

Abstract
Quantum machine learning has experienced significant progress in both software and hardware development in the recent years and has emerged as an applicable area of near-term quantum computers. In this work, we investigate the feasibility of utilizing quantum machine learning (QML) on real clinical datasets. We propose two QML algorithms for data classification on IBM quantum hardware: a quantum distance classifier (qDS) and a simplified quantum-kernel support vector machine (sqKSVM). We utilize these different methods using the linear time quantum data encoding technique () for embedding classical data into quantum states and estimating the inner product on the 15-qubit IBMQ Melbourne quantum computer. We match the predictive performance of our QML approaches with prior QML methods and with their classical counterpart algorithms for three open-access clinical datasets. Our results imply that the qDS in small sample and feature count datasets outperforms kernel-based methods. In contrast, quantum kernel approaches outperform qDS in high sample and feature count datasets. We demonstrate that the encoding increases predictive performance with up to + 2% area under the receiver operator characteristics curve across all quantum machine learning approaches, thus, making it ideal for machine learning tasks executed in Noisy Intermediate Scale Quantum computers.
Subject terms: Computer science, Quantum physics, Medical research
Introduction
Quantum technologies promise to revolutionize the future of information and computation using quantum devices to process massive amounts of data. To date, considerable progress has been made from both software and hardware points of view. Many researches are underway to simplify quantum algorithms1–8 in order to implement them on existing, so-called Noisy Intermediate Scale Quantum (NISQ) computers9. As a result, small quantum devices based on photons, superconductors, or trapped ions are capable of efficiently running scalable quantum algorithms6,7,10. Quantum Machine Learning (QML) is a particularly interesting approach, as it is suited for existing NISQ architectures11–15. While conventional machine learning is generally applied to process large amounts of data, many research fields cannot provide such large datasets. One example is medical research, where collecting cohorts that represent certain characteristics of diseases routinely results in small datasets16. NISQ devices can efficiently execute algorithms with shallow depth and a low number of qubits9. Therefore, it appears logical to exploit the potential of QML executed on NISQ devices incorporating clinical datasets.
However, the execution of QML algorithms in the form of practical quantum gate operations is non-trivial. First, the classical data needs to be encoded into quantum states. For this purpose, prior QML algorithms assume that a quantum random access memory (QRAM) device for storing the data is present17. Nevertheless, to date, such practical devices are not available. Second, since the output of quantum algorithms are obviously quantum states, the efficient classical bits of information must be extracted through quantum measurements. To date, various classical data encoding approaches have been proposed6,7,18–21. In particular, encoding classical numerical features into quantum states has the advantage to utilize number of qubits (a.k.a. linear time encoding) in relation to number of input features18–21. This approach allows to utilize NISQ devices with a small number of qubits and to minimize quantum noise, while at the same time maintaining quantum speedup14. In contrast, to date, this approach in combination with quantum machine learning appears to be underrepresented.
In light of the above proceedings, we hypothesize that clinically-relevant quantum prediction models can be built on NISQ devices employing the encoding, having prediction performances comparable to classic ML approaches.
In our work, we propose two quantum machine learning approaches that rely on the encoding approach, thus, not requiring the presence of a fault-tolerant quantum circuit for implementation of quantum RAM17. Previously proposed techniques for estimation of the inner product with Hadamard Test and Swap Test assume that there is a quantum RAM or a quantum circuit that store both index of data and their values22,23. To construct a quantum database (QDB) from classical data, -qubits are required for sample and -feature counts, where , , and 1 is considered as qubit register24. In contrast, the encoding technique utilizes only qubit and steps to classically access to data without allocating extra qubits to the index of entries of dataset. First, we demonstrate a simple and efficient quantum distance classifier (qDC) executable on existing NISQ devices. Second, we present a simplified quantum-kernel SVM (sqKSVM) approach using quantum kernels which can be executed once without optimization instead of twice with optimization as in case of the quantum-kernel SVM (qKSVM) approach6,7.
In order to test our hypothesis, we demonstrate the performance of the qDC and the sqKSVM approaches using real clinical data and compare their performances to qKSVM, as well as to classic computing counterparts such as k-nearest neighbors25 and classic support vector machines26.
Results
Dataset
This study incorporated three open-access clinical datasets that have been presented and evaluated in various contexts27–29. Each dataset underwent redundancy reduction by correlation matrix analysis30 followed by a tenfold cross-validation split with a training-validation ratio of 80–20%16. Training sets of the folds were subjects of feature ranking analysis31 and the highest-ranking eight as well as 16 (if available) features were selected for further analysis. The resulted dataset configurations were analyzed by class imbalance ratios and the quantum advantage score (a.k.a. difference geometry)20 for quantum kernel methods. Table 1 demonstrates the characteristics of the data configurations as well as the results of the imbalance ratio and the quantum advantage scores (for estimation of the quantum advantage scores , see Appendix E of the supplementary material).
Table 1.
Clinical datasets utilized for the study with their sample and selected feature count as well as their imbalance ratios and quantum advantage scores .
| Dataset | #Samples | Imbalance Ratio | #Features | Reference | |
|---|---|---|---|---|---|
| Pediatric Bone Marrow Transplant 2-year survival | 134 | 0.33 | 8 | 0.40 | 27 |
| 16 | 0.60 | ||||
| Wisconsin Breast Cancer Malign-vs-benign | 569 | 0.37 | 8 | 1.30 | 28 |
| 16 | 3.50 | ||||
| Heart Failure Mortality | 300 | 0.5 | 8 | 0.42 | 29 |
Given a two-class dataset, the imbalance ratio () is , where is the number of minority class and is the total number of samples. Furthermore, measures the similarities of quantum kernel and linear classical kernel functions of the same dataset.
Encoding strategies
This study relies on the data encoding strategy which uses sequences of Pauli-Y gate rotations () and gates (see Appendix A of the supplementary material) to result in a number of encoding qubits18,19,21. puts each qubit in a superposition state and s entangle qubits. The data encoding feature map with the application of and is given by32
| 1 |
where . In Eq. (1), is the encoding map from the Euclidean space to the Hilbert space and is the model circuit for data encoding, which maps to another ket vector of input data . To find a relationship between the input data and , see Appendix A of the supplementary material.
In contrast, previously proposed quantum ML-specific encoding utilizes a block of the Hadamard gates followed by a block of Pauli-Z gate rotations () are applied to each qubit7. To entangle the qubits, nearest neighbor s are also applied. The features of data samples are considered as angles of rotations and the required number of qubits for data encoding are equal to the number of features. The data encoding feature map with the application of the Hadamard, and is given by7
| 2 |
where . is the model circuit for N features data encoding.
In order to compare the predictive performance of the above two data encoding strategies, the qDC, the sqKSVM and the qKSVM (see Appendix C of the supplementary material) approaches were compared utilizing a number of features. This analysis was executed using the Pennylane simulator environment33, while the sqKSVM was also evaluated on the IBMQ Melbourne machine (see “Methods”). Table 2 demonstrates the cross-validation area under the receiver operator characteristics curve (AUC) performance values of the quantum ML algorithms in relation to the and encoding qubit strategies.
Table 2.
Comparison of the cross-validation AUC performance for different data encodings.
| Dataset | qDC | qKSVM | sqKSVM | sqKSVM* | qubits |
|---|---|---|---|---|---|
| Pediatric Bone Marrow Transplant 2YS | 0.62 | 0.63 | 0.62 | 0.61 | |
| 0.61 | 0.63 | 0.61 | 0.59 | ||
| Wisconsin Breast Cancer Malign-vs-benign | 0.92 | 0.92 | 0.88 | 0.87 | |
| 0.90 | 0.91 | 0.87 | 0.85 | ||
| Heart failure Mortality | 0.62 | 0.51 | 0.51 | 0.50 | |
| 0.60 | 0.51 | 0.51 | 0.50 |
The qDC, qKSVM, and sqKSVM run on Pennylane simulator for . For the encoding, features are encoded into qubits with sequences of Pauli-Y gate rotations () and s. In another strategy, features are encoded into qubits with sequences of the Hadamard gates, Pauli-Z gate () rotations followed by nearest neighbor s.
*The sqKSVM was also executed on the IBMQ Melbourne machine for reference comparison.
Quantum and classic machine learning predictive performance evaluation
The quantum distance classifier (qDC) first calculates the distance between the state vector of a test sample and each state vector of the training sample in set and set and, then, assigns a label of the test sample to the label of the closest set. In the qDC, we divide the training set, with number of samples, based on their labels into two subset and , where contains only label with the number of samples and contains only label with the number of samples with . The task is to determine the label of the given test sample , if or . Mathematically, if is the state vector of the test sample as well as and , then the label of is determined by , if , otherwise . The distance between the vectors is given by8 i.e.
| 3 |
where is the norm of a vector. Therefore, the task is to calculate the inner product with a quantum computer.
The two different approaches to estimate with quantum computers are Hadamard Test22 and the Swap Test23. For the simplified quantum kernel SVM (sqKSVM), we first need to note that the standard form of the quantum kernelized binary classifiers is
| 4 |
where is the unknown label, is the label of the th training sample, is the th component of the support vector , is the number of training data, and is the kernel matrix of all the training-test pairs.
For a given dataset , one option to bypass the drawbacks of the qKSVM algorithm (see Appendix C of the supplementary material) as presented in6,7 is to set uniform weight , in case of (balanced dataset). Otherwise, for the majority class and for the minority class. Thresholding the value yields the binary output as following
| 5 |
In Eq. (5), is defined as (see Appendix F of the supplementary material)
| 6 |
The dataset configurations were utilized to estimate the performance of quantum and classic machine learning algorithms incorporated in this study. Performance estimation was done by confusion matrix analytics34. Prediction models were built based on the given training subset, followed by evaluating the respective validation subsets of each fold. Average area under the receiver operator characteristics curve (AUC) was calculated across validation cases for each predictive model. To build predictive models, quantum ML approaches included the qDC, the sqKSVM and the qKSVM (see Appendix C of supplementary material) were utilized. Classic machine learning approaches were k-nearest neighbors (ckNN)25 and support vector machines (cSVM)26. See Table 3 for the comparison of cross-validation AUC performances of quantum and classic computing algorithm within the dataset configurations.
Table 3.
Comparison of the cross-validation AUC performance with QML and ML algorithms.
| Dataset | #Features | sqKSVM | qKSVM | qDC | cSVM | ckNN |
|---|---|---|---|---|---|---|
| Pediatric Bone Marrow Transplant 2YS | 8 | 0.61 | 0.63 | 0.60 | 0.64 | 0.61 |
| 16 | 0.66 | 0.69 | 0.64 | 0.71 | 0.64 | |
| Wisconsin Breast Cancer Malign-vs-benign | 8 | 0.87 | 0.92 | 0.91 | 0.89 | 0.90 |
| 16 | 0.88 | 0.93 | 0.90 | 0.89 | 0.93 | |
| Heart Failure Mortality* | 8 | 0.50 | 0.51 | 0.60 | 0.53 | 0.58 |
For all QML algorithms, features are encoded into qubits with sequences of Pauli-Y gate rotations () and s. All QML algorithms were executed on the IBMQ Melbourne machine.
*Heart failure has no 16-feature variant, since the maximum number of features are 13.
Estimation of the probability of errors rate
Our experimental demonstrations are performed on the 15-qubit IBMQ Melbourne processor based on superconducting transmon qubits. The experiment has been conducted on the Wisconsin Breast Cancer dataset with 8 and 16 features, given, that this dataset provided the highest predictive cross-validation performance. On the NISQ device and simulator, each circuit is run with a fixed number of measurement shots (= 8192). We plot scatter diagrams for the inner product values from the simulator and the inner product from the NISQ device in Fig. 1. To show the correlation between the experimental and the simulator values of the inner products, we also fit optimal lines using least square regression in Fig. 1. To measure the difference between the inner products from the simulator and the inner product from the NISQ device, the root mean square error (RMSE) was calculated. The value of RMSE was 0.039 (3.9%) and 0.075 (7.5%) for 8 and 16 feature counts, respectively (Fig. 1). Therefore, the fidelities of the quantum circuits on the quantum cloud device were estimated 96% and 92.5% for the 8 and 16 feature counts, respectively. For more details of the experiment see Appendix G of the Supplementary material.
Figure 1.

Scatter diagrams of simulator inner products vs. experiment inner products for both the train state vectors and test state vectors. This data corresponds to the Wisconsin Breast Cancer dataset with 8 (left) and 16 (right) features. The red lines represent optimal fit lines based on least-squared regression.
The depolarizing noise model represents a linear relationship between the ideal (simulator) and the noisy (experiment) values of the inner products based on Eq. (14) in “Methods”. Nevertheless, the slope of the fit lines in Fig. 1 show that the depolarizing noise model cannot estimate the true value of probability of error rate (). This is due to gate errors35 that are originated from miscalibration of quantum Hardware, not being covered by the depolarizing noise model.
Discussion
In this study, we aimed to investigate the effect of two encoding strategies in various quantum machine learning-built clinical prediction models. Next to prior quantum machine learning approaches, we also proposed two methods specifically designed for the encoding approach.
Our results demonstrate that the encoding in combination with low-complexity quantum machine learning approaches provides comparable or better results than the encoding approach with previously-proposed quantum machine learning methods. This advantage was demonstrated not only in a simulator environment, but also utilizing NISQ devices. The low algorithmic quantum complexity also aims towards building prediction models that may be easier to interpret in the future, especially in light of the high complexity of classic machine learning approaches36. In contrast, it is important to emphasize, that the proposed quantum machine learning processes are also applicable in big data, given, that calculating the inner product of quantum states in NISQ devices can be done efficiently with the encoding approach21,22. The data encoding is also more robust against noise compared to the data encoding, since it uses less number of noisy qubits of the NISQ device to estimate the inner product of quantum states10.
After encoding data from classical Euclidean space into quantum Hilbert space, the distance between data points may increase or decrease, which has implications in case of kernel methods20. The score can represent, whether distances between data points would increase or decrease after data encoding. For further explanations see Supplemental Appendix E.
When feature count increases, increases as well, because quantum state vectors of input features become closer due to the high dimensionality property of the Hilbert space. Higher feature count significantly influences performance in a positive way if is < 1 (e.g. + 5–6% AUC in the Pediatric bone marrow dataset). It has been shown that classical ML models are competitive or outperform quantum ML approaches when is small20. Nevertheless, we demonstrated that when , higher feature count does not contribute much to the performance increase (e.g. 1% difference in the Wisconsin breast cancer dataset). It is important to point out that a high (> 1) alone does not mean that the dataset is not ideal for kernel-based quantum machine learning. Specifically, the highest AUC of 0.93 was achieved in the 16 feature counts Wisconsin breast cancer dataset, while it also demonstrated the highest , which also confirms prior findings20. In contrast, the same dataset in the classic SVM resulted in 0.89 AUC. We hypothesize that this phenomenon is due to the high sample count of the Wisconsin breast cancer dataset (M = 569). In general, the imbalance ratio of the datasets did not appear to be correlated with predictive performance. The increased AUC with up to 2% compared to the encoding when comparing the execution of the quantum machine learning approaches using simulation environment. This behavior was also identifiable with executions in NISQ devices, in case of kernel methods and the qDC. We hypothesize that lower AUC performance for the encoding method in the simulator environment and NISQ device is due to higher number of qubits which likely lead to lower value of inner products. This is in line with the findings in20.
In general, the qKSVM demonstrated 2–5% higher AUC compared to the sqKSVM. The relative performance increase of the qKSVM was in relation to sample count and feature count. Specifically, the qKSVM showed an average 2% higher AUC with small sample count (Heart failure and Pediatric bone datasets), while it had 5% higher AUC in the Wisconsin breast cancer dataset. Nevertheless, both the qKSVM and the sqKSVM increased its AUC with double feature counts in the small Pediatric bone marrow dataset. This level of performance increase was not identifiable in the larger Wisconsin breast cancer dataset. Classic SVM demonstrated similar properties in relation to higher feature counts in small datasets20, while it was outperformed by the qKSVM in the large Wisconsin breast cancer dataset.
In conclusion, quantum SVM approaches benefit from higher feature count in general, where the qKSVM—due to relying on optimization—has a particular benefit compared to the sqKSVM. In contrast, the sqKSVM algorithm reduces the time complexity of the qKSVM algorithm significantly, which may be advantageous in case of large datasets on NISQ devices. In the large Wisconsin breast cancer dataset, the qDC demonstrated higher performance compared to the sqKSVM, especially in small feature counts (0.91 AUC vs 0.87 AUC in the qDC and the sqKSVM respectively in 8 features). The qDC resulted in the highest AUC of 0.60 across all other quantum (0.50–0.51 AUC) and classic machine learning (0.53–0.58 AUC) approaches in the Heart failure dataset. We hypothesize that this is due to the distribution characteristics of the samples belonging to the two subclasses in the feature space, which challenges classification with kernel methods. Generally, the performance of the executed quantum and classic machine learning approaches are comparable within the collected cohorts (Table 3).
According to our findings, quantum distance approaches can provide high performance with small feature and sample counts, which is particularly ideal for NISQ devices. In contrast, quantum kernel methods appear to provide high performance with high feature and sample counts. We demonstrated that the encoding strategy allows to execute quantum ML algorithms for highly dimensional clinical datasets on low qubit count NISQ devices. In general, quantum machine learning benefits from utilizing the encoding strategy, as it increases predictive performance and reduces execution time in NISQ devices, while keeping model complexity lower. Our experiments also pointed out an important implication of how noise shall be estimated. As such, the depolarizing noise model cannot cover gate errors.
We consider our findings of high importance in relation to building future quantum ML prediction models in NISQ devices for clinically-relevant cohorts and beyond.
Methods
All experiments of this study were performed in accordance with the respective guidelines and regulations of the open-access data sources this study relied on. For details, see section “Access”.
Estimation of the inner product and
Figure 2 shows the quantum circuit for estimation of the real part of with the Hadamard Test.
Figure 2.

Quantum circuit computes the real part of the inner product . The Hadamard gate puts the ancilla qubit () into uniform superposition. A single-controlled unitary gate entangles the exited state of the ancilla qubit with the training data state vector (). The gate flips the ancilla qubit. Another single unitary controlled gate entangles the state vector of the test data () with the excited state of the ancilla qubit. A second gate flips the ancilla qubit. The Hadamard gate on the ancilla qubit interferences train and test data state vectors. The ancilla qubit is measured using a Pauli- gate. The real value of is estimated from Eq. (9). The measurement gate is done by a Pauli- gate and .
To estimate the real part of on the quantum computer with the Hadamard Test, the training and test data needs to be prepared in a quantum state as
| 7 |
where and are the quantum states for the train and test datasets, respectively.
Then the Hadamard gate on the ancilla qubit interferences the training vector with the test vector
| 8 |
Finally, the measuring quantum state given in Eq. (8) in the computational basis gives probability as
| 9 |
where is the value of the probability of measurement on the state of Eq. (8) and . Since our datasets are real values . See Appendix H of the Supplementary material for details of the estimation of the inner product on the IBMQ Melbourne machine with the Hadamard Test.
The inner product can also be estimated on a quantum computer with the Swap Test (see Fig. 3). The Hadamard gate is applied on the ancilla qubit to create a superposition of , i.e.
| 10 |
Figure 3.

Quantum Circuit to compute . The model circuits encode train and test data into quantum states and . The Hadamard gate on the ancilla qubit () generates a superposition of the quantum state including the train and test datasets. The application of the single-controlled swap gates with the ancilla qubit as the control results in an entangled state of Eq. (10). Another Hadamard gate on the ancilla qubit interferences and . The ancilla qubit on the state is measured in the Z basis. Therefore, the value of can be obtained from Eq. (12).
The application of the single-controlled swap gates on the state given in Eq. (10) entangles the ancilla qubit with . The resulted entangled quantum state is . Then, another Hadamard gate interferences the product state of the state vectors of the training and the test i.e.
| 11 |
Measuring the quantum state given in Eq. (11) in the computational basis yields with the probability
| 12 |
where is the value of the probability of measurement on the state of Eq. (11). See Appendix D of the Supplementary material for details of the estimation of the inner product on the IBMQ Melbourne machine with the Hadamard Test.
Simplified quantum kernel support vector machine
The quantum Support Vector Machine algorithm is proposed in37 for big data classification. They show exponential speedup for their algorithm via quantum mechanically access to data. Nevertheless, this approach is not ideal for NISQ devices9. To date, two separate qKSVM approaches are proposed for data classification via classical access to data6,7. In these approaches, the quantum circuits must run twice on the quantum computer and a cost function needs to be optimized on the classical computer to compute the support vector7. We propose a simplified version qKSVM called sqKSVM as shown in Fig. 4.
Figure 4.
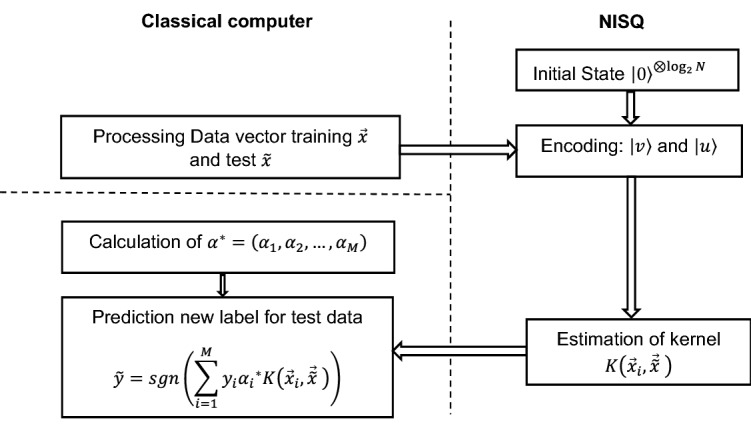
Schematic of the sqKSVM for data classification algorithm. First, the training data vector and test are prepared on a classical computer. Next, the original training data and test data are encoded into quantum states followed by computing the kernel matrix of all pairs of the training-test data with a NISQ computer. If are considered to be a solution of the support vector, the binary classifier can be constructed based on Eq. (5).
Software and hardware
For classical machine learning algorithms, we use classical machine learning (CML) libraries of scikit-learn38. Pennylane-Qiskit33 is used for quantum circuit simulation and quantum experiment for designing quantum computing programs. Pennylane-Qiskit 0.13.0 plugin integrates the Qiskit quantum computing framework to the Pennylane simulator.
For executing quantum algorithms on existing quantum computers, this study relied on IBM’s remote quantum machines (https://quantum-computing.ibm.com/) that can run quantum programs with noisy qubits. Since IBM quantum computers only support single-qubit gate and two-qubit gate operations, complex gate operations must be decomposed into elementary supported gates before mapping the quantum circuit on noisy hardware. Owing to the specific architecture of IBM quantum computers, all two-qubit gate operations must satisfy the constraints imposed by the coupling map39, i.e., if is the control qubit and is the target qubit, can only be applied if there is coupling between and . In case of running the QML algorithms on the quantum computer, we choose the 15-qubits IBMQ Melbourne machine with the supported gates , , and , where is identity single-qubit gate, is single-qubit arbitrary rotation gates with as two-qubit gate. Figure 5 shows the coupling map of the IBMQ Melbourne with its gate error rates.
Figure 5.

Topology and coupling map of the IBMQ Melbourne (https://quantum-computing.ibm.com/services). Single-qubit error rate is the error induced by applying the single-qubit gates. error is the error of the only two-qubit gates. Each circle represents a physical superconducting qubit and each shows coupling between neighbor qubits.
Depolarizing noise model
A simple model to describe incoherent noise is the depolarizing noise model. For a qubit pure quantum state , the depolarizing noise operator (channel) leads to a loss of information with probability and with probability the system is left untouched40. The state of the system after this noise is
| 13 |
where denotes the noise channel, is a density matrix, is the probability of error rate that depends on NISQ devices, the gate operations, and the depth of the quantum circuit, and is the () identity matrix.
The expectation value of observable for a state represented by a density matrix is given by
| 14 |
where is the noisy expectation value and is the noiseless expectation value41.
Supplementary Information
Author contributions
All co-authors of this paper were involved in the conceptualization of the study, in writing, in the critical review as well as final approval to submit this paper. Specific author contributions are as follows: S.M.: Quantum machine learning design, implementation and execution. C.B.: Development environment support, algorithm design. C.S.: Classic machine learning comparative analysis. D.K.: Data preparation, cross-validation scheme, performance evaluation. S.H., R.W.: Simulator environment establishment, support in algorithm optimization and execution. W.D., L.P.: Study design, supervision.
Funding
This work was funded by Medizinische Universität Wien, FocusXL-2019 grant “Foundations of a Quantum Computing Lab at the CMPBME”.
Data availability
The source code of the implemented quantum algorithms can be accessed by the link: https://github.com/sassan72/Quantum-Machine-learning. For classical machine learning executions, this study relied on the scikit-learn library38: https://scikit-learn.org/stable/. All included open-access datasets are accessible through the following links: Pediatric bone marrow transplant dataset27: https://archive.ics.uci.edu/ml/datasets/Bone+marrow+transplant%3A+children. Wisconsin breast cancer dataset28: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic). Heart failure dataset29: https://www.kaggle.com/andrewmvd/heart-failure-clinical-data.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-022-05971-9.
References
- 1.Suzuki Y, et al. Amplitude estimation without phase estimation. Quant. Inf. Process. 2020;19:75. doi: 10.1007/s11128-019-2565-2. [DOI] [Google Scholar]
- 2.Tanaka T, et al. Amplitude estimation via maximum likelihood on noisy quantum computer. Quant. Inf. Process. 2021;20:293. doi: 10.1007/s11128-021-03215-9. [DOI] [Google Scholar]
- 3.Grinko D, Gacon J, Zoufal C, Woerner S. Iterative quantum amplitude estimation. NPJ Quant. Inf. 2021;7:52. doi: 10.1038/s41534-021-00379-1. [DOI] [Google Scholar]
- 4.Aaronson S, Rall P. Quantum approximate counting. Simplified. 2019 doi: 10.1137/1.9781611976014.5. [DOI] [Google Scholar]
- 5.Bouland, A., van Dam, W., Joorati, H., Kerenidis, I. & Prakash, A. Prospects and challenges of quantum finance. (2020).
- 6.Schuld M, Killoran N. Quantum machine learning in feature Hilbert spaces. Phys. Rev. Lett. 2019;122:040504. doi: 10.1103/PhysRevLett.122.040504. [DOI] [PubMed] [Google Scholar]
- 7.Havlíček V, et al. Supervised learning with quantum-enhanced feature spaces. Nature. 2019;567:209–212. doi: 10.1038/s41586-019-0980-2. [DOI] [PubMed] [Google Scholar]
- 8.Wiebe, N., Kapoor, A. & Svore, K. Quantum algorithms for nearest-neighbor methods for supervised and unsupervised learning. (2014).
- 9.Preskill J. Quantum computing in the NISQ era and beyond. Quantum. 2018;2:79. doi: 10.22331/q-2018-08-06-79. [DOI] [Google Scholar]
- 10.Johri S, et al. Nearest centroid classification on a trapped ion quantum computer. NPJ Quant. Inf. 2021;7:122. doi: 10.1038/s41534-021-00456-5. [DOI] [Google Scholar]
- 11.Saggio V, et al. Experimental quantum speed-up in reinforcement learning agents. Nature. 2021;591:229–233. doi: 10.1038/s41586-021-03242-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Steinbrecher GR, Olson JP, Englund D, Carolan J. Quantum optical neural networks. NPJ Quant. Inf. 2019;5:60. doi: 10.1038/s41534-019-0174-7. [DOI] [Google Scholar]
- 13.Peters, E. et al. Machine learning of high dimensional data on a noisy quantum processor. (2021).
- 14.Liu Y, Arunachalam S, Temme K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 2021;17:1013–1017. doi: 10.1038/s41567-021-01287-z. [DOI] [Google Scholar]
- 15.Hubregtsen, T. et al. Training Quantum Embedding Kernels on Near-Term Quantum Computers. (2021).
- 16.Papp L, Spielvogel CP, Rausch I, Hacker M, Beyer T. Personalizing medicine through hybrid imaging and medical big data analysis. Front. Phys. 2018;6:2. doi: 10.3389/fphy.2018.00051. [DOI] [Google Scholar]
- 17.Giovannetti V, Lloyd S, Maccone L. Architectures for a quantum random access memory. Phys. Rev. A. 2008;78:052310. doi: 10.1103/PhysRevA.78.052310. [DOI] [PubMed] [Google Scholar]
- 18.Schuld M, Petruccione F. Supervised Learning with Quantum Computers. Springer International Publishing; 2018. [Google Scholar]
- 19.Möttönen M, Vartiainen JJ, Bergholm V, Salomaa MM. Quantum circuits for general multiqubit gates. Phys. Rev. Lett. 2004;93:130502. doi: 10.1103/PhysRevLett.93.130502. [DOI] [PubMed] [Google Scholar]
- 20.Huang H-Y, et al. Power of data in quantum machine learning. Nat. Commun. 2021;12:2631. doi: 10.1038/s41467-021-22539-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Schuld M, Bocharov A, Svore KM, Wiebe N. Circuit-centric quantum classifiers. Phys. Rev. A. 2020;101:032308. doi: 10.1103/PhysRevA.101.032308. [DOI] [Google Scholar]
- 22.Schuld M, Fingerhuth M, Petruccione F. Implementing a distance-based classifier with a quantum interference circuit. EPL Europhys. Lett. 2017;119:60002. doi: 10.1209/0295-5075/119/60002. [DOI] [Google Scholar]
- 23.Blank C, Park DK, Rhee J-KK, Petruccione F. Quantum classifier with tailored quantum kernel. NPJ Quant. Inf. 2020;6:41. doi: 10.1038/s41534-020-0272-6. [DOI] [Google Scholar]
- 24.Park DK, Petruccione F, Rhee J-KK. Circuit-based quantum random access memory for classical data. Sci. Rep. 2019;9:3949. doi: 10.1038/s41598-019-40439-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Zhang Z. Introduction to machine learning: k-nearest neighbors. Ann. Transl. Med. 2016;4:218–218. doi: 10.21037/atm.2016.03.37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Chang C-C, Lin C-J. LIBSVM. ACM Trans. Intell. Syst. Technol. 2011;2:1–27. doi: 10.1145/1961189.1961199. [DOI] [Google Scholar]
- 27.Sikora M, Wróbel Ł, Gudyś A. GuideR: A guided separate-and-conquer rule learning in classification, regression, and survival settings. Knowl.-Based Syst. 2019;173:1–14. doi: 10.1016/j.knosys.2019.02.019. [DOI] [Google Scholar]
- 28.Dua, D. & Graff, C. {UCI} Machine Learning Repository. University of California, Irvine, School of Information and Computer Scienceshttp://archive.ics.uci.edu/ml (2017).
- 29.Chicco D, Jurman G. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Med. Inform. Decis. Mak. 2020;20:16. doi: 10.1186/s12911-020-1023-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Krajnc D, et al. Breast tumor characterization using [18F]FDG-PET/CT imaging combined with data preprocessing and radiomics. Cancers. 2021;13:1249. doi: 10.3390/cancers13061249. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Papp L, et al. Supervised machine learning enables non-invasive lesion characterization in primary prostate cancer with [68Ga]Ga-PSMA-11 PET/MRI. Eur. J. Nucl. Med. Mol. Imaging. 2020 doi: 10.1007/s00259-020-05140-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Schuld, M. Supervised quantum machine learning models are kernel methods. (2021).
- 33.Bergholm, V. et al. PennyLane: Automatic differentiation of hybrid quantum-classical computations. (2018).
- 34.Luque A, Carrasco A, Martín A, de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019;91:216–231. doi: 10.1016/j.patcog.2019.02.023. [DOI] [Google Scholar]
- 35.Leymann F, Barzen J. The bitter truth about gate-based quantum algorithms in the NISQ era. Quantum Sci. Technol. 2020;5:044007. doi: 10.1088/2058-9565/abae7d. [DOI] [Google Scholar]
- 36.Carvalho DV, Pereira EM, Cardoso JS. Machine learning interpretability: A survey on methods and metrics. Electronics. 2019;8:832. doi: 10.3390/electronics8080832. [DOI] [Google Scholar]
- 37.Rebentrost P, Mohseni M, Lloyd S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014;113:130503. doi: 10.1103/PhysRevLett.113.130503. [DOI] [PubMed] [Google Scholar]
- 38.Pedregosa, F. et al. Scikit-learn: Machine Learning in Python. (2012).
- 39.Wille, R., Hillmich, S. & Burgholzer, L. Efficient and Correct Compilation of Quantum Circuits. in 2020 IEEE International Symposium on Circuits and Systems (ISCAS) 1–5 (IEEE, 2020). 10.1109/ISCAS45731.2020.9180791.
- 40.Nielsen MA, Chuang IL. Quantum Computation and Quantum Information. Cambridge University Press; 2010. [Google Scholar]
- 41.Urbanek, M. et al. Mitigating depolarizing noise on quantum computers with noise-estimation circuits. (2021). [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The source code of the implemented quantum algorithms can be accessed by the link: https://github.com/sassan72/Quantum-Machine-learning. For classical machine learning executions, this study relied on the scikit-learn library38: https://scikit-learn.org/stable/. All included open-access datasets are accessible through the following links: Pediatric bone marrow transplant dataset27: https://archive.ics.uci.edu/ml/datasets/Bone+marrow+transplant%3A+children. Wisconsin breast cancer dataset28: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic). Heart failure dataset29: https://www.kaggle.com/andrewmvd/heart-failure-clinical-data.