

Abstract
Quantum machine learning models have shown successful generalization performance even when trained with few data. In this work, through systematic randomization experiments, we show that traditional approaches to understanding generalization fail to explain the behavior of such quantum models. Our experiments reveal that state-of-the-art quantum neural networks accurately fit random states and random labeling of training data. This ability to memorize random data defies current notions of small generalization error, problematizing approaches that build on complexity measures such as the VC dimension, the Rademacher complexity, and all their uniform relatives. We complement our empirical results with a theoretical construction showing that quantum neural networks can fit arbitrary labels to quantum states, hinting at their memorization ability. Our results do not preclude the possibility of good generalization with few training data but rather rule out any possible guarantees based only on the properties of the model family. These findings expose a fundamental challenge in the conventional understanding of generalization in quantum machine learning and highlight the need for a paradigm shift in the study of quantum models for machine learning tasks.
Subject terms: Quantum information, Qubits, Computational science
Understanding machine learning models’ ability to extrapolate from training data to unseen data - known as generalisation - has recently undergone a paradigm shift, while a similar understanding for their quantum counterparts is still missing. Here, the authors show that uniform generalization bounds pessimistically estimate the performance of quantum machine learning models.
Introduction
Quantum devices promise applications in solving computational problems beyond the capabilities of classical computers1–5. Given the paramount importance of machine learning in a wide variety of algorithmic applications that make predictions based on training data, it is a natural thought to investigate to what extent quantum computers may assist in tackling machine learning tasks. Indeed, such tasks are commonly listed among the most promising candidate applications for near-term quantum devices6–9. To date, within this emergent field of quantum machine learning (QML) a body of literature is available that heuristically explores the potential of improving learning algorithms by having access to quantum devices10–20. Among the models considered, parameterized quantum circuits (PQCs), also known as quantum neural networks (QNNs), take center stage in those considerations21–23. For fine-tuned problems in quantum machine learning, quantum advantages in computational complexity have been proven over classical computers24–27, but to date, such advantages rely on the availability of full-scale quantum computers, not being within reach for near-term architectures. While for PQCs such an advantage has not been shown yet, a growing body of literature is available that investigates their expressivity28–34, trainability35–44, and generalization45–60—basically aimed at understanding what to expect from such quantum models. Among those studies, the latter notions of generalization are particularly important since they are aimed at providing guarantees on the performance of QML models with unseen data after the training process.
The importance of notions of generalization for PQCs is actually reflecting the development in classical machine learning: Vapnik’s contributions61 have laid the groundwork for the formal study of statistical learning systems. This methodology was considered standard in classical machine learning theory until roughly the last decade. However, the mindset put forth in this work has been disrupted by seminal work62 demonstrating that the conventional understanding of generalization is unable to explain the great success of large-scale deep convolutional neural networks. These networks, which display orders of magnitude more trainable parameters than the dimensions of the images they process, defied conventional wisdom concerning generalization.
Employing clever randomization tests derived from non-parametric statistics63, the authors of ref. 62 exposed cracks in the foundations of Vapnik’s theory and its successors64, at least when applied to specific, state-of-the-art, large networks. Established complexity measures, such as the well-known VC dimension or Rademacher complexity65, among others, were inadequate in explaining the generalization behavior of large classical neural networks. Their findings, in the form of numerical experiments, directly challenge many of the well-established uniform generalization bounds for learning models, such as those derived in, e.g., refs. 66–68. Uniform generalization bounds apply uniformly to all hypotheses across an entire function family. Consequently, they fail to distinguish between hypotheses with good out-of-sample performance and those which completely overfit the training data. Moreover, uniform generalization bounds are oblivious to the difference between real-world data and randomly corrupted patterns. This inherent uniformity is what grants long reach to the randomization tests: exposing a single instance of poor generalization is sufficient to reduce the statements of mathematical theorems to mere trivially loose bounds.
This state of affairs has important consequences for the emergent field of QML, as we explore here. Noteworthy, current generalization bounds in quantum machine learning models have essentially uniquely focused on uniform variants. Consequently, our present comprehension remains akin to the classical machine learning canon before the advent of ref. 62. This observation raises a natural question as to whether the same randomization tests would yield analogous outcomes when applied to quantum models. In classical machine learning, it is widely acknowledged that the scale of deep neural networks plays a crucial role in generalization. Analogously, it is widely accepted that current QML models are considerably distant from that size scale. In this context, one would not anticipate similarities between current QML models and high-achieving classical learning models56,57.
In this article, we provide empirical, long-reaching evidence of unexpected behavior in the field of generalization, with quite arresting conclusions. In fact, we are in the position to challenge notions of generalization, building on similar randomization tests that have been used in ref. 62. As it turns out, they already yield surprising results when applied to near-term QML models employing quantum states as inputs. Our empirical findings, also in the form of numerical experiments, reveal that uniform generalization bounds may not be the right approach for current-scale QML. To corroborate this body of numerical work with a rigorous underpinning, we show how QML models can assign arbitrary labels to quantum states. Specifically, we show that PQCs are able to perfectly fit training sets of polynomial size in the number of qubits. By revealing this ability to memorize random data, our results rule out the good generalization guarantees with few training data from uniform bounds54,58. To clarify, our experiments do not study the generalization capacity of state-of-the-art QML. Instead, we expose the limitation of uniform generalization bounds when applied to these models. While QML models have demonstrated good generalization performance in some settings20,47,54,58,69–71, our contributions do not explain why or how they achieve it. We highlight that the reasons behind their successful generalization remain elusive.
Results
Statistical learning theory background
We begin by briefly introducing the necessary terminology for discussing our findings in the framework of supervised learning. We denote as the input domain and as the set of possible labels. We assume there is an unknown but fixed distribution from which the data originate. Let represent the family of functions that map to . The expected risk functional R then quantifies the predictive accuracy of a given function f for data sampled according to . The training set, denoted as S, comprises N samples drawn from . The empirical risk then evaluates the performance of a function f on the restricted set S. The difference between R(f) and is referred to as the generalization gap, defined as
| 1 |
The dependence of gen(f) on S is implied, as evident from the context. Similarly, the dependence of R(f), , and gen(f) on is also implicit. We employ to represent any complexity measure of a function family, such as the VC dimension, the Rademacher complexity, or others65. It is important to note that these measures are properties of the whole function family , and not of single functions .
In the traditional framework of statistical learning, the way in which the aforementioned concepts relate to one another is as follows. The primary goal of supervised learning is to minimize the expected risk R associated to a learning task, which is an unattainable goal by construction. The so-called bias-variance trade-off stems from rewriting the expected risk as a sum of the two terms
| 2 |
This characterization as a trade-off arises from the conventional understanding that diminishing one of these components invariably leads to an increase of the other. Two negative scenarios exist at the extremes of the trade-off. Underfitting occurs when the model exhibits high bias, resulting in an imperfect classification of the training set. Conversely, overfitting arises when the model displays high variance, leading to a perfect classification of the training set. Overfitting is considered detrimental as it may cause the learning models to learn spurious correlations induced by noise in the training data. Accommodating this noise in the data would consequently lead to suboptimal performance on new data, i.e., poor generalization. Concerning the model selection problem, practitioners are thus tasked with identifying a model with the appropriate model capacity for each learning task, aiming to strike a balance in the trade-off. These notions are explained more extensively in refs. 52,53.
The previously described scenario is no longer applicable, as demonstrated below. Modern-day (quantum) learning models display good generalization performance while being able to completely overfit the data. This phenomenon is sometimes linked to the ability of learning models to memorize data. The term memorization is defined here as the occurrence of overfitting without concurrent generalization. It is essential to clarify that overfitting, in this context, means perfect fitting of the training set, regardless of its generalization performance. Furthermore, a model is considered to have memorized a training set when both overfitting and poor generalization occur simultaneously. Overall, a high model capacity, particularly in relation to memorization ability, is found to be non-detrimental in addressing learning tasks of practical significance. This phenomenon was initially characterized for large (overparameterized) deep neural networks in ref. 62. In this manuscript, we present analogous, unexpected behavior for current-scale (non-overparameterized) parameterized quantum circuits.
Randomization tests
Our goal is to improve our understanding of PQCs as learning models. In particular, we tread in the domain of generalization and its interplay with the ability to memorize random data. The main idea of our work builds on the theory of randomization tests from non-parametric statistics63. Figure 1 contains a visualization of our framework.
Fig. 1. Visualization of our framework.

a In the empirical experiments, a distribution of labeled quantum data undergoes a randomization process, leading to a corrupted data distribution . The training and a test set are drawn independently from each distribution. Then, the training sets are fed into an optimization algorithm, which is employed to identify the best fit for each data set individually from a family of parameterized quantum circuits . This process generates two hypotheses: one for the original data foriginal and another for the corrupted data fcorrupted. We empirically find that the labeling functions can perfectly fit the training data, leading to small training errors. In parallel, foriginal achieves a small test error, indicating good learning performance, and quantified by a small generalization gap gen(foriginal) = small. On the contrary, the randomization process causes fcorrupted to achieve a large test error, which in turn results in a large generalization gap gen(fcorrupted) = large. b Regarding uniform generalization bounds, it is worth noting that this corner of QML literature assigns the same upper bound gunif to the entire function family without considering the specific characteristics of each individual function. Finally, we combine two significant findings: (1) We have identified a hypothesis with a large empirical generalization gap, and (2) the uniform generalization bounds impose identical upper bounds on all hypotheses. Consequently, we conclude that any uniform generalization bound derived from the literature must be regarded as “large'', indicating that all such bounds are loose for that training data size. The notion of loose generalization bound does not exclude the possibility of achieving good generalization; rather, it fails to explain or predict such successful behavior.
Initially, we train QNNs on quantum states whose labels have been randomized and compare the training accuracy achieved by the same learning model when trained on the true labels. Our results reveal that, in many cases, the models learn to classify the training data perfectly, regardless of whether the labels have been randomized. By altering the input data, we reach our first finding:
Observation 1
(Fitting random labels). Existing QML models can accurately fit random labels to quantum states.
Next, we randomize only a fraction of the labels. We observe a steady increase in the generalization error as the label noise rises. This suggests that QNNs are capable of extracting the residual signal in the data while simultaneously fitting the noisy portion using brute-force memorization.
Observation 2
(Fitting partially corrupted labels). Existing QML models can accurately fit partially corrupted labels to quantum states.
In addition to randomizing the labels, we also explore the effects of randomizing the input quantum states themselves and conclude:
Observation 3
(Fitting random quantum states). Existing QML models can accurately fit labels to random quantum states.
These randomization experiments result in a remarkably large generalization gap after training without changing the circuit structure, the number of parameters, the number of training examples, or the learning algorithm. As highlighted in ref. 62 for classical learning models, these straightforward experiments have far-reaching implications:
Quantum neural networks already show memorization capability for quantum data.
The trainability of a model remains largely unaffected by the absence of correlation between input states and labels.
Randomizing the labels does not change any properties of the learning task other than the data itself.
In the following, we present our experimental design and the formal interpretation of our results. Even though it would seem that our results contradict established theorems, we elucidate how and why we can prove that uniform generalization bounds are vacuous for currently tested models.
Numerical results
Here, we show the numerical results of our randomization tests, focusing on a candidate architecture and a well-established classification problem: the quantum convolutional neural network (QCNN)69 and the classification of quantum phases of matter.
Classifying quantum phases of matter accurately is a relevant task for the study of condensed-matter physics72,73. Moreover, due to its significance, it frequently appears as a benchmark problem in the literature72,74. In our experiments, we consider the generalized cluster Hamiltonian
| 3 |
where n is the number of qubits, Xi and Zi are Pauli operators acting on the ith qubit, and j1 and j2 are coupling strengths. Specifically, we classify states according to which one of four symmetry-protected topological phases they display. As demonstrated in ref. 75, and depicted in Fig. 2, the ground-state phase diagram comprises the phases: (I) symmetry-protected topological, (II) ferromagnetic, (III) anti-ferromagnetic, and (IV) trivial.
Fig. 2. Phase diagram of the generalized cluster Hamiltonian.
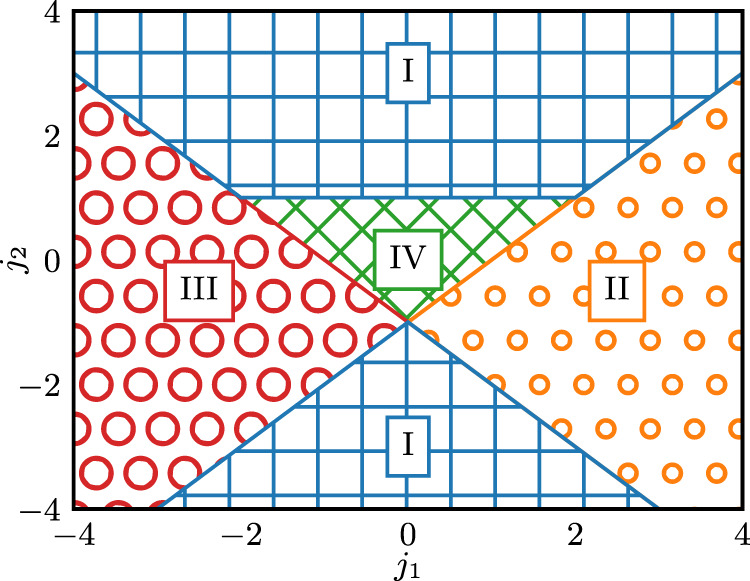
The ground-state phase diagram of the Hamiltonian of Eq. (3). It comprises the phases: (I) symmetry-protected topological, (II) ferromagnetic, (III) anti-ferromagnetic, and (IV) trivial.
The learning task we undertake involves identifying the correct quantum phase given the ground state of the generalized cluster Hamiltonian for some choice of (j1, j2). We generate a training set by sampling coupling coefficients uniformly at random in the domain j1, j2 ∈ [ − 4, 4], with N being the number of training data points, representing the ground state vectors of H corresponding to the sampled (j1, j2), and yi denoting the corresponding phase label among the aforementioned phases. In particular, labels are length-two bit strings yi ∈ {(0, 0), (0, 1), (1, 0), (1, 1)}.
We employ the QCNN architecture presented in ref. 69 to address the classification problem. By adapting classical convolutional neural networks to a quantum setting, QCNNs are particularly well-suited for tasks involving spatial and temporal patterns, which makes this architecture a natural choice for phase classification problems. A unique feature of the QCNN architecture is the interleaving of convolutional and pooling layers. Convolutional layers consist of translation-invariant parameterized unitaries applied to neighboring qubits, functioning as filters between feature maps across different layers of the QCNN. Following the convolutional layer, pooling layers are introduced to reduce the dimensionality of the quantum state while retaining the relevant features of the data. This is achieved by measuring a subset of qubits and applying translationally invariant parameterized single-qubit unitaries based on the corresponding measurement outcomes. Thus, each pooling layer consistently reduces the number of qubits by a constant factor, leading to quantum circuits with logarithmic depth relative to the initial system size. These circuits share a structural similarity to the multiscale entanglement renormalization ansatz76. Nevertheless, in instances where the input state to the QCNN exhibits, e.g., a high degree entanglement, the efficient classical simulation of the circuit becomes infeasible.
The operation of a QCNN can be interpreted as a quantum channel specified by parameters ϑ, mapping an input state ρin into an output state ρout, represented as . Subsequently, the expectation value of a task-oriented Hermitian operator is measured, utilizing the resulting ρout.
Our implementation follows that presented in ref. 54. The QCNN maps an input state vector , consisting of n qubits, into a 2-qubit output state. For the labeling function given the output state, we use the probabilities of the outcome of each bit string when the state is measured in the computational basis (p00, p01, p10, p11). In particular, we predict the label according to the measurement outcome with the lowest probability according to
| 4 |
For each experiment repetition, we generate data from the corresponding distribution . For training, we use the loss function
| 5 |
This classification rule and loss function, which involve selecting the outcome with the lowest probability, was already utilized in ref. 54. The authors found that employing this seemingly counter-intuitive loss function lead to good generalization performance. Thus, given a training set , we minimize the empirical risk
| 6 |
We consider three ways of altering the original data distribution from where data is sampled, namely: (a) data wherein true labels are replaced by random labels , (b) randomization of only a fraction r ∈ [0, 1] of the data, mixing real and corrupted labels in the same distribution , and (c) replacing the input quantum states with random states , instead of randomizing the labels. In each of these randomization experiments, the generalization gap and the risk functionals are defined according to the relevant distribution . In all cases, the correlations between states and labels are gradually lost, which means we can control how much signal there is to be learned. In experiments where data-label correlations have vanished entirely, learning is impossible. One could expect the impossibility of learning to manifest itself during the training process, e.g., through lack of convergence. We observe that training the QCNN model on random data results in almost perfect classification performance on the training set. At face value, this means the QCNN is able to memorize noise.
In the following experiments, we approximate the expected risk R with an empirical risk using a large test set T. This test set is sampled independently from the same distribution as the training set S. In particular, the test set contains 1000 points for all the experiments, .
Additionally, we report our results using the probability of error, which is further elucidated below. Consequently, we employ the term error instead of risk. Henceforth, we refer to test accuracy and test error as accurate proxies for the true accuracy and expected risk, respectively. All our experiments follow a three-step process:
Create a training set and a test set .
Find a function f that approximately minimizes the empirical risk of Eq. (6).
Compute the training error , test error , and the empirical generalization gap .
For ease of notation, we shall employ gen(f) instead of genT(f) while discussing the generalization gap without reiterating its empirical nature.
Random labels
We start our randomization tests by drawing data from , wherein the true labels have been replaced by random labels sampled uniformly from {(0, 0), (0, 1), (1, 0), (1, 1)}. In order to sample from , a labeled pair can be obtained from the original data distribution , after which the label y can be randomly replaced. In this experiment, we have employed QCNNs with varying numbers of qubits n ∈ {8, 16, 32}. For each qubit number, we have generated training sets with different sizes N ∈ {5, 8, 10, 14, 20} for both random and real labels. The models were trained individually for each (n, N) combination.
In Fig. 3a, we illustrate the results obtained when fitting random and real labels, as well as random states (discussed later). Each data point in the figure represents the average generalization gap achieved for a fixed training set size N for the different qubit numbers n. We observe a large gap for the random labels, close to 0.75, which should be seen as effectively maximal: perfect training accuracy and the same test accuracy as random guessing would yield. This finding suggests that the QCNN can be adjusted to fit the random labels in the training set, despite the labels bearing no correlation to the input states. As the training set sizes increase, since the capacity of the QCNN is fixed, achieving a perfect classification accuracy for the entire training set becomes increasingly challenging. Consequently, the generalization gap diminishes. It is worth noting that a decrease in training accuracy is also observed for the true labeling of data54.
Fig. 3. Randomization tests for quantum phase recognition.

a Generalization gap as a function of the training set size achieved by the quantum convolutional neural network (QCNN) architecture. The QCNN is trained on real data, random label data, and random state data. The horizontal dashed line is the largest generalization gap attainable, characterized by zero training error and test error equal to random guessing (0.75 due to the task having four possible classes). The shaded area corresponds to the standard deviation across different experiment repetitions. For the real data and random labels, we employed 8, 16, and 32 qubits, while for the random states, we employed 8, 10, and 12 qubits. We observe that both random labels and random states exhibit a similar trend in the generalization gap, with a slight discrepancy in height due to the different relative frequencies of the four classes under the respective randomization protocols. In both cases, the test accuracy fails to surpass that of random guessing. Notably, the largest generalization gap occurs in the random labels experiments when using a training set of up to size N = 10, highlighting the memorization capacity of this particular QCNN. The training with uncorrupted data yields behavior in accordance with previous results54. b Test error as a function of the ratio of label corruption after training the QCNN on training sets of size N ∈ 4, 6, 8 and n = 8. The plot illustrates the interpolation between uncorrupted data (r = 0) and random labels (r = 1). As the label corruption approaches 1, the test accuracy drops to levels of random guessing. The dependence between the test error and label corruption reveals the ability of the QCNN to extract remaining signal despite the noise in the initial training set. The inset focuses on the case N = 6. It conveys the optimization speed for four different levels of corruption, namely, 0, 2, 4, and 6 out of 6 labels being corrupted, and provides insights into the average convergence time. The shaded area denotes the variance over five experiment repetitions with independently initialized QCNN parameters. Surprisingly, on average, fitting completely random noise takes less time than fitting unperturbed data. This phenomenon emphasizes that QCNNs can accurately memorize random data.
Corrupted labels
Next to the randomization of labels, we further investigate the QCNN fitting behavior when data come with varying levels of label corruption , ranging from no labels being altered (r = 0) to all of them being corrupted (r = 1). The experiments consider different number of training points N ∈ {4, 6, 8}, and a fixed number of qubits n = 8. For each combination of (n, N), we start the experiments with no randomized labels (r = 0). Then, we gradually increase the ratio of randomized labels until all labels are altered, that is, r ∈ {0, 1/N, 2/N, …, 1}. Figure 3b shows the test error after convergence. In all repetitions, this experiment reaches 100% training accuracy. We observe a steady increase in the test error as the noise level intensifies. This suggests that QCNNs are capable of extracting the remaining signal in the data while simultaneously fitting the noise by brute force. As the label corruption approaches 1, the test error converges to 75%, corresponding to the performance of random guessing.
The inset in Fig. 3b focuses on the experiments conducted with N = 6 training points. In particular, we examine the relationship between the learning speed and the ratio of random labels. The plot shows an average over five experiment repetitions. Remarkably, each individual run exhibits a consistent pattern: the training error initially remains high, but it converges quickly once the decrease starts. This behavior was also reported for classical neural networks62. The precise moment at which the training error begins to decrease seems to be heavily dependent on the random initialization of the parameters. However, it also relates to the signal-to-noise ratio r in the training data. Notably, we observe a long and stable plateau for the intermediate cases r = 1/3 and r = 2/3, roughly halfway between the starting training error and zero. This plateau represents an average between those runs where the rapid decrease has not yet started and those where the convergence has already been achieved, leading to significant variance. Interestingly, in the complete absence of correlation between states and labels (r = 1), the QCNN, on average, perfectly fits the training data even slightly faster than for the real labels (r = 0).
Random states
In this scenario, we introduce randomness to the input ground state vectors rather than to the labels. Our goal is to introduce a certain degree of randomization into the quantum states while preserving some inherent structure in the problem. To achieve this, we define the data distribution for the random quantum states in a specific manner instead of just drawing pure random states uniformly.
To sample data from , we first draw a pair from the original distribution , and then we apply the following transformation to the state vector : We compute the mean μψ and variance σψ of its amplitudes and then sample new amplitudes randomly from a Gaussian distribution . After the new amplitudes are obtained, we normalize them. The random state experiments were performed with varying numbers of qubits n ∈ {8, 10, 12} and training set sizes N ∈ {5, 8, 10, 14, 20}.
In Fig. 3a, we show the results for fitting random input states, together with the random and real label experiment outcomes. The empirical generalization gaps achieved by the QCNN for random states exhibit a similar shape to those obtained for random labels. Indeed, a slight difference in the relative occurrences of each of the four classes leads to improved performance by biased random guessing. We observe that the QCNN can perfectly fit the training set for few data, and then the generalization gap decreases, analogously to the scenario with random labels.
The case of random states presents an intriguing aspect. The QCNN architecture was initially designed to unveil and exploit local correlations in input quantum states69. However, our randomization protocol in this experiment removes precisely all local information, leaving only global information from the original data, such as the mean and the variance of the amplitudes. This was not the case in the random labels experiment, where the input ground states remained unaltered while only the labels were modified. The ability of the QCNN to memorize random data seems to be unaffected despite its structure to exploit local information.
Implications
Our findings indicate that novel approaches are required in studying the capabilities of quantum neural networks. Here, we elucidate how our experimental results fit the statistical learning theoretic framework. The main goal of machine learning is to find the expected risk minimizer fopt associated with a given learning task,
| 7 |
However, given the unknown nature of the complete data distribution , the evaluation of R becomes infeasible. Consequently, we must resort to its unbiased estimator, the empirical risk . We let an optimization algorithm obtain f*, an approximate empirical risk minimizer
| 8 |
Nonetheless, although is an unbiased estimator for R(f), it remains uncertain whether the empirical risk minimizer f* will yield a low expected risk R(f*). The generalization gap gen(f) then comes in as the critical quantity of interest, quantifying the difference in performance on the training set and the expected performance on the entire domain R(f).
In the literature, extensive efforts have been invested in providing robust guarantees on the magnitude of the generalization gap of QML models through so-called generalization bounds45–52,54,58,59,65. These theorems assert that under reasonable assumptions, the generalization gap of a given model can be upper bounded by a quantity that can depend on various parameters. These include properties of the function family, the optimization algorithm used, or the data distribution. The derivation of a generalization bound for a learning model typically involves rigorous mathematical calculations and often considers restricted scenarios. Many results in the literature fit the following template:
Generic uniform generalization bound
Let be a hypothesis class, and let be any data-generating distribution. Let R be a risk functional associated to , and its empirical version, for a given set of N labeled data: . Let be a complexity measure of . Then, for any function , the generalization gap gen(f) can be upper bounded, with high probability, by
| 9 |
where usually is given explicitly. We make the dependence of gunif on N implicit for clarity. The high probability is taken with respect to repeated sampling from of sets S of size N.
We refer to these as uniform generalization bounds by virtue of them being equal for all elements f in the class . Also, these bounds apply irrespective of the probability distribution . There exists a singular example that does not fit the template in ref. 57. In this particular case, the authors introduce a robustness-based complexity measure, resulting in a bound that depends on both the data distribution and the learned hypothesis, albeit very indirectly. As a result, it presents difficulties for quantitative predictions.
The usefulness of uniform generalization bounds lies in their ability to provide performance guarantees for a model before undertaking any computationally expensive training. Thus, it becomes of interest to identify ranges of values for and N that result in a diminishing or entirely vanishing generalization gap (such as the limit N → ∞). These bounds usually deal with asymptotic regimes. Thus it is sometimes unclear how tight their statements are for practical scenarios.
In cases where the risk functional is itself bounded, we can further refine the bound. For example, if we take Re to be the probability of error
| 10 |
we can immediately say that, for any f, there is a trivial upper bound on the generalization gap gen(f)≤1. Thus, the generalization bound could be rewritten as
| 11 |
This additional threshold renders the actual value of of considerable significance.
We now have the necessary tools to discuss the results of our experiments properly. Randomizing the data simply involves changing the data-generating distribution, e.g., from the original to a randomized . As we have just remarked, the r.h.s. of Eq. (9) does not change for different distributions, implying that the same upper bound on the generalization gap applies to both data coming from , or corrupted data from . If data from is such that inputs and labels are uncorrelated, then any hypothesis cannot be better than random guessing in expectation. This results in the expected risk value being close to its maximum. For instance, in the case of the probability of error and a classification task with M classes, if each input is assigned a class uniformly at random, then it must hold for any hypothesis f,
| 12 |
indicating that the expected risk must always be large.
A large risk for a particular example does not generally imply a large generalization gap gen(f) ≉ Re(f). For instance, if a learning model is unable to fit a corrupted training set S, , then one would have a small generalization gap gen(f) ≈ 0. Conversely, for the generalization gap of f to be large gen(f) ≈ 1 − 1/M, the learning algorithm must find a function that can actually fit S, with . Yet, even in this last scenario, the uniform generalization bound still applies.
Let us denote the size of the largest training set S for which we found a function fr able to fit the random data (which leads to a large generalization gap gen(fr) ≈ 1 − 1/M). Since the uniform generalization bound applies to all functions in the class , we have found
| 13 |
as an empirical lower bound to the generalization bound. This reveals that the generalization bound is vacuous for training sets of size up to . Noteworthy is also that, further than , there is a regime where the generalization bound remains impractically large.
The strength of our results resides in the fact that we did not need to specify a complexity measure . Our empirical findings apply to every uniform generalization bound, irrespective of its derivation. This gives strong evidence for the need for a perspective shift to the study of generalization in quantum machine learning.
Analytical results
In the previous section, we provided evidence that QNNs can accurately fit random labels in near-term experimental set-ups. Our empirical findings are restricted to the number of qubits and training samples we tested. While these limitations seem restrictive, they are actually the relevant regimes of interest, considering the empirical evidence. In this section, we formally study the memorization capability of QML models of arbitrary size, beyond the NISQ era, in terms of finite sample expressivity. Our goal is to establish sufficient conditions for demonstrating how QML models could fit arbitrary training sets, and not to establish that it is always possible in a worst-case scenario.
Finite sample expressivity refers to the ability of a function family to memorize arbitrary data. In general, expressivity is the ability of a hypothesis class to approximate functions in the entire domain . Conversely, finite sample expressivity studies the ability to approximate functions on fixed-size subsets of . Although finite sample expressivity is a weaker notion of expressivity, it can be seen as a stronger alternative to the pseudo-dimension of a hypothesis family45,65.
The importance of finite sample expressivity lies in the fact that machine learning tasks always deal with finite training sets. Suppose a given model is found to be able to realize any possible labeling of an available training set. Then, reasonably one would not expect the model to learn meaningful insights from the training data. It is plausible that some form of learning may still occur, albeit without a clear understanding of the underlying mechanisms. However, under such circumstances, uniform generalization bounds would inevitably become trivial.
Theorem 1
(Finite sample expressivity of quantum circuits). Let ρ1, …, ρN be unknown quantum states on qubits, with , and let W be the Gram matrix
| 14 |
If W is well-conditioned, then, for any real numbers, we can construct a quantum circuit of depth poly(n) as an observable such that
| 15 |
The proof is given in Supplementary Note 1. Theorem 1 gives us a constructive approach to, given a finite set of quantum states and real labels, find a quantum circuit that produces each of the labels as the expectation value for each of the input states. This should give an intuition for why QML models seem capable of learning random labels and random quantum states. Nevertheless, as stated, the theorem falls short in applying specifically to PQCs. The construction we propose requires query access to the set of input states every time the circuit is executed. We estimate the values employing the SWAP test. The circuit that realizes the SWAP test bears little relation to usual QML ansätze. Ideally, if possible, one should impose a familiar PQC structure and drop the need to use the input states.
Next, we propose an alternative, more restricted version of the same statement, keeping QML in mind as the desired application. For it, we need a sense of distinguishability of quantum states.
Definition 1
(Distinguishability condition). We say n-qubit quantum states ρ1, …, ρN fulfill the distinguishability condition if we can find intermediate states based on some generic quantum state approximation protocol such that they fulfill the following:
For each i ∈ [N], is efficiently preparable with a PQC.
- The matrix can be efficiently constructed, with entries
16 The matrix is well-conditioned.
Notable examples of approximation protocols are those inspired by classical shadows77 or tensor networks78. For instance, similarly to classical shadows, one could draw unitaries from an approximate poly(n)-design using a brickwork ansatz with poly(n)-many layers of i.i.d. Haar random 2-local gates. For a given quantum state ρ, one produces several pairs (U, b) where U is the randomly drawn unitary and b is the bit-string outcome after performing a computational basis measurement of UρU†, and one refers to each individual pair as a snapshot. Notice that this approach does not follow exactly the traditional classical shadows protocol. Our end goal is to prepare the approximation as a PQC, rather than utilizing it for classical simulation purposes. In particular, we do not employ the inverse measurement channel, since that would break complete positivity and thus the corresponding approximation would not be a quantum state. For each snapshot, one can efficiently prepare the corresponding quantum state by undoing the unitary that was drawn after preparing the corresponding computational basis state vector . Given a collection of snapshots {(U1, b1), …, (UM, bM)}, an approximation protocol would consist of preparing the mixed state . Since each bm is prepared with at most n Pauli-X gates and each Um is a brickwork PQC architecture, this approximation protocol fulfills the restriction of efficient preparation from Definition 1. Whether or not this or any other generic approximation protocol is accurate enough for a specific choice of quantum states we discuss in Methods’ subsection “Analytical methods”. There, we present an algorithm in Box 1 together with its correctness statement as Theorem 3. Given the input states ρ1, …, ρN Box 1 moreover allows to combine several quantum state approximation protocols in order to produce a well-conditioned matrix of inner products .
Theorem 2
(Finite sample expressivity of PQCs) Let ρ1, …, ρN be unknown quantum states on qubits, with , and fulfilling the distinguishability condition of Definition 1. Then, we can construct a PQC of poly(n) depth as a parameterized observable such that, for any real numbers, we can efficiently find a specification of the parameters ϑy such that
| 17 |
The proof is given in Supplementary Note 2, which uses ideas reminiscent to the formalism of linear combinations of unitary operations79. With Theorem 2, we understand that PQCs can produce any labeling of arbitrary sets of quantum states, provided they fulfill our distinguishability condition.
Notice that Definition 1 is needed for the correctness of Theorem 2. We require knowledge of an efficient classical description of the quantum states for two main reasons. On the one hand, PQCs are the object of our study. Hence, we need to prepare the approximation efficiently as a PQC. In addition, on the other hand, the distinguishability condition is also enough to prevent us from running into computation-complexity bottle-necks, like those arising from the distributed inner product estimation results in ref. 80.
Discussion
We next discuss the implications of our results and suggest research avenues to explore in the future. We have shown that quantum neural networks (QNNs) can fit random data, including randomized labels or quantum states. We provided a detailed explanation of how to place our findings in a statistical learning theory context. We do not claim that uniform generalization bounds are wrong or that any prior results are false. Instead, we show that the statements of theorems that fit our generic uniform template must be vacuous for the regimes where the models are able to fit a large fraction of random data. We have brought the randomization tests of ref. 62 to the quantum level. We have selected one of the most promising QML architectures for our experiments, known as the quantum convolutional neural network (QCNN). We have considered the task of classifying quantum phases of matter, which is a state-of-the-art application of QML.
Our numerical results suggest that we must reach further than uniform generalization bounds to fully understand quantum machine learning (QML) models. In particular, experiments like ours immediately problematize approaches based on complexity measures like the VC dimension, the Rademacher complexity, and all their uniform relatives. To the best of our knowledge, essentially all generalization bounds derived for QML so far are of the uniform kind. Therefore, our findings highlight the need for a perspective shift in generalization for QML. In the future, it will be interesting to conduct causation experiments on QNNs using non-uniform generalization measures. Promising candidates for good generalization measures in QML include the time to convergence of the training procedure, the geometric sharpness of the minimum the algorithm converged to, and the robustness against noise in the data81.
The structure of the QCNN, with its equivariant and pooling layers, results in an ansatz with restricted expressivity. Its core features, including intermediate measurements, parameter-sharing, and logarithmic depth, make the QCNN a smaller model than other, deeper PQCs, like a brickwork ansatz with completely unrestricted parameters. In the language of traditional statistical learning, this translates to higher bias and lower variance. Consequently, for the same task, the QCNN tends towards underfitting, posing a greater challenge in achieving perfect fitting of the training set compared to a more expressive model. As a result, the QCNN is anticipated to exhibit better generalization behavior when compared to the usual hardware-efficient ansätze82. The QCNN thus is assigned lower generalization bounds than other larger models, due to the higher variance of the latter. Therefore, our demonstration that uniform generalization bounds applied to the QCNN family are trivially loose immediately implies that the same bounds applied to less restricted models must also be vacuous. Stated differently, our findings for a small model, the QCNN, inherently apply to all larger models, including the hardware-efficient ansatz. Furthermore, our study adds to the evidence supporting the need for a proper understanding of symmetries and equivariance in QML58,83–85.
In addition to our numerical experiments, we have analytically shown that polynomially-sized QNNs are able to fit arbitrary labeling of data sets. This seems to contradict claims that few training data are provably sufficient to guarantee good generalization in QML, raised e.g. in ref. 54. Our analytical and numerical results do not preclude the possibility of good generalization with few training data but rather indicate we cannot guarantee it with arguments based on uniform generalization bounds. The reasons why successful generalization might occur have yet to be discovered.
We employ the rest of this section to comment on the significance of our randomization experiments, and also describe the parallelisms and differences between our work and the seminal ref. 62, which served as the basis for our experimental design. In particular, two primary factors warrant consideration: the size of the model, and the size of the training set. In our learning task, quantum phase recognition problem for systems of up to 32 qubits, we use training sets comprised of up to 20 labeled pairs. In the following paragraphs we elucidate whether these should be considered large or small; capable of overfitting or memorizing; and whether the results of our experiments are due to finite sample size artifacts.
Upon first glance, the training set sizes employed in our randomization experiments may seem relatively small. However, it is essential to consider the randomization study within its relevant context. As previously mentioned, good generalization performance has been reported in QML, particularly for classifying quantum phases of matter using a QCNN architecture54. At present, this combination of model and task is also among the best leading approaches concerning generalization within the QML literature. The key fact is that our randomization tests use the same training set sizes as the original experiments which reported good generalization performance. The question whether the randomization results are caused by the relative ease to find patterns that fit the given labels from the small set of data is ruled out by the fact that these small set sizes suffice to solve the original problem. If the QCNN were able to fit the random data only because of finite sample size artifacts, we would anticipate the expected risk and the generalization gap to be considerably large even for the original data. Given our observation of successful generalization for data sampled from the original distribution, we conclude that these training sets are not too small, but rather large enough.
Both our study and ref. 62 have in common that the learning models considered were regarded as among the best in terms of generalization for state-of-the-art benchmark tasks. Also, the randomization experiments in both cases employed datasets taken from state-of-the-art experiments of the time. Yet, and in spite of the similarities, it is imperative to recognize that the learning models employed in these studies are fundamentally different. They not only operate on distinct computing platforms of a physically different nature, but also the functions produced by neural networks are typically different from those produced by parameterized quantum circuits. As a consequence, caution is warranted in expecting these two different learning models to behave equally when faced with randomization experiments based on unrelated learning tasks. The fact that the quantum and classical learning models display similar results should not be taken for granted.
A key distinction lies in the notion of overparameterization, which plays a critical role in classical machine learning. It is important to distinguish the notion of overparameterization in classical ML from the recently introduced definition of overparameterization in QML42, which under the same name, deals with different concepts. The deep networks studied in ref. 62 have far more parameters than both the dimension of the input image and the training set size. This brings us to refer to these as large models. Conversely, we argue that the QCNN qualifies as a small model. Although the number of parameters in the considered architectures is larger than the size of the training sets, they exhibit a logarithmic scaling with the number of qubits. Meanwhile, the number of dimensions of the quantum states scales exponentially. Hence, it is inappropriate to categorize the models we have investigated as large in the same way as the classical models in ref. 62. We find the ability of small quantum learning models to fit random data as unexpected, as witnessed by the many works on uniform generalization bounds for quantum models published during the aftermath of ref. 62. This observation reveals a promising research direction: not only must we rethink our approach to studying generalization in QML, but we must also recognize that the mechanisms leading to successful generalization in QML may differ entirely from those in classical machine learning. On a higher level, this work exemplifies the necessity of establishing connections between the literature on classical machine learning and the evolving field of quantum machine learning.
Methods
Numerical methods
This section provides a comprehensive description of our numerical experiments, including the computation techniques employed for the random and real label implementations, as well as the random state and partially corrupted label implementations.
Random and real label implementations
The test and training ground state vectors of the cluster Hamiltonian in Eq. (3) have been obtained as variational principles over matrix product states in a reading of the density matrix renormalization group ansatz86 through the software package Quimb87. We have utilized the matrix product state backend from TensorCircuit88 to simulate the quantum circuits. In particular, a bond dimension of χ = 40 was employed for the simulations of 16- and 32-qubit QCNNs. We find that further increasing the bond dimension does not lead to any noticeable changes in our results.
Random state and partially-corrupted label implementations
In this scenario, the test and training ground state vectors were obtained directly diagonalizing the Hamiltonian. Note that our QCNN comprised a smaller number of qubits for these examples, namely, n ∈ {8, 10, 12}. The simulation of quantum circuits was performed using Qibo89, a software framework that allows faster simulation of quantum circuits.
For all implementations, the training parameters were initialized randomly. The optimization method employed to update the parameters of the QCNN during training is the CMA-ES90, a stochastic, derivative-free optimization strategy. The code generated under the current study is also available in ref. 91.
Analytical methods
Here, we shed light on the practicalities of Definition 1, a requirement for our central Theorem 2. The algorithm in Box 1 allows for several approximation protocols to be combined to increase the chances of fulfilling the assumptions of Definition 1. Indeed, we can allow for the auxiliary states to be linear combinations of several approximation states while staying in the mindset of Definition 1. Then, we can cast the problem of finding an optimal weighting for the linear combination as a linear optimization problem with a positive semi-definite constraint.
With Theorem 3, we can assess the distinguishability condition of Definition 1 for specific states ρ1, …, ρN and specific approximation protocols. Theorem 3 also considers the case where different approximation protocols are combined, which does not contradict the requirements of Theorem 2.
Theorem 3
(Conditioning as a convex program 1). Let ρ1, …, ρN be unknown, linearly-independent quantum states on n qubits, with . For any i ∈ [N], let be approximations of ρi, each of which can be efficiently prepared using a PQC. Assume the computation of in polynomial time for any choice of i, j and k. Call σ = (σ1, …, σN). The real numbers define the auxiliary states as
| 18 |
and the matrix of inner products with entries
| 19 |
| 20 |
Then, . Further, one can then decide in polynomial time whether, given ρ1, …, ρN, σ, and , there exists a specification of such that is well-conditioned in the sense that . And, if there exists such a specification, a convex semi-definite problem (SDP) outputs an instance of α ← SDP(ρ, σ, κ) for which is well-conditioned. If it exists, one can also find in polynomial time the α with the smallest or norm.
Proof
The inequality follows from Gershgorin’s circle theorem92, given that all entries of are bounded between [0, 1]. In particular, the largest singular value of the matrix reaches the value N when all entries are 1.
The expression
| 21 |
is a linear constraint on α and , for i, j ∈ [N], while
| 22 |
in matrix ordering is a positive semi-definite constraint. is equivalent with , while means that the smallest singular value of is lower bounded by κ, being equivalent with
| 23 |
for an invertible . The test whether such a is well-conditioned hence takes the form of a semi-definite feasibility problem93. One can additionally minimize the objective functions
| 24 |
and
| 25 |
both again as linear or convex quadratic and hence semi-definite problems. Overall, the problem can be solved as a semi-definite problem, that can be solved in a run-time with low-order polynomial effort with interior point methods. Duality theory readily provides a rigorous certificate for the solution93.
In the proof, we refrain from explicitly specifying the definition of σ in relation to the original states ρ1, …, ρN. Indeed, the success criterion is that the resulting matrix is well-conditioned. As a sufficient condition, we could have required both that the Gram matrix is well-conditioned, and that for each i ∈ [N] there is at least one k ∈ [m] such that is close to ρi for some distance metric. Under this condition, we would expect to be well-conditioned. Nonetheless, this condition is not necessary. In general, it is plausible that each of the states constructed from σ are not close to each of the original states ρi, resulting in not being close to W, while still being well-conditioned. In this situation, the construction from Theorem 2 still holds.
We propose using Box 1 to construct the optimal auxiliary states , given the unknown input states ρ1, …, ρN and a collection of available approximation protocols A1, …, Am. The algorithm produces an output of either 0 in cases where no combination of the approximation states satisfies the distinguishability condition, or it provides the weights α necessary to construct the auxiliary states as a sum of approximation states. In Theorem 3, we prove the correctness of the algorithm.
The construction of σ from the input states ρ1, …, ρN plays an intuitive role in the success of Box 1. Let us consider two scenarios. First, we assume the Gram matrix of the initial states W is well-conditioned, and that for each i ∈ [N] there is at least one k ∈ [m] such that . In this instance, there exists at least one specification of real values α for which is well-conditioned. It suffices to set αj,k = δj,k, the latter denoting the Kronecker delta. This guarantees that the algorithm in Box 1 outputs a satisfactory α (potentially of minimal norm) in polynomial time. Conversely, we now consider a scenario where the approximation protocols employed to construct σ all yield failures, resulting in for all i ∈ [N] and k ∈ [m]. In this case, there is no choice of α for which is well conditioned and Box 1 necessarily outputs 0, also within polynomial time.
We refer to the proof of Theorem 2, in Supplementary Note 2, for an explanation of how to construct the intermediate states as a linear combination of auxiliary states σi without giving up the PQC framework.
Box 1 Convex optimization state approximation.
Require:
1: ρ = (ρ1, …, ρN) ⊳ Quantum states
2: A = (A1, …, Am) ⊳ State approximation algorithms
3: κ ⊳ Condition number
Ensure: α such that is well-conditioned if possible, 0 otherwise.
4:
5: for i ∈ [N], k ∈ [m] do
6:
7: end for
8:
9:
10:
11: α SDP(ρ, σ, κ) ⊳ From proof of Theorem 3
12:
13: if SDP fails then
14: return 0 ⊳ No suitable α found
15:
16: else
17: return α ⊳ well-conditioned
18: end if
Supplementary information
Acknowledgements
We would like to thank Matthias C. Caro, Vedran Dunjko, Johannes Jakob Meyer, and Ryan Sweke for useful comments on an earlier version of this manuscript and Christian Bertoni, José Carrasco, and Sofiene Jerbi for insightful discussions. We also acknowledge the BMBF (MUNIQC-Atoms, Hybrid), the BMWK (EniQmA, PlanQK), the QuantERA (HQCC), the Quantum Flagship (PasQuans2), the MATH+ Cluster of Excellence, the DFG (CRC 183, B01), the Einstein Foundation (Einstein Research Unit on Quantum Devices), and the ERC (DebuQC) for financial support.
Author contributions
The project has been conceived by C.B.-P. Experimental design has been laid out by E.G.-F. Analytical results have been proven by E.G.-F. and J.E. Numerical experiments have been performed by C.B.-P. The project has been supervised by C.B.-P. All authors contributed to writing the manuscript.
Peer review
Peer review information
Nature Communications thanks Dong-Ling Deng and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Data availability
The data used in this study are available in the Zenodo database in ref. 91.
Code availability
The code used in this study is available in the Zenodo database in ref. 91.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Jens Eisert, Email: jense@zedat.fu-berlin.de.
Carlos Bravo-Prieto, Email: c.bravo.prieto@fu-berlin.de.
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-024-45882-z.
References
- 1.Shor, P. W. Algorithms for quantum computation: discrete logarithms and factoring. In Proceedings 35th Annual Symposium on Foundations of Computer Science, 124–134 (IEEE, Santa Fe, NM, USA, 1994). 10.1109/SFCS.1994.365700.
- 2.Montanaro A. Quantum algorithms: an overview. npj Quant. Inf. 2016;2:15023. doi: 10.1038/npjqi.2015.23. [DOI] [Google Scholar]
- 3.Arute F, et al. Quantum supremacy using a programmable superconducting processor. Nature. 2019;574:505–510. doi: 10.1038/s41586-019-1666-5. [DOI] [PubMed] [Google Scholar]
- 4.Wu Y, et al. Strong quantum computational advantage using a superconducting quantum processor. Phys. Rev. Lett. 2021;127:180501. doi: 10.1103/PhysRevLett.127.180501. [DOI] [PubMed] [Google Scholar]
- 5.Hangleiter D, Eisert J. Computational advantage of quantum random sampling. Rev. Mod. Phys. 2023;95:035001. doi: 10.1103/RevModPhys.95.035001. [DOI] [Google Scholar]
- 6.Biamonte J, et al. Quantum machine learning. Nature. 2017;549:195–202. doi: 10.1038/nature23474. [DOI] [PubMed] [Google Scholar]
- 7.Dunjko V, Briegel HJ. Machine learning & artificial intelligence in the quantum domain: a review of recent progress. Rep. Prog. Phys. 2018;81:074001. doi: 10.1088/1361-6633/aab406. [DOI] [PubMed] [Google Scholar]
- 8.Schuld, M. & Petruccione, F. Machine Learning with Quantum Computers (Springer International Publishing, 2021). 10.1007/978-3-030-83098-4.
- 9.Carleo G, et al. Machine learning and the physical sciences. Rev. Mod. Phys. 2019;91:045002. doi: 10.1103/RevModPhys.91.045002. [DOI] [Google Scholar]
- 10.Schuld M, Fingerhuth M, Petruccione F. Implementing a distance-based classifier with a quantum interference circuit. Europhys. Lett. 2017;119:60002. doi: 10.1209/0295-5075/119/60002. [DOI] [Google Scholar]
- 11.Havlíček V, et al. Supervised learning with quantum-enhanced feature spaces. Nature. 2019;567:209–212. doi: 10.1038/s41586-019-0980-2. [DOI] [PubMed] [Google Scholar]
- 12.Schuld M, Killoran N. Quantum machine learning in feature Hilbert spaces. Phys. Rev. Lett. 2019;122:040504. doi: 10.1103/PhysRevLett.122.040504. [DOI] [PubMed] [Google Scholar]
- 13.Benedetti M, et al. A generative modeling approach for benchmarking and training shallow quantum circuits. npj Quant. Inf. 2019;5:45. doi: 10.1038/s41534-019-0157-8. [DOI] [Google Scholar]
- 14.Zhu D, et al. Training of quantum circuits on a hybrid quantum computer. Sci. Adv. 2019;5:eaaw9918. doi: 10.1126/sciadv.aaw9918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Pérez-Salinas A, Cervera-Lierta A, Gil-Fuster E, Latorre JI. Data re-uploading for a universal quantum classifier. Quantum. 2020;4:226. doi: 10.22331/q-2020-02-06-226. [DOI] [Google Scholar]
- 16.Coyle B, Mills D, Danos V, Kashefi E. The born supremacy: quantum advantage and training of an ising born machine. npj Quant. Inf. 2020;6:60. doi: 10.1038/s41534-020-00288-9. [DOI] [Google Scholar]
- 17.Lloyd, S., Schuld, M., Ijaz, A., Izaac, J. & Killoran, N. Quantum embeddings for machine learning. arXiv:2001.0362210.48550/arXiv.2001.03622 (2020).
- 18.Hubregtsen T, et al. Training quantum embedding kernels on near-term quantum computers. Phys. Rev. A. 2022;106:042431. doi: 10.1103/PhysRevA.106.042431. [DOI] [Google Scholar]
- 19.Rudolph MS, et al. Generation of high-resolution handwritten digits with an ion-trap quantum computer. Phys. Rev. X. 2022;12:031010. [Google Scholar]
- 20.Bravo-Prieto C, et al. Style-based quantum generative adversarial networks for Monte Carlo events. Quantum. 2022;6:777. doi: 10.22331/q-2022-08-17-777. [DOI] [Google Scholar]
- 21.Benedetti M, Lloyd E, Sack S, Fiorentini M. Parameterized quantum circuits as machine learning models. Quant. Sci. Tech. 2019;4:043001. doi: 10.1088/2058-9565/ab4eb5. [DOI] [Google Scholar]
- 22.Cerezo M, et al. Variational quantum algorithms. Nat. Rev. Phys. 2021;3:625–644. doi: 10.1038/s42254-021-00348-9. [DOI] [Google Scholar]
- 23.Bharti K, et al. Noisy intermediate-scale quantum algorithms. Rev. Mod. Phys. 2022;94:015004. doi: 10.1103/RevModPhys.94.015004. [DOI] [Google Scholar]
- 24.Sweke R, Seifert J-P, Hangleiter D, Eisert J. On the quantum versus classical learnability of discrete distributions. Quantum. 2021;5:417. doi: 10.22331/q-2021-03-23-417. [DOI] [Google Scholar]
- 25.Liu Y, Arunachalam S, Temme K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 2021;17:1013. doi: 10.1038/s41567-021-01287-z. [DOI] [Google Scholar]
- 26.Jerbi S, Trenkwalder LM, Poulsen Nautrup H, Briegel HJ, Dunjko V. Quantum enhancements for deep reinforcement learning in large spaces. PRX Quantum. 2021;2:010328. doi: 10.1103/PRXQuantum.2.010328. [DOI] [Google Scholar]
- 27.Pirnay N, Sweke R, Eisert J, Seifert J-P. A super-polynomial quantum-classical separation for density modelling. Phys. Rev. A. 2023;107:042416. doi: 10.1103/PhysRevA.107.042416. [DOI] [Google Scholar]
- 28.Sim S, Johnson PD, Aspuru-Guzik A. Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms. Adv. Quant. Tech. 2019;2:1900070. doi: 10.1002/qute.201900070. [DOI] [Google Scholar]
- 29.Bravo-Prieto C, Lumbreras-Zarapico J, Tagliacozzo L, Latorre JI. Scaling of variational quantum circuit depth for condensed matter systems. Quantum. 2020;4:272. doi: 10.22331/q-2020-05-28-272. [DOI] [Google Scholar]
- 30.Wu Y, Yao J, Zhang P, Zhai H. Expressivity of quantum neural networks. Phys. Rev. Res. 2021;3:L032049. doi: 10.1103/PhysRevResearch.3.L032049. [DOI] [PubMed] [Google Scholar]
- 31.Herman D, et al. Expressivity of variational quantum machine learning on the Boolean cube. IEEE Trans. Quant. Eng. 2023;4:1–18. doi: 10.1109/TQE.2023.3255206. [DOI] [Google Scholar]
- 32.Hubregtsen T, Pichlmeier J, Stecher P, Bertels K. Evaluation of parameterized quantum circuits: on the relation between classification accuracy, expressibility, and entangling capability. Quant. Mach. Intell. 2021;3:1–19. [Google Scholar]
- 33.Haug T, Bharti K, Kim MS. Capacity and quantum geometry of parametrized quantum circuits. PRX Quantum. 2021;2:040309. doi: 10.1103/PRXQuantum.2.040309. [DOI] [Google Scholar]
- 34.Holmes Z, Sharma K, Cerezo M, Coles PJ. Connecting ansatz expressibility to gradient magnitudes and barren plateaus. PRX Quantum. 2022;3:010313. doi: 10.1103/PRXQuantum.3.010313. [DOI] [Google Scholar]
- 35.McClean JR, Boixo S, Smelyanskiy VN, Babbush R, Neven H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 2018;9:4812. doi: 10.1038/s41467-018-07090-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Cerezo M, Sone A, Volkoff T, Cincio L, Coles PJ. Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat. Commun. 2021;12:1791. doi: 10.1038/s41467-021-21728-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Arrasmith A, Cerezo M, Czarnik P, Cincio L, Coles PJ. Effect of barren plateaus on gradient-free optimization. Quantum. 2021;5:558. doi: 10.22331/q-2021-10-05-558. [DOI] [Google Scholar]
- 38.Kim J, Kim J, Rosa D. Universal effectiveness of high-depth circuits in variational eigenproblems. Phys. Rev. Res. 2021;3:023203. doi: 10.1103/PhysRevResearch.3.023203. [DOI] [Google Scholar]
- 39.Wang S, et al. Noise-induced barren plateaus in variational quantum algorithms. Nature Comm. 2021;12:6961. doi: 10.1038/s41467-021-27045-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Pesah A, et al. Absence of barren plateaus in quantum convolutional neural networks. Phys. Rev. X. 2021;11:041011. [Google Scholar]
- 41.Marrero CO, Kieferová M, Wiebe N. Entanglement-induced barren plateaus. PRX Quantum. 2021;2:040316. doi: 10.1103/PRXQuantum.2.040316. [DOI] [Google Scholar]
- 42.Larocca M, Ju N, García-Martín D, Coles PJ, Cerezo M. Theory of overparametrization in quantum neural networks. Nat. Comp. Sci. 2023;3:542–551. doi: 10.1038/s43588-023-00467-6. [DOI] [PubMed] [Google Scholar]
- 43.Sharma K, Cerezo M, Cincio L, Coles PJ. Trainability of dissipative perceptron-based quantum neural networks. Phys. Rev. Lett. 2022;128:180505. doi: 10.1103/PhysRevLett.128.180505. [DOI] [PubMed] [Google Scholar]
- 44.Rudolph, M. S. et al. Trainability barriers and opportunities in quantum generative modeling. arXiv:2305.0288110.48550/arXiv.2305.02881 (2023).
- 45.Caro MC, Datta I. Pseudo-dimension of quantum circuits. Quant. Mach. Intell. 2020;2:14. doi: 10.1007/s42484-020-00027-5. [DOI] [Google Scholar]
- 46.Abbas A, et al. The power of quantum neural networks. Nature Comp. Sci. 2021;1:403–409. doi: 10.1038/s43588-021-00084-1. [DOI] [PubMed] [Google Scholar]
- 47.Banchi L, Pereira J, Pirandola S. Generalization in quantum machine learning: a quantum information standpoint. PRX Quantum. 2021;2:040321. doi: 10.1103/PRXQuantum.2.040321. [DOI] [Google Scholar]
- 48.Bu K, Koh DE, Li L, Luo Q, Zhang Y. Effects of quantum resources and noise on the statistical complexity of quantum circuits. Quant. Sci. Technol. 2023;8:025013. doi: 10.1088/2058-9565/acb56a. [DOI] [Google Scholar]
- 49.Bu, K., Koh, D. E., Li, L., Luo, Q. & Zhang, Y. Rademacher complexity of noisy quantum circuits. arXiv:2103.0313910.48550/arXiv.2103.03139 (2021).
- 50.Bu K, Koh DE, Li L, Luo Q, Zhang Y. Statistical complexity of quantum circuits. Phys. Rev. A. 2022;105:062431. doi: 10.1103/PhysRevA.105.062431. [DOI] [Google Scholar]
- 51.Du Y, Tu Z, Yuan X, Tao D. Efficient measure for the expressivity of variational quantum algorithms. Phys. Rev. Lett. 2022;128:080506. doi: 10.1103/PhysRevLett.128.080506. [DOI] [PubMed] [Google Scholar]
- 52.Gyurik C, Dunjko V. Structural risk minimization for quantum linear classifiers. Quantum. 2023;7:893. doi: 10.22331/q-2023-01-13-893. [DOI] [Google Scholar]
- 53.Caro MC, Gil-Fuster E, Meyer JJ, Eisert J, Sweke R. Encoding-dependent generalization bounds for parametrized quantum circuits. Quantum. 2021;5:582. doi: 10.22331/q-2021-11-17-582. [DOI] [Google Scholar]
- 54.Caro MC, et al. Generalization in quantum machine learning from few training data. Nat. Commun. 2022;13:4919. doi: 10.1038/s41467-022-32550-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Caro MC, et al. Out-of-distribution generalization for learning quantum dynamics. Nat. Commun. 2023;14:3751. doi: 10.1038/s41467-023-39381-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Qian, Y., Wang, X., Du, Y., Wu, X. & Tao, D. The dilemma of quantum neural networks. IEEE Trans. Neu. Net. Learn. Syst. 10.1109/TNNLS.2022.3208313, 1–13 (2022). [DOI] [PubMed]
- 57.Du Y, Yang Y, Tao D, Hsieh M-H. Problem-dependent power of quantum neural networks on multiclass classification. Phys. Rev. Lett. 2023;131:140601. doi: 10.1103/PhysRevLett.131.140601. [DOI] [PubMed] [Google Scholar]
- 58.Schatzki, L., Larocca, M., Nguyen, Q. T., Sauvage, F. & Cerezo, M. Theoretical guarantees for permutation-equivariant quantum neural networks. npj Quantum Inf.10, 12 (2024).
- 59.Peters, E. & Schuld, M. Generalization despite overfitting in quantum machine learning models. Quantum7, 1210 (2023).
- 60.Haug, T. & Kim, M. S. Generalization with quantum geometry for learning unitaries. arXiv:2303.1346210.48550/arXiv.2303.13462 (2023).
- 61.Vapnik VN, Chervonenkis AY. On the uniform convergence of relative frequencies of events to their probabilities. Th. Prob. Appl. 1971;16:264–280. doi: 10.1137/1116025. [DOI] [Google Scholar]
- 62.Zhang, C., Bengio, S., Hardt, M., Recht, B. & Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM. 64, 107–115 (2021).
- 63.Edgington, E. S. & Onghena, P. Randomization Tests. Statistics: A Series of Textbooks and Monographs. 4 edn. (Chapman & Hall/CRC, Philadelphia, PA, 2007).
- 64.Valiant LG. A theory of the learnable. Commun. ACM. 1984;27:1134–1142. doi: 10.1145/1968.1972. [DOI] [Google Scholar]
- 65.Shalev-Shwartz, S. & Ben-David, S. Understanding machine learning (Cambridge University Press, Cambridge, England, 2014). 10.1017/CBO9781107298019.
- 66.Vapnik, V. The Nature of Statistical Learning Theory (Springer Science & Business Media, 1999). 10.1007/978-1-4757-3264-1.
- 67.Bartlett PL, Mendelson S. Rademacher and gaussian complexities: Risk bounds and structural results. J. Mach. Learn. Res. 2003;3:463–482. [Google Scholar]
- 68.Mukherjee S, Niyogi P, Poggio T, Rifkin R. Learning theory: stability is sufficient for generalization and necessary and sufficient for consistency of empirical risk minimization. Adv. Comput. Math. 2006;25:161–193. doi: 10.1007/s10444-004-7634-z. [DOI] [Google Scholar]
- 69.Cong I, Choi S, Lukin MD. Quantum convolutional neural networks. Nat. Phys. 2019;15:1273–1278. doi: 10.1038/s41567-019-0648-8. [DOI] [Google Scholar]
- 70.Kottmann K, Metz F, Fraxanet J, Baldelli N. Variational quantum anomaly detection: Unsupervised mapping of phase diagrams on a physical quantum computer. Phys. Rev. Res. 2021;3:043184. doi: 10.1103/PhysRevResearch.3.043184. [DOI] [Google Scholar]
- 71.Jerbi, S. et al. The power and limitations of learning quantum dynamics incoherently. arXiv:2303.1283410.48550/arXiv.2303.12834 (2023).
- 72.Carrasquilla J, Melko RG. Machine learning phases of matter. Nat. Phys. 2017;13:431–434. doi: 10.1038/nphys4035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Sachdev, S. Quantum phases of matter (Cambridge University Press, Massachusetts, 2023). 10.1017/9781009212717.
- 74.Broecker P, Carrasquilla J, Melko RG, Trebst S. Machine learning quantum phases of matter beyond the fermion sign problem. Sci. Rep. 2017;7:8823. doi: 10.1038/s41598-017-09098-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Verresen R, Moessner R, Pollmann F. One-dimensional symmetry protected topological phases and their transitions. Phys. Rev. B. 2017;96:165124. doi: 10.1103/PhysRevB.96.165124. [DOI] [Google Scholar]
- 76.Vidal G. Class of quantum many-body states that can be efficiently simulated. Phys. Rev. Lett. 2008;101:110501. doi: 10.1103/PhysRevLett.101.110501. [DOI] [PubMed] [Google Scholar]
- 77.Huang H-Y, Kueng R, Preskill J. Predicting many properties of a quantum system from very few measurements. Nat. Phys. 2020;16:1050–1057. doi: 10.1038/s41567-020-0932-7. [DOI] [Google Scholar]
- 78.Rudolph, M. S., Chen, J., Miller, J., Acharya, A. & Perdomo-Ortiz, A. Decomposition of matrix product states into shallow quantum circuits. arXiv:2209.0059510.48550/arXiv.2209.00595 (2022).
- 79.Childs AM, Wiebe N. Hamiltonian simulation using linear combinations of unitary operations. Quantum Inf. Comput. 2012;12:901–924. [Google Scholar]
- 80.Anshu, A., Landau, Z. & Liu, Y. Distributed quantum inner product estimation. In Proceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing, STOC 2022, 44–51 (Association for Computing Machinery, 2022). 10.1145/3519935.3519974.
- 81.Jiang, Y., Neyshabur, B., Mobahi, H., Krishnan, D. & Bengio, S. Fantastic generalization measures and where to find them. arXiv:1912.0217810.48550/arXiv.1912.02178 (2019).
- 82.Kandala A, et al. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature. 2017;549:242–246. doi: 10.1038/nature23879. [DOI] [PubMed] [Google Scholar]
- 83.Meyer JJ, et al. Exploiting symmetry in variational quantum machine learning. PRX Quantum. 2023;4:010328. doi: 10.1103/PRXQuantum.4.010328. [DOI] [Google Scholar]
- 84.Skolik A, Cattelan M, Yarkoni S, Bäck T, Dunjko V. Equivariant quantum circuits for learning on weighted graphs. npj Quant. Inf. 2023;9:47. doi: 10.1038/s41534-023-00710-y. [DOI] [Google Scholar]
- 85.Larocca M, et al. Group-invariant quantum machine learning. PRX Quantum. 2022;3:030341. doi: 10.1103/PRXQuantum.3.030341. [DOI] [Google Scholar]
- 86.White SR. Density matrix formulation for quantum renormalization groups. Phys. Rev. Lett. 1992;69:2863. doi: 10.1103/PhysRevLett.69.2863. [DOI] [PubMed] [Google Scholar]
- 87.Gray J. QUIMB: a python library for quantum information and many-body calculations. J. Open Source Soft. 2018;3:819. doi: 10.21105/joss.00819. [DOI] [Google Scholar]
- 88.Zhang S-X, et al. Tensorcircuit: a quantum software framework for the NISQ era. Quantum. 2023;7:912. doi: 10.22331/q-2023-02-02-912. [DOI] [Google Scholar]
- 89.Efthymiou S, et al. Qibo: a framework for quantum simulation with hardware acceleration. Quantum Sci. Tech. 2021;7:015018. doi: 10.1088/2058-9565/ac39f5. [DOI] [Google Scholar]
- 90.Hansen, N., Akimoto, Y. & Baudis, P. CMA-ES/pycma on Github 10.5281/zenodo.2559634 (2019).
- 91.Gil-Fuster, E., Eisert, J. & Bravo-Prieto, C. Understanding quantum machine learning also requires rethinking generalization. Zenodo database10.5281/zenodo.10277124 (2023). [DOI] [PubMed]
- 92.Gershgorin SA. Über die Abgrenzung der Eigenwerte einer Matrix. Bulletin de l’Académie des Sciences de l’URSS. Classe des sciences mathématiques et naturelles. 1931;6:749–754. [Google Scholar]
- 93.Boyd, S. & Vanderberghe, L. Convex optimization (Cambridge University Press, Cambridge, 2004). 10.1017/CBO9780511804441.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data used in this study are available in the Zenodo database in ref. 91.
The code used in this study is available in the Zenodo database in ref. 91.