

Summary
Whole-brain connectome data characterize the connections among distributed neural populations as a set of edges in a large network, and neuroscience research aims to systematically investigate associations between brain connectome and clinical or experimental conditions as covariates. A covariate is often related to a number of edges connecting multiple brain areas in an organized structure. However, in practice, neither the covariate-related edges nor the structure is known. Therefore, the understanding of underlying neural mechanisms relies on statistical methods that are capable of simultaneously identifying covariate-related connections and recognizing their network topological structures. The task can be challenging because of false-positive noise and almost infinite possibilities of edges combining into subnetworks. To address these challenges, we propose a new statistical approach to handle multivariate edge variables as outcomes and output covariate-related subnetworks. We first study the graph properties of covariate-related subnetworks from a graph and combinatorics perspective and accordingly bridge the inference for individual connectome edges and covariate-related subnetworks. Next, we develop efficient algorithms to exact covariate-related subnetworks from the whole-brain connectome data with an 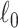 norm penalty. We validate the proposed methods based on an extensive simulation study, and we benchmark our performance against existing methods. Using our proposed method, we analyze two separate resting-state functional magnetic resonance imaging data sets for schizophrenia research and obtain highly replicable disease-related subnetworks.
norm penalty. We validate the proposed methods based on an extensive simulation study, and we benchmark our performance against existing methods. Using our proposed method, we analyze two separate resting-state functional magnetic resonance imaging data sets for schizophrenia research and obtain highly replicable disease-related subnetworks.
Keywords: Brain connectome, Combinatorics, 𝓁0 shrinkage, Graph theory, Multivariate edge variables
1. Introduction
Brain connectome analysis has attracted growing research interest in the field of neuroscience, aiming at revealing systematic neurophysiological patterns associated with human behaviors, cognition, and brain diseases (Simpson and others, 2013; Hu and others, 2022). In the past two decades, developments in neuroimaging techniques—including functional magnetic resonance imaging (fMRI) and diffusion tensor imaging—have facilitated large-scale measurements of whole-brain functional and structural connectivity (Bowman and others, 2012). In these experiments, brain neuroimaging data are collected for each participant to form a brain connectivity network characterizing the wiring among neural populations.
The brain connectome data can be encoded as a set of weighted networks on a common set of nodes shared by all participants, where a node represents a brain area and a weighted edge delineates the strength of the functional covariation or structural linkage between brain areas (Lukemire and others, 2021; Xia and Li, 2017; Cai and others, 2019; Warnick and others, 2018). Participants with different behavioral and clinical conditions tend to exhibit distinct brain connectivity patterns at global and local levels. In these studies, statistical methods have played a central role in discovering the systematic effects of a covariate (e.g., a clinical condition) on brain networks and have led to a comprehensive understanding of the underlying neurophysiopathological mechanisms (Zhang and others, 2017; Durante and others, 2018; Kundu and others, 2018; Cao and others, 2019; Wang and others, 2019).
In the present research, we focus on statistical methods for modeling multivariate connectivity edges constrained in a connectome adjacency matrix as outcomes and clinical and demographic conditions as covariates (Simpson and others, 2019; Zhang and others, 2023). These methods are alternatives to covariate-related connectivity network methods using principal component analysis and independent component analysis techniques (e.g., Shi and Guo, 2016; Zhao and others, 2021) that take time series at multiple brain regions as the input connectome data for each participant. Therefore, the two sets of methods can provide complementary perspectives to characterize the connectome patterns associated with the covariate of interest. In the neuroimaging literature, brain network analysis often refers to the analysis of prespecified “networks” (e.g., default mode network [DMN]), which boils down to assessing the association between the covariate and the averaged connection strength of edges in the network (Craddock and others, 2013). However, analysis of prespecified networks may miss the true covariate-related network while introducing false-positive findings. Lastly, cluster-wise multivariate edge inference methods (e.g., network-based statistic [NBS]) have also been used widely with the control of family-wise error rate (FWER) (Zalesky and others, 2010). The covariate-related networks in NBS are formed by a three-step procedure: (i) performing statistical analysis on each edge and attaining corresponding test statistics; (ii) applying a threshold to the test statistics of all edges and then searching the maximally connected networks of suprathreshold edges in the whole-brain connectome; (iii) conducting permutation tests for detected networks to control FWER. However, based on graph theories, a small proportion of suprathreshold covariate-related edges based on a sound threshold can almost surely connect all nodes in the connectome (Stepanov, 1970), and selecting subnetworks as a set of covariate-related edges involving all brain areas is less biologically meaningful (Craddock and others, 2013). Consequently, utilizing current methods for covariate-related network analysis (e.g., NBS) can result in a subpar inferential accuracy due to the presence of false-positive noise that hinders the extraction of subnetworks and the lack of statistical theory for testing extracted subnetworks.
To fill this gap, we propose a procedure called Statistical Inference for Covariate-Related Subnetworks (SICERS). We first define a covariate-related subnetwork as a set of edges associated with the covariate of interest that constitute an organized graph structure (e.g., a community and interconnected communities). Evaluating the network-level effect of a covariate on the whole-brain connectome requires (i) identifying subnetworks concentrated with covariate-related edges and (ii) allocating a large proportion of covariate-related edges into covariate-related subnetworks. We first show that given no network-level effect of a covariate, the chance of discovering a moderate-sized subnetwork concentrated with covariate-related edges is close to zero (by Lemma 2.1). In other words, detecting a reasonably sized and dense covariate-related subnetwork suggests the true effect on a brain network. This property is critical and motivates our method developments for subnetwork extraction and network-level inference. We demonstrate the SICERS procedure in Figure 1.
Fig. 1.

The SICERS pipeline: (a) define brain regions as nodes and connectivity metrics between each pair of nodes as edges; (b) and (c) calculate the connectivity matrix for each single subject in a study, where each off-diagonal element in the matrix represents the connectivity strength between two nodes, then identify differential connectivity patterns between clinical groups; (d) plot the edge-wise statistical inference, where each off-diagonal element is a negatively logarithmically transformed 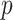 -value (e.g., two-sample-test
-value (e.g., two-sample-test 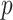 -value per edge between clinical groups and a hotter point in the heatmap suggests larger group-wise difference); (e) reveal the disease-related subnetwork detected by SICERS; (f) show the corresponding 3D (3D) brain image. Note that (e) was obtained by reordering the nodes in (d) by listing the detected subnetwork first (i.e., these two graphs are isomorphic).
-value per edge between clinical groups and a hotter point in the heatmap suggests larger group-wise difference); (e) reveal the disease-related subnetwork detected by SICERS; (f) show the corresponding 3D (3D) brain image. Note that (e) was obtained by reordering the nodes in (d) by listing the detected subnetwork first (i.e., these two graphs are isomorphic).
The article makes several contributions. First, our method provides a new tool for handling multivariate edge variables in brain connectome data for covariate-related subnetwork analysis. We develop a strategy to consolidate edge- and network-level analysis from a graph and combinatorics perspective, and propose an inference approach that is designed to test data-driven subnetworks (i.e., not prespecified) using a graph probabilistic model. Second, we develop an efficient algorithm to optimize the objective function for covariate-related subnetwork detection, which integrates dense subgraph extraction and community detection by imposing an 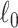 penalty on network edges. The
penalty on network edges. The 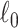 shrinkage term can effectively reduce the impact of false-positive noise and thus minimizes false-positive subnetwork detection. Our algorithm is also compatible with computationally intensive inference methods (e.g., permutation tests). Lastly, our findings in the data example reveal a novel schizophrenia-disrupted brain connectivity network that links three primary disease-related subnetworks including the DMN, salience network (SN), and central executive network (CEN) (Manoliu and others, 2014).
shrinkage term can effectively reduce the impact of false-positive noise and thus minimizes false-positive subnetwork detection. Our algorithm is also compatible with computationally intensive inference methods (e.g., permutation tests). Lastly, our findings in the data example reveal a novel schizophrenia-disrupted brain connectivity network that links three primary disease-related subnetworks including the DMN, salience network (SN), and central executive network (CEN) (Manoliu and others, 2014).
2. Methods
2.1. Background: brain connectome data and edge-wise inference
We denote 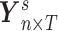 as the region-level fMRI time series for a participant
as the region-level fMRI time series for a participant 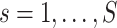 , where
, where 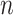 is the number of regions of interest, and
is the number of regions of interest, and 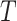 is the length of time series. We assume that fMRI data are registered into a common template and thus brain regions are identical across participants (e.g., the Brainnetome Atlas by Fan and others, 2016). Let
is the length of time series. We assume that fMRI data are registered into a common template and thus brain regions are identical across participants (e.g., the Brainnetome Atlas by Fan and others, 2016). Let 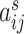 denote the connection strength between a pair of regions
denote the connection strength between a pair of regions 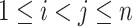 , which can be calculated by the correlation (or partial correlation/spectral coherence) between the two corresponding region-wise time series. A weighted
, which can be calculated by the correlation (or partial correlation/spectral coherence) between the two corresponding region-wise time series. A weighted 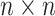 adjacency matrix
adjacency matrix 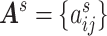 records all
records all 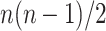 pair-wise connectivity measures for participant
pair-wise connectivity measures for participant 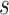 .
. 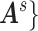 maps to a population-level brain connectome structural graph
maps to a population-level brain connectome structural graph 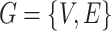 , where the node set
, where the node set 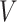 (
(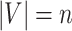 ) represents regions of interest, the edge set
) represents regions of interest, the edge set 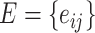 indicates the functional connections between regions.
indicates the functional connections between regions. 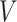 and
and 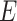 are identical across participants because we assume that the neurobiological definitions of brain regions and connectivity are shared across participants (Simpson and others, 2013).
are identical across participants because we assume that the neurobiological definitions of brain regions and connectivity are shared across participants (Simpson and others, 2013). 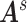 are multivariate random variables capturing the connection strengths of an individual, and thus outcomes. In addition, for each participant, we observe a vector of profiling covariates (e.g., the clinical status and demographic variables), denoted by
are multivariate random variables capturing the connection strengths of an individual, and thus outcomes. In addition, for each participant, we observe a vector of profiling covariates (e.g., the clinical status and demographic variables), denoted by 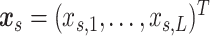 .
.
Our goal is to assess the associations between 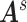 and
and 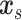 , revealing the underlying covariate-related neural connectomic mechanisms. Naturally, one can apply commonly used multivariate statistical models (e.g., multiple testing, regularized correction, and low-rank regression models) to identify a set of edges associated with covariates of interest. Consider a generalized linear model (Zhang and others, 2023):
, revealing the underlying covariate-related neural connectomic mechanisms. Naturally, one can apply commonly used multivariate statistical models (e.g., multiple testing, regularized correction, and low-rank regression models) to identify a set of edges associated with covariates of interest. Consider a generalized linear model (Zhang and others, 2023):
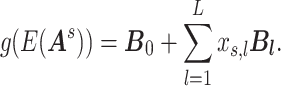 |
(2.1) |
Without loss of generality, we focus on one covariate of interest (e.g., clinical diagnosis) while adjusting for other confounding variables. Because subnetworks can vary among different covariates, we can perform covariate-specific subnetwork analysis and apply the procedure for each covariate of interest or interaction. Let  be the associated matrix of regression coefficients of interest. Then, the corresponding edge-wise hypotheses are
be the associated matrix of regression coefficients of interest. Then, the corresponding edge-wise hypotheses are
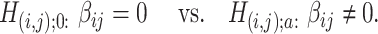 |
(2.2) |
As our interest is to identify covariate-related subnetworks instead of individual parameters that 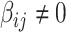 , we present
, we present 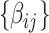 in a binary graph
in a binary graph 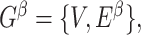 where
where 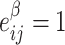 if
if 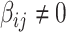 otherwise 0. In practice, we note that covariate-related edges
otherwise 0. In practice, we note that covariate-related edges 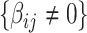 only contribute a small proportion of edges in the brain connectome (Chen and others, 2016), and more importantly their appearance in the network is concentrated in a few block-structured subnetworks (i.e.,
only contribute a small proportion of edges in the brain connectome (Chen and others, 2016), and more importantly their appearance in the network is concentrated in a few block-structured subnetworks (i.e., 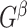 is not random). Our proposed SICERS method will provide novel procedures for estimation and inference on these latent covariate-related subnetworks to answer the fundamental scientific problem of how a covariate of interest systematically affects the brain connectome.
is not random). Our proposed SICERS method will provide novel procedures for estimation and inference on these latent covariate-related subnetworks to answer the fundamental scientific problem of how a covariate of interest systematically affects the brain connectome.
2.2. The general model
As a starting point, we propose a general graph model that decomposes the population brain connectome structural graph into subnetworks related to the covariate and a subgraph that is not related to the covariate:
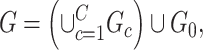 |
(2.3) |
where each 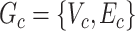 is a covariate-related subnetwork,
is a covariate-related subnetwork, 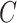 is the number of subnetworks (neural subsystems) altered by the covariate, and
is the number of subnetworks (neural subsystems) altered by the covariate, and 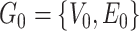 is the remainder of
is the remainder of 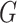 (i.e., covariate irrelevant). Specifically,
(i.e., covariate irrelevant). Specifically, 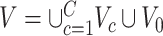 ,
, 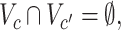 and
and 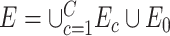 . In other words,
. In other words, 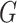 is formed by the union of
is formed by the union of 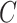 mutually disjoint covariate-related subnetworks
mutually disjoint covariate-related subnetworks 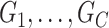 and singleton nodes that do not belong to any subnetwork.
and singleton nodes that do not belong to any subnetwork. 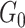 is defined as a union of singleton nodes and edges not in
is defined as a union of singleton nodes and edges not in 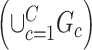 .
. 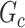 distinguishes itself from
distinguishes itself from 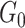 as the density of covariate-related edges is higher in
as the density of covariate-related edges is higher in 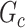 than
than 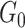 , that is,
, that is, 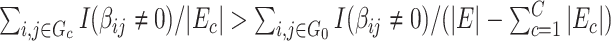 . We further define
. We further define 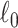 as the graph norm that measures the number of edges of a covariate-related subnetwork of
as the graph norm that measures the number of edges of a covariate-related subnetwork of 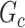 , that is,
, that is, 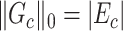 . Consequently,
. Consequently, 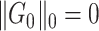 and
and 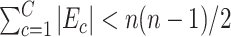 assuming that
assuming that 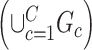 covers all nonisolated covariate-related edges.
covers all nonisolated covariate-related edges.
Our model is closely related to but distinct from classical network models. When 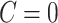 , the model can be viewed as an Erdős–Renyi graph. In the general scenarios where
, the model can be viewed as an Erdős–Renyi graph. In the general scenarios where 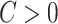 , our model differs from the traditional block structure in clustering and community-detection algorithms because our focus is on covariate-related subnetworks
, our model differs from the traditional block structure in clustering and community-detection algorithms because our focus is on covariate-related subnetworks 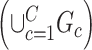 while treating
while treating 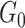 as irrelevant information.
as irrelevant information. 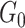 consists exclusively of singletons and has
consists exclusively of singletons and has 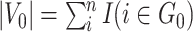 and
and 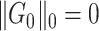 , which resembles the nondense component of the dense subgraph model (Wu and others). On the other hand, our method differs from dense subgraph discovery models because we simultaneously consider multiple subnetworks
, which resembles the nondense component of the dense subgraph model (Wu and others). On the other hand, our method differs from dense subgraph discovery models because we simultaneously consider multiple subnetworks 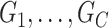 . Therefore, our model is a combination of a dense subgraph model and a block structure model.
. Therefore, our model is a combination of a dense subgraph model and a block structure model.
2.3. Statistical inference for covariate-related subnetworks
The statistical inference for covariate-related subnetworks 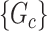 is distinct from the classical statistical inference on a single well-defined parameter (e.g.,
is distinct from the classical statistical inference on a single well-defined parameter (e.g., 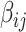 ). In the context of graph models, the inference of
). In the context of graph models, the inference of 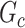 is naturally linked with graph theory and combinatorics. We propose a statistical inference framework to test covariate-related subnetworks when neither
is naturally linked with graph theory and combinatorics. We propose a statistical inference framework to test covariate-related subnetworks when neither 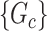 nor
nor 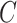 is known in (2.3). We consider the following test for the existence of the subnetwork structure:
is known in (2.3). We consider the following test for the existence of the subnetwork structure:
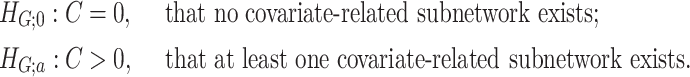 |
(2.4) |
Here, 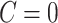 means
means 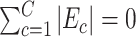 , that is, no covariate-related subnetwork exists. We propose the following lemma (2.1) as a graph–combinatorics-based procedure, to determine the rejection region for (2.4) based on the graph properties of subnetworks (i.e., the size and density of a subnetwork).
, that is, no covariate-related subnetwork exists. We propose the following lemma (2.1) as a graph–combinatorics-based procedure, to determine the rejection region for (2.4) based on the graph properties of subnetworks (i.e., the size and density of a subnetwork).
Specifically, we derive lemma (2.1) for network-level inference in the context of association parameter binary graph 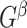 and covariate-related subnetworks defined by the general model of population connectome structural graph
and covariate-related subnetworks defined by the general model of population connectome structural graph 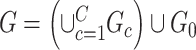 . Without loss of generality, we define the densities of
. Without loss of generality, we define the densities of 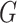 and covariate-related subnetworks subgraph by
and covariate-related subnetworks subgraph by
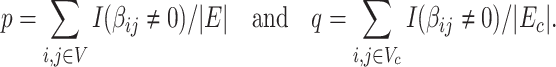 |
(2.5) |
Directly developing inference method for covariate-related subnetworks is challenging, because 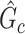 is unknown before analyzing the sample data. We adopt the concept of “maximum quasiclique” in graph theory as an alternative to develop the inference theory while alleviating the required prior knowledge of
is unknown before analyzing the sample data. We adopt the concept of “maximum quasiclique” in graph theory as an alternative to develop the inference theory while alleviating the required prior knowledge of 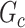 . In
. In 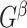 , for any
, for any 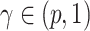 , we call a subnetwork of this binary network a “
, we call a subnetwork of this binary network a “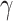 -quasi clique” if its observed edge density is at least
-quasi clique” if its observed edge density is at least 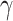 . Define a maximum
. Define a maximum 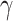 quasiclique
quasiclique 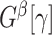 to be the largest-in-size
to be the largest-in-size 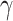 -quasi clique in
-quasi clique in 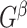 , and let
, and let 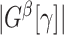 be the number of nodes in
be the number of nodes in 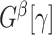 .
. 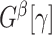 can be detected using computationally efficient procedures in the existing literature; see Wu and Hao (2015) for a comprehensive review. Under the null hypothesis
can be detected using computationally efficient procedures in the existing literature; see Wu and Hao (2015) for a comprehensive review. Under the null hypothesis 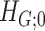 , the graph
, the graph 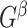 becomes an Erdős–Renyi graph with
becomes an Erdős–Renyi graph with  . Next, we derive the probability bounds for the size given density for
. Next, we derive the probability bounds for the size given density for 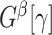 under
under 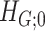 and
and 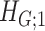 .
.
Lemma 2.1
In a binary graph
,
is true, that is,
, assume that for any
,
where
denotes a loose lower bound, and
large enough such that
. Then, we have
is true, assume that all subnetworks satisfy
and set
for a small enough constant
, such that
. Then, we have
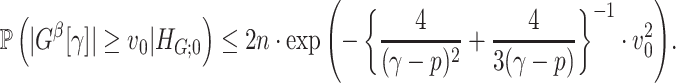
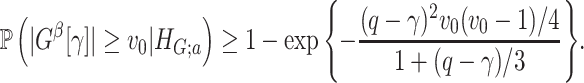
Intuitively, Lemma 2.1 states that (i) the probability of a nonsmall and dense subnetwork existing under 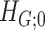 is almost zero, whereas (ii) the probability of a nonsmall and dense subnetwork existing under
is almost zero, whereas (ii) the probability of a nonsmall and dense subnetwork existing under 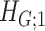 approaches 1. Therefore, the probability bounds in Lemma 2.1 can be used to calculate both the type I error rate of an observed
approaches 1. Therefore, the probability bounds in Lemma 2.1 can be used to calculate both the type I error rate of an observed 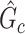 and the strength of
and the strength of 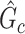 associated with the covariate. Under simple scenarios where there is only one subnetwork present in
associated with the covariate. Under simple scenarios where there is only one subnetwork present in 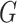 , we can directly calculate the type I error of
, we can directly calculate the type I error of 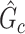 by
by 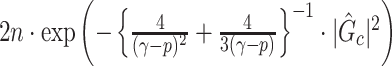 , and then reject
, and then reject 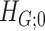 if the type I error is less than the significance level
if the type I error is less than the significance level 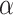 . However, the inference procedure in our application is more complex as multiple covariate-related subnetworks may exist. In the field of neuroimaging statistics, a widely used statistical inference method for simultaneously testing multiple covariate-related subnetworks
. However, the inference procedure in our application is more complex as multiple covariate-related subnetworks may exist. In the field of neuroimaging statistics, a widely used statistical inference method for simultaneously testing multiple covariate-related subnetworks 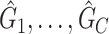 is the family-wise error control (FWER) strategy (e.g., permutation tests), which requires comparing subnetworks with different densities and sizes. For example,
is the family-wise error control (FWER) strategy (e.g., permutation tests), which requires comparing subnetworks with different densities and sizes. For example, 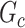 and
and 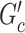 are subnetworks with densities and sizes (
are subnetworks with densities and sizes (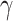 ,
, 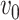 ) and (
) and (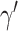 ,
, 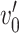 ) respectively. Lemma 2.1 provides a viable solution for the comparison by calculating two probability bounds
) respectively. Lemma 2.1 provides a viable solution for the comparison by calculating two probability bounds 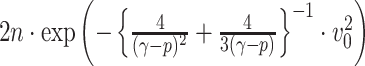 versus
versus 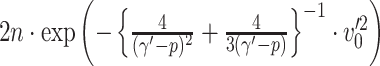 . The subnetwork with a lower probability bound is considered to have a stronger association with the covariate, as it is less likely to occur under
. The subnetwork with a lower probability bound is considered to have a stronger association with the covariate, as it is less likely to occur under 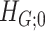 (see details in Section 2.5).
(see details in Section 2.5).
2.4. Extracting covariate-related subnetworks via ℓ0 graph norm penalty
We aim to extract covariate-related subnetworks 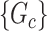 from the dependent variables and covariates
from the dependent variables and covariates 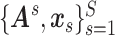 . We first estimate and test
. We first estimate and test 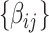 by (2.1). For a continuous brain connectivity measure (e.g., Fisher’s Z transformed correlation coefficients), both classic general linear model and autoregressive multivariate model accounting for the dependence can be applied (Bowman, 2005; Chen and others, 2020). Although the latter provides a more accurate inference (particularly for a small sample), the computational cost is much higher. In practice, for a sample of hundreds of participants, we adopt the general linear model because the statistical inference results of these two methods show little difference. The statistical inferential results for
by (2.1). For a continuous brain connectivity measure (e.g., Fisher’s Z transformed correlation coefficients), both classic general linear model and autoregressive multivariate model accounting for the dependence can be applied (Bowman, 2005; Chen and others, 2020). Although the latter provides a more accurate inference (particularly for a small sample), the computational cost is much higher. In practice, for a sample of hundreds of participants, we adopt the general linear model because the statistical inference results of these two methods show little difference. The statistical inferential results for 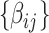 (e.g., the test statistics or
(e.g., the test statistics or 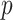 -values) can be stored in a matrix
-values) can be stored in a matrix 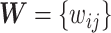 (e.g.,
(e.g., 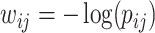 ), which will be used as the input to extract covariate-related subnetworks. We adopt
), which will be used as the input to extract covariate-related subnetworks. We adopt 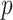 -values (and
-values (and 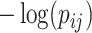 ) due to its popularity in high-dimensional data analysis [e.g., false-discovery rate (FDR) and Manhattan plot] and capability to discern
) due to its popularity in high-dimensional data analysis [e.g., false-discovery rate (FDR) and Manhattan plot] and capability to discern 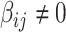 versus
versus 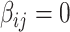 . Nevertheless, our method is applicable to
. Nevertheless, our method is applicable to 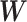 generated from any valid statistical model.
generated from any valid statistical model.
Our goal is to cover covariate-related edges using a set of well-organized subgraphs with minimal (edge) sizes to achieve inference efficiency and accuracy in accordance with Lemma 2.1. We constrain subnetworks 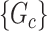 in a plausible network structure, where
in a plausible network structure, where 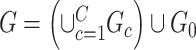 , for the reasons stated in Section 2.2. Therefore, our model resembles but is distinct from the stochastic block model, where all nodes are assigned to a few communities, and the submatrix model, which only covers
, for the reasons stated in Section 2.2. Therefore, our model resembles but is distinct from the stochastic block model, where all nodes are assigned to a few communities, and the submatrix model, which only covers 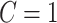 . This graph structure—with several small communities and a majority of singleton nodes—poses a unique challenge for estimation. This is determined by the fact that a small proportion of edges are associated with the covariate.
. This graph structure—with several small communities and a majority of singleton nodes—poses a unique challenge for estimation. This is determined by the fact that a small proportion of edges are associated with the covariate.
As a highlight of our method, while most conventional community-detection techniques for stochastic block models typically demand relatively balanced community sizes 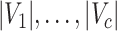 that would contain most nodes
that would contain most nodes 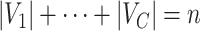 or
or 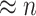 , our method addresses the case where all the blocks
, our method addresses the case where all the blocks 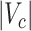 put together could constitute only a small portion of the whole graph, that is,
put together could constitute only a small portion of the whole graph, that is, 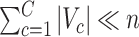 . Therefore, our approach can be considered as a tool for informative subnetwork extraction rather than clustering or community detection. As illustrated in Figure 2, several conventional community-detection techniques may encounter difficulties in extracting meaningful subnetworks from the inference matrix
. Therefore, our approach can be considered as a tool for informative subnetwork extraction rather than clustering or community detection. As illustrated in Figure 2, several conventional community-detection techniques may encounter difficulties in extracting meaningful subnetworks from the inference matrix 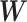 of an rs-fMRI brain connectome study (Adhikari and others, 2019).
of an rs-fMRI brain connectome study (Adhikari and others, 2019).
Fig. 2.

Subnetwork extraction by SICERS versus classical community-detection algorithms on a 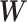 matrix with a structure of
matrix with a structure of 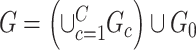 : (a) spectral clustering with 10 communities in Von Luxburg (2007); (b) Louvain method by Blondel and others (2008); (c) INFOMAP algorithm by Rosvall and Bergstrom (2008); (d) SICERS community detection.
: (a) spectral clustering with 10 communities in Von Luxburg (2007); (b) Louvain method by Blondel and others (2008); (c) INFOMAP algorithm by Rosvall and Bergstrom (2008); (d) SICERS community detection.
To extract covariate-related subnetworks based on 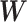 appears a conceptually straightforward approach by optimizing a valid objective function (e.g., likelihood function) in the conventional network community-detection literature (Bickel and Chen, 2009; Zhao and others, 2012). However, the results of these methods tend to yield subnetworks with a small proportion of covariate-related edges due to the false-positive noise. Instead, we resort to an
appears a conceptually straightforward approach by optimizing a valid objective function (e.g., likelihood function) in the conventional network community-detection literature (Bickel and Chen, 2009; Zhao and others, 2012). However, the results of these methods tend to yield subnetworks with a small proportion of covariate-related edges due to the false-positive noise. Instead, we resort to an 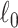 graph norm penalty-based objective function to extract covariate-related subnetworks from
graph norm penalty-based objective function to extract covariate-related subnetworks from 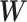 , where most edges are associated with the covariate. Our objective function is inspired by Lemma 2.1 and is thus specifically tailored for subnetwork-wise inference. The idea is very simple: for any detected subnetwork
, where most edges are associated with the covariate. Our objective function is inspired by Lemma 2.1 and is thus specifically tailored for subnetwork-wise inference. The idea is very simple: for any detected subnetwork 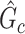 , we reward edge weights within this subnetwork while penalizing based on its size (i.e., increasing density and size). This objective function can lead to the discovery of a set of subnetworks with the maximal density and number of covariate-related edges. As shown in Lemma 2.1, the probability of observing a certain-sized covariate-related subnetwork (a
, we reward edge weights within this subnetwork while penalizing based on its size (i.e., increasing density and size). This objective function can lead to the discovery of a set of subnetworks with the maximal density and number of covariate-related edges. As shown in Lemma 2.1, the probability of observing a certain-sized covariate-related subnetwork (a 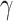 -quasi clique) is slim with a high density
-quasi clique) is slim with a high density 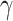 . Similar ideas have been adopted in some network community-detection methods (Zhang and others, 2016). Specifically, we define
. Similar ideas have been adopted in some network community-detection methods (Zhang and others, 2016). Specifically, we define
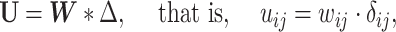 |
(2.6) |
where “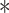 ” denotes the Hadamard (element-wise) matrix product and
” denotes the Hadamard (element-wise) matrix product and 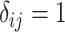 if
if 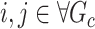 and 0 otherwise. Clearly,
and 0 otherwise. Clearly, 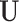 depends on the specified structure of the underlying graph
depends on the specified structure of the underlying graph 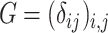 . Define
. Define 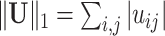 and
and 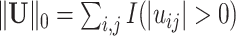 , where
, where  and
and  are matrix-element-wise
are matrix-element-wise 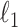 and
and 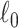 norms.
norms. 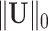 is equivalent to the
is equivalent to the 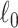 graph norm, because we define
graph norm, because we define 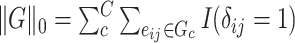 in Section 2.2. Our core proposal is the following
in Section 2.2. Our core proposal is the following 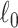 graph norm shrinkage criterion:
graph norm shrinkage criterion:
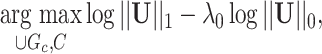 |
(2.7) |
where 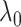 is a tuning parameter.
is a tuning parameter.
Optimizing the objective function (2.7) simultaneously estimates the number of subnetworks and the subnetwork memberships of all nodes in 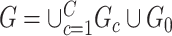 . Here, we consider a singleton as a subnetwork. The objective function (2.7) maximizes the edge weights with minimally sized subnetworks, which is mathematically equivalent to extracting maximally sized subnetworks (quasicliques) sizes while maximizing the density. Therefore, the optimization of (2.7) is governed by two goals: covering high-weight informative edges and using minimally sized subnetworks. Maximizing the first term
. Here, we consider a singleton as a subnetwork. The objective function (2.7) maximizes the edge weights with minimally sized subnetworks, which is mathematically equivalent to extracting maximally sized subnetworks (quasicliques) sizes while maximizing the density. Therefore, the optimization of (2.7) is governed by two goals: covering high-weight informative edges and using minimally sized subnetworks. Maximizing the first term 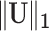 can increase sensitivity by allocating a maximal number of high-weight edges to subnetworks, which promotes larger subnetworks; this is concordant with our aforementioned views in Section 2.3. In that, prespecifying density
can increase sensitivity by allocating a maximal number of high-weight edges to subnetworks, which promotes larger subnetworks; this is concordant with our aforementioned views in Section 2.3. In that, prespecifying density 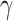 in Lemma (2.1) is not required because 2.7 automatically maximizes subnetwork density and size. We also penalize the
in Lemma (2.1) is not required because 2.7 automatically maximizes subnetwork density and size. We also penalize the 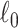 graph norm for maximizing the density of subnetworks. The second term can also suppress false-positive noise, because false-positive edges tend to be distributed in a random pattern in
graph norm for maximizing the density of subnetworks. The second term can also suppress false-positive noise, because false-positive edges tend to be distributed in a random pattern in 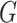 rather than in an organized subgraph (Chen and others, 2015).
rather than in an organized subgraph (Chen and others, 2015).
The conflicting nature of the two goals leads to a balance between the different goals that they represent in the optimization procedure, thereby producing meaningful results. The balance between them is tuned by 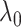 ; specifically,
; specifically, 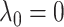 would send all nodes to one subnetwork, whereas a large
would send all nodes to one subnetwork, whereas a large 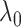 prefers small communities and singletons (nodes not in any community, thus contributing zero
prefers small communities and singletons (nodes not in any community, thus contributing zero 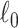 graph norm) even to the true community structure. In our theoretical analysis, we specify the range of tuning parameter
graph norm) even to the true community structure. In our theoretical analysis, we specify the range of tuning parameter 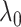 (depending on
(depending on 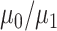 ) in which our criterion provides a consistent estimation of the community structure, thereby controlling well the rates of both types of errors in the multiple testing procedure. In practice, select
) in which our criterion provides a consistent estimation of the community structure, thereby controlling well the rates of both types of errors in the multiple testing procedure. In practice, select 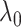 based on the likelihood function of the network (see supplementary material available at Biostatistics online).
based on the likelihood function of the network (see supplementary material available at Biostatistics online).
We optimize (2.7) and extract covariate-related subnetworks using Algorithm 1. Specifically, we perform a grid search for 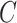 . For each value of
. For each value of 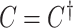 , let
, let 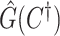 be the estimated network structure by optimizing (2.7), and let
be the estimated network structure by optimizing (2.7), and let 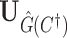 be the corresponding matrix from Hadamard matrix multiplication.
be the corresponding matrix from Hadamard matrix multiplication. 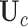 is the submatrix of
is the submatrix of 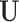 corresponding to
corresponding to 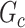 . The outcome provides a set of maximal subnetworks with high density. In the supplementary material available at Biostatistics online, we provide detailed implementation and theoretical results to guarantee the consistency and optimality of
. The outcome provides a set of maximal subnetworks with high density. In the supplementary material available at Biostatistics online, we provide detailed implementation and theoretical results to guarantee the consistency and optimality of 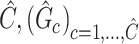 .
.
Algorithm 1:
Subnetwork estimation
Data: Input:
; tuning parameter
1. For
to
2. Optimize
(see details in the supplementary material available at Biostatistics online)
3. Select
such that
Output:
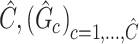
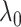
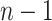
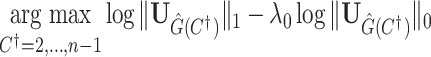
2.5. Testing covariate-related subnetworks
Given a set of estimated covariate-related subnetworks 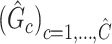 , our goal is to assess statistical significance for each subnetwork. This is more general than the aforementioned hypothesis test (2.4) because the subnetwork-wise inference is needed for more than one subnetwork. Note that the testing hypothesis on a covariate-related subnetwork
, our goal is to assess statistical significance for each subnetwork. This is more general than the aforementioned hypothesis test (2.4) because the subnetwork-wise inference is needed for more than one subnetwork. Note that the testing hypothesis on a covariate-related subnetwork 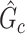 is distinct from classical statistical hypothesis tests because the parameters of the null hypothesis are based on an estimated
is distinct from classical statistical hypothesis tests because the parameters of the null hypothesis are based on an estimated 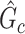 rather than prespecified parameters. Because a subnetwork
rather than prespecified parameters. Because a subnetwork 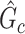 can be considered as a cluster of edges, we adopt the commonly used permutation tests to examine the significance of
can be considered as a cluster of edges, we adopt the commonly used permutation tests to examine the significance of 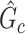 while controlling FWER (Zalesky and others, 2010; Nichols, 2012; Chen and others, 2015). However, the test statistic in the classic permutation tests is often trivial (e.g., using the number of supra-threshold edges in
while controlling FWER (Zalesky and others, 2010; Nichols, 2012; Chen and others, 2015). However, the test statistic in the classic permutation tests is often trivial (e.g., using the number of supra-threshold edges in 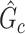 as the test statistic). Building on Lemma 2.1, we propose a new test statistic to reflect the combinatorial probability for a covariate-related subnetwork with a given density and size under the null hypothesis. We present the steps of our test in Algorithm 2.
as the test statistic). Building on Lemma 2.1, we propose a new test statistic to reflect the combinatorial probability for a covariate-related subnetwork with a given density and size under the null hypothesis. We present the steps of our test in Algorithm 2.
Algorithm 2:
Assess the significance of
Data: Input:
,
,
,
,
,
1. With a sound cut-off
, set the binarized graph
2. Estimate overall and within-subnetwork edge densities
and
and set
3. Calculate (Lemma 2.1)
-value-based test statistic by integrating
on its distribution
:
4. Shuffle the group labels of the data and implement SICERS
times, and for each simulation
, store the maximal test statistic
5. Calculate the percentile of
in
as the FWER
-value and reject the null hypothesis if
Output: FWER significance values for
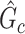
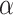
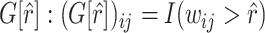
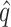
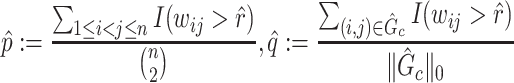
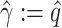
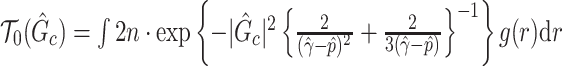
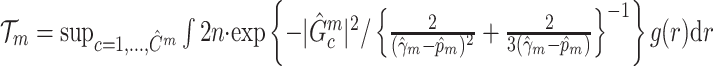
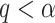
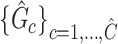
The above procedure can also be used to test the omnibus hypothesis (2.4) for 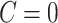 versus
versus 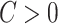 , because any single reasonably sized and dense subnetwork
, because any single reasonably sized and dense subnetwork 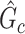 can lead to a small
can lead to a small 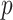 -value. The null distribution of the test statistic in (2.4) can be simulated well by the permutation procedure. Therefore, the FWER can be controlled effectively by the above permutation test, yielding a corrected
-value. The null distribution of the test statistic in (2.4) can be simulated well by the permutation procedure. Therefore, the FWER can be controlled effectively by the above permutation test, yielding a corrected 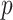 -value for each
-value for each 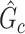 (Nichols, 2012).
(Nichols, 2012).
3. Simulations
In this section, we evaluate the performance of our method on synthetic data and compare it with benchmarks. We assess the accuracy of SICERS on two levels: (i) subnetwork-level inference accuracy by tallying the false-positive and false-negative covariate-related subnetworks; (ii) edge-level assessment to measure the quality of significant covariate-related subnetwork and overall performance by comparing 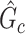 with
with 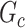 and counting the false-positive and false-negative edges. The covariate-related subnetwork inference is satisfactory only if network- and edge-level inference are both accurate.
and counting the false-positive and false-negative edges. The covariate-related subnetwork inference is satisfactory only if network- and edge-level inference are both accurate.
First, we simulate brain connectome data 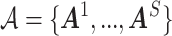 in a common two-sample testing setting, although we can easily extend it to the regression setting. We consider two cohorts of participants with equal sample sizes. We denote healthy controls by
in a common two-sample testing setting, although we can easily extend it to the regression setting. We consider two cohorts of participants with equal sample sizes. We denote healthy controls by 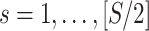 and patients by
and patients by 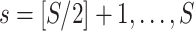 , where
, where  denotes the floor operator. The number of brain regions is
denotes the floor operator. The number of brain regions is 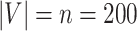 , and there are 19 000 edges correspondingly. We consider two disease-related subnetworks
, and there are 19 000 edges correspondingly. We consider two disease-related subnetworks 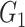 and
and 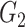 with
with 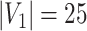 and
and 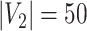 . For a patient
. For a patient 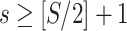 , for all
, for all 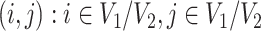 , we set
, we set 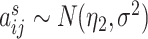 ; for all other
; for all other 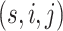 , we set
, we set 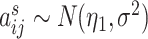 . We vary
. We vary 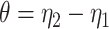 and
and 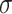 to emulate different effect sizes (i.e., signal-to-noise ratios). We set the variance term
to emulate different effect sizes (i.e., signal-to-noise ratios). We set the variance term 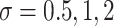 given
given 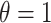 , corresponding to values of Cohen’s
, corresponding to values of Cohen’s 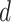 of
of 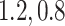 , and 0.5, respectively. Two sample sizes of
, and 0.5, respectively. Two sample sizes of 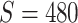 and
and 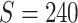 were used. For each combination of parameters, we simulate 100 repeated data sets.
were used. For each combination of parameters, we simulate 100 repeated data sets.
For each brain connectome data set 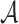 , we perform edge-wise two-sample tests on
, we perform edge-wise two-sample tests on 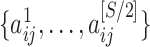 versus
versus 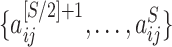 and obtain the inference matrix
and obtain the inference matrix 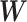 by
by 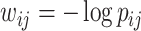 . We then apply SICERS to
. We then apply SICERS to 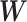 , estimating disease-related subnetworks and performing subnetwork-level statistical inference. We benchmark our approach against the popular methods for brain connectivity analysis including NBS and comparable subnetwork extraction methods by dense subgraph extraction algorithms (e.g., greedy) and community-detection algorithms (e.g., Louvain).
, estimating disease-related subnetworks and performing subnetwork-level statistical inference. We benchmark our approach against the popular methods for brain connectivity analysis including NBS and comparable subnetwork extraction methods by dense subgraph extraction algorithms (e.g., greedy) and community-detection algorithms (e.g., Louvain).
Subnetwork-level inference results. First, we evaluate the accuracy of SICERS at the network-level. Correctly identifying a covariate-related subnetwork involves two aspects: (i) extracting a 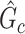 that is close to
that is close to 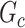 and (ii) rejecting the null hypothesis for
and (ii) rejecting the null hypothesis for 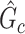 . Therefore, we consider that our goal of network-level inference is met if SICERS rejects the null hypothesis for an estimated subnetwork
. Therefore, we consider that our goal of network-level inference is met if SICERS rejects the null hypothesis for an estimated subnetwork 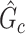 that is similar to
that is similar to 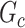 (e.g., the Jaccard index for edge sets of
(e.g., the Jaccard index for edge sets of 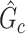 and
and 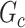 is greater than 50
is greater than 50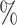 ). We denote an estimated subnetwork as a false-positive finding when we reject the null hypothesis and the Jaccard index between
). We denote an estimated subnetwork as a false-positive finding when we reject the null hypothesis and the Jaccard index between 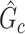 and
and 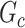 is less than 50
is less than 50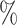 . We record a false-negative finding for
. We record a false-negative finding for 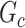 if we fail to estimate
if we fail to estimate 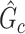 with a Jaccard index of greater than
with a Jaccard index of greater than 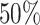 in reference to
in reference to 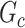 and reject the null hypothesis. We calculate the power and false-positive rate (FPR) as the proportions of true-positive and false-positive inference across the 100 repeated data sets with the corresponding standard errors.
and reject the null hypothesis. We calculate the power and false-positive rate (FPR) as the proportions of true-positive and false-positive inference across the 100 repeated data sets with the corresponding standard errors.
The results for the network-level summarized statistics are presented in Table 1. Our network-level inference is generally robust and accurate for both 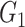 and
and 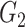 . The power and FPR of network-level inference rely on the capability of subnetwork extraction because the power is 0 if no
. The power and FPR of network-level inference rely on the capability of subnetwork extraction because the power is 0 if no 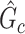 is detected and FPR is high if the significant
is detected and FPR is high if the significant 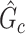 largely deviates from
largely deviates from 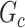 . The subnetwork extracted by NBS is often different from
. The subnetwork extracted by NBS is often different from 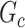 due to the influence of noise, which leads to low power and high FPR. The inference accuracy is also determined by the subnetwork size, effect size, sample size, and noise level (results for a range of network sizes are in supplementary material available at Biostatistics online). SICERS outperforms the comparable methods due to the superior performance of its
due to the influence of noise, which leads to low power and high FPR. The inference accuracy is also determined by the subnetwork size, effect size, sample size, and noise level (results for a range of network sizes are in supplementary material available at Biostatistics online). SICERS outperforms the comparable methods due to the superior performance of its 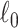 shrinkage-based subnetwork extraction and advanced inference approach (see Algorithm 2).
shrinkage-based subnetwork extraction and advanced inference approach (see Algorithm 2).
Table 1.
Network-level inference results across all settings. The power is calculated separately for each of the two subnetworks (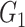
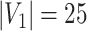 and
and 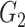
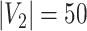 ), while the FPR is based on the aggregate false-positive findings. The means (standard deviations) of power and FPR are summarized based on 100 repeated simulations. SICERS generally performs well for all settings, followed by Louvain, Dense, and NBS. The Power and FPR largely rely on accurate subnetwork extraction and inference. Large subnetwork size, effect size, and sample size can improve the accuracy of subnetwork extraction and yield greater test statistics, thus increase power and sensitivity. SICERS outperforms the other methods because the
), while the FPR is based on the aggregate false-positive findings. The means (standard deviations) of power and FPR are summarized based on 100 repeated simulations. SICERS generally performs well for all settings, followed by Louvain, Dense, and NBS. The Power and FPR largely rely on accurate subnetwork extraction and inference. Large subnetwork size, effect size, and sample size can improve the accuracy of subnetwork extraction and yield greater test statistics, thus increase power and sensitivity. SICERS outperforms the other methods because the 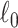 shrinkage and our new statistical inference methods can better capture and characterize covariate-related subnetworks
shrinkage and our new statistical inference methods can better capture and characterize covariate-related subnetworks
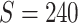
|
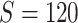
|
|||||||
|---|---|---|---|---|---|---|---|---|
Cohen’s 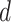
|
1.2 | 0.8 | 0.5 | 1.2 | 0.8 | 0.5 | ||
| SICERS | Power |
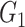
|
1(0) | 0.98(0.14) | 0.84(0.37) | 1(0) | 1(0) | 0.86(0.35) |
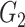
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) | ||
| FPR | 0(0) | 0.05(0.13) | 0.03(0.09) | 0(0) | 0.03(0.09) | 0.03(0.09) | ||
| Louvain | Power |
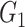
|
1(0) | 0.92(0.27) | 1(0) | 1(0) | 0.86(0.35) | 1(0) |
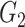
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) | ||
| FPR | 0.08(0.17) | 0.07(0.16) | 0(0) | 0.11(0.2) | 0.09(0.19) | 0.01(0.05) | ||
| Dense | Power |
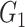
|
1(0) | 1(0) | 0.36(0.48) | 1(0) | 1(0) | 0.06(0.24) |
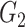
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) | ||
| FPR | 0(0) | 0.33(0) | 0.44(0.08) | 0(0) | 0.33(0) | 0.49(0.04) | ||
| NBS | Power |
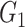
|
0.14(0.35) | 0(0) | 0(0) | 0.26(0.44) | 0(0) | 0(0) |
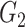
|
1(0) | 0(0) | 0(0) | 1(0) | 0(0) | 0(0) | ||
| FPR | 0.1(0.21) | 1(0) | 1(0) | 0.08(0.2) | 1(0) | 1(0) | ||
Edge-level inference results. Given significant covariate-related subnetworks, we further evaluate the deviation of 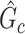 from
from 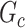 by measuring the edge-level difference. The
by measuring the edge-level difference. The 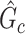 versus
versus 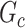 differences are measured at the edge-level with respect to sensitivity and FDR as follows:
differences are measured at the edge-level with respect to sensitivity and FDR as follows: 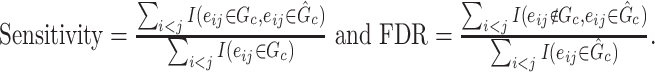
Table 2 summarizes the performance of all methods in all settings. In general, SICERS, network detection, and dense algorithms can recover the covariate-related subnetworks. When the effect size is smaller, network detection and subgraph extraction algorithms tend to cover a maximal number of informative edges and thus also include false-positive edges in the estimated subnetworks; therefore, the detected subnetworks may differ from the true network. SICERS is more robust to false-positive noise for small effect size because it imposes an 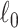 penalty term on the objective function. NBS is more sensitive to noise because the subnetwork detection extraction algorithm of NBS seeks maximally connected components. Lastly, we compare the network analysis method with the univariate method BH-FDR (
penalty term on the objective function. NBS is more sensitive to noise because the subnetwork detection extraction algorithm of NBS seeks maximally connected components. Lastly, we compare the network analysis method with the univariate method BH-FDR (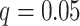 ). Without the aid of graph information, the univariate inference method tends to select a high proportion of false-positive edges and fails to recognize the network structure.
). Without the aid of graph information, the univariate inference method tends to select a high proportion of false-positive edges and fails to recognize the network structure.
Table 2.
Edge-level inference results across all settings. The TPR and FDR are calculated separately for each of the two subnetworks (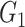
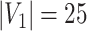 and
and 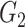
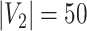 ). The means (standard deviations) of TPR and FDR are summarized based on 100 repeated simulations. TPR is determined by the proportion of edges in
). The means (standard deviations) of TPR and FDR are summarized based on 100 repeated simulations. TPR is determined by the proportion of edges in 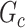 that can be recovered by
that can be recovered by 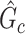 , and FDR is the proportion of edges in
, and FDR is the proportion of edges in 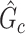 are not in
are not in 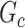 . TPR = 1 and FDR = 0 suggest a perfect recovery of
. TPR = 1 and FDR = 0 suggest a perfect recovery of 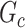 by
by 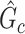 . SICERS outperforms the comparable methods because the objective function can maximize the signal while suppressing noise, and thereby better recovers the underlying true
. SICERS outperforms the comparable methods because the objective function can maximize the signal while suppressing noise, and thereby better recovers the underlying true 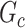 .
.
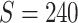
|
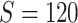
|
|||||||
|---|---|---|---|---|---|---|---|---|
Cohen’s 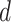
|
1.2 | 0.8 | 0.5 | 1.2 | 0.8 | 0.5 | ||
| SICERS | TPR |
|
1(0) | 0.87(0.2) | 0.91(0.19) | 1(0) | 0.9(0.2) | 0.88(0.2) |
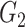
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) | ||
| FDR |
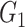
|
0(0) | 0(0) | 0(0.01) | 0(0) | 0.02(0.04) | 0.02(0.04) | |
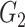
|
0(0) | 0.03(0.04) | 0.09(0.21) | 0(0) | 0.04(0.05) | 0.09(0.19) | ||
| Louvain | TPR |
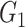
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) |
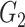
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) | ||
| FDR |
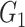
|
0.21(0.1) | 0.58(0.12) | 0.44(0.11) | 0.25(0.11) | 0.58(0.12) | 0.41(0.16) | |
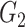
|
0.16(0.06) | 0.03(0.03) | 0.04(0.04) | 0.16(0.05) | 0.02(0.03) | 0.03(0.03) | ||
| Dense | TPR |
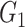
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) |
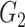
|
1(0) | 1(0) | 1(0) | 1(0) | 1(0) | 1(0) | ||
| FDR |
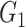
|
0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | |
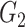
|
0(0) | 0(0) | 0.35(0.27) | 0(0) | 0(0) | 0.52(0.13) | ||
| NBS | TPR |
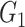
|
1(0) | NA | NA | 1(0) | NA | NA |
|
1(0) | NA | NA | 1(0) | NA | NA | ||
| FDR |
|
0.28(0.05) | NA | NA | 0.21(0.1) | NA | NA | |
|
0.59(0.16) | NA | NA | 0.54(0.21) | NA | NA | ||
| BH-FDR | TPR | 1(0) | 0.95(0) | 0.94(0) | 1(0) | 0.94(0.01) | 0.75(0.01) | |
| FDR | 0.18(0.01) | 0.5(0) | 0.54(0) | 0.18(0.01) | 0.5(0) | 0.54(0.01) | ||
The average computing time of SICERS is around 14 min (greedy: 6 min and Louvain: 3 min) on a PC with Intel i7-9700K CPU and 16GB of RAM.
4. Applications to brain connectome data
4.1. Data background
We applied our SICERS method to rs-fMRI brain connectome analysis for schizophrenia research. The data were collected at the School of Medicine of the University of Maryland to investigate the associations of brain functional connectivity (Adhikari and others, 2019). The imaging acquisition parameters, patient inclusion and exclusion criteria, and preprocessing steps are described in detail in the supplementary material available at Biostatistics online.
To assess the replicability of brain connectome analysis, we used two independent data sets: a primary set  and a validation set
and a validation set 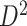 . The primary data set
. The primary data set 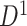 contained 70 schizophrenia patients (age =
contained 70 schizophrenia patients (age = 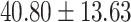 years) and 70 control subjects (age =
years) and 70 control subjects (age = 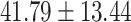 years) matched by age (
years) matched by age (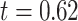 ,
, 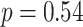 ) and sex ratio (
) and sex ratio (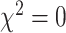 ,
,  ). The validation data set
). The validation data set 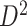 contained another 30 individuals with schizophrenia (age =
contained another 30 individuals with schizophrenia (age = 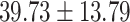 years) and 30 control subjects (age =
years) and 30 control subjects (age = 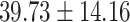 years) matched by age (
years) matched by age (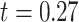 ,
, 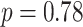 ) and sex ratio (
) and sex ratio (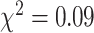 ,
, 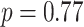 ). The primary and validation data sets were randomly selected and shared recruitment procedures, inclusion and exclusion criteria, and imaging acquisition and preprocessing steps. Nodes of the connectome graph
). The primary and validation data sets were randomly selected and shared recruitment procedures, inclusion and exclusion criteria, and imaging acquisition and preprocessing steps. Nodes of the connectome graph 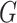 were specified by the commonly used automated anatomical labeling (AAL). Time courses of all voxels within a 10-mm sphere around the centroid of each region were preprocessed as region-wise signals, followed by calculating 4005 Pearson correlation coefficients between the time courses of the 90 AAL regions (i.e.,
were specified by the commonly used automated anatomical labeling (AAL). Time courses of all voxels within a 10-mm sphere around the centroid of each region were preprocessed as region-wise signals, followed by calculating 4005 Pearson correlation coefficients between the time courses of the 90 AAL regions (i.e., 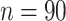 in all
in all 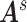 ). We used Fisher’s
). We used Fisher’s 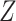 transformation and normalization to obtain connectivity matrices. We performed statistical analysis on these data sets separately, identified the covariate-related subnetworks, and compared significant disease-related subnetworks for
transformation and normalization to obtain connectivity matrices. We performed statistical analysis on these data sets separately, identified the covariate-related subnetworks, and compared significant disease-related subnetworks for 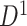 and
and 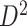 . We also compared the results obtained by SICERS with those of conventional edge-wise inference and commonly used network methods.
. We also compared the results obtained by SICERS with those of conventional edge-wise inference and commonly used network methods.
4.2. Covariate-related subnetworks
For 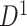 , we first conducted an edge-wise Wilcoxon rank sum test for each age and sex adjusted edge
, we first conducted an edge-wise Wilcoxon rank sum test for each age and sex adjusted edge 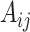 to obtain the
to obtain the 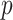 -value
-value 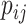 and the inference matrix
and the inference matrix 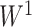 with elements
with elements 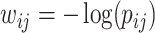 , although regression models could also be applied. Then, we applied SICERS to
, although regression models could also be applied. Then, we applied SICERS to 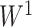 , and our method detected one significant subnetwork
, and our method detected one significant subnetwork 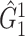 with an empirical subnetwork
with an empirical subnetwork 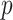 -value of less than
-value of less than 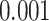 . This subnetwork contained 22 nodes, including the left medial frontal cortex, bilateral insula, bilateral anterior and middle cingulate cortices, bilateral Heschl gyrus and superior temporal cortices, bilateral paracentral and postcentral cortices, right precentral cortex, and precuneus (Figures 3(a)–(c)) (a full list of region names is given in Table S1 of the supplementary material available at Biostatistics online).
. This subnetwork contained 22 nodes, including the left medial frontal cortex, bilateral insula, bilateral anterior and middle cingulate cortices, bilateral Heschl gyrus and superior temporal cortices, bilateral paracentral and postcentral cortices, right precentral cortex, and precuneus (Figures 3(a)–(c)) (a full list of region names is given in Table S1 of the supplementary material available at Biostatistics online).
Fig. 3.

Applying SICERS to clinical data 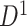 (a)–(c) and replication data
(a)–(c) and replication data 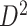 (d)–(f). (a) A heatmap of
(d)–(f). (a) A heatmap of 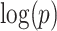 of the first data set (
of the first data set (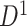 ); hotter pixels indicate more differential edges between cases and controls, and there is no apparent topological pattern for these hot edges. (b) We then perform SICERS in
); hotter pixels indicate more differential edges between cases and controls, and there is no apparent topological pattern for these hot edges. (b) We then perform SICERS in 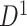 and find a significant subnetwork [the bold square, which is magnified in (c)]. (c) The enlarged disease-relevant subnetwork in
and find a significant subnetwork [the bold square, which is magnified in (c)]. (c) The enlarged disease-relevant subnetwork in 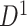 with region names. (d) A heatmap of
with region names. (d) A heatmap of 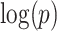 of the second data set (
of the second data set (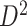 ). (e) The disease-relevant subnetwork was detected by using
). (e) The disease-relevant subnetwork was detected by using 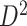 alone. (f) The enlarged network in
alone. (f) The enlarged network in 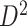 with region names. To save space here, versions of the enlarged plots (c) and (f) with more-readable axis labels are included in the supplementary material available at Biostatistics online.
with region names. To save space here, versions of the enlarged plots (c) and (f) with more-readable axis labels are included in the supplementary material available at Biostatistics online.
We then applied the same steps of SICERS to 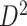 and also detected one significant subnetwork
and also detected one significant subnetwork 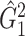 of 21 nodes, including the left medial superior frontal gyrus, bilateral insula, bilateral anterior and middle cingulate cortices, bilateral Heschl gyrus, Rolandic operculums, supplementary motor areas, paracentral lobules, postcentral lobules, and left precuneus (Figures 3(d) and (e)). In both
of 21 nodes, including the left medial superior frontal gyrus, bilateral insula, bilateral anterior and middle cingulate cortices, bilateral Heschl gyrus, Rolandic operculums, supplementary motor areas, paracentral lobules, postcentral lobules, and left precuneus (Figures 3(d) and (e)). In both 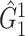 and
and 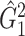 , most edges showed reduced connectivity in patients with schizophrenia.
, most edges showed reduced connectivity in patients with schizophrenia.
4.3. Replicability of disease-related subnetworks
A remarkable feature of our method is the high replicability of its network-level findings. Specifically, we find that the disease-related subnetworks for 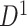 and
and 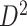 are almost identical (
are almost identical (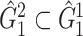 ), which would occur with near-zero probability if significant
), which would occur with near-zero probability if significant 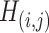 ’s were not organized as subnetworks but rather scattered randomly. This demonstrates that the subnetwork structure detected by our method reflects not randomness but significant patterns that emerge stably across different independently collected data batches.
’s were not organized as subnetworks but rather scattered randomly. This demonstrates that the subnetwork structure detected by our method reflects not randomness but significant patterns that emerge stably across different independently collected data batches.
We also applied the NBS and univariate inference methods to input data (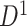 and
and 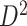 ). Neither NBS nor BH-FDR selected significant subnetworks/edges due to influence of noise. Rather, the uncorrected
). Neither NBS nor BH-FDR selected significant subnetworks/edges due to influence of noise. Rather, the uncorrected 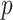 -value of
-value of 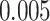 —a commonly used threshold in the field of neuroimaging (Derado and others, 2010)—was applied to
—a commonly used threshold in the field of neuroimaging (Derado and others, 2010)—was applied to 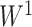 and
and 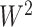 ; 430 and 22 suprathreshold edges, respectively, were reported for the two data sets. However, among the two sets of suprathreshold edges, only two edges overlapped. To summarize, for these data sets, none of the benchmark methods rejected any individual
; 430 and 22 suprathreshold edges, respectively, were reported for the two data sets. However, among the two sets of suprathreshold edges, only two edges overlapped. To summarize, for these data sets, none of the benchmark methods rejected any individual 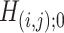 and thus they all reported no pattern discovery, whereas our SICERS method—by exploiting the network structure—detected significant subnetwork structure with good replicability.
and thus they all reported no pattern discovery, whereas our SICERS method—by exploiting the network structure—detected significant subnetwork structure with good replicability.
4.4. Biological insights from the covariate-related subnetwork
The brain region constellation of the covariate-related subnetwork consists of inferior frontal, superior temporal, insula, cingulate, and paracentral areas (as shown in Figure S5 in supplementary material available at Biostatistics online). These brain regions comprise three well-known networks: the SN (bilateral), part of the DMN, and part of the CEN. A large body of literature on schizophrenia research has reported well-replicated findings in the neurobiology of schizophrenic disorders pertaining to these three networks (Orliac and others, 2013). The consensus is that functional connections within and between these networks are weaker in patients with schizophrenia than in healthy controls (Lynall and others, 2010), although the potentially confounding effects of medications in these studies have not been ruled out effectively. This is aligned well with our finding that all edges in the disease-related subnetwork show decreased connectivity strengths in patients. Our findings regarding disease-related subnetworks are novel because they provide an integrated understanding of the intrinsic large-scale networks altered by the brain disorder. They reveal systematically the disruption of high-level coordination between neural populations that is linked with clinical symptoms of schizophrenia, including deficits in information processing or blunted reward (SN), language (temporal gyri), and anhedonia (CEN), and—more importantly—the integrated function formed by the interactions of these networks. In summary, our disease-related subnetwork analysis provides a comprehensive investigation of disease-specific brain networks and thus can yield new insights to understand the complex neurobiology of a brain disorder. We further demonstrate the utility of our method by investigating the age- and sex (covariate)-related subnetworks based on 22 000 participants collected from UK Biobank in supplementary material available at Biostatistics online.
5. Discussion
We have developed a new tool—SICERS—to identify covariate-related subnetworks in brain connectome data. Our work represents a new strategy for handling multivariate edge variables as outcomes constrained in an adjacency matrix. In practice, a covariate may influence a small proportion of edge outcomes that may reside in organized subgraphs/subnetworks. Like the popular cluster-wise inference for brain activity analysis, SICERS aims to extract covariate-related subnetworks as clusters of covariate-related edges for connectome analysis. However, extracting latent covariate-related subnetworks is more challenging than extracting activity clusters of spatially adjacent voxels. A small proportion of selected edges can almost surely connect nodes into a subnetwork including all nodes, and a covariate-related subnetwork involving all nodes is neither biologically sound nor statistically accurate. To address this challenge, we define a covariate-related subnetwork as a subgraph of an organized structure (e.g., a community) and concentrated with covariate-related edges. Lemma 1 demonstrates that the chance of a false-positive, nontrivial, and dense subnetwork is close to zero. Using both theoretical and numerical results in Sections 3 and 4, we further show that by leveraging this property, our subnetwork-level analysis can improve both network-level and edge-level sensitivity while controlling the false-positive findings.
We implement computationally efficient algorithms for SICERS to extract subnetworks covering maximal covariate-related edges (high sensitivity) with 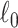 penalty on subnetwork size. The
penalty on subnetwork size. The 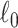 penalty ensures that the selected subnetworks are dense and suppresses false-positive edges (i.e., fewer nodes are included). Our algorithm differs from dense subgraph extraction algorithms because SICERS can reveal multiple subnetworks more effectively (as seen in the simulations). Our algorithm also suggests that implementing the
penalty ensures that the selected subnetworks are dense and suppresses false-positive edges (i.e., fewer nodes are included). Our algorithm differs from dense subgraph extraction algorithms because SICERS can reveal multiple subnetworks more effectively (as seen in the simulations). Our algorithm also suggests that implementing the 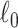 penalty for multivariate edge variables can be less computationally expensive than the
penalty for multivariate edge variables can be less computationally expensive than the 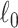 penalty for the traditional variable selection setting of a vector of variables. In addition, we perform the network-level statistical inference by the permutation test to control the FWER (Eklund and others, 2016) with tailored subnetwork-level test statistics. Since SICERS focuses on network-level inference, it cannot capture individual covariate-related edges that are not part of subnetworks. An alternative approach is to use edge-level inference with FWER/FDR correction to identify individual covariate-related edges.
penalty for the traditional variable selection setting of a vector of variables. In addition, we perform the network-level statistical inference by the permutation test to control the FWER (Eklund and others, 2016) with tailored subnetwork-level test statistics. Since SICERS focuses on network-level inference, it cannot capture individual covariate-related edges that are not part of subnetworks. An alternative approach is to use edge-level inference with FWER/FDR correction to identify individual covariate-related edges.
SICERS is generally applicable to multivariate edge variables, for example, structural and functional brain connectome data. Although we focus on a single covariate in SICERS, we can extend the method straightforwardly to a contrast of parameters combining multiple covariates or a dominating factor of multiple covariates by dimension–reduction techniques. The software package for SICERS is at https://github.com/shuochenstats/SICERS.
Supplementary Material
Acknowledgments
Conflict of Interest: The authors declare no conflict of interest.
Contributor Information
Shuo Chen, Division of Biostatistics and Bioinformatics, Department of Epidemiology and Public Health, University of Maryland School of Medicine, 660 W. Redwood Street Baltimore, MD 21201, USA and Maryland Psychiatric Research Center, Department of Psychiatry, University of Maryland School of Medicine, Baltimore, 55 Wade Avenue, Catonsville, MD 21228, USA.
Yuan Zhang, Department of Statistics, Ohio State University, 1958 Neil Ave, Columbus, OH 43210, USA.
Qiong Wu, Department of Biostatistics, Epidemiology, and Informatics, School of Medicine, University of Pennsylvania, 423 Guardian Dr, Philadelphia, PA 19104, USA.
Chuan Bi, Maryland Psychiatric Research Center, Department of Psychiatry, University of Maryland School of Medicine, Baltimore, 55 Wade Avenue, Catonsville, MD 21228, USA.
Peter Kochunov, Maryland Psychiatric Research Center, Department of Psychiatry, University of Maryland School of Medicine, Baltimore, 55 Wade Avenue, Catonsville, MD 21228, USA.
L Elliot Hong, Maryland Psychiatric Research Center, Department of Psychiatry, University of Maryland School of Medicine, Baltimore, 55 Wade Avenue, Catonsville, MD 21228, USA.
Supplementary material
Supplementary material is available at http://biostatistics.oxfordjournals.org.
Funding
This work was supported by the National Institutes of Health under Award Numbers 1DP1DA04896801, EB008432 and EB008281.
References
- Adhikari, B. M., Hong, L. E., Calhoun, V. D., Du, X., Chen, S.. and others. (2019). Functional network connectivity impairments and core cognitive deficits in schizophrenia. Human Brain Mapping 40, 4593–4605. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bickel, P. J. and Chen, A. (2009). A nonparametric view of network models and Newman–Girvan and other modularities. Proceedings of the National Academy of Sciences United States of America 106, 21068–21073. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blondel, V. D., Guillaume, J.-L., Lambiotte, R. and Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment 2008, P10008. [Google Scholar]
- Bowman, F. D. (2005). Spatio-temporal modeling of localized brain activity. Biostatistics 6, 558–575. [DOI] [PubMed] [Google Scholar]
- Bowman, F. D., Zhang, L., Derado, G. and Chen, S. (2012). Determining functional connectivity using fMRI data with diffusion-based anatomical weighting. NeuroImage 62, 1769–1779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cai, T., Li, H., Ma, J. and Xia, Y. (2019). Differential Markov random field analysis with an application to detecting differential microbial community networks. Biometrika 106, 401–416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cao, X., Sandstede, B. and Luo, X. (2019). A functional data method for causal dynamic network modeling of task-related fMRI. Frontiers in Neuroscience 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen, S., Bowman, F. D. and Mayberg, H. S. (2016). A Bayesian hierarchical framework for modeling brain connectivity for neuroimaging data. Biometrics 72, 596–605. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen, S., Kang, J., Xing, Y. and Wang, G. (2015). A parsimonious statistical method to detect groupwise differentially expressed functional connectivity networks. Human Brain mapping 36, 5196–5206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen, S., Xing, Y., Kang, J., Kochunov, P. and Hong, L. E. (2020). Bayesian modeling of dependence in brain connectivity data. Biostatistics 21, 269–286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Craddock, R. C., Jbabdi, S., Yan, C.-G., Vogelstein, J. T., Castellanos, F. X.. and others. (2013). Imaging human connectomes at the macroscale. Nature Methods 10, 524. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Derado, G., Bowman, F. D. and Kilts, C. D. (2010). Modeling the spatial and temporal dependence in fMRI data. Biometrics 66, 949–957. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Durante, D., Dunson, D. B.. and others. (2018). Bayesian inference and testing of group differences in brain networks. Bayesian Analysis 13, 29–58. [Google Scholar]
- Eklund, A., Nichols, T. E. and Knutsson, H. (2016). Cluster failure: why fMRI inferences for spatial extent have inflated false-positive rates. Proceedings of the National Academy of Sciences United States of America 113, 7900–7905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan, L., Li, H., Zhuo, J., Zhang, Y., Wang, J.. and others. (2016). The human brainnetome atlas: a new brain atlas based on connectional architecture. Cerebral Cortex 26, 3508–3526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hu, Y., Zeydabadinezhad, M., Li, L. and Guo, Y. (2022). A multimodal multilevel neuroimaging model for investigating brain connectome development. Journal of the American Statistical Association 117, 1134–1148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kundu, S., Ming, J., Pierce, J., McDowell, J. and Guo, Y. (2018). Estimating dynamic brain functional networks using multi-subject fMRI data. NeuroImage 183, 635–649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lukemire, J., Kundu, S., Pagnoni, G. and Guo, Y. (2021). Bayesian joint modeling of multiple brain functional networks. Journal of the American Statistical Association 116, 518–530. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lynall, M.-E., Bassett, D. S., Kerwin, R., McKenna, P. J., Kitzbichler, M., Muller, U. and Bullmore, E. (2010). Functional connectivity and brain networks in schizophrenia. Journal of Neuroscience 30, 9477–9487. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Manoliu, A., Riedl, V., Zherdin, A., Mühlau, M., Schwerthöffer, D.. and others. (2014). Aberrant dependence of default mode/central executive network interactions on anterior insular salience network activity in schizophrenia. Schizophrenia Bulletin 40, 428–437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nichols, T. E. (2012). Multiple testing corrections, nonparametric methods, and random field theory. Neuroimage 62, 811–815. [DOI] [PubMed] [Google Scholar]
- Orliac, F., Naveau, M., Joliot, M., Delcroix, N.. and others. (2013). Links among resting-state default-mode network, salience network, and symptomatology in schizophrenia. Schizophrenia Research 148, 74–80. [DOI] [PubMed] [Google Scholar]
- Rosvall, M. and Bergstrom, C. T. (2008). Maps of random walks on complex networks reveal community structure. Proceedings of the national academy of sciences 105, 1118–1123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shi, R. and Guo, Y. (2016). Investigating differences in brain functional networks using hierarchical covariate-adjusted independent component analysis. The Annals of Applied Statistics 10, 1930. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simpson, S. L., Bahrami, M. and Laurienti, P. J. (2019). A mixed-modeling framework for analyzing multitask whole-brain network data. Network Neuroscience 3, 307–324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simpson, S. L., Bowman, F. D. and Laurienti, P. J. (2013). Analyzing complex functional brain networks: fusing statistics and network science to understand the brain. Statistics Surveys 7, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stepanov, V. E. (1970). On the probability of connectedness of a random graph g_m(t). Theory of Probability & Its Applications 15, 55–67. [Google Scholar]
- Von Luxburg, U. (2007). A tutorial on spectral clustering. Statistics and Computing 17, 395–416. [Google Scholar]
- Wang, W., Zhang, X. and Li, L. (2019). Common reducing subspace model and network alternation analysis. Biometrics 75, 1109–1120. [DOI] [PubMed] [Google Scholar]
- Warnick, R., Guindani, M., Erhardt, E., Allen, E., Calhoun, V. and Vannucci, M. (2018). A Bayesian approach for estimating dynamic functional network connectivity in fMRI data. Journal of the American Statistical Association 113, 134–151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu, Q. and Hao, J.-K. (2015). A review on algorithms for maximum clique problems. European Journal of Operational Research 242, 693–709. [Google Scholar]
- Wu, Q., Huang, X., Culbreth, A. J., Waltz, J. A., Hong, L. E. and Chen, S.. Extracting brain disease-related connectome subgraphs by adaptive dense subgraph discovery. Biometrics. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xia, Y. and Li, L. (2017). Hypothesis testing of matrix graph model with application to brain connectivity analysis. Biometrics 73, 780–791. [DOI] [PubMed] [Google Scholar]
- Zalesky, A., Fornito, A. and Bullmore, E. T. (2010). Network-based statistic: identifying differences in brain networks. Neuroimage 53, 1197–1207. [DOI] [PubMed] [Google Scholar]
- Zhang, J., Sun, W. W. and Li, L. (2023). Generalized Connectivity Matrix Response Regression with Applications in Brain Connectivity Studies, Journal of Computational and Graphical Statistics 32, 252–262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang, T., Yin, Q., Caffo, B.. and others. (2017). Bayesian inference of high-dimensional, cluster-structured ordinary differential equation models with applications to brain connectivity studies. The Annals of Applied Statistics 11, 868–897. [Google Scholar]
- Zhang, Y., Levina, E., Zhu, J.. and others. (2016). Community detection in networks with node features. Electronic Journal of Statistics 10, 3153–3178. [Google Scholar]
- Zhao, Y., Levina, E., Zhu, J.. and others. (2012). Consistency of community detection in networks under degree-corrected stochastic block models. The Annals of Statistics 40, 2266–2292. [Google Scholar]
- Zhao, Y., Wang, B., Caffo, B. S. and Luo, X. (2021). Covariate assisted principal regression for covariance matrix outcomes. Biostatistics 22, 629–645. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.