

Abstract
Decision models can combine information from different sources to simulate the long-term consequences of alternative strategies in the presence of uncertainty. A cohort state-transition model (cSTM) is a decision model commonly used in medical decision-making to simulate the transitions of a hypothetical cohort among various health states over time. This tutorial focuses on time-independent cSTM, where transition probabilities among health states remain constant over time. We implement time-independent cSTM in R, an open-source mathematical and statistical programming language. We illustrate time-independent cSTMs using a previously published decision model, calculate costs and effectiveness outcomes, conduct a cost-effectiveness analysis of multiple strategies, including a probabilistic sensitivity analysis. We provide open-source code in R to facilitate wider adoption. In a second, more advanced tutorial, we illustrate time-dependent cSTMs.
1. Introduction
Policymakers are often tasked with allocating limited healthcare resources under constrained budgets and uncertainty about future outcomes. Health economic evaluations might inform their final decisions. These economic evaluations often rely on decision models to synthesize evidence from different sources and project long-term outcomes of various alternative strategies. A commonly used decision model is the discrete-time cohort state-transition model (cSTM), often referred to as a Markov model.1
A cSTM is a dynamic mathematical model in which a hypothetical cohort of individuals transition between different health states over time. A cSTM is most appropriate when the decision problem has a dynamic component (e.g., the disease process can vary over time) and can be described using a reasonable number of health states. cSTMs are often used because of their transparency, efficiency, ease of development, and debugging. cSTMs are usually computationally less demanding than individual-based state-transition models (iSTMs), providing the ability to conduct PSA and value-of-information (VOI) analyses that otherwise might not be computationally feasible with iSTMs.2 cSTMs have been used to evaluate screening and surveillance programs,3,4 diagnostic procedures,5 disease management programs,6 interventions,7 and policies.8
In a recent review, we illustrated the increased use of R’s statistical programming framework in health decision sciences. We provided a summary of available resources to apply to medical decision making.9 Many packages have been explicitly developed to estimate and construct cSTMs in R. For example, the markovchain10 and heemod11 packages are designed to build cSTMs using a pre-defined structure. The markovchain package simulates time-independent, and time-dependent Markov chains but is not designed to conduct economic evaluations. heemod is a well-structured R package for economic evaluations. However, these packages are necessarily stylized and require users to specify the structure and inputs of their cSTM in a particular way potentially without fully understanding how cSTMs work. Using these packages can be challenging if the desired cSTM does not fit within this structure.
This tutorial demonstrates how to conduct a full cost-effectiveness analysis (CEA) comparing multiple interventions and implementing probabilistic sensitivity analysis (PSA) without needing a specialized cSTM package. We first describe each of the components of a time-independent cSTM. Then, we illustrate the implementation of these components with an example. Our general conceptualization should apply to other programming languages (e.g., MATLAB, Python, C++, and Julia). The reader can find the most up-to-date R code of the time-independent cSTM and the R code to create the tutorial graphs in the accompanying GitHub repository (https://github.com/DARTH-git/cohort-modeling-tutorial-intro) to replicate and modify the example to fit their needs. We assume that the reader is familiar with the basics of decision modeling and has a basic understanding of programming. Thus, a prior introduction to R, “for” loops, and linear algebra for decision modelers is recommended. The linear algebra concepts used throughout the code are explained in more detail in the Supplementary Material.
This introductory tutorial aims to (1) conceptualize time-independent cSTMs for implementation in a programming language and (2) provide a template for implementing these cSTMs in base R. We focus on using R base packages, ensuring modelers understand the concept and structure of cSTMs and avoid the limitation of constructing cSTMs in a package-specific structure. We used previously developed R packages for visualizing CEA results and checking cSTMs are correctly specified.
2. Cohort state-transition models (cSTMs)
A cSTM consists of a set of nS mutually exclusive and collectively exhaustive health states. The cohort is assumed to be homogeneous within each health state. Individuals in the cohort residing in a particular health state are assumed to have the same characteristics and are indistinguishable from one another. The cohort could transition between health states with defined probabilities, which are called “transition probabilities”. A transition probability represents the chance that individuals in the cohort residing in a state in a given cycle transition to another state or remain in the same state. In a cSTM, a one-cycle transition probability reflects a conditional probability of transitioning during the cycle, given that the person is alive at the beginning of the cycle.12
In a cSTM, the transition probabilities only depend on the current health state in a given cycle, meaning that the transition probabilities do not depend on the history of past transitions or time spent in a given state. This property is often referred to as the “Markovian assumption.”13-15 This tutorial focuses on time-independent cSTM, meaning that model parameters, such as transition probabilities or reward (e.g., costs or utilities associated with being in a particular health state), do not vary with time. We discuss time-dependence in cSTMs in an accompanying advanced tutorial.16
2.1. Rates versus probabilities
In discrete-time cSTMs, cohort dynamics are described by the probability of transitioning between states. However, these transitions might be reported in terms of rates in the literature, or probabilities may not always be available in the desired cycle length. For example, transition probabilities might be available from published literature in one time period (e.g., annual) and might differ from the model’s cycle length scale (e.g., monthly). Below, we illustrate a simple approach to converting from rates to probabilities and using rates to convert probabilities from one time scale to another.
While probabilities and rates are often numerically similar in practice, there is a subtle but important conceptual difference between them. A rate represents the instantaneous force of an event occurrence per unit time, while a probability represents the cumulative risk of an event over a defined period.
To illustrate this difference further, let us assume that after 10,000 person-years of observation of healthy individuals (e.g., 10,000 individuals observed for an average of 1 year, or 5,000 individuals observed for an average of 2 years, etc.), we observe 500 events of interest (e.g., becoming sick from some disease). The annual event rate of becoming sick, μyearly, is then equal to μyearly = 500/10, 000 = 0.05.
If we then wanted to know what proportion of an initially healthy cohort becomes sick at the end of the year, we can convert the annual rate of becoming sick into an annual probability of becoming sick using the following equation:
| (1) |
resulting in pyearly = 1 − exp (−0.05) = 0.0488. Equation (1) assumes that the rate of becoming sick is constant over the year, implying that the time until a healthy person becomes sick is exponentially distributed. The parameter pyearly is the transition probability from healthy to sick in a cSTM when using an annual cycle length.
If we were concerned that an annual cycle length was too long to capture disease dynamics accurately, we could use a monthly cycle length. To calculate monthly rates, we divide the annual rate by 12:
| (2) |
To convert to monthly transition probabilities, we apply equation (1):
| (3) |
We divide by 12 because of the number of months (desired cycle length) in a year (cycle length of the given data). If the original or desired cycle length differed, we would divide by a different factor (e.g., annual to weekly: 52; monthly to annual: 1/12; annual to daily: 365.25, etc.).
These equations are also helpful for computing probabilities when studies (e.g., survival analyses) provide rates rather than transition probabilities assuming exponentially distributed transition times.
3. Time-independent cSTM dynamics
A cSTM consists of three core components: (1) a state vector, mt, that stores the distribution of the cohort across all health states in cycle t where t = 0, …, nT; (2) the cohort trace matrix, M, that stacks mt for all t and represents the distribution of the cohort in the various states over time; and (3) a transition probability matrix, P.17 If the cSTM is comprised of nS discrete health states, mt is a 1 × nS vector and P is a nS × nS matrix. The i-th element of mt, where i = 1, …, nS, represents the proportion of the cohort in the i-th health state in cycle t, referred to as m[t,i]. Thus, mt is written as:
The elements of P are the transition probabilities of moving from state i to state j, p[i,j], where {i, j} = 1, …, nS and all should have values between 0 and 1.
For P to be a correctly specified transition probability matrix, each row of the transition probability matrix must sum to one, for all i = 1, …, nS.
The state vector at cycle t + 1 (mt+1) is then calculated as the matrix product of the state vector at cycle t, mt, and the transition probability matrix, P, such that
where m1 is computed from m0, the initial state vector with the distribution of the cohort across all health states at the start of the simulation (cycle 0). Then, we iteratively apply this equation through t = (nT − 1).
The cohort trace matrix, M, is a matrix of dimensions (nT + 1) × nS where each row is a state vector (−mt−), such that
Note that the initial cycle (i.e., cycle 0) corresponds to t = 0, which is on the first row of M. Thus, M stores the output of the cSTM, which could be used to compute various epidemiological, and economic outcomes, such as life expectancy, prevalence, cumulative resource use, and costs, etc. Table 1 describes the elements related to the core components of cSTM and their suggested R code names. For a more detailed description of the variable types, data structure, R name for all cSTM elements, please see the Supplementary Material.
Table 1:
Components of a cSTM with their R name.
| Element | Description | R name |
|---|---|---|
| nS | Number of states | n_states |
| m 0 | Initial state vector | v_m_init |
| m t | State vector in cycle t | v_mt |
| M | Cohort trace matrix | m_M |
| P | Time-independent transition probability matrix | m_P |
4. Case study: Sick-Sicker model
Here, we use the previously published 4-state “Sick-Sicker” model for conducting a CEA of multiple strategies to illustrate the various aspects of cSTM implementation in R.18,19 Figure 1 represents the state-transition diagram of the Sick-Sicker model.
Figure 1:
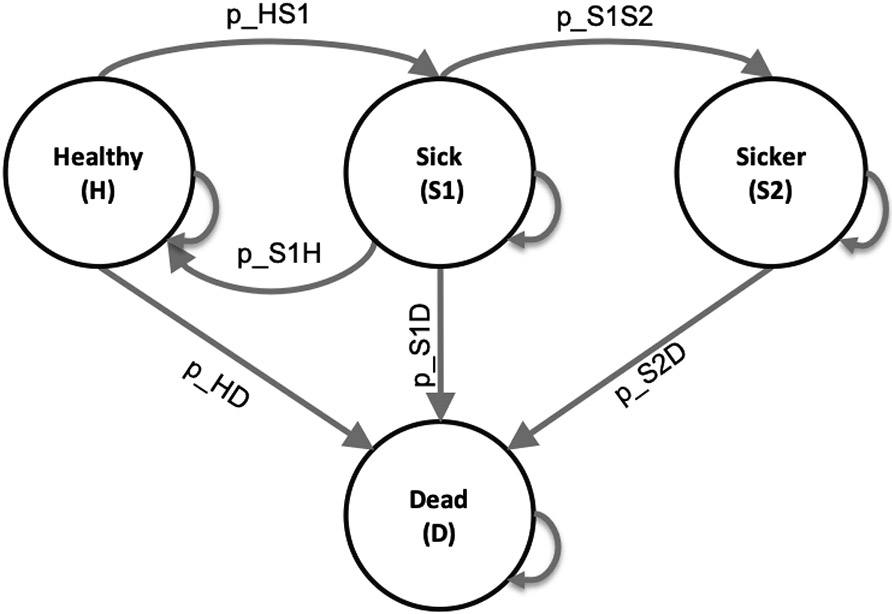
State-transition diagram of the time-independent Sick-Sicker cohort state-transition model, showing all possible states (labeled with state names) and transitions (labeled with transition probability variable names).
The model simulates a cohort at risk of a hypothetical disease with two stages, “Sick” and “Sicker”, to compute the expected costs and quality-adjusted life years (QALYs) of the cohort over time. All the parameters of the Sick-Sicker model and the corresponding R variable names are presented in Table 2. The naming of these parameters and variables follows the notation described in the DARTH coding framework.20 Briefly, we define variables by <x>_<y>_<var_name>, where x is the prefix that indicates the data type (e.g., scalar (no prefix), v for vector, m for matrix, a for array, df for data frame, etc.), y is the prefix indicating variable type (e.g., p for probability, r for rate, hr for hazard ratio, c for cost c, u for utility, etc.), and var_name is some description of the variable presented separated by underscores. For example, v_p_HD denotes the vector of transition probabilities from health state “H” to health state “D”. In later sections we will define and name all the other parameters.
Table 2:
Description of parameters, their R variable name, base-case values and distribution.
| Parameter | R name | Base-case | Distribution |
|---|---|---|---|
| Number of cycles (nT) | n_cycles | 75 years | - |
| Names of health states (n) | v_names_states | H, S1, S2, D | - |
| Annual discount rate for costs | d_c | 3% | - |
| Annual discount rate for QALYs | d_e | 3% | - |
| Number of PSA samples (K) | n_sim | 1,000 | - |
| Annual constant transition rates | |||
| - Disease onset (H to S1) | r_HS1 | 0.150 | gamma(30, 200) |
| - Recovery (S1 to H) | r_S1H | 0.500 | gamma(60, 120) |
| - Disease progression (S1 to S2) | r_S1S2 | 0.105 | gamma(84, 800) |
| Annual mortality | |||
| - Background mortality rate (H to D) | r_HD | 0.002 | gamma(20, 10000) |
| - Hazard ratio of death in S1 vs H | hr_S1 | 3.0 | lognormal(log(3.0), 0.01) |
| - Hazard ratio of death in S2 vs H | hr_S2 | 10.0 | lognormal(log(10.0), 0.02) |
| Annual costs | |||
| - Healthy individuals | c_H | $2,000 | gamma(100.0, 20.0) |
| - Sick individuals in S1 | c_S1 | $4,000 | gamma(177.8, 22.5) |
| - Sick individuals in S2 | c_S2 | $15,000 | gamma(225.0, 66.7) |
| - Dead individuals | c_D | $0 | - |
| Utility weights | |||
| - Healthy individuals | u_H | 1.00 | beta(200, 3) |
| - Sick individuals in S1 | u_S1 | 0.75 | beta(130, 45) |
| - Sick individuals in S2 | u_S2 | 0.50 | beta(230, 230) |
| - Dead individuals | u_D | 0.00 | - |
| Treatment A cost and effectiveness | |||
| - Cost of treatment A, additional to state-specific health care costs | c_trtA | $12,000 | gamma(73.5, 163.3) |
| - Utility for treated individuals in S1 | u_trtA | 0.95 | beta(300, 15) |
| Treatment B cost and effectiveness | |||
| - Cost of treatment B, additional to state-specific health care costs | c_trtB | $12,000 | gamma(86.2, 150.8) |
| - Reduction in rate of disease progression (S1 to S2) as hazard ratio (HR) | hr_S1S2_trtB | log(0.6) | lognormal(log(0.6), 0.02) |
In this model, we simulate a hypothetical cohort of 25-year-olds in the “Healthy” state (denoted “H”) until they reach a maximum age of 100 years. We will simulate the cohort dynamics in annual cycle lengths, requiring a total of 75 one-year cycles. The total number of cycles is denoted as nT and defined in R as n_cycles. The model setup is as follows. Healthy individuals are at risk of developing the disease when they transition to the “Sick” state (denoted by “S1”) with an annual rate of r_HS1. Sick individuals are at risk of further progressing to a more severe disease stage, the “Sicker” health state (denoted by “S2”) with an annual rate of r_S1S2. Individuals in S1 can recover and return to H, as depicted in Figure 1 by the arc labeled p_S1H. However, once individuals reach S2, they cannot recover; the rate of transitioning to S1 or H from S2 is zero. Individuals in H face a constant background mortality (labeled p_HD in Figure 1) due to other causes of death. Individuals in S1 and S2 face an increased hazard of death, compared to healthy individuals, in the form of a hazard ratio (HR) of 3 and 10, respectively, relative to the background mortality rate. We transform all transition rates to probabilities following the Section “Rates versus probabilities” approach. All transitions between non-death states are assumed to be conditional on surviving each cycle. Individuals in S1 and S2 also experience increased health care costs and reduced quality of life (QoL) compared to individuals in H. When individuals die, they transition to the absorbing “Dead” state (denoted by “D”), meaning that once the proportion of the cohort arrives in that state, they remain. We discount both costs and QALYs at an annual rate of 3%.
We are interested in evaluating the cost-effectiveness of four strategies: the standard of care (strategy SoC), strategy A, strategy B, and a combination of strategies A and B (strategy AB). Strategy A involves administering treatment A that increases the QoL of individuals in S1 from 0.75 (utility without treatment, u_S1) to 0.95 (utility with treatment A, u_trtA). Treatment A costs $12,000 per year (c_trtA).19 This strategy does not impact the QoL of individuals in S2, nor does it change the risk of becoming sick or progressing through the sick states. Strategy B uses treatment B to reduce only the rate of Sick individuals progressing to the Sicker state by 40% (i.e., a hazard ratio (HR) of 0.6, hr_S1S2_trtB), costs $13,000 per year (c_trtB), and does not affect QoL. Strategy AB involves administering both treatments A and B.
We assume that it is not possible to distinguish between Sick and Sicker patients; therefore, individuals in both disease states receive the treatment under the treatment strategies. After comparing the four strategies in terms of expected QALYs and costs, we calculate the incremental cost per QALY gained between non-dominated strategies.
The following sections include R code snippets. All R code is stored as a GitHub repository and can be accessed at https://github.com/DARTH-git/cohort-modeling-tutorial-intro. We initialize the input parameters in the R code below by setting the variables to their base-case values. We do this process as the first coding step, all in one place, so the updated value will carry through the rest of the code when a parameter value changes.
## General setup cycle_length <- 1 # cycle length equal one year (use 1/12 for monthly) n_age_init <- 25 # age at baseline n_age_max <- 100 # maximum age of follow up n_cycles <- (n_age_max - n_age_init)/cycle_length # time horizon, number of cycles v_names_states <- c("H", "S1", "S2", "D") # the 4 health states of the model: # Healthy (H), Sick (S1), Sicker (S2), Dead (D) n_states <- length(v_names_states) # number of health states d_e <- 0.03 # annual discount rate for QALYs of 3% d_c <- 0.03 # annual discount rate for costs of 3% v_names_str <- c("Standard of care", # store the strategy names "Strategy A", "Strategy B", "Strategy AB") ## Transition probabilities (annual), and hazard ratios (HRs) r_HD <- 0.002 # constant annual rate of dying when Healthy (all-cause mortality rate) r_HS1 <- 0.15 # constant annual rate of becoming Sick when Healthy r_S1H <- 0.5 # constant annual rate of becoming Healthy when Sick r_S1S2 <- 0.105 # constant annual rate of becoming Sicker when Sick hr_S1 <- 3 # hazard ratio of death in Sick vs Healthy hr_S2 <- 10 # hazard ratio of death in Sicker vs Healthy ### Process model inputs ## Constant transition probability of becoming Sick when Healthy # transform rate to probability and scale by the cycle length p_HS1 <- 1 - exp(-r_HS1 * cycle_length) ## Constant transition probability of becoming Healthy when Sick # transform rate to probability and scale by the cycle length p_S1H <- 1 - exp(-r_S1H * cycle_length) ## Constant transition probability of becoming Sicker when Sick # transform rate to probability and scale by the cycle length p_S1S2 <- 1 - exp(-r_S1S2 * cycle_length) # Effectiveness of treatment B hr_S1S2_trtB <- 0.6 # hazard ratio of becoming Sicker when Sick under treatment B ## State rewardy ## Costs c_H <-2000 # annual cost of being Healthy c_S1 <- 4000 # annual cost of being Sick c_S2 <- 15000 # annual cost of being Sicker c_D <- 0 # annual cost of being dead c_trtA <- 12000 # annual cost of receiving treatment A c_trtB <- 13000 # annual cost of receiving treatment B # Utilities u_H <- 1 # annual utility of being Healthy u_S1 <- 0.75 # annual utility of being Sick u_S2 <- 0.5 # annual utility of being Sicker u_D <- 0 # annual utility of being dead u_trtA <- 0.95 # annual utility when receiving treatment A
To compute the background mortality risk, p_HD, from the background mortality rate for the same cycle length (i.e., cycle_length = 1), we apply Equation (1) to r_HD. To compute the mortality risks of the cohort in S1 and S2, we multiply the background mortality rate r_HD by the hazard ratios hr_S1 and hr_S2, respectively, and then convert back to probabilities using Equation (1). These calculations are required because hazard ratios only apply to rates and not to probabilities. The code below performs the computation in R. In the darthtools package (https://github.com/DARTH-git/darthtools), we provide R functions that compute transformations between rates and probabilities since these transformations are frequently used.
## Mortality rates r_S1D <- r_HD * hr_S1 # annual rate of dying when Sick r_S2D <- r_HD * hr_S2 # annual rate of dying when Sicker ## Cycle-specific probabilities of dying cycle_length <- 1 p_HD <- 1 - exp(-r_HD * cycle_length) # annual background mortality risk (i.e., probability) p_S1D <- 1 - exp(-r_S1D * cycle_length) # annual probability of dying when Sick p_S2D <- 1 - exp(-r_S2D * cycle_length) # annual probability of dying when Sicker
To compute the risk of progression from S1 to S2 under treatment B, we multiply the hazard ratio of treatment B by the rate of progressing from S1 to S2 and transform it to probability by applying Equation (1).
## Transition probability of becoming Sicker when Sick for treatment B # apply hazard ratio to rate to obtain transition rate of becoming Sicker when Sick # for treatment B r_S1S2_trtB <- r_S1S2 * hr_S1S2_trtB # transform rate to probability # probability to become Sicker when Sick under treatment B p_S1S2_trtB <- 1 - exp(-r_S1S2_trtB * cycle_length)
For the Sick-Sicker model, the entire cohort starts in the H state. Therefore, we create the 1 × nS initial state vector v_m_init with all of the cohort assigned to the H state:
v_m_init <- c(H = 1, S1 = 0, S2 = 0, D = 0) # initial state vector
The variable v_m_init is used to initialize M represented by m_M for the cohort under strategy SoC. We also create a trace for each of the other treatment-based strategies.
## Initialize cohort trace for SoC m_M <- matrix(NA, nrow = (n_cycles + 1), ncol = n_states, dimnames = list(0:n_cycles, v_names_states)) # Store the initial state vector in the first row of the cohort trace m_M[1, ] <- v_m_init ## Initialize cohort trace for strategies A, B, and AB # Structure and initial states are the same as for SoC m_M_strA <- m_M # Strategy A m_M_strB <- m_M # Strategy B m_M_strAB <- m_M # Strategy AB
Note that the initial state vector, v_m_init, can be modified to account for the cohort’s distribution across the states at the start of the simulation. This distribution can also vary by strategy if needed.
Since the Sick-Sicker model consists of 4 states, we create a 4 × 4 transition probability matrix for strategy SoC, m_P. We initialize the matrix with default values of zero for all transition probabilities and then populate it with the corresponding transition probabilities. To access an element of m_P, we specify first the row name (or number) and then the column name (or number) separated by a comma. For example, we could access the transition probability from state Healthy (H) to state Sick (S1) using the corresponding row or column state-names as characters m_P["H", "S1"]. We assume that all transitions to non-death states are conditional on surviving to the end of a cycle. Thus, we first condition on surviving by multiplying the transition probabilities times 1 - p_HD, the probability of surviving a cycle. For example, to obtain the probability of transitioning from H to S1, we multiply the transition probability from H to S1 conditional on being alive, p_HS1 by 1 - p_HD. We create the transition probability matrix for strategy A as a copy of the SoC’s transition probability matrix because treatment A does not alter the cohort’s transition probabilities.
## Initialize transition probability matrix for strategy SoC m_P <- matrix (0, nrow = n_states, ncol = n_states, dimnames = list(v_names_states, v_names_states)) # row and column names ## Fill in matrix # From H m_P["H", "H"] <- (1 - p_HD) * (1 - p_HS1) m_P["H", "S1"] <- (1 - p_HD) * p_HS1 m_P["H", "D"] <- p_HD # From S1 m_P["S1", "H"] <- (1 - p_S1D) * p_S1H m_P["S1", "S1"] <- (1 - p_S1D) * (1 - (p_S1H + p_S1S2)) m_P["S1", "S2"] <- (1 - p_S1D) * p_S1S2 m_P["S1", "D"] <- p_S1D # From S2 m_P["S2", "S2"] <- 1 - p_S2D m_P["S2", "D"] <- p_S2D # From D m_P["D", "D"] <- 1 ## Initialize transition probability matrix for strategy A as a copy of SoC's m_P_strA <- m_P
Because treatment B alters progression from S1 to S2, we created a different transition probability matrix to model this treatment, m_P_strB. We initialize m_P_strB as a copy of m_P and update only the transition probabilities from S1 to S2 (i.e., p_S1S2 is replaced with p_S1S2_trtB). Strategy AB also alters progression from S1 to S2 because it uses treatment B, so we create this strategy’s transition probability matrix as a copy of the transition probability matrix of strategy B.
## Initialize transition probability matrix for strategy B m_P_strB <- m_P ## Update only transition probabilities from S1 involving p_S1S2 m_P_strB["S1", "S1"] <- (1 - p_S1D) * (1 - (p_S1H + p_S1S2_trtB)) m_P_strB["S1", "S2"] <- (1 - p_S1D) * p_S1S2_trtB ## Initialize transition probability matrix for strategy AB as a copy of B's m_P_strAB <- m_P_strB
Once all transition matrices are created, we verify they are valid by checking that each row sums to one and that each entry is between 0 and 1. In the darthtools package (https://github.com/DARTH-git/darthtools), we provide R functions that do these checks and have been described previously.20
### Check if transition probability matrices are valid ## Check that transition probabilities are [0, 1] m_P >= 0 && m_P <= 1 m_P_strA >= 0 && m_P_strA <= 1 m_P_strB >= 0 && m_P_strB <= 1 m_P_strAB >= 0 && m_P_strAB <= 1 ## Check that all rows sum to 1 rowSums(m_P) == 1 rowSums(m_P_strA) == 1 rowSums(m_P_strB) == 1 rowSums(m_P_strAB) == 1
Next, we obtain the cohort distribution across the 4 states over 75 cycles using a time-independent cSTM under all four strategies. To achieve this, we iteratively compute the matrix product between each of the rows of m_M and m_P, and between m_M_strB and m_P_strB, respectively, using the %*% symbol in R at each cycle using a for loop
# Iterative solution of time-independent cSTM for(t in 1:n_cycles){ # For SoC m_M[t + 1, ] <- m_M[t, ] %*% m_P # For strategy A m_M_strA[t + 1, ] <- m_M_strA[t, ] %*% m_P_strA # For strategy B m_M_strB[t + 1, ] <- m_M_strB[t, ] %*% m_P_strB # For strategy AB m_M_strAB[t + 1, ] <- m_M_strAB[t, ] %*% m_P_strAB }
Table 3 shows the cohort trace matrix M of the Sick-Sicker model under strategies SoC and A for the first six cycles. The whole cohort starts in the H state and transitions to the rest of the states over time. Given that the D state is absorbing, the proportion in this state increases over time. A graphical representation of the cohort trace for all the cycles is shown in Figure 2.
Table 3:
The distribution of the cohort under strategies SoC and A for the first six cycles of the time-independent Sick-Sicker model. The first row, labeled with cycle 0, contains the distribution of the cohort at time zero.
| Cycle | H | S1 | S2 | D |
|---|---|---|---|---|
| 0 | 1.000 | 0.000 | 0.000 | 0.000 |
| 1 | 0.859 | 0.139 | 0.000 | 0.002 |
| 2 | 0.792 | 0.189 | 0.014 | 0.005 |
| 3 | 0.755 | 0.206 | 0.032 | 0.008 |
| 4 | 0.729 | 0.208 | 0.052 | 0.011 |
| 5 | 0.707 | 0.206 | 0.072 | 0.015 |
Figure 2:

Cohort trace of the time-independent cSTM under strategies SoC and A.
5. Cost and effectiveness outcomes
We are interested in computing the total QALYs and costs accrued by the cohort over a predefined time horizon for a CEA. In the advanced cSTM tutorial,16 we describe how to compute epidemiological outcomes from cSTMs, such as survival, prevalence, and life expectancy.2 These epidemiological outcomes are often used to produce other measures of interest for model calibration and validation.
5.1. State rewards
A state reward refers to a value assigned to individuals for being in a given health state. These could be either utilities or costs associated with remaining in a specific health state for one cycle in a CEA context. The column vector y of size nT + 1 can represent the total expected reward of an outcome of interest for the entire cohort at each cycle. To calculate y, we compute the matrix product of the cohort trace matrix times a vector of state rewards r of the same dimension as the number of states (nS), such that
| (4) |
For the Sick-Sicker model, we create a vector of utilities and costs for each of the four strategies considered. The vectors of utilities and costs in R, v_u_SoC and v_c_SoC, respectively, represent the utilities and costs in each of the four health states under SoC, scaled by the cycle length (values are shown in Table 2).
# Vector of state utilities under SOC v_u_SoC <- c(H = u_H, S1 = u_S1, S2 = u_S2, D = u_D) * cycle_length # Vector of state costs under SoC v_c_SoC <- c(H = c_H, S1 = c_S1, S2 = c_S2, D = c_D) * cycle_length
We account for the benefits and costs of both treatments individually and their combination to create the state-reward vectors under treatments A and B (strategies A and B, respectively) and when applied jointly (strategy AB). Only treatment A affects QoL, so we create a vector of utilities specific to strategies involving treatment A (strategies A and AB), v_u_strA and v_u_strAB. These vectors will have the same utility weights as for strategy SoC except for being in S1. We assign the utility associated with the benefit of treatment A in that state, u_trtA. Treatment B does not affect QoL, so the vector of utilities for strategy involving treatment B, v_u_strB, is the same as for SoC.
# Vector of state utilities for strategy A v_u_strA <- c(H = u_H, S1 = u_trtA, S2 = u_S2, D = u_D) * cycle_length # Vector of state utilities for strategy B v_u_strB <- c(H = u_H, S1 = u_S1, S2 = u_S2, D = u_D) * cycle_length # Vector of state utilities for strategy AB v_u_strAB <- c(H = u_H, S1 = u_trtA, S2 = u_S2, D = u_D) * cycle_length
Both treatments A and B incur a cost. To create the vector of state costs for strategy A, v_c_strA, we add the cost of treatment A, c_trtA, to the state costs of S1 and S2. Similarly, when constructing the vector of state costs for strategy B, v_c_strB, we add the cost of treatment B, c_trtB, to the state costs of S1 and S2. Finally, for the vector of state costs for strategy AB, v_c_strAB, we add both treatment costs to the state costs of S1 and S2.
# Vector of state costs for strategy A v_c_strA <- c(H = c_H, S1 = c_S1 +c_trtA, S2 = c_S2 + c_trtA, D = c_D) * cycle_length # Vector of state costs for strategy B v_c_strB <- c(H = c_H, S1 = c_S1 + c_trtB, S2 = c_S2 + c_trtB, D = c_D) * cycle_length # Vector of state costs for strategy AB v_c_strAB <- c(H = c_H, S1 = c_S1 + (c_trtA + c_trtB), S2 = c_S2 + (c_trtA + c_trtB), D = c_D) * cycle_length
To compute the expected QALYs and costs for the Sick-Sicker model under SoC and strategy A, we apply Equation (4) by multiplying the cohort trace matrix, m_M, times the corresponding strategy-specific state vectors of rewards. Similarly, to compute the expected rewards for strategies B and AB, we multiply the cohort trace matrix accounting for the effectiveness of treatment B, m_M_strB, times their corresponding state vectors of rewards.
# Vector of QALYs under SoC v_qaly_SoC <- m_M %*% v_u_SoC # Vector of costs under SoC v_cost_SoC <- m_M %*% v_c_SoC # Vector of QALYs for strategy A v_qaly_strA <- m_M_strA %*% v_u_strA # Vector of costs for strategy A v_cost_strA <- m_M_strA %*% v_c_strA # Vector of QALYs for strategy B v_qaly_strB <- m_M_strB %*% v_u_strB # Vector of costs for strategy B v_cost_strB <- m_M_strB %*% v_c_strB # Vector of QALYs for strategy AB v_qaly_strAB <- m_M_strAB %*% v_u_strAB # Vector of costs for strategy AB v_cost_strAB <- m_M_strAB %*% v_c_strAB
5.2. Within-cycle correction
A discrete-time cSTM involves an approximation of continuous-time dynamics to discrete points in time. The discretization might introduce biases when estimating outcomes based on state occupancy.21 One approach to reducing these biases is to shorten the cycle length, requiring simulating the model for a larger number of cycles, which can be computationally burdensome. Another approach is to use within-cycle corrections (WCC).2,22 In this tutorial, we use Simpson’s 1/3rd rule by multiplying the rewards (e.g., costs and effectiveness) by 1/3 in the first and last cycles, by 4/3 for the odd cycles, and by 2/3 for the even cycles.23,24 We implement the WCC by generating a column vector wcc of size nT + 1 with values corresponding to the first, t = 0, and last cycle, t = nT, equal to 1/3, and the entries corresponding to the even and odd cycles with 2/3 and 4/3, respectively.
Since the WCC vector is the same for costs and QALYs, we only require one vector (v_wcc). We create v_wcc by defining two indicator functions that tell us whether the vector entries are even or odd, filled with the corresponding factors given by Simpson’s 1/3rd rule. We used the function command that reads a vector x and applies the modulo operation %% that returns the remainder of dividing each of the vector entries by 2. If the remainder of the i − th entry is 0, the entry is even, or it is odd if the remainder is 1 otherwise.
# First, we define two functions to identify if a number is even or odd is_even <- function(x) x %% 2 == 0 is_odd <- function(x) x %% 2 != 0 ## Vector with cycles v_cycles <- seq(1, n_cycles + 1) ## Generate 2/3 and 4/3 multipliers for even and odd entries, respectively v_wcc <- is_even(v_cycles)*(2/3) + is_odd(v_cycles)*(4/3) ## Substitute 1/3 in first and last entries v_wcc[1] <- v_wcc[n_cycles + 1] <- 1/3
5.3. Discounting future rewards
We often discount future costs and benefits by a specific rate to calculate the net present value of these rewards. We then use this rate to generate a column vector with cycle-specific discount weights d of size nT + 1 where its t-th entry represents the discounting for cycle t
where d is the cycle-length discount rate. At the end of the simulation, we multiply the vector of expected rewards, y, by a discounting column vector. The total expected discounted outcome summed over the nT cycles, y, is obtained by the inner product between y transposed, y′, and d,
| (5) |
The discount vectors for costs and QALYs for the Sick-Sicker model with annual cycles, v_dwc and v_dwe, respectively, scaled by the cycle length, are
# Discount weight for effects v_dwe <- 1 / ((1 + (d_e * cycle_length)) ^ (0:n_cycles)) # Discount weight for costs v_dwc <- 1 / ((1 + (d_c * cycle_length)) ^ (0:n_cycles))
The functions and code for creating the WCC and discounting vectors above are single lines of code that affect the entire vectors of rewards used to compute the health and economic outputs of the model. To compute the total expected discounted QALYs and costs under all four strategies accounting for both discounting and WCC, we incorporate wcc in equation (5) using an element-wise multiplication with d, indicated by the ⊙ sign. The element-wise multiplication computes a new vector with elements that are the products of the corresponding elements of wcc and d.
| (6) |
To compute the total expected discounted and WCC-corrected QALYs under all four strategies in R, we apply Equation (6) to the reward vectors of each strategy.
## Expected discounted QALYs under SoC n_tot_qaly_SoC <- t(v_qaly_SoC) %*% (v_dwe * v_wcc) ## Expected discounted costs under SoC n_tot_cost_SoC <- t(v_cost_SoC) %*% (v_dwc * v_wcc) ## Expected discounted QALYs for strategy A n_tot_qaly_strA <- t(v_qaly_strA) %*% (v_dwe * v_wcc) ## Expected discounted costs for strategy A n_tot_cost_strA <- t(v_cost_strA) %*% (v_dwc * v_wcc) ## Expected discounted QALYs for strategy B n_tot_qaly_strB <- t(v_qaly_strB) %*% (v_dwe * v_wcc) ## Expected discounted costs for strategy B n_tot_cost_strB <- t(v_cost_strB) %*% (v_dwc * v_wcc) ## Expected discounted QALYs for strategy AB n_tot_qaly_strAB <- t(v_qaly_strAB) %*% (v_dwe * v_wcc) ## Expected discounted costs for strategy AB n_tot_cost_strAB <- t(v_cost_strAB) %*% (v_dwc * v_wcc)
The total expected discounted QALYs and costs for the Sick-Sicker model under the four strategies accounting for within-cycle correction are shown in Table 4.
Table 4:
Total expected discounted QALYs and costs per average individual in the cohort of the Sick-Sicker model by strategy accounting for within-cycle correction.
| Costs | QALYs | |
|---|---|---|
| Standard of care | $151,580 | 20.711 |
| Strategy A | $284,805 | 21.499 |
| Strategy B | $259,100 | 22.184 |
| Strategy AB | $378,875 | 23.137 |
6. Incremental cost-effectiveness ratios (ICERs)
We combine the total expected discounted costs and QALYs for all four strategies into outcome-specific vectors, v_cost_str for costs and v_qaly_str for QALYs. So far, we have used base R to create and simulate cSTMs. For the CEA, we use the various functions from R package dampack (https://cran.r-project.org/web/packages/dampack/)25 that are also included as supplementary material to calculate the incremental costs and effectiveness and the incremental cost-effectiveness ratio (ICER) between non-dominated strategies and create the data frame df_cea with this information. These outcomes are required inputs to conduct a CEA. We included function from ‘dampack’ for the probabilistic sensitivity analysis (PSA) below.
### Vector of costs v_cost_str <- c(n_tot_cost_SoC, n_tot_cost_strA, n_tot_cost_strB, n_tot_cost_strAB) ### Vector of effectiveness v_qaly_str <- c(n_tot_qaly_SoC, n_tot_qaly_strA, n_tot_qaly_strB, n_tot_qaly_strAB) ### Calculate incremental cost-effectiveness ratios (ICERs) df_cea <- dampack::calculate_icers(cost = v_cost_str, effect = v_qaly_str, strategies = v_names_str)
SoC is the least costly and effective strategy, followed by Strategy B producing an expected incremental benefit of 1.473 QALYs per individual for an additional expected cost of $107,521 with an ICER of $72,988/QALY followed by Strategy AB with an ICER $125,764/QALY. Strategy A is a dominated strategy (Table 5). Strategies SoC, B and AB form the cost-effectiveness efficient frontier (Figure 3).
Table 5:
Cost-effectiveness analysis results for the Sick-Sicker model. ND: Non-dominated strategy; D: Dominated strategy.
| Strategy | Costs ($) | QALYs | Incremental Costs ($) | Incremental QALYs | ICER ($/QALY) | Status |
|---|---|---|---|---|---|---|
| Standard of care | 151,580 | 20.711 | NA | NA | NA | ND |
| Strategy B | 259,100 | 22.184 | 107,521 | 1.473 | 72,988 | ND |
| Strategy AB | 378,875 | 23.137 | 119,775 | 0.952 | 125,764 | ND |
| Strategy A | 284,805 | 21.499 | NA | NA | NA | D |
Figure 3:
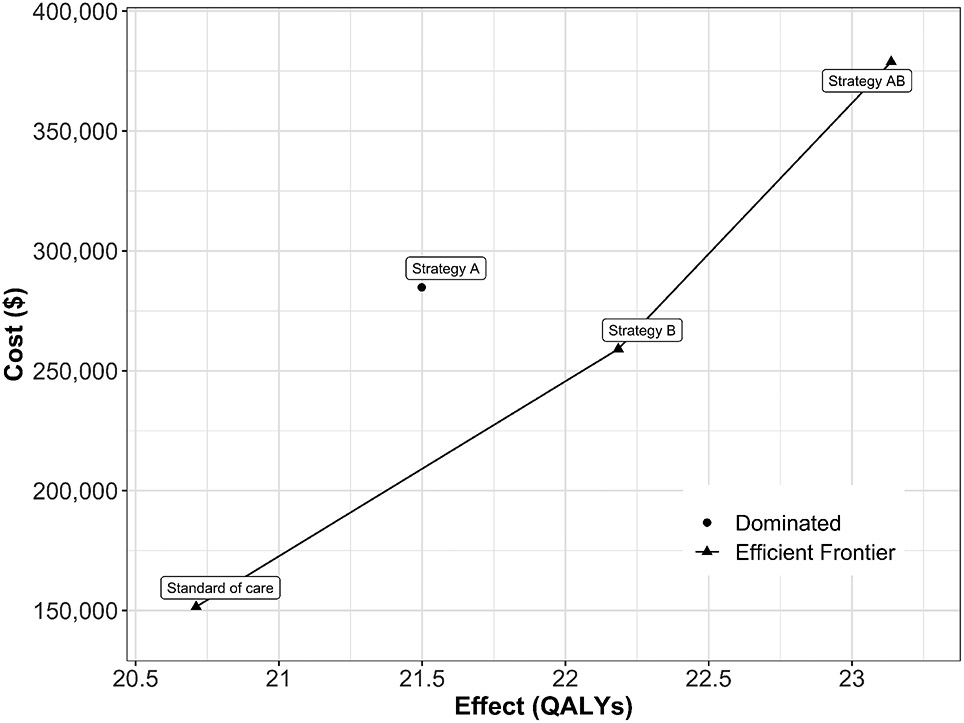
Cost-effectiveness efficient frontier of the cost-effectiveness analysis based on the time-independent Sick-Sicker model.
7. Probabilistic sensitivity analysis
To quantify the effect of model parameter uncertainty on cost-effectiveness outcomes, we conducted a PSA by randomly drawing K parameter sets (n_sim) from distributions that reflect the current uncertainty in model parameter estimates.26 The distribution for all the parameters and their values are described in Table 2 and in more detail in the Supplementary Material. We compute model outcomes for each sampled set of parameter values (e.g., total discounted cost and QALYs) for each strategy. In a previously published manuscript, we describe the implementation of these steps in R.20 Briefly, to conduct the PSA, we create three R functions:
generate_psa_params(n_sim, seed): a function that generates a sample of size n_sim for the model parameters, df_psa_input, from their distributions defined in Table 2. The function input seed sets the seed of the pseudo-random number generator used in sampling parameter values, which ensures reproducibility of the PSA results.
decision_model(l_params_all, verbose = FALSE): a function that wraps the R code of the time-independent cSTM described in section 3. This function requires inputting a list of all model parameter values, l_params_all and whether the user wants print messages on whether transition probability matrices are valid via the verbose parameter.
calculate_ce_out(l_params_all, n_wtp = 100000): a function that calculates total discounted costs and QALYs based on the decision_model function output. This function also computes the net monetary benefit (NMB) for a given willingness-to-pay threshold, specified by the argument n_wtp. These functions are provided in the accompanying GitHub repository of this manuscript.
To conduct the PSA of the CEA using the time-independent Sick-Sicker cSTM, we sampled 1,000 parameter sets from their distributions. We assumed commonly used distributions to describe their uncertainty for each type of parameter. For example, gamma for transition rates, lognormal for hazard ratios, and beta for utility weights.22,27-29 For each sampled parameter set, we simulated the cost and effectiveness of each strategy. Results from a PSA can be represented in various ways. For example, the joint distribution, 95% confidence ellipse, and the expected values of the total discounted costs and QALYs for each strategy can be plotted in a cost-effectiveness scatter plot (Figure 4),29 where each of the 1,000 simulations are plotted as a point in the graph. The CE scatter plot for CEA using the time-independent model shows that strategy AB has the highest expected costs and QALYs. Standard of care has the lowest expected cost and QALYs. Strategy B is more effective and least costly than Strategy A. Strategy A is a strongly dominated strategy.
Figure 4:

Cost-effectiveness scatter plot.
Figure 5 presents the cost-effectiveness acceptability curves (CEACs), which show the probability that each strategy is cost-effective, and the cost-effectiveness frontier (CEAF), which shows the strategy with the highest expected net monetary benefit (NMB), over a range of willingness-to-pay (WTP) thresholds. Each strategy’s NMB is computed using NMB = QALY × WTP − Cost30 for each PSA sample. At WTP thresholds less than $80,000 per QALY gained, strategy SoC has both the highest probability of being cost-effective and the highest expected NMB. This switches to strategy B for WTP thresholds between $80,000 and $120,000 per QALY gained and to strategy AB for WTP thresholds greater than or equal to $120,000 per QALY gained.
Figure 5:

Cost-effectiveness acceptability curves (CEACs) and frontier (CEAF).
The CEAC and CEAF do not show the magnitude of the expected net benefit lost (i.e., expected loss) when the chosen strategy is not the cost-effective strategy in all the samples of the PSA. To complement these results, we quantify expected loss from each strategy over a range of WTP thresholds with the expected loss curves (ELCs). These curves quantify the expected loss from each strategy over a range of WTP thresholds (Figure 6). The expected loss considers both the probability of making the wrong decision and the magnitude of the loss due to this decision, representing the foregone benefits of choosing a suboptimal strategy. The expected loss of the optimal strategy represents the lowest envelope of the ELCs because, given current information, the loss cannot be minimized further. The lower bound of the ELCs represents the expected value of perfect information (EVPI), which quantifies the value of eliminating parameter uncertainty. We refer the reader to previously published literature for a more detailed description of CEAC, CEAF, and ELC interpretations and the R code to generate them.31
Figure 6:

Expected loss curves (ELCs) and expected value of perfect information (EVPI).
8. Discussion
In this introductory tutorial, we provided a step-by-step mathematical conceptualization of time-independent cSTMs and a walk-through of their implementation in R using a hypothetical disease example with accompanying code throughout the tutorial. While some of the presented implementation details are specific to the R programming language, much of the code structure shown in this tutorial would be similar in other programming languages. Thus, readers may use this tutorial as a template for coding cSTMs more generally in different programming languages.
The parameterization of our example model assumes all parameters are known, or at least, the characterization of their uncertainty is known (i.e., we know their distributions). However, to construct a real-world cSTM, modelers must conduct a thorough synthesis of current evidence to determine these appropriate structures and inform all parameters based on the current evidence. For example, literature must be carefully considered when determining whether transitions between non-death health states are estimated conditional on being alive or are estimated as competing risks along with mortality risks.26 Similarly, our PSA analysis simplifies reality where all model parameters are assumed to be independent of each other. However, parameters could be correlated or have a rank order, and appropriate statistical methods that simulate these correlations or rank order might be needed.32 We encourage modelers to use appropriate statistical methods to accurately synthesize and quantify model parameters’ uncertainty. For example, for the PSA of our case study, we used distributions based on the type of parameters following standard recommendations. For a more detailed description of how to choose distributions, we refer the reader to other literature.29,33 In addition, modelers should appropriately specify all model parameters for the cycle length of the model.22
In general, cSTMs are recommended when the number of states is considered “not too large”2 This recommendation arises because it becomes more challenging to keep track of their construction as the number of states increases. It is possible to build reasonably complex cSTMs in R as long as the computer’s RAM can store the size of the transition probability matrix and outputs of interest. For time-independent cSTMs, in general, this should not be a problem with the capacity of current RAM in personal computers. An alternative to reduce the explosion of disease states is iSTMs, a type of STM where simulated individuals transition between health states over time.2 We have previously published a tutorial on the implementation of iSTMs in R.19
With increasing model complexity and interdependency of functions to conduct various analyses like PSA, it is essential to ensure all code and functions work as expected and all elements of the cSTM are valid. We can achieve this by creating functions that help with model debugging, validation, and thorough unit testing. In the accompanying GitHub repository, we provide functions to check that transition probability matrices and their elements are valid. These functions are an example of a broader standard practice in software development called unit testing that requires building functions to test and check that the model and model-based analysis perform as intended.34 However, unit testing is beyond the scope of this tutorial. We refer the reader to a previously published manuscript that describes unit testing in more detail and provides accompanying code.20
In this tutorial, we implemented a cSTM using a (discrete-time) transition matrix. However, cSTM can also be implemented via (discrete-time) difference equations or (continuous-time) differential equations in R.35,36 We refer readers interested in learning more on continuous-time cSTMs to previously published manuscripts21,37-39 and a tutorial using R.40 Finally, the variable names used in this paper reflect our coding style. While we provide standardized variable names, adopting these conventions is ultimately a personal preference.
In summary, this tutorial provides a conceptualization of time-independent cSTMs and a step-by-step guide to implement them in R. We aim to add to the current body of literature and material on building this type of decision model so that health decision scientists and health economists can develop cSTMs in a more flexible, efficient, open-source manner and to encourage increased transparency and reproducibility. In the advanced cSTM tutorial, we explore generalizing this framework to time-dependent cSTM, generating epidemiological outcomes, and incorporating transition rewards.
Supplementary Material
Acknowledgements
Dr. Alarid-Escudero was supported by grants U01-CA199335 and U01-CA253913 from the National Cancer Institute (NCI) as part of the Cancer Intervention and Surveillance Modeling Network (CISNET), and a grant by the Gordon and Betty Moore Foundation. Miss Krijkamp was supported by the Society for Medical Decision Making (SMDM) fellowship through a grant by the Gordon and Betty Moore Foundation (GBMF7853). Dr. Enns was supported by a grant from the National Institute of Allergy and Infectious Diseases of the National Institutes of Health under award no. K25AI118476. Dr. Hunink received research funding from the American Diabetes Association, the Netherlands Organization for Health Research and Development, the German Innovation Fund, Netherlands Educational Grant ("Studie Voorschot Middelen"), and the Gordon and Betty Moore Foundation. Dr. Jalal was supported by a grant from the National Institute on Drug Abuse of the National Institute of Health under award no. K01DA048985. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. The funding agencies had no role in the design of the study, interpretation of results, or writing of the manuscript. The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report. We also want to thank the anonymous reviewers of Medical Decision Making for their valuable suggestions and the students who took our classes where we refined these materials.
References
- 1.Kuntz KM, Russell LB, Owens DK, Sanders GD, Trikalinos TA, Salomon JA. Decision Models in Cost-Effectiveness Analysis. In: Neumann PJ, Sanders GD, Russell LB, Siegel JE, Ganiats TG, editors. Cost-effectiveness in health and medicine. Second. New York, NY: Oxford University Press; 2017. p. 105–36. [Google Scholar]
- 2.Siebert U, Alagoz O, Bayoumi AM, Jahn B, Owens DK, Cohen DJ, et al. State-Transition Modeling: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force-3. Medical Decision Making [Internet]. 2012;32(5):690–700. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X12455463 [DOI] [PubMed] [Google Scholar]
- 3.Suijkerburjk AWM, Van Hoek AJ, Koopsen J, De Man RA, Mangen MJJ, De Melker HE, et al. Cost-effectiveness of screening for chronic hepatitis B and C among migrant populations in a low endemic country. PLoS ONE. 2018;13(11):1–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Sathianathen NJ, Konety BR, Alarid-Escudero F, Lawrentschuk N, Bolton DM, Kuntz KM. Cost-effectiveness Analysis of Active Surveillance Strategies for Men with Low-risk Prostate Cancer. European Urology [Internet]. 2019;75(6):910–7. Available from: https://linkinghub.elsevier.com/retrieve/pii/S0302283818308534 [DOI] [PubMed] [Google Scholar]
- 5.Lu S, Yu Y, Fu S, Ren H. Cost-effectiveness of ALK testing and first-line crizotinib therapy for non-small-cell lung cancer in China. PLoS ONE. 2018;13(10):1–2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Djatche LM, Varga S, Lieberthal RD. Cost-Effectiveness of Aspirin Adherence for Secondary Prevention of Cardiovascular Events. PharmacoEconomics - Open [Internet]. 2018;2(4):371–80. Available from: 10.1007/s41669-018-0075-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Smith-Spangler CM, Juusola JL, Enns EA, Owens DK, Garber AM. Population Strategies to Decrease Sodium Intake and the Burden of Cardiovascular Disease: A Cost-Effectiveness Analysis. Annals of Internal Medicine [Internet]. 2010;152(8):481–7. Available from: http://annals.org/article.aspx?articleid=745729 [DOI] [PubMed] [Google Scholar]
- 8.Pershing S, Enns EA, Matesic B, Owens DK, Goldhaber-Fiebert JD. Cost-Effectiveness of Treatment of Diabetic Macular Edema. Annals of Internal Medicine. 2014;160(1):18–29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Jalal H, Pechlivanoglou P, Krijkamp E, Alarid-Escudero F, Enns EA, Hunink MGM. An Overview of R in Health Decision Sciences. Medical Decision Making [Internet]. 2017;37(7):735–46. Available from: http://journals.sagepub.com/doi/10.1177/0272989X16686559 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Spedicato GA. Discrete Time Markov Chains with R. The R Journal [Internet]. 2017;9(2):84–104. Available from: https://journal.r-project.org/archive/2017/RJ-2017-036/RJ-2017-036.pdf [Google Scholar]
- 11.Filipović-Pierucci A, Zarca K, Durand-Zaleski I. Markov Models for Health Economic Evaluation: The R Package heemod. arXiv:170203252v1 [Internet]. 2017;April:30. Available from: http://arxiv.org/abs/1702.03252 [Google Scholar]
- 12.Miller DK, Homan SM. Determining Transition Probabilities: Confusion and Suggestions. Medical Decision Making [Internet]. 1994. Feb;14(1):52–8. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X9401400107 [DOI] [PubMed] [Google Scholar]
- 13.Kuntz KM, Weinstein MC. Modelling in economic evaluation. In: Drummond MF, McGuire A, editors. Economic evaluation in health care: Merging theory with practice. 2nd ed. New York, NY: Oxford University Press; 2001. p. 141–71. [Google Scholar]
- 14.Sonnenberg FA, Beck JR. Markov models in medical decision making: A practical guide. Medical Decision Making [Internet]. 1993;13(4):322–38. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X9301300409 [DOI] [PubMed] [Google Scholar]
- 15.Beck JR, Pauker SG. The Markov process in medical prognosis. Medical Decision Making [Internet]. 1983;3(4):419–58. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X8300300403 [DOI] [PubMed] [Google Scholar]
- 16.Alarid-Escudero F, Krijkamp E, Enns EA, Yang A, Hunink MGGM, Pechlivanoglou P, et al. A Tutorial on Time-Dependent Cohort State-Transition Models in R using a Cost-Effectiveness Analysis Example. arXiv:210813552v1 [Internet]. 2021;1–41. Available from: https://arxiv.org/abs/2108.13552 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Iskandar R. A theoretical foundation of state-transition cohort models in health decision analysis. PLOS ONE [Internet]. 2018;13(12):e0205543. Available from: https://www.biorxiv.org/content/early/2018/09/28/430173 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Enns EA, Cipriano LE, Simons CT, Kong CY. Identifying Best-Fitting Inputs in Health-Economic Model Calibration: A Pareto Frontier Approach. Medical Decision Making [Internet]. 2015;35(2):170–82. Available from: http://www.ncbi.nlm.nih.gov/pubmed/24799456 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Krijkamp EM, Alarid-Escudero F, Enns EA, Jalal HJ, Hunink MGM, Pechlivanoglou P. Microsimulation Modeling for Health Decision Sciences Using R: A Tutorial. Medical Decision Making [Internet]. 2018. Apr;38(3):400–22. Available from: http://journals.sagepub.com/doi/10.1177/0272989X18754513 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Alarid-Escudero F, Krijkamp E, Pechlivanoglou P, Jalal H, Kao S-YZ, Yang A, et al. A Need for Change! A Coding Framework for Improving Transparency in Decision Modeling. PharmacoEconomics [Internet]. 2019;37(11):1329–39. Available from: 10.1007/s40273-019-00837-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.van Rosmalen J, Toy M, O’Mahony JF. A Mathematical Approach for Evaluating Markov Models in Continuous Time without Discrete-Event Simulation. Medical Decision Making [Internet]. 2013. May;33(6):767–79. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X13487947 [DOI] [PubMed] [Google Scholar]
- 22.Hunink MGGM Weinstein MC, Wittenberg E, Drummond MF, Pliskin JS Wong JB, et al. Decision Making in Health and Medicine [Internet]. 2nd ed. Cambridge: Cambridge University Press; 2014. Available from: http://ebooks.cambridge.org/ref/id/CBO9781139506779 [Google Scholar]
- 23.Elbasha EH, Chhatwal J. Theoretical foundations and practical applications of within-cycle correction methods. Medical Decision Making. 2016;36(1):115–31. [DOI] [PubMed] [Google Scholar]
- 24.Elbasha EH, Chhatwal J. Myths and misconceptions of within-cycle correction: a guide for modelers and decision makers. PharmacoEconomics. 2016;34(1):13–22. [DOI] [PubMed] [Google Scholar]
- 25.Alarid-Escudero F, Knowlton G, Easterly CA, Enns EA. Decision analytic modeling package (dampack) [Internet]. 2021. Available from: https://cran.r-project.org/web/packages/dampack/%20https://github.com/DARTH-git/dampack [Google Scholar]
- 26.Briggs AH, Weinstein MC, Fenwick EAL, Karnon J, Sculpher MJ, Paltiel AD. Model Parameter Estimation and Uncertainty Analysis: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force Working Group-6. Medical Decision Making. 2012. Sep;32(5):722–32. [DOI] [PubMed] [Google Scholar]
- 27.Parmigiani G, Samsa GP, Ancukiewicz M, Lipscomb J, Hasselblad V, Matchar DB. Assessing uncertainty in cost-effectiveness analyses: Application to a complex decision model. Medical Decision Making. 1997;17(4):390–401. [DOI] [PubMed] [Google Scholar]
- 28.Parmigiani G. Measuring uncertainty in complex decision analysis models. Statistical Methods in Medical Research [Internet]. 2002;11(6):513–37. Available from: http://smm.sagepub.com/cgi/doi/10.1191/0962280202sm307ra%5Cnhttp://smm.sagepub.com/content/11/6/513.short [DOI] [PubMed] [Google Scholar]
- 29.Briggs AH, Goeree R, Blackhouse G, O’Brien BJ. Probabilistic Analysis of Cost-Effectiveness Models: Choosing between Treatment Strategies for Gastroesophageal Reflux Disease. Medical Decision Making [Internet]. 2002. Jul;22(4):290–308. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/027298902400448867 [DOI] [PubMed] [Google Scholar]
- 30.Stinnett AA, Mullahy J. Net Health Benefits: A New Framework for the Analysis of Uncertainty in Cost-Effectiveness Analysis. Medical Decision Making [Internet]. 1998. Apr;18(2):S68–80. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X9801800209 [DOI] [PubMed] [Google Scholar]
- 31.Alarid-Escudero F, Enns EA, Kuntz KM, Michaud TL, Jalal H. "Time Traveling Is Just Too Dangerous" But Some Methods Are Worth Revisiting: The Advantages of Expected Loss Curves Over Cost-Effectiveness Acceptability Curves and Frontier. Value in Health. 2019;22(5):611–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Goldhaber-Fiebert JD, Jalal HJ. Some Health States Are Better Than Others: Using Health State Rank Order to Improve Probabilistic Analyses. Medical Decision Making [Internet]. 2015;36(8):927–40. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X15605091 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Briggs AH, Ades AE, Price MJ. Probabilistic Sensitivity Analysis for Decision Trees with Multiple Branches: Use of the Dirichlet Distribution in a Bayesian Framework. Medical Decision Making [Internet]. 2003. Aug;23(4):341–50. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X03255922 [DOI] [PubMed] [Google Scholar]
- 34.Wickham H, Bryan J. Testing. In: R packages Organize, test, document and share your code. 2nd ed. Sebastopol, CA: O’Reilly Media; 2021. p. 1–3. [Google Scholar]
- 35.Grimmett G, Welsh D. Markov Chains. In: Probability: An introduction [Internet]. 2nd ed. Oxford University Press; 2014. p. 203–3. Available from: www.statslab.cam.ac.uk/{~}grg/teaching/chapter12.pdf [Google Scholar]
- 36.Axler S, Gehring FW, Ribet KA. Difference Equations. In New York, NY: Springer; 2005. Available from: http://link.springer.com/10.1007/0-387-27645-9 [Google Scholar]
- 37.Cao Q, Buskens E, Feenstra T, Jaarsma T, Hillege H, Postmus D. Continuous-Time Semi-Markov Models in Health Economic Decision Making: An Illustrative Example in Heart Failure Disease Management. Medical Decision Making [Internet]. 2016;36(1):59–71. Available from: http://mdm.sagepub.com/cgi/doi/10.1177/0272989X15593080 [DOI] [PubMed] [Google Scholar]
- 38.Begun A, Icks A, Waldeyer R, Landwehr S, Koch M, Giani G. Identification of a multistate continuous-time nonhomogeneous Markov chain model for patients with decreased renal function. Medical Decision Making [Internet]. 2013;33(2):298–306. Available from: http://www.ncbi.nlm.nih.gov/pubmed/23275452 [DOI] [PubMed] [Google Scholar]
- 39.Soares MO, Canto E Castro L. Continuous time simulation and discretized models for cost-effectiveness analysis. PharmacoEconomics [Internet]. 2012. Dec;30(12):1101–17. Available from: http://www.ncbi.nlm.nih.gov/pubmed/23116289 [DOI] [PubMed] [Google Scholar]
- 40.Frederix GWJ, van Hasselt JGC, Severens JL, Hövels AM, Huitema ADR, Raaijmakers JAM, et al. Development of a framework for cohort simulation in cost-effectiveness analyses using a multistep ordinary differential equation solver algorithm in R. Medical Decision Making [Internet]. 2013;33(6):780–92. Available from: http://www.ncbi.nlm.nih.gov/pubmed/23515213 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.