

Abstract
In order to solve the problem of cross-regional customized bus (CB) route planning during the COVID-19, we develop a CB route planning method based on an improved Q-learning algorithm. First, we design a sub-regional route planning approach considering commuters’ time windows of pick-up stops and drop-off stops. Second, for the CB route with the optimal social total travel cost, we improve the traditional Q-learning algorithm, including state-action pair, reward function and update rule of Q value table. Then, a setup method of CB stops is designed and the path impedance function is constructed to obtain the optimal operating path between each of the two stops. Finally, we take three CB lines in Beijing as examples for numerical experiment, the theoretical and numerical results show that (i) compared with the current situation, although the actual operating cost of optimized route increases slightly, it is covered by the reduction of travel cost of passengers and the transmission risk of COVID-19 has also dropped significantly; (ii) the improved Q-learning algorithm can solve the problem of data transmission lag effectively and reduce the social total travel cost obviously.
Keywords: Customized bus, route planning, reinforcement learning, Q-learning algorithm, time window
I. Introduction
In recent years, with the rapid growth of the economy and society, the traffic congestion become more and more serious. Figure 1 is a trend chart of China’s automobile numbers from 2015 to 2019. From this figure, it can be seen from this figure that the growth rate of automobile numbers has remained above 10% from 2015 to 2019 in China. Compared with other traffic modes such as private cars and taxis, public transportation not only saves infrastructure resources, but also has irreplaceable advantages in terms of passenger transportation capacity and energy saving and emission reduction. The congestion cost of the car in Guangzhou is 1.48 yuan/(person/km), while the congestion cost of the bus is 0.24 yuan/(person/km). For the cost of environmental pollution, the cost of the car is 2.06 yuan/(person/km), while the bus is only 0.004 yuan/(person/km) [1], so public transport travel can greatly reduce the cost of social travel. Furthermore, as people’s living standards improve, passengers have put forward higher expectations for the comfort of transportation and the convenience of transfer, the travel needs of residents have shown a trend of diversification. Besides, passengers have different travel time windows, especially during the COVID-19 period, due to the advocacy of the government and enterprises, the phenomenon of staggered commuting will become more and more common, therefore, the diversity of demand for passengers will become more and more obvious. The contradiction between the single service mode of traditional public transportation and the diversified travel needs of residents has become increasingly prominent. The development of diversified public transportation is imminent.
FIGURE 1.

The trend of automobile numbers from 2015 to 2019 in China.
With the continuous construction of urbanization, the phenomenon of “separation of workplace and residence” in large cities has become more and more common. Within the six districts of Beijing, only 16.03% of the residents have achieved employment near the area where they live, 26.61% of the employees live near the area where they work. The population is mainly concentrated outside the Fourth Ring Road at 7:00 and mainly concentrated within the Fourth Ring Road at 10:00 due to work; population distribution situation at 18:00 and 23:00 are just the opposite, which means the separation of workplace and residence in Beijing is obvious [2]. The commuting time between residential and working areas is long and requires multiple transfers. Therefore, a kind of cross-regional CB that travels between residential and work areas and with low/no transfer has emerged. CB is an advanced, personalized and flexible demand response public transportation mode, which has the advantages of high reliability and comfort, as well as relative time saving [1], [2]. CB integrates passengers’ travel demands and other information, provides services for travelers with similar needs, such as starting and ending points, travel time, etc., and sets CB stops, operation routes according to passengers’ travel needs, only passengers who make a reservation in advance can enjoy the customized bus service. Therefore, the passengers’ travel demands for customized buses are relatively fixed. The ticket fares are between the regular bus and taxi prices, passengers can enjoy one seat for each person, free WIFI, no transfer and other high-quality services that cannot be provided by regular buses, which can attract more passengers and reduce the number of car trips and the traffic burden on the road.
Meanwhile, when a major public health emergency such as COVID-19 occurs, public transportation is also facing major challenges in blocking the epidemic. Cross-regional CB travel can realize direct connection between residential areas and work areas without multiple transfers, reducing the risk of disease transmission. With the normalization of epidemic prevention and control, in order to avoid excessive concentration of personnel, many companies have implemented management measures such as “staggered commuting”. Staggered commuting stipulates the commuting time of different types of employees, the purpose is to reduce the number of employees arriving and leaving at the same time, thereby reducing the risk of transmission of COVID-19. In our research, staggered commuting is reflected in the different time windows of passengers. Because we consider the travel time cost of all passengers, compared with the normal state, changes in the time window will lead to different path planning results. Therefore, how to plan a reasonable CB operation route according to the passenger’s travel time window (Due to the uncertainty of the road traffic state, it is difficult for the CB to depart/arrive at the pick-up/drop-off stops accurately at the time required by the passengers. Therefore, a small range of fluctuations in the departure/arrival time of the CB are allowed, which is called time window. If the departure time submitted by the passenger is 7:00 and the time fluctuation of 10 min is allowed, the time window is [6:50,7:10].) to reduce the total social travel cost (the summation of the bus operation cost and the passenger travel cost) is very important.
There is a growing research interest in CB route planning. In terms of theoretical research, most existing studies on CB route planning focused on the heuristic algorithm [3]–[5]. For route planning, various strategies have been proposed based on different objective functions, such as minimizing operation cost, total delay time of passengers and so on [6]–[8]. Different from the above studies, Considering the time window restrictions of pick-up stops and drop-off stops, this paper will focus on the CB route planning based on improved Q-learning algorithm which has the advantages of fast convergence speed and global optimal solution. Besides, in order to optimize the total time costs of passengers, we design a sub-regional route planning approach considering commuters’ time windows of pick-up stops and drop-off stops. Finally, we take three cross-regional CB lines in Beijing as examples for numerical experiment, the results show that the social total travel cost of the route planned by our method is greatly reduced.
The remainder of this paper is organized as follows. In Section II, an overview of existing relevant research literature is summarized and the main contributions of this research is introduced. Section III describes the application scenarios in detail. Section IV introduces the improved algorithm design, and then builds the path impedance function based on historical data to obtain the optimal path between two stops. In Section V, we take three CB lines in Beijing as numerical examples. Conclusions and suggestions for future research and some proposals for CB operation are given in Section VI. The main content framework of this study is shown in Figure 2.
FIGURE 2.

Research structure.
II. Literature Review
This study is mainly related to the following two branches of existing literature, and contributions to this article are listed at the end of this section.
A. CB Transit
The CB transit has been studied by some researchers. Liu and Ceder [3] presented a systematic and comprehensive analysis on a CB system. Wang et al. [11] constructed a multi-objective optimization model of CB routes, and clearly described the four processes of CB operation in the form of mathematical expressions, and designed a solution method based on NSGA-II algorithm. Shao et al. [12] established a variable-route bus dispatching two-level planning model with the goal of the largest number of people served and the smallest passenger travel time, and compared different algorithms through simulation experiments. Aiming at the shortest running time of all emergency CB lines and the constraint that passenger occupancy rate does not exceed the safety threshold, Ma et al. [13] built an optimization model of emergency CB routes in public health emergencies and designed a genetic algorithm to solve the model. Wang et al. [14] proposed three different survival models to study the mechanism of subscription behavior, among which the shared vulnerability model that considered the unobserved heterogeneity was the most appropriate. Yu et al. [15] introduced a method of generating bus route and stop planning suggestions based on massive demand data. A link network is generated from the input, which represents the shared path of the demand. Through community detection, the link network is divided into communities with similar travel routes. By examining the core-peripheral structure, the core part of the community is matched with the road network to generate customized bus routes. Hao et al. [16] constructed a complete theoretical framework that considers travel constraints and service quality satisfaction-behavior to explore parents’ choices for CB. In order to identify the origin and destination distribution of potential passengers, a spatial clustering algorithm based on pair density was proposed, using this algorithm, a method for extracting potential passengers from ordinary bus passengers based on bus smart card data was introduced [17]. Huang et al. [18] established a two-stage framework and optimized the bus route by establishing three nonlinear programming models. Bie et al. [19] proposed a mixed scheduling method combining the all-stop service and the stop-skipping service, the method optimizes scheduling strategies for multiple routes by minimizing total passenger travel time. Han et al. [20] presented a detailed flow chart of a CB network planning methodology, including individual reservation travel demand data processing, CB line origin destination (OD) area division considering quantity constraints of demand in areas and distance constraints based on agglomerative hierarchical clustering.
However, the above research did not consider the requirements of commuters for the time windows of the drop-off stops. In fact, commuters are more concerned about the time to arrive at the drop-off stop. In our study, we designed a route planning method for sub-regions considering the requirements of passengers’ time windows of pick-up and drop-off stops.
B. Solution Algorithm
The algorithm for vehicle route planning can be divided into two categories: precise algorithm and heuristic algorithm. The precise algorithm includes dynamic programming method, network flow algorithm, branch and bound method, greedy algorithm, column method and so on [21]–[23]. Accurate algorithms can only solve small scale problems, and their complexity will increase exponentially with the enlargement of the problem scale, while large scale models can only be solved by heuristic algorithms. At present, the heuristic algorithms for vehicle route planning are mainly divided into two categories: population method and trajectory method. Population method mainly includes ant colony algorithm, bee colony algorithm, particle swarm algorithm, genetic algorithm and other intelligent algorithms [24]–[27], while trajectory algorithm mainly includes simulated annealing algorithm, tabu search algorithm, iterative local search, variable neighborhood search, large-scale neighborhood search algorithm and so on [28]–[30]. Since the study CB optimization problem is combinatorial that is non-deterministic polynomial-time hard (NP-hard) [31] [32]. Lyu et al. [8] used a variety of travel data to optimize the location, route, timetable, and the probability of passengers choosing CB. The above planning method must fit the model parameters through training data, and reflect the status of the road network through weight parameters. Randomness, according to the corresponding algorithm to solve the planned route, the training of this kind of parameter model often results in the deviation of the model parameters due to the abnormal value of the data. In the actual model, it is necessary to increase the assumptions to achieve reasonable results, and the actual problems are difficult to verify. Gao and Huang [33] used a polynomial algorithm to analyze the number of discrete path distributions and pointed out that the number of parameters has an exponential relationship with the number of road sections. Some parametric models have unsatisfactory solution results due to high parameter dimensions. In addition, some scholars have carried out research on line network optimization based on non-parametric models. Mao and Z [34] designed a non-parametric reinforcement learning model to solve the adaptive path problem in stochastic time-varying networks. Research shows that the combination of Q learning and tree-based function approximation performs better than traditional stochastic dynamic programming methods during peak demand periods. In addition, reinforcement learning algorithm is also widely used in traffic signal optimization and other fields [35]–[37]. Reinforcement learning is one of the paradigms and methodologies of machine learning, and it is a research hotspot in the field of control decision-making [38]. In the research of CB route planning, reinforcement learning is rarely combined. In practical application, Q-learning algorithm, as a classic representative of reinforcement Learning, has always been the target algorithm of great concern in various fields [39]. Nevertheless, the traditional Q-learning algorithm has the problems of slow solving speed and low efficiency [40]. Our study adopts the method of reinforcement learning to configure and optimize the CB routes, which is of great significance in improving the quality of CB service and meeting the needs of passengers for personalized travel.
C. Objectives and Contributions
The above-mentioned representative studies have achieved rich results, but they did not consider the optimization of time windows of drop-off stops and most of them used heuristic algorithms to solve route planning problems, which have problems such as convergence to local optimal solutions and slow solution speed. Q-learning algorithm has attracted wide attention due to its low requirement for environment model and excellent self-updating ability. Besides, considering that the traditional Q-learning algorithm has the problems of slow solving speed and low efficiency, we propose a cross-regional CB route planning method based on the improved Q-learning algorithm.
The contributions of this study include: (i) we designed a route planning method for sub-regions, which can achieve the optimization of time windows of drop-off stops; (ii) the improved Q-learning algorithm where the Q value update strategy is improved to promote the algorithm efficiency is designed to solve the CB operation route with the optimal total travel cost; (iii) based on historical data, a path impedance function is constructed to determine the optimal operation path between two stops.
III. Scenario Setting
A. Service Mode
The scene diagram of this mode is shown in Figure 3, in the single region to single region service mode, we set bus stops based on travel demands at both ends of the CB line (pick-up area, drop-off area).
FIGURE 3.

Scene graph of single region to single region service mode.
In order to better optimize the total time costs of passengers, we transform the entire route plan into two single-region route plans. The scene graph is shown in Figure 4 and Figure 5. When solving the route of pick-up area, define 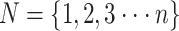 as the real stops in the pick-up area, and the virtual stop
as the real stops in the pick-up area, and the virtual stop 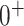 is set as the starting stop of the route, its distance from each actual stops is same and it is a positive number close to 0. The drop-off area is regarded as a virtual stop
is set as the starting stop of the route, its distance from each actual stops is same and it is a positive number close to 0. The drop-off area is regarded as a virtual stop 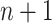 as the terminal stop of the route, and the distance between stop
as the terminal stop of the route, and the distance between stop 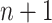 and each real stops is the actual distance. The time when the pick-up area arrives at the terminal is the departure time of the drop-off area; when solving the route of the drop-off area, define
and each real stops is the actual distance. The time when the pick-up area arrives at the terminal is the departure time of the drop-off area; when solving the route of the drop-off area, define 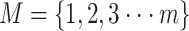 as the real stops in the drop-off area, the pick-up area is regarded as the virtual stop
as the real stops in the drop-off area, the pick-up area is regarded as the virtual stop 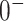 as the starting stop of the route, the distance between it and each actual stops is the actual distance, the virtual stop
as the starting stop of the route, the distance between it and each actual stops is the actual distance, the virtual stop 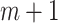 is set as the line terminal stop, its distance from each actual stops is same and it is a positive number close to 0.
is set as the line terminal stop, its distance from each actual stops is same and it is a positive number close to 0.
FIGURE 4.

Scene graph of pick-up area.
FIGURE 5.

Scene graph of drop-off area.
B. Time Window
According to the actual situation, cross-regional travel for commuting has certain requirements for departure time and arrival time, so passengers will provide the platform with expected departure time and arrival time, the platform divides passengers whose departure time and location are close to the same stop, assuming that all passengers arrive at the stop on time at the specified time. The time windows of CB’s pick-up and drop-off stops are shown in Figure 6. The two-dimensional plane composed of x-axis and y-axis indicates the position of the stops, and z-axis represents time axis. If the CB arrives before or within the travel time window of the stop, there is no delay time, and the passengers have no travel time cost; otherwise, the delay time and the travel time cost of passengers occur.
FIGURE 6.
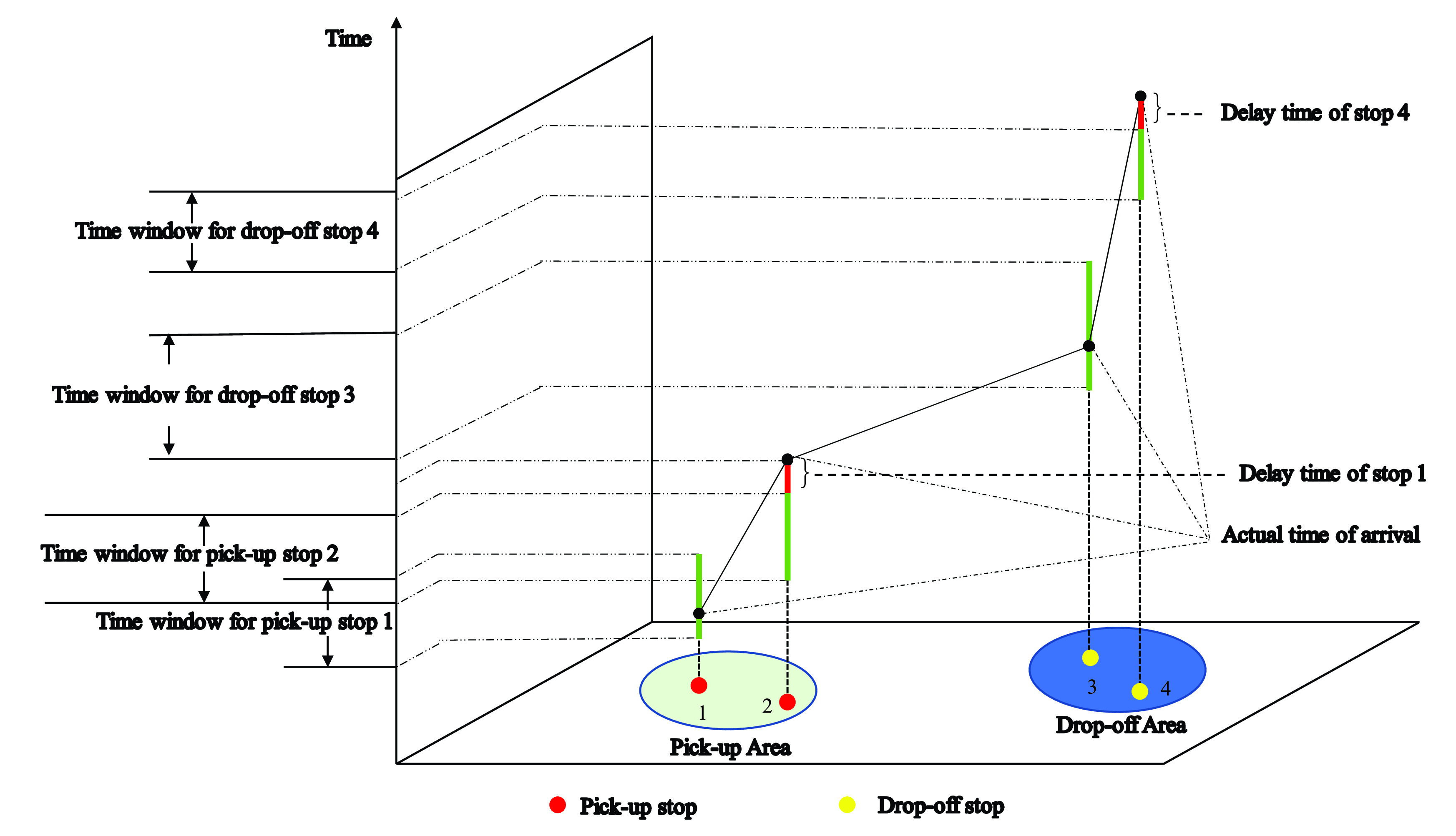
The time windows of CB’s pick-up stops and drop-off stops.
IV. Methodology
A. Traditional Q-Learning Algorithm
The research environment of this study can be modeled as a deterministic Markov decision process, which can be viewed as a tuple  , where
, where 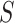 is a finite set of states,
is a finite set of states, 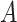 is a finite set of actions, and
is a finite set of actions, and 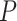 is the probability of moving to the next state,
is the probability of moving to the next state, 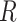 is the reward function, for instance,
is the reward function, for instance, 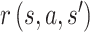 represents the immediate reward received when agent performs action
represents the immediate reward received when agent performs action 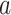 in state
in state 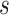 and move to state
and move to state 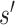 .
.
The motivation of the learning ability of the Q-learning algorithm comes from the reward value of the environment feedback after the agent takes an action [39]. The algorithm flow of Q-learning is shown in Figure 7. The Q-learning algorithm is a value iterative algorithm. Its decision-making process and update process are related to the Q value list generated by the Q-value table. The Q-value table is a matrix of state-action pairs, when the Q values in the Q-value table do not change, it indicates that the Q-value table has converged. The establishment of the Q value list depends on the return of rewards for updating. When the agent chooses an action, the environment will transfer state and give instant rewards, correct actions will be rewarded, and wrong actions will be punished. The basic update rule is as follows:
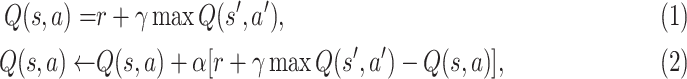 |
where 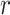 is the instant reward obtained;
is the instant reward obtained; 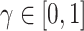 is the discount factor which indicates the importance the agent attaches to experience, when the agent updates its state, it will comprehensively consider immediate benefits [
is the discount factor which indicates the importance the agent attaches to experience, when the agent updates its state, it will comprehensively consider immediate benefits [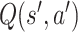 ] and memory benefits [
] and memory benefits [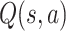 ], the memory benefits refer to the maximum value of the utility value in the action of the next state in the agent memory (Q value table). Therefore, the larger the discount factor, the more the agent attaches importance to memory benefits;
], the memory benefits refer to the maximum value of the utility value in the action of the next state in the agent memory (Q value table). Therefore, the larger the discount factor, the more the agent attaches importance to memory benefits; 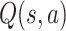 represents the value determined by the state and action,
represents the value determined by the state and action, 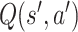 means the Q value of the action
means the Q value of the action 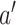 taken in the next state
taken in the next state 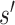 ;
; 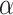 is the learning rate which defines how much the current q-value will move towards the direction of the latest update.
is the learning rate which defines how much the current q-value will move towards the direction of the latest update.
FIGURE 7.

Traditional Q-learning algorithm flow.
B. State-Action Pair Design
In order to implement the Q-learning algorithm to plan the CB route, the state-action pairs and reward function of the agent learning process are the main considerations. Therefore, the first step in applying Q-learning is to define states and actions [42].
1). State Design
This section is intended to illustrate: a) the CB stops are represented as states; b) the setting method of the CB stop (state).
The CB is represented as an agent, and the bus stops (including real and virtual stops) are represented as the states, the states do not change with t, because the stops are static. The real stops are set by K-Means clustering method. First, K data objects are randomly selected from the passenger travel point set. Each centroid is defined by the mean of the data objects contained in the cluster, and each remaining object is divided into corresponding clusters according to its mean distance from each cluster, the newly obtained mean point is calculated, and the clusters are re-assigned and updated until the value of each cluster. The mean value or the center of mass no longer changes. The steps of K-means cluster analysis method for cluster analysis of dynamic travel demands in a small area are:
-
Step 1:
Process the dynamic data set and determine the location coordinates of passengers;
-
Step 2:
Establish a reservation request data set
 ;
; -
Step 3:
Analyze the dynamic request location distribution, select
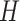 initial cluster centers
initial cluster centers 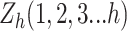 from it;
from it; -
Step 4:Using
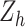 as a reference point, calculate the distance between other dynamic requests
as a reference point, calculate the distance between other dynamic requests 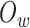 and the point
and the point 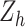 , and divide the requested data into the category of the nearest cluster center, namely
, and divide the requested data into the category of the nearest cluster center, namely
If the Eq. (3) is satisfied, it means
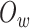 belongs to the cluster
belongs to the cluster 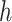 ;
; -
Step 5:
Update the sample points in all cluster areas
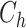 , and use the mean value of the sample points in all cluster areas as the new cluster center
, and use the mean value of the sample points in all cluster areas as the new cluster center 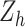 ;
; -
Step 6:According to the square error criterion, calculate the square error
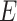 .
.
where
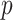 indicates the sample point in clustering
indicates the sample point in clustering 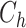 , and
, and 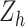 is the new clustering center of clustering region
is the new clustering center of clustering region 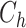 .
. -
Step 7:
Perform iterative calculation on the square error
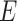 . When the error sum of squares is locally minimum, the operation is completed; otherwise, return to Step 4.
. When the error sum of squares is locally minimum, the operation is completed; otherwise, return to Step 4.
After analyzing the dynamic travel demands using the K-means cluster analysis method, assume that the coordinate of the 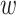 request in the
request in the 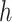 cluster center is
cluster center is 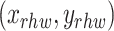 , the coordinates of the composite stop are
, the coordinates of the composite stop are 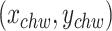 , and the maximum acceptable walking distance of passengers is
, and the maximum acceptable walking distance of passengers is 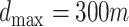 . Determine whether the vehicle responds to the ride request according to the following formula:
. Determine whether the vehicle responds to the ride request according to the following formula:
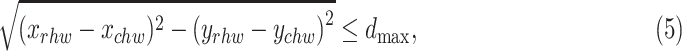 |
according to the service range of the ridesharing stop, the number of passengers that each cluster center accepts customized services can be determined.
2). Action Design
Going to different stations means different actions. In order to avoid local optimum, the bus agent chooses different actions in each state according to the 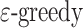 strategy, that is, chooses the action with the largest Q value with probability
strategy, that is, chooses the action with the largest Q value with probability 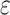 , and chooses other actions for exploration with probability
, and chooses other actions for exploration with probability 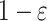 , and then moves to the next state. Introduce decision variables:
, and then moves to the next state. Introduce decision variables:
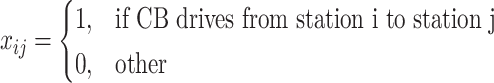 |
when solving the routes in the pick-up area, the requirements at the end of an episode are as follows:
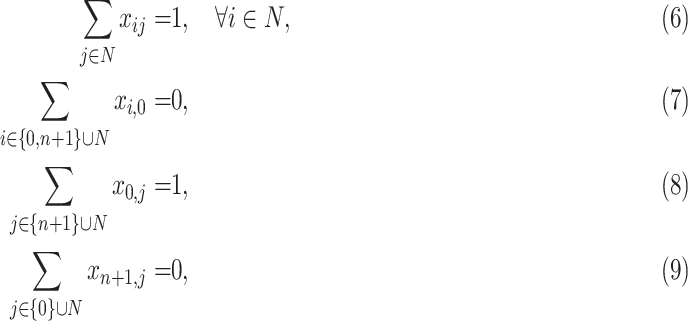 |
Eq. (6) indicates that the bus agent traverses all the real stops; Eq. (7) represents that the bus agent will not return to the virtual stop 0; Eq. (8) means that the virtual stop 0 is the starting stop; and Eq. (9) expresses that the virtual stop is the terminal stop.
Similarly, the conditions for the end of an episode in the drop-off area are as follows:
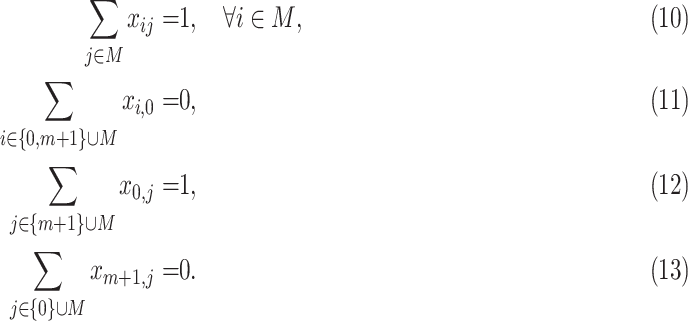 |
C. Path Impedance
It should be noted that the path is formed by multiple connecting road sections between two adjacent stops, route is defined as a directed line which is from the start stop to the terminal stop. However, there are often multiple alternative paths between two stops, and determining the routes between stops is the basis for constructing the public transport network. Since the paths between stops are independent and contain multiple road sections, this article uses historical data to calculate the travel time of the road section, and then determines the least impedance path.
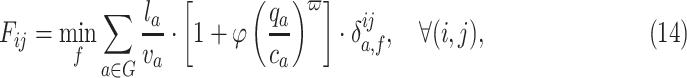 |
where 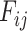 represents the impedance of the path
represents the impedance of the path 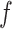 between the stop
between the stop 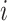 and the stop
and the stop 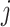 ;
; 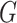 means the set of road sections;
means the set of road sections; 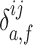 indicates the path-road section associated variable, if the road section
indicates the path-road section associated variable, if the road section 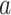 belongs to the path
belongs to the path 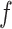 between stop
between stop 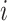 and stop
and stop 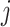 , the value is 1, otherwise the value is 0;
, the value is 1, otherwise the value is 0; 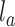 is the length of the road section
is the length of the road section 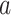 ;
; 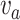 represents the free flow speed of the CB;
represents the free flow speed of the CB; 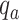 means the actual traffic volume of the road section
means the actual traffic volume of the road section 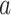 , which can be obtained through historical data;
, which can be obtained through historical data; 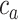 expresses the traffic capacity of the road section
expresses the traffic capacity of the road section 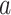 ;
; 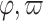 are constant parameters. As is shown in Figure 8, there are three optional paths between stop
are constant parameters. As is shown in Figure 8, there are three optional paths between stop 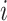 and stop
and stop 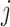 , and path 2 has the smallest impedance, and then path 2 is selected as the operation path of stop
, and path 2 has the smallest impedance, and then path 2 is selected as the operation path of stop 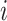 and stop
and stop 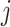 .
.
FIGURE 8.

Path selection scenarios between two stops.
D. Reward Function Design
The reward function plays a guiding role in the agent training process. The purpose of this part is to evaluate the actions taken by the agent. The purpose of training is to maximize the final cumulative reward value, where the reward value is set as the opposite of the cost, that is, the higher the cost, the smaller the reward value. The reward function designed in this paper comprehensively considers the operating cost of the CB company and the travel time cost of passengers to obtain the route with the best total travel cost.
1). Reward Function for Operating Costs
The operating cost of a CB company includes fixed costs and vehicle operating costs. Vehicle operating costs are positively correlated with the length of the running line. The fuel consumption cost of vehicle operation (the product of the line length and the unit fuel consumption cost) is directly used to represent its operating cost.
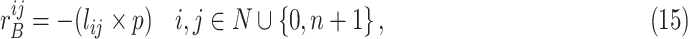 |
where 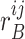 indicates the operating cost between the current stop
indicates the operating cost between the current stop 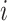 and the stop
and the stop 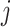 ;
; 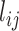 means the distance between the stop
means the distance between the stop 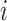 and the stop
and the stop 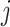 ;
; 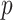 represents the unit fuel consumption cost.
represents the unit fuel consumption cost.
2). Reward Function of Passenger’s Time Costs
Assuming that passengers arrive at the stop at the earliest time within the time window, the time cost of the passenger is the time cost of waiting due to the late arrival of the CB (the bus arrives later than time window). Eq. (16) is the reward function of passenger’s time cost.
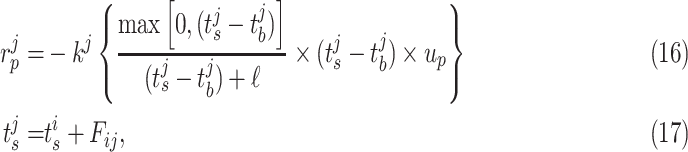 |
where 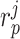 represents the time cost of passengers at the stop
represents the time cost of passengers at the stop 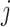 ;
; 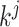 is the number of passengers at the stop
is the number of passengers at the stop 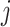 ;
; 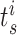 means the actual time for the CB to arrive at the stop
means the actual time for the CB to arrive at the stop 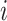 ;
; 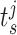 represents the actual time for the CB to arrive at the stop
represents the actual time for the CB to arrive at the stop 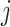 , that is, the sum of the time of arrival at the stop
, that is, the sum of the time of arrival at the stop 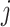 and the path impedance (operation time) between the stop
and the path impedance (operation time) between the stop 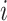 and the stop
and the stop 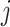 ;
; 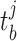 indicates the latest time in the time window of stop
indicates the latest time in the time window of stop 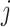 ;
; 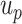 means the time value of passengers. According to the actual situation, the time value of passengers in the drop-off area is higher than that in the pick-up area;
means the time value of passengers. According to the actual situation, the time value of passengers in the drop-off area is higher than that in the pick-up area; 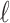 is a positive number close to 0, avoiding the denominator being 0.
is a positive number close to 0, avoiding the denominator being 0.
If the actual arrival time of CB is within the time window of the stop, 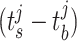 is negative, therefore
is negative, therefore 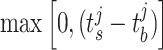 is 0, there is no delay time cost; If the actual arrival time of CB is after the latest time in the time window of the stop,
is 0, there is no delay time cost; If the actual arrival time of CB is after the latest time in the time window of the stop, 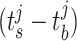 is positive, therefore,
is positive, therefore, 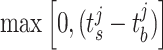 is
is 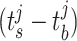 ,
, 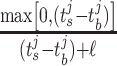 is approximately equal to 1, the delay time occurs. Therefore
is approximately equal to 1, the delay time occurs. Therefore 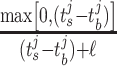 is essentially a “decision variable” to judge if the CB arrives stop outside the time window, then the reward value of passenger’s time cost for the bus agent is determined by Eq. (16). In both the pick-up area and the drop-off area, passengers require that the actual arrival time of CB should not be later than the time window of the stop,
is essentially a “decision variable” to judge if the CB arrives stop outside the time window, then the reward value of passenger’s time cost for the bus agent is determined by Eq. (16). In both the pick-up area and the drop-off area, passengers require that the actual arrival time of CB should not be later than the time window of the stop, 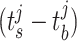 means the difference between the actual arrival time and the latest time in the time window. Hence, Eq. (16) can describe the time deviation between the pick-up area and the drop-off area.
means the difference between the actual arrival time and the latest time in the time window. Hence, Eq. (16) can describe the time deviation between the pick-up area and the drop-off area.
3). Comprehensive Reward Function
The optimization goals of Eq. (15) and Eq. (16) have the same direction, and the multi-objective optimization is transformed into single-objective optimization, and the final reward function is:
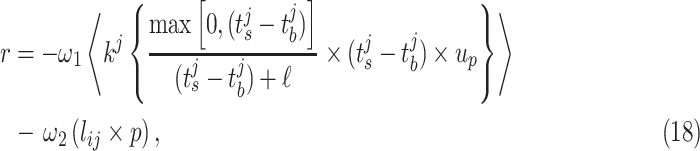 |
where 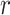 indicates the reward function;
indicates the reward function; 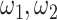 respectively are the weight coefficients of operating cost and passenger time cost [20], the other variables and parameters have been explained above.
respectively are the weight coefficients of operating cost and passenger time cost [20], the other variables and parameters have been explained above.
E. Algorithm Improvement
The Q-learning algorithm has the problem of data transmission lag in the Q value update process, which causes the Q value of the subsequent state to not be fed back to the forward state in time to update the Q value, which affects the convergence speed of the Q value. In this study, the “backtracking” idea is used to improve the update rules of the Q-value table to solve the problem of data transmission lag, improve the convergence speed of the algorithm, and shorten the path planning time.
First define the memory matrix 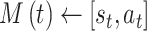 to record the state-action pairs experienced by the bus agent in sequence. Suppose
to record the state-action pairs experienced by the bus agent in sequence. Suppose 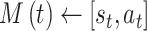 is a matrix with rows and 2 columns, at the beginning of training, since no prior experience is set for the agent, so the initial input of all Q values in the memory matrix is 0. where
is a matrix with rows and 2 columns, at the beginning of training, since no prior experience is set for the agent, so the initial input of all Q values in the memory matrix is 0. where  is the number of states experienced from the initial moment to the current moment. Use
is the number of states experienced from the initial moment to the current moment. Use 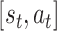 in
in 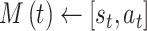 as the index to find the Q value corresponding to the previous “state-action” and update it. Then subtract 1 from
as the index to find the Q value corresponding to the previous “state-action” and update it. Then subtract 1 from 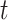 and determine whether
and determine whether 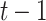 is 0. If it is 0, it means that the Q value of all the “state-actions” experienced by state
is 0. If it is 0, it means that the Q value of all the “state-actions” experienced by state 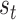 has been updated; if it is not 0, continue to index the previous sequence “The Q value of “state-action” is updated until all Q values are updated, so that the Q values of n states are updated without repeated training n times. The update formula is shown in equation (19), where
has been updated; if it is not 0, continue to index the previous sequence “The Q value of “state-action” is updated until all Q values are updated, so that the Q values of n states are updated without repeated training n times. The update formula is shown in equation (19), where 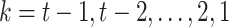 .
.
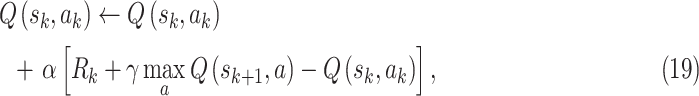 |
F. Algorithm Flow
Since the reward and punishment value includes the passenger’s time cost, which is related to the actual time when the bus arrives at the stop, the reward and punishment value of each action in this state must be recalculated every time it reaches a state. A step-by-step procedure to search for the optimal route using the improved Q-learning algorithm is shown in Figure 9 and discussed below.
-
Step I:
The initial input of all Q values in the Q value table is 0, and let
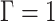 to start the first training.
to start the first training. -
Step II:
Initialize the state, and let
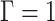 .
. -
Step III:
Update the reward value for all actions based on the current state.
-
Step IV:
Select the next action according to
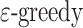 strategy, then move to the new state.
strategy, then move to the new state. -
Step V:
Update the memory matrix
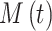 and previous Q value.
and previous Q value. -
Step VI:
Determine if an episode has been completed according to the set training conditions. If an episode is not completed, let
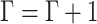 , and then judge if the maximum number of training steps has been reached, if so, go back to Step II; otherwise go back to Step IV. If an episode is completed, let i = i +1 and then go to Step VII.
, and then judge if the maximum number of training steps has been reached, if so, go back to Step II; otherwise go back to Step IV. If an episode is completed, let i = i +1 and then go to Step VII. -
Step VII:
Determine if the Q-value table has converged (the Q values in the Q-value table do not change). If Q-value table does not converge, it is judged if the maximum episode number has been reached, if the maximum number of episodes is reached, the training ends, if the maximum number of episodes is not reached, go back to Step II. If Q-value table has converged, the training ends.
FIGURE 9.

Improved Q-learning algorithm flow.
V. Case Study
A. Line Information
We take three existing customized bus lines in Beijing as examples to verify the effectiveness of the proposed algorithm. These three CB lines are typical cross-regional CB lines, and they are similar to other cross-regional CB lines in Beijing, passing through large residential areas and workspace, which are effective measures provided by Beijing to support enterprises to resume work and production under the normal situation of epidemic prevention and control, the project requires that the location of the stops cannot be changed, that is, the location of the stops is fixed, however the service order of the stops can be optimized according to the passengers’ time window information. Meantime in order to compare the optimization results more intuitively and focus on the effectiveness of the algorithm, we directly adopt the location settings of the original stops. the stops’ information (numbered according to the order of service) of the pick-up and drop-off areas is shown in Table 1.
TABLE 1. Information of CB Stops.
| Route ID | Pick-up stop | Drop-off stop |
|---|---|---|
| 1 | Liuxing Garden(1), East Gate of Shangbei Center(2), Longteng yuan(3), New Longcheng(4) | Zhongguancun(5), Haidian Huangzhuang(6), Haidian Middle Street(7), West Exit of Haidian Avenue(8) |
| 2 | East Exit of Huashijiang community(1), Huashijiang Community(2), Tuqiao Subway Stop(3), Li yuan Subway Stop(4), Jiukeshu Subway Stop(5), Nikko Kiyoshi(6) | South Exit of Guangshun South Street(7), East Exit of Futong East Street(8), Guofeng Beijing(9), Fu’an Road(10), Wangjing Metro Stop(11), East Exit of Xiyang East Road(12), East Exit of Wangjing North Road(13) |
| 3 | Yizhung Jinmaoyue Community(1), Haizifu Community(2), Nanhai Community 2(3), Nanhai Community 3(4), Taihe Community(5), Zhongxin Garden(6), Taihe yuan Community(7) | Ciqikou Street(8), Chongwenmen(9) |
Field data surveys are used to obtain the actual operating route of the CB, the time of departure from the stop and the time of arrival at the stop, the number of passengers who pick up and drop off bus. Investigators are assigned to the three routes. One sits at the front door and records the CB’s arrival time, the number of passengers who pick up bus, and the average boarding time, and the other sitting at the back door records the number of passengers who drop off bus, the average alighting time, and the departure time. The actual expected departure time of passengers is obtained by issuing questionnaires on the CB, and the time window is determined.
Route 1 contains 4 pick-up stops and 4 drop-off stops, Route 2 contains 6 pick-up stops and 7 drop-off stops, and Route 3 contains 7 pick-up stops and 2 drop-off stops. Table 2 lists the number of passengers and time window information for the three CB routes’ stops.
TABLE 2. Passenger Number and Time Windows of Three Routes.
| Route 1 | Route 2 | Route 3 | ||||||
|---|---|---|---|---|---|---|---|---|
| Stop ID | PN | TW | Stop ID | PN | TW | Stop ID | PN | TW |
| 1 | 6 | [7:05,7:15] | 1 | 3 | [7:00,7:10] | 1 | 5 | [7:00,7:10] |
| 2 | 12 | [7:15,7:25] | 2 | 5 | [7:15,7:25] | 2 | 3 | [7:00,7:10] |
| 3 | 5 | [7:10,7:20] | 3 | 7 | [7:00,7:10] | 3 | 4 | [7:10,7:20] |
| 4 | 7 | [7:10,7:20] | 4 | 2 | [7:20,7:30] | 4 | 6 | [7:05,7:15] |
| 5 | 6 | [7:45,7:55] | 5 | 7 | [7:20,7:30] | 5 | 2 | [7:10,7:20] |
| 6 | 13 | [8:10,8:20] | 6 | 6 | [7:25,7:35] | 6 | 5 | [7:00,7:10] |
| 7 | 5 | [7:50,8:00] | 7 | 8 | [8:00,8:10] | 7 | 3 | [7:15,7:25] |
| 8 | 6 | [8:15,8:25] | 8 | 3 | [7:55,8:05] | 8 | 11 | [7:45,7:55] |
| 9 | 6 | [7:55,8:05] | 9 | 17 | [7:55,8:05] | |||
| 10 | 4 | [8:05,8:15] | ||||||
| 11 | 2 | [8:10,8:20] | ||||||
| 12 | 3 | [8:10,8:20] | ||||||
| 13 | 4 | [8:15,8:25] | ||||||
NOTE: PN - Passenger Number; TW - Time Window
B. Variable and Parameter Settings
A sensitivity analysis based on the condition with Route 1 is performed to explore the relation between model parameters and optimized results. The learning rate and discount factor are the most critical parameters in the Q-Learning algorithm. We adjust different parameter combinations in the Q-Learning algorithm to obtain the optimal parameter settings. The value range of the learning rate and discount factor is set as [0.1, 0.9], and perform training experiment according to the value of 0.1 unit. The parameter sensitivity analysis results are shown in Figure 10, the horizontal axis represents the discount factor, the vertical axis indicates the learning rate, and different colors represent different iterations, the following conclusions can be drawn that when the learning rate is within the range of [0.1,0.5] and the discount factor is within the range of [0.1,0.5], with the increase of the learning rate, the iterations on the whole presents an increasing trend; when the learning rate is within the range of [0.5,0.9] and the discount factor is within the range of [0.1,0.4], the iterations decrease as a whole with the increase of the discount factor; when the value range of the discount factor is [0.6,0.8] and the value range of the learning rate is [0.1,0.4], the iterations of the agent is relatively small compared to other parameter combinations, which indicates that the agent can complete the training faster, that is, the performance of the algorithm is better, and when the learning rate is 0.3, and the discount factor is 0.8, the algorithm efficiency is the highest. Besides, The CB speed and oil price are set according to the actual situation in Beijing [43], and the time value of passengers is
FIGURE 10.

Parameter sensitivity analysis result.
calculated according to Beijing’s per capita income in 2019. The parameter and variable settings are shown in Table 3.
TABLE 3. Variable and parameter settings.
| Variable | Description | Value |
|---|---|---|
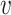 |
Bus free flow speed, set as a constant | 30 km/h |
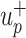 |
Time value of passenger in pick-up area | 1 yuan/min |
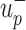 |
Time value of passenger in drop-off area | 2 yuan/min |
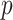 |
Fuel consumption cost per unit operating mileage | 3 yuan/km |
| Parameter | Description | Value |
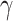 |
Discount factor | 0.8 |
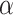 |
Learning rate | 0.3 |
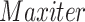 |
Max exploration steps | 100 |
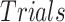 |
Maximum episodes | 500 |
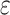 |
Exploration factor | 0.8 |
| 1 | Constant, avoid the denominator being 0 | 0.01 |
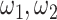 |
Weight coefficient | 0.6, 0.4 |
 |
parameter | 0.15, 0.4 |
C. Result Analysis
Based on actual data, the path with the least impedance is obtained by Eq (14), and Table 4 shows the distance between the stops.
TABLE 4. CB Stops’ Distance Matrix(km).
| Stop ID of Route 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1.1 | 1.8 | 4.3 | – | – | – | – |
| 2 | 1.1 | 0 | 1.2 | 2.9 | – | – | – | – |
| 3 | 1.8 | 1.2 | 0 | 2.1 | – | – | – | – |
| 4 | 4.3 | 2.9 | 2.1 | 0 | – | – | – | – |
| 5 | – | – | – | – | 0 | 0.5 | 1 | 0.5 |
| 6 | – | – | – | – | 0.5 | 0 | 0.5 | 0.8 |
| 7 | – | – | – | – | 1 | 0.5 | 0 | 0.6 |
| 8 | – | – | – | – | 0.5 | 0.8 | 0.6 | 0 |
This experiment is based on Python 3.6.4 programming, the computer configuration is Lenovo Y7000, the processor is i5-8300H, the graphics card NG GTX 1050, and the simulation environment we used is OpenAl Gym, the training results are shown in Figure (11 a-c) and Table 5.
Figure (11 a-c) and Table 5 show the convergence process of Q-value table and the comparison of algorithm performance. The total steps (y-axis) represents the number of steps which the agent needs to complete a training, iteration (x-axis) represents the number of training. From Figure (11 a-c), we can see that the number of steps for the agent to complete a training session continues to decrease with the number of iterations, until the number of exploration steps no longer changes. It directly means that the optimal strategy is learned by agent, namely, the Q-value table converges. When the Q value converges, the number of iterations of the improved Q-Learning algorithm is significantly less than that of the traditional Q-Learning algorithm. From Table 5 we can draw that compared with traditional Q-learning, the improved Q-learning training times of Route 1 is reduced by 37.9%, the solution time become shorter by 41.7%, and the optimization rate of training times and solving time of Route 2 has also reached more than 20%, the optimization rate of training times and solving time of Route 3 are both about 34%. Indicating that the improved Q-learning algorithm has improved, the problem of lag in data transmission significantly improves the convergence speed of the algorithm and shortens the route planning time.
FIGURE 11.

The convergence process of Q-value table.
TABLE 5. Comparison of Algorithm Performance.
| Route | Route 1 | Route 2 | Route 3 | |||
|---|---|---|---|---|---|---|
| Training metrics | Iterations | Solving time/s | Iterations | Solving time/s | Iterations | Solving time/s |
| Traditional Q-learning | 153 | 187 | 246 | 266 | 162 | 196 |
| Improved Q-learning | 95 | 109 | 192 | 212 | 106 | 131 |
| Optimization rate | 37.9% | 41.7% | 22% | 20.3% | 34.6% | 33.2% |
The route solved by the improved Q-learning are as follows (stops’ number):
-
Route 1:
1-3-4-2-5-7-6-8;
-
Route 2:
1-3-2-5-4-6-8-9-7-10-11-12-13,
-
Route 3:
1-2-4-5-3-6-7-8-9,
the cost information after route optimization is shown in Table 6.
TABLE 6. Comparison of Route Cost Comparison.
| Route | Fuel consumption cost (yuan) | Time cost (yuan) | Total cost (yuan) | Total coat optimization rate |
|---|---|---|---|---|
| Current Route 1 | 86 | 149 | 235 | 39.1% |
| Optimized Route 1 | 92 | 51 | 143 | |
| Current Route 2 | 147 | 244 | 391 | 35.9% |
| Optimized Route 2 | 174.8 | 76 | 250.8 | |
| Current Route 3 | 134 | 164 | 298 | 28.2% |
| Optimized Route 3 | 125 | 89 | 208 |
According to the results of the numerical experiment in Table 6, we can obtain the following observations. (i) Although the fuel consumption cost of the optimized Route 1 has increased by 6 yuan compared with the original route, the time cost of individual passenger has been reduced by 98 yuan, the average lost time of passengers has been reduced from 4.97 min to 1.7 min, and the total travel cost has been reduced by 39.1 %. (ii) The fuel consumption cost of the optimized Route 2 has increased by 27.8 yuan compared with the original route, but the time cost of passengers has been reduced by 168 yuan, the average lost time of individual passenger has been reduced from 5.42 min to 1.69 min, and the total travel cost has been reduced by 35.9%. (iii) The fuel consumption cost of the optimized Route 3 has increased by 9 yuan compared with the original route, but the time cost of individual passenger has been reduced by 75 yuan, the average lost time of passengers has been reduced from 5.85 min to 3.17 min, and the total travel cost has been reduced by 28.2%. This method can effectively reduce the total social travel cost. (IV) Compared with the original route, the waiting time of passengers on Route 1, Route 2 and Route 3 are reduced by 65.8%, 68.9% and 45.7% respectively. The average waiting time of the three routes is reduced by 60.1%. Assuming that the gathering time of passengers is positively correlated with the spread probability of COVID-19, it is believed that the probability of transmission of the COVID-19 is also correspondingly reduced sharply.
Through the above analysis, CB operation companies can consider increasing the fare moderately (after optimization, Route 1, Route 2 and Route 3 will increase the fare by 0.12 yuan/person, 0.58 yuan/person and 0.32 yuan/person, respectively) to make up for the business operating costs after route optimization. The increase, that is, maintaining the same operating cost as the status quo. In this case, because the bus fare is only a transfer payment and is not included in the total social travel cost, the reduction in the total social travel cost is all due to the contribution of the passenger travel cost reduction.
VI. Discussions and Conclusion
In this study, we propose a CB route planning method based on the improved Q-learning algorithm to solve the problem of cross-regional CB route planning during the COVID-19. Under such a method, the total social travel cost, including the operation cost and travel cost, is minimized. First, we design a sub-regional route planning approach considering commuters’ time windows of pick-up stops and drop-off stops. Secondly, we develop the improved Q-learning algorithm, including state-action pair, reward function and update rule of Q value table. Specially, according to the operating cost of the bus company and the time cost of passengers, the reward function is set, and the “backtracking” idea is applied to the Q-learning algorithm to improve the update efficiency of the Q value table. Moreover, through the numerical experiment, we obtain the following conclusions. (i) The improved Q-learning algorithm can effectively increase the solution speed and improve the lag of data transmission. (ii) The optimized CB route can effectively reduce the total social travel cost and the transmission risk of COVID-19, thereby providing new ideas for CB route planning and pricing.
As the development of this study, in the future research, the passenger’s dynamic travel needs can be considered to make real-time planning of the CB route, besides, it is also possible to consider the situation of the passengers late or early to the stops and the different requirements for time window of passengers at the same stop.
Biographies

Ange Wang born in Shandong, China. He received the bachelor’s degree from East China Jiaotong University, and was awarded Outstanding Graduate in 2019. After obtaining the recommendation exemption admission qualifications, he is currently pursuing the master’s degree in transportation planning and management with the Faculty of Urban Construction, Beijing University of Technology. His research interests include resource allocation for customized buses and shared parking. He has published a total of three academic articles (SCI/EI), applied for three national invention patents, and won the 2018 National Scholarship and National Encouragement Scholarship of China.

Hongzhi Guan received the B.S. degree from the Xi’an Highway College, Chang’an University, in 1982, and the Ph.D. degree from Kyoto University, Japan, in 1997. He is currently a Professor with the Beijing University of Technology and a Doctoral Tutor. He is also the author of more than 20 books and more than 200 articles. His research interests include traffic behavior analysis and modeling, traffic policy analysis, public transportation planning and management, parking planning and management, and traffic psychology research. He is also a member of the Transportation Steering Committee, Ministry of Education and the Vice Chairman of the Traffic Engineering Teaching Guidance Subcommittee, the Ministry of Public Security, the Central Civilization Office, the Ministry of Housing and Urban-Rural Development, and the Ministry of Transport’s National Urban Traffic Civilization and Smooth Improvement Action Plan Expert Group Expert, World Transport Conference (WTC) Executive Committee members, and other social work.

Pengfei Wang received the B.S. degree in transportation engineering from the North China University of Science and Technology, China, in 2007, and the M.S. and Ph.D. degrees in information sciences from Tohoku University, Japan, in 2010 and 2016, respectively. He is currently a Distinguished Professor with the Key Laboratory of Urban Security and Disaster Engineering of Ministry of Education, Beijing University of Technology, China, and an Associate Professor with the School of Civil Engineering and Mechanics, Yanshan University, China. He has published more than 40 academic articles and some of them are published in Transportation Research Part B: Methodological, Transportation Research Part C: Emerging Technologies, and China Journal of Highway and Transport. He is also a member of the China Highway and Transportation Society, the Urban Planning Society of China. He received the Tohoku University Professor Fujino Incentive Award, in 2015, the Construction Engineering Research Award, in 2016, the Chinese Government Award for Outstanding Self-Financed Students Aboard, in 2017, and the Golden Mention of Qian Xuesen Award of Urbanology in 2019.

Liqun Peng received the Ph.D. degree in intelligent transportation system engineering from the Wuhan University of Technology, China, in 2015. He was a Postdoctoral Fellow with the University of Alberta, from 2016 to 2017. He is currently an Associate Professor with the School of Transportation and Logistics, East China Jiaotong University. His research interests include optimization theory for both transportation and logistics problems.

Yunqiang Xue received the B.S. and M.S. degrees in mathematics and applied mathematics, pure mathematics from Shandong Normal University, in 2005 and 2008, respectively, and the Ph.D. degree in transportation engineering from the Beijing University of Technology, China, in 2017. He was the Deputy Director with the Jinan Urban Transport Research Center, Jinan Public Traffic Company, China, from 2008 to 2013, and a Visiting Scholar with the Department of Engineering, University of Cincinnati, Cincinnati, OH, USA, from 2015 to 2016. He has been an Assistant Professor with the School of Transportation and Logistics, Traffic Engineering, East China Jiaotong University, China, since 2017, and has also been a Postdoctoral Researcher with the School of Transportation, Southeast University, China, since 2018. He has coauthored more than 40 journal and conference papers, including the Journal of Advanced Transportation, KSCE Journal of Engineering, Sustainability, and Mathematical Problems in Engineering. He has coauthored four books including one teaching textbook, such as Quantitative Evaluation Method and Mechanism of the Feasibility of Private Capital Investment in Urban Public Transport (Press of Southwest Jiaotong University, China, 2019), The Analysis Methods of Transportation Systems (Press of Southwest Jiaotong University, China, 2018), The Operation Dispatch and Management of Urban Public Transport (China Communications Press, China, 2012). His research interests include the operation and management of urban public transport, the planning of management of transportation, urban parking, and mathematical modeling.
Funding Statement
This work was supported in part by the National Natural Science Foundation of China under Grant 71971005, in part by the Project Sponsored by Beijing Municipal Natural Science Foundation under Grant 8202003, in part by the Natural Science Foundation of Hebei Province under Grant E2018407051, in part by the Hebei Province for the Returned Overseas Chinese Scholars under Grant C20190333, and in part by the Fundamental Research Funds for Universities of Hebei Province under Grant 2020JK020.
References
- [1].Fan X., “A study on the social cost comparison between public transportation and car travel,” Highways Automot. Appl., no. 1, pp. 53–55, Feb. 2012.
- [2].Baidu Maps, Beijing, China. (Apr. 2016). 2016 Beijing Resident Travel Big Data Report. [Online]. Available: http://science.china.com.cn/2016-04/28/content_8738133.htm
- [3].Liu T. and Ceder A., “Analysis of a new public-transport-service concept: Customized bus in China,” Transp. Policy, vol. 39, pp. 63–76, Apr. 2015. [Google Scholar]
- [4].Wang J., Yamamoto T., and Liu K., “Role of customized bus services in the transportation system: Insight from actual performance,” J. Adv. Transp., vol. 2019, pp. 1–14, Aug. 2019. [Google Scholar]
- [5].Le Vine S., Lee-Gosselin M., Sivakumar A., and Polak J., “A new approach to predict the market and impacts of round-trip and point-to-point carsharing systems: Case study of London,” Transp. Res. D, Transp. Environ., vol. 32, pp. 218–229, Oct. 2014. [Google Scholar]
- [6].Ma J., Yang Y., Guan W., Wang F., Liu T., Tu W., and Song C., “Large-scale demand driven design of a customized bus network: A methodological framework and Beijing case study,” J. Adv. Transp., vol. 2017, pp. 1–14, Mar. 2017. [Google Scholar]
- [7].Tong L., Zhou L., Liu J., and Zhou X., “Customized bus service design for jointly optimizing passenger-to-vehicle assignment and vehicle routing,” Transp. Res. C, Emerg. Technol., vol. 85, pp. 451–475, Dec. 2017. [Google Scholar]
- [8].Lyu Y., Chow C.-Y., Lee V. C. S., Ng J. K. Y., Li Y., and Zeng J., “CB-planner: A bus line planning framework for customized bus systems,” Transp. Res. C, Emerg. Technol., vol. 101, pp. 233–253, Apr. 2019. [Google Scholar]
- [9].Huang D., Gu Y., Wang S., Liu Z., and Zhang W., “A two-phase optimization model for the demand-responsive customized bus network design,” Transp. Res. C, Emerg. Technol., vol. 111, pp. 1–21, Feb. 2020. [Google Scholar]
- [10].Yan F. and Wang Y. Y., “Modeling and solving the vehicle routing problem with multiple fuzzy time windows,” J. Transp. Syst. Eng. Inf. Technol., vol. 16, no. 6, pp. 182–188, 2016. [Google Scholar]
- [11].Wang J., Cao Y., and Wang Y., “CB route vehicle schedule method considering travel time windows,” China J. Highway Transp., vol. 31, no. 5, pp. 143–150, May 2018. [Google Scholar]
- [12].Shao Z., Zhang Q., Wang S., Zhang X., and Li W., “Optimization algorithms for scheduling of flex-route buses,” J. Transp. Inf. Saf., vol. 5, pp. 12–17, Jul. 2018. [Google Scholar]
- [13].Ma C., Wang C., Hao W., Liu J., and Zhang Z., “Emergency customized bus route optimization under public health emergencies,” J. Traffic Transp. Eng., vol. 20, no. 3, pp. 89–99, Jun. 2020. [Google Scholar]
- [14].Wang J., Yamamoto T., and Liu K., “Key determinants and heterogeneous frailties in passenger loyalty toward customized buses: An empirical investigation of the subscription termination hazard of users,” Transp. Res. C-Emerg. Technol., vol. 115, no. 6, pp. 1–15, Jun. 2020. [Google Scholar]
- [15].Yu Q., Zhang H., Li W., Song X., Yang D., and Shibasaki R., “Mobile phone GPS data in urban customized bus: Dynamic line design and emission reduction potentials analysis,” J. Clean Prod., vol. 272, no. 10, pp. 1–15, Jun. 2020. [Google Scholar]
- [16].Hao J., Zhang L., Ji X., and Tang J., “Modeling and analyzing of family intention for the customized student routes: A case study in China,” Phys. A, Stat. Mech. Appl., vol. 542, Mar. 2020, Art. no. 123399. [Google Scholar]
- [17].Qiu G., Song R., He S., Xu W., and Jiang M., “Clustering passenger trip data for the potential passenger investigation and line design of customized commuter bus,” IEEE Trans. Intell. Transp. Syst., vol. 20, no. 9, pp. 3351–3360, Sep. 2019. [Google Scholar]
- [18].Huang K., Xu L., Chen Y., Cheng Q., and An K., “Customized bus route optimization with the real-time data,” J. Adv. Transp., vol. 2020, pp. 1–9, Aug. 2020. [Google Scholar]
- [19].Bie Y., Tang R., Liu Z., and Ma D., “Mixed scheduling strategy for high frequency bus routes with common stops,” IEEE Access, vol. 8, pp. 34442–34454, Feb. 2020. [Google Scholar]
- [20].Han Z., Chen Y., Li H., Zhang K., and Sun J., “Customized bus network design based on individual reservation demands,” Sustainability, vol. 11, no. 19, pp. 1–25, Oct. 2019. [Google Scholar]
- [21].Eshragh A., Esmaeilbeigi R., and Middleton R., “An analytical bound on the fleet size in vehicle routing problems: A dynamic programming approach,” Oper. Res. Lett., vol. 48, no. 3, pp. 350–355, May 2020. [Google Scholar]
- [22].Behnke M., Kirschstein T., and Bierwirth C., “A column generation approach for an emission-oriented vehicle routing problem on a multigraph,” Eur. J. Oper. Res., vol. 288, no. 3, pp. 794–809, Feb. 2021. [Google Scholar]
- [23].Nucamendi-Guillén S., Angel-Bello F., Martínez-Salazar I., and Cordero-Franco A. E., “The cumulative capacitated vehicle routing problem: New formulations and iterated greedy algorithms,” Expert Syst. Appl., vol. 113, pp. 315–327, Dec. 2018. [Google Scholar]
- [24].Liang C., Zhang X., and Han X., “Route planning and track keeping control for ships based on the leader-vertex ant colony and nonlinear feedback algorithms,” Appl. Ocean Res., vol. 101, Aug. 2020, Art. no. 102239. [Google Scholar]
- [25].Sedighizadeh D. and Mazaheripour H., “Optimization of multi objective vehicle routing problem using a new hybrid algorithm based on particle swarm optimization and artificial bee colony algorithm considering precedence constraints,” Alexandria Eng. J., vol. 57, no. 4, pp. 2225–2239, Dec. 2018. [Google Scholar]
- [26].Chen J. and Shi J., “A multi-compartment vehicle routing problem with time windows for urban distribution—A comparison study on particle swarm optimization algorithms,” Comput. Ind. Eng., vol. 133, pp. 95–106, Jul. 2019. [Google Scholar]
- [27].Karakatic S., “Optimizing nonlinear charging times of electric vehicle routing with genetic algorithm,” Expert Syst. Appl., vol. 164, Feb. 2021, Art. no. 114039. [Google Scholar]
- [28].Zidi I., Al-Omani M., and Aldhafeeri K., “A new approach based on the hybridization of simulated annealing algorithm and tabu search to solve the static ambulance routing problem,” Procedia Comput. Sci., vol. 159, pp. 1216–1228, Sep. 2019. [Google Scholar]
- [29].Chen G., Hu D., and Chien S., “Optimizing battery-electric-feeder service and wireless charging locations with nested genetic algorithm,” IEEE Access, vol. 8, pp. 67166–67178, 2020. [Google Scholar]
- [30].Aksen D., Kaya O., Salman F. S., and Ö. Tüncel, “An adaptive large neighborhood search algorithm for a selective and periodic inventory routing problem,” Eur. J. Oper. Res., vol. 239, no. 2, pp. 413–426, Dec. 2014. [Google Scholar]
- [31].Sun Q., Chien S., Hu D., Chen G., and Jiang R.-S., “Optimizing multi-terminal customized bus service with mixed fleet,” IEEE Access, vol. 8, pp. 156456–156469, Sep. 2020. [Google Scholar]
- [32].Baugh J. W., Kakivaya G. K. R., and Stone J. R., “Intractability of the dial-a-ride problem and a multiobjective solution using simulated annealing,” Eng. Optim., vol. 30, no. 2, pp. 91–123, Feb. 1998. [Google Scholar]
- [33].Gao S. and Huang H., “Real-time traveler information for optimal adaptive routing in stochastic time-dependent networks,” Transp. Res. C, Emerg. Technol., vol. 21, no. 1, pp. 196–213, Apr. 2012. [Google Scholar]
- [34].Mao C. and Shen Z., “A reinforcement learning framework for the adaptive routing problem in stochastic time-dependent network,” Transp. Res. C, Emerg. Technol., vol. 93, pp. 179–197, Aug. 2018. [Google Scholar]
- [35].Grunitzki R. and Bazzan A. L. C., “Comparing two multiagent reinforcement learning approaches for the traffic assignment problem,” in Proc. Brazilian Conf. Intell. Syst. (BRACIS), Uberlandia, Brazil, Oct. 2017, pp. 139–144. [Online]. Available: http://apps-webofknowledgecom.libziyuan.bjut.edu.cn:8118/full_record.do?product=WOS&search_mode=GeneralSearch&qid=7&SID=6FmkM6UeDWtuFETulof&page=1&doc=1 [Google Scholar]
- [36].Guo J. and Harmati I., “Evaluating semi-cooperative Nash/Stackelberg Q-learning for traffic routes plan in a single intersection,” Control Eng. Pract., vol. 102, Sep. 2020, Art. no. 104525. [Google Scholar]
- [37].Alsaleh R. and Sayed T., “Modeling pedestrian-cyclist interactions in shared space using inverse reinforcement learning,” Transp. Res. F, Traffic Psychol. Behav., vol. 70, pp. 37–57, Apr. 2020. [Google Scholar]
- [38].Meyer E., Robinson H., Rasheed A., and San O., “Taming an autonomous surface vehicle for path following and collision avoidance using deep reinforcement learning,” IEEE Access, vol. 8, pp. 41466–41481, Mar. 2020. [Google Scholar]
- [39].Zhou B., “A reinforcement learning scheme for the equilibrium of the in-vehicle route choice problem based on congestion game,” Appl. Math. Comput., vol. 371, no. 4, pp. 1–18, Apr. 2020. [Google Scholar]
- [40].Kong S. S., Zhou B., Yang P., Yang Z., Fang H., and Feng J., “Reinforcement learning for vehicle route optimization in SUMO,” in Proc. 20th IEEE Int. Conf. High Perform. Comput. Commun., Exeter, U.K., Jun. 2018, pp. 1468–1473. [Online]. Available: http://apps-webofknowledgecom.libziyuan.bjut.edu.cn:8118/full_record.do?product=WOS&search_mode=GeneralSearch&qid=3&SID=6FmkM6UeDWtuFETulof&page=1&doc=1 [Google Scholar]
- [41].Low E. S., Ong P., and Cheah K. C., “Solving the optimal path planning of a mobile robot using improved Q-learning,” Robot. Auto. Syst., vol. 115, pp. 143–161, May 2019. [Google Scholar]
- [42].Maoudj A. and Hentout A., “Optimal path planning approach based on Q-learning algorithm for mobile robots,” Appl. Soft Comput., vol. 97, Dec. 2020, Art. no. 106796. [Google Scholar]
- [43].Quan Y.et al. , “Beijing transport development annual report 2019,” Beijing Transp. Inst., Beijing, China, Tech. Rep., Jul. 2019. [Google Scholar]