

Abstract
The chemical machinery of life must have been catalytic from the outset. Models of the chemical origins have attempted to explain the ecological mechanisms maintaining a minimum necessary diversity of prebiotic replicator enzymes, but little attention has been paid so far to the evolutionary initiation of that diversity. We propose a possible first step in this direction: based on our previous model of a surface-bound metabolic replicator system we try to explain how the adaptive specialization of enzymatic replicator populations might have led to more diverse and more efficient communities of cooperating replicators with two different enzyme activities. The key assumptions of the model are that mutations in the replicator population can lead towards a) both of the two different enzyme specificities in separate replicators: efficient “specialists” or b) a “generalist” replicator type with both enzyme specificities working at less efficiency, or c) a fast-replicating, non-enzymatic “parasite”. We show that under realistic trade-off constraints on the phenotypic effects of these mutations the evolved replicator community will be usually composed of both types of specialists and of a limited abundance of parasites, provided that the replicators can slowly migrate on the mineral surface. It is only at very weak trade-offs that generalists take over in a phase-transition-like manner. The parasites do not seriously harm the system but can freely mutate, therefore they can be considered as pre-adaptations to later, useful functions that the metabolic system can adopt to increase its own fitness.
Introduction
The complex, specific and efficient biocatalysts (enzymes) present in all recent forms of life are obviously the products of long Darwinian adaptation, therefore they could not be present on prebiotic Earth. The strongest evolutionary pressure must have affected the spatial structure and the amino acids closest to the active centre of the enzymes, i.e., the details of the peptide structure most responsible for the catalytic function. Maintaining the specific amino acid sequence (primary structure) of an enzyme has evolutionary relevance only as long as it affects its catalytic function. It is mostly the evolutionary “wobbling” of the less important structural elements in distant taxa that explains the divergence of enzymes which are similar in terms of the spatial structure of their active centres and in their biological function (i.e., they catalyse the same reaction), but still have very different amino acid sequences.
Studies of early evolution have long acknowledged the essential role catalysts must have played in the origin of life. It was in Wächtershäuser's hypothesis of the “prebiotic pizza” where inorganic compounds were first assumed to carry the function of early biocatalysts [1]–[3]. According to the hypothesis the first chemical reactions ultimately leading to life would have taken place on mineral (e.g., pyrite) surfaces. The prebiotic pizza offers a solution to the thermodynamic problem of condensation reactions yielding water molecules among their products in an environment saturated with water (i.e., in the “prebiotic soup”; [4]). The surface of pyrite is also capable of adsorbing organic substrates, thereby increasing their concentrations and catalysing their reactions. Even though this inorganic catalytic effect might have been neither very specific nor very efficient, it might have been sufficient to aid the emergence of the first relatively complex, enzyme-like macromolecule catalysts, which could have worked bound to the surface themselves thereafter [5], [6]. Whether these first catalytic macromolecules were peptides (like most biocatalysts today) or some very different chemical species is still debated [7], [8]. The reason why the first evolvable biocatalysts could not be peptides is that the transmission of the information content of peptides to the next generation would have required a very complicated and very specific cellular apparatus - as a peptide-based genetic machinery - for which there is no evidence in extant organisms [4], [9]. It seems more plausible to assume that the first enzymes were macromolecules produced on mineral surfaces, capable of playing the dual role of the phenotypic function of biocatalysis and that of genetic information transfer, thus evading the difficult problem of the lack of translation at the wake of life. The most likely candidate for this role is the RNA molecule, because it can bind to mineral surfaces due to its electrostatic charges, and its production on mineral surfaces has been proven experimentally [10]–[13]. The nucleobase sequence of RNA stores biologically meaningful information that, in principle, is not difficult to copy, and within-strand Watson-Crick type base-pairing may produce various complicated and reproducible spatial structures which may show very different catalytic activities depending on the base sequence of the molecule (RNA World, [14]–[19]). Recent empirical research has provided ample support to this hypothesis by demonstrating the wide spectrum of catalytic activities of RNA, which led to the hypothesis of a surface-bound RNA World [10]–[13], [15], [20], [21].
Of course there remain many – so far unresolved – questions with regard to the chemical mechanisms implied by the RNA World hypothesis. To mention just a few: the synthesis of ribose, phosphates and the four nucleobases under plausible prebiotic environmental conditions is far from straightforward, but in the light of recent empirical work they seem not hopeless either. For example the formose reaction (a possible route for ribose synthesis) and the Stercker-synthesis (amino acids, nucleobases and many more biologically important compounds) require very different chemical milieu [22]–[25] suggesting that they should have been separated in space if these were to produce ribose and nucleobases for RNA replication. However, recently it was shown that there exists a different chemical route to nucleotides which works at neutral pH and provides an excellent yield [26], [27]. Another notorious problem is that of the concatenation of nucleotides: without activator agents (e.g. imidazole) the proper 3′-5′ direction is not exclusive in the concatenation reaction. Schwartz and his co-workers have shown that phosphites are able to conduct the concatenation of nucleotides in the right direction in water without any activator agent present, and the phosphite would oxidise to phosphate during the reaction [28]. Mineral surfaces also promote the proper 3′-5′ direction of concatenation into long oligonucleotides (40–60-mers) [13], [25] and the homochiral segregation of sugar molecules [29], [30] without which the polymerization process would be blocked by enantiomeric cross-inhibition [31]. von Kiedrowski's suggests that RNA constituents must have been polymerized on mineral surfaces, but many other reactions essential on the way to life could have taken place in the water body of the prebiotic ocean [32].
Yet another problematic issue of the RNA World hypothesis is the “Holy Grail” of prebiotic evolution: the self-replication of RNA molecules, or, more precisely, the lack of an efficient RNA-replicase ribozyme. The problem is connected to Eigen's paradox [33] which states in the present context that the precise replication of long ribozymes requires long ribozymes to catalyse their replication. This remains true even if neutral-mutations are considered [34]. There are two possible solutions for the information integration problem: either many short RNA molecules need to cooperate in a compulsory fashion, or an RNA-replicase ribozyme has to evolve somehow “from scratch”, and maintain its own sequence just like that of many other, cooperating ribozymes. Recent experimental results show that both ways are chemically feasible to some extent already. For example, four RNA molecules are shown to cooperate in catalysing their own ligation into a single strand ribozyme [35]–[37]. RNA replicase ribozymes have been seeked for for decades, but it was only very recently that a substantial step forward was taken in that respect: in an in vitro evolution project [38] a 189-nucleotide RNA molecule has been discovered that was able to elongate its own 95-nucleotide primer in a template-directed manner. The fidelity of the replication process was 99.4%.
In spite of such empirical “missing links” in connection to the RNA World hypothesis it seems quite probable that the earliest self-reproducing macromolecules with catalytic activities would have been RNA (or very similar) molecules. Theoretical studies suggest that simple (RNA-like) molecules of very weak specificity and efficiency could have evolved to much more specific and efficient enzymatic replicators, through gradual adaptation [39]–[41]. However, due to strict constraints on their spatial structure, the evolution of enzymes is not as simple as assumed in these models. The longer the replicator the more complex its spatial structure will be. This has two important consequences: first, it is not easy to find the “native” conformation of a long macromolecule, and second, a complicated spatial structure makes template-copying more difficult, because long molecules have to be unfolded before being replicated. Such long and complex molecules have a significant fitness handicap at replication compared to shorter and simpler, therefore easy-to-copy ones. However, there is an indirect way to compensate for the direct fitness loss due to structural complexity: complex replicators may have much better catalytic properties. Provided that – due to its catalytic effect – the complex replicator can significantly contribute to the production of its own monomers, its local monomer supply will be higher than that of its simpler, non-catalytic competitors. This indirect fitness advantage may be sufficient to overcompensate the fitness loss caused by decreased replicability, and the catalytic replicator may spread in the population. Of course the above argument applies only to single-step monomer production, i.e., we have to assume that the successful replicator enzyme A catalyzes the terminal step of the production of its own monomers – and that all the other resources of replication are present in the environment in sufficient concentrations (i.e., the replicator population is heterotrophic in all other respects). Such an ecological situation is very unlikely to last long: due to increased consumption, some of the substrates of the catalysed reaction will become in short supply as the increasing population of replicator enzyme A depletes them, creating selective pressure towards a second enzymatic activity B to produce the substrate of replicator A, and so on. This Liebig type argument constitutes part of Szathmáry's “progressive sequestration” scenario [42].
How can this second enzymatic activity B be obtained by a population of replicators showing enzyme activity A? There are essentially two plausible ways to get there: “enzyme promiscuity” and “enzyme cooperation”. “Enzyme promiscuity” means that a single enzyme is capable of catalyse two (or more) different reactions. This was considered an almost impossible option until very recently, because the dominant view on peptide folding allowed only for a single “native” conformation, and therefore just a single catalytic activity for a peptide enzyme. The conventional view seems to be considerably weakened by now, because quite a few peptide and RNA enzymes have been revealed to admit either more than one native conformations, each of which have to be present to accomplish a single function [43], or more than one native conformations, each with a different function [44]–[47]. Such “multi-functional” enzymes are pre-adapted for later diversification and specialization, to yield different single-functional types, basically by each type gradually losing all but a single activity, and the activity retained becoming more and more specific and efficient. This leads to the second option: the cooperation of two or more different enzymes within the same “molecular community”. Coexistence and (co)evolution within such molecular communities have been studied for more than 30 years now, mainly by means of mathematical and simulation models, all of which seek a solution to the basic ecological problem: how could a number of different molecular replicators – using common resources for their replication, therefore being strong competitors of each other – form a stable assembly? All the answers given so far assume some kind of cooperation within the replicator community, to offset the effect of competition which would certainly ruin molecular diversity otherwise. The hypercycle model assumes that the cooperation may be direct, each replicator specifically catalysing the replication of just one other member of the molecular community in a circular topology [40], [33]. Kaufmann's autocatalytic network model [7] also assumes specific and direct catalytic help among different replicators, but not in the rigid circular topology of the hypercycle. According to our metabolic replicator model, the molecular species of the community may be coupled through indirect mutualism, in which case cooperation and coexistence are mediated by a common metabolism which is driven by the replicators as enzymes producing monomers for the community [48], [49]. Whichever approach we take, we need to answer two questions: 1) what makes and keeps the molecular cooperators of the community distinct and specialized, and 2) what saves the community from being invaded and destroyed by parasitic replicators?
We attempt to answer these questions using a simple model of enzymatic speciation in a surface-bound, metabolically coupled replicator population. Each replicator might have two enzyme activities (E1 and E2, catalysing two different keystone reactions of the metabolism), but this versatility is paid in catalytic efficiency: both enzyme activities of the “generalists” are weak. E1 can be increased by mutation, but only at the expense of E2, and vice versa, i.e., the two enzyme activities are in trade-off. Schultes & Bartel [46] have provided solid empirical proof of the E1/E2 trade-off for two different folds of the same RNA sequence, each of which had a different catalytic activity: one fold was a ligase, the other catalysed a cleavage reaction. The two enzyme activities have shown strict trade-off: the ligase fold was very weak at cleavage, the cleavage fold was bad at ligation, and the artificial intermediate folds were weak in both activities.
In accordance with the steric constraints on replication mentioned above, we assume that efficient enzyme replicators have a complicated secondary structure which makes them difficult to copy. We assume that replication is a simple, template-directed, non-enzymatic process weakly catalysed by the surface itself. This amounts to postulating that enzyme activities and replication rates (fitnesses) are also traded off: good enzymes make poor templates for replication, and vice versa. With these restraints we ask under what circumstances the emergence and the persistence of a community of specialized metabolic replicators can be expected, and to what extent parasitic sequences (fast replicating, short molecules of weak catalytic activity) undermine the efficiency and stability of the metabolic system.
Methods
The model is a two-dimensional cellular automaton of toroidal lattice topology to avoid edge-effects. Each of the 300×300 square lattice sites may be empty or occupied by a single replicator molecule at any point of time. The basic assumptions with respect to replication and metabolism are similar to those of our earlier Metabolic Replicator Model [48]:
replicators bind to a mineral surface (represented by the lattice) and they are template-replicated there;
each replicator has a “basic fitness” parameter, which is its replication rate (k) under ideal environmental conditions; this parameter specifies the quality of a replicator - as a template - in its own replication process.
each replicator is able to catalyze one or two essential reactions of a hypothetical metabolic network;
each of the two catalytic activities (E1 and E2) are necessary for metabolism to produce monomers for replication;
metabolism supplies monomers locally only to sites which have a non-zero sum of enzyme activity in both E1 and E2 within their metabolic neighbourhood (i.e., if any of the two activities is missing from the metabolic neighbourhood, the replicator in the focal site cannot replicate for lack of monomers).
the random walk (diffusion) of replicators is constrained by their adherence to the mineral surface;
To study molecular speciation within the metabolic model, we allow for mutational changes in three traits of the replicators: the two enzyme activities (E1 and E2) and k, the replication rate under ideal conditions (i.e., for a local excess of monomers). The changes in the mutable traits are constrained by a three-way trade-off relation as described later (in 2.3). Based on their mutable traits (E1, E2 and k) replicators can be classified into four different phenotype categories:
specialists: with a single, strong enzyme activity (either E1 or E2) and a small replication rate k;
generalists: with two, roughly equal enzyme activities (E1 = E2≠0.0), replication rate depending on the actual values of E1 and E2, and a small replication rate k;
parasites: replicators without metabolic activity (E1 = E2 = 0.0) but of high replication rate;
all the rest: intermediate phenotypes with different enzymatic activities and replication rates.
With these assumptions we ask which of these phenotype categories evolve in the model, and what determines the actual outcome of the speciation process?
At t = 0, the simulations are initiated with 80% of the sites occupied by replicator molecules, the phenotypes of which are attributed at random (of course with the three-way trade-off constraints considered). We use an asynchronous random updating algorithm to determine the phenotype distribution of the replicator population at the next, (t+1)th generation. A schematic representation of the algorithm is given on Figure 1, and the details of the interaction modules are explained below.
Figure 1. The E1/E2/k trade-off relation.

The E1−E2−k trade-off surface as defined by Eq. 6. The trade-off function constrains the phenotypes of newly emerging mutant replicators below the surface. A: convex function representing strong trade-off both between the two enzyme activities E1/E2 and between enzyme activities and replication rate, E/k. (b = 0.6 and g = 0.6). B: a function with convex (strong) E1/E2 trade-off and concave (weak) E/k trade-off (b = 0.6 and g = 1.67). C: concave (weak) E1/E2 and convex (strong) E/k trade-off (b = 1.67 and g = 0.6). D: both the E1/E2 and the E/k trade-offs are concave (weak) (b = 1.67 and g = 1.67). Other parameters: Emax = 10, kmin = 2, kmax = 4.
1. “Death”
Replicators may disappear from the mineral surface for different reasons. They may simply detach and move away from the surface, or they may disintegrate due to chemical “corrosion” (e.g., hydrolysis). Hydrolysis is more frequent in longer molecules, but longer replicators remain adhered to the surface for a longer time. These two effects counteract each other, so we assume that the net dependence of death rates on replicator length is negligible. From the viewpoint of the metabolic system, these events are all “deaths”, and we treat them as such. We assume that deaths occur at a constant rate pd independent of other traits of the replicator itself and of the other ones in its neighbourhood. If the site being updated contains a molecule, then it disappears with probability pd, leaving the site empty. We used pd = 0.1 throughout our simulations.
2. Metabolism and competition
If the updated site is empty, then the replicators in its replication neighbourhood (i.e., in its von Neumann neighbourhood) compete for the site to put a copy of themselves there. The chance of replicator i to win the site is proportional to its actual fitness Wi, which is the product of its replication rate ki and its local metabolic supply Mi:
| (1) |
The metabolic supply Mi depends on the two enzyme activities within the metabolic (Moore) neighbourhood of replicator i in a multiplicative manner:
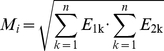 |
(2) |
where n is the size of the metabolic neighbourhood. Mi is the geometric mean of the local enzyme activities, therefore with any one of the enzyme types missing from the metabolic neighbourhood of i the local metabolic supply is zero and replicator i cannot be copied.
Even those replicators of which both enzyme activities are non-zero (phenotypes 2. and 4. above) can catalyse only one of the corresponding reactions at a time, since the two different enzyme activities are attributed to two different secondary structures of the molecule. We assume that within the time span of a single generation the replicators do not change conformation, but they can do so between two generations with transition probability
| (3) |
s measures (on the 0.0–1.0 scale) to what extent the replicator in question can be considered as a “specialist”. Eq. 3 assumes that specialist replicators (s = 1.0) never change conformation from one generation to the next, whereas “generalists” (of roughly equal enzyme activities for both keystone reactions) almost always do. From the viewpoint of molecular speciation this is not necessarily a realistic assumption; we use it as a worst-case scenario of conformation change from the viewpoint of enzyme specialization: in pure populations of generalist replicators the regular swaps of individual enzyme activities (i.e., of conformation) keeps their metabolism running locally everywhere, whereas purely specialist populations might get stuck in one of the two conformations for a long time, and their local metabolism may break down for lack of the complementary enzyme activity.
The chance of replicator i to copy itself onto a neighbouring empty site is
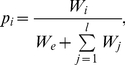 |
(4) |
where j runs through the replication neighbourhood of the empty site, and We quantifies the tendency of a site to remain empty (We = 20.0). We sets the effect of absolute enzymatic activities in the neighbourhood: weak claims for replication within the replication neighbourhood result in the “no replication” event with a higher probability. Thus the probability that an empty site remains empty is
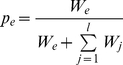 |
(5) |
The next state of the empty site is determined by a random draw using the probabilities of Eq's. 4 and 5.
Note that the qualitative behaviour of the model is not affected if we use the Moore-type replication neighbourhood (with l = 8) instead of the von Neumann-type (l = 4).
3. Mutation and enzyme activity trade-offs
The winner of the local competition for space may be a copy of replicator i from within the replication neighbourhood of the empty site. The copy will be “mutated” with probability pm. The mutant copy will be different from the template with respect to its primary (sequence) and secondary (folding) structures alike, which in turn might have an effect on the phenotype of the offspring, in terms of both enzymatic functionality and replicability. We allow for phenotype changes in three parameters of the replicators: the two enzyme activities (E1 and E2), and the basic replication rate k. As explained in the Introduction, these traits are in a three-way trade-off: efficient enzymes cannot be very good at template replication, and any one of the two enzyme activities can increase only at the expense of the other. These trade-off relations constrain the feasible part of the phenotype space (Figure 1) to under the trade-off constraint surface C(E1, E2) given by Eq. 6:
| (6) |
where Emax (Emax = 10.0) is the absolute maximum of the enzyme activities, kmax (kmax = 2.0 or 2.5 or 4.0 in all simulations) is the highest, kmin (kmin = 2.0) is the lowest possible replication rate of any replicator in the metabolic system, and b and g determine the strength of the trade-offs which affects the shape of the trade-off surface. This formulation allows us to independently manipulate – through the parameters b and g – the convexity of the E1−E2 and E−k trade-off dependencies, respectively. For the enzyme activities, the strict trade-off constraint applies if E1+E2<Emax, which in turn means 0.0<b<1.0. Then the trade-off function is convex (strong) on the E1−E2 plane, and the smaller b is, the more restrictive the trade-off. b = 1.0 represents the limiting case of E1+E2 = Emax, so that the two enzyme activities together are equivalent to a single specialist's activity. The trade-off is less restrictive for E1+E2<2Emax, which translates to 1.0<b<∞ and a concave (weak) trade-off function. The upper limit b = ∞ represents no trade-off at all: whichever role the enzyme plays, it works as if it were a perfect specialist. The same applies to the trade-off between enzyme activities and replication rates: g describes the strength and shape of the trade-off between E1+E2 and k, and the smaller it is, the more convex (stronger) the trade-off relation.
Mutant phenotypes are assigned to the copies of a parent replicator template by a random draw of a point (E1, E2, k) from below the trade-off surface, so that 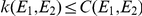 ,
, 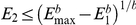 ,
, 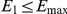 . Mutants can be similar or quite different from their parents, which is reasonable to assume for replicator molecules of complex phenotypes: the effects of a mutation on the enzyme activities and the replication rate of an enzymatic replicator are difficult to predict, and they can be of any magnitude, depending on which part of the macromolecular structure is affected. Note that the average mutation is deleterious: selection shifts the phenotype distribution of the replicators towards the trade-off surface (i.e., to higher enzymatic efficiencies and replication rates), but mutants are drawn at random from below the surface.
. Mutants can be similar or quite different from their parents, which is reasonable to assume for replicator molecules of complex phenotypes: the effects of a mutation on the enzyme activities and the replication rate of an enzymatic replicator are difficult to predict, and they can be of any magnitude, depending on which part of the macromolecular structure is affected. Note that the average mutation is deleterious: selection shifts the phenotype distribution of the replicators towards the trade-off surface (i.e., to higher enzymatic efficiencies and replication rates), but mutants are drawn at random from below the surface.
4. Diffusion
Since the replicators are assumed to be bound to the mineral surface by reversible secondary (non-covalent) chemical bonds, their movement on the mineral surface is possible. We have modelled this movement by a simple site-swap algorithm: we choose two neighbouring replicators at random, and swap their positions. The intensity of the resulting diffusion process depends on how many site swaps are allowed per replication (generation) on average, which is defined in the diffusion parameter D of the model. Note that even at D = 0.0 a minimum of mixing occurs due to the fact that the copy of each template is placed into one of the neighbouring sites during replication, i.e., the offspring moves away from the parent. Again, we have tried two different neighbourhoods for site swapping, and found that choosing neighbours from the von Neumann or the Moore neighbourhood makes no detectable difference in the outcomes of simulation.
Results
The model predicts the coexistence of multiple replicator species and also enzyme specialization for a large part of its parameter space, even at relatively weak trade-off constraints and limited replicator mobility. Parasites are usually present in the evolved metabolic system at small densities
We have screened the effects of changing the crucial model parameters on the outcome of replicator evolution in terms of enzyme specialization and efficiency (i.e., specificity and parasitism). Having run the simulations for sufficiently long times we determined the phenotype distribution of the persistent replicators within the three-dimensional (E1, E2, kmax) trait space. Since the trait space under the trade-off constraint surface C(E1,E2) (Eq. 6) is continuous, it is a matter of definition which of its parts we consider to contain “specialist”, “generalist” and “parasitic” replicator phenotypes. We used the E1/E2 projection of the three-dimensional trait space to define these phenotype classes. The “absolute” specialists are those replicators which sit on the E1 or the E2 axis of the projected plane, whereas absolute generalists are found on the 45° straight line between these axes. The absolute parasite occupies the origin. Any replicator sufficiently close to these parts of the E1/E2 plane can be classified as belonging to the corresponding phenotype. Accordingly, we have defined the phenotype categories as shown on Figure 2.
Figure 2. Types of replicators on the E1−E2 phase plane.

Specialists (dark grey lines), generalists (light grey box), parasites (black triangle) and all the rest (white). The dashed line represents the E1/E2 trade-off relation.
Two of the five relevant model parameters – the shape of the trade-off function of the enzymatic activities (b) and the diffusion rate (D) – had a strong effect in the sense that changing them across a sufficiently wide range of their possible values results in qualitative changes in the outcomes. The remaining three parameters (the mutation rate pm, the trade-off shape parameter g for replicator enzyme activity and replicability, and the highest possible replication rate kmax) are of much weaker effect. We explain these results below in more detail. Since changing the neighbourhood definition for the replication or the diffusion algorithm did not make substantial differences in the results of simulation, we used the von Neumann neighbourhood for replication and the Moore neighbourhood for diffusion throughout the simulations presented.
1. The effects of the trade-off parameters (b and g) and the replication rate (kmax)
The actual shape of the E1/E2 trade-off surface (i.e., the parameter b, Figure 1) has an almost all-or-none type effect on the enzyme specialization process: trade-off relations that are convex beyond a certain threshold (for D = 0, kma x = 2.5 and g = 1.0 the threshold is at about b∼0.6) yield a high frequency (>80%) of specialists; higher values of b result in an overwhelming dominance of generalists, but with their frequency almost completely detached from the actual value of b (Figure 3a). This phase-transition-like behavior is preserved at higher replicator mobility as well, but then the threshold of generalist dominance shifts to a very concave shape of the trade-off function: for D = 5 it is at b = 1.67 (Figure 3b). This means that at somewhat higher replicator mobility specialization pays even if the trade-off between the two enzyme specificities is rather loose (note that as b approaches infinity, the trade-off approaches zero).
Figure 3. Frequencies of replicator types.

A: The frequencies of specialist and generalist replicators as a function of the b parameter, at D = 0; B: the same, at D = 5. Other parameters: pm = 0.01, g = 1.0 and kmax = 2.5 at the 150.000th generation. Note that the frequency of parasitic replicators is less then 1% everywhere in this parameter setting, so we have not plotted it here.
The evolved enzyme activities and the corresponding (evolved) replication rate of the specialized replicators depend on the kmax parameter: the larger it is, the smaller the actual enzyme activities at equilibrium, because the direct evolutionary advantage of achieving a high replication rate compensates for the loss in the indirect advantage of having a better monomer supply within the metabolic neighbourhood. This leads to the evolutionary shift of the replicators towards a tendency of becoming parasites – the stronger the temptation (i.e., the higher kmax) the closer the replicator community creeps to parasitism. Yet, even at a high advantage of parasitism (kmax = 4.0) the replicators remain enzymatically active and specialized, at least for convex trade-off relations. It is only at very concave E1/E2 trade-off functions (i.e., at b>1.67 for moderate D = 5 replicator mobility) where generalists dominate the replicator community (expect for g<1.0 when parasites also appear), but this represents a case of very weak trade-off between the two enzyme activities, therefore it is biochemically unlikely to occur.
We have run a similar series of simulations changing g, the E/k trade-off parameter as well, with the general conclusion that g has a much weaker effect on catalytic specialization than b. Its straightforward but moderate and quantitative effect is that very convex E/k trade-off functions (very small g values) decrease the frequency of generalists and at high mobility it helps the parasites in spreading.
2. The effects of diffusion (D)
The mobility of replicators (expressed by the diffusion parameter D) has a twofold effect on the efficiency of metabolism, the first aspect of which is positive, and the second one negative (cf. [47]). First, it mixes the different types of enzymatic replicators on the surface, i.e., it dissolves the large, homogeneous patches of replicator clones (consisting of identical ribozymes) which would inevitably arise due to template and copy remaining neighbours in the absence of diffusion. Since the inside of a homogeneous patch of specialized enzymatic replicators lacks the complementary replicators needed to run the metabolism locally, the spatial mixing of specialized replicators is necessary to some extent for the metabolic system to work – metabolism would stop producing monomers and thus replication would be impossible almost everywhere on the surface (except for the borderlines between different patches) otherwise. However, generalist replicators (i.e., those which can switch between different enzyme activities) do not need to be spatially mixed to run local metabolisms, because even clone-mates can complement each other metabolically. This is why generalists almost always exclude specialists at very slow diffusion (D = 0.0, Figure 4). (Note that the survival of specialists at b≤0.4 is due to the minimal diffusion inherent in the replication algorithm). As the diffusion of replicators becomes faster, specialists become viable and –depending weakly on the shape parameter b of the trade-off function between the two enzyme activities – they may win the competition against generalists (Figure 5).
Figure 4. The distribution of enzyme activities without diffusion at different b and kmax values.

Horizontal axes: enzyme activities E1 and E2; vertical axis: the frequency of replicators in the lattice, with the corresponding combinations of E1 and E2.. Other parameters: pm = 0.01, D = 0 and g = 1.0, at generation 150.000.
Figure 5. The distribution of enzyme activities with diffusion at different b and kmax values.

Axes labeled as in Figure 4. Other parameters: pm = 0.01, D = 5 and g = 1.0, at generation 150.000.
The second effect of increasing replicator mobility is negative for the metabolic system as a whole: parasitic replicators can invade. In a well-mixed population it is the parasitic replicator that has the highest fitness, because it has a high chance of finding itself in a metabolically complete assembly of cooperating replicators which it can exploit then for its own benefit. Since parasites, just as cooperators, can replicate only in a complete metabolic neighbourhood (to which they do not contribute at all), the spatial aggregation of kin replicators, i.e. slow diffusion, prevents the uncontrolled spread of parasites. In fact parasites need to be relatively mobile for taking a sizeable share of abundance within the lattice habitat, because they need to disperse far apart from their clone-mates to be efficient in exploiting the cooperators. Parasite aggregates are doomed to even faster extinction than enzymatic replicator aggregates. As a consequence, at small to moderate rates of diffusion we observe the coexistence of cooperators and parasites.
The balance of cooperators (enzymatic replicators of relatively small rate of population growth k) and parasites (replicators of high growth rate with no or very weak enzyme activities E1 and/or E2) within the replicator community depends on the contribution of two fitness components to population growth. One is the trivial direct contribution through the growth parameter k, the other is the indirect contribution to one's own fitness through the local production of monomers for replication that in turn depends on higher values of E1 and/or E2. With the possibility of mutational changes in these parameters (which is constrained by the E/k trade-off relation), the relative weights of the direct and indirect fitness components can be regulated through selection. Obviously, the actual weights of direct and indirect selection are determined by the diffusion parameter: the higher D is, the larger the effect of direct selection relative to that of the indirect one, which means more parasites and less efficient metabolism. This effect is clearly visible on Figs. 3 and 4: the replicator populations approach the origin of the E1/E2 trade-off plane and achieve high values of k as D increases. The “temptation” to become a parasite is the highest if losing some enzyme activity may result in a substantial increase of replication rate, i.e., at high values of kmax.
Discussion
In vitro selection experiments [20], [21] aimed at producing RNA molecules of different phenotypes have suggested that the functional diversity of RNA molecule populations consisting even of rather short digital (nucleotide) sequences might have been sufficiently high for booting up life on prebiotic Earth [5], [6]. It is very likely that, among the many possible functionalities that RNA molecules can possess, some may have evolved to catalyse the copying of the RNA molecule itself and of other RNA molecules, but the template-replicase ribozyme is still to be discovered [17], [50]. Theoretical models [41], [49], [51] have demonstrated that, once some basic functionalities ensuring the self-reproduction of the inhabitants of the RNA world are in place, the way to obtaining more efficient functions (i.e., higher fitness) through Darwinian RNA evolution is open. The resulting communities of early replicators must have evolved towards higher efficiency through cooperation in the long run, but short-term competition among different RNA sequences was obviously inevitable, because the different RNA species must have used the same resources (monomers) for replication. The basically ecological problems of the competitive exclusion of slower replicating RNA sequences and the possible invasion of parasitic ones have been tackled in quite a few theoretical studies [33], [48], [51]–[55]. It is difficult, in many cases impossible, to separate evolutionary and ecological aspects of replicator evolution [56], [57]. This statement applies to the present model as well, in which we have established ecological conditions for the evolution of specialized and efficient enzymatic replicators under different trade-off constraints among two enzyme specificities and the replication rates of metabolically coupled replicators. The trade-off function represents an inseparable relation between the genuine chemical-biochemical constraints on the metabolic roles that replicators can play in the system and the ecological trait of their potential population growth rate kmax.
Increasing enzymatic activity provides better monomer supply for the replicator in its own immediate neighbourhood, therefore it helps its own reproduction by supplying more resources. However, the price of this ecological advantage due to more efficient local catalysis is to be paid by the replicator in terms of its decreased replication rate kmax. This lower replication potential is a direct consequence of the stable and compact secondary structure which is a necessary trait for an efficient catalyst, but obviously makes the replicator more difficult to copy. Parasitic replicators which do not contribute to monomer production but are able to use up the monomer supply faster due to their loose, easily unfoldable and thus easy-to-copy secondary structure are at an ecological advantage compared to the metabolically active enzymatic replicators. Therefore we might expect the parasites to destroy the metabolic system altogether, finally leaving the surface devoid of replicators altogether. Yet, this is not what actually happens. We have found that increasing kmax (i.e., the existence of the E/kmax trade-off) results in the evolved replicator population becoming less efficient catalytically but still remaining active and specialized: the majority of the replicators edge closer to the origin of the E1/E2 trait plane (i.e., they shift towards parasitism) but they still stay on the specialist axes (cf. Figure 5). This shows that the indirect positive effect of metabolic activity becomes decisive for the dynamics of the system with the frequency of parasites increasing in the replicator population. In all versions of the metabolic model [48], [49] – just as in the present one – it is the indirect metabolic cooperation of the replicators and their limited mobility that makes the system persistent in spite of the differences in replication rates. For the enzymatic replicators to be able to replicate they need their metabolic neighbourhood to be complete. This requires the presence of all replicator species within the metabolic neighbourhood in the previous models, and the presence of all enzyme activities in this one. In the absence of diffusion there is only one way to maintain all the necessary enzyme activities within a metabolic neighbourhood consisting of identical replicators: all of them must be “generalists” with both enzyme functions present in the same macromolecule – of course at a low activity on both accounts, because this is what the E1/E2 trade-off constraint permits. Even very modest replicator diffusion allows for enzymatic replicator specialization, because it mixes different specialized replicator species, so that they can be present together in most metabolic neighbourhoods, allowing for a more efficient local metabolism and, consequently, for the exclusion of less efficient generalists (Figure 5). Our results also suggest that – between rather wide limits – the actual shape of the E/kmax trade-off function (the parameter g) does not have a decisive effect on enzymatic replicator specialization and the survival of the system. It is only for biochemically infeasible, very concave E/kmax trade-off shapes that specialized enzymatic replicators are displaced by generalists.
As we have briefly mentioned in Sect. 3.1., there are direct and indirect selection effects which influence the evolution of enzymatic functions. Indirect selection favours those functions of the replicators which have a positive influence on their cooperation through which they gain indirect benefits. Under indirect selection the replicators evolve towards becoming more efficient enzymes, the communities of which have more chances to spread due to their better resource supply. Efficient specialists are expected to show up only at a minimum of spatial mixing: replicator mobility helps to harvest indirect selective advantages. Direct selection attempts to maximize the growth rate of the replicators, which pushes the system towards the prevalence of parasites according to the E/kmax trade-off constraint. Direct selection is responsible for decreasing the enzyme activities of replicators, and, at the extreme, the dominance of parasites and the collapse of the metabolic system. Real parasites can spread only within metabolically active neighbourhoods, because pure parasite patches produce no resources for replication, and they die out. Therefore, parasites cannot evolve in the absence of diffusion, i.e., at zero replicator mobility. Increased diffusion helps the parasites in finding exploitable neighbourhoods and to avoid the pure-parasite dead end of the dynamics of the system. Under such circumstances parasites coexist with the enzymatic replicators [48], [49]. That is, direct and indirect selection are both enhanced by diffusion [49]; indirect selection helps coexistence, whereas direct selection favours parasitism. We have shown that at a large interval of the D parameter axis these two effects are balanced, and the result is a community of more or less specialized and efficient enzymatic replicators, infected by a population of parasites.
Just like in the model of Könnyű and Czárán [49], the controlled presence of the parasite may be even advantageous for the metabolic system as a whole: lacking selective pressures sufficiently effective to completely eliminate it, and also lacking any positive selection to maintain its sequence information, the parasite may freely mutate. Thus it can wander about in the sequence space, and it has a chance to find a function there which is useful for the system as a whole. That is, the parasite is persistent and pre-adapted to many possible beneficial functions, including new metabolic enzyme activities, replicase activity, or membrane production. All these functions must have evolved at some stage of the origin of life, leading to the first membrane-covered macromolecule communities (proto-cells), in which a new and more efficient level of selection described in the stochastic corrector model [53], [57] could have acted to maintain the optimal molecular composition of the earliest living creatures.
Acknowledgments
We wish to thank three anonymous referees for their valuable comments.
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: The project was supported by the Hungarian Research Foundation (OTKA) Grant No. K67907. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Wächtershäuser G. Evolution of the first metabolic cycles. Proceedings of the National Academy of Sciences of the USA. 1990;87:200–204. doi: 10.1073/pnas.87.1.200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Wächtershäuser G. Life as we don't know it. Science. 2000;289:1307–1308. doi: 10.1126/science.289.5483.1307. [DOI] [PubMed] [Google Scholar]
- 3.Wächtershäuser G. On the chemistry and evolution of the pioneer organism. Chemistry and Biodiversity. 2007;4:584–602. doi: 10.1002/cbdv.200790052. [DOI] [PubMed] [Google Scholar]
- 4.Maynard-Smith J, Szathmáry E. The major transitions of evolution. Oxford: W.H. Freeman/Spectrum; 1995. [Google Scholar]
- 5.Ma W, Yu C, Zhang W, Hu J. Nucleotide synthetase ribozymes may have emerged first in the RNA world. RNA. 2007;13:2012–2019. doi: 10.1261/rna.658507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Garay J. Active centrum hypothesis: the origin of chiral homogenity and the RNA-World. Bio Systems. 2010 doi: 10.1016/j.biosystems.2010.09.004. In press. [DOI] [PubMed] [Google Scholar]
- 7.Kauffman S. Autocatlytic sets of proteins. Journal of Theoretical Biology. 1986;119:1–24. doi: 10.1016/s0022-5193(86)80047-9. [DOI] [PubMed] [Google Scholar]
- 8.Nelson KE, Levy M, Miller SL. Peptide nucleic acids rather than RNA may have been the firs genetic molecule. Proceedings of the National Academy of Sciences of the USA. 2000;97:3868–3871. doi: 10.1073/pnas.97.8.3868. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Orgel LE. Some consequences of the RNA world hypothesis. Origins of Life and Evolution of Biospheres. 2003;33:211–18. doi: 10.1023/a:1024616317965. [DOI] [PubMed] [Google Scholar]
- 10.Ferris JP, Hill RA, Liu R, Orgel LE. Synthesis of long prebiotic oligomers on mineral surfaces. Nature. 1996;381:59–61. doi: 10.1038/381059a0. [DOI] [PubMed] [Google Scholar]
- 11.Franchi M, Ferris JP, Gallori E. Cations as mediators of the adsorption of nuclec acids on clay surfaces in prebiotic environments. Origins of Life and Evolution of Biospheres. 2003;33:1–16. doi: 10.1023/a:1023982008714. [DOI] [PubMed] [Google Scholar]
- 12.Franchi M, Gallori E. A surface-mediated origin of RNA World: biogenic activities of clay-absorbed RNA molecules. Gene. 2005;346:205–214. doi: 10.1016/j.gene.2004.11.002. [DOI] [PubMed] [Google Scholar]
- 13.Ferris JP. Montmorillonite-catalysed formation of RNA oligomers: the possible role of catalysis in the origins of life. Philosohical Transactions of the Royal Society B. 2006;361:1777–1786. doi: 10.1098/rstb.2006.1903. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Gilbert W. Origin of life: the RNA world. Nature. 1986;319:618. [Google Scholar]
- 15.Joyce GF. The antiquity of RNA-based evolution. Nature. 2002;418:214–221. doi: 10.1038/418214a. [DOI] [PubMed] [Google Scholar]
- 16.Lilley DMJ. The origins of RNA catalysis in ribozyme. Trends in Biochemical Sciences. 2003;28:495–501. doi: 10.1016/S0968-0004(03)00191-9. [DOI] [PubMed] [Google Scholar]
- 17.Chen X, Li N, Ellington AD. Ribozyme catalysis of metabolism in the RNA World. Chemistry & Biodiversity. 2007;4:633–655. doi: 10.1002/cbdv.200790055. [DOI] [PubMed] [Google Scholar]
- 18.Cech TR. Crawling out of the RNA World. Cell. 2009;136:599–602. doi: 10.1016/j.cell.2009.02.002. [DOI] [PubMed] [Google Scholar]
- 19.McConnell TS, Hercchlag D, Cech TR. Effects of divalent metal ions on individual steps of the Tetrahymena ribozyme reaction. Biochemistry. 1997;36:8293–8303. doi: 10.1021/bi9700678. [DOI] [PubMed] [Google Scholar]
- 20.Landweber LF, Simon PJ, Wagner TA. Ribozyme engineering and early evolution. Bio Science. 1998;48:94–103. [Google Scholar]
- 21.Bartel DP, Unrau PS. Constructing an RNA world. Trends in Genetics. 1999;15:M9–M13. [PubMed] [Google Scholar]
- 22.Ferris JP, Joshi PC, Edelson EH, Lawless JG. HCN: A plausible source of purines, pyrimidines and amino acids on the primitive Earth. Journal of Molecular Evolution. 1978;11:293–311. doi: 10.1007/BF01733839. [DOI] [PubMed] [Google Scholar]
- 23.Ferris JP, Hagan JR. HCN and chemical evolution: the possible role of cyano compounds in prebiotic synthesis. Tetrahedron. 1984;40:1093–1120. doi: 10.1016/s0040-4020(01)99315-9. [DOI] [PubMed] [Google Scholar]
- 24.Weber AL. Sugar-driven prebiotic sythesis of 3,5(6)-dimethylpyrazin-2-one: a possible nucleobase of a primitve replication process. Origins of Life and Evolution of Biospheres. 2008;38:279–292. doi: 10.1007/s11084-008-9141-6. [DOI] [PubMed] [Google Scholar]
- 25.Robertson MP, Joyce GF. The origins of the RNA world. Cold Spring Harbor Perspectives in Biology. 2010:1–22. doi: 10.1101/cshperspect.a003608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Powner MW, Gerland B, Sutherland JD. Synthesis of activated pyrimidine ribonucleotides in prebiotic plausible conditions. Nature. 2009;459:239–42. doi: 10.1038/nature08013. [DOI] [PubMed] [Google Scholar]
- 27.Powner MW, Sutherland JD, Szostak JW. Chemoselective multicomponent one-pot assembly of purine precursors in water. Journal of American Chemical Society. 2010;132:16677–16688. doi: 10.1021/ja108197s. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Schwartz AW. Phosphorus in prebiotic chemistry. Philosohical Transactions of the Royal Society B. 2006;361:1743–1749. doi: 10.1098/rstb.2006.1901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Bielski R, Tencer M. A possible path to the RNA World: enantioselective and diastereoselective purification of ribose. Origins of Life and Evolution of Biospheres. 2007;37:167–175. doi: 10.1007/s11084-006-9022-9. [DOI] [PubMed] [Google Scholar]
- 30.Hazen RM, Filley TR, Goodfriend GA. Selective adsorption of L- and D-amino acids on calcite: implications for biochemical homochirality. Proceedings of the National Academy of Sciences of the USA. 2001;98:5487–5490. doi: 10.1073/pnas.101085998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Joyce GF, Visser GM, van Boeckel CA, van Boom JH, Orgel LE, et al. Chiral selection in poly(C)-directed synthesis of oligo(G). Nature. 1984;310:602–604. doi: 10.1038/310602a0. [DOI] [PubMed] [Google Scholar]
- 32.von Kiedrowski G. Priomrdial soup or creps. Nature. 1996;381:20–21. doi: 10.1038/381020a0. [DOI] [PubMed] [Google Scholar]
- 33.Eigen M, Schuster P. The Hypercycle. Berlin: Springer-Verlag; 1979. [Google Scholar]
- 34.Kun Á, Santos M, Szathmáry E. Real ribozymes suggest a relaxed error threshold. Nature Genetics. 2005;37:1008–1011. doi: 10.1038/ng1621. [DOI] [PubMed] [Google Scholar]
- 35.Riley CA, Lehman N. Generalized RNA-directed recombination of RNA. Chamistry & Biology. 2003;10:1233–1243. doi: 10.1016/j.chembiol.2003.11.015. [DOI] [PubMed] [Google Scholar]
- 36.Hayden EJ, Lehman N. Self-assemblyof a group I intron from inactive oligonucleotide fragments. Chamistry & Biology. 2006;13:909–918. doi: 10.1016/j.chembiol.2006.06.014. [DOI] [PubMed] [Google Scholar]
- 37.Burton AS, Lehman N. Enhancing the prebiotic relevance of a set of covalently self-assembling autorecombining RNAs through in vitro selection. Journal of Molecular Evolution. 2010;70:233–241. doi: 10.1007/s00239-010-9325-3. [DOI] [PubMed] [Google Scholar]
- 38.Wochner A, Attwater J, Coulson A, Holliger P. Ribozyme-catalyzed transcription of an active ribozyme. Science. 2011;332:209–212. doi: 10.1126/science.1200752. [DOI] [PubMed] [Google Scholar]
- 39.Kacser H, Beeby R. Evolution of catalytic proteins or On the origin of enzyme species by means of natural selection. Journal of Molecular Evolution. 1984;20:38–51. doi: 10.1007/BF02101984. [DOI] [PubMed] [Google Scholar]
- 40.Scheuring I. Avoiding catch-22 of early evolution by stepwise increase in copy fidelity. Selection. 2000;1–3:13–23. [Google Scholar]
- 41.Szabó P, Scheuring I, Czárán T, Szathmáry E. In silico simulations reveal that replicators with limited dispersal evolve towards higher efficiency and fidelity. Nature. 2002;420:340–343. doi: 10.1038/nature01187. [DOI] [PubMed] [Google Scholar]
- 42.Szathmáry E. Coevolution of metabolic networks and membranes: the scenario of progressive sequestration. Philosohical Transactions of the Royal Society B. 2007;362:1781–1787. doi: 10.1098/rstb.2007.2070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Huang Z, Pei W, Han Y, Jayaseelan S, Shekhtman A, et al. One RNA aptamer sequence, two structures a collaborating pair that inhibits AMPA receptors. Nucleid Acids Research. 2009;37:4022–4032. doi: 10.1093/nar/gkp284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.O'Brien PJ, Herschlag D. Catalytic promiscuity and the evolution of new enzymatic activities. Chemistry and Biology. 1999;6:R91–R105. doi: 10.1016/S1074-5521(99)80033-7. [DOI] [PubMed] [Google Scholar]
- 45.Ancel WL, Fontana W. Plasticity, evolvability, and modularity in RNA. Journal of Experimental Zoology (Mol. Dev. Evol.) 2000;288:242–283. doi: 10.1002/1097-010x(20001015)288:3<242::aid-jez5>3.0.co;2-o. [DOI] [PubMed] [Google Scholar]
- 46.Schultes EA, Bartel DP. One sequence, two ribozymes: implication for the emergence of new ribozyme fold. Science. 2000;289:448–452. doi: 10.1126/science.289.5478.448. [DOI] [PubMed] [Google Scholar]
- 47.Khersonsky O, Roodveldt C, Tawfik DS. Enzyme promiscuity, evolutionary and mechanistic aspects. Current Opinion in Chemical Biology. 2006;10:498–508. doi: 10.1016/j.cbpa.2006.08.011. [DOI] [PubMed] [Google Scholar]
- 48.Czárán T, Szathmáry E. U D, R L, J MJA, editors. Coexistence of replicators in prebiotic evolution. The Geometry of Ecological Interactions, IIASA and Cambridge University Press. 2000. pp. 116–134.
- 49.Könnyű B, Czárán T, Szathmáry E. Prebiotic replicase evolution in a surface-bound metabolic system: parasites as a source of adaptive evolution. BMC Evol Biol. 2008;8:267. doi: 10.1186/1471-2148-8-267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.McGinness K, Joyce GF. In search of an RNA replicase rybozyme. Chemistry and Biology. 2003;10:5–14. doi: 10.1016/s1074-5521(03)00003-6. [DOI] [PubMed] [Google Scholar]
- 51.Scheuring I, Czárán T, Szabó P, Károlyi Gy, Toroczkai Z. Spatial models of prebiotic evolution: soup before pizza? Origins of Life and Evolution of Biospheres. 2003;33:319–355. doi: 10.1023/a:1025742505324. [DOI] [PubMed] [Google Scholar]
- 52.Maynard-Smith J. Hypercycles and the origin of life. Nature. 1979;280:445–446. doi: 10.1038/280445a0. [DOI] [PubMed] [Google Scholar]
- 53.Szathmáry E, Demeter L. Group selection of early replicators and the origin of life. Journal of Theoretical Biology. 1987;128:463–486. doi: 10.1016/s0022-5193(87)80191-1. [DOI] [PubMed] [Google Scholar]
- 54.Boerljis C, Hogeweg P. Spiral wave structure in pre-biotic evolution: hypercicles stable against parasite. Physica D. 1991;48:17–28. [Google Scholar]
- 55.Károlyi Gy, Péntek I, Scheuring I, Tél T, Toroczkai Z. The antiquity of RNA-based evolution. Proceedings of the National Academy of Sciences of the USA. 2000;97:13661–13665. doi: 10.1073/pnas.240242797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Meszena G, Szathmáry E. Adaptive dinamics of parabolic replicators. Selection. 2001;1–2:147–159. [Google Scholar]
- 57.Zintzaras E, Santos M, Szathmáry E. Living under the challenge of information decay: the stochastic corrector model vs. hypercycles. Journal of Theoretical Biology. 2002;217:167–181. doi: 10.1006/jtbi.2002.3026. [DOI] [PubMed] [Google Scholar]