

Abstract
Physical and mental health are determined by an interplay between nature, for example genetics, and nurture, which encompasses experiences and exposures that can be short or long-lasting. The COVID-19 pandemic represents a unique situation in which whole communities were suddenly and simultaneously exposed to both the virus and the societal changes required to combat the virus. We studied 27,537 population-based biobank participants for whom we have genetic data and extensive longitudinal data collected via 19 questionnaires over 10 months, starting in March 2020. This allowed us to explore the interaction between genetics and the impact of the COVID-19 pandemic on individuals’ wellbeing over time. We observe that genetics affected many aspects of wellbeing, but also that its impact on several phenotypes changed over time. Over the course of the pandemic, we observed that the genetic predisposition to life satisfaction had an increasing influence on perceived quality of life. We also estimated heritability and the proportion of variance explained by shared environment using variance components methods based on pedigree information and household composition. The results suggest that people’s genetic constitution manifested more prominently over time, potentially due to social isolation driven by strict COVID-19 containment measures. Overall, our findings demonstrate that the relative contribution of genetic variation to complex phenotypes is dynamic rather than static.
Author summary
All over the world we have experienced the influence of the COVID-19 pandemic on our wellbeing. However, the impact may not have been the same for everyone. We know that physical and mental health are affected partly by nature, for example genetics, and partly by environmental factors, for example the COVID-19 pandemic. Here, we explored the interaction between genetics and the impact of the COVID-19 pandemic on individuals’ wellbeing over time. We observed that genetics not only influenced many aspects of wellbeing, but also that this impact changed over time during the pandemic. Our results suggest that the relative contribution of an individuals’ genetics increased over time. Overall, our findings demonstrate that the relative contribution of genetic variation to complex phenotypes, such as wellbeing, is dynamic rather than static.
Introduction
Early 2020, life all over the world was dramatically impacted by the COVID-19 pandemic, which represents a unique situation in which whole communities were suddenly and simultaneously exposed to both the virus and the societal changes required to combat the virus. In response to the pandemic the Lifelines COVID-19 cohort was initiated within the Lifelines prospective follow-up biobank. Online questionnaires were sent out to participants starting March 30th 2020, to investigate the (genetic) risk factors for COVID-19 and its health and societal impacts, including a wide variety of physical and mental health and lifestyle behaviour phenotypes [1,2].
Since the start of the pandemic, the genetics of COVID-19 and the impact of the COVID-19 pandemic on mental health over time have been extensively investigated separately [3,4]. Here, we aimed to explore the interaction between genetics and the impact of the COVID-19 pandemic on individuals’ wellbeing over time. Physical and mental health are known to be determined by an interplay between nature, for example genetics, and nurture, which encompasses experiences and exposures that can be short or long-lasting. Health conditions of individuals are also often the product of interplay between genetics and the environment. Depressive episodes, for example, are partly the result of an interaction between stressful life-events and a genetic predisposition to depression [5–8]. We hypothesize that the COVID-19 pandemic is a potentially traumatic life-event, having previously been associated to highly significant levels of psychological distress [9–12], and therefore expect to observe a dynamic relative contribution of genetics on wellbeing during the pandemic.
Results and discussion
To explore the role of genetics in individual’s experiences of the COVID-19 pandemic, we studied the impact of genetic variation on physical and mental health and lifestyle behaviours in the Lifelines biobank, a prospective follow-up cohort study of 167,000 participants living in the three northern provinces of the Netherlands. The repeated questionnaires allowed us to longitudinally track physical and mental health and lifestyle behaviours, and we report here on results for the 19 questionnaires sent over the first 10 months of the project (Fig 1, and S1 and S2 Tables). In total, we had genotype data for 27,537 participants of whom 17,831 had completed at least one questionnaire during the first half of the study period as well as at least one questionnaire during the second half of our study (S1 Fig). The 17,831 participants with longitudinal data completed on average 13 questionnaires. We used the genetic data to calculate 17 polygenic scores (PGSs) for each participant based on summary statistics of genome-wide association studies (GWASs) for BMI [13], COVID-19 susceptibility and severity [3], educational attainment [14], life satisfaction [15], personality traits [16,17], behavioural traits [18–20] and psychiatric diseases [21–24] (S3 and S4 Tables and S2 Fig). We also estimated heritability and the proportion of variance explained by shared environment using variance components methods based on Lifelines pedigree and household data.
Fig 1. Overview of the Lifelines COVID-19 cohort.

a) Our study is based on the Lifelines prospective follow-up cohort study and the accompanying Lifelines Corona Research project in which we sent out repeated questionnaires. b) We used 27,537 participants from European ancestry for whom we have genotype data available. c) Using the results of genome-wide association studies, we calculated polygenic scores (PGSs) for 17 traits. d) The relation between 17 PGSs and 288 outcomes was assessed using linear, logistic and ordered logistic regression models. e) Repeated questionnaire items allow us to study the temporal variation in the contribution of genetics to each of 46 PGS-outcome pairs using a longitudinal mixed-effects model and heritability analysis. The base layer of the map in panel a was retrieved from: geodata.nationaalgeoregister.nl/cbsgebiedsindelingen/wfs?request=GetFeature&service=WFS&version=2.0.0&typeName=cbs_provincie_2021_gegeneraliseerd&outputFormat=json.
Baseline association analyses
Within the 27,537 samples with genotype data available we performed a baseline association analyses between the 17 PGSs and the responses to 288 questionnaire and questionnaire derived outcome items (S5 Table). We observed 302 Bonferroni-corrected significant associations for 143 unique outcomes (Figs 2 and S3, and S6 and S7 Tables) (Bonferroni-corrected α ≤ 0.05). This indicates a genetic influence on the features measured by the corresponding questionnaire items, which covered aspects of mental health, attitudes towards pandemic public health measures, COVID-19 exposures and cases, and physical health. For instance, we observe that high PGSs for Neuroticism, Schizophrenia and Depression are positively associated with outcome items about personality traits, health complaints, fatigue, and exhaustion (i.e. Neuroticism-PGS and “felt nervous”, p-value = 1.88×10-23; Neuroticism-PGS and “felt tired quickly”, p-value = 2.65×10-16), whereas we saw the opposite direction of association for the Life satisfaction-PGS where a high PGS is associated with lower “chest pain” scores (p-value = 4.48×10−10). The PGSs for Life satisfaction and Neuroticism are also, respectively, negatively and positively associated to other health complaints and wellbeing items (i.e., Neuroticism-PGS and “excessive worrying”, p-value = 6.75×10−13; Life satisfaction-PGS and “quality of life”; p-value = 8.13×10−14). The observation that people with a high genetic burden for psychological traits score lower on wellbeing related questions is in concordance with previous literature [25–27].
Fig 2. Significant associations of PGSs and question answers at baseline.

A Z-score heatmap highlighting significant associations between questionnaire outcome items and polygenic scores (PGSs). In total, we analysed 288 questionnaire items and questionnaire-derived items, of which 143 have a significant association with at least one PGS. We observe significant associations of the PGSs for Depression, Life satisfaction, Neuroticism and Schizophrenia with wellbeing. Additionally, COVID-19 sentiments are associated to PGS traits including Educational attainment, Neuroticism and Worry/Vulnerability. Associations were estimated between PGS and outcome items using a multivariate model (linear, logistic, or ordered logistic regression) with age, sex, household size, having children and having chronic disease used as covariates. The ‘Ever positive SARS-CoV-2’ item was determined from answers to all questionnaires. For all other items we used the first time the question was asked. We used two PGSs related to physical activity (Accelerometer-based physical activity & Moderate to vigorous physical activity). For clarity we used the maximum Z-score of these two PGSs for the physical activity column in this figure.
There are also PGSs that are significantly associated to the outcomes of several COVID-19–related questions. For instance, we observe many significant associations between the PGS for Educational attainment and variables pertaining to COVID-19 developments, including opinions about these developments (e.g., “having trust in the government’s response to the COVID-19 pandemic”; p-value = 1.05×10−9) and public health measures (e.g., “not shaking hands”; p-value = 6.39×10−7). Furthermore, we observed positive associations between the PGS for Worry/Vulnerability and “worry about infecting someone else” (p-value = 2.41×10−6), and between the PGS for Alcohol consumption and “whether or not individuals avoid facilities like bars and restaurants as a COVID-19 precaution” (p-value = 9.65×10−8). In November 2020, individuals with a genetic predisposition for risky behaviour indicated they were more often planning to travel outside the country to go skiing/snowboarding (p-value = 7.73×10−07), although the opportunity ultimately did not arise due to COVID-19 related restrictions. This shows that existing PGSs can also inform on responses that are specific to the current pandemic. Indicating that the behaviour of individuals during the pandemic can be influenced by known behavioural genetic factors that are captured by the PGSs from existing GWASs.
Longitudinal analyses
Most GWASs are conducted at a single point in time and identify a static relationship between genetics and a trait. Due to the synchronized and prolonged exposure of the COVID-19 pandemic we were able to determine if this genotype-phenotype relationship can change over time. To do so we performed longitudinal analyses within 17,831 samples using mixed-effect models for 46 PGS–question pairs that had a significant baseline association and that have been asked at multiple timepoints (S8 Table). Fourteen of these showed a time dependent effect at nominal significance (p-value ≤ 0.05). At a false-discovery rate (FDR) of 0.05, 11 PGS–question pairs showed a significant time dependent effect (including the PGSs for Life satisfaction, Neuroticism, Depression, Schizophrenia, and COVID-19 susceptibility, S4 Fig and S9 Table and S1 Note), of which two were Bonferroni significant: genetic predisposition of COVID-19 susceptibility with a positive SARS-CoV-2 PCR test and the PGS for Life satisfaction with “felt tired”.
An increased effect of genetics on wellbeing over time
We found that the PGSs for Life satisfaction, Neuroticism and Depression affected five correlated outcomes related to wellbeing (S4 Fig and S9 Table). We observed time-dependent effects for “perceived quality of life”, “feeling good”, “was easily tired”, “feeling tired” and “feeling physically exhausted”. Since the PGSs of these traits, as well as the answers to the questions, are either positively or negatively correlated to each other (S1 and S5 Figs), we assume that this is a single effect. In the interest of clarity, we focus our discussion below on the effect of the Life satisfaction-PGS on “perceived quality of life”.
The mean perceived quality of life varied over time, with a peak during the summer of 2020 that was likely due to summer holidays and warm weather, but also because COVID-19-related restrictions and infections were at a minimum at that time (Figs 3, S6 and S7 and S10 Table). As expected, we observed that the PGS for Life satisfaction is positively associated with “perceived quality of life” (p-value = 8.13×10−14).
Fig 3. The genetic contribution to perceived quality of life increased over the course of the pandemic.

a) Course of mean quality of life over time. b) Fitted longitudinal model for quality of life stratified by the PGS for Life satisfaction of the samples genotyped on the Global Screening Array (for other samples see S4 Fig). The shaded area represents the 95% confidence interval for the model fit. c) Contribution of the Life satisfaction-PGS to perceived quality of life over time. The diverging lines indicate the increased importance of the Life satisfaction PGS to perceived quality of life as time progresses. d) Regression coefficients of the Life satisfaction PGS and perceived quality of life over time. The error bars represent the 95% confidence interval for the regression coefficients. This shows an increase in the explained variance of the PGS during the COVID-19 pandemic.
What is intriguing is that the effect of the PGS for Life satisfaction on the perceived quality of life increased across the pandemic (p-value = 3.1×10−3) (Fig 3). At the end of the summer, the mean perceived quality of life started to decline, but participants with a higher Life satisfaction-PGS appear to be more resilient and reported smaller decreases in quality of life, while participants with a lower PGS reported a stronger decrease in their reported quality of life. This shows that genetic predisposition has increased in importance over the course of the pandemic.
There are several possible social and psychological explanations for the increasing influence of genetics on the reported quality of life over time. One possibility is that, due to lockdown restrictions, people had fewer social contacts, which are known to affect wellbeing [28]. This social isolation could explain a diminished environmental influence on wellbeing relative to the genetic component. Alternatively, traumatic events can trigger depressive episodes in people with a genetic predisposition for depression and people who have a strong neurotic personality respond more strongly to stressors [29,30]. Since the Life satisfaction-PGS is negatively correlated with the Depression-PGS (Pearson r: -0.64 p-value: ≤2.22×-308) and Neuroticism-PGS (Pearson r: -0.71 p-value: ≤2.22×-308), this could potentially explain people’s reduced resilience in the presence of the prolonged stress caused by the pandemic. This is also consistent with our finding that people with a high PGS for Depression or Neuroticism report being more tired, an effect that also increased in strength as the pandemic progressed. Either of these factors–social isolation or traumatic impact–could explain why people with a lower PGS for Life satisfaction had more difficulty dealing with the COVID-19 pandemic.
An alternate possibility is that the arrival of COVID-19 and the accompanying lockdown measures had a very strong impact on the quality of life of the society, such that the contribution of genetics on perceived quality of life was suddenly much smaller. Over time, with a waning impact of this stressor, the effect of genetics became more dominant, reflecting a return to the impact it had prior to the emergence of COVID-19. Unfortunately, we cannot directly test this hypothesis since we have no pre-pandemic measurement on perceived quality of life. However, the Twins Early Development Study on adult twins in Great Britain did show that the first month of lockdown did not result in major changes in the genetic or environmental origins in psychological or attitudinal traits compared to a pre-pandemic timepoint [31]. A similar observation was made by the Netherlands Twin Register, they did not find a significantly altered heritability for well-being related outcomes before and after the start of the pandemic [32]. Both these studies support the explanation that the increase in the contribution of genetics that we observe is a consequence of the ongoing pandemic rather than a slow return to a pre-pandemic situation.
To the best of our knowledge, we are the first to show an increased relative impact of genetics on wellbeing during the COVID-19 pandemic. In a study in twins from the UK by Rimfeld et al. [33] heritability estimates for depression, general anxiety and other (wellbeing) items were studied, and compared over time at five different timepoints. The first of which was set in 2018, and later timepoints set from July 2020 to March 2021. This study did not show a change in heritability over time, whereas we do observe this effect. This might be explained by the relatively low sample size compared to our study. In addition, the studied samples were strictly confined to young adults in the UK, whereas we have studied a much broader range of Dutch adults. The results of both our studies could therefore coexist together and do not fully contradict each other.
Host genetic contribution to COVID-19 infections
A change in the influence of genetics, as seen in PGSs, over time is not restricted to wellbeing outcomes. We also observed a change in the influence of the PGS for COVID-19 susceptibility on actual infections. As expected, we observed a strong increase in the number of infections among participants over the course of our study (Fig 4). At the start of our study in March 2020, only 198 infections within our region had been reported by the government, whereas this number had increased to 7,579 in January 2021 [34]. While the PGS for COVID-19 susceptibility increased the risk of being infected (p-value = 1.28×10−22), we also observed that the effect of this PGS declined over time (p-value = 5.15×10−30).
Fig 4. COVID-19 incidence increases over time with a decreased importance of genetic COVID-19 susceptibility.

a) Kaplan-Meier curve stratified by genetic risk for COVID-19 infections. b) Fitted logistic longitudinal model for COVID-19 shows increasing infections regardless of genetic risk. The shaded area represents the 95% confidence interval for the model fit. c) The contribution of COVID-19 susceptibility to the risk of having had COVID-19 slowly decreased over time. d) Regression coefficients of the COVID-19 susceptibility PGS and ever testing positive for SARS-CoV-2 by PCR test over time. The error bars represent the 95% confidence interval for the regression coefficients. The plot shows a decrease in the variance explained by the PGS during the COVID-19 pandemic.
One possible explanation for this is testing bias. At the beginning of the pandemic in the Netherlands, testing was almost exclusively reserved for severely ill patients. It was only in June 2020 that anyone with symptoms could get a test [35] and only in the months following that testing was extended to asymptomatic individuals who had been in contact with someone who had tested positive for a SARS-CoV-2 infection. We suspect that the same testing bias exists in other cohorts of the COVID-19 susceptibility GWAS. Additionally, several cohorts that contributed to the COVID-19 susceptibility GWAS are based on hospitalized patients. Therefore, some of the GWAS signal is likely informative for COVID-19 severity rather than susceptibility, which could explain that the performance of the corresponding PGS diminishes once infected people with few or no symptoms are being widely tested.
Alternatively, it could be that the contribution of host’s genetics on COVID-19 susceptibility is different for new SARS-CoV-2 variants. Near the end of our study the more the infectious B.1.1.7 (Alpha) variant was in the process of becoming the dominant variant in the Netherlands, this might also explain why the PGS of the COVID-19 susceptibility GWAS was becoming less informative.
As we discuss above, this probably reflects a different mechanism; a shift in who tests positive over time compared to changes in wellbeing items. This does support to the idea that these interaction effects are real and need to be considered when applying PGS in other contexts.
Sensitivity analysis of longitudinal models
We used three different strategies to validate the 11 outcomes vs PGS interactions that we found using the longitudinal mixed-effects models. First, to rule out that these observed effects are caused by attrition bias we also performed analyses on a subset of samples, totalling 7,502 samples, who had completed questionnaires at 1, 4, 7 and 10 months (S2 Note and S9 Table). Using this subset, we could test 10 out of the 11 interaction effects, one model did not converge in this subset and could not be validated. We found that all interactions show the same effect direction and that four are Bonferroni significant within this subset. This shows that non-random dropouts of participants are not driving our findings.
Secondly, we calculated the association between the PGS-outcome pairs at each timepoint separately and subsequently tested whether the strength of this association changed over time (S11 Table and S8 Fig). While such models are simplistic and underpowered, they do allow us to confirm the validity of the results from our mixed-effects models. Herein we were able to Bonferroni significantly replicate 9 out of 11 interactions.
Finally, in the mixed-effects models we rely on PGSs as a basis for the variance that is explained by genetics. However, here it is important to note that a change in the variance explained by a single PGS may not necessarily reflect all the impact of genetics. Gene-environment interactions may cause the PGS to be less effective while the total contribution of genetics as a whole stays constant. Considering this, we aimed to validate our results independently from PGSs. We have done so by estimating the heritability of each of the seven outcome items for which we observed a variable genetic contribution over time in our longitudinal models (S13 Table). We were able to estimate the heritability for each timepoint separately for six outcome items, and then tested whether the heritability increased or decreased over time. We were not able to reliably estimate the heritability for all timepoints for the ‘Ever positive SARS-CoV-2’ item since we did not have enough cases at the start of the pandemic. For four outcome items (‘Felt good’, ‘Felt physically exhausted’, ‘Felt tired’, and ‘Was easily tired’, p-value ≤ 0.05) we observed a significant increase of heritability over time (S10 Fig) without significant changes to the contribution of shared environment over time (S11 Fig). The two other outcomes (‘Concerned about the COVID-19 pandemic’ and ‘Quality of Life’) could not be validated using this method. This might be the result of limited power as the heritability estimates are small and have a relatively large standard error. Given that all the effects are in the expected direction, and that we can convincingly validate the increased genetic contribution on four outcome items, we are confident that the results obtained using the mixed-effects models and the PGSs are reliable.
Limitations
While the Lifelines cohort is representative of the general population [1], not all of the Lifelines participants decided to fill in our COVID-19 questionnaires and we could only include samples that had been genotyped. Both introduced a sample bias compared to the whole cohort. For instance, the average PGSs of some traits were different between genotyped individuals that did not take part in this study compared to the 27,537 samples used in our baseline analysis (S9 Fig), indicating a small genetic bias for the willingness to fill-in the COVID-19 questions. In addition, some of the answers to our baseline outcomes were also different for our sample set compared to the participants that were not genotyped (S12 Table), indicating a bias in the selection of samples that where genotyped. It is therefore possible that our estimated effect sizes do not exactly reflect the effects in the general population.
It should be noted that the samples used in this study are also part of the GWASs for BMI, educational attainment, and COVID-19 susceptibility (S3 Table). For the BMI and educational attainment GWASs this only holds for the samples genotyped using the HumanCytoSNP-12 array. Here, we found that all significant associations are also nominally significant (p-value ≤ 0.05) and have the same direction when only using the samples not included in the BMI and educational attainment GWASs. Most effects, 83 out of the 89, are even Bonferroni significant using only the GSA data. For the COVID-19 susceptibility we cannot rule out that the baseline association between the PGS and infection status is biased by the overlapping samples. However, this does not explain the change in PGS performance over time.
Implication
Although the genetic effect on wellbeing became stronger over time, its contribution remains relatively small. The effect sizes of interaction effects are small as well. However, the accuracy of PGSs is currently still limited, which likely has hampered our ability to find larger effects. In reality, the effect of genetics on each of these traits is expected to be larger. Furthermore, our findings do demonstrate that it is not only the presence or absence of environmental stimuli that can modulate the effect of genetic variants, the duration of a stimulus in conjunction with a genetic background can also modulate the outcome. Accounting for this by the use of longitudinal biobanks can help improve the power of GWASs to detect associated variants [36], enable more accurate risk predictions using PGSs and allow more accurate patient stratification [37], and provide insights into the complex interplay of genetic predisposition and environment on diseases and traits [38].
Conclusion
We have been in the unique position to observe a synchronized and prolonged exposure to a shared continuous stress factor and an increasingly abundant infectious disease. This allowed us to observe longitudinal changes in the relative contribution of nature and nurture on wellbeing and COVID-19 infections. Our results indicate that participant’s responses to the COVID-19 pandemic were at least partially driven by their genetic predisposition and that this genetic contribution changes over time.
Methods
Ethics statement
The Lifelines study was approved by the ethics committee of the University Medical Center Groningen, document number METc2007/152. All participants signed an informed consent form prior to enrolment.
Cohort
We selected study participants from the Lifelines COVID-19 cohort [2], for which 139,713 adult participants with a known email address were approached from the Lifelines population cohort [1]. Lifelines is a prospective multigenerational population cohort following 167,000 individuals in the three northern provinces of the Netherlands (Drenthe, Friesland, Groningen) since 2006, and collects detailed information and biological samples from its participants (Fig 1). The repeated questionnaires sent out to the Lifelines COVID-19 cohort include items about sociodemographic parameters, chronic diseases, COVID-19 infection, general health and symptoms, medication use, mental health, well-being, social life and lifestyle. At least once a month, participants were invited to respond to these questionnaires. In total, 19 questionnaires were sent out between March 30, 2020 and January 5, 2021. On average, 39,066 participants responded to each questionnaire (S1 Table).
Genetic data and PGSs
Within the Lifelines population cohort 36,339 participants have been genotyped using the Global Screening Array. An additional 14,463 participants have been genotyped using the HumanCytoSNP-12 chip, making the total number of genotyped individuals 50,802.
Genotyped individuals were filtered to only include samples of European ancestry according to principal component analysis. Genotype data from arrays were separately imputed on the Sanger imputation server using the Human Reference Consortium reference panel [39].
We calculated PGSs by applying PRS-CS [40] with our defined set of traits (S3 Table). We did this separately for each of the two genotyping arrays. For each of the traits, we downloaded the complete summary statistics from the indicated source. To comply with the PRS-CS input format, we added reference SNP identifiers (RSIDs) to the GWAS summary statistics, when these were not initially present. This was done by matching genomic locations for each of the variants to those from dbSNP [41]. For the genotype data generated with the HumanCytoSNP array, RSIDs were matched to the genotype data when the genomic location and both the alleles matched variants from dbSNP (build 152). This was not necessary for the genotype data generated with the GSA. Thereafter, we excluded SNPs with ambiguous alleles. We also removed SNPs with a minor allele frequency below 0.01, an imputation score below 0.3, or a missing call rate greater than 0.25. Data was converted to bpgen format using PLINK 2.0 to maintain allelic dosage information [42,43].
PRS-CS accounts for inaccuracies in effect sizes and linkage disequilibrium (LD) patterns using a reference panel and through shrinkage of effect-size estimates. It does not require pruning or thresholding of variants. PRS-CS was run on each autosome separately using the processed PLINK datasets and the complete GWAS summary statistics. We used the European reference LD panel provided by the PRS-CS authors and the default for the other parameter options. PLINK 2.0 was used to sum variant dosages from the PLINK datasets, weighted by the posterior effect sizes calculated by PRS-CS. Finally, we summed the PGSs that were calculated separately for each of the autosomes and scaled the outcomes to have a mean of 0 and a standard deviation of 1.
Questionnaire quality control
Of the 50,802 genotyped Lifelines participants, 27,537 participants completed at least one COVID-19 questionnaire and are of European descent. To ensure that our questionnaires were filled in reliably, we performed a principal component analysis (PCA) for each of the 19 questionnaires to detect spurious signals. To enable this quality control, we first selected questions that were answered by at least 95% of the participants of that questionnaire. This resulted in at least 98 questions per questionnaire that were answered by nearly all participants. Subsequently, we calculated the per participant missing rate for each questionnaire for these questions. For each participant, we excluded the questionnaires with more than 5% “missing-ness”. The answers to questions with a maximum of 5% missingness were normalized to have a mean of 0 and a standard deviation of 1. At this point, we still had some missing values in our data, which prevented us from performing a simple PCA. There are many ways to resolve this, but for the purpose of quality control, we decided to simply fill missing answers with the mean answer for that question. Subsequently, we normalized each sample to have a mean of 0 and standard deviation of 1. Finally, we performed a PCA on the sample correlation matrix. This did not detect any outliers with a standard deviation larger than 4, suggesting the absence of respondents who filled out the questionnaires with erroneous answers. As such, we did not need to remove samples from the dataset.
Next, to include participants with long-term follow-up, we selected participants who had completed at least one questionnaire in the first half of our study and at least one questionnaire in the second half (before and after August 31, 2020, respectively). Using these criteria, we ultimately included 17,831 participants who had completed an average of 13 out of the 19 questionnaires (S1 Fig and S1 Table).
We assessed the effects of quality control and sample exclusions on the PGSs by comparing the participants who were included in this study to those who were invited to take part in the Lifelines COVID-19 questionnaires but were not included. These either did not respond or did not pass quality control. Welsh’s t-tests are used to assess whether differences were significant. For seven traits in the samples genotyped using the Global Screening Array (GSA), and for three traits in the samples genotyped using the HumanCytoSNP-12 array, the PGSs of the included samples in longitudinal analyses are different compared to the samples that were invited (S9 Fig). The figure also demonstrates that sample selection based on quality control has been favourable for controlling false positives caused by loss to follow-up.
Outcome items
We recoded questionnaire items to a binary, ordinal or continuous variable when this was not already the case (S5 Table). We made sure that the ordering of the ordinal and dichotomous answers corresponded to the directionality implied by the given label or question. Additionally, we removed answer options that did not fit on the ordinal scale, like answers indicating that the question was not applicable to the individual. Questionnaire items with an approximate continuous scale were analysed as continuous variables, whereas items with a more limited number of answer options or for which the answers were not approximately normally distributed were analysed as ordinal or binary variables. After recoding, we removed all the questions where the most frequent answer was given by more than 99% of the participants.
In addition to single questionnaire items, we derived a set of additional outcome items. Current depressive episode was calculated using the decision tree from the standardized “Mini-International Neuropsychiatric Interview (M.I.N.I.)” version 5.0.0. questionnaire manual [44]. We excluded the question “Did you feel tired or without energy almost every day?” because this question was not available in all questionnaires. We also excluded the timepoints for which the question “Did you repeatedly consider hurting yourself, feel suicidal, or wish that you were dead?” was not available.
We determined whether participants were ever tested positive for a SARS-CoV-2 infection with a PCR test. For this, we used a series of questions asking if a PCR test was performed and if the test result was positive or negative. The resulting “ever positive SARS-CoV-2 PCR test” variable was defined per participant and set as True for all following questionnaires, starting from the first self-reported positive SARS-CoV-2 PCR test.
BMI was calculated using the most recent self-reported body weight in the questionnaires and the height that had been measured during the most recent physical visit. Weight values below 20 kg and above 220 kg were removed. Values with an absolute difference of more than 20 kg compared to the last previous questionnaire were also removed. The first value was compared to the second and third value and was removed if the absolute difference to the second value was more than 20 kg and that to the third value was more than 30 kg. If only two questionnaires were completed, both points were removed if the absolute difference was more than 20 kg.
Covariates
We used the participant’s sex as registered in the Personal Records Database [45]. Their age, derived using date of birth and date of questionnaire completion, was available for every questionnaire. We used the age at the time of the most recently completed questionnaire. We also assessed if participants live alone or not. This was defined as having zero household members, which we determined using the most recent self-reported number of household members. We also determined whether participants have children living at home using the question on whether participants have children and the most recent number of household members reported below 18 years of age. Chronic illness was extracted from the most recent self-reported chronic disease item, based on the question: ‘Do you have a chronic health condition?’. Time was defined as days since March 30, 2020.
Baseline associations
To identify correlations between responses to questionnaire items and PGSs, we fitted models between all PGSs and both the questionnaire items and derived items within 27,537 participants. First, we filtered the questions for which the answers were not directly influenced by the participant. For example, we removed questions about choices made by their employer. After manual selection, we removed all the questions that were answered by less than 50% of the participants of the questionnaire in which that particular question was asked.
For each question, we selected the appropriate regression model. We chose a normal linear regression model for normally distributed outcomes, a logistic model for binomial data and an ordinal logistic regression model for ordered categorical data.
The models were fitted using the ‘statsmodels’ package. The quantitative questions were fitted using the OLS class, the binominal questions were fitted using the Logit class and the ordinal questions were fitted by the ‘OrderedModel’ class. For the ‘OrderedModel’, we set the ‘distr’ option to logit, set the maximal number of iterations to 10,000 and set the optimizer to the Broyden-Fletcher-Goldfarb-Shanno (BFGS) method. The models were fitted for each PGS and each question individually while adjusting for sex, age, age2, chronic illness, living alone and children living at home.
The models were fitted separately for each genotype array and the regression coefficients and p-values were combined with the inverse-variance weighting method. Afterwards, the p-values were translated to Z-scores and filtered on significance using a Bonferroni-corrected α of 0.05.
Longitudinal models
For all PGS–question pairs for which we identified a significant baseline association, we tested if this effect was stable over time within 17,831 participants. There are 237 PGS-question pairs for questions that did have longitudinal data. For 46 PGS-question pairs we were able to fit mixed-effects models with a random intercept, time and time2 per participant (except for the model for “ever positive SARS-CoV-2 PCR test” in which we only used a fixed intercept). To investigate differences in changes over time, we included interaction with time for all included variables:
Herein, us and ε denote the sample random effect intercept and the residual error. Time was denoted as days since March 30, 2020. We included time and time2 to model the non-linear changes over time and adjusted for sex, age (mean-centred), age2, chronic illness (0/1), living alone (0/1) and children living at home (0/1).
We used the lme function from the nlme package for questions with a quantitative answer. Here, we used the optim optimizer [46]. For “ever positive SARS-CoV-2 PCR test”, we used the R GLM function with binominal logit link function [47]. The other questions, which have binary outcomes, were fitted using the glmer function with the binominal logit link function and nAGQ = 0 parameter from the lme4 package [48].
Since our cohort was genotyped on two different genotyping arrays, we fitted the model above for each array separately. We used inverse-variance weighting to combine the estimates and standard errors for each term in the model [49]. These where then used to calculate the combined Z-score and p-value that we used to determine the significance of each term.
Sensitivity analyses
To assess that our findings obtained using the longitudinal mixed-effects models were not driven by non-random dropout of participants, misspecification of our model, or the nature of the PGSs, we have done three sensitivity analyses.
Attrition bias sample subset
We selected 7502 samples that all completed questionnaires 4, 9, 14, and 19 to create a sample that is guaranteed not to suffer from attrition bias or non-random censoring. Using only this subset of samples with answers given only at these four time points we reran all longitudinal models for which we found a significant PGS × time interaction.
Validity of mixed-effects models
We performed a sensitivity analysis using separate linear and logistic models for each questionnaire item on each individual timepoint for the 17,831 samples with longitudinal data. The resulting regression coefficients of the PGSs for each timepoint were subsequently correlated with time to analyse if the effect of the PGSs on the different (derived) outcomes changed over time. For each timepoint and each item, we used linear, logistic, or ordinal regression models which were also used by calculating the baseline associations, including recoding criteria and parameters for the models and with adjustment for sex, age, age2, chronic illness, living alone and children living at home. The regression coefficients of the PGSs were extracted from the models and grouped per question. These models were fitted separately for each genotype array and the regression coefficients were combined with the inverse-variance weighting method. Subsequently, for each PGS and each question, we calculated the Pearson correlation between PGS regression coefficients and time to analyse if the effect of the PGS on the answer to the question changed over time. For each question, time was defined as the number of days that had passed when the questionnaire containing the relevant question was sent out, since March 30, 2020.
Heritability estimates
We also wanted to validate the altered impact of genetics independent of the PGSs. Therefore, we calculated heritability estimates and the variance explained by shared environment based on pedigree information and household composition. This was done for each of the available timepoints, the total and phenotypic variances were estimated from the linear mixed model using the ASReml-R package. This analysis was also performed in the 17,831 samples with longitudinal data. Narrow-sense heritability was calculated using pedigree information as:
and the proportions of variance explained by shared family environment was calculated as:
Herein, Is the additive genetic variance, is the shared environmental variance, and is the residual variance. All estimates were adjusted for sex, age, age2, chronic illness, living alone and children living at home. To test the significance of the h2 estimates (h2 > 0), the model in which all variances were estimated was compared to a model in which additive genetic variances was constrained to be zero using a likelihood-ratio test. Shared environment was determined by assessing whether individuals lived in the same household at the baseline assessment in Lifelines.
Within these estimates we subsequently attempted to model longitudinal effects. For each of the outcomes, we modelled the heritability using time as the independent variable in a linear model. Herein, time was defined as the number of days that had passed when the questionnaire containing the relevant outcome was sent out, since March 30, 2020. The same models were applied to variances explained by shared environment.
Correlation with nationwide statistics
We collected a number of publicly available datasets that we hypothesized might be able to explain part of the variation in the perceived quality of life over the course of the pandemic. We collected three variables that convey the state of the pandemic in the Netherlands: the confirmed COVID-19 cases per day published by the Dutch National Institute for Public Health and the Environment (RIVM) [34], the intensive care unit (ICU) occupancy by COVID-19 patients published by the ‘Landelijk Coördinatiecentrum Patiënten Spreiding’ (LCPS) [50] and, as a measure of the severity of lockdown in the Netherlands, we downloaded the ‘Stringency Index’ from the Oxford COVID-19 Government Response Tracker [51]. Additionally, we retrieved the relative change in work- and recreational-related mobility from the Google COVID-19 Community Mobility Reports [52]. Finally, we downloaded a dataset on the weather per day from The Royal Netherlands Meteorological Institute for a central Northern Netherlands weather station (Eelde, Drenthe) [53].
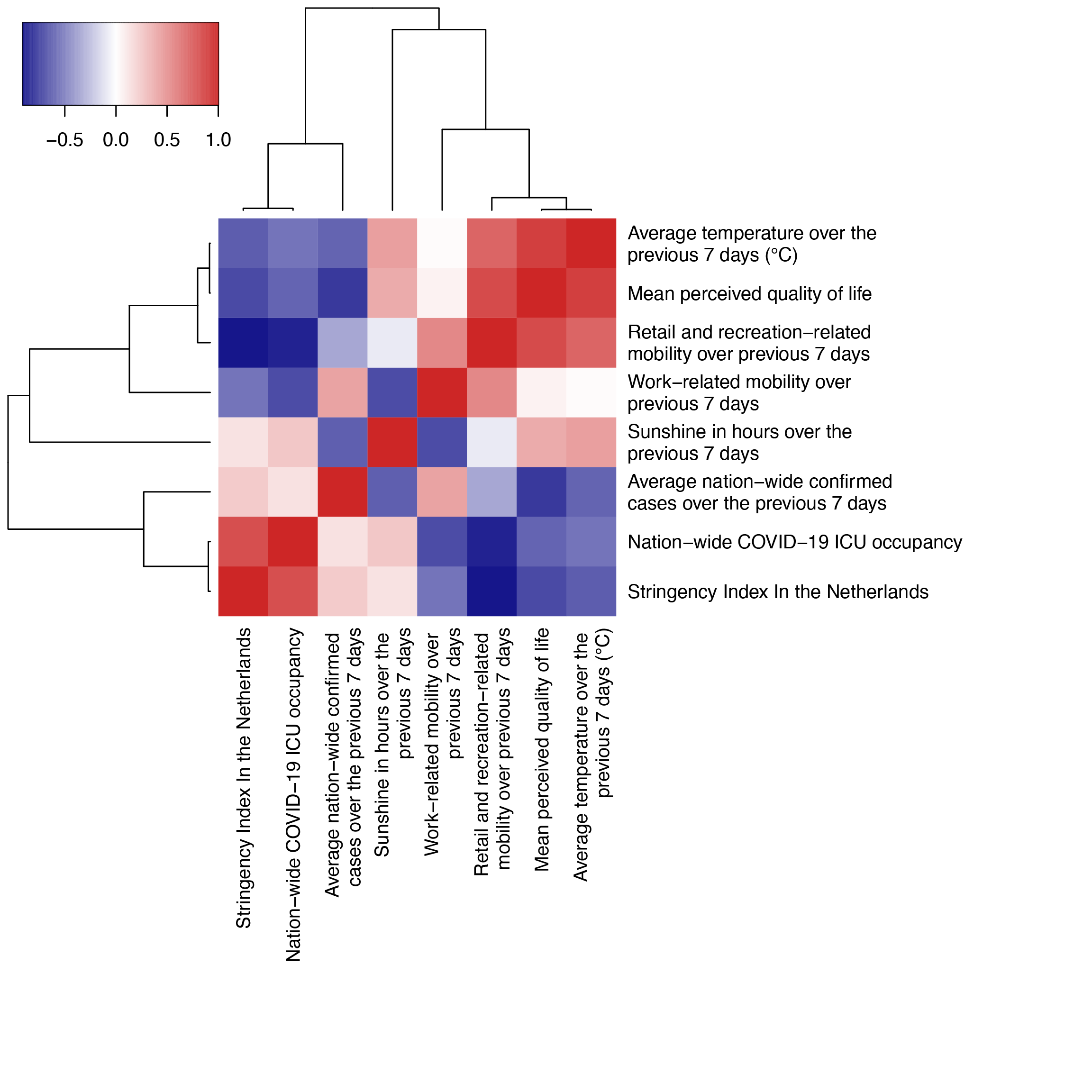
A 7-day moving average was calculated for the confirmed COVID-19 cases, the relative change in both work and recreational mobility, the hours of sunshine per day and the average temperature over 24 hours (in degrees Celsius). These variables are visualized together with the ICU occupancy by COVID-19 patients and the Stringency Index (S6 Fig). Together with the publicly available variables, this figure presents the mean perceived quality of life per questionnaire over the average response date for that questionnaire.
For each of the visualized variables, we extracted the values that coincided with the average response dates for the questionnaires. Thereafter, the Pearson correlation was calculated between each of these variables and the mean perceived quality of life (S7 Fig and S10 Table).
Supporting information
19 questionnaires were sent from March 2020 to January 2021. The interval varies from weekly to monthly. The number of samples that we used in baseline and in longitudinal analyses are represented in columns 5 and 6 respectively.
(XLSX)
Descriptive statistics for the two sample selections in our cohort. 27,537 baseline samples were used for baseline associations, and 17,831 samples were used in the longitudinal analysis. We show the total number of samples, the distribution of age and BMI, and the frequencies of values for the other covariates. Chronic illness was extracted from the most recent self-reported chronic disease item.
(XLSX)
The PGSs for the traits and diseases that were assessed.
(XLSX)
The output produced by Linkage disequilibrium score regression for each combination of selected traits.
(XLSX)
The overview of questions that have been tested for associations with polygenic scores. The full questions and answers have been translated into English from Dutch. Some questions are specific to the context of a broader question or heading. In these cases, the overarching question or heading is separated from the specific question by a ’/’. The third column represents how the individual answers have been coded in the regression model.
(XLSX)
The Z-Scores for baseline associations between polygenic scores (columns), and outcome items (rows). Some questions are specific to the context of a broader question or heading. In these cases, the overarching question or heading is separated from the specific question by a ’/’.
(XLSX)
The p-values for baseline associations between polygenic scores (columns), and outcome items (rows). Some questions are specific to the context of a broader question or heading. In these cases, the overarching question or heading is separated from the specific question by a ’/’.
(XLSX)
The overview of questions that have been tested for interaction effects between polygenic scores and time. Some questions are specific to the context of a broader question or heading. In these cases, the overarching question or heading is separated from the specific question by a ’/’.
(XLSX)
Significance of PRS × Time interaction term. Models that did not converge to a solution are omitted.
(XLSX)
The Pearson correlations calculated between the mean perceived quality of life and 7 publicly available variables. From these variables values were sampled at the average response dates of the questionnaires.
(XLSX)
Results of the sensitivity analysis for the overtime interaction between a question from the questionnaire and the PGS trait.
(XLSX)
A comparison of samples that have been genotyped and samples that have not been genotyped based on all significant baseline questions. Questions that in our baseline analysis have been considered continuous were tested using a t-test. All other questions were analysed using a Fisher’s exact test. For these questions simulated p-values (based on 1e+07 replicates) were used when there were more than two answer options. We applied a Bonferroni correction for all questions based on 143 questions.
(XLSX)
The estimated narrow-sense heritability (expressed as h2), and variance explained by shared environment. Shared environment was determined by assessing whether individuals lived in the same household.
(XLSX)
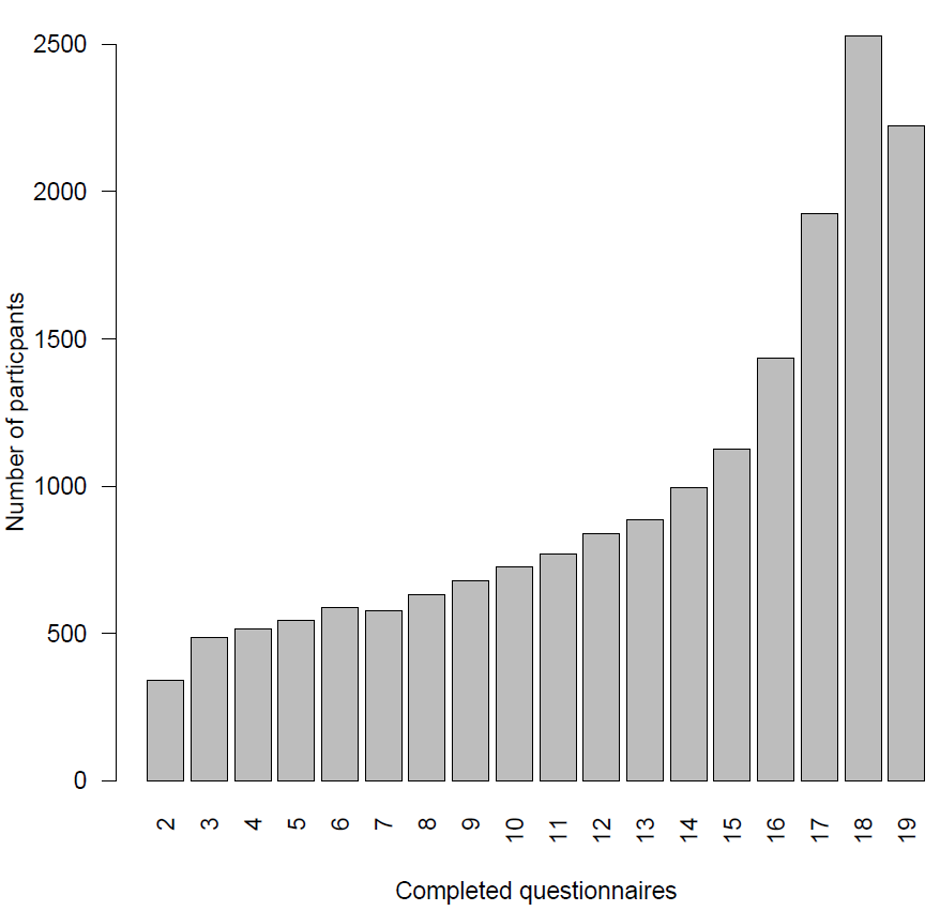
The 17,831 selected participants completed on average 13 questionnaires ranging from 2 to 19.
(PNG)
{kind=link}
Pearson r correlations between the calculated PGSs of all 27.537 participants.
(PNG)
{kind=link}
The baseline associations between PGS and the different outcomes. The baseline association are obtained by a meta-analysis over samples run on Global Screening Array and the HumanCytoSNP-12.
(PDF)
Each significant interaction between time (denoted in days starting from March 30, 2020) and PGS visualized over time, stratified by the PGS for which the interaction was observed to be significant. The 10th percentile, the median and the 90th percentile illustrate how the PGS interacts with time. On top the complete model for its respective outcome measure is presented. Herein the contributions of all terms are considered, and the temporal aspect of the outcome variable can be seen and compared with the interaction effect. The shaded areas represent the 95% confidence interval of the model fit. On the bottom only the relative contribution of the PGS is taken into consideration. Converging percentile lines indicate that the PGSs have a decreasing effect on the outcome measure. Contrariwise, diverging percentile lines indicate that a PGS has an increasing effect on the outcome measure showing that genetics play an increasingly important role.
(PDF)
The spearman correlation estimates calculated for the wellbeing and fatigue items for which the impact of genetics has significantly increased during the pandemic. The heatmap shows that the items ‘Was easily tired’, ‘Felt tired’, and ‘Felt physically exhausted’ are highly correlated (Spearman’s rho = 0.69–0.85). The item ‘Felt good is also correlated to these items (Spearman’s rho for ‘Was easily tired’ = -0.60). Quality of life is correlated to the other items as well (Spearman’s rho values for ‘Was easily tired’ and ‘Felt fine’ are equal to -0.25 and 0.25 respectively). The baseline instance of every question was used. From all 27,537 participants the pairwise complete observations were used to handle missing values.
(PNG)
{kind=link}
The rise and fall of the mean perceived quality of life coincides with the development of the COVID-19 pandemic in the Netherlands. The panels 1–3 present the confirmed COVID-19 cases, COVID-19 ICU occupancy, and stringency of the measures respectively. These figures indicate three instances with a large number of COVID-19 patients and a consequent high lockdown stringency. These instances coincide with low and decreasing mean perceived quality of life as can be seen in panel 8. The lockdown stringency is also in part reflected in the retail and recreational-related mobility, and to a lesser degree the work-related mobility (panels 4–5). Panels 6–7 present the increase of the average temperature and the hours of sunshine respectively during the spring and summer months, and their subsequent decrease during autumn and winter. Of these weather-related variables, we observe that the correlation of the mean perceived quality of life and the average temperature is especially strongly correlated (Pearson r = 0.88, p-value = 1.07×10−3). It is therefore likely that the development in the mean perceived quality of life is in part a seasonal, weather influenced, effect. However, given that mean perceived quality of life is also strongly negatively correlated with the Stringency Index (Pearson r = -0.71, p-value = 1.28×10−6), we think it is conceivable that the state of the pandemic is equally influencing the quality of life participants are experiencing.
(EPS)
The Pearson r correlation estimates calculated within 7 publicly available variables (averaged over 7 days if indicated) and the mean perceived quality of life. For each of the variables, we extracted the values that coincided with the average response dates for the questionnaires.
(PNG)
{kind=link}
We validated our findings by fitting models for each PGS and each question separately for each questionnaire. The regression coefficients of the PGS were extracted from the models and plotted according to the date of each questionnaire. The error bars represent the 95% confidence interval for the regression coefficients. The plots showed a change in regression coefficient over time which indicates that the PGS explains less or more variance of the question outcome over time.
(PDF)
Polygenic scores (PGSs) for the participants that were included in this study compared to those that were invited to take part in the Lifelines COVID-19 questionnaires, but that were not included because they either did not respond or did not pass quality control. The p-values for Welch’s t-tests are shown to indicate whether the two groups differ significantly or not. Panel A, C and E show the participants that were genotyped using the Global Screening Array. Panel B, D and F show the participants that were genotyped using the HumanCytoSNP-12 array. Panel A and B show the 27,537 baseline samples compared to all other invited samples. Panel C and D show the 17,831 samples used in longitudinal analysis compared to all other invited samples. From these, 10 out of 34 p-values are smaller than an a priori Bonferroni corrected alpha of 0.05. This indicates that a small genetic bias is introduced for the willingness to fill-in the COVID-19 questions. Panel E and F show the 27,537 baseline samples compared to the 17,831 samples used in longitudinal analysis. Herein, the differences in Educational attainment and schizophrenia are highly significant. Should all baseline samples be included in the longitudinal analysis, such differential attrition would have biased our results. This suggests that selecting a confined set of samples for longitudinal analysis was appropriate.
(PDF)
Narrow sense heritability estimates (h2) modelled over time show a significant increase for 4 out of 6 outcome items. In each of the panels the annotated r2 depicts the explained variance of the model, while the p-value represents the p-value of the effect size of the time variable. Error bars represent the standard errors of the heritability estimates. The blue line and shaded area represent the fit and the standard error of the linear model respectively.
(EPS)
Explained variances of environment (c2) based on shared households modelled over time for 6 outcomes. No significant effect of time is observed. In each of the panels the annotated r2 depicts the explained variance of the linear model, while the p-value represents the p-value of the effect size of the time variable. Error bars represent the standard errors of the estimated values. The blue line and shaded area represent the fit and the standard error of the linear model respectively.
(EPS)
(DOCX)
(DOCX)
(PDF)
(PDF)
Acknowledgments
We thank the UMCG Genomics Coordination Center, the UG Center for Information Technology and their sponsors BBMRI-NL & TarGet for storage and compute infrastructure. We thank Katherine McIntyre for the English editing of our manuscript. The authors wish to acknowledge the services of the Lifelines Cohort Study, the contributing research centers delivering data to Lifelines, all the study participants, and the contributions of the investigators to this study: Raul Aguirre-Gamboa, Patrick Deelen, Lude Franke, Jan A Kuivenhoven, Esteban A Lopera Maya, Ilja M Nolte, Serena Sanna, Harold Snieder, Morris A Swertz, Judith M Vonk and Cisca Wijmenga. The authors wish to acknowledge the efforts of the Lifelines Corona Research Initiative and the following initiative participants: H. Marike Boezen, Jochen O. Mierau, Lude H. Franke, Jackie Dekens, Patrick Deelen, Pauline Lanting, Judith M. Vonk, Ilja Nolte, Anil P.S. Ori, Annique Claringbould, Floranne Boulogne, Marjolein X.L. Dijkema, Henry H. Wiersma, C.A. Robert Warmerdam, Soesma A. Jankipersadsing and Irene V. van Blokland.
Data Availability
Results were frequently shared with participants and the general public through interactive infographics on the Corona Barometer website (https://coronabarometer.nl/). The individual-level data that support the findings in this publication were obtained from the Lifelines biobank under project application number ov20_0554. Due to privacy reasons the individual-level data can’t be made publicly available but can be made available upon reasonable request. This request should be directed to the Lifelines Research Office through email (research@lifelines.nl) or by using the application form on their website (https://www.lifelines.nl/researcher/how-to-apply/apply-here). All code that is central to this paper is made available via GitHub (https://github.com/molgenis/covid19_prs_time). Other analyses of genotype data and publicly available reference data is performed using standard bioinformatics practices, for which the code is made available upon request.
Funding Statement
LHF is supported by grants from the Dutch Research Council (ZonMW-VIDI 917.14.374 and ZonMW-VICI 09150182010019 to LHF) and by an ERC Starting Grant, grant agreement 637640 (ImmRisk) and through a Senior Investigator Grant from the Oncode Institute. PD is supported by a grant from the Dutch Research Council (ZonMW-VENI 9150161910057 to PD). The Lifelines Biobank initiative has been made possible by funding from the Dutch Ministry of Health, Welfare and Sport, the Dutch Ministry of Economic Affairs, the University Medical Center Groningen (UMCG the Netherlands), the University of Groningen, the Northern Provinces of the Netherlands, FES (Fonds Economische Structuurversterking), SNN (Samenwerkingsverband Noord Nederland) and REP (Ruimtelijk Economisch Programma). The generation and management of GWAS genotype data for the Lifelines Cohort Study is supported by the UMCG Genetics Lifelines Initiative (UGLI) and by a Spinoza Grant from NWO, awarded to Cisca Wijmenga. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Scholtens S, Smidt N, Swertz MA, Bakker SJ, Dotinga A, Vonk JM, et al. Cohort Profile: LifeLines, a three-generation cohort study and biobank. Int J Epidemiol. 2015;44: 1172–1180. doi: 10.1093/ije/dyu229 [DOI] [PubMed] [Google Scholar]
- 2.Mc Intyre K, Lanting P, Deelen P, Wiersma HH, Vonk JM, Ori APS, et al. Lifelines COVID-19 cohort: investigating COVID-19 infection and its health and societal impacts in a Dutch population-based cohort. BMJ Open. 2021;11: e044474. doi: 10.1136/bmjopen-2020-044474 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.COVID-19 Host Genetics Initiative. Mapping the human genetic architecture of COVID-19. Nature. 2021. [cited 17 Nov 2021]. doi: 10.1038/s41586-021-03767-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Robinson E, Sutin AR, Daly M, Jones A. A systematic review and meta-analysis of longitudinal cohort studies comparing mental health before versus during the COVID-19 pandemic in 2020. J Affect Disord. 2022;296: 567–576. doi: 10.1016/j.jad.2021.09.098 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Colodro-Conde L, Couvy-Duchesne B, Zhu G, Coventry WL, Byrne EM, Gordon S, et al. A direct test of the diathesis-stress model for depression. Mol Psychiatry. 2018;23: 1590–1596. doi: 10.1038/mp.2017.130 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Arnau-Soler A, Adams MJ, Clarke T-K, MacIntyre DJ, Milburn K, Navrady L, et al. A validation of the diathesis-stress model for depression in Generation Scotland. Transl Psychiatry. 2019;9: 25. doi: 10.1038/s41398-018-0356-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Chasiropoulou C, Siouti N, Mougiakos T, Dimitrakopoulos S. The diathesis-stress model in the emergence of major psychiatric disorders during military service. Psychiatr Psychiatr. 2019;30: 291–298. doi: 10.22365/jpsych.2019.304.291 [DOI] [PubMed] [Google Scholar]
- 8.Coleman JRI, Peyrot WJ, Purves KL, Davis KAS, Rayner C, Choi SW, et al. Genome-wide gene-environment analyses of major depressive disorder and reported lifetime traumatic experiences in UK Biobank. Mol Psychiatry. 2020;25: 1430–1446. doi: 10.1038/s41380-019-0546-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Brooks SK, Webster RK, Smith LE, Woodland L, Wessely S, Greenberg N, et al. The psychological impact of quarantine and how to reduce it: rapid review of the evidence. Lancet Lond Engl. 2020;395: 912–920. doi: 10.1016/S0140-6736(20)30460-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Xiong J, Lipsitz O, Nasri F, Lui LMW, Gill H, Phan L, et al. Impact of COVID-19 pandemic on mental health in the general population: A systematic review. J Affect Disord. 2020;277: 55–64. doi: 10.1016/j.jad.2020.08.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Qiu J, Shen B, Zhao M, Wang Z, Xie B, Xu Y. A nationwide survey of psychological distress among Chinese people in the COVID-19 epidemic: implications and policy recommendations. Gen Psychiatry. 2020;33: e100213. doi: 10.1136/gpsych-2020-100213 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Sun S, Goldberg SB, Lin D, Qiao S, Operario D. Psychiatric symptoms, risk, and protective factors among university students in quarantine during the COVID-19 pandemic in China. Glob Health. 2021;17: 15. doi: 10.1186/s12992-021-00663-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Yengo L, Sidorenko J, Kemper KE, Zheng Z, Wood AR, Weedon MN, et al. Meta-analysis of genome-wide association studies for height and body mass index in ∼700000 individuals of European ancestry. Hum Mol Genet. 2018;27: 3641–3649. doi: 10.1093/hmg/ddy271 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Lee JJ, Wedow R, Okbay A, Kong E, Maghzian O, Zacher M, et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat Genet. 2018;50: 1112–1121. doi: 10.1038/s41588-018-0147-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Baselmans BML, Jansen R, Ip HF, van Dongen J, Abdellaoui A, van de Weijer MP, et al. Multivariate genome-wide analyses of the well-being spectrum. Nat Genet. 2019;51: 445–451. doi: 10.1038/s41588-018-0320-8 [DOI] [PubMed] [Google Scholar]
- 16.Nagel M, Jansen PR, Stringer S, Watanabe K, de Leeuw CA, Bryois J, et al. Meta-analysis of genome-wide association studies for neuroticism in 449,484 individuals identifies novel genetic loci and pathways. Nat Genet. 2018;50: 920–927. doi: 10.1038/s41588-018-0151-7 [DOI] [PubMed] [Google Scholar]
- 17.Hill WD, Weiss A, Liewald DC, Davies G, Porteous DJ, Hayward C, et al. Genetic contributions to two special factors of neuroticism are associated with affluence, higher intelligence, better health, and longer life. Mol Psychiatry. 2020;25: 3034–3052. doi: 10.1038/s41380-019-0387-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Klimentidis YC, Raichlen DA, Bea J, Garcia DO, Wineinger NE, Mandarino LJ, et al. Genome-wide association study of habitual physical activity in over 377,000 UK Biobank participants identifies multiple variants including CADM2 and APOE. Int J Obes 2005. 2018;42: 1161–1176. doi: 10.1038/s41366-018-0120-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Karlsson Linnér R, Biroli P, Kong E, Meddens SFW, Wedow R, Fontana MA, et al. Genome-wide association analyses of risk tolerance and risky behaviors in over 1 million individuals identify hundreds of loci and shared genetic influences. Nat Genet. 2019;51: 245–257. doi: 10.1038/s41588-018-0309-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Liu M, Jiang Y, Wedow R, Li Y, Brazel DM, Chen F, et al. Association studies of up to 1.2 million individuals yield new insights into the genetic etiology of tobacco and alcohol use. Nat Genet. 2019;51: 237–244. doi: 10.1038/s41588-018-0307-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Schizophrenia Working Group of the Psychiatric Genomics Consortium. Biological insights from 108 schizophrenia-associated genetic loci. Nature. 2014;511: 421–427. doi: 10.1038/nature13595 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.International Obsessive Compulsive Disorder Foundation Genetics Collaborative (IOCDF-GC) and OCD Collaborative Genetics Association Studies (OCGAS). Revealing the complex genetic architecture of obsessive-compulsive disorder using meta-analysis. Mol Psychiatry. 2018;23: 1181–1188. doi: 10.1038/mp.2017.154 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Howard DM, Adams MJ, Shirali M, Clarke T-K, Marioni RE, Davies G, et al. Genome-wide association study of depression phenotypes in UK Biobank identifies variants in excitatory synaptic pathways. Nat Commun. 2018;9: 1470. doi: 10.1038/s41467-018-03819-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Matoba N, Liang D, Sun H, Aygün N, McAfee JC, Davis JE, et al. Common genetic risk variants identified in the SPARK cohort support DDHD2 as a candidate risk gene for autism. Transl Psychiatry. 2020;10: 265. doi: 10.1038/s41398-020-00953-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Costa PT, McCrae RR. Influence of extraversion and neuroticism on subjective well-being: Happy and unhappy people. J Pers Soc Psychol. 1980;38: 668–678. doi: 10.1037//0022-3514.38.4.668 [DOI] [PubMed] [Google Scholar]
- 26.Watson D, Pennebaker JW. Health complaints, stress, and distress: Exploring the central role of negative affectivity. Psychol Rev. 1989;96: 234–254. doi: 10.1037/0033-295x.96.2.234 [DOI] [PubMed] [Google Scholar]
- 27.Okbay A, Baselmans BML, De Neve J-E, Turley P, Nivard MG, Fontana MA, et al. Genetic variants associated with subjective well-being, depressive symptoms, and neuroticism identified through genome-wide analyses. Nat Genet. 2016;48: 624–633. doi: 10.1038/ng.3552 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Umberson D, Montez JK. Social Relationships and Health: A Flashpoint for Health Policy. J Health Soc Behav. 2010;51: S54–S66. doi: 10.1177/0022146510383501 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Xin Y, Wu J, Yao Z, Guan Q, Aleman A, Luo Y. The relationship between personality and the response to acute psychological stress. Sci Rep. 2017;7: 16906. doi: 10.1038/s41598-017-17053-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Brown GW, Harris TO. Depression and the serotonin transporter 5-HTTLPR polymorphism: A review and a hypothesis concerning gene–environment interaction. J Affect Disord. 2008;111: 1–12. doi: 10.1016/j.jad.2008.04.009 [DOI] [PubMed] [Google Scholar]
- 31.Rimfeld K, Malanchini M, Allegrini AG, Packer AE, McMillan A, Ogden R, et al. Genetic Correlates of Psychological Responses to the COVID-19 Crisis in Young Adult Twins in Great Britain. Behav Genet. 2021;51: 110–124. doi: 10.1007/s10519-021-10050-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.de Vries LP, van de Weijer MP, Pelt DHM, Ligthart L, Willemsen G, Boomsma DI, et al. Gene-by-Crisis Interaction for Optimism and Meaning in Life: The Effects of the COVID-19 Pandemic. Behav Genet. 2021. [cited 17 Jan 2022]. doi: 10.1007/s10519-021-10081-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Rimfeld K, Malanchini M, Arathimos R, Gidziela A, Pain O, McMillan A, et al. The consequences of a year of the COVID-19 pandemic for the mental health of young adult twins in England and Wales. 2021. Oct p. 2021.10.07.21264655. doi: 10.1101/2021.10.07.21264655 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Rijksinstituut voor Volksgezondheid en Milieu. COVID-19 dataset. 4 Jun 2021 [cited 7 Apr 2021]. Available: https://data.rivm.nl/covid-19/
- 35.Ministerie van Volksgezondheid W en S. Vanaf 1 juni testen mogelijk voor iedereen met milde klachten—Nieuwsbericht—Rijksoverheid.nl. Ministerie van Algemene Zaken; 27 May 2020 [cited 14 Apr 2021]. Available: https://www.rijksoverheid.nl/actueel/nieuws/2020/05/27/vanaf-1-juni-testen-mogelijk-voor-iedereen-met-milde-klachten
- 36.McAllister K, Mechanic LE, Amos C, Aschard H, Blair IA, Chatterjee N, et al. Current Challenges and New Opportunities for Gene-Environment Interaction Studies of Complex Diseases. Am J Epidemiol. 2017;186: 753–761. doi: 10.1093/aje/kwx227 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Shi M, O’Brien KM, Weinberg CR. Interactions between a Polygenic Risk Score and Non-genetic Risk Factors in Young-Onset Breast Cancer. Sci Rep. 2020;10: 3242. doi: 10.1038/s41598-020-60032-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Jolicoeur-Martineau A, Belsky J, Szekely E, Widaman KF, Pluess M, Greenwood C, et al. Distinguishing differential susceptibility, diathesis-stress, and vantage sensitivity: Beyond the single gene and environment model. Dev Psychopathol. 2020;32: 73–83. doi: 10.1017/S0954579418001438 [DOI] [PubMed] [Google Scholar]
- 39.the Haplotype Reference Consortium. A reference panel of 64,976 haplotypes for genotype imputation. Nat Genet. 2016;48: 1279–1283. doi: 10.1038/ng.3643 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Ge T, Chen C-Y, Ni Y, Feng Y-CA, Smoller JW. Polygenic prediction via Bayesian regression and continuous shrinkage priors. Nat Commun. 2019;10: 1776. doi: 10.1038/s41467-019-09718-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Sherry ST. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res. 2001;29: 308–311. doi: 10.1093/nar/29.1.308 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Purcell S, Chang C. PLINK 2.0. Available: www.cog-genomics.org/plink/2.0/
- 43.Chang CC, Chow CC, Tellier LC, Vattikuti S, Purcell SM, Lee JJ. Second-generation PLINK: rising to the challenge of larger and richer datasets. GigaScience. 2015;4. doi: 10.1186/s13742-015-0047-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.van Vliet IM, de Beurs E. [The MINI-International Neuropsychiatric Interview. A brief structured diagnostic psychiatric interview for DSM-IV en ICD-10 psychiatric disorders]. Tijdschr Voor Psychiatr. 2007;49: 393–397. [PubMed] [Google Scholar]
- 45.Koninkrijksrelaties M van BZ en. Personal Records Database (BRP)—Personal data—Government.nl. Ministerie van Algemene Zaken; 19 Oct 2017 [cited 15 Apr 2021]. Available: https://www.government.nl/topics/personal-data/personal-records-database-brp
- 46.Pinheiro J, Bates D, DebRoy S, Sarkar D, R Core Team. nlme: Linear and Nonlinear Mixed Effects Models. 2021. Available: https://CRAN.R-project.org/package=nlme [Google Scholar]
- 47.R Core Team. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing; 2008. doi: 10.1007/978-3-540-74686-7 [DOI] [Google Scholar]
- 48.Bates D, Mächler M, Bolker B, Walker S. Fitting Linear Mixed-Effects Models Using lme4. J Stat Softw. 2015;67: 1–48. doi: 10.18637/jss.v067.i01 [DOI] [Google Scholar]
- 49.Hartung J. Statistical meta-analysis with applications. Hoboken, N.J.: Wiley; 2008. Available: http://archive.org/details/statisticalmetaa0000hart [Google Scholar]
- 50.Landelijk Coördinatiecentrum Patiënten Spreiding. Datafeed. In: LCPS [Internet]. 13 Apr 2021 [cited 13 Apr 2021]. Available: https://lcps.nu/datafeed/
- 51.Hale T, Angrist N, Goldszmidt R, Kira B, Petherick A, Phillips T, et al. A global panel database of pandemic policies (Oxford COVID-19 Government Response Tracker). Nat Hum Behav. 2021. doi: 10.1038/s41562-021-01079-8 [DOI] [PubMed] [Google Scholar]
- 52.COVID-19 Community Mobility Report. In: COVID-19 Community Mobility Report [Internet]. 13 Apr 2021 [cited 13 Apr 2021]. Available: https://www.google.com/covid19/mobility
- 53.The Royal Netherlands Meteorological Institute. KNMI—Daggegevens van het weer in Nederland. 13 Apr 2021 [cited 13 Apr 2021]. Available: https://www.knmi.nl/nederland-nu/klimatologie/daggegevens