

Summary
Besides relying heavily on sensory and reinforcement feedback, motor skill learning may also depend on the level of motivation experienced during training. Yet, how motivation by reward modulates motor learning remains unclear. In 90 healthy subjects, we investigated the net effect of motivation by reward on motor learning while controlling for the sensory and reinforcement feedback received by the participants. Reward improved motor skill learning beyond performance-based reinforcement feedback. Importantly, the beneficial effect of reward involved a specific potentiation of reinforcement-related adjustments in motor commands, which concerned primarily the most relevant motor component for task success and persisted on the following day in the absence of reward. We propose that the long-lasting effects of motivation on motor learning may entail a form of associative learning resulting from the repetitive pairing of the reinforcement feedback and reward during training, a mechanism that may be exploited in future rehabilitation protocols.
Keywords: Neuroscience, Behavioral neuroscience, Sensory neuroscience, Cognitive neuroscience
Graphical abstract
Highlights
-
•
Reward improves motor learning beyond performance-based reinforcement feedback
-
•
Reward boosts specifically reinforcement-based adjustments in motor commands
-
•
These effects persist on the following day, in the absence of reward
Neuroscience; Behavioral neuroscience; Sensory neuroscience; Cognitive neuroscience
Introduction
Motor skill learning is the process by which the speed and accuracy of movements improve with practice (Krakauer et al., 2019). A significant amount of research has long since demonstrated that motor learning relies on sensory feedback, which allows reducing movement errors (e.g., Shadmehr et al., 2010; Tseng et al., 2007). More recently, some studies have shown that reinforcement feedback, allowing the adjustment of movements based on knowledge of performance, also plays a role in motor learning (Bernardi et al., 2015; Galea et al., 2015; Mawase et al., 2017; Palminteri et al., 2011; Therrien et al., 2016; Wachter et al., 2009). The contribution of reinforcement feedback to motor learning seems to be particularly important when the quality of the available sensory feedback is low (Cashaback et al., 2017; Izawa and Shadmehr, 2011). These observations suggest that reinforcement feedback may be critical for motor rehabilitation (Quattrocchi et al., 2017; Roemmich and Bastian, 2018), where patients often exhibit sensory impairments in addition to their motor disability (Connell, 2008; Hepworth et al., 2016). However, before clinical translation can occur, significant research is required to characterize the optimal conditions in which sensory and reinforcement feedback can improve motor learning.
One key factor that may influence sensory- and reinforcement-based motor learning is motivation (Lewthwaite and Wulf, 2017). This idea is in line with an ethological perspective: in nature, animals are motivated to learn efficiently motor behaviors that have been repetitively associated with rewarding outcomes, in order to increase the likelihood of reaching these outcomes again in the future (Barron et al., 2010; Yamazaki et al., 2016). Whereas past research on motivation has traditionally focused on the impact of reward on decision-making (Balleine and O'Doherty, 2010; Bush et al., 2002; Dayan and Niv, 2008; Derosiere et al., 2017b; 2017a; Gershman and Daw, 2017; Hare et al., 2011; O'Doherty, 2004; Padoa-Schioppa, 2011; Schultz, 2015; Shima and Tanji, 1998), there has been a recent rise in interest regarding its influence on motor learning (Therrien et al., 2016, Mawase et al., 2017, Uehara et al., 2019; Vassiliadis et al., 2019; Chen et al., 2017; Sporn et al., 2020, Vassiliadis and Derosiere, 2020, Holland et al., 2019).
To tackle this issue, previous studies have investigated motor skill learning with different types of reinforcement and reward. This research showed that the combination of reinforcement (providing knowledge of performance) and reward (providing motivation) can influence motor skill learning (e.g., Abe et al., 2011; Steel et al., 2019, 2016; Wachter et al., 2009; Wilkinson et al., 2015). A key aspect of the aforementioned studies is that they considered reinforcement and reward in a bonded way, with the rewarded participants being also the ones receiving performance-based reinforcement feedback. The assumption underlying this approach is that receiving knowledge of performance (e.g., points or binary feedback) provides a form of intrinsic reward that by itself increases motivation to perform well (Leow et al., 2018). However, in addition to the intrinsically rewarding properties of reinforcement, knowledge of performance also provides a learning signal to the motor system that can influence motor learning (Bernardi et al., 2015; Galea et al., 2015; Huang et al., 2011; Kim et al., 2019; Leow et al., 2018; Mawase et al., 2017; Nikooyan et al., 2015; Shmuelof et al., 2012; Therrien et al., 2016; Uehara et al., 2018). In contrast, extrinsic reward increases motivation to perform well without conveying any additional learning signal (Berke, 2018). In accordance with a dissociable role of reinforcement and reward in motor learning, past research has shown that certain subpopulations of neurons in the motor cortex (i.e., a key region of the motor learning network; Krakauer et al., 2019) are responsive to the outcome of previous movements irrespective of reward (Levy et al., 2020), while others respond to reward regardless of the previous outcome (Ramkumar et al., 2016). Put together, these elements indicate that estimating the net impact of reward on motor learning requires controlling for the effect of the reinforcement feedback on the learning process. Based on these elements, we experimentally uncoupled knowledge of performance from reward to test the hypothesis that reward induces a specific improvement in motor skill learning and maintenance.
Another important question relates to how, at the single-trial level, motivation by reward may affect motor skill learning and maintenance. As such, computational models of motor learning posit that movement errors can be corrected based on sensory and reinforcement feedbacks on a trial-by-trial basis (Cashaback et al., 2017), with possible interactions between these two processes (Izawa and Shadmehr, 2011). Sensory-based motor learning relies on the ability to produce motor commands that match predicted sensory consequences (e.g., visual, somatosensory consequences; Sidarta et al., 2016; Bernardi et al., 2015). Conversely, reinforcement-based motor learning is thought to depend on the ability to efficiently regulate between-trial motor variability based on previous outcomes (Dhawale and Smith, 2017; Pekny et al., 2015; Sidarta et al., 2016; Therrien et al., 2016; Uehara et al., 2019; Wu et al., 2014). Importantly, in this framework, reward may have a global influence, enhancing both sensory- and reinforcement-based adjustments from one trial to another, or could have a more specific effect, boosting only one of the two learning systems (Galea et al., 2015; Kim et al., 2019). Here, we investigated the impact of reward on sensory- and reinforcement-based motor adjustments during motor skill learning at the single-trial level, in a situation where they can both contribute to the learning process.
Healthy participants (n = 90) trained on a pinch-grip force reproduction task with limited sensory feedback over two consecutive days while we manipulated the reinforcement feedback and reward on Day 1. By removing visual feedback on most trials, we ensured that the learning process would largely depend on the integration of somatosensory and reinforcement feedbacks (Bernardi et al., 2015; Izawa and Shadmehr, 2011; Sidarta et al., 2019). Moreover, subjects were distributed in three groups where training involved sensory (S) feedback only (Group-S; n = 30), sensory and reinforcement (SR) feedback (Group-SR; n = 30), or both feedbacks and a reward (SRR, Group-SRR; n = 30). Monetary gains were used as they are known to strongly modulate the motivation to engage in various tasks (Grogan et al., 2020a, 2020b; Manohar et al., 2015; Schultz, 2015; Shadmehr et al., 2019). We investigated how participants learned and maintained the skill depending on the type of feedback experienced during training. We found that while sensory and reinforcement feedbacks were not sufficient for the participants to learn the task in the present study, adding reward during training markedly improved motor performance. Reward-related gains in motor learning were maintained on Day 2, even if subjects were no longer receiving a reward on that day. Importantly, single-trial analyses showed that reward specifically increased reinforcement-related adjustments in motor commands, with this effect being maintained on Day 2, in the absence of reward. The pinch-grip force task used here also allowed considering adjustments separately for the speed of force initiation and the accuracy of the performed force, both in terms of variability and amplitude. Importantly, we found that reward did not affect the control of all motor components in the same way, with the amplitude component turning out to be the more strongly influenced by the presence of reward.
Altogether, the present results provide evidence that motivation by reward can improve motor skill learning and maintenance even when the task is performed with the same knowledge of performance. More importantly, this effect seems to entail a specific potentiation of reinforcement-related adjustments in the motor command at the single-trial level. These behavioral results are important to characterize the mechanisms by which reward can improve motor learning and may guide future motivational interventions for rehabilitation (McGrane et al., 2015).
Results
Ninety healthy participants practiced a pinch-grip force task over two consecutive days. The task required participants to hold a pinch grip sensor in their right hand and to squeeze it as quickly as possible in order to move a cursor displayed on a computer screen in front of them, from an initial position to a fixed target (Figure 1A). The force required to reach the target (TargetForce) corresponded to 10% of the individual maximum voluntary contraction (MVC). In most of the trials (90%), participants practiced the task with very limited sensory feedback: The cursor disappeared when the generated force reached half of the TargetForce. In the remaining trials (10%; not considered in the analyses), full vision of the cursor allowed participants to be visually guided toward the TargetForce and therefore to be reminded of the somatosensory sensation corresponding to the TargetForce. Hence, in this task, learning relied mostly on the successful reproduction of the TargetForce based on somatosensory feedback (Raspopovic et al., 2014), with the target somatosensory sensation being regularly reminded to the participants through the full vision trials. To learn the task, subjects were provided with six training blocks (40 trials each; i.e., total of 240 training trials; Figure 1B), during which Group-S subjects trained with sensory feedback only (Block-S), Group-SR subjects trained with sensory and reinforcement feedback (Block-SR), and Group-SRR subjects trained with both feedbacks and a monetary reward (Block-SRR). Notably, the groups were comparable for a variety of features including age, gender, TargetForce, difficulty of the task, muscular fatigue, and final monetary gains (see STAR Methods, Table 1). Beside the training blocks, all participants performed the task in a Block-SR setting so that the familiarization, the pre- and post-training assessments on Day 1, as well as Re-test on Day 2, occurred in the same conditions in the three experimental groups. This design allowed us to investigate the effect of reinforcement and reward, both on learning and on maintenance of the learned motor skill. Importantly, in Block-SR and Block-SRR, the binary reinforcement feedback depended on the Error, estimated as the absolute difference between the TargetForce and the exerted force over the whole trial (excluding the first 150 ms, Figure 1C; Abe et al., 2011; Steel et al., 2016). Hence, to be successful, participants had to reduce the Error by approximating the TargetForce as quickly and accurately as possible.
Figure 1.

The motor skill learning task
(A) Time course of a trial in the motor skill learning task. Each trial started with the appearance of a sidebar and a target. After a variable preparatory phase (800-1000ms), a cursor appeared in the sidebar, playing the role of a “Go” signal. At this moment, participants were required to pinch the force transducer to bring the cursor into the target as quickly as possible and maintain it there until the end of the task (2000ms). Notably, on most trials, the cursor disappeared halfway toward the target (as displayed here). Then, a reinforcement feedback was provided in the form of a colored circle for 1000ms and provided binary knowledge of performance (Success or Failure in Block-SR and Block-SRR) or was non-informative (Block-S). The reinforcement feedback was determined based on the comparison between the Error on the trial and the individual success threshold (computed in the Calibration block, see STAR Methods). Finally, each trial ended with a reminder of the color/feedback association and potential reward associated to good performance (1500ms).
(B) Experimental procedure. On Day 1, all participants performed two familiarization blocks in a Block-SR condition. The first one involved full vision of the cursor while the second one provided only partial vision and served to calibrate the difficulty of the task on an individual basis (See STAR Methods). Then, Pre- and Post-training Block-SR assessments were separated by 6 blocks of training in the condition corresponding to each individual group (Block-S for Group-S, Block-SR for Group-SR and Block-SRR for Group-SRR). Day 2 involved a Familiarization block (with partial vision) followed by a Re-test assessment (4 Block-SR pooled together). There was no recalibration on Day 2.
(C) Example of a force profile. Force applied (in % of MVC) during the task. Participants were asked to approximate the TargetForce as quickly and accurately as possible to minimize the Error (gray shaded area). As shown on the Figure, this Error depended on the speed of force initiation (ForceInitiation) and on the accuracy of the maintained force, as reflected by its amplitude with respect to the TargetForce (ForceAmplError) and its variability (ForceVariability). Note that the first 150ms of each trial were not considered for the computation of the Error.
Table 1.
Group features and muscle fatigue in the three experimental groups (mean ± SE)
| Group-S (n = 30) | Group-SR (n = 30) | Group-SRR (n = 30) | F(2,87) | p | |
|---|---|---|---|---|---|
| Age (years) | 23.9 ± 0.67 | 23.3 ± 0.50 | 23.9 ± 0.43 | 0.34 | 0.71 |
| Gender (number of females) | 19 | 19 | 20 | / | / |
| Success threshold (% MVC) | 2.8 ± 0.01 | 2.8 ± 0.01 | 2.9 ± 0.01 | 0.13 | 0.88 |
| TargetForce (Newtons) | 5.3 ± 0.30 | 4.7 ± 0.25 | 5.1 ± 0.21 | 1.16 | 0.31 |
| Sensitivity to reward (score) | 37.1 ± 1.18 | 35.6 ± 1.11 | 37.5 ± 1.14 | 0.79 | 0.46 |
| Sensitivity to punishment (score) | 42.3 ± 1.59 | 42.0± 1.59 | 40.9 ± 1.46 | 0.22 | 0.81 |
| Muscle fatigue – Day 1 (MVCPOST in % of MVCPRE) | 95.7 ± 2.39 | 99.0 ± 2.61 | 98.6 ± 2.57 | 0.51 | 0.60 |
| Muscle fatigue – Day 2 (MVCPOST in % of MVCPRE) | 94.6 ± 2.74 | 93.9 ± 1.52 | 97.0 ± 1.89 | 0.60 | 0.55 |
The 2 last columns provide the results of one-way ANOVAs' ran with the factor GroupTYPE.
Reward improves motor skill learning
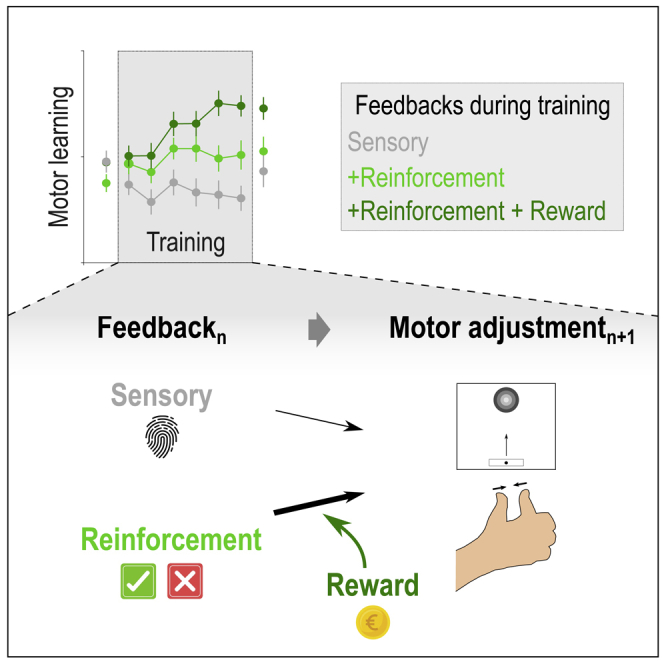
Participants’ initial performance was comparable in all groups: The Error in the Pre-training block equaled 3.14 ± 0.18% MVC in Group-S, 3.33 ± 0.17% MVC in Group-SR and 3.30 ± 0.15% MVC in Group-SRR (one-way ANOVA: F(2,87) = 0.37, p = 0.69, partial η2 = 0.0084; Figure 2A). In contrast, skill learning, estimated as the training-related reduction in Error on Day 1 (Normalized Error = Post-training Error expressed in % of Pre-training Error) varied as a function of the group (Figure 2B). As such, learning was stronger in the Group-SRR compared to the two other groups (ANOVA: F(2,87) = 4.41, p = 0.015, partial η2 = 0.092; post-hocs: Group-SRR vs. Group-SR: p = 0.014, Cohen's d = 0.60; Group-SRR vs. Group-S: p = 0.010, d = 0.98), with no significant difference between Group-S and Group-SR (p = 0.91, d = 0.025). This was confirmed by a subsequent analysis showing that learning was significant in the Group-SRR (Post-training = 80.7 ± 3.5% of Pre-training; single-sample ttest against 100%: t(29) = −5.49, p < 0.00001, d = −1.42), but not in Group-S (Post-training = 103.9 ± 5.15% of Pre-training; t(29) = 0.75, p = 0.46, d = 0.19) or in Group-SR (Post-training = 102.9 ± 8.80% of Pre-training; t(29) = 0.33, p = 0.745, d = 0.085). Skill maintenance on Day 2, estimated as the Error at Re-test in percentage of Pre-training, was not significantly different between the groups (F(2,87) = 1.96, p = 0.15, partial η2 = 0.043; Figure 2C). However, in Group-SRR, we found that the Error at Re-test remained lower than at Pre-training (Re-test = 85.6 ± 5.01% of Pre-training; single-sample ttest against 100%: t(29) = −2.88, p < 0.0073, d = −0.74) demonstrating that the skill was maintained, while this effect was not significant in the two other groups (Group-S: Re-test = 100.5 ± 4.63% of Pre-training; t(29) = 0.11, p = 0.92, d = −0.12, Group-SR: Re-test = 97.0 ± 6.82% of Pre-training; t(29) = −0.45, p = 0.66, d = −0.028). Hence, while reinforcement alone did not contribute to reduce the Error in this task, its combination with reward successfully helped participants to learn and maintain the skill, as also evident when considering the averaged success rates (Figure 2D) and individual force profiles (Figure 2E).
Figure 2.

Effect of reward on motor skill learning
(A) Error. Average Error is represented across practice for the three experimental groups (gray: Group-S, light green: Group-SR, dark green: Group-SRR). The gray shaded area highlights the blocks concerned by the reinforcement manipulation. The remaining blocks were performed with knowledge of performance only (i.e., in a Block-SR setting).
(B) Skill learning. Bar plot (left) and violin plot (right, each dot = one subject) representing skill learning (quantified as the Error in Post-training blocks expressed in percentage of Pre-training blocks) in the three experimental groups. Skill learning was significantly enhanced in Group-SRR compared to the two other groups. This result remained significant when removing the subject showing an extreme value in the Group-SR (ANOVA: F(2,86) = 6.44, p = 0.0025, partial η2 = 0.13; post-hocs; Group-SRR vs. Group-SR: p = 0.027; Group-SRR vs. Group-S: p = 0.00064; Group-SR vs. Group-S: p = 0.21).
(C) Skill maintenance. Bar plot (left) and violin plot (right) representing skill maintenance quantified as the Error in Re-test blocks expressed in percentage of Pre-training blocks) in the three experimental groups.
(D) Success. Proportion of successful trials for each block.
(E) Force profiles. Individual force profiles of one representative subject of Group-S (left), Group-SR (middle) and Group-SRR (right) in the Pre- (gray) and Post-training blocks (blue). Note the better approximation of the TargetForce and the reduced inter-trial variability at Post-training in the exemplar subject of Group-SRR.
∗: significant difference between groups (p<0.05). #: significant difference within a group between normalized Post-training Error and a constant value of 100% (p<0.017 to account for multiple comparisons). Data are represented as mean ± SE
Reward boosts reinforcement-related adjustments during motor skill learning
To identify the mechanisms at the basis of the effect of reward on motor learning, we quantified how much participants adjusted motor commands based on reinforcement or sensory feedback at the single-trial level. This allowed us to estimate how subjects relied on each type of feedback on a trial-by-trial basis and how this behavior was affected by reward. In order to investigate reinforcement-related adjustments in motor commands, we computed the absolute between-trial change (BTC) in Error (ErrorBTC = |Errorn+1-Errorn|) following successful or failed trialn of similar Error in the three groups (STAR Methods, see also (Pekny et al., 2015; Uehara et al., 2019) for similar approaches in reaching tasks). Comparing ErrorBTC depending on the Outcome of the previous trial (Success or Failure) allowed us to estimate how much participants modified their force profile based on the reinforcement feedback. Notably, considering changes in the Error in absolute terms allowed us to explore the effect of reward on the magnitude of the adjustments in the different groups, regardless of their directionality (increase or decrease in the Error). We found that ErrorBTC was generally higher after failed than successful trials (two-way ANOVA; main effect of Outcome: F(1,84) = 8.66, p = 0.0042, partial η2 = 0.093; Figure 3A), consistent with an exploration process following failed trials (Uehara et al., 2019; Pekny et al., 2015). Interestingly, this difference between failed and successful trials was modulated by GroupTYPE (Outcome x GroupTYPE: F(2,84) = 11.47, p < 0.001, partial η2 = 0.21): While it was significant in Group-SR and Group-SRR (post-Success vs. post-Failure: p = 0.028, d = −0.54 and p < 0.001, d = −0.92 respectively), this effect was only at the trend level for Group-S (p = 0.060, d = 0.29). Relatedly, post-hoc tests revealed that post-Success ErrorBTC was significantly lower in Group-SRR than in Group-S (p = 0.026, d = −0.54), but not different between Group-SR and Group-S (p = 0.24, d = −0.23) and between Group-SR and Group-SRR (p = 0.30, d = 0.29). Besides, post-Failure ErrorBTC was significantly higher in Group-SRR than in Group-S (p = 0.040, d = 0.65). Yet, it was not different between Group-SR and Group-S (p = 0.14, d = 0.48) and between Group-SR and Group-SRR (p = 0.58, d = −0.16). Hence, providing a reward on top of reinforcement feedback led to a particularly low ErrorBTC following successful trials and a particularly high ErrorBTC following failed trials. This analysis suggests that reward modulated between-trial changes in behavior in response to the reinforcement feedback, regardless of whether reinforcement was positive or negative. To further confirm this, we directly compared the magnitude of reinforcement-based adjustments between the three groups, by expressing the ErrorBTC following failed trials relative to the ErrorBTC following successful trials. Doing so, we found a significant effect of the GroupTYPE during Day 1 training (F(2,84) = 10.27, p < 0.001, partial η2 = 0.20; Figure 3A). As expected, participants of the Group-SR adjusted their force profile depending on the reinforcement feedback, while participants of the Group-S were unable to do so (post-hocs; Group-S vs. Group-SR: p = 0.022, d = −0.68). Interestingly, this ability to adjust motor commands based on the reinforcement was amplified by reward (Group-SR vs. Group-SRR: p = 0.036, d = −0.57). This result suggests that one mechanism through which reward improves motor learning is the potentiation of reinforcement-related adjustments in motor commands. To further test this idea, we evaluated the relationship between the magnitude of reinforcement-based changes in motor commands and the average success rate in the following trial across all subjects. Consistently, we found that the magnitude of reinforcement-related adjustments was strongly associated to the probability of success (R2 = 0.62; p = 1.5 x 10−19; Figure 3B): The more participants adjusted their behavior based on the reinforcement feedback in a given trial (e.g., by reducing ErrorBTC following Success and/or by increasing it following a Failure), the more they were likely to be successful in the following trial, supporting the view that these adjustments were relevant in the present task. Hence, these data suggest that the effect of reward on motor skill learning relies on the ability to adjust movements based on the reinforcement feedback.
Figure 3.

Between-trial adjustments in the Error
(A) Reinforcement-based adjustments in the Error during Day 1 training. Absolute between-trial adjustments in the Error (ErrorBTC = |Errorn+1-Errorn|) according to the reinforcement feedback (i.e., Success or Failure) encountered at trialn in the three GroupTYPES (gray: Group-S, light green: Group-SR, dark green: Group-SRR). Notably, these bins of trials were constituted based on the success threshold-normalized Error at trialn in order to compare adjustments in motor commands following trials of similar Error in the three groups. Stars denote significant group differences in ErrorBTC for a given outcome (left panel, see STAR Methods). Reinforcement-based adjustments (ErrorBTC after Failure in percentage of ErrorBTC after Success) were compared in the three GroupTYPES (right panel).
(B) Correlations between the magnitude of reinforcement-based adjustments in the Error and the average success rate on the next trial, showing the relevance of these adjustments in the present task. Each dot represents a subject.
(C, D) Same for Day 2 training. Note that reinforcement-based adjustments in motor commands remained amplified in GroupSRR, despite the absence of reward on Day 2.
(E) Sensory-based adjustments in the Error during Day 1 training. ErrorBTC following trialsn with Failures of different Error magnitudes (left panel). Sensory-based adjustments (ErrorBTC after Large Failure in percentage of ErrorBTC after Small Failure) were compared in the three GroupTYPES (right panel).
(F) Correlations between the magnitude of sensory-based adjustments in the Error and the probability of success on the next trial, showing the relevance of these adjustments for task success.
(G, H) Same for Day 2 training. ∗: p < 0.05. Data are represented as mean ± SE.
In the second step, we asked whether such single-trial effects were maintained on Day 2, while all participants performed the task with sensory and reinforcement feedback, but in the absence of reward (i.e., in a Block-SR setting). Interestingly, there was also an Outcome × GroupTYPE interaction: F(2,78) = 3.75, p = 0.027, partial η2 = 0.088) demonstrating differences in the way participants relied on the reinforcement feedback on Day 2 based on the type of training experienced on Day 1 (Figure 3C). All groups displayed a larger ErrorBTC following a failed compared to a successful trial (Group-S: p< 0.018, d = 0.46; Group-SR: p < 0.001, d = 0.75; Group-SRR: p < 0.001, d = 1.13). Notably though, post-hoc tests did not identify any group difference in post-Success ErrorBTC (Group-SR vs. Group-SRR: p = 0.13, d = 0.72; Group-SR vs. Group-S: p = 0.96, d = −0.019; Group-SRR vs. Group-S: p = 0.12, d = −0.56) nor did it do so in post-Failure ErrorBTC (Group-SR vs. Group-SRR: p = 0.33, d = −0.20; Group-SR vs. Group-S: p = 0.35, d = 0.25; Group-SRR vs. Group-S: p = 0.058, d = 0.39). Yet, when expressing ErrorBTC in Post-Failure relative to Post-Success trials, we found that participants receiving reward in Group-SRR adjusted more of their movements according to the reinforcement feedback compared to Group-S and Group-SR (F(2,78) = 3.53, p = 0.034, partial η2 = 0.083; post-hocs; Group-S vs. Group-SRR: p = 0.017, d = −0.66, Group-SR vs. Group-SRR: p = 0.039, d = −0.56, Figure 3C). There was no difference between Group-S and Group-SR (p = 0.72, d = −0.10). Here, again, the magnitude of reinforcement-based adjustments correlated with the success in the next trial (R2 = 0.51; p = 5.5 x 10−14; Figure 3D). Hence, the effect of reward on reinforcement-based adjustments can persist on a subsequent session of training, even after reward removal.
As explained above, we evaluated reinforcement-based adjustments by comparing ErrorBTC following successful or failed trials. However, by definition, successful and failed trials did not only differ with respect to the reinforcement feedback obtained at trialn, but also regarding the experienced sensory feedback. Hence, the reward effect reported above could be specific to reinforcement-based adjustments, or may reflect a different reliance on the sensory feedback (or a combination of both). To disentangle these possibilities, we reasoned that the extent to which participants relied on the somatosensory feedback to adjust their movements could be estimated by computing ErrorBTC following failed trials of different Error magnitudes (i.e., small or large Failure). In other words, we contrasted ErrorBTC following trials with the same reinforcement feedback (i.e., Failure) but with different somatosensory experiences (i.e., resulting from Small or Large Failures). Here too, we found a significant Outcome × GroupTYPE interaction on the ErrorBTC (F(2,76) = 5.15, p = 0.0080, partial η2 = 0.12; Figure 3E). As such, adjustments were greater after Large than after Small Failures in Group-SR and Group-SRR (p < 0.001, d = 0.65 and p < 0.001, d = 1.20, respectively), but not in Group-S (p = 0.50, d = 0.19). Post-hoc tests also indicated that adjustments after a Large Failure were greater in Group-SR and Group-SRR than in Group-S (p < 0.001, d = 1.15 and p < 0.001, d = 1.31, respectively), but not different between Group-SR and Group-SRR (p = 0.26 p < 0.001, d = 0.25). After Small Failures, ErrorBTC was also larger in Group-SR than in Group-S (p = 0.042, d = 0.56), but not different between Group-SR and Group-SRR (p = 0.31, d = 0.30) and between Group-SRR and Group-S (p = 0.34, d = 0.44). This indicates that while subjects of the Group-SR and Group-SRR adjusted the Error depending on the sensory feedback, participants of the Group-S were not able to do so, suggesting that training with reinforcement feedback allowed participants to be more sensitive to the sensory feedback (Galea et al., 2015; Bernardi et al., 2015), regardless of whether they received reward or not. Consistently, we found a GroupTYPE effect (F(2,76) = 5.05, p = 0.0087, partial η2 = 0.12; Figure 3E) on the magnitude of sensory-based adjustments (ErrorBTCfollowing Large Failures expressed relative to ErrorBTC following Small Failures), which was driven by differences between Group-S and the two other groups (post-hocs; Group-S vs. Group-SR: p = 0.0056, d = −0.73, Group-S vs. Group-SRR: p = 0.011, d = −0.85). Importantly, we did not find any difference between Group-SR and Group-SRR (p = 0.90, d = −0.033). Then, similarly as for the reinforcement-based changes, we found that the magnitude of sensory-based adjustments correlated with the subsequent probability of success (R2 = 0.34, p = 1.8 x 108; Figure 3F), demonstrating that these adjustments were also relevant in the learning process.
On Day 2, the effect of Outcome persisted (F(1,68) = 15.20, p < 0.001, partial η2 = 0.18) with a trend for a GroupTYPE effect (F(2,68) = 3.12, p = 0.051, partial η2 = 0.084) but no Outcome × GroupTYPE interaction (F(2,68) = 3.12, p = 0.46, partial η2 = 0.013). Consistently, the magnitude of sensory-based adjustments was not different between the GroupTYPES (F(2,68) = 0.41, p = 0.67, partial η2 = 0.012, Figure 3G). Note, though, that similarly to Day 1, sensory-based adjustments significantly correlated with the probability of success on Day 2 (R2 = 0.13, p = 0.0022; Figure 3H). Hence, the absence of reward effects on sensory-based adjustments on Day 1 and 2 cannot be explained by the fact that participants did not rely on this type of feedback.
The single-trial analyses on ErrorBTC revealed significant differences in the way participants of each group adjusted their motor commands based on the reinforcement and the sensory feedback. However, the distribution of the Error data could have contributed to these single-trial effects. Indeed, even for random adjustments in motor commands (e.g., based on a Gaussian process), adjustments following small or large Errorn (i.e., in the tails of the Error distribution) would be larger than adjustments following Errorn close to the mean of the distribution. Hence, to ensure that group differences in Error distribution did not contribute to our single-trial results, we ran a control analysis in which we shuffled the Error data for each subject (with 10,000 permutations), and then re-computed reinforcement and sensory-based adjustments exactly as in the main analysis. Importantly, we did not find any GroupTYPE effect on these shuffled data neither for reinforcement- (Day 1: F(2,84) = 1.6, p = 0.21, partial η2 = 0.04; Day 2: F(2,78) = 0.89, p = 0.41, partial η2 = 0.02) nor for sensory-based adjustments (Day 1: F(2,76) = 0.02, p = 0.98, partial η2 = 0.0006; Day 2: F(2,78) = 0.20, p = 0.82, partial η2 = 0.006). This analysis indicates that the differences in single-trial adjustments reported here were not related to a sampling bias.
Reward boosts reinforcement-based adjustments at a specific level of motor control
As a last step, we asked whether the effect of reward on between-trial adjustments in motor commands concerned all aspects of force control or only some specific motor components. To do so, we investigated how reinforcement and sensory feedback shaped adjustments in the speed and accuracy of force production in the three GroupTYPES by dissecting each force profile into three separate components (Figure 1B). To evaluate the speed at which the force was generated, we computed the time required for force initiation (i.e., the time required to reach half of the TargetForce: ForceInitiation). To assess the accuracy of the force, we computed the force difference between the average amplitude of the generated force and the TargetForce (ForceAmplError), and the variability (standard deviation/mean) of the maintained force (ForceVariability). Notably, both indicators of force accuracy were computed in the second half of the trial (i.e., the last 1000 ms), well after force initiation, when participants maintained a stable level of force.
We compared between-trial changes in ForceInitiation (ForceInitiation-BTC), ForceAmplError (ForceAmplError-BTC), and ForceVariability (ForceVariability-BTC) following Success or Failure trials of similar Error magnitude in the three groups. The ANOVA run on the ForceInitiation-BTC data revealed a significant Outcome × GroupTYPE interaction (F(2,84) = 7.62, p < 0.001, partial η2 = 0.15) that was driven by the fact that post-Success and post-Failure ForceInitiation-BTC were different in Group-SR and Group-SRR (p < 0.001, d = −1.04 and p < 0.001, d = −1.59, respectively) but not in Group-S (p = 0.10, d = −0.27). Moreover, post-Success changes in ForceInitiation were smaller in Group-SRR than in Group-S (p = 0.023, d = −0.56); it also tended to be smaller in Group-SR than in Group-S (p = 0.071, d = −0.49), while it was comparable in Group-SR and Group-SRR (p = 0.65, d = 0.14). Corroborating these results, we found that reinforcement feedback impacted the modulation of initiation speed (expressed as ForceInitiation-BTC following a Failure in percentage of ForceInitiation-BTC following a Success; F(2,84) = 8.50, p < 0.001, partial η2 = 0.17; post-hocs: Group-S vs. Group-SR: p = 0.0011, d = −0.84, Group-S vs. Group-SRR: p < 0.001, d = −1.09; Figure 4A). Interestingly though, we did not find any effect of reward on the reinforcement-based adjustment of speed (Group-SR vs. Group-SRR: p = 0.78, d = −0.072). At the level of ForceAmplError, we found again an Outcome × GroupTYPE interaction (F(2,84) = 14.07, p < 0.001, partial η2 = 0.25; Figure 4B) that was driven by the fact that post-Success and post-Failure ForceAmplError-BTC were different in Group-SR and Group-SRR (p < 0.001, d = −0.97 and p = 0.0034, d = −1.44, respectively) but not in Group-S (p = 0.99, d = −0.0002). Group comparisons at post-Success and post-Failure did not evidence any significant difference in ForceAmplError-BTC. Notably though, there was a trend for the post-Success ForceAmplError-BTC to be smaller in Group-SRR than in Group-S (p = 0.066, d = −0.42). Interestingly, direct comparison of reinforcement-related changes in ForceAmplError-BTC (post-Failure vs. post-Success) revealed a significant effect of reward (F(2,84) = 9.54, p < 0.001, partial η2 = 0.19; Figure 4B). As such, participants of the Group-SRR modulated more the ForceAmplError according to the reinforcement feedback than subjects of the two other groups (Group-S vs. Group-SRR: p < 0.001, d = −1.04, Group-SR vs. Group-SRR: p = 0.018, d = −0.70). Notably, there was also a trend for Group-SR to be different from Group-S (p = 0.064, d = −0.50). Finally, analysis of ForceVar-BTC did not reveal any Outcome × GroupTYPE interaction (F(2,84) = 0.79, p = 0.46, partial η2 = 0.018; Figure 4C), neither did it show a GroupTYPE effect (F(2,84) = 0.81, p = 0.45, partial η2 = 0.020; Figure 4C) on reinforcement-based adjustments (ForceVar-BTC post-Failure vs. post-Success). Hence, while reward strongly influenced reinforcement-based adjustments of force amplitude, it did not modulate the between-trial regulation of the speed at which the force was initiated or the variability of the maintained force. This suggests that the effect of reward on reinforcement-related adjustments was not global (i.e., affecting all aspects of the movement) but rather specific to force amplitude.
Figure 4.

Between-trial adjustments in initiation time, amplitude error and variability
Reinforcement-based adjustments in the ForceInitiation (A), ForceAmplError (B) and ForceVariability (C). Absolute between-trial changes (BTC) for each motor component (ForceBTC = |Forcen+1-Forcen|) according to the reinforcement feedback (i.e., Success or Failure) encountered at trialn in the three GroupTYPES (gray: Group-S, light green: Group-SR, dark green: Group-SRR). Notably, these bins of trials were constituted based on the success threshold-normalized Error at trialn. Stars denote significant group differences in ErrorBTC for a given outcome (left panel). Reinforcement-based adjustments (ForceBTC after Failure in percentage of ForceBTC after Success) in the three GroupTYPES (right panel). Sensory-based adjustments in the ForceInitiation (D), ForceAmplError (E) and ForceVariability (F). ForceBTC following trialsn with Failures of different Error magnitudes (left panel). Sensory-based adjustments (ForceBTC after Large Failure in percentage of ForceBTC after Small Failure) in the three GroupTYPES (right panel). ∗: p < 0.05. Data are represented as mean ± SE.
We also considered the effect of the sensory feedback on between-trial adjustments by comparing ForceInitiation-BTC, ForceAmplError-BTC, and ForceVariability-BTC following failed trials of different Error magnitudes (i.e., small or large Failure). Contrary to the global ErrorBTC index, we did not find any Outcome ×GroupTYPE interaction neither for ForceInitiation-BTC (F(2,76) = 0.54, p = 0.59, partial η2 = 0.014), nor for ForceAmplError-BTC (F(2,76) = 2.80, p = 0.067, partial η2 = 0.069) or ForceVariability-BTC (F(2,76) = 1.25, p = 0.29, partial η2 = 0.032). Consistently, we did not find any significant difference in the way participants from the different groups adjusted individual motor components depending on the size of the preceding Failure (Large vs. Small Failure on Figures 4D–4F; ForceInitiation-BTC: F(2,76) = 0.10, p = 0.90, partial η2 = 0.0026; ForceAmplError-BTC: F(2,76) = 2.57, p = 0.083, partial η2 = 0.063; ForceVariability-BTC: F(2,76) = 2.46, p = 0.092, partial η2 = 0.061). This analysis supports the idea that reward did not increase the sensitivity to the sensory feedback, but rather boosted specific adjustments in motor commands in response to the reinforcement feedback.
Finally, as a control analysis, we characterized the respective influence of each motor component in the Error, which determined task success. As such, in addition to representing different levels of force control (i.e., initiation, amplitude and variability), the motor components evaluated here may also bear different relevance for task success (van der Kooij et al., 2021). For each participant, we ran separate partial linear regressions on the Error data with ForceInitiation, ForceAmplError or ForceVariability as predictors. Notably, we used partial regressions here to assess the relationship between the Error and each motor component, while controlling for the effect of the other motor components in the correlation. Interestingly, we found that ForceAmplError explained the largest part of variance in the Error (r = 0.96 ± 0.003; p<0.05 in 90/90 subjects). ForceInitiation also explained a large part of variance in the Error (r = 0.81 ± 0.01; p<0.05 in 90/90 subjects), while ForceVariability explained a smaller, yet significant in most subjects, part of variance (r = 0.22 ± 0.03; p<0.05 in 68/90 subjects). Hence, although all motor parameters were relevant for task success, the ForceAmplError was the most influential factor.
Altogether, our results demonstrate that reward potentiates reinforcement-based adjustments in motor commands and that this effect persists even after reward removal on the subsequent day. The data also show that this effect does not concern all components of the movement, but specifically the amplitude of the force which was the most relevant factor for task success.
Discussion
In this study, we investigated the net effect of reward on motor learning while controlling for the reinforcement feedback received by the participants. Our results provide evidence that reward can improve motor skill learning and that this effect is related to a specific potentiation of reinforcement-related adjustments in motor commands. Strikingly, the potentiation of such adjustments persisted on a subsequent day in the absence of reward. Moreover, such boosting of reinforcement-based adjustments did not concern all components of force production but only the amplitude, which was the most relevant one for task success. These findings shed light on the mechanisms through which reward can durably enhance motor performance. They also lay the groundwork for future rehabilitation strategies involving optimized sensory and reinforcement feedbacks.
A main goal of the present study was to explore the net effect of reward on motor skill learning by experimentally dissociating it from the reinforcement feedback. As such, previous motor learning studies have often coupled reinforcement and reward (e.g., Abe et al., 2011; Steel et al., 2019, 2016; Wachter et al., 2009; Wilkinson et al., 2015), based on the underlying assumption that receiving knowledge of performance (e.g., points or binary feedback) provides a form of intrinsic reward that can by itself increase motivation to perform well (Leow et al., 2018). However, in addition to providing some form of intrinsic reward, reinforcement feedback also provides a learning signal to the motor system that can influence motor learning (Bernardi et al., 2015; Galea et al., 2015; Huang et al., 2011; Kim et al., 2019; Leow et al., 2018; Mawase et al., 2017; Nikooyan et al., 2015; Shmuelof et al., 2012; Therrien et al., 2016; Uehara et al., 2018). In order to assess the net effect of motivation on motor learning, we therefore compared groups of participants trained with different monetary rewards but with the exact same reinforcement feedback. We found that motivation by reward allowed marked improvements in motor performance that were maintained after reward removal and even 24 h later (Figure 2). Notably, this was the case despite the fact that reinforcement alone was not sufficient to influence motor learning in our task. This demonstrates that the motivational context experienced during training can by itself strongly influence motor skill learning beyond performance-based reinforcement feedback.
The prospect of obtaining rewards for good performance enhances motivation but does not provide any additional learning signal to the motor system (Berke, 2018). Yet, it may boost the reliance on sensory and/or reinforcement feedbacks (Kim et al., 2019). To explore this possibility, we developed an analysis allowing us to investigate how participants adjusted their motor commands based on sensory or reinforcement feedbacks while controlling for differences in performance between the groups (see STAR Methods for more details). Interestingly, we found that reward specifically boosted reinforcement-based adjustments, following both positive and negative feedbacks, while sensory-based adjustments remained unaffected by reward (Figure 3). This suggests that reward boosted both the reproduction of successful behavior (exploitation) and correction of motor commands after failure (exploration; Dhawale et al., 2017). This was the case despite the fact that both types of feedback were relevant to improve motor performance at the single-trial level (Figures 3B, 3D, 3F, 3H). This result suggests that reward increases the reliance on reinforcement information during the learning process, with less effect on sensory-based adjustments. Interestingly, this finding may explain why tasks that strongly emphasize sensory-based learning (over reinforcement-based learning; Cashaback et al., 2017; Izawa and Shadmehr, 2011), often show less sensitivity to motivation. Accordingly, monetary reward shows little impact on sensorimotor adaptation (Galea et al., 2015; Hill et al., 2020) and on motor skill acquisition in tasks that strongly rely on sensory feedback (e.g., Abe et al., 2011; Steel et al., 2016; Widmer et al., 2016). The differential effect of reward on sensory and reinforcement-based adjustments may be due to the qualitatively different learning processes that are driven by these two types of feedbacks (Cashaback et al., 2017; Uehara et al., 2018). As such, while sensory feedback promotes error correction by providing directional feedback (Shadmehr et al., 2010), reinforcement can guide motor exploration based on binary feedback about task success (Therrien et al., 2016). Our results, along with the observation that monetary rewards are less effective in tasks where learning is dominated by sensory feedback, suggest that the potential of reward to improve motor learning relies on the boosting of a reinforcement learning mechanism. Based on this, we propose that the susceptibility of a given motor learning task to reward may depend on the relative contribution of sensory and reinforcement feedbacks in the learning process. Characterizing what type of motor tasks can benefit from motivational interventions is an important line of future work to translate fundamental motor control research into innovative rehabilitation procedures.
The finding of a reward-dependent boosting of reinforcement-based adjustments is in line with previous neuroimaging results showing that reward increases reinforcement-related activity in the striatum in the context of motor learning (Widmer et al., 2016). This reward-driven increase in striatal activity is reduced after a stroke (even when the striatum is unlesioned), a process that may contribute to the motor learning deficits observed in these patients (Widmer et al., 2019). Moreover, such reward-dependent modulation of motor adjustments has been shown to rely on dopamine (Galea et al., 2013; Pekny et al., 2015), a key neurotransmitter of the striatal circuitry. Based on these elements and on the causal role of the striatum in reinforcement-based adjustments in motor commands (Nakamura and Hikosaka, 2006; Williams and Eskandar, 2006), we suspect that this region may be crucial for the beneficial effect of reward observed in the present study. Notably, the cerebellum (Carta et al., 2019; Heffley et al., 2018; Sendhilnathan et al., 2020; Vassiliadis et al., 2019; Wagner et al., 2017) and frontal areas (Dayan et al, 2014, 2018; Hamel et al., 2018; Palidis et al., 2019; Ramakrishnan et al., 2017; Sidarta et al., 2016) are also likely to contribute to reward-based motor learning. Further investigations are required to better delineate the neurophysiological bases of reward-related improvements in motor learning.
The beneficial effect of reward on single-trial adjustments was maintained on Day 2, even after reward removal. As in Day 1 training, reinforcement-based adjustments were boosted while sensory-based adjustments remained unchanged by reward. This persistent change in the specific reaction to the reinforcement feedback after reward removal is suggestive of an associative learning process. In associative learning, presentation of a neutral stimulus (i.e., a conditioned stimulus) that has been consistently paired with a rewarding stimulus (i.e., an unconditioned stimulus) during a training period elicits a behavior that was initially only generated in reaction to the reward (Pavlov, 1927; Rescorla and Wagner, 1972). Following this framework, it is possible that the repetitive pairing of the reinforcement feedback with the reward during training induced an implicit association between the two events that remained evident when the reward was removed. This could explain why strong reinforcement-specific adjustments were maintained on Day 2 in the reward group, even though no rewards were at stake anymore. Such associative learning processes are known to strongly influence autonomic responses (Pool et al., 2019), inhibitory control (Avraham et al., 2020; Lindström et al., 2019; Verbruggen et al., 2014), decision making (Lindström et al., 2019), and even sensorimotor adaptation (Avraham et al., 2020) in humans. We propose that associative learning may also contribute to the durable influence of motivation on motor skill learning (Abe et al., 2011; Sporn et al., 2020).
In order to better characterize the effect of reward on motor learning, we considered separately the different components of the movement and found that force amplitude was the most strongly affected, while the speed of initiation and force variability remained largely insensitive to reward. This suggests that reward can have a selective influence on the regulation of a specific component of motor control. Importantly, an estimation of the respective influence of each motor component on task success also showed that force amplitude was the most relevant component for the task. Notably, the specificity of the effect of reward on the regulation of one motor component is in accordance with the idea that multidimensional motor tasks (i.e., requiring the control of multiple motor components) can be decomposed in subtasks that are learned separately in the motor system (Ghahramani and Wolpert, 1997) In this framework, learning of the different motor components may depend on their respective relevance for task success (Ghahramani and Wolpert, 1997; van der Kooij et al., 2021). Such task relevance may be estimated based on a priori knowledge of the task (e.g., following instructions; Popp et al., 2020) and through the reliance on a credit assignment system allowing to estimate the particular influence of each motor component on task success through trial and error (McDougle et al., 2016; Parvin et al., 2018). Based on this idea, we believe that the strong relationship between the amplitude of the force and task success in the present task pushed participants of the reward group to largely modulate this component based on the reinforcement feedback. If this is the case, this would suggest that it is possible to affect the training of specific motor abilities by modulating the weight of individual motor components in the computation of the reinforcement feedback, an aspect that could be exploited in future rehabilitation protocols. Alternatively, reward might have specifically modulated the amplitude of the force independently of the relevance of this parameter. Although the present study cannot rule out this hypothesis, we believe that such interpretation is unlikely given previous demonstration that reward can improve several aspects of motor control concomitantly (Codol et al., 2020; Manohar et al., 2015). Another possibility is that reinforcement feedback alone was sufficient to maximally modulate initiation time and variability in this task, precluding us from observing a difference with the reward-based training because of some form of ceiling effect. Further studies are required to disentangle these potentially co-existing interpretations to guide the development of component-specific rehabilitation therapies (Norman et al., 2017).
Limitations of the study
Our findings suggest that extrinsic reward can improve the acquisition and maintenance of a motor skill by boosting reinforcement-based adjustments in motor commands. However, it should be noted that here we focused on a very simple unimanual task in which performance relied on the ability to modulate a 1-degree of freedom force. While our analysis of the different motor components suggests that reward may also improve the learning of more complex tasks (by selectively boosting the adjustment of the most relevant dimensions for task success), future studies should address the generalizability of our results by using tasks engaging more complex skills.
Besides, our single-trial analysis suggests that reward affects differently sensory and reinforcement-based adjustments in motor commands. Yet, sensory and reinforcement feedbacks were always coupled in the present task. We did so on purpose to avoid inducing conflict in the learning process, yet the reward effect we report here could be influenced by the relationship between these feedbacks. Hence, follow-up investigations should assess the effect of reward on sensory and reinforcement-based adjustments in situations where both feedback types are dissociated (Cashaback et al., 2017).
STAR★Methods
Key resources table
| REAGENT or RESOURCE | SOURCE | IDENTIFIER |
|---|---|---|
| Deposited Data | ||
| Motor learning data ('All_Variables.mat') | This paper | https://osf.io/5pjem/ |
| Subjects characteristics ('Subjects_characteristics.xlsx') | This paper | https://osf.io/5pjem/ |
| Software and Algorithms | ||
| Matlab vR2007 7.5 and R2018a | Mathworks | www.mathworks.com/products/matlab.html |
| Statistica 10 | StatSoft Inc. | https://www.statsoft.de/en/software/tibco-statisticatm |
| Psychophysics Toolbox | Psychtoolox.org | http://psychtoolbox.org/ |
Resource availability
Lead contact
Further information and requests should be directed to the lead contact, Pierre Vassiliadis (pierre.vassiliadis@uclouvain.be).
Materials availability
This study did not generate new unique reagents.
Data and code availability
-
•
Motor learning data ('All_Variables.mat') and de-identified subjects characteristics ('Subjects_characteristics.xlsx') are freely available via an open-access data sharing repository (https://osf.io/5pjem/).
-
•
This paper does not report original code.
-
•
Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.
Experimental model and subject details
A total of 90 right-handed healthy volunteers participated in the present study (58 women, 23.7 ± 0.3 years old; mean ± SE). Handedness was determined via a shortened version of the Edinburgh Handedness Inventory (Oldfield, 1971). None of the participants suffered from any neurological or psychiatric disorder, nor were they taking any centrally-acting medication. All participants gave their written informed consent in accordance with the Ethics Committee of the Université Catholique de Louvain (approval number: 2018/22MAI/219) and the principles of the Declaration of Helsinki. Subjects were financially compensated for their participation. Finally, all participants were asked to fill out a French adaptation of the Sensitivity to Punishment and Sensitivity to Reward Questionnaire (SPSRQ; Lardi et al., 2008; Torrubia et al., 2001).
Method details
General aspects
Participants were seated approximately 60 cm in front of a computer screen (refresh rate = 100 Hz) with their right forearm positioned at a right angle on the table. The task was developed on Matlab 7.5 (the Mathworks, Natick, Massachusetts, USA) exploiting the Psychophysics Toolbox extensions (Brainard, 1997; Pelli, 1997) and consisted in an adaptation of previously used motor learning tasks (Abe et al., 2011; Mawase et al., 2017; Steel et al., 2016). The task required participants to squeeze a force transducer (Arsalis, Belgium) between the index and the thumb to control the one-dimension motion of a cursor displayed on the screen. Increasing force resulted in the cursor moving vertically and upward. Each trial started with a preparatory phase in which a sidebar appeared at the bottom of the screen and a target at the top (Figure 1A). After a variable time interval, a cursor popped up in the sidebar and participants had to pinch the transducer to move the cursor as quickly as possible from the sidebar to the target and maintain it there for the rest of the task. The level of force required to reach the target (TargetForce) was individualized for each participant and set at 10% of maximum voluntary contraction (MVC). Notably, squeezing the transducer before the appearance of the cursor was considered as anticipation and therefore led to an interruption of the trial. Such trials were discarded from further analyses. At the end of each trial, a binary reinforcement feedback represented by a colored circle was provided to the subject followed by a reminder of the color/feedback association and potential monetary reward associated with good performance (see Reinforcement feedback section below).
Sensory feedback
We provided only limited visual feedback to the participants (Mawase et al., 2017). As such, on most trials (90%), the cursor disappeared shortly after the subject started to squeeze the force transducer (partial vision trials); it became invisible as soon as the generated force became larger than half of the TargetForce (i.e., 5% of MVC). Conversely, the remaining trials (10%) provided a continuous vision of the cursor (full vision trials). Therefore, on most trials, participants had limited visual information and had to rely exclusively on somatosensory feedback to generate the TargetForce. Importantly, full vision trials were not considered in the analyses.
Reinforcement feedback
At the end of each trial, subjects were presented with a binary reinforcement feedback indicating performance. Success on the task was determined based on the Error; that is, the absolute force difference between the TargetForce and the exerted force (Figure 1B; Abe et al., 2011; Steel et al., 2016). The Error was computed for each frame refresh (i.e., at 100Hz) from 150 ms to the end of the trial and then averaged for each trial (Steel et al., 2016) and expressed in percentage of MVC. This indicator of performance allowed us to classify a trial as successful or not based on an individualized success threshold (see below). When the Error on a given trial was below the threshold (negative normalized Error), the trial was considered as successful, and when it was above the threshold (positive normalized Error), the trial was considered as failed. Hence, task success depended on the ability to reduce the Error by approximating the TargetForce as quickly and accurately as possible. Importantly, participants were told explicitly that both speed and accuracy were taken into account to determine task success. In summary, to be successful, participants knew that they had to quickly initiate the force and be as accurate as possible in reproducing the TargetForce.
In different blocks of trials, we manipulated the reinforcement feedback and reward provided during training. In Block-S, the reinforcement feedback was non-informative (magenta circle regardless of performance), and participants could only rely on somatosensory feedback to perform the task. In Block-SR, the reinforcement feedback consisted of a yellow (representing a successful trial) or blue circle (representing a failed trial), providing knowledge of performance (Figure 1A). In Block-SRR, this knowledge of performance was associated with a monetary reward (+8 cents or 0 cent for Success or Failure, respectively). Therefore, contrarily to Block-S, Block-SR and Block-SRR provided knowledge of performance and this feedback was associated with a monetary reward in Block-SRR.
Experimental procedure
Subjects’ performance was tested for two consecutive days (Day 1 and Day 2; Figure 1C). On Day 1, we first measured the individual MVC to calculate the TargetForce. Notably, MVC was measured before and after both sessions to assess potential muscle fatigue related to the training (see 4.4.3). Participants then performed 2 blocks of Familiarization. In the first block, participants performed 20 full vision trials; it served to familiarize the subjects with the task in a Block-SR setting (Full vision block). Subsequently, all blocks were composed of a mixture of full vision trials (10% of total trials) and partial vision trials (90% of total trials). The second Familiarization block consisted of 20 trials and allowed us to determine baseline performance to individualize the difficulty of the task for the rest of the experiment (Calibration block). For every subject, each partial vision trial of the Calibration block was classified in terms of Error from the lowest to the greatest in percentage of MVC. We took the 35th percentile of the Error to determine the individual success threshold. Success thresholds were constrained between 2 and 3.5% of MVC by asking participants to repeat the Calibration block when the computed threshold was outside these boundaries. Those parameters were determined based on pilot data to obtain coherent learning curves among individuals.
After the Familiarization and Calibration blocks, the first experimental session consisted of 280 trials divided in 8 blocks. All subjects started with a Block-SR of 20 trials to evaluate the performance at Pre-training and similarly ended the session with a Post-training assessment of 20 trials. In between, 6 Training blocks of 40 trials were performed by the participants (Figure 1B). During this Training period, individuals were split into 3 separate groups (GroupTYPE: Group-S, Group-SR or Group-SRR) depending on the type of blocks they performed during training. As such, Group-S completed Block-S, Group-SR performed Block-SR and Group-SRR trained under Block-SRR condition. Contrasting performance in the Pre- and Post-training blocks allowed us to evaluate learning of the skill under the three training conditions. 24h later, subjects performed the task again with the same TargetForce and success threshold. After a 20 trial Familiarization used to remind the task to participants, they performed 140 trials split in 4 blocks; all were performed in a Block-SR setting. This Re-test session allowed us to assess skill maintenance 24h after training.
Quantification and statistical analysis
Statistical analyses were carried out with Matlab 2018a (the Mathworks, Natick, Massachusetts, USA) and Statistica 10 (StatSoft Inc., Tulsa, Oklahoma, USA). Post-hoc comparisons were always conducted using the Fisher’s LSD procedure. The significance level was set at p ≤ 0.05, except in the case of correction for multiple comparisons (see below).
Motor skill learning and maintenance
The main aim of the present study was to evaluate the effect of reward on motor skill learning and maintenance. To assess skill learning, we expressed the median Error at Post-training in percentage of the value obtained at Pre-training. To evaluate skill maintenance, we expressed the median Error during the Re-test session in percentage of Pre-training. First, we compared skill learning and maintenance between the groups through one-way ANOVAs with the factor GroupTYPE. Then, we explored the significance of skill learning and maintenance within each group by conducting Bonferroni-corrected single sample t-tests on these percentage data against a constant value of 100% (i.e., corresponding to the Pre-training level).
As explained above, task performance depended on both the speed and the accuracy of the produced force (Figure 1B). We characterized the effect of reward on these different levels of force control, by evaluating separately the speed of force initiation and the accuracy of the maintained force. To evaluate the speed of force initiation, we measured the force initiation time (ForceInitiation) which was defined as the delay between the appearance of the cursor and the moment where the applied force reached 5% of MVC (i.e., corresponding to half of the TargetForce). Force accuracy was evaluated in the second half of the trial (i.e., the last 1000 ms), through two different parameters. First, we computed the Amplitude Error of the force (ForceAmplError), defined as the absolute difference between the mean force exerted in the last 1000 ms of the trial and the TargetForce. It reflected how much the amplitude of the maintained force differed from the TargetForce. Second, force accuracy was also characterized by considering the variability of the maintained force, with high levels of variability causing increases in the Error. To assess force variability (ForceVariability), we computed the coefficient of variation of the force in the second half of the trial (i.e., standard deviation of force/mean force). In summary, to be successful, participants had to quickly initiate the force (i.e., low ForceInitiation) and be as accurate as possible (i.e., low ForceAmplError and ForceVariability).
As a control, we verified that the three motor components described above (i.e., ForceInitiation, ForceAmplError, and ForceVariability) were closely related to the Error, and therefore were relevant for task success. To do so, we ran partial linear regressions on the Error data with ForceInitiation, ForceAmplError and ForceVariability as predictors to estimate the respective influence of each motor component on the Error, while controlling for the effect of the other components. Interestingly, we found that ForceAmplError explained the largest part of variance in the Error (r = 0.96 ± 0.003; p<0.05 in 90/90 subjects). ForceInitiation also explained a large part of variance in the Error (r = 0.81 ± 0.01; p<0.05 in 90/90 subjects), while ForceVariability explained a smaller, yet significant in most subjects, part of variance (r = 0.22 ± 0.03; p<0.05 in 68/90 subjects). Hence, although all motor parameters were relevant for task success, the ForceAmplError was the most influential factor.
Between-trial adjustments in motor commands
A second goal of the present study was to assess the effect of reward on between-trial adjustments in motor commands. Specifically, we aimed at evaluating how motor commands were adjusted based on reinforcement and sensory feedback in our three experimental groups.
To do so, for each trialn we computed the absolute between-trial change (BTC) in Error (ErrorBTC; see (Pekny et al., 2015; Uehara et al., 2019) for similar approaches in reaching tasks).
In order to study how much motor commands were adjusted based on previous experience, we compared adjustments in motor commands following trials of different Error magnitudes. To do so, we first subtracted each subject’s individual success threshold to the Error data. Hence, normalized Errors below 0 corresponded to successful trials and normalized Errors above 0 corresponded to failed trials. Then, we split the Error data in consecutive bins of 1% of MVC and averaged the corresponding ErrorBTC. This allowed us to compare ErrorBTC following trials of similar Errorn across the groups.
As a first step, to better understand how motor commands were adjusted based on the reinforcement feedback, we compared ErrorBTC following bins of Success or Failure trials of neighboring Error magnitudes (BinSuccess:-1% < Errorn< 0% MVC; BinFailure: 0% < Errorn< 1% MVC). Fixing the boundaries of BinSuccess and BinFailure allowed us to compare reinforcement-related adjustments between the groups while controlling for the magnitude of Errorn; an aspect that might directly influence between-trial adjustments. First, we performed a two-way ANOVA with the factors Outcome (Success or Failure) and GroupTYPE. We then computed reinforcement-based adjustments as the percentage change in ErrorBTC in BinFailure compared to BinSuccess. This index allowed us to determine in a single measure how participants from the different groups adjusted their behavior based on the reinforcement obtained in the previous trial.
These analyses were conducted separately on the Day 1 and Day 2 data. We had to exclude 3 and 9 participants for Day 1 and Day 2 analyses, respectively, because they had less than 7 trials in at least one of the two bins (remaining subjects on Day 1: Group-S = 29; Group-SR = 28; Group-SRR = 30; Day 2: Group-S = 26; Group-SR = 27; Group-SRR = 28). For the remaining participants, an average of 56 ± 3 and 39 ± 2 trials were included for each bin for Day 1 and Day 2 analyses, respectively. Reinforcement-based changes in ErrorBTC were compared between the groups through one-way ANOVAs with the factor GroupTYPE.
As a second step, we evaluated how participants adjusted movements when they could only rely on the sensory feedback. We compared ErrorBTC following bins of Failure trials of different Error magnitudes (BinSmall-Failure: 0% < Errorn< 1% MVC; BinLarge-Failure: 1% < Errorn< 2% MVC). In this case, the reinforcement feedback was the same in the two bins and the only difference between the trials consisted in the magnitude of the Error experienced at trialn. Again, we first performed a two-way ANOVA with the factors Outcome (Small or Large Failure) and GroupTYPE. We then computed sensory-based adjustments as the percentage change in ErrorBTC in BinLarge-Failure compared to BinSmall-Failure. This index allowed us to determine how participants adjusted their behavior based on the previous somatosensory experience, in the absence of any difference in the reinforcement feedback obtained.
This analysis was first run on the Day 1 data. We had to exclude 12 participants because they had less than 7 trials in at least one of the two bins (remaining subjects: Group-S = 27; Group-SR = 28; Group-SRR = 24). For Day 2, applying the same procedure led to the exclusion of 29 subjects with a lower number of participants in the Group-SRR (15 subjects). For this reason, we ran another analysis where we exceptionally excluded participants only if they had less than 5 trials in one bin. This allowed us to keep a reasonable number of participants in each group (19 subjects excluded; remaining subjects: Group-S = 24; Group-SR = 26; Group-SRR = 21). Notably, both analyses (i.e., with 7-trials or 5-trials cutoff) gave similar results and we only present the latter in the Results section. For the remaining participants, an average of 47 ± 3 and 29 ± 2 trials were included for each bin for Day 1 and Day 2 analyses, respectively. Sensory-based changes in ErrorBTC were compared between the groups through a one-way ANOVA with the factor GroupTYPE.
As a last step, we asked whether the effect of reward on between-trial adjustments in motor commands concerned all aspects of force control, or only specific motor components. To do so, we investigated reinforcement-based and sensory-based adjustments in ForceInitiation, ForceAmplError and ForceVariability, using the same method described above for the average Error. We first performed two-way ANOVAs with the factors Outcome (reinforcement-based analysis: Success or Failure sensory-based analysis: Small or Large Failure) and GroupTYPE. Then, to assess reinforcement-based adjustments, we contrasted between-trial changes in ForceInitiation (ForceInitiation-BTC), ForceAmplError (ForceAmplError-BTC) and in ForceVariability (ForceVariability-BTC) following BinSuccess and BinFailure. Sensory-based adjustments were computed by contrasting ForceInitiation-BTC, ForceAmplError-BTC and ForceVariability-BTC following BinSmall-Failure and BinLarge-Failure. These data were compared between the groups through one-way ANOVAs with the factor GroupTYPE.
Group features, muscle fatigue and monetary gains
As a control, we verified that our 3 groups were comparable in terms of age, success threshold, TargetForce, and Sensitivity to Reward and to Punishment (i.e., as assessed by the SPSRQ questionnaire). As displayed in Table 1, one-way ANOVAs on these data did not reveal any significant differences between the groups.
We also assessed muscle fatigue on Day 1 and Day 2 (Derosière et al., 2014; Derosiere and Perrey, 2012) by expressing the MVC obtained after each session (MVCPOST) in percentage of the MVC measured initially (MVCPRE). The relative change of MVC was not different according to the GroupTYPE (Day 1, F(2,87) = 0.51, p = 0.60; Day 2, F(2,87) = 0.60, p = 0.55; Table 1). As an additional safety check, we wanted to make sure that the decrements in MVC caused by the training period of Day 1 could not impair performance. To test this, we compared MVCPOST (expressed in % of MVCPRE) with a fixed value of 10% of MVCPRE (i.e., corresponding to the TargetForce) through Bonferroni-corrected single sample t-tests. This analysis revealed that MVCPOST levels were always significantly above the TargetForce (Group-S: t(29) = 35.84, p < 0.001; Group-SR: t(29) = 34.14, p < 0.001 and Group-SRR: t(29) = 34.44, p < 0.001). Hence, force decrements caused by the training were comparable between groups and are unlikely to have limited task performance.
In a final step, we checked that the monetary gains obtained at the end of the experiment were similar between groups. Subjects received a fixed show-up fee corresponding to 10 euros/hour of experiment. In addition, participants also gained a monetary bonus. This bonus was set at 10 euros for subjects in Group-SR and Group-S while it was variable from 0 to 20 euros according to the Group-SRR performance (gain of 8 cents per successful trial in Block-SRR). Importantly, this bonus procedure in Block-SRR was determined to match that obtained in the other groups; it corresponded to 10.4 ± 0.67 euros. A t-test revealed that the total ending remuneration was similar across the different GroupTYPES (t(29) = 0.57; p = 0.57).
Acknowledgments
We would like to thank Benvenuto Jacob and Julien Lambert for helping with the development of the task and Wanda Materne for assistance with data acquisition. P.V. was a PhD student supported by the Fund for Research training in Industry and Agriculture (FRIA/FNRS; FC29690), and grants by the Platform for Education and Talent (Gustave Boël - Sofina Fellowships) and Wallonie-Bruxelles International. G.D. was a post-doctoral fellow supported by the Belgian National Funds for Scientific Research (FNRS, 1B134.18). F.C.H. was supported by the Defitech Foundation (Morges, CH). J.D. was supported by grants from the Belgian FNRS (F.4512.14) and the Fondation Médicale Reine Elisabeth (FMRE).
Author contributions
Pierre Vassiliadis: Conceptualization, Methodology, Formal Analysis, Investigation, Data Curation, Writing – Original Draft, Writing – Review & Editing, Visualization, Funding acquisition.
Gerard Derosiere: Conceptualization, Methodology, Writing – Review & Editing.
Cecile Dubuc: Methodology, Investigation, Data Curation, Writing – Review & Editing.
Aegryan Lete: Investigation, Data Curation, Writing – Review & Editing.
Frederic Crevecoeur: Conceptualization, Writing – Review & Editing.
Friedhelm C. Hummel: Conceptualization, Writing – Review & Editing, Supervision.
Julie Duque: Conceptualization, Methodology, Writing – Review & Editing, Supervision, Funding acquisition.
Declaration of interests
The authors declare no conflict of interest.
Published: July 23, 2021
References
- Abe M., Schambra H., Wassermann E.M., Luckenbaugh D., Schweighofer N., Cohen L.G. Reward improves long-term retention of a motor memory through induction of offline memory gains. Curr. Biol. 2011;21:557–562. doi: 10.1016/j.cub.2011.02.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Avraham G., Taylor J.A., Ivry R.B., McDougle S.D. An associative learning account of sensorimotor adaptation. bioRxiv. 2020 doi: 10.1101/2020.09.14.297143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balleine B.W., O’Doherty J.P. Human and rodent homologies in action control: corticostriatal determinants of goal-directed and habitual action. Neuropsychopharmacology. 2010;35:48–69. doi: 10.1038/npp.2009.131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barron A.B., Søvik E., Cornish J.L. The roles of dopamine and related compounds in reward-seeking behavior across animal phyla. Front. Behav.Neurosci. 2010;4:1–9. doi: 10.3389/fnbeh.2010.00163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berke J.D. What does dopamine mean? Nat. Neurosci. 2018;21:787–793. doi: 10.1038/s41593-018-0152-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bernardi N.F., Darainy M., Ostry D.J. Somatosensory contribution to the initial stages of human motor learning. J. Neurosci. 2015;35:14316–14326. doi: 10.1523/JNEUROSCI.1344-15.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brainard D.H. The psychophysics toolbox. Spat. Vis. 1997;10:433–436. doi: 10.1163/156856897X00357. [DOI] [PubMed] [Google Scholar]
- Bush G., Vogt B.A., Holmes J., Dale A.M., Greve D., Jenike M.A., Rosen B.R. Dorsal anterior cingulate cortex: a role in reward-based decision making. Proc. Natl. Acad. Sci. U. S. A. 2002;99:523–528. doi: 10.1073/pnas.012470999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carta I., Chen C.H., Schott A.L., Dorizan S., Khodakhah K. Cerebellar modulation of the reward circuitry and social behavior. Science. 2019;80:363. doi: 10.1126/science.aav0581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cashaback J.G.A., McGregor H.R., Mohatarem A., Gribble P.L. Dissociating error-based and reinforcement-based loss functions during sensorimotor learning. PLoS Comput. Biol. 2017;13:1–28. doi: 10.1371/journal.pcbi.1005623. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X., Holland P., Galea J.M. The effects of reward and punishment on motor skill learning. Curr.Opin.Behav. Sci. 2017;20:83–88. doi: 10.1016/j.cobeha.2017.11.011. [DOI] [Google Scholar]
- Codol O., Holland P.J., Manohar S.G., Galea J.M. Reward-based improvements in motor control are driven by multiple error-reducing mechanisms. J. Neurosci. 2020;40:3604–3620. doi: 10.1523/JNEUROSCI.2646-19.2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Connell L.A. Somatosensory impairment after stroke: frequency of different deficits and their recovery. 2008. [DOI] [PubMed]
- Dayan E., Hamann X.J.M., Averbeck B.B., Cohen L.G. Brain structural substrates of reward dependence during. Behav. Perform. 2014;34:16433–16441. doi: 10.1523/JNEUROSCI.3141-14.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dayan E., Herszage J., Laor-Maayany R., Sharon H., Censor N. Neuromodulation of reinforced skill learning reveals the causal function of prefrontal cortex. Hum. Brain Mapp. 2018;39:4724–4732. doi: 10.1002/hbm.24317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dayan P., Niv Y. Reinforcement learning: the good, the bad and the ugly. Curr.Opin.Neurobiol. 2008;18:185–196. doi: 10.1016/j.conb.2008.08.003. [DOI] [PubMed] [Google Scholar]
- Derosière G., Alexandre F., Bourdillon N., Mandrick K., Ward T.E., Perrey S. Similar scaling of contralateral and ipsilateral cortical responses during graded unimanual force generation. Neuroimage. 2014;85:471–477. doi: 10.1016/j.neuroimage.2013.02.006. [DOI] [PubMed] [Google Scholar]
- Derosiere G., Perrey S. Relationship between submaximal handgrip muscle force and NIRS-measured motor cortical activation. Adv. Exp. Med. Biol. 2012;737:269–274. doi: 10.1007/978-1-4614-1566-4_40. [DOI] [PubMed] [Google Scholar]
- Derosiere G., Vassiliadis P., Demaret S., Zénon A., Duque J. Learning stage-dependent effect of M1 disruption on value-based motor decisions. Neuroimage. 2017;162:173–185. doi: 10.1016/j.neuroimage.2017.08.075. [DOI] [PubMed] [Google Scholar]
- Derosiere G., Zénon A., Alamia A., Duque J. Primary motor cortex contributes to the implementation of implicit value-based rules during motor decisions. Neuroimage. 2017;146:1115–1127. doi: 10.1016/j.neuroimage.2016.10.010. [DOI] [PubMed] [Google Scholar]
- Dhawale A.K., Smith M.A. 2017. The Role of Variability in Motor Learning. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dhawale A.K., Smith M.A., Ölveczky B.P. The role of variability in motor learning. Annu. Rev. Neurosci. 2017;40:479–498. doi: 10.1146/annurev-neuro-072116-031548. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Galea J.M., Mallia E., Rothwell J., Diedrichsen J. The dissociable effects of punishment and reward on motor learning. Nat. Neurosci. 2015;18:597–602. doi: 10.1038/nn.3956. [DOI] [PubMed] [Google Scholar]
- Galea J.M., Ruge D., Buijink A., Bestmann S., Rothwell J.C. Punishment-induced behavioral and neurophysiological variability reveals dopamine-dependent selection of kinematic movement parameters. J. Neurosci. 2013;33:3981–3988. doi: 10.1523/JNEUROSCI.1294-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gershman S.J., Daw N.D. 2017. Reinforcement Learning and Episodic Memory in Humans and Animals : An Integrative Framework. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghahramani Z., Wolpert D.M. Modular decomposition in visuomotor learning. Nature. 1997;386:392–395. doi: 10.1038/386392a0. [DOI] [PubMed] [Google Scholar]
- Grogan J.P., Sandhu T.R., Hu M.T., Manohar S.G. Dopamine promotes instrumental motivation, but reduces reward-related vigour. bioRxiv. 2020;9:e58321. doi: 10.1101/2020.03.30.010074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grogan John P., Sandhu T.R., Hu M.T., Manohar S.G. Dopamine promotes instrumental motivation, but reduces reward-related vigour. Elife. 2020;9:1–20. doi: 10.7554/eLife.58321. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hamel R., Savoie F.A., Lacroix A., Whittingstall K., Trempe M., Bernier P.M. Added value of money on motor performance feedback: increased left central beta-band power for rewards and fronto-central theta-band power for punishments. Neuroimage. 2018;179:63–78. doi: 10.1016/j.neuroimage.2018.06.032. [DOI] [PubMed] [Google Scholar]
- Hare T.A., Schultz W., Camerer C.F., O’Doherty J.P., Rangel A. Transformation of stimulus value signals into motor commands during simple choice. Proc. Natl. Acad. Sci. U. S. A. 2011;108:18120–18125. doi: 10.1073/pnas.1109322108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heffley W., Song E.Y., Xu Z., Taylor B.N., Hughes M.A., McKinney A., Joshua M., Hull C. Coordinated cerebellar climbing fiber activity signals learned sensorimotor predictions. Nat. Neurosci. 2018;21:1431–1441. doi: 10.1038/s41593-018-0228-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hepworth L.R., Rowe F.J., Walker M.F., Rockliffe J. 2016. Post-stroke Visual Impairment : A Systematic Literature Review of Types and Recovery of Visual Conditions Post-stroke Visual Impairment : A Systematic Literature Review of Types and Recovery of Visual Conditions. [DOI] [Google Scholar]
- Hill C.M., Stringer M., Waddell D.E., Del Arco A. Punishment feedback impairs memory and changes cortical feedback-related potentials during motor learning. Front. Hum. Neurosci. 2020;14:1–14. doi: 10.3389/fnhum.2020.00294. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holland P., Codol X., Oxley E., Taylor M., Hamshere E., Joseph S., Huffer L., Gale X.M. Domain-specific working memory, but not dopamine-related genetic variability, shapes reward-based motor learning. J. Neurosci. 2019;39:9383–9396. doi: 10.1523/JNEUROSCI.0583-19.2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang V.S., Haith A., Mazzoni P., Krakauer J.W. Rethinking motor learning and savings in adaptation paradigms: model-free memory for successful actions combines with internal models. Neuron. 2011;70:787–801. doi: 10.1016/j.neuron.2011.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Izawa J., Shadmehr R. Learning from sensory and reward prediction errors during motor adaptation. PLoS Comput. Biol. 2011;7:1–12. doi: 10.1371/journal.pcbi.1002012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim H.E., Parvin D.E., Ivry R.B. The influence of task outcome on implicit motor learning. Elife. 2019;8:1–28. doi: 10.7554/eLife.39882. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer J.W., Hadjiosif A.M., Xu J., Wong A.L., Haith A.M. Motor learning. Compr. Physiol. 2019;9:613–663. doi: 10.1002/cphy.c170043. [DOI] [PubMed] [Google Scholar]
- Lardi C., Billieux J., D’Acremont M., Van derLinden M. A French adaptation of a short version of the sensitivity to punishment and sensitivity to reward questionnaire (SPSRQ) Pers. Individ. Dif. 2008;45:722–725. doi: 10.1016/j.paid.2008.07.019. [DOI] [Google Scholar]
- Leow L.A., Marinovic W., de Rugy A., Carroll T.J. Task errors contribute to implicit aftereffects in sensorimotor adaptation. Eur. J. Neurosci. 2018;48:3397–3409. doi: 10.1111/ejn.14213. [DOI] [PubMed] [Google Scholar]
- Levy S., Lavzin M., Benisty H., Ghanayim A., Dubin U., Achvat S., Brosh Z., Aeed F., Mensh B.D., Schiller Y. Cell-type-specific outcome representation in the primary motor cortex. Neuron. 2020;107:954–971.e9. doi: 10.1016/j.neuron.2020.06.006. [DOI] [PubMed] [Google Scholar]
- Lewthwaite R., Wulf G. Optimizing motivation and attention for motor performance and learning. Curr.Opin. Psychol. 2017;16:38–42. doi: 10.1016/j.copsyc.2017.04.005. [DOI] [PubMed] [Google Scholar]
- Lindström B., Golkar A., Jangard S., Tobler P.N., Olsson A. Social threat learning transfers to decision making in humans. Proc. Natl. Acad. Sci. U. S. A. 2019;116:4732–4737. doi: 10.1073/pnas.1810180116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Manohar S.G., Chong T.T., Apps M.A.J., Jarman P.R., Bhatia K.P., Husain M., Manohar S.G., Chong T.T., Apps M.A.J., Batla A., Stamelou M. Reward pays the cost of noise reduction in motor and cognitive control article reward pays the cost of noise reduction in motor and cognitive control. Curr. Biol. 2015;25:1707–1716. doi: 10.1016/j.cub.2015.05.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mawase F., Uehara S., Bastian A.J., Celnik P. Motor learning enhances use-dependent plasticity. J. Neurosci. 2017;37:2673–2685. doi: 10.1523/JNEUROSCI.3303-16.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McDougle S.D., Boggess M.J., Crossley M.J., Parvin D., Ivry R.B., Taylor J.A. Credit assignment in movement-dependent reinforcement learning. Proc. Natl. Acad. Sci. U. S. A. 2016;113:6797–6802. doi: 10.1073/pnas.1523669113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McGrane N., Galvin R., Cusack T., Stokes E. Addition of motivational interventions to exercise and traditional physiotherapy: a review and meta-analysis. Physiother. (United Kingdom) 2015;101:1–12. doi: 10.1016/j.physio.2014.04.009. [DOI] [PubMed] [Google Scholar]
- Nakamura K., Hikosaka O. Facilitation of saccadic eye movements by postsaccadic electrical stimulation in the primate caudate. J. Neurosci. 2006;26:12885–12895. doi: 10.1523/JNEUROSCI.3688-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nikooyan A.A., Ahmed A.A., Nikooyan A.A., Ahmed A.A. Reward feedback accelerates motor learning. J. Neurphysiol. 2015;113:633–646. doi: 10.1152/jn.00032.2014. [DOI] [PubMed] [Google Scholar]
- Norman S.L., Lobo-Prat J., Reinkensmeyer D.J. How do strength and coordination recovery interact after stroke? A computational model for informing robotic training. IEEE Int. Conf. Rehabil. Robot. 2017:181–186. doi: 10.1109/ICORR.2017.8009243. [DOI] [PubMed] [Google Scholar]
- O’Doherty J.P. Reward representations and reward-related learning in the human brain: Insights from neuroimaging. Curr.Opin.Neurobiol. 2004;14:769–776. doi: 10.1016/j.conb.2004.10.016. [DOI] [PubMed] [Google Scholar]
- Oldfield R.C. The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia. 1971;9:97–113. doi: 10.1016/0028-3932(71)90067-4. [DOI] [PubMed] [Google Scholar]
- Padoa-Schioppa C. Neurobiology of economic choice: a good-based model. Annu. Rev. Neurosci. 2011;34:333–359. doi: 10.1146/annurev-neuro-061010-113648. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palidis D.J., Cashaback J.G.A., Gribble P.L. Neural signatures of reward and sensory error feedback processing in motor learning. J. Neurophysiol. 2019;121:1561–1574. doi: 10.1152/jn.00792.2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palminteri S., Lebreton M., Worbe Y., Hartmann A., Lehéricy S., Vidailhet M., Grabli D., Pessiglione M. Dopamine-dependent reinforcement of motor skill learning: evidence from Gilles de la Tourette syndrome. Brain. 2011;134:2287–2301. doi: 10.1093/brain/awr147. [DOI] [PubMed] [Google Scholar]
- Parvin D.E., McDougle S.D., Taylor J.A., Ivry R.B. Credit assignment in a motor decision making task is influenced by agency and not sensorimotor prediction errors. J. Neurosci. 2018;38:3601–3617. doi: 10.1523/JNEUROSCI.3601-17.2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pavlov I. Oxford Univ. Press; 1927. Conditioned Reflexes: An Investigation of the Physiological Activity of the Cerebral Cortex. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pekny S.E., Izawa J., Shadmehr R. Reward-dependent modulation of movement variability. J. Neurosci. 2015;35:4015–4024. doi: 10.1523/JNEUROSCI.3244-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pelli D.G. The VideoToolbox software for visual psychophysics: transforming numbers into movies. Spat. Vis. 1997;10:437–442. doi: 10.1163/156856897X00366. [DOI] [PubMed] [Google Scholar]
- Pool E.R., Pauli W.M., Kress C.S., O’Doherty J.P. Behavioural evidence for parallel outcome-sensitive and outcome-insensitive Pavlovian learning systems in humans. Nat. Hum. Behav. 2019;3:284–296. doi: 10.1038/s41562-018-0527-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Popp N.J., Yokoi A., Gribble P.L., Diedrichsen J. The effect of instruction on motor skill learning. J. Neurophysiol. 2020;124:1449–1457. doi: 10.1152/JN.00271.2020. [DOI] [PubMed] [Google Scholar]
- Quattrocchi G., Greenwood R., Rothwell J.C., Galea J.M., Bestmann S. Reward and punishment enhance motor adaptation in stroke. J. Neurol. Neurosurg. Psychiatry. 2017;88:730–736. doi: 10.1136/jnnp-2016-314728. [DOI] [PubMed] [Google Scholar]
- Ramakrishnan A., Byun Y.W., Rand K., Pedersen C.E., Lebedev M.A., Nicolelis M.A.L. Cortical neurons multiplex reward-related signals along with sensory and motor information. Proc. Natl. Acad. Sci. U. S. A. 2017;114:E4841–E4850. doi: 10.1073/pnas.1703668114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramkumar P., Dekleva B., Cooler S., Miller L., Kording K. Premotor and motor cortices encode reward. PLoS One. 2016;11:1–13. doi: 10.1371/journal.pone.0160851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Raspopovic S., Capogrosso M., Petrini F.M., Bonizzato M., Rigosa J., Pino G.D., Carpaneto J., Controzzi M., Boretius T., Fernandez E. Restoring natural sensory feedback in real-time bidirectional hand prostheses. Sci. Transl. Med. 2014;6:222ra19. doi: 10.1126/scitranslmed.3006820. [DOI] [PubMed] [Google Scholar]
- Rescorla R., Wagner A. A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In: Black A.H., Prokasy W.F., editors. Classical Conditioning II: Current Research. And Theory. 1972. pp. 64–99. [Google Scholar]
- Roemmich R.T., Bastian A.J. Closing the loop: from motor neuroscience to neurorehabilitation. Annu. Rev. Neurosci. 2018;41:415–429. doi: 10.1146/annurev-neuro-080317-062245. [DOI] [PubMed] [Google Scholar]
- Schultz W. Neuronal reward and decision signals: from theories to data. Physiol. Rev. 2015;95:853–951. doi: 10.1152/physrev.00023.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sendhilnathan N., Ipata A.E., Goldberg M.E. Neural correlates of reinforcement learning in mid-lateral cerebellum. Neuron. 2020;106:188–198.e5. doi: 10.1016/j.neuron.2019.12.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shadmehr R., Reppert T.R., Summerside E.M., Yoon T., Ahmed A.A. Movement vigor as a Re fl ection of subjective economic utility. Trends Neurosci. 2019;xx:1–14. doi: 10.1016/j.tins.2019.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shadmehr R., Smith M.A., Krakauer J.W. 2010. Error Correction, Sensory Prediction , and Adaptation in Motor Control. [DOI] [PubMed] [Google Scholar]
- Shima K., Tanji J. Role for cingulate motor area cells in voluntary movement selection based on reward. Science. 1998;282:1335–1338. doi: 10.1126/science.282.5392.1335. [DOI] [PubMed] [Google Scholar]
- Shmuelof L., Huang V.S., Haith A.M., Delnicki R.J., Mazzoni P., Krakauer J.W. Overcoming motor “forgetting” through reinforcement of learned actions. J. Neurosci. 2012;32:14617–14621a. doi: 10.1523/JNEUROSCI.2184-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sidarta A., Vahdat S., Bernardi N.F., Ostry D.J. Somatic and reinforcement-based plasticity in the initial stages of human motor learning. J. Neurosci. 2016;36:11682–11692. doi: 10.1523/JNEUROSCI.1767-16.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sidarta X.A., Van Vugt X.F.T., Ostry D.J. Control of Movement Somatosensory working memory in human reinforcement-based motor learning. J. Neurophysiol. 2019;120:3275–3286. doi: 10.1152/jn.00442.2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sporn S., Chen X., Galea J.M. Reward-based invigoration of sequential reaching. bioRxiv. 2020:1–38. doi: 10.1101/2020.06.15.152876. [DOI] [Google Scholar]
- Steel A., Silson E.H., Stagg C.J., Baker C.I. Differential impact of reward and punishment on functional connectivity after skill learning. Neuroimage. 2019;189:95–105. doi: 10.1016/j.neuroimage.2019.01.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steel A., Silson E.H., Stagg C.J., Baker C.I. The impact of reward and punishment on skill learning depends on task demands. Sci. Rep. 2016;6:1–9. doi: 10.1038/srep36056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Therrien A.S., Wolpert D.M., Bastian A.J. Effective reinforcement learning following cerebellar damage requires a balance between exploration and motor noise. Brain. 2016;139:101–114. doi: 10.1093/brain/awv329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Torrubia R., Ávila C., Moltó J., Caseras X. The sensitivity to punishment and sensitivity to reward questionnaire (SPSRQ) as a measure of Gray’s anxiety and impulsivity dimensions. Pers. Individ. Dif. 2001;31:837–862. doi: 10.1016/S0191-8869(00)00183-5. [DOI] [Google Scholar]
- Tseng Y.-W., Diedrichsen J., Krakauer J.W., Shadmehr R., Bastian A.J. Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J. Neurophysiol. 2007;98:54–62. doi: 10.1152/jn.00266.2007. [DOI] [PubMed] [Google Scholar]
- Uehara S., Mawase F., Celnik P. Learning similar actions by reinforcement or sensory-prediction errors rely on distinct physiological mechanisms. Cereb.Cortex. 2018;28:3478–3490. doi: 10.1093/cercor/bhx214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Uehara S., Mawase F., Therrien A.S., Cherry-allen K.M., Celnik P., Hopkins J. 2019. Interactions between Motor Exploration and Reinforcement Learning. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Kooij K., van Mastrigt N.M., Crowe E.M., Smeets J.B.J. Learning a reach trajectory based on binary reward feedback. Sci. Rep. 2021;11:1–15. doi: 10.1038/s41598-020-80155-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vassiliadis P., Derosiere G. Selecting and executing actions for rewards. J. Neurosci. 2020;40:6474–6476. doi: 10.1523/JNEUROSCI.1250-20.2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vassiliadis P., Derosiere G., Duque J. Beyond motor noise : considering other causes of impaired reinforcement learning in cerebellar patients. eNeuro. 2019;6:1–4. doi: 10.1523/ENEURO.0458-18.2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Verbruggen F., Best M., Bowditch W.A., Stevens T., McLaren I.P.L. The inhibitory control reflex. Neuropsychologia. 2014;65:263–278. doi: 10.1016/j.neuropsychologia.2014.08.014. [DOI] [PubMed] [Google Scholar]
- Wachter T., Lungu O.V., Liu T., Willingham D.T., Ashe J. Differential effect of reward and punishment on procedural learning. J. Neurosci. 2009;29:436–443. doi: 10.1523/JNEUROSCI.4132-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wagner M.J., Kim T.H., Savall J., Schnitzer M.J., Luo L. Cerebellar granule cells encode the expectation of reward. Nature. 2017;544:96–100. doi: 10.1038/nature21726. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Widmer M., Lutz K., Luft A.R. Reduced striatal activation in response to rewarding motor performance feedback after stroke. Neuroimage Clin. 2019;24:102036. doi: 10.1016/j.nicl.2019.102036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Widmer M., Ziegler N., Held J., Luft A., Lutz K. Rewarding feedback promotes motor skill consolidation via striatal activity. Prog. Brain Res. 2016;229:303–323. doi: 10.1016/bs.pbr.2016.05.006. [DOI] [PubMed] [Google Scholar]
- Wilkinson L., Steel A., Mooshagian E., Zimmermann T., Keisler A., Lewis J.D., Wassermann E.M. Online feedback enhances early consolidation of motor sequence learning and reverses recall deficit from transcranial stimulation of motor cortex. Cortex. 2015;71:134–147. doi: 10.1016/j.cortex.2015.06.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williams Z.M., Eskandar E.N. Selective enhancement of associative learning by microstimulation of the anterior caudate. Nat. Neurosci. 2006;9:562–568. doi: 10.1038/nn1662. [DOI] [PubMed] [Google Scholar]
- Wu H.G., Miyamoto Y.R., Castro L.N.G., Ölveczky B.P., Smith M.A. Temporal structure of motor variability is dynamically regulated and predicts motor learning ability. Nat. Neurosci. 2014;17:312–321. doi: 10.1038/nn.3616. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yamazaki Y., Hikishima K., Saiki M., Inada M., Sasaki E., Lemon R.N., Price C.J., Okano H., Iriki A. Neural changes in the primate brain correlated with the evolution of complex motor skills. Nat. Publ. Gr. 2016;6:31084. doi: 10.1038/srep31084. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
-
•
Motor learning data ('All_Variables.mat') and de-identified subjects characteristics ('Subjects_characteristics.xlsx') are freely available via an open-access data sharing repository (https://osf.io/5pjem/).
-
•
This paper does not report original code.
-
•
Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.