

Summary:
In data collection for predictive modeling, under-representation of certain groups, based on gender, race/ethnicity, or age, may yield less-accurate predictions for these groups. Recently, this issue of fairness in predictions has attracted significant attention, as data-driven models are increasingly utilized to perform crucial decision-making tasks. Existing methods to achieve fairness in the machine learning literature typically build a single prediction model in a manner that encourages fair prediction performance for all groups. These approaches have two major limitations: i) fairness is often achieved by compromising accuracy for some groups; ii) the underlying relationship between dependent and independent variables may not be the same across groups. We propose a Joint Fairness Model (JFM) approach for logistic regression models for binary outcomes that estimates group-specific classifiers using a joint modeling objective function that incorporates fairness criteria for prediction. We introduce an Accelerated Smoothing Proximal Gradient Algorithm to solve the convex objective function, and present the key asymptotic properties of the JFM estimates. Through simulations, we demonstrate the efficacy of the JFM in achieving good prediction performance and across-group parity, in comparison with the single fairness model, group-separate model, and group-ignorant model, especially when the minority group’s sample size is small. Finally, we demonstrate the utility of the JFM method in a real-world example to obtain fair risk predictions for under-represented older patients diagnosed with coronavirus disease 2019 (COVID-19).
Keywords: algorithmic bias, algorithmic fairness, joint estimation, under-represented population
1. Introduction
1.1. Applied Context
The issue of making fair predictions has attracted significant attention recently in machine learning as a critical issue in the application of data-driven models. Though machine learning models are increasingly utilized to perform crucial decision-making tasks, recent evidence reveals that many carefully designed algorithms can learn biases from the underlying data and exploit these inequities when making predictions. For example, large systematic biases in prediction performance have been detected for machine learning models in areas such as recidivism prediction relative to race (Angwin et al., 2016), ranking of job candidates relative to gender (Lahoti et al., 2018) and face recognition relative to both race and gender (Ryu et al., 2018; Buolamwini and Gebru, 2018).
There is an emerging recognition that such biases in data often leads to unfair performance from predictive models in healthcare for certain groups (Char et al., 2018), such as women (Larrazabal et al., 2020), ethnic and racial minorities (Seyyed-Kalantari et al., 2020; Chen et al., 2021), and individuals with public insurance (Seyyed-Kalantari et al., 2020; Chen et al., 2021). Biased representations of different populations in biomedical studies, and the under-performance for under-represented populations, limit the potential benefits that can be achieved for these communities. In particular, when model-based predictions are used to prioritize patients for rationed services (e.g. organ transplantation, care management programs, or ICU services), under-performance for the under-represented patient populations will lead to unfair treatments for these patients (Paulus and Kent, 2020).
A particularly motivating example that we use in this paper is the mortality prediction for patients infected with coronavirus disease 2019 (COVID-19). As of January 23 2021, COVID-19 has infected more than 96 million people globally, accounting for more than 2 million known deaths. Older patients are particularly vulnerable to severe outcomes and death due to COVID-19. The Centers for Disease Control and Prevention (CDC) reported that the fatality rate was 18.8% for patients older than 80 years whereas the overall fatality rate is estimated at 5% or less for all patients (Kompaniyets and Goodman, 2021). This difference in survival highlights an urgent need for risk stratification of older patients with COVID-19 based on routine clinical assessments. However, most COVID-19 studies have not been stratified by age groups (Tehrani et al., 2021). Thus, as an example, when applying a risk prediction equation generated from the general population to older patients with COVID-19, the model in Tehrani et al. (2021) predicts high-risk scores overall due to their older age, higher prevalence of comorbidities and more laboratory abnormalities. This resulted in insufficient and unfair risk stratification for these patients as not all older patients are at the same risk of death from COVID-19 (Tehrani et al., 2021).
1.2. Existing Approaches
Methods to address fairness in the machine learning literature typically begin with a formal probabilistic definition of fairness. In the context of risk prediction, predictive fairness at the group level means that a risk prediction model has performance characteristics (such as accuracy, ranking, or calibration) that are relatively independent of group membership. For example, if the false positive rate for a classification model is defined as , where is the model’s prediction, then enforcing equality can be stated as requiring that these distributions be as close as possible between groups. Other definitions include demographic parity (Calders et al., 2009), equalized odds or equal opportunity (Hardt et al., 2016), disparate treatment, and impact and mistreatment (Zafar et al., 2019, 2017a). It is well-recognized that there is no unique optimal way to define fairness, leading to trade-offs between different approaches (Zafar et al., 2017b).
Given a fairness criterion, the second component of a fairness strategy requires an algorithmic approach, typically consisting of either 1) pre-processing the data by mapping the training data to a transformed space where the dependencies between sensitive attributes and class labels disappear (Kamiran and Calders, 2012; Dwork et al., 2018); or 2) post-processing of a trained prediction model; for example, (Kamishima et al., 2012; Hardt et al., 2016) modify the probability of the decision being positive and negative predictions from an existing classifier to limit unfair discrimination; or 3) “in-process” methods, where fairness is accounted for during training of a model by adding a fairness constraint to the objective function. Examples of in-process methods include Zemel et al. (2013) who proposed to learn a fair representation of the data and classifier parameters by optimizing a non-convex function, and Zafar et al. (2017b) who defined a convex function as a measure of (un)fairness and suggested optimizing accuracy subject to the convex fairness constraints as well as their converse.
A key feature of nearly all existing approaches is that a single set of classifier parameters is estimated using fairness criteria that encourage fair prediction performance across all groups. This approach has two main limitations: i) fairness is often achieved by compromising accuracy of some groups; ii) the underlying relationship between dependent and independent variables may not be the same across groups, and the differences in predictive features may be of interest. In the example of predicting mortality risk for patients with COVID-19, while one would expect some features to have the same association with mortality for both older and younger patients, the associations between mortality and other features may be different between age groups. For instance, being overweight or obese (Body Mass Index [BMI] > 25kg/m2) increases the risk for mortality associated with COVID-19, particularly among adults aged < 65 years (Kompaniyets and Goodman, 2021) However, geriatric BMI guidelines are different from those for younger adults. For older adults, higher BMIs are often associated with greater energy stores and a better nutritional state overall, which is beneficial for patients’ survival outcomes when serious infections develop.
Estimating separate prediction models for each group does not leverage potential similarities between the groups. Moreover, estimating a single prediction model, even while using fairness criteria, will likely result in sub-optimal estimation or prediction performance for one group in order to achieve fair performance with a single set of parameters shared across groups. Outside the context of algorithmic fairness, Danaher et al. (2014) proposed the joint graphical lasso method, a technique for jointly estimating multiple models corresponding to distinct but related conditions. Their approach is based upon a penalized log-likelihood approach, which penalizes the differences between parameter estimates across groups. Penalized log-likelihood approaches have often been used by other authors like Yuan and Lin (2007), Friedman et al. (2007b) etc. for similar estimation purposes while minimizing the disparities in estimates across groups. In all such cases, however, prediction performance was not emphasized.
In this paper, we propose the joint fairness model, a technique for jointly estimating multiple logistic regression models corresponding to distinct but related groups, in order to achieve fair prediction performance across groups. The model parameters are estimated by encouraging prediction fairness, while simultaneously ensuring high predictive accuracy irrespective of heterogeneity across groups. The rest of this paper is organized as follows. In Section 2, we present the proposed joint fairness model. Section 3 describes the algorithm to find its optimal solution. In Section 4, we discuss asymptotic consistency of the estimators. We illustrate the performance of our proposed approach in simulation studies in Section 5; and apply our approach to the motivating example of predicting COVID-19 mortality outcomes for patients of different age groups in Section 6. Finally, we summarize and discuss our findings in Section 7.
2. Problem Formulation
For binary outcomes, consider K groups of datasets with representing group membership. Throughout the paper, group memberships are known and observed. Assuming that the observations are independently distributed, then yki ~ Bernoulli(pki), and is the predicted value based on predictor features Xki. We focus on the development of a fair prediction approach for the widely-used logistic regression model. The log-likelihood of the logistic model for the data from all groups takes the form
| (1) |
Define . Maximizing the likelihood function in (1) with respect to βk in each group separately yields the maximum likelihood estimates of parameters for each group k, thus making separate predictions per group. If we ignore group memberships, can be estimated by maximizing the likelihood function in equation (1) setting all equal to a single global parameter vector and making predictions per individual (irrespective of group) using that global parameter vector.
If the K datasets correspond to observations collected from K distinct but related groups, then one might wish to borrow strength across the K groups to estimate β and predict , rather than estimating parameters βk for each group separately, or estimating a single set of βk for all k which could lead to heterogeneous prediction performance across the groups. Therefore, instead of estimating β by maximizing the likelihood in equation (1), we consider a penalized log-likelihood approach and jointly estimate β by maximizing an objective function of in equation (1) subject to constraints on (i) fairness, (β; X, y, λF) (ii) parameter similarity, (β; λSim), and (iii) parameter sparsity, (β; λSp).
| (2) |
We propose a fairness penalty function (β; X, y, λF) that encourages each group to have similar predictive performance. In this work we use equalized odds (Hardt et al., 2016) which encourages each group to have similar false positive rates (FPRs) and false negative rates (FNRs). Thus, we want to minimize the absolute difference between FPRj and , and that between FNRj and . Under the logistic regression model, the absolute differences of FPRs and FNRs are nonconvex due to the nonconvexity of the sigmoid function. We will instead minimize the absolute difference of the expected linear components of the two groups . The proposition below shows that the absolute difference of the expected probabilities is upper-bounded by the absolute difference of the expected linear components. Thus, minimizing group differences in expected linear components guarantees that group difference of false predictions is minimized.
Proposition 2.1: For any 1 ⩽ j, k ⩽ K, j ≠ k, and y ∈ {0, 1} the following inequality holds:
Proof: See Web Appendix 4.
Note that the empirical estimate of the expectation is
where Sky = {i : yki = y} is a subgroup of subjects with a true response value y in group k, with y ∈ {0, 1}. Thus, our fairness penalty, that bridges the between-group gaps in the linear components of FPRk and FNRk, is defined as:
| (3) |
where the summation represents for notational simplicity.
The similarity penalty (β; λSim) is chosen to encourage similarity across the K parameter estimates. Here we use the generalized fused lasso penalty (Hoefling, 2010; Danaher et al., 2014; Dondelinger et al., 2018) defined as
| (4) |
herein referred to as the fusion-similarity penalty. The sparsity penalty is chosen to encourage sparse estimates and to avoid ill-defined maximum likelihood estimates when sample sizes nk < p.
| (5) |
In the three penalty functions, λF, λSim, and λSp are nonnegative hyperparameters. Here , and are convex penalty functions, so that the objective function in equation (2) is convex in β. The proposed model jointly estimates β to achieve fair performance across groups, herein referred to as the joint fairness model (JFM). In contrast, the dominant approach for fair predictions in the current literature is to estimate a single set of β parameters with constraints on the quality of performance metrics across groups. In the context of logistic regression, Bechavod and Ligett (2017) proposed a Single Fairness Model (SFM) to minimize the following objective function.
In contrast to the proposed JFM, it does not allow for group-specific different βks, leading to two potential limitations: i) fairness is often achieved by compromising the likelihood (ℓ(β; Xk, yk)) of some groups; ii) inflexible model mis-specification when the βks are different.
The proposed JFM objective function improves prediction parity through three components. First, it considers a weighted group total likelihood to upweight the groups with smaller sample sizes. Second, (β; X, y, λF) encourages estimates that achieve fair performance across groups. Third, the similarity penalty term improves estimation and prediction efficiencies when multiple subgroups are related but not identical (Hoefling, 2010; Danaher et al., 2014). Computationally, we found that multiple different combinations of often result in very similar objective values; thus, the similarity term can help optimization algorithms for the JFM converge to one of the multiple combinations by favoring similar values of . Other formats of the similarity penalty could be used in our proposed JFM framework. For example, the group lasso penalty (Yuan and Lin, 2006) has been shown to encourage similar sparsity patterns across groups (Obozinski et al., 2010; Danaher et al., 2014), while the fused lasso term is more aggressive in encouraging similar estimates. The penalty functions in (3), (4), and (5) are based on the L1 norm. They can be flexibly adapted to an L2 penalization or to a combination of L1 and L2 penalizations. The differences between L1 and L2 penalties have been well discussed in the literature (Tibshirani, 1996; Zou and Hastie, 2005). For the fairness penalty, Bechavod and Ligett (2017) showed that there are no significant differences in the empirical predictive performances between the L1 and L2 fairness penalty forms other than the L2 form of the similarity penalty penalizes large differences more aggressively so that models have less chance to obtain group-specific estimates.
3. Accelerated Smoothing Proximal Gradient Algorithm for JFM
In this section, we introduce an accelerated smoothing proximal gradient (ASPG) algorithm (Chen et al., 2012) to solve Problem (2) for the JFM. The objective function of (2) is convex in β so that a global optimal solution can be attained. However, conventional proximal gradient-based or coordinate descent approaches (generally used for lasso-like methods) cannot be directly applied to solve Problem (2) because there is no closed-form solution for the proximal operator associated with and .
3.1. Nesterov smooth approximation
To overcome the difficulty originating from the non-differentiability of the fairness and similarity penalties, we decouple the terms into a linear combination of the decision variables via the dual norm and then apply the Nesterov smoothing approximation (Nesterov, 2005). We start with matrix representations of the fairness penalty terms and , where is defined as below. Similarly, we use the matrix representation of the similarity penalty with F defined as below.
Here, is the average predictor vector for group k with true outcome y, and Ip is the p-dimensional identity matrix. The matrix form of the fairness penalty term and the similarity penalty term is therefore defined as:
Thus, the objective function (2) can be written in matrix form:
| (6) |
where the associated proximal operator of does not have a closed form solution. We apply the Nesterov smooth approximation to approximate by a smooth function
| (7) |
Proposition A.1 in Web Appendix 1 provides the maximum gap between and its Nesterov approximation fμ(β; λF, λSim).
As demonstrated in Proposition A.2 in Web Appendix 1, for any μ > 0, fμ(β; λF, λSim) is smooth and convex with respect to β, whose gradient takes the following form:
| (8) |
where . Moreover, the gradient is Lipschitz continuous with a Lipschitz constant , where denotes the matrix spectral norm (which is equivalent to the largest singular value of the matrix). We can show further that α* can be calculated as , where (·) is the projection onto the unit L∞ ball such that , where is the indicator function. Details are provided in Web Appendix 1.
3.2. Accelerated Smoothing Proximal Gradient Algorithm
With substituted by the Nesterov smooth approximation fμ(β; λF, λSim), problem (6) becomes
| (9) |
whose first two terms are convex smooth functions. Although the sparsity penalty term is non-differentiable, it can be managed through the proximal gradient method using the soft-thresholding operator with a closed form solution (Friedman et al., 2007a).
Algorithm l presents the proposed ASPG algorithm, starting from parameter initialization, to gradient descent iterations with proximal and momentum steps, until convergence. Although Algorithm 1 minimizes the Nesterov smooth approximation, Theorem 3.1 proves that the solution can reach arbitrarily close to the global optimum of Problem (2).
Algorithm 1.
Accelerated Smoothing Proximal Gradient (ASPG) Algorithm for the JFM
| 1: Input: Data Xk, yk for k = 1 … K, hyperparameters λF, λSim, λSp, ϵ, μ |
| 2: Output: solving the joint fairness objective function (2). |
| 3: Initialize: β(0) = 0, γ(0) = 0, s(0) = 1 |
| 4: max {λmax(XkTXk) : k = 1, ⋯, K} + μ−1 |
| 5: for t ⩾ 1 do |
| 6: α(t) = γ(t−1) − L−1 (−∇ℓ (γ(t−1))) + ∇fμ (γ(t−1))) |
| 7: β(t) = (α(t); L−1λSp) |
| 8: if ‖β(t) − β(t−1)‖2 ⩽ ϵ |
| 9: |
| 10: |
| 11: t ← t + 1 |
| 12: end for |
| 13: ← β(t). |
Theorem 3.1: Let {β(t) : t = 1, 2, ⋯} be a sequence generated by Algorithm 1. Then for any t ⩾ 1 and desired δ > 0
where β* and β** are global minimizers of Problem (9) and Problem (2), respectively and L is the Lipschitz constant of the function in (7).
Proof: See Web Appendix 4.
Based on Theorem 3.1, the rate of the convergence of Algorithm 1 is , given a desired accuracy ε > 0. The complexity of a single iteration of Algorithm 1 is ((n+K2)pK). For additional details see Propositions A.4 and A.5 in Web Appendix 1. The proposed JFM Algorithm 1 is for the fusion-similarity term. The algorithm can be readily extended to include a group-similarity term as presented in Web Appendix 2.
4. Asymptotic properties of the JFM estimates
We now present asymptotic results for the JFM parameter estimates obtained by solving Problem (2). We assume p remains constant and n increases to infinity.
Consider the following assumptions:
Assumption 1. (βk)/nk → Ck, where Ck is a positive definite p×p matrix, for k = 1, ⋯, K, where (βk) is the information matrix of size p × p. For simplicity, we assume there are no intercept terms in βk.
Assumption 2. As , where is the empirical information matrix, and Ip is a p × p identity matrix.
The following theorem proves -consistency for the estimators, complying with the fairness and similarity constraints between the two groups as well as the sparsity constraint. We note that the theorem holds even if the sample size of one group increases faster than the other group’s.
Theorem 4.1: Let for k = 1, ⋯, K, minimize the loss function (2). If , and , then under the assumptions 1 and 2
| (10) |
where ,
Here , and , where , and for .
Proof: See Web Appendix 4.
5. Simulation Study
We performed a series of simulations to evaluate the proposed JFM, and compared it with the approaches of a group-separate individual logistic regression model, a group-ignorant vanilla logistic regression model, and the SFM method (Bechavod and Ligett, 2017) implemented using an SFM-ASPG algorithm (see Web Appendix 3). When applying the group-separate model, regression coefficients were estimated for each group separately with an L1 penalty. The group-ignorant model estimates a single logistic regression with group membership as an additional covariate with an L1 penalty.
5.1. Simulation Setup
We consider a two-group problem (K = 2) for simplicity, with group 1 as the over-represented group and group 2 as the under-represented group with respect to the sample sizes. The training samples were simulated as follows. The predictor matrix Xk was independently generated from a standard normal distribution. The binary outcome yki was then simulated from Bernoulli(πi(xki)), where . Out of the total number of features, 40% in each group had non-zero coefficients (β’s). The non-zero coefficients were each set to the value 3. The simulations were conducted under three scenarios to investigate performances at various levels of shared parameters, sample sizes and dimensionalities.
Scenario 1 (Difference in True Model): The proportion of shared features between the two groups ranged from 0% to 100% of features with non-zero coefficients. The intercepts were selected so that the baseline event prevalences were at 30% and 50% for the under- and over-represented groups The sample sizes were set at 500 and 200 for group 1 and 2 respectively. The number of features was set to p = 100. Note that when small proportions of features are shared between groups, the fairness and similarity penalty terms are mis-specified given that Xβk and βk are different between groups. As a result, performances in these settings allow us to investigate the robustness of the JFM approach to mis-specification of the fairness and similarity penalty terms.
Scenario 2 (Difference in Sample Size): The sample size of the under-represented group (group 2) ranged from 50 to 300 while the sample size of group 1 was fixed at 500. The number of features was set to p = 100. Half of the features with non-zero coefficients were shared between the groups.
Scenario 3 (High Dimensionality): The number of features p ranged from 50 to 2,000. Sample sizes were 500 and 200 for group 1 and 2 respectively. For each value of p, 40 features had non-zero coefficients, with half of the non-zero features being shared.
We evaluated the methods on independent test datasets with large sample sizes (n = 1,000 for both groups) under the same simulation setups. The Area under the Receiver Operating Characteristic curve (AUC) was used to assess the predictive ability of each model. Prediction unfairness was assessed by the group difference in AUCs. In addition, Mean Squared Errors (MSEs) for all were examined to assess parameter estimation performance, and TPRs of the associated features and TNRs of the non-associated features were used to assess variable selection performance. Medians and interquartile ranges (IQRs) of the assessment metrics were generated from 20 replicates for each experiment. Predictive performances and their unfairness in terms of FPR and FNR were calculated with a predicted probability cutoff of 0.5, as presented in Web Appendix 8. We present additional simulation scenarios in Web Appendix 9.
5.2. Choice of the Hyperparameters
The group-ignorant model, group-separate model, SFM, and JFM contain 1, K, 2, and K + 2 hyperparameters respectively. For every method, five-fold cross-validation on the training dataset was used to determine the hyperparameters. For the vanilla models (group-separate and group-ignorant), the lasso penalty term was selected by optimizing cross-validation AUCs. For the fairness-aware models (SFM and JFM), we investigated and compared a series of evaluation metrics for selecting hyperparameters using cross-validation. The metrics include overall AUCs and Brier scores (defined as ) on all samples (ignoring group memberships), group average of AUCs or Brier scores, and the group average of AUCs or Brier scores subtracting their disparities. Web Appendix 7, Web Figures 2, 3, and 4 demonstrate the empirical performance of the hyperparameters selected by the various strategies in the test datasets for the simulation scenarios. In summary, we find that the hyperparameters optimizing cross-validated group-average metrics showed better performance than sample-average or average metrics subtracting disparities. The hyperparameters optimizing AUCs in general generated the best AUC performances, while the hyperparameters optimizing Brier scores generated the best MSEs from the perspective of parameter estimation. We find that both are better empirically than threshold-based metrics such as classification accuracy. Lastly, the group average calculated by the harmonic mean is more robust than the arithmetic mean when the group sample sizes are unbalanced.
5.3. Simulation Results
For Scenario 1, Figure 1(a) displays the estimated AUC for the under-represented group versus the proportion of shared features in the two groups. The AUCs of the under-represented group from the JFM, SFM, and group-ignorant models improved as the proportion of shared features increased. The SFM and group-ignorant models were highly sensitive to the percentage of shared non-zero features as they both estimate a single set of parameters for both groups. In contrast, the JFM showed consistently higher AUC than the other three methods. When the proportion of shared features is high, the JFM estimated higher AUCs and smaller variances than those from the group-separate model. The JFM’s overall AUC performance was similar to that of the SFM and the group-ignorant model. When the proportion of shared features is low, the JFM estimated higher AUCs than the SFM and the group-ignorant model, and showed similar AUC to the group-separate model. Figure 1(b) displays the estimated AUC for the majority group against the proportion of shared features in the two groups. The JFM was robust in achieving comparable AUC to that of the group-separate model. The SFM and group-ignorant models were highly sensitive to the percentage of shared features for the majority group, with lower AUCs when the proportion of shared parameters is low.
Figure 1:
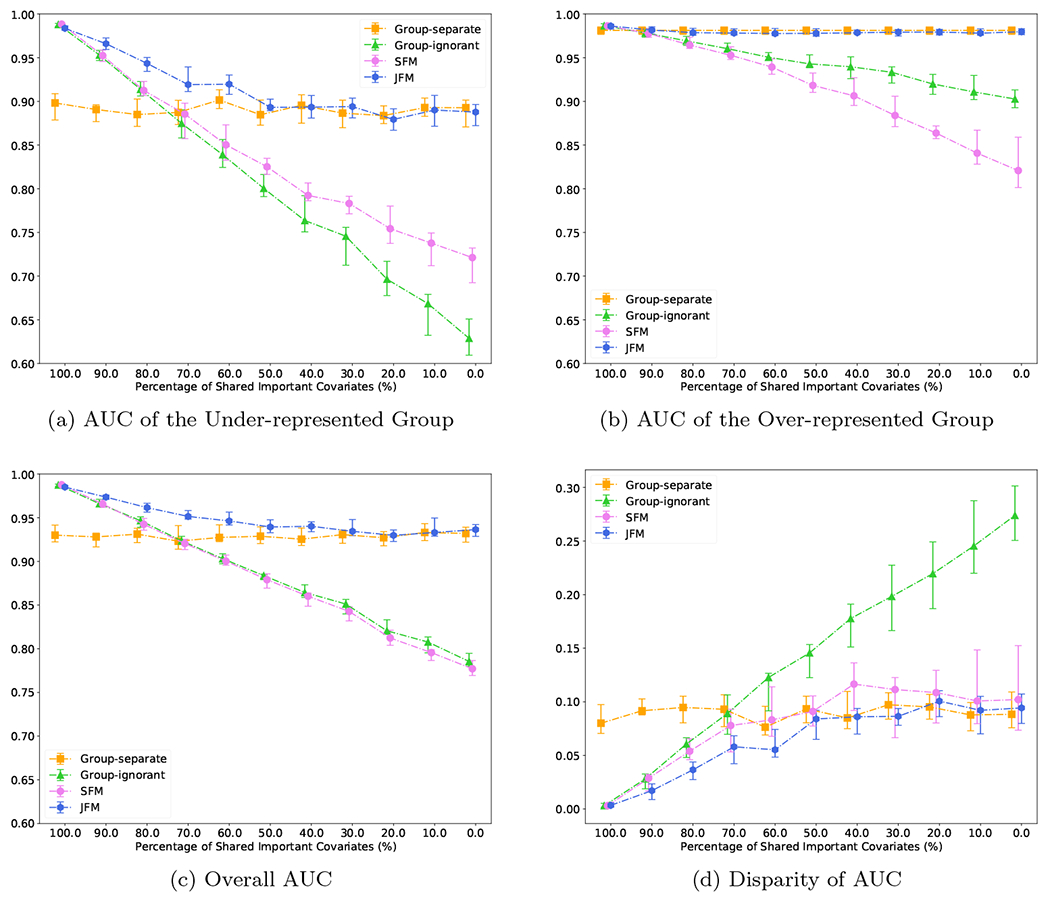
Experimental Results for Scenario 1
Figure 1(c) displays the estimated overall AUCs, and Figure 1(d) displays the group disparity of the AUCs from the four approaches. In particular, although both the SFM and JFM achieved smaller disparities than the group-ignorant model in Figure 1(d), Figure 1(a–b) underscores the limitation of the SFM with no flexibility of group-specific parameters. When the true models of the two groups are different, the SFM often achieved better parity by compromising the performance for the majority group. These figures together demonstrate that the JFM achieves fair prediction performance robustly across the range of possible proportions of shared features between groups, by training the classifiers jointly with a flexible parameterization. Web Figure 5(a) through 5(d) compares the average of prediction TPR and TNR and disparity in TPR and TNR differences of the four methods. The patterns are similar to those observed for AUCs. Coefficient MSEs are presented in Figure 4(a–b) for the minority and majority groups respectively. Under varying proportions of the shared parameters, JFM achieves the smallest MSEs across different methods for the minority group and similar MSEs to the group-separate model for the majority group, demonstrating its improvement for parameter estimation especially for the minority group. Web Figure 14(a) through 14(f) compares the variable selection TPRs and TNRs of the four methods. The patterns are similar to MSEs.
Figure 4:
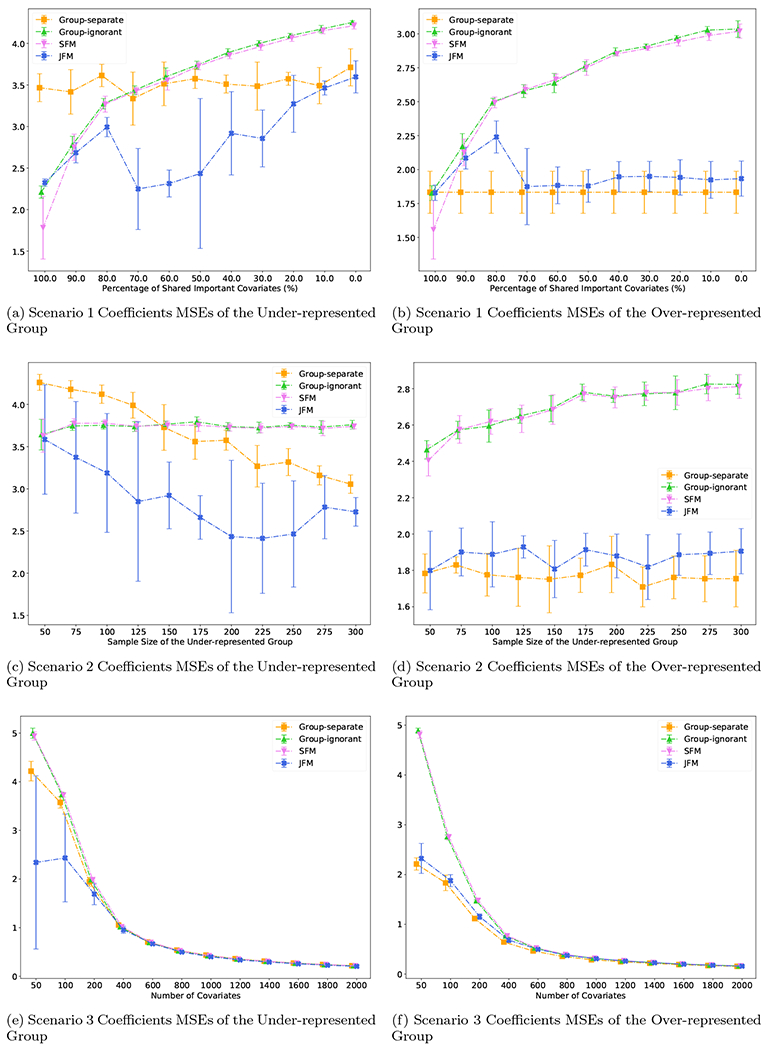
Coefficients MSEs for Scenario 1 – 3
Figure 2 displays the performance of the four methods as a function of the sample size of the under-represented group, with other settings fixed. In Figure 2(a), the AUCs of the under-represented group from all models improved as sample size of that group increased. The JFM showed consistently higher AUCs and smaller variances than those from all the other models. JFM outperforms the other models the most when the minority group’s sample size is small, showing the benefits of borrowing information between groups in situations with unbalanced sample sizes. Figure 2(b) illustrates that the AUC of the majority group was not impacted for the JFM and group-separate methods. However, the AUC of the majority group decreased as the sample size of the under-represented group increased for the SFM and the group-ignorant models. This decrease highlights an undesirable aspect of these two methods, namely, they compromise accuracy by estimating a single set of classifier parameters. Figure 2(c) and 2(d) illustrates that the JFM achieves overall satisfactory AUCs and parity between groups across varying sample sizes of the under-represented group. Web Figure 6 compares the average of TPR and TNR and disparity of TPR and TNR of the four methods. In addition, the JFM substantially reduced coefficient MSEs (Figure 4(c)) under all simulated sample sizes for the minority group compared to all competing methods. The MSEs were similar between the JFM and the group separate model for the majority group, and both were lower than the MSEs of the group ignorant and SFM models.
Figure 2:
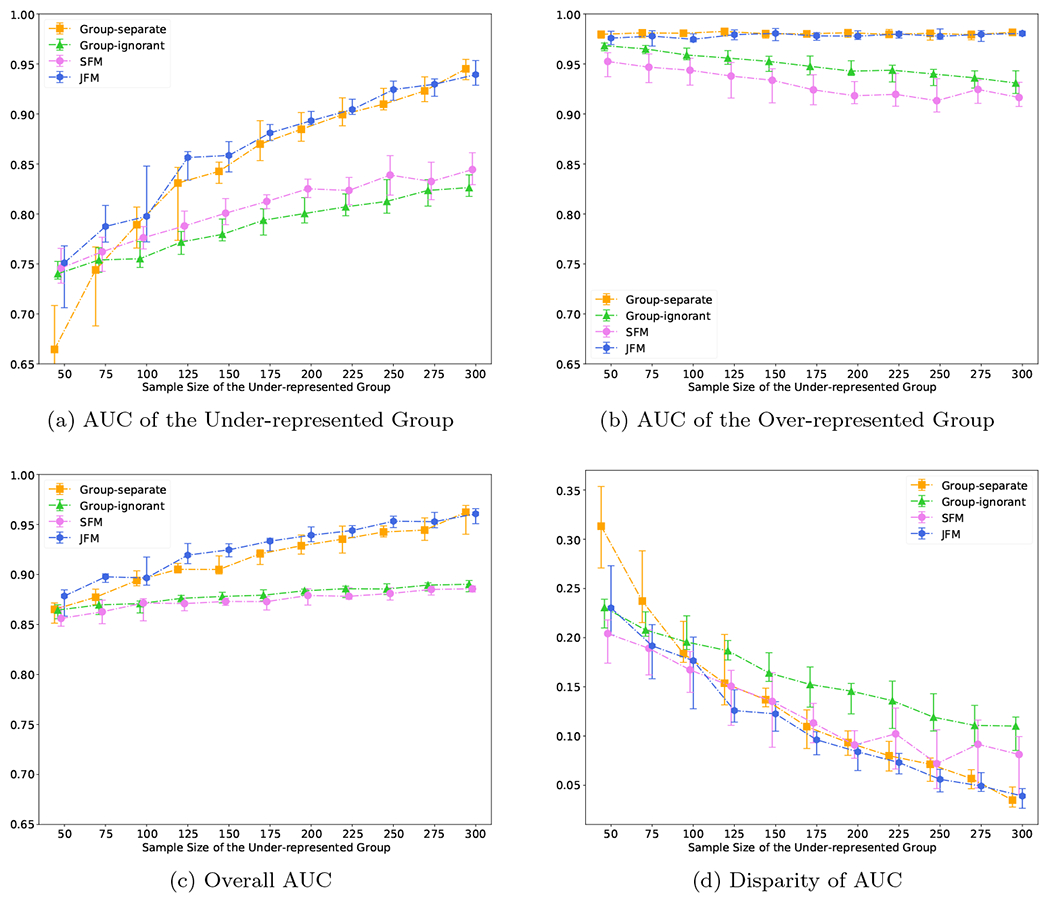
Experimental Results for Scenario 2
Figure 3 displays the performance of the four methods while varying the number of features from 200 to 2000, and holding the number of associated features constant at 40. It demonstrates that the JFM method in going from low dimensional to high dimensional settings can maintain overall satisfactory prediction performances and parity between groups. Web Figure 11 displays the performance of the four methods while varying the number of features from 200 to 2000, and setting the number of associated features to a fixed proportion of the total number of features. The resultant patterns are similar to Figure 3. The JFM consistently had the smallest MSEs under all simulated numbers of covariates for both the minority and majority groups. In particular, the JFM showed the largest reduction of MSEs with small number of covariates.
Figure 3:
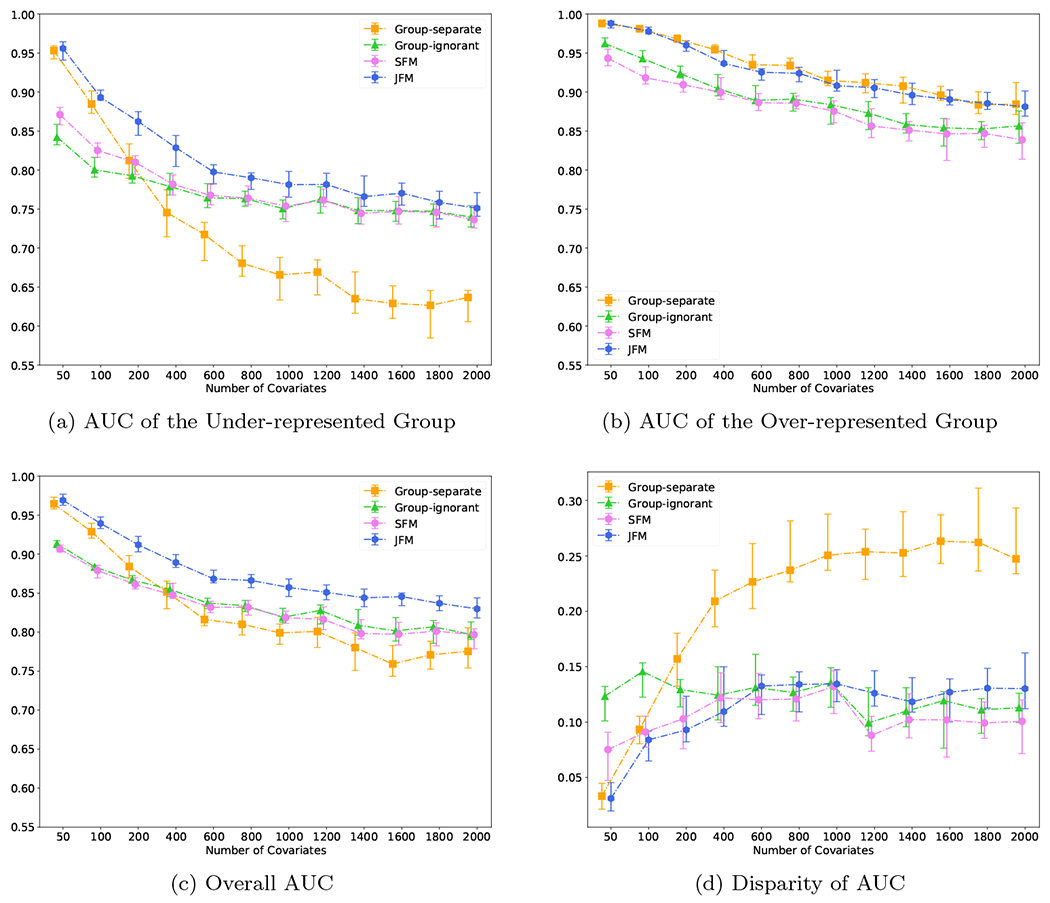
Experimental Results for Scenario 3
We investigated the empirical computational complexity of the JFM approach as a function of increasing numbers of features and sample sizes in Web Appendix 3. Web Figure 1 shows that the JFM computation time is approximately (p1.5) and (n). This matches our theoretical analysis on complexity since the per-iteration complexity is (np) and the rate of convergence is (p0.5). Details are presented in Web Appendix 6. We also implemented an alternative JFM algorithm using a group lasso similarity penalty (referred to as JFM-Group, Web Figure 15), and compared its performance with JFM-Fusion (presented above). The results showed largely similar performances. The JFM-Fusion showed slightly better predictive performance than the JFM-Group when the two groups share more than 80% of the features, which is in line with previous reports that the fusion penalty term more aggressively enforces similarities across groups (Yuan and Lin, 2006; Obozinski et al., 2010; Danaher et al., 2014).
6. COVID-19 Risk Prediction Case Study
We applied the JFM, in comparison with other methods, to predict mortality related to COVID-19 from patients’ routine ambulatory encounters and laboratory records prior to COVID-19 infection, with the goal of better stratification of patient risk for clinical management. We used a retrospective EHR dataset of 11,594 patients of age 50+ with laboratory-confirmed COVID-19 at New York University Langone Health (NYULH) from March 2020 to February 2021. Among the 11,594 patients, 1,242 (10.7%) died of COVID-19. The patients were divided into four groups by their age at the time of COVID-19 diagnosis: 50-64, 6574, 75-84, and 85+ with 5, 905 (50.9%), 2, 946 (25.4%), 1, 814 (15.6%), and 929 (8.0%) patients, respectively. The observed mortality rates were 4.44%, 11.17%, 18.96% and 33.05%, respectively. Candidate features (p = 82) included demographic variables, such as age, sex, race/ethnicity, smoking status, body mass index (BMI); common chronic disease history such as diabetes, dementia, chronic kidney diseases (CKD); Myocardial Infarction (MI) & Atrial Fibrillation (AF); and routinely collected laboratory markers, such as lipid panels, blood panels, albumin, creatinine, aspartate aminotransferase (AST) etc. obtained from patients routine ambulatory histories before their COVID-19 infections. To build the prediction models, we randomly split the dataset into training (n = 8, 115, 70%) and testing (n = 3, 479, 30%) sets. We first standardized all features to zero-mean and unit variance. Five-fold cross-validation was conducted on the training set to determine the hyperparameters for each model. Hyperparameters for the group-separate and group-ignorant models were selected to maximize the groupwise AUCs and the overall AUC, respectively, while those for the SFM and JFM were determined to maximize the harmonic mean of groupwise AUCs. Subsequently, we trained the final models with the optimal hyperparameters using the entire training set and applied the final models to the testing dataset to demonstrate their predictive performance. We repeated the training/testing split 10 times and averaged the performances across the 10 splits. Table 1 presents the AUCs and the averages of TPR and TNR of the four methods for each age group. The JFM performed better across all age groups than the separate model did, demonstrating that joint modeling yields higher efficiency. Compared with the group ignorant model, the JFM performed better in the three older age groups, with comparable AUC for the 50-64 age group, which resulted in smaller disparities in prediction performance overall. This phenomenon supports the observed pattern in simulation studies that the JFM reduced disparities in prediction performances without impacting those from the majority groups. In contrast, the SFM tended to reduce prediction disparities by lowering the performances for the majority groups. Figure 5 presents the boxplots of odds ratios (ORs) of selected demographic and clinical features estimated by the JFM. These results support the hypothesis that some features have common associations between groups, and some have group-specific ORs. For example, the decreasing OR estimates of BMI along age-groups confirmed the prior hypothesis that the association between BMI and COVID-19 mortality is heterogeneous between age-groups. In the JFM estimates, BMI is positively associated with higher risks of COVID-19 mortality for patients younger than 75, but with smaller and even reversed ORs in the oldest age groups. For older adults, higher BMIs are often associated with greater energy stores and a better nutritional state overall, which is beneficial for patients’ survival outcomes when infected by COVID-19. The proportion of underweight patients (BMI<18) increased from 0.6% in the age group 50-64 to 5.5% in the age group 85+. The underweight status, often a proxy of frailness, has been repeatedly reported as a strong risk factor of COVID-19-induced multi-organ failure and mortality in older patients (Tehrani et al., 2021). On the other hand, the JFM can improve efficiencies for covariates with rare prevalence in a subgroup. For instance, dementia has been reported as a risk factor with COVID-19 mortality. In the group-separate model, dementia was insignificant in patients aged 50-64, mainly due to its low prevalence in this group (0.6%). In contrast, dementia was significantly associated with mortality in all age groups with similar ORs in the JFM estimates.
Table 1:
Predictive Performance on COVID-19 Case Study
| Models | AUCs | Average of TPR and TNR | ||||||
|---|---|---|---|---|---|---|---|---|
| 50-64 | 65-74 | 75-84 | Over 85 | 50-64 | 65-74 | 75-84 | Over 85 | |
| Group-separate | 0.838 | 0.773 | 0.709 | 0.649 | 0.780 | 0.722 | 0.669 | 0.632 |
| Group-ignorant | 0.855 | 0.786 | 0.735 | 0.659 | 0.803 | 0.731 | 0.687 | 0.639 |
| SFM | 0.847 | 0.774 | 0.728 | 0.660 | 0.791 | 0.724 | 0.688 | 0.640 |
| JFM | 0.852 | 0.791 | 0.736 | 0.672 | 0.794 | 0.731 | 0.690 | 0.659 |
Figure 5:
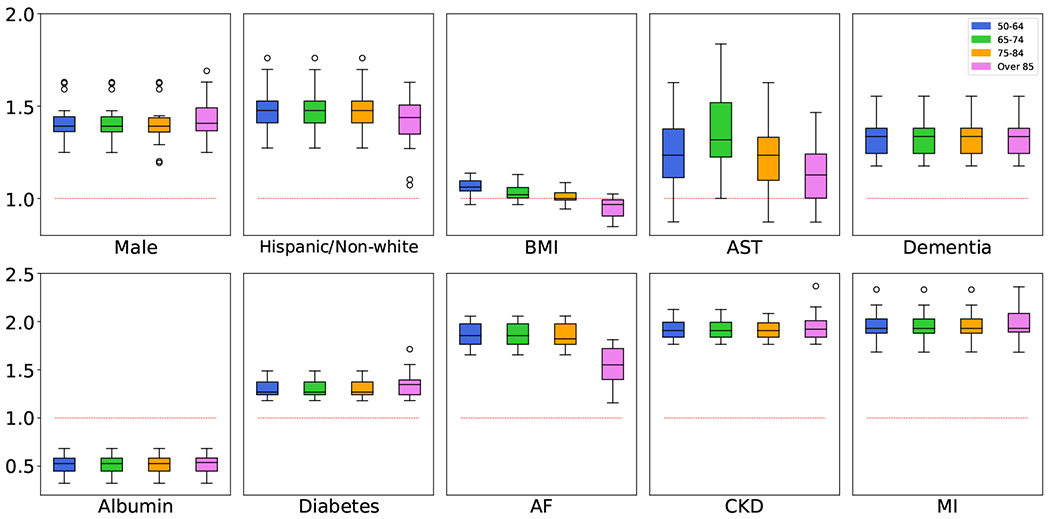
Estimated Odds Ratios for COVID-19 Dataset
7. Conclusions and Discussion
In this study we introduced a joint fairness model for jointly estimating sparse parameters, on the basis of observations drawn from distinct but related groups, with the goal of achieving fair performances across groups. We employ an efficient accelerated smoothing proximal gradient algorithm to solve the joint fair objective function, which has convex penalty functions. Our algorithm is computationally tractable for high-dimensional datasets. Further, we presented the asymptotic distributions of . Our JFM predictions outperform competing approaches over a range of simulations and in an example application dataset.
We note that the JFM relies on separate hyperparameters (K + 2 hyperparameters) to control sparsity, fairness and similarity. This reliance can be viewed as a strength rather than a drawback because one can vary separately the amount of similarity, sparsity and fairness to enforce in the group-specific estimates. In situations with many groups, further assumptions can be made to reduce the number of sparsity hyperparameters (i.e. λSpk = ckλSp). Possible choices of ck include so that sparsity is inversely proportional to the number of samples.
While nearly all existing fairness-aware prediction approaches estimate a single set of classifier parameters, one exception is a recent study that proposes using multi-task learning (MTL) to improve algorithm fairness (Oneto et al., 2019). However, MTL research focuses on joint architecture, optimization, and task relationship learning, which is a different emphasis from the proposed JFM approach to improve risk prediction performance for underrepresented populations.
Theorem 4.1 established consistency of the JFM estimators. Its asymptotic distribution needs to be further investigated to lay the foundation of its inference. Moving forward, the proposed JFM framework can be extended for time-to-event outcomes by using similar constraints to those proposed here. It can also in principle be extended to non-linear models by adding a suitable fairness penalty term to the objective function.
Given the increasing ability to subclassify diseases according to their molecular features and the recognition that substantial heterogeneity exists in many molecular subtypes, most diseases will be eventually classified into a collection of multiple subtypes with unbalanced sample sizes. Therefore, the proposed JFM has wide application potential to improve prediction efficiencies and reduce subgroup prediction disparities beyond applications addressing gender, race/ethnicity and age disparities.
A Python package implementing the JFM is available at https://github.com/hyungrok-do/joint-fairness-model.
Supplementary Material
Footnotes
Publisher's Disclaimer: This article has been accepted for publication and undergone full peer review but has not been through the copyediting, typesetting, pagination and proofreading process, which may lead to differences between this version and the Version of Record. Please cite this article as doi: 10.1111/biom.13632
Supporting Information
Web Appendices, Figures and Proofs referenced in Sections 2, 3, 4 and 5 are available with this paper at the Biometrics website on Wiley Online Library. The codes for the proposed JFM is available both on Wiley Online Library and on GitHub: https://github.com/hyungrok-do/joint-fairness-model.
Data Availability Statement
The data that support the findings in this paper are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
References
- Angwin J, Larson J, Mattu S, and Kirchner L (2016). Machine bias. ProPublica, May, 23:2016. [Google Scholar]
- Bechavod Y and Ligett K (2017). Penalizing unfairness in binary classification. arXiv preprint arXiv:1707.00044 [Google Scholar]
- Buolamwini J and Gebru T (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency, pages 77–91. [Google Scholar]
- Calders T, Kamiran F, and Pechenizkiy M (2009). Building classifiers with independency constraints. In 2009 IEEE International Conference on Data Mining Workshops, pages 13–18. [Google Scholar]
- Char DS, Shah NH, and Magnus D (2018). Implementing machine learning in health care—addressing ethical challenges. The New England journal of medicine, 378(11):981. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen IY, Pierson E, Rose S, Joshi S, Ferryman K, and Ghassemi M (2021). Ethical machine learning in healthcare. Review of Biomedical Data Science, 4(1):123–144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X, Lin Q, Kim S, Carbonell JG, Xing EP, et al. (2012). Smoothing proximal gradient method for general structured sparse regression. The Annals of Applied Statistics, 6(2):719–752. [Google Scholar]
- Danaher P, Wang P, and Witten DM (2014). The joint graphical lasso for inverse covariance estimation across multiple classes. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 76(2):373–397. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dondelinger F, Mukherjee S, and Initiative TADN (2018). The joint lasso: high-dimensional regression for group structured data. Biostatistics, 21(2):219–235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dwork C, Immorlica N, Kalai AT, and Leiserson M (2018). Decoupled classifiers for group-fair and efficient machine learning. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency, pages 119–133. [Google Scholar]
- Friedman J, Hastie T, Höfling H, Tibshirani R, et al. (2007a). Pathwise coordinate optimization. The annals of applied statistics, 1(2):302–332. [Google Scholar]
- Friedman J, Hastie T, and Tibshirani R (2007b). Sparse inverse covariance estimation with the graphical lasso. Biostatistics, 9(3):432–441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hardt M, Price E, and Srebro N (2016). Equality of opportunity in supervised learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems, page 3323–3331, Red Hook, NY, USA. Curran Associates Inc. [Google Scholar]
- Hoefling H (2010). A path algorithm for the fused lasso signal approximator. Journal of Computational and Graphical Statistics, 19(4):984–1006. [Google Scholar]
- Kamiran F and Calders T (2012). Data preprocessing techniques for classification without discrimination. Knowledge and Information Systems, 33(1):1–33. [Google Scholar]
- Kamishima T, Akaho S, Asoh H, and Sakuma J (2012). Fairness-aware classifier with prejudice remover regularizer. pages 35–50. [Google Scholar]
- Kompaniyets L and Goodman AB (2021). Body mass index and risk for covid-19–related hospitalization, intensive care unit admission, invasive mechanical ventilation, and death. MMWR Morb Mortal Wkly Rep 2021, 70:355–361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lahoti P, Weikum G, and Gummadi KP (2018). ifair: Learning individually fair data representations for algorithmic decision making. CoRR, abs/1806.01059. [Google Scholar]
- Larrazabal AJ, Nieto N, Peterson V, Milone DH, and Ferrante E (2020). Gender imbalance in medical imaging datasets produces biased classifiers for computer-aided diagnosis. Proceedings of the National Academy of Sciences, 117(23):12592–12594. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nesterov Y (2005). Smooth minimization of non-smooth functions. Mathematical programming, 103(1):127–152. [Google Scholar]
- Obozinski G, Taskar B, and Jordan MI (2010). Joint covariate selection and joint subspace selection for multiple classification problems. Statistics and Computing, 20(2):231–252. [Google Scholar]
- Oneto L, Doninini M, Elders A, and Pontil M (2019). Taking advantage of multitask learning for fair classification. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, page 227–237. [Google Scholar]
- Paulus JK and Kent DM (2020). Predictably unequal: understanding and addressing concerns that algorithmic clinical prediction may increase health disparities. NPJ digital medicine, 3(1):1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ryu HJ, Adam H, and Mitchell M (2018). Inclusivefacenet: Improving face attribute detection with race and gender diversity. In Fairness, Accountability, and Transparency in Machine Learning (FAT/ML). Fairness, Accountability, and Transparency in Machine Learning (FAT/ML). [Google Scholar]
- Seyyed-Kalantari L, Liu G, McDermott M, Chen IY, and Ghassemi M (2020). Chexclusion: Fairness gaps in deep chest x-ray classifiers. In BIOCOMPUTING 2021: Proceedings of the Pacific Symposium, pages 232–243. World Scientific. [PubMed] [Google Scholar]
- Tehrani S, Killander A, Åstrand P, Jakobsson J, and Gille-Johnson P (2021). Risk factors for death in adult covid-19 patients: Frailty predicts fatal outcome in older patients. International Journal of Infectious Diseases, 102:415–421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tibshirani R (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288. [Google Scholar]
- Yuan M and Lin Y (2006). Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1):49–67. [Google Scholar]
- Yuan M and Lin Y (2007). Model selection and estimation in the gaussian graphical model. Biometrika, 94(1):19–35. [Google Scholar]
- Zafar MB, Valera I, Gomez Rodriguez M, and Gummadi KP (2017a). Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. [Google Scholar]
- Zafar MB, Valera I, Gomez-Rodriguez M, and Gummadi KP (2019). Fairness constraints: A flexible approach for fair classification. Journal of Machine Learning Research, 20(75):1–42. [Google Scholar]
- Zafar MB, Valera I, Rogriguez MG, and Gummadi KP (2017b). Fairness constraints: Mechanisms for fair classification. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54, pages 962–970. [Google Scholar]
- Zemel R, Wu Y, Swersky K, Pitassi T, and Dwork C (2013). Learning fair representations. volume 28, pages 325–333. [Google Scholar]
- Zou H and Hastie T (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society. Series B (Statistical Methodology), 67(2):301–320. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data that support the findings in this paper are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.