

Abstract
In biomedical studies, ordered bivariate survival data are frequently encountered when bivariate failure events are used as outcomes to identify the progression of a disease. In cancer studies, interest could be focused on bivariate failure times, for example, time from birth to cancer onset and time from cancer onset to death. This paper considers a sampling scheme, termed interval sampling, in which the first failure event is identified within a calendar time interval, the time of the initiating event can be retrospectively confirmed and the occurrence of the second failure event is observed subject to right censoring. In a cancer data application, the initiating, first and second events could correspond to birth, cancer onset and death. The fact that the data are collected conditional on the first failure event occurring within a time interval induces bias. Interval sampling is widely used for collection of disease registry data by governments and medical institutions, though the interval sampling bias is frequently overlooked by researchers. This paper develops statistical methods for analysing such data. Semiparametric methods are proposed under semi-stationarity and stationarity. Numerical studies demonstrate that the proposed estimation approaches perform well with moderate sample sizes. We apply the proposed methods to ovarian cancer registry data.
Keywords: Bivariate survival distribution, Copula, Interval sampling, Semiparametric model, Semi-stationarity, Stationarity
1. Introduction
Ordered bivariate survival data arise frequently in biomedical studies when bivariate failure events are considered to be the major outcomes to identify the progression of a disease. In cancer studies, for example, it is of interest to understand the process from birth to cancer onset, and then to death. Disease registry or surveillance systems commonly collect data with incidence of disease occurring within a calendar time interval. This is referred to as interval sampling, and we consider the induced sampling bias problems in this paper.
Consider a case population where two failure events occur in chronological order following the occurrence of the initiating event, and a case refers to the presence of the first failure event. Denote the calendar time of the initiating event by T, the time from the initiating event to the first failure event by Y and the time from the first event to the second event by Z. The variables Y and Z are expected to be correlated because they come from the same subject. Bivariate failure times (Y, Z) are the outcome variables of interest in this paper. Wang & Wells (1998), Lin et al. (1999) and Schaubel & Cai (2004) proposed estimation methods for bivariate or multivariate survival data subject to right censoring. This paper focuses on developing estimation approaches for analysing survival data collected under the interval sampling scheme.
In this paper, the case population under interval sampling is made up of subjects whose first failure event occurs within a calendar time interval [0, t0], which is described by the constraint −T ⩽ Y ⩽ t0 − T. Thus, Y is observed subject to double truncation and individuals with the first failure event occurring before time 0 or after time t0 are excluded. The observation of Z is subject to right censoring because of loss to follow-up or end-of-study, and the induced sampling bias due to its correlation with the first failure time Y. Then, if the second failure event occurs before calendar time of censoring C ⩽ t0, it is uncensored and Z is observed subject to the further constraint Y + Z ⩽ C − T, and otherwise it is censored with censoring time C − (T + Y). Figure 1 shows the schema for bivariate survival data with interval sampling with constant C = t0.
Fig. 1.
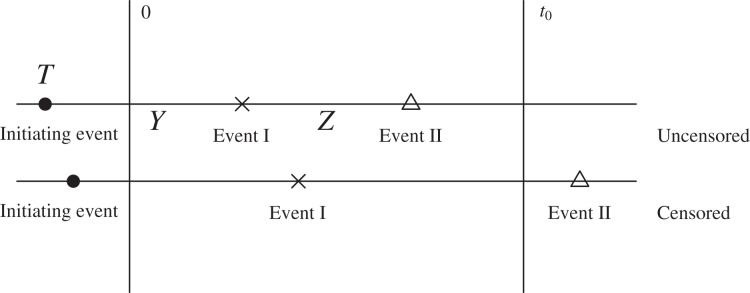
The interval sampling cohort with event I occurring within time interval [0, t0], T is the calendar time of the initiating event (T ⩽ t0) and (Y, Z) are the bivariate failure times of interest.
The research is motivated by statistical problems arising in analysis of cancer registry data. In this application, T is the calendar time of birth of an ovarian cancer patient, and Y and Z are, respectively, age of cancer onset and residual lifetime after cancer onset. Using age as the scale, the cancer event occurs at age Y and death occurs at age Y + Z. Due to interval sampling, Y is observed subject to double truncation and Z is subject to possibly dependent right censoring. With long survival times, sampling bias is nonnegligible, especially in the natural history of cancers. It is also important to develop methods to study the joint survival distribution for bivariate survival data. For example, the survival function of one failure time conditional on the other, such as the conditional probability of surviving more than five years given disease onset at age 50 years or older, is often of interest in practice. A joint survival function estimator can be used to produce an estimator for such a conditional survival function, and it enables one to compare the failure time distributions between two or more groups.
The inference procedures are developed for the case population experiencing the first failure event within the calendar time interval [0, t0]. Assume that the initiating events occur over calendar time with rate function λ (t) for t ⩽ t0, which is the average number of events in unit time at t or an unconditional probability function defined for a point process:
where N(t) is the total number of events prior to time t. For instance, λ (t) is the unconditional birth rate over calendar time for the study population. For the case population, let fY,Z (y, z), fY (y) and fZ (z) denote the population joint density function of (Y, Z) and the marginal densities of Y and Z, respectively. Let FY (y) and FZ(z) denote the corresponding population distribution functions of Y and Z, where y− = inf{y : FY (y) > 0}, y+ = sup{y : FY (y) < 1}, z− = inf{z : FZ (z) > 0}, z+ = sup{z : FZ (z) < 1} and t− = inf{t : λ (t) > 0}. To reduce mathematical complexity in our discussion, assume that the failure time Y has finite support, that is, y+ < ∞. Here we use this as a technical condition under which the density function of T and the joint density functions of (T, Y), (T, Y, Z) can be defined. The constraint y+ < ∞ is not required for the inferential results of (Y, Z), but does make the likelihood discussion much easier. In this paper, we focus on the case population, so all the subjects under study experience the disease within the calendar time interval, which explains why the constraint y+ < ∞ is reasonable. Let g(t) denote the population density function of T in the interval [−y+, t0 − y−], for instance, the population density of birth times. It is derived as a normalized rate function from λ (t),
| (1) |
and the corresponding population distribution function is denoted by G(t). Assume (T1, Y1, Z1), …, (Tn, Yn, Zn) are independent and identically distributed. Consider the following assumptions.
Assumption 1. The disease process is independent of when the initiating event occurs, that is, (Y, Z) is independent of T.
Assumption 2. The initiating event occurs at a constant rate over calendar time, that is, λ (t) is constant for −y+ ⩽ t ⩽ t0 − y−, so that G(·) is uniform(−y+, t0 − y−).
The two assumptions are fundamental for studying the probability structures of the primary outcomes in this paper. We say that the model is semi-stationary if only Assumption 1 is satisfied, stationary if both Assumptions 1 and 2 are satisfied and nonstationary if neither Assumption 1 nor 2 is assumed. The discussion here is focused on the semi-stationary and stationary conditions. However, Assumptions 1 and/or 2 could be violated when, for instance, an improved screening strategy was developed and it might lead to earlier disease detection. In this article, we propose a statistical framework to properly analyse the bivariate survival time with interval sampling under semi-stationarity and stationarity, and study inference on the joint distribution and dependence structure of bivariate survival data.
2. Semiparametric Estimation under Semi-stationarity
2.1. Estimation of θ
In this section, we consider a general situation when only Assumption 1 holds, and focus on a semi-stationary model to estimate the joint survival function on the basis of observed biased data. For simplicity, we consider constant censoring, where the observation of death ends at calendar time t0. This can be replaced by random censoring. Specifically, we consider a joint model for T and (Y, Z), and parameterize the distribution function of T by G(t; θ), where θ ∈ Θ and Θ is an open set in Rk. For example, in cancer studies, G describes the birth rate for cancer patients. Particular interest is focused on estimation of the parameter θ in G(t; θ) and the joint survival function of (Y, Z).
The estimation of θ is complicated by the bias from interval sampling. We explore the sampling bias on the distribution of T. For the interval sampling cohort, the calendar time of the initiating event, T, is observable subject to the constraint −Y ⩽ T ⩽ t0 − Y. The joint density of observed (t, y) can be written as
where g(t) is the population density function of T. Thus, the sampling density of T, pT (t), is proportional to its population density g(t),
and is generally biased under either stationarity or semi-stationarity, which implies systematic bias when using the ordinary empirical distribution to estimate the so-called birth rate of diseased patients for cancer registry data.
The conditional likelihood approach is used to estimate parameter θ. When Assumption 1 is assumed, the joint density of uncensored (t, y, z) can be derived as the density of (T, Y, Z) conditional on −T ⩽ Y ⩽ t0 − T and Y + Z ⩽ t0 − T :
| (2) |
The first bracketed term above, denoted by pT | Y,Z(t | y, z), specifies the conditional density of observed t given observed uncensored (y, z); the second bracketed term, denoted by pY,Z(y, z) is the joint density of uncensored (y, z). Thus, the conditional likelihood function of observed t given observed (y, z) is
The target parameter θ is the only parameter involved in the conditional likelihood, since the nuisance parameter fY,Z (·, ·) is eliminated by conditioning. The conditional maximum likelihood estimator of θ, denoted by θ̂, can be derived by maximizing Lc(θ) for θ ∈ Θ. Large sample properties of θ̂ are obtained using techniques similar to those of Andersen (1970). Under regularity conditions and as n → ∞, θ̂ converges in probability to θ, and n1/2(θ̂ − θ) converges weakly to a mean zero multivariate normal distribution with variance-covariance matrix , where Ic = E[{∂ log pT|Y,Z (Ti | Yi, Zi)/∂θ}{∂ log pT | Y,Z (Ti | Yi, Zi)/∂θ}T] is the Fisher information matrix for the conditional likelihood function Lc(θ).
2.2. Estimation of joint survival function SY,Z(y, z)
In many situations, the maximum likelihood approach produces efficient estimators. In our case, the full likelihood function L can be expressed as the product of the conditional likelihood and the marginal likelihood: L{θ, fY,Z(·, ·)} = Lc(θ) × LY,Z {θ, fY,Z(·, ·)}, where Lc involves only θ. In this section, we show that the semiparametric maximum likelihood estimator of SY,Z(y, z) can be derived by a two-step procedure.
First consider the case when θ is known. As shown in (2), the joint density function pY,Z(y, z) of uncensored (y, z) can be written as
| (3) |
Define a weight function h(y, z) = G(t0 − y − z) − G(−y), which describes the selection bias of observing (y, z). Its value coincides with the probability that initiating events occur within the window (−y, t0 − y − z]. The sampling density pY,Z(y, z) is generally biased and proportional to the population density fY,Z(y, z), and the direction of bias is determined by h(y, z). Thus, an estimator of the joint survival function of (Y, Z) is
If θ is known, ŜY,Z (y, z, θ) can be proved to be the nonparametric maximum likelihood estimator of SY,Z (y, z), a special case of Vardi (1985). As n → ∞, ŜY,Z (y, z, θ) is consistent, and the process n1/2{ŜY,Z (y, z, θ) − SY,Z (y, z)} converges weakly to a bivariate zero-mean Gaussian process with covariance function
where H = ∫ ∫{G(t0 − u − υ; θ) − G(−u; θ)} fY,Z (u, υ) du dυ, and H−1 = ∫ ∫{G(t0 − u − υ; θ) − G(−u; θ)}−1 fY,Z(u, υ) du dυ. A consistent variance estimator σ̂2 can be obtained by replacing H and H−1 by empirical distribution functions, and SY,Z (y, z) by ŜY,Z (y, z, θ).
Now suppose θ is unknown. We replace θ in ŜY,Z (y, z, θ) by the conditional maximum likelihood estimator θ̂ and derive an estimator of SY,Z (y, z) as ŜY,Z (y, z, θ̂). This can be proved to be the semiparametric maximum likelihood estimator using an argument similar to that in Wang (1989). The error of ŜY,Z (y, z, θ̂) can be decomposed into two terms,
where the first error term is determined by σ2. The error in the second term is generated by the use of θ̂ to estimate θ. The distributions of the two terms can be proved to be asymptotically orthogonal to each other because θ in the second term is estimated by the conditional likelihood estimator. This property will be used in the proof of Theorem 1 in the Appendix.
Therefore, the joint survival function can be estimated by
where (Yi, Zi) are the uncensored bivariate failure times, ŜY,Z (y, z, θ̂) is a weighted empirical estimator and SY,Z(y, z) is identifiable on the domain {(y, z) : y + z ⩽ t0 − t−}. The estimator ŜY,Z(y, z, θ̂) has the following properties.
Theorem 1. The estimator ŜY,Z (y, z, θ̂) is consistent, and as n → ∞, the process n1/2{ŜY,Z (y, z, θ̂) − SY,Z (y, z,)} converges weakly to a bivariate zero-mean Gaussian process with covariance function Σ = ∇θŜY,Z (y, z, θ)T ∇θŜY,Z (y′, z′, θ) + σ2.
The proof can be found in the Appendix. Vector notation for the gradient ∇θ is used since θ ∈ Rk. A consistent estimator of Σ is Σ̂ = ∇θ ŜY,Z (y, z, θ̂)T ∇θ ŜY,Z (y′, z′, θ̂) + σ̂2.
The above joint survival function estimate can be used to produce an estimator ŜY (y, 0, θ̂) for the marginal survival function. The same approach of modelling (T, Y, Z) could be applied to (T, Y) and a more efficient estimator of SY (y) is
where Ỹi is the observed first failure time and θ̂* is obtained by maximizing the conditional likelihood function of the observed {t} given the observed {y}. Compared with the {Yi}, which are from uncensored bivariate failure times (Yi, Zi), the {Ỹi} contain more data points. Also, ŜY (y, θ̂*) can be proved to be a semiparametric maximum likelihood estimator of SY (y).
The marginal survival function of Z is not in general easily estimated under semi-stationarity due to induced sampling bias and dependent censoring; however, it is possible to estimate the conditional probability function prZ|Y(Z > z | y1 < Y ⩽ y2) = {SY,Z (y1, z) − SY,Z (y2, z)}/{SY (y1) − SY (y2)} as long as y + z ⩽ t0 − t−. In fact, this conditional probability may be of interest even when SZ is estimable. An estimator of prZ|Y (Z > z | y1 < Y ⩽ y2) is
Estimation of such a conditional survival function can be used in exploratory analysis to detect possible correlation between Y and Z, as shown in the Supplementary Material.
The stationary condition when both Assumptions 1 and 2 hold is often of interest both in practice and theory. We have proposed a stationary model, assuming G is uniform, to estimate the joint survival function, which is a special case of the semi-stationary model and the method discussed in this section. The details of the stationary model are provided in the Supplementary Material. When G is totally unknown, the development of a nonparametric approach to estimate the joint survival function is possible. Using our notation, the conditional density of observed y given t is
from which the nonparametric maximum likelihood estimator of SY (y) can be obtained by a conditional likelihood approach developed by Efron & Petrosian (1999) for doubly truncated data. The semiparametric model is generally a compromise between the nonparametric model and the stationary model, and is designed to incorporate the parametric information from the distribution function G. Moreover, the semiparametric estimator ŜY (y, θ̂) has an explicit form and manageable asymptotic expressions for development of large sample properties, while the Efron–Petrosian estimator must be computed using an iterative algorithm. Although it is interesting to extend the nonparametric estimation technique to the bivariate case, we will not pursue this here.
It is important to check the validity of the parametric distribution assumption H0 : T ∼ G(t; θ). This can be done by plotting the nonparametric maximum likelihood estimate Ĝn(t) against Ĝ(t, θ̂). Since T is also doubly truncated subject to the constraint −Y ⩽ T ⩽ t0 − Y, estimating G is essentially dual to estimating SY. Shen (2008) provided an algorithm to jointly compute the nonparametric maximum likelihood estimators of both G and SY. The plot is used to examine the adequacy of the fit of the parametric distribution of T.
The above method uses only uncensored data. However, most disease registry data involve a large number of subjects over a long time period, and many observations are uncensored. In general, the proportion of uncensored data would be typically sufficient, or more than sufficient, for use of the proposed method. Nevertheless, with a slightly stronger model assumption in § 3, we have developed a method to analyse the bivariate survival data based on both uncensored and censored observations. Another possible solution is to utilize the information from censored observations in estimating θ in G(t; θ). We could model (T, Y) to obtain a conditional maximum likelihood estimator θ̂* based on observed first failure time {Ỹi}, instead of modelling (T, Y, Z) using only uncensored bivariate failure times {Yi, Zi}. In general, θ̂* is expected to be more efficient than θ̂, and accordingly, a new weight {G(t0 − Yi − Zi; θ̂*) − G(−Yi ; θ̂*)} could be used to replace {G(t0 − Yi − Zi ; θ̂) − G(−Yi ; θ̂)} in constructing the weighted empirical joint survival function estimator. In this way, we may take advantage of some information from censored observations, at least for the first failure time. The properties of the resulting joint survival function estimator with the new weight, as well as its efficiency gain, are under investigation.
3. Semiparametric Copula Model under Stationarity
3.1. Failure time distributions
The estimation method proposed in § 2 only uses uncensored data and particularly focuses on adjusting for the sampling bias from double truncation. In this section, we estimate the bivariate survival function based on both censored and uncensored observations. With a slightly stronger assumption on the dependence structure of the bivariate distribution, a semiparametric copula model under stationarity is used, which allows one to model and estimate the margins and dependence separately. We investigate the semiparametric copula model by a two-stage estimation approach similar to those of Genest et al. (1995) and Shih & Louis (1995). We first explore the probability structure for each failure time marginally and obtain the nonparametric consistent estimators for marginal survival functions under stationarity, ignoring the dependence. Then these estimators are substituted into a conditional likelihood for the association parameter, yielding a pseudo likelihood (Gong & Samaniego, 1981). The association parameter is then estimated by solving the estimating equation derived from the pseudo conditional likelihood.
First, we consider the first failure time Y, which is sampled given −T ⩽ Y ⩽ t0 − T. The joint density of observed (t, y) can be written as
Under stationarity when T is uniformly distributed, the marginal density of observed y, pY (y), becomes fY (y), so the sampling density of y coincides with its population density and double truncation from interval sampling does not result in bias on Y. Therefore, the nonparametric estimator of SY (y) is simply the empirical survival function , where Ỹi is the observed first failure time. The nonparametric maximum likelihood estimator of SY (y), ŜY (y), is consistent.
For the second failure time Z, we investigate its probability structure under stationarity. Specifically, we show that the sampling distribution of Z is the same as the target population distribution. Let W = T + Y denote the calendar time when the first failure event occurs. With sampling window [0, t0], only those cases satisfying 0 ⩽ W ⩽ t0 are included in the sampling population. The stationary condition implies that fY,Z | T (y, z | t) = fY,Z (y, z) and λ (t) = λ0 for −y+ < t ⩽ t0 − y−. The occurrence rate of the first failure event at W = w over the calendar time window [0, t0] can then be derived as
| (4) |
That is, the occurrence rate of the first failure event is the same as that of the initiating event. Also, the joint rate function of (Z, W) is
| (5) |
From (4) and (5), we conclude that fZ (z) = fZ | W (z | w) almost surely for all (w, z), so Z is independent of W. The censoring time for observing Z is C − W, where C is the calendar time of censoring. If C is a constant, for example, the calendar time of the end of study, the independence of Z and W implies the independence of Z and C − W. This independent censoring also extends to the situation when C is not a constant, simply by imposing independence between Z and C, as commonly employed in a survival model. Therefore, survival data {{min(zi, ci − wi), I (zi ⩽ ci − wi)} : ci ⩾ wi} can be treated as right-censored for obtaining the Kaplan–Meier estimator of the marginal survival function SZ (z).
3.2. Copula model and two-stage semiparametric estimation
Suppose the bivariate failure times (Y, Z) come from the Cα copula for some association parameter α, where Cα is a distribution function with density cα on [0, 1]2. Then the joint survival function and density function of (Y, Z) are
A two-stage estimation strategy is used to estimate the association parameter α. For observed data (t, y, x, δ) where x = min(z, c − t − y) and δ = I (z ⩽ c − t − y), the conditional likelihood function of {(yi, xi, δi)} given {ti} is
In derivation of Lc(α), the distribution of T is eliminated by conditioning. Under stationarity, however, T follows a uniform distribution, and the conditional and unconditional likelihoods contain the same information on α. Here we use the conditional likelihood only for simplicity. The two margins SY (y) and SZ (z) are estimated by the empirical survival function ŜY (y) and the Kaplan–Meier estimator ŜZ (z), respectively. Denote {SY (yi), SZ (xi)} by (ui, υi) for i = 1, …, n. The conditional likelihood of α is
| (6) |
Since the denominator of Lc(α) is a function of SY that does not involve α, it is appropriate to estimate α by maximizing (6). Let
The semiparametric estimator α̂ for α is the solution to the pseudo score function derived from the pseudo conditional likelihood
The following conditions are assumed to develop large sample properties for α̂.
Condition 1. The standard regularity conditions for the maximum likelihood estimator hold.
Condition 2. The functions Wα {α, SY (y), SZ (z)}, Vα {α, SY (y), SZ (z)}, Vα,1{α, SY (y), SZ (z)} and Vα,2{α, SY (y), SZ (z)} are continuous and bounded for (y, z) ∈ 𝒜 = [y−, y+] × [z−, z+], where
The asymptotic properties of α̂ are summarized as follows.
Theorem 2. The estimator α̂ is consistent, and as n → ∞, n1/2(α̂ − α0) converges weakly to the normal distribution with mean zero and variance .
A consistent estimator of ρ2 is obtained as . The precise definitions of and together with the details of the proof can be found in the Supplementary Material.
For the bivariate survival function, a natural estimator is then obtained by replacing the unknown quantities in the copula model SY,Z (y, z) = Cα {SY (y), SZ (z)} by appropriate estimators. Specifically, the margins SY (y) and SZ (z) are replaced by their nonparametric estimators, the empirical survival function for Y and the Kaplan–Meier estimator for Z, and α is replaced by the two-stage association estimator α̂. The asymptotic properties of ŜY,Z (y, z) are summarized in Theorem 3, with the proof provided in the Supplementary Material.
Theorem 3. The estimator ŜY,Z (y, z) is consistent, and as n → ∞, the process n1/2{ŜY,Z (y, z) − SY,Z (y, z)} converges weakly to a bivariate zero-mean Gaussian process with covariance function [∂C{α, SY (y), SZ (z)}/∂α]2 ρ2 + ω2(y, z).
4. Simulation Studies
4.1. Joint survival function estimation under semi-stationarity
We evaluate the finite-sample performance of the semiparametric estimator ŜY,Z (y, z, θ̂) under semi-stationarity by simulation. Data {(t1, y1, z1), …, (tn, yn, zn)} with interval sampling are generated for the semi-stationary model. Define T = −3K + 10, where K ∼ exp(θ), and let the bivariate failure times (Y, Z) be generated from Clayton’s (1978) copula, SY,Z (y, z) = {SY (y)−α + SZ (z)−α − 1}−1/α, with unit exponential margins and association parameter α = 2. An observation (t, y, z) is included in the dataset if and only if 0 ⩽ t + y ⩽ 10 and is censored if t + y + z ⩾ 10. The proportion of uncensored observations is around 0.6. We generate 1000 simulated samples with n = 400.
Table 1 summarizes the empirical bias, average model-based standard error of θ̂ and ŜY,Z (y, z, θ̂), empirical standard error and 95% coverage probability of ŜY,Z (y, z, θ̂) at nine time-points (y, z), where y and z take values 0.22, 0.51 and 0.92, corresponding to marginal survival probabilities of 0.8, 0.6 and 0.4. The confidence interval is constructed based on the estimated asymptotic variance, and the empirical 95% coverage probability is based on the 1000 confidence intervals. The estimators are approximately unbiased and the model-based variance estimators work well, with coverage probabilities close to 95% at most time-points. As θ increases, the biases and standard errors increase.
Table 1.
Simulation summary statistics for ŜY,Z under semi-stationarity
| θ | Bias(θ̂) | SE(θ̂) | y | z | SY,Z | Bias(ŜY,Z) | SEe(ŜY,Z) | SEm(ŜY,Z) | CP(ŜY,Z) |
|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 0.6 | 7.9 | 0.22 | 0.22 | 0.686 | −0.1 | 3.2 | 3.2 | 96 |
| 0.51 | 0.547 | −0.3 | 3.7 | 3.6 | 96 | ||||
| 0.92 | 0.383 | −0.2 | 4.1 | 3.9 | 96 | ||||
| 0.51 | 0.22 | 0.547 | 0.1 | 3.7 | 3.6 | 96 | |||
| 0.51 | 0.469 | −0.1 | 3.9 | 3.7 | 95 | ||||
| 0.92 | 0.353 | −0.1 | 3.9 | 3.9 | 95 | ||||
| 0.92 | 0.22 | 0.383 | −0.2 | 4.1 | 3.8 | 94 | |||
| 0.51 | 0.353 | −0.2 | 4.1 | 3.9 | 95 | ||||
| 0.92 | 0.295 | −0.1 | 4.1 | 3.9 | 95 | ||||
| 1.0 | 0.8 | 9.0 | 0.22 | 0.22 | 0.686 | −0.1 | 3.7 | 3.6 | 95 |
| 0.51 | 0.547 | −0.1 | 4.5 | 4.6 | 96 | ||||
| 0.92 | 0.383 | −0.2 | 5.2 | 5.1 | 95 | ||||
| 0.51 | 0.22 | 0.547 | −0.2 | 4.4 | 4.3 | 95 | |||
| 0.51 | 0.469 | −0.2 | 4.8 | 4.7 | 94 | ||||
| 0.92 | 0.353 | −0.1 | 5.2 | 5.2 | 94 | ||||
| 0.92 | 0.22 | 0.383 | −0.2 | 5.2 | 5.2 | 95 | |||
| 0.51 | 0.353 | −0.2 | 5.4 | 5.3 | 95 | ||||
| 0.92 | 0.295 | −0.3 | 5.5 | 5.3 | 95 | ||||
| 2.0 | 1.0 | 16.7 | 0.22 | 0.22 | 0.686 | −0.7 | 5.7 | 5.6 | 96 |
| 0.51 | 0.547 | −0.9 | 7.7 | 7.6 | 98 | ||||
| 0.92 | 0.383 | −1.4 | 9.6 | 9.5 | 97 | ||||
| 0.51 | 0.22 | 0.547 | −0.9 | 7.7 | 7.6 | 96 | |||
| 0.51 | 0.469 | −1.1 | 8.7 | 8.5 | 96 | ||||
| 0.92 | 0.353 | −1.2 | 10.0 | 9.5 | 95 | ||||
| 0.92 | 0.22 | 0.383 | −1.0 | 9.4 | 8.9 | 94 | |||
| 0.51 | 0.353 | −1.1 | 9.8 | 9.2 | 95 | ||||
| 0.92 | 0.295 | −1.4 | 10.3 | 9.7 | 95 |
Bias(θ̂), empirical bias (×102) of θ̂; SE(θ̂), average model-based standard error (×102) of θ̂; Bias(ŜY,Z), empirical bias (×102) of ŜY,Z; SEe(ŜY,Z), empirical standard error (×102) of ŜY,Z; SEm(ŜY,Z), average model-based standard error (×102) of ŜY,Z; CP(ŜY,Z), nominal 95% coverage probability of ŜY,Z.
4.2. Semiparametric copula model under stationarity
The performances of the two-stage estimator α̂ and joint survival function estimator ŜY,Z (y, z) in the semiparametric copula model under stationarity are examined by simulation. Two sampling schemes are explored: random sampling and interval sampling. A set of data {(t1, y1, z1), …, (tn, yn, zn)} is generated with interval sampling: define T = −13K + 9, where K ∼ U(0, 1), and generate bivariate failure times (Y, Z) from three Archimedean copula models: Clayton’s family, a positive stable copula and Frank’s family, whose explicit expressions are given in the Supplementary Material. For each copula, we use unit exponential margins, and choose three values of α in order to accommodate different levels of dependence between Y and Z. An observation (t, y, z) is included in the dataset if and only if 0 ⩽ t + y ⩽ 10 and is censored if t + y + z ⩾ 10. For each value of α we generate 1000 simulated samples with n = 400.
Table 2 presents simulation results for α̂ and ŜY,Z (y, z) = C{α̂, ŜY (y), ŜZ (z)}. The estimated joint survival probability is reported at two time-points, (y, z) = (0.22, 0.22) and (0.22, 0.51), and is there denoted by S1 and S2. For the three copula models, the proposed method performs quite well with both sampling plans. The biases of α̂, Ŝ1 and Ŝ2 are fairly small. For the association parameter, the empirical standard error and average model-based standard error are generally close, which may imply that inference about α is reasonably good. The empirical coverage probabilities are all quite close to 95%. The stronger the dependence of (Y, Z), indicated by a larger absolute value of α, the bigger the bias and standard error for α̂. However, no such phenomenon is observed for Ŝ1 and Ŝ2.
Table 2.
Simulation summary statistics for α̂ and ŜY,Z under different sampling schemes for samples from Clayton’s family, positive stable frailties and Frank’s family
| Model | α | Sampling | Bias(α̂) | SEe(α̂) | SEm(α̂) | CP(α̂) | Bias(Ŝ1) | SEe(Ŝ1) | CP(Ŝ1) | Bias(Ŝ2) | SEe(Ŝ2) | CP(Ŝ2) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clayton | 0.50 | Random | 1.2 | 9.3 | 7.8 | 97 | 0.5 | 2.3 | 97 | 0.3 | 2.3 | 95 |
| Interval | 2.0 | 10.8 | 9.2 | 96 | 0.3 | 2.5 | 94 | 0.2 | 3.0 | 94 | ||
| 1.33 | Random | 1.4 | 14.9 | 12.7 | 98 | 0.4 | 2.4 | 97 | 0.2 | 2.5 | 94 | |
| Interval | 4.7 | 17.9 | 16.3 | 97 | 0.4 | 2.8 | 96 | 0.5 | 3.2 | 94 | ||
| 3.00 | Random | 5.4 | 26.1 | 24.3 | 98 | 0.3 | 2.1 | 97 | 0.1 | 2.4 | 96 | |
| Interval | 10.2 | 30.4 | 28.5 | 97 | −0.4 | 3.0 | 95 | −0.7 | 3.3 | 94 | ||
| Positive Stable | 1.25 | Random | 0.1 | 2.6 | 1.8 | 94 | 0.3 | 2.7 | 98 | 0.1 | 2.6 | 96 |
| Interval | 0.6 | 5.8 | 4.9 | 94 | 0.3 | 2.5 | 98 | 0.3 | 2.8 | 96 | ||
| 1.67 | Random | 0.3 | 6.7 | 5.2 | 94 | 0.1 | 2.2 | 96 | 0.2 | 2.7 | 94 | |
| Interval | 0.7 | 9.5 | 7.8 | 94 | −0.2 | 2.9 | 96 | −0.2 | 3.1 | 96 | ||
| 2.50 | Random | 1.3 | 10.3 | 8.3 | 95 | 0.3 | 2.1 | 94 | −0.2 | 2.6 | 96 | |
| Interval | 2.2 | 15.5 | 13.7 | 94 | 0.3 | 3.0 | 96 | 0.2 | 2.8 | 94 | ||
| Frank | 2.00 | Random | 1.4 | 32.8 | 31.2 | 96 | 0.3 | 2.1 | 97 | −0.2 | 2.2 | 96 |
| Interval | 1.4 | 35.7 | 34.3 | 96 | 0.4 | 2.3 | 96 | 0.3 | 2.5 | 95 | ||
| −1.00 | Random | 0.6 | 28.0 | 26.7 | 95 | 0.6 | 2.3 | 94 | 0.4 | 2.3 | 94 | |
| Interval | 1.0 | 34.7 | 32.9 | 95 | 0.5 | 2.5 | 94 | 0.4 | 2.8 | 94 | ||
| −2.00 | Random | 2.3 | 32.0 | 30.8 | 95 | 0.3 | 2.4 | 95 | 0.4 | 2.3 | 94 | |
| Interval | 1.6 | 37.2 | 35.5 | 95 | 0.4 | 2.6 | 95 | 0.5 | 3.0 | 94 |
Bias(α̂), empirical bias (×102) of α̂; SEe(α̂), empirical standard error (×102) of α̂; SEm(α̂), average model-based standard error (×102) of α̂; CP(α̂), 95% coverage probability of α̂; Bias(Ŝ1), empirical bias (×102) of Ŝ1 with S1 = SY,Z (0.22, 0.22); SEe(Ŝ1), empirical standard error (×102) of Ŝ1; CP(Ŝ1), 95% coverage probability of Ŝ1; Bias(Ŝ2), empirical bias (×102) of Ŝ2 with S2 = SY,Z (0.22, 0.51); SEe(Ŝ2), empirical standard error (×102) of Ŝ2; CP(Ŝ2), nominal 95% coverage probability of Ŝ2.
5. Application to SEER cancer registry data
5.1. Analysis under semi-stationarity
This section presents an analysis of ovarian cancer data collected by the Surveillance, Epidemiology and End-Results programme to address statistical issues arising from interval sampling and to study the natural history of ovarian cancer. The programme is an epidemiological surveillance system consisting of population-based cancer registries designed to track cancer incidence and survival in the U.S.A. Collection of the data began from 1 January 1973 (Ries et al., 2005). The registries routinely collect information on newly diagnosed cancer patients residing in geographically defined areas representing 26 percent of the U.S. population. Information is available on each person’s birth date, cancer diagnosis date, death date, type of cancer, sex, race, state of residence, etc. The cohort of interest consists of 36 728 ovarian cancer patients diagnosed from 1973 to 2002 under interval sampling, among whom 24 236 died before 31 December 2002, and others were censored. In the analysis, the initiating time is birth time, T, and the bivariate failure times are age of cancer onset, Y and residual lifetime, Z.
In analysis of the data from this study, residual lifetime after cancer onset was typically analysed by regression methods such as the proportional hazards model, conditioning on age of cancer onset. These analyses treat age-onset as a conditional variable and therefore should be interpreted conditionally. Our focus here is unconditional analysis of disease natural history, that is, it is unconditional on age of cancer onset. Nevertheless, all the models considered in this paper have a certain conditional component, since the data are observed conditioning on the fact the subjects were diagnosed with cancer within the study time interval. The age of cancer onset distribution was typically empirically estimated and the median age of cancer onset was reported in Altekruse et al. (2010). However, such a statistical analysis is biased because the marginal distribution of age of cancer onset from the sampling population is subject to bias due to interval sampling, and the joint distribution of age of cancer onset and residual lifetime is also sampling-biased. Existing analyses have commonly ignored these biases.
We apply the method developed under semi-stationarity to the ovarian cancer data, assuming that (Y, Z) is independent of T. All the variables are analysed on a scale in years. As discussed in § 2.1, the sampling density of T is generally biased and it is not appropriate to use the empirical method to estimate the birth rate. To estimate the distribution of T, we use two polynomial models for the rate function λ (t) in (1): a linear model λ (t) = c0 + θ1t, and a quadratic polynomial model λ (t) = c0 + θ1t + θ2t2, where c0 is a positive-valued constant.
The density plots in Fig. 2(a) show that the difference between linear and quadratic models is small. The figure also demonstrates the huge bias in estimating the birth density by the empirical method. An increasing trend in birth rate for the case cohort over the calendar time is found in both models. Such a trend could be explained by the post-World War II baby boom or the improvement of ovarian cancer screening techniques. Given the similarity of the two polynomial models, the linear model is chosen as the birth density in analysis. With λ (t) = c0 + θt, we have θ̂ = 3.914 (0.030). The validity of this parametric model was assessed by plotting the nonparametric maximum likelihood estimator Ĝn(t) (Shen, 2008) against Ĝ(t, θ̂) for the distribution function of T in Fig. 2(b), which suggests the assumption of linear birth rate is approximately correct.
Fig. 2.

Birth density plots and scatter-plot of Ĝn(t) against Ĝ(t, θ̂). (a) Birth density plots: the biased empirical estimate (solid), the linear model estimate (dash) and the quadratic model estimate (dot). (b) Scatter-plot of Ĝn(t) against Ĝ(t, θ̂) with 95% pointwise confidence bands based on bootstrap (dash). The diagonal line y = x is shown as a reference. Non-G, nonparametric estimator Ĝn(t); Para-G, parametric estimator Ĝ(t, θ̂).
The joint survival probability estimators are calculated using both empirical and proposed methods. To obtain the standard errors of estimated joint survival probabilities, we adopt a non-parametric bootstrap method, resampling subjects with replacement from the dataset. The resampling procedure is repeated 500 times for the overall cancer patients, white patients and nonwhite patients, respectively. While the asymptotic variance of ŜY,Z (y, z, θ̂) has a rather complicated form, the ordinary bootstrap method would provide a direct and robust way to estimate the standard error. Table 3 summarizes the results at nine bivariate time-points, with y = 62.2, 69.8, 77.5 years and z = 0.25, 1.58, 4.58 years, corresponding to the quartiles of observed age of cancer onset and residual lifetime. The table provides the empirical and proposed estimated joint survival probabilities with bootstrap standard errors, and shows clear differences between the empirical and proposed estimates. As indicated by (3), the empirical estimate is generally biased since it does not account for interval sampling. The analytical result suggests that the empirical method may underestimate the joint survival probabilities, given our model specification on the distribution of T. Table 3 also provides estimated joint survival probabilities by race. It is shown that white patients are likely to be diagnosed at older ages and survive longer than nonwhite patients, consistent with the literature (Ries et al., 2005). The impact of age of cancer onset on residual lifetime, explored in the Supplementary Material, suggests negative association between age of onset and residual lifetime.
Table 3.
Estimated joint survival probabilities at quartiles of observed age of cancer onset and residual lifetime
| All | White | Nonwhite | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| y | z | Ŝemp | Ŝprop | SE | Ŝemp | Ŝprop | SE | Ŝemp | Ŝprop | SE |
| 62.2 | 0.25 | 62.2 | 62.3 | 4.0 | 63.1 | 62.9 | 4.2 | 56.9 | 57.3 | 1.0 |
| 1.58 | 36.7 | 40.2 | 2.6 | 37.5 | 40.7 | 2.7 | 30.7 | 34.4 | 1.0 | |
| 4.58 | 16.0 | 22.2 | 1.5 | 16.3 | 22.7 | 1.7 | 12.1 | 17.5 | 0.8 | |
| 69.8 | 0.25 | 41.2 | 45.1 | 2.9 | 42.0 | 45.7 | 3.0 | 34.8 | 39.1 | 1.1 |
| 1.58 | 22.0 | 26.8 | 1.8 | 22.7 | 27.3 | 1.9 | 17.3 | 21.9 | 1.1 | |
| 4.58 | 9.3 | 13.9 | 0.9 | 9.3 | 14.3 | 1.2 | 6.4 | 10.5 | 0.7 | |
| 77.5 | 0.25 | 18.9 | 24.3 | 1.6 | 19.2 | 24.8 | 1.8 | 14.4 | 19.6 | 1.0 |
| 1.58 | 8.6 | 12.8 | 0.9 | 8.9 | 13.0 | 1.0 | 6.4 | 10.0 | 0.7 | |
| 4.58 | 3.4 | 6.2 | 0.5 | 3.4 | 6.3 | 0.6 | 2.2 | 4.5 | 0.5 | |
y, age of cancer onset; z, residual lifetime; Ŝemp, empirical estimate of joint survival probability (×102); Ŝprop, proposed estimate of joint survival probability (×102); SE, bootstrap standard error (×102) based on 500 replications.
5.2. Example of the copula model under stationarity
We now illustrate the copula model under stationarity considered in § 3. The analysis in § 5.1 shows that in general the birth rate of the ovarian cancer patients increases over time. To apply the semiparametric copula model proposed under stationarity, we restrict the study population to 12 363 ovarian cancer patients who were born between 1920 and 1930, and assume a constant birth rate for this sub-cohort. The constant birth rate assumption is checked by plotting the nonparametric estimator of birth distribution against its parametric estimator. Figure 2 of the Supplementary Material suggests that this assumption is fairly reasonable.
A negative association between age of ovarian cancer onset and residual lifetime is found in § 5.1. Hence, we choose a Frank copula model to fit the dependence structure. Under stationarity, the marginal survival functions of age of onset and residual lifetime are consistently estimated by the empirical survival function and the Kaplan–Meier estimator. For the overall sub-cohort of 12 363 patients, the estimated association parameter α̂ = −3.69 with 95% confidence interval (−3.97, −3.40) and bootstrap percentile confidence interval (−3.92, −3.42). The first interval is constructed based on the asymptotic normality, in which the standard error of α̂ is computed using 500 bootstrap resamples. The corresponding estimated rank correlation coefficient τ̂ = −0.36 with 95% confidence interval (−0.39, −0.34) and bootstrap percentile confidence interval (−0.38, −0.34). For white patients, α̂ = −3.73 with 95% confidence interval (−4.06, −3.39) and bootstrap percentile confidence interval (−4.16, −3.47). For nonwhite patients, α̂ = −3.39 with 95% confidence interval (−4.31, −2.47) and bootstrap percentile confidence interval (−4.27, −2.49). There is a significant negative association between age of cancer onset and residual lifetime, for all the three groups, though the magnitude of the association is slightly different between white and nonwhite patients and the confidence intervals are wider for the nonwhite group due to its smaller size.
6. Concluding remarks
Under regularity conditions, we develop large sample properties for the association parameter estimator α̂ in copula model. In particular, we assume boundedness of the score function and its partial derivatives. This assumption was also adopted by Shih & Louis (1995) and many others in the derivation of large sample properties for their two-stage estimator of α in a copula model. However, some popular copula functions, such as the positive stable copula, are equivalent to the independence copula when the association parameter takes its value on the boundary of the parameter space. In this case, the score function and its partial derivatives may be unbounded. The violation was discussed by Chen et al. (2010), who extended the asymptotic results allowing for copulas with unbounded score function and partial derivatives. While this is not the major focus of this paper, we rely on the boundedness assumption to derive the large sample properties. The likelihood theory cannot easily be developed when this assumption is invalid, which makes testing independence of bivariate survival data possibly problematic using the copula model. Therefore, a nonparametric test of independence between bivariate survival times with interval sampling needs to be developed.
The assessment of risk factors or treatments is always crucial in biomedical studies, and an appropriate Cox regression model would allow for multiple risk factors. While our current method focuses on the natural history of disease progression, another interesting extension is to develop efficient estimating methods of the regression model for bivariate survival data with interval sampling. In some applications, information about time-dependent variables becomes available only after a certain time. For example, the treatment information of the ovarian cancer patients under study is provided by SEER-Medicare Link Data (Warren et al., 2002), which were collected from 1986. Therefore, a prevalent sample is involved and this further complicates the analysis. In such settings, methods need to be developed to address the problems and bias arising from both interval and prevalent sampling. The copula model approach could be extended to accommodate covariates with a regression model in studying the association.
Acknowledgments
We thank the editor, an associate editor and two referees for constructive suggestions that have improved the paper. This work was supported by the National Institutes of Health, U.S.A.
Appendix.
Proof of Theorem 1. We study the consistency and asymptotic normality of ŜY,Z (y, z, θ̂). If θ is known, the properties of ŜY,Z (y, z, θ) follow from Vardi (1985) with a weight function involving θ, and thus ŜY,Z (y, z, θ) − SY,Z (y, z) converges to 0 in probability. Since θ̂ → θ in probability and ŜY,Z (y, z, θ) is continuous, ŜY,Z (y, z, θ̂) − ŜY,Z (y, z, θ) converges to 0 in probability. Therefore, ŜY,Z (y, z, θ̂) − SY,Z (y, z) = {ŜY,Z (y, z, θ) − SY,Z (y, z)} + {ŜY,Z (y, z, θ̂) − ŜY,Z (y, z, θ)} converges to 0 in probability. This completes the proof of consistency of ŜY,Z (y, z, θ̂).
Observe that
| (A1) |
As identified in § 2.2, the process n1/2{ŜY,Z (y, z, θ) − SY,Z (y, z)} converges weakly to a bivariate zero-mean Gaussian process with covariance function σ2. By counting process methodology (van der Vaart, 1998), the first term in (A1) can be approximated by
| (A2) |
where E{ϕ(θ, Yi, Zi, y, z)} = 0 for each θ.
To develop an asymptotic result for the second term in (A1), the additional variation due to estimating θ by θ̂ needs to be handled. Empirical process and semiparametric inference techniques are employed for the asymptotic properties of the second term in (A1). Note that ŜY,Z (y, z, θ) can be re-expressed as the empirical process , where . In § 2.1, it has been shown that n1/2(θ̂ − θ) converges in distribution to a mean zero multivariate normal distribution with variance-covariance matrix , where θ̂ is the maximum likelihood estimator from the conditional likelihood function Lc(θ). Therefore, by functional delta method for the empirical process (Kosorok, 2008), we get that n1/2{ŜY,Z (y, z, θ̂) − ŜY,Z (y, z, θ)} → N{0, ∇θŜY,Z (y, z, θ)T ∇θ ŜY,Z (y, z, θ)} in distribution. Thus, the second term in (A1) can be approximated by
| (A3) |
where E{φ(Ti, Yi, Zi)} = E{∂ log pT | Y,Z (Ti | Yi, Zi)/∂θ} = 0. Combining (A2) and (A3), we get
| (A4) |
Also the corresponding distributions of these two terms are asymptotically orthogonal to each other, since
| (A5) |
Therefore, (A4) and (A5) imply that n1/2{ŜY,Z (y, z, θ̂) − SY,Z (y, z)} converges weakly to a bivariate zero-mean Gaussian process with covariance function Σ, specified as ∇θ ŜY,Z (y, z, θ)T ∇θ ŜY,Z (y′, z′, θ) + σ2. It is natural to estimate Σ by Σ̂ =∇θ ŜY,Z (y, z, θ̂)T ∇θ ŜY,Z (y′, z′, θ̂) + σ̂2. The consistency of ŜY,Z (y, z, θ̂), ŜY,Z (y′, z′, θ̂), Îc and σ̂2 implies that Σ̂ is a consistent estimator of Σ.
Supplementary Material
Supplementary material available at Biometrika online includes joint survival function estimation under stationarity and the corresponding simulation, a description of Archimedean copula models used in simulation, supplementary figures and table for the analysis in § 5, and detailed proofs of Theorems 2 and 3.
References
- Altekruse SF, Kosary CL, Krapcho M, Neyman N, Aminou R, Waldron W, Ruhl J, Howlader N, Tatalovich Z, Cho H, et al., editors. SEER Cancer Statistics Review. Bethesda, MD: National Cancer Institute; 2010. pp. 1975–2007. [Google Scholar]
- Andersen EB. Asymptotic properties of conditional likelihood estimators. J. R. Statist. Soc. B. 1970;32:283–301. [Google Scholar]
- Chen X, Fan Y, Pouzo D, Ying Z. Estimation and model selection of semiparametric multivariate survival functions under general censorship. J Economet. 2010;157:129–42. doi: 10.1016/j.jeconom.2009.10.021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clayton DG. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika. 1978;65:141–51. [Google Scholar]
- Efron B, Petrosian V. Nonparametric methods for doubly truncated data. J Am Statist Assoc. 1999;94:824–34. [Google Scholar]
- Genest C, Ghoudi K, Rivest L-P. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika. 1995;82:543–52. [Google Scholar]
- Gong G, Samaniego FJ. Pseudo maximum likelihood estimation: theory and applications. Ann Statist. 1981;9:861–9. [Google Scholar]
- Kosorok MR. Introduction to Empirical Processes and Semiparametric Inference. New York: Springer; 2008. [Google Scholar]
- Lin D-Y, Sun W, Ying Z. Nonparametric estimation of gap time distributions for serial events with censored data. Biometrika. 1999;86:59–70. [Google Scholar]
- Ries LAG, Eisner MP, Kosary CL, Hankey BF, Miller BA, Clegg L, Mariotto A, Feuer EJ, Edwards BK, editors. SEER Cancer Statistics Review. Bethesda, MD: National Cancer Institute; 2005. pp. 1975–2002. [Google Scholar]
- Schaubel DE, Cai J. Nonparametric estimation of gap time survival functions for ordered multivariate failure time data. Statist Med. 2004;23:1885–900. doi: 10.1002/sim.1777. [DOI] [PubMed] [Google Scholar]
- Shen P-S. Nonparametric analysis of doubly truncated data. Ann Inst Statist Math. 2008;62:835–53. [Google Scholar]
- Shih JH, Louis TA. Inferences on the association parameters in copula models for bivariate survival data. Biometrics. 1995;51:1384–99. [PubMed] [Google Scholar]
- van der Vaart AW. Asymptotic Statistics. Cambridge: Cambridge University Press; 1998. [Google Scholar]
- Vardi Y. Empirical distributions in selection bias models. Ann Statist. 1985;13:178–203. [Google Scholar]
- Wang M-C. A semiparametric model for randomly truncated data. J Am Statist Assoc. 1989;84:742–8. [Google Scholar]
- Wang W-J, Wells MT. Nonparametric estimation of successive duration times under dependent censoring. Biometrika. 1998;85:561–72. [Google Scholar]
- Warren JL, Klabunde CN, Schrag D, Bach PB, Riley GF. Overview of the SEER-Medicare data: content, research applications, and generalizability to the United States elderly population. Med. Care. 2002;40:3–18. doi: 10.1097/01.MLR.0000020942.47004.03. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material available at Biometrika online includes joint survival function estimation under stationarity and the corresponding simulation, a description of Archimedean copula models used in simulation, supplementary figures and table for the analysis in § 5, and detailed proofs of Theorems 2 and 3.