

Introduction
Heart failure (HF) is a common condition with a profound impact on patients and the health care system. Heart failure with preserved ejection fraction (HFpEF) comprises nearly half of all cases of HF, affects over 3 million US adults, and is underdiagnosed.1 Multiple risk factors and conditions, such diabetes, hypertension, obesity, metabolic syndrome, and aging, contribute to inflammation and endothelial dysfunction and ultimately leads to the multiorgan, systemic syndrome of HFpEF in many patients.2 Others can develop the syndrome of HFpEF for other reasons, including due to genetic variants (e.g., hypertrophic cardiomyopathy), infiltration of the myocardium (such as cardiac amyloidosis), or other toxic-metabolic myocardial insults. Regarding of its etiology, HFpEF remains a highly morbid condition that negatively impacts quality of life, is marked by frequent hospitalizations and high mortality rate, and has few therapeutic options despite numerous clinical trials testing various medications and devices. Machine learning (ML) has the potential to improve diagnosis and treatment of patients with HFpEF, although its impact thus far has been limited.
ML, a domain that arose from the fields of statistics and computer science, focuses on teaching computers to learn from data, interpret it, and make predictions. It enables internet search, speech recognition, image identification, and human-computer interactions by learning from large datasets.3–5 ML is not a new field but has been gaining considerable attention within the health care and cardiovascular research communities over the past several years. The reasons for this trend are likely multifactorial, in part due to improved processing power and the availability of large datasets with a large number of variables (features).6,7 Indeed, the inability to interpret the increasingly high density of data coming from diverse sources in the clinical setting is one of the key reasons why ML may be uniquely poised to help clinicians and researchers avoid a loss of potentially valuable information that could improve clinical decision-making and patient care.
HFpEF is a prototypical cardiovascular condition that may benefit from ML because of its inherent heterogeneity, the need for improved classification, and the challenges in HFpEF diagnosis and treatment.8 Here we first briefly highlight several unmet needs within the HFpEF field that may benefit from ML approaches. Next, we provide an overview of key types of ML and concepts within the field. We describe several challenges and pitfalls of ML and provide a roadmap for the evaluation of ML studies. Finally, we discuss future directions of ML in HFpEF and the broader field of precision cardiovascular medicine.
The unmet need for better approaches to heart failure diagnosis and management
HFpEF is a heterogenous condition with multiple pathways that lead to its development. Identifying less common etiologies of HFpEF, such as cardiac amyloidosis, hypertrophic cardiomyopathy, and cardiac sarcoidosis, can be challenging. Earlier diagnosis of cardiomyopathies with specific treatment options may lead to improved quality of life and survival. For example, cardiac amyloidosis is likely far more common than previously realized and may comprise up to 5–7% of HFpEF cases.9,10 Prior studies have revealed the presence of early clinical clues of cardiac amyloidosis, including symptoms, laboratory abnormalities, and changes on echocardiograms and electrocardiograms (ECG).11–13 Identifying early signs is essential given the emergence of novel therapies that can halt cardiac amyloidosis disease progression and improve prognosis.14,15
The majority of patients with HFpEF develop the condition in the setting of one of more risk factors and conditions—such as diabetes, hypertension, obesity, metabolic syndrome, sedentary lifestyle, chronic kidney disease, and ischemic heart disease. Numerous clinical trials in patients with HFpEF have failed to show a difference in their primary outcome.2,16 This may be in part due to the heterogeneity of patients with HFpEF and the need for better sub-classification. ML can be used to uncover patterns in diverse data and identify subgroups of patients with distinct pathophysiologic profiles and potential differential responses to therapy. ML approaches are designed to leverage the vast amounts of available data and account for higher-order interactions, multi-dimensionality, and non-linear effects, and may complement conventional statistical methods.17 ML algorithms can be applied to either data from HFpEF observational cohorts for identifying novel subgroups or predictors of adverse outcomes or data from HFpEF clinical trial participants for hypothesis-generating, post-hoc analyses to identify subgroups of patients with HF who benefited from the intervention. While there is some debate about whether responder analyses are possible in clinical trials, it is possible that lack of that targeting may explain why numerous clinical trials in HFpEF have failed to show a difference in their primary outcome.
Identifying appropriate patients and enrolling in HF clinical trials has become increasingly challenging, particularly in the United States (US). Despite the high prevalence of HF, in North America and Western Europe the typical clinical trial enrollment rate is a dismal 1–2 patients per year per site in HF trials.18 For example, in the Treatment of Preserved Cardiac Function Heart Failure with an Aldosterone Antagonist (TOPCAT) trial, which randomized HFpEF patients to spironolactone vs. placebo, the average US enrollment rate was only 1.4 patients per site per year even though HFpEF is a leading cause of hospitalization in the US. This problem could be addressed by better identification of eligible patients though applying ML to EHR data.
A substantial literature exists on risk prediction for hospitalization and mortality in patients with HFpEF. Although the majority of risk models for patients with HFpEF were developed in cohorts with all types of HF, there are a few models developed specifically for patients with HFpEF (such as the I-PRESERVE Score and ARIC Score).19 The majority of models have modest discrimination and calibration at best.19 ML has to potential to lead to the development of either higher performing models using more diverse data sources (i.e., EHR, imaging, ECG, sensors) or a more parsimonious set of variables that will facilitate deployment with EHR systems. For example, the Machine Learning Assessment of RisK and EaRly mortality in Heart Failure (MARKER-HF) risk model uses eight laboratory variables to predict 90-day and 1-year mortality and with similar performance to other risk models that require more data, much of which are not readily available in the EHR.20,21 Thus, ML has the potential to improve prediction for patients with HFpEF, though trials studying the implementation of these algorithms as part of routine care will be needed prior to wider adoption.
Overview of machine learning techniques
Artificial intelligence (AI) broadly refers to computer systems designed to perform tasks that usually require human intelligence (Figure 1). ML enables AI computer systems through learning from data without explicit programming. ML algorithms can be broadly categorized, depending on the nature of the data that are used in the training process. Supervised learning algorithms (Figure 2) are given labeled training data, so that each training instance consists of features (e.g. age, gender, blood pressure, left ventricular ejection fraction) and a label (e.g., HF diagnosis, mortality, HF hospitalization,) indicating the class to which the instance belongs.4 The algorithms then learn to predict the outcome or label based on the aforementioned features, with the goal of making accurate predictions in new patients. Unsupervised learning algorithms (Figure 2) are given unlabeled data and aim to discover intrinsic patterns in the data (e.g., sub-populations such as sub-phenotypes, or clusters). A hybrid of these two approaches is called semi-supervised learning, which uses a combination of labeled and unlabeled data.22 Semi-supervised algorithms can be particularly useful in building predictive models when limited amounts of labeled data are available. Lastly, reinforcement learning a form of ML that seeks to find an optimal set of sequential actions in a prespecified environment/domain to maximize a defined reward or goal.23 Reinforcement learning—which has been used to successfully teach computers how to play and win games (by sequentially playing the game and learning from mistakes)—can also be applied to the healthcare setting (e.g., if we want to ask how the sequence and timing of interventions affects outcomes).
Figure 1. Artificial Intelligence and Machine Learning.

Schema of the relationship between artificial intelligence, machine learning, and “deep” learning. SVM = Support vector machines, RF = random forests, KNN = k-nearest neighbor, PCA = principal components analysis, DNN = deep neural network, CNN = convolutional neural network, RNN = recurrent neural network, GAN = generative adversarial network, VAE = variational autoencoder.
From Wehbe RM, Khan SS, Shah SJ, Ahmad FS. Predicting High-Risk Patients and High-Risk Outcomes in Heart Failure. Heart Fail Clin. 2020 Oct;16(4):387–407.
Figure 2. Types of Machine Learning.

In supervised machine learning, the outcomes (labels) are provided so that the machine learning algorithm can be trained to identify features that can successfully predict these outcomes (or labels) in external datasets. In the example provided, deep phenotypic data from the active treatment arm of a HFpEF clinical trial could be analyzed using a statistical learning approach in order to identify features (“signature”) of treatment response. The resultant classifier could then be used to determine whether it could successfully predict treatment responders in a similar previously completed clinical trial (post-hoc analysis) or in a new prospective trial of “all comers.” Alternatively, patients could be screened by the classifier and only enrolled in a new, prospective, targeted treatment trial if they met criteria for being a “treatment responder.” Unsupervised machine learning can be applied to a heterogeneous clinical syndrome such as HFpEF in order to identify homogeneous sub-groups of patients by looking for intrinsic patterns within data from these patients. The identified sub-groups can then be examined to determine whether they have differential outcomes or responses to therapies. See Supplementary Table 1 for definitions of the examples of machine learning algorithms shown in the figure. HFpEF = heart failure with preserved ejection fraction; RCT = randomized controlled trial.
Types of machine learning approaches
Supervised machine learning
In supervised learning, algorithms are developed using labeled training data (Figure 2). This means that for each item in the training set, we know the features (variables) and the outcome to be estimated. For example, several studies have attempted to use supervised ML to predict re-hospitalization in HF patients. In these studies, the computer is told who was re-hospitalized and who was not, and the algorithm may estimate for each participant whether he or she will be re-hospitalized based on predefined features. There are several different supervised ML techniques, and each has its relative strengths and weakness Example of these approaches include linear and logistic regression, support vector machines,24 and random forests.25
Unsupervised machine learning
Unsupervised learning differs from supervised learning in that the algorithms are developed based on intrinsic patterns in the data (i.e., the data are unlabeled). Unsupervised ML can be used to identify subgroups (i.e., sub-phenotypes) within a heterogeneous clinical syndrome. For example, suppose we wanted to identify subgroups within the clinical syndrome of HFpEF with the goal of designing a trial to test the effect of a targeted therapy on reducing the risk of HF hospitalization. We can cast this as an unsupervised learning problem in which the training dataset does not come with pre-assigned labels (i.e., “outcomes”). Unsupervised learning algorithms evaluate intrinsic relationships and patterns in the data to identify subgroups and reduce dimensionality, and typically include clustering, principal components analysis (dimensionality reduction), association rules (pattern mining), or factorization algorithms (Figure 2). In healthcare, clustering is one of the most popular approaches.
Clustering creates groups of similar patients. Clustering algorithms have multiple variations, among which the most popular ones include k-means clustering, hierarchical clustering, and model-based clustering. The algorithms generally measure the distance between individual features to identify clusters, and there are several different methods for determining the optimal number of clusters.26,27 Additional details on different types of clustering are included in Supplemental Table 1. Importantly, clustering is a way of dividing the population into groups so that patients are different across groups and similar within each group.
Beyond clustering, there are many other unsupervised learning techniques. For example, if we have a population of patients with HFpEF, we may expect a sub-group of patients to vary along one dimension (e.g. general health status) that is reflected in many different aspects of their medical history (and thus many different features within the dataset). In this case dimensionality reduction methods like principal component analysis or factor analysis28 are often used.
Deep learning, natural language processing, and additional machine learning techniques
Deep learning
Deep learning, which is an extension of neural networks, is a popular approach that attempts to overcome a major disadvantage of conventional ML techniques: their inability to effectively interpret and process high-dimensional raw signal data, such as audio and images.5,29 As a result of this limitation, attempts to apply ML to echocardiographic data have mostly relied upon measured and annotated quantitative measurements by highly experienced echocardiographers.30 Instead, deep learning can often learn from raw data (such as the pixel values from an image or raw text from the EHR) using a hierarchy of increasingly complex and discriminative layers of processing. A key benefit of deep learning is its ability to learn features directly from data without the need for painstaking feature annotation by domain experts, a process known as feature engineering. Deep learning applications can have varying architectures, each with different strengths and limitations. These include these include convolutional neural networks, recurrent neural networks, autoencoders, and generative adversarial network.5
Deep learning is a technique that can be applied for very large datasets with either structured or unstructured data (e.g., imaging or ECG repositories). Deep learning can also be applied to a smaller dataset (e.g. medical images), if there exists a similar large dataset (e.g., an archive of conventional photographic images) on which the analytical model can be pre-trained in an approach called transfer learning.31
Natural language processing (NLP)
Natural language processing (NLP) applies computational algorithms to the problem of recovering structure from text and speech. These algorithms can be based on hand-coded rules, machine-learned models, or (commonly) a blend of both approaches. In the clinical domain, NLP can be used to extract clinically relevant information from a large number of clinical notes that are commonly found in the EHR.32,33 In fact, deep learning algorithms have been applied with great success to many NLP tasks.34 At the lowest level, NLP algorithms are used to segment text into words (or “tokens”), which can be further analyzed for part of speech (e.g., noun, verb, adjective), and other lexical features. Other NLP algorithms are then applied to recover higher-level linguistic structure, such as sentences, phrases, and sentential parses. These structures can subsequently be used as features for recognizing and extracting semantically meaningful chunks of information from text, such as entities that are mentioned and relations between these entities. In the clinical domain, such entities can be diseases, drugs, symptoms, and medications. They could also be events and their temporal properties, such as an adverse reaction occurring after treatment was performed or a drug prescribed.35,36
Transformers
Transformers are a relatively novel class of deep learning methods for analyzing sequence data based on self-attention that have been leveraged with remarkable success for complex NLP tasks.37 For example, researchers at Google (Mountain View, CA)38 developed Bidirectional Encoder Representations from Transformers (BERT), and multiple groups have extended this work by pre-training BERT models on corpuses of biomedical and clinical text and then testing those models on biomedical and health care tasks, including readmission prediction.39–42 OpenAI (San Francisco, CA), one of the leaders in developing generalized AI models, created the Generative Pre-trained Transformer 3 (GPT-3),43, which is a highly sophisticated language model that is able to generate text and conversations mimicking humans, though its adoption into healthcare settings will require additional research and thoughtful exploration of its potential and pitfalls.44
In the realm of clinical medicine, NLP can be an effective method to derive structured data from the EHR due to the large amount of unstructured, free text entries in hospital and clinic notes, discharge summaries, imaging reports, procedure reports, and the like. In HFpEF, NLP can serve a variety of purposes such as detecting HFpEF and cardiomyopathies to assist with earlier diagnosis or providing data for use in developing strategies to reduce hospital readmissions in patients with HFpEF.45–49 Leveraging NLP algorithms could have a significant impact on HFpEF clinical trials. For example, NLP-assisted identification of suitable clinical trial patients could save time and money as it often takes study coordinators large amounts of time to screen single patients for HF trials, which often have complex inclusion and exclusion criteria. Applied in this manner, NLP could reduce the time needed for HF clinical trial screening from the EHR from several days (when done by humans) to just a few minutes when done by a computer.
When designing ML systems, the choice of the method—which depends on several factors including the size of the dataset, the number and informativeness of the features, and the ultimate research question or goal—is central.
Feature Selection, Hyperparameters, Overfitting, and Regularization
Feature selection is one of the most critical aspects of ML and depends on the task. For image classification, having large, labeled, and balanced datasets is key to successful model development. For other tasks, such as subtyping HFpEF with clinical data, selecting features that are informative and orthogonal increasing the likelihood of identifying meaningful clusters.
Aside from feature selection, there are design choices that must be made by the ML scientist when training a ML model. These model parameters that are explicitly set to control the learning process are called “hyperparameters” (e.g., model algorithm/architecture and size, learning rate, number of clusters in unsupervised learning). Theoretically, these hyperparameters could be tuned such that a given model would fit the training data perfectly. However, such a model would be unlikely to generalize well to new, unseen datasets because it would have modelled noise inherent in the training dataset in addition to the true relationship between data inputs and outputs/labels. This is an example of overfitting and is a consequence of the concept of the bias-variance tradeoff.
A model that has overfit to training data but does not generalize well to external datasets would be said to have low bias and high variance – bias is an expression of the error of the model in approximating a complex function that governs real-life processes, while variance is an expression of the sensitivity of model performance to subtle changes from one dataset to the next. Conversely, a model that is underfit is said to have high bias and low variance, likely because it is too simplistic to approximate the true underlying relationship between data inputs and outputs. Such a model would perform poorly on the given task, but performance would be robust to subtle changes from one dataset to the next. The goal in training any model is to attempt to resolve this trade-off and minimize both bias and variance as much as possible.
There are several strategies to resolve this trade-off on a given dataset including acquiring additional training data, adjusting the complexity of the model, and methods such as model ensembling, transfer learning, and regularization. Regularization refers to a family of methods that impose some sort of penalty or constraint on the model to prevent overly confident predictions and overfitting on the training data. Examples include penalized regression, data augmentation, dropout, and early stopping of the training process. The idea of regularization is foundational for most ML techniques.50
Train-Test Paradigm
During the training process, it is crucial that the ML scientist monitor for overfitting. This is done via a validation dataset. Validation datasets can be a hold-out partition of the training set or alternatively when data size is limited can take the form of k-fold cross-validation, where the training set is iteratively partitioned into k number of subsets, with one subset being used as the validation dataset during each iteration. It is important to note that this is distinct from the concept of “validation datasets” used to validate a given model in the risk prediction literature. In contrast, validation datasets in ML are strictly used during model development as a litmus test to monitor for overfitting (evident when performance on the training set significantly exceeds performance on the validation set). For this reason, the “validation dataset” is also often referred to as a “development dataset” in the ML literature. A validation dataset does nothing to “validate” a model given information leak can occur during the training process while adjusting hyperparameters and one can begin to overfit to the validation dataset itself. While cross-validation can help mitigate this somewhat, there is no substitute for a separate hold-out test dataset. In order to accurately assess a given model’s performance, the model must be evaluated on a test set that the model was not exposed to during the training process – this can either be a distinct hold-out partition from the original dataset or, ideally, a completely separate, external dataset. The careful choice of a testing strategy is essential for any ML approach, and ideally should be developed during the planning stages of comprehensive ML projects.
Case studies in machine learning
Detection of rare causes of heart failure with preserved ejection fraction
The widespread adoption of EHRs and the availability of repositories of digitized cardiovascular diagnostic testing, such as echocardiograms, cardiac MRIs, and ECGs, have enabled the development of algorithms for a range of tasks, including automation of measurements (i.e. left ventricular ejection fraction, diastolic dysfunction), enhancing image quality, disease diagnosis, and risk prediction for disease development or prognosis.51–53 In HFpEF, underlying etiologies remain underdiagnosed, especially for rare causes, such as cardiac amyloidosis.
Several studies have examined the use different types of data to identify patients with specific etiologies of HFpEF. In 2018, Zhang et al. used convolutional neural networks to train a model to accurately identify different echocardiographic views and predict specific diseases related to HFpEF (hypertrophic cardiomyopathy, cardiac amyloidosis, and pulmonary arterial hypertension) with good discrimination (C-statistics=0.85–0.93).54 Tison et al. developed a deep learning model for ECG data to predict cardiac structure and function as well as specific diseases with good discrimination for hypertrophic cardiomyopathy, cardiac amyloidosis, and pulmonary arterial hypertension (C-statistics=0.86–0.94).55 Grant et al. developed an end-to-end pipeline to automatically quantify left ventricular hypertrophy and predict its etiology with an area under the curve of 0.83 for cardiac amyloidosis and 0.98 for hypertrophic cardiomyopathy.56 Using ECG and echocardiographic data to identify those with cardiac amyloidosis, Goto et al. demonstrated that the stepwise use of deep learning initially ECG data to identify those at high risk and then on echocardiographic data for those increased the positive predictive value from 33% to 74–77% in cohorts from two institutions.57 Huda et al. trained a ML model using ICD codes to identify patients with wild-type transthyretin cardiac amyloidosis and found good to excellent performance in four external validation cohorts, including a large, integrated health system.58
Taken together, these studies demonstrate the promise of using ML to identify rare, subtypes of HFpEF on different types of data. Future areas of research HFpEF etiology detection includes exploring the use of state-of-the-art NLP models, incorporating longitudinal changes in diverse data types, and fusing multiple data types into a single model. Lastly, although the above studies have shown promising, “in silico” results, implementation studies are needed to understand whether these technologies can be deployed to impact the care and outcomes with patients with HFpEF.
Phenomapping of heart failure with preserved ejection fraction
Shah et al.30 hypothesized that the application of ML techniques to dense phenotypic data (“phenomapping”) would yield a novel classification system for HFpEF, and that the identified “pheno-groups” would have unique pathophysiological profiles and differential outcomes. Phenotypic features utilized in the study included clinical variables, physical characteristics, laboratory data, ECG parameters, and echocardiographic variables. Figure 3 details the key steps of the study. The investigators identified 3 distinct classes (pheno-groups) of HFpEF patients with differing clinical characteristics and profiles and differential rates of cardiovascular hospitalization and death. The 3 clusters were replicated in an independent, prospective validation cohort. This approach highlights the importance of having an a priori hypothesis; using high quality, quantitative data; and validating in a separate cohort.
Figure 3. Example of an Unsupervised Machine Learning Workflow for the Identification of Novel Heart Failure with Preserved Ejection Fraction (HFpEF) Subtypes.

(A) The workflow for unsupervised machine learning begins with data processing, including examination of missing values, multiple imputation, transformation, scaling, and correlation testing, to understand the relationship between the features (variables) to be selected for the analysis. Shown here is an example of a heatmap displaying the correlation between laboratory, electrocardiographic, and echocardiographic features that were used in phenomapping of HFpEF (the color key corresponds to the range of correlation coefficients shown in the heatmap). The point of this type of analysis is to remove highly correlated features prior to the unsupervised learning analyses. (B) Next, various types of unsupervised machine learning analyses can be used to identify clusters within the data. In the displayed example, agglomerative hierarchical clustering was used to create an initial heatmap to demonstrate the heterogeneity of the HFpEF patients and the presence of potential clusters. (C) Concomitant with unsupervised learning analyses is the need to determine the optimal number of clusters. In the example shown here, model-based clustering was used on the HFpEF dataset, and the optimal number of clusters was determined using the Bayesian information criterion (BIC) analyses. The lowest BIC value corresponds to 3 clusters, which is the optimal number in this example. (D) Once the optimal number and composition of the clusters is identified, differences in clinical characteristics, including outcomes, can be compared among the clusters. In the example shown here, the 3 HFpEF clusters differed significantly in survival free of cardiovascular hospitalization or death, and represented 3 distinct clinical profiles of HFpEF. In the example shown here, pheno-group #1 was characterized by younger patients with relatively normal B-type natriuretic peptide and moderate diastolic dysfunction; pheno-group #2 included obese, diabetic patients with the worst left ventricular relaxation and high prevalence of obstructive sleep apnea; and pheno-group #3 was composed of older patients with significant right ventricular dysfunction, pulmonary hypertension, chronic kidney disease, and electrical and myocardial remodeling.
Adapted from Shah SJ, Katz DH, Selvaraj S, Burke MA, Yancy CW, Gheorghiade M, Bonow RO, Huang CC, Deo RC. Phenomapping for novel classification of heart failure with preserved ejection fraction. Circulation. 2015 Jan 20;131(3):269–79.
Several other studies of applied similar phenomapping techniques to patients with HFpEF and are reviewed in detail along with HFpEF therapeutic implications by Galli et al.59 The overlap in similar phenotypes across multiple cohorts of patients using different unsupervised learning approaches suggests that certain pheno-groups may represent a distinct pathophysiological profile and have a differential response to therapeutics. A recent study by Pandey et al. used deep-learning models with a limited number of echocardiographic measurements of systolic and diastolic function to characterize the severity of diastolic dysfunction and identify subgroups with differential risks of adverse events and potential response to spironolactone.60 For this study and other similar studies, the identification of pheno-groups should represent the starting point for future investigations, such as mechanistic studies of the underlying pathogenies of HFpEF or clinical trials testing targeted interventions. Moreover, future studies will ideally move beyond applying ML algorithms to selected groups of echocardiographic measurements to using ML to analyze the echocardiographic images themselves, along with other types of unstructured data, such as ECGs and clinical notes, in combination with other structured demographic and clinical data. Advantages of these approaches are (1) increased throughput, reproducibility, and scalability (due to the lack of needing human echocardiographic measurements), and (2) use of multi-modal datasets, which increase likelihood of orthogonal (and therefore more informative) input features into ML models.
Discussion
We have highlighted some of the unmet needs in HFpEF and ways in which ML may be used to address these challenges, include rare etiology detection, identification of subtypes with different outcomes and potentially differential response to therapeutics, and increased efficiency for clinical trial recruitment through using NLP. Although studies using ML are becoming increasingly common in the healthcare field, as with any newly applied methodology, a healthy amount of skepticism is warranted. It is unlikely that ML alone will be able to solve the problem of disentangling the heterogeneity of and enhancing therapeutic targeting in HFpEF. For example, one could argue that even more important than any analytical technique is the availability of orthogonal (i.e., uncorrelated) features that provide a more comprehensive viewpoint of the patients and outcomes under investigation. Furthermore, the “hype” of any new (or newly applied) analytical technique can often lead to errors in its application and interpretation, as detailed below. Finally, ML could fall prey to the lifecycle of several other novel diagnostic and analytical techniques in medicine.
Several groups have published or are in the process of developing guidelines for the design, reporting, and evaluation of ML studies in health care.61–67 Below, we offer complementary recommendations to help guide future work in applying ML to HFpEF investigations (Table 1).
Table 1.
Evaluative Framework for Machine Learning Studies
| Categories | Evaluation Criteria |
|---|---|
| Study question and design | ✓ Does machine learning offer specific advantages over other statistical modeling approaches? ✓ If yes, then why? Potential criteria include the data source, feature learning, outcomes, or combination of these. |
| Data | ✓ Are data being collected primarily for (1) research or (2) clinical/administrative purposes? ✓ Are the issues of biases and data quality (i.e. completeness, heterogeneity, density, accuracy, and representativeness) described and addressed? |
| Approach | ✓ Were the reasons for the selected approaches specified (i.e. supervised vs unsupervised vs semi-supervised vs reinforcement learning, model selection)? ✓ If complex models are used, are we sure simpler models would not do better? Was the model chosen a priori? ✓ Is the internal validation convincing? ✓ Was the testing dataset separated prior to model training and was there an external validation? ✓ Is the causality convincing or could features used for prediction have been produced by the outcome? ✓ Is performance properly quantified both for internal and external validation? ✓ Was the model performance compared to other models addressing the same clinical question? |
| Clinical relevance and generalizability | ✓ Do the results have clinical relevance or provide mechanistic insight into the pathophysiology of the clinical syndrome of interest? ✓ How well should we expect the study population to generalize to the target population? |
We should not apply ML algorithms to every large dataset or research question; rather, we must think critically about how ML would be better than a traditional approach for the specific research question at hand. Developing a priori hypotheses and analytical plans, informed by prior research and clinical insights (from clinical domain experts), may be helpful to reduce spurious findings. For many research questions, a conventional statistical approach or study design will be sufficient. ML cannot overcome threats to validity that occur with subgroup analyses in smaller data sets or traditional, post-hoc clinical trial analyses. Findings from these analyses, although potentially important, are hypothesis-generating and need to be viewed with the same level of caution as other observational studies.
Bigger data does not necessarily imply better data. First, if many of the variables included in the dataset are highly correlated with each other, the addition of all these variables to the analysis is unlikely to be helpful. Orthogonal data types (i.e., data that are not highly correlated with each other and yet meaningful to the disease or outcome of interest) are essential. Second, the size of the dataset cannot overcome poor data quality or bias introduced from the data or study design. For example, data from EHRs and other clinical systems are often of poor quality, incomplete, and biased.68,69 Although longitudinal and/or multiple imputation can be used,70,71 the missing data are likely not random. Any imputation of data or exclusion of participants with incomplete data will likely introduce bias into the results. Lastly, ML has the potential to detect and/or perpetuate structural racism, and there is a growing body of research on ways to ensure that ML, especially when applied in health care settings, increases equity.
Concurrent with the continued growth in the amount of data, the systems to collect, store, and organize data—and ML methods themselves—are rapidly evolving. For example, as discussed earlier, deep learning has dramatically evolved since the mid-2000s, leading to significant improvements in speech and visual object recognition.5,29 Incorporating the latest advances in data management and ML into existing and future studies will be critical to finding meaningful application of ML to HFpEF. Large-scale HF clinical trials should be designed with ML in mind such that dense phenotypic, -omic, and physical activity (e.g., accelerometer) data are collected and training and validation subsets should be outlined in advance.
For both unsupervised and supervised ML approaches, validation in an external test dataset, similar to traditional risk prediction models,72,73 is critically important to establish the accuracy of the model. Given the fact that the ideal datasets for ML will be unique due to the requirement for large amounts of variables from multiple domains, validation for unsupervised learning analyses will not always be immediately possible due to the lack of an appropriate test dataset. However, any ML study without a test cohort should be viewed as hypothesis-generating only, with a requirement for future validation prior to further research of identified sub-groups or integration into clinical practice.
In the case of supervised learning, validation is a requirement given the need to test the accuracy of the algorithm.74 For supervised models, measures of discrimination and calibration should therefore be reported. Also, whenever using a complex ML algorithm, the results should be compared to those of a simpler algorithm.
In general, care must be taken in the evaluation of the quality and promise of ML algorithms. For models intended to inform clinical practice, the development of a new classification system or prediction model is not sufficient to change practice. These models must be deployed clinically, with formal testing of their performance and clinical impact; not surprisingly, the implementation of risk tools into clinical practice may not change clinical practice,75 and additional studies for the use of ML models in clinical practice are needed, including hybrid-effectiveness studies.76 “Dataset shift” is a mismatch between the data on which the model is deployed and on which it was trained and can occur for numerous reasons, including changes in technology, the patient population, clinician behavior, or clinical workflows.77 This mismatch can lead to change in model performance and highlights the need for a health system governance infrastructure to monitor and address model performance and impact over time.77,78
Future advancements in HFpEF precision medicine may require a combination of the ML techniques. Difference ML approaches, such as NLP, deep learning, unsupervised ML, and supervised ML, could be used for specific tasks as part of a larger framework in order to efficiently identify novel approaches to the classification and treatment of HFpEF in clinical trials (Figure 4).
Figure 4. Conceptual Framework for the Integration of Machine Learning Approaches for Novel Classification and Treatment of Heterogeneous Clinical Syndromes such as Heart Failure.
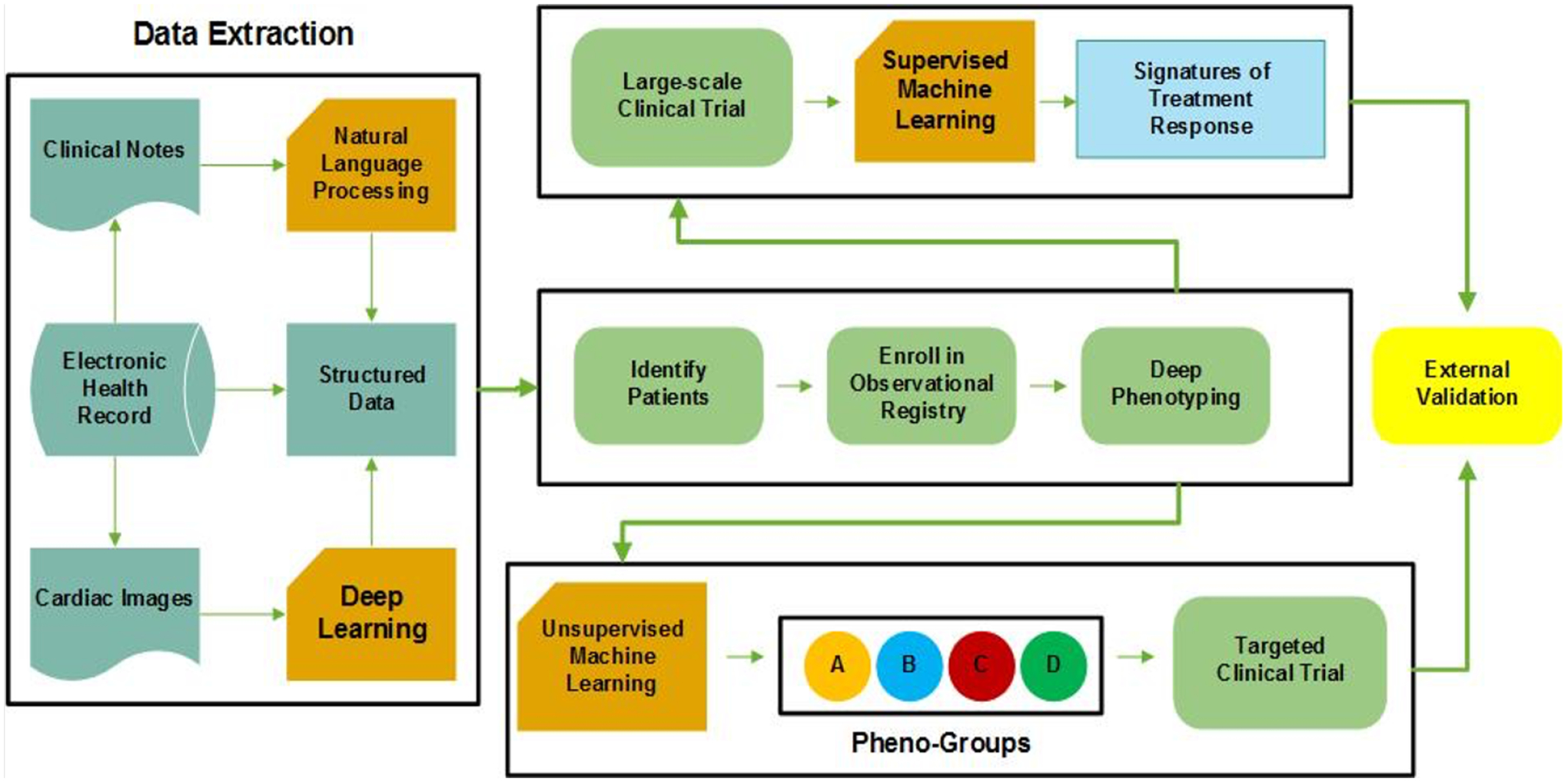
In this precision medicine conceptual framework, four areas of machine learning discussed here (unsupervised learning, supervised learning, deep learning, and natural language processing) are used in combination to classify and provide targeted treatment for a heterogeneous clinical syndrome such as heart failure. NLP = natural language processing.
Conclusions
HFpEF is a morbid and costly clinical syndrome with significant heterogeneity. ML is an exciting tool that may help address some of the major challenges in HFpEF and in cardiovascular medicine. However, as with the application of any new technique, methodical and thoughtful application of ML to specific, hypothesis-driven questions will be essential if it is to make a lasting impact on the field of HFpEF.
Supplementary Material
Synopsis:
Heart failure (HF) with preserved ejection fraction (HFpEF) represents a prototypical cardiovascular condition in which machine learning may improve targeted therapies and mechanistic understanding of pathogenesis. Machine learning, which involves algorithms that learn from data, has the potential to guide precision medicine approaches for complex clinical syndromes such as HFpEF. It is therefore important to understand the potential utility and common pitfalls of machine learning so that it can be applied and interpreted appropriately. Unmet needs in HFpEF that could benefit from machine learning include: (1) earlier diagnosis of HFpEF and its etiology; (2) improved classification (sub-phenotyping) of HF; (3) improved management of HFpEF through prediction of therapeutic responsiveness and HF hospitalization; and (4) improved identification of HFpEF patients for clinical trials. There are two main settings of machine learning, supervised learning and unsupervised learning. In supervised learning, predefined outcomes or labels are used to develop models to help predict future outcomes. In unsupervised learning, algorithms are applied to unlabeled data to understand intrinsic patterns within the data (e.g., for novel classification of HF subtypes). These techniques can be applied to many different data types, including clinical characteristics, cardiovascular diagnostic testing (i.e., imaging, labs, electrocardiograms, sensors), and clinical notes. While machine learning holds considerable promise for HFpEF, it is subject to several potential pitfalls (e.g., bias, confounding, overfitting, and lack of external validation), which are important factors to consider when interpreting machine learning studies.
Key Points:
Heart failure with preserved ejection fraction is a heterogenous, morbid condition with several unmet needs.
Machine learning has the potential to guide precision medicine approaches for heart failure with preserved ejection fraction, such as identification of rare etiologies, sub-phenotyping, and increasing the efficiency of clinical trial enrollment.
Understanding the strengths, limitations, and pitfalls of machine learning approaches is critical to realizing the potential of machine learning to impact the health of patient with heart failure with preserved ejection fraction.
Clinical Care Points:
Machine learning has promise to improve identifying and treating different subtypes of patients with HFpEF but also pitfalls.
Machine learning approaches may ultimately contribute improvements in care for patients with HFpEF, but applications must be rigorously developed and tested prior to implementation into clinical care.
Acknowledgments
We would like to thank Mark Berendsen, MLIS, and Linda O’Dwyer, MA, MSLIS, AHIP, for their assistance with the literature review for this paper.
Funding Sources
Dr. Ahmad was supported by grants from the Agency for Healthcare Research and Quality (K12HS026385), National Institutes of Health/National Heart, Lung, and Blood Institute (K23HL155970) and the American Heart Association (AHA number 856917). Dr. Luo was supported by grants from National Institutes of Health (U01TR003528, 1R01LM013337). Dr. Thomas was supported by a grant from the Irene D. Pritzker Foundation. The statements presented in this work are solely the responsibility of the author(s) and do not necessarily represent the official views of the Patient-Centered Outcomes Research Institute® (PCORI®), the PCORI® Board of Governors or Methodology Committee, the Agency for Healthcare Research and Quality, the National Institutes of Health, or the American Heart Association.
Disclosure Statement:
FA receives consulting fees from Amgen. Pfizer, and Livongo Teladoc outside of this work. SJS has received research grants from the National Institutes of Health (R01 HL107577, R01 HL127028, R01 HL140731, R01 HL149423), Actelion, AstraZeneca, Corvia, Novartis, and Pfizer; and has received consulting fees from Abbott, Actelion, AstraZeneca, Amgen, Aria CV, Axon Therapies, Bayer, Boehringer-Ingelheim, Boston Scientific, Bristol-Myers Squibb, Cardiora, CVRx, Cytokinetics, Edwards Lifesciences, Eidos, Eisai, Imara, Impulse Dynamics, Intellia, Ionis, Ironwood, Lilly, Merck, MyoKardia, Novartis, Novo Nordisk, Pfizer, Prothena, Regeneron, Rivus, Sanofi, Shifamed, Tenax, Tenaya, and United Therapeutics. JT receives consulting fees from Edwards, Abbott, GE, and Caption Health and reports spouse employment with Caption Health
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
REFERENCES
- 1.Virani SS, Alonso A, Aparicio HJ, et al. Heart Disease and Stroke Statistics-2021 Update: A Report From the American Heart Association. Circulation. 2021;0(0):CIR0000000000000950. [DOI] [PubMed] [Google Scholar]
- 2.Shah SJ, Kitzman DW, Borlaug BA, et al. Phenotype-Specific Treatment of Heart Failure With Preserved Ejection Fraction: A Multiorgan Roadmap. Circulation. 2016;134(1):73–90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Murphy KP. Machine Learning. MIT Press; 2012. [Google Scholar]
- 4.Bishop CM. Pattern Recognition and Machine Learning. Springer; 2006. [Google Scholar]
- 5.Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge, MA: MIT Press; 2016. [Google Scholar]
- 6.Obermeyer Z, Emanuel EJ. Predicting the Future - Big Data, Machine Learning, and Clinical Medicine. N Engl J Med. 2016;375(13):1216–1219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Altman RB, Ashley EA. Using “big data” to dissect clinical heterogeneity. Circulation. 2015;131(3):232–233. [DOI] [PubMed] [Google Scholar]
- 8.Shah SJ. Precision Medicine for Heart Failure with Preserved Ejection Fraction: An Overview. J Cardiovasc Transl Res. 2017;10(3):233–244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Kittleson MM, Maurer MS, Ambardekar AV, et al. Cardiac Amyloidosis: Evolving Diagnosis and Management: A Scientific Statement From the American Heart Association. Circulation. 2020;142(1):e7–e22. [DOI] [PubMed] [Google Scholar]
- 10.Kazi DS, Bellows BK, Baron SJ, et al. Cost-Effectiveness of Tafamidis Therapy for Transthyretin Amyloid Cardiomyopathy. Circulation. 2020;141(15):1214–1224. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Aus dem Siepen F, Hein S, Prestel S, et al. Carpal tunnel syndrome and spinal canal stenosis: harbingers of transthyretin amyloid cardiomyopathy? Clin Res Cardiol. 2019;108(12):1324–1330. [DOI] [PubMed] [Google Scholar]
- 12.Falk RH, Alexander KM, Liao R, Dorbala S. AL (Light-Chain) Cardiac Amyloidosis: A Review of Diagnosis and Therapy. J Am Coll Cardiol. 2016;68(12):1323–1341. [DOI] [PubMed] [Google Scholar]
- 13.Geller HI, Singh A, Alexander KM, Mirto TM, Falk RH. Association Between Ruptured Distal Biceps Tendon and Wild-Type Transthyretin Cardiac Amyloidosis. JAMA. 2017;318(10):962–963. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Donnelly JP, Hanna M. Cardiac amyloidosis: An update on diagnosis and treatment. Cleve Clin J Med. 2017;84(12 Suppl 3):12–26. [DOI] [PubMed] [Google Scholar]
- 15.Wechalekar AD, Gillmore JD, Hawkins PN. Systemic amyloidosis. Lancet. 2016;387(10038):2641–2654. [DOI] [PubMed] [Google Scholar]
- 16.Butler J, Fonarow GC, Zile MR, et al. Developing therapies for heart failure with preserved ejection fraction: current state and future directions. JACC Heart Fail. 2014;2(2):97–112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Goldstein BA, Navar AM, Carter RE. Moving beyond regression techniques in cardiovascular risk prediction: applying machine learning to address analytic challenges. Eur Heart J. 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Gheorghiade M, Vaduganathan M, Greene SJ, et al. Site selection in global clinical trials in patients hospitalized for heart failure: perceived problems and potential solutions. Heart Fail Rev. 2014;19(2):135–152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Wehbe RM, Khan SS, Shah SJ, Ahmad FS. Predicting High-Risk Patients and High-Risk Outcomes in Heart Failure. Heart Fail Clin. 2020;16(4):387–407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Adler ED, Voors AA, Klein L, et al. Improving risk prediction in heart failure using machine learning. European Journal of Heart Failure. 2020;22(1):139–147. [DOI] [PubMed] [Google Scholar]
- 21.Greenberg B, Adler E, Campagnari C, Yagil A. A machine learning risk score predicts mortality across the spectrum of left ventricular ejection fraction. European Journal of Heart Failure. 2021;23(6):995–999. [DOI] [PubMed] [Google Scholar]
- 22.Zhou X, Belkin M. Chapter 22 - Semi-Supervised Learning. In: Diniz PSR, Suykens JAK, Chellappa R, Theodoridis S, eds. Academic Press Library in Signal Processing. Vol 1. Elsevier; 2014:1239–1269. [Google Scholar]
- 23.Sutton RS, Barto AG. Reinforcement Learning: An Introduction, 2nd edition. Cambridge, Massachusetts: MIT Press; 2017. [Google Scholar]
- 24.Vapnik V, Golowich SE, Smola A. Support vector method for function approximation, regression estimation, and signal processing. Advances in Neural Information Processing Systems 9. 1997;9:281–287. [Google Scholar]
- 25.Liaw A, Wiener M. Classification and Regression by randomForest. R News. 2002;2/3:18–22. [Google Scholar]
- 26.Hartigan JA, Wong MA. A k-means clustering algorithm. Appl Stat. 1979;28:100–108. [Google Scholar]
- 27.Ng A, Jordan M, Weiss Y. On spectral clustering: analysis and an algorithm. In: Dietterich T, Becker S, Ghahramani Z, eds. Advances in Neural Information Processing Systems 14. Vol 14. Cambridge: MIT Press; 2002:849–856. [Google Scholar]
- 28.Jolliffe IT. Principal Component Analysis and Factor Analysis. In: Principal Component Analysis. New York, NY: Springer New York; 1986:115–128. [Google Scholar]
- 29.LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–444. [DOI] [PubMed] [Google Scholar]
- 30.Shah SJ, Katz DH, Selvaraj S, et al. Phenomapping for novel classification of heart failure with preserved ejection fraction. Circulation. 2015;131(3):269–279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Shin HC, Roth HR, Gao M, et al. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans Med Imaging. 2016;35(5):1285–1298. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Hirschberg J, Manning CD. Advances in natural language processing. Science. 2015;349(6245):261–266. [DOI] [PubMed] [Google Scholar]
- 33.Zeng Z, Deng Y, Li X, Naumann T, Luo Y. Natural Language Processing for EHR-Based Computational Phenotyping. IEEE/ACM Trans Comput Biol Bioinform. 2019;16(1):139–153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Goldberg Y A primer on neural network models for natural language processing. arXivorg. 2015. [Google Scholar]
- 35.Nadkarni PM, Ohno-Machado L, Chapman WW. Natural language processing: an introduction. Journal of the American Medical Informatics Association : JAMIA. 2011;18(5):544–551. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Luo Y, Thompson WK, Herr TM, et al. Natural Language Processing for EHR-Based Pharmacovigilance: A Structured Review. Drug Saf. 2017;40(11):1075–1089. [DOI] [PubMed] [Google Scholar]
- 37.Vaswani A, Shazeer NM, Parmar N, et al. Attention is All you Need. ArXiv. 2017;abs/1706.03762. [Google Scholar]
- 38.Devlin J, Chang M-W, Lee K, Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Paper presented at: NAACL2019. [Google Scholar]
- 39.Alsentzer E, Murphy J, Boag W, et al. Publicly Available Clinical BERT Embeddings. ArXiv. 2019;abs/1904.03323. [Google Scholar]
- 40.Huang K, Altosaar J, Ranganath R. ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission. ArXiv. 2019;abs/1904.05342. [Google Scholar]
- 41.Lee J, Yoon W, Kim S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2019;36(4):1234–1240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Rasmy L, Xiang Y, Xie Z, Tao C, Zhi D. Med-BERT: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. npj Digital Medicine. 2021;4(1):86. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Brown TB, Mann B, Ryder N, et al. Language Models are Few-Shot Learners. ArXiv. 2020;abs/2005.14165. [Google Scholar]
- 44.Korngiebel DM, Mooney S. Considering the possibilities and pitfalls of Generative Pre-trained Transformer 3 (GPT-3) in healthcare delivery. NPJ Digital Medicine. 2021;4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Byrd RJ, Steinhubl SR, Sun J, Ebadollahi S, Stewart WF. Automatic identification of heart failure diagnostic criteria, using text analysis of clinical notes from electronic health records. Int J Med Inform. 2014;83(12):983–992. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Friedlin J, McDonald CJ. A natural language processing system to extract and code concepts relating to congestive heart failure from chest radiology reports. AMIA Annu Symp Proc. 2006;Annual Symposium Proceedings/AMIA Symposium.:269–273. [PMC free article] [PubMed] [Google Scholar]
- 47.Ho JC, Ghosh J, Steinhubl SR, et al. Limestone: high-throughput candidate phenotype generation via tensor factorization. J Biomed Inform. 2014;52:199–211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Peissig PL, Santos Costa V, Caldwell MD, et al. Relational machine learning for electronic health record-driven phenotyping. J Biomed Inform. 2014;52:260–270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Vijayakrishnan R, Steinhubl SR, Ng K, et al. Prevalence of heart failure signs and symptoms in a large primary care population identified through the use of text and data mining of the electronic health record. J Card Fail. 2014;20(7):459–464. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Schölkopf B, Smola AJ. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. Cambridge: MIT Press; 2001. [Google Scholar]
- 51.Litjens G, Ciompi F, Wolterink JM, et al. State-of-the-Art Deep Learning in Cardiovascular Image Analysis. JACC: Cardiovascular Imaging. 2019;12(8_Part_1):1549–1565. [DOI] [PubMed] [Google Scholar]
- 52.Seetharam K, Brito D, Farjo PD, Sengupta PP. The Role of Artificial Intelligence in Cardiovascular Imaging: State of the Art Review. Frontiers in Cardiovascular Medicine. 2020;7(374). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Luo Y, Mao C, Yang Y, et al. Integrating hypertension phenotype and genotype with hybrid non-negative matrix factorization. Bioinformatics. 2019;35(16):2885. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Zhang J, Gajjala S, Agrawal P, et al. Fully Automated Echocardiogram Interpretation in Clinical Practice. Circulation. 2018;138(16):1623–1635. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Tison GH, Zhang J, Delling FN, Deo RC. Automated and Interpretable Patient ECG Profiles for Disease Detection, Tracking, and Discovery. Circ Cardiovasc Qual Outcomes. 2019;12(9):e005289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Duffy G, Cheng P, Yuan N, et al. High-Throughput Precision Phenotyping of Left Ventricular Hypertrophy with Cardiovascular Deep Learning. ArXiv. 2021;abs/2106.12511. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Goto S, Mahara K, Beussink-Nelson L, et al. Artificial intelligence-enabled fully automated detection of cardiac amyloidosis using electrocardiograms and echocardiograms. Nature Communications. 2021;12(1):2726. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Huda A, Castaño A, Niyogi A, et al. A machine learning model for identifying patients at risk for wild-type transthyretin amyloid cardiomyopathy. Nature Communications. 2021;12(1):2725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Galli E, Bourg C, Kosmala W, Oger E, Donal E. Phenomapping Heart Failure with Preserved Ejection Fraction Using Machine Learning Cluster Analysis: Prognostic and Therapeutic Implications. Heart Failure Clinics. 2021;17(3):499–518. [DOI] [PubMed] [Google Scholar]
- 60.Pandey A, Kagiyama N, Yanamala N, et al. Deep-Learning Models for the Echocardiographic Assessment of Diastolic Dysfunction. JACC Cardiovascular imaging. 2021;14(10):1887–1900. [DOI] [PubMed] [Google Scholar]
- 61.Collins GS, Dhiman P, Andaur Navarro CL, et al. Protocol for development of a reporting guideline (TRIPOD-AI) and risk of bias tool (PROBAST-AI) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ Open. 2021;11(7):e048008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Liu Y, Chen P-HC, Krause J, Peng L. How to Read Articles That Use Machine Learning: Users’ Guides to the Medical Literature. JAMA. 2019;322(18):1806–1816. [DOI] [PubMed] [Google Scholar]
- 63.Sengupta PP, Shrestha S, Berthon B, et al. Proposed Requirements for Cardiovascular Imaging-Related Machine Learning Evaluation (PRIME): A Checklist: Reviewed by the American College of Cardiology Healthcare Innovation Council. JACC: Cardiovascular Imaging. 2020;13(9):2017–2035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Vasey B, Clifton DA, Collins GS, et al. DECIDE-AI: new reporting guidelines to bridge the development-to-implementation gap in clinical artificial intelligence. Nature Medicine. 2021;27(2):186–187. [DOI] [PubMed] [Google Scholar]
- 65.Stevens LM, Mortazavi BJ, Deo RC, Curtis L, Kao DP. Recommendations for Reporting Machine Learning Analyses in Clinical Research. Circulation: Cardiovascular Quality and Outcomes. 2020;13(10):e006556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Liu X, Faes L, Calvert MJ, Denniston AK. Extension of the CONSORT and SPIRIT statements. The Lancet. 2019;394(10205):1225. [DOI] [PubMed] [Google Scholar]
- 67.Norgeot B, Quer G, Beaulieu-Jones BK, et al. Minimum information about clinical artificial intelligence modeling: the MI-CLAIM checklist. Nature Medicine. 2020;26(9):1320–1324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Bae CJ, Griffith S, Fan Y, et al. The Challenges of Data Quality Evaluation in a Joint Data Warehouse. EGEMS (Wash DC). 2015;3(1):1125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Hersh WR, Weiner MG, Embi PJ, et al. Caveats for the use of operational electronic health record data in comparative effectiveness research. Med Care. 2013;51(8 Suppl 3):S30–37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Wells BJ, Chagin KM, Nowacki AS, Kattan MW. Strategies for handling missing data in electronic health record derived data. EGEMS (Wash DC). 2013;1(3):1035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Luo Y, Szolovits P, Dighe AS, Baron JM. 3D-MICE: integration of cross-sectional and longitudinal imputation for multi-analyte longitudinal clinical data. Journal of the American Medical Informatics Association : JAMIA. 2018;25(6):645–653. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Lloyd-Jones DM. Cardiovascular risk prediction: basic concepts, current status, and future directions. Circulation. 2010;121(15):1768–1777. [DOI] [PubMed] [Google Scholar]
- 73.Steyerberg EW, Moons KG, van der Windt DA, et al. Prognosis Research Strategy (PROGRESS) 3: prognostic model research. PLoS Med. 2013;10(2):e1001381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Saeb S, Lonini L, Jayaraman A, Mohr DC, Kording KP. Voodoo Machine Learning for Clinical Predictions. bioRxiv. 2016. [Google Scholar]
- 75.Peiris D, Usherwood T, Panaretto K, et al. Effect of a computer-guided, quality improvement program for cardiovascular disease risk management in primary health care: the treatment of cardiovascular risk using electronic decision support clusterrandomized trial. Circ Cardiovasc Qual Outcomes. 2015;8(1):87–95. [DOI] [PubMed] [Google Scholar]
- 76.Curran GM, Bauer M, Mittman B, Pyne JM, Stetler C. Effectiveness-implementation Hybrid Designs: Combining Elements of Clinical Effectiveness and Implementation Research to Enhance Public Health Impact. Medical Care. 2012;50(3):217–226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Finlayson SG, Subbaswamy A, Singh K, et al. The Clinician and Dataset Shift in Artificial Intelligence. New England Journal of Medicine. 2021;385(3):283–286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Guo LL, Pfohl SR, Fries J, et al. Systematic Review of Approaches to Preserve Machine Learning Performance in the Presence of Temporal Dataset Shift in Clinical Medicine. Appl Clin Inform. 2021;12(4):808–815. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.