

Abstract
In addition to conventional immunoglobulin, camelids and cartilaginous fish express a special class of antibody that consists only of heavy (H) chain (HCAbs). In the holocephalan elephantfish there are two HCAb classes, one of which has evolved surprising features. The H chain genes in cartilaginous fish are organized as 20–200 minigenes, or clusters, each consisting of VH, 1–3 DH, JH gene segments with one set of constant region exons. We report that HHC2 (holocephalan H chain antibody 2) evolved from IgM H chain clusters, but its DH gene segments have diverged considerably. The three DH in HHC2 clusters are A-rich, so that 1–3 potential reading frames for each DH encode lysine and arginine. All three are incorporated into the rearranged VDJ, ensuring the ligand-binding site carries multiple basic residues, as cDNA sequences demonstrate. The electropositive character in HHC2 CDR3 is accompanied by a paucity of aromatic amino acids, the latter feature at variance to the established, interactive role of tyrosine not only in ligand-binding but generally at interfaces of protein complexes. The selection for these divergent HHC2 features challenges currently accepted ideas on what determines antibody reactivity and molecular recognition.
Keywords: H chain antibody, Gene Rearrangement, Repertoire Development
Introduction
The classical immunoglobulin (Ig) unit is composed of two heavy (H) chains and two light (L) chains, but in camelids and cartilaginous fish a special class of antibody is expressed without L chain [1]. These are called H chain antibodies (HCAbs), as each H chain V region by itself interacts with ligand. We report characteristics evolved in one class of fish HCAb that are unique among vertebrate Ig.
The ligand-binding site in conventional Ig is formed by six loops, called complementarity-determining regions (CDR), three from each chain, where CDR1 and CDR2 are part of the germline (GL) VL or VH gene segment. CDR3 is generated somatically through V(D)J recombination, a process where the L chain VL gene segment joins to JL gene segment and the H chain VH gene segment joins to DH and JH gene segments [2,3]. The recombinase, RAG1/2, binds motifs called recombination signal sequences (RSS) flanking two gene segments and introduces nicks at the top strand 5’ of the RSS at either gene [reviewed in ref. 4]. This is followed by cleavage at the bottom strands, resulting in double-stranded breaks that will be resolved by joining the two gene segments with elimination of the intervening sequence. Significantly, the cleavage process produces hairpins at the gene segment coding flanks, which are opened asymmetrically. The overhanging ends are processed by nucleolytic trimming as well as addition of non-templated (N) nucleotides by terminal deoxynucleotidyl transferase before ligation. The recombined joint can contain deletions and the added N region. If the trimming was not extensive the coding flank can be present along with palindromic sequence that is due to the hairpin opening (P nucleotides). The processing of DNA ends that generates the CDR3 is thus the most important source of lymphocyte antigen receptor diversification [5] in species not employing gene conversion during B cell repertoire generation.
As sequence and structural data became available it was observed that a small array of amino acids, present at higher frequencies, mediate much of the chemical interactions in molecular recognition [6–8]. Most studies have identified tyrosine (Tyr) in particular as the most frequently occurring amino acid participating in antigen recognition in mouse and human antibodies [9,10]. The aromatic side chain in Tyr and in tryptophan (Trp) contributes to a wide variety of chemical bonding through π-interactions and hydrogen-bonding. Such observations formed the basis of models for molecular recognition and for constructing synthetic antibodies [7,11]. The occurrence of Tyr, particularly in CDR3, is the result not only of its being encoded in the mouse and human GL DH gene segments but also by post-rearrangement selection of the B cell receptor repertoire [12].
The properties of molecular recognition derived from antibody-antigen structures are not different for HCAbs, respectively known as VHH and IgNAR in camelids and sharks, despite the known contribution of L chain to epitope surface area, stability, and antibody specificity [1,13,14]. However the significant difference lies in the ability of HCAbs to recognize concave surfaces or clefts, as observed in interactions of camelid VHH and shark IgNAR with the recessed enzymatic site of hen egg lysozyme (HEL) [15,16].
The particular biological value of HCAbs in species as disparate as camelids and sharks is not clear, but HCAb genes arose separately in the two cartilaginous fish subclasses, Elasmobranchs (sharks, skates, and rays) and Holocephalans, which diverged 410 million years ago [17,18] (Fig.1A). Both Callorhincus milii, the elephantfish (abbreviated as efish), and another holocephalan, ratfish, carry genes encoding one class of similar HCAbs, which we here call HHC1 for Holocephalan Heavy Chain antibody-1 [10].
Figure 1.
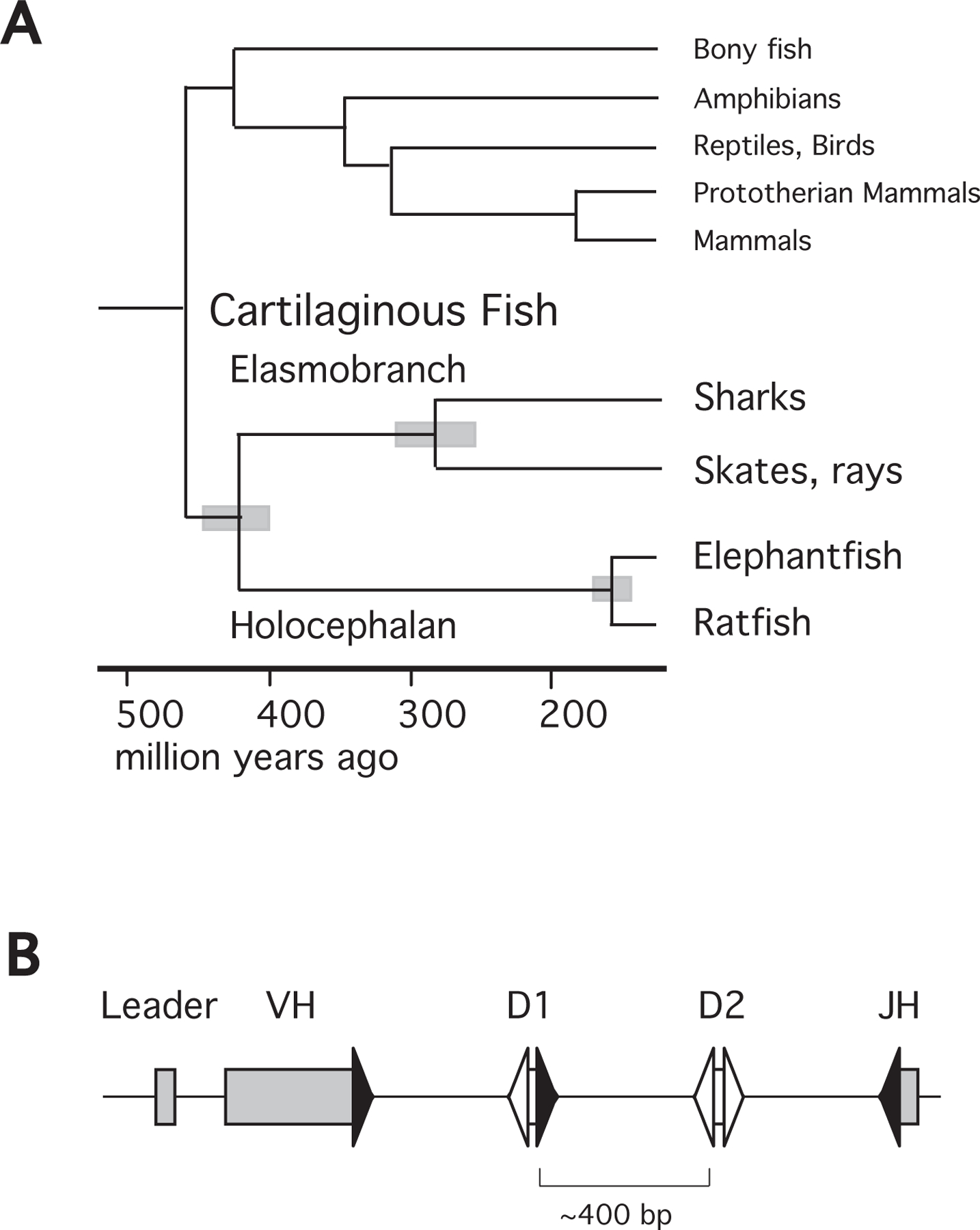
A. Phylogeny of gnathostome (jawed) vertebrates. The tree shows evolutionary relationships among cartilaginous fish and other major vertebrate lineages. The time scale is in million of years from the present for estimated divergence times [17,70]. The gray bars at the nodes indicate estimated intervals of divergence times for the extant subclasses of cartilaginous fish, Elasmobranchii and Holocephali, the orders Selachii (sharks) and Batoidea (skates, rays), and in the order Chimaeriformes the families Callorhinchidae (Callorhincus milii, elephant fish), Chimaeridae (Hydrolagus colliei, spotted ratfish). B. Arrangement of gene segments at an Igμ cluster. GL organization of VH, D1, D2, and JH gene segments flanked by RSS. Average distance between gene segments is about 400 bp, as indicated. Signal sequence and gene segments are labeled, filled triangles indicate RSS with 23 bp spacers, open triangles those with 12 bp spacers.
The IgH and IgL genes in cartilaginous fishes are respectively organized as multiple VH-D1-D2-JH-CH and VL-JL-CL independent minigenes (Fig.1B) [20,21], in contrast to the megabases-long multigenic mouse Ig loci [22,23]. V(D)J recombination takes place primarily within the Igμ minigene, or “cluster”, which is about 20 kb from leader to the C region transmembrane exons. In the nurse shark the H chain clusters are >120 kb apart [24] and appear to function autonomously; H chain exclusion results from asynchronous rearrangement at individual genes within a given time window [25,26]. The activation of any shark IgH cluster is discrete, independent of neighboring IgH as well as its allele and in both respects differs from V(D)J recombination in mouse and humans, which involves a multistep process progressively mobilizing large swaths of chromatin [27,28; for a recent review, see 29].
Inasmuch as the nature of antibody combining sites appear conserved in evolution [30], we report very different properties in a second efish HCAb class, HHC2. The DH genes in HHC2 diverged to encode mostly lysine (Lys) and arginine (Arg), and basic amino acids are indeed prominent in the resultant VDJ. In mouse and human systems electropositive ligand-binding sites are generally associated with anti-DNA or autoimmune antibodies [31–34], but in HHC2 electropositive CDR3 are uniquely the rule.
Results
Novel H chain cluster
In the course of examining Igμ clusters in the efish genome (Fig. 2, Igμ), two kinds of IgH genes encoding HCAbs were observed. One was previously mentioned [18] as similar to that described in ratfish [19], HHC1. In both ratfish and efish the HHC1 CH1 closely resembles the HHC1 CH2. Whereas efish Cμ1 and Cμ2 exons aligned poorly with each other and showed 59% nucleotide identity, the HHC1 CH1 was 83% identical to CH2, without gapping (AAVX02045384.1). There was in fact 90% identity in the 3’-most 211 bp of the HHC1 CH1 (330 bp) and CH2 (321 bp) exons, suggesting its probable derivation by gene conversion from CH2.
Figure 2.
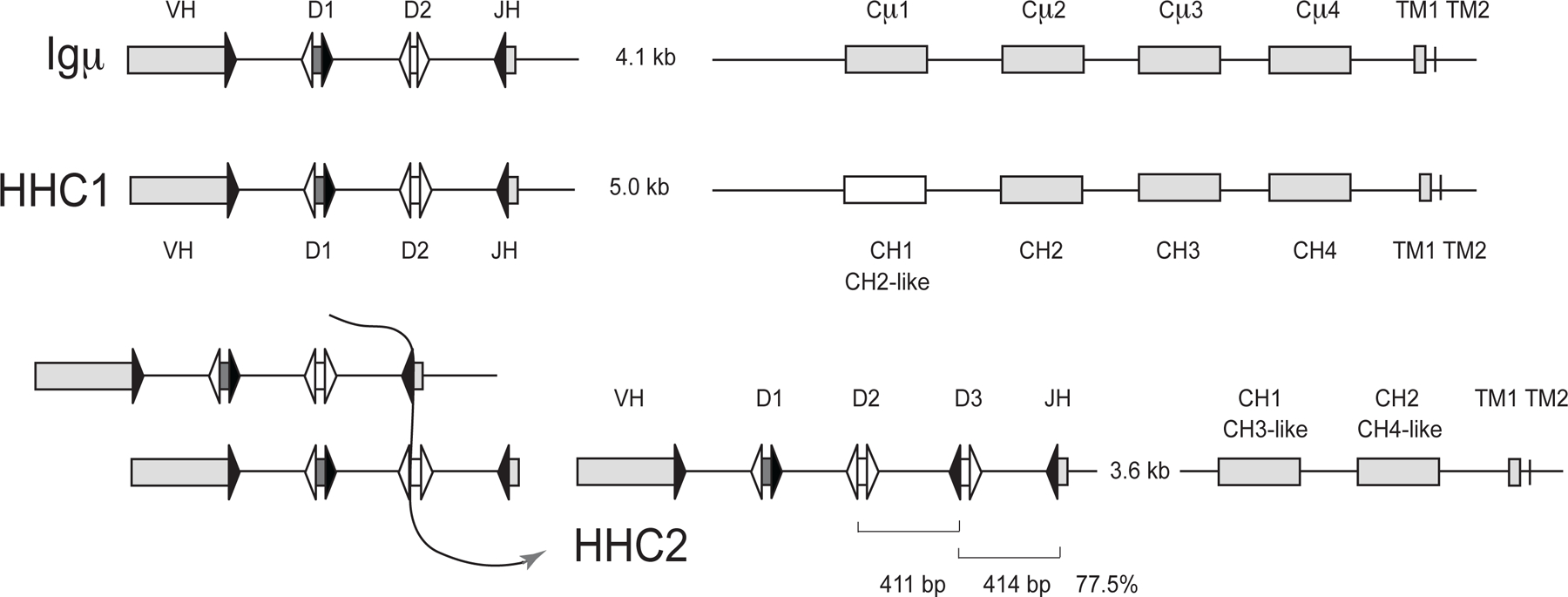
Organization of Igμ, HHC1, and HHC2 clusters in the efish germline. Top. The Igμ cluster was derived from the overlap of KI636074.1 (signal sequence, VH gene segments, Cμ1, Cμ2) with AAVX02048050.1 (J-C intron, Cμ1–4 to TM2), and AAVX02033970.1 (Cμ2 to TM2). Middle. HHC1 was derived from AAVX02046069.1 (signal sequence, VH gene segments, CH1–3) and AAVX02045384.1 (CH1–4 to TM2). Bottom. At right: HHC2 organization is from AAVX02033307.1. Analysis of the HHC2 showed 77.5% identity over the regions indicated in brackets, suggesting (at left) that a duplication event generated the third D gene segment and the intersegmental sequence. Signal sequences are not depicted for simplicity. Rectangles represent VH gene segments and C region exons (as labeled). The HHC1 CH1 sequence showed homology to its CH2 exon. The HHC2 CH1 and CH2 exons showed similarity to the μ and HHC1 CH3 and CH4, as indicated. Triangles represent recombination signal sequences with 23 bp spacer (filled) or 12 bp spacer (open). The J-C intron sizes are shown, but otherwise distances are not to scale.
HHC2 was novel and contained three DH gene segments, referred to as D1-D3. The only sequence in the database (AAVX02033307.1; at 2633–12,279 bp) complete from leader to transmembrane exons was 9.6 kb in length, containing a 3.5 kb J-C intron and two CH exons that were respectively similar to the CH3 and CH4 of both μ and HHC1. The overall organizations of the three IgH are depicted in Fig. 2, their reconstructions from database sequences are detailed in the legend.
The 77.5% identity between the interval from D2 to D3–23RSS and that from D3 to JH-23RSS in HHC2 (respectively bracketed as 411 bp and 414 bp in Fig. 2, right) suggested that the D3 and its downstream intersegmental sequence probably arose from a recombination event as shown in Fig. 2 (left).
Relationship of three IgH clusters
GL HHC2 clusters extending from VH to CH2 tailpiece (TP) were cloned from efish individual 1 (“efish 1”) liver DNA. Seven sequences with unique VH were obtained from efish individual 1 and two from efish2. The subfamilies, called Groups 1–6, are very similar, and Groups 1 and 2 were entered into the database (accession numbers MN958903, MN958904). In Fig. 3 a representative μ amino acid sequence is compared to those from HHC1 and HHC2. VH from Igμ share 77% nucleotide identity with HHC1 VH and 75% identity with HHC2 VH; the latter two share 74% identity; thus they are long diverged and different VH families. However, HHC1 and HHC2 carried similar substitutions at FR2, a region where six positions (V37, R38, G44, L45, E46, W47) affect the VH/VL interface and are highly conserved among vertebrate VH [13]. However, two (R38, E46) are not in direct contact and participate in folding; these are also unchanged in all efish FR2. The other four were replaced in HHC1 and HHC2: the Val in μ was substituted by Tyr, and positions 44, 45, and 47 by Gln, Gln/Arg, Asn/Lys, thereby altering the hydrophobic character of what would have been the VH interface with VL [35].
Figure 3.

Predicted amino acid sequences of VH and CH from the three elephantfish H chain classes. VH: Alignment of GL μ (m113), HHC1, and HHC2 VH sequences. The framework (FR) and complementarity-determining regions (CDR) are indicated, with the latter underlined. Numbering is according to Kabat et al. [36], with the ones digit designating the amino acid position. FR2 residues V37, R38, G44, L45, E46, and W47, conserved at the VH/VL interface [35], are indicated below the three sequences. Those in direct contact with VL are underlined. CH, Alignment of C regions with tailpiece from μ (Cμ1-Cμ4), HHC1 (CH1-CH4) and HCC2 (CH1-CH2, analogous to CH3-CH4 in μ and HHC1). The arrow overhead designates the Cys in Cμ1 predicted to disulfide bond to L chain. The second arrow with asterisk designates the site at which alternative splicing to the transmembrane tail occurs. TM, Alignment of deduced amino acid sequence from two transmembrane exons. The transmembrane helix region is indicated by italicization (TMHMM v2.0). Dashes indicate gaps, dots identity. The GL m113 VH was cloned in this study, the HHC1 VH is from whole genome shotgun sequence AAVX02046069.1. The HHC2 VH and CH is genomic clone 12 isolated in this study [accession number MN958903], the TM is part of the entire cluster in AAVX02033307.1. The μ CH sequence is from the EST AFM88216.1 and matching Cμ3, Cμ4 and TM from AAVX02044970.1. The CH and TM of HHC1 is deduced from CH exons in KI637562.1,
Given the similarity of changes at their VH it is presumed that HHC2 arose from an HHC1-like cluster. However, the deletion event that removed two C exons from the precursor HHC2 could have been either an internal deletion or unequal crossingover with either Igμ or HHC1 cluster. All three IgH share identity in the first ~1.5 kb of the J-C intron and about 500 bp upstream of the CH3 exon in Igμ/HHC1 and the homologous “CH1” of HHC2. This similarity suggested that the deletion in the pre-HHC2 cluster included the latter part of the J-C intron, CH1, and CH2.
The CH3, CH4-TP nucleotide sequences are similar in all the IgH. CH3 and CH4 in HHC1 share 79% and 84% identity with the respective Cμ exons. The CH1 exons in HHC2 contained 85% and 82% identity with the respective HHC1 and Cμ CH3. The HHC2 CH2-TP exon is 83% and 86% identical with the HHC1 CH4-TP and Cμ4-TP. Imbedded in the last C domain exon of all three Ig classes is the alternative splicing site to downstream transmembrane exons (Fig. 3, asterisked arrow). The transmembrane helix is very well conserved (Fig. 3, TM, italicized), indicating that all three H chain classes potentially act as cell surface receptors and are secreted.
HHC2 V gene segments
Out of 27 efish1 GL clones, six HHC2 clusters and a pseudogene were distinguishable by VH, D1–3, JH and CH sequences. The VH are 86–98% identical at the nucleotide level and within one family, but a different family from the other Ig classes. There exist more HHC2 clusters, found after using different PCR primers (later sections), but the VH were all variants of the original six. The members are here called “Groups”.
CDR3 in HHC2, μ, and HHC1
The GL D sequences in HHC2 are different from those of efish μ and HHC1 as well as nurse shark μ, ω and DNAR (Fig. 4). The predicted amino acids in HHC2 D gene segments included one or more amino acids with a positively charged side chain in almost every reading frame (Fig. 4, in red), whereas, in contrast to the frequently encoded aromatic amino acids in all other DH, only Tyr is present in one reading frame, if at all, in HHC2 D3 (Fig. 4, highlighted in yellow).
Figure 4.

Representative GL D gene segments from elephantfish and nurse shark IgH clusters. Each IgH class heading is shown with the D gene organization, underneath which each D gene segment is given with its deduced amino acid sequences. Dashes indicate stops, Arg and Lys are in red, Tyr and Trp are highlighted. Sources of the sequences: HHC2 (AAVX02044307.1, clones 24 and 1 were obtained in this study, MN958903, MN958904), HHC1 (AAVX02046069.1, AAVX02046834.1, AAVX02063300.1), elephantfish Igμ (AAVX02046860.1, AAVX02046576.1), IgNAR (L38968.1, L38965.1), Igω (KF192883.1), nurse shark Igμ (DQ867384, DQ857385).
To determine whether somatically rearranged HHC2 joints reflected these unusual features, cDNA from the three Ig classes were cloned from efish1 spleen. The CDR3 are shown in Fig. 5 and 6. Nucleotides encoding Arg and Lys are indicated in red among the in-frame VDJ, those encoding Tyr, Phe or Trp are highlghted in yellow. In HHC2 there are 1–5 Lys/Arg codons in 23 out of 24 D/N/P sequences compared to 1–2 in 11/23 μ and 10/17 HHC1 (Fig. 6, top). In HHC2 there are six cDNA encoding an aromatic amino acid in D/N/P compared to 14/23 in μ and 15/17 in HHC2.
Figure 5.
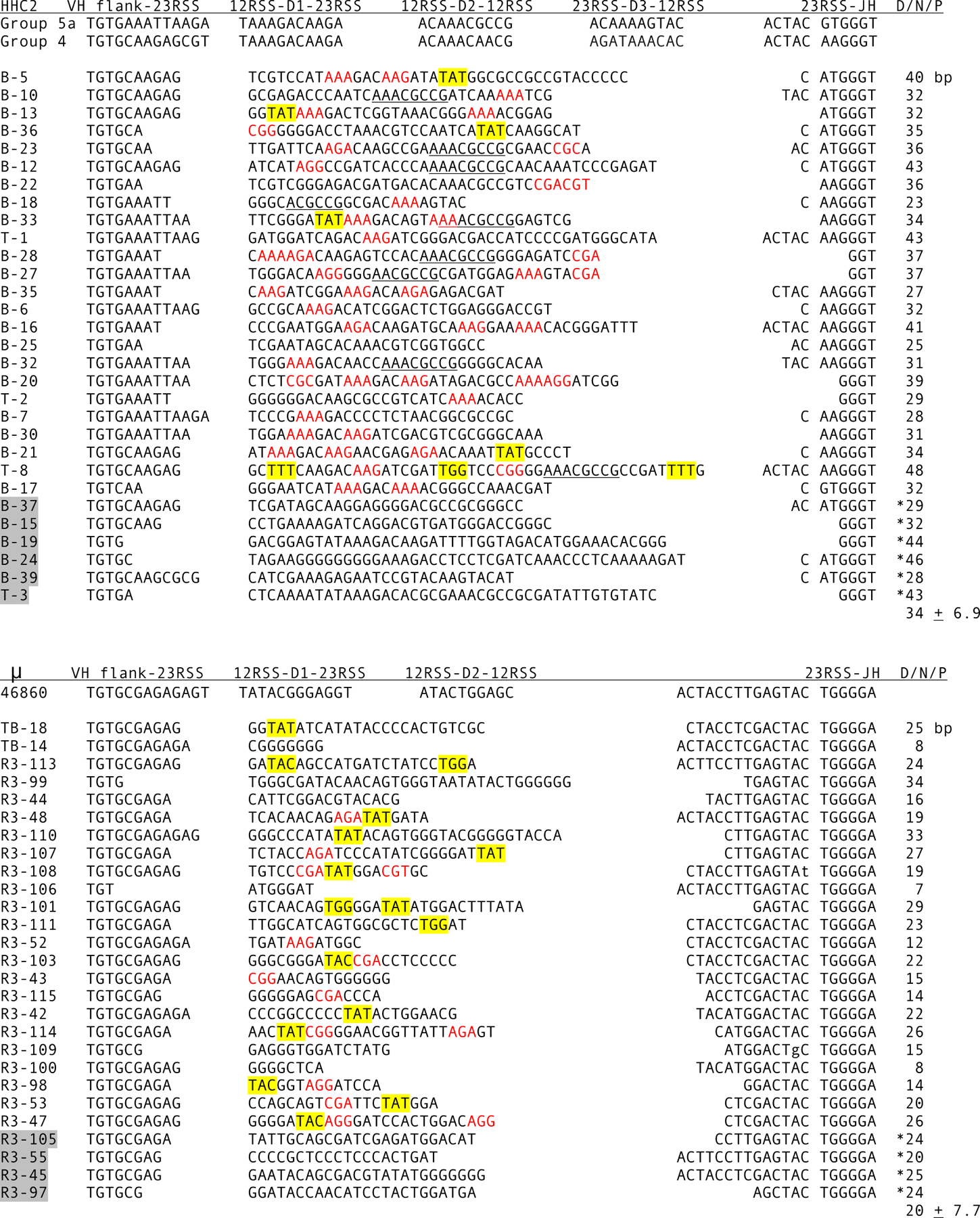
CDR3 in HHC2 and μ cDNA. Top, HHC2 junctions (accession numbers MN888965-MN888974). Bottom, Junctions in μ cDNA. Each group was compared to known HHC2 and μ GL flanks, of which representative VH, D, and JH flanks are shown at the top, as labeled. The first codon is TGT (codon 92, Kabat numbering) and the last codon, in JH, is GGN (codon 104), part of the JH Gly-X-Gly motif. A space has been inserted in front of codon 103, almost always TGG in vertebrate HCDR3, in order to show where the end of CDR3 is regarded in both HHC2 and μ in this study. Highlighted clone names indicate nonproductive VDJ. Encoded Arg and Lys are indicated in red. Contribution to CDR3 from D and N/P additions are shown in the column at right. The average number of nucleotides (± S.D.) in D/N/P was calculated without the asterisked values from non-productive sequences.
Figure 6.
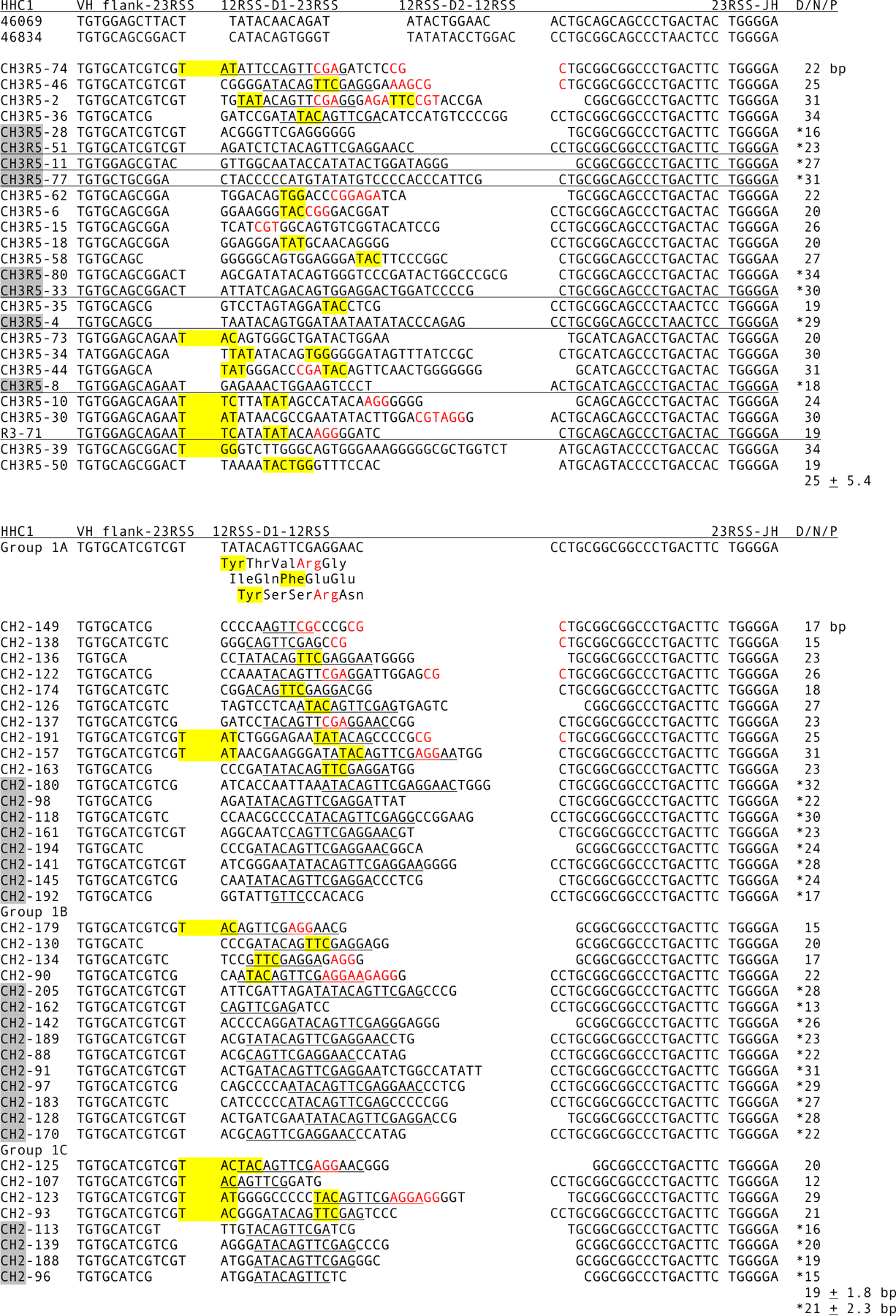
CDR3 in HHC1 cDNA. Top, Junctions in HHC1 cDNA. The cDNA were compared to GL HHC1 VH gene segment flanks, of which two have been identified in the database, at top. Reference HHC1 VH gene segments are from AAVX02046069.1 and AAVX02046834.1. The sequences have been classified into eight genes on the basis of identity at the VH and JH flanks. VH and C sequence generally confirm the groupings. See legend to Fig. 4 for details. Bottom, Junctions in HHC1 Group 1 cDNA. The GL gene was cloned, accession number MN958905, and the VH, JH flanks and D gene segment shown as the reference sequence, with the deduced amino acid sequence of D in three possible reading frames. The cDNA were classified into three genes, Group 1a-c, as shown, and the D sequence contribution underlined. The average number of nucleotides (± S.D.) in D/N/P was calculated with and without the asterisked values from non-productive sequences.
HHC2 CDR3 contain the largest proportion of somatically generated sequence, as tabulated in the “D/N/P” columns in Figs. 5 and 6. Although the average HHC2 CDR3 is 12 codons and slightly longer than the 10.6 codons in μ, its JH 5’ flank is shorter, with only eight nucleotides preceding the sequence encoding the conserved Gly-X-Gly motif [36]. Additionally, there is a third rearrangement event in HHC2 with attendant TdT activity. In contrast, the JH flank is 17 bp in μ and 23 bp in HHC1. The contribution of D gene, N and P addition in HHC2 is on the average 34 bp, 94% of the CDR3 loop, compared to 20 bp in μ CDR3 (63%). In HHC1 the long JH flank contributes to a longer average CDR3 of 15.5 codons, but the D/N/P contribution is 25 bp, providing only 54% of the loop (Fig. 6 top).
No bias for Arg encoded by HHC1 DH
Eight kinds of HHC1 sequences are shown in Fig. 6, top, categorized by the distinctive VH and JH flanks. The first six HHC1 cDNAs (Fig. 6, top) belong to a subfamily that we shall refer to as “HHC1 Group 1”. The Group 1 GL cluster contains a single D that is a 17 bp “germline (GL)-joining” of D1 and D2, like a recombined D1D2, shown as the reference sequence in Fig. 6, bottom (accession number MN958905). GL-joining is a non-somatic phenomenon that has been observed frequently within cartilaginous fish Ig clusters [37,38] and suggested to occur through RAG1/2 activity in the germ cells because some joint sequences are consistent with P nucleotide insertions [39]. P nucleotides are a signature of RAG1/2 activity, being generated through the hairpin DNA intermediate [40]. The first six (TATACA) and last five (GGAAC) base pairs of the Group 1 D match the respective 5’ and 3’ portions of the D1 and D2 of HHC1 sequence 46069 (Fig. 4), suggesting that it derived from a similar ancestral cluster. Group 1 cDNA were cloned to determine if basic residues are preferentially included when Arg is encoded by DH in two reading frames. SHM was also assessed from these sequences (next section).
All DH contributions are underlined for Group 1 CDR3. Arg residues were present in 11/18 in-frame CDR3, not different from 10/17 in the total HHC1 pool (Fig. 6, top), nor from μ. Of the total 22 in-frame Group 1 sequences (Fig. 6 top and bottom) all reading frames of DH were represented equally. Of 15 CDR3 using frames 1 and 3, 10 contained Arg whereas 11 included Tyr, which was at the 5’ end of the DH (Fig. 6, bottom, reference sequence), showing an absence of biased selection with regard to Arg encoded in the DH.
Somatic Hypermutation
As assessed by differences in C region, especially at the Cμ1-Cμ2 junction, there are at least 13–15 Igμ clusters in efish1. For HHC1 and HHC2, the respective C regions were similar among the IgH, but in HHC1 eight genes could be classified by distinctive VH and JH flanks, making identification of VDJ GL origins reliable (Fig. 6 top). HHC1 Group 1 was selected for examination because FR1 and CH could be specifically targeted in PCR, and its transcripts were abundant in the HHC1 pool.
The cloned Group 1 cDNA were encoded by three GL variants, as assessed by a few differences in VH between 1a and 1b/1c and in C between 1b and 1c (not shown). Examination of cDNA showed little evidence for SHM in the 208 bp of VH, from FR1 up to the TGT at the flank, plus 45 bp of JH. In 40 unique sequences, of which 18 are in-frame, the frequency of substitutions in V and J was 1/10,120 bp (0.01%) compared the frequency of Q5-induced mutations of 2/8,960 bp (0.02%) in 224 bp C region.
The efish1 was 3–4 years of age, as determined by fork length [41], and was not sexually mature. Nurse sharks at 3–4 years of age are also not sexually mature but their immunity is adult in terms of their immune system components and antibody response [42]. In non-immunized sharks extensive substitution has been observed in H and L chains where >90% of H chains are of the secreted form [43–45]. A comparison of secreted versus membrane forms of IgNAR demonstrated that the substitutions were acquired during immune responses [46]. It is not known if antibody maturation occurs in holocephalans, but it is clear that efish differ from elasmobranchs.
Rearrangement involving five gene segments
Partially rearranged Igμ clusters with one, two, or three deletion rearrangements (1R, 2R, 3R) can be cloned from nurse shark thymic DNA [25]. This is in contrast to nurse shark sIgM-positive B cells, where rearrangements are almost all 3R, or VDDJ [25,26]; inversions are deleterious and rarely observed. PCR was performed on efish1 splenic genomic DNA, which would include T cells, to amplify rearranged genes from the HHC2 Group 2 subfamily. Most of the clones were 4R, or VDDDJ, but a few contained 3R and 2R configurations. The sequences derived from four GL genes, of which three, Group 2a-c, differed slightly in D sequence and a pseudogene (not shown). HHC2 Group 2a (Fig. 7) had been isolated in the previous experiments, and the D sequences of 2b and 2c are based on unrecombined flanks, intact D sequences in CDR3, and similarity to D genes from other clusters. Because of the subfamily-specific amplification, the D gene assignment in CDR3 could be made with confidence, showing that in Groups 2a-c most somatic rearrangements involved all three D gene segments.
Figure 7.

Partial rearrangements of HHC2 from genomic DNA of spleen. Rearranged HHC2 Group 2 clusters were amplified from splenic DNA using primers in FR1 and J-C intron and cloned. Minor but consistent differences among the sequences led to classifications of the sequences into four subgroups, 2a-2c. The CDR3 were analyzed and sequence assigned to VH and JH flanks, D1, D2, D3, and p or N additions. Sequences were isolated fully rearranged (called gDNA VDJ), two-rearrangement (V-DDD-J), and three-rearrangement (V-DDDJ, VDD-DJ). One clone, cVDD-DJ 112, was found among cDNA sequences. The VH and JH flanks were either available as GL or deduced. Unrecombined flanks are indicated with [RSS] in gray. N regions are shown in upper case and P regions in lower case. In-frame cDNA submitted as accession numbers MN888975-MN888991.
The rearrangements between neighboring RSS follow the 12/23 rule to form VD, D1D2, D2D3, D3JH; but two other deletional recombination events are theoretically possible, VH to D2 and D2 to JH. In three instances it was difficult to distinguish a D1 contribution (Fig. 7, clones VDJ-32, VDJ-30, VDJ-39), which could be interpreted as VH to D2 rearrangement.
Among partial rearrangements, three from genomic DNA and one cDNA, all show different configurations: V-DDDJ, VDD-DJ, and V-DDD-J. In every case the presence of an already formed D2D3 or D3JH would have prevented D2 to JH recombination. Of the 14 clones shown in Fig. 7, none lacked or would have lacked D3 involvement. Considering this group as representative of HHC2 rearrangement products, D2 to JH recombination occurs at less than 1 in 14 or <7% frequency. Similar results were obtained in another subgroup, HHC2 Group 1 (not shown).
Discussion
This study characterizes a novel HCAb in the holocephalan C. milii that we named HHC2. Another HCAb, here called HHC1, was previously noted [18] as similar to the HCAb in the chimaera ratfish [19]; HHC1 thus rose between 410 and 161 mya, after the emergence of holocephalans and before divergence of the callorhinchid from chimaerid families [17] (Fig.1A). HHC2 however was not described in ratfish libraries, in spite of extensive screening in that study [19]. HCAb clusters with the μ-related structure as found in holocephalans have not been detected in the course of screening eleven genomes’ worth of a nurse shark BAC library with a Cμ3-Cμ4 probe [unpub. data], and IgNAR remains the only known HCAb among elasmobranchs [18]. HCAbs arose independently in the two subclasses of cartilaginous fish, attesting to their value, although a specialized function is not clear.
In immunized nurse sharks affinity maturation was detected in IgNAR and monomeric IgM but not pentameric IgM [46–48]. It appears that the SHM process in sharks is an exceptional one that developed after elasmobranch divergence although efish carry a homologous cAID gene. Aside from frequency, an unusual feature of elasmobranch SHM is the tandem 2–5 bp mutations that comprise 50% of substitutions [44,45], differences that between sister phyla may include the processing of cAID-induced lesions.
Other than histological identification of immune cells and tissues, little is known of holocephalan fish immunity. Whereas HHC1 can be likened to shark IgNAR, with their respective four and five C domains and disulfide-bonded CDRs, HHC2 is unique among antibodies in its paratope characteristics. Because of its unambiguous descent from μ, HHC2-specific changes at VH, CH and particularly D1–3 demonstrate the flexibility in the multiple cluster organization to evolve antigen receptors with novel features.
Cluster Rearrangement
As shown in elasmobranchs, V(D)J rearrangement at Ig clusters primarily takes place within the cluster, where the gene segments are only 300–700 bp apart [49]. Although the 12/23 rule for V(D)J recombination [50,51] permits six kinds of deletional recombination events, the HHC2 genomic rearrangement patterns show that VDDDJ is the prominent one.
It is not clear what controls rearrangement hierarchy in the shark or efish Ig cluster. An individual RSS sequence can be evaluated through an algorithm developed from characteristics of physiological mouse and human RSS and given a functionality score [https://www.itb.cnr.it/rss/analyze.html]. For instance, in gene 2a, VH and D1 rearrangement are predicted disfavored by a poor score at one RSS and, anecdotally, the incomplete gene 2a 3R isolated is V-DDDJ (Fig. 7). However, all other RSS in gene 2a scored well, so cleavage efficiency by itself does not explain the absence of inversions. Recent RAG1/2 crystal structures showed that the 12RSS and 23RSS are severely bent at the spacer and the bending is location-sensitive, suggesting that spacer sequence combinations could be important [52]. Spacer compatibility, currently not measurable, could influence the recombination efficiency of RSS pairs.
Thus despite of the gain in an additional D gene segment, the HHC2 cluster largely lacks combinatorial potential. In any case, the observed consequence of rearranging all three D genes is to guarantee inclusion of Lys if not Arg, the most striking feature of HHC2 compared to all other Ig CDR3.
D contribution to CDR3
Although HHC1 and HHC2 have a common origin in Igμ, the D gene segments in HHC2 have diverged considerably. The Igμ and HHC1 D generally resemble those of nurse shark Igμ and Igω in nucleotide sequence and the amino acids encoded, which tend to be Tyr and Trp (Fig. 4), unlike the HHC2 D gene segments which encode Lys in 6–7 out of 9 reading frames and Arg in 2–3 for the three D genes (Fig. 4, in red). Not surprisingly Lys is present in HHC2 CDR3 at 11.8% (Fig. 8), in contrast to its frequency at 1–2% in all six mammalian CDRs of H and L chains, making Lys among their 3–4 least represented amino acids [10]. In almost 7000 published mouse and human H chain CDR3 Lys is present at <2%, Arg at 6%, and Tyr at 25% in mouse and 13% in human sequences [8], distributions similar to those obtained from nurse shark μ, efish μ, HHC1 and published HCAb CDR3 in IgNAR and two llama VHH families (Fig. 8). Moreover, the same most frequent amino acids were observed in mouse (Tyr, Gly (15%) and Ser (9%)) and human CDR3 (Gly (15%), Tyr, Ser (9%)) [8]. Aside from low Tyr and high Lys representation in HHC2, Cys in IgNAR is also exceptional because of the stabilizing disulfide bonds within its lengthy CDR3. Otherwise, amino acid usage show a distribution unexceptional for conventional Ig and HCAbs: Gly, Ser, Asp [6,8,9].
Figure 8.
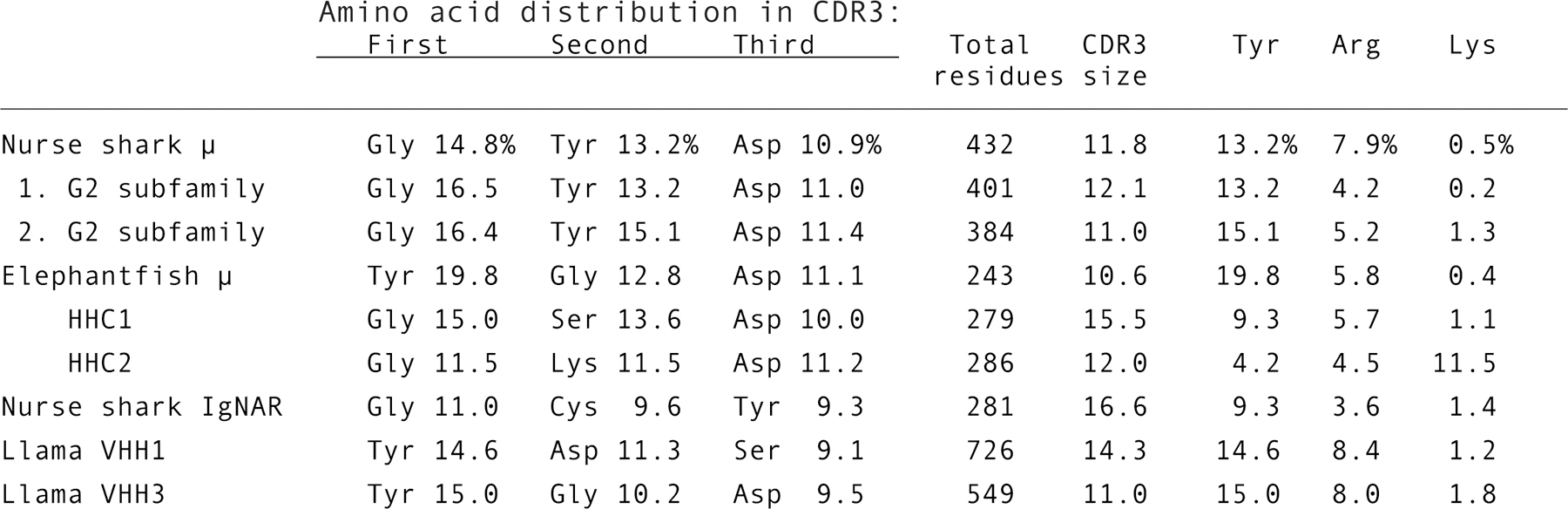
Distribution of amino acids in H chain CDR3. Amino acid frequency was tallied for CDR3 from efish μ, HHC1, HHC2, and nurse shark μ (all five subfamilies), and two G2 subfamily H chains from two spleen cDNA libraries (unpublished data). Sequence information was used from IgNAR [73] and from llama VHH1 and VHH3 subfamilies, chosen for the absence of disulfide bonding between CDR [74]. The CDR3 sequences according to Kabat numbering [36] include positions 95–102 or IMGT positions 107–117.
An overall comparison of D/N/P-encoded amino acids in the three efish Ig classes is shown in Fig. 9A, grouped according to sidechain properties. A comparison of population frequencies across the board showed that overall amino acid frequencies between μ and HHC1 are not significantly different, but both are different from HHC2 (Fig. 9B). These comparisons suggest that, although HHC1 are HCAbs, their CDR3 exclusive of flanking sequence are overall not very dissimilar from those of μ. This is not to say that their antigen-combining sites are alike, but that the central part of the CDR3, which involves most interactions with ligands [53], carries similar arrays of amino acids and thus similar interactive capabilities for ligand-bonding.
Figure 9.
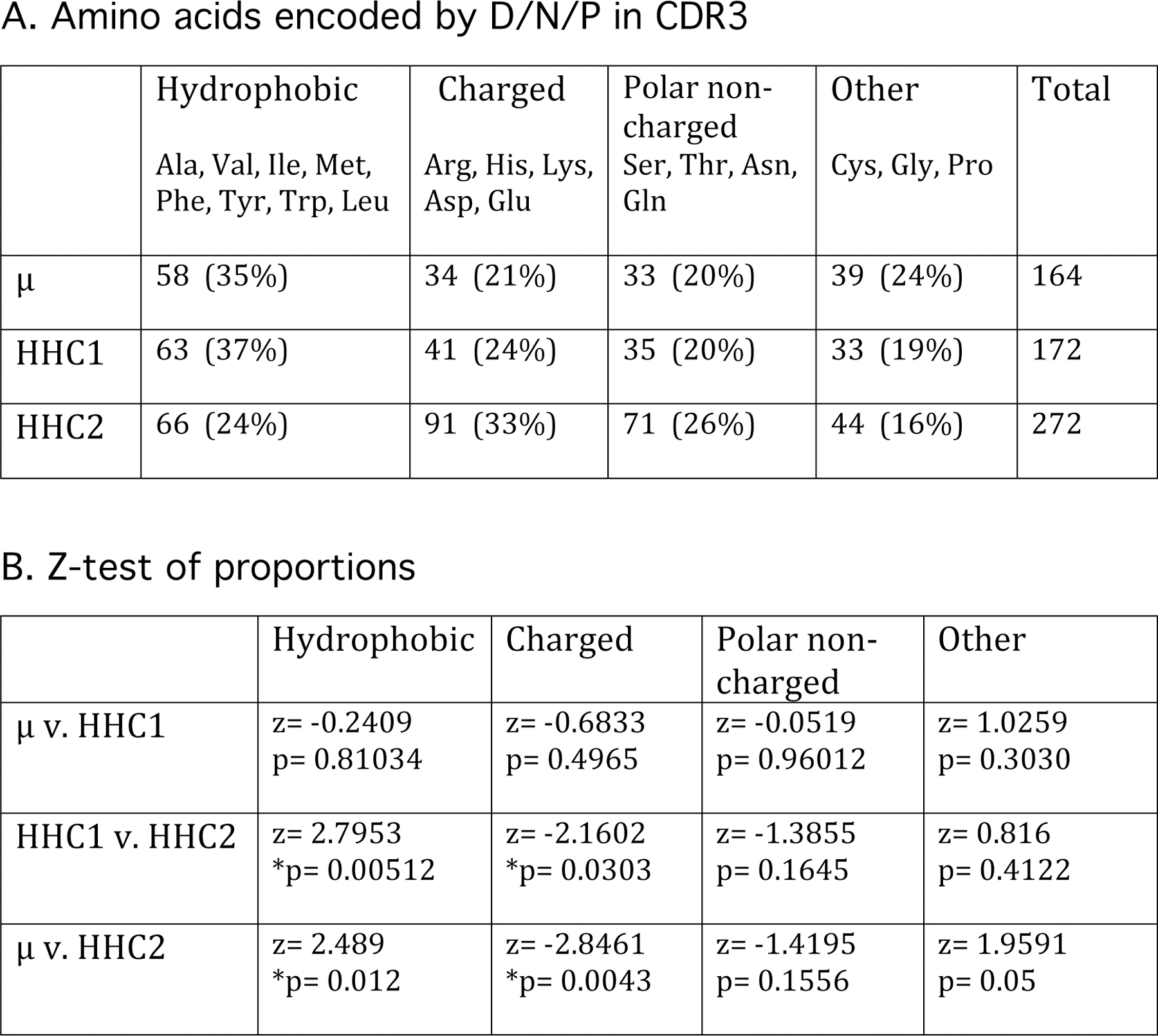
Amino acid content in D/N/P portion of efish H chain CDR3. A. Amino acids encoded by D/N/P sequence in μ, HHC1, and HHC2 CDR3 shown in Figures 5 and 6 (top) were categorized into four groups according to side chain characteristics. B. The two-sample z-test of proportions (https://www.socscistatistics.com/tests/ztest/default2) was applied to each combination per category. For a two-tailed test at 5% significance the critical value for the z score is 1.96. Significant differences between populations (p<0.05) are asterisked.
HHC2 CDR3 are unique in Lys and Tyr content. Examination of the CDR1 and CDR2 of the six HHC2 GL families show that they are also poor in Tyr but otherwise contain amino acid distributions similar to those in mammalian H chain sequences. The HHC2 combining sites are thus generally deprived of aromatic residues that in conventional Ig repertoires are responsible for the greatest number of contacts with ligand [6,9,10,54].
Balance of germline sequence versus selection
Although Arg is encoded in the HHC2 D genes, its 4.5% frequency in CDR3 is same as in nurse shark H chains of the G2 subfamily whose CDR3 are of similar length (Fig. 9) and whose D1 and D2 genes do not encode Arg (Fig. 4). In the latter case, Arg arises through the 68–75% CG-rich N region addition [55] and high SHM frequency in elasmobranch Ig [46,48,56]. Interestingly, in HHC2 most Arg in CDR3 also originated from N addition. For instance, Arg is encoded in two reading frames of D1 and in one reading frame of some D2 (Fig. 4) but of the 16 Arg encoded by D/N/P region in Fig. 5 (top), only four were derived from any D sequence (B-23, B-28, B-35, B-20). Moreover, one D2 (ACAAACGCCG, Fig. 4 and 7) potentially encodes two Arg, and although this gene segment was used in nine cDNAs (Fig. 5, underlined; B-10, B-23, B-12, B-18, B-33, B-28, B-27, B-32, T-8), “CGCCGN” does not encode Arg in any of them. Compared with the unbiased expression of GL-encoded Arg in HHC1, these HHC2 CDR3 suggest a selection against multiple Arg, and possibly favoring positions near the CDR3 loop base to account for their N-region origin.
These instances demonstrate the importance of post-rearrangement selection balancing usage of GL-encoded elements. Arg, like Tyr, provides considerable bonding versatility, being capable of five H-bonds, pseudo-π interactions, salt bridges. In mammals, Arg is the second most frequently acquired mutation at antigen-combining sites [57], generally confirmed on the population level by high through-put sequencing of Ig from antigen-experienced human B cells that gained a significant positive charge increase compared to the naive population [58]. Although Arg contributes to increased binding affinity, mutations to Arg can, by the same token, be a trade-off in specificity [54,59]. Moreover, acquisition of Arg during development or from SHM is thought potentially to lead to autoimmune reactivity [60,31–34].
We suggest that Arg is encoded in the HHC2 D because the presence of an interactive-enabling amino acid such as Arg is advantageous; Tyr is not favored in HHC2 D gene segments or by N addition. The Lys amino side chain on the other hand in most respects appears to be a lesser version of Arg guanidinium group in the number of H-bonding donors, the stability of cation-π interactions [61], all of which make Arg a desirable acquisition in mature antibodies that make for a favorable binding energy [62]. Yet in HHC2 it is Lys that is prominently encoded in D1-D3. The selection for Lys presence in CDR3 suggests that the densely charged NH3+ group in Lys lends greater electropositivity to the antibody combining site without the pathogenic potential of autoreactivity. Although Lys can interact with the phosphate backbone of DNA, Arg can also H-bond with greater stability to the nucleotide base [63] and many antibody interactions with DNA involve Arg [33,64–66].
The influence on the B cell repertoire by GL-encoded DH sequence versus somatic selection on CDR3 was explored in a series of experiments (reviewed in 67) using lines of mice that carried a single mutated knock-in DH gene segment with reading frames enriched in Arg and/or encoding hydrophobic amino acids, usually disfavored in CDR3 [8,12]. The total numbers of B cells were reduced, and a skewed Ig repertoire led to impaired responses after immunization or experimental infection. While post-rearrangement selection favored Tyr-bearing receptors, the mutant sequence was nonetheless retained for the majority of cells. These studies demonstrated that the gene in the GL will predominate, in spite of its disadvantageous consequences for the animal’s well-being; the authors concluded that the natural DH, usually Tyr-rich in most species, have been evolutionarily selected to generate protective antibodies.
What epitopes have the HHC2 genes evolved to detect? Because of Lys scarcity in vertebrate Ig CDRs there is little information on its interaction with epitopes other than that it does not tend to bind Asp or Glu on protein antigens [68]. Lys and Arg were both selected for in HHC2 D1–3 and the commonality is their positive charge at physiological pH, which in efish serum is about 8 (data not shown). Their interactions could involve anion groups such as phosphate; for instance, Arg/Lys in H chain CDR2 are phosphate-binding in phospho-specific monoclonal antibodies [69]. One possibility is that efish have evolved a specialized Ig repertoire directed against microorganisms with negatively-charged surfaces such as bacterial phospholipids. Due to their flexible CDR3, unconstrained by intrachain disulfide bonding or interaction with L chain, the HHC2 could be more effective in their penetration into viral glycan shields. We can only speculate at this time, and the types of epitopes detected by the HHC2 binding sites await investigation by phage display libraries or in a transgene system.
Materials and methods
Animals
Elephantfish (Callorhincus milii) were among targeted species collected off Banks Peninsula, South Island, New Zealand, during a routine trawl survey by the National Institute of Water and Atmospheric Research for the New Zealand Ministry for Primary Industries [70]. The specimens were sampled for gonad stage and fin spines. efish1 was female and efish2 male, both estimated to be 3–4 years of age, and slices of spleen and liver were placed in RNAlater (Ambion). Due to degradation, RNA isolation using lithium chloride-urea proved to be the more efficacious technique [71], as judged by the integrity of the 18S and 28S RNA species. DNA was extracted from liver and spleen by conventional methods.
PCR and RT-PCR
PCR was performed using genomic DNA or cDNA preparations. GL HHC2 genes were amplified using LongAmp Taq DNA polymerase (New England BioLabs) with primers targeting the leader intron (EFL2, 5’-TCTCACTGTYCCTGTGTC-3’) and CH2 (nEFCR2, 5’-TGAGAATCCAATGGCAAG-3’). The 7 kb fragments were cloned into pGEM-T-Easy (Invitrogen) and sequenced (Genewiz). Rearranged genomic HHC2 family-specific genes were amplified from splenic DNA after 20 cycles with primers in FR1 (efishF2F1, 5’-AGGCAGATTTGGTTCTCA-3’) and in the J-C intron (efishF2R4, 5’-GTCACTCATCCCACGATA-3’), followed by 35 cycles with nested primers (efishF2F2, 5’-GCAGATTTGGTTCTCACA-3’ and efishF2R3, 5’-CACGATATTCAGGTCCTC-3’).
First strand cDNA synthesis (Superscript III, Life Technologies) was primed with oligo dT, followed by 32 cycles of PCR using primers in leader (aEFL, 5’-TCTCTCAGTCTGCTGCTG-3’) and Cμ3 (EFCH3R3, 5’-TCCAAGTCACGTTGACGT-3’) to obtain μ H chain sequence of about 1.1 kb. For HHC2, cDNA was primed with the EFCH3R3 which targeted its CH1, followed by PCR amplification using primers in the HHC2 FR1 (D3EF3, 5’-CAGCGGGWTTRATCTCAG-3’) and CH1 (EFCH3R, 5’-GACACATGTYAGCGTTAC-3’) that generated 450 bp HHC2 fragments as well as some μ at 1 kb, since the reverse primer also annealed to Cμ3. For HHC1, cDNA was primed specifically with CH3R4 (CACATGTTAGCGTTACAGA), and PCR products of about 1.1 kb were generated with primers in HHC1 FR1 (aEFL4 CCTGAGACTGACCTG) and CH3 (CH3R5 CCATCAAAACCTGTCGCT).
One HHC1 cluster, called “Group 1” in the Results, was amplified from genomic DNA using specific oligos in FR1 (efCH2FR1F, 5’-GCAGATCCAGCGGATTTGA-3’) and the JH (efCH2JHR, 5’-GTCACCGCTGTGCCTTG-3’). To assess SHM in Group 1 VDJ, cDNA was primed with CH3R4 and 600 bp PCR products were generated with primers in VH and CH2 (Sal1CH2FR1F, 5’-ATGTCGACGCAGATCCAGCGGATTTGA-3’; Sal1CH2CH1R2/1, 5’-ATGTCGACCTGGCGGGGACCGTCAA-3’) after 35 cycles of PCR with Q5 high-fidelity DNA polymerase (New England BioLabs). Sal1 restriction endonuclease sites were incorporated into the primers, and the sequences were cloned into pUC19.
Genomic sequences for HHC1 (MN958905) and HHC2 (MN958903, MN958904) were submitted to GenBank (http://www.ncbi.nlm.nih.gov), as were cDNA sequences for HHC1 (MN888965-MN888974) and HHC2 (MN888975-MN888991).
Supplementary Material
SFigure 1. Alignment of elephantfish HCAb VH with conventional and HCAb VH of other species. CDR1 and CDR2 (underlined) are according to Kabat et al. (36), who inserted gaps after residues 35 and 52 in the CDR. Dots indicate identity, dashes gaps. Elephantfish HHC2 (MN958903), HHC1 (AAVX02046069.1), spotted ratfish μ (AAC12884.1) and HCAb (AAC12909.1), horn shark (CAA31799.1), catfish (ACD38546.1), Xenopus (OCU01394.1), green sea turtle (EMP41230.1), chicken (AAA50802.1), human VH3 (AAQ05430.1), mouse (AAK54033.1), rabbit (AAC39229.1), llama VH (AJ401073), VHH subfamily III (AJ238046), subfamily I (AJ238059.1), IgNAR type 1 (AY114781.1). Residues in FR2 enabling VH-alone are highlighted in the HCAb sequences.
Acknowledgments.
We thank Warrick Lyon for collecting the specimens. We also thank Louis Du Pasquier for comments on the manuscript, and Robyn Stanfield, Usha Govindarajulu, Serge Muyldermanns, and Matthias Feige for clarifying myriad and statistical issues. The DNA sequences reported here were submitted to GenBank and assigned accession numbers as specified. These studies have been supported by the National Institutes of Health GM068095 (E.H.).
Abreviations.
- GL
germline
- HCAb
heavy chain antibody
- HHC
holocephalan heavy chain
- RSS
recombination signal sequence
Footnotes
The authors declare no conflict of interest.
References
- 1.Flajnik MF, Deschacht N, and Muyldermans S A case of convergence: why did a simple alternative to canonical antibodies arise in sharks and camels? PLoS Biol 2011. 9(8):e1001120. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Gellert M, V(D)J recombination: RAG proteins, repair factors, and regulation. Annu. Rev. Biochem 2002. 71: 101–132 [DOI] [PubMed] [Google Scholar]
- 3.Schatz DG and Ji Y Recombination centres and the orchestration of V(D)J recombination. Nat. Rev. Immunol 2011. 11: 251–263. [DOI] [PubMed] [Google Scholar]
- 4.Xu JL and Davis MM Diversity in the CDR3 region of V(H) is sufficient for most antibody specificities. Immunity 2000. 13: 37–45. [DOI] [PubMed] [Google Scholar]
- 5.Schatz DG, and Swanson PC V(D)J recombination: mechanisms of initiation. Annu Rev Genet 2011. 45:167–202. [DOI] [PubMed] [Google Scholar]
- 6.Mian IS, Bradwell AR and Olson AJ Structure, function and properties of antibody binding sites. J. Mol. Biol 1991. 217: 133–151. [DOI] [PubMed] [Google Scholar]
- 7.Birtalan S, Zhang Y, Fellouse FA, Shao L, Schaefer G and Sidhu SS The intrinsic contributions of tyrosine, serine, glycine and arginine to the affinity and specificity of antibodies. J. Mol. Biol 2008. 377: 1518–1528. [DOI] [PubMed] [Google Scholar]
- 8.Zemlin M, Klinger M, Link J, Zemlin C, Bauer K, Engler JA, Schroeder HW Jr., and Kirkham PM Expressed murine and human CDR-H3 intervals of equal length exhibit distinct repertoires that differ in their amino acid composition and predicted range of structures. J. Mol. Biol 2003. 334: 733–749. [DOI] [PubMed] [Google Scholar]
- 9.Ramaraj T, Angel T, Dratz EA, Jesaitis AJ and Mumey B Antigen- antibody interface properties: composition, residue interactions, and features of 53 non- redundant structures. Biochim. Biophys. Acta 2012. 1824: 520–532. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Kunik V and Ofran Y The indistinguishability of epitopes from protein surface is explained by the distinct binding preferences of each of the six antigen- binding loops. Protein Eng. Des. Sel 2013. 26: 599–609. [DOI] [PubMed] [Google Scholar]
- 11.Fellouse FA, Barthelemy PA, Kelley RF and Sidhu SS Tyrosine plays a dominant functional role in the paratope of a synthetic antibody derived from a four amino acid code. J. Mol. Biol 2006. 357: 100–114. [DOI] [PubMed] [Google Scholar]
- 12.Ivanov II, Schelonka RL, Zhuang Y, Gartland GL, Zemlin M and Schroeder HW Jr., Development of the expressed Ig CDR-H3 repertoire is marked by focusing of constraints in length, amino acid use, and charge that are first established in early B cell progenitors. J Immunol 2005. 174: 7773–7780. [DOI] [PubMed] [Google Scholar]
- 13.Muyldermans S Nanobodies: natural single-domain antibodies. Annu. Rev. Biochem 2013. 82: 775–797. [DOI] [PubMed] [Google Scholar]
- 14.Henry KA and MacKenzie CR Antigen recognition by single-domain antibodies: structural latitudes and constraints 2018. 10: 815–826. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.De Genst E, Silence K, Decanniere K, Conrath K, Loris R, Kinne J, Muyldermans S and Wyns L Molecular basis for the preferential cleft recognition by dromedary heavy-chain antibodies. Proc. Natl. Acad. Sci. U S A 2006. 103: 4586–4591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Stanfield RL, Dooley H, Verdino P, Flajnik MF and Wilson IA Maturation of shark single-domain (IgNAR) antibodies: evidence for induced-fit binding. J. Mol. Biol 2007. 367: 358–372. [DOI] [PubMed] [Google Scholar]
- 17.Inoue JG, Miya M, Lam K, Tay BH, Danks JA, Bell J, Walker TI and Venkatesh B Evolutionary origin and phylogeny of the modern holocephalans (Chondrichthyes: Chimaeriformes): a mitogenomic perspective. Mol. Biol. Evol 2010. 27: 2576–2586. [DOI] [PubMed] [Google Scholar]
- 18.Venkatesh B, Lee AP, Ravi V, Maurya AK, Lian MM, Swann JB, Ohta Y, Flajnik MF, Sutoh Y, Kasahara M, Hoon S, Gangu V, Roy SW, Irimia M, Korzh V, Kondrychyn I, Lim ZW, Tay BH, Tohari S, Kong KW, Ho S, Lorente-Galdos B, Quilez J, Marques-Bonet T, Raney BJ, Ingham PW, Tay A, Hillier LW, Minx P, Boehm T, Wilson RK, Brenner S and Warren WC Elephant shark genome provides unique insights into gnathostome evolution. Nature 2014. 505: 174–179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Rast JP, Amemiya CT, Litman RT, Strong SJ and Litman GW Distinct patterns of IgH structure and organization in a divergent lineage of chrondrichthyan fishes. Immunogenet 1998. 47: 234–245. [DOI] [PubMed] [Google Scholar]
- 20.Riblet R, Honjo T, Alt FW and Neuberger MS The immunoglobulin heavy chain genes of mouse. In: Molecular Biology of B cells, eds. Elsevier, Academic Press, Amsterdam. 2004. p. 19–26. [Google Scholar]
- 21.Zachau HG, Honjo T, Alt FW and Neuberger MS Immunoglobulin κ genes of human and mouse. In: Molecular Biology of B cells, eds. Elsevier, Academic Press, Amsterdam. 2004. p. 27–36. [Google Scholar]
- 22.Hinds KR and Litman GW Major reorganization of immunoglobulin VH segmental elements during vertebrate evolution. Nature 1986. 320: 546–549. [DOI] [PubMed] [Google Scholar]
- 23.Litman GW, Anderson MK and Rast JP Evolution of antigen binding receptors. Annu. Rev. Immunol 1999. 7: 109–147. [DOI] [PubMed] [Google Scholar]
- 24.Lee V, Huang JL, Lui MF, Malecek K, Ohta Y, Mooers A and Hsu E The evolution of multiple isotypic IgM heavy chains in the shark. J. Immunol 2008. 180: 7461–7470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Malecek K, Lee V, Feng W, Huang JL, Flajnik MF, Ohta Y and Hsu E 2008. Immunoglobulin heavy chain exclusion in the shark. PLoS Biol 2008. 6: e157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Zhu C, Feng W, Weedon J, Hua P, Stefanov D, Ohta Y, Flajnik MF and Hsu E The multiple shark Ig H chain genes rearrange and hypermutate autonomously. J. Immunol 2011. 187: 2492–2501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Kosak ST, Skok JA, Medina KL, Riblet R, Le Beau MM, Fisher AG and Singh H Subnuclear compartmentalization of immunoglobulin loci duringlymphocyte development. Science 2002. 296: 158–162. [DOI] [PubMed] [Google Scholar]
- 28.Jhunjhunwala S, van Zelm MC, Peak MM, Cutchin S, Riblet R, van Dongen JJ, Grosveld FG, Knoch TA and Murre C The 3D structure of the immunoglobulin heavy-chain locus: implications for long-range genomic interactions. Cell 2008. 133: 265–279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Johanson TM, Chan WF, Keenan, and Allan CR Genome organization in immune cells: unique challenges. Nat. Rev. Immunol 2019. 19: 448–456. [DOI] [PubMed] [Google Scholar]
- 30.Ivanov II, Link JM, Ippolito GC, Schroeder HW Jr. Constraints on hydropathicity and sequence composition of HCDR3 are conserved across evolution. In: Zanetti M, Capra JD, eds. The Antibodies London: Taylor and Francis Group. 2002. 43–67. [Google Scholar]
- 31.Shlomchik M, Mascelli M, Shan H, Radic MZ, Pisetsky D, Marshak-Rothstein A and Weigert M Anti-DNA antibodies from autoimmune mice arise by clonal expansion and somatic mutation. J. Exp. Med 1990. 171: 265–292. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Tillman DM, Jou NT, Hill RJ and Marion TN Both IgM and IgG anti- DNA antibodies are the products of clonally selective B cell stimulation in (NZB x NZW)F1 mice. J. Exp. Med 1992. 176: 761–769. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Radic MZ, Mackle J, Erikson J, Mol C, Anderson WF and Weigert M, Residues that mediate DNA binding of autoimmune antibodies. J. Immunol 1993. 150: 4966–4977. [PubMed] [Google Scholar]
- 34.Giles I, Lambrianides N, Pattni N, Faulkes D, Latchman D, Chen P, Pierangeli S, Isenberg D and Rahman A Arginine residues are important in determining the binding of human monoclonal antiphospholipid antibodies to clinically relevant antigens. J. Immunol 2006.177: 1729–1736. [DOI] [PubMed] [Google Scholar]
- 35.Chothia C, Novotný J, Bruccoleri R and Karplus M, Domain association in immunoglobulin molecules. The packing of variable domains. J. Mol. Biol 1985. 186: 651–663. [DOI] [PubMed] [Google Scholar]
- 36.Kabat EA, Wu TT, Perry HM, Gottesman KS and Foeller C, Sequences of proteins of immunological interest 5th ed. (Washington, D.C.: U.S. Dept. of Health and Human Services; ). 1991. [Google Scholar]
- 37.Kokubu F, Litman R, Shamblott MJ, Hinds K and Litman GW, Diverse organization of immunoglobulin VH gene loci in a primitive vertebrate. EMBO J 1988. 7: 3413–3422. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Rumfelt LL, Avila D, Diaz M, Bartl S, McKinney EC and Flajnik MF, A shark antibody heavy chain encoded by a nonsomatically rearranged VDJ is preferentially expressed in early development and is convergent with mammalian IgG. Proc. Natl. Acad. Sci. U S A 2001. 98: 1775–1780. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Lee SS, Fitch D, Flajnik MF and Hsu E (2000) Rearrangement of immunoglobulin genes in shark germ cells. J. Exp. Med 191: 1637–1648. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Lafaille JJ, DeCloux A, Bonneville M, Takagaki Y, and Tonegawa S Junctional sequences of T cell receptor gamma delta genes: implications for gamma delta T cell lineages and for a novel intermediate of V-(D)-J joining. Cell 1989. Dec 1;59(5):859–70. [DOI] [PubMed] [Google Scholar]
- 41.Francis MP and Maolagáin CÓ Growth-band counts from elephantfish Callorhinchus milii fin spines do not correspond with independently estimated ages. J. Fish Biol 2019. 95: 743–752. [DOI] [PubMed] [Google Scholar]
- 42.Dooley H and Flajnik MF Antibody repertoire development in cartilaginous fish. Dev. Comp. Immunol 2006. 30: 43–56. [DOI] [PubMed] [Google Scholar]
- 43.Diaz M, Velez J, Singh M, Cerny J and Flajnik MF Mutational pattern of the nurse shark antigen receptor gene (NAR) is similar to that of mammalian Ig genes and to spontaneous mutations in evolution: the translesion synthesis model of somatic hypermutation. Int. Immunol 1999. 11: 825–833. [DOI] [PubMed] [Google Scholar]
- 44.Lee SS, Tranchina D, Ohta Y, Flajnik MF and Hsu E Hypermutation in shark immunoglobulin light chain genes results in contiguous substitutions. Immunity 2002. 16: 571–582. [DOI] [PubMed] [Google Scholar]
- 45.Zhu C and Hsu E, Error-prone DNA repair activity during somatic hypermutation in shark B lymphocytes. J. Immunol 2010. 185: 5336–5359. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Dooley H, Stanfield RL, Brady RA and Flajnik MF, First molecular and biochemical analysis of in vivo affinity maturation in an ectothermic vertebrate. Proc Natl Acad Sci U S A 2006. 103: 1846–18451. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Voss EW and Sigel MM Distribution of 19S and 7S IgM antibodies during the immune response in the nurse shark. J. Immunol 1971. 106:1323–1329. [PubMed] [Google Scholar]
- 48.Dooley H and Flajnik MF, Shark immunity bites back: affinity maturation and memory response in the nurse shark, Ginglymostoma cirratum. Eur J Immunol 2005. 35: 936–945. [DOI] [PubMed] [Google Scholar]
- 49.Hsu E Assembly and expression of shark Ig genes. J. Immunol 2016. 196: 3517–3523. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Early P, Huang H, Davis M, Calame K and Hood L An immunoglobulin heavy chain variable region gene is generated from three segments of DNA: VH, D and JH. Cell 1980. 19: 981–992. [DOI] [PubMed] [Google Scholar]
- 51.Sakano H, Maki R, Kurosawa Y, Roeder W and Tonegawa S Two types of somatic recombination are necessary for the generation of complete immunoglobulin heavy-chain genes. Nature 1980. 286: 676–83. [DOI] [PubMed] [Google Scholar]
- 52.Kim MS, Chuenchor W, Chen X, Cui Y, Zhang X, Zhou ZH, Gellert M, and Yang W Cracking the DNA Code for V(D)J Recombination. Mol Cell 2018. Apr 19;70(2):358–370.e4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Padlan EA Anatomy of the antibody molecule. Mol. Immunol 1994. 31: 169–217. [DOI] [PubMed] [Google Scholar]
- 54.Birtalan S, Fisher RD, and Sidhu SS The functional capacity of the natural amino acids for molecular recognition. Mol Biosyst 2010. 6: 1186–1194. [DOI] [PubMed] [Google Scholar]
- 55.Malecek K, Brandman J, Brodsky JE, Ohta Y, Flajnik MF and Hsu E Somatic hypermutation and junctional diversification at Ig heavy chain loci in the nurse shark. J Immunol 2005. 175: 8105–8115. [DOI] [PubMed] [Google Scholar]
- 56.Diaz M, Greenberg AS and Flajnik MF Somatic hypermutation of the new antigen receptor gene (NAR) in the nurse shark does not generate the repertoire: possible role in antigen-driven reactions in the absence of germinal centers. Proc Natl Acad Sci U S A 1998. 95: 14343–14348. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Burkovitz A, Sela-Culang I and Ofran Y Large-scale analysis of somatic hypermutations in antibodies reveals which structural regions, positions and amino acids are modified to improve affinity. FEBS J 2014. 281: 306–319. [DOI] [PubMed] [Google Scholar]
- 58.DeKosky BJ, Lungu OI, Park D, Johnson EL, Charab W, Chrysostomou C, Kuroda D, Ellington AD, Ippolito GC, Gray JJ, and Georgiou G Large-scale sequence and structural comparisons of human naive and antigen-experienced antibody repertoires. Proc. Natl. Acad. Sci. U.S.A 2016. 113, E2636–E2645 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Tiller KE, Li L, Kumar S, Julian MC, Garde S and Tessier PM Arginine mutations in antibody complementarity-determining regions display context-dependent affinity/specificity trade-offs. J Biol Chem 2017. 292: 16638–16652. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Wardemann H, Yurasov S, Schaefer A, Young JW, Meffre E and Nussenzweig MC Predominant autoantibody production by early human B cell precursors. Science 2003. 301: 1374–1377. [DOI] [PubMed] [Google Scholar]
- 61.Kumar K, Woo SM, Siu T, Cortopassi WA, Duarte F, and Paton RS Cation-π interactions in protein-ligand binding: theory and data-mining reveal different roles for lysine and arginine. Chem Sci 2018. 9: 2655–2665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Mishra AK and Mariuzza RA Insights into the Structural Basis of Antibody Affinity Maturation from Next- Generation Sequencing. Front Immunol 2018. 9:117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Esadze A, Chen C, Zandarashvili L, Roy S, Pettitt BM and Iwahara J Changes in conformational dynamics of basic side chains upon protein-DNA association. Nucleic Acids Res 2016. 44: 6961–6970. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Stanfield RL and Eilat D Crystal structure determination of anti-DNA Fab A52. Proteins 2014. 82: 1674–1678. [DOI] [PubMed] [Google Scholar]
- 65.Wloch MK, Clarke SH, and Gilkeson GS Influence of VH CDR3 arginine and light chain pairing on DNA reactivity of a bacterial DNA-induced anti-DNA antibody from a BALB/c mouse. J Immunol 1997. 159: 6083–6090. [PubMed] [Google Scholar]
- 66.Li Z, Schettino EW, Padlan EA, Ikematsu H and Casali P Structure-function analysis of a lupus anti-DNA autoantibody: central role of the heavy chain complementarity-determining region 3 Arg in binding of double- and single-stranded DNA. Eur J Immunol 2000. 30:2015–2026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Khass M, Vale AM, Burrows PD and Schroeder HW Jr. The sequences encoded by immunoglobulin diversity (DH ) gene segments play key roles in controlling B-cell development, antigen-binding site diversity, and antibody production. Immunol Rev 2018. 284: 106–119. [DOI] [PubMed] [Google Scholar]
- 68.Wang M, Zhu D, Zhu J, Nussinov R and Ma B Local and global anatomy of antibody-protein antigen recognition. J. Mol. Recognit 2018. 31: e2693. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Koerber JT, Thomsen ND, Hannigan BT, Degrado WF and Wells JA Nature-inspired design of motif-specific antibody scaffolds. Nat Biotechnol 2013. 31: 916–921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.MacGibbon DJ, Beentjes MP, Lyon WS and Ladroit Y Inshore trawl survey of Canterbury Bight and Pegasus Bay, April–June 2018 (KAH1803). New Zealand Fisheries Assessment Report, 2019. 2019/03, 136p [Google Scholar]
- 71.Auffray C and Rougeon F Purification of mouse immunoglobulin heavy- chain messenger RNAs from total myeloma tumor RNA. Eur. J. Biochem 1980. 107: 303–314. [DOI] [PubMed] [Google Scholar]
- 72.Benton MJ and Donoghue PC Paleontological evidence to date the tree of life. Mol. Biol. Evol 2007. 24: 26–53. [DOI] [PubMed] [Google Scholar]
- 73.Greenberg AS, Avila D, Hughes M, Hughes A, McKinney EC and Flajnik MF A new antigen receptor gene family that undergoes rearrangement and extensive somatic diversification in sharks. Nature 1995. 374: 168–173. [DOI] [PubMed] [Google Scholar]
- 74.Harmsen MM, Ruuls RC, INijman J, Niewold TA, Frenken LG and de Geus B, Llama heavy-chain V regions consist of at least four distinct subfamilies revealing novel sequence features. Mol. Immunol 2000. 37: 579–590. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
SFigure 1. Alignment of elephantfish HCAb VH with conventional and HCAb VH of other species. CDR1 and CDR2 (underlined) are according to Kabat et al. (36), who inserted gaps after residues 35 and 52 in the CDR. Dots indicate identity, dashes gaps. Elephantfish HHC2 (MN958903), HHC1 (AAVX02046069.1), spotted ratfish μ (AAC12884.1) and HCAb (AAC12909.1), horn shark (CAA31799.1), catfish (ACD38546.1), Xenopus (OCU01394.1), green sea turtle (EMP41230.1), chicken (AAA50802.1), human VH3 (AAQ05430.1), mouse (AAK54033.1), rabbit (AAC39229.1), llama VH (AJ401073), VHH subfamily III (AJ238046), subfamily I (AJ238059.1), IgNAR type 1 (AY114781.1). Residues in FR2 enabling VH-alone are highlighted in the HCAb sequences.