

Abstract
We propose a penalized variable selection method for the Cox proportional hazards model with interval censored data. It conducts a penalized nonparametric maximum likelihood estimation with an adaptive lasso penalty, which can be implemented through a penalized EM algorithm. The method is proven to enjoy the desirable oracle property. We also extend the method to left truncated and interval censored data. Our simulation studies show that the method possesses the oracle property in samples of modest sizes and outperforms available existing approaches in many of the operating characteristics. An application to a dental caries data set illustrates the method’s utility.
Keywords: Adaptive lasso, Caries research, EM algorithm, interval censoring, left truncation, oracle property, semiparametric inference, variable selection
1. Introduction
In biomedical and epidemiological studies, a large number of potential predictors are often collected with the goal of evaluating their effects on a given phenotypic endpoint. For example, the Detroit Dental Health Project (DDHP) collected a wide variety of hypothesized oral health factors covering parenting, diet intake, health behaviors, dental care, social and physical environments, etc., aiming to identify the predictors of early childhood caries in low-income African-American children. Guided by the Fisher-Owens et al.’s1 conceptual model, Ismail et al.2 compiled from the DDHP data a list of over thirty possible predictors for caries progression, and tested their associations with the increment of decayed, filled and missing tooth surfaces between study waves.
Regression modeling is a standard practice to study jointly the effects of multiple predictors on a response. When the number of candidate predictors is large, building a regression model including all of them is undesirable because it has low prediction accuracy and is hard to interpret (Hastie et al.3, section 3.3). For these reasons, variable selection has become an important focus in regression modeling. There have been many statistical methods on variable selection. Among them, a popular class of methods is variable selection via regularization, also known as penalized variable selection. This class of methods has the key advantage of simultaneously selecting important variables and estimating their effects on the outcome. Popular penalized variable selection methods include the lasso,4 the smoothly clipped absolute deviation5 (SCAD), and the adaptive lasso.6 The last two methods enjoy the so-called oracle property: when the sample size is large, they build the regression model as if they knew which of the variables are important. Most of the existing penalized variable selection methods were proposed for linear or generalized linear models, where the outcome is fully observed. There are some methods for censored time-to-event responses. For instance, lasso, SCAD, and adaptive lasso have been extended to the Cox model for right censored data by Tibshirani,7 Fan and Li,8 and Zhang and Lu,9 respectively.
Interval censored time-to-event outcomes arise widely from cohort studies of chronic disease progression, where a subject’s disease status is assessed periodically and thus the time to disease onset is known up to lying between two clinical exams. For instance, in the Detroit Dental Health Project, age of onset of dental caries is interval censored, since the participants’ caries status was assessed periodically every two to three years in the study. As an another example, the Bangkok Metropolitan Administration injecting drug users cohort study10 examined the subjects for HIV-1 sero-conversion approximately every four months, leading to interval censored time to HIV-1 infection.
Regression analysis for interval censored data has been studied extensively. See Section 5 of Zhang and Sun11 for a review of the literature prior to 2010. Rigorous semiparameric regression methods for mixed case interval censored data,12 which is the most general type, were developed more recently. Zhang et al.13 proposed a sieve maximum likelihood approach for the Cox regression with such data and established its asymptotic properties. Zeng et al.14 developed a nonparametric maximum likelihood procedure and associated asymptotic theory for a class of semiparametric transformation models.
Despite the extensive literature on regression analysis for interval censored data, variable selection methods for such outcomes are scarce. To the best of our knowledge, there are only three published works15–17 on penalized variable selection for interval censored data. Wu and Cook15 assume a proportional hazards model with a piecewise constant baseline hazard function, and perform the variable selection through penalized likelihood estimation with a lasso, SCAD, or adaptive lasso penalty. Although the underlying idea seems quite intuitive, these authors did not provide a careful study of the asymptotic property of the method, and more importantly used a marginal-quantile-based approach to specify the number and location of break points for the piecewise constant baseline hazard function, which is ad hoc. Scolas et al.16 considered variable selection for interval censored data with a cure fraction and assumed a parametric accelerated failure time mixture cure model. They performed the variable selection via penalized likelihood estimation with double adaptive lasso penalties. Like Wu and Cook15 and Scolas et al.16 did not study the asymptotic property of their procedure. Zhao et al.17 in a recently accepted paper, performed the variable selection for the Cox model with interval censored data through an iteratively reweighted Ridge regression. This approach has two thresholding parameters to tune and uses a sieve estimator for the baseline hazard, which does not have a closed-form updating formula. Hence, it is computationally demanding. Although the article has a proof of oracle property, the simulations therein did not assess the asymptotic normality of the estimators of non-zero regression coefficients.
In this paper, we propose another penalized variable selection method for the Cox proportional hazards model with interval censored data. Unlike Wu and Cook15 and Zhao et al.,17 our method avoids approximating the baseline hazard by piecewise constant function, other splines or any polynomial. Instead, it performs the variable selection via a penalized nonparametric maximum likelihood estimation (PNPMLE) with an adaptive lasso penalty. We carefully characterize the support of the PNPMLE of cumulative baseline hazard based on the work of Alioum and Commenges,18 and develop a penalized EM algorithm, similar in spirit to the EM algorithms in Wang et al.19 and Zeng et al.,14 to carry out the penalized nonparametric maximum likelihood estimation. An advantage of our algorithm over Wu and Cook’s15 and Zhao et al.’s17 is that the PNPMLE of the baseline hazard has a closed-form updating formula, enhancing the stability and speed of the penalized estimation. We show that our method enjoys the oracle property through both mathematical proof and numerical experiments. We also provide an explicit formula to estimate the covariance matrix of the penalized estimator, which was not provided by Wu and Cook15 and Zhao et al.,17 and demonstrate its accuracy in simulations. In addition, we extend the method to left truncated and interval censored data, which has application to longitudinal studies of chronic disease progression where participants are disease-free at enrollment. To the best of our knowledge, this is the first penalized variable selection method for left truncated and interval censored data.
The rest of the article is organized as follows. In Section 2, we describe the algorithm of the penalized variable selection method, a procedure for tuning the penalty parameter, and the approach to estimate the covariance matrix of the penalized estimator. In Section 3, we establish the oracle property of our method, with the proof relegated to a Web Appendix. The extension to left truncated and interval censored data is elaborated in Section 4. Section 5 presents some numerical experiments to evaluate the finite-sample performance of the methods, followed by an application to the DDHP data to identify predictors for age of caries onset in Section 6. We conclude the article by discussing several future research directions.
2. Methodology
2.1. Data and model
We consider a random sample of n independent subjects. Let Ti and Zi, respectively, denote the time-to-event of interest and a d-dimensional vector of covariates for subject i (i = 1, …, n). We study how to select significant covariates among Zi for the time-to-event outcome Ti in the situation where Ti is subject to mixed case interval censoring.12 Denote the sequence of inspection times for subject i by . Define Δik = I(Vi,k−1 < Ti ≤ Vik) (k = 1, …, Ki) with Vi0 = 0, and . Then the observed data consist of .
We assume that the inspection process is independent of the time to event given the covariates, i.e. . We also assume that the conditional distribution of Ti given Zi satisfies the Cox proportional hazards model
| (1) |
where λ(t|Zi) ≡ limΔt→0+ pr(t ≤ Ti < t + Δt|Ti ≥ t, Zi)/Δt, λ(t) is an unspecified baseline hazard function, and β is a vector of unknown regression parameters.
2.2. Variable selection
We conduct the variable selection via a semiparametric adaptive lasso estimation. Let Li and Ri denote, respectively, the last inspection time before Ti and the first inspection time after Ti. Set Li = 0 if Ti is smaller than Vi1 and Ri = ∞ if Ti is larger than , i.e. Ti is right censored. Under the Cox model (1) and the mixed case interval censoring, the logarithm of the observed-data likelihood is
| (2) |
where and the convention, exp{−Λ(∞) exp(βTZi)} = 0, is used. The semiparametric adaptive lasso estimation is
| (3) |
where is the unpenalized nonparametric maximum likelihood estimator for β, which can be obtained using the EM algorithm introduced below but without penalty, θ is a thresholding parameter whose selection is discussed later, and the maximization with respect to Λ is over the space of nondecreasing nonnegative functions. We denote the estimator from equation (3) by .
The penalty in equation (3) does not involve Λ. Thus the support set over which increases is the same as that of the unpenalized nonparametric maximum likelihood estimator (NPMLE) for Λ, which was characterized by Alioum and Commenges.18 Specifically, the estimator increases only on so-called maximal intersections: intervals of the form (l, u] where , and there is no Li or Ri in (l, u). Additionally, is indifferent to how it increases on the maximal intersections, as only the overall jump sizes over (l, u]’s (u < ∞), , affect the penalized likelihood in equation (3). Write the maximal intersections with a finite upper endpoint as (l1, u1], …, (lm, um]. According to the characterization of , we can assume, just for the purpose of computing , that Λ is flat on . Define λk = Λ(uk) − Λ(lk) (k = 1, …, m). Then the log likelihood ln(β, Λ) can be written as ln(β, λ), where λ = (λ1, …, λm)T, and
Direct maximization of is challenging because of no closed-form expression for the maximizer , whose dimension increases with the sample size. In the spirit of Zeng et al.,14 we propose an EM algorithm for the adaptive lasso estimation as follows. Let Wik (i = 1, …, n; k = 1, …, m) be independent Poisson random variables with means λk exp(βTZi). Define and . Consider and Ri = ∞} ∪ {(Li, Ri, Zi, Ai = 0, Bi > 0) : 1 ≤ i ≤ n and Ri < ∞} as an observed data set, where Ai = 0 means that Ai is observed to be zero and Bi > 0 means that Bi is observed to be positive. The log likelihood of has the form
which is the same as ln(β, λ). Therefore, we can maximize via an EM algorithm by treating , where , as the complete data corresponding to .
The complete-data log likelihood is
| (4) |
At the E-step, we compute, , the conditional means of Wik’s given the observed data and the current parameter updates (β(s), λ(s)) (s = 0, 1, …,). For uk ≤ Li, Ê(Wik) = 0 since Ai = 0. For Li < uk ≤ Ri with Ri < ∞
At the M-step, we first maximize the expected complete-data log likelihood with respect to λ conditioning on β. The maximizer has an analytical expression
Plugging into the conditional expectation of equation (4), we update β by maximizing
where
and . To perform this maximization, we approximate −Q(β, λ(s+1)(β)|β(s), λ(s)) by a second-order Taylor expansion around β(s). It can be written in a quadratic form 2−1(Y − Xβ)T(Y − Xβ), where X is from the Cholesky decomposition of , that is ∇2Q(β(s)) = XTX, and Y = (XT)−1 {∇2Q(β(s))β(s) − ∇Q(β(s)) with . Then we minimize
| (5) |
to obtain β(s+1), using the modified shooting algorithm in Zhang and Lu.9 The corresponding update for λ is λ(s+1) = λ(s+1) (β(s+1)).
The EM algorithm stops if the maximum of the absolute differences between the estimates at two successive iterations is smaller than, say 10−3. We choose the initial parameter values (β(0), λ(0)) to be the unpenalized nonparametric maximum likelihood estimator , which can be obtained from the same EM algorithm as the above except that the objective function (5) becomes 2−1(Y − Xβ)T(Y – Xβ). Note that this unpenalized version of EM algorithm is different from the EM algorithm in Zeng et al.,14 as their algorithm does not make use of the characterization of the NPMLE for cumulative baseline hazard but estimates its jump sizes at every Li > 0 and Ri < ∞, which is unnecessary and takes longer.
2.3. Covariance matrix of the adaptive lasso estimator
The estimator obtained from equation (3) is equivalent to the solution of the following penalized profile likelihood estimation
| (6) |
where lpn(β) = supΛ ln(β, Λ). Adapting the standard error derivation in Section 4.1 of Lu and Zhang20 to equation (6), the covariance matrix of can be estimated by a sandwich formula
| (7) |
where ∇2lpn(β) is the negative hessian of lpn(β), , and . Here we take the convention 0/0 = 0 and set 1/0 to a very large number, say 1010. A detailed derivation of equation (7) is given in the Web Appendix.
Since lpn(β) does not have a closed form, we calculate using a second-order numerical difference as in Murphy and van der Vaart21 (see the first equation on Page 384), that is
| (8) |
where ei is the ith unit vector in and hn = Op(n−1/2). The value of lpn(β) can be evaluated using the EM algorithm in Section 2.2 with β held fixed.
2.4. Thresholding parameter tuning
Like all other penalized variable selection methods, the performance of our adaptive lasso estimator depends critically on the choice of the thresholding parameter θ. To select it, we minimize the following Bayesian information criterion
| (9) |
where is the active set identified by the adaptive lasso estimation with thresholding parameter θ, and |αθ| is its size. For generalized linear models with a fixed number of covariates, the adaptive lasso with the thresholding parameter selected using BIC identifies the true model consistently.22,23 This motivates us to use BIC to select the thresholding parameter in our variable selection method.
3. Asymptotic properties
We study the asymptotic properties of the adaptive lasso estimator obtained from maximizing the penalized likelihood
| (10) |
with respect to β and Λ. Denote the true value of β by , where β10 denotes the vector of all q non-zero components (1 ≤ q ≤ d) and β20 the vector of zero components. Write as accordingly.
We assume the following regularity conditions:
-
(C1)
The true value β0 belongs to the interior of a known compact set ℬ. The union of the supports of (V1, …, VK) is a finite interval [ζ, τ], where 0 < ζ < τ < ∞. The true value of Λ(·), denoted by Λ0(·), is strictly increasing and continuously differentiable on [ζ, τ], and 0 < Λ0(ζ) < Λ0(τ) < ∞.
-
(C2)
The covariate vector Z is bounded almost surely.
-
(C3)
The covariance matrix of Z is positive definite.
-
(C4)
The number of inspection times, K, is positive almost surely, and E(K) < ∞. Additionally, pr(Vj+1 − Vj ≥ η|Z, K) = 1 (j = 1, …, K − 1) for some positive constant η. Furthermore, the conditional densities of (Vj, Vj+1) given (Z, K), denoted by fj(s, t|Z, K) (j = 1, …, K − 1), have continuous second-order derivatives with respect to s and t when t − s > η and are continuously differentiable with respect to Z.
(C1) is the regularity condition 1 assumed in Zeng et al.14 (C2) and (C3) are the special cases of their regularity conditions 2 and 3, respectively. (C4) is almost the same as their regularity condition 4 except that we do not assume pr(VK = τ|Z, K) to be greater than a positive constant since this assumption is too restrictive and unnecessary for proving the asymptotic properties in Zeng et al.,14 as discussed by Zeng et al.24 The regularity condition 5 in Zeng et al.14 automatically holds for the Cox proportional hazards model. (C1)–(C4) ensure the root-n consistency of the unpenalized maximum likelihood estimator ,14 which is required for the penalty term in equation (10) to be an adaptive lasso penalty as defined in Zou.6 These conditions also ensure that the log profile likelihood lpn(β) has a quadratic expansion around β0 (Zeng et al.,14 Remark A1). Our proofs of the asymptotic properties of rely on it.
The following asymptotic results are obtained under the above regularity conditions. Their proofs are relegated to the Web Appendix.
Theorem 1. If , then .
Theorem 2. If and nθn → ∞, then has the following properties:
;
, where Ĩ10 is the upper-left q × q sub-matrix of the efficient Fisher information matrix for β, denoted by Ĩ0, as given implicitly in Zeng et al.14
The consistency and sparsity of shown in Theorem 1 and Theorem 2(i), respectively, imply that the adaptive lasso estimator enjoys the selection consistency property, that is, limn→∞ pr(𝒜n = {1, …, q}) = 1 with . Theorem 2(ii) implies that the adaptive lasso estimator for the non-zero regression parameters is semiparametrically efficient as if the unimportant covariates were known. It is more efficient than the unpenalized maximum likelihood estimator , whose covariance matrix is , the leading q × q sub-matrix of .
4. Extension to left truncated and interval censored data
In this section, we extend the variable selection method to left truncated and interval censored data. Such data have one additional variable Vi0 (i = 1, …, n), the time to entering the study, to the observed data described in Section 2.1. Left truncation means that the random sample comes from the subpopulation of subjects whose time to event is greater than his/her time to study entry, also called left truncation time. To avoid confusion in understanding the sampling plan, we define T*, and Z* to be the time to event, left truncation time and covariate vector of a subject from the target population, respectively. Then (Ti, Vi0, Zi) (i = 1, …, n) are a random sample from the subpopulation of (T*, , Z*) with . To describe the assumption below on the inspection process, we introduce a positive random variable Uk (k = 1, …, K) to represent the time from study entry to the k-th inspection of a sampled subject, where K denotes the random total number of inspections. Hence Uik = Vik − Vi0 (i = 1, …, n; k = 1, …, Ki). Define . We assume that T* is independent of (, K, ) given Z* and that the joint distribution of (, K, , Z*) does not involve β and Λ.
Under the above assumptions, the log likelihood of left truncated and interval censored data is, up to an additive constant free of (β, Λ),
| (11) |
where the superscript (T) means truncation. We perform the variable selection through the following semiparametric adaptive lasso estimation
| (12) |
where is the unpenalized nonparametric maximum likelihood estimator for β, which can be obtained using the EM algorithm below except no penalty being involved, θ is a thresholding parameter whose selection can follow the method in Section 2.4, and the maximization with respect to Λ is over the space of nondecreasing nonnegative functions. We denote the estimator from equation (12) by .
Similar to the case of interval censored data, has the same characterization as the unpenalized nonparametric maximum likelihood estimator for Λ, which was given in Alioum and Commenges.18 Specifically, the estimator increases only on intervals of the form (l, u] where , and there is no Li, Ri or Vi0 in (l, u). Additionally, is indifferent to how it increases on those intervals, as only the overall jump sizes over (l, u]’s with l > 0 and u < ∞, , affect the penalized likelihood in equation (12). Write the intervals (l, u]’s with l > 0 and u < ∞ as (l1, u1], …, (lm, um]. According to the characterization of , we can assume, just for the purpose of computing , that Λ is flat on . Define λk = Λ(uk) − Λ(lk) (k = 1, …, m). Then the log likelihood can be written as , where λ = (λ1, …, λm)T, and
In view of the similarity between and ln(β, λ), the semiparametric adaptive lasso estimation (12) can be performed using the same EM algorithm as for the case of interval censored data except that the indices uk ≤ Li are replaced by Vi0 < uk ≤ Li throughout the algorithm. The covariance matrix of the resulting estimator can be estimated using the same approach as in Section 2.3.
5. Numerical experiments
To evaluate the finite sample performance of our variable selection methods, we conducted numerical experiments in two cases, one without left truncation and one with it. In the former, we also compare the performance of our method with Wu and Cook’s15 and Zhang and Lu’s,9 for the latter of which the event times were obtained using mid-point imputations. We used the R codes developed by those authors to implement Wu and Cook’s15 and Zhang and Lu’s9 methods. It is worthwhile to also compare our method with Zhao et al.’s17 in simulations. However, due to the lack of available software implementing their method and the difficulty of implementing by ourselves, we did not make the comparison.
The simulation scenario is the following. For every subject of a sample, a vector of ten covariates is generated from a multivariate normal distribution, Zi ~ MVN10(0, Σ) where Σ is the covariance matrix whose ij-th element is Σij = 0.5|i−j|. We set βj = 0.5 for j = 1, 2, 9, and 10, and βj = 0 for j = 3, …, 8 in the Cox model, λ(t|Zi) = λ(t) exp(βTZi). We use the Weibull hazard as the baseline hazard function, λ(t) = κη(ηt)κ−1 with κ = 1.5 and η = 0.2, which renders P(Ti < 10|Zi = 0) ≈ 0.95. The number of planned inspections is three, but we allow subjects to miss each of the second and third planned inspections with a 5% chance so that the actual number of inspections could vary across subjects. This mimics the actual follow-up of the DDHP study. In the untruncated case, the inspection times V1, V2 and V3 are generated from V1 ~ U(3.2, 4.8), V2 = V1 + U(1.5, 2.5), and V3 = V2 + U(1.5, 2.5). In the truncated case, we generate the left-truncation time V0 from V0 = 2.5 + U(0, 4), and the inspection times are obtained from V1 = V0 + U(3.2, 4.8), V2 = V1 + U(1.5, 2.5) and V3 = V2 + U(1.5, 2.5). The proportions of subjects being right-censored are 24.2% in the untruncated case and 29.7% in the truncated case. We considered two sample sizes, 200 and 400. One thousand Monte Carlo samples were generated for each sample size. However, for 247 Monte Carlo samples of size 200 and 210 samples of size 400, Wu and Cook’s15 method failed to converge for a wide range of thresholding parameter values. We removed these Monte Carlo samples from computing the simulation performance measurements for their method.
Table 1 gives the variable selection percentages of our method, Zhang and Lu’s9 method based on mid-point imputation, and Wu and Cook’s15 method in the untruncated case. Our method’s selection percentages of significant covariates are almost 1 and higher than the other two methods. Our method’s selection percentages of non-significant covariates are less than 8% for n = 200 and less than 5% for n = 400, slightly worse than Zhang and Lu’s9 but better than Wu and Cook’s.15 All the three methods’ variable selection percentages improved with the sample size. Table 2 shows the average numbers of correct and incorrect zero coefficients as well as the mean squared error of the coefficient estimator, , where Σ is the population covariance matrix of the covariates. Our method outperforms the other two in terms of the average numbers of incorrect zero coefficients and the mean squared error. Zhang and Lu’s9 method has a relatively large mean squared error because of the estimation bias for the non-zero coefficients caused by the mid-point imputation, as shown in Table 3. Our method’s average numbers of correct zero coefficients are only worse than Zhang and Lu’s,9 but are still reasonably good. Table 3 gives the mean estimate, the empirical standard error of the estimator, the mean of the standard error estimates, and the coverage of the Normal-based confidence interval for the non-zero coefficients. For the variance estimation of our method and the oracle method, we set hn = 5n−1/2. Concurring with the theory, our method performs like the oracle method as the sample size increases. Even in small samples, our variance formula (7) is rather accurate, and our estimators for the non-zero coefficients showed normality, as reflected by the coverage of the Normal-based confidence intervals and the Normal Q-Q plots in Figure 1(a). Zhang and Lu’s9 estimators were shown to be biased. This is because of the mid-point imputation. Wu and Cook’s15 method performs well in terms of bias and empirical variance, but it has convergence issues as mentioned earlier. The standard errors and the coverage of the Normal-based confidence intervals for Wu and Cook’s15 method were not computed, because the bootstrap, suggested by them for computing the standard errors, experienced convergence issues for some of the bootstrap samples. Figure 1 shows that our regularized estimators for the non-zero coefficients converge to Normal in distribution as the sample size increases.
Table 1.
The variable selection percentages of our method, Zhang and Lu’s9 method based on mid-point imputation, and Wu and Cook’s15 method in the untruncated case.
| N | Method | Z 1 | Z 2 | Z 3 | Z 4 | Z 5 | Z 6 | Z 7 | Z 8 | Z 9 | Z 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 200 | Ours | 0.997 | 0.993 | 0.067 | 0.067 | 0.069 | 0.060 | 0.072 | 0.066 | 0.992 | 0.993 |
| ZL | 0.974 | 0.963 | 0.038 | 0.019 | 0.032 | 0.030 | 0.035 | 0.035 | 0.967 | 0.971 | |
| WC | 0.991 | 0.992 | 0.121 | 0.102 | 0.112 | 0.086 | 0.106 | 0.130 | 0.987 | 0.983 | |
| 400 | Ours | 1.000 | 1.000 | 0.037 | 0.026 | 0.042 | 0.040 | 0.047 | 0.033 | 1.000 | 1.000 |
| ZL | 0.999 | 0.998 | 0.012 | 0.009 | 0.008 | 0.009 | 0.012 | 0.008 | 1.000 | 0.999 | |
| WC | 0.996 | 0.995 | 0.113 | 0.086 | 0.085 | 0.090 | 0.106 | 0.109 | 0.996 | 0.998 |
Table 2.
Average numbers of correct and incorrect zero coefficients and mean squared errors of the coefficient estimators in the untruncated case.
| n | Method | Correct (6) | Incorrect (0) | MSE |
|---|---|---|---|---|
| 200 | Ours | 5.599 | 0.025 | 0.083 |
| ZL | 5.811 | 0.125 | 0.297 | |
| WC | 5.343 | 0.048 | 0.098 | |
| 400 | Ours | 5.775 | 0 | 0.034 |
| ZL | 5.942 | 0.004 | 0.229 | |
| WC | 5.411 | 0.015 | 0.043 |
Table 3.
Simulation results on the estimation of the non-zero coefficients in the untruncated case.
| n = 200 | n = 400 | |||||||
|---|---|---|---|---|---|---|---|---|
| Coef | Est | CP | SE | SEE | Est | CP | SE | SEE |
| Oracle | ||||||||
| β1 = 0.5 | 0.531 | 0.974 | 0.123 | 0.137 | 0.518 | 0.963 | 0.085 | 0.090 |
| β2 = 0.5 | 0.535 | 0.972 | 0.124 | 0.136 | 0.516 | 0.961 | 0.090 | 0.089 |
| β9 = 0.5 | 0.536 | 0.972 | 0.127 | 0.137 | 0.517 | 0.953 | 0.087 | 0.089 |
| β10=0.5 | 0.525 | 0.969 | 0.124 | 0.136 | 0.517 | 0.961 | 0.084 | 0.090 |
| Our method | ||||||||
| β1= 0.5 | 0.481 | 0.939 | 0.140 | 0.139 | 0.491 | 0.952 | 0.091 | 0.091 |
| β2 = 0.5 | 0.483 | 0.948 | 0.147 | 0.150 | 0.488 | 0.948 | 0.098 | 0.098 |
| β9 = 0.5 | 0.484 | 0.955 | 0.148 | 0.149 | 0.488 | 0.947 | 0.094 | 0.098 |
| β10=0.5 | 0.476 | 0.936 | 0.142 | 0.138 | 0.490 | 0.937 | 0.091 | 0.091 |
| Zhang and Lu’s9 | ||||||||
| β1 = 0.5 | 0.298 | 0.470 | 0.133 | 0.097 | 0.318 | 0.299 | 0.089 | 0.068 |
| β2 = 0.5 | 0.296 | 0.493 | 0.134 | 0.097 | 0.314 | 0.280 | 0.090 | 0.068 |
| β9 = 0.5 | 0.300 | 0.485 | 0.135 | 0.097 | 0.314 | 0.285 | 0.090 | 0.068 |
| β10 = 0.5 | 0.295 | 0.469 | 0.132 | 0.097 | 0.315 | 0.285 | 0.086 | 0.068 |
| Wu and Cook’s15 | ||||||||
| β1 = 0.5 | 0.514 | – | 0.132 | – | 0.507 | – | 0.094 | – |
| β2 = 0.5 | 0.514 | – | 0.139 | – | 0.504 | – | 0.101 | – |
| β9 = 0.5 | 0.515 | – | 0.150 | – | 0.504 | – | 0.102 | – |
| β10 = 0.5 | 0.512 | – | 0.146 | – | 0.505 | – | 0.091 | – |
Note: The standard errors and the coverage of the Normal-based confidence intervals for Wu and Cook’s15 method were not computed due to the bootstrap, suggested by them for computing the standard errors, experiencing convergence issues for some of the bootstrap samples. Oracle: the unpenalized nonparametric maximum likelihood estimation with only the covariates whose coefficients are non-zero, i.e. Z1, Z2, Z9 and Z10; Coef: regression coefficient; Est: empirical average of the parameter estimator; CP: empirical coverage of the 95% Normal-based confidence interval; SE: empirical standard error of the parameter estimator; SEE: empirical average of the standard error estimator.
Figure 1.
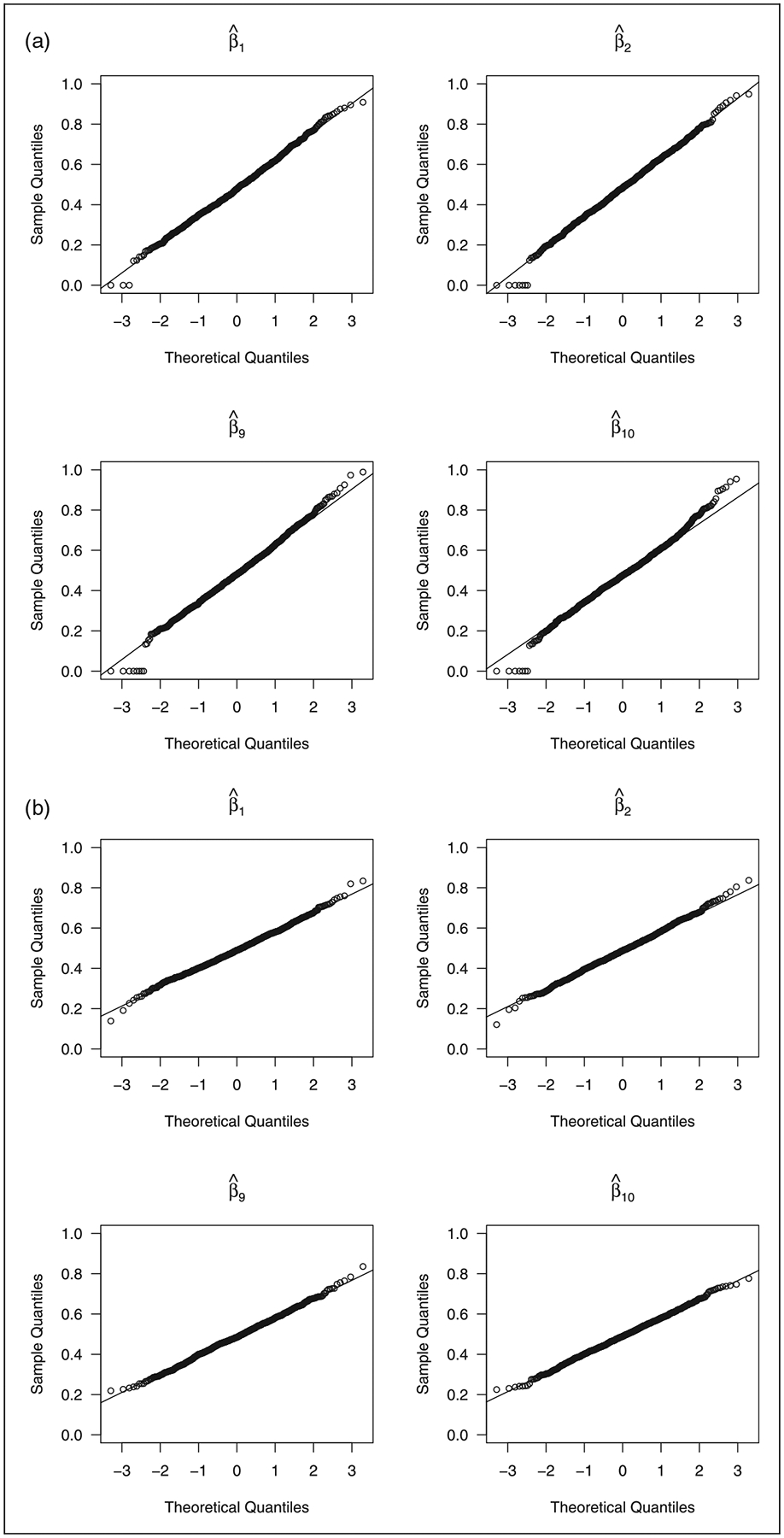
Normal Q–Q plots of the proposed estimators for the non-zero coefficients in the untruncated case. (a) n = 200; (b) n = 400.
The simulation results for the truncated case are in the Web Appendix. In the truncated case, our adaptive lasso method also performed very well in terms of variable selection percentages, average numbers of correct and incorrect zero coefficients, and estimation accuracy of the non-zero coefficients. Figure S1 in the Web Appendix shows that the distributions of our regularized estimators for the non-zero coefficients converge to Normal as the sample size increases. For the variance estimation of our method and the oracle method in the truncated case, we again set hn = 5n−1/2.
6. Application
We apply the proposed method to the data of Detroit Dental Health Project. This is a longitudinal study that was designed to understand the oral health of low income African-American children in the city of Detroit. A total of 1021 dyads of children and their caregivers were enrolled in the study. The study collected a broad array of hypothesized determinants of oral health and made tooth-surface-level caries assessments on the participants over three waves from 2003 to 2007. The subjects considered in our analysis are the child participants. At Wave I, the children’s age range is 0–5 years with an average of 2.6. In the analysis, we consider the event of interest to be that a child has any non-cavitated or cavitated lesion in the primary dentition. We use age as the time scale and call the time to event age to caries. According to the study design, each child had one to three inspection times depending on whether he or she missed study visits. So the age to caries is either left censored, interval censored or right censored. The number of children in the analyzed data set is 1020, because one child does not have age-at-inspection information. We study the effects of child-, family- and community-level factors on mouth-level primary dental caries development. A list of variables considered in the analysis are in Table 4. All of them except WATER were picked out from Ismail et al.4 by excluding the obviously time-varying predictors therein. These variables’ values at Wave I were used in the analysis, assuming that the time-dependent variables in the list did not change much during the follow-up, which is reasonable to some extent owing to the dichotomization of many of the time-dependent variables.
Table 4.
The candidate covariates considered in the analysis of Detroit Dental Health Project.
| Variable name | Variable description |
|---|---|
| Child-level | |
| GENDER | Gender of child |
| WEIGHT | Weight-for-age percentile |
| BRUSHRATE | Brushing frequency during the preceding week (0 for < 7; 1 for ≥ 7) |
| WIPE | Frequency of wiping teeth of the child (0 = never or rarely; 1 = sometimes or usually) |
| WATER | Frequency of cleaning teeth of the child with water (0 = never or rarely; 1 = sometimes or usually) |
| WIC | Participating in WIC (0 = no; 1 = yes) |
| HEADSTART | Participating in Head Start (0 = no; 1 = yes) |
| Family-level | |
| OHSE | Caregiver’s score of perception of self-efficacy related to brushing the child’s teeth regularly |
| KBU | Caregiver’s score of knowledge of bottle use |
| KCOH | Caregiver’s score of knowledge of children’s oral hygiene |
| OHF | Caregiver’s belief in oral health fatalism (0 = neutral, disagree, or strongly disagree; 1 = agree or strongly agree) |
| KITCHEN | Water filter/purifier on kitchen tap (0 = no; 1 = yes) |
| CESD | Caregiver’s depressive symptoms (0 = absence; 1 = presence) |
| PARENTSTRESS | Caregiver’s parenting stress score |
| SUPPORT | Social support received by the caregiver (0 = low; 1 = high) |
| EDU | Caregiver’s education attainment (0 = less than high school; 1 = high school diploma or more) |
| EMPLOYMENT | Caregiver’s full-time employment status (0 = no; 1 = yes) |
| RELIGIOUSNESS | Caregiver’s frequency of attending religious services (0 for less than three times a month; for at least once a week) |
| Community-level | |
| DENTIST | Number of dentists in the neighborhood |
| GROCER | Number of grocery stores in the neighborhood |
| CHURCH | Number of churches in the neighborhood |
The data analysis results are shown in Table 5. Six covariates, BRUSHRATE, WIPE, HEADSTART, OHSE, KBU and EDU, were selected into the Cox model by the proposed adaptive lasso approach. All of their effect directions except WIPE’s make common sense. A possible explanation about the positive effect of WIPE could be that the wiping cloth was dirty so that wiping teeth accelerated the caries development. As can be seen from Table 5, the 5%-level two-sided Wald tests for each covariate based on the nonparametric maximum likelihood estimation would pick BRUSHRATE, WIPE, HEADSTART and OHSE as significant covariates, a subset of the covariates selected by the adaptive lasso. This test-based variable selection approach suffers from the multipletesting issue, especially in this case of 21 candidate covariates.
Table 5.
Results of the analysis of Detroit Dental Health Project.
| Variable | NPMLE | Adaptive lasso |
|---|---|---|
| Child-level | ||
| GENDER | −0.037 (0.038) | 0 (−) |
| WEIGHT | −0.028 (0.038) | 0 (−) |
| BRUSHRATE | −0.111 (0.041) | −0.189 (0.084) |
| WIPE | 0.181 (0.040) | 0.342 (0.083) |
| WATER | 0.016 (0.040) | 0 (−) |
| WIC | 0.036 (0.040) | 0 (−) |
| HEADSTART | −0.117 (0.037) | −0.268 (0.105) |
| Family-level | ||
| OHSE | −0.080 (0.039) | −0.093 (0.052) |
| KBU | −0.079 (0.043) | −0.040 (0.041) |
| KCOH | 0.040 (0.044) | 0 (−) |
| OHF | 0.036 (0.040) | 0 (−) |
| KITCHEN | 0.013 (0.037) | 0 (−) |
| CESD | −0.005 (0.040) | 0 (−) |
| PARENTSTRESS | −0.054 (0.042) | 0 (−) |
| SUPPORT | 0.032 (0.043) | 0 (−) |
| EDU | −0.069 (0.041) | −0.082 (0.081) |
| EMPLOYMENT | −0.033 (0.039) | 0 (−) |
| RELIGIOUSNESS | −0.051 (0.042) | 0 (−) |
| Community-level | ||
| DENTIST | 0.056 (0.050) | 0 (−) |
| GROCER | 0.021 (0.050) | 0 (−) |
| CHURCH | −0.043 (0.045) | 0 (−) |
Note: Standard errors are given in the parentheses. NPMLE: the coefficient estimate from the nonparametric maximum likelihood estimation; Adaptive lasso: the coefficient estimate from the proposed shrinkage method.
7. Discussion
Section 4 actually also provides an unpenalized nonparametric maximum likelihood estimation algorithm for the Cox model with left truncated and interval censored data. The covariance matrix of the corresponding regression coefficient estimator can be estimated using the profile likelihood method.25 These approaches, to the best of our knowledge, are new in the literature. They performed well in finite samples, as seen in Table S3 of the Web Appendix.
The proposed variable selection method can be readily extended to interval censored data with time-dependent covariates whose trajectories are fully observed, e.g., marital status and parity. The asymptotic properties for the extension can be also easily derived based on this paper and Zeng et al.,14 which considered fully-observed time-dependent covariates. Computationally, it is straightforward to extend our method to other semiparametric transformation models in Zeng et al.14 and to other penalties like SCAD. The proofs of the corresponding asymptotic theories would be a bit more involved though, since the profile likelihood for other transformation models is a more complex function of regression parameters and SCAD is not a convex penalty. A more interesting and challenging extension is to the high-dimensional setting, i.e. d is comparable to n or even much larger than n. We are working on this problem.
Supplementary Material
Acknowledgements
The dental caries data presented in this article come from the Detroit Dental Health Project, which was funded by the National Institute for Dental and Craniofacial Research (NIDCR) under the grant U-54DE14261. The authors would like to thank the Deputy Director of this project, Dr Woosung Sohn, for providing the data and permitting the use.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: CL was supported in part by the grant R03DE027429 from NIDCR. DT was supported in part by the grants R03DE027108 and U54MD011227 from NIH.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
- 1.Fisher-Owens SA, Gansky SA, Platt LJ, et al. Influences on children’s oral health: a conceptual model. Pediatrics 2007; 120: e510–e520. [DOI] [PubMed] [Google Scholar]
- 2.Ismail A, Sohn W, Lim S, et al. Predictors of dental caries progression in primary teeth. J Dental Res 2009; 88: 270–275. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Hastie T, Tibshirani R and Friedman J. The elements of statistical learning: data mining, inference and prediction. 2nd ed. Springer, 2009. [Google Scholar]
- 4.Tibshirani R Regression shrinkage and selection via the lasso. J Royal Stat Soc Ser B (Methodological) 1996; 58: 267–288. [Google Scholar]
- 5.Fan J and Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc 2001; 96: 1348–1360. [Google Scholar]
- 6.Zou H The adaptive lasso and its oracle properties. J Am Stat Assoc 2006; 101: 1418–1429. [Google Scholar]
- 7.Tibshirani R The lasso method for variable selection in the Cox model. Stat Med 1997; 16: 385–395. [DOI] [PubMed] [Google Scholar]
- 8.Fan J and Li R. Variable selection for Cox’s proportional hazards model and frailty model. Annals Stat 2002; 30: 74–99. [Google Scholar]
- 9.Zhang HH and Lu W. Adaptive lasso for Cox’s proportional hazards model. Biometrika 2007; 94: 691–703. [Google Scholar]
- 10.Vanichseni S, Kitayaporn D, Mastro TD, et al. Continued high HIV-1 incidence in a vaccine trial preparatory cohort of injection drug users in Bangkok, Thailand. AIDS 2001; 15: 397–405. [DOI] [PubMed] [Google Scholar]
- 11.Zhang Z and Sun J. Interval censoring. Stat Meth Med Res 2010; 19: 53–70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Schick A and Yu Q. Consistency of the GMLE with mixed case interval-censored data. Scand J Stat 2000; 27: 45–55. [Google Scholar]
- 13.Zhang Y, Hua L and Huang J. A spline-based semiparametric maximum likelihood estimation method for the Cox model with interval-censored data. Scand J Stat 2010; 37: 338–354. [Google Scholar]
- 14.Zeng D, Mao L and Lin DY. Maximum likelihood estimation for semiparametric transformation models with interval-censored data. Biometrika 2016; 103: 253–271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Wu Y and Cook RJ. Penalized regression for interval-censored times of disease progression: selection of HLA markers in psoriatic arthritis. Biometrics 2015; 71: 782–791. [DOI] [PubMed] [Google Scholar]
- 16.Scolas S, El Ghouch A, Legrand C, et al. Variable selection in a flexible parametric mixture cure model with interval-censored data. Stat Med 2016; 35: 1210–1225. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Zhao H, Wu Q, Li G, et al. Simultaneous estimation and variable selection for interval-censored data with broken adaptive ridge regression. J Am Stat Assoc. Epub ahead of print 22 April 2019. DOI: 10.1080/01621459.2018.1537922. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Alioum A and Commenges D. A proportional hazards model for arbitrarily censored and truncated data. Biometrics 1996; 52: 512–524. [PubMed] [Google Scholar]
- 19.Wang L, McMahan CS, Hudgens MG, et al. A flexible, computationally efficient method for fitting the proportional hazards model to interval-censored data. Biometrics 2016; 72: 222–231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Lu W and Zhang HH. Variable selection for proportional odds model. Stat Med 2007; 26: 3771–3781. [DOI] [PubMed] [Google Scholar]
- 21.Murphy SA and van der Vaart AW. Observed information in semi-parametric models. Bernoulli 1999; 5: 381–412. [Google Scholar]
- 22.Zhang Y, Li R and Tsai CL. Regularization parameter selections via generalized information criterion. J Am Stat Assoc 2010; 105: 312–323. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hui FKC, Warton DI and Foster SD. Tuning parameter selection for the adaptive lasso using ERIC. J Am Stat Assoc 2015; 110: 262–269. [Google Scholar]
- 24.Zeng D, Gao F and Lin DY. Maximum likelihood estimation for semiparametric regression models with multivariate interval-censored data. Biometrika 2017; 104: 505–525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Murphy SA and van der Vaart AW. On profile likelihood. J Am Stat Assoc 2000; 95: 449–465. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.