total a virtual cohort of 8800 FCMFM matrices to be potentially used for classifier training. Such a cohort can be downloaded as a MATLAB workspace within Extended Data 1 FC_cohort.mat (available at the address https://github.com/FunDyn/VirtualCohorts). To generate Figure 9A, showing a dimensionally reduced representation of the relative distances between these 8800 virtual matrices, we used an exact t-SNE projection (Maaten and Hinton, 2008) of the vectors of upper-triangular parts of the different FCMFMs toward a two-dimensional space, using a default perplexity value of 30 and no-exaggeration.
Figure 9.

The Virtual cohorts. We created virtual cohorts of surrogate FC data, generating 100 different FCMFM matrices for each of the 88 subjects in the ADNI dataset with an available SCemp. A, Shown here is a low-dimensional t-SNE projection of the resulting 8800 virtual FCMFMs, colored depending on the associated subject label (blue for control subjects, yellow for MCI patients, and red for AD patients). For the subjects in the ADNI FC + SC subset, we also projected the actual empirical FCemp connectome and link their projections to one virtual connectome within the cohort for the matching subjects. All FCemp connectomes appear grouped in a single cluster, since all far away to connectomes in dual space (they belong to a different space, so appear as “distant” in this projected view emphasizing differences within virtual space). However, virtual cohorts interrelations reproduce an exploded view of the fine structure of this All FCemp cluster. Virtual connectomes within a same virtual cohort are closer between them than connectomes belonging to different cohorts since they maintain a strict relation to their empirical counterparts and are thus good candidates for data augmentation applications. B, We show, on top, example alternative connectomes within a representative cohort for a single subject that could be used as alternative identity preserving distorted connectomes for data augmentation applications, analogously to slightly distorted versions of object images (on the bottom) used to boost training of object classifiers.
On the same t-SNE projection, beyond the FCMFM connectomes within the virtual cohort connectomes we show as well additional FC connectomes, for the sake of comparison (using the same t-SNE neural network adopted for projecting the virtual cohort connectomes on the Euclidean plane). Specifically, for the 12 subjects with available FCemp in addition to SCemp, we also show the projected positions corresponding to the real FCemp. Moreover, we also show positions of bivirtual FCs generated from the FCemp only subset paired to the corresponding FCemp projection.
Code accessibility
Code/software to perform procedures described in the paper is freely available online at https://github.com/FunDyn/VirtualCohorts. The code is available as Extended Data 1, together with workspaces including virtual cohorts. Code is designed for MATLAB and was run on Mac OS 10.15 system.
Results
Connectomic data may have gaps: the example of ADNI
The first dataset we have chosen to focus in the framework of this study corresponds to one of the earliest and most popular available datasets in AD research, including a substantial amount of structural and functional connectomic information, i.e., the ADNI database (adni.loni.usc.edu). ADNI is impressive for the variety of features it aimed at systematically gathering (Fig. 1A). Importantly, based on the T1, DTI and rsBOLD fMRI images available through the ADNI datasets, state-of-the-art processing pipelines can be used to extract subject-specific structural and resting-state functional connectomes, compiled into connectivity matrices adapted to the brain parcellation of choice (Fig. 1B; for details, see Materials and Methods).
Figure 1.

Connectomic information extracted from the ADNI dataset has gaps. A, The different dataset releases by the ADNI consortium include a variety of information relative to different biomarkers and imaging modalities. Here, we focus on structural and fMRI features and, chiefly: T1, DTI (allowing to extract empirical structural connectomes), and rsfMRI BOLD time series (allowing to extract empirical functional connectomes). B, Matrices SCemp and FCemp summarizing connectomic information about, respectively, SC and FC are obtained via elaborated multistep processing pipelines, using various software including FreeSurfer, FSL, ANTS, and MRtrix3. C, The total number of subjects in healthy aging dataset is 49 between the ages of 18 and 80 (mean = 42.16 ± 18.37; 19 male/30 female) in which with approximately equal number of subjects they were divided into four categories (I:IV). The total number of ADNI-derived subjects investigated in this study is 244, in which 74 subjects were control, while 119 subjects labeled as MCI, and 51 subjects as AD. Out of these 244, FCemp could be extracted for 168 subjects, and SCemp for 88. However, SCemp and FCemp were both simultaneously available for just a minority of 12 subjects (referred to as the SCemp + FCemp subset). The available data are shown in blue and the missing data in gray, the SCemp + FCemp subset is shown in pink.
We had access to 244 overall subjects (119 labeled as MCI and 51 as AD, thus 170 patients, in addition to 74 control subjects, see Materials and Methods) for which MRI data had been gathered. We could extract an FC matrix for 168 subjects (starting from rsfMRI) and a SC matrix (starting from DTI) for 88 subjects. However, only for a minority of 12 subjects rsBOLD and DTI information were both available. In a majority of cases, either DTI or rsBOLD were missing (Fig. 1C). This reduced number of “complete” subjects constitutes a serious challenge to attempts of automatedly categorize them through machine learning or inference approaches capitalizing on both SC and FC features simultaneously. As a matter of fact, the total numbers of AD-labeled and MCI-labeled subjects in this complete subset decreased, respectively, to just two and four, against six controls. In these conditions, the development of effective data completion strategies would be an important asset toward the development of classifier schemes exploiting FC/SC synergies. Therefore, approaches to “fill gaps” (completion) and, possibly, even artificially boosting sample size (augmentation) are veritably needed.
Control dataset: healthy aging
To confirm the robustness of all following analyses performed on the first ADNI dataset, we also consider in the following comparisons with analogous analyses conducted on a second control dataset. In this previously analyzed dataset (Zimmermann et al., 2016; Battaglia et al., 2020), we considered 49 healthy adult subjects covering an age-span from 18 to 80 years that we split in four age classes (for details, see Materials and Methods). For all these 49 subjects, both FCemp and SCemp are simultaneously available, thus extending the number of subjects for which a ground truth connectome against which evaluate the performance of each tested completion pipeline is possible.
We also note that connectomes in the two ADNI and healthy aging datasets were defined in terms of different brain parcellations, involving a different number of regions. This fact will allow further testing the robustness of our analyses against changes of the used parcellation.
Linking SC and resting-state FC via computational modeling
As previously mentioned, FC and SC are related only indirectly through the rich nonlinear dynamics supported by brain networks (Ghosh et al., 2008; Deco et al., 2011; Kirst et al., 2016). MFM of large-scale brain networks has emerged initially as the key tool to predict the emergent dynamic patterns of resting-state FC, from spontaneous dynamics constrained by SC (Ghosh et al., 2008). It is thus natural to propose the use of model-based solutions to perform data-completion, which, in both the SC-to-FC and FC-to-SC directions, requires to capture the interrelation between the two as mediated by dynamics.
Large-scale mean-field brain network models are specified by (1) a parcellation of cortical and subcortical brain areas; (2) a co-registered input SC matrix in the same parcellation; (3) a forward solutions linking source and sensor space; (4) a neuronal mass model, describing the nonlinear dynamics of the regions at each of the nodes of the SC matrix; (5) a choice of a few global parameters (e.g., scale of strength of interregional connectivity or speed of signal propagation along fiber tracts); (6) an external input given to the different regions, that, in the simplest case, corresponds to simple white noise uncorrelated across each of the different sites and of homogeneous strength. TVB enables the complete workflow from brain images to simulation (TVB; Sanz-Leon et al., 2013, 2015). Personalization is accomplished by the subject-specific structural skeleton, ingredients (1) through (4), which has been demonstrated to be individually predictive (Proix et al., 2017; Melozzi et al., 2019). Simulations of the model can be run to generate surrogate BOLD time series of arbitrary length (for details, see Materials and Methods) and the associated simulated resting-state FC, time-averaged (static FC) or even time-resolved (FC dynamics or dFC; Hansen et al., 2015). The thus obtained simulated FC will depend on the chosen global parameters, setting the dynamic working point of the model. The model dynamics will eventually switch between alternative dynamical regimes when its global control parameters cross specific critical points. Tuning global parameters will thus uniquely determine, in which regime the model operates. Mean-field large scale models constrained by empirical SC tend to generate simulated resting-state FC that best matches empirical observations when the dynamic working point of the model lies in the proximity of a model’s critical point (Deco et al., 2011, 2013; Hansen et al., 2015; Triebkorn et al., 2020).
We here chose one of the simplest possible whole-brain network model designs, which emphasizes activity-based network organization (as opposed to reorganization because of synchronization) and thus ignores interregional propagation delays. This approach is frequently used in the literature (Deco et al., 2013; Hansen et al., 2015; Aerts et al., 2018) and has the advantage of avoiding the need for complex delay differential equation integration schemes (for more details, see Discussion). Activation-based approaches adopt particularly simple neural mass models such as the reduced Wong–Wang model (Deco et al., 2013), in which the dynamics of an isolated brain region is approximated by either one of two possible steady states, one “down state” at low firing rate and an “up state” at high firing rate, a feature initially meant to mimic bi-stability in working memory or decision-making (Wong and Wang, 2006). By varying G, the model will switch from a low-coupling regime, in which all regional activations are low to a high-coupling regime, in which all regional activations are high, passing through an intermediate range, in which both regimes can exist in a multistable manner and regions display spatially and temporally heterogeneous activations (a changing mix of high and low firing rates). The best fit between simulated and empirical FC occurs slightly before the critical rate instability, at which modes of activity with low firing rate disappear (Deco et al., 2013).
As alternatives to the just described nonlinear MFMs of resting-state brain dynamics, simpler SLMs have also been considered (Goñi et al., 2014; Messé et al., 2014; Saggio et al., 2016). In these models, the activity of each region is modeled as a stochastic process (linear, in contrast to the nonlinear neural mass dynamics of conventional MFMs), biased by the fluctuations of the other regions weighted by the SC connectome (see Materials and Methods). SLMs have also two different regimes. In the first regime, the activities of all regions converge to a fixed-point of constant mean fluctuating activities, while, in the second, regional activities diverge with exponential growth. Once again, the best fit between the simulated and the empirical resting-state FCs is observed when tuning the model parameters slightly below the critical point (Hansen et al., 2015; Saggio et al., 2016).
MFMs and SLMs provide thus two natural ways to generate simulated resting-state FCs, depending on the chosen dynamic regime, starting from a selected SC. Strategies have also been devised to approximately solve the inverse problem of determining which SC matrix should be used as input to a model to give rise to a simulated FC matching a specific, predetermined target matrix. For the SLM, a simple analytic solution to the inverse problem exists (Saggio et al., 2016). For MFMs, inverse problems have not been studied with the same level of rigor, but algorithms have been introduced that iteratively adjust the weights of the SC matrix currently embedded in the model to improve the fit between simulated and target FCs (Gilson et al., 2016, 2018). We will show later that these algorithms, although initially designed to identify changes of effective connectivity occurring between resting state and task conditions, have the potential to cope with the actual problem of MFM inversion, providing reasonably good ansatz for SC inference.
As linear approaches are significantly faster than nonlinear approaches, it is important to study their performance alongside nonlinear approaches to confirm the actual justification of the use of more complicated algorithms. We will see that for one of the two considered datasets, the ADNI one, nonlinear methods are superior for the data completion applications we are interested in. However, performance of completion happened to be slightly superior for the SLM-based than for the MFM-based methods in the case of the second healthy aging dataset (hence the interest of exploring and benchmarking both linear and nonlinear completion strategies).
Model-driven data completion
Figure 2 summarizes many of the modeling operations described in the previous section framing them in the specific context of connectomic data completion. MRI data can be used to generate empirical SC matrices SCemp (from DTI) or FCemp (from rs fMRI BOLD). By embedding the empirical matrix SCemp into a nonlinear MFM or a linear SLM, it is possible to compute surrogate FC matrices (Fig. 2A, upward arrows), denoted, respectively, FCMFM and FCSLM.The MFM and SLM global parameters are suitably tuned (slightly subcritical) then FCMFM and FCSLM will be maximally similar to the empirical FCemp (dynamic working point tuning; Fig. 2A, dashed gray arrows). Starting from the empirical matrix FCemp, one can then infer surrogate SC matrices (Fig. 2A, downward arrows), either by using a linear theory, developed by Saggio et al. (2016), to compute a surrogate SCSLM; or by exploiting nonlinear effective connectivity algorithm, generalized from Gilson et al. (2016, 2018), to infer a surrogate SCMFM starting from a random initial guess (see section Non-linear FC-to-SC completion).
Figure 2.

From MFM to connectomic data completion. A, We present here a graphical summary of the various computational simulation and inference strategies used in this study to bridge between different types of connectivity matrices. Mean-field simulation and the associated analytic theory can be used to generate virtual FC, through simulations of resting-state whole-brain models embedding a given input SC connectome (ascending arrows). Algorithmic procedures, that may still include computational simulation steps, can be used to perform the inverse inference of a virtual SC that is compatible with a given input FC (descending arrows). Both simulation and inference can be performed using simpler linear (green arrows) or nonlinear (blue arrows) approaches. When the input SC (or FC) connectomes used as input for FC simulation (or SC inverse inference) correspond to empirical connectomes SCemp (or FCemp), derived from T1 and DTI (fMRI) images, then model simulation (inversion) can be used to complete gaps in the dataset, whenever FCemp (or SCemp) is missing. We refer then to these operations as (B) SC-to-FC completion and (C) FC-to-SC completion. Both exist in linear and nonlinear versions.
When connectomic data are incomplete (only SCemp or only FCemp are available, but not both simultaneously), computational simulation or inference procedures can be used to fill these gaps: by using FCMFM or FCSLM as virtual replacements for a missing FCemp (Fig. 2B), or by using SCMFM or SCSLM as virtual replacements for a missing SCemp (Fig. 2C). The quality of the model-generated virtual SCs and FCs can be assessed by comparing them with the actual empirical counterparts for the small subset of subjects for which both SCemp and FCemp are simultaneously available. Optimizing the quality of the virtually completed matrices on subjects for which both empirical connectomes are available (as, e.g., the subset of ADNI SCemp + FCemp subjects), also allows extrapolating target criteria for identifying when the model is operating a suitable dynamic working point, that can be evaluated solely based on simulated dynamics when a fitting target matrix is missing and thus fitting quality cannot be explicitly measured (compare Figs. 3 and 4). We can thus translate these criteria into precise algorithmic procedures that inform linear or nonlinear SC-to-FC and FC-to-SC completion (see Tables 1, 2; Extended Data Tables 1-1, 2-1).
Figure 4.

Non-linear FC-to-SC data completion. An iterative procedure can be used to perform resting-state simulations of an MFM model starting from a randomly guessed structural connectome SC* and progressively modify this SC* to make it compatible with a known target FCemp. A, Starting from an initial random SC*(0) matrix, there is no correlation between the target FCemp and the generated FC*(0) matrix. However, by adjusting the weights of the used SC* through the algorithm of Table 2, SC* gradually develops a richer organization, leading to an increase of the correlation between FC* and FCemp (violet dashed line) and in parallel, of the correlation between SC* and SCemp (violet solid line), as shown here for a representative subject within the SCemp + FCemp subset. The algorithm stops when the correlation between FC* and the input target FCemp reaches a desired quality threshold (here 0.7 after 2000 iterations) and the SC* at the last iteration is used as virtual surrogate SCMFM. B, The boxplot shows the distribution of correlation between SCemp and SCMFM for all subjects in the SCemp + FCemp ADNI subset and the healthy ageing dataset. C, The correlation between SCemp and SCMFM can vary using different random initial connectomes SC*(0). Here, we show a boxplot of the percent dispersions of the correlation values obtained for different initial conditions around the median correlation value. The fact that these dispersions lie within a narrow interval of ±2.5% indicates that the expected performance is robust against changes of the initial conditions. See Extended Data Figure 4-1 for linear FC-to-SC completion.
Linear SC-to-FC data completion. The functional data completion can also be done using the linear model starting from SCemp matrices. A, Systematic exploration (for a representative subject) of the dependency of correlation between FCemp and FCSLM on the SLM parameter G (global scale of long-range connectivity strength) shown by the violet line indicates that the best fitting value G* (dashed line) can be obtained slightly before the critical point of the system Gcritic = which since the SCemp matrices are normalized to one = 1 and Gcritic = 1. The green lines display 5th and 95th percentiles of bootstrap resampling. The inset boxplot gives the distribution of G* over all the subjects in the SCemp + FCemp subset; for the SLM SC-to-FC completion, we used a common value G*ref = 0.83, equal to the median of the boxplot. B, The boxplot reports the distribution of Pearson correlation between FCemp and FCSLM for all subjects from the SCemp + FCemp subset with a median equal to 0.243 for the ADNI dataset and 0.377 for the healthy ageing dataset. C, In case of using the common value G*reffor all subjects instead of the actual personalized optimum G* for each subject in the SCemp + FCemp subset, the value of quality loss for each subject is shown in the boxplot with median equal to 0.5%. Download Figure 3-1, EPS file (1.4MB, eps) .
The dependency of best MFM fit zone on additional regional dynamics parameters. In the non-linear data completion, the global parameters of the MFM model are G (interregional coupling strength), τ (synaptic time-constant of within-region excitation), ω (relative strength of recurrent within-region connections), and I (external input) which parameters G and τ were investigated in this paper (see Fig. 3). Here, we showed for different values of and I, the narrow concave stripe of Figure 3A as the representative of the best fitting zone is slightly shifted in the G/τ plane, suggesting G and τ are more sensitive parameters and need to be explored rather than and I. Download Figure 3-2, EPS file (529KB, eps) .
Linear FC-to-SC data completion. Using the linear model, it is equivalently possible to infer the structural SCSLM matrices from FCemp. Since in this approach the free parameters of SLM model appear as scaling factor, they do not affect the correlation of the inferred SCSLM with the SCemp so there is no need for parameter exploration here. The distribution of the correlation values for all the subjects from the SCemp + FCemp ADNI subset is shown in the boxplot with median equal to 0.21 and 0.42 for the healthy ageing dataset. Download Figure 4-1, EPS file (1.4MB, eps) .
We now, provide more details on implementation and performance for each of the four mentioned types of data completion.
Linear SC-to-FC completion
In linear SC-to-FC completion, a simple SLM (see Materials and Methods) is constructed based on the available SCemp and its direct simulations or even, in a much faster manner, analytical formulas deriving from the model’s theory are used to generate the associated virtual Pearson correlation matrix FCSLM (Extended Data Fig. 3-1). In this SLM scheme, once the driving noise strength is arbitrarily chosen and fixed and the input connectome SCemp is specified, there remains a single parameter to adjust, the global scale of long-range connectivity strength G. Extended Data Figure 3-1A shows a systematic exploration, performed on subjects from the ADNI SCemp + FCemp subset, of how the completion quality depends on tuning this parameter G. As shown by the main plot in Extended Data Figure 3-1A for a representative subject, increasing G the correlation between the empirical FCemp and the simulated FCSLM, derived here from direct SLM simulations, initially grows to peak in proximity of a critical value G*. The correlation then drops dramatically when further increasing G beyond the critical point G*.
The exact value of G* depends on the specific personalized SCemp connectome embedded into the SLM and is therefore different for each subject. Extended Data Figure 3-1A, small boxplot inset, gives the distribution of the personalized G* over all the subjects in the ADNI SCemp + FCemp subset. However, when performing linear FC completion because BOLD data and FCemp are missing, the exact location of the fitting optimum cannot be determined. To perform linear SC-to-FC completion for the ADNI subjects with missing BOLD we chose to always use a common prescribed value G*ref = 0.83, set to be equal to the median of the personalized G* over the SCemp + FCemp subset of ADNI subjects.
Once a G*ref value and a noise strength are set, the linear completion can be further sped-up by the fact that the covariance matrix FCSLM for these frozen parameters can be analytically evaluated, as discussed in Saggio et al. (2016). Therefore, one can directly apply the SLM analytical formulas (see Materials and Methods) on the available SCemp as input, without the need for performing direct simulations to generate surrogate BOLD first. Extended Data Figure 3-1B,C analyzes the expected performance of this “simulation-less” procedure, as benchmarked by applying it on the ADNI SCemp + FCemp subset. The boxplot in Extended Data Figure 3-1B (centermost box) reports a median Pearson correlation between the linear virtual FCSLM and the actual empirical FCemp close to ∼0.24 for the ADNI dataset. This correlation is larger and rise to ∼0.37 for the healthy aging dataset, in which FCSLM are generated from SCemp using precisely the same algorithm. Extended Data Figure 3-1C indicates then the percent loss in correlation that has been caused by using the common value G*ref and the analytical formula to evaluate the linear virtual FCSLM rather than direct simulations at the actual personalized optimum G* for each of the ADNI SCemp + FCemp subjects. The median quality loss is ∼0.5%, indicating that the lack of personalized tuning of the SLM working point is only a minor issue and that is acceptable to speed-up completion by relying on analytical evaluations.
The median Pearson correlations of ∼0.24 or ∼0.37 between the linear virtual FCSLM and the actual empirical FCemp for the ADNI and the healthy aging datasets, respectively, are significant but still absolutely weak. A way to assess whether linear SC-to-FC completion is worthy, despite these low correlation values, it is possible to compare the achieved reconstruction quality with the one that one could trivially achieve by simply taking the SCemp connectome itself as surrogate FC, since we know that SC and FC connectomes are already strongly related (Hagmann et al., 2008). This strategy of using the other connectome to perform FC completion would be even faster than SLM-based completion. We thus computed the percent improvement in rendering FCemp via FCSLM for subjects in the ADNI SCemp + FCemp subset and for subjects in the healthy aging datasets. As shown in Extended Data Figure 2-1A, for the ADNI dataset, the use of FCSLM resulted systematically in a worse performance (median drop −15%; for definition, see Materials and Methods) in reproducing the actual FCemp than using the other available connectome SCemp. However, in the case of the healthy aging dataset, the use of FCSLM resulted in a clearly better performance than when using the other connectome (median improvement +40%). Thus, the performance of linear SC-to-FC completion can be good but was not robustly maintained across the two considered datasets.
Viability of data completion. We checked whether the performance of data completion based on the algorithmic procedures of Tables 1, 2 or Extended Data Tables 1-1, Tables 2-1 is superior to the one of a trivial strategy in which the target connectome to reconstruct is just taken to be identical to the other connectome (i.e., using SC, when trying to reconstruct missing FC; or using FC, when trying to reconstruct missing SC). A, B, We computed percent improvement in data completion over the trivial other connectome strategy using a SLM-based or an MFM-based data completion method, focusing on the SCemp + FCemp subset for which both ground truth connectomes are known. A, Percent improvements in data completion when completing FC from SC. B, Percent improvements in data completion when completing SC from FC. For the SLM-based functional data completion approach, the use of FCSLM on the ADNI dataset resulted in a worse performance (median drop –15%; for definition, see Materials and Methods); however, for the healthy ageing dataset, the use of FCSLM resulted in a clearly better performance than when using the other connectome (median improvement +40%); similarly, applying the SLM-based approach for the structural data completion, the use of SCSLM rather than FCemp as an ersatz for SCemp leads to drops of improvements in quality with a median value of approximately –20%, for the ADNI dataset but an increase of nearly ∼50% for the healthy aging dataset. Thus, the performance of linear data completion can yield to good results, but this performance did not robustly generalize through datasets. On the other hand, for the MFM-based functional data completion, the median improvement was close to ∼20% for both datasets which can go as high as +60% in some subjects; using the same approach but for the structural data completion, the performance was lower than non-linear SC-to-FC data completion, with median improvement of ∼15% for the ADNI dataset and of ∼10% for the healthy aging dataset. Download Figure 2-1, EPS file (1.4MB, eps) .
Non-linear SC-to-FC completion
In nonlinear SC-to-FC completion, a more complex MFM (see Materials and Methods) is constructed based on the available SCemp and is simulated to generate surrogate BOLD data and the associated Pearson correlation matrix FCMFM (Fig. 3). Non-linear mechanistic MFM models are supposedly more compliant with neurophysiology than the phenomenological SLMs. Furthermore, because of their non-linearities, they are potentially able to capture complex emergent collective dynamics resulting in non-trivial dFC (which SLMs cannot render, compare Hansen et al., 2015). However, MFMs have also more parameters and are computationally costlier to simulate than SLMs.
We chose here to limit ourselves to MFMs based on a reduced Wong–Wang regional dynamics (for model equations, see Materials and Methods), which has previously been used to successfully reproduce rsFC (Deco et al., 2013) and dFC (Hansen et al., 2015) starting from empirical SC, despite its relative simplicity with respect to other possible neural masses implemented in the TVB platform. In addition to the global scale of long-range connectivity strength G, the MFM model dynamics depend also on regional dynamics parameters. In Figure 3, we froze all local parameters but the NMDA decay time-constant τ, since they affected the dynamic behavior of the model less than the other control parameters and, in particular, did not alter qualitatively the repertoire of accessible dynamical regimes (compare Fig. 3A and Extended Data Fig. 3-2). The simulated collective dynamics and the resulting nonlinear virtual FCMFM will depend on the choice of the free control parameters G and τ. In Figure 3A, we have explored the dependency of the correlation between FCMFM and the actual empirical FCemp as a function of G and τ achievable over the subjects in the ADNI SCemp + FCemp subset. As evident in Figure 3A, this dependence is non-monotonic and the best-fitting qualities are concentrated in a narrow concave stripe across the G/τ plane. Figure 3B,C reports zoom of Figure 3A into increasingly smaller regions, revealing an extended zone of high fitting quality which some absolute optimum parameters G* and τ* (here G* = ∼ 1.5 and τ* = 25).
Remarkably, this best-fitting quality zone on the G/τ plane is associated as well to other properties that can be evaluated just based on the simulated dynamics (and, therefore even when the actual target FCemp is unknown and missing). We found that the best fit quality systematically occurs in a region where three criteria are jointly met (Fig. 3D–F).
First, there is a mixture of “ignited” regions with large activation and of not yet ignited regions with a weaker firing rate (spatial heterogeneity; Fig. 3D). Conversely, when moving out of the best-fitting zone, the activity becomes more spatially homogeneous, either with all regions stable at low (for G <<< G*) or high (for G >>> G*) firing rates.
Second, the time-averaged FCMFM has a complex modular organization between order and disorder, associated to high average clustering coefficient, in contrast with the absence of clustering observed for G <<< G* or G >>> G* (structured FC; Fig. 3E).
Third, the simulated collective dynamics give rise to meta-stability of FC along time, i.e., to a non-trivially structured dFC, which alternates between “knots” of transiently slowed-down FC network reconfiguration and “leaps” of accelerated reconfigurations. Such non-triviality of dFC can be detected by the inspection of the so-called dFC matrix (Hansen et al., 2015; Arbabyazd et al., 2020; Battaglia et al., 2020; Lombardo et al., 2020), representing the similarity between FC matrices computed at different time-windows (see Materials and Methods). In this dFC matrix analysis, dFC knots are visualized as blocks with high inter-FC correlations, while dFC leaps give rise to stripes of low inter-FC correlation. The prominence of the block structure of the dFC matrix can be measured by the dFC clustering coefficient (see Materials and Methods), higher when the dFC matrix includes more evident knots. The dFC clustering coefficient is higher in the best fit zone, while it drops moving outside it toward G <<< G* or G >>> G* (structured dFC; Fig. 3F).
By scanning the G/τ plane in search of a zone with simultaneous spatial heterogeneity of activations, structured FC and structured dFC, the MFM model parameters can be tuned to bring it in a zone invariantly resulting in relatively higher fitting quality. Figure 3G shows the analysis of the expected performance of this procedure, as benchmarked by applying it on the ADNI SCemp + FCemp subset (on the center) and the healthy aging dataset (on the right). We measured a median Pearson correlation between the nonlinear virtual FCMFM and the actual empirical FCemp close to ∼0.32 for both datasets, which is larger than for FCSLM in the case of the ADNI but slightly maller in the case of healthy aging datasets.
Table 1 provides a compact pseudo-code for the nonlinear SC-to-FC completion procedure (for all details, see Materials and Methods). Non-linear SC-to-FC completions for the DTI-only subjects in the considered ADNI dataset can be downloaded as part of Extended Data 1 FC_MFM.
The value of correlation with FCemp achieved by FCMFM can thus be larger than the one achieved by FCSLM and also appear more robust, since attained in both datasets. Nevertheless, it remains necessary to check, as previously for the FCSLM, that it constitutes an improvement on the trivial strategy over taking the other connectome as substitute (i.e., taking FC to be identical to SCemp). In Extended Data Figure 2-1A, we show that this is indeed the case, unlike for linear SC-to-FC completion. The procedure sketched in Extended Data Table 1-1 led to a median improvement on using the other connectome approaching ∼20% for both datasets that can go as high as +60% in some subjects.
Linear FC-to-SC completion
In linear FC-to-SC completion, we use once again the analytic theory derived for the SLM (Saggio et al., 2016) to deterministically compute a surrogate SCSLM as a function of the available FCemp or, more precisely, of the rsBOLDemp time series used to derive FCemp. In this scheme, the linear virtual SCSLM is indeed taken to be directly proportional to the inverse covariance of the BOLD time series (see Materials and Methods). The proportionality constant would depend on the free parameters chosen for the SLM, serving as a link between FC and SC. Here, we set arbitrarily this constant to the unit value.
Extended Data Figure 4-1 shows the analysis of the expected performance of this procedure, as benchmarked by applying it on the ADNI SCemp + FCemp subset. For this ADNI dataset, we measured a median Pearson correlation between the linear virtual SCSLM and the actual empirical SCemp close to ∼0.22. On the healthy aging dataset, this correlation rose even up to ∼0.42.
Extended Data Table 2-1 provides a pseudo-code for the linear FC-to-SC completion procedure (for all details, see Materials and Methods). linear FC-to-SC completions for the BOLD-only subjects in the considered ADNI and the healthy ageing datasets can be downloaded as part of Extended Data 1 SC_SLM.
As for SC-to-FC completions, we confirmed if the performance reached by linear FC-to-SC completion is superior to the one that is obtainable through the trivial strategy of using the other connectome (in this case, the available FCemp). In Extended Data Figure 2-1B, we show that using SCSLM rather than FCemp as an ersatz for SCemp leads to drops of improvements in quality with a pattern similar to the reverse SC-to-FC completion, i.e., a drop in quality, with a median value of approximately −20%, for the ADNI dataset but an increase of ∼50% for the healthy aging dataset. Once again, thus, linear FC-to-SC completion can yield good results, but this performance did not robustly generalize through datasets.
Non-linear FC-to-SC completion
Non-linear FC-to-SC completion consists in the inference of a SCMFM matrix that, used as input to an MFM, produces as output a simulated FC* matrix highly correlated with the available empirical FCemp (Fig. 4). This nonlinear inverse problem is more sophisticated than linear FC-to-SC completion, because, for the MFM a theory providing an explicit formal link between input structural connectome (SC*) and output functional connectome (FC*) is not available, unlike for the SLM. Note indeed that MFMs, at the best-fitting dynamic working point, give rise not just to a single dynamical mode, but to a multiplicity of them (Deco and Jirsa, 2012; Hansen et al., 2015; Golos et al., 2015) and that each of them may be associated, in general, to a different state-specific FC (Battaglia et al., 2012; Hansen et al., 2015; Kirst et al., 2016) so that the final static FC* results from averaging over a mixture of different states sampled in stochastic proportions. Therefore, to derive the FC* associated with a given input SC*, it is necessary to run explicit MFM simulations, long enough to sample a variety of possible dynamical states.
Gilson et al. (2016, 2018) have introduced iterative optimization procedures aiming at updating a current guess for the input SC* to a model to improve the match between the model output FC* and a target FCemp. They initially conceived such a procedure as a form of effective connectivity analysis, aiming at constructing models which capture the origin of subtle changes between resting state and task conditions. Thus, starting from an empirical SC connectivity and from a model reproducing suitably rest FC, they slightly adjusted SC weights through an iterative procedure to morph simulated FC in the direction of specific task-based FCs. Nothing however prevents to use the same algorithm in a more radical way, to grow from purely random initial conditions a suitable effective connectome, as an ersatz of missing SCemp, compatible with the observed FCemp.
In this effective connectivity procedure connectome weights are iteratively and selectively adjusted as a function of the difference occurring between the current FC* and the target FCemp. Such optimization leads to infer refined connectomes, that, with respect to empirical DTI SC matrix, may display non-symmetric connections (distinguishing thus between “feeder” and “receiver” regions as in Gilson et al., 2016) or enhanced interhemispheric connections, usually under-estimated by DTI (as in Gilson et al., 2018). Here, we use a similar algorithm to learn a suitable nonlinear virtual SCMFM.
The initial SC*(0) is taken to be a matrix with fully random entries. An MFM embedding such SC*(0) is built and simulations are run to generate an output FC*(0) which is compared with the target FCemp of the subject for which FC-to-SC completion must be performed. The used SC*(0) is then modified into a different SC*(1) = SC*(0) + λΔFC(0) matrix, by performing a small update step in the direction of the gradient defined by the difference ΔFC(0) = FCemp – FC*(0). A new simulation is then run to produce a new FC(1). The produce is repeated generating new SC(1) = SC(i-1) + λΔFC(i-1) until when the difference between FC(1) and the target FCemp becomes smaller than a specified tolerance, i.e., |ΔFC(1)| < ε. The last generation SC(1) is then taken as nonlinear virtual surrogate SCMFM (for details, see Materials and Methods).
Figure 4A provides an illustration of the nonlinear FC-to-SC completion when applied to subjects in the ADNI ADNI SCemp + FCemp subset. In the first step, the matrix SC*(0) is random and there is no correlation between the output FC*(0) and FCemp. Advancing through the iterations, SC*(k) develops gradually more complex internal structures and correspondingly, the correlation between FC*(k) and FCemp increases until when it reaches the desired quality threshold, here set to CCtarget = 0.7. This threshold quality is usually reached after ∼1500 iterations. In the ADNI SCemp + FCemp subset we take advantage of the availability of the actual SCemp to quantify as well the convergence of SC*(k) toward SCemp. Figure 4A shows that advancing through the iterations, the correlation between SC*(k) and SCemp improves, in agreement with our hypothesis that effective connectivity can provide a reasonable replacement for SC. The expected quality of reconstruction, as estimated from results on the ADNI SCemp + FCemp subset is reported in Figure 4B and amounts to an expected correlation between SCMFM and SCemp of ∼0.31. For the healthy aging dataset, we obtain a slightly smaller median value of ∼0.28, but the difference is not statistically significant.
Table 2 provides a compact pseudo-code for the nonlinear FC-to-SC completion procedure (for all details, see Materials and Methods). Non-linear FC-to-SC completions for the BOLD-only subjects in the considered ADNI dataset can be downloaded as part of Extended Data 1 SC_MFM.
As for SC-to-FC completion, we then confirmed if the nonlinear FC-to-SC completion SCMFM does provide a superior reconstruction of SCemp than the trivial alternative offered by just taking the other connectome (the available FCemp). As shown in Extended Data Figure 2-1B, the use of nonlinear FC-to-SC completion led to a median improvement on the order of ∼15% for the ADNI dataset and of ∼10% for the healthy aging dataset. If the improvement achieved by nonlinear completion is smaller than for linear completion in the healthy aging dataset, nonlinear FC-to-SC completions succeeds in the ADNI dataset where its linear counterpart failed. Therefore, nonlinear FC-to-SC computational generation provides a worthy strategy for data completion, although not yet as efficient as SC-to-FC completion.
We note that nonlinear FC-to-SC completion, as for nonlinear SC-to-FC completion, is a non- deterministic procedure, meaning that a different SCMFM is generated depending on the starting initial condition SC*(0). However, the different nonlinear virtual surrogates lie at distances from the common actual ground truth SCemp which are tightly concentrated around the median correlation. As revealed by Figure 4C, the reported correlations between SCMFM and SCemp were within a narrow interval of ±2.5% of the relative difference from the median distance for all the tested random initial conditions (30 per subject, see Materials and Methods), showing that the expected performance is poorly affected by the initial conditions. This stochastic aspect of the nonlinear completion algorithm is going to allow us to generate not just one but arbitrarily many completions, starting from each available empirical connectivity matrix (see later section).
Virtual and bivirtual duals
SLMs and MFMs have thus the capacity to bridge from SC to FC or from FC to SC in a way that, in most cases, goes beyond capturing the mere similarity between the empirical SCemp and FCemp connectomes. When using these models for data completion, the input matrix is always an empirical matrix (SCemp or FCemp) and the output a surrogate virtual matrix (respectively, FCvirt or SCvirt, where the index “virt” refers generally to any completion algorithm, i.e., either using the SLM or the MFM models). However, the algorithms presented in Tables 1, 2 and Extended Data Tables 1-1, 2-1 can still be applied even when the input connectivity matrix is already a virtual matrix. In this case, the input could be surrogate matrices (SCvirt or FCvirt) from data completion and the output would be bivirtual (respectively, FCbivirt or SCbivirt), i.e., twice virtual, since, to obtain them starting from an empirical input connectome, two different model-based procedures have to be chained. The final result of passing an original empirical connectome through two chained completion procedures is then a bivirtual surrogate matrix of the same type (structural or functional) of the initially fed connectome. In other words, SCemp is mapped to a SCbivirt (passing through an intermediate FCvirt step) and FCemp is mapped to an FCbivirt (passing through an intermediate SCvirt step). If the information loss is not too high, pairs of virtual and bivirtual SC and FC connectomes should be shared instead of pairs involving empirical connectomes, potentially reducing difficulties to disclosing in public personal clinical data (see Discussion).
The virtual and bivirtual matrices obtained by operations of data-completion can be seen as a set of connectomes dual to the original real connectome. In mathematics, one often speaks of “duality” relations when two alternative spaces are put into relation by an element-to-element structure-preserving mapping. Here, one could reinterpret our algorithmic procedures for SC-to-FC or FC-to-SC completion as mapping between alternative “spaces” in which to describe the interrelations between the connectomes of different subjects. Although our definition of duality is not as rigorous as in more mathematical contexts (as in the case, e.g., of linear algebra dual or bidual spaces; or in graph theory, where duality refers to node-to-link transformations), we will see that dissimilarities or similarities between the personalized connectomes of different subjects are substantially preserved by the application of completion procedure that maps an original space of empirical connectomes into a dual space of virtual connectomes. In other way, the information carried by a set of connectomes and by the set of their dual counterparts is, at least in part, equivalent (compare Figs. 5-7; Table 3; Discussion). In this view, the first “dualization” operation would map a real connectome to a virtual connectome of a different type (a virtual dual, swapping SC with FC). The second dualization would then map it to a bivirtual dual of the same type (mapping SC to SC and FC to FC; compare Figs. 5A,B, center cartoons, 7A). If the completion quality is good, then empirical connectomes and their bivirtual duals should be highly related between them. Before, discussing more in detail the crucial issue of the preservation or loss of personalized information in duals, we start here by performing a self-consistency check of the data completion procedures and compare thus the start (FCemp or SCemp) and the end (FCbivirt or SCbivirt) points of dualization chains.
Figure 5.

Bivirtual connectomes. This figure shows the correspondence between empirical and bivirtual SC and FC pairs, both when using chained linear (SLM-based) and nonlinear (MFM-based) completion procedures. A, For 88 subjects from the ADNI-subset with only SCemp available, considering the linear bivirtual completion chain SCemp to FCSLM to SCbi-SLM, we obtained a median correlation between SCemp and SCbi-SLM equal to 0.63 and 0.92 for 49 subjects from the healthy ageing dataset (green boxplot); simultaneously, considering the nonlinear bivirtual completion chain SCemp to FCMFM to SCbi-MFM, we obtained a median correlation between SCemp and SCbi-MFM equal to 0.58 for the ADNI datast and 0.64 for the healthy ageing dataset (blue boxplot). B, For 168 subjects from the ADNI-subset with only FCemp available, considering the linear bivirtual completion chain FCemp to SCSLM to FCbi-SLM, we obtained a median correlation between FCemp and FCbi-SLM equal to 0.12 and 0.42 for 49 subjects from healthy ageing dataset (green boxplot); simultaneously, considering the nonlinear bivirtual completion chain FCemp to SCMFM to FCbi-MFM, we obtained a median correlation between FCemp and FCbi-MFM equal to 0.59 for the ADNI dataset and 0.45 for the healthy ageing dataset (blue boxplot).
Figure 5 shows the correspondence between empirical and bivirtual SC and FC pairs, both when using SLM-based and MFM-based procedures. We first evaluated the quality of SCbivirt generation, over the ADNI-subset of 88 subjects for which a SCemp matrix was available and over the healthy aging dataset (Fig. 5A). Considering the nonlinear bivirtual completion chain SCemp to FCMFM to SCbi-MFM we obtained a median correlation between SCemp and SCbi-MFM of ∼0.58 for ADNI dataset and ∼0.64 for the healthy aging dataset. This quality of rendering aligned well with the performance of the linear bi-virtual completion with a correlation between SCemp and SCbi-SLM of ∼0.63 for the ADNI dataset. On the healthy aging dataset, linear bivirtual duals SCbi-SLM were of exceptionally high quality, reaching a correlation with SCemp nearly as high as ∼0.92.
We then evaluated the quality of FCbivirt generation over the ADNI-subset of 168 subjects for which an FCemp matrix was available and over the healthy aging dataset (Fig. 5B). Considering the nonlinear bivirtual completion chain FCemp to SCMFM to FCbi-MFM the median correlation between FCemp and FCbi-MFM was of ∼0.59 for the ADNI dataset and of ∼0.45 for the healthy aging dataset. Moving to linear bivirtual FCbi-SLM, the performance on the healthy aging dataset was of ∼0.42, equivalent to the nonlinear duals. However, linear bivirtual dualization failed for the ADNI dataset, with a correlation dropping to ∼0.12, not surprisingly given the poor quality of already the first step from FCemp to SCMFM. Even in this latter case, nevertheless, the empirical-to-bivirtual correlations remained significant.
Are dual connectomes still personalized?
Although significant, correlations between virtual and bivirtual with matching empirical connectomes can be small. Is this average performance sufficient not to lose subject-specific information through the various steps of transformation? The most straightforward way to answer to this question is to check whether FC(bi)virt or SC(bi)virt connectomes are closer to the FCemp or SCemp of the same subject from which they derive than to the ones of other generic subjects. Since SCs and FCs are related but not identical and their divergence can be stronger or weaker depending on the subjects (Zimmermann et al., 2019) the answer to this question is not obvious and must be checked.
We therefore introduced a measure of the improvement in connectome matching obtained by using personalized virtual and bivirtual duals rather than generic connectomes. The coefficient ΔPers (see Materials and Methods) quantifying the percent improvement obtained by using personalized connectomes are tabulated in Table 5 for the different types of completion.
Table 5.
Percent improvement in connectome matching obtained by using personalized virtual and bivirtual duals
| Type of completion | ΔPers ADNI | ΔPers healthy aging |
|
|---|---|---|---|
| SCemp to FCvirt | Linear | +26 7% | +12 4% |
| Nonlinear | +17 ± 5% | +13 ± 4% | |
| SCemp to SCbivirt | Linear | +40 18% | +23 8% |
| Nonlinear | +17 5% | +13 4% | |
| FCemp to SCvirt | Linear | +51 35% | +28 22% |
| Nonlinear | +200 37% | +87 19% | |
| FCemp to FCbivirt | Linear | +46 70% | +17 28% |
| Nonlinear | +297 140% | +108 52% | |
| FCemp test/retest ΔPers | +22 13% | ||
Indicated values for real/virtual and bivirtual dual are mean ± SD of the mean over subjects.
Improvements by personalization were always positive, indicating that on average some subject-specific information is preserved. These numbers, however, are diverse between datasets and completion types. Furthermore, they should be compared with the uncertainty itself existing on empirical connectomes. Indeed the ΔPers analysis implicitly assume that empirical connectomes are exact reference comparison terms. In reality, there is a strong uncertainty on empirical connectome themselves, with an elevated test-retest variability within individual subjects (Wang et al., 2012; Chen et al., 2015; Termenon et al., 2016). In particular, the connectomic dataset released together with the study by Termenon et al. (2016) allows an evaluation of what would be the expected “empirical personalization improvement” in the case in which we actually had to compare two connectomes obtained empirically for a same subject and assess how more similar are they between them, than to a connectome of the same type but obtained from a different subject. Termenon et al. (2016) considers data mediated from the Human Connectome Project and provides for 100 subjects two different FCemp matrices deriving from different scans. Using a definition of the ΔPers coefficient analogous to the one used for virtual and bivirtual completions but adapted to these test-retest empirical dataset, one can estimate a value of ΔPers of about ∼+22% for empirical FCs. In other words, the similarity between two FCemp from a same subject is expected to be only a 22% larger than similarity with FCemp from different subjects. We do not dispose of an analogous estimation for SCemp connectomes, however we expect personalization improvements to be even in this case comparable in value, if not smaller, given that intersubject variability for SCemp connectomes tend to be smaller than for FCemp (Zimmermann et al., 2019).
The ΔPers registered for bivirtual dual connectomes are of the same order of magnitude than this empirical expectancy allowing us to conclude that they are “personalized” at least as much as empirical connectomes (and at least according to this rough ΔPers measure). In some cases, notably for nonlinear bivirtual FC duals, the similarity with the original empirical connectome is way larger than what expected for empirical test-retest scans, probably because of the fact, that the effective connectivity algorithm used for FCemp to SCMFM nonlinear completion emphasize similarities between SC and FC, thus allowing FCbi-MFM to more faithfully mirror FCemp without being fully identical to it (average correlation between FCbi-MFM and FCemp is of ∼0.4–0.6; compare Fig. 5B). Remarkably, this strong preservation of personalization by bivirtual duals is achieved despite smaller relative improvements by personalization at the first step of the dualization chain, e.g., the transition from empirical to simple virtual duals. This means that the variability generated in the simulation leading to virtual duals, although large must maintain important subject-specific features useful to regenerate a good personalization at the following stage of generating the bivirtual dual. This also means that the ΔPers measure could be a too rough and not sensitive enough metric of personalization, since it weights equally any difference or similarity in the connectomes, independently from their relevance. Better, complementary measures of personalization are thus needed.
Since individual connectomes are affected by a necessary uncertainty a more reliable measure of the quality of personalization can be achieved by looking at the capacity of dualization to preserve overall preservation of intersubject relations rather than specific individual data-points. Indeed, individual connectomes could be distorted through the mapping into dual virtual and bivirtual spaces, but if the distortion is such to maintain the subject’s connectome close to other subjects’ connectome to which it was close and far from other subjects’ connectome from which it was far, then the possibility to discriminate subject categories based on connectome features could still be preserved. Therefore, we computed the distances between the empirical connectomes SCemp (or FCemp) of different subjects and the intersubject distances for corresponding pairs of subjects but, this time, between their bivirtual dual connectomes SCbi-virt (or FCbi-virt). As shown in Figure 6 and Extended Data Table 5-1, the correlation between the intersubject distances in real and bidual spaces were noticeable and significant, for both ADNI and healthy aging datasets and for both MFM-based and SLM-based approaches (Extended Data Table 5-1), apart from the very poor performance of bivirtual linear FC completion in the ADNI (expected, given previously reported failures in this case). We also noticed that distances between bivirtual duals were often amplified, with respect to the original empirical distances. The space of dual bivirtual connectomes can thus be considered as a “virtual mirror” of the real connectome space, reproducing to a reasonable extent despite some deformation of the geometry of the original distribution of subjects.
Inter-subject distances for empirical - bivirtual pairs. Download Table 5-1, DOCX file (16.6KB, docx) .
Subject classification based on real and virtual connectomes
The compilation of large datasets, including connectivity data from structural and functional neuroimaging is considered essential for the development of algorithmic patient stratification and predictive approaches. Here, we have described approaches for connectomic data completion and studied their consistency. We now show that such completion procedures are also compliant, in perspective, with the extraction via machine learning algorithms of the personalized information preserved in duals.
As a first proof-of-concept, we studied here two simple (and academic) supervised classification problems in which subjects are separated into different classes based on connectomic features, empirical and/or virtual, used as input. First, in the ADNI dataset, we try separating subjects into two subgroups of control and patients (i.e., MCI or AD) subjects. Second, in the healthy aging dataset, we separate subjects into four classes of age, from the youngest to the oldest. Importantly, input features can be computed from all different types of connectomes (at least for the subjects for which they were available): empirical SCemp or FCemp; their virtual duals FCMFM or SCMFM; or their bivirtual duals SCbi-MFM or FCbi-MFM (see Fig. 7).
Discriminating control and patient subjects in the ADNI dataset
For the first toy classification problem, we used target classification labels already provided within the ADNI dataset, assuming them to be exact (for a summary of the used stratification criteria, see Materials and Methods). We performed then classification based on input vectors of regional node strengths estimated subject-by-subject from the connectome matrices of interest (Q = 96 input features, corresponding to the number of brain regions in the used parcellation, see Materials and Methods). As supervised classifier algorithm, we chose a variant (Seiffert et al., 2010) of the random forest algorithm, which is particularly suitable when the number of input features is of the same order of the number of available data-points in the training set (Breiman, 2001), as in our case.
Examples of ADNI classifications based on empirical connectomes are shown in Figure 7, notably, based on SCemp matrices (Fig. 7B, green line) or on FCemp matrices (Fig. 7C, green line). The available subjects were randomly split into a training set and a testing set (with maintained relative proportions of the different classification labels). Figure 7B,C describe the average generalization performance for classifiers trained on the training set and evaluated on a testing set. Training and testing on real empirical connectomes, we achieved a moderate but significantly above chance level classification performance, as revealed by the green Receiver-Operator-Curves (ROC) in Figure 7B,C, for both SCemp and FCemp connectomes, deviating away from the diagonal (corresponding to chance level classification performance). As a more quantitative measure, one can also measure the median area under the ROC curve (AUC), here equal to ∼0.69 for the SCemp on SCemp classifier and to ∼0.75 for the FCemp on FCemp classifier. AUC scores for different types of classification on the ADNI dataset are compiled in Extended Data Table 3-1, Table 3-2.
Discriminating control and patient subjects in the ADNI subset with only SC connectomes. Download Table 3-1, DOCX file (16.6KB, docx) .
Discriminating control and patient subjects in the ADNI subset with only FC connectomes. Download Table 3-2, DOCX file (16.6KB, docx) .
Age class discriminations on the healthy ageing dataset. A, The classification performances when the classifier was train and tested on the same virtual connectome is above chance level (∼0.25) with maximum accuracy of ∼0.42 for FCSLM-bi and minimum accuracy of ∼0.29 for FCMFM-bi. B, The classification accuracy dropped when the classifier was trained on the virtual connectome and tested on the empirical connectome. The only cases where the accuracy was above chance level was when the classifier was trained on SCSLM and SCSLM-bi and tested on FCemp connectome, with an accuracy of ∼0.28. Download Figure 7-1, EPS file (2.5MB, eps) .
We considered then ADNI classification based on virtual and bivirtual duals instead of empirical connectomes. In this case of “dual space classification” (Fig. 7B), virtual and bivirtual duals are used both when training the classifiers and when evaluating them. Therefore, to classify a new empirical connectome with a “dual space classifier,” it is first necessary to “lift” it in dual space, i.e., to map it via data completion algorithms to the suitable type of dual for which the classifier has been trained. Figure 7B shows two examples of dual space ADNI classification based on FCMFM (blue curve, median AUC ∼0.64) and SCbiMFM (magenta curve, median AUC ∼0.59), respectively, virtual dual and bivirtual duals of the real connectomes SCemp. Once again, for both virtual and bivirtual duals, classification performance remained above chance level. While the classification performance drops slightly with respect to classification with the actual empirical connectomes, this drop was not significant for a broad range of the most conservative decision thresholds. Above chance-level classification is thus possible as well using dual connectomes generated from data completion, achieving performances substantially equivalent to the one obtained for empirical connectomes.
We considered finally the case of ADNI classifiers trained on bivirtual duals and then evaluated on empirical connectomes (Fig. 7C). In this case of “cross-space classification,” the trained classifier is able to operate in a performing manner as well on a different type of connectomes (e.g., empirical) than the one for which it has been trained (e.g., bivirtual dual). Therefore, to classify a new empirical connectome with a “cross-space classifier,” it is not necessary to first lift in dual space as for dual space classifiers. Figure 7C shows an example of cross-space classification trained on bivirtual dual FCbiMFM and then tested on FCemp (orange curve, median AUC ∼0.70). Remarkably, the performance was not significantly different for most decision thresholds from classification trained and tested on empirical FCemp connectomes. Therefore, classification of empirical connectomes based on classifier trained on virtual connectomes is possible as well.
Significant classification was possible even for some other combinations of connectomes (see Extended Data Table 3-1, Table 3-2); however, performance was poorer in most cases. We did not attempt classification based on SLM-based virtual and bivirtual duals, given the deceiving quality of connectome rendering by these linear methods (in the ADNI dataset).
Discriminating age classes in the healthy aging dataset
For the second toy classification problem, we split the subjects in the healthy aging datasets into four age categories and used the ordinal number of the age class from I to IV as target classification label. As input features we did not use any more high-dimensional vectors of connection strengths but the loadings on the first 10 principal components of each connectivity matrices. As classifier we still used random forests Breiman algorithm (for full detail, see Materials and Methods). As before, we highlight here a few examples of classification with real empirical connectomes (Fig. 7D), classification in dual space (Fig. 7E) and cross-space classification (Fig. 7F). We characterize performance both in terms of general accuracy (fraction of subjects correctly classified in their age class) and of detailed confusion matrices between the actual and the predicted age classes, revealing typical error syndromes. General accuracies were typically above the chance level of ∼25%, approaching (or exceeding), for instance, ∼37% for classifiers: trained and tested on SCemp (Fig. 7D, center, ∼37% accuracy) or FCemp (Fig. 7D, right, ∼43% accuracy), or, in virtual dual space, on SCSLM (Fig. 7E, center, ∼45% accuracy) or FCMFM (Fig. 6D, center, ∼43% accuracy). For cross-space classification examples, accuracies dropped but remained, e.g., of ∼35% for classifiers trained on SCMFM and generalized on FCemp (Fig. 7F, center) or of ∼30% when trained on FCSLM and tested on FCemp. More examples are shown in Extended Data Figure 7-1, including for classifiers using bivirtual connectomes (e.g., classifiers trained and tested on FCbi-SLM with an accuracy of ∼42%; but a minority of classifications were below chance level, e.g., trained on FCbi-SLM and tested on FCemp, with an accuracy of only ∼19%).
General accuracy does not reflect fully the performance, since it averages over all possible classes. The capability to proper classify subjects of specific classes could be much larger. For instance, all but one of the classifiers highlighted in Figure 7D–F would classify elderly subjects in the IVth age class (58–80 years) with accuracies exceeding ∼60%. Furthermore, when misclassified, subjects tended to be attributed to neighboring but not radically different age classes, e.g., Class I (18–25 years) with Class II (26–39), or Class IV (58–80 years) with Class III (40–57), more rarely mixing up classes with stronger age separation. Such misclassification may also reflect meaningfully differences between subjects, whose connectome could look “younger” or “older” than the median of their age class, possibly reflecting cognitive differences, large within each age class (compare Glisky, 2007; Battaglia et al., 2020). The analysis of factors explaining misclassification goes however beyond the scope of the present study.
As a matter of fact, we are still far from providing authentically useful examples of classification, neither on the ADNI dataset nor on the healthy aging dataset. However, this was not our aim here, the chosen classification problems themselves being rather academic and serving as first proofs-of-concept. Importantly, we can at least show that dual and cross-space classification performance, if not good, was not much worse than for real empirical connectomes. This step is already sufficient to show that empirical and virtual duals share an extractable part of information and that this shared information can be still relevant for classification.
Such information preservation, despite loose correspondence, can be explained by revealing the similarity of network topology features between real connectomes and their bivirtual duals, independently from our capacity to achieve more or less performing classifications based on these features.
Matching network topology between real and virtual connectomes
The connectome matrices describe the weighted undirected topology of graphs of structural or FC. All information conveyed by these connectomes about pathology or other conditions is potentially encoded into this network topology. While genuine model-free analyses of network topology across all scales are still under development, see, for instance, promising topological data analyses approaches (Petri et al., 2014; Sizemore et al., 2018), classic graph theoretical features provide a first multifaceted characterization of the specific features of each individual connectome object (Bullmore and Sporns, 2009). We evaluated here for each empirical connectome SCemp or FCemp a spectrum of different graph theoretical features. In particular we evaluated for both the ADNI and the healthy aging datasets and for each brain region within each of the connectomes (for details, see Materials and Methods): the total strengths (sum of the connection weights of all the links incident the region), the clustering coefficients (tendency of the regions neighboring to the considered node to also be interconnected between them), and the centrality coefficients (tendency for any path linking two different nodes in the network to pass through the considered node), evaluated via the PageRank algorithm (Brin and Page, 1998). We also evaluated for each connectome its modular partition into communities, by using a Louvain algorithm with default parameters (Blondel et al., 2008). Finally, we also inspected the global link weight distributions. We then evaluated analogous quantities for the dual connectomes associated with each of the connectomes, focusing here, for conciseness and simplicity, on bivirtual duals, sharing a common nature (structural or functional) with their correspondent empirical partner.
In Figure 8, we illustrate this correspondence between graph-theoretical features evaluated for different real/bivirtual dual connectome pairs in the ADNI dataset. An analogous figure for the healthy aging dataset is shown in Extended Data Figure 8-1, showing qualitatively equivalent results. To compare node degrees, clustering and centrality features we plot, for every brain region in every connectome, the feature value evaluated in a real connectome against the corresponding feature value evaluated in the associated bivirtual dual. To compare community structures, we evaluate for every real/bivirtual dual connectome pair the relative mutual information MI normalized by entropy H (see Materials and Methods) between the community labels extracted for the two connectomes, with 0% ≤ MI/H ≤ 100% and 100% corresponding to perfect overlap. We show results for ADNI (or healthy aging) SC real/bivirtual dual pairs in Figure 8A (Extended Data Fig. 8-1A) and for FC pairs in Figure 8B (Extended Data Fig. 8-1B). In all cases we find correspondence between real and bivirtual dual connectome features significantly above chance levels. Highly significant real/bivirtual dual correlations subsist for regional strengths and centralities. For ADNI FC, these correlations can become as high as CCmedian = 0.66 (95% bootstrap confidence interval) for regional strengths and CCmedian = 0.55 (95% bootstrap confidence interval) for regional centralities. Correlations are found even for regional clustering coefficients, even if the small values of clustering coefficients observed in SCemp connectomes are systematically overestimated in the denser bivirtual dual SCbiMFM. Finally, concerning community matching, for SC and FC real/bivirtual dual pairs we found a median relative mutual information of ∼61% and ∼45%, respectively, for the ADNI dataset, safely above chance level (estimated at ∼16%, permutation-based 95% confidence interval; see Table 3 for the superior correspondence at the single subject level). For the healthy aging dataset, for both SC and FC these correlations were even higher (Extended Data Fig. 8-1) with CCmedian 0.8 for regional strengths, centralities, and clustering coefficients of SC real/bivirtual dual parts and CCmedian 0.7 for the FC real/bivirtual dual parts. Finally, for the community matching for SC pairs the median relative mutual information was ∼44% and for FC pairs ∼50% (see Table 4 for the superior correspondence at the single subject level for healthy aging dataset).
Correspondence of network topology between empirical and their bivirtual dual connectomes (healthy aging dataset). We show here scatter plots of connectivity strengths (top center), local clustering coefficients (top right) and local centrality coefficients (bottom center) for different brain regions and subjects, plotting feature values for empirical connectomes versus their bivirtual counterparts and the histograms over different subjects of the relative mutual information (normalized between 0 and 1, the latter corresponding to perfect matching) between the community structures (bottom right) of empirical connectomes and their bivirtual duals. Results are shown in panel A for SC and in panel B for FC connectomes for the healthy ageing dataset (see Fig. 8 for the comparison with the ADNI dataset). Again, for both cases, we see a remarkable correlation at the ensemble level between network topology features for empirical bivirtual connectomes (see Table 4 for the superior correspondence at the single subject level for the ageing dataset). Download Figure 8-1, EPS file (9.8MB, eps) .
The analyses of Figure 8 and Extended Data Figure 8-1 are performed at the ensemble level, i.e., pooling network features estimated from different subjects into a same point cloud. However, network features can have important variations of values not only across regions but also across subjects, which is expected to be a key indicator of subject-specific traits useful for classification. The capability to preserve these traits would thus be a crucial factor allowing the achievement of personalization when generating virtual and bivirtual duals. Therefore, we computed correlations between vectors of regional features in real and empirical connectomes but now limited to be within individual subjects obtaining thus, for every feature type, a different correlation value for every subject. Table 3 (for the ADNI dataset) and Table 4 (for the healthy aging dataset) show that within-subject correlations were also high (apart for SC clustering) and, for FC, even superior to ensemble-level correlations, manifesting, once again, the personalized nature of bivirtual dual connectomes. Indeed, when computing personalized correlations for pairs of real and bivirtual connectomes associated to a same matching subject, they resulted systematically superior to unpersonalized control correlations evaluated over real/bivirtual connectome pairs assembled out of different subjects (see Materials and Methods). Percent improvements in same-subject real/dual correlations with respect to average correlations in cross-subject pairs are compiled as well in Tables 3, 4. Personalization can lead to very strong percent improvements in real/virtual topology correlations, particularly in the case of FC connectomes. The operation of dualization thus preserves aspects of network topology which are specific to each subject and not just generic to a connectome ensemble.
Finally, we plot in Extended Data Figure 6-1, global distributions of link weights for the different types of connectomes and both datasets. Most distributions displayed an overall similarity in shape: SC weights distributions with a peak at small values and a fat right tail; FC weights distribution more symmetric and with a broader peak at intermediate strengths. These different distribution shapes reflect that SCemp networks are diluted matrices with a few strong connections only, while FCemp networks have a higher and more uniform density of connections. Virtual and bivirtual SC connectomes tend to have fatter right tails (and even displaced mode peaks for SCMFM), reflecting that, in absence of any arbitrary sparsification strategy, completion pipelines generate surrogate SCs without the sparsity constraint and, thus, with less near-zero link weights. Such systematic discrepancy, well visible in Extended Data Figure 6-1, however, does not prevent correlations between single subject-specific connectivity traits to remain strong, which is a necessary condition for personalized predictive information preservation.
The global distributions of link weights for all different types of connectomes. Most of the distributions show similarity in shape with their empirical counterparts (pink). SC weights distributions with a peak for small values and a fat right tail; FC weights distributions with more symmetric and a broader peak at intermediate strengths. Download Figure 6-1, EPS file (597.2KB, eps) .
Virtual cohorts
All nonlinear data completion algorithms involve a stochastic component. Therefore, by construction, each simulation run will provide different virtual and bivirtual connectomes, associated with the same empirical seed connectome. This property allows the generation of an arbitrarily large ensemble of surrogate virtual connectomes, forming the virtual cohorts associated with a specific subject (see Materials and Methods). Every virtual cohort maintains a strict relation to its empirical counterparts because all the matrices in the cohort are dual to the same original empirical connectome. In particular, distances between virtual connectomes sampled within two different virtual cohorts were always closely correlated to the distance between the respective seed connectomes of the two cohorts. The close relationship between the original data and the respective virtual cohorts (already studied in Fig. 6 for individual instances of bivirtual connectomes) is visually manifested in Figure 9A where a distance-respecting nonlinear t-SNE projection (Maaten and Hinton, 2008) has been used to represent in two dimensions the virtual cohorts of surrogate virtual FCMFMs associated to the 88 subjects with available SCemp in the ADNI dataset (among which, thus, also the 12 of the SC + FC subset). Every dot corresponds here to the two-dimensional projection of a high-dimensional virtual dual FCMFM (100 different virtual FCMFMs have been generated starting from each one of the 88 SCemp connectomes). Clusters of dots (color-coded by their nature, of control subjects or MCI and AD patients) are visually evident in the projection indicating that the distance between dual connectomes within each virtual cohort is smaller than the distance between dual connectomes belonging to different cohorts.
We also plotted, for comparison, the cloud of the projected FCemp connectomes for the twelve subjects of the ADNI SC + FC dataset for which it was available, and connected these projections via a thin line to the projection of one of their virtual FCMFM images in the corresponding subjects’ virtual cohorts. The projections for all the FCemp connectomes seem to collapse in a single additional cluster close to the center of the global t-SNE map. This collapse manifests that empirical connectomes and virtual connectomes live in different spaces, as previously stressed (Fig. 7A). Eventually, when projecting a sample composed of hundred more virtual than empirical connectomes, the two-dimensional rendering of the original high-dimensional metric relations is dominated by virtual connectomes. Therefore, the cloud of the empirical connectomes’ projections appears, using a figurative image, as a “distant galaxy,” with the dots (“stars”) associated to different subjects appearing grouped in a small region of the observation field. Nevertheless, the distances between stars within the distant galaxy are mirrored by the distances between the foreground FCMFM cohorts “globular clusters” mapped to each of these distant background FCemp stars. The thin lines linking FCemp to one of their FCMFM images reveal indeed the global t-SNE projection contains an exploded view of the projection of the original SC + FC subset FCemp connectomes (further confirming for virtual cohorts the preservation of intersubject distances in bivirtual duals revealed by Tables 3, 4).
A further analogy could be drawn between generating a cohort of virtual connectomes rather than a single virtual connectome and between generating an ensemble of slightly rotated or distorted images (Fig. 9B). Different connectomes in a same cohort could be conceptualized as different “views” of the same connectome (as the four representative connectomes in the top of Fig. 9B, sampled within the cohort of a same subject) much like different transformations of a single image that modify the exact appearance but do not prevent losing the identity of the depicted object (as the four warped kittens at the bottom of Fig. 9B). For these reasons, the generation of virtual cohorts including a larger number of identity-preserving redundant connectome items may become in perspective beneficial to classifiers training, as a form of “data augmentation,” commonly used in machine learning applications in image recognition (Taylor and Nitschke, 2018; see Discussion).
Discussion
We have here demonstrated the feasibility of connectomic dataset completion using algorithms based on mean-field computational modeling. In particular, we have completed an ADNI gold standard connectomic dataset and verified that analogous completion performance could be reached on a control healthy aging dataset. We have then shown that machine learning classifiers trained on virtual connectomes can reach comparable performance to those trained on empirical connectomes. This renders the classification of novel empirical connectomes via classifiers trained exclusively on virtual connectomes possible. Furthermore, the generation of virtual and bivirtual dual connectomes is a procedure preserving at least some personalized information about detailed network topology. As a consequence, virtual cohorts offer an immense opportunity to enable or unblock, and, in perspective, possibly improve machine learning efforts on large patient databases.
Incomplete datasets for clinical research are certainly among the factors contributing to slow progress in the development of new diagnostic and therapeutic tools in neurodegenerative diseases and AD in particular. Our data completion procedures provide a step forward toward “filling dataset gaps” since they allowed us to infer FC when only SC was available or SC when only FC were available. Such procedures for data completion could easily be implemented within popular neuroinformatic platforms as TVB. TVB provides practical graphical interfaces or fully scriptable code-line environments for “plug-and-play” large-scale brain network behavior, signal emulation, and dataset management, including simulating SC and FC with adjustable complexity MFMs or SLMs (Sanz-Leon et al., 2013). In this way, capitalizing on the software built-in capabilities, even the more elaborated nonlinear completion algorithms could become accessible to non-expert users with only a little training. The possibility of having access to both types of connectomic information brought up by model-based data completion is vital because structural and FC convey complementary information. It has been shown for instance, that analyses of SC-to-FC interrelations can yield better characterizations and group discriminations than analyses of SC or FC alone in a variety of pathologies or conditions (Zhang et al., 2011; Davis et al., 2012; Zimmermann et al., 2016; Straathof et al., 2019).
Indeed, FC networks in the resting-state do not merely mirror SC but are believed to be the by-product of complex dynamics of multiscale brain circuits (Honey et al., 2007; Deco et al., 2011). As such, they are constrained but not entirely determined by the underlying anatomy (encoded in the SC matrix), as also confirmed by the fact that variability between FCs of different subjects may be larger than the one between SCs (Zimmermann et al., 2019). Indeed, FC also carries valuable information about the dynamic regime giving rise to the observed resting-state activity fluctuations (Hansen et al., 2015) and FC differences are thus leveraged by the nonlinear effects of dynamics that small variations in SC can have and that MFM models can in principle capture.
In particular, brain networks are thought to operate at a regime close to criticality. For a fixed SC, the resulting FC would be different depending on how closely dynamics is tuned to be in proximity of a critical working point (Deco et al., 2013; Hansen et al., 2015). This information that brain networks are supposed to operate close to a critical boundary is used to generate the surrogate virtual FCMFM, when performing nonlinear SC-to-FC completion. Thus, FCMFM carries indirectly extra information about a (putative) dynamic regime that was not conveyed by the original empirical SC (nor by virtual completions with linear SLM-based pipelines). This effective “reinjection” of information could potentially compensate for unavoidable loss, compare “data processing inequality” (Cover and Thomas, 2006), along the algorithmic processing chain represented by completion. This could be a possible explanation for the superior performance of nonlinear methods in the ADNI dataset completion. For this compensation to happen, however, the guess about the right working point should be close to reality. In this paper we were implicitly supposing that all the subjects have the same working point of dynamic operation (e.g., the same distance from critical rate instability; Hansen et al., 2015). Now, pathology or aging may precisely be also altering this working point itself, making of our assumption in MFM-based completion only an approximation. For instance, the distributions of matching between empirical and virtual community structure in FC connectomes for the healthy aging dataset (Extended Data Fig. 8-1B) are clearly bimodal, indicating that the used completion ansatz may be more appropriate for certain subjects than for others. Thus, diverse working points of dynamic operation for different subjects, here not accounted for, may contribute to the inferior performance of nonlinear methods in the healthy aging dataset. We defer to future studies considerations about how to further optimize the selection of a working point.
When both empirical SC and FC were available, we could measure the quality of reconstruction achieved by our models. The correlation reached between empirical and reconstructed connectivity matrices is only moderate, however. There are multiple reasons for this limited performance. One evident reason is the simplicity of the neural mass model adopted in our proof-of-concept illustration. The Wong–Wang neural mass model is able only to express two states of lower or higher local activation (Wong and Wang, 2006). Instead, neuronal populations can display a much more extensive repertoire of possible dynamics, including, e.g., coherent oscillations at multiple frequencies, bursting, or chaotic trajectories (Stefanescu and Jirsa, 2008; Spiegler et al., 2011). Synchronization in a network depends on various factors, including frequency, network topology, and time delays via signal propagation, all of which have been ignored here and in large parts of the literature (Deco et al., 2009; Petkoski and Jirsa, 2019). It is acknowledged that delay-less approaches serve as a useful approximation (Deco et al., 2015). Nevertheless, we are aware that our choice to restrict our analyses on the subset of activation-based mechanisms introduces critical limitations. Indeed, our models, ignoring delay-mediated synchronization, are incapable of capturing a range of dynamic oscillatory behaviors, such as multifrequency coupling or multiphase coupling. More sophisticated mean-field virtual brain models could thus reach superior performance (Stefanovski et al., 2019), going beyond the first proof-of-concept examples presented here.
However, even such a simple model, achieving such a limited reconstruction performance proved to be consistent and useful. First, when concatenating data completion pipelines to give rise to bivirtual data, we found a robust self-consistency, i.e., remarkable matching between, e.g., the original SC (or FC) and the bivirtual SCbi-MFM (or FCbi-MFM) generated via the intermediated FCMFM (or SCMFM) step. This self-consistent correspondence is not limited to generic correlations but captures actual personalized aspects of detailed network topology (Table 3 and Fig. 8 for the ADNI dataset and Table 4 and Extended Data Fig. 8-1 for the healthy aging dataset). Second, classification performance reached based on empirical data could be nearly equated by classifiers trained on virtual or bivirtual dual connectomes (Fig. 7). Therefore, even if the reconstruction quality of our model-based completion procedures is modest, a meaningful relationship with the original seed data are still maintained, even after two steps of virtual completion. The use of simple models has the additional advantage of being less computationally expensive to simulate. SLMs are even simpler and faster to run than our basic MFMs and their performance was better than the one of nonlinear models in many aspects when dealing with the healthy aging dataset. Note that SLMs have been shown to be very performing in rendering static aspects of FC in other contexts as well (Hansen et al., 2015; Messé et al., 2014). However, linear models were down-performing on the ADNI dataset, while nonlinear models performance seemed more stable across datasets. This shows once again that linear and nonlinear models may capture different facets of the actual, possibly unknown empirical connectomes and that there is an interest in computing and sharing both type of surrogates, given their potential complementarity.
In terms of computation costs, basic MFMs as our virtual brains based on the Wong–Wang model, provide a reasonable compromise between computational speed and the need to render structured brain dynamics beyond mere Gaussian fluctuations (Haken, 1983) constrained by SC. The most expensive aspect of nonlinear completion procedures –both SC-to-FC and FC-to-SC– is however their iterative nature. Indeed, not just one, but many virtual brain simulations must be performed, to scan parameter space for the best working point for FC simulation (compare Fig. 3) or to grow from random initial conditions an effective connectivity matrix sufficiently mature to render genuine aspects of SC (compare Fig. 4). Note however that, in reality, the number of iterations can be dramatically reduced by choosing good guesses for initial conditions. In the case of SC-to-FC completion, the a priori knowledge that best working point lie close to a critical line and that the monitored metrics landscape is convex, a bisection search strategy (Boyd and Vandenberghe, 2004) can be used instead of exhaustive grid search. In the case of FC-to-SC completion, starting from an initial SC* conditions close to a generic group-averaged SC connectome rather than fully random can speed-up convergence.
We have provided in Figure 7 the first proof of concept of the possibility to use virtual and bivirtual connectomes for performing subject classification. For the purpose of classification, data completion procedures are seen as veritable computational bridges between alternative “spaces” in which to perform machine learning, linked by duality relations (Fig. 7A). We propose in this respect two possible types of strategy. The first one is to abandon the “real space” of actual empirical connectomes and to operate directly in dual spaces (Fig. 7B). In these approaches, empirical connectomes would have to be transformed into their virtual or bivirtual dual counterparts as a necessary preprocessing step. In the second type of strategy, classifiers trained in dual spaces are used to operate in the real space. While such approach does not require the virtualization of empirical input connectomes before their classification, performance could be potentially reduced by a possible systematic mismatch in input feature distributions between real and dual spaces (Fig. 8 and Extended Data Fig. 8-1 show, for instance, some network features such as, respectively, SC clustering or SC weights themselves tend to get overestimated in dual connectomes). The specific examples highlighted in Figure 7B,C for ADNI patient discrimination and Figure 7D–F for healthy aging age class prediction show comparable qualities of classification for dual space and cross-space classifications (in both cases, not significantly decreases with respect to classification in real space). Generally, we were able only to reach poor classification performances, barely above chance level. However, the performance was not significantly better for direct classification based on empirical connectomes. As a matter of fact, we have to acknowledge that we are still far from being able to reliably discriminate subject classes based on connectome features, independently from training being performed on real or dual connectomes. We would like to stress that the number of used input features, e.g., K = 96, corresponding to the number of regions in the used parcellation (see Materials and Methods) for which connectivity strengths were computed in the ADNI dataset classification problem, is comparable to the number of subjects in the considered dataset (N = 88 or 178, respectively, for ADNI subjects with available SCemp or FCemp). Therefore, it is not surprising that high performances are difficult to access, even when using classification approaches specially adapted to this situation, as in our case. Superior classification performance could be potentially reached via a more careful feature selection (Guyon and Elisseeff, 2003) that goes beyond the scope of the current study. Hopefully, future attempts to classification will be able to approach more robustly these tendential performances. Given the high degree of personalized correspondence between real and dual connectomes (compare Table 3 for the ADNI dataset and Table 4 for the healthy aging dataset), we are confident that any performance level reached by future classifiers trained in real space could be closely approached by classifiers trained in dual virtual and bivirtual spaces.
In perspective, the use of virtual connectomes could become beneficial to the training of machine learning algorithms in a further way. The use of a wider ensemble of surrogate date with statistical distributions of multidimensional features equivalent to the original data are a common practice in machine learning, known as data augmentation (Yaeger et al., 1997; Taylor and Nitschke, 2018), as previously mentioned. Data augmentation is, e.g., very popular in object recognition (where surrogate training data are produced by clipping or variously transforming copies of the original training images). Data augmentation aims to expand the training dataset beyond the initially available data to boost the learning by a classifier of the target categories (e.g., object identities). Crucial for dataset augmentation applications is that the surrogate data generated are not just identical to the actual data with some added noise but are genuinely new and can serve as actual good guesses for alternative (unobserved) instances of data-points belonging to the same category (compare Fig. 9B). Indeed, if information cannot be created (Cover and Thomas, 2006), redundant information can nevertheless improve the performance of decoding and classification (Guyon and Elisseeff, 2003). Computational models such as MFM do not provide mappings between input and output connectomes, but rather between statistical ensembles of connectomes, with both mean and correlated dispersion realistically shaped by trustworthy nonlinear dynamics. In other words, differences between alternative connectomes in a generated surrogate virtual cohort are not mere “noise,” but reflect realistic data-compliant possibilities of variation. The different connectome realizations sample indeed the specific landscapes of possible FCs that may be compatible with a given SCs, degenerate because the allowed dynamics to unfold along with low-dimensional manifolds, rather than being frozen in strict vicinity of a trivial fixed point (Mehrkanoon et al., 2014; Pillai and Jirsa, 2017). Therefore, given that interrelations between virtual cohorts mirror interrelations between empirical subjects (Figs. 6, 8; Extended Data Fig. 8-1; Table 3-Table 5; Extended Data Table 5-1), the generation of surrogate virtual cohorts of arbitrarily large size could provide natural candidates for future data augmentation applications.
However, by capitalizing exclusively on redundancy, augmentation cannot replace the gathering of more empirical data (Carrillo et al., 2012; Toga et al., 2016). Unfortunately, federation (or even mining) of data are often impeded by unavoidable juridical concerns linked to strict and diverse regulations (de Rosnay, 2017; Thorogood et al., 2018) The use of virtual cohorts may once again relieve this burden. Virtual cohorts maintain their statistical relation to the original data, in a way sufficiently good to be exploitable for classification, but do not precisely match the original data, maintaining an inherent variability. This fact may constitute a feature rather than a bug, in the context of data sharing. Indeed, if virtual data carry information operationally equivalent to the one carried by empirical data, they do not carry exactly the same information. It is not, therefore, possible to exactly reconstruct the original subject data from virtualized connectomes, and privacy concerns would be considerably reduced if not entirely removed by sharing dual space images of actual data, eventually demultiplied into virtual cohorts, rather than the original real space data. We thus anticipate a near future in which virtual cohorts, providing vast numbers of virtual and bivirtual connectivity information, will play an increasing role in massive data-driven explorations of factors predictive of pathology and, in particular, neurodegenerative disease progression.
Synthesis
Reviewing Editor: Gustavo Deco, Universitat Pompeu Fabra
Decisions are customarily a result of the Reviewing Editor and the peer reviewers coming together and discussing their recommendations until a consensus is reached. When revisions are invited, a fact-based synthesis statement explaining their decision and outlining what is needed to prepare a revision will be listed below. The following reviewer(s) agreed to reveal their identity: Matthieu Gilson.
Very interesting idea for virtual data completion but then avoids testing it directly. The problem they describe is an important one: how to impute missing FC or SC when only one is available for a subject. The authors propose a method using virtual connectomes from computational modeling. Reviewer 1:
The authors propose a solution to the problem of predicting functional connectivity or structural connectivity (FC or SC) when one of them is missing for a subject, by using dynamic models of brain activity. As the authors state, many data sets have incomplete data for subjects with either SC or FC but not both. If the method reliably could perform "data completion" of the missing data it would expand use of these data. This is thus an interesting proposal to an interesting problem. The manuscript is clearly written and figures are clear.
The central framing and claim of the modeling method is that it can estimate an individual's FC or SC connectome using their other connectome. To do so successfully, the estimated connectome must contain individual-specific features. I find it perplexing that the authors perform many, many analyses that do not address this central issue, and avoid reporting straightforward analyses that do address it. Most results relate to similarity of empirical and virtual connectomes. They do not measure whether that virtual connectome is closer to the individual subject than to a the empirical connectome of a different individual, or to the group-average connectome. If a virtual connectome method produces only common features but not individual features, then it could not be useful for data completion of individual subjects who are missing one FC/SC connectome.
The entire premise of virtual data completion depends on there being linked subject specificity in SC and FC. I direct the authors to a recent paper from the groups of Randy McIntosh and Petra Ritter: Zimmermann et al., 2019, Network Neuroscience, "Subject specificity of the correlation between large-scale structural and functional connectivity". Their abstract reads: "We show that using simple linear associations, the relation between an individual's SC and FC is not subject specific for five of the datasets. Subject specificity of SC-FC fit is achieved only for one of the six datasets, the multimodal Glasser Human Connectome Project (HCP) parcellated dataset. We show that subject specificity of SC-FC correspondence is limited across datasets due to relatively small variability between subjects in SC compared with the larger variability in FC." If SC-FC correspondence is so low by their methods, then it may be unlikely this modeling-based data completion method would be successful and it should be directly tested to evaluate the proposed method.
Perhaps the proposed method does not generate compelling performance, at least for this data set. This would not be surprising given the empirical analysis on lack of SC-FC correspondence from Zimmermann et al. 2019 (and why would ADNI have higher SC-FC correspondence than the data sets in Zimmermann et al., 2019) . The paper does not show report the straightforward analysis of whether virtual connectome's predict individual FC/SC features (e.g. greater similarity for self vs other). Without reporting this, or contextualizing it, the current paper may instead give readers a mistaken impression that this method can be successfully deployed. Therefore, it would be helpful for readers to see these straightforward analyses. And the framing of the paper could be correspondingly improved to communicate this. The discussion section should give context of current performance, and prospects for future improvement. My conclusion from the paper is that it proposes a very interesting idea for virtual data completion but then avoids testing it directly.
----------------------------------------------
Reviewer 2:
The authors address an interesting problem related to the limited access to neuroimaging data for clinical diagnostic. They propose a method to complement empirical data with virtual data created using whole-brain modeling: using either a linear or non-linear whole-brain model. They construct virtual samples (SCs or FCs) from empirical samples, and go further by constructing "bi-virtual" samples. They study the properties of those samples for classification, in particular the important point that subjects are separated in a similar manner by the empirical and by the virtual SCs/FCs (correlation plots in Fig 5). The manuscript is globally well organized and written, but I still have concerns about specific points that would clarify the scope of the results, as detailed below.
Major concerns:
- I understand the choice of the ADNI dataset for the validation of the proposed method as AD-MCI can be predicted based on either empirical SC or FC (or both). However, this dataset is known to be difficult in terms of prediction performance to separate controls, MCI and AD patients. This can in fact be seen in panels B and C of Fig 6, where the performance of empirical data are above chance level, but not very far away. Therefore, the decrease of performance for the proposed method is not so obvious to assess, as compared to a situation where classification would reach something like 70 or 80%. To understand the real power of the method, the authors should have chosen a different dataset, even a non-clinical one like HCP to discriminate tasks where FC does a good job to test the classification based on (bi)virtual-FC.
- The virtual SC appears to be a full matrix for the two estimation methods (Fig 2), which is in fact closely related to partial correlations for the SLM, see Eq (4) that corresponds to a (dynamical) estimates calculated from the FC matrices. This is also true for the non-linear model in Fig 4. It means that both types of virtual SCs sit in a rather different (multivariate) space than empirical SC matrices, despite the fact that they exhibit similar network metrics (as shown in Fig 7). I would thus expect that the distributions of their respective weights are quite different, for example between empirical SC and bi-virtual SC. Could the authors comment about this point?
- Fig 3: What is the computational power necessary to perform such a grid search at the single patient level?
- "Linear FC-to-SC completion is not viable" in Results: This claim is only supported by the comparison with the SLM model of the same authors. As shown in previous studies (Messe et al PLoS Comput Biol 2014), different dynamics can generate very similar correlation patterns from SC in terms of goodness of fit of empirical static FCs, either linear or nonlinear including the dynamic mean field used here. Likewise, the same linear model can lead to good or chance-level classification performance depending on the fitting method used (Gilson et al Network Neurosci 2020). In other words, a model cannot be considered independently of its optimization method here. The authors should moderate this claim, or at least discuss it.
- Extended Data Figure 2-1: The authors could also show similar correlation plots to those in Fig 5 between the distances between pairs of empirical SCs and pairs of virtual FCs, to evaluate each "branch" of the completion.
- Fig 6B-C: the patient vs control classification is an interesting point, but what about the 3-class classification "control vs MCI vs AD"? The comparison between virtual and empirical SCs/FCs would be even more informative to the reader about the sensitivity of the proposed method. Instead of ROC curves, classification accuracies compared to their counterpart chance level obtained by shuffling data labels could be used to quantify the classification performance.
- Fig 6D: The generated FCs by the nonlinear model are indeed clustered for each subject, but this suggests that these generated FCs are rather similar, with some "numerical" noise for different simulations. In this plot, where would be the empirical FCs for the 12 subjects that can be taken as "ground truth", thereby comparing their virtual and empirical FCs. Going further, the same visual demonstration could be done with mixed empirical and bi-virtual FCs, to see whether the bi-virtual FCs further fill the gaps between empirical FCs. This would motivate the use of bi-virtual samples, which is not so clear to me in the present manuscript.
- In Introduction "Here we propose a new solution aiming at relieving these problems of partially missing features and limited sample size"; In Discussion "Our data completion procedures provide a step forward toward "filling dataset gaps"" and "It thus may be considered as a form of "reinjection" or "sharpening" of information, present in the full data set": If the classification accuracy was better for virtual samples than empirical ones, this claim would be supported. However, as the authors say in other parts of the manuscript, the virtual-based classification is "comparable" (even though a bit lower), so I would conclude that information is still lost in the data transformation (although not much). In comparison, creating thousands of surrogate images by zooming, rotating, etc. increases a lot the classification performance of deep networks (also involving *very* large datasets). In particular, validation with a bigger dataset appears necessary, with way more empirical data with both SC and FC that could be used as "ground truth", which here is "only" 12 subjects (5% of all subjects roughly).
- Also about this point, about the Extended Data Figures 3-1: I have trouble understanding the benchmark of the "completions" of the empirical FCs/SCs (for the 12 subjects with both FCs and SCs as ground truth) that relies on a comparison with "the trivial strategy over taking the "other connectome" as substitute (i.e. taking FC to be identical to SCemp)". For the models, I can see two ways of assessing their value: with the goodness of fit to reproduce data (e.g. empirical SC in fitted model to reproduce FC, as measured by CC) or as a preprocessing step in the classification pipeline (e.g. estimated virtual SC would improve classification, as opposed to empirical FC). But in that part of the manuscript the authors talk about "information improvement", and it is not clear to me why they do not stick to the same metrics as in the rest of the paper.
Minor comments:
- In Introduction, "average functional connectivity properties in the resting-state can be accounted for by the spontaneous collective activity of brain networks informed by empirical structural connectivity (SC) when the system is tuned to operate slightly below a critical point of instability (Deco et al., 2011, 2012)" and "Analogously, algorithmic procedures based on mean-field modeling steps (Gilson et al., 2016; 2018) can be used to address the inverse problem of inferring SC from FC (FC-to-SC completion)": The authors use the terminology SC for the connectivity inserted in the generative model that reproduces the FC. In doing so, they seem biased by considering resting state fMRI data, as opposed to task-evoked activity. What I mean is that the same connectivity backbone (topology speaking) will generate distinct FCs for several tasks or conditions, but the weights or efficacies of the connections may be modulated (in addition to dynamic properties of nodes). This is usually related to the general concept of effective connectivity, which has several flavors in the literature and is mentioned later, in particular in the Discussion. The authors should introduce this earlier than page 11, to specify their own terminology in the Introduction.
- The "Material and Methods" organization in subsections should be improved, in particular with "Two type of computational whole brain models" with the two "SLM models" and "MFM models" that have other subsections whose structure don't appear clearly in the current presentation.
- In Discussion, another issue with the ADNI dataset, which is its multicentric nature that makes those data difficult to align (e.g. correct for scanner heterogeneity). Could the authors comment on this point, as it is likely to be still an issue for their envisaged framework?
- The pseudocode in Extended Data 1 is vague and does not bring much information to the reader. Some variables are not properly defined and not understandable at first read, like in the 1st line of FC-to-SC completion: what is C with respect to FC_emp, used to return C^{-1}. A reference to the Equation in Methods would help.
Author Response
Answers to reviewers
Reviewer #1
The authors propose a solution to the problem of predicting functional connectivity or structural connectivity
(FC or SC) when one of them is missing [...] If the method reliably could perform “data completion” of the
missing data it would expand use of these data. This is thus an interesting proposal to an interesting problem.
The manuscript is clearly written, and figures are clear.
We thank the reviewer for her positive appreciation.
The central framing and claim of the modeling method is that it can estimate an individual's FC or SC
connectome using their other connectome. To do so successfully, the estimated connectome must contain
individual-specific features.
We agree with the reviewer. This is one of the reasons why we explicitly evaluated how correlations between real
and virtual connectome topologies are dramatically improved when looking at personalized rather than generic
rendering of this topology. This is what was already shown in former Table 3 (now Tables 3 and 4). For instance,
topology matching between personalized empirical and bivirtual functional connectome pairs is > 260% better
than topology matching with generic connectomes, for all the considered graph metrics (strength, clustering,
centrality, community structure). Furthermore, pairwise distances between empirical or virtual connectomes for
different pairs of subjects are highly correlated (former Figure 5C-D, now Figure 6 and Table 3). Last but not
least, virtual cohorts associated to distinct subjects are clearly separated (former Figure 6D, now Figure 9A)
showing that subject identity is maintained.
Reading the reviews, we realized that this fact was not presented in a clear enough way. We thus have now created
an ad hoc results section “Are dual connectomes still personalized?” where we more directly present results about
the effective personalization of our virtual connectomes. See later for details about changes.
Most results relate to similarity of empirical and virtual connectomes. They do not measure whether that virtual
connectome is closer to the individual subject than to the empirical connectome of a different individual, or to
the group-average connectome.
It is true that several analyses focus on the general functioning of the completion pipelines. It is not true however
that we do not address the issue of personalization. The three analyses mentioned before (separability of virtual
cohorts associated to different subjects, correlation between empirical and virtual pairwise inter-connectome
distances and improved within-subject empirical-to-virtual topology matching) were precisely important
confirmations of personalization.
The reviewer is right however that we did not perform a direct check of the improvement in empirical-virtual
correlation, in terms of straight comparison of the rendering quality for personalized vs generic connectomes. We
have now computed: CCpersonalized, i.e. the average correlation between empirical connectomes and corresponding
virtual connectomes for the same subject; and, CCgeneric, i.e. the average correlation between empirical
connectomes and connectomes of other subjects. We find that, for all type of virtual or bivirtual connectomes
personalized correlations tend to be better than generic correlations. To properly quantify it we have introduced
an Improvement by Personalization coefficient ∆Pers and we evaluated it for all the types of tested completions,
and, for Functional Connectivity at least, on empirical data as well for the sake of comparison.
For simulated data one can define CCpersonalized = CC[Connvirt(a subject), Connemp(same subject)], where “Conn"
refers to the considered connectome matrix of the SC or of the FC type. Analogously, CCgeneric = Group average
of CC[Connvirt(same subject), Connemp(a different subject)]. The Improvement by Personalization coefficient is
then defined as ∆Pers = (CCpersonalized - CCgeneric) / CCgeneric. This number was always significantly larger than zero
for all types of virtual and bivirtual completion performed, as reported in the novel Table 5 indicating that our
completion preserves personalized information, although not perfectly.
Interestingly, at least for FC, we can estimate from empirical data how much the improvement by personalization
could be expected to be in the case in which a first FC extraction for a given subject had to be replaced by a second
one coming from a second scan from the same subject vs a scan for another generic subject. We can achieve such
estimation thanks to a dataset mediated from the Human Connectome Project conceived to probe test/retest variability (Termenon et al., 2016). In this dataset, every one of 100 subjects underwent two resting state scans,
so that two FCemp can be extracted for each of them. If we redefine CCpersonalized = CC[FCemp(same subject scan 1),
FCemp(same subject scan 2)] and CCgeneric = Group average of CC[FCemp(same subject scan 1), FCemp(other
subjects)], then we can always evaluate ∆Pers = (CCpersonalized - CCgeneric) / CCgeneric using the same formula. For
empirical FC we thus obtain an improvement by personalization of ∼+22%, which is of the same order of
magnitude or not dramatically superior to improvements we can get with virtual and bivirtual data (e.g. ∆Pers =
+18% for bivirtual linear completion on health aging dataset.
We would like to stress that the fact that these ∆Pers coefficients are not very large even for empirical data suggests
that may not be the most relevant way to track personalization. Even if two connectomes are generally different
(direct CCs between connectomes are only rough whole-brain-averaged comparisons), they may still be strongly
similar in specific topological aspects as e.g. the spectrum of region specific graph-theoretical metrics. These
aspects are genuinely capturing topological idiosyncracies in the FC or SC of different subjects. Now, we find
that despite low ∆Pers, correlations between topological metrics in empirical and virtual connectomes are very high
and that the improvement in these correlations when computing them between empirical and personalized virtual
connectomes can rise to > 300% for some of the features! (cf. Table 3). So, we think that there are better indicators
of successful personalization of virtual connectomes than the ∆Pers coefficient and that these better indicators do
provide strong evidence for successful personalization in our virtual connectomes for both the probed datasets,
the ADNI one (already included at first submission) and the healthy aging one (added now in this new version).
All our new ∆Pers analyses are now grouped with previously made personalization aspects analyses into a new
section of the manuscript results explicitly focusing on improvements by personalization (“Are dual connectomes
still personalized?”)
I direct the authors to a recent paper from the groups of Randy McIntosh and Petra Ritter: Zimmermann et
al., 2019, Network Neuroscience, “Subject specificity of the correlation between large-scale structural and
functional connectivity”. [...] If SC-FC correspondence is so low by their methods, then it may be unlikely this
modeling-based data completion method would be successful and it should be directly tested to evaluate the
proposed method.
We thank the reviewer for this interesting remark. Here we did not specifically studied SC to FC correspondences,
however, it is true that the two are highly correlated in empirical as in virtual data. Furthermore, the degree of
variability between FCs of different subjects is larger than the one between SCs of different subjects. It is thus an
interesting question to see whether we can get still Improvement by Personalization in FC completion although
starting from SC matrices relatively more similar between subjects.
Now we find that ∆Pers for virtual FCs can go up +11% (linear virtual completion on aging dataset) and is always
significant (even for the smallest found improvements of ∆Pers = +3% for linear virtual completion on ADNI
dataset or of ∆Pers = +5% for nonlinear virtual completion on ADNI dataset). So, even if imperfect, completion
still fills the gap in a direction which is better compliant with personalized specificities than a generic completion.
Considering bivirtual completion, the initial starting empirical FCs have a larger inter-subject variability than
virtual FCs completed from empirical SCs. This diversity is very well-preserved by our concatenated completion
pipelines, leading to ∆Pers for bivirtual FCs that can be well over +100%.
Thus, our completion procedures: i) capture significantly at least some of the inter-subject variability in FC when
completing from SCemp toward FCvirt; ii) do not flatten down the variability between different FCemp when
replacing them with FCbivirt.
The paper does not show report the straightforward analysis of whether virtual connectome's predict individual
FC/SC features (e.g. greater similarity for self vs other).
Eventually, we already reported findings on the preservation of personalized information, so it is not completely
true that we did not study the issue. We have now added new measures of personalization quality along the
direction requested by the reviewer, as previously mentioned, and improved the joint presentation of old and new
results by building a new ad hoc manuscript session on personalization. We hope that now the reviewer will be
satisfied.Therefore, it would be helpful for readers to see these straightforward analyses. And the framing of the paper
could be correspondingly improved to communicate this.
We hope that our new formulations and extended analyses go in the requested direction.
The discussion section should give context of current performance, and prospects for future improvement.
Since the previous manuscript version, we already said explicitly in the Discussion that: “The correlation reached
between empirical and reconstructed connectivity matrices is only moderate [...]”. We then commented on
possible reasons for that: “One evident reason is the simplicity of the neural mass model adopted in our proof-of-concept illustration. The Wong-Wang neural mass model is able only to express two states of lower or higher
local activation"; or; yet: “Synchronization in a network depends on various factors, including frequency, network
topology, and time delays via signal propagation, all of which have been ignored here [...]” and “our models,
ignoring delay-mediated synchronization, are incapable of capturing a range of dynamic oscillatory behaviors”.
After commenting on these limitations, we then propose finally as prospect for future improvement: “More
sophisticated mean-field virtual brain models could thus reach superior performance (see e.g. Stefanovski et al.,
2019), going beyond the first proof-of-concept examples presented here”.
My conclusion from the paper is that it proposes a very interesting idea for virtual data completion but then
avoids testing it directly.
We have now added more straightforward testing as suggested by the reviewer, further improving the presentation
of the many other (and, in our opinion, stronger) personalization results we already had, thanks to an ad hoc novel
section and new ad hoc tables (redesigned Tables 3 and 4, plus Table 5, etc.). We are aware that there is room for
improvement and we explicitly acknowledge it in the discussion, but we believe we have provided sufficient
evidence that our approach is already working, at least as a first proof of concept.
Reviewer #2
The authors address an interesting problem related to the limited access to neuroimaging data for clinical
diagnostic. [...] They study the properties of those samples for classification, in particular the important point
that subjects are separated in a similar manner by the empirical and by the virtual SCs/FCs (correlation plots
in Fig 5). The manuscript is globally well organized and written...
We thank the reviewer for her appreciation.
I understand the choice of the ADNI dataset for the validation of the proposed method as AD-MCI can be
predicted based on either empirical SC or FC (or both). However, this dataset is known to be difficult in terms
of prediction performance to separate controls, MCI and AD patients. This can in fact be seen in panels B and
C of Fig 6, where the performance of empirical data are above chance level, but not very far away. Therefore,
the decrease of performance for the proposed method is not so obvious to assess...
The reviewer is right. As a matter of fact the separability of subject categories is poor even from empirical data,
so our preservation of classification performance with virtual and bivirtual connectomes is a preservation of a...
bad performance. Indeed we think that the most compelling evidence for the quality of personalized rendering of
connectivity by virtual connectomes come from the graph feature correlations of former Figure 7 (now Figure 8)
and Tables 3 and 4. We focused on ADNI and still think is important to do it, because it is a “canonic” shared
dataset and, as such, it also epitomizes limitations that such dataset can have.We have however followed the
reviewer's suggestions and...
To understand the real power of the method, the authors should have chosen a different dataset, even a non-clinical one like HCP to discriminate tasks where FC does a good job to test the classification based on
(bi)virtual-FC.
... we have thus now expanded our study demonstrating the feasibility of data completion on a second dataset,
investigating SC and FC variations along healthy aging. Such data were already analyzed in Battaglia et al. (2020)
and, previously, Zimmermann et al. (2016), among others. Besides serving as control, to show that similar
completion quality performance can be achieved on two independent datasets, this dataset is also suitable to
perform prediction of age class (age span from 18 to 80 years), based on both empirical data and their virtual and
bivirtual counterparts.
The virtual SC appears to be a full matrix for the two estimation methods (Fig 2), which is in fact closely related
to partial correlations for the SLM, see Eq (4) that corresponds to a (dynamical) estimates calculated from the
FC matrices. This is also true for the non-linear model in Fig 4. It means that both types of virtual SCs sit in a
rather different (multivariate) space than empirical SC matrices, despite the fact that they exhibit similar
network metrics (as shown in Fig 7). I would thus expect that the distributions of their respective weights are
quite different, for example between empirical SC and bi-virtual SC. Could the authors comment about this
point?
We thank the reviewer for her comment. Certainly, virtual and bivirtual SCs are denser than empirical SCs. To
follow reviewer's suggestion, we now checked weight distributions as well. As shown in the novel Extended Data
Figure 6-1, distributions of empirical SC weights have a narrow peak on low weights and are strongly right skewed
with a fast-decaying right tail, for both considered dataset (ADNI and aging). All virtual and bivirtual distributions
have a qualitatively similar shape, however, the right tail is fatter and more slowly decaying. The best
convergence, at least by visual comparison in the new Extended Data Figure 6-1 seems to be achieved for bivirtual
linear SC completion on the ADNI dataset, and the worst correspondence for virtual nonlinear SC completion on
the Aging dataset.
The match is at best qualitative and definitely not quantitatively perfect. Nevertheless, this does not prevent us
for finding very good correspondences between empirical and completed SCs, as shown in former Figure 7 (now
Figure 8) and now confirmed in a second dataset as well. Fig 3: What is the computational power necessary to perform such a grid search at the single patient level?
The reviewer is right that we did not discuss computational costs. Simulating a MFM is costly in terms of time
and a different MFM simulation has to be run for every pixel in the searched grid. So the time cost would scale
linearly in the number of probed parameter combinations (or, equivalently, the space cost, since different runs can
be run in parallel if more computing cores are available).
It must be noted that the fact that we target a critical boundary as best fit zone reduces the computational costs.
First, the monitored metrics have a non-monotonic variation when passing through the critical boundary so that
one can explore the grid using a bisection method. In this way, at every step of the bisection search, the range of
exploration is progressively narrowed until a local min or max of the target features is found. Thus, the number
of simulations to perform to roughly capture a point on the boundary is dramatically reduced with respect to
exhaustive search. Second, different subjects have small differences in the best fine zone but the qualitative shape
of the phase diagram is preserved across subjects, so that using as initial conditions parameters already optimized
for another subject provides a good guess already close to the real optimum and this can once again reduce the
number of iterations needed to detect a best fit point.
We now comment on this aspect in the Discussion.
"Linear FC-to-SC completion is not viable” in Results: This claim is only supported by the comparison with
the SLM model of the same authors. As shown in previous studies (Messe et al PLoS Comput Biol 2014),
different dynamics can generate very similar correlation patterns from SC in terms of goodness of fit of
empirical static FCs, either linear or nonlinear including the dynamic mean field used here. Likewise, the same
linear model can lead to good or chance-level classification performance depending on the fitting method used
(Gilson et al Network Neurosci 2020). In other words, a model cannot be considered independently of its
optimization method here. The authors should moderate this claim, or at least discuss it.
We agree that our statement is too strong, since limited to our own SLM implementation. Ourselves found
equivalent performance in fitting FCemp with the SLM or the MFM in our previous works. The poor performance
of SLM may thus have been linked to the specifically considered ADNI dataset or to our procedure.
As a matter of fact, indeed, in the newly added Aging dataset, the SLM works even better than the MFM. This is
the case, notably, of improvement on “using the other connectome” discussed in Extended Data Figure 2-1 which
is larger for SLM-based than for MFM-based completion in the Aging (but not the ADNI) dataset. It must be
noted, however, that for FC completion, MFM-based completions provide the distributions of weights the most
compliant with the empirically observed one, for both datasets.
We have now removed all claims of absolute superiority of MFM and SLM, presenting the good performance of
SLM in the Aging dataset completions and making a comparative discussion of respective merits in the discussion.
Extended Data Figure 2-1: The authors could also show similar correlation plots to those in Fig 5 between
the distances between pairs of empirical SCs and pairs of virtual FCs, to evaluate each “branch” of the
completion.
We have now added as well selected scatter plots for the second Aging dataset in the new Extended Data Figure
8-1, and compiled inter-distances correlations for all the types of completion in Tables 3 and 4. In all cases a
strongly significant correlation subsists.
Fig 6B-C: the patient vs control classification is an interesting point, but what about the 3-class classification
"control vs MCI vs AD”? The comparison between virtual and empirical SCs/FCs would be even more
informative to the reader about the sensitivity of the proposed method. Instead of ROC curves, classification
accuracies compared to their counterpart chance level obtained by shuffling data labels could be used to
quantify the classification performance.
As the Reviewer previously mentioned, classification even based on ADNI empirical data is a difficult task and
performance for the three classes problem can be deceptively low, hence our choice (now explicitly mentioned in
text) to illustrate the feasibility of classification on the simpler (and more academic task) of patient vs control. For ADNI two-class classification, we now provide systematic AUC information for many more train/test
combinations of data in the new Extended Data Tables 3-1 and 3-2. We then perform a new multi-class
classification task, showing for it confusion matrices, on the healthy aging dataset.
We divided the age-span from 18 to 80 years of the subjects into four age classes and we performed the task of
classifying subjects into one of the four classes. The complete classification performance is illustrated via a
confusion matrix analysis in novel panels of the Figure 7, as well as in Extended Data Figure 7-1. Even in this
case we can support the feasibility of classification with virtual and bivirtual duals with performances comparable
to empirical space, as well as classification of novel empirical data with classifiers trained on virtual duals.
We thus think that we provide consistent additional evidence of the feasibility of classification with completed
connectomes, even if the performance remains poor using our simple methods. Since here the main focus is on
introducing the general concept of data completion and virtual/bivirtual duals rather than emphasizing specific
applications in predictions we felt that exploring more sophisticated prediction strategies was a research topic per
se and out of scope in this first study.
The generated FCs by the nonlinear model are indeed clustered for each subject, but this suggests that these
generated FCs are rather similar, with some “numerical” noise for different simulations. In this plot, where
would be the empirical FCs for the 12 subjects that can be taken as “ground truth", thereby comparing their
virtual and empirical FCs. Going further, the same visual demonstration could be done with mixed empirical
and bi-virtual FCs, to see whether the bi-virtual FCs further fill the gaps between empirical FCs. This would
motivate the use of bi-virtual samples, which is not so clear to me in the present manuscript.
We have now added to the t-SNE projections the original empirical connectome from which the cohorts are
generated. This shows that virtual connectomes do indeed belong to a different space than the original
connectomes appearing in the two-D projection as a “distant galaxy” additional cluster. Nevertheless, we are also
able to show graphically in the redesigned Figure 9A that an exploded distribution of virtual cohorts mirrors in
the dual space the original positions of the 12 empirical connectomes. We now comment this aspect in a new
expanded Results section on virtual cohorts.
In Introduction “Here we propose a new solution aiming at relieving these problems of partially missing
features and limited sample size"; In Discussion “Our data completion procedures provide a step forward
toward “filling dataset gaps"” and “It thus may be considered as a form of “reinjection” or “sharpening” of
information, present in the full data set”: If the classification accuracy was better for virtual samples than
empirical ones, this claim would be supported. However, as the authors say in other parts of the manuscript,
the virtual-based classification is “comparable” (even though a bit lower), so I would conclude that
information is still lost in the data transformation (although not much).
The Reviewer is right. We have now reduced the strenght of our claim. Since the abstract we say: “virtual
connectomic datasets with network connectivity information equivalent à comparable to the one of the original
data”. In the Introduction we say: “We show that the information that we can extract from computationally inferred
connectivity matrices are largely equivalent à only moderately degraded with respect to the one carried by the
original empirical data.”. And similar downplaying elsewhere.
In comparison, creating thousands of surrogate images by zooming, rotating, etc. increases a lot the
classification performance of deep networks (also involving very large datasets).
We also think that data augmentation is a potentially interesting application, even if at the moment the “ground
truth” empirical sample size of the datasets we consider is too small to properly discriminate the benefits of
augmentation from overfitting. We now better emphasize the promise of augmentation since the Results section,
even adding a figure panel in Figure 9B to more visually illustrate the concept.In particular, validation with a bigger dataset appears necessary, with way more empirical data with both SC
and FC that could be used as “ground truth", which here is “only” 12 subjects (5% of all subjects roughly).
The Reviewer is right. We have now validated all our analyses on a second, four times larger dataset for which
ground truth is available, confirming all our results.
About the Extended Data Figures 3-1: I have trouble understanding the benchmark of the “completions” of
the empirical FCs/SCs (for the 12 subjects with both FCs and SCs as ground truth) that relies on a comparison
with “the trivial strategy over taking the “other connectome” as substitute (i.e. taking FC to be identical to
SCemp)”. For the models, I can see two ways of assessing their value: with the goodness of fit to reproduce
data (e.g. empirical SC in fitted model to reproduce FC, as measured by CC) or as a preprocessing step in the
classification pipeline (e.g. estimated virtual SC would improve classification, as opposed to empirical FC). But
in that part of the manuscript the authors talk about “information improvement", and it is not clear to me why
they do not stick to the same metrics as in the rest of the paper.
We think that the reviewer refers to Figure 2-1? There we use a different metric of quality because the test we
make is different. Our measure is way simpler than the ones proposed by the reviewer. In presence of a gap in
dataset, one could always imagine a ultrafast and straightforward algorithm, which corresponds to receive as input
the available connectome and just return as output an exact copy of the input. Indeed SC and FC are related and
the input SC already carries information about the target FC, and viceversa, even without need to run a
sophisticated completion algorithm to extract it. If the quality of reconstruction of a data completion algorithm
does not go beyond this trivial algorithm then it is not worth spending computational resources to run it.
We agree that there is no “information improvement” and we have now corrected the text. However there can be
"too much information destruction", so that, after completion, the information extractable about the connectome
to reconstruct may be even poorer than the one the input was already carrying. This what happens for instance for
linear completion in the ADNI dataset (but not the Aging one). We now refrain from speaking about
"improvement” and speak everywhere or “smaller” or “larger degradation of information”.
The authors use the terminology SC for the connectivity inserted in the generative model that reproduces the
FC. In doing so, they seem biased by considering resting state fMRI data, as opposed to task-evoked activity.
What I mean is that the same connectivity backbone (topology speaking) will generate distinct FCs for several
tasks or conditions, but the weights or efficacies of the connections may be modulated (in addition to dynamic
properties of nodes). This is usually related to the general concept of effective connectivity, which has several
flavors in the literature and is mentioned later, in particular in the Discussion. The authors should introduce
this earlier than page 11, to specify their own terminology in the Introduction.
We have now clarified the sense in which we interpret Gilson's & coworkers' effective connectivity as an ersatz
for Structural Connectivity since the Introduction, by saying...: “Analogously, algorithmic procedures based on
mean-field modeling steps ('effective connectivity' approaches by Gilson et al., 2016; 2018) can be used to address
the inverse problem of inferring a reasonable ersatz of SC from resting state FC”. Similar wording is used
elsewhere, notably later in Results where we say: “They initially conceived such a procedure as a form of
"effective connectivity” analysis, aiming at constructing models which capture the origin of subtle changes
between resting state and task conditions. Thus, starting from an empirical SC connectivity and from a model
reproducing suitably rest FC, they slightly adjusted SC weights through an iterative procedure to morph simulated
FC in the direction of specific task-based FCs. Nothing however prevents to use the same algorithm in a more
radical way, to grow from purely random initial conditions a suitable effective connectome, as an ersatz of missing
SCemp, compatible with the observed FCemp.”
References
- Aerts H, Schirner M, Jeurissen B, Van Roost D, Achten E, Ritter P, Marinazzo D (2018) Modeling brain dynamics in brain tumor patients using the virtual brain. eNeuro 5:ENEURO.0083-18.2018. 10.1523/ENEURO.0083-18.2018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Allen GI, Amoroso N, Anghel C, Balagurusamy V, Bare CJ, Beaton D, Bellotti R, Bennett DA, Boehme KL, Boutros PC, Caberlotto L, Caloian C, Campbell F, Chaibub Neto E, Chang YC, Chen B, Chen CY, Chien TY, Clark T, Das S, et al. (2016) Crowdsourced estimation of cognitive decline and resilience in Alzheimer’s disease. Alzheimers Dement 12:645–653. 10.1016/j.jalz.2016.02.006 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arbabyazd LM, Lombardo D, Blin O, Didic M, Battaglia D, Jirsa V (2020) Dynamic functional connectivity as a complex random walk: definitions and the dFCwalk toolbox. MethodsX 7:101168. 10.1016/j.mex.2020.101168 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Avants BB, Tustison NJ, Song G, Cook PA, Klein A, Gee JC (2011) A reproducible evaluation of ANTs similarity metric performance in brain image registration. Neuroimage 54:2033–2044. 10.1016/j.neuroimage.2010.09.025 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Battaglia D, Witt A, Wolf F, Geisel T (2012) Dynamic effective connectivity of inter-areal brain circuits. PloS Comput Biol 8:e1002438. 10.1371/journal.pcbi.1002438 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Battaglia D, Boudou T, Hansen ECA, Lombardo D, Chettouf S, Daffertshofer A, McIntosh AR, Zimmermann J, Ritter P, Jirsa V (2020) Dynamic Functional Connectivity between order and randomness and its evolution across the human adult lifespan. Neuroimage 222:117156. 10.1016/j.neuroimage.2020.117156 [DOI] [PubMed] [Google Scholar]
- Beckett LA, Donohue MC, Wang C, Aisen P, Harvey DJ, Saito N; Alzheimer’s Disease Neuroimaging Initiative (2015) The Alzheimer’s disease neuroimaging initiative phase 2: increasing the length, breadth, and depth of our understanding. Alzheimers Dement 11:823–831. 10.1016/j.jalz.2015.05.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bezgin G, Solodkin A, Bakker R, Ritter P, McIntosh AR (2017) Mapping complementary features of cross-species structural connectivity to construct realistic “virtual brains.” Hum Brain Mapp 38:2080–2093. 10.1002/hbm.23506 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. J Stat Mech 2008:P10008. 10.1088/1742-5468/2008/10/P10008 [DOI] [Google Scholar]
- Boyd S, Vandenberghe L (2004) Convex optimization. Cambridge: Cambridge University Press. [Google Scholar]
- Braak H, Braak E (1991) Neuropathological stageing of Alzheimer-related changes. Acta Neuropathol 82:239–259. 10.1007/BF00308809 [DOI] [PubMed] [Google Scholar]
- Braak H, Alafuzoff I, Arzberger T, Kretzschmar H, Del Tredici K (2006) Staging of Alzheimer disease-associated neurofibrillary pathology using paraffin sections and immunocytochemistry. Acta Neuropathol 112:389–404. 10.1007/s00401-006-0127-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breiman L (2001) Random forests. Mach Learn 45:5–32. 10.1023/A:1010933404324 [DOI] [Google Scholar]
- Brin S, Page L (1998) The anatomy of a large-scale hypertextual Web search engine. Comput Netw 30:107–117. 10.1016/S0169-7552(98)00110-X [DOI] [Google Scholar]
- Bullmore E, Sporns O (2009) Complex brain networks: graph theoretical analysis of structural and functional systems. Nat Rev Neurosci 10:186–198. 10.1038/nrn2575 [DOI] [PubMed] [Google Scholar]
- Carrillo MC, Bain LJ, Frisoni GB, Weiner MW (2012) Worldwide Alzheimer’s disease neuroimaging initiative. Alzheimers Dement 8:337–342. 10.1016/j.jalz.2012.04.007 [DOI] [PubMed] [Google Scholar]
- Casanova R, Barnard RT, Gaussoin SA, Saldana S, Hayden KM, Manson JE, Wallace RB, Rapp SR, Resnick SM, Espeland MA, Chen JC; WHIMS-MRI Study Group and the Alzheimer’s disease Neuroimaging Initiative (2018) Using high-dimensional machine learning methods to estimate an anatomical risk factor for Alzheimer’s disease across imaging databases. Neuroimage 183:401–411. 10.1016/j.neuroimage.2018.08.040 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen B, Xu T, Zhou C, Wang L, Yang N, Wang Z, Dong HM, Yang Z, Zang YF, Zuo XN, Weng XC (2015) Individual variability and test-retest reliability revealed by ten repeated resting-state brain scans over one month. PLoS One 10:e0144963. 10.1371/journal.pone.0144963 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chiesa PA, Cavedo E, Lista S, Thompson PM, Hampel H, Initiative APM; Alzheimer Precision Medicine Initiative (APMI) (2017) Revolution of resting-state functional neuroimaging genetics in Alzheimer’s disease. Trends Neurosci 40:469–480., 10.1016/j.tins.2017.06.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cole JH, Franke K (2017) Predicting age using neuroimaging: innovative brain ageing biomarkers. Trends Neurosci 40:681–690. 10.1016/j.tins.2017.10.001 [DOI] [PubMed] [Google Scholar]
- Cover TM, Thomas JA (2006) Elements of information theory. Hoboken: Wiley. [Google Scholar]
- Cuingnet R, Gerardin E, Tessieras J, Auzias G, Lehéricy S, Habert MO, Chupin M, Benali H, Colliot O; Alzheimer’s Disease Neuroimaging Initiative (2011) Automatic classification of patients with Alzheimer’s disease from structural MRI: a comparison of ten methods using the ADNI database. Neuroimage 56:766–781. 10.1016/j.neuroimage.2010.06.013 [DOI] [PubMed] [Google Scholar]
- Davis SW, Kragel JE, Madden DJ, Cabeza R (2012) The architecture of cross-hemispheric communication in the aging brain: linking behavior to functional and structural connectivity. Cereb Cortex 22:232–242. 10.1093/cercor/bhr123 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deco G, Jirsa VK (2012) Ongoing cortical activity at rest: criticality, multistability, and ghost attractors. J Neurosci 32:3366–3375. 10.1523/JNEUROSCI.2523-11.2012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deco G, Jirsa V, McIntosh AR, Sporns O, Kötter R (2009) Key role of coupling, delay, and noise in resting brain fluctuations. Proc Natl Acad Sci USA 106:10302–10307. 10.1073/pnas.0901831106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deco G, Jirsa VK, McIntosh AR (2011) Emerging concepts for the dynamical organization of resting-state activity in the brain. Nat Rev Neurosci 12:43–56. 10.1038/nrn2961 [DOI] [PubMed] [Google Scholar]
- Deco G, Ponce-Alvarez A, Mantini D, Romani GL, Hagmann P, Corbetta M (2013) Resting-state functional connectivity emerges from structurally and dynamically shaped slow linear fluctuations. J Neurosci 33:11239–11252. 10.1523/JNEUROSCI.1091-13.2013 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deco G, Tononi G, Boly M, Kringelbach ML (2015) Rethinking segregation and integration: contributions of whole-brain modelling. Nat Rev Neurosci 16:430–439. 10.1038/nrn3963 [DOI] [PubMed] [Google Scholar]
- Dennis EL, Thompson PM (2014) Functional brain connectivity using fMRI in aging and Alzheimer’s disease. Neuropsychol Rev 24:49–62. 10.1007/s11065-014-9249-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Rosnay MD (2017) The legal and policy framework for scientific data sharing, mining and reuse. Éditions de la Maison des sciences de l’homme, 9782735123865.
- Desikan RS, Ségonne F, Fischl B, Quinn BT, Dickerson BC, Blacker D, Buckner RL, Dale AM, Maguire RP, Hyman BT, Albert MS, Killiany RJ (2006) An automated labeling system for subdividing the human cerebral cortex on MRI scans into gyral based regions of interest. Neuroimage 31:968–980. 10.1016/j.neuroimage.2006.01.021 [DOI] [PubMed] [Google Scholar]
- Doan NT, Engvig A, Zaske K, Persson K, Lund MJ, Kaufmann T, Cordova-Palomera A, Alnæs D, Moberget T, Brækhus A, Barca ML, Nordvik JE, Engedal K, Agartz I, Selbæk G, Andreassen OA, Westlye LT; Alzheimer’s Disease Neuroimaging Initiative (2017) Distinguishing early and late brain aging from the Alzheimer’s disease spectrum: consistent morphological patterns across independent samples. Neuroimage 158:282–295. 10.1016/j.neuroimage.2017.06.070 [DOI] [PubMed] [Google Scholar]
- Fillmore PT, Phillips-Meek MC, Richards JE (2015) Age-specific MRI brain and head templates for healthy adults from 20 through 89 years of age. Front Aging Neurosci 7:44. 10.3389/fnagi.2015.00044 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston KJ, Harrison L, Penny W (2003) Dynamic causal modelling. Neuroimage 19:1273–1302. 10.1016/S1053-8119(03)00202-7 [DOI] [PubMed] [Google Scholar]
- Ghosh A, Rho Y, McIntosh AR, Kötter R, Jirsa VK (2008) Noise during rest enables the exploration of the brain’s dynamic repertoire. PLoS Comput Biol 4:e1000196. 10.1371/journal.pcbi.1000196 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gilson M, Moreno-Bote R, Ponce-Alvarez A, Ritter P, Deco G (2016) Estimation of directed effective connectivity from fMRI functional connectivity hints at asymmetries of cortical connectome. PLoS Comput Biol 12:e1004762. 10.1371/journal.pcbi.1004762 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gilson M, Deco G, Friston KJ, Hagmann P, Mantini D, Betti V, Romani GL, Corbetta M (2018) Effective connectivity inferred from fMRI transition dynamics during movie viewing points to a balanced reconfiguration of cortical interactions. Neuroimage 180:534–546. 10.1016/j.neuroimage.2017.09.061 [DOI] [PubMed] [Google Scholar]
- Glisky EL (2007) Changes in cognitive function in human aging. In: Brain aging: models, methods, and mechanisms (Riddle DR, ed). Boca Raton: CRC/Taylor and Francis. [PubMed] [Google Scholar]
- Golos M, Jirsa V, Daucé E (2015) Multistability in large scale models of brain activity. PLoS Comput Biol 11:e1004644. 10.1371/journal.pcbi.1004644 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goñi J, van den Heuvel MP, Avena-Koenigsberger A, Velez de Mendizabal N, Betzel RF, Griffa A, Hagmann P, Corominas-Murtra B, Thiran J-P, Sporns O (2014) Resting-brain functional connectivity predicted by analytic measures of network communication. Proc Natl Acad Sci USA 111:833–838. 10.1073/pnas.1315529111 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gorgolewski K, Burns CD, Madison C, Clark D, Halchenko YO, Waskom ML, Ghosh SS (2011) Nipype: a flexible, lightweight and extensible neuroimaging data processing framework in python. Front Neuroinform 5:13. 10.3389/fninf.2011.00013 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3:1157–1182. [Google Scholar]
- Hagmann P, Cammoun L, Gigandet X, Meuli R, Honey CJ, Wedeen VJ, Sporns O (2008) Mapping the structural core of human cerebral cortex. PLoS Biol 6:e159. 10.1371/journal.pbio.0060159 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haken H (1983) Synergetics. Nonequilibrium phase transitions and self-organization in physics, chemistry and biology , Ed 3. New York: Springer. [Google Scholar]
- Hansen EC, Battaglia D, Spiegler A, Deco G, Jirsa VK (2015) Functional connectivity dynamics: modeling the switching behavior of the resting state. Neuroimage 105:525–535. 10.1016/j.neuroimage.2014.11.001 [DOI] [PubMed] [Google Scholar]
- Henstridge CM, Hyman BT, Spires-Jones TL (2019) Beyond the neuron–cellular interactions early in Alzheimer disease pathogenesis. Nat Rev Neurosci 20:94–108. 10.1038/s41583-018-0113-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Honey CJ, Kötter R, Breakspear M, Sporns O (2007) Network structure of cerebral cortex shapes functional connectivity on multiple time scales. Proc Natl Acad Sci USA 104:10240–10245. 10.1073/pnas.0701519104 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horien C, Noble S, Greene AS, Lee K, Barron DS, Gao S, O’Connor D, Salehi M, Dadashkarimi J, Shen X, Lake EMR, Constable RT, Scheinost D (2021) A hitchhiker’s guide to working with large, open-source neuroimaging datasets. Nat Hum Behav 5:185–193. 10.1038/s41562-020-01005-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iacono D, Markesbery W, Gross M, Pletnikova O, Rudow G, Zandi P, Troncoso JC (2009) The Nun study: clinically silent AD, neuronal hypertrophy, and linguistic skills in early life. Neurology 73:665–673. 10.1212/WNL.0b013e3181b01077 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iddi S, Li D, Aisen PS, Rafii MS, Thompson WK, Donohue MC; Alzheimer’s Disease Neuroimaging Initiative (2019) Predicting the course of Alzheimer’s progression. Brain Inform 6:6. 10.1186/s40708-019-0099-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iyappan A, Kawalia SB, Raschka T, Hofmann-Apitius M, Senger P (2016) NeuroRDF: semantic integration of highly curated data to prioritize biomarker candidates in Alzheimer’s disease. J Biomed Semant 7:45. 10.1186/s13326-016-0079-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jirsa VK, Proix T, Perdikis D, Woodman MM, Wang H, Gonzalez-Martinez J, Bernard C, Bénar C, Guye M, Chauvel P, Bartolomei F (2017) The virtual epileptic patient: individualized whole-brain models of epilepsy spread. Neuroimage 145:377–388. 10.1016/j.neuroimage.2016.04.049 [DOI] [PubMed] [Google Scholar]
- Kirst C, Timme M, Battaglia D (2016) Dynamic information routing in complex networks. Nat Commun 7:11061. 10.1038/ncomms11061 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kodamullil AT, Younesi E, Naz M, Bagewadi S, Hofmann-Apitius M (2015) Computable cause-and-effect models of healthy and Alzheimer’s disease states and their mechanistic differential analysis. Alzheimers Dement 11:1329–1339. 10.1016/j.jalz.2015.02.006 [DOI] [PubMed] [Google Scholar]
- Komarova NL, Thalhauser CJ (2011) High degree of heterogeneity in Alzheimer’s disease progression patterns. PLoS Comput Biol 7:e1002251. 10.1371/journal.pcbi.1002251 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kötter R, Wanke E (2005) Mapping brains without coordinates. Philos Trans R Soc Lond B Biol Sci 360:751–766. 10.1098/rstb.2005.1625 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lombardo D, Cassé-Perrot C, Ranjeva J-P, Le Troter A, Guye M, Wirsich J, Payoux P, Bartrés-Faz D, Bordet R, Richardson JC, Felician O, Jirsa V, Blin O, Didic M, Battaglia D (2020) Modular slowing of resting-state dynamic functional connectivity as a marker of cognitive dysfunction induced by sleep deprivation. Neuroimage 222:117155. 10.1016/j.neuroimage.2020.117155 [DOI] [PubMed] [Google Scholar]
- Lutkenhoff ES, Rosenberg M, Chiang J, Zhang K, Pickard JD, Owen AM, Monti MM (2014) Optimized brain extraction for pathological brains (optiBET). PLoS One 9:e115551. 10.1371/journal.pone.0115551 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maaten L, Hinton G (2008) Visualizing data using t-SNE. J Mach Learn Res 9:2579–2605. [Google Scholar]
- Margolis R, Derr L, Dunn M, Huerta M, Larkin J, Sheehan J, Guyer M, Green ED (2014) The National Institutes of Health’s big data to knowledge (BD2K) initiative: capitalizing on biomedical big data. J Am Med Inform Assoc 21:957–958. 10.1136/amiajnl-2014-002974 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mehrkanoon S, Breakspear M, Boonstra TW (2014) Low-dimensional dynamics of resting-state cortical activity. Brain Topogr 27:338–352. 10.1007/s10548-013-0319-5 [DOI] [PubMed] [Google Scholar]
- Melozzi F, Bergmann E, Harris JA, Kahn I, Jirsa V, Bernard C (2019) Individual structural features constrain the functional connectome. bioRxiv 613307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Messé A, Rudrauf D, Benali H, Marrelec G (2014) Relating structure and function in the human brain: relative contributions of anatomy, stationary dynamics, and non-stationarities. PLoS Comput Biol 10:e1003530. 10.1371/journal.pcbi.1003530 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore P, Lyons T, Gallacher J; Alzheimer’s Disease Neuroimaging Initiative (2019) Random forest prediction of Alzheimer’s disease using pairwise selection from time series data. PLoS One 14:e0211558. 10.1371/journal.pone.0211558 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moradi E, Pepe A, Gaser C, Huttunen H, Tohka J; Alzheimer’s Disease Neuroimaging Initiative (2015) Machine learning framework for early MRI-based Alzheimer’s conversion prediction in MCI subjects. Neuroimage 104:398–412. 10.1016/j.neuroimage.2014.10.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mungas D, Beckett L, Harvey D, Tomaszewski Farias S, Reed B, Carmichael O, Olichney J, Miller J, DeCarli C (2010) Heterogeneity of cognitive trajectories in diverse older persons. Psychol Aging 25:606–619. 10.1037/a0019502 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Patterson C (2018) World Alzheimer report 2018: the state of the art of dementia research: new frontiers. London: Alzheimer’s Disease International (ADI). [Google Scholar]
- Petkoski S, Jirsa VK (2019) Transmission time delays organize the brain network synchronization. Philos Trans A Math Phys Eng Sci 377:20180132. 10.1098/rsta.2018.0132 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petri G, Expert P, Turkheimer F, Carhart-Harris R, Nutt D, Hellyer PJ, Vaccarino F (2014) Homological scaffolds of brain functional networks. J R Soc Interface 11:20140873. 10.1098/rsif.2014.0873 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pillai AS, Jirsa VK (2017) Symmetry breaking in space-time hierarchies shapes brain dynamics and behavior. Neuron 94:1010–1026. 10.1016/j.neuron.2017.05.013 [DOI] [PubMed] [Google Scholar]
- Poldrack RA, Gorgolewski KJ (2014) Making big data open: data sharing in neuroimaging. Nat Neurosci 17:1510–1517. 10.1038/nn.3818 [DOI] [PubMed] [Google Scholar]
- Proix T, Spiegler A, Schirner M, Rothmeier S, Ritter P, Jirsa VK (2016) How do parcellation size and short-range connectivity affect dynamics in large-scale brain network models? Neuroimage 142:135–149. 10.1016/j.neuroimage.2016.06.016 [DOI] [PubMed] [Google Scholar]
- Proix T, Bartolomei F, Guye M, Jirsa VK (2017) Individual brain structure and modelling predict seizure propagation. Brain 140:641–654. 10.1093/brain/awx004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rathore S, Habes M, Iftikhar MA, Shacklett A, Davatzikos C (2017) A review on neuroimaging-based classification studies and associated feature extraction methods for Alzheimer’s disease and its prodromal stages. Neuroimage 155:530–548. 10.1016/j.neuroimage.2017.03.057 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rombouts SA, Barkhof F, Goekoop R, Stam CJ, Scheltens P (2005) Altered resting state networks in mild cognitive impairment and mild Alzheimer’s disease: an fMRI study. Hum Brain Mapp 26:231–239. 10.1002/hbm.20160 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Saggio ML, Ritter P, Jirsa VK (2016) Analytical operations relate structural and functional connectivity in the brain. PLoS One 11:e0157292. 10.1371/journal.pone.0157292 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sanchez E, Toro C, Carrasco E, Bonachela P, Parra C, Bueno G, Guijarro F (2011) A knowledge-based clinical decision support system for the diagnosis of Alzheimer disease. 2011 IEEE 13th International Conference on e-Health Networking, Applications and Services IEEE, pp 351–357. 10.1109/HEALTH.2011.6026778 [DOI] [Google Scholar]
- Sanz-Leon P, Knock SA, Woodman MM, Domide L, Mersmann J, McIntosh AR, Jirsa V (2013) The virtual brain: a simulator of primate brain network dynamics. Front Neuroinform 7:10. 10.3389/fninf.2013.00010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sanz-Leon P, Knock SA, Spiegler A, Jirsa VK (2015) Mathematical framework for large-scale brain network modeling in the virtual brain. Neuroimage 111:385–430. 10.1016/j.neuroimage.2015.01.002 [DOI] [PubMed] [Google Scholar]
- Schirner M, Rothmeier S, Jirsa VK, McIntosh AR, Ritter P (2015) An automated pipeline for constructing personalized virtual brains from multimodal neuroimaging data. Neuroimage 117:343–357. 10.1016/j.neuroimage.2015.03.055 [DOI] [PubMed] [Google Scholar]
- Seiffert C, Khoshgoftaar TM, Van Hulse J, Napolitano A (2010) RUSBoost: a hybrid approach to alleviating class imbalance. IEEE Trans Syst Man Cyber A Syst Hum 40. [Google Scholar]
- Shen K, Bezgin G, Hutchison RM, Gati JS, Menon RS, Everling S, McIntosh AR (2012) Information processing architecture of functionally defined clusters in the macaque cortex. J Neurosci 32:17465–17476. 10.1523/JNEUROSCI.2709-12.2012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen K, Bezgin G, Schirner M, Ritter P, Everling S, McIntosh R (2019a) A macaque connectome for large-scale network simulations in the virtual brain. bioRxiv 480905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen K, Goulas A, Grayson DS, Eusebio J, Gati JS, Menon RS, McIntosh AR, Everling S (2019b) Exploring the limits of network topology estimation using diffusion-based tractography and tracer studies in the macaque cortex. Neuroimage 191:81–92. 10.1016/j.neuroimage.2019.02.018 [DOI] [PubMed] [Google Scholar]
- Sizemore AE, Giusti C, Kahn A, Vettel JM, Betzel RF, Bassett DS (2018) Cliques and cavities in the human connectome. J Comput Neurosci 44:115–145. 10.1007/s10827-017-0672-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spiegler A, Knösche TR, Schwab K, Haueisen J, Atay FM (2011) Modeling brain resonance phenomena using a neural mass model. PLoS Comput Biol 7:e1002298. 10.1371/journal.pcbi.1002298 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stefanescu RA, Jirsa VK (2008) A low dimensional description of globally coupled heterogeneous neural networks of excitatory and inhibitory neurons. PLoS Comput Biol 4:e1000219. 10.1371/journal.pcbi.1000219 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stefanovski L, Triebkorn P, Spiegler A, Diaz-Cortes MA, Solodkin A, Jirsa V, McIntosh AR, Ritter P; Alzheimer’s Disease Neuroimaging Initiative (2019) Linking molecular pathways and large-scale computational modeling to assess candidate disease mechanisms and pharmacodynamics in Alzheimer’s disease. bioRxiv 600205. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Straathof M, Sinke MR, Dijkhuizen RM, Otte WM (2019) A systematic review on the quantitative relationship between structural and functional network connectivity strength in mammalian brains. J Cereb Blood Flow Metab 39:189–209. 10.1177/0271678X18809547 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor L, Nitschke G (2018) Improving deep learning with generic data augmentation. In: 2018 IEEE Symposium Series on Computational Intelligence (SSCI), pp 1542–1547. [ 10.1109/SSCI.2018.8628742 [DOI] [Google Scholar]
- Termenon M, Jaillard A, Delon-Martin C, Achard S (2016) Reliability of graph analysis of resting state fMRI using test-retest dataset from the Human Connectome Project. Neuroimage 142:172–187. 10.1016/j.neuroimage.2016.05.062 [DOI] [PubMed] [Google Scholar]
- Thorogood A, Mäki-Petäjä-Leinonen A, Brodaty H, Dalpé G, Gastmans C, Gauthier S, Gove D, Harding R, Knoppers BM, Rossor M, Bobrow M; Global Alliance for Genomics and Health, Ageing and Dementia Task Team (2018) Consent recommendations for research and international data sharing involving persons with dementia. Alzheimers Dement 14:1334–1343. 10.1016/j.jalz.2018.05.011 [DOI] [PubMed] [Google Scholar]
- Toga AW, Neu SC, Bhatt P, Crawford KL, Ashish N (2016) The global Alzheimer’s association interactive network. Alzheimers Dement 12:49–54. 10.1016/j.jalz.2015.06.1896 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Triebkorn P, Zimmermann J, Stefanovski L, Roy D, Solodkin A, Jirsa V, Deco G, Breakspear M, McIntosh AR, Ritter P (2020) Identifying optimal working points of individual virtual brains: a large-scale brain network modelling study. bioRxiv 2020.03.26.009795. [Google Scholar]
- Van Essen DC, Smith SM, Barch DM, Behrens TEJ, Yacoub E, Ugurbil K; WU-Minn HCP Consortium (2013) The WU-Minn human connectome project: an overview. Neuroimage 80:62–79. 10.1016/j.neuroimage.2013.05.041 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Horn JD, Toga AW (2014) Human neuroimaging as a “big data” science. Brain Imaging Behav 8:323–331. 10.1007/s11682-013-9255-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Vos F, Koini M, Schouten TM, Seiler S, van der Grond J, Lechner A, Schmidt R, de Rooij M, Rombouts SA (2018) A comprehensive analysis of resting state fMRI measures to classify individual patients with Alzheimer’s disease. Neuroimage 167:62–72. 10.1016/j.neuroimage.2017.11.025 [DOI] [PubMed] [Google Scholar]
- Walter M, Alizadeh S, Jamalabadi H, Lueken U, Dannlowski U, Walter H, Olbrich S, Colic L, Kambeitz J, Koutsouleris N, Hahn T, Dwyer DB (2019) Translational machine learning for psychiatric neuroimaging. Prog Neuropsychopharmacol Biol Psychiatry 91:113–121. 10.1016/j.pnpbp.2018.09.014 [DOI] [PubMed] [Google Scholar]
- Wang JY, Abdi H, Bakhadirov K, Diaz-Arrastia R, Devous MD Sr (2012) A comprehensive reliability assessment of quantitative diffusion tensor tractography. Neuroimage 60:1127–1138. 10.1016/j.neuroimage.2011.12.062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Z, Wang J, Zhang H, Mchugh R, Sun X, Li K, Yang QX (2015) Interhemispheric functional and structural disconnection in Alzheimer’s disease: a combined resting-state fMRI and DTI study. PLoS One 10:e0126310. 10.1371/journal.pone.0126310 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weiner MW, Veitch DP, Aisen PS, Beckett LA, Cairns NJ, Green RC, Harvey D, Jack CR Jr, Jagust W, Morris JC, Petersen RC, Salazar J, Saykin AJ, Shaw LM, Toga AW, Trojanowski JQ; Alzheimer’s Disease Neuroimaging Initiative (2017) The Alzheimer’s disease neuroimaging initiative 3: continued innovation for clinical trial improvement. Alzheimers Dement 13:561–571. 10.1016/j.jalz.2016.10.006 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wong KF, Wang XJ (2006) A recurrent network mechanism of time integration in perceptual decisions. J Neurosci 26:1314–1328. 10.1523/JNEUROSCI.3733-05.2006 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Woodman MM, Pezard L, Domide L, Knock SA, Sanz-Leon P, Mersmann J, McIntosh AR, Jirsa V (2014) Integrating neuroinformatics tools in the virtual brain. Front Neuroinform 8:36. 10.3389/fninf.2014.00036 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wyman BT, Harvey DJ, Crawford K, Bernstein MA, Carmichael O, Cole PE, Crane PK, DeCarli C, Fox NC, Gunter JL, Hill D, Killiany RJ, Pachai C, Schwarz AJ, Schuff N, Senjem ML, Suhy J, Thompson PM, Weiner M, Jack CR, et al. (2013) Standardization of analysis sets for reporting results from ADNI MRI data. Alzheimers Dement 9:332–337. 10.1016/j.jalz.2012.06.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yaeger LS, Lyon RF, Webb BJ (1997) Effective training of a neural network character classifier for word recognition. Adv Neural Inf Proces Syst 9:807–816. [Google Scholar]
- Zhang D, Shen D; Alzheimer’s Disease Neuroimaging Initiative (2012) Multi-modal multi-task learning for joint prediction of multiple regression and classification variables in Alzheimer’s disease. Neuroimage 59:895–907. 10.1016/j.neuroimage.2011.09.069 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Z, Liao W, Chen H, Mantini D, Ding JR, Xu Q, Wang Z, Yuan C, Chen G, Jiao Q, Lu G (2011) Altered functional–structural coupling of large-scale brain networks in idiopathic generalized epilepsy. Brain 134:2912–2928. 10.1093/brain/awr223 [DOI] [PubMed] [Google Scholar]
- Zimmermann J, Ritter P, Shen K, Rothmeier S, Schirner M, McIntosh AR (2016) Structural architecture supports functional organization in the human aging brain at a regionwise and network level. Hum Brain Mapp 37:2645–2661. 10.1002/hbm.23200 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zimmermann J, Griffiths J, Schirner M, Ritter P, McIntosh AR (2019) Subject specificity of the correlation between large-scale structural and functional connectivity. Netw Neurosci 3:90–106. 10.1162/netn_a_00055 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
provides a pseudo-code for the linear SC-to-FC completion procedure (see Materials and Methods for all details). Linear SC-to-FC completions for the DTI-only subjects in the considered ADNI dataset and the healthy ageing dataset can be downloaded as part of Extended Data 1 FC_SLM. Download Table 1-1, DOCX file (16.6KB, docx) .
MATLAB scripts for connectome generation and workspaces including virtual SC and FC connectomes generated with our data completion pipelines as well as virtual cohorts. All workspaces available at https://github.com/FunDyn/VirtualCohorts. Download Extended Data 1, ZIP file (63.8MB, zip) .
Pseudo-code for linear FC-to-SC completion procedure (see Materials and Methods for all details). Linear FC-to-SC completions for the DTI-only subjects in the considered ADNI dataset and the healthy ageing dataset can be downloaded as part of Extended Data 1 SC_SLM. Download Table 2-1, DOCX file (16.6KB, docx) .
Linear SC-to-FC data completion. The functional data completion can also be done using the linear model starting from SCemp matrices. A, Systematic exploration (for a representative subject) of the dependency of correlation between FCemp and FCSLM on the SLM parameter G (global scale of long-range connectivity strength) shown by the violet line indicates that the best fitting value G* (dashed line) can be obtained slightly before the critical point of the system Gcritic = which since the SCemp matrices are normalized to one = 1 and Gcritic = 1. The green lines display 5th and 95th percentiles of bootstrap resampling. The inset boxplot gives the distribution of G* over all the subjects in the SCemp + FCemp subset; for the SLM SC-to-FC completion, we used a common value G*ref = 0.83, equal to the median of the boxplot. B, The boxplot reports the distribution of Pearson correlation between FCemp and FCSLM for all subjects from the SCemp + FCemp subset with a median equal to 0.243 for the ADNI dataset and 0.377 for the healthy ageing dataset. C, In case of using the common value G*reffor all subjects instead of the actual personalized optimum G* for each subject in the SCemp + FCemp subset, the value of quality loss for each subject is shown in the boxplot with median equal to 0.5%. Download Figure 3-1, EPS file (1.4MB, eps) .
The dependency of best MFM fit zone on additional regional dynamics parameters. In the non-linear data completion, the global parameters of the MFM model are G (interregional coupling strength), τ (synaptic time-constant of within-region excitation), ω (relative strength of recurrent within-region connections), and I (external input) which parameters G and τ were investigated in this paper (see Fig. 3). Here, we showed for different values of and I, the narrow concave stripe of Figure 3A as the representative of the best fitting zone is slightly shifted in the G/τ plane, suggesting G and τ are more sensitive parameters and need to be explored rather than and I. Download Figure 3-2, EPS file (529KB, eps) .
Linear FC-to-SC data completion. Using the linear model, it is equivalently possible to infer the structural SCSLM matrices from FCemp. Since in this approach the free parameters of SLM model appear as scaling factor, they do not affect the correlation of the inferred SCSLM with the SCemp so there is no need for parameter exploration here. The distribution of the correlation values for all the subjects from the SCemp + FCemp ADNI subset is shown in the boxplot with median equal to 0.21 and 0.42 for the healthy ageing dataset. Download Figure 4-1, EPS file (1.4MB, eps) .
Viability of data completion. We checked whether the performance of data completion based on the algorithmic procedures of Tables 1, 2 or Extended Data Tables 1-1, Tables 2-1 is superior to the one of a trivial strategy in which the target connectome to reconstruct is just taken to be identical to the other connectome (i.e., using SC, when trying to reconstruct missing FC; or using FC, when trying to reconstruct missing SC). A, B, We computed percent improvement in data completion over the trivial other connectome strategy using a SLM-based or an MFM-based data completion method, focusing on the SCemp + FCemp subset for which both ground truth connectomes are known. A, Percent improvements in data completion when completing FC from SC. B, Percent improvements in data completion when completing SC from FC. For the SLM-based functional data completion approach, the use of FCSLM on the ADNI dataset resulted in a worse performance (median drop –15%; for definition, see Materials and Methods); however, for the healthy ageing dataset, the use of FCSLM resulted in a clearly better performance than when using the other connectome (median improvement +40%); similarly, applying the SLM-based approach for the structural data completion, the use of SCSLM rather than FCemp as an ersatz for SCemp leads to drops of improvements in quality with a median value of approximately –20%, for the ADNI dataset but an increase of nearly ∼50% for the healthy aging dataset. Thus, the performance of linear data completion can yield to good results, but this performance did not robustly generalize through datasets. On the other hand, for the MFM-based functional data completion, the median improvement was close to ∼20% for both datasets which can go as high as +60% in some subjects; using the same approach but for the structural data completion, the performance was lower than non-linear SC-to-FC data completion, with median improvement of ∼15% for the ADNI dataset and of ∼10% for the healthy aging dataset. Download Figure 2-1, EPS file (1.4MB, eps) .
Inter-subject distances for empirical - bivirtual pairs. Download Table 5-1, DOCX file (16.6KB, docx) .
Discriminating control and patient subjects in the ADNI subset with only SC connectomes. Download Table 3-1, DOCX file (16.6KB, docx) .
Discriminating control and patient subjects in the ADNI subset with only FC connectomes. Download Table 3-2, DOCX file (16.6KB, docx) .
Age class discriminations on the healthy ageing dataset. A, The classification performances when the classifier was train and tested on the same virtual connectome is above chance level (∼0.25) with maximum accuracy of ∼0.42 for FCSLM-bi and minimum accuracy of ∼0.29 for FCMFM-bi. B, The classification accuracy dropped when the classifier was trained on the virtual connectome and tested on the empirical connectome. The only cases where the accuracy was above chance level was when the classifier was trained on SCSLM and SCSLM-bi and tested on FCemp connectome, with an accuracy of ∼0.28. Download Figure 7-1, EPS file (2.5MB, eps) .
Correspondence of network topology between empirical and their bivirtual dual connectomes (healthy aging dataset). We show here scatter plots of connectivity strengths (top center), local clustering coefficients (top right) and local centrality coefficients (bottom center) for different brain regions and subjects, plotting feature values for empirical connectomes versus their bivirtual counterparts and the histograms over different subjects of the relative mutual information (normalized between 0 and 1, the latter corresponding to perfect matching) between the community structures (bottom right) of empirical connectomes and their bivirtual duals. Results are shown in panel A for SC and in panel B for FC connectomes for the healthy ageing dataset (see Fig. 8 for the comparison with the ADNI dataset). Again, for both cases, we see a remarkable correlation at the ensemble level between network topology features for empirical bivirtual connectomes (see Table 4 for the superior correspondence at the single subject level for the ageing dataset). Download Figure 8-1, EPS file (9.8MB, eps) .
The global distributions of link weights for all different types of connectomes. Most of the distributions show similarity in shape with their empirical counterparts (pink). SC weights distributions with a peak for small values and a fat right tail; FC weights distributions with more symmetric and a broader peak at intermediate strengths. Download Figure 6-1, EPS file (597.2KB, eps) .