

Abstract
Compelling evidence suggests that human cognitive function is strongly influenced by genetics. Here, we conduct a large-scale exome study to examine whether rare protein-coding variants impact cognitive function in the adult population (n = 485,930). We identify eight genes (ADGRB2, KDM5B, GIGYF1, ANKRD12, SLC8A1, RC3H2, CACNA1A and BCAS3) that are associated with adult cognitive function through rare coding variants with large effects. Rare genetic architecture for cognitive function partially overlaps with that of neurodevelopmental disorders. In the case of KDM5B we show how the genetic dosage of one of these genes may determine the variability of cognitive, behavioral and molecular traits in mice and humans. We further provide evidence that rare and common variants overlap in association signals and contribute additively to cognitive function. Our study introduces the relevance of rare coding variants for cognitive function and unveils high-impact monogenic contributions to how cognitive function is distributed in the normal adult population.
Subject terms: Genetics research, Genetic association study, Neurodevelopmental disorders
Analysis of rare coding variants in the UK Biobank identifies eight genes associated with adult cognitive function, including KDM5B. Rare and common variant signals overlap and contribute additively to the phenotype.
Main
Cognitive function is a complex trait consisting of mental processes that include attention, memory, processing speed, spatial ability, language and problem-solving1–4. General cognitive function and specific cognitive domains can be reliably measured across individuals in the human population and throughout the life span2. Cognitive function in adults, as ascertained either directly via cognitive tests or using proxy measures such as educational attainment (EDU), is strongly influenced by genetics and shows substantial genetic correlation with physical and mental health outcomes as well as mortality1. Nearly 4,000 cognitive function loci of individually small effect sizes have been identified through common variant-based genome-wide association studies (GWAS)2–6. GWAS have also demonstrated shared genetic contributions between cognitive function and neurodevelopmental disorders7–10, for which large-scale exome studies have identified hundreds of underlying genes7,11–13. However, beyond a proposed deleterious effect of exome-wide rare protein-truncating variant (PTV) burden14,15, no studies have yet systematically interrogated the impact of rare coding variants on cognitive phenotypes in the adult general population.
To advance gene discovery for cognitive phenotypes beyond GWAS and gain deeper insights into the shared genetic components between adult cognitive function and neurodevelopmental disorders, we analyzed exome sequencing and genome-wide genotyping data from 454,787 UK Biobank (UKB) participants with measures of cognitive function. We show that adult cognitive function is strongly influenced by the exome-wide burden of rare protein-coding variants and identify and replicate eight genes that are associated with adult cognitive phenotypes. For one of these cognitive function genes, KDM5B, we demonstrate in mice and humans that reduced cognitive function at the population level can be part of a phenotypic spectrum in which cognitive performance depends on the genetic dose of a single gene. Finally, our study bridges a gap between common complex trait and rare disease genetics by demonstrating that adult cognitive function is influenced by additive effects between rare and common variant-based polygenic risk that can be traced to overlapping genomic loci and biological pathways.
Results
The UKB is a prospective cohort study of over 500,000 participants with extensive health and lifestyle data and genome-wide genotyping and sequencing16–22. We chose to study the genetic basis of three distinct, yet interrelated phenotypes that previous studies used to approximate adult cognitive function: educational attainment (EDU); reaction time (RT); and verbal-numerical reasoning (VNR)23. EDU is derived from a survey regarding years of schooling, which is genetically correlated with both adult (rg = 0.66) and childhood cognitive function (rg = 0.72) (refs. 5,24,25). RT is based on a digital test that measures processing speed, a component of general cognitive function26,27. VNR is a measure of general cognitive function based on questionnaires. We annotated exome sequencing data from 454,787 UKB participants18,19 for PTVs, missense variants and synonymous variants28,29 and identified rare coding variants with a minor allele frequency (MAF) < 10−5 in the UKB, following previous exome studies on cognition-related traits12,14,15,21,30. We further annotated all variants according to gene intolerance to loss-of-function (LoF) and missense variants for deleteriousness31. In total, we analyzed 649,321 protein-truncating, 5,431,793 missense and 3,060,387 synonymous rare variants.
Rare variants influence adult cognitive function
We first examined the impact of rare coding variant burden on EDU, RT and VNR in unrelated UKB participants of European (EUR) ancestry (n = 321,843; Fig. 1a and Supplementary Tables 1 and 2). We showed that exome-wide PTV and missense burden have significant deleterious effects on cognitive function, which is reflected in lower EDU, longer RT and lower VNR scores per variant count (exome-wide PTV burden: P = 1.95 × 10−21 for EDU, 8.79 × 10−19 for RT and 6.99 × 10−22 for VNR; missense burden: P = 5.95 × 10−24 for EDU, 5.95 × 10−4 for RT and 4.87 × 10−12 for VNR). Consistent with previous exome studies12–15,30, the most pronounced signals were driven by PTVs and damaging missense variants (missense badness, PolyPhen-2, and constraint (MPC) > 3 and 3 ≥ MPC > 2) in LoF-intolerant genes (pLI ≥ 0.9) (refs. 32,33). The effect sizes of PTV and the MPC > 3 missense burden in LoF-intolerant genes were not significantly different (Fig. 1), suggesting that both classes of variants may impact cognitive function similarly. The synonymous variant burden showed an inverse, albeit small, effect on EDU (exome-wide β = 0.0087, P = 8.59 × 10−75), but not on RT and VNR.
Fig. 1. Impact of exome-wide burden of rare protein-coding variants and gene discovery based on the PTV burden for EDU, RT and VNR in EUR samples in the UKB.

a, The effects of protein-truncating, missense (stratified by MPC) and synonymous variant burden on EDU, RT and VNR across the exome and stratified by genes intolerant (pLI ≥ 0.9) or tolerant (pLI < 0.9) to PTVs. Unrelated UKB EUR samples were included in this analysis (n = 318,844 for EDU, n = 319,536 for RT and n = 128,812 for VNR). pLI is the probability of being LOF-intolerant as recorded in the gnomAD database. Missense variants were classified according to deleteriousness (MPC) into three tiers: MPC > 3; 3 ≥ MPC > 2; and other missense variants not in the previous two tiers. The number of genes included in each burden was labeled. Data are presented as effect size estimates (β) with 95% confidence intervals (CIs). b, Exome-wide, gene-based PTV burden association for EDU (related UKB EUR sample n = 393,758). The −log10 P values (two-sided t-test) for each gene were plotted against the genomic position (Manhattan plot). The orange dashed line indicates the Bonferroni-corrected exome-wide significance level per phenotype (P < 0.05/15,782 = 3.17 × 10−6 for EDU). The purple triangles indicate Bonferroni-significant genes. The orange triangles indicate FDR-significant genes (FDR Q < 0.05). c, Observed −log10 P value (two-sided t-test) plotted against expected values (Q–Q plot) for exome-wide, gene-based PTV burden association for EDU. The orange dashed line indicates the Bonferroni-corrected exome-wide significance level per phenotype (P < 0.05/15,782 = 3.17 × 10−6 for EDU). d, Exome-wide, gene-based PTV burden association for RT (related UKB EUR sample n = 394,600). The −log10 P values (two-sided t-test) for each gene were plotted against the genomic position (Manhattan plot). The orange dashed line indicates the Bonferroni-corrected exome-wide significance level per phenotype (P < 0.05/15,798 = 3.16 × 10−6 for RT). e, Observed −log10 P value (two-sided t-test) plotted against the expected values (Q–Q plot) for exome-wide, gene-based PTV burden association for RT. The orange dashed line indicates the Bonferroni-corrected exome-wide significance level per phenotype (P < 0.05/15,798 = 3.16 × 10−6 for RT). f, Exome-wide, gene-based PTV burden association for VNR (related UKB EUR sample n = 159,026). The −log10 P values (two-sided t-test) for each gene were plotted against the genomic position (Manhattan plot). The orange dashed line indicates the Bonferroni-corrected exome-wide significance level per phenotype (P < 0.05/11,905 = 4.20 × 10−6 for VNR). g, Observed −log10 P value (two-sided t-test) plotted against the expected values (Q–Q plot) for exome-wide, gene-based PTV burden association for VNR. The orange dashed line indicates the Bonferroni-corrected exome-wide significance level per phenotype (P < 0.05/11,905 = 4.20 × 10−6 for VNR).
After the exome-wide burden analyses, we performed gene-based PTV burden tests to identify genes associated with EDU, RT and VNR using two-step whole-genome regression implemented in regenie34. By analyzing 397,434 EUR samples in the UKB, we identified eight genes associated with one or more cognitive phenotypes at exome-wide significance after Bonferroni correction (Table 1 and Fig. 1b–g). These cognitive function genes included KDM5B (for all three phenotypes), ADGRB2, GIGYF1, SLC8A1, BCAS3 (for EDU), ANKRD12 (for VNR and for EDU with false discovery rate (FDR) significance), RC3H2 and CACNA1A (for VNR). As expected, PTV burden in these eight genes showed deleterious effects on cognitive function14,15. We also identified five putative cognitive function genes at an FDR of Q < 5% (NDUFA6, ARHGEF7, C11orf94, KIF26A and MAP1A; Supplementary Tables 3–5). In addition to the EUR samples, we also examined the impact of rare coding variants in UKB participants of South Asian (SAS) (n = 9,224) and African (AFR) (n = 8,406) ancestries; Supplementary Tables 4–7 and Supplementary Figs. 1 and 2). However, analyses in non-EUR samples were underpowered to replicate our findings in UKB EUR samples.
Table 1.
Exome-wide, gene-based, PTV burden association-identified genes for EDU, RT and VNR in EUR samples in the UKB
| Gene symbol | Associated phenotype(s) | EDU | RT | VNR | Known gene–phenotype relationships | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| β (95% CI) | P | n PTV carrier | β (95% CI) | P | n PTV carrier | β (95% CI) | P | n PTV carrier | |||
| ADGRB2 | EDUa | −0.664 (−0.854 to −0.473) | 8.55 × 10−12 | 71 | 0.159 (−0.070 to 0.388) | 0.174 | 70 | −0.615 (−0.976 to −0.255) | 8.28 × 10−4 | 25 | |
| KDM5B | EDUa/RTa/VNRa | −0.307 (−0.419 to −0.195) | 8.68 × 10−8 | 204 | 0.447 (0.311 to 0.582) | 9.60 × 10−11 | 201 | −0.547 (−0.750 to −0.344) | 1.24 × 10−7 | 79 | MIM: autosomal recessive intellectual developmental disorder-65 |
| Exome study: DD, ASD | |||||||||||
| GIGYF1 | EDUa | −0.492 (−0.660 to −0.324) | 9.80 × 10−9 | 91 | 0.275 (0.076 to 0.473) | 6.78 × 10−3 | 93 | −0.490 (−0.771 to −0.209) | 6.43 × 10−4 | 41 | Exome study: DD, ASD |
| ANKRD12 | VNRa/EDUb | −0.310 (−0.445 to −0.176) | 6.26 × 10−6 | 142 | 0.101 (−0.057 to 0.260) | 0.210 | 146 | −0.694 (−0.941 to −0.447) | 3.77 × 10−8 | 53 | Exome study: SCZ |
| SLC8A1 | EDUa | −0.992 (−1.371 to −0.613) | 2.84 × 10−7 | 18 | 0.202 (−0.250 to 0.654) | 0.381 | 18 | NA | NA | 4 | |
| RC3H2 | VNRa | −0.337 (−0.612 to −0.062) | 0.016 | 34 | 0.132 (−0.196 to 0.461) | 0.430 | 34 | −1.126 (−1.576 to −0.676) | 9.32 × 10−7 | 16 | |
| CACNA1A | VNRa | −0.210 (−0.391 to −0.029) | 0.023 | 78 | 0.352 (0.129 to 0.575) | 1.95 × 10−3 | 74 | −0.824 (−1.159 to −0.490) | 1.33 × 10−6 | 29 | MIM: spinocerebellar ataxia-6; type 2 episodic ataxia; familial hemiplegic migraine-1; developmental and epileptic encephalopathy-42. Exome study: DD |
| BCAS3 | EDU | −0.419 (−0.592 to −0.246) | 1.99 × 10−6 | 86 | 0.207 (−0.003 to 0.417) | 0.054 | 83 | −0.361 (−0.670 to −0.053) | 0.022 | 34 | MIM: Hengel–Maroofian–Schols syndrome |
The sample sizes, number of genes tested and λGC for each phenotype are as follows: nsample = 393,758, ntest = 15,782 and λGC = 0.967 for EDU; nsample = 394,600, ntest = 15,798 and λGC = 0.961 for RT; and nsample = 159,026, ntest = 11,905 and λGC = 0.959 for VNR. We excluded genes with fewer than ten PTV carriers from the analysis. The ‘associated phenotype(s)’ column indicates the phenotype for each gene with Bonferroni significance (adjusted by ntest for each phenotype). aIndicates genes that showed exome-wide significant association (bold) after Bonferroni correction across all tests (two-sided t-test: P < 0.05/43,485 = 1.15 × 10−6). bFDR was significant for EDU. β values represent rank-based inverse-normal transformed phenotypes and correspond to s.d. change in the phenotype. The table was sorted according to the lowest P value across three phenotypes.
We next aimed to replicate our findings in three independent EUR cohorts: the SUPER-Finland study (9,883 cases with psychosis); Northern Finland Intellectual Disability (NFID) study (1,097 cases with intellectual disability (ID), 11,774 controls)35; and Mass General Brigham Biobank (MGBB) (8,389 population cohort), for which exome sequencing and cognitive function phenotypes were available. We performed association analyses on an aggregated gene set of all eight cognitive function genes identified in the UKB against developmental disorders (DDs)/ID (SUPER-Finland and NFID studies), academic performance (SUPER-Finland study) and EDU (SUPER-Finland study and MGBB). Consistent with our findings in the UKB, PTV burden was associated with lower EDU (β = −0.424, P = 0.0021), lower academic performance (β = −0.338, P = 0.0125) and higher risk for DD/ID (odds ratio (OR) = 4.812, P = 8.30 × 10−4) in the SUPER-Finland study (Supplementary Table 8). The association between the cognitive function gene set and cognitive function in the SUPER-Finland study was conditioned on all samples from this cohort being cases with psychosis, which suggests that the observed effects on cognitive function were independent from and in addition to the potential effects of psychosis. In the NFID study, PTV burden in the cognitive function gene set was also associated with higher risk for DD/ID (OR = 4.973, P = 3.63 × 10−5). The MGBB data showed concordant results in the general population (β = −0.731, P = 0.5013 for EDU). Meta-analyses across replication cohorts for DD/ID (SUPER-Finland and NFID studies) showed lower association P values (P = 1.57 × 10−8; Supplementary Table 8) than the individual studies. Replication analyses for individual genes yielded supportive results but did not reach statistical significance due to the much smaller replication sample sizes than those in the UKB. Overall, our replication analyses validated that LoF in the cognitive function genes identified in the UKB reduces adult cognitive function.
To systematically assess whether the LoF of the eight cognitive genes also impacted phenotypes beyond cognitive function, we conducted PTV burden-based phenome-wide association studies (PheWAS) with 3,150 phenotypes in unrelated UKB EUR samples. Indeed, PheWAS suggested pleiotropy for six of the eight cognitive function genes. For instance, a rare PTV burden in KDM5B was not only strongly associated with all three cognitive function phenotypes studied (β = −0.307, P = 8.68 × 10−8 for EDU; β = 0.447, P = 9.60 × 10−11 for RT; β = −0.547, P = 1.24 × 10−7 for VNR), but also showed 16 additional phenome-wide significant associations related to muscle function (for example, hand grip strength (right), P = 1.02 × 10−7), skeletal phenotypes (for example, heel bone mineral density T-score, automated (right), P = 2.93 × 10−7), bipolar disorder (BD) (P = 3.04 × 10−7) and pain medication use (pregabalin, P = 2.27 × 10−10), among others (Extended Data Fig. 1 and Supplementary Table 9). Similarly, the PheWAS for ANKRD12 identified 11 phenome-wide significant associations including dysarthria and anarthria (motor disorders with speech deficit; International Classification of Diseases 10th Revision (ICD-10) code R47.1; P = 2.28 × 10−9), which suggests a potential mechanism of how ANKRD12 might affect VNR and EDU. Other notable phenome-wide-significant associations include type 2 diabetes and related phenotypes for GIGYF1 (refs. 36,37), chlorpromazine (antipsychotic) use and impaired cognitive function and awareness (ICD-10 code R41.8) for ADGRB2 (Supplementary Fig. 3 and Supplementary Table 9). The substantial pleiotropy indicates that these genes do not impact cognitive function in isolation. To provide insights into the potential mechanisms, we curated known and proposed medical and biological roles for all genes identified in our study (Table 1, Supplementary Table 7 and Supplementary Information).
Extended Data Fig. 1. PTV burden-based phenome-wide association analysis (3,150 phenotypes) for KDM5B in the UK Biobank unrelated European samples (N = 321,843).

FEV1 Z-score is Inverted GLI 2012 z-score for FEV1. Phenotypes were grouped and color-coded from left to right in the following categories: biomarker; composite phenotypes; family history; ICD-10 cause of death, ICD-10 congenital malformations; deformations and chromosomal abnormalities; ICD-10 diseases of the circulatory system; ICD-10 diseases of the digestive system; ICD-10 diseases of the eye and adnexa; ICD-10 diseases of the genitourinary system; ICD-10 diseases of the musculoskeletal system and connective tissue; ICD-10 diseases of the nervous system; ICD-10 diseases of the respiratory system; ICD-10 diseases of the skin and subcutaneous tissue; ICD-10 endocrine, nutritional and metabolic diseases; ICD-10 mental, behavioral and neurodevelopmental disorders; ICD-10 neoplasms; ICD-10 pregnancy, childbirth and the puerperium; ICD-10 symptoms, signs and abnormal clinical and laboratory findings, not elsewhere classified; operation code; self-reported illness: cancer; self-reported illness: non−cancer; self-reported medication. Bonferroni corrected p-value (two-sided t-test) significance threshold was 0.05/3150 = 1.59×10−5.
Cognition and neurodevelopmental genes overlap
Sequencing has identified hundreds of genes underlying DDs and autism spectrum disorder (ASD) that both diseases partially share12,13. As some of the genes we identified are known to cause Mendelian DDs (Table 1), we aimed to elucidate the overall rare genetic variation overlap between adult cognitive function, DDs and ASD. We tested whether the rare coding variant burdens in 285 DD-associated genes and 102 ASD-associated genes are associated with adult cognitive function. We observed significant deleterious effects of PTV burden in DD and ASD genes on all three cognitive phenotypes analyzed (Fig. 2a and Supplementary Table 10), while damaging missense variants (MPC > 3 or 3 ≥ MPC > 2) also showed similar deleterious effects.
Fig. 2. Impact of rare coding variants on cognitive function in DD and ASD genes.

a, The effects of protein-truncating, missense (stratified by MPC) and synonymous variant burden in the exome sequencing study identified DD13 and ASD genes12 on EDU, RT and VNR. Unrelated UKB EUR samples were included in this analysis (n = 318,844 for EDU, n = 319,536 for RT and n = 128,812 for VNR). Missense variants were classified according to deleteriousness (MPC) into three tiers: tier 1, MPC > 3; tier 2, 3 ≥ MPC > 2; tier 3 includes all missense variants not in tier 1 or 2. Data are presented as effect size estimates (β) with 95% CIs. b, Comparison between gene-based associations for DD, EDU and VNR (PTV de novo mutation enrichment tests (simulation-based test) and DeNovoWEST (simulation-based test) for DD; rare PTV burden association tests (two-sided t-test) for EDU and VNR). Each dot represents a gene that was identified for DD in Kaplanis et al.13 or for EDU or VNR in the current exome analysis. The dots are color-coded according to the phenotypes (DD, ASD, EDU and VNR) that the gene is significantly associated with exome-wide. The size and shade of the dots represent the pLI for the gene. EDU and VNR genes are labeled with gene names.
To identify individual genes linking DD, ASD and adult cognitive function, we next extracted PTV de novo mutation enrichment and de novo weighted enrichment simulation test (DeNovoWEST) P values12,13 and compared the relative impact of rare coding variants in a combined DD, ASD, EDU and VNR gene set (Fig. 2b and Supplementary Table 11). KDM5B and GIGYF1 stood out from these analyses because, interestingly, both genes are LoF-tolerant despite being a cause of DD. CACNA1A was also notable because its association with DD was primarily driven by missense variants, whereas PTV burden was primarily associated with VNR. This is consistent with earlier findings for CACNA1A, in which both LoF and gain of function mutations may cause neurological diseases with a spectrum of partially overlapping clinical phenotypes38–43. We repeated these analyses with 2,020 confirmed or probable rare disease genes from the Developmental Disorder Genotype-Phenotype Database (DDG2P) and observed similar results (Extended Data Fig. 2 and Supplementary Tables 10 and 11). Our analyses support that PTVs and missense variants in KDM5B, GIGYF1 and CACNA1A underlie a continuum of conditions with various degrees of cognitive impairment.
Extended Data Fig. 2. Impact of rare coding variants in genes identified in the Developmental Disorder Genotype - Phenotype Database (DDG2P) on cognitive function.

a. The effects of protein-truncating, missense (stratified by MPC) and synonymous variant burden in exome sequencing study identified DDG2P on EDU, RT and VNR. Unrelated UKB EUR samples were included for this analysis (N = 318,844 for EDU, 319,536 for RT, and 128,812 for VNR). DDG2P database (https://www.deciphergenomics.org/ddd/ddgenes) was accessed on December 23, 2020. Missense variants were classified by deleteriousness (MPC) into 3 tiers: tier 1 with MPC > 3; tier 2 with 3 ≥ MPC > 2; tier 3 includes all missense variants not in tier 1 or 2. We note that the effect of damaging missense variants out scaled that of PTV burden for DDG2P genes. This is most likely explained by UKB participants being depleted for highly penetrant PTVs in this gene set that cause disease onset in childhood13. Data are presented in effect size estimates (β) with 95% confidence intervals. b. Comparison between gene-based associations for genes from DDG2P database, EDU and VNR (PTV DNM enrichment [simulation-based test] and DeNovoWEST [simulation-based test] for DD; rare PTV burden associations [two-sided t-test] for EDU and VNR). Each dot represents a gene that is identified for DD in Kaplanis et al. 2020 and for EDU or VNR in the current exome analysis. The dots are color-coded according to the phenotypes (DD, ASD, or EDU) that the gene is exome-wide significantly associated with. The size and shade of the dots are representing the pLI for the gene. EDU and VNR genes are labeled with gene names.
KDM5B gene dosage determines clinical phenotype
Homozygous (HOM) and compound heterozygous (HET) mutations in the histone lysine demethylase encoded by KDM5B cause an autosomal recessive intellectual developmental disorder (IDD) with dysmorphic features (MIM 618109) (refs. 44,45). In a HET state, KDM5B PTVs were overrepresented in the cases of the Deciphering Developmental Disorders study7. To better understand the phenotypic spectrum of KDM5B LoF, we examined the phenotypes documented for KDM5B PTV carriers in UKB EUR samples (Fig. 3). As expected, EDU and VNR were on average lower in KDM5B PTV carriers (n = 204 for EDU and n = 79 for VNR) than in noncarriers (standardized, residualized phenotype mean = −0.3669 for EDU and −0.5387 for VNR). We identified 35 KDM5B PTV carriers who had been diagnosed with psychiatric disorders, epilepsy or Parkinson disease based on hospital diagnostic codes (enriched for disease cases compared with EUR non-KDM5B PTV carriers; P = 0.0005). EDU was impaired to a similar extent in KDM5B PTV carriers with and without such comorbidities (Supplementary Table 12). Notably, all individuals carrying HET PTVs annotated as pathogenic or likely pathogenic in ClinVar showed reduced EDU and VNR to a similar degree as carriers of novel KDM5B PTVs, and none of the three UKB participants HET for the pathogenic p.Arg299Ter variant (rs1558498928) had diagnostic records of IDD. We also found similar evidence for low cognitive function irrespective of comorbidities among CACNA1A PTV carriers (Extended Data Fig. 3 and Supplementary Table 13).
Fig. 3. Phenotypic characterization of KDM5B in humans.

Distribution of EDU and VNR scores for KDM5B PTV carriers in the UKB. ClinVar probably pathogenic variants for IDD (MIM 618109) were annotated. Samples with inpatient ICD-10 records of psychiatric (SCZ, BD, depression, substance use disorder or anxiety and stress disorders), neurodegenerative and neurodevelopmental disorders were annotated. Phenotypes were residualized by sex, age, age2, sex by age, sex by age2, top 20 principal components and recruitment centers and were rank-based inverse-normal transformed. The blue (for EDU) and red (for VNR) lines represent fitted locally estimated scatterplot smoothing (LOESS) regression on standardized, residualized phenotypes. The gray bands represent 95% CIs for the fitted LOESS regression.
Extended Data Fig. 3. Distribution of cognitive phenotypes (educational attainment and verbal-numerical reasoning) for CACNA1A PTV carriers.

ClinVar pathogenic/likely pathogenic variants for epileptic encephalopathy (MIM 617106) and/or type 2 episodic ataxia (MIM 108500) was annotated. Samples with inpatient ICD-10 (International Classification of Diseases version-10) records of psychiatric (schizophrenia, bipolar disorder, depression, substance use disorder and/or anxiety and stress disorders), neurodegenerative and neurodevelopmental disorders were annotated. Phenotypes were residualized by sex, age, age2, sex by age interaction, sex by age2 interaction, top 20 PCs, and recruitment center and inverse rank-based normal transformed. The blue line (for EDU) and red line (for VNR) represent fitted loess regression on standardized, residualized phenotypes. The gray bands represent 95% confidence intervals for the fitted loess regression.
Based on our findings in the UKB and KDM5B’s role in disease, we hypothesized that lower EDU and VNR in HET KDM5B PTV carriers may be explained by a gene dosage effect where HET PTV carriers show an attenuated phenotype relative to individuals with HOM KDM5B LoF mutations. To test this hypothesis, we conducted a series of cognitive and behavioral tests in a previously reported Kdm5b mouse model45. Relative to wild-type (WT) siblings, both HET and HOM Kdm5b mutant mice showed cognitive, behavioral and skeletal phenotypes consistent with an additive effect of Kdm5b LoF (Fig. 4a). Specifically, mutant mice showed deficits in spatial memory (Barnes maze), reduced new object recognition and behavioral abnormalities, such as increased anxiety (light–dark box). Furthermore, skeletal abnormalities observed in HOM knockout mice, such as changes in craniofacial dimensions or transitional vertebrae, were also present in HET Kdm5b mice with an intermediate severity or frequency (Extended Data Fig. 4). An additive effect of Kdm5b LoF was further supported by Kdm5b mRNA levels in the whole-brain tissue of embryonic HET mice and the frontal cortex (FC), hippocampus (HIP) and cerebellum (CB) tissues of adult HET mice being at an intermediate level between WT and HOM mutant mice (Fig. 4b). Consistently, 92% of the 723 differentially expressed genes (DEGs) identified by RNA sequencing (RNA-seq) (FDR Q < 0.1) in the Kdm5b mutant mouse brain showed the same directionality of change in both HOM and HET mice, with a globally smaller effect size in HET mice than HOM mice (Fig. 4c and Extended Data Fig. 5). We also found that Kdm5b brain expression is higher during the embryonic stages than in adult murine tissues (Fig. 4b) and followed a pattern very similar to KDM5B brain mRNA levels across the human life span46 (Supplementary Fig. 4 and Supplementary Tables 14 and 15). Consistent with the biological function of Kdm5b, more genes were differentially expressed in embryonic Kdm5b mutant mice than in adults, with a strong enrichment of genes with roles in brain development, synapse function and brain structure (Fig. 4c, Supplementary Fig. 5 and Supplementary Tables 16 and 17). In summary, our data from both mice and humans provide strong evidence that KDM5B LoF modulates cognition, behavior, skeletal phenotypes and brain mRNA expression in a dose-dependent manner.
Fig. 4. Kdm5b LoF alleles display a gene dosage effect on behavioral, cognitive and molecular phenotypes in mice.

a, Mice carrying Kdm5b LoF alleles showed a dose-dependent decrease in spatial memory performance (Barnes maze; two-sided Wald test based on an additive genetic effect with P = 0.012; Kdm5b+/− n = 34 (P = 0.031) and Kdm5b−/− n = 15 (P = 0.005) mice spent less time around the goalbox than WT controls, n = 24); showed a dose-dependent decrease in object recognition memory performance (new object recognition; two-sided Wald test based on an additive genetic effect with P = 0.042; Kdm5b+/− n = 32 (P = 0.038) and Kdm5b−/− n = 15 (P = 0.011) mice had reduced discrimination compared to WT controls, n = 26); and showed a dose-dependent increase in anxiety-related behavior (light–dark box; two-sided Wald test based on an additive genetic effect with P = 0.008; Kdm5b+/− n = 15 (P = 0.025) and Kdm5b−/− n = 34 (P = 0.004) mice spent less time in the light compared to WT controls). P values are based on two-sided Wald tests from a double generalized linear model (dglm v.1.8.5). For the box plot, the center line represents the median, the box limits represent the interquartile range (IQR) and the whiskers indicate the minimum and maximum values. The heatmaps show the relative time spent around various arenas during the trial period of each assay, as a composite of all mice of the same genotype (Barnes maze and light–dark box) or the trace for a single representative animal (new object recognition). Kdm5b+/− (HET) and Kdm5b−/− (HOM) mice spent less time around the goalbox (Barnes maze), showed reduced discrimination of the new object (new object recognition) and spent more time in the dark zone (light–dark box) compared with WT controls. b, Normalized RNA-seq read counts of Kdm5b gene expression in WT, Kdm5b+/− and Kdm5b−/− mice across embryonic and adult tissues as indicated (n = 7 for WT, n = 7 for Kdm5b+/− HET and n = 8 for Kdm5b−/− HOM embryonic mice whole brain; n = 6, 5 and 6 for the FC of WT, HET and HOM adult mice; n = 6, 6 and 6 for the HIP of WT, HET and HOM adult mice; n = 6, 6 and 6 for the CB of WT, HET and HOM adult mice). For the box plot, the center line represents the median, the box limits represent the IQR and the whiskers indicate the minimum and maximum values. c, Heatmap of expression changes (log2 fold change) in DEGs in Kdm5b+/− (HET) and Kdm5b−/− (HOM) mice across embryonic and adult tissues as indicated. There is a strong correlation between direction of change in expression in both mutant genotypes. The Venn diagrams show the overlap of DEGs in both Kdm5b+/− and Kdm5b−/− mice across tissues and stages. Created with BioRender.com.
Extended Data Fig. 4. Kdm5b loss-of-function impacts craniofacial and skeletal features in mice in a dose-dependent manner.

An intermediate effect on cranial length (additive genotype effect two-sided P = 0.0268) and height (additive genotype effect two-sided P = 0.0056) is detected in Kdm5b+/− mice, but not in cranial width (additive genotype effect two-sided P = 0.3090). For the boxplot, the center line represents the median, the box limits represent the IQR, and the whiskers indicate the minimum and maximum values. A fully penetrant transitional vertebrae phenotype seen in Kdm5b−/− mice (N = 21) is observed at a lower frequency in Kdm5b+/− mice (N = 40, Fisher’s exact test vs Kdm5b+/+ two-sided P = 0.0189).
Extended Data Fig. 5. Correlation in differential gene expression between heterozygous and homozygous Kdm5b mutant mice.

Log2-fold change of differentially expressed genes plotted for Kdm5b+/− (y-axis) and Kdm5b−/− (x-axis) mice across embryonic and adult brain tissues as indicated. There is a strong correlation between direction of change in expression in both mutant genotypes (robust linear regression line and slope shown in red).
Rare and common variant signals intersect
We further tested whether the genes identified through our PTV burden analysis in the UKB overlap with the genetic loci identified in previous common variant-based EDU5 and cognitive function GWAS4. Indeed, we identified overlapping signals between an EDU GWAS locus on chromosome 1 and ADGRB2, which showed PTV burden association with EDU. Notably, the PTVs for which carriers showed lower than average EDU and VNR and the GWAS top associated SNPs were in close genomic proximity, prioritizing ADGRB2 as the most likely causal gene of the GWAS association signal (Extended Data Fig. 6). We also identified overlapping signals with the FDR-significant EDU gene NDUFA6, thus prioritizing NDUFA6 over other genes at this GWAS locus (Extended Data Fig. 7). To further characterize the overlap between rare coding and common variant associations with cognitive function, we used UKB exomes to calculate rare coding variant burdens for genes identified in cognitive function-related GWAS. PTV burden in EDU GWAS genes showed significant effects on all three cognitive phenotypes (β = −0.023 and P = 3.69 × 10−7 for EDU; β = 0.017 and P = 6.38 × 10−5 for RT; β = −0.033 and P = 4.05 × 10−6 for VNR), while PTV burden in cognitive function and schizophrenia (SCZ) GWAS genes showed significant effects on EDU. Significant effects were also observed for missense variants (Supplementary Figs. 6–8 and Supplementary Table 18).
Extended Data Fig. 6. Overlap between educational attainment GWAS (Lee et al.5) locus on chromosome 1 and ADGBR2 identified in PTV burden analysis in UKB.

Regional plot of educational attainment GWAS association test results were generated around top independent SNP rs10798888. Additional associations from GWAS catalog were annotated with the associated phenotypes in the regional plot. EDU and VNR score for ADGRB2 PTV carriers in UKB were plotted (both phenotypes were residualized by sex, age, age2, sex by age, sex by age2, top 20 PCs and recruitment centers and were inverse rank-based normal transformed). Samples with inpatient ICD-10 (International Classification of Diseases version-10) records of psychiatric, neurodegenerative, and neurodevelopmental disorders were annotated. The blue line (for EDU) and red line (for VNR) represent fitted loess regression on standardized, residualized phenotypes. The gray bands represent 95% confidence intervals for the fitted loess regression.
Extended Data Fig. 7. Overlap between cognitive function GWAS (Lam et al.48) locus on chromosome 22 and NDUFA6 identified in PTV burden analysis in UKB (FDR significant for EDU).

Regional plot of cognitive function GWAS association test results were generated for top independent SNP rs5751191 and the extended LD region. Additional associations from GWAS catalog were annotated with the associated phenotypes in the regional plot. Number of PTV carriers and gene-based PTV burden association p-value were extracted for genes in the region.
GWAS have identified biological pathways of potential relevance to cognitive function2,3. To further explore the biological mechanisms through which rare variants might impact cognitive function, we performed PTV burden analysis of 13,011 gene sets from the Molecular Signatures Database in the UKB (Supplementary Fig. 9 and Supplementary Table 19). We identified 182, 66 and 56 Bonferroni-corrected significant gene sets for EDU, RT and VNR, respectively. The most significant gene sets were involved in synaptic function, neurogenesis, neuronal differentiation and neuronal development. These signatures highly overlapped with those from cognitive function GWAS2, suggesting that rare and common variants modulate cognitive function through similar mechanisms. Further analyses showed that the burden of PTV and damaging missense variants in genes with brain-specific expression impacted cognitive function more strongly than when genes were primarily expressed in other tissues (Extended Data Fig. 8 and Supplementary Table 20), which is also consistent with previous GWAS findings2,3,5.
Extended Data Fig. 8. The effects of protein-truncating, missense (stratified by MPC) and synonymous variant burden in genes stratified by brain-specific expression.

Unrelated UKB EUR samples were included for this analysis (N = 318,844 for EDU, 319,536 for RT, and 128,812 for VNR). Genes were stratified by elevated expression in brain tissue (2,587 genes), elevated expression in other tissues but also expressed in brain (5,298 genes) and no tissue specific expression (8,342 genes). Number of genes included in the burden is annotated for each set. Data are presented in effect size estimates (β) with 95% confidence intervals.
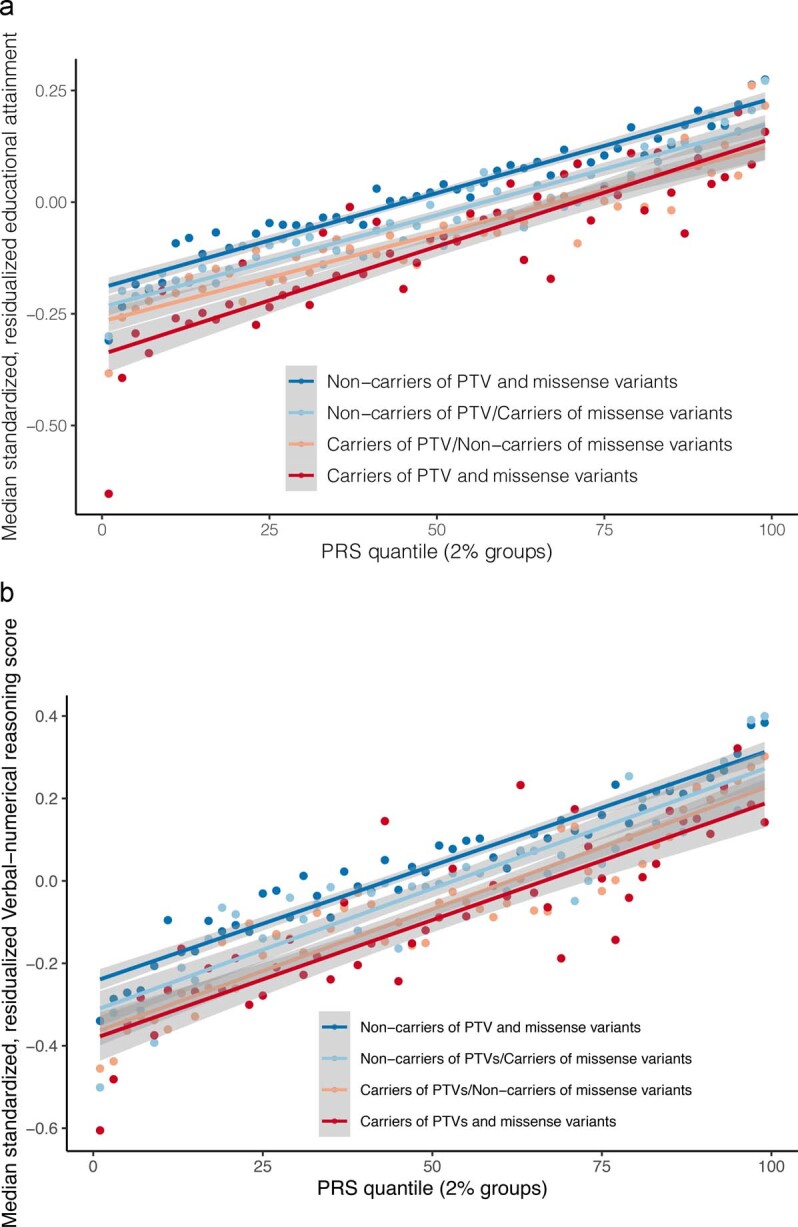
Finally, we explored the relationship between rare coding variants and common variant-based polygenic risk on cognitive function. We calculated polygenic risk scores (PRS) in unrelated EUR samples in the UKB using imputed genome-wide genotype data and SNP weights based on cognitive function GWAS (excluding the UKB samples)4 using PRS-CS47, where a higher PRS reflects the genetic liability of increased cognitive function. We tested the joint effects of PRS and carrier status for PTVs or MPC > 2 damaging missense variants in LOF-intolerant genes (pLI ≥ 0.9) on EDU and VNR. These analyses showed that the effects of PRS and rare coding variants are additive (PRS interaction test P = 0.27 for PTV and P = 0.21 for damaging missense for EDU, P = 0.72 for PTV and P = 0.59 for damaging missense for VNR; Fig. 5, Extended Data Fig. 9 and Supplementary Tables 21 and 22). For EDU, the conditional effects of PRS, PTV carrier status and damaging missense carrier status were 0.116, −0.095 and −0.053, respectively while the adjusted partial R2 values were 0.013, 0.0015 and 0.0005, respectively (P = 8.96 × 10−949 for PRS, 7.33 × 10−109 for PTV and 6.76 × 10−38 for missense variants). Similar results were observed for VNR. Our results suggest that the genetic prediction of cognitive function through PRS can be further refined by integrating rare coding alleles.
Fig. 5. Contribution of common and rare coding variants to EDU and VNR.

a,b, The impact of cognitive function PRS and carrier status of PTV or damaging missense variants (MPC > 2) in LOF-intolerant genes (pLI > 0.9) on EDU (a) and VNR (b). Unrelated UKB EUR samples were included in this analysis with n = 318,844 for EDU and n = 128,812 for VNR. EDU and VNR were residualized by sex, age, age2, sex by age, sex by age2, top 20 principal components and recruitment centers and rank-based inverse-normal transformed. The effect (and 95% CI) of PRS and rare coding variant carrier status on residualized, transformed EDU/VNR was estimated using linear regression, with noncarriers of PTV and damaging missense variants with PRS in the middle quantile as the reference (Ref.) group. Data are presented as effect size estimates (β) with 95% CIs.
Extended Data Fig. 9. The impact of cognitive function polygenic score and carrier status of PTV and/or damaging missense variants (MPC > 2) in LoF intolerant genes (pLI > 0.9) on a) educational attainment and b) verbal-numerical reasoning.
The impact of cognitive function polygenic score (PRS) and carrier status of PTV and/or damaging missense variants (MPC > 2) in LoF intolerant genes (pLI > 0.9) on a) EDU and b) VNR. EDU and VNR were residualized by sex, age, age2, sex by age, sex by age2, top 20 PCs and recruitment centers and inverse rank-based normal transformed. Median of educational attainment was calculated for individuals stratified by PRS quantiles (in 2% groups) and PTV and/or damaging missense variant carrier status. The blue and red lines represent fitted linear regressions for standardized, residualized phenotypes by PRS percentile groups, stratified by rare coding variant carrier status. The gray bands represent 95% confidence intervals for each of the fitted linear regression.
Discussion
In this study, we present a large-scale exome sequencing study on cognitive function phenotypes in the adult general population. Our findings support previous evidence that an increased exome-wide burden of rare PTVs is associated with lower cognitive function14,15 and extend this observation to deleterious missense variants. The large number of exome-sequenced participants in the UKB allowed us to identify eight distinct cognitive function genes, with additional evidence from three independent EUR cohorts. Notably, several of these cognitive function genes have established roles in neurodevelopmental disorders. Our results suggest that a fraction of adults in the normal general population have lower cognitive abilities as a consequence of defects in single disease genes.
Our study is a natural extension of previous GWAS on cognitive function and EDU2–6. While highly successful in identifying associated loci through common variants, applying the GWAS approach to cognitive function has received substantial criticism, especially on potential biases due to ancestry, geography and environmental or cultural differences between subpopulations25,48. Cognitive function is difficult to assess in isolation for its substantial genetic and nongenetic overlap with other traits25. For instance, EDU is not only reflective of childhood and adult IQ, but also strongly correlates with other traits including income, parental age at birth, alcohol dependence or neuroticism25. Furthermore, as suggested by recent studies, EDU is a combination of multiple factors at both phenotypic and genetic levels24,49,50. Using GWAS of EDU and general cognitive function, common genetic associations of EDU have been shown to contain components of both general cognitive ability and noncognitive skills and overlap with psychiatric disorders24,49,50. Nevertheless, we are confident that the results of our exome study are less susceptible to such biases than GWAS. First, we analyzed three distinct phenotypes (EDU, RT and VNR) that each capture different aspects of general cognitive function49. The consistency of exome-wide, gene set-level and gene-level associations across EDU, RT and VNR, which also translate to independent exome-sequenced cohorts, increases the confidence that our gene findings are indeed biologically relevant. Second, five of the eight cognitive function genes (KDM5B (ref. 12,13) (MIM 618109), ANKRD12 (ref. 30), CACNA1A (MIM 183086, MIM 108500 and MIM 617106), GIGYF1 (refs. 12,13) and BCAS3 (MIM 619641)) are either established Mendelian DD genes or have also been identified in previous exome studies on SCZ30,51, DD13 or ASD12. The biological relevance of the genes discovered in this study is consistent with the well-established tight genetic relationships between cognitive traits and diseases. Third, multiple lines of evidence from our analyses yielded clues to a gene’s biological mechanisms and relevance to cognitive function. For instance, ANKRD12 was associated with both EDU and VNR in our exome-wide PTV burden association tests; it is also associated with dysarthria and anarthria, myasthenia gravis and disorders of calcium metabolism in our PTV burden PheWAS. This suggests that cognitive dysfunction in individuals with ANKRD12 LoF is accompanied by imbalances in motor coordination or muscle function and might be part of a yet undescribed genetic syndrome. Likewise, ADGRB2, on top of its association with EDU exome-wide PTV burden analyses, was associated with impairment of cognitive function (ICD-10 code R41.8) in our PTV burden-based PheWAS.
A particularly intriguing example for how diseases with cognitive impairment and adult cognitive function intersect is KDM5B, a gene that encodes a histone lysine demethylase with roles in neuronal differentiation45,52–54, which we interrogated further in humans and mice. Biallelic mutations in KDM5B cause an autosomal recessive IDD44,45,53, while HET PTVs have been linked to severe DD7,13,45 and ASD12 with presumed incomplete penetrance45,55. However, because previous studies focused on patients, the relevance of KDM5B LoF in adult cognitive function in the general population has not yet been appreciated. Unlike most other DD genes13, KDM5B is LoF-tolerant, leading to a relatively high PTV carrier rate of approximately 1:1,900 participants in the UKB. As UKB participants tend to be healthier and more educated than the general UK population56,57, it can be expected that KDM5B PTV carrier rates in the general EUR population are even higher. Our results strongly suggest a gene dosage effect for KDM5B, where biallelic, near-complete LoF for KDM5B will lead to more severely impaired cognitive function as observed in patient cohorts, whereas HET KDM5B LoF will present with only moderate cognitive impairment that overlaps with the spectrum of cognitive function in the normal population. Notably, KDM5B showed pleiotropic effects on muscle strength, bone density, growth hormone levels and BD, among others, in our PheWAS. This pleiotropy partially overlaps with the dose-dependent cognitive, behavioral and skeletal symptoms in our Kdm5b mouse model45 as well as KDM5B patients44. It will be interesting to investigate the phenotypic spectrum of KDM5B LoF in humans more comprehensively, for instance, through PheWAS in additional biobanks or targeted follow-up of PTV carriers in recall studies. Genes with a dosage sensitivity like the one described in this study for KDM5B are ideal drug targets because the degree of genetic impairment may guide the development of gene-directed therapeutic interventions58,59. KDM5B is already an established drug target with molecules inhibiting its enzymatic activity in preclinical development for cancer60. It could be interesting to explore whether activators exist that might improve cognitive phenotypes61,62.
A particular strength of exome studies is that genes and variants identified through rare variant tests tend to exhibit much larger effect sizes than common variants identified in GWAS. For example, HET carriers of KDM5B PTVs show on average fewer than 1.51 years of schooling than noncarriers. In contrast, lead SNPs in the most recent EDU GWAS based on three million individuals only show a median 1.4 week increase in schooling per allele (with the 5th and 95th percentiles of the estimated effect being 0.9 and 3.5 weeks, respectively)6. This demonstrates that exome studies may uncover substantially stronger genetic effects and complement GWAS to describe the genetic architecture of cognitive function more comprehensively. This is further supported in the case of ADGRB2 and NDUFA6, which our results suggest as the most probable causal genes in loci identified in EDU and cognitive function GWAS5.
With both exome sequencing and genome-wide genotype data in the UKB, we were able to explore the relative contribution of common variant-based polygenic risk and rare coding variant burden to cognitive function. Our results provide evidence that rare coding variants affect EDU and VNR additively to PRS and thus suggest that genetic prediction can be further improved by combining PRS and the rare coding variant burden. Similar findings were reported previously for other common complex phenotypes51,63–65. Although the phenotypic variance explained by rare coding variants is much smaller than that explained by PRS because of allele frequency constraints, rare coding variants provide orthogonal predictive power that is not relying on external training GWAS (like PRS) and is thus less susceptible to biases66.
Future studies are needed to better understand the biological basis of how the genes and variants reported in this study impact cognitive function and related diseases. Moreover, our findings do not imply direct applications in clinical practice, such as for prenatal genetic screening67,68, and should be interpreted with similar caution as reported in GWAS6. Further work is also needed to assess how well the results from our study can be extrapolated to ancestries other than EUR populations. Nevertheless, our results provide a starting point toward expanding our knowledge on how rare genetic variants impact cognitive function at the population level and support a convergence of rare and common genetic variations that jointly contribute to the spectrum of cognitive traits and diseases.
Methods
The UKB is approved by the North West Multi-centre Research Ethics Committee (https://www.ukbiobank.ac.uk/learn-more-about-uk-biobank/about-us/ethics). The current study was conducted under UKB application no. 26041. The data in the UKB were collected after written informed consent was obtained from all participants. The Human Research Committee of the MGB approved the Biobank research protocol (no. 2009P002312) (ref. 69). The data in the MGBB were collected after broad-based written consent was obtained from all participants. The Coordinating Ethical Committee of the Helsinki and Uusimaa Hospital Region approved the SUPER-Finland study on 16 July 2015 (pilot) and 9 February 2016 (full study). All participants of the SUPER-Finland study signed an informed consent that permits research use of collected samples and data. The ethical committees of the Northern Ostrobothnia Hospital District and the Hospital District of Helsinki and Uusimaa approved the NFID study. All participants or their legal guardians provided written informed consent to participate in the study. The breeding and housing of mice, and all procedures for the Kdm5b LOF mouse experiments were assessed by the Animal Welfare and Ethical Review Body of the Wellcome Sanger Institute and conducted under a UK Home Office license (no. P6320B89B) in accordance with institutional guidelines.
Cognitive function phenotypes in UKB
The UKB is a prospective cohort study of the UK population with over 500,000 participants16. Participants were aged between 40 and 69 years at recruitment in 2006–2010 and provided extensive phenotypic data17. We extracted three cognitive function phenotypes for our analysis: EDU; RT; and VNR23. EDU is based on a survey of years of schooling that reflects both cognitive function and noncognitive components24. We extracted the UKB data field 6138 ‘Qualifications’ collected at baseline as a measure of EDU and converted multiple-choice categories to years of schooling as outlined by Lee et al.5. RT is a measure of processing speed, which is a component of general cognitive function2,4,26,27, implemented as a digital assessment at baseline (UKB data field no. 20023) (ref. 2). VNR is a score measured using a structured questionnaire, which contains 13 questions that focus on assessing crystalized and fluid intelligence in both verbal and numerical aspects (UKB data field no. 20016). Note that only a subset of 165,453 UKB participants completed the VNR assessment at baseline, while EDU (n = 497,844 at baseline collection) and RT (n = 496,660 at baseline collection) data were collected for almost the entire UKB. For the association analyses in the UKB samples, we rank-based inverse-normal transformed the phenotypes. While higher EDU and VNR scores indicate better cognitive function, longer RT represents worse cognitive function.
The UKB whole-exome sequencing data
Whole-exome sequencing (WES) data from UKB participants was generated by the Regeneron Genetics Center on behalf of the UKB Exome Sequencing Consortium, which is a collaboration between AbbVie, Alnylam Pharmaceuticals, AstraZeneca, Biogen, Bristol Myers Squibb, Pfizer, Regeneron and Takeda18. Briefly, WES was done on an Illumina NovaSeq 6000 platform using xGen Exome capture kits. Sequencing reads were aligned to the GRCh38 reference genome using the Burrows–Wheeler Aligner-MEM (v.0.7.17) (refs. 18,70). Single-nucleotide variants and indels were called by first generating gVCF files using the WeCall variant caller v.1.1.2 (Genomics PLC) and then joint-called using the GLnexus joint genotyping tool (v.0.4.0) (refs. 18,21,71). The joint-called, project-level VCF was then filtered by the Regeneron Genetics Center quality control (QC) pipeline (the ‘Goldilocks’ set). As of November 2020, we obtained QC-passed WES data from 454,787 UKB participants. The UKB can release these data publicly to approved researchers via their Research Analysis Platform.
We annotated variants using Variant Effect Predictor (VEP) v.96 (ref. 28) with genome build GRCh38. Stop-gain, splice site-disruptive and frameshift variants were further assessed by Loss-Of-Function Transcript Effect Estimator (LOFTEE) (a VEP plugin)29 and high-confidence predicted LOF variants were retained for analysis. Missense variants were further annotated for deleteriousness using the MPC score31. We also annotated variants based on gene intolerance to LOF using pLI (probability of being LOF-intolerant) v.2.1.1 (refs. 29,32). All predicted variants were mapped to GENCODE72 (release 30) canonical transcripts.
For the association analysis, we filtered variants to include only those with a MAF < 1.0 × 10−5 in the UKB (649,321 PTVs, 5,431,793 missense variants and 3,060,387 synonymous variants) to enrich for pathogenic variants. In previous exome studies, the impact of an exome-wide ultrarare variant burden was associated with EDU, ID and psychiatric disorders. In these studies, ultrarare variants were defined as variants observed in fewer than 1 in 74,839 individuals (allele frequency < 1.34 × 10−5) or 1 in 201,176 individuals (allele frequency < 2.49 × 10−6) (refs. 14,15) in external reference samples. A recent large-scale exome study for SCZ also adopted a minor allele count cutoff of fewer than 5 alleles in 24,248 cases and 97,322 population controls, which corresponds to a MAF cutoff of 2.06 × 10−5 (ref. 30). Our choice of variant filtering for MAF < 1.0 × 10−5 is in line with these previous studies.
The UKB genome-wide genotype data
We used imputed genotype data provided by the UKB with additional QC filtering. Genome-wide genotyping was performed for all UKB participants and imputed with the Haplotype Reference Consortium73 and UK10K74 plus 1000 Genomes Project reference panels75, resulting in a total of more than 90 million variants. We performed QC on the genotyping data by filtering out variants with an imputation quality INFO score < 0.8 and variants with a MAF < 0.01 using PLINK v.2.00 (ref. 76). We filtered out 1,804 individuals whose reported gender differed from their genetic gender, individuals showing sex chromosome aneuploidies, as well as 133 individuals who had withdrawn from the UKB (as of 24 August 2020).
To identify UKB samples from different genetic ancestries, we performed population assignment based on population structure using principal component analysis (PCA) with the 1000 Genomes Project reference samples (n sample = 2,504) from five major population groups: AFR; American (AMR); East Asian (EAS); EUR; and SAS. Details of the genetic PCA-based population assignment can be found in the Supplementary Information. We identified 8,406 AFR samples, 1,085 AMR samples, 1,609 EAS samples, 458,197 EUR samples, 9,224 SAS samples and 8,874 samples without explicit population assignment. Due to the small sample sizes, we did not analyze further the samples in the EAS and AMR groups. We also did not analyze further samples without an explicit population assignment. Within-population PCA was performed for the AFR, EUR and SAS samples for subsequent association analyses.
Gene set-based rare coding variant burden test
Analysis overview
To estimate the association between cognitive function phenotypes (EDU, RT and VNR) and gene set-based rare coding variant burdens, we rank-based inverse-normal transformed the phenotypes and fitted a linear regression in unrelated UKB samples in samples from the same population group (as described in the section on population assignment). To minimize potential population stratification and confounding, we adjusted for sex, age, age2, sex by age interaction, sex by age2 interaction, top 20 principal components (PCs) and recruitment centers (as categorical variables) in all association analyses. We ran additional sensitivity analyses accounting for 40 PCs to assess the potential residual population stratification and found that the exome-wide burden results were consistent (Supplementary Table 2). The effect size (β), 95% CIs and P values were calculated for each burden association. The significance level of the burden association was determined using Bonferroni correction for the number of association tests in the defined set of analysis and is provided in Supplementary Tables 1, 2, 6, 7, 10 and 18–20.
Exome-wide burden
To characterize the effects of exome-wide rare coding variant burden on cognitive function, we calculated the cumulative minor allele counts of rare coding variants (MAF < 1.0 × 10−5) for each variant functional class as defined by the VEP28, LOFTEE32, MPC31 and pLI scores32. We defined the following variant classes: PTVs; high-confidence LOF variants; missense variants classified according to deleteriousness (MPC) into tier 1 for MPC > 3, tier 2 for 3 ≥ MPC > 2 and tier 3 for other missense variants not in the previous two tiers; and synonymous variants (identified by VEP). We further classified variants according to the LOF intolerance of the gene (pLI ≥ 0.9 or pLI < 0.9) in which the variant resides. The exome-wide rare coding variant burdens for each variant class were calculated and burden association tests were performed in the EUR, SAS and AFR samples in the UKB.
Gene set burden
We also calculated the rare coding variant burdens for several gene sets, including genes identified in: (1) exome studies for ASD (n gene = 102)11, DD (n gene = 285)13 and the DDG2P (https://www.deciphergenomics.org/ddd/ddgenes; n gene = 2,020); (2) GWAS for EDU (n gene = 1,140) (ref. 5), cognitive function (n gene = 807) (ref. 4), SCZ (n gene = 3,542) (ref. 77), BD (n gene = 218) (ref. 78) and depression (n gene = 269) (ref. 79); (3) gene sets annotated in the Molecular Signatures Database (v.7.2; n gene set annotated = 13,011); (4) gene sets with brain tissue expression specificity annotated in the Human Brain Atlas80 (n gene annotated = 16,270). Details on the calculation of gene set burdens and association analyses can be found in Supplementary Information.
Exome-wide, gene-based PTV burden test
To identify genes associated with adult cognitive function, we calculated the rare PTV burden for each gene and performed burden association analyses. We used two-step whole-genome regression implemented in regenie for association testing34. Regenie accounts for population stratification and sample relatedness, which allowed us to leverage a larger sample size by including related samples. Regenie first fits a stacked block ridge regression to obtain leave-one-chromosome-out (LOCO) genetic prediction of the phenotype of interest; in the second step, the association test is carried out by fitting regression models conditioning on the LOCO predictions derived in the first step.
For the regenie step 1 regression, we first performed sample QC and then genotype QC by excluding variants with a genotyping call rate less than 90%, Hardy–Weinberg equilibrium test P < 10−15 and MAF < 1%. This retained 565,124 genotyped variants for the step 1 regression. We fitted a regenie first-step regression for rank-based inverse-normal transformed EDU, RT and VNR separately, adjusting for sex, age, age2, sex by age interaction, sex by age2 interaction, top 20 PCs and recruitment centers with tenfold cross-validation (regenie v.1.0.6.7) (ref. 34). For the regenie step 2 association test, we implemented an in-house pipeline (R v.3.6.1) for rare PTV burden association tests conditioned on the first-step LOCO prediction, following the linear regression model for association testing described in the regenie publication34. We treated the LOCO prediction as an offset in the linear regression model where rank-based inverse-normal transformed EDU, RT and VNR were regressed on gene-based rare PTV burden, adjusting for the same covariates used in the step 1 regression. We excluded genes with fewer than ten PTV carriers from the gene-based PTV burden analysis, which leads to a variable number of tests performed for each phenotype, especially for VNR, which has a much smaller sample size. We repeated the two-step regenie regression in the UKB EUR, SAS and AFR samples.
For the EUR samples, the sample sizes and number of genes tested for each cognitive function phenotype were as follows: n sample = 393,758 and test n = 15,782 for EDU; n sample = 394,600 and test n = 15,798 for RT; and n sample = 159,026 and test n = 11,905 for VNR. The Bonferroni correction for multiple testing was based on the actual number of tests performed per phenotype and across the three phenotypes. The significance levels for the gene-based rare PTV burden association tests were Bonferroni-corrected for the number of tests for each phenotype separately, which are 0.05/15,782 = 3.17 × 10−6 for EDU, 0.05/15,798 = 3.16 × 10−6 for RT and 0.05/11,905 = 4.20 × 10−6 for VNR. Note that seven of the eight cognitive function genes (that is, all except BCAS3) identified in our PTV burden association analysis in the UKB EUR samples were also exome-wide-significant after Bonferroni correction across all tests (P < 0.05/43,485 = 1.15 × 10−6). Additionally, we identified five genes with an FDR Q < 0.05 for EDU and VNR in the UKB EUR samples. For the SAS samples, the sample sizes and number of genes tested were as follows: n sample = 8,181 and test n = 1,247 for EDU; n sample = 8,018 and test n = 1,187 for RT; n sample = 4,430 and test n = 331 for VNR. For the AFR samples, the sample sizes and number of genes tested were as follows: n sample = 7,504 and test n = 887 for EDU; n sample = 7,331 and test n = 844 for RT; n sample = 3,890 and test n = 179 for VNR.
Replication cohorts
To replicate our gene findings from the exome-wide, gene-based PTV burden tests in the UKB, we performed gene set-based and gene-based PTV burden association tests in three independent cohorts with samples of EUR ancestry: the SUPER-Finland study; the NFID study; and the MGBB. Details of phenotype, genotype and exome sequencing data processing and QC can be found in the Supplementary Information. In each replication cohort, we calculated PTV burdens for two cognitive function gene sets, including the eight genes with Bonferroni-corrected significance and the 13 genes with FDR significance identified in the UKB EUR samples. We also calculated the PTV burdens of individual cognitive genes with at least five rare PTV carriers (ADGRB2, KDM5B, GIGYF1, ANKRD12 and KIF26A) in the NFID study. PTV burden association tests were then performed between the PTV burdens and cognitive traits in the replication cohorts. For the SUPER-Finland study, association tests were performed between PTV burdens and DD/ID, academic performance compared with schoolmates and EDU using either linear or logistic regression, adjusted for ten PCs, imputed sex, sequence assay and total number of coding variants in the genome. For the NFID study, we tested associations between PTV burdens and DD/ID using a logistic regression, adjusted for sex and the top ten PCs. In addition, we performed a meta-analysis of the DD/ID association with PTV burdens between the SUPER-Finland and NFID studies using an inverse-variance weighted random-effects meta-analysis. For the MGBB, we tested the association between PTV burdens and EDU using a linear regression, which was adjusted for sex, age, age2, sex by age interaction, sex by age2 interaction and the top 20 PCs. ORs, 95% CIs and P values were calculated for all association tests and meta-analyses.
Phenome-wide association analysis
To explore the cognitive function genes identified for potential pleiotropic effects, we performed a PTV burden phenome-wide association analysis across 3,150 UKB phenotypes derived semiautomatically. Binary phenotypes included ICD-10 codes from inpatient records (congenital malformations; deformations and chromosomal abnormalities; diseases of the circulatory system; diseases of the digestive system; diseases of the eye and adnexa; diseases of the genitourinary system; diseases of the musculoskeletal system and connective tissue; diseases of the nervous system; diseases of the respiratory system; diseases of the skin and subcutaneous tissue; endocrine, nutritional and metabolic diseases; mental, behavioral and neurodevelopmental disorders; neoplasms; pregnancy; childbirth and the puerperium; symptoms, signs and abnormal clinical and laboratory findings; not elsewhere classified) and death records (ICD-10 cause of death), self-reported illness (cancer, non-cancer), self-reported medication, surgery and operation codes, and family history (father’s, mother’s and siblings’ illnesses were combined into a single phenotype for each of the 12 family history illnesses ascertained in the UKB questionnaires). Quantitative phenotypes included biomarkers such as blood cell count, blood biochemistry, infectious disease antigen assays and physical measurements. A list of all phenotypes with phenotype categories, UKB field numbers and phenotype full names can be found in Supplementary Table 9.
We restricted the phenome-wide association analysis to 321,843 unrelated UKB EUR samples and excluded binary phenotypes with fewer than 100 cases in our analysis. PTV burden testing for binary phenotypes was performed in all individuals using logistic regression, controlling for sex, age, age2, sex by age interaction, sex by age2 interaction, top 20 PCs and assessment centers. For binary phenotypes with a PTV burden association P < 0.01, we repeated the analysis using Firth’s logistic regression to account for situations where the logistic regression outputs may be biased due to separation81. For quantitative phenotypes, we excluded phenotypes with fewer than 100 observations. For each quantitative phenotype, individuals with outlier phenotype values (>5 s.d. from the mean) were excluded. The PTV burden test for quantitative traits was performed using linear regression on rank-based inverse-normal transformed phenotypes in all individuals, controlling for sex, age, age2, sex by age, sex by age2, top 20 PCs and assessment centers. We defined a Bonferroni-corrected phenome-wide significance threshold (using the number of tests per gene) of 1.59 × 10−5 (0.05/3,150).
Characterization of cognitive phenotypes in KDM5B and CACNA1A PTV carriers
KDM5B is an established Mendelian disease gene, with HOM or compound HET mutations causing autosomal recessive ID (MIM 618109) (refs. 44,45). Similarly, CACNA1A is also an established disease gene with HET mutations causing developmental and epileptic encephalopathy (MIM 617106) (refs. 41,42), type 2 episodic ataxia (MIM 108500) (ref. 40) or spinocerebellar ataxia (MIM 183086) (refs. 38,39). To better understand the relationship between PTVs in KDM5B and CACNA1A and cognitive function phenotypes, we first processed EDU and VNR in the UKB EUR samples by residualizing EDU and VNR with sex, age, age2, sex by age interaction, sex by age2 interaction, top 20 PCs and recruitment centers and then standardized the residuals using rank-based inverse-normal transformation. Then, we plotted the standardized, residualized EDU and VNR for each PTV carrier against the genomic position of the PTV to characterize the phenotypic distribution of KDM5B and CACNA1A PTV carriers. We further compared the standardized, residualized EDU and VNR between three groups of PTV carriers for KDM5B and CACNA1A: (1) PTV carriers who do not have any inpatient ICD-10 diagnostic codes for neurological, psychiatric or neurodegenerative disorders or carry ClinVar pathogenic or likely pathogenic variants; (2) PTV carriers with inpatient ICD-10 diagnostic codes for neurological, psychiatric or neurodegenerative disorders; (3) PTV carriers of ClinVar pathogenic or likely pathogenic variants.
Kdm5b mouse model
To experimentally investigate the potential additive dosage effect of Kdm5b LoF, we performed behavioral tests, morphological measurements and brain differential gene expression analysis in WT, HET and HOM Kdm5b LoF mice. A mouse Kdm5b LoF allele (Mouse Genome Informatics ID: 6153378) was generated previously45 using CRISPR/CAS9 mediated deletion of coding exon 7 (ENSMUSE00001331577), leading to premature translational termination due to a downstream frameshift. Breeding of testing cohorts was performed on a C57BL/6NJ background. Mice were housed in specific pathogen‐free mouse facilities with a 12-hour light–dark cycle (lights on at 7:30), an ambient room temperature of 21 °C and 55% humidity at the Research Support Facility of the Wellcome Sanger Institute. They were in mixed genotype cages (2–5 mice), and housed in individually ventilated cages (GM500, Tecniplast) containing Aspen chip bedding and environmental enrichment (Nestlets nesting material and cardboard play tunnels, Datesand). Food and water were provided ad libitum.
We applied a battery of behavioral tests commonly used to study mice for signs of perturbed neurodevelopment, including light–dark box (adapted from Gapp et al.82), Barnes maze probe trial and new object recognition (Supplementary Information). We assessed a cohort of 25 WT, 34 HET and 15 HOM Kdm5b mutant male mice at 10 weeks of age. Behavioral tests were carried out between 9:00 and 17:00, after 1 hour of habituation to the testing room. Experimenters were blind to genotype; mouse movements were recorded with an overhead infrared video camera for later tracking using automated video tracking (EthoVision XT 11.5, Noldus Information Technology). We also measured mouse cranial length and width, skull height and transitional vertebrae phenotype with X-ray whole-body radiography for 15 Kdm5b+/+, 12 Kdm5b+/− and 9 Kdm5b−/− mice (Supplementary Information).
All statistical analyses of mouse data were performed using R (v.4.1.3). Data were first transformed to achieve normality, using Box–Cox transformation (MASS package v.7.3–55) for behavioral data (λ limit = −2, 2) or quantile normalization (qnorm function) for X-ray data. Testing for genotype effect was performed using a double generalized linear model (dglm package v.1.8.5). The type of object used for new object recognition had a small (6%) and significant (P = 0.036) effect; therefore, it was used as a covariate for Box–Cox transformation and dglm. For visualization purposes, residual values were calculated from the linear model and z-scores were calculated relative to WT.
We also performed differential gene expression analysis for the Kdm5b mouse to assess the impact of the Kdm5b HET and HOM mutations on brain gene expression. RNA-seq was done for whole-brain embryonic tissue, and for the FC, HIP and CB of adult WT, HET and HOM Kdm5b mice. Differential gene expression and log2 fold changes were obtained, and P values for differences in gene expression were calculated. A P threshold of 0.10 was used to identify significant differences between WT and mutant samples. In addition, Gene Ontology (GO) enrichment analysis was performed to identify functionally enriched terms in the DEGs (with a 5% FDR threshold). In all analyses, the background consisted of only genes expressed in the tissue studied. GO terms with more than 1,000 genes were excluded from the analysis. The European Nucleotide Archive (ENA) accession numbers for the RNA-seq sequences reported are listed in Supplementary Table 17. Further details on Kdm5b mouse RNA extraction, sequencing, data processing and analyses can be found in the Supplementary Information.
Overlapping rare and common variant association signals
To compare and contrast the genetic loci identified through the common variant association tests in GWAS to the genes identified in our rare PTV burden analysis, we cross-checked all independent genome-wide significant variants in the most recent, largest EDU GWAS5 and cognitive function GWAS4 with the 13 cognitive function-associated genes identified in the current study. For the EDU GWAS, we assessed the independent genome-wide significant variants listed in Lee et al.5 (See Supplementary Table 2 for any nearby genes with significant PTV burden association with cognitive function phenotypes.) We identified one SNP, rs10798888 (chr1:31733498 (GRCh38); MAF = 0.1725; EDU association P = 5.15 × 10−14), where ADGRB2 (PTV burden P = 8.55 × 10−12 for EDU in the UKB EUR samples) is located in a nearby region. We then extracted the region surrounding SNP rs10798888 from the full summary statistics of the EDU GWAS (excluding the 23andMe data) obtained from the Social Science Genetic Association Consortium (SSGAC), generated regional plots (https://my.locuszoom.org/)83 of the GWAS results and compared these with the cognitive function phenotypes (EDU and VNR) among PTV carriers in the UKB EUR samples. Variants in the GWAS regional plots were further annotated for previous GWAS associations registered in the GWAS catalog using LocusZoom’s automated annotation feature.
For the cognitive function GWAS, we processed the GWAS summary statistics from Lam et al.4 with a GWAS summary statistics QC pipeline50 and used FUMA84 to identify independent genome-wide-significant loci for cognitive function from the GWAS. We identified one genome-wide-significant locus with the top independent genome-wide-significant SNP rs5751191 (chr22:41974987 (GRCh38), association P = 2.02 × 10−12) that overlapped with NDUFA6 (PTV burden P = 6.98 × 10−6, FDR Q = 0.016 for EDU in the UKB EUR samples). We extracted variants in the region that covered the variants in linkage disequilibrium with the top SNP rs5751191 (R2 > 0.6) to generate a regional plot and identified genes in the region to extract the corresponding PTV burden association P values and the number of PTV carriers in the UKB EUR samples.
Contributions of common variants and rare damaging coding variants to EDU and VNR
We examined the relative contribution of common variants and rare damaging coding variants to cognitive function. To do so, we first calculated the PRS to capture the impact of genome-wide common variants on cognitive function, using imputed genome-wide genotypes and variant weights derived using PRS-CS47 based on a cognitive function GWAS meta-analysis4 and a precomputed linkage disequilibrium reference panel based on the 1000 Genomes Project phase 3 EUR superpopulation samples. The cognitive function GWAS meta-analysis included only samples of EUR ancestry from the latest cognitive genomics consortium (COGENT) data freeze, excluding samples from the UKB4. The PRS-CS global shrinkage parameter ϕ was set to 0.01 because cognitive function is highly polygenic4. Using PRS-CS-derived variant weights and QC-imputed genotypes, we calculated PRS as a weighted sum of counted alleles across the genome using PLINK v.2.00. Then, after the exome-wide burden analysis, we identified rare damaging coding variant carriers as carriers of rare PTV or damaging missense variants with an MPC > 2 in LOF-intolerant genes (pLI > 0.9) across the exome.
To demonstrate the relative impact of PRS and rare damaging coding variant carrier status, we plotted standardized, residualized EDU and VNR against PRS, stratified according to rare damaging coding variant carrier status in unrelated UKB EUR samples. The phenotypes were residualized by sex, age, age2, sex by age interaction, sex by age2 interaction, top 20 PCs and recruitment centers and then rank-based inverse-normal transformed. The samples were grouped by PRS in 20% or 2% quantiles and are shown in Fig. 5 and Extended Data Fig. 9. The median of standardized, residualized EDU and VNR was calculated and plotted for each PRS group. We further assessed the prediction performance of cognitive function PRS and rare damaging coding variant carrier status for EDU and VNR. We fitted linear regression models by regressing rank-based inverse-normal transformed EDU and VNR on PRS and rare damaging coding variant carrier status jointly, adjusted for covariates, in unrelated UKB EUR samples. The regression coefficients, association P values and partial R2 were estimated85. We further examined the interaction between PRS and rare damaging coding variant carrier status by adding an interaction term to the linear regression model and tested for significant interaction effects. We also modeled PRS as both a continuous and a binary variable by dividing samples in the top 10% PRS group versus the remaining 90%.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Online content
Any methods, additional references, Nature Portfolio reporting summaries, source data, extended data, supplementary information, acknowledgements, peer review information; details of author contributions and competing interests; and statements of data and code availability are available at 10.1038/s41588-023-01398-8.
Supplementary information
Supplementary Methods, Note and Figs. 1–9.
Acknowledgements
We thank all the participants and researchers of the UKB. The use of UKB data (WES, genome-wide genotyping and phenotypic data) in the current study is approved under application no. 26041. We thank the participants and researchers of the MGBB for providing genomic and health information data. We thank all study participants for their generous participation at the THL Biobank, the FINRISK 1992–2012, Health 2000–2011, SUPER-Finland and NFID studies. The healthy control samples and data used in the NFID study analysis were obtained from the THL Biobank. We thank the staff from the Wellcome Sanger Institute’s Research Support Facility for mouse husbandry and support, the Sanger Institute Sample Management and DNA Pipelines for providing the RNA-seq and V. Iyer and G. G. Noell (Human Genetics Informatics, Wellcome Sanger Institute) for bioinformatics support. M.L. and T.L. were supported by the National Institute of Mental Health of the National Institutes of Health (NIH) under award no. R01MH117646 (T.L., principal investigator). The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
Extended data
Source data
Statistical source data.
Author contributions
C.-Y.C. and H.R. conceived and supervised the study. C.-Y.C., R.T., T.G., M.L., T.S., L.U. and J.Z.L. performed the analyses. G.S.-A., M.S., C.R. and H.I. conducted the mouse experiments. M.E.H. and S.S.G. supervised the mouse experiments. M.D. and A.P. supervised the analyses in the SUPER and NFID studies. C.-Y.C. and H.R. wrote the original manuscript. R.T., T.G., M.L., G.S.-A., T.S., L.U., T.F., M.D., A.P., E.A.T., H.H., M.E.H., S.S.G. and T.L. critically revised the manuscript. All authors reviewed and approved the final version of the manuscript.
Peer review
Peer review information
Nature Genetics thanks the anonymous reviewers for their contribution to the peer review of this work.
Data availability
Full summary of the PTV burden association results derived from the UKB in this study can be found in Supplementary Table 4. For instructions on how to access the UKB exome sequencing data, see https://www.ukbiobank.ac.uk/enable-your-research/research-analysis-platform. For the SUPER-Finland study, individual-level genotype and diagnosis data are available through the THL biobank (https://thl.fi/en/web/thl-biobank/for-researchers/sample-collections/super-study). For the NFID study, due to consent and EU privacy regulations (General Data Protection Regulation), individual-level data can be used for research defined in the consent. Upon reasonable requests, aggregate-level data can be requested from the Institute of Molecular Medicine, University of Helsinki (FIMM) data access committee (fimm-dac@helsinki.fi); individual-level data can be used for collaborative research given that it is within the scope of the consent. Individual-level data are handled in a dedicated computational environment designated by FIMM. MGBB data are not publicly available due to privacy and ethical restrictions. Please contact the MGBB for further information on data access (https://www.massgeneralbrigham.org/en/research-and-innovation/participate-in-research/biobank/for-researchers). All Kdm5b mouse RNA-seq sequences (GRCm38) can be found at the ENA archive (https://www.ebi.ac.uk/ena/browser/home) using the accession numbers listed in Supplementary Table 17. The pLI score is available at https://storage.googleapis.com/gcp-public-data–gnomad/release/2.1.1/constraint/gnomad.v2.1.1.lof_metrics.by_gene.txt.bgz. The MPC score is available at ftp://ftp.broadinstitute.org/pub/ExAC_release/release1/regional_missense_constraint/ (open access ftp site, no registration required). The Brainspan RNA-seq data are available at https://www.brainspan.org/static/download.html. The Human Protein Atlas data are available at https://www.proteinatlas.org/humanproteome/brain/human+brain. The DDG2P gene list is available at https://www.deciphergenomics.org/ddd/ddgenes. The SSGAC EDU GWAS summary statistics are available at https://thessgac.com/ (registration required); the EDU GWAS summary statistics file used in this study can be accessed at https://thessgac.com/papers/3/12 (accessible after registration). Source data are provided with this paper.
Code availability
The code used in this study can be found at Zenodo (10.5281/zenodo.7822074) (ref. 86). The software and software packages used include: R v.3.6.1 and v.4.1.3 (packages gprofiler2 v.0.2.1, MASS v.7.3-55, dglm v.1.8.5, data.table v.1.12.8, dplyr v.1.0.0, ggplot2 v.3.3.l, GSA v.1.03.l); PRS-CS v.1.0.0 (https://github.com/getian107/PRScs); PLINK v.2.00 (https://www.cog-genomics.org/plink/2.0); PLINK v.1.90 beta (https://www.cog-genomics.org/plink/); VEP v.96 (https://useast.ensembl.org/info/docs/tools/vep/index.html); LOFTEE (https://github.com/konradjk/loftee); regenie v.1.0.6.7 (https://rgcgithub.github.io/regenie/); Hail v.0.2 (https://github.com/hail-is/hail); LocusZoom v.0.14.0 (https://my.locuszoom.org/); FUMA v.1.3.7 (https://fuma.ctglab.nl/); FastQC v.0.11.8 (https://github.com/s-andrews/FastQC); STAR v.2.7.3a (https://code.google.com/archive/p/rna-star/); featureCounts v.2.0.0 (https://subread.sourceforge.net/); and DESeq2 v.1.34.0 (http://www.bioconductor.org/packages/release/bioc/html/DESeq2.html).
Competing interests
C.-Y.C., T.F., E.A.T., H.R. and members of the Biogen Biobank team are employees of Biogen. R.T. is an employee of Dewpoint Therapeutics. J.Z.L. is an employee of GSK. M.E.H. is a cofounder, shareholder and nonexecutive director of Congenica, and an advisor to AstraZeneca. The other authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A list of authors and their affiliations appears at the end of the paper.
Contributor Information
Chia-Yen Chen, Email: chiayenc@gmail.com.
Heiko Runz, Email: heiko.runz@gmail.com.
The SUPER-Finland study:
Aija Kyttälä, Amanda Elliott, Anders Kämpe, Andre Sourander, Annamari Tuulio-Henriksson, Anssi Solismaa, Antti Tanskanen, Ari Ahola-Olli, Arto Mustonen, Arttu Honkasalo, Asko Wegelius, Atiqul Mazumder, Auli Toivola, Benjamin Neale, Elina Hietala, Elmo Saarentaus, Erik Cederlöf, Erkki Isometsä, Heidi Taipale, Imre Västrik, Jaana Suvisaari, Jari Tiihonen, Jarmo Hietala, Johan Ahti, Jonne Lintunen, Jouko Lönnqvist, Juha Veijola, Julia Moghadampour, Jussi Niemi-Pynttäri, Kaisla Lahdensuo, Katja Häkkinen, Katriina Hakakari, Kimmo Suokas, Marjo Taivalantti, Markku Lähteenvuo, Martta Kerkelä, Minna Holm, Nina Lindberg, Noora Ristiluoma, Olli Kampman, Olli Pietiläinen, Risto Kajanne, Sari Lång-Tonteri, Solja Niemelä, Steven E. Hyman, Susanna Rask, Teemu Männynsalo, Tiina Paunio, Tuomas Jukuri, Tuomo Kiiskinen, Tuula Kieseppä, Ville Mäkipelto, Willehard Haaki, and Zuzanna Misiewicz
The Northern Finland Intellectual Disability study:
Mitja I. Kurki, Jarmo Körkkö, Jukka Moilanen, and Outi Kuismin
Extended data
is available for this paper at 10.1038/s41588-023-01398-8.
Supplementary information
The online version contains supplementary material available at 10.1038/s41588-023-01398-8.
References
- 1.Lam M, et al. Large-scale cognitive GWAS meta-analysis reveals tissue-specific neural expression and potential nootropic drug targets. Cell Rep. 2017;21:2597–2613. doi: 10.1016/j.celrep.2017.11.028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Davies G, et al. Study of 300,486 individuals identifies 148 independent genetic loci influencing general cognitive function. Nat. Commun. 2018;9:2098. doi: 10.1038/s41467-018-04362-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Savage JE, et al. Genome-wide association meta-analysis in 269,867 individuals identifies new genetic and functional links to intelligence. Nat. Genet. 2018;50:912–919. doi: 10.1038/s41588-018-0152-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Lam M, et al. Identifying nootropic drug targets via large-scale cognitive GWAS and transcriptomics. Neuropsychopharmacology. 2021;46:1788–1801. doi: 10.1038/s41386-021-01023-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Lee JJ, et al. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat. Genet. 2018;50:1112–1121. doi: 10.1038/s41588-018-0147-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Okbay A, et al. Polygenic prediction of educational attainment within and between families from genome-wide association analyses in 3 million individuals. Nat. Genet. 2022;54:437–449. doi: 10.1038/s41588-022-01016-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.McRae JF, et al. Prevalence and architecture of de novo mutations in developmental disorders. Nature. 2017;542:433–438. doi: 10.1038/nature21062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Niemi MEK, et al. Common genetic variants contribute to risk of rare severe neurodevelopmental disorders. Nature. 2018;562:268–271. doi: 10.1038/s41586-018-0566-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Grove J, et al. Identification of common genetic risk variants for autism spectrum disorder. Nat. Genet. 2019;51:431–444. doi: 10.1038/s41588-019-0344-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Lord C, et al. Autism spectrum disorder. Nat. Rev. Dis. Primers. 2020;6:5. doi: 10.1038/s41572-019-0138-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Satterstrom FK, et al. Autism spectrum disorder and attention deficit hyperactivity disorder have a similar burden of rare protein-truncating variants. Nat. Neurosci. 2019;22:1961–1965. doi: 10.1038/s41593-019-0527-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Satterstrom FK, et al. Large-scale exome sequencing study implicates both developmental and functional changes in the neurobiology of autism. Cell. 2020;180:568–584. doi: 10.1016/j.cell.2019.12.036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Kaplanis J, et al. Evidence for 28 genetic disorders discovered by combining healthcare and research data. Nature. 2020;586:757–762. doi: 10.1038/s41586-020-2832-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Ganna A, et al. Ultra-rare disruptive and damaging mutations influence educational attainment in the general population. Nat. Neurosci. 2016;19:1563–1565. doi: 10.1038/nn.4404. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ganna A, et al. Quantifying the impact of rare and ultra-rare coding variation across the phenotypic spectrum. Am. J. Hum. Genet. 2018;102:1204–1211. doi: 10.1016/j.ajhg.2018.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Sudlow C, et al. UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 2015;12:e1001779. doi: 10.1371/journal.pmed.1001779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Bycroft C, et al. The UK Biobank resource with deep phenotyping and genomic data. Nature. 2018;562:203–209. doi: 10.1038/s41586-018-0579-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Van Hout CV, et al. Exome sequencing and characterization of 49,960 individuals in the UK Biobank. Nature. 2020;586:749–756. doi: 10.1038/s41586-020-2853-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Szustakowski JD, et al. Advancing human genetics research and drug discovery through exome sequencing of the UK Biobank. Nat. Genet. 2021;53:942–948. doi: 10.1038/s41588-021-00885-0. [DOI] [PubMed] [Google Scholar]
- 20.Wang Q, et al. Rare variant contribution to human disease in 281,104 UK Biobank exomes. Nature. 2021;597:527–532. doi: 10.1038/s41586-021-03855-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Backman JD, et al. Exome sequencing and analysis of 454,787 UK Biobank participants. Nature. 2021;599:628–634. doi: 10.1038/s41586-021-04103-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Sun BB, et al. Genetic associations of protein-coding variants in human disease. Nature. 2022;603:95–102. doi: 10.1038/s41586-022-04394-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Lyall DM, et al. Cognitive test scores in UK Biobank: data reduction in 480,416 participants and longitudinal stability in 20,346 participants. PLoS ONE. 2016;11:e0154222. doi: 10.1371/journal.pone.0154222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Demange PA, et al. Investigating the genetic architecture of noncognitive skills using GWAS-by-subtraction. Nat. Genet. 2021;53:35–44. doi: 10.1038/s41588-020-00754-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Abdellaoui A, Verweij KJH. Dissecting polygenic signals from genome-wide association studies on human behaviour. Nat. Hum. Behav. 2021;5:686–694. doi: 10.1038/s41562-021-01110-y. [DOI] [PubMed] [Google Scholar]
- 26.Deary IJ, Johnson W, Starr JM. Are processing speed tasks biomarkers of cognitive aging? Psychol. Aging. 2010;25:219–228. doi: 10.1037/a0017750. [DOI] [PubMed] [Google Scholar]
- 27.Deary IJ. Intelligence. Curr. Biol. 2013;23:R673–R676. doi: 10.1016/j.cub.2013.07.021. [DOI] [PubMed] [Google Scholar]
- 28.McLaren W, et al. The Ensembl Variant Effect Predictor. Genome Biol. 2016;17:122. doi: 10.1186/s13059-016-0974-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Karczewski KJ, et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature. 2020;581:434–443. doi: 10.1038/s41586-020-2308-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Singh T, et al. Rare coding variants in ten genes confer substantial risk for schizophrenia. Nature. 2022;604:509–516. doi: 10.1038/s41586-022-04556-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Samocha, K. E. et al. Regional missense constraint improves variant deleteriousness prediction. Preprint at bioRxiv10.1101/148353 (2017).
- 32.Lek M, et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature. 2016;536:285–291. doi: 10.1038/nature19057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Fuller ZL, Berg JJ, Mostafavi H, Sella G, Przeworski M. Measuring intolerance to mutation in human genetics. Nat. Genet. 2019;51:772–776. doi: 10.1038/s41588-019-0383-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Mbatchou J, et al. Computationally efficient whole-genome regression for quantitative and binary traits. Nat. Genet. 2021;53:1097–1103. doi: 10.1038/s41588-021-00870-7. [DOI] [PubMed] [Google Scholar]
- 35.Kurki MI, et al. Contribution of rare and common variants to intellectual disability in a sub-isolate of Northern Finland. Nat. Commun. 2019;10:410. doi: 10.1038/s41467-018-08262-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Deaton AM, et al. Gene-level analysis of rare variants in 379,066 whole exome sequences identifies an association of GIGYF1 loss of function with type 2 diabetes. Sci. Rep. 2021;11:21565. doi: 10.1038/s41598-021-99091-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Jurgens SJ, et al. Analysis of rare genetic variation underlying cardiometabolic diseases and traits among 200,000 individuals in the UK Biobank. Nat. Genet. 2022;54:240–250. doi: 10.1038/s41588-021-01011-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Subramony SH, Fratkin JD, Manyam BV, Currier RD. Dominantly inherited cerebello-olivary atrophy is not due to a mutation at the spinocerebellar ataxia-I, Machado–Joseph disease, or Dentato-Rubro–Pallido-Luysian atrophy locus. Mov. Disord. 1996;11:174–180. doi: 10.1002/mds.870110210. [DOI] [PubMed] [Google Scholar]
- 39.Zhuchenko O, et al. Autosomal dominant cerebellar ataxia (SCA6) associated with small polyglutamine expansions in the alpha 1A-voltage-dependent calcium channel. Nat. Genet. 1997;15:62–69. doi: 10.1038/ng0197-62. [DOI] [PubMed] [Google Scholar]
- 40.Subramony SH, et al. Novel CACNA1A mutation causes febrile episodic ataxia with interictal cerebellar deficits. Ann. Neurol. 2003;54:725–731. doi: 10.1002/ana.10756. [DOI] [PubMed] [Google Scholar]
- 41.Allen AS, et al. De novo mutations in epileptic encephalopathies. Nature. 2013;501:217–221. doi: 10.1038/nature12439. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Myers CT, et al. De novo mutations in SLC1A2 and CACNA1A are important causes of epileptic encephalopathies. Am. J. Hum. Genet. 2016;99:287–298. doi: 10.1016/j.ajhg.2016.06.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Indelicato E, Boesch S. From genotype to phenotype: expanding the clinical spectrum of CACNA1A variants in the era of next generation sequencing. Front. Neurol. 2021;12:639994. doi: 10.3389/fneur.2021.639994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Faundes V, et al. Histone lysine methylases and demethylases in the landscape of human developmental disorders. Am. J. Hum. Genet. 2018;102:175–187. doi: 10.1016/j.ajhg.2017.11.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Martin HC, et al. Quantifying the contribution of recessive coding variation to developmental disorders. Science. 2018;362:1161–1164. doi: 10.1126/science.aar6731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Kang HJ, et al. Spatio-temporal transcriptome of the human brain. Nature. 2011;478:483–489. doi: 10.1038/nature10523. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Ge T, Chen C-Y, Ni Y, Feng YA, Smoller JW. Polygenic prediction via Bayesian regression and continuous shrinkage priors. Nat. Commun. 2019;10:1776. doi: 10.1038/s41467-019-09718-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Abdellaoui A, Dolan CV, Verweij KJH, Nivard MG. Gene–environment correlations across geographic regions affect genome-wide association studies. Nat. Genet. 2022;54:1345–1354. doi: 10.1038/s41588-022-01158-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.de la Fuente J, Davies G, Grotzinger AD, Tucker-Drob EM, Deary IJ. A general dimension of genetic sharing across diverse cognitive traits inferred from molecular data. Nat. Hum. Behav. 2021;5:49–58. doi: 10.1038/s41562-020-00936-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Lam M, et al. Collective genomic segments with differential pleiotropic patterns between cognitive dimensions and psychopathology. Nat. Commun. 2022;13:6868. doi: 10.1038/s41467-022-34418-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Lencz T, et al. Novel ultra-rare exonic variants identified in a founder population implicate cadherins in schizophrenia. Neuron. 2021;109:1465–1478. doi: 10.1016/j.neuron.2021.03.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Dey BK, et al. The histone demethylase KDM5b/JARID1b plays a role in cell fate decisions by blocking terminal differentiation. Mol. Cell. Biol. 2008;28:5312–5327. doi: 10.1128/MCB.00128-08. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Schmitz SU, et al. Jarid1b targets genes regulating development and is involved in neural differentiation. EMBO J. 2011;30:4586–4600. doi: 10.1038/emboj.2011.383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Han M, Xu W, Cheng P, Jin H, Wang X. Histone demethylase lysine demethylase 5B in development and cancer. Oncotarget. 2017;8:8980–8991. doi: 10.18632/oncotarget.13858. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Lebrun N, et al. Novel KDM5B splice variants identified in patients with developmental disorders: functional consequences. Gene. 2018;679:305–313. doi: 10.1016/j.gene.2018.09.016. [DOI] [PubMed] [Google Scholar]
- 56.Fry A, et al. Comparison of sociodemographic and health-related characteristics of UK Biobank participants with those of the general population. Am. J. Epidemiol. 2017;186:1026–1034. doi: 10.1093/aje/kwx246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Batty GD, Gale CR, Kivimäki M, Deary IJ, Bell S. Comparison of risk factor associations in UK Biobank against representative, general population based studies with conventional response rates: prospective cohort study and individual participant meta-analysis. BMJ. 2020;368:m131. doi: 10.1136/bmj.m131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Plenge RM, Scolnick EM, Altshuler D. Validating therapeutic targets through human genetics. Nat. Rev. Drug Discov. 2013;12:581–594. doi: 10.1038/nrd4051. [DOI] [PubMed] [Google Scholar]
- 59.Plenge RM. Priority index for human genetics and drug discovery. Nat. Genet. 2019;51:1073–1075. doi: 10.1038/s41588-019-0460-5. [DOI] [PubMed] [Google Scholar]
- 60.Jose A, et al. Histone demethylase KDM5B as a therapeutic target for cancer therapy. Cancers. 2020;12:2121. doi: 10.3390/cancers12082121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Vallianatos CN, Iwase S. Disrupted intricacy of histone H3K4 methylation in neurodevelopmental disorders. Epigenomics. 2015;7:503–519. doi: 10.2217/epi.15.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Xhabija B, Kidder BL. KDM5B is a master regulator of the H3K4-methylome in stem cells, development and cancer. Semin. Cancer Biol. 2019;57:79–85. doi: 10.1016/j.semcancer.2018.11.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Kuchenbaecker KB, et al. Evaluation of polygenic risk scores for breast and ovarian cancer risk prediction in BRCA1 and BRCA2 mutation carriers. J. Natl Cancer Inst. 2017;109:djw302. doi: 10.1093/jnci/djw302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Oetjens MT, Kelly MA, Sturm AC, Martin CL, Ledbetter DH. Quantifying the polygenic contribution to variable expressivity in eleven rare genetic disorders. Nat. Commun. 2019;10:4897. doi: 10.1038/s41467-019-12869-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Fahed AC, et al. Polygenic background modifies penetrance of monogenic variants for tier 1 genomic conditions. Nat. Commun. 2020;11:3635. doi: 10.1038/s41467-020-17374-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Duncan L, et al. Analysis of polygenic risk score usage and performance in diverse human populations. Nat. Commun. 2019;10:3328. doi: 10.1038/s41467-019-11112-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Karavani E, et al. Screening human embryos for polygenic traits has limited utility. Cell. 2019;179:1424–1435. doi: 10.1016/j.cell.2019.10.033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Turley P, et al. Problems with using polygenic scores to select embryos. N. Engl. J. Med. 2021;385:78–86. doi: 10.1056/NEJMsr2105065. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Castro VM, et al. The Mass General Brigham Biobank Portal: an i2b2-based data repository linking disparate and high-dimensional patient data to support multimodal analytics. J. Am. Med. Inform. Assoc. 2022;29:643–651. doi: 10.1093/jamia/ocab264. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Li H, Durbin R. Fast and accurate short read alignment with Burrows–Wheeler transform. Bioinformatics. 2009;25:1754–1760. doi: 10.1093/bioinformatics/btp324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Lin, M. F. et al. GLnexus: joint variant calling for large cohort sequencing. Preprint at bioRxiv10.1101/343970 (2018).
- 72.Frankish A, et al. GENCODE reference annotation for the human and mouse genomes. Nucleic Acids Res. 2019;47:D766–D773. doi: 10.1093/nar/gky955. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.McCarthy S, et al. A reference panel of 64,976 haplotypes for genotype imputation. Nat. Genet. 2016;48:1279–1283. doi: 10.1038/ng.3643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Walter K, et al. The UK10K project identifies rare variants in health and disease. Nature. 2015;526:82–90. doi: 10.1038/nature14962. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Auton A, et al. A global reference for human genetic variation. Nature. 2015;526:68–74. doi: 10.1038/nature15393. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Chang CC, et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. Gigascience. 2015;4:7. doi: 10.1186/s13742-015-0047-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Trubetskoy V, et al. Mapping genomic loci implicates genes and synaptic biology in schizophrenia. Nature. 2022;604:502–508. doi: 10.1038/s41586-022-04434-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Stahl EA, et al. Genome-wide association study identifies 30 loci associated with bipolar disorder. Nat. Genet. 2019;51:793–803. doi: 10.1038/s41588-019-0397-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Howard DM, et al. Genome-wide meta-analysis of depression identifies 102 independent variants and highlights the importance of the prefrontal brain regions. Nat. Neurosci. 2019;22:343–352. doi: 10.1038/s41593-018-0326-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Sjöstedt E, et al. An atlas of the protein-coding genes in the human, pig, and mouse brain. Science. 2020;367:eaay5947. doi: 10.1126/science.aay5947. [DOI] [PubMed] [Google Scholar]
- 81.Heinze G. A comparative investigation of methods for logistic regression with separated or nearly separated data. Stat. Med. 2006;25:4216–4226. doi: 10.1002/sim.2687. [DOI] [PubMed] [Google Scholar]
- 82.Gapp K, et al. Potential of environmental enrichment to prevent transgenerational effects of paternal trauma. Neuropsychopharmacology. 2016;41:2749–2758. doi: 10.1038/npp.2016.87. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Boughton AP, et al. LocusZoom.js: interactive and embeddable visualization of genetic association study results. Bioinformatics. 2021;37:3017–3018. doi: 10.1093/bioinformatics/btab186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Watanabe K, Taskesen E, van Bochoven A, Posthuma D. Functional mapping and annotation of genetic associations with FUMA. Nat. Commun. 2017;8:1826. doi: 10.1038/s41467-017-01261-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Efron B. Regression and ANOVA with zero-one data: measures of residual variation. J. Am. Stat. Assoc. 1976;73:113–121. [Google Scholar]
- 86.Chen, C.-Y. et al. Scripts for the manuscript ‘The impact of rare protein coding genetic variation on adult cognitive function’. Zenodohttps://zenodo.org/record/7713321 (2023). [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Methods, Note and Figs. 1–9.
Data Availability Statement
Full summary of the PTV burden association results derived from the UKB in this study can be found in Supplementary Table 4. For instructions on how to access the UKB exome sequencing data, see https://www.ukbiobank.ac.uk/enable-your-research/research-analysis-platform. For the SUPER-Finland study, individual-level genotype and diagnosis data are available through the THL biobank (https://thl.fi/en/web/thl-biobank/for-researchers/sample-collections/super-study). For the NFID study, due to consent and EU privacy regulations (General Data Protection Regulation), individual-level data can be used for research defined in the consent. Upon reasonable requests, aggregate-level data can be requested from the Institute of Molecular Medicine, University of Helsinki (FIMM) data access committee (fimm-dac@helsinki.fi); individual-level data can be used for collaborative research given that it is within the scope of the consent. Individual-level data are handled in a dedicated computational environment designated by FIMM. MGBB data are not publicly available due to privacy and ethical restrictions. Please contact the MGBB for further information on data access (https://www.massgeneralbrigham.org/en/research-and-innovation/participate-in-research/biobank/for-researchers). All Kdm5b mouse RNA-seq sequences (GRCm38) can be found at the ENA archive (https://www.ebi.ac.uk/ena/browser/home) using the accession numbers listed in Supplementary Table 17. The pLI score is available at https://storage.googleapis.com/gcp-public-data–gnomad/release/2.1.1/constraint/gnomad.v2.1.1.lof_metrics.by_gene.txt.bgz. The MPC score is available at ftp://ftp.broadinstitute.org/pub/ExAC_release/release1/regional_missense_constraint/ (open access ftp site, no registration required). The Brainspan RNA-seq data are available at https://www.brainspan.org/static/download.html. The Human Protein Atlas data are available at https://www.proteinatlas.org/humanproteome/brain/human+brain. The DDG2P gene list is available at https://www.deciphergenomics.org/ddd/ddgenes. The SSGAC EDU GWAS summary statistics are available at https://thessgac.com/ (registration required); the EDU GWAS summary statistics file used in this study can be accessed at https://thessgac.com/papers/3/12 (accessible after registration). Source data are provided with this paper.
The code used in this study can be found at Zenodo (10.5281/zenodo.7822074) (ref. 86). The software and software packages used include: R v.3.6.1 and v.4.1.3 (packages gprofiler2 v.0.2.1, MASS v.7.3-55, dglm v.1.8.5, data.table v.1.12.8, dplyr v.1.0.0, ggplot2 v.3.3.l, GSA v.1.03.l); PRS-CS v.1.0.0 (https://github.com/getian107/PRScs); PLINK v.2.00 (https://www.cog-genomics.org/plink/2.0); PLINK v.1.90 beta (https://www.cog-genomics.org/plink/); VEP v.96 (https://useast.ensembl.org/info/docs/tools/vep/index.html); LOFTEE (https://github.com/konradjk/loftee); regenie v.1.0.6.7 (https://rgcgithub.github.io/regenie/); Hail v.0.2 (https://github.com/hail-is/hail); LocusZoom v.0.14.0 (https://my.locuszoom.org/); FUMA v.1.3.7 (https://fuma.ctglab.nl/); FastQC v.0.11.8 (https://github.com/s-andrews/FastQC); STAR v.2.7.3a (https://code.google.com/archive/p/rna-star/); featureCounts v.2.0.0 (https://subread.sourceforge.net/); and DESeq2 v.1.34.0 (http://www.bioconductor.org/packages/release/bioc/html/DESeq2.html).