

Abstract
Purpose:
Passively generated cell-phone location (“mobility”) data originally intended for commercial use has become frequently used in epidemiologic research, notably during the COVID-19 pandemic to study the impact of physical-distancing recommendations on aggregate population behavior (e.g., average daily mobility). Given the opaque nature of how individuals are selected into these datasets, researchers have cautioned that their use may give rise to selection bias, yet little guidance exists for assessing this potential threat to validity in mobility-data research. Through an example analysis of cell-phone-derived mobility data, we present a set of conditions to guide the assessment of selection bias in measures comparing aggregate mobility patterns over time and between groups.
Methods:
We specifically consider bias in measures comparing group-level mobility in the same group (difference, ratio, percent difference) and between groups (difference in differences, ratio of ratios, ratio of percent differences). We illustrate no-bias conditions in these measures through an example comparing block-group-level mobility between income groups in U.S. metro areas before (January 1st-March 10, 2020) and after (March 11th-April 19th, 2020) the day COVID-19 was declared a pandemic.
Results:
Within-group contrasts describing mobility over time, especially for the higher-income decile, were expected to be most resistant to bias during the example study period.
Conclusions:
The presented conditions can be used to assess the susceptibility to selection bias of group-level measures comparing mobility. Importantly, they can be used even without knowledge of the degree of bias in each group at each time point. We further highlight links between no-bias principles originating in epidemiology and economics, showing that certain assumptions (e.g., parallel trends) can apply to biases beyond their original application.
Keywords: big data, epidemiologic methods, mobility, COVID-19, selection bias, difference-in-differences
INTRODUCTION
Epidemiologists conducting descriptive and etiologic research may rely on unconventional measures of population behavior derived from ‘big data.’1–3 One recent example in the early months of the COVID-19 pandemic was the urgent need to understand the impact of physical-distancing recommendations on population behavior. Researchers3–11 and journalists12–14 used data derived from cell phone GPS to quantify population movement at the aggregate level. Such passively generated location (“mobility”) data have become more available as a result of the emergent data-collection paradigm wherein global-position-system (GPS) traces of consenting users are collected by certain cell-phone apps which then send location data to commercial firms.10,15 These firms, such as Safegraph or Cuebiq, then mask, aggregate, or anonymize the data in some way and make them available for commercial or research purposes.16–18
Epidemiologists and population-health scientists interested in characterizing the relationship between community mobility and health may see both the promise and the pitfalls of the use of such ‘big data’.10,15 On the one hand, mobility data can have a high degree of measurement accuracy and a large sample size at a comparatively low cost. On the other hand, researchers may be wary that use of the data may give rise to biased estimates.19–21 This concern is relevant whether community mobility is the target for inference (e.g., describing differential response to public-health efforts to influence mobility22) or community mobility is an ecologic exposure in relation to a separate population-health outcome.8
A specific concern is selection bias,10,23 which occurs when the parameter of interest in a target population differs from its estimate in the dataset available for analysis.24,25 Research using mobility data may be particularly prone to selection bias. For one, the way observations arrive into the dataset is often opaque.26 Some firms inform users that their data may be aggregated for research or commercial purposes.18 Many firms, though, do not disclose which specific apps send them data, leading to uncertainty regarding who ends up in the analysis dataset.16–18 A second challenge is that selection occurs both between and within individuals. Not every individual in the target population may ever use an app that sends data to one of these firms. Further, those who do use these apps may only do so for certain periods of time, so only part of their daily mobility may be sampled. Considering these challenges, selection bias may threaten the validity of research using mobility data unless the target population is the analysis dataset itself.
An encouraging nuance, however, is that the presence of bias when using these data sources for epidemiologic purposes will depend on the research question and the measure used to answer that question. Specifically, bias in comparison measures (e.g., those that compare a mobility measure between groups or between time points or both) can depend on both the measure used and its scale, whether the scale is relative (as in a ratio) or absolute (as in a difference).25,27,28 Relative comparison measures are useful for considering the strength of a comparison, while absolute comparison measures are useful for understanding the overall magnitude or burden of a comparison.27,29,30 It has long been documented in epidemiology that selection bias will only distort an odds ratio—a relative measure—if selection proportions differ by both exposure and disease.24 However, the same condition does not necessarily apply for the risk ratio31—another relative measure—or the risk difference25—an absolute measure.
To inform no-bias conditions for absolute measures, the econometrics literature offers guidance, specifically the extensive literature on the difference in differences.32,33 In its classic formulation, a difference-in-differences analysis assumes that the linear difference between the outcome variable across time periods would have been the same between groups were it not for an intervention or treatment.32 This parallel-trends assumption is typically used in studies aiming to estimate causal effects, relaxing an otherwise stricter assumption of no unmeasured confounding. The same parallel-trends assumption may be useful for relaxing assumptions related to selection bias, but its utility for biases beyond those pertaining to causal inference is not commonly presented. (As a note on terminology, selection bias is sometimes used in economics to describe what epidemiologists call confounding. See page 264 of Modern Epidemiology 4th Edition (ME4)34 and Heckman [198535, 199036] for historical examples. Here, we use the term as defined above, and we do not distinguish between selection bias for descriptive versus effect measures.37) Given the range of disciplines using mobile-phone-generated mobility data, from public health and epidemiology10 to social sciences38 and transportation research,1,15 the research community would benefit from an overview of no-bias conditions inspired by both the epidemiologic and econometric traditions.
In this paper, we present conditions under which selection bias is not expected to be a threat to valid conclusions when commercially derived mobile-phone data are used to compare population mobility patterns. In an example analysis using Cuebiq® data, we describe no-bias conditions in six measures making group-level comparisons. Three of the measures (the difference, ratio, and percent difference) make within-group comparisons, and the other three (the difference in differences, ratio of ratios, and ratio of percent differences) compare within-group contrasts between groups. We consider the plausibility of each no-bias condition in a step-by-step process. We conclude by noting that certain assumptions, including the parallel trends of the difference in differences, can apply for biases beyond those for which they were initially developed. Epidemiologists and other researchers using mobility data can use these conditions to guide the choice of measures used to answer their research question and more clearly articulate assumptions regarding the presence of selection bias in those measures.
METHODS
Target population and data sources
We first describe the conditions for no bias. Then, through an example analysis, we highlight how researchers can use these conditions to make more informed conclusions about study validity with respect to selection bias. The goal of our example study is to compare the change in Census block-group-level aggregate mobility between the top and bottom deciles of median household income in U.S. metro areas before and after March 11, 2020, when WHO declared a global pandemic. That is, the outcome of interest is population mobility, and the exposures under study are the income groups and time periods. The target population is the 21,670 United States metro block groups in either the top 10th percentile of median household income for their state (j=1; n = 10,815 block groups) or the bottom 10th percentile (j=0; n = 10,855 block groups). Household income is defined by the 2014–2018 American Community Survey. We estimate mobility in this population using Cuebiq aggregated mobile phone location data, which are collected by select smartphone apps from about 15 million people anonymous users who opted in to data collection for research purposes through a GDPR and CCPA compliant framework. Cuebiq data have been used by journalists and researchers during the COVID-19 pandemic.5,7,13,14 For each device in their sample, Cuebiq calculates a mobility index, derived from the base-19 logarithm of the daily distance the device travels. The mobility index is bounded by 0 and 5.39 We were provided the median mobility index, henceforth mobility index, summarized by home census block group. Home is defined where the device is observed most often at night.
Notation and definitions of absolute and relative measures
We calculate the estimated mean mobility index, denoted as , in each income group over two time periods: before (t=0; January 1, 2020—March 10, 2020) and after March 11, 2020 (t=1; March 11, 2020—April 19, 2020). Note that we use to denote the estimated mean mobility index, but it could refer to any estimated summary measure (e.g., mean distance traveled) in any group j at time t. To compare group-level mobility over time within the same group, we estimate the difference , the ratio , and the percent difference . To compare within-group changes between groups, we estimate the difference in differences , the ratio of ratios , and the ratio of percent differences . The difference and the difference in differences are absolute measures; they keep the units of their constituent measures. The ratio, the percent difference, the ratio of ratios, and the ratio of percent differences are relative measures; their units cancel.
In Table 1, we define these estimated measures (those with the hat notation) in terms of their estimands (without the hat notation) in the target population and corresponding bias factors. Selection bias is often defined in terms of selection probabilities.24 Following the measurement-error literature,28,40,29,44 we use bias-factor notation because our focus is the bias of a continuous group-level summary measure, which is not easily expressed as a function of the proportion of underlying study participants, as in selection probabilities. The additive bias factor, αj,t, is defined as . The multiplicative bias factor, βj,t, is defined as . Estimated measures describing a contrast on the absolute scale are defined with αj,t, and estimated measures describing a contrast on the relative scale are defined with βj,t. In the main text, we assume that the sample is constant once it is drawn and thus do not conceptualize the estimates or the bias factors as random variables. In the appendix, we consider the estimates as varying between imagined study replications.
Table 1.
Definitions of the measures and their estimates defined with bias factors.
| Measure name | Scale | Estimand | Estimateb |
|---|---|---|---|
| Linear difference, Dj | Absolute | Dj = Yj,1 − Yj,0 | |
| Ratio, Rj | Relative | ||
| Percent difference,a PDj | Relative | ||
| Difference in differences, DD | Absolute | DiD = (Y1,1 − Y1,0) − (Y0,1 − Y0,0) | |
| Ratio of ratios, RR | Relative | ||
| Ratio of percent differences, RPD | Relative |
We omit the 100% multiplier for simplicity of notation; it does not affect conclusions.
For expressions involving the relative bias factor, we stipulate that βj,t ≠ 0 so that the adjacent Yj,t does not drop out of the expression, creating unusual results.
Conditions for no bias
Adapting the definition above,25 selection bias would arise if the summary measure as estimated by the Cuebiq data differed from the corresponding parameter in the broader target population. We assume the source of the systematic error is the selection process (who is in the sample?) and not measurement (how is mobility measured?). In the discussion, we comment on how the same conditions can apply for systematic measurement error.
Table 2 and Figure 1 present the conditions for no bias in the summary measures, with progressively less strict assumptions from Conditions 1 to Conditions 4.1 and 4.2. The conditions are sufficient but not necessary. We algebraically justify these conditions in Web Appendix 1. In Web Appendix 2, we consider the conditions when the bias factors are viewed as random variables. In our formulation, estimators for absolute measures are statistically unbiased by linearity of expectation, and estimators for relative measures are statistically consistent but not necessarily statistically unbiased because the expectation of a quotient of two random variables is not in general the quotient of their expectations.41 Condition 1 states that all values of are unbiased, a strict condition. Condition 2 allows bias in but states that the bias is equivalent between all groups and time periods. If Condition 2 is met on the absolute scale, then all absolute measures ( and ) are unbiased, and if it is met on the relative scale, then all relative measures (, , , and ) are unbiased.
Table 2.
Conditions sufficient for measures to be unbiased.
| Number | Descriptiona | Scale | Notationb | Sufficient for these summary measures to be unbiased. |
|---|---|---|---|---|
| 1 | There is no bias in any group in any time period. | Absolute | α0,0 = α0,1 = α1,0 = α1,1 = 0. | , |
| Relative | β0,0 = β0,1 = β1,0 = β1,1 = 1. | , , , | ||
| 2 | Bias is the same in all groups and time periods. | Absolute | α0,0 = α0,1 = α1,0 = α1,1 = α. | , |
| Relative | 0 ≠ β0,0 = β0,1 = β1,0 = β1,1 = β. | , , , | ||
| 3.1. | Bias is the same between time periods within group. | Absolute | α0,0 = α0,1 = α0,t, and α1,0 = α1,1 = α1,t. | , |
| Relative | 0 ≠ β0,0 = β0,1 = β0,t, and 0 ≠ β1,0 = β1,1 = β1,t. | , , , | ||
| 3.2. | Bias is the same between groups within time period. | Absolute | α0,0 = α1,0 = αj,0, and α0,1 = α1,1 = αj,1. | |
| Relative | 0 ≠ β0,0 = β1,0 = βj,0, and 0 ≠ β0,1 = β1,1 = βj,1. | |||
| 4.1. | The between-time-period trend in bias is the same between groups. | Absolute | α1,1 − α1,0 − α0,1 − α0,0 = αj,1 − αj,0. | |
| Relative | . | |||
| 4.2. | The between-group trend in bias is the same between time periods. | Absolute | α1,1 − α0,1 − α1,0 − α0,0 = α1,t − α0,t. | |
| Relative | . | |||
| 5 | Neither the between-time-period trend in bias is the same between groups, nor is the between-group trend in bias the same between time periods. | Absolute | α1,1 − α1,0 ≠ α0,1 − α0,0 and α1,1 − α0,1 ≠ α1,0 − α0,0. | None |
| Relative | . | None |
The meaning of the word trend in conditions 4.1. and 4.2 depends on the scale. Please refer to the notation for further precision.
For expressions involving the multiplicative bias factor, we stipulate that βj,t ≠ 0 so that the adjacent Yj,t does not drop out of the expression, creating unusual results.
Figure 1.
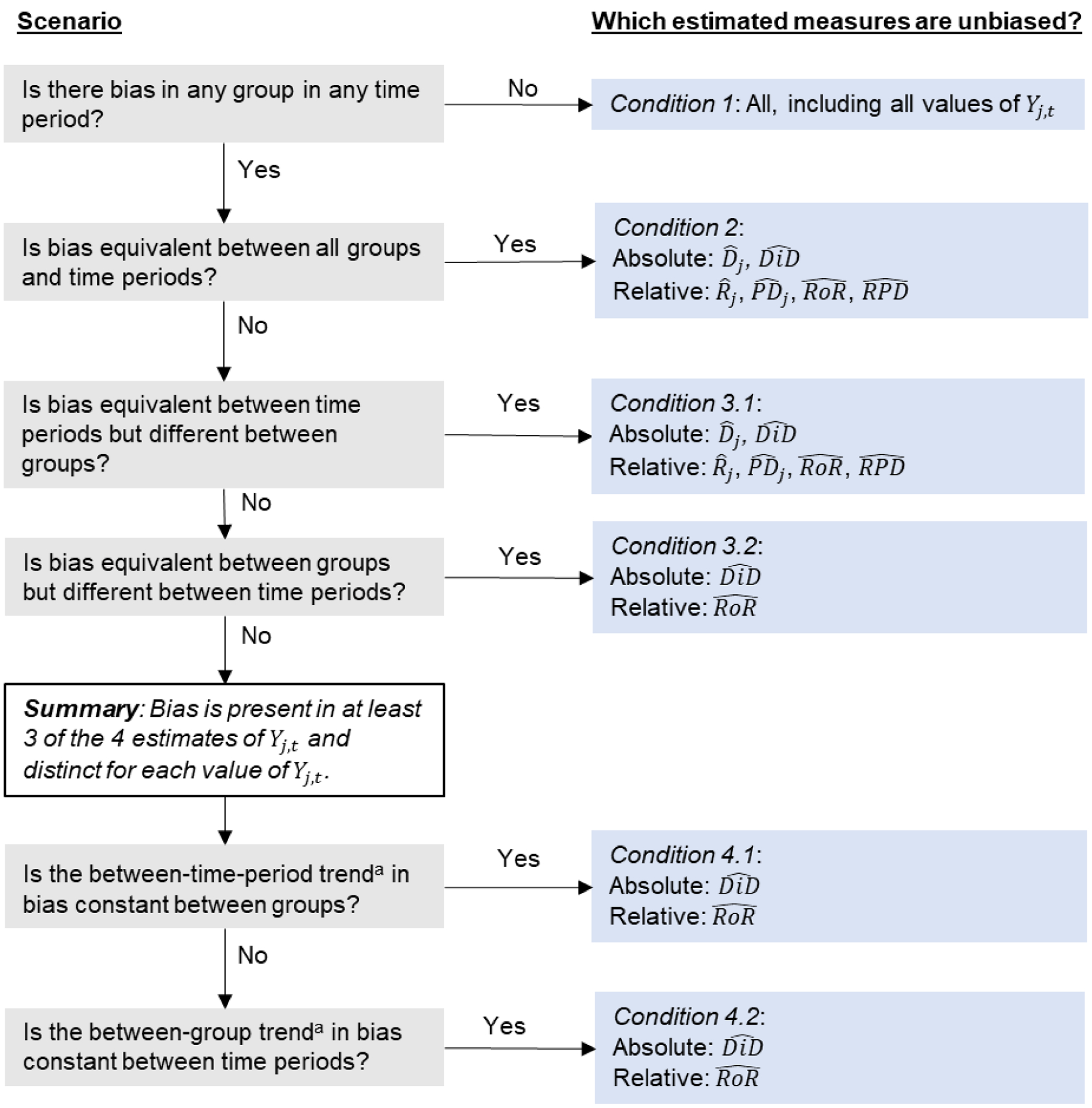
Flow chart of the bias patterns.
aThe precise meaning of the word trend in Conditions 4.1 and 4.2 depends on the scale. Please refer to the notation in Table 2 for further precision.
Under Conditions 3.1 and 3.2, bias may vary between groups or between time periods, but not both. If Condition 3.1 is met on the absolute scale, then all absolute measures are unbiased, and if it is met on the relative scale, then all relative measures are unbiased. Under Condition 3.2, bias differs between time periods but is equivalent between groups. If this pattern is met additively, then only is unbiased, and if met multiplicatively, then only is unbiased.
Under Conditions 4.1 and 4.2, bias is distinct in each of the four group-time combinations, but either the between-time-period trend in bias is constant between groups (4.1), or the between-group trend in bias is constant between time periods (4.2). If Condition 4.1 is met on the absolute scale, then only the is expected to be unbiased. This condition is the classic parallel-trends assumption in difference-in-differences analyses.32 Meanwhile, if Condition 4.1 is met on the relative scale, then only is unbiased. If Condition 4.2 is met on the absolute scale, then is again expected to be unbiased, as justified by the same difference-in-differences assumptions. If Condition 4.2 is met on the relative scale, then only , but not , is expected to be unbiased. Note that Conditions 4.1 and 4.2 suffice for but not for because the ratio of ratios is a cross-product ratio,42 so it is invertible like an odds ratio,43,47 whereas the ratio of percent differences, like a risk ratio, is not generally invertible.
Finally, if bias is distinct for each value of , and there is neither a constant temporal trend in bias between groups nor a constant between-group trend in bias between time periods, then no measures are expected to be unbiased.
RESULTS
The estimated mean daily mobility index by group is presented in Figure 2. The estimated summary measures and the least restrictive condition(s) under which they are unbiased are also presented in Table 3. Between January 1st and March 10th of 2020, the top 10th percentile had an average mobility index of 3.88, which fell to 1.74 between March 11th and April 19th. Meanwhile, the bottom 10th percentile had an average mobility index of 3.77 before March 11th and 3.14 thereafter.
Figure 2.
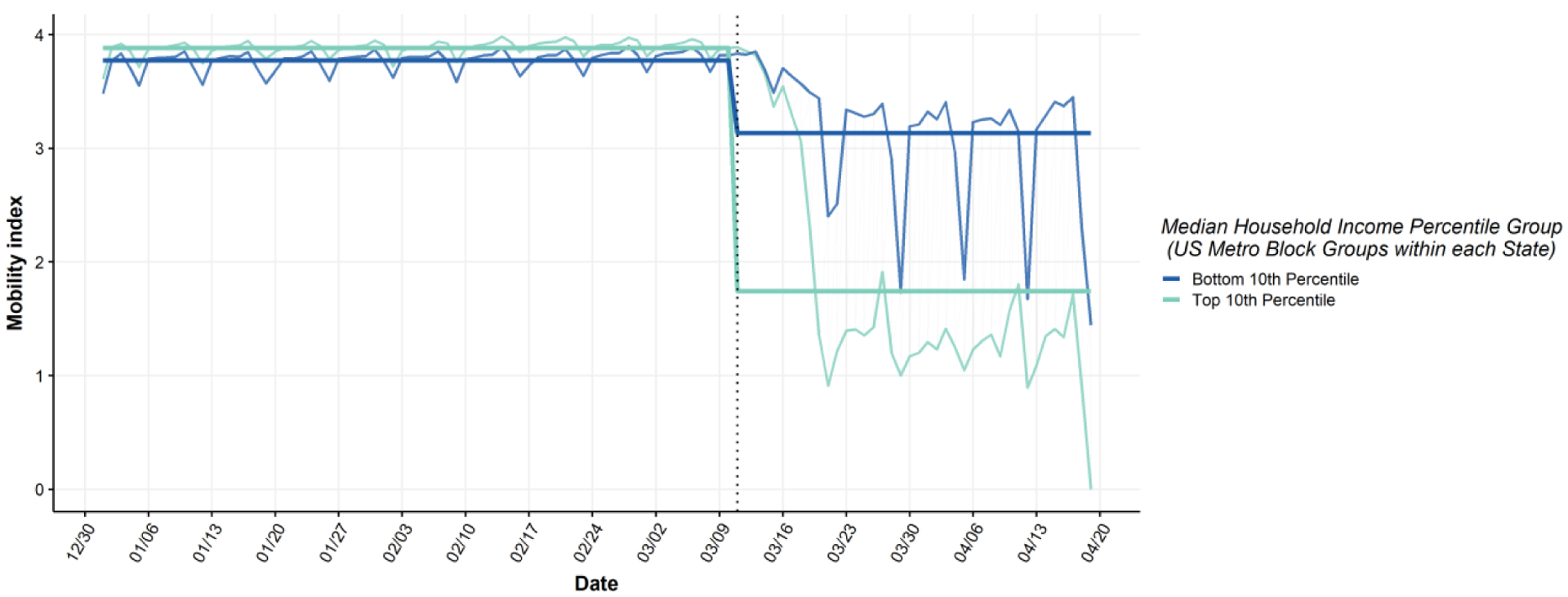
Daily mobility index among US metro block groups in the top and bottom 10th percentile of median household income before (January 1st-March 10th) and after (March 11th-April 19th) the WHO declaration of COVID-19 as a global pandemic. Household income is defined by the 2014–2018 American Community Survey.
Table 3.
Comparing estimated mean mobility index within and between groups in US metro block groups in the top 10th and bottom 10th state-specific percentiles before (January 1, 2020-March 1, 2020) and after (March 11, 2020-April 19, 2020) the WHO announced a global pandemic.
| Estimated mean mobility in each time point | Within-group estimated measures | Between-group estimated measures | ||||||
|---|---|---|---|---|---|---|---|---|
| t=0 | t=1 | |||||||
| Top 10th percentile, j = 1 | 3.88 | 1.74 | −2.14 | 0.45 | −55.2% | −1.51 | 0.54 | 3.27 |
| Bottom 10th percentile, j = 0 | 3.77 | 3.14 | −0.64 | 0.83 | −16.9% | |||
| Least strict condition(s) sufficient for unbiasedness | 1 | 1 | 3.1 | 3.1 | 3.1 | 4.1, 4.2 | 4.1, 4.2 | 3.1 |
Following the stepwise process in Figure 1, we consider the plausibility of each condition. The mobility measures by group and time period are only unbiased—stated circularly—if they are unbiased (Condition 1). Smartphone adoption has risen to about 80% in the United States,44 but unequal access persists both to the devices themselves48 and to the high-speed networks they rely on.45 Thus, at the outset, we expect that there may have been bias in at least one group during at least one period, ruling out Condition 1.
Measures comparing time periods or groups have less strict no-bias conditions. Differential access to smartphones between income groups also suggests that neither Condition 2 nor Condition 3.2 is met. One may plausibly assume, however, that any bias in the mobility index between income groups was stable over time within group (Condition 3.1), given the short timeframe of the study (January 1, 2020-April 19, 2020). If so, then in each group the estimated difference (; ), ratio (; ), and percent difference (; ) would be valid. On the other hand, the pandemic initially had a strikingly disparate economic impact.46,47 Unexpected job loss combined with limited savings48 may have resulted in difficulty paying phone bills for the lower-income group during this time period.49 As a result, Condition 3.1. is more plausible for the high-income decile. Still, for this short period, Condition 3.1 is defensible even for the low-income decile, as major phone carriers and lenders were encouraged by the Federal Communication Commission and the Federal Reserve to offer leniency on payment plans in March and April of 2020.50,51
To assess the validity of the between-group measures, we consider Conditions 4.1 and 4.2, which are less stringent than Conditions 3.1 and 3.2. The plausibility of these conditions for this example again largely depends on the extent to which smartphone use was disrupted in the low-income group after March 11th. We assume the disruption was negligible for this short study period and thus that the discrepancy in bias between groups was constant over time (Condition 4.2), meaning the difference-in-differences and the ratio of ratios would have been valid.
Summarizing, for this study, we expect the three measures comparing mobility over time in the high-income decile (; ; ) are the least susceptible to selection bias. Even if Cuebiq’s sample is biased at each time point in the high-income group, if the bias was constant over time (Condition 3.1), as is plausible given the pandemic’s limited immediate economic impact on the high-income group, then these estimates would be valid. For reasons mentioned, we are cautiously confident in the validity of the between-group contrast measures (; ; ) and the within-group contrasts for the lower-income decile (; ; ).
DISCUSSION
Passive cell-phone-generated location (“mobility”) data have become commonly used in epidemiologic research and practice, most prominently for COVID-19 epidemiology.6,8–11 Beyond COVID-19, additional epidemiologic topics include migration patterns following severe weather,52 active transportation,15 and other health-relevant topics.38 Making inference on the relationship between an aggregate population behavior (e.g., average daily mobility) and a health outcome requires clarity on the validity of the measures derived from data sources not originally intended for epidemiological research. In this paper, we use the example of cell-phone mobility to describe assumptions needed to make unbiased estimates of certain measures describing population behavior from a source of big data, with attention to the problem of differential selection into the big dataset. Informed by no-bias principles in epidemiology and economics,25,31,32 we specifically described a set of conditions that can be used to guide the assessment of selection bias in measures comparing aggregate mobility patterns.
A practical advantage of the conditions is that they can be used to consider the presence of bias in comparison measures even if the degree of bias is not known in any of the groups under study at any time. In our example, we did not know the true population parameter for any of the four values of this mobility index in the group-by-time contingency table. Acquiring that knowledge would have required information on the movement patterns of all individuals in our target population of the 21,670 United States metro block groups in the two income deciles over the course of the study period, or at least a representative summary measure known to be correct. That information was not feasible to collect. We thus used the stepwise process highlighted in Figure 1 to consider which comparison measures may suffer least from selection bias. In this example, we reasoned that within-group measures comparing mobility over time in the higher-income decile were probably least resistant to bias and thus could choose to calculate these measures and present this rationale, assumptions, and conclusions accordingly.
In addition to helping to guide the choice of measure to answer the research question, consideration of these conditions can help readers critically evaluate existing journalism and literature using mobility data. In their early reporting on the pandemic, The New York Times reported relative changes in mobility patterns using a percent difference.14 As they implied, the relative measure is less susceptible to bias than if they had reported group-specific absolute measures over time.6 This manuscript offers justification for their approach; Condition 3.1 would suffice. Researchers have also used comparison measures when describing changes in mobility over the course of the pandemic.6,9 Jay and colleagues used a difference-in-differences approach to assess changes in population mobility between groups using Safegraph data.6 As in our analysis, the time period of that study was fairly short (January 6th-May 3rd, 2020). Thus, either Condition 4.1 or Condition 4.2 is likely to have been met, suggesting the DiD estimate was robust to selection bias.
As noted in the introduction, the presented conditions are not new. Some have long been used in epidemiology,25,31 while others have a history of use in economics.32 By presenting them together in this manner, we hope to emphasize links between the conditions and that their principles can apply for biases beyond those for which they were developed. On page 321 of ME 4,24 the expression of the odds ratio with inverse-selection weights in Equation 14–2 is analogous to the definition of the ratio-of-ratios estimate in this manuscript’s Table 1. Both are cross-product ratios42,53 with multiplicative factors applied in each of the four cells of the contingency table. Conditions 3.1, 3.2, 4.1, and 4.2 are variations of the axiom that there is only bias in an odds ratio when selection is associated with both exposure and outcome.24,25,31 Alternatively stated, these conditions are sufficient for the overall selection bias factor in ME4’s Equation 14–1 to be one (“…no bias occurs if the selection bias factor is one [p. 322].”).
Perhaps a more novel insight is our illustration that the parallel-trends assumption from difference-in-differences analyses can be used to reason with selection bias. The DiD approach is typically used to relax no-confounding assumptions related to causal inference.37 Our presentation shows that the core principle of the DiD—that bias can cancel when two differences are taken—can also apply when the bias in view is selection bias rather than confounding. Conditions 4.1 and 4.2 also underscore that the above-noted adage from epidemiology, that bias in an odds ratio only manifests when selection is associated with both exposure and outcome,24,25,31 essentially invokes the parallel-trends assumption of the DiD on a different scale. This point is also illustrated by Athey and Imbens, whose change-in-changes model relaxes the additive-scale-dependence of the DiD.54
Although not the present focus, the no-bias conditions may also be useful for addressing measurement error55 in research using mobile-phone data. For example, Hunter and colleagues used passively generated location data to classify and quantify walking behavior.7 Suppose walking were measured with systematic error, but that this bias did not differ additively between income groups or time periods. If so, then Condition 2 would apply, and the corresponding additive summary measures comparing walking within and between groups would be valid.
In summary, skepticism regarding selection bias is certainly warranted when using passively generated mobility data. Nevertheless, certain comparison measures may be rather resistant to bias. Researchers across disciplines using mobile-phone-generated data may use these conditions to guide the choice of comparison measure and to assess the susceptibility of those measures to selection bias.
Supplementary Material
Acknowledgments:
We thank Dr. Dana Flanders for helpful comments.
Funding:
This work was supported in part by the National Heart, Lung, and Blood Institute (F31HL143900). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Michael Garber reports financial support was provided by National Institutes of Health.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Conflicts of interest: none declared.
References
- 1.Chen C, Ma J, Susilo Y, Liu Y, Wang M. The promises of big data and small data for travel behavior (aka human mobility) analysis. Transp Res Part C Emerg Technol. 2016;68:285–299. doi: 10.1016/j.trc.2016.04.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Kamel Boulos MN, Resch B, Crowley DN, et al. Crowdsourcing, citizen sensing and sensor web technologies for public and environmental health surveillance and crisis management: Trends, OGC standards and application examples. Int J Health Geogr. 2011;10:1–29. doi: 10.1186/1476-072X-10-67 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Buckee CO, Balsari S, Chan J, et al. Aggregated mobility data could help fight COVID-19. Science. 2020;368(6487):145–146. doi: 10.1126/science.abb8021 [DOI] [PubMed] [Google Scholar]
- 4.Klein B, Larock T, Mccabe S, et al. Assessing changes in commuting and individual mobility in major metropolitan areas in the United States during the COVID-19 outbreak. Published online 2020:1–29. [Google Scholar]
- 5.Bakker M, Berke A, Groh M, Moro E. Effect of Social Distancing Measures in the New York City Metropolitan Area.
- 6.Jay J, Bor J, Nsoesie E, et al. Neighborhood income and physical distancing during the COVID-19 pandemic in the U.S. Nat Hum Behav. Published online 2020:2020.06.25.20139915. doi: 10.1038/s41562-020-00998-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hunter RF, Garcia L, de Sa TH, et al. Effect of COVID-19 response policies on walking behavior in US cities. Nat Commun. 2021;12(1):1–12. doi: 10.1038/s41467-021-23937-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Kephart JL, Delclòs-Alió X, Rodríguez DA, et al. The effect of population mobility on COVID-19 incidence in 314 Latin American cities: a longitudinal ecological study with mobile phone location data. Lancet Digit Health. Published online 2021:716–722. doi: 10.1016/s2589-7500(21)00174-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Kang Y, Gao S, Liang Y, Li M, Rao J, Kruse J. Multiscale dynamic human mobility flow dataset in the U.S. during the COVID-19 epidemic. Sci Data. 2020;7(1):1–13. doi: 10.1038/s41597-020-00734-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Grantz KH, Meredith HR, Cummings DAT, et al. The use of mobile phone data to inform analysis of COVID-19 pandemic epidemiology. Nat Commun 2020 111. 2020;11(1):1–8. doi: 10.1038/s41467-020-18190-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Fletcher KM, Espey J, Grossman MK, et al. Social vulnerability and county stay-at-home behavior during COVID-19 stay-at-home orders, United States, April 7–April 20, 2020. Ann Epidemiol. 2021;64:76–82. doi: 10.1016/j.annepidem.2021.08.020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Out in the open - Democracies contain epidemics most effectively | Graphic detail. The Economist. Published 2020. Accessed June 15, 2020. https://www.economist.com/graphic-detail/2020/06/06/democracies-contain-epidemics-most-effectively [Google Scholar]
- 13.Valentino-DeVries J, Lu D, Dance GJX. Location Data Says It All: Staying at Home During Coronavirus Is a Luxury. The New York Times. https://www.nytimes.com/interactive/2020/04/03/us/coronavirus-stay-home-rich-poor.html. Published 2020. Accessed May 2, 2020. [Google Scholar]
- 14.Glanz J, Carey B, Holder J, et al. Where America Didn’t Stay Home Even as the Virus Spread. The New York Times. https://www.nytimes.com/interactive/2020/04/02/us/coronavirus-social-distancing.html. Published 2020. Accessed May 2, 2020. [Google Scholar]
- 15.Lee K, Sener IN. Emerging data for pedestrian and bicycle monitoring: Sources and applications. Transp Res Interdiscip Perspect. 2020;4(xxxx):100095. doi: 10.1016/j.trip.2020.100095 [DOI] [Google Scholar]
- 16.Privacy Policy. SAFEGRAPH. Accessed February 28, 2022. https://www.safegraph.com/privacy-policy
- 17.Smith G. Privacy and Accountability: Why We Created a Sensitive Points of Interest Policy. https://www.cuebiq.com/resource-center/resources/privacy-accountability-sensitive-points-of-interest-policy/
- 18.Privacy Center - Cuebiq. Accessed November 26, 2020. https://www.cuebiq.com/about/privacy-commitment/
- 19.Kaye K. The dangers of using flawed location data to fight COVID-19. Fast Company. https://www.fastcompany.com/90489173/flawed-incomplete-smartphone-location-data-is-being-used-to-fight-covid-19. Published April 14, 2020. Accessed May 5, 2020. [Google Scholar]
- 20.Griffin GP, Mulhall M, Simek C, Riggs WW. Mitigating Bias in Big Data for Transportation. J Big Data Anal Transp. 2020;2(1):49–59. doi: 10.1007/s42421-020-00013-0 [DOI] [Google Scholar]
- 21.Vanderklaauw N, Sansum H, Pestre G. Investigating Bias in SARS-CoV-2 Social Distancing Metrics Using Simulated Human Mobility Data. Preprint. 2020;(May):1–25. [Google Scholar]
- 22.Armstrong DA, Lebo MJ, Lucas J. Do COVID-19 policies affect mobility behaviour? evidence from 75 Canadian and American cities. Can Public Policy. 2020;46:S127–S144. doi: 10.3138/CPP.2020-062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Garber MD, Watkins KE, Kramer MR. Comparing bicyclists who use smartphone apps to record rides with those who do not: Implications for representativeness and selection bias. J Transp Health. 2019;15. doi: 10.1016/j.jth.2019.100661 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Lash TL, Rothman KJ. Selection Bias and Generalizability. In: Lash TL, VanderWeele TJ, Haneuse S, Rothman KJ, eds. Modern Epidemiology. 4th Edition. Wolters Kluwer; 2021. [Google Scholar]
- 25.Hernán MA. Invited commentary: Selection bias without colliders. Am J Epidemiol. 2017;185(11):1048–1050. doi: 10.1093/aje/kwx077 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Mooney SJ, Garber MD. Sampling and Sampling Frames in Big Data Epidemiology. Curr Epidemiol Rep. 2019;6(1):14–22. doi: 10.1007/s40471-019-0179-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.King NB, Harper S, Young ME. Use of relative and absolute effect measures in reporting health inequalities: Structured review. BMJ Online. 2012;345(7878):e5774–e5774. doi: 10.1136/bmj.e5774 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Heid IM, Küchenhoff H, Miles J, Kreienbrock L, Wichmann HE. Two dimensions of measurement error: Classical and Berkson error in residential radon exposure assessment. J Expo Anal Environ Epidemiol. 2004;14(5):365–377. doi: 10.1038/sj.jea.7500332 [DOI] [PubMed] [Google Scholar]
- 29.VanderWeele T. Explanation in Causal Inference: Methods for Mediation and Interaction. Oxford University Press; 2015. [Google Scholar]
- 30.Harper S, King NB, Meersman SC, Reichman ME, Breen N, Lynch J. Implicit Value Judgments in the Measurement of Health Inequalities. MILBANK Q. 2010;88(4):4–29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Greenland S. Response and Follow-up Bias in Cohort Studies. Am J Epidemiol. 1977;106(3). doi: 10.1093/aje/kwx106 [DOI] [PubMed] [Google Scholar]
- 32.Lechner M. The Estimation of Causal Effects by Difference-in-Difference Methods. Found Trends® Econom. 2010;4(3):165–224. doi: 10.1561/0800000014 [DOI] [Google Scholar]
- 33.Wing C, Simon K, Bello-Gomez RA. Designing Difference in Difference Studies: Best Practices for Public Health Policy Research. Annu Rev Public Health. 2018;39:453–469. doi: 10.1146/annurev-publhealth-040617-013507 [DOI] [PubMed] [Google Scholar]
- 34.VanderWeele TJ, Rothman KJ, Lash TL. Confounding and Confounders. In: Lash TL, VanderWeele TJ, Haneuse S, Rothman KJ, eds. Modern Epidemiology. 4th Edition. Wolters Kluwer; 2021. [Google Scholar]
- 35.Heckman JJ, Robb R. ALTERNATIVE METHODS FOR EVALUATING THE IMPACT OF INTERVENTIONS An Overview. Vol 30.; 1985:239–267. [Google Scholar]
- 36.Heckman J. Varieties of Selection Bias. Am Econ Rev. 1990;80(2):313–318. [Google Scholar]
- 37.Smith LH. Selection Mechanisms and Their Consequences: Understanding and Addressing Selection Bias. Curr Epidemiol Rep. 2020;7(4):179–189. doi: 10.1007/s40471-020-00241-6 [DOI] [Google Scholar]
- 38.Saxon J. Empirical Measures of Park Use in American Cities, and the Demographic Biases of Spatial Models. Geogr Anal. Published online 2020. doi: 10.2139/ssrn.3502949 [DOI] [Google Scholar]
- 39.Cuebiq’s COVID-19 Mobility Index (CMI). https://help.cuebiq.com/hc/en-us/articles/360041285051-Cuebiq-s-COVID-19-Mobility-Index-CMI-
- 40.Armstrong BG. Effect of measurement error on epidemiological studies of environmental and occupational exposures. Occup Environ Med. 1998;55(10):651–656. doi: 10.1136/oem.55.10.651 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Lehman E, Leighton FT, Meyer AR. Expectation. In: Mathematics for Computer Science. Samurai Media Limited; 2010:467–492. [Google Scholar]
- 42.Armitage P. The Use of the Cross-Ratio in Aetiological Surveys. J Appl Probab. 1975;12(S1):349–355. doi: 10.1017/s0021900200047768 [DOI] [Google Scholar]
- 43.Cummings P. The relative merits of risk ratios and odds ratios. Arch Pediatr Adolesc Med. 2009;163(5):438–445. doi: 10.1001/archpediatrics.2009.31 [DOI] [PubMed] [Google Scholar]
- 44.Demographics of Mobile Device Ownership and Adoption in the United States | Pew Research Center. Accessed May 7, 2020. https://www.pewresearch.org/internet/fact-sheet/mobile/#who-is-smartphone-dependent
- 45.Friedline T, Chen Z. Digital Redlining and the Fintech Marketplace: Evidence from U.S. Zip Codes. J Consum Aff. Published online 2020. doi: 10.1111/joca.12297 [DOI] [Google Scholar]
- 46.Saraiva C. How a ‘K-Shaped’ Recovery Is Widening U.S. Inequality. The Washington Post. https://www.washingtonpost.com/business/how-a-k-shaped-recovery-is-widening-us-inequality/2020/12/10/baa6bc08-3aad-11eb-aad9-8959227280c4_story.html. Published 2020. Accessed April 25, 2021. [Google Scholar]
- 47.Tracking the COVID-19 Recession’s Effects on Food, Housing, and Employment Hardships. Center on Budget and Policy Priorities; 2021. Accessed April 25, 2021. https://www.cbpp.org/research/poverty-and-inequality/tracking-the-covid-19-recessions-effects-on-food-housing-and [Google Scholar]
- 48.Morrissey M. The State of American Retirement Savings. Economic Policy Institute; Accessed April 25, 2021. https://www.epi.org/publication/the-state-of-american-retirement-savings/ [Google Scholar]
- 49.Vogels EA, Perrin A, Rainie L, Anderson M. 53% of Americans Say Internet Has Been Essential During COVID-19 Outbreak. Pew Research Center; 2020. Accessed May 3, 2021. https://www.pewresearch.org/internet/2020/04/30/53-of-americans-say-the-internet-has-been-essential-during-the-covid-19-outbreak/ [Google Scholar]
- 50.Keep Americans Connected. Federal Communications Commission. Accessed May 3, 2021. https://www.fcc.gov/keep-americans-connected
- 51.Federal Reserve Board - Agencies encourage financial institutions to meet financial needs of customers and members affected by coronavirus. Accessed May 3, 2021. https://www.federalreserve.gov/newsevents/pressreleases/bcreg20200309a.htm
- 52.Acosta R, Kishore N, Irizarry R, Buckee C. Quantifying the Dynamics of Migration after a Disaster: Impact of Hurricane Maria in Puerto Rico. Published online 2020:1–7. doi: 10.1101/2020.01.28.20019315 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Gart JJ. The Analysis of Ratios and Cross-Product Ratios of Poisson Variates with Application to Incidence Rates. Commun Stat - Theory Methods. 1978;7(10):917–937. doi: 10.1080/03610927808827683 [DOI] [Google Scholar]
- 54.Athey S, Imbens GW. Identification and inference in nonlinear difference-in-differences models. Econometrica. 2006;74(2):431–497. doi: 10.1111/j.1468-0262.2006.00668.x [DOI] [Google Scholar]
- 55.Thomas D, Stram D, Dwyer J. Exposure measurement error: Influence on exposure-disease relationships and methods of correction. Annu Rev Public Health. 1993;14:69–93. doi: 10.1146/annurev.pu.14.050193.000441 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.