

To the Editor:
Case–control studies allow for efficient sampling schemes but are subject to bias when controls fail to represent the exposure distribution in the population from which the cases were sampled. Identifying this population, known as the study base, is often a challenge, and controls may be chosen out of convenience or to avoid other types of bias, such as exposure misclassification.1 On the other hand, it may be straightforward to completely ascertain or randomly sample cases, as they may be enumerated in registries, hospital records, or other sampling frames.
When inappropriate control selection is suspected to have occurred, it can be informative to conduct a sensitivity analysis to investigate the possible extent of the resulting bias. In this letter, we show that a recently developed framework for simple sensitivity analysis2–4 can be extended to this situation. We demonstrate with an example, and we provide a more detailed derivation in the eAppendix; http://links.lww.com/EDE/B670.
MacMahon et al5 conducted a case-control study of pancreatic cancer patients whom they compared with controls who were patients of the same physicians as the cases but who had different illnesses. After adjusting for age, cigarette smoking, and sex, they found an odds ratio of 2.7 (95% confidence interval = 1.6, 4.7) comparing drinkers of at least 3 cups per day to non-coffee drinkers.
However, soon after the study was published, multiple possible sources of bias were described.6 In particular, many of the control patients had gastrointestinal disorders, which the investigators failed to account for. If the controls drank less coffee than the general source population due to their illnesses, selection bias would result, exaggerating the association between coffee and pancreatic cancer.
To quantify the possible size of this bias, consider the ratio of the observable odds ratio from case–control data (ORobs) to the odds ratio that would have been estimated had the entire study base been sampled (ORtrue). For simplicity, assume that any bias from the case–control study is due to poor control selection.
It is possible to derive a bound similar to that in Smith and VanderWeele4 but with different definitions for the parameters resulting from the different causal structure (Figure) and estimand of interest. Specifically, if we assume that selection (S = 1) of cases (Y = 1) is independent of exposure status (A ∈{01,}) (possibly conditional on measured covariates C), but that control (Y = 0) selection is not independent of exposure without additionally conditioning on unmeasured factor(s) U, then:
Where
To understand these parameters, suppose that U represents a binary indicator of gastrointestinal illness that affects coffee drinking and also makes hospital visits (and therefore selection as a control) more likely. With respect to the example, describes the increased probability of drinking ≥3 cups of coffee per day in eligible controls without gastrointestinal disorders compared with those with gastrointestinal disorders, is the increased probability of no coffee drinking in eligible controls with gastrointestinal disorders compared with those without gastrointestinal disorders, is the increased probability of gastrointestinal disorders in controls who were selected for the study compared with those who were not, and is the increased probability of a healthy GI system in controls who were not selected for the study compared with those who were selected.
FIGURE.
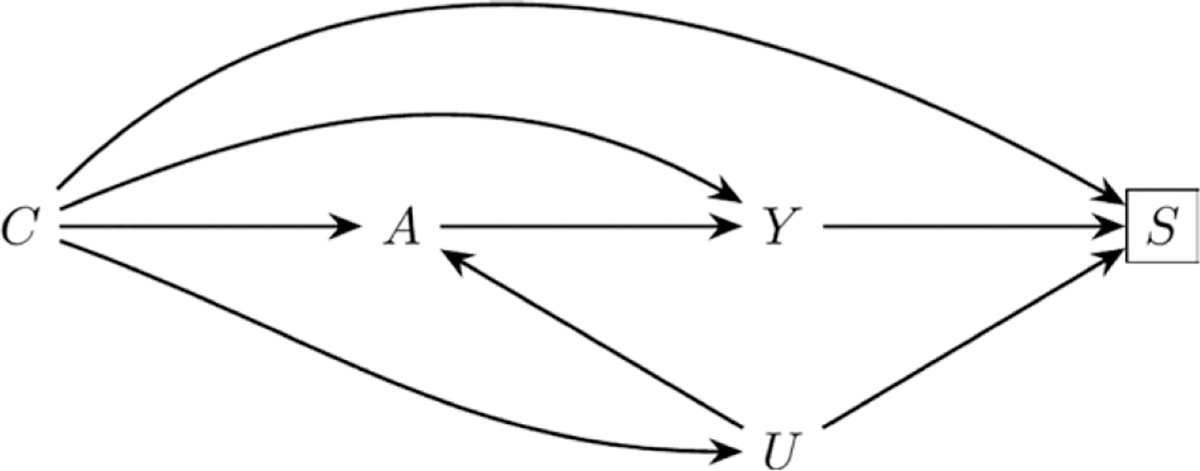
A directed acyclic graph describing a causal structure that could lead to selection bias. In the example in the text, A is coffee consumption, Y is pancreatic cancer, S is selection into the study, C is measured covariates, and U is gastrointestinal disorders.
We could propose various values for these parameters to “correct” for, or bound, selection bias. For example, suppose that among eligible controls with gastrointestinal disorders, only 5% drink at least 3 cups of coffee daily. However, among those with healthy gastrointestinal tracts, 30% drink that amount. Then and . Next suppose that among selected controls, the prevalence of gastrointestinal disorders is 0.45, but among nonselected eligible controls, it is 0.1. Assuming for the purposes of the example that gastrointestinal disorders is binary, then and , then using these values in the formula for bound above, we would obtain 1.87. Thus we would have ORtrue ≥2.7 / 1.87. = 1.44., where 2.7 was the observed odds ratio and 1.87 the bound constructed from the proposed parameters. In other words, if we assume that eligible study participants outside the hospital had a 10% prevalence of gastrointestinal disorders and those without such disorders were 6 times more likely to be heavy coffee drinkers than those with such disorders, then had they been included in the sampling frame, 1.44 is a lower bound for the estimate of the odds ratio relating coffee drinking and pancreatic cancer, conditional on sex, age, and smoking status.
We could repeat this exercise with a range of other values or allow for a more complex unmeasured factor (e.g., severe gastrointestinal disorder, mild discomfort, healthy gastrointestinal tract), as well as repeat with the lower bound of the confidence interval.
To make this type of sensitivity analysis easy to perform, we have created an online calculator available at http://selection-bias.louisahsmith.com.
Supplementary Material
Acknowledgments
This work was supported by grant R01CA222147 from the National Institutes of Health (T.V.W.).
Footnotes
The authors report no conflicts of interest.
Supplemental digital content is available through direct URL citations in the HTML and PDF versions of this article (www.epidem.com).
Contributor Information
Louisa H. Smith, Department of Epidemiology, Harvard T.H. Chan School of Public Health, Boston, MA
Tyler J. VanderWeele, Departments of Epidemiology and Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA
REFERENCES
- 1.Wacholder S, McLaughlin JK, Silverman DT, Mandel JS. Selection of controls in case-control studies. I. principles. Am J Epidemiol. 1992;135:1019–1028. [DOI] [PubMed] [Google Scholar]
- 2.Ding P, VanderWeele TJ. Sensitivity analysis without assumptions. Epidemiology. 2016;27:368–377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.VanderWeele TJ, Ding P. Sensitivity analysis in observational research: introducing the e-value. Ann Intern Med. 2017;167:268–274. [DOI] [PubMed] [Google Scholar]
- 4.Smith LH, VanderWeele TJ. Bounding bias due to selection. Epidemiology. 2019;30:509–516. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.MacMahon B, Yen S, Trichopoulos D, Warren K, Nardi G. Coffee and cancer of the pancreas. N Engl J Med. 1981;304:630–633. [DOI] [PubMed] [Google Scholar]
- 6.Feinstein AR, Horwitz RI, Spitzer WO, Battista RN. Coffee and pancreatic cancer. The problems of etiologic science and epidemiologic case-control research. JAMA. 1981;246:957–961. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.