

Abstract
We conduct a genome-wide association study (GWAS) of educational attainment (EA) in a sample of ~3 million individuals and identify 3,952 approximately uncorrelated genome-wide-significant SNPs. A genome-wide polygenic predictor, or polygenic index (PGI), explains 12-16% of EA variance and contributes to risk prediction for ten diseases. Direct effects (i.e., controlling for parental PGIs) explain roughly half the PGI’s magnitude of association with EA and other phenotypes. The correlation between mate pairs’ PGIs is far too large to be consistent with phenotypic assortment alone, implying additional assortment on PGI-associated factors. In an additional GWAS of dominance deviations from the additive model, we identify no genome-wide-significant SNPs, and a separate X-chromosome additive GWAS identifies 57.
INTRODUCTION
Educational attainment (EA) is an important dimension of socioeconomic status that features prominently in research by social scientists, epidemiologists, and other medical researchers. EA is strongly related to a range of health behaviors and outcomes, including mortality1. For this reason, and because EA can be measured accurately at low cost, cohort studies used in genetic epidemiology and medical research routinely measure participants’ EA.
The most recent genome-wide association study (GWAS) meta-analysis of EA had a combined sample size of ~1.1 million individuals2. Here, we report and analyze results from an updated meta-analysis of EA in a combined sample nearly three times larger (N = 3,037,499). The increase comes from expanding the sample for the association analyses from 23andMe, Inc., from ~365,000 to ~2.3 million genotyped research participants. As before, our core analysis is a GWAS of autosomal SNPs. Our updated meta-analysis identifies 3,952 approximately uncorrelated SNPs at genome-wide significance, compared to 1,271 in the previous study. The larger sample size yields more accurate effect-size estimates that allow us to construct a genome-wide polygenic index (PGI) (also called a polygenic score) that has greater prediction accuracy, increasing the percentage of variance in EA explained from 11-13% to 12-16%, depending on the validation sample, an increase of approximately 20%. In meta-analyses of the expanded 23andMe sample and the UK Biobank3, we also conduct an updated GWAS of the X chromosome (N = 2,713,033) and the first large-scale “dominance GWAS” (i.e., a SNP-level GWAS of dominance deviations) of EA on the autosomes (N = 2,574,253). In our updated X-chromosome GWAS, we increase the number of approximately uncorrelated genome-wide-significant SNPs from 10 to 57. Our dominance GWAS identifies no genome-wide-significant SNPs. Moreover, with high confidence we can rule out the existence of any common SNPs whose dominance effects explain more than a negligible fraction of the variance in EA. Table 1 summarizes the GWAS conducted in this paper and compares them to previous large-scale GWAS of educational attainment.
Table 1.
Comparison to Previous Large-Scale GWASs of EA
| Additive GWAS, Autosomes |
Additive GWAS, X Chromosome |
Dominance GWAS, Autosomes |
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNPs |
PGI R2 |
SNPs |
PGI R2 (C + T, P < 1) |
SNPs |
|||||||||||||
| N | # SNPs | # Loci | Mean χ2 |
LDpred, HapMap3 SNPs |
C + T, P<5e-8 |
N | # SNPs | # Loci |
Mean χ2 |
male | female | pooled | N | # SNPs | # Loci |
Mean χ2 |
|
| EA1 | 126,559 | 2,310,444 | 4 | 1.24 | 2.64% | 0.03% | - | - | - | - | - | - | - | - | - | - | - |
| EA2-D | 293,723 | 9,256,490 | 74 | 1.46 | 5.81% | 0.46% | - | - | - | - | - | - | - | - | - | - | - |
| EA2-C | 405,072 | 9,918,450 | 162 | 1.63 | 6.91% | 0.93% | - | - | - | - | - | - | - | - | - | - | - |
| EA3 | 1,131,881 | 10,016,266 | 1,271 | 2.91 | 10.09% | 4.03% | 694,894 | 205,865 | 10 | 2.60 | 0.04% | 0.00% | 0.01% | - | - | - | - |
| EA4 | 3,037,499 | 10,675,380 | 3,952 | 4.90 | 13.43% | 7.18% | 2,713,033 | 211,581 | 57 | 5.24 | 0.29% | 0.10% | 0.19% | 2,574,253 | 5,870,596 | 0 | 1.00 |
Summary overview of GWASs meta-analyses of educational attainment. # SNPs is number of markers included in final GWAS meta-analysis of EduYears; # Loci: number of approximately independent SNPs that reached genome-wide significance; Mean χ2: average test statistic for SNPs with MAF > 1% and N > 0.9 × Nmax. where Nmax is the maximum sample size across all SNPs. To maximize comparability across studies, PGIs are generated using SNPs available in all GWAS (all five GWAS for autosomal PGI and EA3-EA4 for the X chromosome PGI) and uniform procedures described in the Supplementary Note. C+T stands for “clumping and thresholding”. The autosomal PGI R2’s are a sample-size weighted average of the incremental-R2’s from HRS and Add Health. The X Chr PGI R2’s are the incremental-R2’s from HRS. The incremental-R2 is the increase in R2 after adding the PGI to a regression of EA on controls (a full set of dummy variables for year of birth, an indicator variable for sex, a full set of interactions between sex and year of birth, and the first 10 principal components of the genomic relatedness matrix). EA1: Rietveld et al.61 combined meta-analysis of discovery and replication cohorts. EA2-D: Okbay et al.62 meta-analysis of discovery cohorts. EA2-C: Okbay et al.62 meta-analysis of discovery and replication cohorts. EA3: Lee et al.2 meta-analysis of discovery cohorts. EA4: Current study.
The rest of the paper investigates the scope and sources of the PGI’s predictive power. We first document that the EA PGI not only predicts a range of cognitive phenotypes as has been found in previous work2,4, but it also adds non-trivial predictive power for 10 diseases we examine, even after controlling for disease-specific PGIs. Next, using a combined sample of ~53,000 individuals with genotyped siblings and ~3,500 individuals with both parents genotyped, we examine the predictive power of the EA PGI controlling for parental EA PGIs. By controlling for parental EA PGIs, we isolate the component of predictive power that is due to direct effects5,6: causal effects of an individual’s genetic material on that individual. For EA and 22 other phenotypes, controlling for the parental EA PGIs roughly halves the EA PGI’s association with the phenotype. In contrast, when we examine PGIs for height, BMI, and cognitive performance, controlling for parental PGIs has far less impact on their associations with their corresponding phenotype. Thus, the EA PGI stands out as unusual in terms of how much of its predictive power is not due to direct effects.
Finally, we use PGIs to study assortative mating. Using 862 genotyped mate pairs in the UK Biobank and 1,603 pairs in Generation Scotland7, we estimate the correlation between mate pair PGIs for EA, as well as for height. For height, the correlation between mate pairs’ PGIs is close to that expected under phenotypic assortment (i.e., all similarity between mate pairs on the genetic component of the phenotype arises via matching on the phenotype). Once again, EA is different: the correlation between mate-pair PGIs for EA is much larger than one would expect from phenotypic assortment on EA. We find evidence that population structure captured by principal components and assortment on cognitive performance explain some, but not all, of the excess mate-pair PGI correlation. These findings shed further light on the EA PGI’s predictive power for EA and other phenotypes: the factors on which mate pairs assort that are not EA but are correlated with the EA PGI—for example (we speculate) geographic location at courtship age—likely also contribute to the PGI’s predictive power.
For a less technical description of the paper and of how it should—and should not—be interpreted, see the Frequently Asked Questions in Supplementary Data 1.
RESULTS
Additive GWAS of EduYears in Autosomes
We conducted a sample-size-weighted meta-analysis of association results on EA, measured as number of years of schooling completed (EduYears), by combining three sets of summary statistics: public results from our previous meta-analysis of 69 cohorts (N = 324,162, excluding UKB and 23andMe), new association results from 23andMe (N = 2,272,216), and new association results from a GWAS we conducted in UKB with an improved coding of the EA measure (N = 441,121; see Supplementary Note). All analyses were conducted in samples of European genetic ancestries, included controls for sex, year of birth, their interaction, and genetic principal components, and applied a uniform set of quality-control procedures (see Supplementary Note for a comprehensive description). The final meta-analysis contains association results for ~10 million SNPs. The quantile-quantile plot in Extended Data Figure 1 shows that the P values deviate strongly from the uniform distribution. According to the LD score regression8 intercept (1.66), confounding accounts for 7% of the inflation, similar to previous GWAS of EA2 (see Extended Data Figure 2 for the LD score plot). The Manhattan plot in Fig. 1 and many of our subsequent analyses are based on test statistics adjusted for the LD score intercept.
Figure 1. Manhattan plots for the additive and dominance GWAS.

The top panel (green) is the additive GWAS (n = 3,037,499 individuals), and the bottom panel (red) is the dominance GWAS (n = 2,574,253 individuals). The P value and mean χ2 value are based on inflation-adjusted two-sided Z-tests. The x axis is chromosomal position, and the y axis is the significance on a −log10 scale. The dashed line marks the threshold for genome-wide significance (P = 5 × 10−8).
We identify 3,952 lead SNPs, defined as approximately uncorrelated (pairwise r2 < 0.1) variants with an association P value below 5×10−8. At the stricter threshold9 of P < 1×10−8, the number declines to 3,277 (Supplementary Table 1; see Supplementary Note for a description of the clumping algorithm). To assess the sensitivity of our conclusions about the number of independent SNPs, we conducted a conditional-joint (COJO) analysis10. This analysis identified 2,925 SNPs (Supplementary Table 2); 41 of these are in LD (r2 > 0.1) with other COJO lead SNPs and may represent secondary associations within a locus. Adjusted for the winner’s curse, we find that the effects of our lead SNPs are consistently quite small. On average, an additional copy of the reference allele of the median SNP is associated with 1.4 weeks more schooling: the effects at the 5th and 95th percentiles (in absolute value) are 0.9 and 3.5 weeks, respectively (see Supplementary Note for details on these calculations). We also examined the out-of-sample replicability of the lead SNPs identified in the most recent previous meta-analysis2. In the independent 23andMe data, the replication record is broadly in line with theoretical predictions derived from an empirical Bayesian framework described in the Supplementary Note (see Extended Data Figure 3).
Biological Annotation
To compare results from biological annotation of our meta-analysis to that of the most recent previous meta-analysis, we applied stratified LD score regression11 to both sets of summary statistics using a recent set of SNP annotations12. The results are very similar across the two meta-analyses, but standard errors are smaller when using the current meta-analysis results, as expected given the larger sample size (Supplementary Figures 1a-d). Notably, we replicate the unexpected result of relatively weak enrichment of genes highly expressed in glial cells (astrocytes and oligodendrocytes) relative to neurons.
X-Chromosome GWAS Results
To update the previous X chromosome analysis, we conducted a sample-size-weighted meta-analysis of mixed-sex association results from UK Biobank and 23andMe (N = 2,713,033) for ~200,000 SNPs on the X chromosome (Extended Data Figure 4). We identified 57 lead SNPs with estimated effects in the range 1 to 3 weeks of schooling. Our findings are fully consistent with earlier conclusions: SNP heritability due to the X chromosome of 0.4% and (using sex-stratified association analyses in the UK Biobank) a male-female genetic correlation on the X chromosome close to unity (rg = 0.94, S.E. = 0.03).
Dominance GWAS
We conducted a GWAS of dominance deviations from the additive model (Supplementary Note) by meta-analyzing summary statistics from association analyses conducted in 23andMe and UKB (N = 2,574,253). Theory and evidence from the quantitative genetics literature, including findings from two recent papers13,14 that estimated dominance SNP heritability across dozens of phenotypes (but not EA), suggest that dominance effects explain at most a very small share of the variance in polygenic phenotypes15. Nevertheless, in the behavior genetics literature, when the phenotypic correlation between monozygotic twins is more than twice as large as the phenotypic correlation between dizygotic twins, it remains common practice to attribute the violation of the additive model to dominance variance.
The Manhattan plot from our dominance GWAS is shown in red in the bottom panel of Fig. 1. There are no genome-wide-significant SNPs. Power calculations indicate that, at genome-wide significance, we had 80% power to detect dominance effects with an R2 of 0.0015% (Supplementary Note). Such effect sizes would be over an order of magnitude smaller than the largest additive effects (R2 ≈ 0.04%). Therefore, the absence of genome-wide-significant SNPs suggests that dominance effects of common SNPs, taken individually, are negligibly small.
Next, we turn to the combined dominance effects of common SNPs. Applying an adapted version of LD Score regression to the summary statistics, we estimate a SNP heritability of 0.00015 (S. E. = 0.00024), which is statistically indistinguishable from zero (P = 0.54). In the Supplementary Note, we report additional analyses (that rely on different assumptions) that similarly conclude that the combined variance explained by dominance deviations in common SNPs is negligible. Our results do not rule out the possibility that rare SNPs have substantial dominance effects.
Even when the phenotypic variance across individuals explained by dominance is negligible, the combined dominance effects on an individual can be substantial when homozygosity (which is deleterious on average) is increased genome-wide due to inbreeding16. This reduction of fitness-related phenotypic values is called directional dominance, or inbreeding depression (ID). We applied a recently developed method that uses dominance GWAS summary statistics to estimate ID17. Our estimate implies the offspring of first cousins have on average ~1.0 fewer month of EA (P = 0.04) than the offspring of unrelated individuals.
Polygenic Prediction
We assessed empirically how well a polygenic index (PGI) derived from the autosomal GWAS of additive variation predicts a host of phenotypes related to EA, academic achievement, and cognition. We used three European genetic ancestry holdout samples from the National Longitudinal Study of Adolescent to Adult Health (Add Health)18, a representative sample of American adolescents followed into adulthood; the Health and Retirement Study (HRS)19, a representative sample of Americans over age 50; and the Wisconsin Longitudinal Study (WLS)20, a sample of individuals who graduated from high school in Wisconsin in 1957. Because of the range restriction for EduYears in WLS, we do not use it to evaluate predictive power for EA. Our measure of prediction accuracy is the “incremental R2”: the gain in coefficient of determination (R2) when the PGI is added as a covariate to a regression of the phenotype on a set of baseline controls (sex, dummy variables for birth year and/or age at assessment, their interactions, and 10 principal components of the genomic relatedness matrix). All PGIs that we analyze are based on a meta-analysis that excluded Add Health, HRS, and WLS.
A PGI constructed using only genome-wide-significant SNPs has an incremental R2 of 9.1% in Add Health and 7.0% in HRS (Extended Data Figure 5). For all PGI analyses hereafter, unless stated otherwise we use a PGI generated from HapMap3 SNPs using the software LDpred21. This PGI explains 15.8% of the variance in EduYears in Add Health and 12.0% in HRS (Extended Data Figure 6). The sample-size-weighted mean is 13.3%. Fig. 2a depicts how the predictive power has increased as GWAS sample sizes have increased. Fig. 2b shows that the prevalence of college completion varies a great deal over PGI deciles (see Extended Data Figures 7a-b for prevalences of high school completion and grade retention). For example, only 7.3% and 6.8% of individuals in the lowest PGI decile have a college degree in Add Health and HRS, respectively, compared to 70.7% and 53.0% in the highest PGI decile. Fig. 2c, which displays scatterplots of individuals’ EA versus their PGIs, shows that throughout the PGI distribution, there is substantial variation in EA at the individual level. Thus, while average EA varies substantially across the PGI distribution, the PGI cannot be used to meaningfully predict an individual’s EA.
Figure 2. Polygenic prediction.

Panel (a): Predictive power of the EA PGI as a function of the size of the GWAS discovery sample, with expected predictive power shown by the dashed lines (see Supplementary Note section 5.5). Panel (b): Prevalence of College Completion by EA PGI decile, with 95% confidence intervals. Panel (c): Scatterplot of EA PGI (residualized on 10 PCs) and EduYears (residualized on sex, a full set of birth-year dummies, their interactions, and 10 PCs). Prediction samples for all panels are European-ancestry participants in the National Longitudinal Study of Adolescent to Adult Health (Add Health, N = 5,653) and the Health and Retirement Study (HRS, N = 10,843). All PGIs were constructed from EduYears GWAS results that exclude Add Health and HRS, using the software LDpred assuming a normal prior for SNP effect sizes. Incremental R2 is the difference between the R2 from a regression of EduYears on the PGI and the controls (sex, a full set of birth year dummies, their interactions, and 10 PCs) and the R2 from a regression of EduYears on just the controls. The individual-level data plotted in Panel (c) have been jittered by adding a small amount of noise to each observation.
In post hoc analyses, we found that a PGI generated from ~2.5 million pruned common SNPs using the software SBayesR22 is more predictive than our LDpred PGI. It explains 17.0% of the variance in EduYears in Add Health and 12.9% in HRS, with a sample-size-weighted mean of 14.3% (Supplementary Table 3).
We supplemented our analyses of education outcomes with other cognitive and academic achievement outcomes (Supplementary Table 4). For example, in Add Health, we found that the PGI explains 8.7% of the variation in Peabody verbal test scores and 12.3% in overall GPA. In WLS, the PGI explains 6.1% of the variation in Henmon-Nelson test scores and 7.7% in high school grade percentile rank.
PGIs like ours that are constructed from GWAS in samples of European genetic ancestries are generally found to have much lower predictive power in samples with other genetic ancestries; for example, on average across phenotypes, estimates of relative accuracy (ratio of R2) in African-genetic-ancestry to European-genetic-ancestry samples have been 22%23 and 36%24. When we used our PGI to predict EduYears in samples with African genetic ancestries from the HRS (N = 2,507) and Add Health (N = 1,716), the incremental R2 was 1.3% (95% CI: 0.6% to 2.2%) and 2.3% (95% CI: 1.1% to 3.7%), implying that the relative accuracies for EA in the HRS and Add Health are only 11% and 15%, respectively. Using the UKB, we find that the relative accuracy is smaller than would be predicted based on population differences in allele frequencies and LD alone (Online Methods), and this discrepancy is greater for EA than has been found in prior work25 for height, BMI, and six other phenotypes (Extended Data Figure 8 and Supplementary Table 5). The remaining reduction in predictive power is due to factors including epistasis (although epistatic variance is likely small13,15), gene-environment interactions, and differences between populations in gene-environment correlations, assortative mating, and environmental variance.
Predicting Disease Risk
Among individuals of European genetic ancestries in the UK Biobank, we estimated the predictive power of the EA PGI for ten common diseases for which large-scale GWASs have been conducted (Fig. 3). Because disease status is dichotomous, we assess predictive power using Nagelkerke’s coefficient of determination26. Consistent with prior work that has estimated non-zero genetic correlations between EA and many diseases and health-related phenotypes27, some using an earlier EA PGI1,28,29, our EA PGI significantly predicts all ten diseases (all ten P values are smaller than 3 × 10−8; Supplementary Table 6). The mean incremental R2 across all ten diseases is 0.63%. This predictive power is non-trivial compared with the average incremental R2 of 1.19% for disease-specific PGIs constructed using summary statistics from large-scale GWASs of the diseases. Moreover, the EA and disease-specific PGIs contribute roughly independently to predicting disease risk: the incremental R2 from adding both PGIs and their interaction to the regression model is typically roughly equal to the sum of the incremental R2’s of each of the two PGIs considered separately. Higher values of the EA PGI correspond to lower relative risk for each of the ten diseases (Extended Data Figure 9 and Supplementary Tables 7-8).
Figure 3. Predictive power of the EA PGI, the disease-specific PGI, and their combination for ten diseases in the UK Biobank.

For each disease phenotype, the figure shows the incremental Nagelkerke’s R2 from adding the EA PGI, the disease PGI, or both PGIs and their interaction to a logistic regression of the disease phenotype on covariates. The covariates are sex, a third-degree polynomial in birth year and their interactions with sex, the first 40 PCs, and batch dummies. The error bars represent 95% confidence intervals calculated with the bootstrap percentile method, with 1,000 repetitions.
Within-Family Analyses
Our next set of analyses, like related prior work5,30,31, aim to isolate the component of the PGI’s predictive power that is due to direct effects5,6: causal effects of an individual’s genetic material on that individual. When controls for both parents’ PGIs are included, we refer to the coefficient from a regression of an individual’s phenotype on the individual’s PGI as the direct effect of the PGI; when those controls are omitted, we refer to it as the population effect. (The regression controlling for parental PGIs gives an equivalent estimate of the direct effect of the PGI as a regression on PGIs constructed from transmitted and non-transmitted parental alleles5; see Supplementary Note). The population effect captures the sum of the direct effect, indirect effects from relatives (e.g., genetic influences on parents’ education, socioeconomic status, and behavior), other gene-environment correlation (i.e., correlation between genotypes and environmental exposure, with population stratification being one possible cause), and a contribution from the genetic component of the phenotype that would be uncorrelated with the PGI under random mating but becomes correlated with the PGI due to the linkage disequilibrium between causal alleles induced by assortative mating (Supplementary Note)5,32. Since the PGI is constructed from summary statistics that partly reflect indirect effects and other gene-environment correlation, estimating the direct effect of the PGI is different from estimating the total contribution of direct effects of SNPs33,34, for which relatedness disequilibrium regression35 or summary statistics from within-family GWAS36 could be used.
For this analysis, we used a combined sample of ~53,000 individuals with genotyped siblings and ~3,500 individuals with both parents genotyped (Online Methods and Supplementary Note). Direct-effect estimates from the sibling data may be biased by sibling indirect effects, but estimates of such effects are small, including for some of the phenotypes we study37. The data are from the UKB3, Generation Scotland (GS)7, and the Swedish Twin Registry (STR)38. We did not have sufficient power to study the diseases from Fig. 3 when restricting to these family samples. We instead analyze a set of 23 health, cognitive, and socioeconomic phenotypes, which include cardiometabolic and lung biomarkers related to disease risk (Supplementary Tables 9-10).
Fig. 4a (and Supplementary Table 10) shows our meta-analysis estimates of the direct and population effects of the EA PGI. For predicting EA, the ratio of direct to population effect estimates is 0.556 (S.E. = 0.020), implying that 100% * 0.5562 = 30.9% of the PGI’s R2 is due to its direct effect. This is smaller than the estimate of 48.9% reported in a previous analysis of Icelandic data5. For comparison with EA, we similarly estimate the direct and population effects of PGIs for height, BMI, and cognitive performance on their respective phenotypes (Fig. 4a). The ratio of direct to population effect estimates is 0.910 (S.E. = 0.009) for height, 0.962 (S.E. = 0.017) for BMI, and 0.824 (S.E. = 0.033) for cognitive performance, implying that 82.8%, 92.5%, and 67.9%, respectively, of the PGIs’ R2 are due to their direct effects (Supplementary Tables 11-13). The EA PGI has by far the lowest ratio.
Figure 4. Meta-analysis estimates of direct and population effects of PGIs.

Panel (a): For each PGI, the ratio of the direct effect to the population effect on the phenotype from which the PGI was derived. Panel (b): The effects of the EA PGI on 23 phenotypes. Bars are shaded lighter when the population and direct effects are statistically indistinguishable (two-sided Z-test P > 0.05/23, where 23 is the number of phenotypes under study). For both panels, estimates are from meta-analyses of UKB, GS, and STR samples of siblings and trios. Phenotypes and the PGIs are scaled to have variance one, so effects correspond to partial correlation coefficients. Error bars are 95% confidence intervals. See Supplementary Table 9 for details on phenotypes and Supplementary Tables 10-13 for numerical values underlying this figure.
We similarly assessed how much of the EA PGI’s predictive power for the other 22 phenotypes (other than EA) is due to direct effects. Fig. 4b shows estimates of the population and direct effects of the EA PGI. Across the phenotypes, the inverse-variance-weighted average ratio of direct to population effects is 0.588 (S.E. = 0.013). This is similar to the ratio of 0.556 for the EA PGI on EA. Thus, both for predicting EA and other phenotypes, a substantial part of the EA PGI’s predictive power results from direct effects, but a substantial part results from factors other than direct effects. (For analogous analyses with the PGIs for height, BMI, and cognitive performance, see Supplementary Figures 2a-c, Supplementary Tables 11-13, and Supplementary Note).
Assortative Mating
We also use the PGI to study assortative mating. For this analysis, we use data on genotyped mate pairs in the UK Biobank (862 pairs) and Generation Scotland (1,603 pairs). Under the (commonly assumed) hypothesis of phenotypic assortment—according to which the mate pairs’ genetic components are independent conditional on the mate pairs’ phenotypes39,40—the mate-pair PGI correlation should equal the product of the mate-pair phenotypic correlation, the correlation between the father’s phenotype and PGI, and the correlation between the mother’s phenotype and PGI. We examine whether correlations between mate pairs’ EA PGIs fit this model (Fig. 5a), and we perform the same analysis for the height PGI (Fig. 5b). Height provides a useful comparison because its mate-pair phenotypic correlation (0.290, S.E. = 0.018) and mate-pair PGI correlation (0.106, S.E. = 0.020) are somewhat similar to EA’s mate-pair phenotypic correlation (0.430, S.E. = 0.017) and mate-pair PGI correlation (0.175, S.E. = 0.020). (For completeness, Supplementary Table 14 also shows results for the BMI and cognitive performance PGIs, but these are less informative because the mate-pair PGI correlations are not statistically distinguishable from zero.)
Figure 5. Correlations between mate pairs’ PGIs.
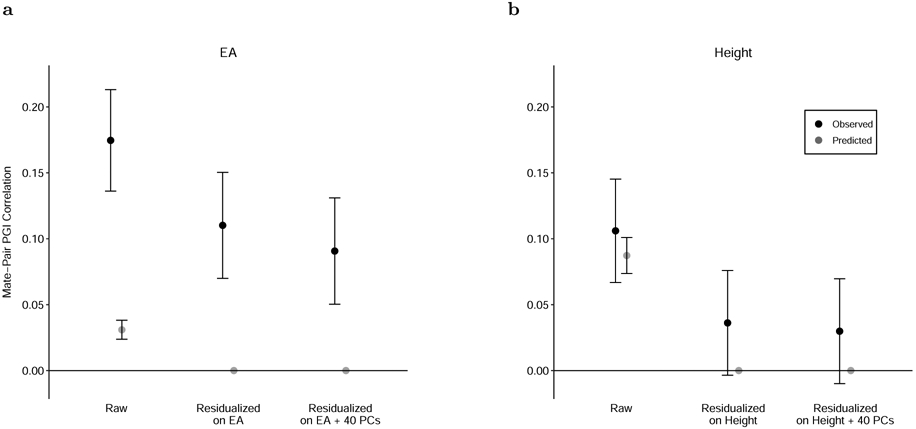
Panel (a): Black dots show the correlation between mate pairs’ EA PGIs (“Raw”) and the correlation between the residuals of the mate pairs’ EA PGIs after regressions with the listed regressors. Gray dots show the predicted correlations under phenotypic assortment, i.e., all correlation between mate pairs’ EA PGIs is explained by assortment on EA itself. N = 2,344 (861 from UKB and 1,483 from Generation Scotland). Panel (b): Analogous but for the height PGI and predictions under phenotypic assortment on height. N = 2,451 (858 from UKB and 1,593 from Generation Scotland). Error bars are 95% confidence intervals. See Supplementary Table 14 for numerical values underlying this figure.
For height, phenotypic assortment predicts a mate-pair PGI correlation of 0.087 (S.E. = 0.007) (the gray point in the figure), which is only somewhat smaller than the observed estimate of 0.106 and is contained within the 95% confidence interval. In contrast, for EA, the predicted value of 0.031 (S.E. = 0.004) is much smaller than, and statistically distinguishable from, the mate-pair PGI correlation of 0.175. Phenotypic assortment on EA would also imply that after residualizing the PGI on EA, the mate-pair PGI correlation should fall to zero. In fact, the correlation falls by only 37%, to 0.110 (S.E. = 0.021).
We explore two plausible explanations of the high mate-pair EA PGI correlation. The first is mate pairs tending to share genetic ancestry. Not all forms of social homogamy generate a mate-pair PGI correlation41, but social homogamy that is related to genetic ancestry—for example, due to geographic proximity that tracks genetic structure in the population—will do so if there are components of genetic ancestry correlated with the PGI. After residualizing the EA PGI on 40 principal components (PCs) of the genomic relatedness matrix in addition to EA, we find that the mate-pair PGI correlation falls to 0.091 (S.E. = 0.021). This implies that some, but not most, of the mate-pair PGI correlation is due to assortment on genetic ancestry captured by the PCs (or some factor correlated with the PCs). In the UKB, further adjustment for birth coordinates and the center where participants were assessed (Online Methods) resulted in a slight reduction of the correlation between mate pairs’ PGIs (Supplementary Table 14), suggesting that geographic factors not captured by the top 40 PCs also contribute to the high mate-pair EA PGI correlation. The second explanation is assortment on a phenotype or composite of phenotypes that is more strongly correlated with the EA PGI than EA itself. The Generation Scotland cohort contains high quality measures of cognitive performance and vocabulary, proxies for plausible candidates of such a composite. In this cohort, after residualizing on these proxies as well as on EA and 40 PCs, the mate-pair PGI correlation is 0.083 (S.E. = 0.027) compared to 0.113 (S.E. = 0.026) when residualizing on EA and PCs alone—which leaves a substantial remainder of the mate-pair PGI correlation unexplained. This remainder is due to assortment on phenotypes correlated with the EA PGI other than EA, cognitive performance, and vocabulary—possibly including various personality traits42-44—and sources of social homogamy other than genetic ancestry captured by the top 40 PCs—possibly including geographic location at courtship age45,46, socioeconomic status, and social class47.
Any factor that contributes to explaining the mate-pair PGI correlation must be correlated with the EA PGI. Therefore, these factors likely contribute to the EA PGI’s predictive power for EA and other phenotypes. Moreover, assortative mating on these factors increases the variance of the component of the EA PGI with which they are correlated, which amplifies their contribution to the EA PGI’s predictive power.
DISCUSSION
The results of previous large-scale GWAS of EA have proven useful across many different areas of research, including medicine48, epidemiology49,50, psychology42, economics51,52, and sociology47,53,54. The substantial increase in power from our large sample size will make the summary statistics from the current paper even more useful. Beyond increasing power, the GWAS reported in this paper also included extensive dominance, within-family, and assortative mating analyses. These analyses illustrate how, as GWAS have advanced from relatively small samples (by today’s standards) that identify just a few SNPs to well-powered analyses of most of the variation from common SNPs, it has become possible to address an ever-increasing set of questions. For example, we find that the EA PGI has predictive power across a broad range of educational, cognitive, and health-related phenotypes and diseases. Our results show that this predictive power derives both from direct genetic effects and from gene-environment correlation (likely including indirect genetic effects from relatives), with assortative mating amplifying the predictive power over what would be expected under random mating.
Our findings are also relevant for informing some decades-old debates in the behavior genetics literature. Because the parameters of a general biometric model cannot be separately identified from a small number of phenotypic correlations among different types of relatives, researchers typically have to assume that some of the parameters equal zero in order to estimate other parameters. In the 1970s, for example, researchers from the Birmingham School55,56, researchers from the Hawaii School57,58, and the sociologist Sandy Jencks famously came up with strikingly different explanations for a set of kinship correlations on cognitive test scores assembled by Jencks59. A careful analysis by Loehlin60 showed that the three sets of researchers arrived at different explanations for the same data primarily due to their divergent assumptions about dominance, assortative mating, and special twin environments.
Although our results concern EA rather than cognitive test scores, we believe they are relevant for evaluating the plausibility of some of the assumptions underlying the modeling approaches that have been used to explain familial resemblance in EA and cognitive phenotypes. Three of our findings are especially relevant: (i) dominance variance due to common variants is negligible, (ii) much of the predictive power of the EA PGI is not explained by direct effects, and (iii) the mate-pair PGI correlation is far too strong to be consistent with assortative mating purely on phenotype. Overall, these findings suggest that any model of EA that requires substantial dominance to fit the data, restricts gene-environment correlations to zero, or assumes assortative mating is purely based on phenotype is likely to be misspecified. Thus, our analyses demonstrate how results from large-scale GWAS and the resulting PGIs can be used to improve the identifiability of behavior-genetic models.
The sample size of the GWAS of EA reported in this paper is the largest published to date. For some purposes, such as attaining greater predictive power for the PGI, there are clearly diminishing returns. However, even larger samples will enable other analyses that have not yet been adequately powered, such as estimating differences in SNP effect sizes across phenotypes or populations and estimating the fraction of variance explained by epistatic interactions13.
ONLINE METHODS
This article is accompanied by a Supplementary Note with further details.
Coding the EduYears phenotype.
As in previous GWAS2,61,62, the EduYears phenotype was coded by mapping the highest level of education that a respondent achieved to an International Standard Classification of Education (ISCED) category and then imputing a years-of-education equivalent for each ISCED category. Details on cohort-level phenotype measures, genotyping and imputation are in Supplementary Table 15.
Our phenotype coding was unchanged from previous GWAS, except in the UK Biobank (UKB). UKB participants with a qualification of “NVQ or HND or HNC or equivalent” but no college or university degree were previously coded as having 19 years of education2,62, but this classification overstates their average years of schooling (Supplementary Note section 1 and Supplementary Figure 3). We therefore recoded EduYears for these participants as the age they reported leaving full-time education (FTE) minus five. We dropped holders of an NVQ/HND/HNC/equivalent who reported leaving FTE before age 12 (fewer than 50 individuals).
In previous GWAS, individuals under 30 years old when EA was measured were excluded to ensure that almost everyone had completed formal schooling. In the 23andMe GWAS for the current paper, ~16% of the individuals are aged 16-29 years old. To explore the effect of including these individuals, we conducted a simulation using the UKB data (see Supplementary Note section 1.2 for details). The results indicate that the inclusion of individuals aged less than 30 in the 23andMe GWAS is unlikely to have materially affected our meta-analysis results.
Additive GWAS.
For our additive GWAS of EduYears, we meta-analyzed three sets of summary statistics: publicly available results from Lee et al.2 that exclude 23andMe and UKB (N = 324,162), new association results from 23andMe (N = 2,272,216), and new association results from a GWAS we conducted in UKB with the identical methodology as in Lee et al. but with the improved coding of EduYears described above (N = 441,121). All cohort-level analyses were restricted to European-genetic-ancestry individuals that passed the cohort’s quality-control filters and, except in 23andMe as described above, whose EA was measured at an age of at least 30. We did not run sex-stratified analyses for the autosomal meta-analysis because there is compelling evidence from our prior work that the male-female genetic correlation for EduYears is close to one. For example, the Okbay et al.62 data yields an estimate of 0.98 (S.E. = 0.029).
To the new 23andMe and UKB results, we applied a quality-control protocol similar to the one described previously62 and implemented in the EasyQC R package but updated to a more recent reference panel and adjusted to account for the large GWAS sample sizes (Supplementary Note section 2.2.5, Supplementary Table 16). Using the software METAL63, for all SNPs that passed the quality control thresholds in the new 23andMe and UKB results, we conducted a sample-size-weighted meta-analysis of these new results with the 69 results files from Lee et al.2 (all except 23andMe and UKB). After the meta-analysis, we inflated the standard errors by the square root of the intercept () from an LD score regression8.
We selected the set of approximately independent genome-wide-significant SNPs using the same iterative clumping algorithm used previously2 and implemented in Plink64, with a pairwise r2 cutoff of 0.1 and no physical distance cutoff (Supplementary Note section 2.2.6, Supplementary Table 1). We assessed the sensitivity of our conclusions about the number of lead SNPs with a conditional and joint multiple-SNP analysis (COJO)10, using the implementation in the GCTA software65 (Supplementary Note section 2.2.7) with SNPs farther than 100 Mb apart assumed to have zero correlation. We applied our clumping algorithm to classify each of the COJO lead SNPs as either “primary” (if retained by the algorithm) or “secondary” (if eliminated) (Supplementary Table 2).
X chromosome analyses.
We conducted separate association analyses of the X chromosome SNPs in UKB and 23andMe (Supplementary Note section 3). The 23andMe analysis (N = 2,272,216) was conducted in a pooled male-female sample using a 0/2 genotype coding for males. The UKB analysis (N = 440,817) was an inverse-variance-weighted meta-analysis (assuming 0/2 genotype coding to match the 23andMe analysis) of sex-stratified association analyses conducted using BOLT-LMM v2.3.466. Following Supplementary Note section 4.1 of Lee et al., we used the sex-stratified UKB analyses to estimate the X chromosome SNP heritability for males and females, as well as the male-female genetic correlation (Supplementary Note section 3.1, Supplementary Table 17).
We performed a sample-size-weighted meta-analysis of the 211,581 SNPs that were available in both UKB and 23andMe, passed the quality control filters (Supplementary Note section 3.3, Supplementary Table 16), and had a sample size greater than 500,000. To adjust for uncontrolled-for population stratification, we inflated the standard errors by the square-root of the LD score intercept from an autosomal meta-analysis of UKB and 23andMe (). We selected the set of approximately independent genome-wide-significant SNPs using the same clumping algorithm as in the additive GWAS (Supplementary Note section 2.2.6).
Dominance GWAS.
We conducted a sample-size-weighted meta-analysis for 5,870,596 autosomal SNPs that passed quality control filters and were available in both the 23andMe (N = 2,272,216) and UKB (N = 302,037) summary statistics. Similar to the additive GWAS, after the meta-analysis we inflated the standard errors by the square root of the intercept from an LD score regression. We used LD scores that account for the faster decay of information from tagged SNPs as a function of LD for dominance effects (see, e.g., ref. 13). The LD score regression was restricted to the set of HapMap3 SNPs, and the dominance LD scores were estimated using the 1000 Genomes Phase 1 reference sample67.
We decomposed the variance in the estimated dominance effect sizes into shares due to true signal, dominance genetic variance, and sampling variation (Supplementary Note section 4.5 and Supplementary Table 18). We also conducted a series of pre-registered replication exercises (https://osf.io/uegqv/) to assess whether the estimates of the dominance effects for various subsets of SNPs are consistent across UKB and 23andMe (Supplementary Note section 4.6 and 8, Supplementary Table 19).
To estimate inbreeding depression (ID) for EA, we used the ldscdom software, which implements a recently developed method17 that uses GWAS summary statistics to obtain an estimate of the slope from the regression of the phenotype of interest (EA) on the inbreeding coefficient across individuals. Supplementary Note section 4.7 provides details, and Supplementary Table 20 shows the estimates of ID for each cohort separately, as well as the inverse-variance-weighted meta-analysis of these two estimates.
Polygenic prediction.
From a GWAS meta-analysis that omits Add Health, HRS and WLS, the SNP weights for our main PGIs were obtained using LDpred (v. 1.0.11)21, assuming a Gaussian prior for the distribution of effect sizes and restricting to HapMap3 SNPs. LD patterns were estimated in a sample of 14,028 individuals and 1,214,408 HapMap3 SNPs from the public release of the Haplotype Reference Consortium (HRC) reference panel68. The PGIs were obtained in Plink269 by multiplying the genotype probabilities at each SNP by the corresponding estimated posterior mean calculated by LDpred, and then summing over all included SNPs (Supplementary Note section 5.1, Supplementary Table 4). We also constructed a PGI for the African-genetic-ancestry individuals in HRS and Add Health using the same LDpred weights (Supplementary Table 21).
The “clumping and thresholding” PGIs with P value cutoffs of 5 × 10−8, 5 × 10−5, 5 × 10−3, and 1 (i.e., all SNPs) were made in Plink269 using the clumping algorithm described in the section “Additive genome-wide-association study meta-analysis” and the procedure described above. The SNP weights were set equal to the coefficient estimates from the meta-analysis (Supplementary Table 3).
The SNP weights for the SBayesR22 PGI were obtained using the GCTB software70. We assume 4 components in the finite mixture model, with initial mixture probabilities π = (0.95, 0.02, 0.02, 0.01) and fixed γ = (0.0, 0.01, 0.1, 1), where γ is a parameter that constrains how the SNP-effect-size variance scales in each of the four distributions. LD was estimated using 2,865,810 pruned common variants from the full UKB European-genetic-ancestry (N ≈ 450,000) data set from Lloyd-Jones et al.22. Weights were obtained for 2,548,339 of these SNPs that overlapped with the summary statistics after excluding the MHC region. PGIs were constructed in Plink269 by multiplying the genotype probabilities at each SNP by the corresponding estimated posterior mean calculated by SBayesR, and then summing over all included SNPs (Supplementary Table 3).
We analysed how well the PGIs predict a host of phenotypes related to educational attainment, academic achievement, and cognition (Supplementary Note section 5.2). All regressions include controls for year of birth or age at assessment, sex, their interactions, and the first 10 principal components (PCs) of the variance-covariance matrix of the genomic relatedness matrix. In our analyses of grade point average outcomes in Add Health, we also controlled for high school fixed effects (Supplementary Note section 5.3).
To evaluate prediction accuracy, we first regress the phenotype on the controls listed above without the PGI. Next, we rerun the regression but with the PGI included. For quantitative phenotypes, our measure of predictive power is the incremental R2: the difference in R2 between the regressions with and without the PGI. For binary outcomes, we proceed similarly but calculate the incremental pseudo-R2 from a Probit regression. We obtain 95% confidence intervals (CIs) around the incremental (pseudo-)R2’s by performing a bootstrap with 1000 repetitions.
Expected prediction accuracy of the EA PGI.
We calculate the expected prediction accuracy of the EA PGI using a generalization of de Vlaming et al.71. The expected coefficient of determination, R2, can be expressed as the following function of the discovery sample size, N:
While A may vary by prediction sample, B does not. We estimate A and B by nonlinear least squares using data from Add Health and HRS. More details of this calculation can be found in Supplementary Note section 5.5.
Analysis of European genetic ancestries to African genetic ancestries relative accuracy in UKB.
We used a method that was recently developed by Wang et al.25 to investigate the factors contributing to the substantial loss of prediction accuracy of the EduYears PGI in samples of African genetic ancestries. We define the European genetic ancestries to African genetic ancestries relative accuracy (RA) as
where and are prediction accuracies of PGIs derived from a GWAS conducted in European-genetic-ancestry populations. To facilitate comparability with Wang et al.’s results for eight other phenotypes, we extended their original analyses to also include EduYears. We thus performed a GWAS of HapMap 3 SNPs (1,365,446 SNPs) in a sample of European-genetic-ancestry individuals in UKB (N = 425,231). We identified 507 approximately independent genome-wide-significant SNPs (using the LD clumping algorithm implemented in Plink64, setting the window size equal to 1 Mb and the LD r2 threshold to 0.1). We then used these 507 SNPs to generate PGIs and evaluate their accuracy in UKB hold-out samples of African-genetic-ancestry individuals (N = 6,514) and European-genetic-ancestry individuals (N = 10,000). To compare our empirical estimate of RA to the RA predicted by the model, we used genotypes from 503 European-genetic-ancestry and 504 African-genetic-ancestry participants in the 1000 Genomes Project to estimate genetic-ancestry-specific MAF and LD correlations between all candidate causal variants (defined as any SNP within a 100 kb window of a genome-wide-significant SNP whose squared correlation with the genome-wide-significant SNP is above 0.45). Following Wang et al., we then substituted these estimates into their Equation (2) (Supplementary Table 5, Extended Data Figure 8).
Prediction of disease risk from the EA PGI.
The EA PGI was constructed using LDpred (v.1.0.11)21, as described above but using the summary statistics of a meta-analysis of EA that excludes UKB. Disease-specific PGIs were constructed using summary statistics from GWAS conducted among participants of European genetic ancestries for nine phenotypes (Supplementary Table 22). The PGI for coronary artery disease was used to predict two diseases: ischaemic heart disease and myocardial infarction. For all phenotypes other than migraine, we generated weights using LDpred and constructed the PGI using Plink1.9. LDpred was run using the same settings and HRC reference data used for the EA PGI. For migraine, only SNPs with association P value < 10−5 were available in the summary statistics, so we generated the PGI using clumping and thresholding. Disease phenotypes were generated based on UKB Category 1712 and Data Field 41270 (Supplementary Note section 6.1.2, Supplementary Tables 23-24).
For the various diseases, we computed the predictive power of (1) the EA PGI, (2) the disease-specific PGI, and (3) these two PGIs together with their interaction (Supplementary Table 6). Our measure of predictive power is the incremental Nagelkerke’s R2 of adding the variable(s) to a logistic regression of the disease phenotype on sex, a third-degree polynomial in birth year and interactions with sex, the first 40 PCs, and batch dummies. 95% confidence intervals (CIs) around the incremental Nagelkerke’s R2 were obtained by performing a bootstrap with 1,000 repetitions.
We also computed the odds ratio for selected diseases by deciles of the EA PGI in UKB (Supplementary Tables 7-8). Odds ratios and 95% confidence intervals were estimated using logistic regression while controlling for covariates (Supplementary Note section 6.2.1).
Comparing direct and population effects.
To compare the direct effect of the PGI on various phenotypes to its population effect, we used data on siblings and trios from UKB3, GS7, and STR38. In both UKB and GS, first-degree relatives were identified using KING with the “--related --degree 1” option72. For parent-offspring relations, the parent was identified as the older individual in the pair. We removed 621 individuals from GS that had been previously identified by GS as being also present in UKB (Supplementary Note section 7.3).
We analyzed PGIs for EA and cognitive performance in all three samples, and height and BMI only in UKB and GS. PGIs were made using GWAS results that exclude GS, STR and all related individuals of up to third degree from UKB (Supplementary Note section 7.3), following the LDpred PGI pipeline described in Supplementary Note section 5.1.
We selected 23 phenotypes related to education, cognition, income, and health (Supplementary Table 9) available in at least one of the datasets. For each phenotype in each dataset, we first regressed the phenotype onto sex and age, age2, and age3, and their interactions with sex. In addition, for UKB, we included as covariates the top 40 genetic PCs provided by UKB and the genotyping array dummies3. For GS and STR, we included the top 20 genetic PCs (see Supplementary Note section 5.3 for how the PCs were created). We then took the residuals from the regression of the phenotype on the covariates and normalized the residuals’ variance within each sex separately, so that the phenotypic residual variance was 1 in each sex in the combined sample of siblings and individuals with both parents genotyped. The PGIs of the phenotyped individuals were also normalized to have variance 1 in the same sample. Thus, effect estimates correspond to (partial) correlations, and their squares to proportions of phenotypic variance explained.
We give an overview of the statistical analyses performed here, with details in Supplementary Note section 7.4. In the siblings, we regressed individuals’ phenotypes onto the difference between the individual’s PGI and the mean PGI among the siblings in that individual’s family, and the mean PGI among siblings in that family. In trios, we regressed phenotypes onto the individual’s PGI and the individual’s father’s and mother’s PGIs. In both the siblings and trios, we used a linear mixed model to account for relatedness in the samples. We meta-analyzed the results from the siblings and trios, accounting for covariance between the estimates from the sibling and trio samples from the same datasets. We applied a transformation to the meta-analysis that accounts for assortative mating to estimate the population effect of the PGI and the difference between the direct and population effects.
Analysis of assortative mating.
We identified mate pairs in UKB (862 mate pairs) and GS (1603 mate pairs) by identifying genotyped parents of genotyped individuals within each sample. Let ry denote the phenotypic correlation between mate pairs, and let rp and rm denote the correlations between the phenotype and PGI for the father and mother, respectively. The correlation between the mate pairs’ PGIs should be equal to ryrprm if the correlation is explained by assortative mating on the phenotype alone, and the relationship between the PGI and the phenotype is linear. To test the model of phenotypic assortment, we estimated the expected correlation between mate pairs’ PGIs by estimating ry, rp, and rm. We estimated the standard error of the product of ry, rp, and rm using 1000 bootstrap samples where we sampled over the mate pairs. We also estimated the correlation between the residual of the father’s PGI after regression onto the father’s phenotype and the residual of the mother’s PGI after regression onto the mother’s phenotype, which should be zero under phenotypic assortment if the relationship between phenotype and PGI is linear. We performed further analyses adjusting for genetic PCs, birth coordinates, UKB assessment center, cognitive performance, and vocabulary to test whether assortative mating on factors related to ancestry, geography, and cognition explained the mate-pair PGI correlations (Supplementary Note section 9).
DATA AVAILABILITY:
GWAS summary statistics can be downloaded from http://www.thessgac.org/data subject to a Terms of Use to ensure responsible use of the data. We provide association results for all SNPs that passed quality-control filters in autosomal, X chromosome, and dominance GWAS meta-analyses that excludes the research participants from 23andMe. SNP-level summary statistics from analyses based entirely or in part on 23andMe data can only be reported for up to 10,000 SNPs. For the complete dominance GWAS meta-analysis, which includes 23andMe, clumped results for the 1,000 SNPs with the smallest P values are provided. For the complete autosomal and X chromosome GWAS meta-analyses, respectively, clumped results for the 8,618 and 141 SNPs with P < 10−5 are provided; this P value threshold was chosen such that the total number of SNPs across the analyses that include data from 23andMe does not exceed 10,000. The full GWAS summary statistics from 23andMe will be made available through 23andMe to qualified researchers under an agreement with 23andMe that protects the privacy of the 23andMe participants. Please visit https://research.23andme.com/collaborate/#dataset-access/ for more information and to apply to access the data.
CODE AVAILABILITY:
The following software packages were used for data analysis: Python version 3.7.4 with packages pandas 0.25.1, scipy 1.3.1, numpy 1.17.2, matplotlib 3.1.1 and argparse 1.1 (https://anaconda.com); R version 4.0.3 with packages EasyQC 9.2, plotrix 3.7.8, tidyr 1.1.3 and readstata13 0.9.2, R version 3.6 with packages ggplot2 3.3 and fmsb 0.7 (https://www.r-project.org); GCTA 1.93.2beta (https://yanglab.westlake.edu.cn/software/gcta/#Overview); GCTB 2.03 (https://cnsgenomics.com/software/gctb/#Overview); Stata 16.1 (https://www.stata.com); PLINK 1.9 (https://www.cog-genomics.org/plink/1.9); PLINK 2 (https://www.cog-genomics.org/plink/2.0); LDpred 1.0.11 (https://github.com/bvilhjal/ldpred); METAL release 2011-03-25 (https://genome.sph.umich.edu/wiki/METAL_Documentation); BOLT-LMM 2.3 (https://alkesgroup.broadinstitute.org/BOLT-LMM/BOLT-LMM_manual.html); LDSC 1.0.1 (https://github.com/bulik/ldsc); SNIPar (https://github.com/AlexTISYoung/SNIPar/tree/EA4).
Extended Data
Extended Data Fig. 1. Quantile-quantile plots for the additive GWAS meta-analysis.

The panels display Q-Q plots, which show the -log10(P-values) based on a two-sided Z-tests for (a) all SNPs and (b) SNPs grouped by minor allele frequency (MAF): rare (<1%), low frequency (1-5%) and common (>5%). The plots and λGC numbers are based on the unadjusted GWAS summary statistics (i.e. with standard errors that were not inflated by the square root of the estimated LD Score intercept). The dotted line represents the expected -log10(P-values) under the null hypothesis. The (barely visible) gray shaded areas in the Q-Q plots represent the 95% confidence intervals under the null hypothesis. The flat horizontal region in the plots is an inversion region in chromosome 17 (17q21.31).
Extended Data Fig. 2. LD score plot from the additive GWAS meta-analysis.

Each point represents an LD score quantile containing 1000 SNPs (except for the last quantile, which contains 709). The x and y coordinates of each point are the mean LD score and the mean statistic of SNPs in that quantile. The LD score regression intercept is 1.663, suggesting that biases due to stratification or cryptic relatedness explain roughly 7% of the inflation in test statistics (see Supplementary Note section 2.2.6).
Extended Data Fig. 3. Replication of EA3 lead SNPs.

We examined the out-of-sample replicability of the 1,504 lead SNPs identified at genome-wide significance in a version of our previously published GWAS meta-analysis of EduYears (EA3), with the UKB GWAS in that analysis replaced by a UKB GWAS that uses the new phenotype coding explained in Supplementary Note section 1.1. Prior to clumping, we dropped SNPs that had a sample size smaller than 80% of the maximum sample size in the updated EA3 data (NEA3,max = 1,130,819), or that had a sample size in the new data smaller than 80% of the maximum sample size of the new data (Nnew,max = 2,272,216). The x axis is the winner’s-curse-adjusted estimate of the SNP’s effect size in the updated EA3 study (calculated using shrinkage parameters estimated using summary statistics from EA3). The y axis is the SNP’s effect size estimated from the subsample of our data that did not contribute to the EA3 GWAS. All effect sizes are from a regression where phenotype and genotype have been standardized to have unit variance. The reference allele is chosen to be the allele estimated to increase EA in EA3. The dashed line is the identity, and the solid line is the fitted regression line. P-values are based on two-sided Z-tests.
Extended Data Fig. 4. Meta-analysis of X chromosome SNPs (N = 2,713,033 individuals).

The meta-analysis was conducted by combining summary statistics from (pooled-sex) association analyses conducted in UK Biobank (N = 440,817 individuals) and 23andMe (N = 2,272,216 individuals); see Supplementary Note section 3.4 for details. Panel (a): Manhattan plot, in which P values are based on summary statistics adjusted for inflation using the same LD score intercept used in the autosomal analyses. The solid line indicates the threshold for genome-wide significance (P = 5 × 10−8 based on a two-sided Z-test adjusted for multiple comparisons). Panel (b): Q-Q plot, in which P values are based on unadjusted Z-test statistics. The dotted line represents the expected -log10(P-values) under the null hypothesis. The (barely visible) gray shaded area in represents the 95% confidence intervals under the null hypothesis.
Extended Data Fig. 5. Predictive power of the EduYears PGI as a function of pruning at different P value thresholds.

Each bar represents the incremental R2 with error bars showing the 95% confidence intervals bootstrapped with 1,000 iterations each. Each clumping and thresholding PGI is based on a set of approximately independent SNPs identified using the clumping algorithm defined in Supplementary Note section 2.2.6. For HRS (N = 10,843 individuals) and Add Health (N = 5,653 individuals) respectively, the number of SNPs included in the PGI is (with P value threshold in parentheses): 3,806 and 3,843 (5 × 10−8); 10,852 and 10,897 (5 × 10−5); 33,159 and 32,693 (5 × 10−3); 281,087 and 247,329 (1); 1,137,480 and 1,170,675 (All HapMap3 SNPs, LDpred); 2,540,570 and 2,548,339 (SBayesR). P-values are based on two-sided Z-tests. Incremental R2 is the difference between the R2 from a regression of EduYears on the PGI and the controls (sex, birth year dummies, their interactions, and 10 PCs) and the R2 from a regression of EduYears on just the controls.
Extended Data Fig. 6. Polygenic index (PGI) prediction in Add Health, HRS and WLS.

Predictive power of the PGI constructed from the current EduYears GWAS results in three independent prediction cohorts: Add Health (N = 5,653), HRS (N = 10,843), and WLS (N = 8,395). Panel (a): Results for education phenotypes available in Add Health and HRS. Panel (b): Results for cognitive and academic achievement phenotypes available in either Add Health, HRS or WLS. Error bars show 95% confidence intervals for the incremental R2, bootstrapped with 1000 iterations each. The number of individuals in the prediction sample for each regression can be found in Supplementary Table 4.
Extended Data Fig. 7. Prevalence of schooling outcomes by EduYears PGI decile.

Each decile contains approximately 1,085 respondents in HRS and 565 in Add Health. Total sample sizes for these phenotypes in each prediction cohort are in Supplementary Table 4. Decile 1 contains the lowest PGI values; decile 10, the highest. Error bars show 95% confidence intervals. Panel (a): High school completion. Panel (b): Grade retention.
Extended Data Fig. 8. European genetic ancestries to African genetic ancestries relative accuracy.

Panel (a) plots the relative accuracy (RA) with error bars representing confidence intervals with +/− 1 standard error. Panel (b) plots the proportion of the loss of accuracy (LOA) explained by LD and MAF calculated as 100% × (1 – RApred(LD+MAF))/(1 – RAobs) with error bars representing confidence intervals with +/− 1 standard error. RA refers to the European genetic ancestries to African genetic ancestries ratio of prediction accuracies (R2) of PGIs trained in a large sample of European-genetic-ancestry UKB participants (N = 6,514). See Supplementary Note section 7 in Wang et al. for additional details. Data underlying this Figure are reported in Supplementary Table 5.
Extended Data Fig. 9. Odds ratio for selected diseases by deciles of the EA PGI in the UK Biobank.

The EA PGI was discretized into deciles (1 = lowest, 10 = highest), and nine dummy variables were created to contrast each of deciles 2-10 to decile 1 as the reference. Odds ratio and 95% confidence intervals (the error bars) were estimated using logistic regression while controlling for covariates (sex, a third-degree polynomial in birth year and interactions with sex, the top 40 PCs, and batch dummies).
Supplementary Material
ACKNOWLEDGMENTS:
We thank E.M. Tucker-Drob for helpful comments and Jian Zeng for help with the SBayesR software. This research was carried out under the auspices of the Social Science Genetic Association Consortium (SSGAC). The analyses reported in the paper fall under National Bureau of Economic Research IRB protocols 19_434, 19_465, and 20_041. This paper uses cohort-level data from Okbay et al. (2016). Information about studies participating in that study can be found in the Additional Acknowledgements Supplementary section of that paper. Per SSGAC policy, we acknowledge the authors of that paper, listed below, as collaborators. 23andMe research participants provided informed consent and participated in the research online, under a protocol approved by the external AAHRPP-accredited IRB, Ethical & Independent Review Services (E&I Review). Participants were included in the analysis on the basis of consent status as checked at the time data analyses were initiated. We would like to thank the research participants and employees of 23andMe for making this work possible. We gratefully acknowledge the contributions of members of 23andMe’s Research Team, whose names are listed below. The research has also been conducted using the UK Biobank Resource under application numbers 11425 and 12505. Informed consent was obtained from UK Biobank subjects. Ethical approval for the Generation Scotland: Scottish Family Health Study (GS:SFHS) was obtained from the Tayside Committee on Medical Research Ethics (on behalf of the National Health Service). H.J, M.B., D. Cesarini, and P.T. were supported by the Ragnar Söderberg Foundation (E42/15), to D. Cesarini; A.O. and P.K. by an ERC Consolidator Grant (647648 EdGe), to P.K.; H.J., M.B., S.M.N., T.G., C.W., J.J., M.N.M., D. Cesarini, P.T., J.P.B., D.J.B., and A.I.Y. by Open Philanthropy (010623-00001), to D.J.B.; R.A. and S.O. by Riksbankens Jubileumsfond (P18-0782:1), to S.O.; N.W., G.G., C.W., L.Y., and D.J.B. by the NIA/NIH (R24-AG065184 and R01-AG042568), to D.J.B.; D.J.B. by the NIA/NIH (R56-AG058726), to T. Galama; P.T. by the NIA/NIMH (R01-MH101244-02 and U01-MH109539-02), to B. Neale; J.S. and P.M.V. by the Australian Research Council (FL180100072), to P.M.V.; and Y.W., L.Y., and P.M.V. by the National Health and Medical Research Council (GNT113400), to P.M.V. The study was also supported by Netherlands Organisation for Scientific Research VENI (016.Veni.198.058, A.O.); the F.G. Meade Scholarship and UQ Research Training Scholarship from the University of Queensland Senate (Y.W.); the Swedish Research Council (2019-00244, S.O.); an MRC University Unit Programme Grant (MC_UU_00007/10, QTL in Health and Disease, C.H.); the Swedish Research Council (421-2013-1061, M.J.); Pershing Square Fund of the Foundations of Human Behavior (D.L.); the Li Ka Shing Foundation (A.K.); the Australian Research Council (DE200100425, L.Y.); the NIA/NIH (K99-AG062787-01, P.T.); the Government of Canada through Genome Canada and the Ontario Genomics Institute (OGI-152, J.P.B.); the Social Sciences and Humanities Research Council of Canada (J.P.B.); and the Australian Research Council (P.M.V.).
Appendix
CONTRIBUTOR LIST FOR THE 23andMe RESEARCH TEAM: Michelle Agee5, Babak Alipanahi5, Adam Auton5, Robert K. Bell5, Katarzyna Bryc5, Sarah L. Elson5, Pierre Fontanillas5, Nicholas A. Furlotte5, Barry Hicks5, David A. Hinds23, Karen E. Huber5, Aaron Kleinman5, Nadia K. Litterman5, Jennifer C. McCreight5, Matthew H. McIntyre5, Joanna L. Mountain5, Carrie A.M. Northover5, Steven J. Pitts5, J. Fah Sathirapongsasuti5, Olga V. Sazonova5, Janie F. Shelton5, Suyash Shringarpure5, Chao Tian5, Joyce Y. Tung5, Vladimir Vacic5, Catherine H. Wilson5.
CONTRIBUTOR LIST FOR THE SOCIAL SCIENCE GENETIC ASSOCIATION CONSORTIUM RESEARCH TEAM: Aysu Okbay1, Jonathan P. Beauchamp26, Mark Alan Fontana25,28, James J. Lee20, Tune H. Pers29, 30, Cornelius A. Rietveld31,32,33, Patrick Turley24,25, Guo-Bo Chen34, Valur Emilsson35,36, S. Fleur W. Meddens37,31,38, Sven Oskarsson6, Joseph K. Pickrell39, Kevin Thom22, Pascal Timshel29,30, Ronald de Vlaming31,32,33, Abdel Abdellaoui40, Tarunveer S. Ahluwalia29,41,42, Jonas Bacelis43, Clemens Baumbach44,45, Gyda Bjornsdottir46, Johannes H. Brandsma47, Maria Pina Concas48, Jaime Derringer49, Tessel E. Galesloot50, Giorgia Girotto51, Richa Gupta52, Leanne M. Hall53,54, Sarah E. Harris55,54, Edith Hofer56,57, Momoko Horikoshi58,59, Jennifer E. Huffman8, Kadri Kaasik60, Ioanna P. Kalafati61, Robert Karlsson7, Augustine Kong21, Jari Lahti60,62, Sven J. van der Lee57, Christiaan de Leeuw37,63, Penelope A. Lind64, Karl-Oskar Lindgren6, Tian Liu65, Massimo Mangino66,67, Jonathan Marten8, Evelin Mihailov68, Michael B. Miller20, Peter J. van der Most69, Christopher Oldmeadow70,71, Antony Payton72,73, Natalia Pervjakova68,74, Wouter J. Peyrot75, Yong Qian76, Olli Raitakari77, Rico Rueedi78,79, Erika Salvi80, Börge Schmidt81, Katharina E. Schraut82, Jianxin Shi83, Albert V. Smith35,84, Raymond A. Poot47, Beate St Pourcain85,86 , Alexander Teumer87, Gudmar Thorleifsson46, Niek Verweij88, Dragana Vuckovic51, Juergen Wellmann89, Harm-Jan Westra90,91,92, Jingyun Yang93,94, Wei Zhao95, Zhihong Zhu34, Behrooz Z. Alizadeh69,96, Najaf Amin33, Andrew Bakshi34, Sebastian E. Baumeister87,97, Ginevra Biino98, Klaus Bønnelykke41, Patricia A. Boyle93,99, Harry Campbell82, Francesco P. Cappuccio100, Gail Davies54,101, Jan-Emmanuel De Neve102, Panos Deloukas103,104, Ilja Demuth105,106, Jun Ding76, Peter Eibich107 ,108, Lewin Eisele81, Niina Eklund74, David M. Evans85,109, Jessica D. Faul110, Mary F. Feitosa111, Andreas J. Forstner112,113, Ilaria Gandin51, Bjarni Gunnarsson46, Bjarni V. Halldórsson46,114, Tamara B. Harris115, Andrew C. Heath116, Lynne J. Hocking117, Elizabeth G. Holliday70,71, Georg Homuth118, Michael A. Horan119, Jouke-Jan Hottenga40, Philip L. de Jager92,120,121, Peter K. Joshi82,122, Astanand Jugessur123, Marika A. Kaakinen124, Mika Kähönen125,126, Stavroula Kanoni103, Liisa Keltigangas-Järvinen60, Lambertus A. L. M. Kiemeney50, Ivana Kolcic127, Seppo Koskinen74, Aldi T. Kraja111, Martin Kroh107, Zoltan Kutalik78,79,122, Antti Latvala52, Lenore J. Launer128, Maël P. Lebreton38,129, Douglas F. Levinson130, Paul Lichtenstein7, Peter Lichtner131, David C. M. Liewald54,101, LifeLines Cohort Study132, Anu Loukola52, Pamela A. Madden116, Reedik Mägi68, Tomi Mäki-Opas74, Riccardo E. Marioni133,54,134, Pedro Marques-Vidal135, Gerardus A. Meddens136, George McMahon85, Christa Meisinger45, Thomas Meitinger131, Yusplitri Milaneschi75, Lili Milani68, Grant W. Montgomery137, Ronny Myhre123, Christopher P. Nelson53,138, Dale R. Nyholt137,139, William E. R. Ollier72, Aarno Palotie140,141,92,142,143,144, Lavinia Paternoster85, Nancy L. Pedersen7, Katja E. Petrovic56, David J. Porteous9,10,11, Katri Räikkönen60,62, Susan M. Ring85, Antonietta Robino145, Olga Rostapshova18,146, Igor Rudan82, Aldo Rustichini147, Veikko Salomaa74, Alan R. Sanders148,149, Antti-Pekka Sarin143,150, Helena Schmidt56,151, Rodney J. Scott71,152, Blair H. Smith153, Jennifer A. Smith69, Jan A. Staessen154,155, Elisabeth Steinhagen-Thiessen105, Konstantin Strauch156,157, Antonio Terracciano158, Martin D. Tobin159, Sheila Ulivi145, Simona Vaccargiu48, Lydia Quaye66, Frank J. A. van Rooij33,160, Cristina Venturini66,67, Anna A. E. Vinkhuyzen34, Uwe Völker118, Henry Völzke87, Judith M. Vonk69, Diego Vozzi145, Johannes Waage41,42, Erin B. Ware95,161, Gonneke Willemsen40, John R. Attia70,71, David A. Bennett93,94, Klaus Berger88, Lars Bertram162,163, Hans Bisgaard41, Dorret I. Boomsma40, Ingrid B. Borecki111, Ute Bültmann164, Christopher F. Chabris165, Francesco Cucca166, Daniele Cusi80,167, Ian J. Deary54,101, George V. Dedoussis61, Cornelia M. van Duijn33, Johan G. Eriksson62,168, Barbara Franke169, Lude Franke170, Paolo Gasparini51,145,171, Pablo V. Gejman148,149, Christian Gieger44, Hans-Jörgen Grabe172,173, Jacob Gratten34, Patrick J. F. Groenen174, Vilmundur Gudnason35,84, Pim van der Harst88,170,175, Caroline Hayward8, David A. Hinds5, Wolfgang Hoffmann87, Elina Hyppönen176,177,178, William G. Iacono20, Bo Jacobsson43,123, Marjo-Riitta Järvelin179,180,181,182, Karl-Heinz Jöckel81, Jaakko Kaprio52,74,143, Sharon L. R. Kardia95, Terho Lehtimäki183,184, Steven F. Lehrer185,186,3, Patrik K. E. Magnusson7, Nicholas G. Martin187, Matt McGue20, Andres Metspalu68,188, Neil Pendleton189,190, Brenda W. J. H. Penninx75, Markus Perola68,74, Nicola Pirastu51, Mario Pirastu48, Ozren Polasek82,191, Danielle Posthuma37,192, Christine Power177, Michael A. Province111, Nilesh J. Samani53,138, David Schlessinger76, Reinhold Schmidt56, Thorkild I. A. Sørensen29,85,193, Tim D. Spector66, Kari Stefansson46,84, Unnur Thorsteinsdottir46,84, A. Roy Thurik31,32,194,195, Nicholas J. Timpson85, Henning Tiemeier33,196,197, Joyce Y. Tung5, André G. Uitterlinden33,198, Veronique Vitart8, Peter Vollenweider135, David R. Weir110, James F. Wilson82,8, Alan F. Wright8, Dalton C. Conley15, Robert F. Krueger20, George Davey Smith85, Albert Hofman33, David I. Laibson18, Sarah E. Medland64, Michelle N. Meyer19, Jian Yang2,34, Magnus Johannesson17, Peter M. Visscher2, Tõnu Esko68, Philipp D. Koellinger1,16 David Cesarini3,22,23 & Daniel J. Benjamin3,4,27.
28 Center for the Advancement of Value in Musculoskeletal Care, Hospital for Special Surgery, New York, NY, USA.
29 The Novo Nordisk Foundation Center for Basic Metabolic Research, Section of Metabolic Genetics, University of Copenhagen, Faculty of Health and Medical Sciences, Copenhagen, Denmark.
30 Statens Serum Institut, Department of Epidemiology Research, Copenhagen, Denmark.
31 Institute for Behavior and Biology, Erasmus University Rotterdam, Rotterdam, The Netherlands.
32 Department of Applied Economics, Erasmus School of Economics, Erasmus University Rotterdam, Rotterdam, The Netherlands.
33 Department of Epidemiology, Erasmus Medical Center, Rotterdam, 3015 GE, The Netherlands.
34 Queensland Brain Institute, University of Queensland, Brisbane, Queensland, Australia.
35 Icelandic Heart Association, Kopavogur, 201, Iceland.
36 Faculty of Pharmaceutical Sciences, University of Iceland, 107 Reykjavík, Iceland.
37 Department of Complex Trait Genetics, Center for Neurogenomics and Cognitive Research, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands.
38 Amsterdam Business School, University of Amsterdam, Amsterdam, 1018 TV, The Netherlands.
39 New York Genome Center, New York, NY 10013, USA.
40 Department of Biological Psychology, VU University Amsterdam, Amsterdam, 1081 BT, The Netherlands.
41 COPSAC, Copenhagen Prospective Studies on Asthma in Childhood, Herlev and Gentofte Hospital, University of Copenhagen, Copenhagen, 2820, Denmark.
42 Steno Diabetes Center, Gentofte, 2820, Denmark.
43 Department of Obstetrics and Gynecology, Institute of Clinical Sciences, Sahlgrenska Academy, Gothenburg, SE 416 85, Sweden.
44 Research Unit of Molecular Epidemiology, Helmholtz Zentrum München, German Research Center for Environmental Health, Neuherberg, 85764, Germany.
45 Institute of Epidemiology II, Helmholtz Zentrum München, German Research Center for Environmental Health, Neuherberg, 85764, Germany.
46 deCODE Genetics/Amgen Inc., Reykjavik, IS-101, Iceland.
47 Department of Cell Biology, Erasmus Medical Center Rotterdam, 3015 CN, The Netherlands.
48 Istituto di Ricerca Genetica e Biomedica U.O.S. di Sassari, National Research Council of Italy, Sassari, 07100, Italy.
49 Psychology, University of Illinois, IL 61820, Champaign, USA.
50 Institute for Computing and Information Sciences, Radboud University Nijmegen, Nijmegen, 6525 EC, The Netherlands.
51 Department of Medical, Surgical and Health Sciences, University of Trieste, Trieste, 34100, Italy.
52 Department of Public Health, University of Helsinki, Helsinki, FI-00014, Finland.
53 Department of Cardiovascular Sciences, University of Leicester, Leicester, LE3 9QP, UK.
54 Centre for Cognitive Ageing and Cognitive Epidemiology, University of Edinburgh, Edinburgh, EH8 9JZ, UK.
55 Centre for Genomic and Experimental Medicine, Institute of Genetics and Molecular Medicine, University of Edinburgh, Edinburgh, UK.
56 Department of Neurology, General Hospital and Medical University Graz, Graz, 8036, Austria.
57 Institute for Medical Informatics, Statistics and Documentation, General Hospital and Medical University Graz, Graz, 8036, Austria.
58 Oxford Centre for Diabetes, Endocrinology & Metabolism, University of Oxford, Oxford, OX3 7LE, UK.
59 Wellcome Trust Centre for Human Genetics, University of Oxford, Oxford, OX3 7BN, UK.
60 Institute of Behavioural Sciences, University of Helsinki, Helsinki, FI-00014, Finland.
61 Nutrition and Dietetics, Health Science and Education, Harokopio University, Athens, 17671, Greece.
62 Folkhälsan Research Centre, Helsingfors, FI-00014, Finland.
63 Institute for Computing and Information Sciences, Radboud University Nijmegen, Nijmegen, 6525 EC, The Netherlands.
64 Quantitative Genetics, QIMR Berghofer Medical Research Institute, Brisbane, QLD 4029, Australia.
65 Lifespan Psychology, Max Planck Institute for Human Development, Berlin, 14195, Germany.
66 Department of Twin Research and Genetic Epidemiology, King's College London, London, SE1 7EH, UK.
67 NIHR Biomedical Research Centre, Guy’s and St. Thomas’ Foundation Trust, London, SE1 7EH, UK.
68 Estonian Genome Center, University of Tartu, Tartu, Estonia.
69 Department of Epidemiology, University of Groningen, University Medical Center Groningen, Groningen, 9700 RB, The Netherlands.
70 Public Health Stream, Hunter Medical Research Institute, New Lambton, NSW 2305, Australia.
71 Faculty of Health and Medicine, University of Newcastle, Newcastle, NSW 2300, Australia.
72 Centre for Integrated Genomic Medical Research, Institute of Population Health, The University of Manchester, Manchester, M13 9PT, UK.
73 School of Psychological Sciences, The University of Manchester, Manchester, M13 9PL, UK.
74 Department of Health, THL-National Institute for Health and Welfare, Helsinki, FI-00271, Finland.
75 Psychiatry, VU University Medical Center & GGZ inGeest, Amsterdam, 1081 HL, The Netherlands.
76 Laboratory of Genetics, National Institute on Aging, Baltimore, MD 21224, USA.
77 Research Centre of Applied and Preventive Cardiovascular Medicine, University of Turku, Turku, 20521, Finland.
78 Department of Medical Genetics, University of Lausanne, Lausanne, 1005, Switzerland.
79 Swiss Institute of Bioinformatics, Lausanne, 1015, Switzerland.
80 Department Of Health Sciences, University of Milan, Milano, 20142, Italy.
81 Institute for Medical Informatics, Biometry and Epidemiology, University Hospital of Essen, Essen, 45147, Germany.
82 Centre for Global Health Research, Usher Institute of Population Health Sciences and Informatics, University of Edinburgh, Edinburgh, UK.
83 Division of Cancer Epidemiology and Genetics, National Cancer Institute, Bethesda, MD 20892-9780, USA.
84 Faculty of Medicine, University of Iceland, Reykjavik, 101, Iceland.
85 MRC Integrative Epidemiology Unit, University of Bristol, Bristol, BS8 2BN, UK.
86 School of Oral and Dental Sciences, University of Bristol, Bristol, BS1 2LY, UK.
87 Institute for Community Medicine, University Medicine Greifswald, Greifswald, 17475, Germany.
88 Department of Cardiology, University Medical Center Groningen, University of Groningen, Groningen, 9700 RB, The Netherlands 107.
89 Institute of Epidemiology and Social Medicine, University of Muenster, Muenster, 48149, Germany.
90 Divisions of Genetics and Rheumatology, Department of Medicine, Brigham and Women’s Hospital, Harvard Medical School, MA 02115, Boston, USA.
91 Partners Center for Personalized Genetic Medicine, Boston, MA 02115, USA.
92 Program in Medical and Population Genetics, Broad Institute of MIT and Harvard, Cambridge, MA 02142, USA.
93 Rush Alzheimer’s Disease Center, Rush University Medical Center, Chicago, IL 60612, USA.
94 Department of Neurological Sciences, Rush University Medical Center, Chicago, IL 60612, USA.
95 Department of Epidemiology, University of Michigan, Ann Arbor, MI 48109, USA.
96 Department of Gastroenterology and Hepatology, University of Groningen, University Medical Center Groningen, Groningen, 9713 GZ, The Netherlands.
97 Institute of Epidemiology and Preventive Medicine, University of Regensburg, Regensburg, D-93053, Germany.
98 Institute of Molecular Genetics, National Research Council of Italy, Pavia, 27100, Italy.
99 Department of Behavioral Sciences, Rush University Medical Center, Chicago, IL 60612, USA.
100 Warwick Medical School, University of Warwick, Coventry, CV4 7AL, UK.
101 Department of Psychology, University of Edinburgh, Edinburgh, EH8 9JZ, UK.
102 Saïd Business School, University of Oxford, Oxford, OX1 1HP, UK.
103 William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, London, EC1M 6BQ, UK.
104 Princess Al-Jawhara Al-Brahim Centre of Excellence in Research of Hereditary Disorders (PACER-HD), King Abdulaziz University, Jeddah, 21589, Saudi Arabia.
105 The Berlin Aging Study II; Research Group on Geriatrics, Charité – Universitätsmedizin Berlin, Germany, Berlin, 13347, Germany.
106 Institute of Medical and Human Genetics, Charité-Universitätsmedizin, Berlin, Berlin, 13353, Germany.
107 German Socio- Economic Panel Study, DIW Berlin, Berlin, 10117, Germany.
108 Health Economics Research Centre, Nuffield Department of Population Health, University of Oxford, Oxford, OX3 7LF, UK.
109 The University of Queensland Diamantina Institute, The Translational Research Institute, Brisbane, QLD 4102, Australia.
110 Survey Research Center, Institute for Social Research, University of Michigan, Ann Arbor, MI 48109, USA.
111 Department of Genetics, Division of Statistical Genomics, Washington University School of Medicine, St. Louis, MO 63018, USA.
112 Institute of Human Genetics, University of Bonn, Bonn, 53127, Germany.
113 Department of Genomics, Life and Brain Center, University of Bonn, Bonn, 53127, Germany.
114 Institute of Biomedical and Neural Engineering, School of Science and Engineering, Reykjavik University, Reykjavik 101, Iceland.
115 Laboratory of Epidemiology, Demography, National Institute on Aging, National Institutes of Health, Bethesda, MD 20892-9205, United States.
116 Department of Psychiatry, Washington University School of Medicine, St. Louis, MO 63110, USA.
117 Division of Applied Health Sciences, University of Aberdeen, Aberdeen, AB25 2ZD, UK.
118 Interfaculty Institute for Genetics and Functional Genomics, University Medicine Greifswald, Greifswald, 17475, Germany.
119 Manchester Medical School, The University of Manchester, Manchester, 9PT, UK.
120 Program in Translational NeuroPsychiatric Genomics, Departments of Neurology & Psychiatry, Brigham and Women’s Hospital, Boston, MA 02115, USA.
121 Harvard Medical School, Boston, MA 02115, USA.
122 Institute of Social and Preventive Medicine, Lausanne University Hospital (CHUV), Lausanne, 1010, Switzerland.
123 Department of Genes and Environment, Norwegian Institute of Public Health, Oslo, N-0403, Norway.
124 Department of Genomics of Common Disease, Imperial College London, London, W12 0NN, UK.
125 Department of Clinical Physiology, Tampere University Hospital, Tampere, 33521, Finland.
126 Department of Clinical Physiology, University of Tampere, School of Medicine, Tampere, 33014, Finland.
127 Public Health, Medical School, University of Split, 21000 Split, Croatia.
128 Neuroepidemiology Section, National Institute on Aging, National Institutes of Health, Bethesda, MD 20892-9205, USA.
129 Amsterdam Brain and Cognition Center, University of Amsterdam, 1018 XA, Amsterdam, The Netherlands.
130 Department of Psychiatry and Behavioral Sciences, Stanford University, Stanford, CA 94305-5797, USA.
131 Institute of Human Genetics, Helmholtz Zentrum München, German Research Center for Environmental Health, Neuherberg, 85764, Germany 155.
132 LifeLines Cohort Study, University of Groningen, University Medical Center Groningen, Groningen, 9713 BZ, The Netherlands.
133 Department of Economics, University of Toronto, Toronto, Ontario, Canada.
134 Medical Genetics Section, Centre for Genomic and Experimental Medicine, Institute of Genetics and Molecular Medicine, University of Edinburgh, Edinburgh, EH4 2XU, UK.
135 Department of Internal Medicine, Internal Medicine, Lausanne University Hospital (CHUV), Lausanne, 1011, Switzerland.
136 Tema BV, 2131 HE Hoofddorp, The Netherlands.
137 Molecular Epidemiology, QIMR Berghofer Medical Research Institute, Brisbane, QLD 4029, Australia.
138 NIHR Leicester Cardiovascular Biomedical Research Unit, Glenfield Hospital, Leicester, LE3 9QP, UK.
139 Institute of Health and Biomedical Innovation, Queensland Institute of Technology, Brisbane, QLD 4059, Australia.
140 Analytic and Translational Genetics Unit, Massachusetts General Hospital, Boston, MA, USA.
141 Stanley Center for Psychiatric Research, Broad Institute of MIT and Harvard, Cambridge, MA, USA.
142 Psychiatric & Neurodevelopmental Genetics Unit, Department of Psychiatry, Massachusetts General Hospital, Boston, MA 02114, USA.
143 Institute for Molecular Medicine Finland (FIMM), University of Helsinki, Helsinki, 00014, Finland.
144 Department of Neurology, Massachusetts General Hospital, Boston, MA 02114, USA.
145 Medical Genetics, Institute for Maternal and Child Health IRCCS “Burlo Garofolo”, Trieste, 34100, Italy.
146 Social Impact, Arlington, VA 22201, USA.
147 Department of Economics, University of Minnesota Twin Cities, Minneapolis, MN 55455, USA.
148 Department of Psychiatry and Behavioral Sciences, NorthShore University HealthSystem, Evanston, IL 60201-3137, USA.
149 Department of Psychiatry and Behavioral Neuroscience, University of Chicago, Chicago, IL 60637, USA.
150 Public Health Genomics Unit, National Institute for Health and Welfare, Helsinki 00300, Finland.
151 Research Unit for Genetic Epidemiology, Institute of Molecular Biology and Biochemistry, Center of Molecular Medicine, General Hospital and Medical University, Graz, Graz, 8010, Austria.
152 Information Based Medicine Stream, Hunter Medical Research Institute, New Lambton, NSW 2305, Australia.
153 Medical Research Institute, University of Dundee, Dundee, DD1 9SY, UK.
154 Research Unit Hypertension and Cardiovascular Epidemiology, Department of Cardiovascular Science, University of Leuven, Leuven, 3000, Belgium.
155 R&D VitaK Group, Maastricht University, Maastricht, 6229 EV, The Netherlands.
156 Institute of Genetic Epidemiology, Helmholtz Zentrum München, German Research Center for Environmental Health, Neuherberg, 85764, Germany.
157 Institute of Medical Informatics, Biometry and Epidemiology, Chair of Genetic Epidemiology, Ludwig Maximilians-Universität, Munich, 81377, Germany.
158 Department of Geriatrics, Florida State University College of Medicine, Tallahassee, FL 32306, USA.
159 Department of Health Sciences and Genetics, University of Leicester, Leicester, LE1 7RH, UK.
160 Department of Internal Medicine, Erasmus Medical Center, Rotterdam, 3015 GE, The Netherlands.
161 Research Center for Group Dynamics, Institute for Social Research, University of Michigan, Ann Arbor, MI 48104, USA.
162 Platform for Genome Analytics, Institutes of Neurogenetics & Integrative and Experimental Genomics, University of Lübeck, Lübeck, 23562, Germany.
163 Neuroepidemiology and Ageing Research Unit, School of Public Health, Faculty of Medicine, The Imperial College of Science, Technology and Medicine, London SW7 2AZ, UK.
164 Department of Health Sciences, Community & Occupational Medicine, University of Groningen, University Medical Center Groningen, Groningen, 9713 AV, The Netherlands.
165 Autism and Developmental Medicine Institute, Geisinger Health System, Lewisburg, PA, USA
166 Istituto di Ricerca Genetica e Biomedica (IRGB), Consiglio Nazionale delle Ricerche, c/o Cittadella Universitaria di Monserrato, Monserrato, Cagliari, 9042, Italy.
167 Institute of Biomedical Technologies, Italian National Research Council, Segrate (Milano), 20090, Italy.
168 Department of General Practice and Primary Health Care, University of Helsinki, Helsinki, 00014, Finland.
169 Departments of Human Genetics and Psychiatry, Donders Centre for Neuroscience, Nijmegen, 6500 HB, The Netherlands.
170 Department of Genetics, University Medical Center Groningen, University of Groningen, Groningen. 9700 RB, The Netherlands.
171 Sidra, Experimental Genetics Division, Sidra, Doha 26999, Qatar.
172 Department of Psychiatry and Psychotherapy, University Medicine Greifswald, Greifswald, 17475, Germany.
173 Department of Psychiatry and Psychotherapy, HELIOS-Hospital Stralsund, Stralsund, 18437, Germany.
174 Econometric Institute, Erasmus School of Economics, Erasmus University Rotterdam, Rotterdam, 3062 PA, The Netherlands.
175 Durrer Center for Cardiogenetic Research, ICIN-Netherlands Heart Institute, Utrecht, 1105 AZ, The Netherlands.
176 Centre for Population Health Research, School of Health Sciences and Sansom Institute, University of South Australia, SA5000, Adelaide, Australia.
177 South Australian Health and Medical Research Institute, Adelaide, SA5000, Australia.
178 Population, Policy and Practice, UCL Institute of Child Health, London, WC1N 1EH, UK.
179 Department of Epidemiology and Biostatistics, MRC-PHE Centre for Environment & Health, School of Public Health, Imperial College London, London, W2 1PG, UK.
180 Center for Life Course Epidemiology, Faculty of Medicine, University of Oulu, Oulu, FI-90014, Finland.
181 Unit of Primary Care, Oulu University Hospital, Oulu, 90029 OYS, Finland.
182 Biocenter Oulu, University of Oulu, FI-90014 Oulu, Finland.
183 Fimlab Laboratories, Tampere, 33520, Finland.
184 Department of Clinical Chemistry, University of Tampere, School of Medicine, Tampere, 33014, Finland.
185 School of Policy Studies, Queen’s University, Kingston, Ontario, Canada.
186 Department of Economics, New York University Shanghai, Pudong, Shanghai, China.
187 Genetic Epidemiology, QIMR Berghofer Medical Research Institute, Brisbane, QLD 4029, Australia.
188 Institute of Molecular and Cell Biology, University of Tartu, Tartu, 51010, Estonia.
189 Centre for Clinical and Cognitive Neuroscience, Institute Brain Behaviour and Mental Health, Salford Royal Hospital, Manchester, M6 8HD, UK.
190 Manchester Institute Collaborative Research in Ageing, University of Manchester, Manchester, M13 9PL, UK.
191 Faculty of Medicine, University of Split, Croatia, Split 21000, Croatia.
192 Department of Clinical Genetics, VU Medical Centre, Amsterdam, 1081 HV, The Netherlands.
193 Institute of Preventive Medicine, Bispebjerg and Frederiksberg Hospitals, The Capital Region, Frederiksberg, 2000, Denmark.
194 Montpellier Business School, Montpellier, 34080, France.
195 Panteia, Zoetermeer, 2715 CA, The Netherlands.
196 Department of Psychiatry, Erasmus Medical Center, Rotterdam, 3015 GE, The Netherlands.
197 Department of Child and Adolescent Psychiatry, Erasmus Medical Center, Rotterdam, 3015 GE, The Netherlands.
198 Department of Internal Medicine, Erasmus Medical Center, Rotterdam, 3015 GE, The Netherlands.
Footnotes
COMPETING INTERESTS: Yunxuan Jiang, Barry Hicks, Chao Tian, David A. Hinds, and the members of the 23andMe Research Team are current or former employees of 23andMe, Inc. All other authors declare no competing interests.
REFERENCES
- 1.Marioni RE et al. Genetic variants linked to education predict longevity. Proc. Natl. Acad. Sci 113, 13366–13371 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Lee JJ et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat. Genet 50, 1112–1121 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Bycroft C et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Harden KP et al. Genetic associations with mathematics tracking and persistence in secondary school. npj Sci. Learn 5, 1 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Kong A et al. The nature of nurture: Effects of parental genotypes. Science (80-. ). 359, 424–428 (2018). [DOI] [PubMed] [Google Scholar]
- 6.Walsh B & Lynch M Associative Effects: Competition, Social Interactions, Group and Kin Selection. in Evolution and Selection of Quantitative Traits (Oxford University Press, 2018). [Google Scholar]
- 7.Smith BH et al. Cohort Profile: Generation Scotland: Scottish Family Health Study (GS:SFHS). The study, its participants and their potential for genetic research on health and illness. Int. J. Epidemiol 42, 689–700 (2013). [DOI] [PubMed] [Google Scholar]
- 8.Bulik-Sullivan BK et al. LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet 47, 291–295 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Wu Y, Zheng Z, Visscher PM & Yang J Quantifying the mapping precision of genome-wide association studies using whole-genome sequencing data. Genome Biol. 18, 86 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Yang J et al. Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat. Genet 44, 369–375 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Finucane HK et al. Partitioning heritability by functional category using GWAS summary statistics. Nat. Genet 47, 1228–1235 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Gazal S et al. Linkage disequilibrium–dependent architecture of human complex traits shows action of negative selection. Nat. Genet 49, 1421–1427 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hivert V et al. Estimation of non-additive genetic variance in human complex traits from a large sample of unrelated individuals. Am. J. Hum. Genet 108, 786–798 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Pazokitoroudi A, Chiu AM, Burch KS, Pasaniuc B & Sankararaman S Quantifying the contribution of dominance effects to complex trait variation in biobank-scale data. bioRxiv (2020) doi: 10.1101/2020.11.10.376897. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Hill WG, Goddard ME & Visscher PM Data and theory point to mainly additive genetic variance for complex traits. PLoS Genet. 4, e1000008 (2008). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Robertson A & Hill WG Population and quantitative genetics of many linked loci in finite populations. Proc. R. Soc. London - Biol. Sci 219, 253–264 (1983). [Google Scholar]
- 17.Yengo L et al. Genomic partitioning of inbreeding depression in humans. Am. J. Hum. Genet 108, 1488–1501 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Harris KM et al. Cohort Profile: The National Longitudinal Study of Adolescent to Adult Health (Add Health). Int. J. Epidemiol 48, 1415–1415k (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Sonnega A et al. Cohort profile: The Health and Retirement Study (HRS). Int. J. Epidemiol 43, 576–585 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Herd P, Carr D & Roan C Cohort Profile: Wisconsin longitudinal study (WLS). Int. J. Epidemiol 43, 34–41 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Vilhjálmsson BJ et al. Modeling Linkage Disequilibrium Increases Accuracy of Polygenic Risk Scores. Am. J. Hum. Genet 97, 576–592 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Lloyd-Jones LR et al. Improved polygenic prediction by Bayesian multiple regression on summary statistics. Nat. Commun 10, 5086 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Martin AR et al. Clinical use of current polygenic risk scores may exacerbate health disparities. Nat. Genet 51, 584–591 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Duncan L et al. Analysis of polygenic risk score usage and performance in diverse human populations. Nat. Commun 10, 1–9 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Wang Y et al. Theoretical and empirical quantification of the accuracy of polygenic scores in ancestry divergent populations. Nat. Commun 11, 1–9 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Nagelkerke NJD A Note on a General Definition of the Coefficient of Determination. Biometrika 78, 691–692 (1991). [Google Scholar]
- 27.Bulik-Sullivan BK et al. An atlas of genetic correlations across human diseases and traits. Nat. Genet 47, 1236–1241 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Ding X, Barban N & Mills MC Educational attainment and allostatic load in later life: Evidence using genetic markers. Prev. Med. (Baltim) 129, 105866 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Huibregtse BM, Newell-Stamper BL, Domingue BW & Boardman JD Genes Related to Education Predict Frailty Among Older Adults in the United States. Journals Gerontol. Ser. B 76, 173–183 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Selzam S et al. Comparing within-and between-family polygenic score prediction. Am. J. Hum. Genet 105, 351–363 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Willoughby EA, McGue M, Iacono WG, Rustichini A & Lee JJ The role of parental genotype in predicting offspring years of education: evidence for genetic nurture. Mol. Psychiatry (2019) doi: 10.1038/s41380-019-0494-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Balbona JV, Kim Y & Keller MC Estimation of Parental Effects Using Polygenic Scores. Behav. Genet 51, 264–278 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Trejo S & Domingue BW Genetic nature or genetic nurture? Introducing social genetic parameters to quantify bias in polygenic score analyses. Biodemography Soc. Biol 64, 187–215 (2018). [DOI] [PubMed] [Google Scholar]
- 34.Fletcher J, Wu Y, Li T & Lu Q Interpreting Polygenic Score Effects in Sibling Analysis. bioRxiv (2021) doi: 10.1101/2021.07.16.452740. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Young AI et al. Relatedness disequilibrium regression estimates heritability without environmental bias. Nat. Genet 50, 1304–1310 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Howe LJ et al. Within-sibship GWAS improve estimates of direct genetic effects. bioRxiv 2021.03.05.433935 (2021) doi: 10.1101/2021.03.05.433935. [DOI] [Google Scholar]
- 37.Kong A, Benonisdottir S & Young AI Family Analysis with Mendelian Imputations. BioRxiv (2020) doi: 10.1101/2020.07.02.185181. [DOI] [Google Scholar]
- 38.Magnusson PKE et al. The Swedish Twin Registry: Establishment of a Biobank and Other Recent Developments. Twin Res. Hum. Genet 16, 317 (2013). [DOI] [PubMed] [Google Scholar]
- 39.Fisher RA The Correlation between Relatives on the Supposition of Mendelian Inheritance. Trans. R. Soc. Edinburgh 52, 399–433 (1918). [Google Scholar]
- 40.Bulmer MG The Mathematical Theory of Quantitative Genetics. (Clarendon Press, 1980). [Google Scholar]
- 41.Reynolds CA, Baker LA & Pedersen NL Multivariate Models of Mixed Assortment: Phenotypic Assortment and Social Homogamy for Education and Fluid Ability. Behav. Genet 30, 455–476 (2000). [DOI] [PubMed] [Google Scholar]
- 42.Belsky DW et al. The Genetics of Success: How Single-Nucleotide Polymorphisms Associated With Educational Attainment Relate to Life-Course Development. Psychol. Sci 27, 957–972 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Mõttus R, Realo A, Vainik U, Allik J & Esko T Educational Attainment and Personality Are Genetically Intertwined. Psychol. Sci 28, 1631–1639 (2017). [DOI] [PubMed] [Google Scholar]
- 44.Smith-Woolley E, Selzam S & Plomin R Polygenic score for educational attainment captures DNA variants shared between personality traits and educational achievement. J. Pers. Soc. Psychol 117, 1145–1163 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Laidley T, Vinneau J & Boardman JD Individual and Social Genomic Contributions to Educational and Neighborhood Attainments: Geography, Selection, and Stratification in the United States. Sociol. Sci 6, 580–608 (2019). [Google Scholar]
- 46.Abdellaoui A et al. Genetic correlates of social stratification in Great Britain. Nat. Hum. Behav 3, 1332–1342 (2019). [DOI] [PubMed] [Google Scholar]
- 47.Belsky DW et al. Genetic analysis of social-class mobility in five longitudinal studies. Proc. Natl. Acad. Sci. U. S. A 115, E7275–E7284 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Bansal V et al. Genome-wide association study results for educational attainment aid in identifying genetic heterogeneity of schizophrenia. Nat. Commun 9, 1–12 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Tillmann T et al. Education and coronary heart disease: Mendelian randomisation study. BMJ 358, j3542 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Belsky DW et al. Genetics and the geography of health, behaviour and attainment. Nat. Hum. Behav 3, 576–586 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Papageorge NW & Thom K Genes, Education, and Labor Market Outcomes: Evidence from the Health and Retirement Study. J. Eur. Econ. Assoc 18, 1351–1399 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Barth D, Papageorge NW & Thom K Genetic Endowments and Wealth Inequality. J. Polit. Econ 128, 1474–1522 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Wedow R et al. Education, Smoking, and Cohort Change: Forwarding a Multidimensional Theory of the Environmental Moderation of Genetic Effects. Am. Sociol. Rev 83, 802–832 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Trejo S et al. Schools as Moderators of Genetic Associations with Life Course Attainments: Evidence from the WLS and Add Health. Sociol. Sci 5, 513–540 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Jinks J & Eaves LJ IQ and Inequality. Nature 248, 287–289 (1974). [Google Scholar]
- 56.Eaves LJ Testing models for variation in intelligence. Heredity (Edinb). 34, 132–136 (1975). [DOI] [PubMed] [Google Scholar]
- 57.Rao DC, Morton NE & Yee S Resolution of cultural and biological inheritance by path analysis. Am. J. Hum. Genet 28, 228–42 (1976). [PMC free article] [PubMed] [Google Scholar]
- 58.Rao D, Morton N & Yee S Analysis of family resemblance. II. A linear model for familial correlation. Am. J. Hum. Genet 26, 331–359 (1974). [PMC free article] [PubMed] [Google Scholar]
- 59.Jencks C et al. Inequality. A Reassessment of the Effect of Family and Schooling in America. (Basic Books, 1972). doi: 10.1126/science.178.4061.603. [DOI] [Google Scholar]
- 60.Loehlin JC Heredity-environment analyses of Jencks’s IQ correlations. Behav. Genet 8, 415–436 (1978). [DOI] [PubMed] [Google Scholar]
- 61.Rietveld CA et al. GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science (80-. ). 340, 1467–1471 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Okbay A et al. Genome-wide association study identifies 74 loci associated with educational attainment. Nature 533, 539–542 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
METHODS-ONLY REFERENCES
- 63.Willer CJ, Li Y & Abecasis GR METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 26, 2190–2191 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Chang CC et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience 4, 1–16 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Yang J, Lee SH, Goddard ME & Visscher PM GCTA: A tool for genome-wide complex trait analysis. Am. J. Hum. Genet 88, 76–82 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Loh P-R et al. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat. Genet 47, 284–290 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.The 1000 Genomes Project Consortium et al. An integrated map of genetic variation from 1,092 human genomes. Nature 491, 56–65 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.McCarthy S et al. A reference panel of 64,976 haplotypes for genotype imputation. Nat. Genet 48, 1279–1283 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Purcell S & Chang C PLINK 2.0 [Google Scholar]
- 70.Zeng J et al. Signatures of negative selection in the genetic architecture of human complex traits. Nat. Genet. 2018 505 50, 746–753 (2018). [DOI] [PubMed] [Google Scholar]
- 71.de Vlaming R et al. Meta-GWAS Accuracy and Power (MetaGAP) Calculator Shows that Hiding Heritability Is Partially Due to Imperfect Genetic Correlations across Studies. PLOS Genet. 13, e1006495 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Manichaikul A et al. Robust relationship inference in genome-wide association studies. Bioinformatics 26, 2867–2873 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
GWAS summary statistics can be downloaded from http://www.thessgac.org/data subject to a Terms of Use to ensure responsible use of the data. We provide association results for all SNPs that passed quality-control filters in autosomal, X chromosome, and dominance GWAS meta-analyses that excludes the research participants from 23andMe. SNP-level summary statistics from analyses based entirely or in part on 23andMe data can only be reported for up to 10,000 SNPs. For the complete dominance GWAS meta-analysis, which includes 23andMe, clumped results for the 1,000 SNPs with the smallest P values are provided. For the complete autosomal and X chromosome GWAS meta-analyses, respectively, clumped results for the 8,618 and 141 SNPs with P < 10−5 are provided; this P value threshold was chosen such that the total number of SNPs across the analyses that include data from 23andMe does not exceed 10,000. The full GWAS summary statistics from 23andMe will be made available through 23andMe to qualified researchers under an agreement with 23andMe that protects the privacy of the 23andMe participants. Please visit https://research.23andme.com/collaborate/#dataset-access/ for more information and to apply to access the data.