

Abstract
This review aimed to arrange the concepts of a network meta-analysis (NMA) and to demonstrate the analytical process of NMA using Stata software under frequentist framework. The NMA tries to synthesize evidences for a decision making by evaluating the comparative effectiveness of more than two alternative interventions for the same condition. Before conducting a NMA, 3 major assumptions—similarity, transitivity, and consistency—should be checked. The statistical analysis consists of 5 steps. The first step is to draw a network geometry to provide an overview of the network relationship. The second step checks the assumption of consistency. The third step is to make the network forest plot or interval plot in order to illustrate the summary size of comparative effectiveness among various interventions. The fourth step calculates cumulative rankings for identifying superiority among interventions. The last step evaluates publication bias or effect modifiers for a valid inference from results. The synthesized evidences through five steps would be very useful to evidence-based decision-making in healthcare. Thus, NMA should be activated in order to guarantee the quality of healthcare system.
Keywords: Network meta-analysis, Treatment outcome, Mixed treatment comparison, Biostatistic
INTRODUCTION
As newly developed drugs conducted the third stage of randomized clinical trials (RCT) are approved for marketing, and enter into the armamentarium of treatment, there is a need for comparative effectiveness research (CER) to evaluate the effectiveness of drugs used for the same treatment goal and meta-analysis to synthesize the results of the CER [1]. Conventional meta-analysis on the treatment effects of new drugs is conducted on the effect size based on pairwise head-to-head direct comparison, but data from direct comparisons are relatively limited [2]. In contrast, the necessity for indirect comparisons among various drugs of the same efficacy used in clinical practice became greater [3,4]. Accordingly, an analytic approach called network meta-analysis (NMA) was developed to include in the meta-analysis not only direct comparisons, but also indirect comparisons based on logical inference; in the latter case, no comparisons are actually performed [3,5-10].
Statistical approaches to NMA are largely classified as frequentist and Bayesian frameworks [7]. Because part of NMA has indirect, multiple comparisons, Bayesian framework seems logically more valid, and 60-70% of NMA studies have taken a Bayesian approach [6,11-13]. However, if the prior probability is not established in the study hypothesis, Bayesian analysis poses many limitations for ordinary researchers using NMA because the problem of establishing prior probability is rather more complex than the problem of testing the research hypothesis, that is, the original purpose of the analysis [7]. In 1997, Bucher et al. [14] proposed an NMA approach based on the frequentist framework using random-effects models. Since then, many methodological developments have taken place [7,15], and articles introducing SAS (https://www.sas.com/en_us/home.html) and Stata (http://www.stata.com) program commands have been presented [12,15,16].
From 2008 onwards, the number of publications based on NMA increased at a rapid pace [2-4,15]. In 2011, the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) defined the concepts related to NMA and established guidelines relating to methodological and statistical issues to help researchers conduct NMA in a valid manner [7,17]. Furthermore, ‘PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-analyses) Network Meta-Analysis checklist’, as a guideline for reporting NMA research outcomes, was also developed [7,18].
As NMA has features of multivariate multi-level analysis fundamentally, clinical researchers, as well as epidemiologists and statisticians, should understand them sufficiently well to perform NMA [19]. Hence, in this article, the terms used in NMA are defined, relevant statistical concepts are summarized, and the NMA analytic process based on the frequentist framework is illustrated using Stata program and an actual example.
INTRODUCTION OF RELATED CONCEPTS
Definition of terms
Since Bucher et al. [14] proposed the concept of indirect treatment comparison (ITC) on treatment effect in 1997, such terms as ‘multiple treatment comparison’ meaning comparison of several treatments [20] and ‘mixed treatment comparison’ (MTC) meaning a combination of direct and indirect comparisons [6] have been introduced.
However, at present, NMA is primarily used to mean a research effort to synthesize the results obtained by comparing several studies which examined multiple treatments [3,5,7,16,21]. ISPOR [7] defines NMA as a comparison of the effectiveness of 2 or more treatments, and categorizes the comparison type as MTC if the network geometry shows a closed loop and ITC if it does not (Figure 1).
Figure 1.
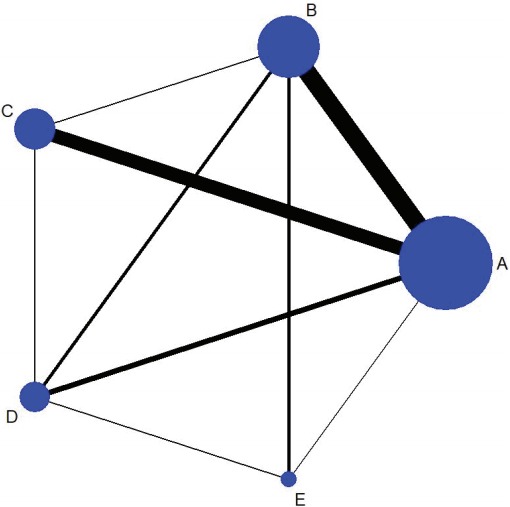
Network geometry. When the obejctive is to examine comparative effectiveness of B-C among the treatments A, B, and C, a closed loop is present if research data comparing all 3 pairs (A-B, B-C, and A-C) exist.
Relevant assumptions
Meta-analysis is a statistical methodology to synthesize the results of several studies, and overall effect size is valid only if various a priori assumptions are satisfied [22]. Furthermore, NMA requires more strict methodological, logical, and statistical assumptions [23,24], about similarity, transitivity, and consistency, respectively [5,12,17,19,25,26]. In NMA, whether each of these is satisfied must also be examined [8,10,19].
Similarity
To compare among the clinical trial studies extracted for analysis, similarity in the methodology used in the studies must be assumed [5,27]. Similarity is qualitatively assessed on each of the selected articles from a methodological point of view, and is not a hypothesis to be tested statistically. To examine similarity, the population, intervention, comparison, and outcome (PICO) technique is used [26]. Specifically, similarity among the studies extracted for analysis is examined for the following 4 items: clinical characteristics of study subjects, treatment interventions, comparison treatments, and outcome measures. If the similarity assumption is not satisfied, not only are the other two assumptions negatively affected [9], but there is also a need to check for the heterogeneity error [10,23].
Transitivity
Transitivity covers the validity of the logical inference, while similarity relates to the methodological feasibility of comparing. To explain simplistically, if direct comparisons of 3 drugs—A, B, and C—treating the same illness found that A was more effective than B, and B was more effective than C, then A can be expected to be more effective than C, even though the two were never directly compared. Such transitivity should be satisfied for all cases in an NMA [4,5,28].
If the researcher compares the outcomes of direct and indirect comparisons according to logical inference, the satisfaction of the transitivity assumption can be examined objectively. Statistical assessment of the outcomes of direct and indirect comparisons is called consistency [4,5,10]. If inconsistency is observed, non-transitivity should be suspected [29]. If non-transitivity is suspected, the presence of effect modifiers influencing treatment effect should first be examined [9,27,30].
Consistency
Consistency, an objective measure of transitivity, means that the comparative effect sizes obtained through direct and indirect comparisons are consistent. Hence, consistency is statistically examined transitivity [5,7,24,31], and some researchers call it coherence [8,21,32]. For this reason, the assumptions of transitivity and consistency can be regarded as similar [9,33,34]. However, the authors of this article differentiate transitivity from consistency to emphasize that the perspectives used are logical and statistical, respectively.
According to a summary of techniques to check the consistency assumption utilized in the existing NMA studies [2], the techniques are categorized as those evaluating the fitness of statistical models [34,35] and those assessing the logical structure of graphs [29]. The model [Y] presented in the Stata program simultaneously considers the level of heterogeneity [H] (which should be examined in any meta-analysis) and the level of inconsistency [C] (for conducting multiple comparisons within a network), as well as the size of the treatment effect [D] of interest [16]. The equation that considers within-study variance (E), Y= D+H+C+E, is called the inconsistency model. If the level of inconsistency is zero, that is, [C= 0], it is considered a consistency model.
Consistency is statistically evaluated based on the confidence interval of the difference in comparative effect size between direct and indirect comparisons [10,32], and inconsistency is observed in approximately 1/8 of NMA studies [23]. It is very important to identify the cause of inconsistency [1,10,23]. Ioannidis [36] proposed 4 kinds of causes of inconsistency—chance, bias in headto-head comparison, bias in indirect comparison, and genuine diversity—and Higgins et al. [35] classified the causes of inconsistency into loop inconsistency, which refers to a difference between direct and indirect comparisons, and design inconsistency, which refers to a difference due to different sets of treatments being compared.
Stata tests for inconsistency have 2 levels [12,16]. The first is a global approach to test for overall inconsistency, in which the level of inconsistency is computed according to the type of between-treatment comparison for all cases and then the values are used to test for global linearity via the Wald test. The second is a local approach, in which each treatment is individually examined (nodesplitting) and the outcomes of direct and indirect comparisons are statistically tested.
Researchers should pay attention to the consistency assumption and explore the presence of effect modifiers causing overall inconsistency in the global approach [12,37,38]. To examine them, sensitivity analysis is utilized [3,30], and if it is determined that an effect modifier is present, performing meta-regression is recommended to adjust the corresponding variable [3,5,38].
Network geometry
Network geometry is a diagram showing the interactions among the articles included in NMA [39]. The diagram provides important information in establishing analytic strategies and interpreting the results [5,8,39], and so it is strongly recommended to use network geometry in presenting the NMA analysis results [1,18]. One of NMA’s features is that network geometry may change with an addition of new research outcomes or new treatments in the comparison set [39].
ILLUSTRATION OF STATA APPLICATION
Preparing for analysis: information extraction and network meta-analysis support program installation
The following research question was formulated to illustrate how to perform NMA: whether transfusion rate in total hip joint replacement is different depending on the method of tranexamic acid administration. During the literature search process, 25 articles were selected and the extraction results are listed in Appendix 1. Drug administration was classified into the following 5 treatments: placebo (A); IV_single use (B); IV_double use (C); topical use (D); and a combination of IV and topical use (E).
As shown in Appendix 1, a long form to code the sample size for each treatment group in a study is recommended because this format makes it easy to understand the commands and also makes it easy to edit data, if necessary.
To perform NMA using Stata, the network package should first be installed [16]. Then, the variables in the analysis should be specified by typing the command < network setup d n, studyvar (study) trtvar(trt) ref(A)> . In the command, < network setup> means that network package is used for analysis. The number of events (< d> ) and the total sample size (< n> ) are entered, in this order. After a comma, the relevant options are entered; < studyvar> refers to the variable for study title; < trtvar> is the variable for treatments; and < ref> is the variable for the reference treatment among the treatments. The command corresponding to the data organized in Appendix 1 is found in Figure 2.
Figure 2.
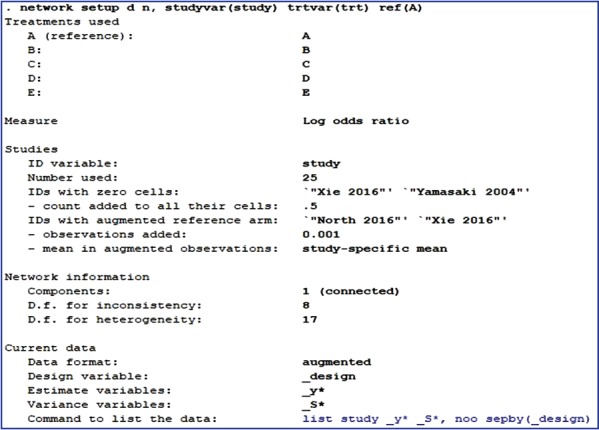
Results of network setup order.
According to Figure 2, the reference treatment is A (placebo). Of the 25 studies, Xie 2016 and Yamasaki 2004 included cells with d= 0, and Stata replaced them with a default value of 0.5. Consequently, 0.5 was assigned to both the intervention and control groups, which increased the sample size per treatment by 1. Also, for studies with no information on the reference treatment, A, as in North 2016 and Xie 2016, Stata generates a tiny amount of data in the reference arm as a default. This practice is called augmented method, and is advantageous because the overall effect size is not affected, errors in the equations can be reduced, and all extracted studies are utilized in the analysis.
Step 1: generating network geometry
The command to draw a network geometry to explore comparative relationships among treatments is < network map > , and Figure 1 shows the outcome of the current example. The size of the 5 nodes—one for each treatment—indicates the number of studies included in the corresponding nodes, while the thickness of the lines connecting 2 nodes indicates the amount of relevant data. Also, all 5 nodes were closed, which confirms that MTC analysis can be performed. To examine the contributions of individual treatments in a table form, the command < netweight> is used.
Step 2: testing for inconsistency
This step in NMA is to statistically test whether the consistency assumption among 3 NMA assumptions is satisfied. To check for overall inconsistency, the command < network meta inconsistency> is used for the inconsistency model provided in Stata, and Figure 3 shows the results of this case study. The p-value displayed at the bottom of Figure 3 is the result of testing for inconsistency at the overall level. Based on the p-value, the null hypothesis cannot be rejected and the consistency assumption could be accepted at the overall level of each treatment.
Figure 3.
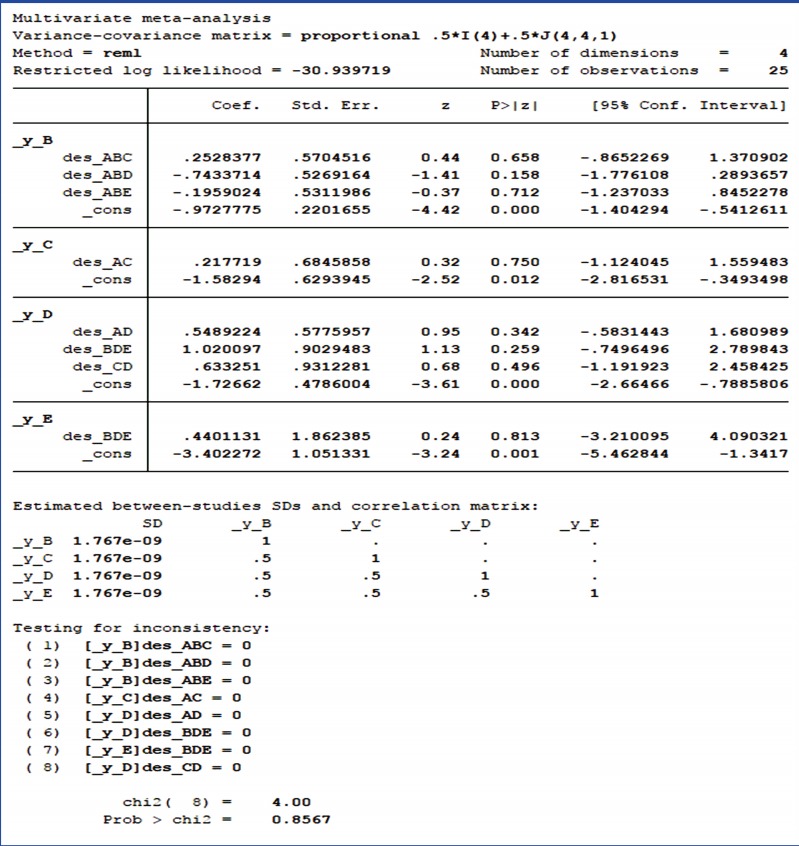
Results of test for inconsistency.
Next, the command < network sidesplit all> is used for the local test on loop inconsistency. Table 1 shows the results of the local inconsistency test in this case study, listing the size of differences for each treatment and the statistical test results. None of the treatments showed statistical significance. Because inconsistency was found to be absent in both global and local tests, the consistency assumption was accepted.
Table 1.
Inconsistency test between direct and indirect treatment comparisons in mixed treatment comparison
| Side | Direct |
Indirect |
Difference |
p>z | |||
|---|---|---|---|---|---|---|---|
| Coefficient | SE | Coefficient | SE | Coefficient | SE | ||
| A B | -1.083 | 0.174 | -0.877 | 0.620 | -0.206 | 0.636 | 0.746 |
| A C | -1.388 | 0.247 | -1.869 | 0.493 | 0.481 | 0.542 | 0.375 |
| A D | -1.378 | 0.265 | -0.738 | 0.413 | -0.640 | 0.479 | 0.182 |
| A E | -3.425 | 0.940 | -3.221 | 1.005 | -0.204 | 0.937 | 0.828 |
| B C | -0.894 | 0.655 | -0.312 | 0.297 | -0.581 | 0.715 | 0.416 |
| B D | 0.099 | 0.462 | -0.241 | 0.329 | 0.340 | 0.567 | 0.548 |
| B E | -2.152 | 0.881 | -2.615 | 1.087 | 0.463 | 0.896 | 0.605 |
| C D | 0.490 | 0.492 | 0.177 | 0.350 | 0.313 | 0.604 | 0.605 |
| D E | -2.550 | 1.254 | -1.956 | 0.958 | -0.595 | 1.314 | 0.651 |
SE, standard error; A, placebo; B, IV_single; C, IV_double; D, topical; E, combination.
Step 3: creating plots and league table of effect size by treatment
To display effect sizes in a plot and a league table, the outcomes should first be stored in memory using the command < network meta consistency> . There are 2 ways in NMA to graphically represent effect size by study and by treatment: network forest plot (NFP) and interval plot. To generate NFP in Stata, the command < network forest, msize (*0.15) diamond eform xlabel (0.1 1 10 100) colors (black blue red) list> is typed. The main command to generate forest plots is < network forest> , and options are specified after a comma. Among the various options, < diamond> uses a diamond shape to show summary effect sizes and < eform> generates transformed indices to make it easy to interpret the forest plot. Other options are there to help in easily visualizing the graph: < msize (*0.15)> decreases the value of individual studies’ effect size by 0.15 times; < xlabel (0.1 1 10 100)> sets the unit on the x axis; and < colors (black blue red)> sets the colors of the effect of each study within a treatment in the comparison set, the pooled effect of a treatment in the comparison set (also called “pooled within design”), and the pooled overall effect (also called “pooled overall”) as black, blue, and red, respectively (Figure 4).
Figure 4.
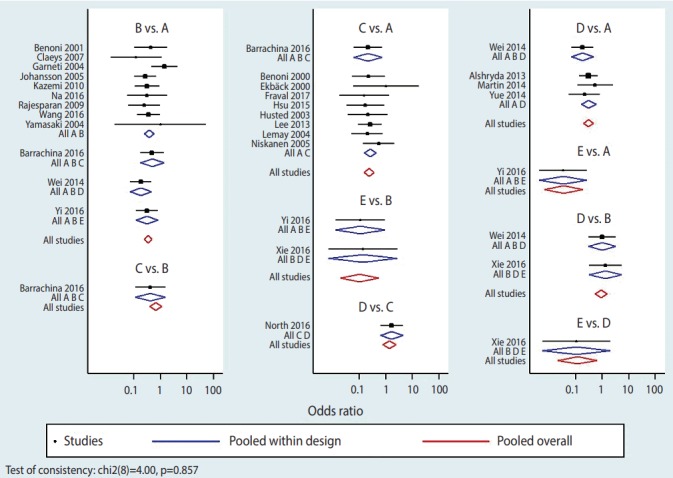
Network forest plot. A, placebo; B, IV_ single; C, IV_double; D, topical; E, combination.
A wide range of information is obtained in an NFP. First, it provides information on the effect size of each study and each treatment. The pooled effect of each treatment in the comparison set (blue color) shows the results of the test for the inconsistency model, And the pooled overall effect (red color) shows the result of the test for the consistency model. Second, the p-value displayed in the lower left of the plot is congruent with the result of the global test on inconsistency, which confirms that the consistency is accepted. Third, heterogeneity among individual studies within a treatment can be visually inspected. Moreover, based on the similarity between the size of pooled effect of each treatment in the comparison set (blue color) and the size of pooled overall effect (red color), it can be determined whether the consistency model is supported.
Although useful information is provided by NFP, readability suffers if the number of articles included in the analysis or treatments in the comparison set is large. In such a case, it is advised to generate interval plots, by typing the command < intervalplot, eform null (1) labels (Placebo IV_single IV_double Topical Combination) separate margin (10 8 5 10) textsize (2) xlabel (0.01 0.1 1 10)> . The main command is < intervalplot> ; < eform> transforms the original logarithmic data into indices for easier interpretation; < null (1)> inputs 1, the value indicating statistically significant difference in a ratio like odds ratio; <label> defines how treatments should be labeled; < separate> and < margin> set the ranges to generate easy-to-read plots, the values of which should be appropriately determined by the user because they vary greatly depending on the number of articles as well as the number of treatments in the comparison set. Figure 5 shows the interval plot obtained by typing the commands discussed above. It is relatively intuitive to compare the effect sizes of individual treatments and very easy to interpret the results. A network league table, shown in Appendix 2, can be created based on the outcome comparing the effect sizes of treatments, which is produced in the Stata result window after the command < intervalplot> is typed.
Figure 5.
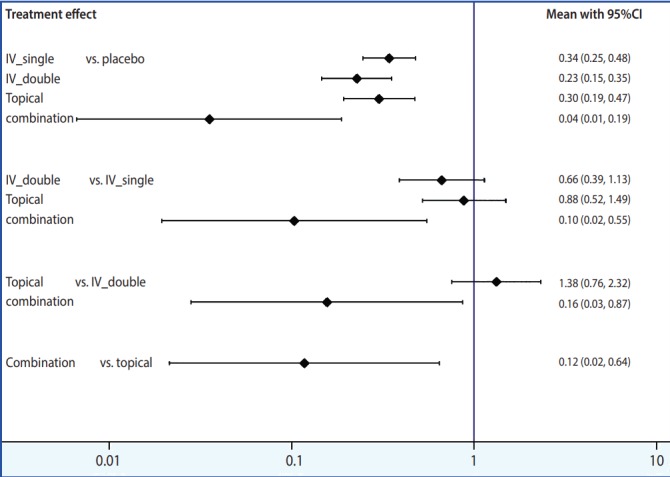
Interval plot. CI, confidence interval.
Step 4: determining relative rankings of treatments
Once comparative effectiveness of the treatments has been evaluated through the previous steps, the next step is to rank order the treatments to identify superiority [12]. In other words, the treatment interventions showing the most superior treatment effect are evaluated.
Stata supports two commands—network rank and surface under the cumulative ranking (SCURA)—to rank order treatments. There is little difference in the outcome between the commands, but it is easier to use network rank, for which the command < network rank min, line cumulative xlabel (1/4) seed (10000) reps (10000) meanrank> is typed. The main command is < network rank> , and < min (or max)> specifies whether superiority should be determined by using ascending or descending order of effect size. In this case study < min> was used because a treatment is more effective as the effect size compared to the reference treatment (placebo, A) is smaller.
As shown in Figure 6, the probability of treatment E (combination) being the best is approximately 98.1%, and the probability for it to be at least the second best is 99.2%. In the SCURA, the surface area for treatment E reaches almost 100%, confirming again that it is the best intervention [40]. The SUCRA command is used for more precise estimation of cumulative ranking probabilities. Based on the SUCRA results, treatment E (combination) is followed by C (IV_double), D (topical), B (IV_single), and A (placebo). A clinical interpretation of the results is that the administration of tranexamic acid, in combination with IV and topical use is recommended to ensure maximum decrease in the probability of transfusion in total hip joint replacement.
Figure 6.

Results of network rank test. A, placebo; B, IV_single; C, IV_double; D, topical; E, combination; SCURA, surface under the cumulative ranking.
Step 5: checking for publication bias
To check for publication bias in NMA, a network funnel plot is created. Because the Stata network package does not directly support the generation of network funnel plots, the data should first be transformed, as demonstrated in Appendix 2. To do so, data should be generated by typing the network forest command with the list option, and the comparative effect size (diff) and standard error (se) are summarized for each pair of treatments within individual articles that are directly compared with each other (t1, t2).
After the data shown in Appendix 3 are uploaded in a new Stata window, the command < netfunnel diff se t1 t2, random bycomparison > is typed to generate network funnel plots. Here, the main command is < netfunnel> ; < diff> is comparative effect size between treatments in logarithmic scale and < se> indicates se; < random> in the option list means the use of a random effect model, and < bycomparison> is to color code treatments. If the user wants to generate selective funnel plots with respect to placebo A, the command < netfunnel diff se t1 t2 if t1= = “A”, random bycomparison> is typed. Once the plots are generated, publication bias is visually inspected using the criterion of symmetry. It is advised to consider performing sensitivity analysis, if necessary.
DISCUSSION AND SUGGESTIONS
So far, the application of NMA within frequentist framework has been demonstrated. Below, we list points for researchers to consider when performing NMA and suggestions for those points.
First, NMA is for direct and indirect comparisons in a set of treatments and it is limited to the results of RCT studies [5]. At the current advancement of the analytic technique, it is not recommended to apply NMA to the results of observational research like cohort study and case-control study. Also, the fact that researchers, funding agencies, the types of drugs approved for marketing in different countries, and the research ethics committees are operated, etc., could affect the RCT research issues and outcomes, should be factored in [41].
Second, the 3 assumptions to be satisfied in NMA should be examined meticulously [25,42]. Of the assumptions, practical decisions from a clinician point of view should be made on the similarity and transitivity assumptions [42]. If inconsistency is concluded via statistical testing, effect modifiers should be identified by utilizing network geometry to thoroughly investigate the relationships among the selected articles [37]. Then, NMA meta-regression should be performed and the results before and after the adjustment with the effect modifiers should be evaluated in order to derive clinically valid conclusions [5,31].
Third, the presence of bias due to small-scale studies should be considered [8]. Studies with a small number of subjects can not only cause publication bias [43], but also generate a relatively large treatment effect [44]. Therefore, it is recommended to evaluate publication bias by using a random effect model [7] and performing sensitivity analysis [3,30].
Fourth, the application of Bayesian framework may be considered, as limitations exist in NMA based on frequentist framework [6,7]. If the ultimate goal of an NMA study is to make a medical decision and predict the outcome under uncertainty, Bayesian framework is more appropriate [11-13]. At present, several statistical programs supporting Bayesian analysis are available, including WinBUGS (https://www.mrc-bsu.cam.ac.uk/software/bugs/) [12].
Evidence synthesized through a systematic review based on meta-analysis is the most powerful with respect to scientific persuasion [45]. Moreover, the outcomes of NMA—an analysis that synthesizes comparative effectiveness through direct and indirect comparisons among treatment interventions with the same treatment goal and rank orders them—have great significance in evidence-based decision making in health care [3,5,46]. Thus, the use of NMA should be facilitated to enhance the quality of health care in Korea, and it is expected that this article will motivate Korean researchers to facilitate the application and practice of NMA.
Acknowledgments
This article is an outcome of the research activities of the Korean Meta-Analysis Study (President: In-Soo Shin).
Appendix 1.
The extracted information from the selected articles for conducting a network meta-analysis using Stata
Appendix 2.
A network league table based on the network meta-analysis from data in Appendix 1
Appendix 3.
The raw data for drawing a network funnel plot from data in Appendix 1
Footnotes
The authors have no conflicts of interest to declare for this study.
SUPPLEMENTARY MATERIAL
Supplementary material (Korean version) is available at http://www.e-epih.org/.
REFERENCES
- 1.Mills EJ, Ioannidis JP, Thorlund K, Schünemann HJ, Puhan MA, Guyatt GH. How to use an article reporting a multiple treatment comparison meta-analysis. JAMA. 2012;308:1246–1253. doi: 10.1001/2012.jama.11228. [DOI] [PubMed] [Google Scholar]
- 2.Donegan S, Williamson P, D’Alessandro U, Tudur Smith C. Assessing key assumptions of network meta-analysis: a review of methods. Res Synth Methods. 2013;4:291–323. doi: 10.1002/jrsm.1085. [DOI] [PubMed] [Google Scholar]
- 3.Biondi-Zoccai G, Abbate A, Benedetto U, Palmerini T, D’Ascenzo F, Frati G. Network meta-analysis for evidence synthesis: what is it and why is it posed to dominate cardiovascular decision making? Int J Cardiol. 2015;182:309–314. doi: 10.1016/j.ijcard.2015.01.023. [DOI] [PubMed] [Google Scholar]
- 4.Caldwell DM. An overview of conducting systematic reviews with network meta-analysis. Syst Rev. 2014;3:109. doi: 10.1186/2046-4053-3-109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Cipriani A, Higgins JP, Geddes JR, Salanti G. Conceptual and technical challenges in network meta-analysis. Ann Intern Med. 2013;159:130–137. doi: 10.7326/0003-4819-159-2-201307160-00008. [DOI] [PubMed] [Google Scholar]
- 6.Lu G, Ades AE. Combination of direct and indirect evidence in mixed treatment comparisons. Stat Med. 2004;23:3105–3124. doi: 10.1002/sim.1875. [DOI] [PubMed] [Google Scholar]
- 7.Jansen JP, Fleurence R, Devine B, Itzler R, Barrett A, Hawkins N, et al. Interpreting indirect treatment comparisons and network meta-analysis for health-care decision making: report of the ISPOR Task Force on Indirect Treatment Comparisons Good Research Practices: part 1. Value Health. 2011;14:417–428. doi: 10.1016/j.jval.2011.04.002. [DOI] [PubMed] [Google Scholar]
- 8.Mills EJ, Thorlund K, Ioannidis JP. Demystifying trial networks and network meta-analysis. BMJ. 2013;346:f2914. doi: 10.1136/bmj.f2914. [DOI] [PubMed] [Google Scholar]
- 9.Jansen JP, Naci H. Is network meta-analysis as valid as standard pairwise meta-analysis? It all depends on the distribution of effect modifiers. BMC Med. 2013;11:159. doi: 10.1186/1741-7015-11-159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Salanti G. Indirect and mixed-treatment comparison, network, or multiple-treatments meta-analysis: many names, many benefits, many concerns for the next generation evidence synthesis tool. Res Synth Methods. 2012;3:80–97. doi: 10.1002/jrsm.1037. [DOI] [PubMed] [Google Scholar]
- 11.Dakin HA, Welton NJ, Ades AE, Collins S, Orme M, Kelly S. Mixed treatment comparison of repeated measurements of a continuous endpoint: an example using topical treatments for primary openangle glaucoma and ocular hypertension. Stat Med. 2011;30:2511–2535. doi: 10.1002/sim.4284. [DOI] [PubMed] [Google Scholar]
- 12.Tonin FS, Rotta I, Mendes AM, Pontarolo R. Network meta-analysis: a technique to gather evidence from direct and indirect comparisons. Pharm Pract (Granada) 2017;15:943. doi: 10.18549/PharmPract.2017.01.943. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Schmitz S, Adams R, Walsh CD, Barry M, FitzGerald O. A mixed treatment comparison of the efficacy of anti-TNF agents in rheumatoid arthritis for methotrexate non-responders demonstrates differences between treatments: a Bayesian approach. Ann Rheum Dis. 2012;71:225–230. doi: 10.1136/annrheumdis-2011-200228. [DOI] [PubMed] [Google Scholar]
- 14.Bucher HC, Guyatt GH, Griffith LE, Walter SD. The results of direct and indirect treatment comparisons in meta-analysis of randomized controlled trials. J Clin Epidemiol. 1997;50:683–691. doi: 10.1016/s0895-4356(97)00049-8. [DOI] [PubMed] [Google Scholar]
- 15.Jones B, Roger J, Lane PW, Lawton A, Fletcher C, Cappelleri JC, et al. Statistical approaches for conducting network meta-analysis in drug development. Pharm Stat. 2011;10:523–531. doi: 10.1002/pst.533. [DOI] [PubMed] [Google Scholar]
- 16.White IR. Network meta-analysis. Stata J. 2015;15:951–985. [Google Scholar]
- 17.Hoaglin DC, Hawkins N, Jansen JP, Scott DA, Itzler R, Cappelleri JC, et al. Conducting indirect-treatment-comparison and networkmeta-analysis studies: report of the ISPOR Task Force on Indirect Treatment Comparisons Good Research Practices: part 2. Value Health. 2011;14:429–437. doi: 10.1016/j.jval.2011.01.011. [DOI] [PubMed] [Google Scholar]
- 18.Hutton B, Salanti G, Caldwell DM, Chaimani A, Schmid CH, Cameron C, et al. The PRISMA extension statement for reporting of systematic reviews incorporating network meta-analyses of health care interventions: checklist and explanations. Ann Intern Med. 2015;162:777–784. doi: 10.7326/M14-2385. [DOI] [PubMed] [Google Scholar]
- 19.Li T, Puhan MA, Vedula SS, Singh S, Dickersin K, Ad Hoc Network Meta-analysis Methods Meeting Working Group Network meta-analysis-highly attractive but more methodological research is needed. BMC Med. 2011;9:79. doi: 10.1186/1741-7015-9-79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hasselblad V. Meta-analysis of multitreatment studies. Med Decis Making. 1998;18:37–43. doi: 10.1177/0272989X9801800110. [DOI] [PubMed] [Google Scholar]
- 21.Lumley T. Network meta-analysis for indirect treatment comparisons. Stat Med. 2002;21:2313–2324. doi: 10.1002/sim.1201. [DOI] [PubMed] [Google Scholar]
- 22.Shim SR, Shin IS, Bae JM. Intervention meta-analysis using STATA software. J Health Info Stat. 2016;41:123–134. (Korean) [Google Scholar]
- 23.Veroniki AA, Vasiliadis HS, Higgins JP, Salanti G. Evaluation of inconsistency in networks of interventions. Int J Epidemiol. 2013;42:332–345. doi: 10.1093/ije/dys222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Bhatnagar N, Lakshmi PV, Jeyashree K. Multiple treatment and indirect treatment comparisons: An overview of network metaanalysis. Perspect Clin Res. 2014;5:154–158. doi: 10.4103/2229-3485.140550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Mills EJ, Bansback N, Ghement I, Thorlund K, Kelly S, Puhan MA, et al. Multiple treatment comparison meta-analyses: a step forward into complexity. Clin Epidemiol. 2011;3:193–202. doi: 10.2147/CLEP.S16526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Reken S, Sturtz S, Kiefer C, Böhler YB, Wieseler B. Assumptions of mixed treatment comparisons in health technology assessments: challenges and possible steps for practical application. PLoS One. 2016;11:e0160712. doi: 10.1371/journal.pone.0160712. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Salanti G, Marinho V, Higgins JP. A case study of multiple-treatments meta-analysis demonstrates that covariates should be considered. J Clin Epidemiol. 2009;62:857–864. doi: 10.1016/j.jclinepi.2008.10.001. [DOI] [PubMed] [Google Scholar]
- 28.Baker SG, Kramer BS. The transitive fallacy for randomized trials: if A bests B and B bests C in separate trials, is A better than C? BMC Med Res Methodol. 2002;2:13. doi: 10.1186/1471-2288-2-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Krahn U, Binder H, König J. A graphical tool for locating inconsistency in network meta-analyses. BMC Med Res Methodol. 2013;13:35. doi: 10.1186/1471-2288-13-35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Dias S, Welton NJ, Sutton AJ, Caldwell DM, Lu G, Ades AE. Evidence synthesis for decision making 4: inconsistency in networks of evidence based on randomized controlled trials. Med Decis Making. 2013;33:641–656. doi: 10.1177/0272989X12455847. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Lu G, Ades AE. Assessing evidence inconsistency in mixed treatment comparisons. J Am Stat Assoc. 2006;101:447–459. [Google Scholar]
- 32.Cipriani A, Furukawa TA, Salanti G, Geddes JR, Higgins JP, Churchill R, et al. Comparative efficacy and acceptability of 12 newgeneration antidepressants: a multiple-treatments meta-analysis. Lancet. 2009;373:746–758. doi: 10.1016/S0140-6736(09)60046-5. [DOI] [PubMed] [Google Scholar]
- 33.Chaimani A, Salanti G, Leucht S, Geddes JR, Cipriani A. Common pitfalls and mistakes in the set-up, analysis and interpretation of results in network meta-analysis: what clinicians should look for in a published article. Evid Based Ment Health. 2017;20:88–94. doi: 10.1136/eb-2017-102753. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dias S, Welton NJ, Caldwell DM, Ades AE. Checking consistency in mixed treatment comparison meta-analysis. Stat Med. 2010;29:932–944. doi: 10.1002/sim.3767. [DOI] [PubMed] [Google Scholar]
- 35.Higgins JP, Jackson D, Barrett JK, Lu G, Ades AE, White IR. Consistency and inconsistency in network meta-analysis: concepts and models for multi-arm studies. Res Synth Methods. 2012;3:98–110. doi: 10.1002/jrsm.1044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Ioannidis JP. Integration of evidence from multiple meta-analyses: a primer on umbrella reviews, treatment networks and multiple treatments meta-analyses. CMAJ. 2009;181:488–493. doi: 10.1503/cmaj.081086. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Saramago P, Sutton AJ, Cooper NJ, Manca A. Mixed treatment comparisons using aggregate and individual participant level data. Stat Med. 2012;31:3516–3536. doi: 10.1002/sim.5442. [DOI] [PubMed] [Google Scholar]
- 38.White IR, Barrett JK, Jackson D, Higgins JP. Consistency and inconsistency in network meta-analysis: model estimation using multivariate meta-regression. Res Synth Methods. 2012;3:111–125. doi: 10.1002/jrsm.1045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Salanti G, Kavvoura FK, Ioannidis JP. Exploring the geometry of treatment networks. Ann Intern Med. 2008;148:544–553. doi: 10.7326/0003-4819-148-7-200804010-00011. [DOI] [PubMed] [Google Scholar]
- 40.Salanti G, Ades AE, Ioannidis JP. Graphical methods and numerical summaries for presenting results from multiple-treatment meta-analysis: an overview and tutorial. J Clin Epidemiol. 2011;64:163–171. doi: 10.1016/j.jclinepi.2010.03.016. [DOI] [PubMed] [Google Scholar]
- 41.Ioannidis JP. Indirect comparisons: the mesh and mess of clinical trials. Lancet. 2006;368:1470–1472. doi: 10.1016/S0140-6736(06)69615-3. [DOI] [PubMed] [Google Scholar]
- 42.Kyrgiou M, Salanti G, Pavlidis N, Paraskevaidis E, Ioannidis JP. Survival benefits with diverse chemotherapy regimens for ovarian cancer: meta-analysis of multiple treatments. J Natl Cancer Inst. 2006;98:1655–1663. doi: 10.1093/jnci/djj443. [DOI] [PubMed] [Google Scholar]
- 43.Ioannidis JP, Cappelleri JC, Lau J. Issues in comparisons between meta-analyses and large trials. JAMA. 1998;279:1089–1093. doi: 10.1001/jama.279.14.1089. [DOI] [PubMed] [Google Scholar]
- 44.Pereira TV, Horwitz RI, Ioannidis JP. Empirical evaluation of very large treatment effects of medical interventions. JAMA. 2012;308:1676–1684. doi: 10.1001/jama.2012.13444. [DOI] [PubMed] [Google Scholar]
- 45.Bae JM. Meta-epidemiology. Epidemiol Health. 2014;36:e2014019. doi: 10.4178/epih/e2014019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Bae JM. Suggestions for the promotion of evidence-based public health in South Korea. Epidemiol Health. 2017;39:e2017030. doi: 10.4178/epih.e2017030. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.