

Abstract
For estimating conditional survival functions, non-parametric estimators can be preferred to parametric and semi-parametric estimators due to relaxed assumptions that enable robust estimation. Yet, even when misspecified, parametric and semi-parametric estimators can possess better operating characteristics in small sample sizes due to smaller variance than non-parametric estimators. Fundamentally, this is a bias–variance trade-off situation in that the sample size is not large enough to take advantage of the low bias of non-parametric estimation. Stacked survival models estimate an optimally weighted combination of models that can span parametric, semi-parametric, and non-parametric models by minimizing prediction error. An extensive simulation study demonstrates that stacked survival models consistently perform well across a wide range of scenarios by adaptively balancing the strengths and weaknesses of individual candidate survival models. In addition, stacked survival models perform as well as or better than the model selected through cross-validation. Finally, stacked survival models are applied to a well-known German breast cancer study.
Keywords: Bias–variance trade-off, Brier score, Cross-validation, Stacked regressions, Survival ensembles, Survival prediction
1. Introduction
Survival function estimation has long been a major component of survival analysis. Yet estimation of conditional survival functions, i.e., survival functions that depend on covariate values, remains a challenging problem. A common semi-parametric approach combines the Cox proportional hazard model with a baseline hazard estimate, e.g., see Kalbfleisch and Prentice (2002). However, if the functional form is misspecified or the proportional hazards assumption is violated, then this approach may perform poorly. In terms of the bias–variance trade-off, the Cox model, and other parametric models, achieve low variance by making distributional and functional form assumptions. If the assumptions are approximately correct, then the bias term is small and the parametric and semi-parametric models perform well. On the other hand, if the assumptions are badly violated, then the bias term can be large and the models perform poorly.
Many non-parametric methods have been proposed to overcome the bias induced by violated assumptions. For example, Kooperberg et al. (1995) propose a flexible spline approach for the log-hazard that encompasses more than a proportional hazards model. Alternatively, tree-based approaches have been considered by several authors (Ishwaran et al., 2008; Bou-Hamad et al., 2011; Zhu and Kosorok, 2012). Despite possessing low bias in a wide variety of situations, non-parametric estimators suffer from high variance and can require a large sample size to perform well. This can lead to surprising situations where misspecified parametric models perform better than non-parametric estimators. Specifically, the effect of bias of misspecified parametric models is smaller than the effect of variance of non-parametric estimators, i.e., the bias–variance trade-off.
This article pursues a flexible estimator of a conditional survival function, i.e., an estimator that performs well when parametric assumptions are approximately correct while also maintaining robustness when parametric assumptions are violated. Traditionally, a single conditional survival function estimator is chosen from a set of candidate models, e.g., using an information criterion (Kooperberg et al., 1995) or through cross-validation. Rather than select a single survival model, our goal is to estimate an optimally weighted combination of several survival models.
A variety of approaches that combine several models, often referred to as ensembles, have been explored in the uncensored setting. One approach, called “stacking,” determines the optimally weighted average of several models by minimizing predicted error. Wolpert (1992) introduced stacking in the context of neural networks, while Breiman (1996) extended the idea to uncensored regression models and showed that stacking could improve prediction error. In particular, Breiman (1996) found that combining fundamentally different regression models, e.g., ridge regression and subset regression, had the largest reduction in prediction error. LeBlanc and Tibshirani (1996) found stacking with a constraint of non-negative weights to be an efficient way to combine models. Van der Laan et al. (2007) independently developed uncensored stacking as the ‘Super Learner’ algorithm, and presented results regarding the stacked estimator's rate of convergence. More recently, Boonstra et al. (2013) used stacking to improve prediction when incorporating different generation sequencing information in high-dimensional genome analysis.
Stacking models in a censored data setting presents additional challenges. Polley and Van der Laan (2011) mention stacking within a general censored data framework and provide an example for hazard function estimation with discrete survival times. This paper differs in two notable ways. First, we focus on estimating conditional survival functions with continuous survival times rather than a hazard function. This requires a different loss function that is tailored directly to estimating survival functions. We are particularly interested in the conditional survival function due to its role in many survival analysis methods; see the last paragraph of Section 7 for several examples. We also pursue the potential advantages of stacking parametric, semi-parametric, and non-parametric estimators. In particular, we show that stacked survival models perform well by giving weight to approximately correct parametric models, while shifting weight to non-parametric estimators when assumptions are violated. This allows stacked survival models to outperform the single model selected via cross-validation and, in some situations, outperform every individual model considered in the stacking procedure. We believe that combining parametric, semi-parametric, and non-parametric estimators is the biggest advantage of stacked survival models.
The remainder of the manuscript is organized as follows: stacked survival models are proposed in Section 2. Section 3 investigates the mean-squared error of stacked survival models with some asymptotic properties presented in Section 4. Section 5 investigates the finite sample performance through an extensive simulation study. Stacked survival models are then applied to the German breast cancer study data set in Section 6, with concluding remarks presented in Section 7.
2. Stacking survival models
Throughout the paper, random variables and observed variables are distinguished by capital and lower case letters, respectively. Our objective is to estimate the survival function of the event time random variable 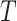 that depends on
that depends on 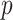 baseline covariates
baseline covariates 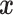 , i.e.,
, i.e., 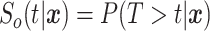 . In survival analysis,
. In survival analysis, 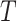 may be only partially observed due to a censoring random variable
may be only partially observed due to a censoring random variable 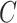 that may also depend on
that may also depend on 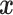 . Define the conditional survival function of the censoring distribution as
. Define the conditional survival function of the censoring distribution as 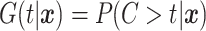 . We assume throughout that the event time and censoring random variables are conditionally independent, i.e.,
. We assume throughout that the event time and censoring random variables are conditionally independent, i.e., 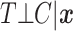 . The observed time is
. The observed time is 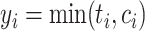 , and
, and 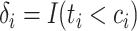 indicates whether an event was observed. Hence, a sample of right censored survival data of size
indicates whether an event was observed. Hence, a sample of right censored survival data of size 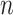 consists of triplets
consists of triplets 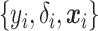 ,
, 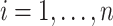 . Using the observed triplets, we can construct, for example, an estimate of the event time survival function from each of
. Using the observed triplets, we can construct, for example, an estimate of the event time survival function from each of 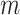 candidate models with the
candidate models with the 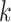 th estimate denoted as
th estimate denoted as 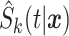 .
.
To combine several predictors, we need a loss function that is tailored to survival functions. Our approach uses the Brier Score [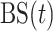 ], which measures the squared error of a survival function at a given time point. In the absence of censoring,
], which measures the squared error of a survival function at a given time point. In the absence of censoring, 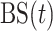 is defined as
is defined as
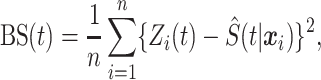 |
(2.1) |
where 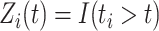 . Note that
. Note that 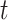 denotes a chosen time point, and
denotes a chosen time point, and 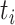 (with the subscript) denotes the event time for the
(with the subscript) denotes the event time for the 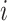 th observation and may not be observed due to censoring.
th observation and may not be observed due to censoring.
Unfortunately, right-censoring implies that equation (2.1) is only partially observed; that is, 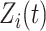 is undefined for censored observations when
is undefined for censored observations when 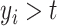 . To correct this issue, we use inverse probability-of-censoring weights (IPCW) to account for the probability of an observation being censored (Lostritto et al., 2012). In particular, the ‘inverse probability-of-censoring-weighted Brier Score’ at time
. To correct this issue, we use inverse probability-of-censoring weights (IPCW) to account for the probability of an observation being censored (Lostritto et al., 2012). In particular, the ‘inverse probability-of-censoring-weighted Brier Score’ at time 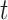 [
[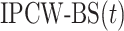 ] can be written as
] can be written as
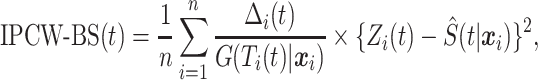 |
(2.2) |
where 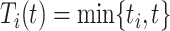 ,
, 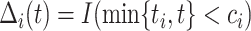 , and
, and 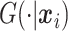 are the conditional survival function of the censoring distribution, which is estimated by a marginal Kaplan–Meier throughout the rest of the paper. From a technical point of view, the IPCWs ensure that the expectations of equations (2.1) and (2.2) are the same (assuming that the estimator of the censoring distribution is uniformly consistent). Thus, the true conditional survival function,
are the conditional survival function of the censoring distribution, which is estimated by a marginal Kaplan–Meier throughout the rest of the paper. From a technical point of view, the IPCWs ensure that the expectations of equations (2.1) and (2.2) are the same (assuming that the estimator of the censoring distribution is uniformly consistent). Thus, the true conditional survival function, 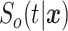 , is the minimizer of
, is the minimizer of 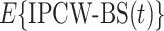 (see supplementary material available at Biostatistics online).
(see supplementary material available at Biostatistics online).
There are several points that are helpful to note for understanding the calculation of the 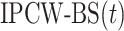 . The values of
. The values of 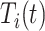 and
and 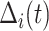 depend on
depend on 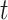 and the censoring status of the
and the censoring status of the 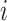 th observation. For each uncensored observation, the value of
th observation. For each uncensored observation, the value of 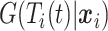 , and therefore the calculation of the weight, depends on whether the event has occurred by time
, and therefore the calculation of the weight, depends on whether the event has occurred by time 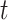 . For censored observations, there are two possible situations at a given time point
. For censored observations, there are two possible situations at a given time point 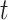 :
Thus, for a fixed time
:
Thus, for a fixed time 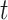 , censored observations with
, censored observations with 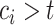 will contribute to the Brier Score, while censored observations with
will contribute to the Brier Score, while censored observations with 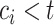 will still contribute to the Brier Score but only indirectly through the estimation of the censoring distribution.
will still contribute to the Brier Score but only indirectly through the estimation of the censoring distribution.
If
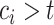 , then
, then 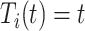 and
and 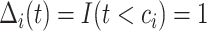 .
.If
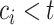 , then
, then 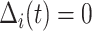 (since
(since 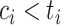 for censored observations) and hence
for censored observations) and hence 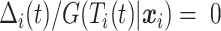 .
.
Since the goal is to estimate the entire conditional survival function, the Brier Score is minimized over a set of time points, say 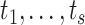 . This implies the following weighted least squares problem with the additional constraints that
. This implies the following weighted least squares problem with the additional constraints that 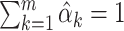 , which is required for the theoretical results, and
, which is required for the theoretical results, and 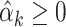 for all
for all 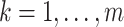 , which has been shown to improve performance in the uncensored setting (Breiman, 1996; LeBlanc and Tibshirani, 1996),
, which has been shown to improve performance in the uncensored setting (Breiman, 1996; LeBlanc and Tibshirani, 1996),
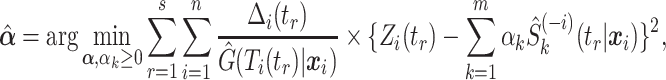 |
(2.3) |
where 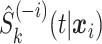 is the survival estimate from the
is the survival estimate from the 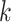 th model while leaving the
th model while leaving the 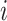 th observation out during the fitting process. This ensures that stacking does not reward model complexity (i.e., does not overfit the data). To reduce computational demands, we use 5-fold cross-validation rather than
th observation out during the fitting process. This ensures that stacking does not reward model complexity (i.e., does not overfit the data). To reduce computational demands, we use 5-fold cross-validation rather than 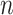 -fold cross-validation to obtain
-fold cross-validation to obtain 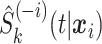 . In particular, the data are randomly split into five roughly equally sized sets and
. In particular, the data are randomly split into five roughly equally sized sets and 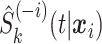 is obtained for observations in a given set by fitting the candidate survival models to the observations in the other four sets. As such, five survival models, rather than
is obtained for observations in a given set by fitting the candidate survival models to the observations in the other four sets. As such, five survival models, rather than 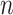 survival models, are fit for each of the
survival models, are fit for each of the 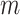 candidate survival models.
candidate survival models.
Finally, the stacked estimate of the conditional survival function with time-independent weights is
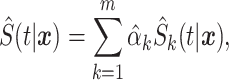 |
(2.4) |
where 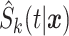 is the
is the 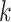 th survival model estimated with all the data.
th survival model estimated with all the data.
Remark 1 —
The Brier Score measures agreement at only one particular time. As such, the value(s) of
over which it is evaluated, i.e.,
, have implications for performance. In particular, care should be taken to avoid picking only very small, or very large
values, though one could also consider unequal weighting or restricting to certain areas of support. We find that nine evenly spaced quantiles of the observed event distribution works well (see supplementary material available at Biostatistics online).
Remark 2 —
Time-dependent stacking, i.e., allowing the weighted combination of models to depend on time, was also considered (see supplementary material available at Biostatistics online). Though potentially adding flexibility, a major flaw of time-dependent stacking is that the conditional survival function may, at times, increase, which violates the non-increasing property of survival functions. As such, this paper focuses on time-independent stacking.
3. Mean-squared error decomposition
We analyze the mean-squared error of the stacked survival model. We start by defining the mean-squared error for the stacked estimator as 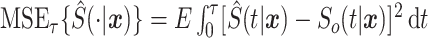 , where the expectation is over the random variable for the covariate space and the sampling distribution of the stacked estimator. This definition of mean-squared error is motivated, in part, by the Brier Score. In particular, supplementary material available at Biostatistics online shows that
, where the expectation is over the random variable for the covariate space and the sampling distribution of the stacked estimator. This definition of mean-squared error is motivated, in part, by the Brier Score. In particular, supplementary material available at Biostatistics online shows that 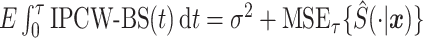 , where
, where 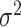 is irreducible prediction error. Similar to the analysis of Fumera and Roli (2005), we show in supplementary material available at Biostatistics online that the mean-squared error decomposes into
is irreducible prediction error. Similar to the analysis of Fumera and Roli (2005), we show in supplementary material available at Biostatistics online that the mean-squared error decomposes into
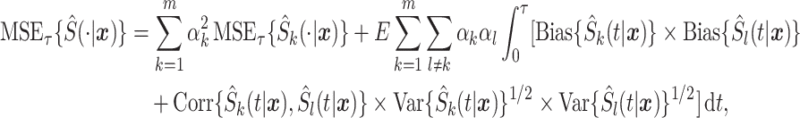 |
where 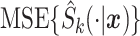 ,
, 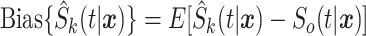 , and
, and 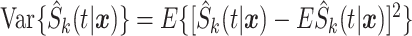 are, respectively, the mean-squared error, bias at time
are, respectively, the mean-squared error, bias at time 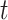 , and variance at time
, and variance at time 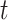 for the
for the 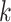 th survival model in the stacking procedure, while
th survival model in the stacking procedure, while 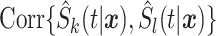 is the correlation at time
is the correlation at time 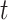 between the
between the 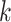 th and
th and 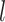 th survival model.
th survival model.
The mean-squared error of the stacked estimator decomposes into two parts: a weighted combination of the mean-squared error of candidate survival models and the interaction between candidate survival models in terms of bias and correlation. The decomposition makes it easy to show, given a set of candidate survival models, that there exists a set of stacking weights such that the stacked estimator possess as good, or better, mean-squared error as the best performing model in the set of candidate survival models. However, this property is not guaranteed after estimating the stacking weights. Thus, careful selection of candidate survival models is warranted.
The MSE decomposition provides insight into how features of candidate survival models impact performance of the stacked estimator. As stated in Section 1, the motivation for stacked survival models is to obtain robustness across a wide variety of scenarios by including models from different classes, i.e., parametric, semi-parametric, and non-parametric models, and with different assumptions (e.g., proportional hazards or accelerated failure time). In this fashion, the stacked estimator may assign more weight to one model in the stack for one scenario and shift to another model, e.g., one based on different assumptions, for a different scenario. This motivates including a set of models that “represent” a variety of classes and types of models, i.e., ensuring a diverse set of candidate survival models (Breiman, 1996). This is also supported by the MSE decomposition as the correlation between diverse models will tend to be lower due to different assumptions.
The next consideration is the number of models of a given type to include in the stack, e.g., the number of Cox proportional hazards models to include. Due to numerous options regarding potential covariates and the functional form of those covariates, e.g., linear terms versus quadratic terms, there are many different Cox models that could be included. However, models with the same distributional assumptions and similar sets of covariates are expected to have similar MSE with a rather high between-model correlation. Since there is no guarantee that only one model among a set of highly correlated models will receive non-zero weight, the MSE decomposition suggests that the stack will perform better by excluding models with small differences in the set of considered covariates. Further discussion, illustrative examples, and simulations are included in supplementary material available at Biostatistics online.
4. Asymptotic properties
We show model selection and uniform consistency for the stacked estimate of the conditional survival function. The former refers to the idea that if the set of stacked models contains uniformly consistent models, then all weight is asymptotically given to those models in the stack. Consistent model selection implies uniform consistency as long as there is at least one uniformly consistent estimator of the conditional survival function. Our main assumption is that there exists no weighted average of misspecified models that approaches the true survival function for every time point included in equation (2.3). Supplementary material available at Biostatistics online contains all of the assumptions and proofs.
Let 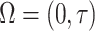 be the support of interest for estimating the conditional survival function, and consider
be the support of interest for estimating the conditional survival function, and consider 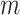 estimators for the stacking procedure. Then
estimators for the stacking procedure. Then
Theorem 4.1 —
Let
be estimated by equation (2.3). Assume that models
, where
, are the only uniformly consistent estimators and conditions (A1)–(A3) in supplementary material available at Biostatistics online hold, then
, in probability, as
.
This ensures that uniformly consistent model(s) will asymptotically receive all of the weight for the stacked conditional survival function estimate in equation (2.4). There can be more than one uniformly consistent estimator, e.g., a correctly specified Weibull model and Cox model. In the special case, when only one model is uniformly consistent, we obtain the corollary:
Corollary 4.2 —
If
is the only uniformly consistent estimator, then
, in probability, as
.
The result of Theorem 4.1 and Corollary 4.2 is required for uniform consistency of the stacked estimator with time-independent weights.
Theorem 4.3 —
Let the stacked estimate of the conditional survival function be defined as
in equation (2.4). Assume that conditions (A1)–(A3) in supplementary material available at Biostatistics online hold then, as
,
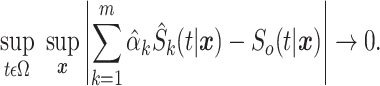
The rate of convergence of the stacked estimator is not addressed here. However, Van der Laan et al. (2007) showed that, in the uncensored case, the stacked estimator's risk converged at either the best rate of a correctly specified model, or slightly slower than the parametric rate. These results are not directly applicable since the Brier Score does not measure the risk of the entire conditional survival function. In addition, distributional results for the conditional survival function are complicated by the constrained estimation of 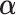 (see supplementary material available at Biostatistics online for in-depth discussion).
(see supplementary material available at Biostatistics online for in-depth discussion).
5. Simulations
An extensive simulation study examines the finite sample performance of stacked survival models. In particular, two settings are investigated: a moderate number of covariates (Section 5.1) and a large number of covariates (Section 5.2).
The simulations are comprised of combinations of an event distribution (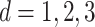 ) and linear form of covariates (
) and linear form of covariates (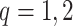 ). The covariate distributions are multivariate normal:
). The covariate distributions are multivariate normal: 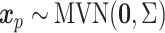 , where
, where 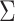 is the correlation matrix and for all
is the correlation matrix and for all 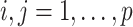 ,
, 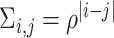 with
with 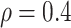 (
(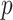 is the vector dimension). Section 5.1 has an eight-dimensional covariate space (i.e.,
is the vector dimension). Section 5.1 has an eight-dimensional covariate space (i.e., 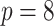 ), while Section 5.2 has a
), while Section 5.2 has a 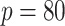 dimensional covariate space. For Section 5.1, the covariate effects are
dimensional covariate space. For Section 5.1, the covariate effects are 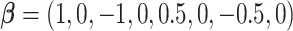 , while for Section 5.2 the first 12 covariate effects are
, while for Section 5.2 the first 12 covariate effects are 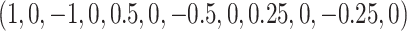 with the other
with the other 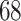 effects set to zero. Two different linear combinations are considered:
effects set to zero. Two different linear combinations are considered: 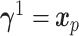 and
and 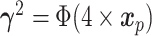 which imply linear and non-linear covariate effects, respectively. The event distributions are defined as
Each subsection investigates every combination of the event distribution (
which imply linear and non-linear covariate effects, respectively. The event distributions are defined as
Each subsection investigates every combination of the event distribution (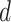 ) and linear form (
) and linear form (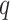 ), i.e., there are six scenarios for both Sections 5.1 and 5.2.
), i.e., there are six scenarios for both Sections 5.1 and 5.2.

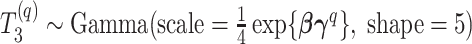
We compare the performance of survival models based on an approximation to the mean squared error presented in Section 3, which we call integrated squared survival error (ISSE):
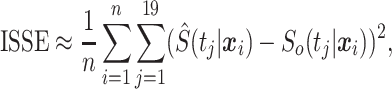 |
where 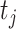 are a fixed set of 19 equally spaced quantiles of the survival time distribution given that an event occurs, and
are a fixed set of 19 equally spaced quantiles of the survival time distribution given that an event occurs, and 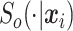 is the true conditional survival function.
is the true conditional survival function.
One comparison of interest for the stacked estimator is the model chosen through cross-validation. We use the integrated Brier Score (IBS) as the measure of the predicted error for selecting the individual model. In particular, the IBS for the 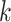 th model is defined as
th model is defined as 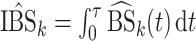 , where
, where 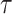 is the maximum observed time and
is the maximum observed time and 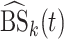 is the estimated Brier Score at time
is the estimated Brier Score at time 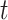 for the
for the 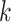 th model (with an out-of-bag estimate of the conditional survival function). The cross-validated estimator is then defined as
th model (with an out-of-bag estimate of the conditional survival function). The cross-validated estimator is then defined as 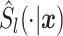 , where
, where 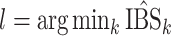 .
.
All simulations were run in R version 3.0.0 (R Development Core Team, 2013). The constrained minimization problem was solved using the alabama package (Varadhan, 2012). The stacking weights, i.e., equation (2.3), were estimated by minimizing the Brier Score over the 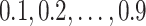 quantiles of the observed event distribution.
quantiles of the observed event distribution.
5.1. Modest-dimensional covariate space
This setting has relatively few covariates (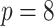 ) with a modest censoring rate (
) with a modest censoring rate (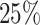 ) and sample size (
) and sample size (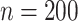 ). This illustrates stacked survival models in a relatively straightforward scenario.
). This illustrates stacked survival models in a relatively straightforward scenario.
The stacked survival models include a Weibull model and log-Normal model as parametric models, a Cox proportional hazards model with an Efron estimate of the baseline cumulative hazard function as a semi-parametric model, and random survival forests (RSFs) as a non-parametric model. The parametric and semi-parametric models include only first-order main effects and no interactions. All of the parametric and semi-parametric models are estimated using the survival package in R (Therneau, 2013), and all of the parametric and semi-parametric models use 5-fold cross-validation to estimate 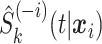 . RSF is estimated with the randomSurvivalForest package in R (Ishwaran and Kogalur, 2013). The RSF is an ensemble of
. RSF is estimated with the randomSurvivalForest package in R (Ishwaran and Kogalur, 2013). The RSF is an ensemble of 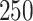 trees grown using package defaults. For RSF,
trees grown using package defaults. For RSF, 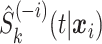 is estimated with the out-of-bag ensemble from the rsf function. The censoring distribution is a uniform distribution for all
is estimated with the out-of-bag ensemble from the rsf function. The censoring distribution is a uniform distribution for all 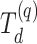 :
: 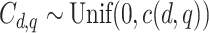 , where
, where 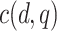 is a constant that depends on
is a constant that depends on 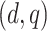 and ensures
and ensures 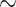 25% censoring.
25% censoring.
The log-Normal and Weibull scenarios with linear covariate effects illustrate performance when there is a correctly specified parametric or semi-parametric model in the stack. Stacking is not expected to perform better than a correctly specified parametric model, but should still perform relatively well in such situations. The Gamma scenario with linear covariate effects illustrates performance when there are approximately correct parametric models in the stack (e.g., a correct mean function). The scenarios with non-linear covariate effects were designed to have badly misspecified parametric and semi-parametric models. Due to the lack of a correctly specified parametric model, stacked survival models should perform relatively well by, in particular, assigning more weight to the non-parametric estimator: RSFs.
Table 1 presents the results in terms of ISSE. Since the goal is an estimator that performs well in a wide variety of situations, the top two estimators are bolded for each scenario. The stacked survival model, i.e., “Stacking”, is a top two estimator for all six scenarios. For the scenarios with non-linear covariate effects, the stacked estimator reduces the ISSE by 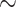 8–15% compared with the best single model. In addition, the stacking procedure outperforms selecting a single model via cross-validation in every situation.
8–15% compared with the best single model. In addition, the stacking procedure outperforms selecting a single model via cross-validation in every situation.
Table 1.
Simulation results for Section 5.1 (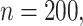
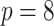 covariates, and
covariates, and 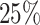 censoring) presented in ISSE over the observed support
censoring) presented in ISSE over the observed support
| Models | Log-Normal | Weibull | Gamma | ||
|---|---|---|---|---|---|
| Linear effects | Single models | Log-Normal | 0.35 | 0.82 | 0.34 |
| Weibull | 0.61 | 0.53 | 0.41 | ||
| Cox | 0.86 | 0.68 | 0.69 | ||
| RSF | 7.26 | 4.88 | 7.36 | ||
| Flexible models | Stacking | 0.42 | 0.58 | 0.37 | |
| CV | 0.72 | 0.70 | 0.53 | ||
| Non-linear effects | Single models | Log-Normal | 4.71 | 2.54 | 5.03 |
| Weibull | 5.17 | 2.27 | 5.30 | ||
| Cox | 5.15 | 2.33 | 5.33 | ||
| RSF | 4.29 | 3.49 | 4.46 | ||
| Flexible models | Stacking | 3.49 | 2.08 | 3.69 | |
| CV | 5.00 | 2.48 | 5.18 |
Each simulation is replicated 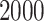 times, and the error is multiplied by
times, and the error is multiplied by 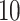 . The two top estimators are bolded for each simulation scenario. ‘RSFs’ stand for RSFs, ‘Stacking’ is stacked survival models, and ‘CV’ is the estimator selected through cross-validation. The standard error for the estimate ISSE for each method in each scenario is <0.01.
. The two top estimators are bolded for each simulation scenario. ‘RSFs’ stand for RSFs, ‘Stacking’ is stacked survival models, and ‘CV’ is the estimator selected through cross-validation. The standard error for the estimate ISSE for each method in each scenario is <0.01.
As an illustration, Table 2 presents the average stacking weights for the individual models. For the linear scenarios, the stacking procedure gives a majority of weight to correctly specified parametric models. The weights are more interesting for the scenarios with non-linear covariate effects. In particular, the parametric models always receive over 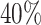 of the weight despite, at times, having
of the weight despite, at times, having 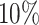 higher ISSE than RSF. This is a good example of stacked survival models combining misspecified parametric models and an inefficient non-parametric model to obtain an estimator that outperforms every single model considered in the stacking procedure.
higher ISSE than RSF. This is a good example of stacked survival models combining misspecified parametric models and an inefficient non-parametric model to obtain an estimator that outperforms every single model considered in the stacking procedure.
Table 2.
Average weights for the individual models included in the stacked survival model for each of the six scenarios in Section 5.1 (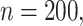
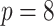 covariates, and
covariates, and 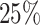 censoring)
censoring)
| Stacked models | Log-Normal | Weibull | Gamma | |
|---|---|---|---|---|
| Linear effects | Log-Normal | 0.61 | 0.19 | 0.42 |
| Weibull | 0.23 | 0.45 | 0.37 | |
| Cox | 0.14 | 0.31 | 0.19 | |
| RSF | 0.02 | 0.05 | 0.02 | |
| Non-linear effects | Log-Normal | 0.34 | 0.12 | 0.27 |
| Weibull | 0.14 | 0.28 | 0.18 | |
| Cox | 0.06 | 0.21 | 0.08 | |
| RSF | 0.46 | 0.39 | 0.47 |
Each simulation is replicated 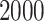 times. ‘RSFs’ stand for random survival forests.
times. ‘RSFs’ stand for random survival forests.
Remark 3 —
RSFs possess tuning parameters that influence performance, e.g., the minimum number of events in a node. While the performance of RSF could be improved by adaptively selecting tuning parameters (e.g., by cross-validation), stacked survival models are likely to also inherit any improvement in RSF since it is included in the stack.
5.2. Large covariate space
This setting has a large number of covariates (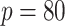 ) relative to the sample size (
) relative to the sample size (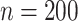 ). The censoring distributions are the same as Section 5.1. In general, the parametric and semi-parametric models used (and stacked) in Section 5.1 will not perform well in large covariate spaces without regularization. As such, they are not included for these scenarios. We instead stack a Cox model with an
). The censoring distributions are the same as Section 5.1. In general, the parametric and semi-parametric models used (and stacked) in Section 5.1 will not perform well in large covariate spaces without regularization. As such, they are not included for these scenarios. We instead stack a Cox model with an 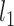 penalty (i.e., lasso), a boosted version of the Cox model, and RSFs. The
penalty (i.e., lasso), a boosted version of the Cox model, and RSFs. The 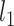 penalized version of the Cox model is fit using the R package penalized with the penalty parameter chosen via cross-validation (Goeman, 2012). The boosted Cox model is fit using the package CoxBoost in R with default tuning parameters (Binder, 2013). RSF is fit in the same manner as Section 5.1.
penalized version of the Cox model is fit using the R package penalized with the penalty parameter chosen via cross-validation (Goeman, 2012). The boosted Cox model is fit using the package CoxBoost in R with default tuning parameters (Binder, 2013). RSF is fit in the same manner as Section 5.1.
The stacked survival model is again a top two estimator in every scenario (see Table 3). Relative to Section 5.1, stacked survival models offer smaller improvements (e.g., 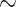 1–5% lower ISSE compared with the cross-validated estimator). However, the improvements in ISSE remain consistent across the scenarios. In addition, the stacking procedure still performs as good, or better, in every scenario as the model selected via cross-validation.
1–5% lower ISSE compared with the cross-validated estimator). However, the improvements in ISSE remain consistent across the scenarios. In addition, the stacking procedure still performs as good, or better, in every scenario as the model selected via cross-validation.
Table 3.
Simulation results for Section 5.2 (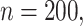
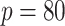 covariates, and
covariates, and 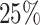 censoring) presented in integrated squared survival error (ISSE) over the observed support
censoring) presented in integrated squared survival error (ISSE) over the observed support
| Models | Log-Normal | Weibull | Gamma | ||
|---|---|---|---|---|---|
| Linear effects | Single models | Cox-Lasso | 2.43 | 1.68 | 2.50 |
| Cox-boosting | 2.60 | 1.75 | 2.66 | ||
| RSF | 2.46 | 1.86 | 2.50 | ||
| Flexible models | Stacking | 2.43 | 1.68 | 2.50 | |
| CV | 2.43 | 1.69 | 2.50 | ||
| Non-linear effects | Single models | Cox-Lasso | 2.02 | 1.03 | 2.08 |
| Cox-boosting | 2.01 | 1.01 | 2.08 | ||
| RSF | 1.89 | 1.15 | 1.95 | ||
| Flexible models | Stacking | 1.97 | 1.00 | 2.04 | |
| CV | 2.01 | 1.03 | 2.07 |
Each simulation is replicated 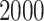 times, and the error is multiplied by
times, and the error is multiplied by 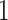 . The two top estimators are bolded for each simulation scenario. ‘RSFs’ stand for random survival forests, ‘Stacking’ is stacked survival models, and ‘CV’ is the estimator selected through cross-validation. The standard error for the estimate ISSE for each method in each scenario is <0.005.
. The two top estimators are bolded for each simulation scenario. ‘RSFs’ stand for random survival forests, ‘Stacking’ is stacked survival models, and ‘CV’ is the estimator selected through cross-validation. The standard error for the estimate ISSE for each method in each scenario is <0.005.
Remark 4 —
Supplementary material available at Biostatistics online presents numerous extensions to the simulation study. In particular, we investigate scenarios with a larger sample size, a high censoring rate, non-monotonic covariate effects, and a misspecified censoring model. In addition, we comment on the required computational time and the influence of the out-of-bag estimator for RSF.
6. German breast cancer study
Stacked survival models are illustrated on a well-known survival benchmark data set: the German breast cancer study (GBCS) described by Hosmer et al. (2008), and accessible at the University of Massachusetts website for statistical software information. There are eight covariates included in the analysis: age at diagnosis, tumor size, tumor grade, number of nodes, menopausal status, the number of progesterone receptors, the number of estrogen receptors, and hormone therapy status. The outcome of interest is the time till death, and there is complete data on 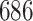 patients with
patients with 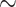 75% censoring. The stacking procedure uses the same models as Section 5.1. That is, the Weibull and log-Normal models are the parametric models, the Cox proportional hazards model is the semi-parametric model, and an RSF is the non-parametric model. The minimum number of deaths (for RSF) is set at
75% censoring. The stacking procedure uses the same models as Section 5.1. That is, the Weibull and log-Normal models are the parametric models, the Cox proportional hazards model is the semi-parametric model, and an RSF is the non-parametric model. The minimum number of deaths (for RSF) is set at 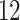 , which was selected by minimizing predicted error among five potential values: 3, 6, 12, 24, and 48.
, which was selected by minimizing predicted error among five potential values: 3, 6, 12, 24, and 48.
We are particularly interested in the association of tumor size and the number of nodes with 5-year survival. In order to evaluate the association, the stacked survival model and each model included in the stacking procedure predicts the 5-year survival rate for each patient in the study. After predicting 5-year survival, a generalized additive model with penalized B-splines for the continuous covariates (i.e., the gam function from the mgcv package; Wood, 2006) estimates the association of tumor size and the number of nodes with 5-year survival while adjusting for the other covariates.
Figure 1 presents the estimated 5-year survival as a function of tumor size and the number of nodes at the median of the other covariates. The parametric/semi-parametric models suggest worse 5-year survival with increasing tumor size and number of nodes. In contrast, RSF suggests that 5-year survival dips slightly 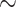 40 mm for tumor size, while 5-year survival for the number of nodes has a sharp early decrease but plateaus after
40 mm for tumor size, while 5-year survival for the number of nodes has a sharp early decrease but plateaus after 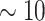 nodes. The stacked survival model— which gives weight to the Weibull model (
nodes. The stacked survival model— which gives weight to the Weibull model (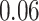 ), the Cox model (
), the Cox model (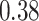 ), and RSF (
), and RSF (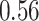 )—is a compromise between the parametric/semi-parametric models and RSF.
)—is a compromise between the parametric/semi-parametric models and RSF.
Fig. 1.
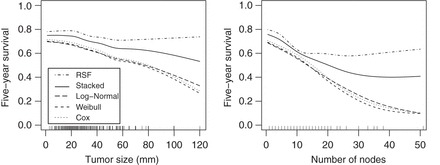
The association of tumor size (mm) and the number of nodes with 5-year survival for the GBCS data set with the other covariates to their median value. The tick marks at the bottom of the plots indicate the skewness of both covariates.
The GBCS data set has a marginal 5-year survival rate of 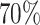 due, in part, to a censoring rate of
due, in part, to a censoring rate of 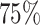 . As such, predicted 5-year survival rates <20% are surprising (i.e., the parametric/semi-parametric models for the number of nodes). Due to the sparsity of patients with
. As such, predicted 5-year survival rates <20% are surprising (i.e., the parametric/semi-parametric models for the number of nodes). Due to the sparsity of patients with 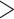 20 nodes, the low model-based predicted probabilities are likely due to parametric/semi-parametric models being heavily influenced by a strong negative association with survival for patients with <20 nodes (
20 nodes, the low model-based predicted probabilities are likely due to parametric/semi-parametric models being heavily influenced by a strong negative association with survival for patients with <20 nodes (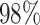 of patients have <20 nodes) through the first-order linear effect (note that the patient with over
of patients have <20 nodes) through the first-order linear effect (note that the patient with over  nodes was censored after 2 years). In contrast, RSF does not require any linearity assumptions and is more influenced by local observations in predicting 5-year survival (Ishwaran et al., 2008). From this perspective, the stacked survival model is balancing model-based predictions that require assumptions of linearity with locally based predictions.
nodes was censored after 2 years). In contrast, RSF does not require any linearity assumptions and is more influenced by local observations in predicting 5-year survival (Ishwaran et al., 2008). From this perspective, the stacked survival model is balancing model-based predictions that require assumptions of linearity with locally based predictions.
Remark 5 —
In this example, the model weights provide insight into how candidate survival models were combined to form the stacked estimate of the conditional survival function. However, we caution against interpreting model weights as an indication of a “correct model.” As noted by a referee, this is particularly dangerous when two models possess similar survival functions due to potential instability in the minimization procedure.
7. Conclusion and future directions
We propose stacking survival models to flexibly estimate conditional survival functions. Stacked survival models can combine several models, spanning the full range of parametric, semi-parametric, and non-parametric estimators. This allows stacking to exploit the low variance of approximately correct parametric models, while maintaining the robustness of non-parametric estimators. As illustrated in the simulation study, stacked survival models give more weight to parametric and semi-parametric models when assumptions are approximately correct, but shift weight to non-parametric estimators when assumptions are badly violated. In this manner, stacked survival models perform well across a wide range of scenarios. In particular, for a given scenario, stacked survival models were found to perform better than the single model chosen through cross-validation and, at times, perform better than any single model considered in the stacking procedure.
In practice, the true underlying data generation process is never known, i.e., one does not choose the true event distribution or functional form of the covariates. This motivates an adaptive approach that can perform well in a wide variety of situations. Cross-validation is currently the most common adaptive approach. Yet, the set of simulations illustrate that stacked survival models perform as good, or better, than the model selected through cross-validation, which picks a single model to receive all the weight (i.e., 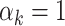 for some
for some 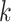 ). As such, stacked survival models warrant consideration whenever cross-validated models are used. Other predictive models could also have been considered, though stacked survival models could inherit any particular advantages of such models through inclusion in the stack.
). As such, stacked survival models warrant consideration whenever cross-validated models are used. Other predictive models could also have been considered, though stacked survival models could inherit any particular advantages of such models through inclusion in the stack.
As shown in Section 3, the MSE decomposition of the stacked survival model depends on the MSE for each candidate model, the pairwise correlation between candidate models, and the weight (i.e., 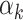 ) given to each model. The correlation term suggests that including an additional model that is very similar, e.g., a model of the same type as one already in the stack but with small differences in the covariates included, may not improve and could harm performance (see supplementary material available at Biostatistics online). While the estimated weights can theoretically be zero, there is no guarantee that this will occur for a highly correlated model. This could motivate a preliminary screen procedure for candidate survival models that is based on pairwise correlations. For example, a procedure to determine the covariate combination and functional form for parametric or semi-parametric models, or determine values of tuning parameters for non-parametric estimators. However, as noted by an anonymous referee, any screening procedure needs to be careful to avoid overfitting by using, for example, nested cross-validation or independent, external data. The advantages of a potential screening procedure deserve further research.
) given to each model. The correlation term suggests that including an additional model that is very similar, e.g., a model of the same type as one already in the stack but with small differences in the covariates included, may not improve and could harm performance (see supplementary material available at Biostatistics online). While the estimated weights can theoretically be zero, there is no guarantee that this will occur for a highly correlated model. This could motivate a preliminary screen procedure for candidate survival models that is based on pairwise correlations. For example, a procedure to determine the covariate combination and functional form for parametric or semi-parametric models, or determine values of tuning parameters for non-parametric estimators. However, as noted by an anonymous referee, any screening procedure needs to be careful to avoid overfitting by using, for example, nested cross-validation or independent, external data. The advantages of a potential screening procedure deserve further research.
Covariate-dependent stacking (or, allowing the 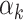 to depend upon
to depend upon 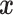 ) is a potential avenue for improving stacked survival models. LeBlanc and Tibshirani (1996) mention this approach for uncensored stacking, and a collaborative group using covariate-dependent stacking won the Netflix Prize competition to improve movie recommendations (Sill et al., 2009). However, extending the stacking procedure to include covariate-dependent weights with the constraints introduced here is not straightforward. For example, Sill et al. (2009) do not constrain their covariate-dependent weights despite prior experiences suggesting that regularization improves performance (Breiman, 1996; LeBlanc and Tibshirani, 1996). Investigation of covariate-dependent stacking and different approaches to constraining the covariate-dependent weights deserves further investigation.
) is a potential avenue for improving stacked survival models. LeBlanc and Tibshirani (1996) mention this approach for uncensored stacking, and a collaborative group using covariate-dependent stacking won the Netflix Prize competition to improve movie recommendations (Sill et al., 2009). However, extending the stacking procedure to include covariate-dependent weights with the constraints introduced here is not straightforward. For example, Sill et al. (2009) do not constrain their covariate-dependent weights despite prior experiences suggesting that regularization improves performance (Breiman, 1996; LeBlanc and Tibshirani, 1996). Investigation of covariate-dependent stacking and different approaches to constraining the covariate-dependent weights deserves further investigation.
The Brier Score, used to estimate the weighted combination of survival models, is essentially an inverse probability-of-censoring-weighted (IPCW) estimate of prediction error. The IPCW estimate requires estimating the (possibly conditional) censoring distribution. The simulation scenarios introduced in Section 5 use a Kaplan–Meier estimator for the censoring distribution that is correctly specified. In our experience, the stacking procedure maintains good operating characteristics when the censoring model is misspecified. However, if there is strong evidence of differential censoring among the covariates, then a conditional estimator may be warranted.
The importance of efficient, yet robust, estimators of conditional survival functions (or, equivalently, conditional distribution functions) continues to grow. Methods in a wide range of areas require estimating a conditional survival function as a nuisance parameter, for example, censored quantile regression (Wey et al., 2014), time-dependent ROC curves (Zheng and Heagerty, 2004), inverse probability-of-censoring-weighted estimators, e.g., Fine and Gray (1999), model-free contrast approaches (Rudser et al., 2012), and dynamic treatment regime methods (Zhao et al., 2011). The simulations presented here suggest that stacking parametric, semi-parametric, and non-parametric models for the nuisance parameter will likely result in better estimation of regression parameters of interest, though these topics warrant further investigation.
Supplementary material
Supplementary material is available online at http://biostatistics.oxfordjournals.org
Conflict of Interest: None declared.
Funding
This work was supported by grants UL1TR000114 of the National Center for Advancing Translational Sciences, U54MD007584 of the National Institute on Minority Health and Health Disparities, and G12MD007601 of the National Institute on Minority Health and Health Disparities.
Supplementary Material
References
- Binder H. (2013) CoxBoost: Cox models by likelihood based boosting for a single survival endpoint or competing risks. R package version 1.4. http://cran.r-project.org/web/packages/CoxBoost/index.html.
- Boonstra P. S., Taylor J. M. G., Mukherjee B. (2013). Incorporating auxiliary information for improved prediction in high-dimensional datasets: an ensemble of shrinkage approaches. Biostatistics 14, 259–272. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bou-Hamad I., Larocque D., Ben-Ameur H. (2011). A review of survival trees. Statistics Surveys 5, 44–71. [Google Scholar]
- Breiman L. (1996). Stacked regressions. Machine Learning 24, 49–64. [Google Scholar]
- Fine J. P., Gray R. J. (1999). A proportional hazards model for the subdistribution of a competing risk. Journal of the American Statistical Association 94, 496–509. [Google Scholar]
- Fumera G., Roli F. (2005). A theoretical and experimental analysis of linear combiners for multiple classifier systems. IEEE Transactions on Pattern Analysis and Machine Intelligence 27, 942–956. [DOI] [PubMed] [Google Scholar]
- Goeman J. J. (2012) Penalized R Package. R package version 0.9-42. http://cran.r-project.org/web/packages/penalized/index.html.
- Hosmer D. W., Lemeshow S., May S. (2008) Applied Survival Analysis: Regression Modeling of Time to Event Data. Hoboken, New Jersey: Wiley. [Google Scholar]
- Ishwaran H., Kogalur U. B. (2013) Random Survival Forests. R package version 3.6.4. http://cran.r-project.org/web/packages/randomSurvivalForest/index.html.
- Ishwaran H., Kogalur U. B., Blackstone E. H., Lauer M. S. (2008). Random survival forests. Annals of Applied Statistics 2, 841–860. [Google Scholar]
- Kalbfleisch J. D., Prentice R. L. (2002) The Statistical Analysis of Failure Time Data. Hoboken, New Jersey: Wiley. [Google Scholar]
- Kooperberg C., Stone C. J., Truong Y. K. (1995). Hazard regression. Journal of the American Statistical Association 90, 78–94. [Google Scholar]
- LeBlanc M., Tibshirani R. (1996). Combining estimates in regression and classification. Journal of the American Statistical Association 91, 1641–1650. [Google Scholar]
- Lostritto K., Strawderman R. L., Molinaro A. M. (2012). A partitioning deletion/substitution/addition algorithm for creating survival risk groups. Biometrics 68, 1146—1156. [DOI] [PubMed] [Google Scholar]
- Polley E. C., Van der Laan M. (2011). Super learning for right-censored data. In: Targeted Learning: Causal Inference for Observational and Experimental Data. Mark van der Laan and Sherri Rose: Springer. [Google Scholar]
- R Development Core Team. (2013). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0. http://www.r-project.org/.
- Rudser K. D., LeBlanc M. L., Emerson S. S. (2012). Distribution-free inference on contrasts of arbitrary summary measures of survival. Statistics in Medicine 31, 1722–1737. [DOI] [PubMed] [Google Scholar]
- Sill J., Takacs G., Mackey L., Lin D. (2009). Feature-weighted linear stacking. Arxiv.
- Therneau T. (2013) Survival Analysis, Including Penalized Likelihood. R package v 2.37-4.
- Van der Laan M. J., Polley E. C., Hubbard A. E. (2007). Super learner. Statistical Applications in Genetics and Molecular Biology 6, 00–00. [DOI] [PubMed] [Google Scholar]
- Varadhan R. (2012). alabama: Constrained Nonlinear Optimization. R package v 2011.9-1. http://cran.r-project.org/web/packages/alabama/index.html.
- Wey A., Wang L., Rudser K. (2014). Censored quantile regression with recursive partitioning based weights. Biostatistics 15, 170–181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wolpert D. H. (1992). Stacked generalization. Neural Network 5, 241–259. [Google Scholar]
- Wood S. N. (2006) Generalized Additive Models: An Introduction with R. Boca Raton, FL: Chapman and Hall. [Google Scholar]
- Zhao Y., Zeng D., Socinski M. A., Kosorok M. R. (2011). Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics 67, 1422–1433. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zheng Y., Heagerty P. J. (2004). Semiparametric estimation of time-dependent ROC curves for longitudinal marker data. Biostatistics 5, 615–632. [DOI] [PubMed] [Google Scholar]
- Zhu R., Kosorok M. R. (2012). Recursively imputed survival trees. Journal of the American Statistical Association 107, 331–340. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.