

Abstract
The standard methods for detecting differential gene expression are mostly designed for analyzing a single gene expression experiment. When data from multiple related gene expression studies are available, separately analyzing each study is not ideal as it may fail to detect important genes with consistent but relatively weak differential signals in multiple studies. Jointly modeling all data allows one to borrow information across studies to improve the analysis. However, a simple concordance model, in which each gene is assumed to be differential in either all studies or none of the studies, is incapable of handling genes with study-specific differential expression. In contrast, a model that naively enumerates and analyzes all possible differential patterns across studies can deal with study-specificity and allow information pooling, but the complexity of its parameter space grows exponentially as the number of studies increases. Here, we propose a correlation motif approach to address this dilemma. This approach searches for a small number of latent probability vectors called correlation motifs to capture the major correlation patterns among multiple studies. The motifs provide the basis for sharing information among studies and genes. The approach has flexibility to handle all possible study-specific differential patterns. It improves detection of differential expression and overcomes the barrier of exponential model complexity.
Keywords: Bayes hierarchical model, Correlation motif, EM algorithm, Microarray, Multiple datasets
1. Introduction
Detecting differentially expressed genes is a basic task in the analysis of gene expression data. The state-of-the-art solutions to this problem, such as limma (Smyth, 2004), SAM (Tusher and others, 2001), edgeR (Robinson and Smyth, 2007; 2008), and DESeq (Anders and Huber, 2010), are mostly designed for analyzing data from a single experiment or study. With 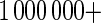 samples stored in public databases such as Gene Expression Omnibus (GEO), it is now very common for scientists to have data from multiple related experiments or studies. An emerging problem is how one can integrate data from multiple studies to more effectively analyze differential expression.
samples stored in public databases such as Gene Expression Omnibus (GEO), it is now very common for scientists to have data from multiple related experiments or studies. An emerging problem is how one can integrate data from multiple studies to more effectively analyze differential expression.
One example that motivated this article is a study of the vertebrate sonic hedgehog (SHH) signaling pathway. SHH is a signaling protein that can bind to patched 1 (PTCH1), a receptor protein in cell membrane (Figure 1(a)). PTCH1 can interact with another membrane protein smoothened (SMO) to repress its activity. In the absence of SHH, PTCH1 keeps SMO inactive. The presence of SHH will repress PTCH1 and activate SMO. The active SMO triggers a signaling cascade to modulate activities of three transcription factors, GLI1, GLI2, and GLI3, which in turn induce or repress the expression of hundreds of downstream target genes. SHH pathway is a core signaling pathway in vertebrate (Ingham and McMahon, 2001). To elucidate the underlying mechanisms linking this pathway to development and diseases, multiple studies have been conducted in different contexts to identify genes whose transcriptional activities are modulated by SHH signaling. Some studies perturb the SHH signal in different tissues by knocking out or over-expressing the pathway's key signal transduction components such as SHH, PTCH1, and SMO, while others compare disease samples with corresponding controls. Table 1 contains eight such datasets in mouse originally collected by Tenzen and others (2006) and Mao and others (2006). Each dataset involves a comparison of genome-wide expression profiles between two different sample types. These data were all generated using Affymetrix Mouse Expression Set 430 arrays. The questions of biological interest include (i) which genes are controlled by the SHH signal in each dataset, (ii) which genes are the core targets that respond to the SHH signal irrespective of tissue type and developmental stage, and (iii) which genes are context-specific targets and are modulated by the SHH signal only in certain conditions.
Fig. 1.

(a) A cartoon illustration of SHH pathway. (b) A numerical example of the data generating model. There exist four motifs in the dataset, with the abundance 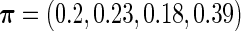 . Each row of the
. Each row of the 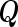 matrix represents a motif and each column corresponds to a study. Thus,
matrix represents a motif and each column corresponds to a study. Thus, 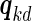 indicates the probability for genes belonging to motif
indicates the probability for genes belonging to motif 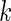 to be differentially expressed in study
to be differentially expressed in study 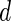 . For example, the probability for genes belonging to motif 1 to be differentially expressed in study 4 is 0.83. The gray scale of the cells in
. For example, the probability for genes belonging to motif 1 to be differentially expressed in study 4 is 0.83. The gray scale of the cells in 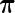 and
and 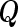 illustrates the probability value. The probability increases from 0 to 1 as the color changes from light to dark. Given
illustrates the probability value. The probability increases from 0 to 1 as the color changes from light to dark. Given 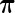 and
and 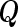 , each gene is assigned a motif indicator
, each gene is assigned a motif indicator 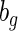 . For instance, the fifth gene belongs to motif 2 (indicated by a cell with a number “2”). Next, the configuration of the fifth gene,
. For instance, the fifth gene belongs to motif 2 (indicated by a cell with a number “2”). Next, the configuration of the fifth gene, 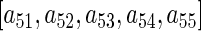 , is generated according to
, is generated according to 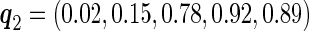 . As a result, the fifth gene is differentially expressed in study 2, 4, and 5. Finally, the moderated t-statistic
. As a result, the fifth gene is differentially expressed in study 2, 4, and 5. Finally, the moderated t-statistic 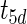 within each study
within each study 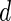 is produced according to the configuration
is produced according to the configuration 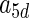 .
.
Table 1.
SHH microarray data description
| Study ID | Condition 1 (case) | Sample No. | Condition 2 (control) | Sample No. | Reference |
|---|---|---|---|---|---|
| 1 | 8somites_smo | 3 | 8somites_wt | 3 | Tenzen and others (2006) |
| 2 | 8somites_ptc | 3 | 8somites_wt | 3 | Tenzen and others (2006) |
| 3 | 13somites_ptc | 3 | 13somites_wt | 3 | Tenzen and others (2006) |
| 4 | head_shh | 3 | head_wt | 3 | Tenzen and others (2006) |
| 5 | limb_shh | 3 | limb_wt | 3 | Tenzen and others (2006) |
| 6 | Medulloblastoma_tumor | 3 | Medulloblastoma_control | 2 | Mao and others (2006) |
| 7 | BCC_tumor | 3 | BCC_control | 3 | Mao and others (2006) |
| 8 | 13somites_smo | 3 | 13somites_wt | 3 | Tenzen and others (2006) |
 and
and  indicate two different developmental stages of embryos; smo indicates mice with mutant Smo; ptc stands for mice with mutant
indicate two different developmental stages of embryos; smo indicates mice with mutant Smo; ptc stands for mice with mutant  wt means wild type; shh represents Shh mutant. Medulloblastoma and BCC are two types of tumors.
wt means wild type; shh represents Shh mutant. Medulloblastoma and BCC are two types of tumors.
For simplicity, below each dataset is called a study. One simple approach to analyze these data is to analyze each study separately using existing state-of-the-art methods such as limma (Smyth, 2004) or SAM (Tusher and others, 2001). This approach is not ideal as it may fail to detect genes with low-fold changes but consistently differential in many or all studies.
Modeling all data jointly may allow one to borrow information across studies to improve the analysis. A simple model to combine data is to assume that each gene is either differential in all studies or non-differential in all studies (Conlon and others, 2006). This concordance model may help with identifying genes with small but consistent expression changes in all studies. However, it ignores the reality that activities of many important genes are tissue- or time-specific. This method will only produce a single gene list that reports and ranks genes in the same way for all studies. It cannot prioritize genes differently for different studies to account for context-specificity.
A more flexible approach is to consider all possible differential expression patterns. Suppose there are 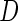 studies and each gene can either be differential or non-differential in each study, there will be
studies and each gene can either be differential or non-differential in each study, there will be 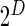 possible differential expression patterns. One can model the data as a mixture of
possible differential expression patterns. One can model the data as a mixture of 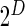 different gene classes. This allows one to deal with context-specificity. However, an obvious drawback is that as the number of studies increases, the number of possible patterns increases exponentially. Thus, the model does not scale well with the increasing
different gene classes. This allows one to deal with context-specificity. However, an obvious drawback is that as the number of studies increases, the number of possible patterns increases exponentially. Thus, the model does not scale well with the increasing 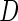 .
.
In this article, we propose a new method, CorMotif, for jointly analyzing multiple studies to improve differential expression detection. This method is both flexible for handling context-specificity and scalable to increasing study number. The key idea is to use a small number of latent probability vectors called “correlation motifs” to model the major correlation patterns among the studies. The motifs essentially group genes into clusters based on their differential expression patterns, and the differential gene detection is coupled with the clustering.
Unlike CorMotif, many methods developed previously for analyzing differential expression in multiple studies or conditions, such as the Empirical Bayes approach by Kendziorski and others (2003) (called “eb1” hereinafter), the method by Jensen and others (2009) and the method by Ruan and Yuan (2011), have exponential model complexity and therefore limited scalability. The XDE approach proposed by Scharpf and others (2009) does not have explosive complexity, but it is not flexible enough to model the heterogeneity among genes in terms of their cross-study correlation patterns. These methods are reviewed in more detail in supplementary material A.1 available at Biostatistics online. Yuan and Kendziorski (2006) explored the idea of coupling clustering with differential expression analysis to better deal with the heterogeneity of genes. However, these authors only considered detecting differential expression between two conditions in one study. Conceptually, their approach may be combined with the model developed by Kendziorski and others (2003) to handle multiple studies. However, such a simple extension would lead to a model (called “eb10best” hereinafter) in which genes are assumed to fall into multiple clusters and each cluster is a mixture of 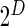 differential patterns. Once again, the model complexity explodes as the dataset number increases. Compared with these methods, CorMotif offers a unique data integration solution in that it addresses study-specificity, heterogeneity among genes, and exponential complexity simultaneously. Below we focus on discussing CorMotif for microarray data since it was motivated by the microarray analysis in the SHH study. However, the idea behind CorMotif is general, and it should be straightforward to develop a similar framework for RNA-seq data.
differential patterns. Once again, the model complexity explodes as the dataset number increases. Compared with these methods, CorMotif offers a unique data integration solution in that it addresses study-specificity, heterogeneity among genes, and exponential complexity simultaneously. Below we focus on discussing CorMotif for microarray data since it was motivated by the microarray analysis in the SHH study. However, the idea behind CorMotif is general, and it should be straightforward to develop a similar framework for RNA-seq data.
2. Methods
2.1. Data structure and preprocessing
Suppose there are 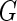 genes and
genes and 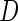 microarray studies. Each study
microarray studies. Each study 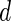 compares two biological conditions (e.g. cancer versus normal), and each condition
compares two biological conditions (e.g. cancer versus normal), and each condition 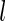 has
has 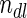 replicate samples. Different studies may be related, but they can compare different biological conditions. Let
replicate samples. Different studies may be related, but they can compare different biological conditions. Let 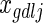 be the normalized and appropriately transformed expression value of gene
be the normalized and appropriately transformed expression value of gene 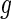 in study
in study 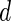 , condition
, condition 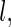 and replicate
and replicate 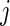 . In this article, all data were normalized and log-transformed using RMA (Irizarry and others, 2003). The ensemble of observed data is
. In this article, all data were normalized and log-transformed using RMA (Irizarry and others, 2003). The ensemble of observed data is 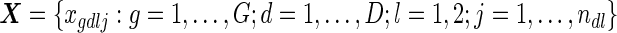 .
.
Each gene can be differentially expressed in some, all, or none of the studies. Let 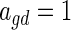 or
or  indicate whether gene
indicate whether gene 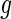 is differentially expressed in study
is differentially expressed in study 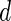 or not.
or not. 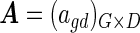 is a
is a 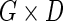 matrix that contains all
matrix that contains all 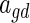 s. Given the observed data
s. Given the observed data 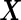 , one is interested in inferring
, one is interested in inferring 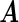 .
.
CorMotif first applies limma (Smyth, 2004) to each study separately. Define 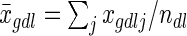 ,
, 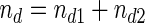 and
and 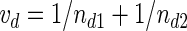 . For gene
. For gene 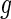 and study
and study 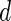 , compute the mean expression difference
, compute the mean expression difference 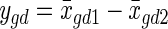 and sample variance
and sample variance 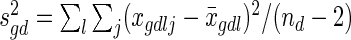 . The limma approach assumes that
. The limma approach assumes that 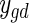 s and
s and 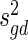 s within each study
s within each study 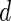 follow a hierarchical model: (i)
follow a hierarchical model: (i) 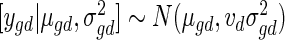 , (ii)
, (ii) 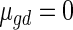 if
if 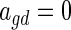 , (iii)
, (iii) 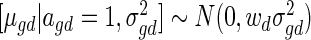 , (iv) [
, (iv) [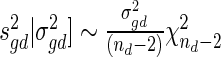 , and (v)
, and (v) 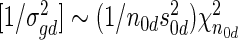 . Here,
. Here, 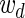 ,
, 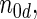 and
and 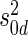 are unknown parameters. Their values can be estimated using the procedure described in Smyth (2004). This hierarchical model allows one to pool information across genes to stabilize the variance estimates. Smyth (2004) shows that it can significantly improve differential gene detection when the sample size
are unknown parameters. Their values can be estimated using the procedure described in Smyth (2004). This hierarchical model allows one to pool information across genes to stabilize the variance estimates. Smyth (2004) shows that it can significantly improve differential gene detection when the sample size 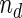 is small. For each study
is small. For each study 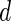 , limma produces a moderated t-statistic for each gene
, limma produces a moderated t-statistic for each gene 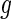 , computed as
, computed as 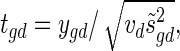 where
where 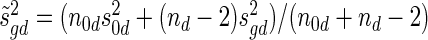 . This statistic summarizes gene
. This statistic summarizes gene 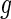 's differential expression information in study
's differential expression information in study 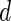 . Under this model, when gene
. Under this model, when gene 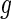 is not differentially expressed in study
is not differentially expressed in study 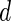 (i.e.
(i.e. 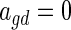 ),
), 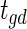 follows a t-distribution
follows a t-distribution 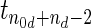 ; when
; when 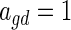 ,
, 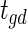 follows a scaled t-distribution
follows a scaled t-distribution 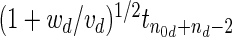 (Smyth, 2004).
(Smyth, 2004).
Next, we arrange all 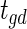 s into a matrix
s into a matrix 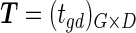 . CorMotif will then use
. CorMotif will then use 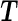 instead of the raw expression values
instead of the raw expression values 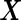 to infer
to infer 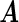 .
.
2.2. Correlation motif model
Organize the differential expression states of gene 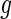 into a vector
into a vector 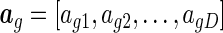 . For
. For 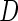 studies,
studies, 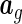 has
has 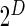 possible configurations. A simple way to describe the correlation among studies is to document the empirical frequency of observing each of the
possible configurations. A simple way to describe the correlation among studies is to document the empirical frequency of observing each of the 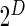 configurations of
configurations of 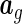 among all genes. This is because
among all genes. This is because 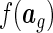 , the joint distribution of
, the joint distribution of 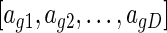 , is known once the probability of observing each configuration is given. This joint distribution will determine how
, is known once the probability of observing each configuration is given. This joint distribution will determine how 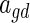 s from different studies are correlated. While simple, this approach is not scalable since it requires
s from different studies are correlated. While simple, this approach is not scalable since it requires 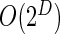 parameters and the parameter space expands exponentially with increasing
parameters and the parameter space expands exponentially with increasing 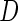 .
.
To avoid this limitation, CorMotif adopts a hierarchical mixture model (Figure 1(b)). The model assumes that genes fall into 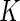 different classes (
different classes (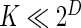 for big
for big 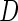 ), and the moderated t-statistics
), and the moderated t-statistics 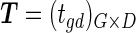 are viewed as generated as follows. First, each gene
are viewed as generated as follows. First, each gene 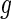 is randomly and independently assigned a class label
is randomly and independently assigned a class label 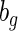 according to probability
according to probability 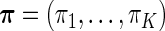 . Here,
. Here, 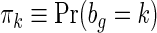 is the prior probability that a gene belongs to class
is the prior probability that a gene belongs to class 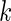 , and
, and 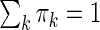 . Secondly, given genes’ class labels (i.e.
. Secondly, given genes’ class labels (i.e. 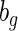 s), genes’ differential expression states
s), genes’ differential expression states 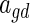 s are generated independently according to probabilities
s are generated independently according to probabilities 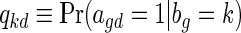 . For genes in the same class
. For genes in the same class 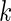 ,
, 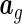 s are generated using the same probabilities
s are generated using the same probabilities 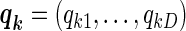 . Thirdly, given the differential expression states
. Thirdly, given the differential expression states 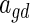 s, genes’ moderated t-statistics
s, genes’ moderated t-statistics 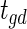 s are generated independently according to
s are generated independently according to 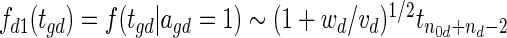 or
or 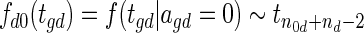 .
.
Let 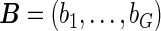 be the class membership for all genes. Organize
be the class membership for all genes. Organize 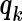 into a matrix
into a matrix 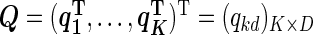 . Let
. Let 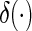 be an indicator function:
be an indicator function: 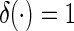 if its argument is true, and
if its argument is true, and 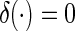 otherwise. Based on the above model, the joint probability distribution of
otherwise. Based on the above model, the joint probability distribution of 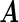 ,
, 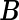 , and
, and 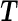 conditional on
conditional on 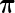 and
and 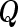 is
is
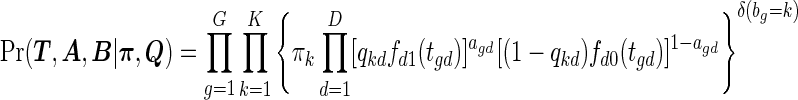 |
(2.1) |
In this model, each gene class 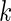 is associated with a vector
is associated with a vector 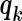 whose elements are the prior probabilities of a gene in this class to be differential in studies
whose elements are the prior probabilities of a gene in this class to be differential in studies 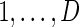 . Each
. Each 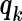 represents a probabilistic differential expression pattern and therefore is called a “motif”. Since
represents a probabilistic differential expression pattern and therefore is called a “motif”. Since 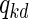 s are probabilities, genes in the same class can have different
s are probabilities, genes in the same class can have different 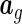 configurations. On the other hand, genes from the same class share the same
configurations. On the other hand, genes from the same class share the same 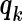 , and hence their differential expression configuration
, and hence their differential expression configuration 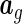 s tend to be similar. Genes in different classes have different
s tend to be similar. Genes in different classes have different 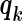 s, and their
s, and their 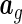 s also tend to be different. Essentially, our model groups genes into
s also tend to be different. Essentially, our model groups genes into 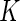 clusters based on
clusters based on 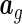 . However, unlike an usual clustering algorithm, here
. However, unlike an usual clustering algorithm, here 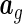 s are unknown.
s are unknown.
Despite the assumption that 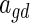 s are a priori independent conditional on the class label
s are a priori independent conditional on the class label 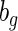 ,
, 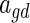 s are no longer independent once the class label
s are no longer independent once the class label 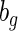 is integrated out. To see this, consider the prior probability that a gene is differentially expressed in all studies. Based on our model,
is integrated out. To see this, consider the prior probability that a gene is differentially expressed in all studies. Based on our model, 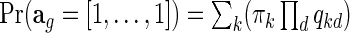 , which is different from the product of the marginals
, which is different from the product of the marginals 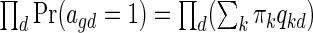 . This explains why the hierarchical mixture model above can be used to describe the correlation among multiple studies. Since the mixture of
. This explains why the hierarchical mixture model above can be used to describe the correlation among multiple studies. Since the mixture of 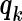 s provides the key to model the cross-study correlation, each vector
s provides the key to model the cross-study correlation, each vector 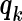 is also called a “correlation motif”.
is also called a “correlation motif”.
A model with 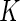 correlation motifs requires
correlation motifs requires 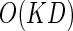 parameters in total. Usually, a small
parameters in total. Usually, a small 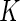 (
(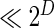 when
when 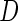 is big) is sufficient to capture the major correlation structure in the real data. Therefore, our method can be easily scaled up to deal with large
is big) is sufficient to capture the major correlation structure in the real data. Therefore, our method can be easily scaled up to deal with large 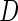 scenarios. When
scenarios. When 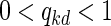 , each
, each 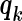 will be able to generate all
will be able to generate all 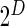 configurations with non-zero probabilities. Thus, our model also retains the flexibility to allow all
configurations with non-zero probabilities. Thus, our model also retains the flexibility to allow all 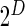 configurations of
configurations of 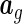 to occur at individual gene level.
to occur at individual gene level.
2.3. Statistical inference
In reality, only 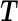 is observed.
is observed. 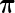 and
and 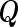 are unknown parameters.
are unknown parameters. 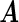 and
and 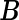 are unobserved missing data. To infer the unknowns from
are unobserved missing data. To infer the unknowns from 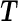 , we first assume that
, we first assume that 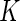 is given and introduce a Dirichlet prior
is given and introduce a Dirichlet prior 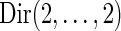 for
for 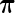 and a Beta prior
and a Beta prior 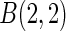 for
for 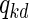 (for a discussion on the choice of prior, see supplementary material A.2 available at Biostatistics online). As a result,
(for a discussion on the choice of prior, see supplementary material A.2 available at Biostatistics online). As a result,
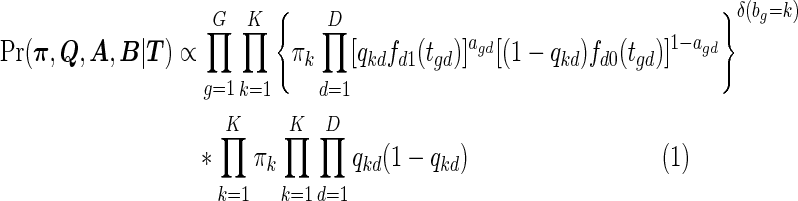 |
(2.2) |
Based on the above posterior distribution, an expectation–maximization (EM) algorithm (Gelman and others, 2004) can be derived to search for the posterior mode of 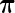 and
and 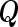 .
.
Using the estimated 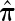 and
and 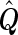 , one can then compute
, one can then compute 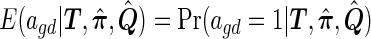 , the posterior probability that gene
, the posterior probability that gene 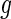 is differentially expressed in study
is differentially expressed in study 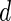 after integrating out the motif membership
after integrating out the motif membership 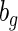 . Next, we rank-order genes in each study separately using
. Next, we rank-order genes in each study separately using 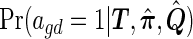 . The ranked lists can be used to choose follow-up targets. Users can also provide a posterior probability cutoff to dichotomize genes into differential or non-differential genes in each study. The default cutoff is 0.5. Users have the option to set the cutoff to other values.
. The ranked lists can be used to choose follow-up targets. Users can also provide a posterior probability cutoff to dichotomize genes into differential or non-differential genes in each study. The default cutoff is 0.5. Users have the option to set the cutoff to other values.
In order to choose the motif number 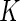 , we use Bayesian Information Criterion (BIC). Details of the EM algorithm and how to use BIC to choose
, we use Bayesian Information Criterion (BIC). Details of the EM algorithm and how to use BIC to choose 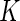 are provided in the supplementary material A.3 and A.4 available at Biostatistics online.
are provided in the supplementary material A.3 and A.4 available at Biostatistics online.
CorMotif improves the differential expression detection by integrating information both across studies and across genes. 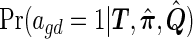 can be decomposed as
can be decomposed as 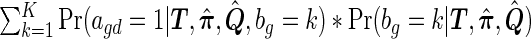 . Here,
. Here, 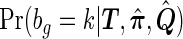 is determined by jointly evaluating gene
is determined by jointly evaluating gene 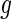 's data in all studies, and
's data in all studies, and 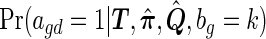 contains information specific to study
contains information specific to study 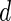 . According to Bayes’ theorem,
. According to Bayes’ theorem, 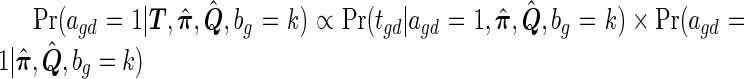 .
. 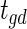 in the first term contains expression information for a given gene
in the first term contains expression information for a given gene 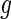 in study
in study 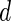 . To compute its denominator, the limma approach also utilized information across genes to help with estimating the variance. Meanwhile, the second term
. To compute its denominator, the limma approach also utilized information across genes to help with estimating the variance. Meanwhile, the second term 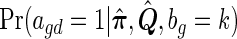 involves prior probabilities given by the correlation motifs (i.e.
involves prior probabilities given by the correlation motifs (i.e. 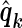 s) which are estimated using data from all genes. Owing to this two-way information pooling (i.e. across both studies and genes), CorMotif uses information more effectively than methods based on only a single gene or a single study. This is especially useful for analyzing studies with relatively weak signal-to-noise ratio.
s) which are estimated using data from all genes. Owing to this two-way information pooling (i.e. across both studies and genes), CorMotif uses information more effectively than methods based on only a single gene or a single study. This is especially useful for analyzing studies with relatively weak signal-to-noise ratio.
3. Simulations
3.1. Compared methods
We compared CorMotif with six other methods: separate limma, all concord, full motif, SAM, eb1, and eb10best. We did not compare the method in Jensen and others (2009) as no software was available for this method. The separate limma approach analyzes each study separately using limma. The moderated t-statistics in each study are assumed to be a mixture of 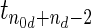 and
and 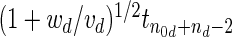 . To better evaluate the gain from data integration, we matched this analysis to CorMotif as much as possible by running an EM algorithm similar to CorMotif to compute the posterior probability for differential expression using 0.5 as default cutoff. Conceptually, this makes separate limma equivalent to CorMotif with a single cluster (
. To better evaluate the gain from data integration, we matched this analysis to CorMotif as much as possible by running an EM algorithm similar to CorMotif to compute the posterior probability for differential expression using 0.5 as default cutoff. Conceptually, this makes separate limma equivalent to CorMotif with a single cluster (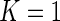 ), and the analysis produces the same gene ranking as limma in each study. All concord assumes that a gene is either differential in all studies or non-differential in all studies (i.e.
), and the analysis produces the same gene ranking as limma in each study. All concord assumes that a gene is either differential in all studies or non-differential in all studies (i.e. 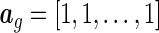 or
or 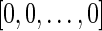 ). Conditional on
). Conditional on 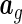 , the model for
, the model for 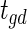 remains the same as CorMotif and limma. Full motif assumes that genes fall into
remains the same as CorMotif and limma. Full motif assumes that genes fall into 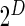 classes, corresponding to the
classes, corresponding to the 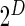 possible
possible 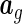 configurations. It can be viewed as a saturated version of CorMotif. All the other methods are applied to
configurations. It can be viewed as a saturated version of CorMotif. All the other methods are applied to 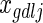 s directly. SAM (Tusher and others, 2001) processes each study separately, whereas eb1 and eb10best analyze all studies jointly. The eb1 method corresponds to the R package EBarrays with lognormal–normal (LNN) and one cluster assumption (Kendziorski and others, 2003). The eb10best method is EBarrays with LNN and multiple cluster assumption, and the cluster number is chosen by EBarrays as the one with the lowest AIC (Yuan and Kendziorski, 2006). We also tried XDE (Scharpf and others, 2009). However, it is based on Markov Chain Monte Carlo (MCMC) and took extremely long computing time, usually 24 h on a machine with 2.7 GHz CPU and 4 Gb RAM for 1000 iterations, for an analysis involving four studies which was the smallest data we analyzed here. Moreover, 1000 iterations usually were not enough for XDE to converge. Therefore, XDE will not be compared hereinafter. eb10best failed to work when it was used to jointly analyze
s directly. SAM (Tusher and others, 2001) processes each study separately, whereas eb1 and eb10best analyze all studies jointly. The eb1 method corresponds to the R package EBarrays with lognormal–normal (LNN) and one cluster assumption (Kendziorski and others, 2003). The eb10best method is EBarrays with LNN and multiple cluster assumption, and the cluster number is chosen by EBarrays as the one with the lowest AIC (Yuan and Kendziorski, 2006). We also tried XDE (Scharpf and others, 2009). However, it is based on Markov Chain Monte Carlo (MCMC) and took extremely long computing time, usually 24 h on a machine with 2.7 GHz CPU and 4 Gb RAM for 1000 iterations, for an analysis involving four studies which was the smallest data we analyzed here. Moreover, 1000 iterations usually were not enough for XDE to converge. Therefore, XDE will not be compared hereinafter. eb10best failed to work when it was used to jointly analyze 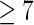 studies. Full motif and eb1 failed when there were 20 studies.
studies. Full motif and eb1 failed when there were 20 studies.
3.2. Model-based simulations
We first tested CorMotif using simulations. In simulation 1, we generated 10 000 genes and four studies according to the four differential patterns in Figure 2(a): 100 genes were differentially expressed in all four studies (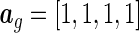 ); 400 genes were differential only in studies 1 and 2 (
); 400 genes were differential only in studies 1 and 2 (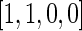 ); 400 genes were differential only in studies 2 and 3 (
); 400 genes were differential only in studies 2 and 3 (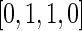 ); 9100 genes were non-differential (
); 9100 genes were non-differential (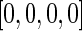 ). Each study had six samples: three cases and three controls. The variances
). Each study had six samples: three cases and three controls. The variances 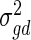 s were simulated from a scaled inverse
s were simulated from a scaled inverse 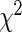 distribution
distribution 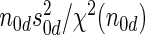 , where
, where 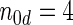 and
and 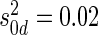 . Given
. Given 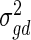 , the expression values were generated using
, the expression values were generated using 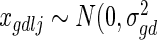 ). Whenever
). Whenever 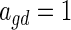 , we drew
, we drew 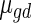 from
from 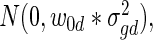 where
where 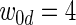 , and
, and 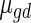 was then added to the expression values of the three cases (i.e.
was then added to the expression values of the three cases (i.e. 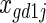 s).
s).
Fig. 2.

Results for the model assumption-based simulations (simulations 1 and 4). Also see supplemental Figure A.1 available at Biostatistics online for simulations 2 and 3. (a) and (g) True motif patterns for simulations 1 and 4. The 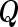 of the true motifs is shown. Each row indicates a motif pattern and each column represents a study. The actual number of genes belonging to each motif (i.e.
of the true motifs is shown. Each row indicates a motif pattern and each column represents a study. The actual number of genes belonging to each motif (i.e. 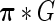 ) is displayed at the right end of each row. The gray scale of the cell
) is displayed at the right end of each row. The gray scale of the cell 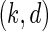 demonstrates the probability of differential expression in study
demonstrates the probability of differential expression in study 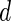 for pattern
for pattern 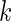 . Black means 1 and white means 0. (b) and (h) The estimated
. Black means 1 and white means 0. (b) and (h) The estimated 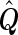 from the learned motifs with
from the learned motifs with 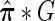 annotated at the end of each row. (c) and (i) BIC plots. It can be seen that motif patterns reported by CorMotif under the minimal BIC are similar to the true underlying motif patterns. (d)–(f) and (j)–(l) Gene ranking performance of different methods in simulations 1 and 4.
annotated at the end of each row. (c) and (i) BIC plots. It can be seen that motif patterns reported by CorMotif under the minimal BIC are similar to the true underlying motif patterns. (d)–(f) and (j)–(l) Gene ranking performance of different methods in simulations 1 and 4. 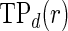 , the number of genes that are truly differentially expressed in study
, the number of genes that are truly differentially expressed in study 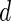 among the top
among the top 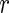 ranked genes by a given method, is plotted against the rank cutoff
ranked genes by a given method, is plotted against the rank cutoff 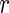 . For each simulation, results for a few representative studies are shown. Each plot is for one study.
. For each simulation, results for a few representative studies are shown. Each plot is for one study.
CorMotif was fit with varying motif number 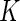 . As Figure 2(c) shows, the minimal BIC was achieved at
. As Figure 2(c) shows, the minimal BIC was achieved at 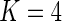 . As a result, four motifs were reported (Figure 2(b)). The reported motifs were very similar to the true underlying differential patterns in Figure 2(a).
. As a result, four motifs were reported (Figure 2(b)). The reported motifs were very similar to the true underlying differential patterns in Figure 2(a).
Different methods were then compared in terms of how good they rank differential genes in each individual study (Figure 2(d)–(f)) as well as how accurate they can infer each gene's differential configuration 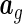 in all studies (Table 2). For each study
in all studies (Table 2). For each study 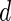 , CorMotif ranks genes using the posterior probability
, CorMotif ranks genes using the posterior probability 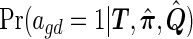 which is obtained after integrating out the motif membership
which is obtained after integrating out the motif membership 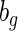 . A gene was called differential in study
. A gene was called differential in study 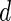 (i.e.
(i.e. 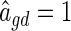 ) if
) if 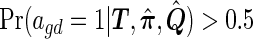 . Both the gene rankings and differential expression calls were different for different studies since
. Both the gene rankings and differential expression calls were different for different studies since 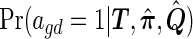 depends on
depends on 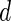 and can change across studies. This is a desirable property as in reality the sets of true differential genes may be different in different studies due to study-specific differential expression, and ultimately one wants to know which genes are differential in each study. Using a similar approach, we obtained gene rankings and differential calls for full motif, eb1 and eb10best which were also study-specific. Separate limma and SAM analyze each study separately and naturally produce study-specific gene ranking and differential calls. For all the methods above, we did not combine differential calls of a gene in
and can change across studies. This is a desirable property as in reality the sets of true differential genes may be different in different studies due to study-specific differential expression, and ultimately one wants to know which genes are differential in each study. Using a similar approach, we obtained gene rankings and differential calls for full motif, eb1 and eb10best which were also study-specific. Separate limma and SAM analyze each study separately and naturally produce study-specific gene ranking and differential calls. For all the methods above, we did not combine differential calls of a gene in 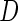 studies into a single call to indicate whether the gene is differential in any study, nor did we use such a combined call to rank genes, since the combined call would fail to capture study-specificity. Unlike the other methods, all concord assumes common differential states in all studies, therefore its gene ranking and differential calls remain the same across studies.
studies into a single call to indicate whether the gene is differential in any study, nor did we use such a combined call to rank genes, since the combined call would fail to capture study-specificity. Unlike the other methods, all concord assumes common differential states in all studies, therefore its gene ranking and differential calls remain the same across studies.
Table 2.
Confusion matrix for simulation 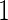
| Method | Differential configuration | 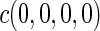 |
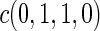 |
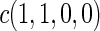 |
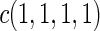 |
|---|---|---|---|---|---|
| CorMotif | 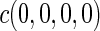 |
9072 | 161 | 165 | 16 |
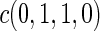 |
3 | 168 | 3 | 7 | |
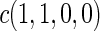 |
3 | 2 | 151 | 6 | |
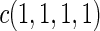 |
0 | 1 | 0 | 33 | |
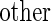 |
22 | 68 | 81 | 38 | |
| separate limma | 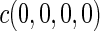 |
9035 | 144 | 144 | 16 |
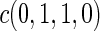 |
0 | 68 | 0 | 5 | |
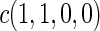 |
0 | 0 | 57 | 6 | |
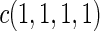 |
0 | 0 | 0 | 4 | |
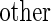 |
65 | 188 | 199 | 69 | |
| all concord |  |
9095 | 236 | 236 | 20 |
 |
0 | 0 | 0 | 0 | |
 |
0 | 0 | 0 | 0 | |
 |
5 | 164 | 164 | 80 | |
 |
0 | 0 | 0 | 0 | |
| full motif | 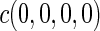 |
9072 | 161 | 164 | 16 |
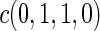 |
4 | 172 | 4 | 7 | |
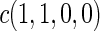 |
3 | 2 | 155 | 6 | |
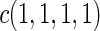 |
0 | 1 | 0 | 35 | |
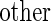 |
21 | 64 | 77 | 36 | |
| eb1 | 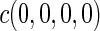 |
62 | 0 | 2 | 0 |
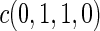 |
2178 | 30 | 22 | 3 | |
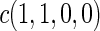 |
569 | 7 | 12 | 0 | |
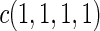 |
753 | 34 | 32 | 64 | |
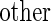 |
5538 | 329 | 332 | 33 | |
| eb10best | 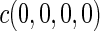 |
0 | 0 | 0 | 1 |
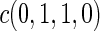 |
316 | 220 | 16 | 10 | |
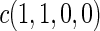 |
180 | 23 | 226 | 10 | |
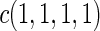 |
5789 | 77 | 52 | 63 | |
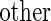 |
2815 | 80 | 106 | 16 | |
| SAM | 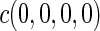 |
9099 | 256 | 279 | 48 |
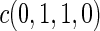 |
0 | 20 | 0 | 3 | |
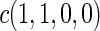 |
0 | 0 | 9 | 2 | |
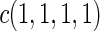 |
0 | 0 | 0 | 1 | |
 |
1 | 124 | 112 | 46 |
The column labels indicate the true underlying patterns and the row labels represent the reported configurations at gene level. For CorMotif, separate limma, all concord, full motif, eb1, and eb10best, differential expression in each study is determined using their default posterior probability cutoff 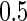 . For SAM, q-value cutoff
. For SAM, q-value cutoff 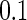 was used to call differential expression. This yields similar number of correct classifications for pattern
was used to call differential expression. This yields similar number of correct classifications for pattern 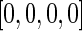 compared with CorMotif.
compared with CorMotif.
To examine if CorMotif can improve gene ranking, in each study and for each method we counted the number of true differential genes (true positives), 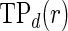 , among the top
, among the top 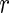 ranked genes, and we plotted
ranked genes, and we plotted 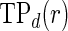 versus
versus 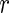 in Figure 2(d)–(f). CorMotif consistently performed among the best in all studies. For instance, Figure 2(d) shows the results for study 1. CorMotif identified 361 true differential genes among its top 500 gene list. This performance was almost the same as the saturated model full motif which identified 362 true positives among the top 500 genes. Among the other methods, eb10best identified 341, all concord identified 292, and the others identified fewer than 292 true positives among the top 500 genes. Thus, CorMotif detected at least 23.6% more true positives compared with any other method except full motif and eb10best. Similarly, among the top 1000 genes, CorMotif and full motif both identified 419 true positives, all concord identified 401, eb10best identified 360, and the other methods identified fewer than 337. CorMotif and full motif detected 4.5% more true positives compared with all concord and improved the ranking by at least 16.4% compared with eb10best and other methods. Both full motif and eb10best have the problem of exponentially growing parameter space. As we will show later, they both will break down when the study number
in Figure 2(d)–(f). CorMotif consistently performed among the best in all studies. For instance, Figure 2(d) shows the results for study 1. CorMotif identified 361 true differential genes among its top 500 gene list. This performance was almost the same as the saturated model full motif which identified 362 true positives among the top 500 genes. Among the other methods, eb10best identified 341, all concord identified 292, and the others identified fewer than 292 true positives among the top 500 genes. Thus, CorMotif detected at least 23.6% more true positives compared with any other method except full motif and eb10best. Similarly, among the top 1000 genes, CorMotif and full motif both identified 419 true positives, all concord identified 401, eb10best identified 360, and the other methods identified fewer than 337. CorMotif and full motif detected 4.5% more true positives compared with all concord and improved the ranking by at least 16.4% compared with eb10best and other methods. Both full motif and eb10best have the problem of exponentially growing parameter space. As we will show later, they both will break down when the study number 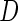 is large.
is large.
To test whether CorMotif can more accurately determine a gene's differential configuration, we constructed the confusion matrix in Table 2. For each gene, its binary differential calls 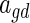 s based on
s based on 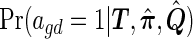 in different studies were arranged into a vector to represent its estimated differential configuration
in different studies were arranged into a vector to represent its estimated differential configuration 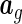 . For CorMotif, separate limma, all concord, full motif, eb1 and eb10best, differential expression was called using their default posterior probability cutoff 0.5. For SAM, q-value cutoff 0.1 was used to call differential expression. At this cutoff, SAM correctly identified similar number of genes with
. For CorMotif, separate limma, all concord, full motif, eb1 and eb10best, differential expression was called using their default posterior probability cutoff 0.5. For SAM, q-value cutoff 0.1 was used to call differential expression. At this cutoff, SAM correctly identified similar number of genes with 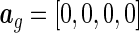 (i.e. non-differential in all studies) compared with CorMotif. This allowed us to meaningfully compare SAM and CorMotif in terms of their ability to find differential genes. Table 2 shows that CorMotif was better at characterizing genes’ true differential configurations compared with most other methods. For instance, among the 400
(i.e. non-differential in all studies) compared with CorMotif. This allowed us to meaningfully compare SAM and CorMotif in terms of their ability to find differential genes. Table 2 shows that CorMotif was better at characterizing genes’ true differential configurations compared with most other methods. For instance, among the 400 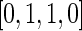 , 400
, 400 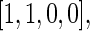 and 100
and 100 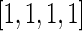 genes, CorMotif correctly reported differential label
genes, CorMotif correctly reported differential label 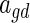 in all four studies for 168, 151, and 33 genes, respectively. In contrast, separate limma only unmistakenly labeled 68, 57, and 4 genes, respectively. Here, the increased power by CorMotif was purely due to the use of correlation motifs to integrate multiple studies, since all other model assumptions made by CorMotif and separate limma are the same. All concord requires genes to have the same differential status in all studies. As such, it is powerful at identifying concordant signals across studies but lacks the flexibility to handle study-specific differential expression: it correctly identified 80 out of 100
in all four studies for 168, 151, and 33 genes, respectively. In contrast, separate limma only unmistakenly labeled 68, 57, and 4 genes, respectively. Here, the increased power by CorMotif was purely due to the use of correlation motifs to integrate multiple studies, since all other model assumptions made by CorMotif and separate limma are the same. All concord requires genes to have the same differential status in all studies. As such, it is powerful at identifying concordant signals across studies but lacks the flexibility to handle study-specific differential expression: it correctly identified 80 out of 100 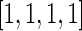 genes, but none of the
genes, but none of the 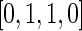 and
and 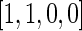 genes were correctly labeled as study-specific. With the default cutoff, eb1 and eb10best only labeled 62 and 0 out of 9100
genes were correctly labeled as study-specific. With the default cutoff, eb1 and eb10best only labeled 62 and 0 out of 9100 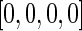 genes as completely non-differential, compared with 9072 labeled by CorMotif. In other words, eb1 and eb10best reported more false-positive differential events. Both were anti-conservative. At the same time, fewer
genes as completely non-differential, compared with 9072 labeled by CorMotif. In other words, eb1 and eb10best reported more false-positive differential events. Both were anti-conservative. At the same time, fewer 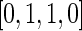 and
and 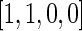 genes were correctly identified by eb1 (30 and 12 versus 168 and 151 by CorMotif). SAM was also poor at identifying the differential patterns
genes were correctly identified by eb1 (30 and 12 versus 168 and 151 by CorMotif). SAM was also poor at identifying the differential patterns 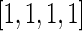 ,
, 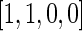 , and
, and 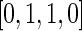 but behaved more conservatively by labeling many of them as
but behaved more conservatively by labeling many of them as 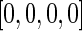 . Among all the methods, only full motif performed slightly better than CorMotif. Even so, CorMotif was able to perform close to this saturated model. Adding up the diagonal elements in the confusion matrix, CorMotif unmistakenly assigned
. Among all the methods, only full motif performed slightly better than CorMotif. Even so, CorMotif was able to perform close to this saturated model. Adding up the diagonal elements in the confusion matrix, CorMotif unmistakenly assigned 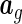 labels to 9424 genes, whereas this number was 9164 for separate limma, 9175 for all concord, 9434 for full motif, 168 for eb1, 509 for eb10best, and 9129 for SAM.
labels to 9424 genes, whereas this number was 9164 for separate limma, 9175 for all concord, 9434 for full motif, 168 for eb1, 509 for eb10best, and 9129 for SAM.
Using a similar approach, we performed simulations 2–4 which involved different study numbers and differential expression patterns. The complete results are shown in Figure 2, see supplementary material Figure A.1 and Tables A.1–A.3 available at Biostatistics online. The conclusions were similar to simulation 1. In many cases, the gain brought by CorMotif was substantial (e.g. Figure 2(j)–(l), see supplementary material Figure A.1(j) and (k) available at Biostatistics online). In particular, simulation 4 had 20 studies. full motif, eb1 and eb10best all failed to run on this data, whereas CorMotif was still able to borrow information across studies (Figure 2(g)–(l)).
3.3. Simulations based on real data
In real data, the distributions for 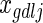 s may deviate from our model assumptions. Therefore, we further evaluated CorMotif using simulations that retained the real data noise structure. In simulation 5, 24 Human U133 Plus 2.0 Affymetrix microarray samples were downloaded from four GEO experiments. Each experiment corresponds to a different tissue and consists of six biological replicates (see supplementary material Table A.4 available at Biostatistics online). After RMA normalization, replicate samples in each experiment were split into three “cases” and three “controls”. We then spiked in differential signals by adding random
s may deviate from our model assumptions. Therefore, we further evaluated CorMotif using simulations that retained the real data noise structure. In simulation 5, 24 Human U133 Plus 2.0 Affymetrix microarray samples were downloaded from four GEO experiments. Each experiment corresponds to a different tissue and consists of six biological replicates (see supplementary material Table A.4 available at Biostatistics online). After RMA normalization, replicate samples in each experiment were split into three “cases” and three “controls”. We then spiked in differential signals by adding random 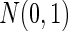 deviates to the three cases according to patterns shown in supplementary material Figure A.2(a) available at Biostatistics online. Data simulated in this way were able to keep the background characteristics in real data. Simulation 5 is similar to simulations 1 and 2. CorMotif again recovered the underlying differential patterns (see supplementary material Figure A.2(b) and (c) available at Biostatistics online). It showed comparable differential gene detection performance to full motif and outperformed the other methods (see supplementary material Figure A.3(a)–(c) and Table A.5 available at Biostatistics online). In a similar fashion, we performed simulations 6 and 7 based on real data (see supplementary material A.5 available at Biostatistics online). These two simulations have the same differential signal patterns as simulations 3 and 4, respectively. Here, the motifs reported by CorMotif differ slightly from the underlying truth, but all the major correlation patterns were captured by the reported motifs (see supplementary material Figure A.2 available at Biostatistics online). Once again, CorMotif performed the best in terms of differential gene detection (see supplementary material Figure A.3 and Tables A.6–A.7 available at Biostatistics online), and eb1, eb10best and full motif failed to run when the study number increased (when they failed, their results were not shown).
deviates to the three cases according to patterns shown in supplementary material Figure A.2(a) available at Biostatistics online. Data simulated in this way were able to keep the background characteristics in real data. Simulation 5 is similar to simulations 1 and 2. CorMotif again recovered the underlying differential patterns (see supplementary material Figure A.2(b) and (c) available at Biostatistics online). It showed comparable differential gene detection performance to full motif and outperformed the other methods (see supplementary material Figure A.3(a)–(c) and Table A.5 available at Biostatistics online). In a similar fashion, we performed simulations 6 and 7 based on real data (see supplementary material A.5 available at Biostatistics online). These two simulations have the same differential signal patterns as simulations 3 and 4, respectively. Here, the motifs reported by CorMotif differ slightly from the underlying truth, but all the major correlation patterns were captured by the reported motifs (see supplementary material Figure A.2 available at Biostatistics online). Once again, CorMotif performed the best in terms of differential gene detection (see supplementary material Figure A.3 and Tables A.6–A.7 available at Biostatistics online), and eb1, eb10best and full motif failed to run when the study number increased (when they failed, their results were not shown).
3.4. Motifs are parsimonious representation of true correlation structures
As we use probability vectors to serve as motifs, it is possible that multiple weak patterns can be merged into a single motif. For instance, two complementary patterns [1,1,0,0] and [0,0,1,1] each with 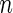 genes can be absorbed into a single motif with
genes can be absorbed into a single motif with 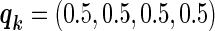 having
having 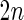 genes. To illustrate, we conducted simulations 8–10 which were composed of the same samples as in simulation 5 and various proportions of differential expression patterns (see supplementary material Figure A.4 available at Biostatistics online). In simulation 9 (see supplementary material Figure A.4(i)–(l) available at Biostatistics online), the relative abundance of two complementary block motifs ([1,1,0,0] and [0,0,1,1]) was small compared with the concordance motif [1,1,1,1], and they were absorbed into a single motif. In simulations 5, 8, and 10 (see supplementary material Figure A.4(a)–(h) and (m)–(p) available at Biostatistics online), the complementary block motifs were more abundant, and the program successfully identified them as separate motifs. In general, we observed that weaker patterns were more likely to be merged than patterns with abundant data support. In all cases, however, CorMotif still provided the best gene ranking results compared with other methods (see supplementary material Figure A.5 available at Biostatistics online). Supplementary material Figures A.4 and A.5 available at Biostatistics online also show that the higher the proportions of study-specific motifs (e.g. [1,1,0,0] and [0,0,1,1]), the better CorMotif will perform compared with the concordance analysis (i.e. all concord) in terms of ranking genes in each study. Together, the analyses here demonstrate that the correlation motifs only represent a parsimonious representation of the correlation structure supported by the available data. One should not expect CorMotif to always recover all the true underlying clusters exactly. In spite of this, our simulations show that CorMotif can still effectively utilize the correlation among studies to improve differential gene detection.
genes. To illustrate, we conducted simulations 8–10 which were composed of the same samples as in simulation 5 and various proportions of differential expression patterns (see supplementary material Figure A.4 available at Biostatistics online). In simulation 9 (see supplementary material Figure A.4(i)–(l) available at Biostatistics online), the relative abundance of two complementary block motifs ([1,1,0,0] and [0,0,1,1]) was small compared with the concordance motif [1,1,1,1], and they were absorbed into a single motif. In simulations 5, 8, and 10 (see supplementary material Figure A.4(a)–(h) and (m)–(p) available at Biostatistics online), the complementary block motifs were more abundant, and the program successfully identified them as separate motifs. In general, we observed that weaker patterns were more likely to be merged than patterns with abundant data support. In all cases, however, CorMotif still provided the best gene ranking results compared with other methods (see supplementary material Figure A.5 available at Biostatistics online). Supplementary material Figures A.4 and A.5 available at Biostatistics online also show that the higher the proportions of study-specific motifs (e.g. [1,1,0,0] and [0,0,1,1]), the better CorMotif will perform compared with the concordance analysis (i.e. all concord) in terms of ranking genes in each study. Together, the analyses here demonstrate that the correlation motifs only represent a parsimonious representation of the correlation structure supported by the available data. One should not expect CorMotif to always recover all the true underlying clusters exactly. In spite of this, our simulations show that CorMotif can still effectively utilize the correlation among studies to improve differential gene detection.
4. Application to the Shh signaling data sets
We used CorMotif to analyze the SHH data in Table 1. The normalized data are available for download as supplementary material Table A.10 available at Biostatistics online. Datasets 1 and 2 compare SMO mutant mice with wild type mice (wt) and PTCH1 mutant with wild type, respectively, in the 8 somite stage of developing embryos. Dataset 3 compares PTCH1 mutant with wild type in 13 somite stage. Datasets 4 and 5 compare SHH mutant with wild type in developing head and limb, respectively. Datasets 6 and 7 study gene expression changes in two SHH-related tumors, medulloblastoma and basal cell carcinoma (BCC), compared with normal samples (control). Dataset 8 compares SMO mutant with wild type in the 13 somite stage of developing embryos. CorMotif was applied to datasets 1–7. Dataset 8 was reserved for testing.
Five motifs were discovered (Figure 3(a) and (b)). Motif 1 mainly represents background. Motif 2 contains genes that have high probability to be differential in all studies. Genes in motif 3 tend to be differential in most studies except for the two involving PTCH1 mutant (i.e. studies 2 and 3). Most genes in motif 4 are not differential in the two studies involving the SHH mutant (i.e. studies 4 and 5) but tend to be differential in all other studies. Motif 5 mainly represents genes differential in tumors (i.e. studies 6 and 7) but not in embryonic development (i.e. studies 1–5). In general, looking at the columns in Figure 3(a), the two studies involving tumors (6,7) are more similar to each other compared with other studies. The two PTCH1 mutant studies (2,3) are also relatively similar, and the same trend holds true for the two SHH mutant studies (4,5).
Fig. 3.

Results for the SHH data. (a) Motif patterns learned from the SHH data composed of 7 studies. (b) BIC plots for the SHH data. (c) Gene ranking performance for SHH study 1. The genes differentially expressed in dataset 8 (13somites_smo versus 13somites_wt) were obtained using separate limma. They were used as the gold standard. 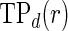 , the number of genes in dataset 1 that are truly differentially expressed among the top
, the number of genes in dataset 1 that are truly differentially expressed among the top 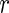 ranked genes by each method, is plotted against the rank cutoff
ranked genes by each method, is plotted against the rank cutoff 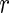 . (d) Differential status claimed by each method for known SHH pathway genes. Dark color indicates differential expression and light color represents non-differential expression.
. (d) Differential status claimed by each method for known SHH pathway genes. Dark color indicates differential expression and light color represents non-differential expression.
In this real data analysis, no comprehensive truth is available for evaluating differential expression calls. Without comprehensive knowledge about the true differential expression states of all genes in all cell types, we can only perform a partial evaluation based on existing knowledge. In this regard, we used dataset 8 as a test. Similar to dataset 1, this dataset compares SMO mutant with wild type. One expects that differential genes in these two datasets should be largely similar. Therefore, we used the top 217 differentially expressed genes detected by separate limma (at the posterior probability cutoff 0.5) in dataset 8 as gold standard to evaluate the gene ranking performance of different methods in dataset 1. Figure 3(c) shows that CorMotif again performed similar to full motif and outperformed all other methods. eb10best failed to run here. We note that since dataset 8 and datasets 2–7 represent more different biological contexts, one cannot use it as gold standard for evaluating these other datasets.
Finally, we examined well-studied SHH responsive target genes. Gli1, Ptch1, Ptch2, Hhip, and Rab34 are known to be regulated by SHH in somites and developing limb (Vokes and others, 2007, 2008). Therefore, we expect them to be differential in studies 1, 2, 3, and 5. Figure 3(d) shows that CorMotif, all concord and full motif were able to correctly identify differential expression of these genes in all these studies, whereas separate limma, SAM, and eb1 failed to do so (they missed some cases). Supplementary material Table A.8 available at Biostatistics online also shows that in many studies, CorMotif, all concord, and full motif provided better rank for these genes compared with separate limma, SAM, and eb1. Hand2 is known to be a SHH target in developing limb but not in somites (Vokes and others, 2008). While separate limma, CorMotif, full motif, and SAM can correctly identify this, all concord and eb1 failed to do so. For all concord, since Hand2 was not differential in studies 1–4, 6, and 7, the method thinks that this gene is not differential in any study. Similarly, Hoxd13 is a limb specific target of SHH signaling (Vokes and others, 2008). While the other methods correctly identified this, all concord failed again by claiming it to be differential in all studies. In all the genes examined, only CorMotif and full motif were able to correctly identify all known differential states.
5. Discussion
Together, our analyses show that CorMotif offers unique advantage over the other methods in the integrative analysis of multiple gene expression studies. Besides its ability to increase statistical power by combining information across studies, CorMotif is also flexible and scalable. Using a few probability vectors instead of 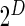 dichotomous vectors to characterize the differential expression patterns provides the key to avoid the exponential growth of parameter space as the study number increases. At the same time, the probabilistic nature of the motifs allows all
dichotomous vectors to characterize the differential expression patterns provides the key to avoid the exponential growth of parameter space as the study number increases. At the same time, the probabilistic nature of the motifs allows all 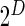 differential patterns to occur in the data at individual gene level.
differential patterns to occur in the data at individual gene level.
The motif matrix Q can be viewed in two different ways. Each row of Q represents a cluster of genes with similar differential expression patterns across studies. Having many different motifs in 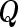 is an indication that a concordance model, such as all concord, may not be enough to describe the correlation structure in the data. On the other hand, each column of
is an indication that a concordance model, such as all concord, may not be enough to describe the correlation structure in the data. On the other hand, each column of 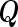 represents differential expression propensities of different gene classes in a given study. If two columns are similar, the corresponding studies share similar differential expression profiles (e.g. studies 6 and 7 in the SHH data are more similar to each other compared with the other studies).
represents differential expression propensities of different gene classes in a given study. If two columns are similar, the corresponding studies share similar differential expression profiles (e.g. studies 6 and 7 in the SHH data are more similar to each other compared with the other studies).
Currently, CorMotif first computes moderated t-statistics 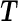 and then applies the correlation motif model to
and then applies the correlation motif model to 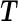 . We used this two-stage approach for considerations of effective presentation, computational efficiency, and clean method comparison (see supplementary material A.6 available at Biostatistics online for a detailed discussion). The present two-stage framework is also very general. For instance, conceptually one can modify
. We used this two-stage approach for considerations of effective presentation, computational efficiency, and clean method comparison (see supplementary material A.6 available at Biostatistics online for a detailed discussion). The present two-stage framework is also very general. For instance, conceptually one can modify 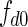 and
and 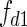 to accommodate other data types such as RNA-seq. A systematic treatment of RNA-seq analysis, though, is beyond the scope of this paper. The EM implementation of CorMotif is computationally tractable. On a single CPU, it took
to accommodate other data types such as RNA-seq. A systematic treatment of RNA-seq analysis, though, is beyond the scope of this paper. The EM implementation of CorMotif is computationally tractable. On a single CPU, it took 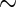 0.35 h to analyze the SHH data for a single
0.35 h to analyze the SHH data for a single 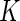 , and
, and 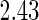 h in total in order to search for the optimal
h in total in order to search for the optimal 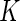 (see supplementary material A.7 and Table A.9 available at Biostatistics online for comparisons with other methods).
(see supplementary material A.7 and Table A.9 available at Biostatistics online for comparisons with other methods).
In the future, CorMotif may be extended in multiple ways. For example, instead of using moderated t-statistics and the two-stage design, one may develop a single coherent model that couples correlation motifs with a more sophisticated model for the raw data 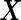 . Also, it remains to be investigated whether the problem of choosing motif number can be better dealt with by a fully Bayesian approach such as by imposing a Dirichlet Process prior for
. Also, it remains to be investigated whether the problem of choosing motif number can be better dealt with by a fully Bayesian approach such as by imposing a Dirichlet Process prior for 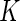 or using a variant of Dirichlet Process prior instead of using BIC. A fully Bayesian model, however, may require MCMC in the implementation, and this may pose additional challenges for developing computationally efficient algorithms capable of handling large datasets.
or using a variant of Dirichlet Process prior instead of using BIC. A fully Bayesian model, however, may require MCMC in the implementation, and this may pose additional challenges for developing computationally efficient algorithms capable of handling large datasets.
6. Software
CorMotif is freely available as an R package in Bioconductor: http://www.bioconductor.org/packages/release/bioc/html/Cormotif.html.
Supplementary material
Supplementary material is available at http://biostatistics.oxfordjournals.org.
Funding
The research is supported by the National Institutes of Health grant R01HG006282. Funding to pay the Open Access publication charges for this article was provided by the National Institutes of Health grant R01HG006282.
Supplementary Material
Acknowledgements
The authors thank Drs Andrew P. McMahon and Junhao Mao for providing the compiled SHH data, and Robert B. Scharpf for his help with running XDE. Conflict of Interest: None declared.
References
- Anders S., Huber W. Differential expression analysis for sequence count data. Genome Biology. 2010;11:106. doi: 10.1186/gb-2010-11-10-r106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Conlon E. M., Song J. J., Liu J. S. Bayesian models for pooling microarray studies with multiple sources of replications. BMC Bioinformatics. 2006;7:1979–1985. doi: 10.1186/1471-2105-7-247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gelman A., Carlin J. B., Stern H. S., Rubin D. B. Bayesian Data Analysis. 2nd edition. New York, NY: Chapman Hall/CRC; 2004. [Google Scholar]
- Ingham P. W., McMahon A. P. Hedgehog signaling in animal development: paradigms and principles. Genes and Development. 2001;15:3059–3087. doi: 10.1101/gad.938601. [DOI] [PubMed] [Google Scholar]
- Irizarry R. A., Hobbs B., Collin F., Beazer-Barclay Y. D., Antonellis K. J., Scherf U., Speed T. P. Exploration, normalization, and summaries of high density oligonucleotide array probe level data. Biostatistics. 2003;4((2)):249–264. doi: 10.1093/biostatistics/4.2.249. [DOI] [PubMed] [Google Scholar]
- Jensen S. T., Erkan I., Arnardottir E. S., Small D. S. Bayesian testing of many hypothesis*many genes: a study of sleep apnea. Annals of Applied Statistics. 2009;3((3)):1080–1101. [Google Scholar]
- Kendziorski C. M., Newton M. A., Lan H., Gould M. N. On parametric empirical bayes methods for comparing multiple groups using replicated gene expression profiles. Statistics in Medicine. 2003;22:3899–3914. doi: 10.1002/sim.1548. [DOI] [PubMed] [Google Scholar]
- Mao J., Ligon K. L., Rakhlin E. Y., Thayer S. P., Bronson R. T., Rowitch D., McMahon A. P. A novel somatic mouse model to survey tumorigenic potential applied to the hedgehog pathway. Cancer Research. 2006;66((20)):10171–10178. doi: 10.1158/0008-5472.CAN-06-0657. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robinson M. D., Smyth G. K. Moderated statistical tests for assessing differences in tag abundance. Bioinformatics. 2007;23:2881–2887. doi: 10.1093/bioinformatics/btm453. [DOI] [PubMed] [Google Scholar]
- Robinson M. D., Smyth G. K. Small-sample estimation of negative binomial dispersion, with applications to sage data. Biostatistics. 2008;9:321–332. doi: 10.1093/biostatistics/kxm030. [DOI] [PubMed] [Google Scholar]
- Ruan L., Yuan M. An empirical bayes approach to joint analysis of multiple microarray gene expression studies. Biometrics. 2011;67:1617–1626. doi: 10.1111/j.1541-0420.2011.01602.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scharpf R. B., Tjelmeland H., Parmigiani G., Nobel A. B. A Bayesian model for cross-study differential gene expression. Journal of the American Statistical Association. 2009;104((488)):1295–1310. doi: 10.1198/jasa.2009.ap07611. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smyth G. K. Linear models and empirical Bayes methods for assessing differential expression in microarray experiments. Statistical Applications in Genetics and Molecular Biology. 2004;3:3. doi: 10.2202/1544-6115.1027. [DOI] [PubMed] [Google Scholar]
- Tenzen T., Allen B. L., Cole F., Kang J. S., Krauss R. S., McMahon A. P. The cell surface membrane proteins cdo and boc are components and targets of the hedgehog signaling pathway and feedback network in mice. Developmental Cell. 2006;10((5)):647–656. doi: 10.1016/j.devcel.2006.04.004. [DOI] [PubMed] [Google Scholar]
- Tusher V. G., Tibshirani R., Chu G. Significance analysis of microarrays applied to the ionizing radiation response. Proceedings of the National Academy of Sciences. 2001;98((9)):5116–5121. doi: 10.1073/pnas.091062498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vokes S. A., Ji H., McCuine S., Tenzen T., Giles S., Zhong S., Longabaugh W. J. R., Davidson E. H., McMahon A. P. Genomic characterization of gli-activator targets in sonic hedgehog-mediated neural patterning. Development. 2007;134:1977–1989. doi: 10.1242/dev.001966. [DOI] [PubMed] [Google Scholar]
- Vokes S. A., Ji H., Wong W. H., McMahon A. P. Whole genome identification and characterization of gli cis-regulatory circuitry in hedgehog-mediated mammalian limb development. Genes Development. 2008;22:2651–2663. doi: 10.1101/gad.1693008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuan M., Kendziorski C. M. A unified approach for simultaneous gene clustering and differential expression identification. Biometrics. 2006;62:1089–1098. doi: 10.1111/j.1541-0420.2006.00611.x. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.