

Abstract
We develop a framework for learning properties of quantum states beyond the assumption of independent and identically distributed (i.i.d.) input states. We prove that, given any learning problem (under reasonable assumptions), an algorithm designed for i.i.d. input states can be adapted to handle input states of any nature, albeit at the expense of a polynomial increase in training data size (aka sample complexity). Importantly, this polynomial increase in sample complexity can be substantially improved to polylogarithmic if the learning algorithm in question only requires non-adaptive, single-copy measurements. Among other applications, this allows us to generalize the classical shadow framework to the non-i.i.d. setting while only incurring a comparatively small loss in sample efficiency. We leverage permutation invariance and randomized single-copy measurements to derive a new quantum de Finetti theorem that mainly addresses measurement outcome statistics and, in turn, scales much more favorably in Hilbert space dimension.
Subject terms: Quantum information, Computer science, Statistics
Most of the current protocols for learning properties of quantum states are based on the assumption that the states are prepared in the same way over time. Here, the authors show a way to remove this assumption, while incurring only a polynomial increase in sample complexity.
Introduction
The advent of quantum technologies has led to a notable amount of tools for quantum state and process learning. These are employed as tools within use cases, but also to test applications and devices themselves. However, almost all existing methods require the assumption that the devices or states being tested are prepared in the same way over time – following an identical and independent distribution (i.i.d.)1–10. In various situations, this assumption should not be taken for granted. For instance, in time correlated noise, states and devices change in time in a non-trivial way11–13. Moreover, in settings where we cannot trust the devices or states – for example, originating from an untrusted, possibly malicious manufacturer, or states that are distributed over untrusted channels – the assumption of i.i.d. state preparations can be exploited by malicious parties to mimic good behavior whilst corrupting the intended application. Avoiding this assumption is crucial for various applications such as verified quantum computation14 or tasks using entangled states in networks15, such as authentication of quantum communication16, anonymous communication17, or distributed quantum sensing18. At the core of the security for these applications is some verification procedure which does not assume i.i.d. resources, however they are all catering for particular states or processes, with independent proofs and with differing efficiencies.
The main contribution of this paper is to develop a framework to extend existing i.i.d. learning algorithms into a fully general (non-i.i.d.) setting while preserving rigorous performance guarantees. See Theorem 1 and Theorem 3 for the type of results we provide. The main technical ingredient is a variant of the quantum de Finetti theorem for randomized permutation invariant measurements (See Theorem 2). As a concrete example, we apply our findings to the task of feature prediction with randomized measurements (classical shadows)7,19,20 (See Proposition 1). We then apply these results to the problem of state verification, allowing us to find the first explicit protocol for verifying an arbitrary multipartite state, showing the power of these techniques.
Results
In the following, we start by showing how to evaluate an algorithm in the non-i.i.d. setting. Then, we show that, in principle, general algorithms can be adapted to encompass non-i.i.d. input states at the expense of an overhead in the copy complexity. Next, we reduce significantly this overhead for incoherent non-adaptive algorithms using our quantum de Finetti theorem. Finally, we apply this extension to the problems of classical shadows and verification of pure states in the non-i.i.d. setting.
Evaluating a learning algorithm
The first difficulty we face is to define what it means for a learning algorithm to achieve some learning task on a non-i.i.d. state. In the i.i.d. setting, a learning algorithm requests N copies of an unknown quantum state and is provided with the quantum state . Subsequently, the learning algorithm makes predictions about a property of the quantum state σ. This algorithm is evaluated by contrasting its predictions with the actual property of the quantum state σ. To motivate our general definition, we imagine a black box from which we can request copies. On the first query, we receive a system that we call A1 and on the kth query, we receive the system Ak. Learning means making a statement about some of the outputs of the black box (e.g., the state is close to ). With the i.i.d. assumption, the black box always outputs the same state. Removing the i.i.d. assumption, the learning algorithm is presented with a general quantum state where N is the number of requested copies. In this case, we have to specify the system about which we make the statement (this is the system that would be used for a later application for example). The most natural choice is to take a system at random among the ones that were requested. In other words, we use the common idea in machine learning of separating the data set (here the N systems that we denote A1, …, AN) into a training set used for estimation and a test set used for evaluation. We refer to Fig. 1 for a visual illustration. This idea was previously used in the context of quantum tomography2, verification21, and generalization bounds22.
Fig. 1. Illustration of a general state learning algorithm.
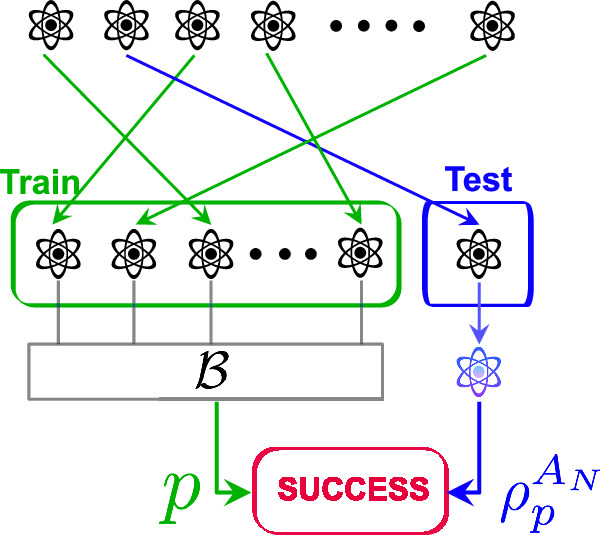
A learning algorithm consumes (N−1) copies of ρ to construct a prediction p. Success occurs if p is (approximately) compatible with the remaining post-measurement test copy .
The choice of which systems are used for training and which are used for testing is random. More specifically, we apply a random permutation (that the learner does not have access to) to the systems A1…AN and we fix the training set to be the first N−1 systems and the test set is composed of the last system. Thus, starting with the general state , we obtain after the random permutation a state that we denote . Written explicitly
where denotes the set of permutations and ρπ is obtained by permuting the systems A1…AN of ρ according to π. The learning algorithm is applied to the training set A1…AN−1 and makes a prediction that we denote p and we test this prediction against the system AN. The learning task will be described by a family of sets SUCCESSε where ε should be seen as a precision parameter. The pair (p, σ) ∈ SUCCESSε if prediction p is correct for the state σ with precision ε. As an example, for the task of predicting M observables O1, …, OM (shadow tomography), we would have p = (p1, …, pM) ∈ [0, 1]M and
Note that this is precisely the learning task which has motivated (i.i.d.) classical shadows7,20.
We evaluate a learning algorithm for the task described by SUCCESSε on the input state as follows. The algorithm takes as input the systems A1…AN−1 and outputs a prediction and a calibration information . The role of the calibration information is to determine the reduced state of AN and can range from trivial to all measurement outcomes. In other words, (c, p) follows the distribution , which we denote by: . For an outcome (c, p), we write for the reduced state of AN of the state conditioned on the outcome of being (c, p). Finally, we define
| 1 |
We make a few remarks about this definition assuming for simplicity. First, in the i.i.d. setting we have that for any and we recover the usual definition of error probability. Second, note that it is essential to consider the state of AN conditioned on the outcome p. One might be tempted to replace with the marginal but this would be both unachievable and undesirable. In fact, consider the simple example and we would like to estimate the value of the observable . Note that . As such, with the naive definition using the marginal which is in this case, the error probability would be given by . Clearly any good learning algorithm should work for the i.i.d. states , and this implies that the error probability is close to 1 for this choice of ρ. For this example, it is desirable that the learning algorithm first detects which of the two states or has been prepared and then learns the state consistently. This is captured by the definition (1).
A third remark about the definition we use is that the error probability is evaluated for the averaged state , or in other words the learner does not have access to the randomly chosen permutation π. Another possibility would be to define the error probability as an average over permutations π of the error probability evaluated for the permuted state ρπ, i.e.,
| 2 |
It turns out that this definition renders learning impossible in many cases. In fact, we show in Supplementary Note 1 that for the simplest possible classical task of estimating the expectation of a binary random variable, it is not possible to achieve for all states. This shows that requiring to be small cannot be achieved in general and it justifies our choice in Eq. (1). We also remark that for verification problems, where the prediction is of the form Accept/Reject and we only want to express the soundness condition for all states in expectation, then the expression for the error probability is linear in the state (see Supplementary Note 4). As such, in this case, whether the permutation is available to the learner or not does not make a difference. With our definition, we have , so to make the notation lighter, we assume in the rest of the paper that ρ is permutation invariant, i.e., .
Adapting a learning algorithm designed for i.i.d. inputs
Our first result transforms any learning algorithm for the task SUCCESSε designed for i.i.d. input states to a learning algorithm for the same task without requiring the i.i.d. assumption at the cost of an increased number of queries.
Theorem 1
(General algorithms in the non-i.i.d. setting). Let ε > 0, 1 ≤ k < N/2 and d be the dimension of the Hilbert spaces A1, …, AN. Let be a learning algorithm designed for i.i.d. input states. There exists a learning algorithm taking arbitrary inputs on N systems and having an error probability (1) satisfying
Note that the evaluation of a learning algorithm is defined by first randomly permuting the systems A1…AN so we may assume that is invariant under permutations and the systems are identically distributed. The first term in the bound of Theorem 1 is the worst case error probability in the i.i.d. setting. So, we can regard the parameter k as the copy complexity within the i.i.d. setting. Hence, in order to attain a low total error probability in the non-i.i.d. setting, it is sufficient to take a total number of copies . This result shows in principle that any learning algorithm designed for i.i.d. states can be transformed into one for general states at an additional cost that is polynomial in the dimension d.
A possible algorithm achieving the performance of Theorem 1, illustrated in Fig. 2 (Left) and formally described in Algorithm 2 (displayed in Box 2), partitions the training data into 3 parts. For that we choose a random number (). The first part has size l−k and each system is measured using some fixed measurement leading to an output string w. The second part is of size k and we apply the learning algorithm and return this prediction. The third part consists of N−l−1 systems that are not used by the learning algorithm.
Fig. 2. Caricature of main results: how to lift an i.i.d. learning algorithm beyond the i.i.d. setting.

Left: the performance of general learning algorithms is covered by our first main result (Theorem 1). Right: the performance of non-adaptive and incoherent learning algorithms is covered by our second main result (Theorem 3). Restricting to non-adaptive and incoherent measurement leads to much better theoretical performance guarantees. is a measurement device with low distortion, w is calibration, p is prediction, is the data processing of the i.i.d. algorithm and is a measurement device uniformly chosen from 's set of measurements. Success occurs if p is (approximately) compatible with the remaining post-measurement test copies or .
To control the error probability of Algorithm , we use the de Finetti theorem of ref. 23 (proof of Theorem 2.4) to obtain the approximation for all 1 ≤ k < N/2:
| gF |
where is the state conditioned on observing the outcome w after measuring the quantum state with a fixed measurement device (which should be an informationally-complete measurement satisfying a low-distortion property) and denotes the reduced quantum state derived by tracing out the systems At for t > 1 from the quantum state . This theorem shows that when measuring a sufficiently large number of systems of a permutation invariant state, the remaining systems become approximately independent. Crucially, in (gF) the approximation of the state by the i.i.d. state is conducted using the trace-norm. This implies that any algorithm utilizing arbitrary measurement strategies that necessitate i.i.d. input states can be generalized to the non-i.i.d. setting at the cost of a new error probability bounded as in Theorem 1. Unfortunately, for some tasks, the additional cost in Theorem 1 is prohibitive. For example, for classical shadows, we expect that the dependence on the dimension d be at most logarithmic.
An example of ref. 24 shows that the dependency in the dimension can not be lifted for a general de Finetti theorem with the trace-norm approximation. On the other hand, the authors of ref. 25 reduced the dependency in the dimension for the LOCC norm. Specifically, it is shown25 that for a permutation invariant state and 1 ≤ k < N, there exists a probability measure denoted as ν, such that the following inequality holds:
| IF |
where the maximization is over measurements channels (a measurement channel corresponding to a measurement device is the quantum channel where is an orthonormal basis). Initially, this might appear adequate for relaxing the assumption of i.i.d. state preparations with a low overhead. However, the process of extending algorithms from i.i.d. inputs to a mixture of i.i.d. states (not to mention permutation-invariant states) is far from straightforward, particularly when dealing with statements that require a correctness with high probability. To address this difficulty, we use the same techniques from ref. 25 and show a randomized local quantum de Finetti theorem.
Theorem 2
(Randomized local de Finetti). Let be a permutation invariant quantum state, be a set of measurement channels and q be a probability measure on . For all 1 ≤ k < N/2, the following inequality holds:
where w is obtained by applying the channel to the systems Ak+1 ⋯ Al of ρ.
The result we establish in Theorem 4 is actually slightly stronger: we do not need to be permutation invariant, it suffices to choose a permutation of the systems (A1, …, AN) at random, and the result above holds in expectation over this choice. Moreover, it suffices to sample (r1, …, rN) ~ qN from a permutation-invariant measure on .
Observe that our de Finetti theorem requires stronger assumptions than the local de Finetti theorem (1F)25: the distribution of the measurement channels should be permutation invariant (as opposed to arbitrary). However, the implications of our de Finetti theorem are also stronger than the local de Finetti theorem (1F) in that it approximates the projection of the permutation invariant state to exactly i.i.d. states (instead of mixture of i.i.d. states).
It is worth noting that the approximation error in Theorem 2 is significantly smaller than the previous approximation error (gF). Notably, the dependence on the local dimension d is logarithmic, which implies that the total number of copies N only needs to scale as , as opposed to the more demanding . However, the approximation of the state by the i.i.d. state in the general trace-norm is no longer guaranteed. This assertion now holds only when applying independent local measurement channels drawn from according to the distribution q on the quantum state . For learning algorithms that are non-adaptive and incoherent (performing single copy measurements using a set of measurement devices chosen before starting the learning procedure), this is enough to bound their error probability and leads to the following theorem.
Theorem 3
(Non-adaptive algorithms in the non-i.i.d. setting). Let ε > 0 and 1 ≤ k < N/2. Let be a learning algorithm designed for i.i.d. input states and performing non-adaptive incoherent measurements. There is an algorithm that takes as input an arbitrary state on N systems and possessing an error probability:
In terms of copy complexity, to ensure an error probability δ, the number of copies in the non-i.i.d. setting should be
where k iid(ε, δ) is a sufficient number of copies needed to achieve δ/2 correctness in the i.i.d. setting with a precision parameter ε/2.
To prove Theorem 3, we provide an algorithm , illustrated in Fig. 2 (Right) and formally described in Algorithm 1 (displayed in Box 1). Note that as is assumed to be incoherent and non-adaptive, it is described by some measurements . The algorithm partitions the training data into 3 parts. We choose a random number (). The first part has size l−k and each system is measured using some measurement , where r is chosen at random. This step gives an output string that we denote w. The second part is of size k and we apply the learning algorithm and return this prediction. The third part consists of N−l−1 systems that are not used by the learning algorithm. Besides this, Algorithm returns also the outcomes w as calibration data.
Many problems of learning properties of quantum states can be solved using algorithms that perform non-adaptive incoherent measurements - that is, measurements which are local on copies and chosen non-adaptively (see Definition 5 for a formal definition). This includes state tomography26, shadow tomography using classical shadows7, testing mixedness27, fidelity estimation1, verification of pure states5 among others. For all these problems, we can apply Theorem 3 to extend these algorithms so that they can operate even for non-i.i.d. input states (see Methods’ subsection “Applications”). Here, we present this extension for observable prediction via classical shadows. The learning task is to ε-approximate M target observables in an unknown d-dimensional state ρ.
Proposition 1
(Classical shadows in the non i.i.d. setting). Fix a collection of M observables Oi on an n-qubit system that are also k-local. Then, we can use (global or local) Clifford measurements to successfully ε-approximate all target observables in the reduced test state with probability at least 2/3. The number of copies required depends on the measurement process (global/local Clifford) and scales as
where hides and factors.
Notably, taking classical shadows techniques allows us to perform verification in the non-i.i.d. setting21 without even revealing or making assumptions on the verified target state.
Box 1 Algorithm 1 - Predicting properties of quantum states in the non-i.i.d. setting - Non-adaptive algorithms.
Require: The measurements of algorithm . A permutation invariant state .
Ensure: Adapt the algorithm to non-i.i.d. inputs .
1. For , sample and .
2. For t = k + 1, …, l, apply to system At and obtain outcome .
3. For t = 1, …, k, apply to system At and obtain outcome .
4. For , let be the first integer such that rs(t) = t.
5. Run the prediction of algorithm to the measurement outcomes and obtain p.
6. Return: .
Application: verification of pure states
The verification of pure states plays an important role in quantum information, notably in the cryptographic setting, where devices, channels or parties are not trusted8. This stems from the view of quantum states as resources for certain tasks, which is the case for many applications in quantum information, where the most challenging part is the preparation (and/or distribution) of large entangled states, with which various applications can be carried out by easier, usually local, operations. In measurement-based quantum computing, computation is carried out by single qubit measurements on a large entangled graph state28. In networks, many applications rely on the sharing of particular entangled resource states, such as anonymous communication29, secret sharing30, and distributed sensing31. In these cases, what this means is that, once we can be sure we have the good resource state, we can confirm the application itself. The ability to verify the resource state is then very useful, especially, for example, if the resource state is issued by an untrusted server, or shared over an untrusted network. In these cases, we would clearly not like to make the assumption of an i.i.d. source since this would correspond to assuming i.i.d. attacks by the malicious party. In the simplest case the malicious party would behave well on some runs (in order to convince the user the state is a good resource), and badly on the others (potentially corrupting the application). We then require verification of pure resources states, without the i.i.d. assumption. Once armed with this, for example, verified quantum computation, can be achieved by verifying the underlying resource graph state32. Similarly, verifying the underlying resource states provides security over untrusted networks for anonymous communication33, secret sharing34 and distributed sensing18.
As an application of Theorem 3 and Proposition 1, we can show that any n-qubit pure state can be verified with either Clifford measurements (see Proposition 4) or Pauli measurements (see Proposition 5). In words, a verification algorithm should accept only when the test set (post-measurement state) is ε-close to the ideal state in fidelity. Our proposed algorithm offers two significant advantages: (a) it does not rely on the assumption of i.i.d. state preparations, and (b) it does not demand prior knowledge of the target pure state during the data acquisition phase (that is, the measurements in the algorithm are independent of the state we wish to verify).
Notably, existing verification protocols in the non-i.i.d. setting are state-dependent, such as stabilizer states15,32,35, weighted graph states, hypergraph states36, and Dicke states37. In contrast, our protocol is independent of the state to be verified. This not only adds to its simplicity but also offers potential advantages in concealing information from the measurement devices regarding the purpose of the test. This blindness is a crucial aspect of many protocols for the verification of computation14, making this feature valuable in such contexts. Moreover, in both network and computational settings, having a universal protocol simplifies the management of verification steps in broader scenarios where different states may be used for various applications.
Discussion
We will now give an overview of the relationship between these results and previous works.
The foundational de Finetti theorem, initially introduced by de Finetti38, states that exchangeable Bernoulli random variables behaves as a mixture of i.i.d. Bernoulli random variables. Subsequently, this statement was quantified and generalized to finite sample sizes and arbitrary alphabets by refs. 39,40. This theorem was further extended to quantum states. Initially in refs. 41,42, the authors established asymptotic generalizations, while in refs. 24,43, the authors presented finite approximations in terms of trace-norm. Later works25,44 improved these approximations for weaker norms: exponential improvements in the dimension dependence are achieved using the one-way LOCC norm, initially for k = 2 by ref. 44, and subsequently for general k by ref. 25. In the mentioned works, the permutation-invariant state was approximated by a mixture of i.i.d. states. In ref. 23, the authors introduced an approximation to i.i.d. states in terms of the trace-norm. In this work, we improve the dimension dependence of this approximation, employing a randomized LOCC norm instead of the trace-norm. Lastly, it is worth noting that information-theoretic proofs for classical finite de Finetti theorems were provided by refs. 45–47.
For the problem of state tomography, the copy complexity in the i.i.d. setting is well-established: Θ(d2/ε2) with coherent measurements3,48, and Θ(d3/ε2) with incoherent measurements4,26,49, where ε denotes the approximation accuracy. In the non-i.i.d. setting, the authors of ref. 2 introduced a formulation for the state tomography problem and presented a result using confidence regions. This result pertains to the asymptotic regime, specifically when the state can be represented as a mixture of i.i.d. states. In this article, we build upon the formulation of ref. 2, and we discern between algorithms that return calibration information and those that do not. Furthermore, we introduce a state tomography algorithm with a finite copy complexity (in the non asymptotic regime). Finally, the authors of ref. 50 have also proposed non-i.i.d. tomography algorithms tailored for matrix product states.
The problem of shadow tomography is known to be solvable with a complexity that grows poly-logarithmically with respect to both the dimension and the number of observables, provided (almost) all i.i.d. copies can be coherently measured6,9,51. However, if we seek to extend this result to the non-i.i.d. setting using our framework, the copy complexity would be polynomial in the dimension. In the case of incoherent measurements, classical shadows7,19,52–57 offer efficient algorithms for estimating properties of certain observable classes. Leveraging our findings, these algorithms can be adapted to the non-i.i.d. setting while maintaining comparable performance guarantees. Importantly, this extension retains efficiency for the same class of observables. Finally, refs. 55,58,59 derived shadow tomography results assuming receipt of independent (though not necessarily identical) copies of states. However, it is worth noting that the assumption of independence, which we overcome in this article, is necessary for their analysis.
Regarding the verification of pure states, optimal and efficient protocols have been proposed in scenarios where the verifier receives independent or product states5,37,60. Recently, considerable attention has been given to the verification of pure quantum states in the adversarial scenario, where the received states can be arbitrarily correlated and entangled21,35,36,61–63. For instance, in ref. 61, the authors proposed efficient protocols for verifying the ground states of Hamiltonians (subject to certain conditions) and polynomial-time-generated hypergraph states. Meanwhile, in ref. 21, the authors introduced protocols to efficiently verify bipartite pure states, stabilizer states, and Dicke states. Noteworthy attention has also been directed towards the verification of graph states21,36,62,63. Furthermore, the authors of ref. 64 studied device-independent verification of quantum states beyond the i.i.d. assumption. Lastly, the verification of continuous-variable quantum states in the adversarial scenario is studied in refs. 65–67. Note that in all these cases the protocols depend explicitly on the state in question.
In summary, we have developed a framework for learning properties of quantum states in the non-i.i.d. setting. The only requirement we impose on the property we aim to learn is the robustness assumption (Definition 3). It would be interesting to analyze the significance of this assumption in the context of the beyond i.i.d. generalizations we prove in the paper (Theorems 5 and 8). Furthermore, while only non-adaptive algorithms that employ incoherent measurements are shown to be extended to encompass non-i.i.d. input states without a loss of efficiency, an open research direction is to investigate whether general algorithms can achieve a similar extension or if there exists an information-theoretic limit.
One of the applications of our results provides the first explicit protocol for verifying any multiparty quantum state, accompanied by clear efficiency statements. However, our results have certain limitations. As discussed in Results’ subsection “Evaluating a learning algorithm”, the choice of the random permutation should be hidden from the learner in general. In addition, for local Pauli measurements, the scaling is exponential in the number of qubits, and while the scaling for Clifford measurements is close to optimal, they are non-local across each copy. In addition, the scaling in the error parameters is not optimal. Nevertheless, we see our results as a first proof-of-principle showing that beyond i.i.d. learning is feasible in many settings with performance guarantees that are comparable to the i.i.d. guarantees. We expect that further work will improve the bounds we obtain both for the general statements as well as using specificities of classes of learning tasks. In addition, we believe that this work will contribute to the transfer of techniques between the areas of learning theory and quantum verification.
Methods
We first present the necessary notation and preliminaries in the next section. This section is essential for a complete understanding of the evaluation of an algorithm in the non-i.i.d. setting and the distinction we make between general and non-adaptive algorithms.
Notation and preliminaries
Let [d] denote the set of integers from 1 to d and [t, s] denote the set of integers from t to s. Hilbert spaces are denoted A, B, … and we will use these symbols for both the label of a quantum system and the system itself. We let dA be the dimension of the Hilbert space A. Let L(A) denote the set of linear maps from A to itself. A quantum state on A is defined as
where ρ ≽ 0 means that ρ is positive semidefinite. The set of quantum states on A is denoted by D(A). For an integer N ≥ 2, we denote the N-partite composite system by A1A2 ⋯ AN = A1 ⊗ A2 ⊗ ⋯ ⊗ AN. A classical-quantum state is a bipartite states that can be written in the form
for some orthonormal basis of the classical outcome space X, where is a probability distribution and for , is a quantum state. It will also be useful to interpret a classical quantum state as , i.e., as a vector of operators acting on B. This interpretation is more appropriate when the classical system takes continuous values. In this case, technically should be interpreted as the space with some measure μ on . Quantum channels are linear maps that can be written in the form
Here, the Kraus operators are linear maps from A to B and satisfy , where is the identity matrix in dA dimensions (). Equivalently, is trace preserving and completely positive. The partial trace is a quantum channel from AB to A defined as
For bipartite state ρAB, we denote the reduced state on A by . In general, for an N-partite state and for two integers t ≤ s ∈ [N], we denote by the quantum state obtained by tracing out the systems Ai for i < t, as well as i > s. In formulas:
In the situation where all systems except one (At for t ∈ [N]) are traced out, we use the notation
A quantum channel Λ with classical output system is called a measurement channel, and is described by a POVM (positive operator-valued measure) where the measurement operators satisfy Mx ≽ 0 and . After performing the measurement on a quantum state ρ ∈ D(A) we observe the outcome with probability . The measurement channel Λ should be viewed as a linear map (preserving positivity and normalization) defined by:
For a measurement operator acting on A, we write ρ conditioned on observing the outcome x by:
Note that this display is only well-defined if . We extend it consistently to by identifying with a single fixed density matrix, e.g. the maximally mixed state. The state ρ and the measurement Λ define a probability measure on by and we will usually write x to be a random variable associated with this measure .
I.i.d. setting - input state
A common assumption in the field of quantum learning is that the learning algorithm is provided with N independent and identically distributed (i.i.d.) copies of the unknown quantum state.
Definition 1
(I.i.d. states). Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems of dimension d. An i.i.d. state refers to an N-partite quantum state ρ ∈ D(A1 ⋯ AN) that can be expressed as ρ = σ⊗N where σ ∈ D(A1) is a quantum state.
An i.i.d. state possesses the characteristic of permutation invariance: if we permute the arrangement of the constituent states σ, the overall state ρ = σ⊗N remains unchanged. For a formal definition of permutation invariance, let be the permutation group of N elements.
Definition 2
(Permutation invariant states). For , let Cπ be the permutation operator corresponding to the permutation π, that is:
A state ρ ∈ D(A1 ⋯ AN) is permutation invariant if for all we have
Note that every i.i.d. state ρ = σ⊗N is permutation-invariant. The converse is not necessarily true, however. Take, for example an N-qubit GHZ state: with . This state is unaffected under permutation operators, but it is very far from an i.i.d. tensor product. It is worthwhile to point out that permutation invariance plays nicely with partial measurements. If ρ is permutation invariant then for an operator acting on A1 ⋯ At, the post-measurement state is also permutation invariant. So we can define the reduced state conditioned on observing x as:
Problems/tasks
In this article, we consider problems of learning quantum states’ properties. These problems can be formulated using a SUCCESS event:
Definition 3
(Success formulation of learning properties of quantum states). A quantum learning problem for states on the system A is defined by: a set of possible predictions together with a set of successful predictions SUCCESS . If (p, σ) ∈ SUCCESS, then p is considered a correct prediction for σ. Otherwise, it is considered incorrect.
Many problems have a precision parameter ε, we write in this case SUCCESSε for the pairs (p, σ) for which p is a correct prediction for σ within precision ε.
We say that the property SUCCESSε satisfies the robustness assumption whenever
Example 1
We illustrate the SUCCESS set for the shadow tomography, full state tomography, verification of a pure state, and testing mixedness problems:
- Shadow tomography: for some family of M observables O1, …, OM satisfying , the objective is to estimate all their expectation values within an additive error ε. In this case, a prediction is an M-tuple of numbers in [0, 1], i.e., and the correct pairs are given by
- State tomography: the objective is to obtain a description of the full state. In this case, a prediction is a description of a density operator, i.e., and we have
- (Tolerant) verification of pure states: in this problem, the objective is to output 0 if the state we have is ε-close to and output 1 if it is 2ε-far from . In this case, the prediction is a bit, i.e., and notice that this is a promise problem in the sense that there are inputs for which any output is valid. For this reason, it is simpler to define the incorrect prediction pairs:
- (Tolerant) testing mixedness of quantum states: this problem is similar to the previous one, except that we are testing if the state is maximally mixed or not. In this case, we have
Observe that all these problems, by the triangle inequality, satisfy the robustness assumption.
Before specifying the algorithms we consider, let us first recall how one could formulate a problem when the input state is non-i.i.d.
Non-i.i.d. setting - input state
Given a learning problem defined by SUCCESSε, in the usual setting, an algorithm takes as an input an i.i.d. state and outputs a prediction p. Then, we say that this algorithm succeeds if (p, σ) belongs to the SUCCESS set. In the setting where the input state is no longer an i.i.d. state, it is not clear when the algorithm succeeds. In what follows, we follow2,21 and present a way to evaluate algorithms with possibly non-i.i.d. input states.
Consider a collection of N finite dimensional quantum systems A1 ≅ ⋯ ≅ AN. We denote the dimension of A1 by d (for an n-qubit system A1, we have d = 2n). This collection is shuffled uniformly at random so that the state is permutation invariant. We need to form two sets:
The train set which consists of the first N−1 copies of the state. Some of these copies are measured in order to construct the estimations necessary for the learning task, and
The test set which consists of the last copy (the state on AN) that is used to test the accuracy of the estimations deduced from the train set. This copy should not be measured.
Since the state can now be entangled, it is possible that the train and test sets cannot be separated from each other. In particular, the measurements we perform on the train set may affect the test set. In addition, the choice of measuring a copy or not can also affect the test set. At the end, we compare the estimations from the train set with the single copy of the test set (see Fig. 3 for an illustration).
Fig. 3. A general algorithm for learning properties of quantum states in the non-i.i.d. setting.
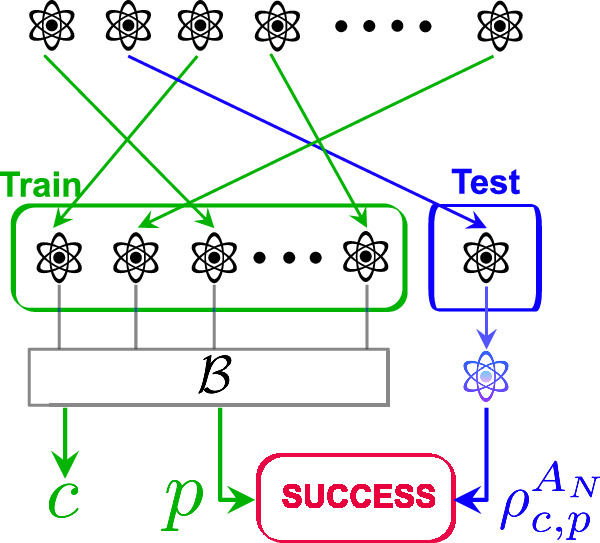
A learning algorithm takes as input the N−1 copies of the train set and returns a prediction p and a calibration c. Success occurs if p is (approximately) compatible with the remaining post-measurement test copy .
Note that in the i.i.d. setting, i.e., ρ = σ⊗N, the train set will be of the form σ⊗N−1 and the test set of the form σ where we compare the estimations deduced from measuring the state σ with the test state σ. Thus we recover the usual setting. The following example illustrates the importance of choosing the test state as the post-measurement state.
Example 2
Consider the following permutation invariant state
If we measure the first system A1 with the canonical basis , we observe m ∈ [d] with probability 1/d and the state collapses to:
After this initial measurement, the state of the last system AN is always equal to . Therefore, it is more appropriate to compare the prediction to rather than the reduced measurement state
Algorithms
In a general algorithm, the prediction can be an arbitrary quantum channel from the train set to a prediction.
Definition 4
(General algorithm). Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems. An algorithm for a learning problem with prediction set is simply a measurement channel .
We will also be interested in a special class of learning algorithms: non-adaptive incoherent algorithms that can only measure each system separately and then apply an arbitrary classical post-processing function.
Definition 5
(Non-adaptive algorithm). Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems. For a non-adaptive algorithm, the prediction channel should be of the form where are measurement channels, and is an arbitrary post-processing channel (aka a classical data processing algorithm).
Error probability
We can assess an algorithm based on its probability of error, which represents the likelihood that its outcomes do not satisfy the desired property for a given test set or state. Note that if a learning algorithm outputs more information than simply the prediction p, this may influence the post-measurement state that we are comparing against and influence the error probability. This leads us to the following definition which allows the learning algorithm to output auxiliary information, which we refer to as calibration. See Fig. 3 for an illustration of algorithms with calibration information.
Definition 6
(Error probability in the non-i.i.d. setting with calibration). Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems. Let be permutation invariant. A learning algorithm with calibration is given by a quantum channel . The error probability of the algorithm on input ρ is:
where (c, p) is a random variable having distribution .
Note that, if ρ is i.i.d., the conditioning on c, p does not have any effect on the post-measurement state and Definition 6 coincides with the usual definition of the error probability.
We refer to Supplementary Note 3 for the distinction between error probabilities with and without calibration. In particular, we are able to extend algorithms to the non-i.i.d. setting without calibration for a wide range of learning problems that can be formulated using a function with reasonable assumptions.
In the following, we state and prove a randomized local de Finetti theorem. We then concentrate on non-adaptive algorithms employing incoherent measurements and illustrate how to extend their applicability to handle non-i.i.d. input states. In Methods’ subsection “Applications”, we apply the results we obtained for non-adaptive algorithms (Theorem 5) to specific examples, including observable prediction with classical shadows, verification of pure states, fidelity estimation, quantum state tomography, and testing the mixedness of states. Finally, in Methods' subsection “General algorithms in the non-i.i.d. setting”, we detail the process of adapting any algorithm to function within the non-i.i.d. framework.
Randomized local de Finetti Theorem
In this section, we state and prove a randomized local de Finetti theorem. Note that the statement does not need the state to be permutation invariant, but we show that for most choices of permutations of the systems (A1, A2, …, AN), the conditional state of the first few copies is close to product.
Theorem 4
(Randomized local de Finetti). Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems of dimension d. Let . Let be a state and let qN be a permutation-invariant measure on . Let be a set of measurement channels with input system A and output system X. Let j = (j1, …, jN) be a random permutation of {1, …, N}, , r = (r1, …, rN) ~ qN and w = (wl+1, …, wk+N/2) be the outcomes of measuring the systems using the measurements . The following inequality holds:
where and we defined the conditional state ρl,r,w as
Note that if is permutation invariant, the random permutation j is not needed and we can replace ji by i and by in the above expressions.
The proof is inspired by refs. 25,68 and 23.
Proof. The mutual information is defined as follows:
where is the Von Neumann entropy of ρ. The mutual information of quantum-classical state is defined as follows:
The chain rule implies:
Moreover, we can apply the data-processing inequality locally, for all quantum channels , let we have:
For every r = (r1, …, rN) define the state:
We have by the chain rule:
| 3 |
By taking the average over the random permutation j and using the fact that the distribution qN is invariant under the permutation of the systems k + 1 and l we have for all k + 1 ≤ l ≤ k + N/2:
hence:
| 4 |
Now using the data-processing inequality for the partial trace channel and the fact that qN is permutation invariant and averaging over j, we obtain for all 2 ≤ i ≤ k and k + 1 ≤ l ≤ k + N/2:
| 5 |
Then we can apply the chain rule to get for all k + 1 ≤ l ≤ k + N/2:
| 6 |
Now, for each k + 1 ≤ l ≤ k + N/2, we introduce the notations πr,w for the states conditioned on the systems taking the value w, and pr(w) for the probability of obtaining outcome w. Hence using Pinsker’s inequality then Cauchy Schwarz’s inequality, we obtain:
| 7 |
Combining the (In)Eqs. (3)–(7) we obtain:
Since for all , we obtain finally the desired inequality:
| 8 |
We refer to Supplementary Note 2 for an illustration of Theorem 4 for a specific permutation invariant state and a specific distribution of measurements.
Non-adaptive algorithms in the non-i.i.d. setting
In this section, our emphasis is on problems related to learning properties of quantum states (as defined in Definition 3) and algorithms that operate through non-adaptive incoherent measurements (as defined in Definition 5). We present a method to extend the applicability of these algorithms beyond the constraint of i.i.d. input states.
Let SUCCESSε define a property of quantum states. We consider a fixed non-adaptive algorithm that performs non-adaptive measurements on the systems which make up the train set. Our approach introduces a strategy outlined in Algorithm 1 (displayed in Box 1) and illustrated in Fig. 4, which extends the functionality of the algorithm to encompass non-i.i.d. states. The input state, denoted as , is now an N-partite state that can be entangled.
Fig. 4. Illustration of Algorithm 1.
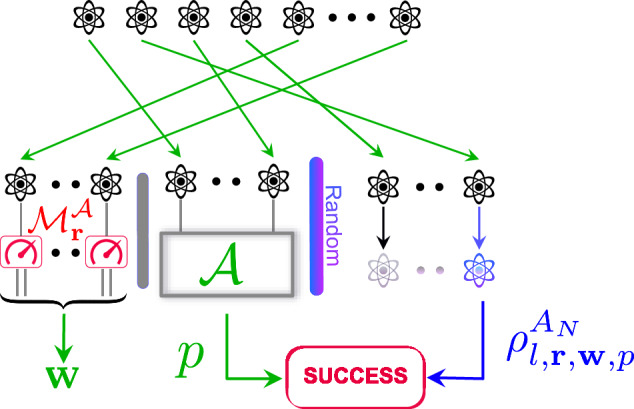
Algorithm 1 measures a large number of the state’s subsystems using that represents measurement devices uniformly chosen from the i.i.d. algorithm’s set of measurements (red and green parts). Then, Algorithm 1 applies the data processing of Algorithm to the outcomes of a part of these subsystems (green part), leading to a prediction p. Algorithm 1 returns the remaining outcomes as calibration w. Success occurs if p is (approximately) compatible with the remaining post-measurement test copy .
In words, given a non-adaptive incoherent algorithm that uses a set of measurement devices , Algorithm 1 measures a large number of the state’s subsystems using measurement devices uniformly chosen from (see Fig. 4, red and green parts). This ensures that the (small) portion of measured subsystems intended for the learning algorithm approximately behave like i.i.d. copies (see Fig. 4, green part). Then, in order to predict the property, Algorithm 1 applies the data processing of Algorithm to the outcomes of these subsystems.
More precisely, since is a non-adaptive algorithm, it performs measurements using the measurements devices . We sample at each time a POVM uniformly at random from the set so we need slightly more copies to span .
Let . For each i ∈ [l], we choose and we measure the system Ai using the measurement .
To compute the prediction, Algorithm considers the outcomes v of measurements . Provided span the set , the prediction algorithm of is applied to the relevant systems (as described in Algorithm 1). The coupon collector’s problem ensures that spans all elements in with high probability.
We can support this algorithm with the following rigorous bound on the failure probability that only depends on problem-specific parameters, as well as the performance of an ideal i.i.d. learning algorithm.
Theorem 5
(Non-adaptive algorithms in the non-i.i.d. setting). Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems of dimension d. Let ε > 0 and . Let be a non-adaptive algorithm suitable for i.i.d. input states and performing measurements with . Algorithm 1 has an error probability satisfying:
Remark 1
The first component of this upper bound essentially represents the error probability of algorithm when applied to an i.i.d. input state , where . Note that here we are not required to control this error probability over all states but only over the post-measurement states . The second component consists of an error term that accounts for the possibility of the input state being non i.i.d..
Remark 2
To achieve an error probability of at most δ, one could start by determining a value for such that for all l, r, w, . Subsequently, the total number of copies can be set to
This choice of training data size ensures that the overall probability of failure obeys , as desired.
Remark 3
The second error term of this upper bound can be improved to through the same proof outlined in Theorem 4 (see Inequality (8)). When the state is i.i.d., the mutual information becomes zero for all local quantum channels . Consequently, the second error term vanishes in the i.i.d. setting and we recover the i.i.d. error probability, albeit with a minor loss: substituting ε with 2ε and with .
Remark 4
In Algorithm 1, the initial stage of measuring systems Ak+1 ⋯ Al (corresponding to outcomes w) can be thought as a projection phase, while the subsequent stage involving measuring the systems A1 ⋯ Ak (corresponding to outcomes v) can be regarded as a learning phase. Note that we utilize only the outcomes v for the prediction component p; however, the outcomes w hold significance in enabling the application of the randomized de Finetti Theorem 4.
Remark 5
Algorithm 1 extends only non-adaptive incoherent algorithms to the non-i.i.d. setting as it applies the measurements of the i.i.d. algorithm chosen uniformly at random. Adaptive algorithms are shown to outperform their non-adaptive counterparts for some learning49,69 and testing70 problems. We leave the question of extending adaptive incoherent algorithms for future work.
The remaining of this section is dedicated to the proof of Theorem 5.
Proof of Theorem 5. In this proof we differentiate between and k. The former is the copy complexity of the non-adaptive algorithm while the latter is a parameter we use for the proof to ensure that all the measurement devices used by the non-adaptive algorithm are sampled. Let l ~ Unif{k + 1, …, k + N/2} and . Algorithm applies measurement to system Ai for all i ∈ [l].
Our proof strategy will be to approximate the reduced post-measurement state by the reduced post-measurement state . Then, we approximate the state by the i.i.d. state using the de Finetti Theorem 4.
More precisely, we write the error probability:
| 9 |
where we used the robustness condition for the problem defined by SUCCESSε.
Let us start with the second term by relating the reduced post-measurement state with . Note that as p is a function of v, it suffices to bound the distance between and , which is done in the following lemma.
Lemma 1
We have for all :
Proof of Lemma 1. We use the notation and where for t ∈ [N]. We have:
and similarly by the data processing inequality we have
So the triangle inequality implies:
On the other hand, we have by the randomized local de Finetti Theorem 4:
Hence we can deduce the following inequality:
| 10 |
Finally, the Markov’s inequality implies:
This completes the proof of Lemma 1.
We now go back to (9) and consider the first term. Let us denote and for the channel mapping the outcomes v and outputting a prediction p (as described in Algorithm 1). We have
using the randomized local de Finetti Theorem 4. To relate
to the behavior of algorithm , we introduce the event that all the measurement devices that algorithm needs are sampled before k:
The union bound implies:
Under we let s(t) ∈ [k] be the smallest integer such that rs(t) = t for . Then
Choosing , and bounding we obtain the desired bound on the error probability.
Applications
In this section, we apply the non i.i.d. framework that we have developed in Methods’ subsection “Non-adaptive algorithms in the non-i.i.d. setting” to address specific and concrete examples. These examples include classical shadows for shadow tomography, the verification of pure states, fidelity estimation, state tomography, and testing mixedness of states.
Classical shadows for shadow tomography
In the shadow tomography problem, we have M ≥ 1 known observables denoted as O1, …, OM, with each observable satisfying , along with N i.i.d. copies of an unknown quantum state σ. The task is now to ε-approximate all M observable values with success probability (at least) 1−δ. In ref. 7, the authors have introduced two specific protocols known as classical shadows, which employ (global) Clifford and Pauli (or local Clifford) measurements to tackle this problem. In their analysis, the authors crucially rely on the assumption of input states being i.i.d., which is essential for the successful application (concentration) of the median of means technique (estimator). Given that both algorithms proposed by ref. 7 are non-adaptive (as defined in Definition 5), we can leverage Theorem 5 to extend the applicability of these algorithms to encompass input states that are not i.i.d..
The initial algorithm employs measurements that follow either the Haar or Clifford distributions. The Haar probability measure stands as the unique invariant probability measure over the unitary (compact) group and is denoted . For the Clifford distribution, certain definitions need to be introduced. We consider an n-qubit quantum system denoted as where d = 2n. First define the set of Pauli matrices as follows:
Subsequently, the Clifford group is defined as the centralizer of the aforementioned set of Pauli matrices:
It is known71,72 that the Clifford group is generated by the Hadamard (H), phase (S) and CNOT gates:
Moreover, the Clifford group is finite (of order at most )72. Sampling a Clifford unitary matrix is given by selecting an element uniformly and randomly from the Clifford group Cl(2n). We denote this distribution by . Importantly, Clifford distribution is a 3-design73–75, that is for all s = 0, 1, 2, 3:
This property of the Clifford distribution has a significant implication: unitaries distributed according to or distributions yield identical performance for the classical shadows7. Now we can state the first result of ref. 7:
Theorem 6
(Ref. 7, rephrased). Let be M observables. There is an algorithm for predicting the expected values of the observables under the state σ to within ε with an error probability δ. This algorithm performs i.i.d. measurements following the distribution (or ), and it requires a total number of i.i.d. copies of the state σ satisfying:
Hence by Theorem 5 there is an algorithm in the non-i.i.d. setting with an error probability:
By taking as the complexity of classical shadows in the i.i.d. setting, we deduce that a total number of copies sufficient to achieve δ-correctness in the non-i.i.d. setting is given by:
where .
Proposition 2
(Classical shadows in the non-i.i.d. setting - Clifford). Let be M observables. There is an algorithm in the non-i.i.d. setting for predicting the expected values of the observables under the post-measurement state to within ε with a copy complexity
The algorithm is described in Algorithm 1, where the non-adaptive algorithm/statistic is the classical shadows algorithm of ref. 7 and the distribution of measurements is (or ).
The second protocol introduced by ref. 7 involves the use of Pauli measurements. This is given by measuring using an orthonormal basis that corresponds to a non-identity Pauli matrix. On the level of the unitary matrix, we can generate this sample by taking U = u1 ⊗ ⋯ ⊗ uN where u1, …, un Unif (Cl(2)). We denote this distribution by . The classical shadows with Pauli measurement have better performance for estimating expectations of local observables.
Theorem 7
(Ref. 7, rephrased). Let be M k-local observables. There is an algorithm for predicting the expected values of the observables under the state σ to within ε with an error probability δ. This algorithm performs i.i.d. measurements following the distribution , and requires a total number of i.i.d. copies of the state σ satisfying:
Now, combining this theorem and Theorem 5, we obtain the following generalization for estimating local properties in the non-i.i.d. setting.
Proposition 3
(Classical shadows in the non-i.i.d. setting - Pauli). Let be M k-local observables. There is an algorithm in the non-i.i.d. setting for predicting the expected values of the observables under the post-measurement state to within ε with an error probability δ and a copy complexity satisfying:
Recently, the authors of53 provide protocols with depth-modulated randomized measurement that interpolates between Clifford and Pauli measurements. Since their algorithms are also non-adaptive, they can be generalized as well to the non-i.i.d. setting using Theorem 5. Other classical shadows protocols54,56,57,76 could also be extended to the non-i.i.d. setting.
Classical shadows can be used for learning quantum states and unitaries of bounded gate complexity77. Our generalization of classical shadows permits to immediately extend the state learning protocol of ref. 77 beyond the i.i.d. assumption and a similar extension should be possible for their unitary learning results.
Verification of pure states
The verification of pure states is the task of determining whether a received state precisely matches the ideal pure state or significantly deviates from it. In this context, we will extend this problem to scenarios where we have M potential pure states represented as , and our objective is to ascertain whether the received state corresponds to one of these pure states or is substantially different from all of them. The traditional problem constitutes a special case with M = 1. To formalize, a verification protocol satisfies:
the completeness condition if it accepts, with high probability, upon receiving one of the pure i.i.d. states , i.e., for all i ∈ [M], we have . Here, the symbol 0 represents the outcome ‘Accept’ or the null hypothesis.
- the soundness condition if when the algorithm accepts, the quantum state passing the verification protocol (post-measurement state conditioned on a passing event) is close to one of the pure states with high probability, i.e.,
In this latter scenario, the protocol can receive a possibly highly entangled state .11
Note that as the prediction for this problem is binary (Accept/Reject), a verification protocol is modeled by an operator ΠAccept, which is given by . The usual way (see e.g., refs. 21,35,36,61–63) of writing the completeness and soundness conditions of a protocol for the case M = 1 of verifying a single pure state is as follows. The completeness condition is
where δc is the completeness parameter, which is the same as what we expressed in terms of . The soundness condition is
| 12 |
Note that this quantity evaluates the expected infidelity of the state conditioned on acceptance, whereas Eq. (11) is slightly different: it evaluates the probability (over p and c) of having a fidelity below 1−ε. It is simple to see that Eq. (11) implies δs ≤ ε + δ. Conversely, using Markov’s inequality, Eq. (12) implies Eq. (11) with . We can, using the same methods, express our findings directly in terms of expectations for the task of verifying one pure state, see Supplementary Note 4 for more details. Here we prove the following verification result with high probability.
Proposition 4
(Verification of pure states in the non-i.i.d. setting - Clifford). Let be a permutation invariant state. Let be M pure states. There is an algorithm using Clifford measurements for verifying whether the (post-measurement) state is a member of or is at least ε-far from them in terms of fidelity with a probability at least 1 − δ and a number of copies satisfying
Proof. We can apply Proposition 2 to estimate the expectation of the observables under the post-measurement state to within ε/4 and with a probability at least 1 − δ using a number of copies . More concretely, we have a set of predictions satisfying (Proposition 2 and Lemma 1):
| 13 |
Then, our proposed algorithm accepts if, and only if there is some i ∈ [M] such that μi ≥ 1 − ε/2. We can verify the completeness and soundness conditions for this algorithm.
Completeness. If the verifier receives one pure state of the form for some i ∈ [M] then every post-measurement state is pure, i.e., and Inequality (13) implies . Hence the algorithm accepts with a probability . Observe that for this algorithm, we can even relax the assumption that the input state is i.i.d.. For instance, we can only ask that the input state is product where for all t ∈ [N], .
- Soundness. Here, we want to prove the following:
If then for some j ∈ [M] we have μj ≥ 1 − ε/2. Hence implies therefore:
where we used Inequality Eq. (13).
The above result uses Clifford measurements, which are non-local. If our primary concern lies in verification with local measurements, an alternative approach would be to apply the non-i.i.d. shadow tomography result for local measurements (Proposition 3). Using the same analysis of this section, we can prove the following proposition.
Proposition 5
(Verification of pure states in the non-i.i.d. setting - Pauli). Let be a permutation invariant state. Let be M pure states. There is an algorithm using local (pauli) measurements for verifying whether the (post-measurement) state is a member of or is at least ε-far from them in terms of fidelity with a probability at least 1 − δ and a number of copies satisfying
Discussion and comparison with previous works on verification of pure states
The main contribution here compared to previous results is that we give the first explicit protocol which works for all multipartite states. This stands in contrast to previous protocols where the desired state must be a ground state of a Hamiltonian satisfying certain conditions61 or a graph state35,36,62,63, or Dicke states21. However, the more efficient protocol uses Clifford measurements, which are non-local. The Pauli measurement case is local, but comes at a cost in scaling with number of systems.
We now go into more detail regarding the different scalings. The optimal copy complexity, or scaling for the number of copies required, with the fidelity error ε, is 1/ε21,78. The scaling with the number of systems n depends on the protocol (e.g. for stabilizer states there are protocols that do not scale with n, but known protocols for the W state scales with n21). Applying our results using Clifford (i.e. entangled over the systems) gives scaling with ε and n as , and for random local Pauli scaling (local) the scaling is . For the Clifford protocol, then, we have similar scaling to optimal known for W states (though with ε scaling as 1/ε6 instead of 1/ε), but our protocol works for all states. The cost here is that measurements are in non-local across each copy. However for certain applications this is not an issue. For example verifying output of computations, Clifford are reasonably within the sets of easy gates, so we have a close to optimal verification for all states that can be implemented. In the case of random Paulis, where measurements are local on copies, we have the same scaling with ε but we get an exponential penalty of n scaling in the error. Given the generality of our protocol to all states though, it is perhaps not so surprising that we have a high dimensional cost. Furthermore, depending on the situation, this scaling may not be the major cost one cares about. Indeed, for small networks dimension will not be the most relevant scaling. We can imagine many applications in this regime. For example small networks of sensors, such as satellites or gravimeters18,31, this scaling would not be prohibitive, but our results would allow for different resource states to be used, for example spin squeezed states, or other symmetric states which exhibit better robustness to noise79. Another example would be small communication networks, where, for example GHZ states can be used for anonymous communication29 or W states for leader election80. On such small scale networks our results would allow for verified versions of these applications over untrusted networks, in a way that is blind to which communication protocol is being applied.
We also point out that we have not optimized over these numbers (rather we were concerned with showing something that works for all states). It is highly likely that these complexities can be improved and we expect that for particular families of states one can find variants where the scaling in the number of systems is polynomial or better. One perspective in this direction coming directly from our results, is the observation that the protocols in the framework of ref. 5, which assume i.i.d. states, use random i.i.d. measurements, therefore our theorem allows them to be applied directly to the non-i.i.d. case. This allows us to take any protocol assuming i.i.d. states, and it works for general (non-i.i.d.) sources with a small cost.
Lastly, our formulation is naturally robust to noise. Such robustness is an important issue for any practical implementation, and indeed it has been addressed for several of the protocols mentioned, see for example35,63,81,82. In terms of the completeness condition, we can easily make out statements robust to noise. For instance, we can relax the requirement to only ask that the input state is a product state where for all t ∈ [N], .
Fidelity estimation
The problem of direct fidelity estimation1,83 consists of estimating the fidelity between the target known pure state and the unknown quantum state ρ by measuring independent copies of ρ. The algorithm of ref. 1 proceeds by sampling i.i.d. random Pauli matrices
where l = ⌈1/(ε2δ)⌉. Then for each i = 1, …, l, the algorithm measures the state ρ with the POVM times where mi is defined as
The algorithm observes where i ∈ {1, …, l} and j ∈ {1, …, mi}. The estimator of the fidelity is then given as follows
In general, in ref. 1, it is proven that the copy complexity satisfies:
to conclude that with probability at least 5/6. This algorithm is non-adaptive and performs independent measurements from the set:
To extend this result to the non-i.i.d. setting, we apply Theorem 5 with the set of measurements and a copy complexity given by . Theorem 5 ensures that we can estimate the fidelity between the ideal state and the post-measurement state to within 3ε with probability at least 5/6 if the total number of copies N satisfies:
By Markov’s inequality we have with probability at least 5/6:
Therefore, by the union bound, our non-i.i.d. algorithm is 1/3-correct and its complexity satisfies:
Proposition 6
(Fidelity estimation in the non-i.i.d. setting). There is an algorithm in the non-i.i.d. setting for fidelity estimation with a precision parameter ε, a success probability at least 2/3 and a copy complexity:
Moreover, in ref. 1, it is showen that for well-conditioned states satisfying for all , for some α > 0, the copy complexity is bounded in expectation as follows:
Similarly, by applying Theorem 5 and Markov’s inequality we can show the following proposition.
Proposition 7
(Fidelity estimation in the non-i.i.d. setting - Well-conditioned states). Let be a well-conditioned state with parameter α > 0. There is an algorithm in the non-i.i.d. setting for fidelity estimation with a precision parameter ε, a success probability at least 2/3 and a copy complexity:
State tomography
In the problem of state tomography, we are given N copies of an unknown quantum state σ and the objective is to construct a (classical description) of a quantum state satisfying with a probability at least 1 − δ.
In the i.i.d. setting, a sufficient number of copies for state tomography in the incoherent setting with a precision ε and an error probability δ is4:
Hence by Theorem 5 there is an algorithm in the non-i.i.d. setting with an error probability:
So a total number of copies sufficient to achieve δ-correctness in the non-i.i.d. setting is:
Proposition 8
(State tomography in the non-i.i.d. setting). There is an algorithm in the non-i.i.d. setting for state tomography with a precision parameter ε, a success probability at least 1 − δ and a copy complexity:
Observe that, unlike the statement of state tomography in the i.i.d. setting4, here we do not have an explicit dependency on the rank of the approximated state. This can be explained by the fact that if the state is not i.i.d. then the post-measurement states can have a full rank even if we start with a pure input state . For instance, let where is the maximally entangled state, and let be an observable. In this case, we have and if all the coefficients are non-zero.
Testing mixedness of states
In the problem of testing mixedness of states, we are given an unknown quantum state σ, which can either be (null hypothesis) or ε-far from it in the trace-norm (alternate hypothesis). The objective is to determine the true hypothesis with a probability of at least 1 − δ. However, this problem does not satisfy the robustness assumption required in Definition 3. Due to this reason, we introduced the tolerant version of this problem in Example 1. To the best of our knowledge, there is no algorithm for the tolerant testing mixedness problem that outperforms the tomography algorithm (naive testing by learning approach). Thus, in this section, we concentrate on the standard (non-tolerant) formulation of testing mixedness of states.
Under the null hypothesis, we assume that the learning algorithm is given the i.i.d. state and is expected to respond with 0 with a probability of at least 1 − δ. On the other hand, under the alternate hypothesis, the learning algorithm receives a (potentially entangled) state . In this scenario, the learning algorithm should output 1 with a probability of at least 1–δ if the post-measurement state is ε-far from . In the i.i.d. case, a sufficient number of copies for testing mixedness of states problem in the incoherent setting with a precision parameter ε and an error probability δ is given by ref. 27:
Hence by Theorem 5
| 14 |
We can apply Theorem 5 only under the alternate hypothesis where the robustness assumption holds. Under the null hypothesis, the robustness assumption no longer holds; however, since we are assuming that the input state is i.i.d., i.e., , we can directly apply the result from ref. 27 in this case. So, from Eq. (14), we deduce that a total number of copies sufficient to achieve δ-correctness in the non-i.i.d. setting is:
Proposition 9
(Testing mixedness of quantum states in the non-i.i.d. setting). There is an algorithm in the non-i.i.d. setting for testing mixedness of quantum states with a precision parameter ε, a success probability at least 1−δ and a copy complexity:
General algorithms in the non-i.i.d. setting
In this section, we present a general framework for extending algorithms designed to learn properties of a quantum state using i.i.d. input states, to general possibly entangled input states. The distinction from Methods’ subsection “Non-adaptive algorithms in the non-i.i.d. setting” lies in the relaxation of the requirement for algorithms to be non-adaptive; meaning, they can now involve adaptive measurements, potentially coherent or entangled (see Definition 4). Coherent measurements are proved to be more powerful than incoherent ones (let alone non-adaptive ones) for tasks such as state tomography3,49, shadow tomography6,9,84 and testing mixedness of states10,85.
As we now consider general algorithms that encompass (possibly) coherent measurements, a suitable candidate for the measurement device in the projection phase (the w part in Algorithm 1) becomes less clear. Furthermore, we require an approximation that excels under the more stringent trace-norm condition, particularly when addressing non-local (non product) observables. To address this challenge, we adopt the approach outlined in ref. 23, utilizing any informationally complete measurement device. We will use the measurement device , having a low distortion with side information, of ref. 86. It satisfies the following important property: the application of the corresponding measurement channel to the system A2 does not diminish the distinguishability between two bipartite states on A1A2 by a factor greater than , wherein represents the dimension of A2. To be precise, the measurement channel satisfies the following inequality for all bipartite states and :
The measurement device will play a crucial role in our algorithm. By applying this channel to a large fraction of the subsystems of a quantum state, we can show that the post-measurement state behaves as an i.i.d. state. Thus, we will be able to use the same algorithm on a small number of the remaining systems.
For a learning algorithm designed for i.i.d. inputs, we construct the algorithm explicitly described in Algorithm 2 (displayed in Box 2) and illustrated in Fig. 5.
Fig. 5. Illustration of Algorithm 2.
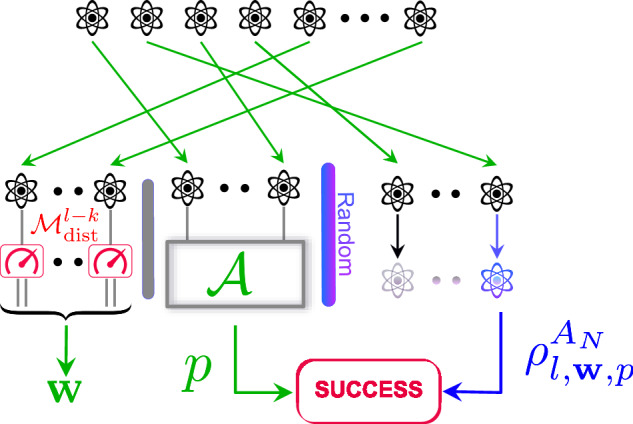
Algorithm 2 measures a large number of the state’s subsystems using the measurement device with low distortion (red and green parts). Then, in order to predict the property, Algorithm 2 applies the data processing of Algorithm to the outcomes of a part these subsystems (green part) leading to a prediction p. Algorithm 2 returns the remaining outcomes as calibration w. Success occurs if p is (approximately) compatible with the remaining post-measurement test copy .
In the following theorem, we relate the error probability of Algorithm 2 with the error probability of the algorithm .
Theorem 8
(General algorithms in the non-i.i.d. setting) Let N ≥ 1 be a positive integer and A1 ≅ A2 ≅ ⋯ ≅ AN be N isomorphic quantum systems of dimension d. Let and 1 ≤ k < N/2. Let be a general algorithm. Algorithm 2 has an error probability satisfying:
Remark 6
To achieve an error probability of at most δ, one could start by determining a value for such that for all w, . Subsequently, the total number of copies can be set to
This choice of sample complexity ensures that , as desired.
In what follows we proceed to prove Theorem 8.
Proof of Theorem 8. First, since we are using the informationally complete measurement device , we can relate the difference between post-measurement states and the actual states. This along with an information theoretical analysis using the mutual information show that measuring using a sufficiently large number of times, transforms the state approximately to an i.i.d. one. Infact, the proof of Theorem 2.4. of ref. 23 together with the distortion with side information measurement device of ref. 86 imply that for k < N/2:
Lemma 2
(Ref. 23, rephrased) Let be a permutation invariant state. For k < N/2, we have
where w = (wk+1, …, wl) is the outcome of measuring each of the systems Ak+1…Al with the measurement .
We write the error probability as
| 15 |
where we use the robustness condition. Using Lemma 2 and the triangle inequality, the first term can be bounded as follows:
For the second term of Eq. (15), we apply the following lemma:
Lemma 3
Let , 1 ≤ k < N/2 and l ~ Unif {k + 1, …, k + N/2}. Let w = (wk+1, …, wl) and p be the outcomes of measuring the state ρ with the measurement on systems Ak+1…Al and on A1…Ak. The following inequality holds:
Proof. Denote by the elements of the POVM corresponding to . Lemma 2 together with the triangle inequality imply:
where we used the equality between states and the inequality as . Therefore, by Markov’s inequality we deduce:
Box 2 Algorithm 2 - Predicting properties of quantum states in the non-i.i.d. setting - General algorithms.
Require: Measurement . A permutation invariant state .
Ensure: Adapt the algorithm to non-i.i.d. inputs .
1. Sample .
2. Apply to each system Ak+1 to Al and obtain the outcome .
3. Run algorithm on systems A1…Ak and obtain the outcome .
4. Return: (l, w, p).
Supplementary information
Acknowledgements
We would like to thank Mario Berta and Philippe Faist for helpful discussions. We acknowledge support from the European Research Council (ERC Grant AlgoQIP, Agreement No. 851716) (O.F. and A.O.), (ERC Grant Agreement No. 948139) (A.O.), (ERC Grant Agreement No. 101117138) (R.K.), from the European Union’s Horizon 2020 research and innovation program under Grant Agreement No 101017733 within the QuantERA II Programme (O.F.) and from the PEPR integrated project EPiQ ANR-22-PETQ-0007 part of Plan France 2030 (O.F., D.M., and A.O.), as well as the QuantumReady and HPQC projects of the Austrian Research Promotion Agency (FFG) (R.K.).
Author contributions
O.F., R.K., D.M., and A.O. contributed extensively to this work.
Peer review
Peer review information
Nature Communications thanks Daniel Hothem, Timothy Proctor and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Data availability
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Code availability
Code availability is not applicable to this article as no code was generated or analysed during the current study.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-024-53765-6.
References
- 1.Flammia, S. T. & Liu, Y.-K. Direct fidelity estimation from few pauli measurements. Phys. Rev. Lett.106, 230501 (2011). [DOI] [PubMed] [Google Scholar]
- 2.Christandl, M. & Renner, R. Reliable quantum state tomography. Phys. Rev. Lett.109, 120403 (2012). [DOI] [PubMed] [Google Scholar]
- 3.O’Donnell, R. & Wright, J. Efficient quantum tomography. In Proceedings of the forty-eighth annual ACM symposium on Theory of Computing, p. 899–912 (Association for Computing Machinery, 2016).
- 4.Kueng, R., Rauhut, H. & Terstiege, U. Low rank matrix recovery from rank one measurements. Appl. Comput. Harmon. Anal.42, 88–116 (2017). [Google Scholar]
- 5.Pallister, S., Linden, N. & Montanaro, A. Optimal verification of entangled states with local measurements. Phys. Rev. Lett.120, 170502 (2018). [DOI] [PubMed] [Google Scholar]
- 6.Aaronson, S. Shadow tomography of quantum states. SIAM J. Comput.49, STOC18–368 (2019). [Google Scholar]
- 7.Huang, H.-Y., Kueng, R. & Preskill, J. Predicting many properties of a quantum system from very few measurements. Nat. Phys.16, 1050–1057 (2020). [Google Scholar]
- 8.Eisert, J. et al. Quantum certification and benchmarking. Nat. Rev. Phys.2, 382–390 (2020). [Google Scholar]
- 9.Bădescu, C. & O’Donnell, R. Improved quantum data analysis. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, p. 1398–1411 (Association for Computing Machinery, 2021).
- 10.Chen, S., Li, J., Huang, B. & Liu, A. Tight bounds for quantum state certification with incoherent measurements. In 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), p. 1205–1213 (IEEE, 2022).
- 11.Bylander, J. et al. Noise spectroscopy through dynamical decoupling with a superconducting flux qubit. Nat. Phys.7, 565–570 (2011). [Google Scholar]
- 12.Yan, F. et al. Rotating-frame relaxation as a noise spectrum analyser of a superconducting qubit undergoing driven evolution. Nat. Commun.4, 2337 (2013). [DOI] [PubMed] [Google Scholar]
- 13.Burnett, J. et al. Evidence for interacting two-level systems from the 1/f noise of a superconducting resonator. Nat. Commun.5, 4119 (2014). [DOI] [PubMed] [Google Scholar]
- 14.Gheorghiu, A., Kapourniotis, T. & Kashefi, E. Verification of quantum computation: An overview of existing approaches. Theory Comput. Syst.63, 715–808 (2019). [Google Scholar]
- 15.Markham, D. & Krause, A. A simple protocol for certifying graph states and applications in quantum networks. Cryptography4, 3 (2020). [Google Scholar]
- 16.Barnum, H., Crépeau, C., Gottesman, D., Smith, A. & Tapp, A. Authentication of quantum messages. In The 43rd Annual IEEE Symposium on Foundations of Computer Science, 2002. Proceedings., 449–458 (IEEE, 2002).
- 17.Brassard, G., Broadbent, A., Fitzsimons, J., Gambs, S. & Tapp, A. Anonymous quantum communication. In Advances in Cryptology–ASIACRYPT 2007: 13th International Conference on the Theory and Application of Cryptology and Information Security, Kuching, Malaysia, December 2-6, 2007. Proceedings 13, p. 460–473 (Springer, 2007).
- 18.Shettell, N., Kashefi, E. & Markham, D. Cryptographic approach to quantum metrology. Phys. Rev. A105, L010401 (2022). [Google Scholar]
- 19.Paini, M. & Kalev, A. An approximate description of quantum states. arXiv preprint arXiv:1910.10543 (2019).
- 20.Elben, A. et al. The randomized measurement toolbox. Nat. Rev. Phys.5, 9–24 (2023). [Google Scholar]
- 21.Zhu, H. & Hayashi, M. General framework for verifying pure quantum states in the adversarial scenario. Phys. Rev. A100, 062335 (2019). [DOI] [PubMed] [Google Scholar]
- 22.Caro, M. C., Gur, T., Rouzé, C., França, D. S. & Subramanian, S. Information-theoretic generalization bounds for learning from quantum data. In The Thirty Seventh Annual Conference on Learning Theory,p. 775–839 (PMLR, 2024).
- 23.Berta, M., Borderi, F., Fawzi, O. & Scholz, V. B. Semidefinite programming hierarchies for constrained bilinear optimization. Math. Program.194, 781–829 (2022).
- 24.Christandl, M., König, R., Mitchison, G. & Renner, R. One-and-a-half quantum de finetti theorems. Commun. Math. Phys.273, 473–498 (2007). [Google Scholar]
- 25.Brandao, F. G. & Harrow, A. W. Quantum de finetti theorems under local measurements with applications. In Proceedings of the forty-fifth annual ACM symposium on Theory of computing, p. 861–870 (2013).
- 26.Guţă, M., Kahn, J., Kueng, R. & Tropp, J. A. Fast state tomography with optimal error bounds. J. Phys. A: Math. Theor.53, 204001 (2020). [Google Scholar]
- 27.Bubeck, S., Chen, S. & Li, J. Entanglement is necessary for optimal quantum property testing. In 2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS), 692–703 (IEEE, 2020).
- 28.Raussendorf, R. & Briegel, H. J. A one-way quantum computer. Phys. Rev. Lett.86, 5188 (2001). [DOI] [PubMed] [Google Scholar]
- 29.Christandl, M. & Wehner, S. Quantum anonymous transmissions. In International Conference On The Theory And Application Of Cryptology And Information Security, p. 217–235 (Springer, 2005).
- 30.Markham, D. & Sanders, B. C. Graph states for quantum secret sharing. Phys. Rev. A: At. Mol. Opt. Phys.78, 042309 (2008). [Google Scholar]
- 31.Komar, P. et al. A quantum network of clocks. Nat. Phys.10, 582–587 (2014). [Google Scholar]
- 32.Hayashi, M. & Morimae, T. Verifiable measurement-only blind quantum computing with stabilizer testing. Phys. Rev. Lett.115, 220502 (2015). [DOI] [PubMed] [Google Scholar]
- 33.Unnikrishnan, A. et al. Anonymity for practical quantum networks. Phys. Rev. Lett.122, 240501 (2019). [DOI] [PubMed] [Google Scholar]
- 34.Bell, B. et al. Experimental demonstration of graph-state quantum secret sharing. Nat. Commun.5, 1–12 (2014). [DOI] [PubMed] [Google Scholar]
- 35.Takeuchi, Y., Mantri, A., Morimae, T., Mizutani, A. & Fitzsimons, J. F. Resource-efficient verification of quantum computing using serfling’s bound. npj Quant. Inf.5, 27 (2019). [Google Scholar]
- 36.Morimae, T., Takeuchi, Y. & Hayashi, M. Verification of hypergraph states. Phys. Rev. A96, 062321 (2017). [Google Scholar]
- 37.Liu, Y.-C., Yu, X.-D., Shang, J., Zhu, H. & Zhang, X. Efficient verification of dicke states. Phys. Rev. Appl.12, 044020 (2019). [Google Scholar]
- 38.De Finetti, B. Breakthroughs in Statistics: Foundations and Basic Theory, p. 134–174 (Springer, 1937).
- 39.Diaconis, P. & Freedman, D. Finite exchangeable sequences. Ann. Probab. 8, 745–764 (1980).
- 40.Diaconis, P. & Freedman, D. A dozen de finetti-style results in search of a theory. Ann. l’IHP Probab. et Stat.23, 397–423 (1987). [Google Scholar]
- 41.Hudson, R. L. & Moody, G. R. Locally normal symmetric states and an analogue of de finetti’s theorem. Z. Wahrscheinlichkeitstheorie Verwandte-. Geb.33, 343–351 (1976). [Google Scholar]
- 42.Caves, C. M., Fuchs, C. A. & Schack, R. Unknown quantum states: the quantum de finetti representation. J. Math. Phys.43, 4537–4559 (2002). [Google Scholar]
- 43.König, R. & Renner, R. A de finetti representation for finite symmetric quantum states. J. Math. Phys.46, 122108 (2005).
- 44.Brandao, F. G., Christandl, M. & Yard, J. Faithful squashed entanglement. Commun. Math. Phys.306, 805–830 (2011). [Google Scholar]
- 45.Gavalakis, L. & Kontoyiannis, I. An information-theoretic proof of a finite de finetti theorem. Electron. Commun. Probab.26, 1–5 (2021). [Google Scholar]
- 46.Gavalakis, L. & Kontoyiannis, I. Mathematics Going Forward: Collected Mathematical Brushstrokes, p. 367–385 (Springer, 2022).
- 47.Berta, M., Gavalakis, L. & Kontoyiannis, I. A third information-theoretic approach to finite de finetti theorems. In 2024 IEEE International Symposium on Information Theory (ISIT), 07–12 (IEEE, 2024).
- 48.Haah, J., Harrow, A. W., Ji, Z., Wu, X. & Yu, N. Sample-optimal tomography of quantum states. In STOC’16—Proceedings of the 48th Annual ACM SIGACT Symposium on Theory of Computing, p. 913–925 (ACM, 2016).
- 49.Chen, S., Huang, B., Li, J., Liu, A. & Sellke, M. When does adaptivity help for quantum state learning? In 2023 IEEE 64th Annual Symposium on Foundations of Computer Science (FOCS), p. 391–404 (IEEE, 2023).
- 50.Cramer, M. et al. Efficient quantum state tomography. Nat. Commun.1, 149 (2010). [DOI] [PubMed] [Google Scholar]
- 51.Aaronson, S., Chen, X., Hazan, E., Kale, S. & Nayak, A. Online learning of quantum states. Adv. Neural Inf. Process. Syst.31 (2018).
- 52.Morris, J. & Dakić, B. Selective quantum state tomography. arXiv preprint arXiv:1909.05880 (2019).
- 53.Bertoni, C. et al. Shallow Shadows: Expectation Estimation Using Low-depth Random Clifford Circuits. Phys. Rev. Lett.133, 020602 (2024). [DOI] [PubMed] [Google Scholar]
- 54.Akhtar, A. A., Hu, H.-Y. & You, Y.-Z. Scalable and flexible classical shadow tomography with tensor networks. Quantum7, 1026 (2023). [Google Scholar]
- 55.Helsen, J. & Walter, M. Thrifty shadow estimation: reusing quantum circuits and bounding tails. Phys. Rev. Lett.131, 240602 (2023). [DOI] [PubMed] [Google Scholar]
- 56.Wan, K., Huggins, W. J., Lee, J. & Babbush, R. Matchgate shadows for fermionic quantum simulation. Commun. Math. Phys.404, 629–700 (2023). [Google Scholar]
- 57.Low, G. H. Classical shadows of fermions with particle number symmetry. arXiv preprint arXiv:2208.08964 (2022).
- 58.Neven, A. et al. Symmetry-resolved entanglement detection using partial transpose moments. npj Quant. Inf.7, 152 (2021). [Google Scholar]
- 59.Fanizza, M., Quek, Y. & Rosati, M. Learning quantum processes without input control. PRX Quant.5, 020367 (2024). [Google Scholar]
- 60.Li, Z., Han, Y.-G. & Zhu, H. Optimal verification of greenberger-horne-zeilinger states. Phys. Rev. Appl.13, 054002 (2020). [Google Scholar]
- 61.Takeuchi, Y. & Morimae, T. Verification of many-qubit states. Phys. Rev. X8, 021060 (2018). [Google Scholar]
- 62.Unnikrishnan, A. & Markham, D. Verification of graph states in an untrusted network. Phys. Rev. A105, 052420 (2022). [Google Scholar]
- 63.Li, Z., Zhu, H. & Hayashi, M. Robust and efficient verification of graph states in blind measurement-based quantum computation. npj Quantum Inf.9, 1–12 (2023).
- 64.Gočanin, A., Šupić, I. & Dakić, B. Sample-efficient device-independent quantum state verification and certification. PRX Quant.3, 010317 (2022). [Google Scholar]
- 65.Chabaud, U., Douce, T., Grosshans, F., Kashefi, E. & Markham, D. Building trust for continuous variable quantum states. 15th Conference on the Theory of Quantum Computation, Communication and Cryptography (TQC 2020) (ed. Flammia, S. T.) 158, 3:1–3:15 (2020).
- 66.Chabaud, U., Grosshans, F., Kashefi, E. & Markham, D. Efficient verification of boson sampling. Quantum5, 578 (2021). [Google Scholar]
- 67.Wu, Y.-D., Bai, G., Chiribella, G. & Liu, N. Efficient verification of continuous-variable quantum states and devices without assuming identical and independent operations. Phys. Rev. Lett.126, 240503 (2021). [DOI] [PubMed] [Google Scholar]
- 68.Brandão, F. G. S. L. & Harrow, A. W. Product-state approximations to quantum states. Commun. Math. Phys.342, 47–80 (2016). [Google Scholar]
- 69.Flammia, S. T. & O’Donnell, R. Quantum chi-squared tomography and mutual information testing. Quantum8, 1381 (2024). [Google Scholar]
- 70.Fawzi, O., Flammarion, N., Garivier, A. & Oufkir, A. On adaptivity in quantum testing. Trans. Mach. Learn. Res. (2023).
- 71.Gottesman, D. Theory of fault-tolerant quantum computation. Phys. Rev. A57, 127 (1998). [Google Scholar]
- 72.Ozols, M. Clifford group. Essays at University of Waterloo (Spring, 2008).
- 73.Webb, Z. The clifford group forms a unitary 3-design. Quantum Inf. Comput.16, 1379–1400 (2016).
- 74.Kueng, R., Zhu, H. & Gross, D. Low rank matrix recovery from clifford orbits. arXiv preprint arXiv:1610.08070 (2016).
- 75.Zhu, H. Multiqubit clifford groups are unitary 3-designs. Phys. Rev. A96, 062336 (2017). [Google Scholar]
- 76.Grier, D., Pashayan, H. & Schaeffer, L. Sample-optimal classical shadows for pure states. Quantum8, 1373 (2024). [Google Scholar]
- 77.Zhao, H. et al. Learning quantum states and unitaries of bounded gate complexity. PRX Quantum5, 040306 (2024).
- 78.Zhu, H. & Hayashi, M. Efficient verification of pure quantum states in the adversarial scenario. Phys. Rev. Lett.123, 260504 (2019). [DOI] [PubMed] [Google Scholar]
- 79.Ouyang, Y., Shettell, N. & Markham, D. Robust quantum metrology with explicit symmetric states. IEEE Trans. Inf. Theory68, 1809–1821 (2021). [Google Scholar]
- 80.D’Hondt, E. & Panangaden, P. The computational power of the w and ghz states. Quant. Info Comput.6, 173–183 (2006). [Google Scholar]
- 81.McCutcheon, W. et al. Experimental verification of multipartite entanglement in quantum networks. Nat. Commun.7, 13251 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Unnikrishnan, A. & Markham, D. Authenticated teleportation and verification in a noisy network. Phys. Rev. A102, 042401 (2020). [Google Scholar]
- 83.da Silva, M. P., Landon-Cardinal, O. & Poulin, D. Practical characterization of quantum devices without tomography. Phys. Rev. Lett.107, 210404 (2011). [DOI] [PubMed] [Google Scholar]
- 84.Chen, S., Cotler, J., Huang, H.-Y. & Li, J. Exponential separations between learning with and without quantum memory. In 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), 574–585 (IEEE, 2022).
- 85.Bădescu, C., O’Donnell, R. & Wright, J. Quantum state certification. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, 503–514 (Association for Computing Machinery, 2019).
- 86.Jee, H. H., Sparaciari, C., Fawzi, O. & Berta, M. Quasi-polynomial time algorithms for free quantum games in bounded dimension. In 48th International Colloquium on Automata, Languages, and Programming (ICALP 2021), vol. 198 of Leibniz International Proceedings in Informatics (LIPIcs), 82:1–82:20 (Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2021).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Code availability is not applicable to this article as no code was generated or analysed during the current study.